
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We develop a method for constructing prediction intervals for a nonstationary variable, such as GDP. The method uses a Factor Augmented Regression (FAR) model. The predictors in the model include a small number of factors generated to extract most of the information in a set of panel data on a large number of macroeconomic variables that are considered to be potential predictors. The novelty of this article is that it provides a method and justification for a mixture of stationary and nonstationary factors as predictors in the FAR model; we refer to this as mixture-FAR method. This method is important because typically such a large set of panel data, for example the FRED-QD, is likely to contain a mixture of stationary and nonstationary variables. In our simulation study, we observed that the proposed mixture-FAR method performed better than its competitor that requires all the predictors to be nonstationary; the MSE of prediction was at least 33% lower for mixture-FAR. Using the data in FRED-QD for the United States, we evaluated the aforementioned methods for forecasting the nonstationary variables, GDP and Industrial Production. We observed that the mixture-FAR method performed better than its competitors.
1 Introduction
Construction of valid probability forecasts of key economic variables, such as GDP and Inflation, is central to making reliable economic policy decisions. There is a large body of literature on constructing probability forecasts for a stationary variable using other stationary variables as predictors. By contrast, the literature on making probability forecasts for a nonstationary variable using a mixture of stationary and nonstationary predictors remains underdeveloped. In a method that has attracted considerable attention, a two-step method involving a factor model for panel data and a regression model for predicting the time series are used jointly (Stock and Watson 2002a). In the first step, the factor model is used for generating a small number of factors to capture most of the information in a set of panel data for a large number of potential predictors. In the second step, the regression model uses the generated factors as predictors, instead of the large number of potential predictors in the panel data. The resulting regression model is known as Factor Augmented Regression (FAR) model, which is one of the well-known models for constructing probability forecasts for a time series (Bernanke, Boivin, and Eliasz Citation2005; Stock and Watson Citation1998a, 1998b, 2002b). The large number of economic variables that are potential predictors typically includes a mixture of stationary and nonstationary variables. Consequently, the collection of factors is also typically a mixture of stationary and nonstationary ones (Bai Citation2004; Eickmeier Citation2005; Moon and Perron Citation2007; Smeekes and Wijler Citation2019). The objective of this article is to develop a new method for constructing a valid prediction interval when the predictors in the prediction model include a mixture of stationary and nonstationary factors.
For the main results of this article, the only nonstationary variables considered are I(1); therefore, we use the term nonstationary as a synonym for I(1).
Related literature
The validity of the aforementioned general approach for constructing forecasts, using an FAR model with estimated factors, has been established when all the variables, including the factors, are stationary (Bai Citation2003; Bai and Ng Citation2002, 2006; Gonçalves and Perron Citation2014), and also when they are all nonstationary (Choi Citation2017), but not when they form a mixture of stationary and nonstationary ones. This article builds on the aforementioned literature and develops a method based on FAR models for forecasting, more specifically for constructing an asymptotically valid prediction interval when the chosen set of factors is a mixture of stationary and nonstationary ones.
Let us consider the case when all the variables are nonstationary. Bai (Citation2004) proposed a method for estimating the number of factors and established the consistency of the estimated factors. The limiting distributions of the estimators of the factors and of the factor loadings have also been obtained. Choi (Citation2017) used a method based on generalized principal components for estimating nonstationary factors, and studied the asymptotic properties of the generated factors, their loadings, and forecasts. Under the assumption , Choi (Citation2017) showed that estimators of the parameters in the forecasting model are consistent and asymptotically normal, and that the forecasts converge at the rate T, where T and N are the time and cross-section dimensions, respectively.
Since the method in this article is an extension of the large literature for forecasting a stationary variable using FAR models, a few comments would be helpful. Suppose that we wish to predict a stationary variable, such as inflation, using a method that requires all the predictors in the prediction equation to be stationary, for example the method in Bai (Citation2003) or that in Bai and Ng (2006). For this scenario, one could either delete all the I(1) variables or use the first differences of the I(1) predictors instead of the original I(1) predictors (Ludvigson and Ng Citation2007; Stock and Watson 2012; Cheng and Hansen Citation2015a). While this adaptation is methodologically valid, it is well-known that differencing level data results in loss of information that may be important for forecasting. Similar concerns also arise when forecasting a nonstationary variable, the topic of this article. In this article, we avoid using first differences as far as possible.
Next, let us consider the case when the set of generated factors is a mixture of stationary and nonstationary variables, and we wish to predict a nonstationary variable, such as GDP, using a method that requires all the predictors to be nonstationary, for example the method in Choi (Citation2017). For this scenario, one possibility is to delete all the predictors that are stationary and apply the method. While this method is valid, deletion of predictors is likely to result in loss of information and hence loss of statistical efficiency.
Empirical results from several studies indicate that the generated factors often tend to be a mixture of stationary and nonstationary variables. For example, Bai (Citation2004) studied employment fluctuations across 60 industries in the United States and found that two nonstationary and one stationary factors explain a large part of the fluctuations in employment. Moon and Perron (Citation2007) studied the Canadian and U.S. interest rates for different maturities and risk, and obtained a mixture of stationary and nonstationary factors. The dominant factors were interpreted as level and slope, as in the term structure literature. In a recent study, Smeekes and Wijler (Citation2019) provided an overview of forecasting macroeconomic time series in the presence of unit roots and cointegration. They compared point forecasts of some key economic variables in the FRED-QD dataset and nowcasting of unemployment in another dataset that was constructed from Google trend using the two methods (a) transforming every series to stationarity, and (b) directly modeling the level data. However, rigorous justification for modeling the level data with unit roots and cointegration in the forecasting model is yet to be provided.
The foregoing discussions of the literature on empirical studies show that there is a need to extend the current literature by developing forecasting methods that use estimators of mixtures of I(0) and I(1) factors as predictors. This is the topic of our article.
The method in this article
In this article, we adapt the methods in the literature for generating factors that may be a mixture of stationary and nonstationary variables. Once they have been generated, we use them as predictors in an FAR model for forecasting nonstationary time series; we refer to this as a mixture-FAR model. We develop new methods for constructing asymptotically valid prediction intervals using the mixture-FAR model. For the special case when all the variables are stationary, our results reduce to the corresponding ones in Bai and Ng (2006). Similarly, for the special case when all the variables are nonstationary, our results reduce to the corresponding ones in Choi (Citation2017). In this sense, our methodology provides a way of combining and extending the existing results on this topic that are limited to the two cases (a) when all the variables are stationary and (b) when all the variables are nonstationary.
We establish the consistency and obtain the asymptotic distribution of estimators of the parameters of the forecasting model. For the case of normally distributed errors in the prediction model, we show that forecast error has an asymptotically normal distribution, and use it to construct asymptotically valid prediction intervals for the one-step ahead forecasts of the dependent variable in the forecast equation.
To evaluate the finite sample properties of the estimators proposed in this article, we conducted a simulation study that involves forecasting an I(1) variable using estimators of a mixture of stationary and nonstationary factors. In these simulations, we observed that the mixture-FAR method developed in this article performed better than the method that requires all the variables to be nonstationary. As an empirical illustration, we evaluated the aforementioned methods for forecasting the nonstationary variables, GDP and Industrial Production (IP), using the quarterly panel data on U.S. macroeconomic variables, known as FRED-QD. We observed that the mixture-FAR model performed better than its aforementioned competitors. This observation also corroborates the general observation of our simulation study, namely, the mixture-FAR method performed better than the competing methods.
The rest of this article is organized as follows. Section 2 introduces the methodology. Section 3 discusses a simulation study. An empirical example is presented in Section 4. Section 5 provides a discussion, and Section 6 concludes. Proofs of theorems, and some simulation results appear in the supplementary material.
2 Methodology
2.1 Model and Notation
Let denote an observable univariate time series that we wish to predict at a future time T + h using the information available up to time T, where h is a given fixed positive integer. Let
denote a set of panel data and
denote a set of observable predictors; Wt may contain lagged values of Yt. The aforementioned FAR method for predicting
uses the following two models:
(1)
(1)
(2)
(2) where Ft is an
vector of unobservable factors,
are idiosyncratic errors, λi is an
vector of factor loadings, and
and
are unknown parameters (
). For the time being, the number of factors r is assumed to be known; later we relax this assumption and replace it by a consistent estimator of r.
The main contribution of our article comes from the fact that we allow the r factors in the FAR-method to be a mixture of stationary and nonstationary variables. We assume that and
are nonstationary.
A comment on Wt is in order. It is valid to remove Wt from the FAR-Model (2) and treat it as another cross-section of the panel . The reason for not doing so is that Wt is seen as a variable that has substantial direct influence on
, for example, Wt could be lags of Yt. By contrast, a factor is generated based on the internal variability among
, but not on its direct influence on
Therefore, the method is likely to be statistically more efficient if Wt is allowed to be separate from the factors as in FAR-model (2).
Let denote the panel data in matrix form,
denote the T × r matrix of unobservable common factors,
denote the matrix of factor loadings, and
denote the matrix of error terms from the factor model. Then the factor model (1) can also be expressed as
Since the stationary and nonstationary terms need to be treated differently, let us write
, where Et is
and nonstationary, Gt is
and stationary, and
Since Et is I(1), we have where ut is stationary. Substituting
, the factor model (1) and the FAR model (2) take the forms
(3)
(3)
(4)
(4) respectively, where
and
As expected, estimates of the coefficients α and β of the nonstationary and stationary variables in the FAR model (4), converge at the rates T and
, respectively. To state the results with such different rates of convergence, we introduce the following scaling matrices:
(5)
(5)
Remark:
The variable Wt may also be stationary; for simplicity we provide the details for nonstationary case only. To be more general, we may define , where c = 1/2 or 1 according as Wt is I(0) or I(1).
For a given matrix A, let denote that it is positive definite, and let
. For given matrices X and Y, let
denote
. Finally, let
and
denote convergence in probability and in distribution, respectively.
2.2 Estimation of the Factor Model and the FAR Model
In the factor model, the numbers of factors {p, q, r} and the factors are both unknown, and hence, they need to be estimated. In this section, we outline the estimation of factors under the assumption that the numbers of factors are known. In the next section, we show that the numbers of factors can be estimated consistently.
Suppose that the numbers of factors {p, q, r} are known. To estimate the factors , we apply principal component analysis [PCA] subject to some identification restrictions, which is common in this area (e.g., Bai and Ng 2013, p. 19). In this method, we minimize
subject to the identification restrictions,
(6)
(6)
The estimator of F is , where
is the eigenvector corresponding to the jth largest eigenvalue of
(
). Let
. Once the factors have been estimated, a corresponding estimator of the factor loading matrix Λ is
. Without loss of generality, we assume that the columns of
are arranged such that the first p have been classified as nonstationary and their corresponding eigenvalues are in the decreasing order, and the remaining q columns have been classified as stationary and their corresponding eigenvalues are in the decreasing order. Therefore, without loss of generality, we write
and
Let , where
are the p eigenvalues of
corresponding to the p columns of
as eigenvectors. Similarly, let
, where
are the
eigenvalues of
corresponding to the q columns of
as eigenvectors. Let
. Therefore,
is equal to the diagonal matrix whose diagonal elements are the
largest eigenvalues of the matrix
multiplied by
We adopt the standard procedure for ensuring that the factors are identified up to a rotation. To this end, we define the rotation matrix . If all the variables are stationary then the foregoing H reduces to the expression in Bai and Ng (Citation2002), and if all the variables are nonstationary then it reduces to the forms in Bai (Citation2004) and Choi (Citation2017).
Let and
; then, H and δ are also functions of the data and the unknown population parameters. Then, the FAR model (4) may be written as
(7)
(7)
Let denote the the ordinary least squares [OLS] estimator of
obtained by regressing
on
(
). Therefore,
(8)
(8)
Later we will show that in (7) is asymptotically centered at zero in the limit, and hence
could be treated as an error term centered at zero for the purposes of estimating
In consequence, it turns out that
has asymptotic mean zero; this result will be used later for deriving prediction intervals for
.
Remark:
While it is not essential for the derivations, the following observation is helpful for interpretation. The asymptotic results show that the stationary and the nonstationary terms behave as if they are independent, and the rotation can be performed separately for the stationary and nonstationary terms. To this end, define ,
, and
Then
converges, in probability, to zero. Consequently, for the asymptotic results, the rotation of the entire factor by H leads to the same results as performing the rotations separately for the nonstationary and stationary factors by H1 and H2, separately.
2.3 Distribution Theory
In this section, we study the asymptotic distributions of the generated factors and the estimators of the regression parameters. First, we introduce some assumptions; in these assumptions, denotes a generic constant, and hence it may be different in its different appearances.
Assumption 1 (Factors and factor loadings). (i) The strictly stationary process ut in satisfies
, for some
, and
is positive definite. (ii)
and
converges, in distribution, as
, to a positive definite random matrix, which we denote by ΣF. (iii) The number of factors r is fixed and hence does not depend on N or T; further, the nonstationary factors are not cointegrated. (iv) The loadings λi are either deterministic and
satisfying
as
, or they are stochastic and
satisfying
as
, for some r × r positive definite nonrandom matrix
. (v) The eigenvalues of
are distinct, almost surely.
If the factors are cointegrated then the stationary and nonstationary factors may not be identified. By assuming ΣF and are positive definite and the eigenvalues of
are distinct, we ensure the identifiability of the r factors.
Next, we obtain closed forms for ΣF. If the factors are all nonstationary, then ΣF is distributed as , where
is a vector of Brownian motions. If the factors are all stationary, then
converges, in probability, to ΣF, the variance-covariance matrix of the factors. If the set of factors is a mixture of I(0) and I(1) series, then
where ΣG is the probability limit of
.
To state the next assumption, let us introduce the following notation:
Assumption 2
(Idiosyncratic errors). (i) and
(
). (ii)
, and
(iii)
, for some
(
), and
(iv)
(v)
(
).
Assumption 2 allows the idiosyncratic errors to have weak serial and cross sectional dependence. Heteroscedasticity is also allowed in both the serial and the cross-section dimensions. Note that Assumption 2 covers the case when eit is stationary (). Note also that we allow weak correlations among the idiosyncratic errors in (1). Thus, the factor model (1) has an approximate factor model structure; for simplicity, we refer to it simply as a factor model.
Assumption 3
(Independence among ).
Let (et, Ft) satisfy
. (ii) There exists a Γt such that
2.3.1 Consistent Estimation of the Numbers of Factors
In this section, we assume that {p, q, r} are unknown, where p and q are the numbers of I(1) and I(0) factors, respectively, and is the total number of factors. The objective of this section is to provide consistent estimators of (p, q, r).
An approach to consistent estimation of (p, q, r) involves the following: (a) estimate r consistently, (b) estimate p consistently, and (c) estimate q consistently using the identity . For consistent estimation of the total number of factors, r, we adapt the method in Bai (Citation2004); for consistent estimation of p and q we adapt the method in Bai (Citation2004) and Bai and Ng (2004) (see also Moon and Perron Citation2007). To estimate of the total number of factors, r, we consider the following factor model for first differences, which follows from the factor model (1) for the original data in level:
(9)
(9) where
and
;
are latent factors. Since each component of Ft is either I(1) or I(0), it follows that ft is stationary. Similarly, xit and zit are stationary for each i. Therefore, (9) is a stationary factor model, the same as that studied in Bai and Ng (Citation2002). Further, if (9) satisfies the conditions (A)–(D) in Bai and Ng (Citation2002), then Theorem 2 and Corollary 1 therein provide a family of consistent estimators of the number of factors, r. This is the method adopted in this article.
Assumptions (A)–(D) in Bai and Ng (Citation2002) for (9) follow from our Assumptions 1–3 that we stated for the factor model in level. Therefore, we conclude that, under Assumptions 1–3, Bai and Ng (Citation2002) provides a family of consistent estimators of r. Empirical implementation of these estimators is discussed in Moon and Perron (Citation2007), sec. 3.1.
For completeness and clarity, we provide one specific consistent estimator of r. Let us write the factor model (9) as when there are k factors, and let
denote the principal components estimator of
Let
,
, and
. Let kmax denote a user supplied maximum for the number of factors. Then we have the following result:
Proposition 1.
Let Assumptions 1–3 hold. Then is a consistent estimator of r.
The consistency result in this proposition holds for the other choices of the information criterion and choices of g(N, T) in Bai and Ng (Citation2002) and Moon and Perron (Citation2007).
Next, we discuss consistent estimation of p, the number of I(1) factors. The unknown integer p can be estimated by adapting the method in Bai (Citation2004). Let us write the factor model(1) as when there are k factors, and let
denote the principal components estimator of
Let and
. Let
denote the variance of the residuals
when the factor model has k factors. Let kmax denote a user supplied maximum for the number of factors. Let
and
where IPC stands for integrated panel criterion. Then we have the following result.
Proposition 2.
Let Assumptions 1–3 hold. Further, assume that the following law of iterated logarithm holds: is nonrandom and positive definite. Then
is a consistent estimator of p.
Let and
be as in Propositions 1 and 2. It follows from these two Propositions that
is a consistent estimator of (p, q, r) under Assumptions 1–3.
In addition to the foregoing method based on IPC, the modified Qc statistic proposed by Bai and Ng (2004) can be applied to determine the number of nonstationary factors. This is called Panel Analysis of Nonstationarity in Idiosyncratic and Common components (PANIC) test. We used the PANIC-test and conducted a comparative study for estimating the number of I(1) factors and testing for nonstationarity. The ADF test can be used for testing for nonstationarity of each factor, wherein the null hypothesis is that the factor is nonstationary. Similarly, the KPSS statistic may be used for testing for stationarity of each factor wherein the null hypothesis is that the factor is stationary. In the implementation of these tests, we would use generated factors since the factors are not observable (Moon and Perron Citation2007). It has been shown that it is valid to use generated factors in such tests (see the first paragraph on p. 1135 in Bai and Ng 2004, and Moon and Perron Citation2007).
Therefore, we have a sound method for estimating the numbers of factors {p, q, r} consistently, estimating the factors, and identifying the I(0) and I(1) factors. We summarize the steps in the following algorithm:
Estimate the total number of factors by
Estimate the total number of I(1) factors by
Estimate the factors by PCA and test each to determine whether it is stationary or not; in the empirical example of Section 4, we applied the ADF and KPSS tests.
It would be prudent to check the results of the foregoing algorithm using other methods. We recommend using the PANIC-test in Bai and Ng (2004)
2.3.2 Consistency of the Generated Factors
In the literature on FAR models, the consistency of the generated factors has been established separately for stationary factors and for nonstationary factors. Bai and Ng (Citation2002) and Bai (Citation2004) showed that the time-averaged mean square of factor estimation error [MSE] has and
convergence rates for I(0) and I(1) factors, respectively. In our setting, the set of latent factors F contains a mixture of
series, and we show that the generated factors are jointly consistent and the convergence rate of MSE is
. To state the consistency of generated factors in the next lemma, let us recall that the rotation matrix H was defined as
.
Lemma 1.
Let Assumptions 1–3 hold. Let . Then we have
For the case when all the factors are stationary, the scaling matrix is
and the convergence rate is
; this is consistent with the corresponding result in Bai (Citation2003). For the case when all the factors are nonstationary,
and the convergence rate is
; this is consistent with Bai (Citation2004).
2.3.3 Asymptotic Distribution of the Generated Factors
To derive the asymptotic distributions of the estimated factors, we introduce the following additional assumption.
Assumption 4
(Weak dependence of idiosyncratic errors).
Lemma 2.
Let Assumptions 1–4 hold. Then as
, where
is a random matrix,
with
denoting the eigenvalues of
, and
is the matrix formed by the corresponding scaled eigenvectors such that
Lemma 3.
Let Assumptions 1–4 hold. Then, as , for each t, we have
where Q is defined in Lemma 2, Γt is defined in Assumption 3, and Q is independent of
.
The results obtained in this Lemma is consistent with Bai (Citation2003) when all the factors are stationary, and it is also consistent with Bai (Citation2004) when all the factors are nonstationary.
2.3.4 Asymptotic Distribution of the Estimators
To obtain the asymptotic distribution of the OLS estimator of δ, we introduce the following additional assumptions.
Assumption 5
(Weak dependence between idiosyncratic and regression errors).
Assumption 5 imposes restrictions on the degree of dependence among the idiosyncratic errors over time, and between the idiosyncratic and regression errors. Part (ii) of Assumption 5 holds if are mutually independent and Assumption 2 holds.
Assumption 6.
Let Then, the following conditions are satisfied. (i)
(
). (ii) The joint convergence,
as
, holds, where ΣL and
are both positive definite with probability one.
It is instructive to note the following four cases having explicit forms for (a) If
are all I(1) and
are I(0), then we have
, where ΣW is the probability limit of
. (b) If
is a mixture of I(0) and I(1) factors and
, then we have
. (c) If both
and
are I(1), then we obtain
, where
and
is the weak limit of
. (d) If
is a mixture of I(0) and I(1) series and
is I(1), then
.
Next, we obtain closed forms for the limiting distribution of in different cases; see Choi (Citation2017). Let
denote the variance of ϵt.
Case 1: If
Case 2: If
Case 3: If
Case 4: If
Theorem 1.
Suppose that Assumptions 1–6 hold and that . Let δ and the OLS estimator
be as in (7) and (8), respectively. Then, as
, we have
and
, where
, and ΣL and
are as defined in Assumptions 1–6.
The appearance of the scaling matrix in Theorem 1 shows that the estimators
, and
converge at the rates
, and T, respectively. Consequently, the limiting distribution in this theorem reduces to the known corresponding results in (a) Bai and Ng (2006) for the FAR model with I(0) variables only, and (b) Choi (Citation2017) for the FAR model with I(1) variables only.
For the case when all the variables are I(0) and for some
, Gonçalves and Perron (Citation2014) showed that there is an asymptotic bias. A similar comment applies to the result in Theorem 1 as well. The unknown matrix
may be estimated by
(10)
(10)
In the supplementary material (see Lemma C.2, Appendix C, supplementary materials), we show that as
This estimator is robust against heteroscedasticity in the regression error. For the special case of homoscedastic errors, a simpler estimator of
is
(11)
(11) where
is an estimator of the variance of regression errors.
2.4 Prediction Interval
Suppose that observations up to time T are available. Let denote the conditional mean
, where
is the information up to time T, and let
be as in (7) and (8). Then, an estimator of
is
; similarly,
is also a point forecast of
. In this section, we obtain a confidence interval for
and a prediction interval for
Let
be the asymptotic variance of
(see Lemma 3), and let
.
Theorem 2.
Let Assumptions 1–6 hold. Further, suppose also that and
as
. Let
be as in Theorem 1, and
denote the variance of the asymptotic distribution of
(see Lemma 3). Then, we have
as
, where
.
The proof of this theorem is in Appendix C of the supplementary material. To provide some insight into the foregoing suggested form for BT, note that the forecast error can be expressed as
(12)
(12)
It turns out that the two terms on the right-hand side of (12) are essentially independent and hence the asymptotic variances simply add up; the two terms on the right hand side of the expression for BT correspond to the two terms in (12).
To apply Theorem 2 for inference in empirical studies, we use as a consistent estimator of
. Using Lemmas 2 and 3, an estimator of
is
where
is an estimator of the asymptotic covariance matrix of
, and
was defined as a diagonal matrix of the largest r eigenvalues of
multiplied by
.
To make use of the form , we need a consistent estimator of ΓT. As suggested by Bai and Ng (2006), depending on the assumptions,
may take one of the following forms:
(13)
(13) where
. For cross sectionally uncorrelated idiosyncratic errors, the first two forms of
in (13) are suitable. If the errors are homoscedastic and
, say, then
can be estimated by
and the second form in (13) would be suitable. The third form in (13) is suitable for estimating the asymptotic variance of generated factors when the idiosyncratic errors have cross sectional correlation.
Let . Then
as
. This may be used for constructing a
asymptotic confidence interval for the conditional mean
; see Appendix C for proofs.
Next, consider constructing a prediction interval for , conditional on the information available at time T. We consider the point forecast
The corresponding forecast error is
(14)
(14)
Therefore, the limiting distribution of forecast error also depends on the distribution of the regression error . Let us suppose that
. Then, it follows from Theorem 2 that the forecasting error
is also asymptotically normal with mean zero and variance
. Let
denote a consistent estimator of
; for example, if
are iid, then we may choose
. Then, an asymptotic 95% prediction interval for
is
(15)
(15) see Appendix C for proofs.
3 Simulation Study: Finite Sample Properties
We carried out a simulation study to evaluate the prediction interval (15), and estimators of the numbers of I(0) and I(1) factors defined in Section 2.3.1; see Propositions 1 and 2. The data generating process [DGP] for the FAR is
(16)
(16)
(17)
(17)
For ρ in (17), we considered the values and 0.9. For the error term ϵt, we considered both homoscedastic and heteroscedastic cases; see below. The T × N panel dataset was generated by the factor model,
with the λi’s drawn from N(0, 1) and the error terms
as stated below. In the notation of the previous section, we have
and
.
We considered 16 combinations of with
100, 200 and
. The parameter values were set at
, and
. We considered the following three DGPs for each ρ: (a) DGP1:
and
(b) DGP2:
and
; (c) DGP3:
is distributed uniformly on [0.5, 1.5], and
. All simulation estimates are based on 5000 repeated samples. Since the FAR model has a lag term, we adopted a burn-in period of 100 time units. We used the
in (11) and (10) for DGP1 and {DGP2, DGP3}, respectively. The results are presented in the following sections.
3.1 Coverage Rates of Prediction Intervals
reports the coverage rates of 95% prediction intervals for The coverage rates of these intervals range from 88% to 98% with most of them being close to the nominal 95%. Therefore, a main observation of the simulation study, based on is the following: in terms of coverage rates, the prediction interval (15) performed quite well.
Table 1 Coverage rates (%) of 95% prediction intervals for one-step ahead forecasts.
The forecast of the conditional mean, as shown in Theorem 2, is asymptotically normal; this result does not require that the functional form of the error distribution be known. The indications are that a residual based bootstrap method is likely to be valid for constructing a confidence interval for the conditional mean , and for constructing a prediction interval for
. At this stage, we have not proved that such a bootstrap method is asymptotically valid. Nevertheless, we believe that an evaluation of a bootstrap procedure is useful and instructive. Therefore, we extended the simulation study in the previous section and evaluated the coverage rates of residual based t-percentile bootstrap prediction intervals when the error distribution is normal and when it is t with 5 degrees of freedom. Since we used residual based bootstrap, it does not assume that the error distribution is known. The results are presented in and of Appendix D in the supplementary materials; they show that the coverage rates of the bootstrap prediction intervals are close to the nominal level. Therefore, indications are that the t-percentile bootstrap is likely to be an asymptotically valid method for constructing prediction intervals.
Table 2 Values of for the performance of mixture-FAR model relative to the corresponding nonstationary-FAR model.
3.2 Performance of Mixture-FAR Relative to Nonstationary FAR
Recall that the nonstationary-FAR model (see Choi Citation2017), requires all the variables in the FAR model to be I(1). We evaluate the out-of-sample forecast performance in terms of out-of-sample R-square, denoted , defined as
(18)
(18) where
prediction using the mixture-FAR model,
prediction using the competing or reference model, and both of these predictions are conditional on information up to time
(
). Thus,
is a measure of how well the mixture-FAR performed during the period
, relative to the competing model. As an example, if
(respectively,
) then an estimate of the MSE of prediction for the mixture-FAR model is 10% lower (respectively, higher) than that for the competing model. For the simulation studies in this section, we chose the nonstationary-FAR as the competing model. Further, forecast evaluations are based on expanding windows for the estimation period, unless the contrary is made clear.
In this part of the study, we considered the DGP1 with and
First, we consider forecasting a nonstationary series Yt using the mixture-FAR model and compare it with the corresponding nonstationary-FAR. provides the results for this comparison. As an example, the interpretation of the entry 0.43 in the cell for
and N = 30 is that the MSE of prediction for the mixture-FAR model is 43% lower than that for the nonstationary-FAR model. The table also shows that, for every case considered, the MSE of prediction for the proposed mixture-FAR model is at least 33% lower than that for the nonstationary-FAR model.
Therefore, the second main observation of our simulation study is the following: the mixture-FAR method performed significantly better than the competing purely nonstationary-FAR, in terms of
3.3 Evaluation of the Estimators of the Numbers of Factors
The DGP for the factor model is and
, and
. We considered 25 combinations of
with
and
. The total number of factors is r = 3, while the number of I(1) factors is p = 1, 2, 3. For all cases, the maximum number of factors is
.
The results are presented in , in the last four columns. These results show that, for and
, the mean of
over 5000 replications is very close to the true value 3. For small values of (N, T), namely N = 10 or T = 10, the estimator
did not perform well. in Appendix D also shows the percentage of times
estimated the true r correctly; the main message in both tables is that
estimates r quite well in large samples. Therefore, the third main observation of our simulation study is the following: for large values of T and N,
estimated the true total number of factors r (=3) very accurately.
Table 3 Mean of the estimated number of factors.
Estimation of the number of I(1) factors and test for nonstationarity
We evaluated the performance of in Proposition 2, where p is the number of I(1) factors. We also used the PANIC-test in Bai and Ng (2004) for comparison. The means of the estimated number of I(1) factors are reported in . Further, for the same simulation study, the percentages of times that the estimate of p was exactly the true population value p, are provided in the supplementary materials ( in Appendix D). The accuracy of the estimators of the number of I(1) factors increases as N and T increase. For estimating the number of nonstationary factors, the results in are consistent with those in Bai (Citation2004) and Bai and Ng (2004). Both estimators provide similar results.
Table 4 Performance of mixture-FAR relative to AR(4), in terms of .
Effect of over- or under-estimation of the total number of factors
We evaluated the MSFE when the total number of factors, r, is over estimated and when it is under estimated. The results are presented in Section 4.3 of the supplementary materials (see pp. 43 and 44). The results therein show that, in terms of MSFE, (a) under-estimation of r leads to substantial loss in forecast performance, and (b) over-estimation of r leads to a negligible loss when N and T are large.
3.4 Efficiency of Using Generated Factors for Testing Stationarity Instead of True Factors
To determine whether a factor is nonstationary or stationary, we apply the ADF or the KPSS tests to the generated factor since the true factor is unobservable. To estimate the loss due to using the generated factors instead of the true factors, we applied the ADF and the KPSS tests to the simulated true factors {F} and to the corresponding generated factors . For a given test, say ADF, let νj denote the proportion of times the test applied to
arrived at the same conclusion as that applied to
, about the nonstationarity of Fj (j = 1, 2, 3). Therefore, νj may be interpreted as the efficiency of using generated factors instead of the true factors. The values of νj are presented in Appendix D; see for the ADF test and Table 6 for the KPSS test. These results lead to the favorable conclusion that the losses due to using the generated factors, instead of the true factors, are small.
Table 5 Values of for mixture-FAR compared to the nonstationary-FAR.
4 Empirical Application
In this section we apply the mixture-FAR model for forecasting two key nonstationary macroeconomic variables, namely the GDP and the IP. Since we use quarterly data, we start with a basic AR(4) model and augment it with factors to construct FAR models. For each model, we compute two sets of prediction intervals, one is based on the asymptotic distribution of the standardized forecast and the other is based on the t-percentile bootstrap; the validity of the bootstrap is yet to be established. Since the bootstrap prediction interval performed well in the simulation studies presented in the previous section, it is reasonable to compare the bootstrap prediction intervals with those based on (15). We also compare and contrast the out-of-sample forecasting performance of the mixture-FAR method with some competing ones.
4.1 Data Description
The data were collected from FRED-QD; a well-known database for macroeconomic variables containing quarterly data. The data consists of 246 U.S. macroeconomic time series for the period 1959:Q1 to 2018:Q4, with a total of 240 (T = 240) observations. We excluded 36 variables because there were missing observations, and chose a balanced panel for 210 variables; for more details, see the updated appendix for FRED-QD at https://s3.amazonaws.com/files.fred.stlouisfed.org/fred-md/FRED-QDappendix.pdf.
There are two categories based on the level of aggregation: 110 “high-aggregates” and 100 “sub-aggregates”. We used the panel data for N = 100 sub-aggregates for estimating the factors by Principal Components Analysis (PCA). These sub-aggregates consist of both stationary and nonstationary time series.
4.2 Estimation of Factors
We applied the method in Proposition 1 in Section 2.3.1 to the panel of 100 sub-aggregate macroeconomic variables and obtained
where r is the total number of factors and
is as in Proposition 1. Then, we applied the method in Proposition 2 in Section 2.3.1 and obtained
, where p is the number of I(1) factors. We applied the ADF and the KPSS tests to identify the I(0) and I(1) factors. The validity of using generated factors for ADF and KPSS tests was discussed in Section 2.3.1. Plots of the two high-aggregate macroeconomic variables, GDP and IP, are presented in . This figure and the results of ADF test show that these two trended variables are I(1). Further, since we obtained a mixture of I(0) and I(1) factors, the mixture-FAR method developed in this article is well suited for forecasting GDP and IP.
Fig. 1 Time series plots of and
for 1959:Q1 – 2018:Q4.
4.3 Out-of-Sample Forecast Performance of Mixture-FAR Method
4.3.1 The Mixture-FAR and the Basic AR(4) Models
We considered the following four models, the basic AR(4) and three mixture-FAR models obtained by augmenting the AR(4) with a mixture of the I(0) and the I(1) factors:
(19)
(19)
(20)
(20)
(21)
(21)
(22)
(22)
Model 4, the basic AR(4), is used as the benchmark for forecast comparison; since we use quarterly data this is a suitable benchmark. Much of this section focuses on comparing Models 1 to 3 with Model 4, in terms of out-of-sample forecast performance.
4.3.2 Performance of Mixture-FAR Relative to AR(4)
We assess the performance of mixture-FAR models (19)–(21) for forecasting GDP and IP in terms of the out-of-sample R2, denoted by , defined in (18). In this section, AR(4) is used as the basic benchmark; later we consider a nonstationary-FAR and a stationary-FAR as the benchmarks. We used the expanding window estimation scheme with three different first estimation periods, and computed the values of
for the three mixture-FAR models (19)–(21) relative to AR(4); they are reported in . The values of
indicate that the mixture-FAR model, Model 2, outperforms the benchmark model AR(4) for forecasting GDP and IP. Overall, the results presented in indicate that Model 2 outperforms the other two models, Models 1 and 3. The results in are for expanding windows; for results based on rolling windows, see Section 5.2.1 of the supplementary materials.
4.3.3 Performance of Mixture-FAR Relative to Nonstationary-FAR
For forecasting a nonstationary variable, such as GDP and IP, a nonstationary-FAR model, wherein all the variables including the factors are nonstationary, has been proposed in the literature (Choi Citation2017). As in the earlier sections, we refer to this model as a nonstationary-FAR model. To implement this method, first we applied principal component analysis to , chose only the nonstationary factors
, and used them as predictors. The nonstationary-FAR model used in this analysis is
We assess the out-of-sample forecast performance of the mixture-FAR model (19) relative to the nonstationary-FAR model Model 5.
The values of for the mixture-FAR model, Model 1, relative to the nonstationary FAR model, Model 5, are presented in . The interpretation of the entry 0.31 in the column for
is the following: For the period 2009–2018, the Sum of Squares of Forecast Error (SSFE) for
is 31% lower for mixture-FAR compared to the nonstationary-FAR. This table also shows that the SSFE for
over the period 2009–2018 is 50% lower for mixture-FAR compared to nonstationary-FAR. In fact, shows that the mixture-FAR method proposed in this article performed significantly better than the method based on a nonstationary-FAR for forecasting GDP and IP.
4.3.4 Other Observations
Performance of mixture-FAR relative to stationary-FAR
Bai and Ng (2006) proposed a method for forecasting a stationary variable using an FAR model, where all the variables and factors are stationary. We refer to this model/method as a stationary-FAR model/method. We adapt this method for forecasting nonstationary variables. To this end, we use the first differences of GDP and IP; see Section 5.1 in the supplementary materials. The results therein show that the mixture-FAR method performed better than the corresponding stationary-FAR method, for forecasting GDP and IP.
Accounting for possible structural breaks
We extended the empirical study to account for possible structural breaks. The details are presented in Section 5.2 of the supplementary materials. The main observation of these investigations is the following: For dealing with structural breaks/instabilities in our empirical study (a) expanding windows performed better than rolling windows overall, and (b) use of subsamples, with data from a certain period of possible structural break/instabilities removed, did not improve forecasting performance.
4.4 Prediction Intervals
We computed 95% prediction intervals, which are based on the asymptotic results derived in Section 2 and the bootstrap, for one-step-ahead predictions of and
. Assuming that the regression error ϵt in (2) is normally distributed, we constructed the asymptotic theory-based point-wise 95% prediction intervals for
and
for the out-of-sample period 2006:Q1 to 2018:Q4. These intervals are shown in together with the observed values of
and
.
Fig. 2 Left Panel: One-step ahead point-wise 95% prediction intervals for using mixture-FAR. The solid line in the middle is the observed values of
. The pair of dashed lines is the asymptotic theory prediction interval; they are easily identified since one curve appears at the top and the other at the bottom, in 2016. The pair of curves with dash and dot, provide the bootstrap prediction interval. Right Panel: The legend is the same as that for the panel on the left, except that GDP is replaced by IP.
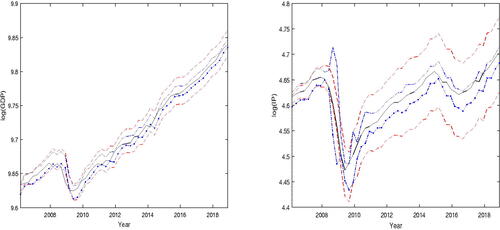
We also estimated the symmetric bootstrap t-percentile prediction intervals using residual bootstrap; to this end, we used 399 bootstrap replications. These are also shown in . One important difference between the asymptotic theory-based and bootstrap prediction intervals is that the latter does not assume that the error distribution has a known functional form.
shows that (a) except for a very short interval around the crisis period 2009, the observed values of GDP lie within the two prediction intervals, and (b) every observed value of IP lies within the two prediction intervals. Overall, the bootstrap prediction interval is narrower than the one based on the asymptotic distribution of the forecast, for GDP and IP. The bootstrap prediction interval for IP around the crisis period 2008 is large; this may be because the financial and economic crisis introduced large volatilities in IP around this period. Overall, both prediction intervals have high coverage rates for GDP and IP.
5 Discussion
One topic of interest is the estimation of the numbers of I(0) and I(1) factors in such a way that they are optimal, in some sense, for the purpose of predicting In this article we considered the information criterion method in Bai and Ng (Citation2002) and Bai (Citation2004). In this method, attention is restricted to the factor model only and the objective is to estimate the numbers of factors to explain the variation within
In some cases, it is possible that all r factors are not needed for forecasting, and fewer than r factors may turn out to have better forecasting performance. This topic has been studied in some recent papers when the FAR model does not have a mixture of I(0) and I(1) factors. In one such approach, residual variance of the factor model, appearing in the information criterion, is replaced by the residual variance from the FAR model (Cheng and Hansen 2015b, Groen and Kapetanios Citation2013). Another approach is to treat it as a model selection problem with each model being defined by one subset of the factors on the right hand side of the FAR model (Djogbenou Citation2021). Extensions of these approaches to our setting wherein there is a mixture of I(0) and I(1) factors in the FAR model would be useful.
The proposed methodology can be adjusted for the case when forecasting variable Yt is stationary. For simplicity, assume that ; however, Wt can also be a set of I(1) variables, or a mixture of I(1) and I(0) variables. Let us consider two cases.
Case 1: Nonstationary factors are assumed to be cointegrated. Let Et be a vector of I(1) factors, and suppose that they are cointegrated. Let Zt be a vector of I(0) factors that are linear combinations of Et. Then, the latent factors,
Case 2: Cointegration of factors is not assumed. In the literature, it has been discussed that a mixture of I(0) and I(1) (also explosive) regressors can be used for forecasting economic and financial time series, see Phillips (Citation2012, Citation2015). Phillips (Citation2015) considered a basic linear predictive model and obtained the prediction of an I(0) variable using an I(1) time series. Hence, we may use a mixture-FAR model to forecast a stationary Yt.
An assumption made in this article is that the number of factors r is fixed. It is possible that in some settings it may be appropriate to consider the case when the number of factors in the FAR model increases to . With high-dimensional data, such a scenario may well be of interest. The factor model with increasing number of factors is studied in Li, Li, and Shi (Citation2017). An extension to incorporate increasing numbers of I(1) and I(0) factors in the mixture-FAR model is an unexplored area. The extension to our setting with generated I(0) and I(1) factors would require substantial development of new methodology.
When using macroeconomic dataset that spans over a long period of time, instabilities may arise in both factor loadings and parameters of the FAR forecasting model. Stock and Watson (2009) and Banerjee, Marcellino, and Masten (Citation2008) demonstrated that even if the factor loadings are structurally unstable, factors may be estimated consistently if the instability is independent across the panel variables. They recommended the use of rolling window method or time-varying parameters for the estimation of FAR model. Rossi (Citation2021) and Giraitis, Kapetanios, and Price (Citation2013) observed that rolling window was suitable when there are structural instabilities in the dataset. Stock and Watson (2009) and Banerjee, Marcellino, and Masten (Citation2008) have also suggested the use of sub-sample for forecasting when there are such instabilities. We investigated such alternative approaches in our empirical study, and the results are reported in Appendix E.
Recently, among others, Breitung and Eickmeier (Citation2011), Corradi and Swanson (Citation2014), and Su and Wang (Citation2017) developed methods to test and model the instabilities in the factor loadings as well as in the FAR model parameters. Further, Wei and Zhang (Citation2020) considered a time-varying FAR model with time-varying factor loadings to capture the structural breaks in a large panel dataset. They used local PCA to estimate the factor loadings in the factor model and the local constant method to estimate the time-varying coefficients in the forecasting model; the asymptotic validity of this method has not yet been established. To our knowledge, the methodological developments and empirical applications to date covered only the stationary setting: stationary panel data, stationary factors, and forecasting stationary time series. Extensions of these methodological developments to our setting for forecasting a nonstationary variable would be useful.
6 Conclusion
This article developed methodology for forecasting nonstationary macroeconomic variables, such as GDP and IP, when a set of panel data is available for a large number of potential predictors. We propose to estimate a small number of factors using the panel data, and use them as predictors for forecasting. The factors are chosen such that they contain a large proportion of the information in the large number of potential predictors. Typically, such a large number of macroeconomic variables would contain a mixture of stationary and nonstationay variables. Therefore, the factors are also very likely to be a mixture of stationary and nonstationary variables, as illustrated by our empirical example.
This article developed a methodology for using the estimated mixture of stationary and nonstationary factors as predictors, and constructing an asymptotically valid prediction interval. The validity of the coresponding method for forecasting has been established in the literature when all the variables are stationary (Bai and Ng 2006), and also when they are all nonstationary (Choi Citation2017), but not when they consist of a mixture of stationary and nonstationary variables. Our article contributes to this gap in the literature.
In our simulation study, the mixture-FAR method developed in this article performed better than the one that uses only nonstationary variables. In an empirical study for forecasting GDP and IP, we compared the mixture-FAR method with some competing ones; we observed that the mixture-FAR method performed better. In summary, this article develops an improved method of forecasting a nonstationary variable using information from stationary and nonstationary variables, and it is of practical significance.
Supplementary Materials
The supplementary materials contains the proofs of the theorems stated in Section 2, and some additional results for the sections on the simulation study and the empirical application.
Supplemental Material
Download PDF (534.2 KB)Acknowledgments
We are grateful to the editor, Christian Hansen, an associate editor, and two reviewers for valuable comments and suggestions. We thank Peter Phillips, Sydney Ludvigson, Benjamin Wong, and the participants at the Monash-Xiamen University Workshop and the 40th International Symposium on Forecasting for their comments and suggestions.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
References
- Bai, J. (2003), “Inferential Theory for Factor Models of Large Dimensions,” Econometrica, 71, 135–171. DOI: 10.1111/1468-0262.00392.
- Bai, J. (2004), “Estimating Cross-Section Common Stochastic Trends in Nonstationary Panel Data,” Journal of Econometrics, 122, 137–183.
- Bai, J., and Ng, S. (2002), “Determining the Number of Factors in Approximate Factor Models,” Econometrica, 70, 191–221. DOI: 10.1111/1468-0262.00273.
- Bai, J. (2004), “A Panic Attack on Unit Roots and Cointegration,” Econometrica, 72, 1127–1177.
- Bai, J. (2006), “Confidence Intervals for Diffusion Index Forecasts and Inference for Factor-Augmented Regressions,” Econometrica, 74, 1133–1150.
- Bai, J. (2013), “Principal Components Estimation and Identification of Static Factors,” Journal of Econometrics, 176, 18–29.
- Banerjee, A., Marcellino, M., and Masten, I. (2008), “Forecasting Macroeconomic Variables Using Diffusion Indexes in Short Samples with Structural Change,” in Forecasting in the Presence of Structural Breaks and Model Uncertainty (Frontiers of Economics and Globalization) (Vol. 3), eds. D. Rapach and M. Wohar, pp. 149–194, Bingley, UK: Emerald Group Publishing Limited.
- Bernanke, B. S., Boivin, J., and Eliasz, P. (2005), “Measuring the Effects of Monetary Policy: A Factor-Augmented Vector Autoregressive (favar) Approach,” The Quarterly Journal of Economics, 120, 387–422. DOI: 10.1162/qjec.2005.120.1.387.
- Breitung, J., and Eickmeier, S. (2011), “Testing for Structural Breaks in Dynamic Factor Models,” Journal of Econometrics, 163, 71–84. DOI: 10.1016/j.jeconom.2010.11.008.
- Cheng, X., and Hansen, B. E. (2015a), “Forecasting with Factor-Augmented Regression: A Frequentist Model Averaging Approach,” Journal of Econometrics, 186, 280–293. DOI: 10.1016/j.jeconom.2015.02.010.
- Cheng, X. (2015b), “Forecasting with Factor-Augmented Regression: A Frequentist Model Averaging Approach,” Journal of Econometrics, 186, 280–293.
- Choi, I. (2017), “Efficient Estimation of Nonstationary Factor Models,” Journal of Statistical Planning and Inference, 183, 18–43. DOI: 10.1016/j.jspi.2016.10.003.
- Corradi, V., and Swanson, N. R. (2014), “Testing for Structural Stability of Factor Augmented Forecasting Models,” Journal of Econometrics, 182, 100–118. DOI: 10.1016/j.jeconom.2014.04.011.
- Djogbenou, A. A. (2021), “Model Selection in Factor-Augmented Regressions with Estimated Factors,” Econometric Reviews, 40, 470–503. DOI: 10.1080/07474938.2020.1808371.
- Eickmeier, S. (2005), “Common Stationary and Non-stationary Factors in the Euro Area Analyzed in a Large-Scale Factor Model,” Discussion paper 2, Studies of the Economic Research Centre.
- Giraitis, L., Kapetanios, G., and Price, S. (2013), “Adaptive Forecasting in the Presence of Recent and Ongoing Structural Change,” Journal of Econometrics, 177, 153–170. DOI: 10.1016/j.jeconom.2013.04.003.
- Gonçalves, S., and Perron, B. (2014), “Bootstrapping Factor-Augmented Regression Models,” Journal of Econometrics, 182, 156–173. DOI: 10.1016/j.jeconom.2014.04.015.
- Groen, J. J. J., and Kapetanios, G. (2013), “Model Selection Criteria for Factor-Augmented Regressions,” Oxford Bulletin of Economics and Statistics, 75, 37–63. DOI: 10.1111/j.1468-0084.2012.00721.x.
- Li, H., Li, Q., and Shi, Y. (2017), “Determining the Number of Factors when the Number of Factors can Increase with Sample Size,” Journal of Econometrics, 197, 76–86. DOI: 10.1016/j.jeconom.2016.06.003.
- Ludvigson, S. C., and Ng, S. (2007), “The Empirical Risk–Return Relation: A Factor Analysis Approach,” Journal of Financial Economics, 83, 171–222. DOI: 10.1016/j.jfineco.2005.12.002.
- Moon, H. R., and Perron, B. (2007), “An Empirical Analysis of Nonstationarity in a Panel of Interest Rates with Factors,” Journal of Applied Econometrics, 22, 383–400. DOI: 10.1002/jae.931.
- Phillips, P. C. (2012), “Folklore Theorems, Implicit Maps, and Indirect Inference,” Econometrica, 80, 425–454.
- Phillips, P. C. (2015), “Halbert White jr. Memorial JFEC Lecture: Pitfalls and Possibilities in Predictive Regression,” Journal of Financial Econometrics, 13, 521–555.
- Rossi, B. (2021), “Forecasting in the Presence of Instabilities: How We Know Whether Models Predict Well and How to Improve Them,” Journal of Economic Literature, 59, 1135–90. DOI: 10.1257/jel.20201479.
- Smeekes, S., and Wijler, E. (2019), “High-Dimensional Forecasting in the Presence of Unit Roots and Cointegration,” Working paper, Department of Quantitative Economics, Maastricht University.
- Stock, J. H., and Watson, M. W. (1998a), “A Comparison of Linear and Nonlinear Univariate Models for Forecasting Macroeconomic Time Series,” Technical Report, National Bureau of Economic Research.
- Stock, J. H. (1998b), “Diffusion Indexes,” Technical Report, National Bureau of Economic Research.
- Stock, J. H. (2002a), “Forecasting Using Principal Components from a Large Number of Predictors,” Journal of the American Statistical Association, 97, 1167–1179.
- Stock, J. H. (2002b), “Macroeconomic Forecasting Using Diffusion Indexes,” Journal of Business & Economic Statistics, 20, 147–162.
- Stock, J. H. (2009), “Forecasting in Dynamic Factor Models Subject to Structural Instability,” in The Methodology and Practice of Econometrics. A Festschrift in Honour of David F. Hendry (Vol. 173), eds. N. Shephard and J. Castle, p. 205, Oxford: Oxford University Press.
- Stock, J. H. (2012), “Generalized Shrinkage Methods for Forecasting Using Many Predictors,” Journal of Business & Economic Statistics, 30, 481–493.
- Su, L., and Wang, X. (2017), “On Time-Varying Factor Models: Estimation and Testing,” Journal of Econometrics, 198, 84–101. DOI: 10.1016/j.jeconom.2016.12.004.
- Wei, J., and Zhang, Y. (2020), “A Time-Varying Diffusion Index Forecasting Model,” Economics Letters, 193, 109337. DOI: 10.1016/j.econlet.2020.109337.