
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The standard vector autoregressive (VAR) models suffer from overparameterization which is a serious issue for high-dimensional time series data as it restricts the number of variables and lags that can be incorporated into the model. Several statistical methods, such as the reduced-rank model for multivariate (multiple) time series (Velu, Reinsel, and Wichern; Reinsel and Velu; Reinsel, Velu, and Chen) and the Envelope VAR model (Wang and Ding), provide solutions for achieving dimension reduction of the parameter space of the VAR model. However, these methods can be inefficient in extracting relevant information from complex data, as they fail to distinguish between relevant and irrelevant information, or they are inefficient in addressing the rank deficiency problem. We put together the idea of envelope models into the reduced-rank VAR model to simultaneously tackle these challenges, and propose a new parsimonious version of the classical VAR model called the reduced-rank envelope VAR (REVAR) model. Our proposed REVAR model incorporates the strengths of both reduced-rank VAR and envelope VAR models and leads to significant gains in efficiency and accuracy. The asymptotic properties of the proposed estimators are established under different error assumptions. Simulation studies and real data analysis are conducted to evaluate and illustrate the proposed method.
1 Introduction
With the recent rapid development of information technology, high-dimensional time series data are routinely collected in various fields, like finance, economics, digital signal processing, neuroscience, and meteorology. Classical vector autoregressive (VAR) models are widely used for modeling multivariate time series data due to their ability to capture dynamic relationships among variables in a system and their flexibility. These models are discussed in many time series textbooks, including Hamilton (Citation1994), Lütkepohl (Citation2005), Tsay (Citation2014), Box et al. (Citation2015), Wei (Citation2019), and others. However, the VAR model suffers from overparameterization, particularly when the number of lags and time series increases. While there are several statistical methods for achieving dimension reduction in time series (Park and Samadi Citation2014, Citation2020; Cubadda and Hecq Citation2022b; Samadi and DeAlwis Citation2023a), they can be inefficient in extracting relevant information from complex data. This is because they fail to differentiate between important and unimportant information, which can obscure the material and useful information. Envelope methods (Cook, Li, and Chiaromonte Citation2010) use reduced subspaces to link the mean function and dispersion matrix through novel parameterizations. By identifying and removing irrelevant information, the envelope model is based only on useful information and is therefore more efficient. The literature presents various methods for multivariate time series analysis, including the canonical transformation (Box and Tiao Citation1977), reduced-rank VAR models (Velu, Reinsel, and Wichern Citation1986; Reinsel, Velu, and Chen Citation2022), scalar component models (Tiao and Tsay Citation1989), LASSO regularization of VAR models (Shojaie and Michailidis Citation2010; Song and Bickel Citation2011), sparse VAR model based on partial spectral coherence (Davis, Zang, and Zheng Citation2016), factor modeling (Stock and Watson Citation2005; Forni et al. Citation2005; Lam and Yao Citation2012), envelope VAR models (Wang and Ding Citation2018; Herath and Samadi Citation2023a, Citation2023b), nonlinear VAR models (Samadi, Hajebi, and Farnoosh Citation2019), and tensor-structure modeling for VAR models (Wang et al. Citation2022a; Wang, Zheng, and Li Citation2021), among others.
Let be a q-dimensional VAR process of order p, VAR(p), given as
(1)
(1)
where
are coefficient matrices, and
is a vector white noise process with mean
, and covariance matrix
, that is,
, and T denotes the sample size. Suppose L is the lag operator and let
be the characteristic polynomial function of the model given as
. Then, the time series in (1) is stationary if all the roots of
are greater than one in modulus.
Modeling high-dimensional multivariate time series is always challenging due to the dependent and high-dimensional nature of the data. Even for moderate dimensions q and p, performing the estimation can be difficult (De Mol, Giannone, and Reichlin Citation2008; Carriero, Kapetanios, and Marcellino Citation2011; Koop Citation2013). The number of coefficient parameters in model (1), , can dramatically increase with the dimension q and the lag order p. Therefore, to improve estimation and make inferences on high-dimensional VAR models, it is necessary to restrict the parameter space to a reasonable and manageable number of parameters. To this end, note that the VAR(p) model in (1) can be rewritten as a VAR(1) model as
(2)
(2)
where
is the vector of lagged variables, that is,
, and
which encompasses the coefficient matrices of lagged variables.
To address the overparameterization issue of the VAR model, we assume that the autoregressive coefficient matrix in model (2) has a reduced-rank structure, similar to the standard reduced-rank regression (RRR) model (Velu, Reinsel, and Wichern Citation1986; Anderson Citation1999, Citation2002; Reinsel, Velu, and Chen Citation2022). This technique improves the accuracy of the estimation of
by reducing the dimensionality of
and
. The envelope model (Cook, Li, and Chiaromonte Citation2010) is a new dimension reduction technique that has a different perspective to achieve efficient estimation by linking the mean function and covariance matrix and using the minimal reducing subspace of the covariance matrix. By combining these two methods, we propose a novel dimensionality reduction model for the VAR process called the reduced-rank envelope vector autoregressive (REVAR) model, which extends the idea of envelopes to the reduced-rank VAR model (RRVAR). As a result, our proposed method is more efficient and parsimonious than both methods alone and outperforms both.
The reduced-rank problem first arose in the multivariate regression analysis to achieve dimension reduction by restricting the rank of the coefficient matrix. Anderson (Citation1951) considered the RRR problem for fixed predictors. Then, Izenman (Citation1975) and Reinsel and Velu (Citation1998) studied the RRR in detail. Asymptotic properties for RRR are discussed by Stoica and Viberg (Citation1996), and Anderson (Citation1999). The RRR models have also been investigated by several other authors (Reinsel and Velu Citation1998; Negahban and Wainwright Citation2011; Chen, Dong, and Chan Citation2013; Basu, Li, and Michailidis Citation2019; Raskutti, Yuan, and Chen Citation2019).
Reduced-rank model for multivariate (multiple) time series (Velu, Reinsel, and Wichern Citation1986; Reinsel and Velu Citation1998; Reinsel, Velu, and Chen Citation2022) often arises in the multivariate statistics literature when coefficient matrices have low-rank structures. The reduced-rank VAR (RRVAR) model is considered by imposing a low-rank structure on the coefficient matrix of model (2), that is, rank . As a result, the number of parameters is decreased and the estimation efficiency is improved. The analysis of RRVAR models has connections with some known methodologies such as principal component analysis (PCA) (Rao Citation1964; Billard, Douzal-Chouakria, and Samadi Citation2023) and canonical analysis (CCA) (Box and Tiao Citation1977; Samadi et al. Citation2017) to achieve dimension reduction and improve predictions. The asymptotic properties of the reduced-rank (RR) and the ordinary least squares (OLS) estimators of the VAR model are studied by Anderson (Citation2002). The RRVAR model has been extended and combined with other approaches in economic and financial modeling, including, common features and RRVAR models (Franchi and Paruolo Citation2011; Centoni and Cubadda Citation2015; Cubadda, Hecq, and Telg Citation2019), structural analysis through RRVAR models (Bernardini and Cubadda Citation2015; Carriero, Kapetanios, and Marcellino Citation2016), Bayesian RRVAR models (Carriero, Kapetanios, and Marcellino Citation2011; Cubadda, Hecq, and Telg Citation2019), partial least squares approach (Cubadda and Hecq Citation2011), the vector error correction model (VECM) under cointegration (Lütkepohl Citation2005, Part II; Hecq, Palm, and Urbain Citation2006), multivariate autoregressive index models (MAI) (Cubadda Guardabascio and Hecq Citation2017; Cubadda, Hecq, and Telg Citation2019), eteroscedastic VAR models (Hetland, Pedersen, and Rahbek Citationin press), time-varying parameter RRVAR models (Brune, Scherrer, and Bura Citation2022). A detailed review of RRVAR models is given in Cubadda and Hecq (Citation2022a). These models are distinctly different from envelope models because there is no link between the mean function and covariance matrix (see (6) in Section 2.2).
While the reduced-rank VAR model achieves an effective dimensionality reduction, in many applications there are additional structures that can be exploited to achieve even higher dimensionality reduction with lower statistical error. The response envelope proposed by Cook, Li, and Chiaromonte (Citation2010) is another parsimonious approach to achieve dimension reduction and improve the estimation efficiency and prediction accuracy of standard multivariate regression models by parsimoniously decreasing the number of parameters. This method is useful in eliminating immaterial information present in the responses and predictors. The envelope method is effective even when the coefficient matrix is full rank, whereas the reduced-rank approach offers no reduction in this case. This is because the envelope uses the smallest reducing subspace of the covariance matrix that contains the mean function. There are several extensions of the basic envelope methodology to other contexts (Su and Cook Citation2011; Cook, Helland, and Su Citation2013; Cook, Forzani, and Zhang Citation2015; Cook and Zhang Citation2015a, Citation2015b; Su et al. Citation2016; Li and Zhang Citation2017; Ding and Cook Citation2018; Lee, M. and Su Citation2020; Forzani and Su Citation2021).
Wang and Ding (Citation2018) extended the envelope regression model proposed by Cook, Li, and Chiaromonte (Citation2010) to the VAR model called the envelope VAR (EVAR) model. The EVAR model provides better performance and is more efficient by removing immaterial information from estimation. Rekabdarkolaee et al. (Citation2020) proposed a spatial envelope model for spatially correlated data in multivariate spatial regression. Samadi and DeAlwis (Citation2023b) introduced the envelope matrix autoregressive (MAR) model (for the MAR model, refer to Samadi Citation2014). Cook, Forzani, and Zhang (Citation2015) proposed a new parsimonious multivariate regression model by combining Anderson’s (Citation1999) RRR model with Cook, Li, and Chiaromonte’s (2010) envelope model, called the reduced-rank envelope model. We incorporate the idea of envelopes (Cook, Li, and Chiaromonte Citation2010; Wang and Ding Citation2018) into Velu, Reinsel, and Wichern’s (1986) RRVAR model and propose a novel efficient parsimonious VAR model for high-dimensional time series data. The proposed reduced-rank envelope VAR model combines the advantages and strengths of both the RRVAR and EVAR models which leads to more accurate estimation and higher efficiency.
We use the following notations and definitions throughout this article. All real k × s matrices are denoted as . The collection of u-dimensional subspaces in a q-dimensional vector space is called the Grassmannian manifold, indicated by
. If
, then
is defined to be the subspace spanned by the columns of
. If
, then the asymptotic covariance matrix of
is denoted as
. The projection matrix onto
in the
inner product is denoted by
, and the projection matrix onto
in the identity inner product is denoted as
. Let
, and
. The operator
stacks the columns of a matrix into a column vector, and the operator
stacks the lower triangular part, including the diagonal, into a vector. Moreover, for any q × q symmetric matrix U, the expansion matrix
is defined such that
, and the contraction matrix
is defined such that
(Henderson and Searle Citation1979). The Moore-Penrose generalized inverse of
is defined as
. The Kronecker product of two matrices
and
is denoted by
, and the symbol “∼” means identically distributed.
The rest of the article is structured as follows. Section 2 provides a comprehensive review of the reduced-rank VAR and the envelope VAR models, along with the introduction of our proposed approach, the reduced-rank envelope VAR (REVAR) model. The derivation of the maximum likelihood estimators (MLEs) for the parameters of the REVAR model is presented in Section 3. In Section 4, we establish the asymptotic properties of the proposed REVAR estimators with and without normality assumption and compare them with those obtained from the standard VAR, RRVAR, and EVAR models. The algorithms for selecting the lag order, rank, and envelope dimensions are outlined in Section 5. To assess the performance of our proposed REVAR model under different error assumptions, Section 6 presents the results of extensive simulation studies, comparing it with the reduced-rank VAR, envelope VAR, and standard VAR models. Real economic datasets are analyzed in Section 7, and our conclusions are summarized in Section 8. The supplementary materials contain the proofs of lemmas and propositions, as well as additional simulations.
2 Reduced-Rank Envelope Vector Autoregression
2.1 Reduced-Rank VAR Model
Suppose the coefficient matrix in model (2) is rank deficient, that is, . As a result, it can be written as a product of two lower dimensional matrices, that is,
. Then, the reduced-rank VAR (RRVAR) model proposed by Velu, Reinsel, and Wichern (Citation1986) is given by
(3)
(3)
where
, and
.
The conditional log-likelihood function of model (2) under the assumption of normality of can be written as (the initial values
are assumed to be given)
(4)
(4)
Then, the maximization of is performed under the condition that rank
, or correspondingly under the RR autoregression parameterization
in model (3). The symbol
is used to exclude unnecessary additive constants from the likelihood function. Before we present the MLEs of the RRVAR model (3), we introduce some notations.
Let , and let
,
, denotes the autocovariance matrix function of
. Also, let
and
given as
Given a series of observations , their sample covariance matrices are denoted by
and
with the divisor T. Without loss of generality, suppose the sample lagged vector
is centered, therefore,
. For ease of notations, we shall drop the subsubscript “t” in
and
when they are subscripted. Let
(
), and
be the sample autocovariance matrices of
and
at lag k, respectively; and
be the sample cross-covariance matrix between
and
. Moreover, let
be the sample covariance matrix of residuals, and
be the sample cross-covariance matrix of the fitted vectors, resulting from a vector autoregression of
on
. The sample canonical correlation matrix between
and
is defined as
, where
. Truncated matrices are denoted by superscripts, for example,
and
are formed by the d eigenvectors associated with the d largest singular values of
and
, respectively.
Note that the decomposition is not unique, as it can be expressed as
for any nonsingular matrix
. The MLEs of the RRVAR model parameters, obtained by Reinsel and Velu (Citation1998), involve normalization constraints for identifiability, such as
, where
and
’s are the eigenvalues of
, for any positive definite matrix
. However, the parameters of interest
and
are identifiable, with
,
. We propose a new framework for ML estimation of
and
that does not require constraints on
or
, and works for any decomposition
with
.
The MLEs of the parameters of the RRVAR model (3), which maximize (4), are associated with the canonical correlations (Anderson Citation2002), and given by and
(5)
(5)
There are different estimators for the RR parameters and
in the literature based on different constraints on
and
. All of them can be reproduced by decomposing the rank-d estimator
given in (5). The OLSVAR estimators of
and
can be obtained by replacing the truncated sample canonical correlation matrices
with their untruncated versions, that is,
and
.
2.2 Envelope VAR Model
The envelope model is a parsimonious model introduced by Cook, Li, and Chiaromonte (Citation2010) for multivariate regression that achieves efficiency gains in estimation and better prediction performance. An envelope model for time series data has been developed by Wang and Ding (Citation2018) in the context of VAR models. Before proceeding further, we introduce the following definitions which will be used in the following sections (see also Cook, Li, and Chiaromonte Citation2010; Cook, Forzani, and Zhang Citation2015).
Definition 2.1.
A subspace is defined to be a reducing subspace of
(
reduces M), if and only if
.
The envelope methodology is based on the notion of reducing subspace, which is essential to the development of theory and practice in functional analysis (Conway Citation1990).
Definition 2.2.
Let and
. Then the M-envelope of
is defined as the intersection of all reducing subspaces of M that contains
and is denoted by
.
Since the intersection of any two reducing subspaces of M is again a reducing subspace of M, Definition 2.2 ensures the existence and uniqueness of envelopes. For ease in notation, we use instead of
. It can be characterized that the M-envelope is the span of some subset of the eigenvectors of M (Cook, Li, and Chiaromonte Citation2010).
Let such that (i)
, and (ii)
, where
is the projection matrix onto
, and
is the orthogonal projection.
and
are called material and immaterial parts of
respectively. Conditions (i) and (ii) together imply that any dependence of
on its lagged values
must be concentrated in the material part of the autoregression, that is,
, while
is invariant to changes in
and becomes white noise and immaterial to the estimation of
. Therefore,
carry all material information in
, and a change in
can affect the distribution of
only via
. If
is normally distributed, then condition (ii) implies that
is independent of
given
. Under the envelope model, it can be shown that (i) and (ii) hold if and only if (a)
, and (b)
is a reducing subspace of
, that is,
(Cook, Li, and Chiaromonte Citation2010). That is, the
is a reducing subspace of
that contains
, and the intersection of all such subspaces is called
-envelope of
, and is denoted as
. Let
, then under the RRVAR model (3),
, where
and
. This is because
.
Let be an orthogonal basis of
with an orthogonal complement basis
such that
is an orthogonal matrix. Since
, there exists a
such that
. Since
is spanned by a subset of
’s eigenvectors, there exist symmetric positive definite matrices
and
such that
. That is,
contains the coordinates of
in terms of the basis matrix
; and
and
carry the coordinates of
relative to
and
, respectively. Thus, the u-dimensional envelope model is summarized as
(6)
(6)
This provides a link between and
. That is, the white noise variation is decomposed into the variation related to the material part of
, that is,
= var
, and the variation related to the immaterial part of
, that is,
= var
. These two are respectively material and immaterial to the estimation of
.
Lam and Tam (Citation2011) and Lam and Yao (Citation2012) developed an approach that uses information from lagged autocovariance matrices via eigendecomposition to estimate the factor loading space. This approach has recently been extended to VAR models by Cubadda and Hecq (Citation2022a, Citation2022b), and Wang et al. (Citation2022b). Although it follows that the orthogonal linear combinations of the factors convey all the relevant information for the estimation (like in the EVAR model), and projection onto its orthogonal complement (like
in the EVAR model) gives white noise, it is distinctly different from the EVAR model as there is no required connection between
and the error covariance matrix
. The main difference between the two approaches is that the envelope methodology exploits connections between
and
using a minimal reducing subspace, and the information of the basis matrix
comes from both the conditional mean and the structure of covariance matrix.
2.3 Reduced-Rank Envelope VAR Model
We propose a new parsimonious model, called the reduced-rank envelope vector autoregressive model (REVAR) model, by incorporating the idea of envelope VAR models into the reduced-rank VAR model. This model improves the accuracy and efficiency of VAR estimation. Given that with
, the RRVAR model (3) can be reparameterized into an envelope structure as
(7)
(7)
where the parameterization
with
forms the EVAR model (6) proposed by Wang and Ding (Citation2018), and the columns of
, are the coordinates of A with respect to the basis
. Then the REVAR model is summarized as follows
(8)
(8)
where
are the same as those in (6). There are no further constraints on
in this model except that all three matrices have rank d. Notice that the constrained parameters
in RRVAR, EVAR, and REVAR models are not unique, however,
and
in (7) are unique. In order to compare the properties of the REVAR model with the RRVAR model, we assume
is known.
Lemma 1.
Suppose is known, then the maximum likelihood estimators (MLEs) of the parameters of the REVAR model (8), which maximize (4) are as follows,
Note that the MLEs obtained in Lemma 1 are based on , however, the final estimators
and
depend on
only through
. That is, for any orthogonal matrix
we have
and
.
As a result, when the envelope is known, we should concentrate on the reduced response time series and obtain the rank-d RRVAR estimator
of the vector autoregression of
on
. Since
, therefore, according to Definition 2.1, the estimator
of
is now reduced by
. Thus,
is a reducing subspace of
that also includes
, that is, the envelope subspace is maintained by the structure of the given ML estimators of the coefficient matrix. We obtain the ML estimator
and show that the REVAR estimators for the coefficient matrix
and covariance matrix
are identical to the estimators in Lemma 1 by substituting
with
.
In comparing the models, notice that if the envelope dimension u is equal to the response dimension, that is, , then there is no immaterial information to be removed by the envelope VAR model and the REVAR model collapses to the RRVAR model (3), that is,
and
. If d = u, then the REVAR model is equivalent to the EVAR model. When d = u = q, the REVAR model collapses to the standard VAR model. There is an extreme situation when
, then both the RRVAR and EVAR models collapse to the standard univariate time series model. In this situation, there would not be any reduction. If
, then both the RRVAR and REVAR models gain efficiency. Extreme cases in the REVAR model are numerically explored in Supplement S8.4 to support these assertions.
3 Estimation
3.1 Parameterization for Each Model
We define the following estimable functions for each model. Let h represent the parameter vector of the standard VAR model (1), and let ,
, and
denote the parameter vectors of the RRVAR, EVAR, and REVAR models, respectively. Since the estimator of the common parameter
is
for all methods, and
is asymptotically independent of the estimators of
and
; therefore,
is omitted from all models. Hence, we have
(9)
(9)
where
,
, and
, respectively. Note that
for the RRVAR model,
for the EVAR model, and
for the REVAR model. To compare the models, we use
to represent the total number of parameters (NOP) in
, and
. Then, the parameter count for each model is
Standard VAR(p) model,
;
Reduced-rank VAR(p) model,
Envelope VAR(p) model,
Reduced-rank envelope VAR(p) model,
The reduced NOP from the standard VAR model to the RRVAR model is , and that is even further reduced from the RRVAR model to the REVAR model by the number of
. Moreover, compared to the standard VAR model, the reduced NOP by the EVAR model is
, and it is further reduced by
from the EVAR model to the REVAR model. It is important to note that envelope models achieve efficiency gains not only from parsimony but mainly from the structure of the covariance matrix. To evaluate the impact of covariance matrix structure and variations in the immaterial and material matrices on the performance of envelope models, we conducted simulations by adjusting the ratios of immaterial variation to material variation, as presented in Supplement S8.5.
3.2 Maximum Likelihood Estimation for the REVAR Model
In this section, we derive the ML estimators of the REVAR model (8) for a given lag order p, rank d, and envelope dimension u. How to select p, d, and u are discussed in Section 5. The MLEs for the REVAR model can be obtained by replacing h with in the log-likelihood function (4) as
and maximizing it with respect to all parameters other than
. Since
lies in a Grassmann manifold (Cook, Li, and Chiaromonte Citation2010), therefore, we cannot analytically find a unique optimal value of
. As it is discussed in Proposition 1, we can obtain
from minimization over a Grassmannian.
To obtain the MLE of , let
be a semiorthogonal matrix and define the standardized version of
as
with sample covariance matrix
. Suppose
, is the ith eigenvalue of
which is also the ith eigenvalue of
.
Proposition 1.
Let denotes the log-likelihood function of the REVAR model (8). Then, it achieves its maximum at
, where
(10)
(10)
(11)
(11)
where the minimization is over the Grassmannian of dimension
, that is,
.
The expansion of the objective function in (10) offers a method of interpreting the log-likelihood functions for envelope-based models. For instance, the objective function of the EVAR model (6) (Wang and Ding Citation2018) can be similarly expanded as follows
(12)
(12)
which is similar to the expression (10) except that the last term in (12) is based on the ordinary least squares method, whereas the last term in (10) is based on the reduced-rank VAR model. In other words, the two expressions in (10) and (12) are the same when d = u.
Proposition 2.
The sample objective function in (11) converges in probability to its population counterpart
uniformly in D, as
. The estimator
is consistent, and
.
The following Proposition provides the MLEs of the REVAR model parameters in (8).
Proposition 3.
The ML estimators for the REVAR model (8) that maximize the conditional log-likelihood function in (4) are ,
, and
Note that rank , and
. In comparison to the RRVAR model,
now has an envelope structure. If u = q, then
, and the REVAR model is reduced to the RRVAR model.
The full Grassmann (FG) optimization method can be computationally slow and expensive, particularly in high-dimensional problems. Therefore, we used the FG algorithm for the small VARs, but for higher dimensional cases, we adapt and employ the one-dimensional (1D) algorithm proposed by Cook and Zhang (Citation2016). The 1D algorithm is computationally more efficient and robust compared to the FG optimization. This is due to the fact that it decomposes the u-dimensional FG optimization into a series of u one-dimensional optimization problems and does not require an initial guess (see Cook and Zhang Citation2018).
4 Asymptotic Properties
In this section, we establish the asymptotic properties of the proposed ML estimators assuming both Gaussian and non-Gaussian white noise processes. We derive their asymptotic distributions under the reduced-rank envelope VAR model and compare their asymptotic efficiencies to those of the OLSVAR, RRVAR, and REVAR models. Related asymptotic results for estimators of the parameters of the RRVAR, EVAR, and OLSVAR models can be found in Anderson (Citation2002), Wang and Ding (Citation2018), and Lütkepohl (Citation2005), respectively. The asymptotic comparison between and
can be found in Anderson (Citation2002). Therefore, our focus here is on comparing
and
. The asymptotic results of
over
are comparable to those of
over
. This is due to the rank reduction constraint present in the material response time series
.
Let be the Fisher information of
. Then, the asymptotic covariance matrix of the OLSVAR estimator of h is given by Lütkepohl (Citation2005)
(13)
(13)
This is also the asymptotic covariance matrix of the unrestricted ML estimator of h. Let us define the gradient matrices of and
as
(14)
(14)
The asymptotic covariance matrices of the RRVAR and REVAR estimators, that is, and
, are provided in Proposition 4, which can be obtained by using the asymptotic theory of overparameterized structural models proposed by Shapiro (Citation1986).
Proposition 4.
Suppose , then it can be shown that
,
, and
. The differences between the asymptotic covariances are as follows
where denotes the Moore-Penrose inverse. Moreover, we have
. Similarly in compared to the envelope VAR estimator,
.
Proposition 5.
Suppose , and the rank of the coefficient matrix
is d. Then,
and
asymptotically follow normal distributions with mean zero and the following covariance matrices
(15)
(15)
(16)
(16)
where
, and
.
The asymptotic variance in (15) follows from Anderson (Citation2002, Equationeq. 5.22(5)
(5) ). Moreover, the asymptotic results in Proposition 5 depend on the decomposed components
and
only through their orthogonal projections
and
, respectively. Therefore, these results are valid for any decomposition
that satisfies
and
.
Proposition 6.
Suppose , then under the REVAR model
follows asymptotic normal distribution with zero mean and covariance
(17)
(17)
(18)
(18)
where from (16) we have
.
The asymptotic advantages of the REVAR over the RRVAR model can be obtained by using the results in Propositions 5 and 6. By subtracting (18) from (16), we have
(19)
(19)
where for a given
, the estimators are defined as
, and
.
4.1 Asymptotic Properties Under Nonnormality
Suppose is the OLSVAR estimator of h under the unrestricted VAR model, and
denote the REVAR estimator. Moreover, we assume that
and
are the true values of h and
, respectively. The following objective function is obtained after maximizing
in (4) with respect to
We now consider as a function of h and
, and define the discrepancy function as
, which satisfies the necessary conditions of Shapiro’s (Citation1986). It can be shown that the second derivative of
, that is,
evaluated at
and
is the Fisher information matrix for h when
is normally distributed. The following proposition gives the asymptotic distribution of
without the normality assumption on
.
Proposition 7.
Assume that the error terms of the reduced-rank envelope VAR model (8) are iid and the fourth moments of are finite. Then,
for some positive definite covariance matrix
, and
, with
, where
and
are defined in (13) and (14), respectively. Particularly,
, where
is the top-left block matrix of
of dimension
.
The -consistency of
, the reduced-rank envelope VAR estimator, relies on the
-consistency of both
and
, despite the nonnormality of the error terms, and the properties of the discrepancy function
. The asymptotic covariance matrix
can be estimated conveniently by plugging in the estimated covariance matrix
into
, but its accuracy depends on the distribution of
for any fixed sample size.
5 Selections of p, d, and u of VAR Models
5.1 Lag Order (p) Selection
The selection of the lag order (p) is an empirical problem and a critical element in the specification of VAR models. Therefore, the first step in VAR analysis is to determine the lag order. To do this, several model selection criteria are employed. The common approach is to fit VAR(p) models with lag orders and select the value of p that minimizes some model selection information criteria (IC). The general form of IC for VAR models is given by
(Lütkepohl Citation2005; Tsay Citation2014), where
, which is the estimated residual covariance matrix for a model of order p, cT
is a sequence that depends on the sample size T,
is a penalty function that penalizes large VAR(p) models. The most common information criteria are the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), given as
where
, is the number of parameters in the standard VAR model.
5.2 Rank (d) Selection
The implicit assumption of RR models is that the coefficient matrix is not of full rank. Optimal rank selection has an important role in dimension reduction. In the context of RRR, Bura and Cook (Citation2003) proposed a rank selection test that follows a Chi-squared distribution and only requires the finite second moments of the response variables. The rank of can be determined using the test statistic
, where
are the eigenvalues of the qp × q matrix
. Under the null hypothesis H0: d = d0, the test statistic
has an asymptotic Chi-square distribution, that is,
(Bura and Cook Citation2003). To find the rank d, one can compute a sequence of test statistics
, for
, and compare them to the percentiles of their corresponding null distributions
. The test procedure stops at the first nonsignificant test of H0: d = d0. Then, d0 is an estimate of the rank of
.
5.3 Envelope Dimension (u) Selection
To select the envelope dimension u, there are two ways. One approach is to simultaneously determine d and u by seeking (d, u) from (0, 0) to (q, q) (), and selecting the (d, u) pair that has the lowest IC value. The IC to determine the optimal (d, u) pair are
where
is the number of REVAR model parameters, and
is the maximized log-likelihood function calculated at the MLEs in Proposition 3. Alternatively, we can first find d using the method in Section 5.2, then search for the value of u from d to q–1 that minimizes AIC or BIC. In this case, under the null hypothesis
, the test statistic
has an asymptotic Chi-square distribution with
degree of freedom, that is,
. The latter method is computationally more efficient.
6 Simulation Studies
In this section, we compare the performance of our proposed REVAR model with the RRVAR, the EVAR model, and the OLSVAR model using simulation studies under different data generating processes (DGP). We simulate data under various parameter settings from model (8) with and
for
and
, respectively. The semiorthogonal matrix
and matrix
are generated from the uniform distribution on (0, 1). The entries of
and p presample observations (
) are generated from the standard normal distribution. Then,
and
are standardized so that
and
, where
is the Frobenius norm, and the coefficient matrix
satisfies the stationary condition. Estimation errors are obtained by comparing the estimated coefficient matrix
to the true coefficient matrix
by using
. We conduct simulation studies under various error distributions with sample sizes of
. Each scenario is replicated 100 times, and the minimum and maximum standard error ratios of coefficient estimates (
and
) are calculated for the M = OLSVAR, EVAR, and RRVAR models compared to our proposed REVAR model. Matlab codes are available upon request.
6.1 Simulation Studies with Normal Errors
In this section, data with normal errors are analyzed. shows the total number of parameters for different VAR models in our simulation studies with various combinations of . The REVAR model has the fewest parameters, making it more parsimonious than other models. Consequently, it significantly outperforms them, as shown in .
Fig. 1 Average estimation errors of moderate-dimensional VAR models with different combinations of against sample size. Refer to for details.
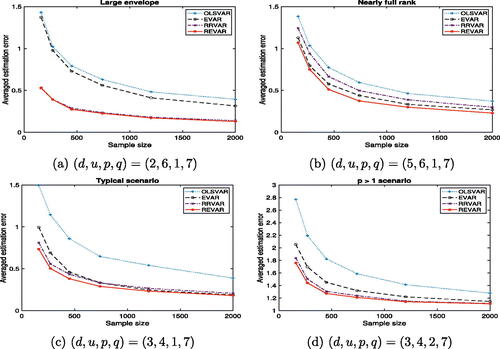
Table 1 Total number of parameters (NOP) in each VAR model correspond to Figure 1.
displays the impact of envelope dimension and rank on the relative performance of each method. The simulation results in are obtained using the full Grassmannian (FG) algorithm. In the scenario with a large envelope dimension (), the RRVAR approach outperforms the OLSVAR approach, while the EVAR model shows a relatively smaller improvement. The REVAR approach has a slight advantage over RRVAR in this scenario. In the second case (), where is almost full rank, the RRVAR method outperforms the OLSVAR by a small margin. Both the EVAR and REVAR approaches demonstrate significant improvement over the RRVAR and OLSVAR, where the REVAR is superior to all others. For the third scenario () neither the EVAR nor RRVAR approaches are favored. Both the RRVAR and EVAR approaches exhibit similar behavior and show substantial improvements compared to the OLSVAR approach. The final scenario () is similar to the third but with a higher number of lags (p).
Our proposed REVAR model combines the advantages and strengths of both reduced-rank and envelope VAR models, demonstrating its superiority over alternative methods in simulation studies.
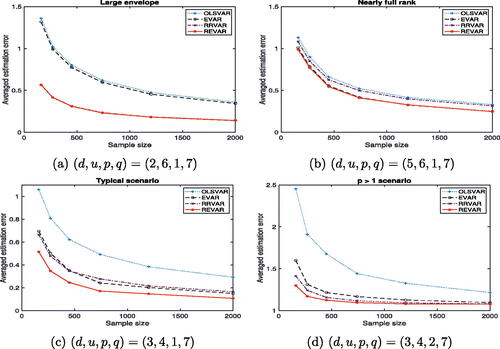
To further investigate the performance of the proposed REVAR model, particularly in higher-dimensional cases, we demonstrate its effectiveness in four additional examples involving medium and large VARs. compares the total number of parameters for each model with different combinations of . Similar to , illustrates the impact of envelope dimension and rank on the comparative performances of each approach. The top row of graphically presents the comparison of the four VAR models for medium-sized VARs with p = 1 and p > 1, while the bottom row shows the comparison for relatively large VARs. All simulation results demonstrate the superiority of our REVAR model with significant improvements over other VAR models. Due to computational costs, the 1D algorithm is used for the simulation studies of medium and large VARs, as it offers faster computation compared to the FG algorithm.
Fig. 2 Average estimation errors of higher-dimensional VAR models with different combinations of against sample size. Refer to for details.
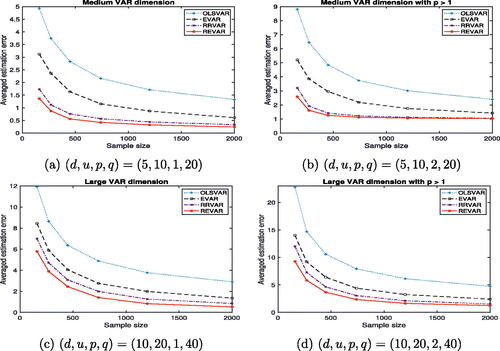
Table 2 Total number of parameters (NOP) in each VAR model correspond to .
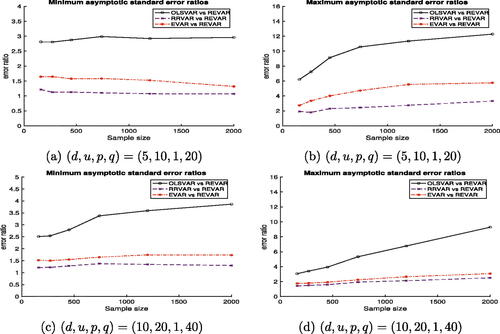
summarizes the minimum and maximum asymptotic standard error ratios of the estimated coefficients for each of the OLSVAR, EVAR, and RVAR models in relation to the proposed REVAR model. The top row of displays these ratios versus the sample size when , while the bottom row shows the ratios for
. All ratios in are greater than one, indicating that the REVAR model achieves the highest efficiency gains by significantly reducing the standard errors of the estimated coefficient matrix compared to the three comparative VAR models.
Fig. 3 Minimum (left panels) and maximum (right panels) asymptotic standard error ratios of coefficient estimates for each VAR model with respect to the proposed REVAR model.
6.2 Simulation Studies with Nonnormal Errors
In this section, simulations are conducted with nonnormal errors using , where
is a vector of iid random variables with a mean of
and a covariance matrix of
. We considered four different distributions, that is, normal, uniform, t6, and
distributions. compares the relative performance of each method across these distributions, in terms of the impact of the envelope dimension and rank. Our experiments demonstrated that the REVAR estimator consistently has the lowest average estimation error compared to the other models across all four distributions. Similar results were obtained for higher-dimensional VAR models, which are presented in Figures S1 and S2 in Supplement S8.1. All the minimum and maximum asymptotic standard error ratios of each VAR model relative to our proposed REVAR model exceed one, indicating that the REVAR model consistently achieves higher efficiency gains (see Figures S3, S4, and S5 in Supplement S8.1).
Fig. 4 Average estimation errors for with Normal, Uniform, t-Student, and Chi-square
distributions, plotted against sample size. Refer to for details.
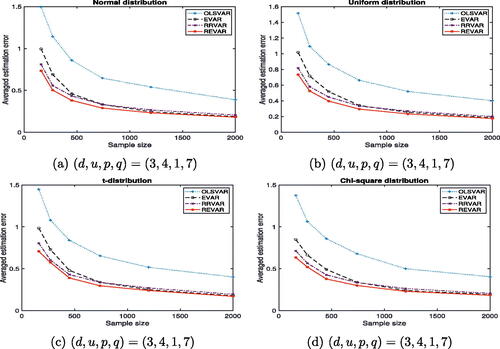
Fig. 5 Average estimation errors of moderate-dimensional VAR models with different for stochastic volatility martingale difference sequence (SV-MDS) errors against sample size.
6.3 Simulation Studies with Martingale Difference Sequence Errors
In this section, we adopt a martingale difference error structure for the analysis. Let be a q-dimensional martingale difference sequence with respect to the increasing sequence of σ-fields
}, where
are
-measurable and
for all
. We also introduce a martingale sequence
for each t, and define the error term as
. To simulate the error structure, we generate
from
distribution and subsequently generate the rest of the sequence from the conditional distribution
. This simulation method has been used in previous studies (Zhao, Wang, and Zhang Citation2011; Zhou and Lin Citation2013). We have also implemented this simulation approach for nonnormal scenarios.
Furthermore, we adopt a stochastic volatility martingale difference sequence model to capture the time-varying volatility in the time series data. The error terms are modeled as
where
with
. This simulation method has been previously utilized by Chang, Jiang, and Shao (Citationin press) and Escanciano and Velasco (Citation2006) for the univariate and multivariate martingale difference hypothesis testing problems, respectively.
Figure S6 displays the impact of envelope dimension and rank when errors are generated from martingale difference sequences, while presents the results for errors generated from stochastic volatility martingale difference sequences. Across both figures, the simulation results consistently demonstrate the superior performance of our proposed REVAR model, revealing significant improvements over other VAR models. Similar findings were observed for higher-dimensional VAR models, as shown in Figures S7 and S8 in Supplement S8.2. Furthermore, all the minimum and maximum asymptotic standard error ratios of each VAR model relative to our proposed REVAR model were found to be greater than one, indicating the consistent efficiency gains achieved by the REVAR model (refer to Figures S9 and S10 in Supplement S8.2)
We conduct a pseudo-real-time forecasting exercise utilizing an expanding window of data to calculate h-step ahead forecasts (). The accuracy of these forecasts is evaluated using the root mean square forecast error (RMSFE):
(20)
(20)
where T0 and T indicate the start and the end of the evaluation sample, respectively, and
is the maximum forecast horizon of interest. Our forecasting simulations encompass various error distributions, such as normal, nonnormal, and martingale difference errors with stochastic volatility (SV). The evaluation sample consists of the last 25% of the data.
Table S2 and Table S3 in Supplement S8.3 present a comprehensive summary of the root mean square forecast error (RMSFEh
) for different forecast horizons (), averaged over the evaluation samples across various error distributions and different DGP scenarios, with a sample size of T = 700. The results consistently demonstrate that our REVAR model outperforms other VAR models in terms of forecast accuracy. Furthermore, all average asymptotic standard error ratios relative to the REVAR model exceed one, indicating greater efficiency gains and improved accuracy in coefficient estimation compared to the comparative VAR models.
summarizes the asymptotic Chi-squared test results for rank selection, envelope dimension, and lag order selections using the BIC criterion at a 0.05 significance level. We performed the simultaneous selection of d and u. The REVAR model with dimensions and
are utilized, with a total NOP in REVAR model of 55 and 72, respectively. The table reports the percentages of correctly identified rank d and envelope VAR dimension u and lag order p for different sample sizes. Most of the other combinations of
employed in the simulation studies yielded similar results, although in some cases, the selection of u and d was less accurate and resulted in higher percentages of overestimation. Consistent with the findings of Forzani and Su (Citation2021), our results indicate that when the information criteria fail to select the true dimensions (u and d), they tend to overestimate these dimensions. Although this overestimation leads to a loss of efficiency, it does not introduce bias into the estimation process. Conversely, underestimation of d and u can indeed lead to biased outcomes. Nevertheless, overestimation of d and u is typically not a major concern (Cook, Forzani, and Zhang Citation2015).
Table 3 Percentage selection of the true dimensions (d and u) and lag order (p).
7 Real Data Analysis
We analyzed four quarterly macroeconomic datasets obtained from the Federal Reserve Economic Quarterly Data (FRED-QD) website, with observations from 1959Q1 to 2019Q4. The first dataset, NIPA, consists of q = 8 macroeconomic variables from the National Income and Product Accounts, including real Gross Domestic Product (GDP) and its components. The second dataset consists of q = 11 variables related to Industrial Production, the third dataset includes q = 20 variables related to Price, and the fourth dataset encompasses q = 8 variables related to Money and Credit. Table S6 in Supplement S9 provides a detailed overview of the variables in each dataset. To ensure stationarity, appropriate transformations were applied to each variable group, such as taking the first difference of the logarithmic series for the 8 NIPA variables. Further details regarding variable descriptions and transformations can be found in McCracken and Ng (Citation2020).
The rank () is determined using the Chi-squared test (Section 5.2) at a significance level of 0.01. The lag order (
) and the envelope dimension (
) are selected based on the BIC criterion as described in Sections 5.1, and 5.3, respectively. We conducted pseudo-real-time forecasting experiments using an expanding window scheme. The process begins with a specific initial fraction of the full sample (1959Q1-2004Q4) and recursively calculated forecasts over the evaluation sample (2005Q1-2019Q4). These forecasts are computed using the stationary bootstrap scheme proposed by Politis and Romano (Citation1994) with 100 bootstrap samples. We assessed the forecasting performance of our proposed REVAR model using the
for different forecast horizons (h) and compared it with other VAR models.
and present the RMSFEh
values () for the NIPA and Price datasets, respectively. Supplementary Tables S4 and S5 in Supplement S9 provide the same results for the Money and Credit, and the Industrial Production datasets, respectively. The results consistently demonstrate the superior forecasting performance of our proposed REVAR model compared to the three competitive VAR models. Moreover, the average asymptotic standard error ratios (
) of the OLSVAR, EVAR, and RRVAR models relative to our proposed REVAR model are consistently greater than one, which indicates significant efficiency gains achieved by the REVAR model.
Table 4 Pseudo-real-time forecasting performance with bootstrap for the NIPA dataset (1959Q1-2019Q4) using an expanding window scheme, evaluated from 2005Q1 to 2019Q4.
Table 5 Pseudo-real-time forecasting performance with bootstrap for the Price dataset (1959Q1-2019Q4) using an expanding window scheme, evaluated from 2005Q1 to 2019Q4.
In order to evaluate the effectiveness of the proposed REVAR model with a larger number of variables, summarizes the RMSFEh
values () using the first 43 variables from the FRED-QD dataset. These results not only show the superior performance of the REVAR model over other VAR models but also highlight its significant efficiency gains and forecasting improvements compared to smaller models.
Table 6 Pseudo-real-time forecasting performance with bootstrap for the initial 43 out of 47 macroeconomic variables in Table S6 (1959Q1-2019Q4), evaluated from 2005Q1 to 2019Q4 using an expanding window scheme.
8 Discussion
In this article, we proposed the reduced-rank envelope VAR (REVAR) model, a parsimonious vector autoregressive model that incorporates the concept of envelopes into the reduced-rank VAR framework. The proposed REVAR approach offers a powerful approach to detect relevant and irrelevant information in VAR models and significantly improve estimation accuracy and efficiency by removing the immaterial information and variations from the VAR process. We derived maximum likelihood (ML) estimators for the REVAR model and investigated their asymptotic properties under various error assumptions, including normality, nonnormality, and martingale difference sequence error assumptions. Through extensive simulation studies and real data analysis, we compared the performance of the proposed REVAR model with that of the standard VAR model, EVAR model, and RRVAR model. Our results consistently demonstrated the superiority of the REVAR model in terms of estimation accuracy, efficiency gains, and forecasting performance across different scenarios and datasets. The technical details, including proofs of propositions and additional simulations, can be found in the Supplementary Materials, providing further insights into the properties of the REVAR model and its estimators.
The REVAR model exhibits remarkable speed. For instance, fitting the model with in averaged just 0.07123 sec, while fitting the
model in took approximately 0.61587 sec, both with a sample size of
. These timings were achieved using an 8-core 3.2 GHz Apple M1 processor (Table S1).
For VAR models with a moderate number of variables and short lag lengths, OLS or ML estimations typically involve hundreds of parameters in coefficient and covariance matrices. More parameters can lead to less precise estimates and larger standard errors, especially with a fixed sample size. Applying the proposed REVAR model can parsimoniously reduce the number of model parameters, thereby improving the estimation efficiency and prediction accuracy. Evidence suggests that increasing the VAR dimension beyond 20 in economic applications does not yield substantial gains (see Banbura, Giannone, and Reichlin Citation2010; Koop Citation2013). However, our simulations and empirical results indicate that the REVAR model is capable of handling large datasets with up to 50 variables while maintaining robust performance.
Furthermore, our proposed REVAR model can be extended to a time-varying parameter model with stochastic volatility. In recent literature, there has been a growing recognition of the importance of stochastic volatility models in forecasting, as opposed to purely time-varying coefficients (Chan and Eisenstat Citation2018). It is worth noting that any subset of components within the decomposition of in (7) can vary over time. However, by employing a common reducing subspace for all
, it becomes feasible to implement a REVAR model with stochastic volatility. While these extensions are not straightforward, they are feasible and currently under investigation.
Supplementary_JBES-P-2022-0218.R2.pdf
Download PDF (629.5 KB)Acknowledgments
Thanks to the Editor, Professor Atsushi Inoue, an Associate Editor, and anonymous referees for their insightful and constructive feedback, which has greatly enhanced the article. Grateful to Professors Raja Velu and Dennis Cook for their helpful suggestions.
Supplementary Materials
The online supplementary materials contain all technical proofs of lemmas and propositions, along with a detailed dataset description, and additional simulation and empirical results.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
References
- Anderson, T. W. (1951), “Estimating Linear Restrictions on Regression Coefficients for Multivariate Normal Distributions,” The Annals of Mathematical Statistics, 22, 327–351. DOI: 10.1214/aoms/1177729580.
- ———(1999), “Asymptotic Distribution of the Reduced Rank Regression Estimator Under General Conditions,” The Annals of Statistics, 27, 1141–1154.
- ———(2002), “Canonical Correlation Analysis and Reduced Rank Regression in Autoregressive Models,” The Annals of Statistics, 30, 1134–1154.
- Banbura, M., Giannone, D., and Reichlin, L. (2010), “Large Bayesian Vector Auto Regressions,” Journal of Applied Econometrics, 25, 71–92. DOI: 10.1002/jae.1137.
- Basu, S., Li, X., and Michailidis, G. (2019), “Low Rank and Structured Modeling of High-Dimensional Vector Autoregressions,” IEEE Transactions on Signal Processing, 67, 1207–1222. DOI: 10.1109/TSP.2018.2887401.
- Bernardini, E., and Cubadda, G. (2015), “Macroeconomic Forecasting and Structural Analysis through Regularized Reduced-Rank Regression,” International Journal of Forecasting, 31, 682–691. DOI: 10.1016/j.ijforecast.2013.10.005.
- Billard, L., Douzal-Chouakria, A., and Samadi, S. Y. (2023), “Exploring Dynamic Structures in Matrix-Valued Time Series via Principal Component Analysis,” Axioms, 12, 570. DOI: 10.3390/axioms12060570.
- Box, G. E., Jenkins, G. M., Reinsel, G. C., and Ljung, G. M. (2015), Time Series Analysis: Forecasting and Control, Hoboken, NJ: Wiley.
- Box, G. E. P., and Tiao, G. C. (1977), “A Canonical Analysis of Multiple Time Series,” Biometrika, 64, 355–365. DOI: 10.1093/biomet/64.2.355.
- Brune, B., Scherrer, W., and Bura, E. (2022), “A State-Space Approach to Time-Varying Reduced-Rank Regression,” Econometric Reviews, 41, 895–917. DOI: 10.1080/07474938.2022.2073743.
- Bura, E., and Cook, R. D. (2003), “Rank Estimation in Reduced-Rank Regression,” Journal of Multivariate Analysis, 87, 159–176. DOI: 10.1016/S0047-259X(03)00029-0.
- Carriero, A., Kapetanios, G., and Marcellino, M. (2011), “Forecasting Large Datasets with Bayesian Reduced Rank Multivariate Models,” Journal of Applied Econometrics, 26, 735–761. DOI: 10.1002/jae.1150.
- ———(2016), “Structural Analysis with Multivariate Autoregressive Index Models,” Journal of Econometrics, 192, 332–348.
- Centoni M., and Cubadda, G. (2015), “Common Feature Analysis of Economic Time Series: An Overview and Recent Developments,” Communications for Statistical Applications and Methods, 22, 1–20. DOI: 10.5351/CSAM.2015.22.5.415.
- Chan, J. C. C., and Eisenstat, E. (2018), “Bayesian Model Comparison for Time-Varying Parameter VARs with Stochastic Volatility,” Journal of Applied Econometrics, 33, 509–532. DOI: 10.1002/jae.2617.
- Chang, J., Jiang, Q., and Shao, X. (in press), “Testing the Martingale Difference Hypothesis in High Dimension,” Journal of Econometrics.
- Chen, K., Dong, H., and Chan, K. S. (2013), “Reduced Rank Regression via Adaptive Nuclear Norm Penalization,” Biometrika, 100, 901–920. DOI: 10.1093/biomet/ast036.
- Conway, J. (1990), A Course in Functional Analysis, New York: Spring-Verlag.
- Cook, R. D., and Zhang, X. (2015a), “Foundations for Envelope Models and Methods,” Journal of the American Statistical Association, 110, 599–611. DOI: 10.1080/01621459.2014.983235.
- ———(2015b), “Simultaneous Envelopes for Multivariate Linear Regression,” Technometrics, 57, 11–25.
- ———(2016), “Algorithms for Envelope Estimation,” Journal of Computational and Graphical Statistics, 25, 284–300.
- Cook, R. D., and Zhang, X. (2018), “Fast Envelope Algorithms,” Statistica Sinica, 28, 1179–1197.
- Cook, R. D., Li, B., and Chiaromonte, F. (2010), “Envelope Models for Parsimonious and Efficient Multivariate Linear Regression,” (with discussion), Statistica Sinica, 20, 927–960.
- Cook, R. D., Helland, I. S., and Su, Z. (2013), “Envelopes and Partial Least Squared Regression,” Journal of the Royal Statistical Society, Series B, 75, 851–877. DOI: 10.1111/rssb.12018.
- Cook, R. D., Forzani, L., and Zhang, X. (2015), “Envelopes and Reduced-Rank Regression,” Biometrika, 102, 439–456. DOI: 10.1093/biomet/asv001.
- Cubadda, G., and Guardabascio, B. (2019), “Representation, Estimation and Forecasting of the Multivariate Index-Augmented Autoregressive Model,” International Journal of Forecasting, 35, 67–79. DOI: 10.1016/j.ijforecast.2018.08.002.
- Cubadda G., Guardabascio B., and Hecq, A. (2017), “A Vector Heterogeneous Autoregressive Index Model for Realized Volatility Measures,” International Journal of Forecasting, 33, 337–344. DOI: 10.1016/j.ijforecast.2016.09.002.
- Cubadda, G., and Hecq, A. (2011), “Testing for common autocorrelation in data-rich environments,” Journal of Forecasting, 30, 325–335. DOI: 10.1002/for.1186.
- Cubadda, G., and Hecq, A. (2022a), “Reduced Rank Regression Models in Economics and Finance,” in Oxford Research Encyclopedia of Economics and Finance, Oxford University Press.
- ———(2022b), “Dimension Reduction for High Dimensional Vector Autoregressive Models,” Oxford Bulletin of Economics and Statistics, 84, 1123–1152.
- Cubadda, G., Hecq, A., and Telg, S. (2019), “Detecting Co-movements in Noncausal Time Series,” Oxford Bulletin of Economics and Statistics, 81, 697–715. DOI: 10.1111/obes.12281.
- Ding, S., and Cook, R. D. (2018), “Matrix Variate Regressions and Envelope Models,” Journal of the Royal Statistical Society, Series B, 80, 387–408. DOI: 10.1111/rssb.12247.
- Davis, R. A., Zang, P., and Zheng, T. (2016), “Sparse Vector Autoregressive Modeling,” Journal of Computational and Graphical Statistics, 25, 1077–1096. DOI: 10.1080/10618600.2015.1092978.
- De Mol, C., Giannone, D., and Reichlin, L. (2008), “Forecasting Using a Large Number of Predictors: Is Bayesian Regression a Valid Alternative to Principal Components?” Journal of Econometrics, 146, 318–328. DOI: 10.1016/j.jeconom.2008.08.011.
- Escanciano, J. C., and Velasco, C. (2006), “Generalized Spectral Tests for the Martingale Difference Hypothesis,” Journal of Econometrics, 134, 151–185. DOI: 10.1016/j.jeconom.2005.06.019.
- Forni, M., Hallin, M., Lippi, M., and Reichlin, L. (2005), “The Generalized Dynamic Factor Model: One-Sided Estimation and Forecasting,” Journal of the American Statistical Association, 100, 830–840. DOI: 10.1198/016214504000002050.
- Forzani, L., and Su, Z. (2021), “Envelopes for Elliptical Multivariate Linear Regression,” Statistica Sinica, 31, 301–332. DOI: 10.5705/ss.202017.0424.
- Franchi, M., and Paruolo, P. (2011), “A Characterization of Vector Autoregressive Processes with Common Cyclical Features,” Journal of Econometrics, 163, 105–117. DOI: 10.1016/j.jeconom.2010.11.009.
- Hamilton, J. (1994), Time Series Analysis, Princeton, NJ: Princeton University Press.
- Hecq, A., Palm, F., and Urbain, J. (2006), “Common Cyclical Features Analysis in VAR Models with Cointegration,” Journal of Econometrics, 132, 117–141. DOI: 10.1016/j.jeconom.2005.01.025.
- Henderson, H. V., and Searle, S. R. (1979), “Vec and vech Operators for Matrices, with Some Uses in Jacobians and Multivariate Statistics,” Canadian Journal of Statistics, 7, 65–81. DOI: 10.2307/3315017.
- Herath, H. M. W. B. and Samadi, S. Y. (2023a), “Partial Envelope and Reduced-Rank Partial Envelope Vector Autoregressive Models,” preprint.
- ———(2023b), “Scaled Envelope Models for Multivariate Time Series,” preprint.
- Hetland, S., Pedersen, R. S., and Rahbek, A. (in press), “Dynamic Conditional Eigenvalue GARCH,” Journal of Econometrics.
- Izenman, A. J. (1975), “Reduced-Rank Regression for the Multivariate Linear Model,” Journal of Multivariate Analysis, 5, 248–264. DOI: 10.1016/0047-259X(75)90042-1.
- Koop, G. M. (2013), “Forecasting with Medium and Large Bayesian VARs,” Journal of Applied Econometrics, 28, 177–203. DOI: 10.1002/jae.1270.
- Lam, K. S., and Tam, L. H. (2011), “Liquidity and Asset Pricing: Evidence from the Hong Kong Stock Market,” Journal of Banking & Finance, 35, 2217–2230. DOI: 10.1016/j.jbankfin.2011.01.015.
- Lam, C., and Yao, Q. (2012), “Factor Modeling for High-Dimensional Time Series: Inference for the Number of Factors,” The Annals of Statistics, 40, 694–726. DOI: 10.1214/12-AOS970.
- Lee, M., and Su, Z. (2020), “A Review of Envelope Models,” International Statistical Review, 88, 658–676. DOI: 10.1111/insr.12361.
- Li, L., and Zhang, X. (2017), “Parsimonious Tensor Response Regression,” Journal of the American Statistical Association, 112, 1131–1146. DOI: 10.1080/01621459.2016.1193022.
- Lütkepohl, H. (2005), New Introduction to Multiple Time Series Analysis, Berlin: Springer.
- McCracken, M. W., and Ng, S. (2020), “FRED-QD: A Quarterly Database for Macroeconomic Research,” Federal Reserve Bank of St. Louis Working Paper 2020-005, DOI: 10.20955/wp.2020.005.
- Negahban, S., and Wainwright, M. J. (2011), “Estimation of (near) Low-Rank Matrices with Noise and High-Dimensional Scaling,” The Annals of Statistics, 39, 1069–1097. DOI: 10.1214/10-AOS850.
- Park, J. H., and Samadi, S. Y. (2014), “Heteroscedastic Modelling via the Autoregressive Conditional Variance Subspace,” Canadian Journal of Statistics, 42, 423–435. DOI: 10.1002/cjs.11222.
- Park, J. H., and Samadi, S. Y. (2020), “Dimension Reduction for the Conditional Mean and Variance Functions in Time Series,” Scandinavian Journal of Statistics, 47, 134–155. DOI: 10.1111/sjos.12405.
- Politis, D. N., and Romano, J. P. (1994), “The Stationary Bootstrap,” Journal of the American Statistical Association, 89, 1303–1313. DOI: 10.1080/01621459.1994.10476870.
- Rao, C. R. (1964), “The Use and Interpretation of Principal Component Analysis in Applied Research,” Sankhyā: The Indian Journal of Statistics, Series A, (1961-2002), 26, 329–358.
- Raskutti, G., Yuan, M., and Chen, H. (2019), “Convex Regularization for High-Dimensional Multi-Response Tensor Regression,” The Annals of Statistics, 47, 1554–1584. DOI: 10.1214/18-AOS1725.
- Reinsel, G. C., and Velu, R. P. (1998), Multivariate Reduced-rank Regression: Theory and Applications, New York: Springer.
- Reinsel, G. C., Velu, R. P., and Chen, K. (2022), Multivariate Reduced-Rank Regression: Theory, Methods and Applications, New York: Springer.
- Rekabdarkolaee, H. M., Wang, Q., Naji, Z., and Fuente, M. (2020), “New Parsimonious Multivariate Spatial Model,” Statistica Sinica, 30, 1583–1604. DOI: 10.5705/ss.202017.0455.
- Samadi, S. Y. (2014), “Matrix Time Series Analysis,” Ph.D. Dissertation, University of Georgia, Athens, GA.
- Samadi, S. Y., Billard, L., Meshkani, M. R., and Khodadadi, A. (2017), “Canonical Correlation for Principal Components of Time Series,” Computational Statistics, 32, 1191–1212. DOI: 10.1007/s00180-016-0667-1.
- Samadi, S. Y., and DeAlwis, T. P. (2023a), “Fourier Methods for Sufficient Dimension Reduction in Time Series,” preprint.
- ———(2023b), “Envelope Matrix Autoregressive Models,” preprint.
- Samadi, S. Y., Hajebi, M., and Farnoosh, R. (2019), “A Semiparametric Approach for Modelling Multivariate Nonlinear Time Series,” Canadian Journal of Statistics, 47, 668–687. DOI: 10.1002/cjs.11518.
- Shapiro, A. (1986), “Asymptotic Theory of Overparameterized Structural Models,” Journal of the American Statistical Association, 81, 142–149. DOI: 10.1080/01621459.1986.10478251.
- Shojaie, A., and Michailidis, G. (2010), “Discovering Graphical Granger Causality Using the Truncating Lasso Penalty,” Bioinformatics, 26, i517–i523. DOI: 10.1093/bioinformatics/btq377.
- Song, S., and Bickel, P. J. (2011), “Large Vector Autoregressions,” arXiv preprint arXiv: 1106.3915.
- Stock, J. H., and Watson, M. W. (2005), “Implications of Dynamic Factor Models for VAR Analysis,” NBER working paper series w11467.
- Stoica, P., and Viberg, M. (1996), “Maximum Likelihood Parameter and Rank Estimation in Reduced-Rank Multivariate Linear Regressions,” IEEE Transactions on Signal Processing, 44, 3069–3078. DOI: 10.1109/78.553480.
- Su, Z., and Cook, R. D. (2011), “Partial Envelopes for Efficient Estimation in Multivariate Linear Regression,” Biometrika, 98, 133–146. DOI: 10.1093/biomet/asq063.
- Su, Z., Zhu, G., Chen, X., and Yang, Y. (2016), “Sparse Envelope Model: Efficient Estimation and Response Variable Selection in Multivariate Linear Regression,” Biometrika, 103, 579–593. DOI: 10.1093/biomet/asw036.
- Tiao, G. C., and Tsay, R. S. (1989), “Model Specification in Multivariate Time Series,” Journal of the Royal Statistical Society, Series B, 51, 157–195. DOI: 10.1111/j.2517-6161.1989.tb01756.x.
- Tsay, R. S. (2014), Multivariate Time Series Analysis: With R and Financial Applications, Hoboken, NJ: Wiley.
- Velu, R. P., Reinsel, G. C., and Wichern, D. W. (1986), “Reduced Rank Models for Multiple Time Series,” Biometrika, 73, 105–118. DOI: 10.1093/biomet/73.1.105.
- Wang, D., Zheng, Y., Lian, H., and Li, G. (2022a), “High-Dimensional Vector Autoregressive Time Series Modeling via Tensor Decomposition,” Journal of the American Statistical Association, 117, 1338–1356. DOI: 10.1080/01621459.2020.1855183.
- Wang, D., Zhang, X., Li, G., and Tsay, R. (2022b), “High-Dimensional Vector Autoregression with Common Response and Predictor Factors,” arXiv:2203.15170.
- Wang, D., Zheng, Y., and Li, G. (2021), “High-Dimensional Low-Rank Tensor Autoregressive Time Series Modeling,” arXiv preprint arXiv:2101.04276.
- Wang, L., and Ding, S. (2018), “Vector Autoregression and Envelope Model,” Stat, 7, e203. DOI: 10.1002/sta4.203.
- Wei, W. W. (2019), Multivariate Time Series Analysis and Applications, Hoboke, NJ: Wiley.
- Zhou, X. C., and Lin, J. G. (2013), “Semiparametric Regression Estimation for Longitudinal Data in Models with Martingale Difference Error’s Structure,” Statistics, 47, 521–534. DOI: 10.1080/02331888.2011.617819.
- Zhao, Z. W., Wang, D. H., and Zhang, Y. (2011), “Limit Theory for Random Coefficient First-Order Autoregressive Process Under Martingale Difference Error Sequence,” Journal of Computational and Applied Mathematics, 235, 2515–2522. DOI: 10.1016/j.cam.2010.11.004.