
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A novel, general two-sample hypothesis testing procedure is established for testing the equality of tail copulas associated with bivariate data. More precisely, using a martingale transformation of a natural two-sample tail copula process, a test process is constructed, which is shown to converge in distribution to a standard Wiener process. Hence, from this test process a myriad of asymptotically distribution-free two-sample tests can be obtained. The good finite-sample behavior of our procedure is demonstrated through Monte Carlo simulations. Using the new testing procedure, no evidence of a difference in the respective tail copulas is found for pairs of negative daily log-returns of equity indices during and after the global financial crisis.
1 Introduction
Measuring dependence between economic variables such as asset returns and, in particular, between their tail events is of crucial importance for risk management, asset pricing, and portfolio choice. The tail dependence structure is, for example, a main ingredient for the computation of high quantiles of aggregate loss distributions, and hence for risk capital requirements, and dictates the extent of idiosyncratic tail risk, and hence the diversification potential, within a collection of assets.
A key question in financial econometrics and international finance is whether the dependence structure between economic variables, in particular asset returns, is constant over time and across markets, regions and institutions, or whether it is subject to variation due to for example, financial market integration, emerging market developments, or financial contagion. Several papers analyze this question using a wide variety of different methodologies; see for example, King and Wadhwani (Citation1990), Longin and Solnik (Citation1995), Forbes and Rigobon (Citation2002), Bekaert, Harvey, and Ng (Citation2005), Bekaert, Hodrick, and Zhang (Citation2009), Christoffersen et al. (Citation2012), Bücher, Jäschke, and Wied (Citation2015), Bormann and Schienle (Citation2020), and the references therein.
In this article, we focus on the tail dependence structure between two risks, which is completely characterized by the bivariate tail copula. In this context, we develop a general procedure to test for the equality of the tail copulas associated with two bivariate samples. The standard one-sample problem, that is, testing for a specific parametric family of tail copulas, has been studied in Can et al. (Citation2015). A challenging feature of the two-sample problem is that the—under the null hypothesis—common tail copula is not specified. This complexity arises naturally as it follows from de Haan and Resnick (Citation1977) that the class of all possible tail copulas is so large that it cannot be represented as a finite-dimensional parametric family, rendering the testing problem nonparametric. A pivotal property of our procedure is that, through a martingale transformation, it leads to asymptotically distribution-free test statistics, so that critical values can be tabulated for universal use and no computer-intensive methods have to be developed and validated.
Our testing approach can be summarized as follows. We first construct two semi-parametric estimators of the tail copulas, one for each sample, consider their suitably normalized difference, and prove that it converges weakly to a nontrivial limiting process under the null hypothesis of tail copula equality. Next, we describe the martingale transformation that transforms this limiting process into a standard bivariate Wiener process. Then, we establish that the empirical counterpart of this transformation, when applied to the empirical process given by the normalized difference of the two tail copula estimators, converges weakly to a standard bivariate Wiener process under the null hypothesis. Finally, two-sample tests for tail copulas can now be conducted by comparing the transformed empirical process to a standard Wiener process. Hence, our approach leads to an asymptotically distribution-free test process and thus, by taking functionals, to asymptotically distribution-free test statistics. In other words, our procedure leads to an entire test process from which we can generate a myriad of asymptotically distribution-free tests.
We illustrate the finite-sample performance of our approach through Monte Carlo simulations. These confirm that tests based on our test process have good size and power performances, notwithstanding the difficult nature of the testing problem considered in this article.
We apply our procedure to test for tail copula equality of equity index returns during and after the global financial crisis. In particular, we analyze the tail dependence structure among the two European equity market indices FTSE 100 (UK) and DAX 30 (Germany) and the two transatlantic equity indices FTSE 100 and S&P 500 (US), during 2008–2011 (sample 1, covering the most volatile days of the global financial crisis and the subsequent European debt crisis) and 2012–2015 (sample 2, covering a “post-crisis” period of equal length). We construct synchronized daily observations of negative log-returns on the basis of high-frequency data using Coordinated Universal Time (UTC). Computing three commonly used test statistics from our test process, we find that the null hypothesis of tail copula equality between the two samples is not rejected, despite a clearly visible change in the marginal distributions of the index returns between the two samples. This finding applies to both the European pair {FTSE 100, DAX 30} and the transatlantic pair {FTSE 100, S&P 500}. That is, although the margins became markedly less volatile from the crisis period to the post-crisis period, no statistical evidence is found for a change in the number of margin-free joint extremes for both pairs of equity market indices.
We briefly describe four papers that are related to the testing problem considered in this article. In Christoffersen et al. (Citation2012), an extensive analysis is conducted of the evolution over time of the regular and tail dependence structures among both developed and emerging financial markets, and the associated diversification potential. Econometrically, a novel dynamic asymmetric copula model of a parametric nature is used to capture asymmetric tail dependence. When assessing tail dependence, attention is restricted to the less informative tail dependence coefficients, rather than to tail copula functions as in the present paper, and their development over a long period of 20 years. In Bücher and Dette (Citation2013) and Bücher, Jäschke, and Wied (Citation2015), new statistical methods are developed for testing tail copula equality, tail copula goodness-of-fit testing, and detecting structural breaks in tail dependence. The methods are applied in Bücher, Jäschke, and Wied (Citation2015) to energy and financial markets data. An important difference between these two papers and the present one is that here convenient distribution-free weak limits of test statistics are obtained, as described above, whereas in Bücher and Dette (Citation2013) and Bücher, Jäschke, and Wied (Citation2015) computer-intensive multiplier bootstrap procedures are employed. Bormann and Schienle (Citation2020) provides a detailed account of tail dependence asymmetries and inequalities in 90 years of U.S. equity data, using a refined nonparametric testing procedure that compares two tail copulas locally piecewise on disjoint intervals employing multiple testing principles. As the corresponding complex limiting distributions do not admit closed-form expressions, finite-sample approximations are simulated using multiplier bootstrap procedures, as in Bücher and Dette (Citation2013) and Bücher, Jäschke, and Wied (Citation2015).
The remainder of this article is organized as follows. In Section 2 we formalize our testing problem and in Section 3 we introduce our initial testing basis, which compares two semi-parametric tail copula estimators constructed separately from the two samples, and analyze its asymptotic behavior. In Section 4 we describe the martingale transformation and in Section 5 we prove that the empirical counterpart of this transformation applied to our initial testing basis converges weakly to a standard Wiener process. In Section 6 our Monte Carlo simulation analysis is presented. Section 7 describes the results of our empirical analysis of equity indices. Conclusions are given in Section 8. The proofs of our theorems and some additional simulation results are deferred to the Appendix, supplementary materials. An R script implementing our testing approach is also provided as a supplementary material.
2 Testing Problem
Consider iid random vectors generated from some bivariate distribution function (df) F and iid random vectors
independently generated from some bivariate df
. Let F have marginal dfs F1, F2 and let
have marginal dfs
, so that
and
for
.
We assume that the dfs F and lie in the respective domains of attraction of bivariate extreme value distributions G and
. This means that there exist normalizing sequences
and
, for j = 1, 2, such that
as
, for all continuity points
of G and
, respectively. The normalizing sequences are chosen in such a way that the margins G1, G2, of G, and the margins
, of
, are in the form of a standard generalized extreme value (GEV) distribution:
(1)
(1)
for j = 1, 2. The constants
and
are the marginal extreme value (EV) indices associated with F and
, respectively. Here, and in the rest of the article, expressions of the form
should be interpreted as
when γ = 0.
The distribution G, hence, the asymptotic joint tail behavior of F, is characterized by the marginal EV indices and the bivariate tail copula R associated with F, which can be defined as
(2)
(2)
The EV indices specify the margins of G through (1), and the function R specifies the dependence structure between the margins. While R is not a copula itself, it does characterize the copula of G, and hence the tail dependence structure of F. Similarly, the distribution
is characterized by
and the tail copula
associated with
, defined analogously to (2). We refer to, for example, the monographs Kotz and Nadarajah (Citation2000), Beirlant et al. (Citation2004), and de Haan and Ferreira (Citation2006) for further details about multivariate extreme value theory.
Observe that
For random variables with continuous margins, R(1, 1) is often referred to as the upper tail dependence coefficient and denoted by λU; see for example, Joe (Citation2001), p. 33. It measures the probability of a “large rank” of X1 conditionally upon a “large rank” of Y1. Indeed,
We also note here that the function R generates a σ-finite measure R on the Borel subsets of via the identity
In this article, we develop a general procedure to construct two-sample tests for the equality of the tail copulas R and . In other words, we assume that we have two random samples independently generated from F and
, and provide a procedure that can be used to test the null hypothesis
against the alternative
, where R and
remain unspecified. Note that, while the bivariate extreme value setting is of a semi-parametric nature, both the null and alternative hypotheses we consider in this article are nonparametric.
3 Comparing Two Tail Copula Estimators
Suppose we have a random sample from F and an independent random sample
from
. Throughout Sections 3–5 we will assume that the null hypothesis holds, that is, R and
are the same tail copula, which we will refer to as R. In the present section, we define two semi-parametric estimators for the tail copula R, computed separately from the two available samples, and we describe the asymptotic behavior of the difference between these two estimators as the sample sizes tend to infinity.
From (2), one can verify that for
, with
(3)
(3) where
(4)
(4)
We also define analogously to (4) and
analogously to (3). We will use the functions
and
as a basis for estimating R from the two available samples. To that end, we let
and
denote intermediate sequences satisfying
as
and
as
. For notational brevity, we will write Rn for
and
for
.
We estimate Rn and hence R by replacing the unknown quantities and γj in (4) by appropriate estimators
and
, for j = 1, 2, and the probability P by the corresponding empirical measure. We define, therefore,
(5)
(5) as an empirical analogue to (4), and we introduce the semi-parametric estimator
(6)
(6)
for the tail copula R. The random variables
and the estimator
are defined analogously to (5) and (6), respectively.
Throughout, we fix δ and T such that . For later reference, we also introduce the process
(7)
(7) and the analogously defined
. It is known, by (Einmahl, de Haan, and Sinha Citation1997, Lemma 3.1), that the weak convergence
holds in the product space
as
. Here,
denotes the Skorokhod space of functions with domain
, and
are independent R-Wiener processes on
, that is, independent zero-mean Gaussian processes with covariance structure
Henceforth, we will omit the arguments and
where appropriate, for ease of notation.
Now, the estimators and
estimate the same tail copula R from two different samples, while they would estimate different tail copulas under the alternative hypothesis. So the normalized difference between
and
is a natural starting point for a two-sample test. Thus, we define
and
Our first result will establish the asymptotic behavior of as
. We first state the necessary assumptions and definitions.
A1. For some 6-variate random vector , we have the joint weak convergence
(8)
(8) as
, in
. Similarly, for some 6-variate random vector
, we have the joint weak convergence
(9)
(9)
as
, in
.
Assumption A1 is formulated such that it allows for flexibility in choosing the estimators. It is fulfilled for, for example, the moment estimators of γj, aj, bj, , and
, provided that k and
are chosen appropriately; see de Haan and Ferreira (Citation2006), sec. 4.2 and 3.5.
A2. The partial derivatives and
exist and are continuous on
.
A3. (i) For some , as
,
(ii) The sequences k and satisfy
and
for some
as
.
Finally, for x > 0 and , we define the following functions:
(10)
(10)
We are now prepared to state the convergence result for .
Theorem 3.1.
If Assumptions A1–A3 hold, then(11)
(11) in
as
.
Remark 3.2.
While the normalized difference between and
provides a natural initial basis for two-sample testing, Theorem 3.1 reveals that it is not easily amenable for this purpose: the distribution of η depends upon the true underlying tail copula R, which is not specified by the null hypothesis, as well as on the true, but unknown, values of the parameters γ1, γ2,
and
. To obtain a suitable testing basis, we will in the next section describe a martingale transformation that will turn η into a standard process with a distribution that depends neither on R nor on the marginal extreme value indices.
Remark 3.3.
The following relationships between the functions f, g, h defined in (10) can be verified, for any x > 0 and :
Using these identities, the limiting process η appearing in (11) can also be written as
This equivalent, but—importantly—more parsimonious, form of the limiting process η, rather than that in (11), will serve as the basis for the martingale transformation described in the next section, which would otherwise be ill-defined.
Remark 3.4.
Although the bivariate case is the most interesting and the most relevant one, the setup and results of this article can be generalized to the d-variate case, for d > 2. We will not pursue this, however, because for d > 2 a d-variate tail copula R on the domain yields, in contrast to when d = 2, only limited information on the tail dependence structure of F.
4 Martingale Transformation
In this section, we describe a martingale transformation that enables us to transform the limiting process η into a standard bivariate Wiener process. The transformation is obtained by a suitable application of the martingale innovation transform approach originally developed in Khmaladze (Citation1981, Citation1988, Citation1993), and used for example, in Koenker and Xiao (Citation2002, Citation2006) for quantile regression, in Khmaladze and Koul (Citation2004) and Delgado, Hidalgo, and Velasco (Citation2005) for goodness-of-fit testing of parametric regression and time series models, and used and extended in Can et al. (Citation2015) for parametric tail copula goodness-of-fit testing. The classical Doob-Meyer decomposition of a Brownian bridge, which turns a Brownian bridge into a standard Brownian motion by subtracting its compensator, occurs as a simple special case of this approach. Heuristically, the present martingale transformation may therefore be understood as the suitable counterpart for η of the Doob-Meyer decomposition for a Brownian bridge.
Consider the representation we derived in Remark 3.3 for the limiting process η of Theorem 3.1. It is easy to see, by direct computation of the covariance, that the process is an R-Wiener process, which we will call
. Thus, η is of the form
(12)
(12) where the Zi are random variables and the Qi are deterministic functions on
, defined by
(13)
(13)
We note that (12) is of the general bivariate form (23) in Can et al. (Citation2015). Hence, η can be transformed into a standard Wiener process by suitably exploiting Theorem 3.1 of that paper. We will formally state this result in Theorem 4.1, but we first introduce some assumptions and notation.
A4. The tail copula R has a positive density on
. The derivatives
and
exist and are continuous on
.
Observe that this condition allows R to have mass on the “axes at infinity” , but it excludes (strict) tail independence, that is,
for all
. We note that it can be tested whether the Ledford-Tawn coefficient of tail dependence is less than 1, see Draisma et al. (Citation2004). If this is the case, the data are tail independent.
Now, with the functions Qi as defined in (13), let us denote for
, so that
where
and similarly for g and h. Let
denote the column vector consisting of
. We will also write
for the vector
with the true parameters
replaced by arbitrary
, the true density r replaced by an arbitrary mapping
, and the true partial derivatives
replaced by arbitrary mappings
from
to
.
We also introduce matrices(14)
(14) and we denote
for
.
The functions bear resemblance to score functions, corresponding to a1, a2, b1, b2, γ1, γ2,
, and
, respectively, using terminology from likelihood analysis. Note the asymmetry between the score functions associated to the two samples, which occurs due to Remark 3.3. Furthermore,
can be viewed as a partial Fisher information matrix built from these scores.
Our next assumption is
A5. The matrices are well-defined and invertible for all
and all
in some neighborhood of
w.r.t. the relevant metrics (Euclidean metric for
, the metric generated by the norm
for
).
We are now equipped to state our martingale transformation result.
Theorem 4.1.
Let η be the limiting process derived in Remark 3.3. If Assumptions A4–A5, confined to the true hold, then the process
(15)
(15) is a standard Wiener process on
, for any
.
Remark 4.2.
Recall (12). The martingale transformation induces a nullification of and normalizes the resulting R-Wiener process to render a standard Wiener process on
. The double integrals with respect to the process η can be understood pathwise as Riemann-Stieltjes integrals; we refer to for example, Towghi (Citation2002), Theorem 1.2(a), for an appropriate existence result.
Remark 4.3.
We note that in the cases and
, we will have
and
, respectively, and the matrix
will be singular. If this information is available, the redundant q-functions can simply be omitted when constructing
, and Theorem 4.1 continues to apply mutatis mutandis. Otherwise, this case may be included by using the Moore-Penrose pseudoinverse of
in (15) and adapting the proof of Theorem 4.1 accordingly. Besides, as we will show by simulations in Section 6, our testing approach, which uses the regular inverse of the matrix
defined above, can in practice still be applied without size distortions when
or
.
5 Two-Sample Testing
Applying the transformation in (15) to , with unknown quantities replaced by estimators, we obtain the following empirical process on
:
(16)
(16) where
and
are short-hand notations for
and
, respectively.
Let K be a univariate density serving as a kernel for kernel density estimation. To estimate the tail copula density r, we propose the nonparametric estimatorwhere
and
, with, for some
,
, uniformly on
.
For the partial derivative , we propose the nonparametric estimator
where now
and
, with, for some
,
, uniformly on
, and where
denotes the derivative of K. The partial derivative
is estimated analogously. In the sequel, we choose K to be the well-known triweight kernel
, for convenience. We will demonstrate, as part of our main theoretical result that follows, that these estimators are consistent.
In view of Theorems 3.1 and 4.1, one might anticipate the empirical process to converge weakly to a standard Wiener process as
. This turns out to be true, and we will formally establish this result in Theorem 5.1, but first we state one more assumption.
A6. The partial derivatives , and
exist and are continuous on
.
Note that this implies that ,
, and
exist and are continuous on
.
Theorem 5.1.
Under Assumptions A1–A6, the process in (16) converges weakly to a standard bivariate Wiener process in
as
, for any
.
Theorem 5.1, our main theoretical result, states that under the null hypothesis , the test process
converges weakly to a distribution-free limiting process, and hence
can be used as a generator of a multitude of asymptotically distribution-free test statistics for testing
. We will not investigate how to construct optimal tests against certain specific alternative hypotheses. Instead, we will study in Section 6 three common examples of nonparametric omnibus tests based on
, not only under the null but also under the alternative hypothesis.
6 Simulations
In this section, we study the finite-sample behavior of the test process in (16), both under the null hypothesis
and the alternative hypothesis
, via Monte Carlo simulations. All the computations of the present section, as well as those of the subsequent Section 7, are implemented in the software R. An.R file for the implementation of our testing approach is provided as a supplement.
To improve the finite-sample approximation of Theorem 5.1, we actually consider the process , an asymptotically equivalent version of
, obtained by replacing k and
by
and
, respectively, in the definition of the normalizing factor
. For each model considered below, we generate 1000 pairs of bivariate samples of size
. We take
and T = 2. In additional simulation results (not reported here), we have seen that the actual choices of the tuning parameters δ and T are relatively unimportant and we have thus fixed them throughout. Also, based on further simulations, we have decided to choose the multiplication factors in the bandwidth to be
. This fixes the bandwidth once k is chosen. The choice of k is known to be important and difficult in extreme value statistics. As a rule of thumb, we consider the relation between k and the sample size n to be
if n is not very large (say,
). If we are in the luxurious situation that
, we suggest
. In the simulations, for
, we take
, but the simulation results under the null hypothesis do not change substantially when k changes within reasonable limits. In particular, we find no clearly visible effect on the PP-plots. Of course, the power is affected when k varies. Indeed, when k becomes larger, the power increases sharply, for two reasons: (i) increased (effective) sample size; and (ii) increased bias. In empirical applications, a further sensitivity analysis can be helpful for a range of k-values, where the largest k is twice the smallest one, with the rule-of-thumb value included; see Section 7. The estimators
and
, j = 1, 2, are taken to be the moment estimators (see, e.g., de Haan and Ferreira (Citation2006), sec. 4.2 and 3.5), and we set, as usual,
(and analogously for
), with
,
denoting the marginal order statistics.
Once a pair of bivariate samples is generated, we construct the process on a 100 × 100 finite grid of equidistant points spanning
. To compare this observed path with a standard Wiener process, we compute three test statistics, namely
(17)
(17) where
is the mesh length, that is, 1/100.
The same statistics are also computed from 10,000 paths of the true standard Wiener process generated on the same grid , to create benchmark distribution tables. Recall that these tables have to be made only once as a consequence of obtaining a distribution-free limit. We denote the statistics, computed from the true Wiener process, by κ,
and A2. For each model, we present PP-plots for a visual comparison of the empirical distributions of κn versus κ,
versus
and
versus A2. We also present rejection frequencies at 5% and 1% significance levels.
6.1 Simulations Under the Null Hypothesis
We consider the following four models:
Model I.F has Gumbel(2) copula and Pareto(3) margins, has Gumbel(2) copula and Pareto(4) margins.
Model II.Both F and have Gumbel(2) copula and Pareto(3) margins.
Model III.F has Clayton(1) survival copula and Pareto(3) margins, has Clayton(1) survival copula and Pareto(4) margins.
Model IV.F has Gumbel(2)-independence mixture copula with equal weights and Pareto(3) margins, has Gumbel(2)-Clayton(1) mixture copula with equal weights and Pareto(4) margins.
Note that we specify each bivariate distribution F (and ) in terms of a copula C and marginal dfs F1, F2, which characterize F via
. Also, Pareto(α) with
refers to the df
; Gumbel(θ) with
refers to the copula
Clayton(θ) with refers to the copula
and therefore the Clayton(θ) survival copula is given by
Since the tail copula of a bivariate df is entirely determined by the copula, the null hypothesis clearly holds in Models I–III, where F and
have identical copulas. In Model IV, the copulas of F and
are different, but
still holds, as both the independence copula and the Clayton(1) copula have upper tail independence (i.e., zero tail copula).
The PP-plots in indicate that the process Wn indeed behaves like a standard Wiener process, providing an empirical confirmation of Theorem 5.1. Moreover, in we present the rejection counts at 5% significance level. For each particular model and test statistic, the rejection count is simply the observed number of times (out of 1000) the test statistic exceeds the 95th percentile of the corresponding distribution obtained from the true Wiener process. In all cases, the observed counts are consistent with the Binomial() distribution, substantiating a good size performance. Note that the results for Model II show that our approach works well when F and
have identical marginal distributions; see Remark 4.3.
Fig. 1 PP-plots for the three test statistics constructed from 1000 simulated sample pairs per model.
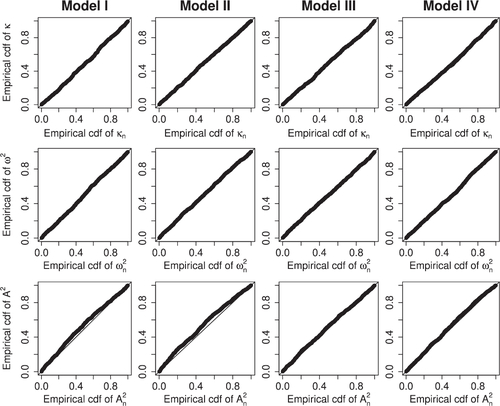
Table 1 Number of rejections in 1000 repetitions at 5% significance level.
6.2 Simulations Under the Alternative Hypothesis
Before describing the simulation models under the alternative, we first note that the estimation of R(x, y) is statistically difficult in the sense that generally the corresponding estimator has considerable bias and variance. For simplicity, consider R(1, 1), the upper tail dependence coefficient. For the sample sizes used in this simulation section, it is hard to distinguish between the values and
, say, so a test cannot achieve a high power in such a case. In order to substantiate this, we reuse the simulation results from the df F with the Clayton(1) survival copula and Pareto(3) margins in Model III above. In this case
. The histogram in depicts the distribution of the 1000 estimates
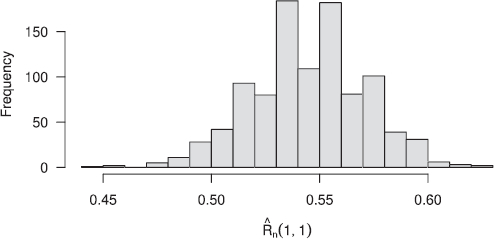
. The (empirical) bias of these estimates is as high as 0.046 and the sample standard deviation is 0.026. We see from the figure that the central 95% of the estimates range from 0.492 to 0.596; the true value is barely included in this interval and the range is rather wide. Note that when performing a two-sample test, the bias and variance of the second sample also have to be taken into account.
Fig. 2 Histogram of values computed from 1000 bivariate samples with Clayton(1) survival copula and Pareto(3) margins.
In this section, we consider the four models listed below. The linear factor model of Model IVa refers to the bivariate random vector(18)
(18) with Z1, Z2 independent and
deterministic parameters.
Model 1a.F has Gumbel(2) copula and Pareto(3) margins, has Gumbel(6) copula and Pareto(4) margins.
Model IIa.F has Gumbel(4) copula and Pareto(3) margins, has Gumbel(1) (i.e., independence) copula and Pareto(4) margins.
Model IIIa.F has Clayton(1) survival copula and Pareto(3) margins, has Clayton(5) survival copula and Pareto(4) margins.
Model IVa.F is the df of the linear factor model (18), with , and
is the df of the same model (18) with
.
As in Section 6.1, we construct PP-plots for each model and each of the three test statistics; see . The PP-plots show dramatic deviations from the behavior under a standard Wiener process. We also present rejection counts at 5% significance level in . As suggested by the PP-plots, the three omnibus tests have high power with, for the present alternatives, Cramér-von Mises outperforming Kolmogorov-Smirnov, and Anderson-Darling performing the best. Based on this, we recommend to apply both the Cramér-von Mises and the Anderson-Darling type test statistics.
Fig. 3 PP-plots for the three test statistics constructed from 1000 simulated sample pairs per model.
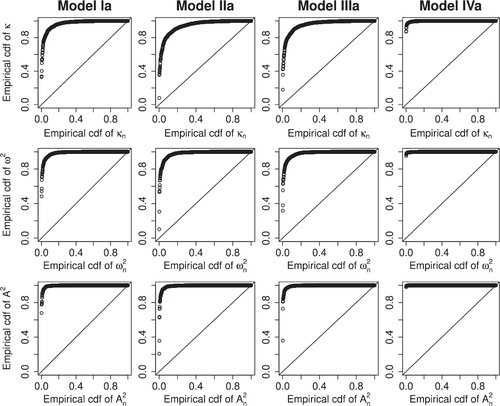
Table 2 Number of rejections in 1000 repetitions at 5% significance level.
In , we also provide empirical power curves at 5% significance level for the three test statistics, computed from a sequence of eight models similar to Model Ia. In each model, F has Gumbel(θ) copula and Pareto(3) margins, has Gumbel(6) copula and Pareto(4) margins, and θ takes a sequence of values in the interval (1, 6) so that the difference of the tail dependence coefficients
takes a sequence of values ranging from 0.1 to 0.8. Observe that the power grows quickly and is high as soon as the difference is 0.2. The exact values of θ that were used, and the corresponding differences
, can be seen in . Each point in a given power curve represents the observed rejection rate at the 5% level among 200 sample pairs.
Fig. 4 Empirical power curves for the three test statistics, constructed from a sequence of eight models similar to Model Ia.
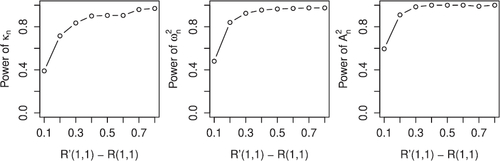
Table 3 Gumbel parameter values used for the empirical power curves, and the corresponding differences .
7 Empirical Analysis
Emboldened by the Monte Carlo simulation results of the previous section, demonstrating good size and power performances, we now take our approach to real equity index data of three financial markets. We take , T = 2 and
as in Section 6, and consider a range of k-values (see below).
An important concern when analyzing multiple financial markets operating in different time zones is the synchronicity of the data, which requires a careful treatment. We use intra-daily data to construct three synchronized time series of daily equity index returns: for FTSE 100 (UK), DAX 30 (Germany), and S&P 500 (US). Data are obtained from the Tick History Database of Thomson Reuters. Our full sample spans the period May 2008 to August 2015. Using Coordinated Universal Time (UTC), care has been taken to account for the change to Daylight Savings Time (DST), which does not occur on the same day around the world.
We focus on the pair {FTSE 100, DAX 30} for a detailed exposition. We construct two bivariate samples from the daily negative log-returns of these two indices: the first sample is generated from the 900 trading days preceding January 1, 2012 (spanning the period from May 23, 2008 to December 31, 2011), and the second sample is generated from the 900 trading days following January 1, 2012 (spanning the period from January 1, 2012 to August 13, 2015). To be more precise, the daily negative log-returns for a given index are the numbers , with pt denoting the index price recorded at 14:30 UTC (13:30 UTC during European DST) on trading day t. Note that the first sample covers some of the most volatile trading days of the global financial crisis and the subsequent European debt crisis, while the second sample can be considered a relatively calm “post-crisis” period. We aim to test whether or not the tail dependence structure in the two samples, as characterized by the tail copula, shows statistical evidence of a change. As an interesting alternative analysis, which we will not pursue here, one could compare the tail copulas associated with the upper and lower tails of the daily bivariate log-returns within the same sampling period. Indeed, these bivariate extremal gains can be seen to be asymptotically independent of the bivariate extremal losses.
displays plots of the daily negative log-returns for the two indices during the two time periods, and provides some sample statistics for these time series. It is visibly clear that the marginal structure changes for both indices from period 1 to period 2, but a possible change in the tail dependence structure is much more difficult to detect by visual inspection. The change in the marginal structure can also be observed in , which plots the estimated extreme value index γ for each marginal dataset over a set of k values ranging from 100 to 200. It is clear that the (right) tail of the daily negative log-returns is heavier in the first period (with EV index estimates firmly positive) than in the second period (with EV index estimates mostly hovering below 0).
Fig. 5 Daily negative log-returns of FTSE 100 (top) and DAX 30 (bottom) in the two periods. Tick marks on the horizontal axes indicate the first trading day of each year.
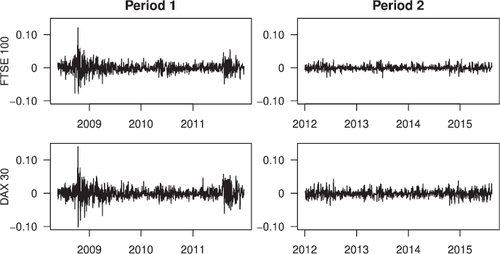
Fig. 6 Estimated marginal extreme value indices of the daily negative log-returns of FTSE 100 and DAX 30 in the two periods.
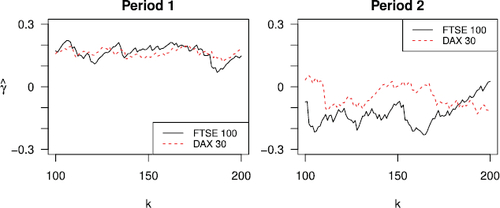
Table 4 Sample statistics of the daily negative log-returns of FTSE 100 and DAX 30 in the two periods.
The next step in our analysis is to transform the observed negative log-returns (Xi, Y i) in period 1 and in period 2 into
and
as described in (5), which leads to estimates
and
of the tail copulas R and
in the two periods. displays scatterplots of the transformed negative log-returns in the two periods, for k = 150. Since the transformation (5) maps joint extremes (Xi, Y i) to points near the origin, the tail copula estimate
is proportional to the number of points
inside the rectangle
(and analogously for
). In particular, the upper tail dependence coefficients R(1, 1) of period 1 and
of period 2 can be estimated by dividing the number of points
or
in
by k. This leads to estimates
and
. The difference is small, and, also in light of the estimator’s substantial bias and variance illustrated in for simulated data, it is not at all clear if it indicates a difference in the true tail copulas R and
. Also note that R(1, 1) does not tell the whole story about tail dependence, which can only be properly described by the entire tail copula R.
Fig. 7 Transformed daily negative log-returns of period 1 and
of period 2, with k = 150. The number of points in the square
, divided by k, gives the estimates
and
.
![Fig. 7 Transformed daily negative log-returns (X̂i,Ŷi) of period 1 and (X̂′i,Ŷ′i) of period 2, with k = 150. The number of points in the square [0,1]2, divided by k, gives the estimates R̂n(1,1)=115/150=0.77 and R̂′n(1,1)=104/150=0.69.](/cms/asset/20c2dddf-8744-4876-8b64-eb28ccf95772/ubes_a_2166050_f0007_c.jpg)
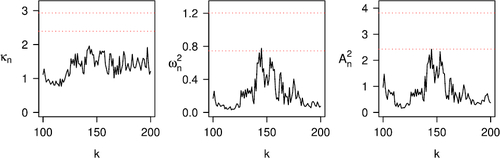
It remains to construct the test process Wn and compute the test statistics in (17), as in Section 6. We do this again for . Plots of the resulting test statistics can be seen in , together with the 95th and the 99th percentiles of their distributions under the null hypothesis. Each test statistic stays below the 95th percentile of the corresponding null distribution essentially for the entire range of k values, leading to non-rejection of the null hypothesis. Thus, the conclusion based on these three test statistics is that the tail dependence structure between the daily negative log-returns of FTSE 100 and DAX 30 does not change from period 1 to period 2, despite the visible evidence of change in the marginal (tail) behaviors of both equity indices.
Fig. 8 The three test statistics in (17) computed from the daily negative log-returns of FTSE 100 and DAX 30 in periods 1 and 2. The dotted lines indicate the 95th and 99th percentiles of the corresponding null distributions.
For an independent verification, we also apply the multiplier bootstrap test for the equality of tail copulas described in Bücher and Dette (Citation2013) to our dataset. An implementation of the partial derivative multiplier (pdm) approach, as outlined in Section 4.1 of that paper, with k = 150 and 500 bootstrap replications, leads to an estimated p-value of 0.42 for the null hypothesis of equal tail copulas, which is consistent with our conclusion.
A possible objection against this application could be that, per period, the data may be serially dependent. First note that pairwise dependence in the tails can only be “positive”; for example, for the countermonotonic copula, the case of perfect negative dependence, the corresponding tail copula is just the 0-function, the same as for the independence copula. Loosely speaking, in case of (positive) serial dependence at high levels, the data contain less information about the underlying df than in the iid case. Hence, estimation errors, that is, variances, become larger and so do therefore the critical values of the tests. As a result, our tests can, in fact, be considered as anticonservative (that is, they overreject): if the null hypothesis is not rejected under the iid assumption, it will not be rejected when serial dependence is taken into account. In the Appendix, we provide some empirical support for this heuristic argument via simulations: rerunning Model III of Section 6.1 with component-wise serial dependence in both samples leads to higher rejection rates as expected. So, our conclusion of no change in tail copulas remains.
Having considered the tail dependence between a pair of European equity indices, we now turn our attention to the tail dependence between the transatlantic pair {FTSE 100, S&P 500}. We compute, like above, the daily negative log-returns of these two indices during the same periods 1 and 2 defined earlier, using daily synchronous index price data recorded at 14:30 UTC (13:30 UTC during European DST). displays plots of the daily negative log-returns for the two indices during the two time periods, and provides sample statistics. As before, we see clear evidence of a change in the marginal behavior of the negative log-returns in period 1 versus in period 2.
Fig. 9 Daily negative log-returns of FTSE 100 (top) and S&P 500 (bottom) in the two periods. Tick marks on the horizontal axes indicate the first trading day of each year.
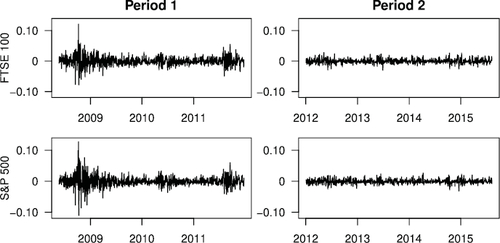
Table 5 Sample statistics of the daily negative log-returns of FTSE 100 and S&P 500 in the two periods.
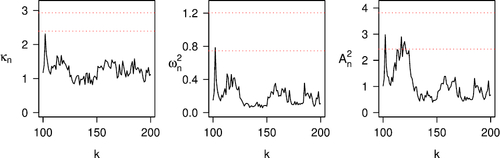
To test if there is a change in the tail dependence structure, we again construct our test process Wn from the two bivariate samples generated from the two periods, and compute the three test statistics in (17) for ; see . We find that each test statistic mostly stays below the 95th percentile of the corresponding null distribution, with a few exceptions at particular k values. Keeping in mind that (i) looking at several k values simultaneously amounts to a multiple testing problem, and (ii) our datasets likely feature some serial dependence, both of which have an upward effect on critical values for the test statistics, we conclude that our testing approach again supports the null hypothesis of no change in the tail dependence structure of the negative log-returns in period 1 versus in period 2.
Fig. 10 The three test statistics in (17) computed from the daily negative log-returns of FTSE 100 and S&P 500 in periods 1 and 2. The dotted lines indicate the 95th and 99th percentiles of the corresponding null distributions.
As with the earlier dataset of {FTSE 100, DAX 30} negative log-returns, we also apply the pdm bootstrap test of Bücher and Dette (Citation2013) to the present dataset, with k = 150 and 500 bootstrap runs. This leads to an estimated p-value of 0.38 for the null hypothesis of equal tail copulas, which is again consistent with our conclusion.
8 Conclusions
We have developed a novel, general procedure to test for the equality of the tail copulas associated with two samples of bivariate data. A natural but complex feature of this problem is that the tail copulas, of which equality is tested for, are not specified. Deploying a martingale transformation of the suitably normalized difference between two semiparametric estimators of the tail copulas, we have constructed a two-sample hypothesis testing process and established its weak convergence to a standard Wiener process under the null hypothesis. Applying our hypothesis testing procedure to samples of negative log-returns of equity indices, during and after the global financial crisis, we find no evidence to reject the null hypothesis of tail copula equality. That is, although large negative returns occur more frequently and severely during crisis versus post-crisis for the pairs of equity indices we have analyzed, our testing procedure reveals that there is no statistical evidence of a change in their tail dependence structure. These findings suggest that, for the highly developed equity markets we consider, whereas inference about marginal (tail) behavior should account for changes over time or across “regimes,” the tail dependence structure appears to be more stable and can thus be inferred from longer time periods.
Supplemental Material
Download Zip (410.2 KB)Acknowledgments
We are very grateful to the Editor Professor Ivan Canay, the Associate Editor, and two referees for many useful comments that greatly improved the article. We also thank Estate V. Khmaladze for stimulating discussions about this article.
Supplementary Materials
Appendix:Proofs of Theorems 3.1, 4.1, 5.1; simulation results under serial dependence. (.pdf file)
Code: R code that implements our testing procedure. (.R file)
Disclosure Statement
The authors report that there are no competing interests to declare.
Additional information
Funding
References
- Beirlant, J., Goegebeur, Y., Teugels, J., and Segers, J. (2004), Statistics of Extremes: Theory and Applications, New York: Wiley.
- Bekaert, G., Harvey, C. R., and Ng, A. (2005), “Market Integration and Contagion,” The Journal of Business, 78, 39–69.
- Bekaert, G., Hodrick, R. J., and Zhang, X. (2009), “International Stock Return Comovements,” The Journal of Finance, 64, 2591–2626.
- Bormann, C., and Schienle, M. (2020), “Detecting Structural Differences in Tail Dependence of Financial Time Series,” Journal of Business & Economic Statistics, 38, 380–392.
- Bücher, A., and Dette, H. (2013), “Multiplier Bootstrap of Tail Copulas with Applications,” Bernoulli, 19, 1655–1687.
- Bücher, A., Jäschke, S., and Wied, D. (2015), “Nonparametric Tests for Constant Tail Dependence with an Application to Energy and Finance,” Journal of Econometrics, 187, 154–168.
- Can, S. U., Einmahl, J. H. J., Khmaladze, E. V., and Laeven, R. J. A. (2015), “Asymptotically Distribution-Free Goodness-of-Fit Testing for Tail Copulas,” Annals of Statistics, 43, 878–902.
- Christoffersen, P., Errunza, V. R., Jacobs, K., and Langlois, H. (2012), “Is the Potential for International Diversification Disappearing? A Dynamic Copula Approach,” The Review of Financial Studies, 25, 3711–3751.
- de Haan, L., and Ferreira, A. (2006), Extreme Value Theory: An Introduction, New York: Springer.
- de Haan, L., and Resnick, S. I. (1977), “Limit Theory for Multivariate Sample Extremes,” Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete, 40, 317–337.
- Delgado, M. A., Hidalgo, J., and Velasco, C. (2005), “Distribution Free Goodness-of-Fit Tests for Linear Processes,” Annals of Statistics, 33, 2568–2609.
- Draisma, G., Drees, H., Ferreira, A., and de Haan, L. (2004), “Bivariate Tail Estimation: Dependence in Asymptotic Independence,” Bernoulli, 10, 251–280.
- Einmahl, J., de Haan, L., and Sinha, A. (1997), “Estimating the Spectral Measure of an Extreme Value Distribution,” Stochastic Processes and Their Applications, 70, 143–171.
- Forbes, K. J., and Rigobon, R. (2002), “No Contagion, Only Interdependence: Measuring Stock Market Comovements,” The Journal of Finance, 57, 2223–2261.
- Joe, H. (2001), Multivariate Models and Dependence Concepts (2nd ed.), Boca Raton, FL: Chapman & Hall/CRC.
- Khmaladze, E. V. (1981), “Martingale Approach in the Theory of Goodness-of-Fit Tests,” Theory of Probability and its Applications, 26, 240–257.
- Khmaladze, E. V. (1988), “An Innovation Approach to Goodness-of-Fit Tests in Rm,” Annals of Statistics, 16, 1503–1516.
- Khmaladze, E. V. (1993), “Goodness of Fit Problem and Scanning Innovation Martingales,” Annals of Statistics, 21, 798–829.
- Khmaladze, E. V., and Koul, H. L. (2004), “Martingale Transforms Goodness-of-Fit Tests in Regression Models,” Annals of Statistics, 32, 995–1034.
- King, M. A., and Wadhwani, S. (1990), “Transmission of Volatility between Stock Markets,” The Review of Financial Studies, 3, 5–33.
- Koenker, R., and Xiao, Z. (2002), “Inference on the Quantile Regression Process,” Econometrica, 70, 1583–1612.
- Koenker, R., and Xiao, Z. (2006), “Quantile Autoregression,” Journal of the American Statistical Association, 101, 980–990.
- Kotz, S., and Nadarajah, S. (2000), Extreme Value Distributions: Theory and Applications, London: Imperial College Press.
- Longin, F., and Solnik, B. (1995), “Is the Correlation in International Equity Returns Constant: 1960–1990?” Journal of International Money and Finance, 14, 3–26.
- Towghi, N. (2002), “Multidimensional Extension of L.C. Young’s Inequality,” Journal of Inequalities in Pure and Applied Mathematics, 3, 1–30.