
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We provide a nonparametric revealed preference approach to demand analysis based on homothetic efficiency. Homotheticity is widely assumed (often implicitly) because it is a convenient and often useful restriction. However, this assumption is rarely tested, and data rarely satisfy testable conditions. To overcome this, we provide a way to estimate homothetic efficiency of consumption choices. The method provides considerably higher discriminatory power against random behavior than the commonly used Afriat efficiency. We use experimental and household survey data to illustrate how our approach is useful for different empirical applications and can provide greater predictive success.
1. INTRODUCTION
Homotheticity of consumer preferences is an important and useful concept in both theoretical and empirical work. If a consumer’s preferences are homothetic, we can deduce his entire preference relation from a single indifference set. Furthermore, testing data for homothetic utility maximization can provide substantially stronger discriminatory power against the alternative hypothesis than testing for utility maximization alone.
Homotheticity has important implications in many different fields. For example, it is important for the construction of superlative index numbers (Diewert Citation1976). In particular, by assuming homotheticity, superlative price indices are independent of the consumer’s standard of living (i.e., utility level). Thus, such indices are independent of the reference quantity base and therefore representative for any welfare level. Statistical agencies construct consumer price indices (CPI) from superlative price indices to provide measures of inflation in the economy. Other fields in which homotheticity plays an important role include the aggregation of consumer demand and the existence of “community indifference curves,” the modeling of separable preference structures and two-stage budgeting, and it is also a common assumption in the international trade literature.
This article provides measures of the homothetic efficiency of a dataset using a revealed preference approach. We introduce the homothetic efficiency index (HEI), which is a homothetic analogue to the well-known Afriat efficiency index (AEI) and can be interpreted as a measure of wasted income. The HEI generalizes the index proposed by Heufer (Citation2013) for the case with only two goods. Just as the AEI, the HEI only reflects the least efficient choice in a dataset. Therefore, to have a more detailed and robust data analysis, we extend this measure by introducing the more disaggregated homothetic efficiency vector (HEV), which provides efficiency indices for each observed choice. We provide a strong theoretical justification for using the HEI and HEV based on the concept of vector-rationalization recently introduced by Halevy, Persitz, and Zrill (Citation2015).
The revealed preference approach was originally developed by Samuelson (Citation1938), but the contributions of Varian (Citation1982, Citation1983) were responsible for spurring its use and initiated a substantial applied literature. Varian’s generalized axiom of revealed preference (GARP) is widely used to test data for consistency with utility maximization. Varian (Citation1983) was the first to provide tests for homotheticity and separability. Since then, contributions analyzing revealed preference methods for separability, such as Swofford and Whitney (Citation1987, Citation1988, Citation1994) and Cherchye et al. (Citation2015), and homotheticity, such as Knoblauch (Citation1993), Liu and Wong (Citation2000), and Heufer (Citation2013), have appeared. However, there remains considerable potential for revealed preference techniques for conditions that extend beyond simple utility maximization. Actual consumption data often violate certain conditions. For homotheticity, Alston et al. (Citation1990) and Serletis and Rangel-Ruiz (Citation2005) found that Varian’s condition is violated at every observation. This finding might explain why tests for homotheticity seem to have grown less in popularity than they could have: as opposed to tests for utility maximization, there was no way to measure the extent of these violations. Approaches that measure this extent should therefore be very useful.
As recently documented by Hands (Citation2016), Paul Samuelson often referred to models that used the assumption of homotheticity or other, similarly strong assumptions as “Santa Claus economics.” Throughout the present article, we adopt the interpretation that homotheticity is indeed a very strong and possibly unrealistic assumption but that it can sometimes provide a good approximation of true preferences. For example, researchers who need the assumption (e.g., for the construction of index numbers) can use our techniques to measure how well a homothetic utility function approximates reality and, if the approximation is close enough, use the result to justify it.
The contribution of Heufer (Citation2013) is only applicable to two-dimensional experimental data. Field and survey data such as household expenditure panel data typically have more than two goods. Testing typical expenditure data for consistency with utility maximization can entail a problem: as price changes between periods are usually small and income increases over time, budgets are often completely contained in other budgets. This can lead to very low test power. For example, Varian (Citation1982) reported that for the data he used, many budgets are contained in the budget of the next period, which implies low test power; see also Bronars (Citation1987) for an analysis of the same data. For household demand, where income changes are usually relatively small, it is plausible to assume that demand is homothetic, and therefore, it is reasonable to test for consistency with homothetic utility maximization, which can lead to considerably higher test power. As budgets do not have to intersect when demand is assumed to increase proportionally, a test for homotheticity can be useful even for Varian’s (Citation1982) dataset with zero test power for utility maximization.
Varian’s (Citation1983) homothetic axiom of revealed preference (HARP) can be easily tested with a set of price-quantity data. It is a necessary and sufficient condition for consistency with homothetic utility maximization and therefore characterizes the hypothesis of homothetic preferences. However, it is a binary test: the data either satisfy HARP or do not. When HARP is violated, the measures introduced here show how close the data come to being consistent with HARP. Both the HEI and the HEV provide the minimal adjustments required to make a dataset consistent with homothetic utility maximization. Our measures allow us to go further than merely rejecting HARP by quantifying and interpreting the extent of the inconsistency.
A related approach was proposed by Blundell, Browning, and Crawford (Citation2003). They suggested combining revealed preference conditions with expansion paths that are nonparametrically estimated using pooled household data. However, their procedure differs from ours in some important respects. First, while their procedure is designed for household panel data, our approach lends itself to panel as well as experimental data. Second, our methods can be meaningfully applied to datasets with any number of observations and are therefore applicable to each individual household in the panel. This allows us to avoid any preference homogeneity assumptions across households and, consequently, optimally exploits the structure of household panel data.
Given the widespread assumption of homotheticity—which is often not even explicitly discussed—it should be tested whenever possible, but it rarely is. Our contribution makes it easy for researchers to determine how consistent their data are with homotheticity. Our efficiency index allows us to separate the cases in which the assumption is justified from those in which it is not.
To illustrate and motivate the methods proposed in this article, we apply them to two datasets. The first application is to a panel of expenditures on nondurable consumption categories for 3,134 Spanish households. These survey data were previously analyzed by Browning and Collado (Citation2001), Crawford (Citation2010), and Cherchye et al. (Citation2015) in different contexts. The second application is to data from an experimental dictator game conducted by Fisman, Kariv, and Markovits (Citation2007). As a means of analyzing the survey and experimental data, we implement an idea proposed by Beatty and Crawford (Citation2011) that combines efficiency and power into a single measure, called predictive success.
Our main results can be summarized as follows. (i) Efficiency can be very high for HARP, thus providing motivation for researchers who rely on the assumption of homothetic preferences. (ii) For consumer choice data, HARP has considerably higher discriminatory power against irrational behavior than does GARP. (iii) Adjusting expenditures for homothetic efficiency can have negligible effects on power. Thus, HARP can have substantially higher power than GARP even when expenditures are adjusted for efficiency. (iv) Based on the measure of predictive success, homotheticity is a better model than utility maximization alone for demand behavior of households in our survey data application.
The remainder of the article is organized as follows. Section 2 addresses utility maximization, while Section 3 addresses homothetic utility maximization; they are organized in parallel. Section 2.1 recalls Afriat’s theorem on rationalization by a utility function, while Section 3.1 defines homotheticity and recalls Varian’s (Citation1983) theorem on rationalization by a homothetic utility function. Section 2.2 discusses efficiency measures and the Afriat efficiency index, while Section 3.2 introduces the first new measure, the homothetic efficiency index, and discusses its properties and implications. Section 2.3 discusses a more disaggregate efficiency measure, called the Varian efficiency vector, while Section 3.3 introduces a corresponding measure for homothetic efficiency, called the homothetic efficiency vector. Section 3.4 introduces and discusses a measure of misspecification that measures how much additional adjustment is necessary to make the data fit homothetic utility maximization after accounting for violations of utility maximization. Section 4 uses two datasets to apply the proposed methods. Section 5 concludes. The Appendix contains all proofs.
2. UTILITY MAXIMIZATION AND EFFICIENCY
2.1. Utility Maximization
We use the following notation: For all , x≧y if xi ⩾ yi for all i = 1, …, L; x ⩾ y if x≧y and x ≠ y; and x > y if xi > yi for all i = 1, …, L. We denote
and
. The commodity space is
, and the price space is
, where L ⩾ 2 is the number of different commodities. A (competitive) budget set is defined as
, where
is the price vector, and income is normalized to 1. A demand function
of a consumer assigns to each budget set the commodity bundle chosen by the consumer. Unless otherwise noted, we assume that demand is exhaustive (i.e., pixi = 1). We also assume that the only observables of the model are N ⩾ 1 different budgets and the corresponding demand of a consumer. The entire set of observations on a consumer is denoted Ω = {(xi, pi)}Ni = 1.
The bundle xi is directly revealed preferred to a bundle x, written , if pixi ⩾ pix; it is strictly directly revealed preferred to x, written
, if pixi > pix; and it is revealed preferred to x, written
, if
is the transitive closure of
, that is, if there exists a sequence xj, …, xk, such that
. The bundle xi is strictly revealed preferred to x, written
, if
for some j, k = 1, …, N.
A set of observations Ω satisfies the generalized axiom of revealed preference (GARP) if for all i, j = 1, …, N, it holds that We say that a utility function
rationalizes a set of observations Ω if u(xi) ⩾ u(y) whenever
. Let
denote the set of all continuous, non-satiated, monotonic, and concave utility functions. GARP is easily testable and a necessary and sufficient condition for utility maximization, as Theorem 1 (Afriat’s theorem) shows.
Theorem 1 (Afriat Citation1967; Diewert Citation1973; Varian Citation1982).
The following conditions are equivalent:
| 1. | the set of observations Ω satisfies GARP; | ||||
| 2. | there exist numbers Ui, λi > 0 such that Ui ⩽ Uj + λjpj(xi − xj) for all i, j = 1, …, N; | ||||
| 3. | there exists a | ||||
2.2. The Afriat Efficiency Index
When a set of observations does not satisfy GARP, it is interesting to obtain a measure of how severe the violation is. One of the most popular measures of the severity of a violation is the Afriat efficiency index (AEI) proposed by Afriat (Citation1972), also called the critical cost efficiency index (CCEI). Define, for some e ∈ [0, 1], the relation as
if e pixi ⩾ pix, and let
be the transitive closure of
; furthermore, define the relation
as e pixi > pix. With these concepts, we can define a new version of GARP, called GARP(e).
Definition 1.
A set of observations Ω satisfies GARP(e) for some e ∈ (0, 1] if for all i, j = 1, …, N, it holds that
Definition 2.
For a set of observations Ω, the Afriat efficiency index (AEI) is the greatest number e such that Ω satisfies .
The AEI is a measure of wasted income: if a consumer has an AEI of e < 1, then he could have obtained the same level of utility by spending only a fraction of e of what he actually spent to obtain this level. One way to compute it is to use a binary search algorithm as described by Varian (Citation1990).
For the rationalization results in both this section and the next, we will make use of a concept called e-rationalization and, later, v-rationalization. This concept has recently been introduced by Halevy, Persitz, and Zrill (Citation2015).
Definition 3.
A utility function e-rationalizes a set of observations Ω if u(xi) ⩾ u(y) whenever
.
For e close to 1, a utility function that e-rationalizes a set of data still comes close to explaining the observed choices. It provides a good motivation and justification to compute and report the AEI and our new homothetic efficiency index in the next section.
Theorem 2.
The following conditions are equivalent:
| 1. | the set of observations Ω satisfies GARP(e); | ||||
| 2. | there exist numbers Ui, λi > 0 such that Ui ⩽ Uj + λjpj(xi/e − xj) for all i, j = 1, …, N; | ||||
| 3. | there exists a | ||||
Theorem 2 is a special case of Theorem 3. We therefore only provide a proof of Theorem 3 in the Appendix. In the inequalities of Theorem 2, the only change relative to the inequalities in Theorem 1 is the addition of e, which relaxes the constraints. In that sense, we can also interpret the AEI as an adjustment to the data that is necessary to make the data fit the utility maximization model.
Reporting the AEI has become standard in empirical studies, particularly experimental studies. See, for example, Sippel (Citation1997), Mattei (Citation2000), Harbaugh, Krause, and Berry (Citation2001), Andreoni and Miller (Citation2002), Février and Visser (Citation2004), Choi et al. (Citation2007b), Fisman, Kariv, and Markovits (Citation2007), Dickinson (Citation2009), and Camille et al. (Citation2011). A common alternative to the AEI is the Houtman–Maks-Index (Houtman and Maks Citation1985), which is based on the maximal subset of a set of choices consistent with GARP; for a computationally feasible approach to compute this index, see Heufer and Hjertstrand (Citation2015). Fleissig and Whitney (Citation2005) showed how to statistically test violations of the Afriat inequalities. Echenique, Lee, and Shum (Citation2011) provided a new measure based on a money pump argument, and Dean and Martin (Citation2015) provided a new measure based on the minimum cost of breaking all cycles or money pumps. Apesteguia and Ballester (Citation2015) provided a measure based on welfare loss.
2.3. The Varian Efficiency Vector
The AEI does not provide information about which observed choices are causing the violation of GARP. To obtain such information, we first consider a generalization of GARP(e):
Definition 4.
A set of observations Ω satisfies GARP(v) for some v ∈ (0, 1]N if for all i, j = 1, …, N, it holds that
Such a vector v can be a more disaggregated measure of efficiency. Varian (Citation1993) defined one such measure, the violation index with
If the data satisfy GARP, then
for all i. Otherwise,
for some i, and this provides information regarding which xi are problematic.
Proposition 1 (Varian Citation1993).
A set of observations Ω satisfies GARP().
Varian (Citation1993) also noted that the vector does not, in general, give the minimum perturbation of budgets required. He provides an improved violation index that is computed by an iterative algorithm. See also Cox (Citation1997) for a discussion of the improved violation index. The “exact” efficiency indices can be computed from the inequalities (Equation1
(1)
(1) ) and (Equation2
(2)
(2) ) below by using a simple mixed integer programming problem. To formulate this procedure, we initially make use of the fact that GARP(v) is equivalent to the following inequalities:
(1)
(1)
(2)
(2)
See Cherchye et al. (Citation2015) for a similar approach in the context of testing for weak separability of the utility function. The inequalities in Equations (Equation1(1)
(1) ) and (Equation2
(2)
(2) ) are equivalent to the existence of numbers Vi and Xij such that, for all observations i, j = 1, …, N,
(c.i)
(c.i)
(c.ii)
(c.ii)
(c.iii)
(c.iii)
(c.iv)
(c.iv)
(c.v)
(c.v)
(c.vi)
(c.vi) where Ai > pixi is a fixed number. We suggest calculating the efficiency indices v by solving the following mixed integer linear programming problem (MILP; this type of approach was introduced to the revealed preference literature by Cherchye et al. Citation2008) with respect to Vi, Xij and vi:
(3)
(3)
Since any solution to an MILP problem is a global solution, this problem is guaranteed to find a global optimum (in the L1-norm) in the efficiency indices v. We can now formally define a vector efficiency index.
Definition 5.
For a set of observations Ω, a Varian efficiency vector (VEV) is a vector such that Ω satisfies GARP
and there does not exist
such that Ω satisfies GARP(v′).
When v is computed using the above MILP-approach, it will be a VEV.
The next definition generalizes e-rationalization introduced in Definition 3.
Definition 6.
A utility function v-rationalizes a set of observations Ω if u(xi) ⩾ u(y) whenever
.
Theorem 3.
The following conditions are equivalent:
| 1. | the set of observations Ω satisfies GARP(v); | ||||
| 2. | there exist numbers Ui, λi > 0 such that Ui ⩽ Uj + λjpj(xi/vj − xj) for all i, j = 1, …, N; | ||||
| 3. | there exists a | ||||
Theorem 3 follows from Theorem 1 in Halevy, Persitz, and Zrill (Citation2015). As their theorem does not contain our condition 2 (it can be constructed from the details of their proof), we include a brief proof of our Theorem 3 in the Appendix. Note that the change to the inequalities in Theorem 3 compared to the inequalities in Theorem 2 consists in replacing the blanket adjustment e with an individual adjustment per observation.
3. HOMOTHETIC EFFICIENCY
3.1. Homothetic Utility Maximization
Homotheticity is a restriction on preferences. We say that a utility function is homothetic if it is a positive monotonic transformation of a linearly homogeneous utility function; that is, if u(x) > u(y), then u(αx) > u(αy) for all α > 0. Varian (Citation1983) provided the following axiom, which he shows is equivalent to homothetic rationalization (Theorem 4).
Definition 7 (Varian Citation1983).
A set of observations Ω satisfies the homothetic axiom of revealed preference (HARP) if for all distinct choices of indices i, j, …, ℓ, it holds that (pixj)(pjxk)⋅⋅⋅(pℓxi) ⩾ 1.
Theorem 4 (Varian Citation1983).
The following conditions are equivalent:
| 1. | the set of observations Ω satisfies HARP; | ||||
| 2. | there exist numbers Ui such that Ui ⩽ Ujpjxi for all i, j = 1, …, N; | ||||
| 3. | there exists a homothetic | ||||
We can always assume that a homothetic utility function u is homogeneous of degree 1 such that u(αx) = αu(x). Thus, a homothetic utility maximizer who consumes xi at pi will consume αxi if prices remain constant but his income is multiplied by α. Recall that we normalized prices such that income at the observed consumption is always 1 (i.e., pixi = 1), which implies that α can be interpreted as income. As Varian (Citation1983) explained, “the Ui’s can be interpreted as utility levels and the λi’s can be interpreted as marginal utilities of income at the various levels of observed consumption.” Together, this implies that a homothetic utility maximizer’s marginal utility of income at xi is ∂u(αxi)/∂α = Ui, in which case Ui is equal to λi.
Setting Ui = λi in the inequalities in condition 2 of Theorem 1 gives us Ui ⩽ Uj + Ujpj(xi − xj), and with pixi = 1, we obtain Ui ⩽ Ujpjxi, which are the inequalities in condition 2 of Theorem 4. This relationship has already been identified by Diewert (Citation1973) and was explored in greater detail by Varian (Citation1983).
3.2. The Homothetic Efficiency Index
The challenge is now to define an appropriate measure of homothetic efficiency that corresponds to the AEI and allows the same or a similar interpretation. A straightforward idea would be to multiply the right-hand side in the condition for HARP in Definition 7 by some e ∈ (0, 1], but this is problematic.
Suppose that we have a set Ω = {(xi, pi)}2i = 1, with p1x2 = 8/5 and p2x1 = 2/5, such that HARP is violated. As (8/5)(2/5) = 16/25, we might want to simply multiply the right-hand side of HARP by 16/25 and call this the homothetic efficiency. However, suppose that the same consumer faces the same two budgets again (observed as p3 and p4) and repeats the choices (observed as x3 and x4). Then, (p1x2)(p2x3)(p3x4)(p4x1) = 256/625, and homothetic efficiency would be reduced, even though the lower bound of wasted income did not increase. Repeating this ad infinitum, the efficiency would drop to zero, even though the consumer clearly enjoys a good amount of utility. Thus, we need to account for the number of choices that go into the left-hand side of HARP. We therefore suggest using the following axiom, called HARP(e), which takes into account the number of scalars that are multiplied.
Definition 8.
A set of observations Ω satisfies HARP(e) for some e ∈ (0, 1] if for all distinct choices of indices i, j, k, …, ℓ, it holds that
Theorem 5 confirms that this definition is a good analog for GARP(e).
As an illustration, consider the situation in (a), which shows two observations. The dashed line shows the boundary of the shifted budget B1 that contains x2. The intersection of the dashed line and the ray through the origin and x1, shown as λx1, gives the demand on the shifted budget if preferences are homothetic. Here, λ is equal to p1x2. Clearly, if the dashed budget were observed and λx1 were chosen, it would be revealed preferred to x2. However, as λx1 is in the interior of budget B2, x2 is strictly revealed preferred to λx1; thus, HARP is violated.
Figure 1. (a) and (b) An illustration of HARP(e) and the homothetic efficiency index (HEI). The example uses x1 = (2, 4), p1 = (1/10, 1/5), x2 = (8, 4), and p2 = (1/10, 1/20). The greatest e for which is satisfied is 4/5. (c) The choices x1 and x2 violate GARP. If x1 is replaced by x′1, the AEI will decrease. (d) The choices x1 and x2 violate HARP but not GARP. If x1 is replaced by x′1, the HEI will decrease.
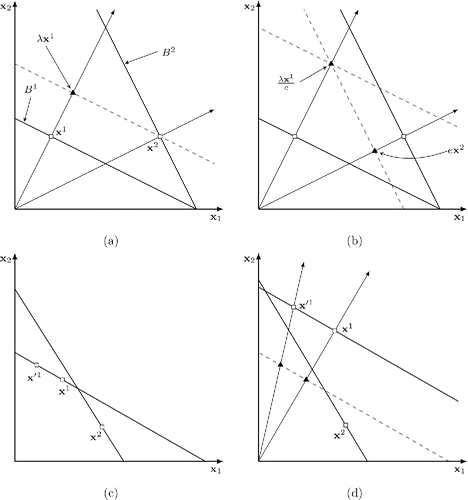
(b) shows that if x1 is scaled upward by a factor equal to λ/e, we find that while x2 is still strictly revealed preferred to it——it is not strictly revealed preferred at efficiency level e—
. This is the smallest e for which ex2 is not strictly revealed preferred to λx1/e and is indeed the smallest e for which HARP(e) is satisfied.
Given HARP(e), we propose the following definition, which is analogous to that of the AEI:
Definition 9.
For a set of observations Ω, the homothetic efficiency index (HEI) is the greatest e ∈ (0, 1] such that Ω satisfies HARP(e).
Note that the HEI cannot increase as the number of observations increases; it can only decrease as more observations are added. This is because the HEI is the minimum over all simple cycles in the data (such as going from xi to itself in the definition of HARP(e)). The cycle that determined the old minimum remains in the data as more observations are added. The HEI can be computed with the same algorithm used for calculating the AEI (simply exchange GARP(e) for HARP(e) in the algorithm) and can be reported as a summary statistic.
Analogous to Theorem 2, the following theorem shows that HARP(e) is necessary and sufficient for homothetic e-rationalization. It serves as our main justification for the definition of the HEI.
Theorem 5.
For any e ∈ (0, 1] the following conditions are equivalent:
| 1. | the set of observations Ω satisfies HARP(e); | ||||
| 2. | there exist numbers Ui such that Ui ⩽ Ujpjxi/e for i, j = 1, …, N; | ||||
| 3. | there exists a homothetic | ||||
Theorem 5 is a special case of Theorem 6. We therefore only provide a proof of Theorem 6 in the Appendix. Theorem 5 also shows why we can still interpret the HEI as a measure of wasted income, just as the AEI. Suppose that a homothetic utility function u e-rationalizes Ω, but u(y) > u(xi) despite that . This contradiction of the ranking of bundles by u with
disappears if we assume that the consumer wasted a fraction e of his income because, by e-rationalization, we must have
.
We again observe that the addition of e to the inequalities in Theorem 5 provides a less stringent version of the inequalities in Theorem 4. Thus, as we can interpret the AEI as an adjustment to the data that is necessary to make them fit the utility maximization model, we can interpret the HEI as an adjustment necessary to make them fit the homothetic utility maximization model.
Beyond the findings in Theorem 5, it is interesting to consider other properties of the HEI. Jerison and Jerison (Citation2012) listed six desirable properties for measures of inconsistency. Let us define (
) as the measures of inconsistency with (homothetic) utility maximization corresponding to the respective efficiency measures. Both these measures satisfy all six properties: both are (a) “well defined for any demand set;” are (b) zero when GARP (HARP) is satisfied and positive otherwise; (c) “increase (or at least do not decrease) when inconsistency seems clearly to increase;” are (d) a “continuous function of prices and quantities demanded;” are (e) “independent of commodity units;” and are (f) “unaffected by changes in prices and incomes that leave all budget sets and consumption choices unchanged.”
Jerison and Jerison (Citation2012) noted that these conditions hold for the AEI. It can be relatively easily verified that the conditions also hold for the HEI. Property (a) holds because e can be set to be arbitrarily close to zero for HARP(e), and (b) holds because the HEI is equal to 1 if HARP is satisfied and less than 1 otherwise. Definition 8 demonstrates that (d) holds because the value of the greatest e for which the inequalities hold must change continuously in changes of the values of the pixj, pjxk, …. Properties (e) and (f) are automatically satisfied given our normalization in Section 2.1, but it can be easily verified that they also hold for a nonnormalized version.
For property (c), Jerison and Jerison (Citation2012) provided a figure, the relevant part of which is reproduced in (c). They state that an inconsistency measure should increase when x1 is replaced by x′1, which is the case for both the measures based on the AEI and the HEI. In addition, (d) illustrates that this is still the case for the HEI when one of the budgets and the choices are scaled up such that the GARP violation is resolved and only the HARP violation remains.
3.3. The Homothetic Efficiency Vector
Similar to the case of the AEI, the HEI is only a lower bound on homothetic efficiency. A homothetic efficiency vector that provides information about how much each budget has to be perturbed to achieve a meaningful kind of consistency while keeping the perturbations minimal would be informative and useful for applied work. We suggest the following straightforward generalization of HARP(e).
Definition 10.
A set of observations Ω satisfies HARP(h) for some h = (h1, …, hN) ∈ (0, 1]N if for all i, j = 1, …, N, it holds that
(4)
(4)
Analogous to Theorem 3, the following theorem shows that HARP(h) is necessary and sufficient for homothetic v-rationalization, or h-rationalization as we call it here.
Theorem 6.
For any h = (h1, …, hN) ∈ (0, 1]N, the following conditions are equivalent:
| 1. | the set of observations Ω satisfies HARP(h); | ||||
| 2. | there exist numbers Ui such that for i, j = 1, …, N
| ||||
| 3. | there exists a homothetic | ||||
The proof of Theorem 6 can be found in the Appendix. Given HARP(h), we propose the following definition, which is analogous to that of the VEV:
Definition 11.
For a set of observations Ω, a homothetic efficiency vector (HEV) is a vector h such that Ω satisfies HARP(h) and there does not exist a h′ ⩾ h such that Ω satisfies HARP(h′).
The problem with computing a vector h with maximal values is that “breaking cycles” is not as easy as in the standard case in Varian (Citation1993). It is not feasible to consider breaking “homothetically revealed preference cycles.” This would amount to solving the NP-hard problem of finding a simple shortest path in a weighted complete graph (i.e., a path that visits each vertex at most once, except for the first vertex if the path is a cycle). The complexity of this endeavor quickly approaches a level that makes computation infeasible. However, it is possible to compute a first-order approximation of the HEV in polynomial time. To see how, we define κi = log (hi) for all i = 1, …, N and note that a first-order Taylor expansion of log (hi) about point 1 yields log (hi) ≃ −(1 − hi), such that
(6)
(6) The left-hand side of the inequalities in Equation (Equation5
(5)
(5) ) is positive, implying that they can be equivalently rewritten as follows (by log-linearization):
(7)
(7) for all i, j = 1, …, N, where ui = log (Ui) and κj = log (hj). Consider the following linear program (solved with respect to κi ∈ ( − ∞, 0] and ui ∈ ( − ∞, ∞) for all i = 1, …, N):
(8)
(8) and define the optimal solutions from this problem as
for all i = 1, …, N. Given the Taylor approximation in Equation (Equation6
(6)
(6) ), the set of numbers
is a first-order approximation to the HEV (in the L1-norm).
Since ∑Ni = 1log (hi) is a monotonic log-transformation of ∏Ni = 1hi, the linear problem in Equation (Equation8(8)
(8) ) is equivalent to solving
(9)
(9) This shows that the problem in Equation (Equation8
(8)
(8) ) does not compute the set of indices closest to the unit vector in a “true” norm. However, solving the problem in Equation (Equation8
(8)
(8) ) has several advantages over, for example, computing the HEV in the Minkowski norm, which would amount to solving the following problem:
subject to Equation (Equation5
(5)
(5) ) for some ϕ ⩾ 1 (the L1-norm corresponds to setting ϕ = 1). First, it is a computationally tractable procedure for large datasets since it can be solved with elementary linear programming techniques, that is, in polynomial time (which is not the case for any optimization problem based on, e.g. the Minkowski norm).
Second, because the Taylor approximation is taken about point 1, a strong theoretical justification for using the first-order approximation is that it should perform very well when the “true” HEV is close to the unit vector. The empirical applications in Section 4 show that homothetic efficiency is indeed close to the unit vector in many cases. Thus, we expect the linear problem in Equation (Equation8(8)
(8) ) to provide a good approximation of the HEV. Third, rephrasing a potentially intractable problem based on a first-order approximation is a commonly used procedure to find maximal elements in constrained optimization problems.
3.4. Missoptimization and Misspecification
As argued above, efficiency measures can be interpreted as the minimal adjustment necessary to make the data fit a particular model. As homotheticity imposes stronger restrictions on demand than utility maximization, adjustment by the HEI and HEV already accounts for any deviation from utility maximization. Indeed, let eA be the AEI and eH the HEI, and we must have eH ⩽ eA, and therefore, the data will always satisfy GARP(eH).
To learn something about the additional requirement imposed by homotheticity, it would be useful to have a measure that only takes into account the additional inefficiency due to the assumption of homotheticity, that is, a measure that controls for the inefficiency already contained in the data due to the violation of GARP. That would provide us with measures of missoptimization and new measures of misspecification, which tells us how well the data fit the specific assumption of homotheticity after accounting for missoptimization.
Using the results of Theorem 2, the AEI can be computed by setting up a linear program to maximize e subject to the existence of numbers Ui, λi > 0 such that Ui ⩽ Uj + λjpj(xi/e − xj). Analogously, the HEI can be computed by setting up a linear program to maximize e subject to the existence of numbers Ui such that Ui ⩽ Ujpjxi/e. Recall that we obtain the latter set of inequalities in the same way as the AEI by setting Ui = λi and using the normalization pixi = 1.
As we know by the AEI that there exist numbers Ui, λi > 0 such that Ui ⩽ Uj + λjpj(xi/eA − xj), we suggest using these adjusted inequalities and imposing the homotheticity restrictions Ui = λi on them. Thus, we obtain Ui ⩽ Uj + Ujpjxi/eA − Ujpjxj, and with the normalization pixi = 1, this reduces to Ui ⩽ Ujpjxi/eA. We can then proceed to add a second index in the same way as we added the original homothetic efficiency index, that is, we can maximize subject to the existence of numbers Ui such that
. This is equivalent to finding the greatest
such that HARP
is satisfied.
It is easy to see that this procedure will set (i.e., the original HEI divided by the original AEI). Thus
is the additional adjustment required to make data that have already been adjusted to fit the utility maximization model also fit the homothetic utility maximization model. We can then interpret 1 − eH/eA as a measure of misspecification (or additional inefficiency). Interestingly, 1 − eH/eA can be written as (eA − eH)/eA, that is, the difference between the AEI and the HEI normalized by the AEI. The same concept can be applied to the vector efficiencies.
Definition 12.
The misspecification index (MSI) is the normalized difference between the AEI eA and the HEI eH:
The MSI based on vector efficiency (MSIV) is the average normalized difference between individual entries of the VEV v = (v1, …, vN) and the HEV h = (h1, …, hN):
Similar to the AEI and HEI, there is no natural acceptable value for the misspecification index. Perhaps Varian’s (Citation1993) possibly tongue-in-cheek suggestion of using an AEI of 0.95 as the critical value—“for sentimental reasons”—is not a bad idea, and analogously, we suggest using an MSI and MSIV of 0.05 as a focal point. In any case, the measures will provide the researcher with information about the (relative) performance of different models. We will report results for both the MSI and the MSIV for the two different datasets we analyze in Section 4.
4. APPLICATIONS
Our aim with this empirical exercise is to show that homothetic efficiency can be high for consumer choice data and that data that are adjusted by the HEV or HEI can have much higher discriminatory power against random behavior than data adjusted by the VEV or AEI. This is particularly true for the survey dataset we analyze in Section 4.1. However, our results from the experimental data in Section 4.2 are less unequivocal. While homothetic utility maximization is a good approximation for some subjects, others exhibit choices that are arguably too far removed from homotheticity to apply the model of homothetic utility maximization. This demonstrates the importance of testing for homotheticity and computing homothetic efficiency before estimating homothetic utility functions.
4.1. Survey Data: Household Expenditures
We illustrate our methods using data from the Spanish Continuous Family Expenditure Survey (Encuesta Continua de Presupuestos Familiares, abbreviated ECPF). These data were obtained from Crawford (Citation2010) and come from a quarterly budget survey, over the period 1985–1997, that interviews Spanish households about their consumption expenditures for up to a maximum of eight consecutive quarters. See also Browning and Collado (Citation2001) for a detailed discussion of the data. We use a subsample of couples with and without children, where the husband is employed full-time and the wife is out of the labor force. We focus exclusively on consumption expenditures on nondurable consumption categories. Overall, we use data containing 21,866 observations on 3134 households.
We begin the analysis by calculating the AEI, HEI, VEV, and HEV for each household. The HEV is computed by solving the linear problem in Equation (Equation8(8)
(8) ). To facilitate comparison with the VEV, we calculated the VEV by slightly modifying the problem in Equation (Equation3
(3)
(3) ). This corresponds to how the HEV is computed and is achieved by first log-linearizing the constraints (Equationc.i
(c.i)
(c.i) )–(Equationc.vi
(c.vi)
(c.vi) ) and then maximizing
, where
. We also computed the VEV in the L1-norm by solving the problem in Equation (Equation3
(3)
(3) ). Interestingly, we obtained practically identical solutions, which suggests that log-linearization provides a very good approximation (see the discussion in Section 3.3).
The results are presented in , where each row reports the mean, minimum, the first, second (median) and third quartiles and the maximum calculated across all households. The entries for the VEV and HEV in the third and fourth rows are averages across all households. For example, to obtain the entry “min,” we first computed min {v1, …, vN} and min {h1, …, hN} for each household and then calculated the mean of these values over all households.
Table 1. Efficiency and misspecification measures (ECPF)
As can be seen, homothetic efficiency is very close to utility maximization efficiency. For example, the mean across all observations and households of the HEV is 0.9960 (compared to the 1.0000 for the VEV). The same table also reports the misspecification measures MSI and MSIV described in Section 3.4. Evidently, the additional adjustment necessary to make the data fit the homothetic model is very limited, which is unsurprising given the very high levels of homothetic efficiency. Based on the measures reported in , we can conclude that homothetic utility maximization performs very well.
The next consideration is test power. The standard approach to calculating the power of revealed preference tests is based on Bronars (Citation1987). We follow Bronars’ approach and generate many random choice sets that are uniformly distributed on the budget sets and compute the fraction of sets that either violate GARP or HARP, which we refer to as the power of GARP and HARP, respectively.
To analyze the loss in power for expenditure-adjusted data, we employ the following three-step procedure: (i) we compute the efficiency index using the observed data; then, (ii) we generate random datasets using Bronars’ approach; and, finally, (iii) we calculate the fraction of sets violating GARP or HARP, where expenditures are adjusted for efficiency. More precisely, we deflate expenditures by the efficiency index computed in the first step when testing whether the randomly generated datasets satisfy GARP or HARP. Repeating the three-step procedure for all four efficiency indices AEI, VEV, HEI, and HEV allows us to compare the loss in discriminatory power across the indices and to analyze the potential loss in power from adjusting expenditures by efficiency.
reports the power of GARP and HARP depending on how expenditures are adjusted. As discussed in the introduction, allowing for deviations from 100% efficiency often leads to a loss in power, which may render the analysis practically meaningless. As seen from , this concern is clearly warranted for utility maximization alone. Indeed, the first, third, and fifth rows show that utility maximization alone barely has any power against uniformly random behavior (the power for the average household is less than 9%) This means that GARP is essentially unable to reject random consumption behavior. In contrast, the second, fourth, and sixth rows show that HARP has substantially more power against uniformly random behavior. Although there is a loss in power for HARP for some households when expenditures are adjusted by the HEV, 50% of the households nevertheless have a power of at least 73%. Notably, the sixth row shows that the loss in power for HARP is negligible when adjusting expenditures by the HEV. More precisely, adjusting income by the HEV has little effect on power, which rather forcefully addresses the concern that adjusting expenditures by efficiency in revealed preference testing renders the analysis meaningless.
Table 2. Power for GARP and HARP (ECPF)
The main conclusions that can be drawn from our results thus far are as follows, (i) The consumption choices of the households are very close to satisfying homothetic preferences (i.e., the households have high homothetic efficiency, and the misspecification is low), and (ii) homotheticity can have much higher discriminatory power against random behavior than utility maximization alone. In fact, the vast majority of households have very high power against random behavior even when expenditures are adjusted by homothetic efficiency.
However, this is a sequential analysis and, as such, fails to give any indication of the trade-off between efficiency and power. Beatty and Crawford (Citation2011) and Heufer (Citation2012) suggested combining efficiency and power into a single measure based on the idea of predictive success originally advanced by Selten (Citation1991) (see also Heufer (Citation2008) for an early application of the trade-off approach to compare two different efficiency indices). Beatty and Crawford’s (Citation2011) measure is computed as the difference between the pass rate and one minus the power. The outcome of this measure is a value between negative one and one. Negative values would suggest that the model fails to describe the preferences of the household: the model does not pass the revealed preference axiom and provides low discriminatory power against random behavior. In contrast, a high and positive predictive success indicates a potentially useful model: it passes the revealed preference axiom and has high power against random behavior.
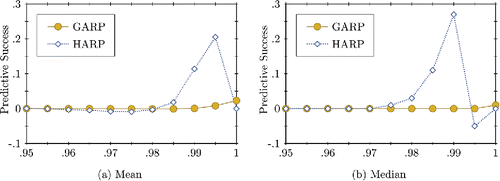
Following Beatty and Crawford (Citation2011) and Heufer (Citation2012), we can use the predictive success to find the optimal level of efficiency across the households as follows. For a given efficiency level e, first calculate HARP(e), which gives the pass rate (either zero or one). Second, calculate the power using HARP(e). Doing so for an arbitrarily fine grid gives the predictive success at each efficiency level. The optimal efficiency level is the one that produces the highest predictive success. presents the results from this analysis. (a) shows the average predictive success across all households for each efficiency level in the grid. As seen from this plot, GARP obtains a maximal predictive success very close to zero at an efficiency level of one. One interpretation of this is that the theory of utility maximization performs about as well as a theory that explains consumer demand as purely random behavior. The results for HARP are quite different. We find that the maximal average predictive success across households is 0.22 obtained at an efficiency level of 0.995. Thus, according to these results, homothetic utility maximization provides a considerably better fit to the data than utility maximization alone at an efficiency level only slightly below one. The results for the median of the predictive success across all households shown in (b) are even more favorable to homothetic utility maximization. In this case, the predictive success is essentially zero for GARP at all efficiency levels but close to 0.3 at an efficiency level of 0.99 for HARP.
Figure 2. Measure of predictive success across all households for each efficiency level in the grid (ECPF).
4.2. Experimental Data: Preferences for Giving
Fisman, Kariv, and Markovits (Citation2007, FKM) analyzed data obtained in a laboratory experiment. They employed the same setup as Andreoni and Miller (Citation2002, AM), that is, a generalized dictator game in which one subject (the dictator) allocates token endowments between himself and an anonymous other subject with different transfer rates. The payoffs of the dictator and the beneficiary are interpreted as two distinct goods and the transfer rates are interpreted as the price ratio. In both papers, the authors estimate CES utility functions, and thus, they implicitly maintain the hypothesis that choices are homothetic. Testing how “close” the choices are to homotheticity is therefore important and should be conducted at least as a pretest to screen out particularly inefficient choices.
Heufer (Citation2013) computed a simple two-dimensional version of homothetic efficiency for both the FKM and the AM data. We only focus on the FKM data here, as they contain 50 choices per subject as opposed to 8 in the AM data. Note that subjects were not required to spend their entire endowment, and a few subjects occasionally chose bundles somewhat below the budget line. One subject made several choices far below the budget line, leading to an AEI and HEI of approximately 0.1, which caused convergence problems for the computation of the VEV. We therefore decided to exclude that subject from the analysis. The results for our measures are presented in .
Table 3. Efficiency and misspecification measures (FKM)
Regarding the first two rows, we find that the AEI is noticeably higher than the HEI for most subjects. However, as discussed above, the AEI and HEI are summary statistics and may be uninformative in describing the entire distribution of the indices. The third and fourth rows of , which provide the results for the VEV and HEV, offer a different picture. These results suggest that homothetic efficiency is close to utility maximization. In particular, the HEV displays the same pattern as the VEV. They are both characterized by one or a few observations with lower values, while the remaining values in the vector are very close to one.
also reports the misspecification measures. If we accept the value of 0.05 suggested in Section 3.4 as the threshold, we find that based on the MSI, slightly less than half of all subjects fit the homothetic utility maximization model well. Again, the picture given by the vector-based MSIV is different; it suggests that more than 75% of all subjects fit the homothetic utility maximization model well.
reports the power of GARP and HARP. The results, in particular for GARP, are very different from the results for the ECPF data in . For the experimental data, the test power for most subjects is very high, while for the household survey data, the test power for GARP is low enough to prevent a meaningful test for utility maximization. As the subjects made choices on 50 budgets, this finding is perhaps unsurprising. Thus, imposing additional restrictions on utility, such as homotheticity, may not be essential for an informative analysis.
Table 4. Power for GARP and HARP (FKM)
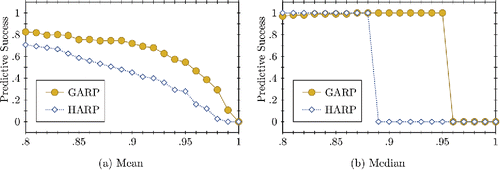
With little to no difference in test power between GARP and HARP, and the fact that homothetic efficiency can never be higher than Afriat efficiency, we cannot expect the predictive success of the homothetic model to be superior. (a) shows that for the average subject, the predictive success of the homothetic utility maximization model is lower for all efficiency levels below one. (b) shows that up until an efficiency level of 0.86, the median predictive success is slightly higher for HARP, but it drops to zero at a level of 0.89, while the predictive success of GARP is 1 for levels between 0.87 and 0.95, after which it drops to zero. This drop to zero occurs because less than half of subjects have an HEI greater than 0.89, or an AEI greater than 0.96.
Figure 3. Measure of predictive success across all subjects for each efficiency level in the grid (FKM).
The conclusions we can draw from the analysis of the experimental data are not as unambiguous as those from the household survey data. Approximately, 50%–75% of the subjects have rather high homothetic efficiency levels and low misspecification values. For these subjects, the measures we have introduced indicate no problems with estimating a homothetic utility function. However, this also means that assuming homothetic preferences and estimating CES utility functions may be problematic for the remaining subjects. Imposing homotheticity on the data to have a model with higher test power seems unnecessary for this dataset, and from the perspective of predictive success, the model of utility maximization alone performs slightly better.
We can think of at least two potential reasons for the differences between the survey and experimental data. First, social preferences are likely to be more context specific (see, e.g., Eckel and Grossman Citation1996), and different wealth levels can be considered a context. Our findings are in line with the results reported by Heufer (Citation2013), who found that many subjects in Fisman, Kariv, and Markovits (Citation2007) deviate substantially from homotheticity. This deviation is more pronounced than in the experiment by Choi et al. (Citation2007a), which uses a similar methodology but is about risk aversion.
Second, Fisman, Kariv, and Markovits (Citation2007) selected normalized prices that vary substantially—they were between 1/50 and 1/100. This resulted in stark differences in the wealth levels between budgets. However, prices and expenditures varied very little in the survey data, which is natural given that prices for everyday goods and income levels do not typically change substantially. It is plausible for such data that after a small increase in income, a household will not drastically reallocate relative expenditures.
5. CONCLUSION
Consumer choice data often violate homothetic utility maximization. In such cases, it would be interesting to know how closely the data approach homothetic utility maximization. For this purpose, we introduced a nonparametric approach to estimating homothetic efficiency of demand data by generalizing Heufer’s (Citation2013) method. We introduced the homothetic efficiency index (HEI) and the homothetic efficiency vector (HEV), which are analogous to the Afriat efficiency index (AEI) and Varian’s improved violation index or Varian efficiency vector (VEV). As with the AEI, the HEI can be interpreted as a measure of wasted income. As a nonparametric approach, our method does not rely on any specific form of a utility function.
Both the HEI and the HEV can be used to adjust data by deflating expenditures to reconstruct bounds on preferred and worse sets. This is motivated by a concept called e- and h-rationalization, which was recently introduced by Halevy, Persitz, and Zrill (Citation2015): for efficiency close to 100%, there still exists a utility function that adequately explains the data as the result of homothetic utility maximization with only minor deviation.
We applied the method to two datasets. The application demonstrates how a dataset that has very low power against the alternative hypothesis of random behavior can still be useful when testing for the stronger condition of homothetic utility maximization. Using the measure of predictive success applied to household survey data, we find that homothetic utility maximization can be considerably more successful in explaining the demand behavior for efficiency levels close to one. However, this is not the case for all types of datasets. For data from a laboratory experiment that already had high test power, the model of utility maximization alone performs slightly better from the perspective of predictive success.
The approach can also be translated to production analysis. Hanoch and Rothschild (Citation1972) and Varian (Citation1984) already described nonparametric ways to test production for homotheticity. As homotheticity of production is assumed in many applications, a nonparametric test that provides a measure of homothetic efficiency independent of a specific production function should at the very least be a useful screening device and robustness check before parameters of a homothetic production function are estimated.
We expect that our results will help to analyze experimental, survey, and field data. It will be worthwhile to test the assumption of homotheticity before estimating homothetic utility functions, to quantify the extent of the violation of homotheticity, and to obtain high test power against the alternative hypothesis of random behavior.
Supplementary Materials
A zip file containing all necessary Matlab codes to replicate the empirical applications is available online.
UBES_A_1319372_Supplement.zip
Download Zip (476 KB)ACKNOWLEDGMENTS
Access to data collected by Raymond Fisman, Shachar Kariv, and Daniel Markovits is gratefully acknowledged. Thanks to an associate editor, the editor, and Linda Hirt-Schierbaum for helpful comments. Thanks to two anonymous referees for comments and suggestions that greatly improved the article.
Related Research Data
REFERENCES
- Afriat, S. N. (1967), “The Construction of Utility Functions From Expenditure Data,” International Economic Review, 8, 67–77.
- ——— (1972), “Efficiency Estimation of Production Functions,” International Economic Review, 13, 568–598.
- Alston, J. M., Carter, C. A., Green, R., and Pick, D. (1990), “Whither Armington Trade Models?” American Journal of Agricultural Economics, 72, 455–467.
- Andreoni, J., and Miller, J. (2002), “Giving According to GARP: An Experimental Test of the Consistency of Preferences for Altruism,” Econometrica, 70, 737–753.
- Apesteguia, J., and Ballester, M. A. (2015), “A Measure of Rationality and Welfare,” Journal of Political Economy, 123, 1278–1310.
- Beatty, T. K. M., and Crawford, I. A. (2011), “How Demanding is the Revealed Preference Approach to Demand?” American Economic Review, 101, 2782–2795.
- Blundell, R., Browning, M., and Crawford, I. (2003), “Nonparametric Engel Curves and Revealed Preference,” Econometrica, 71, 205–240.
- Bronars, S. G. (1987), “The Power of Nonparametric Tests of Preference Maximization,” Econometrica, 55, 693–698.
- Browning, M., and Collado, M. D. (2001), “The Response of Expenditures to Anticipated Income Changes: Panel Data Estimates,” American Economic Review, 91, 681–692.
- Camille, N., Griffiths, C. A., Vo, K., Fellows, L. K., and Kable, J. W. (2011), “Ventromedial Frontal Lobe Damage Disrupts Value Maximization in Humans,” The Journal of Neuroscience, 31, 7527–7532.
- Cherchye, L., De Rock, B., Sabbe, J., and Vermeulen, F. (2008), “Nonparametric Tests of Collectively Rational Consumption Behavior: An Integer Programming Procedure,” Journal of Econometrics, 147, 258–265.
- Cherchye, L., Demuynck, T., De Rock, B., and Hjertstrand, P. (2015), “Revealed Preference Tests for Weak Separability: An Integer Programming Approach,” Journal of Econometrics, 186, 129–141.
- Choi, S., Fisman, R., Gale, D., and Kariv, S. (2007a), “Consistency and Heterogeneity of Individual Behavior under Uncertainty,” American Economic Review, 97, 1921–1938.
- ——— (2007b), “Revealing Preferences Graphically: An Old Method Gets a New Tool Kit,” American Economic Review, 97, 153–158.
- Cox, J. (1997), “On Testing the Utility Hypothesis,” The Economic Journal, 107, 1054–1078.
- Crawford, I. (2010), “Habits Revealed,” The Review of Economic Studies, 77, 1382–1402.
- Dean, M., and Martin, D. (2015), “Measuring Rationality With the Minimum Cost of Revealed Preference Violations,” working paper.
- Dickinson, D. L. (2009), “Experiment Timing and Preferences for Fairness,” The Journal of Socio-Economics, 38, 89–95.
- Diewert, W. E. (1973), “Afriat and Revealed Preference Theory,” Review of Economic Studies, 40, 419–425.
- ——— (1976), “Exact and Superlative Index Numbers,” Journal of Econometrics, 4, 115–145.
- Echenique, F., Lee, S., and Shum, M. (2011), “The Money Pump as a Measure of Revealed Preference Violations,” Journal of Political Economy, 119, 1201–1223.
- Eckel, C. C., and Grossman, P. J. (1996), “Altruism in Anonymous Dictator Games,” Games and Economic Behavior, 16, 181–191.
- Février, P., and Visser, M. (2004), “A Study of Consumer Behavior Using Laboratory Data,” Experimental Economics, 7, 93–114.
- Fisman, R., Kariv, S., and Markovits, D. (2007), “Individual Preferences for Giving,” American Economic Review, 97, 1858–1876.
- Fleissig, A. R., and Whitney, G. A. (2005), “Testing for the Significance of Violations of Afriat’s Inequalities,” Journal of Business and Economic Statistics, 23, 355–362.
- Halevy, Y., Persitz, D., and Zrill, L. (2015), “Parametric Recoverability of Preferences,” working paper.
- Hands, D. W. (2016), “The Individual and the Market: Paul Samuelson on (homothetic) Santa Claus Economics,” The European Journal of the History of Economic Thought, 23, 425–452.
- Hanoch, G., and Rothschild, M. (1972), “Testing the Assumptions of Production Theory: A Nonparametric Approach,” Journal of Political Economy, 80, 256–275.
- Harbaugh, W. T., Krause, K., and Berry, T. R. (2001), “GARP for Kids: On the Development of Rational Choice Behavior,” American Economic Review, 91, 1539–1545.
- Heufer, J. (2008), “A Geometric Measure for the Violation of Utility Maximization,” Ruhr Economic Papers, #69, TU Dortmund University, Discussion Paper.
- ——— (2012), “Testing for Utility Maximization With Error and the Loss of Power,” German Economic Review, 13, 161–173.
- ——— (2013), “Testing Revealed Preferences for Homotheticity With Two-Good Experiments,” Experimental Economics, 16, 114–124.
- Heufer, J., and Hjertstrand, P. (2015), “Consistent Subsets: Computationally Feasible Methods to Compute the Houtman-Maks-Index,” Economics Letters, 128, 87–89.
- Houtman, M., and Maks, J. (1985), “Determining All Maximal Data Subsets Consistent With Revealed Preference,” Kwantitatieve Methoden, 19, 89–104.
- Jerison, M., and Jerison, D. (2012), “Real Income Growth and Revealed Preference Inconsistency,” working paper.
- Knoblauch, V. (1993), “Recovering Homothetic Preferences,” Economics Letters, 43, 41–45.
- Liu, P.-W., and Wong, K.-C. (2000), “Revealed Homothetic Preference and Technology,” Journal of Mathematical Economics, 34, 287–314.
- Mattei, A. (2000), “Full-Scale Real Tests of Consumer Behavior Using Experimental Data,” Journal of Economic Behavior & Organization, 43, 487–497.
- Samuelson, P. A. (1938), “A Note on the Pure Theory of Consumer’s Behavior,” Economica, 5, 61–71.
- Selten, R. (1991), “Properties of a Measure of Predictive Success,” Mathematical Social Sciences, 21, 153–167.
- Serletis, A., and Rangel-Ruiz, R. (2005), “Microeconometrics and Measurement Matters: Some Results From Monetary Economics for Canada,” Journal of Macroeconomics, 27, 307–330.
- Sippel, R. (1997), “An Experiment on the Pure Theory of Consumer’s Behavior,” The Economic Journal, 107, 1431–1444.
- Swofford, J. L., and Whitney, G. A. (1987), “Nonparametric Tests of Utility Maximization and Weak Separability for Consumption, Leisure and Money,” Review of Economics and Statistics, 69, 458–464.
- ——— (1988), “A Comparison of Nonparametric Tests of Weak Separability for Annual and Quarterly Data on Consumption, Leisure, and Money,” Journal of Business and Economic Statistics, 6, 241–246.
- ——— (1994), “A Revealed Preference Test for Weakly Separable Utility Maximization With Incomplete Adjustment,” Journal of Econometrics, 60, 235–249.
- Varian, H. R. (1982), “The Nonparametric Approach to Demand Analysis,” Econometrica, 50, 945–972.
- ——— (1983), “Non-Parametric Tests of Consumer Behaviour,” Review of Economic Studies, 50, 99–110.
- ——— (1984), “The Nonparametric Approach to Production Analysis,” Econometrica, 52, 579–597.
- ——— (1990), “Goodness-of-Fit in Optimizing Models,” Journal of Econometrics, 46, 125–140.
- ——— (1993), Goodness-of-Fit for Revealed Preference Tests, Working Paper, University of Michigan.
APPENDIX A: PROOFS
Proof of Theorem 3.
The equivalence of (1) and (3) is part of Theorem 1 by Halevy, Persitz, and Zrill (Citation2015). The inequalities of condition (2) can be constructed from the details of their proof. In particular, they showed that GARP(v) implies the existence of a function f(x) = min i{fi + λizi(x)} with λi > 0 and f(xi) ⩾ fi. They then defined zi(x) = pix/vi − pixi if x ≠ xi and zi(x) = 0 otherwise and show that with this zi(x), f(x) v-rationalizes Ω. By the definition of f, we then have f(x) ⩽ fi + λipi(x/vi − xi) for all i. With zi(xi) = 0 we have f(xi) ⩽ fi, and together with f(xi) ⩾ fi this implies f(xi) = fi. With fi = Ui, this function can be constructed using the numbers from our condition 2, and as it rationalizes Ω, condition (2) implies (3). Furthermore, if the function exists, the numbers in the inequalities can be taken from the function. As GARP(v) ensures the existence of the function, condition (1) implies (2), which completes the proof.
Proof of Theorem 6.
(1) ⇒ (2): The proof follows Varian (Citation1983) with some adjustments. Parts of it are necessary for the next step, which is why a brief version is included here. Assume HARP(h) holds. Define
(A.1)
(2) ⇒ (3): Define U(x) = min j{Ujpjx/hj} with the Uj defined as in the previous step of the proof. It can be easily verified that
(3) ⇒ (1): This part follows from Varian (Citation1983) with minor obvious adjustments.