Abstract
Learning objects paradigm is widely adopted in e-learning environments. Learning objects management can be improved using semantic technologies from ontology engineering and the semantic web. In this article we use a semantic model of the repository to improve both learning objects retrieval and composition. The use of domain knowledge enables automatic reasoning and makes the system able to import new domain models and use them to interrogate the repository (Arrigoni Neri Citation2005). Learning objects composition is one of the main challenges in e-learning management systems and can be improved exploiting ontological reasoning. The building of a course can be carried out in two phases, in the first phase we compose concept level entities to obtain an outline of the course, then we fill the outline with actual resources from the repository. Both phases can use ontology-based models to capture specific domain knowledge (Arrigoni Neri Citation2006). In order to provide an intuitive and expressive ontology representation, we briefly propose a graphical syntax for the well-known ontology web language (OWL).
INTRODUCTION
Learning objects paradigm is the main response to the need for intelligent e-learning supports. The first definition of a learning object comes from Leading Technology Standards Committee (LTSC) (2000):
…any entity, digital or non-digital, that can be used, re-used, or referenced during technology supported learning.
Such a definition is maybe too general and includes almost any physical or conceptual entity (Wiley Citation1999). For this reason, another definition was proposed by Wiley (Citation2000), which restricts the domain to digital libraries:
…learning object is a digital resource that can be reused to support learning.
Learning objects management needs users and artificial agents to share problem semantics; in early computer aid instruction (CAI) systems, the largest part of semantics was managed by the user, while agents simply used known keywords from metadata whose meaning was not formally defined. Recently, the development of ontologies as formal and explicit representations of world conceptualizations (Gruber Citation1993) and their applications to the semantic web (Berners-Lee, Hendler, and Lassila Citation2001) defined languages for ontologies like resource description framework (RDF) (W3C Worldwide Web Consortium 2004) and ontology web language (OWL) (OWL Web Ontology Reference) and let us go beyond this simple scenario, thanks to the description logics (Baader et al. Citation2003a) funded semantics of ontological languages (Sattler Citation2003; Horrocks and Patel-Schneider Citation2004), and the presence of optimized reasoning algorithms (Horrocks and Sattler Citation2001; Horrocks Citation2002). First of all, ontology engineering improves system modularization, since each software agent can be tailored to work with specific ontology. For example, information retrieval agents can understand an application ontology of electronic resources, while a tutor agent can understand a pedagogical terminology. Ontology mappings can then allow the agents to talk to each other and share the same repository model. Furthermore, before the development of formal logics for ontologies-specific domain semantics had to be directly implemented in the code, designers could not know everything about the domain learning objects that would be talked about. As pointed out in Mohan and McGalla (Citation2003), a learning object management system be open to external contributions and be able to understand third-party domain models.
Ontological systems can be used both to improve already available services and to provide completely new ones. In literature, many applications of ontologies are known, such as closed questions generation (Fischer Citation2001) and ontology composition tests (Laurent Cimolino and Kay 2003). In our system, the semantic model of the repository is used to provide two different services:
-
Learning objects retrieval can be improved by an ontology. The ontology language, namely, OWL (OWL Web Ontology Reference), comes with a formal semantics based on description logics (Baader et al. Citation2003a), so the user can use terms from the ontology to express complex semantic queries relying on a sound and complete reasoning to answer them.
-
Learning objects sequencing involves the knowledge about domain models, learning objects, and the student. This complex process can be carried out by a specialized artificial agent that understands the pedagogic meaning of metadata. Ontology mapping is fundamental to reinterpret the model in a pedagogic perspective.
Furthermore, ontologies are fundamental to:
-
improve interaction with the user, since ontology is shared by the user and artificial agents.
-
improve system modularization; each agent in the system is built using a task-specific ontology; ontological mapping can then let agents talk to each other and share the same repository model.
-
make the system open to external knowledge integration; since data semantics has been formalized in a declarative way, it is possible to import ontological models from the web.
SYSTEM OVERVIEW
VICE is a learning object repository management system whose final users are teachers that want to find resources to compose lessons. At the lower level, the semantic model consists of a complete description of each available resource through an RDF (W3C Worldwide Web Consortium 2004) graph.
We designed and implemented an ontology-based architecture that allows the platform to semantically tag metadata using ontologies freely imported from the web. The obtained semantic model of the repository can be used to search for learning objects that match user needs. In our architecture, we distinguish between the resources model and the contents model. The resources model is the translation in a semantic web language of a classic metadata schema. The ontology of this model is one of the outcomes of the VICE project and therefore it is static and makes our model able to dialogue with the lower levels of the platform. On the other hand, the content model describes the particular knowledge domain the resources talk about. This higher level model contains abstract objects, which is the teachable contents the system can handle, and cannot be assumed to be known by the system designer since it typically changes during the system's life. Therefore the system allows the user to enrich the domain model adding new ontologies from the web.
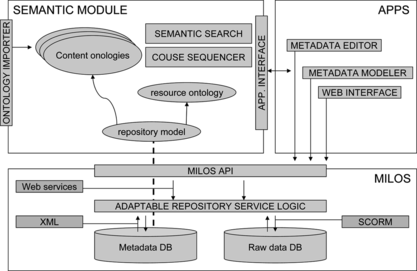
Figure shows the whole VICE architecture. At the lower level, MILOS handles row data and metadata, which are archived in two different databases, encapsulating learning objects according to a sharable content object reference model (SCORM)Footnote 1 standard in order to eventually support web-based content delivery. MILOS API allows higher levels to access its services. A semantic module interfaces with MILOS API to maintain an RDF copy of the metadata repository. It provides an ontology-importing agent to maintain domain models and provides the classic syntactic applications with a simple API to access semantic-enriched tagging.
FIGURE 1 Global VICE functional schema.
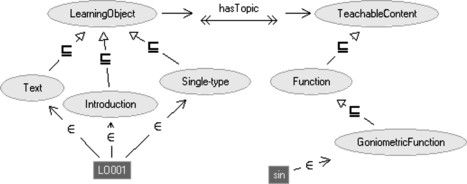
The upper level ontology of VICE expresses the relation between resources and their contents. Each resource in the repository will be classified inside the resource ontology, that is, a learning object will be connected with one or more concepts inside resource ontology through instance of links. The relationship between each resource and its pedagogical contents allows the system to go beyond classic human readable metadata. In fact, while in classic repositories, the topic of a lesson or the topic of an exercise is simply described in natural language, upper ontology uses the role hasTopic to link the resource to a generic TeachableContent, represented by an individual inside a specific content model.
LearningObject and TeachableContent are the top concepts, respectively, of resources and the contents ontologies.
A GRAPHICAL SYNTAX FOR OWL
The first step in ontology integration is the choice of a suitable ontological language. We choose OWL from the W3C Consortium. In particular, we used OWL-DL, that is, the more expressive OWL decidable sublanguage. It corresponds to the well-known description logic HOIN ( +) (Horrocks and Patel-Schneider Citation2004) and allows for complex concept composition in classical Tarsky-style extensive semantics using both Boolean operators and cardinality restrictions over roles.
Ontology languages are fundamental in making artificial agents able to “understand” the meaning of row data but by the same time taken, as the language complexity grows it can become unfeasible for a nontechnical human user to manipulate semantic descriptions. Nowadays, there are graphical syntaxes for the semantic web's lower level languages—XML and RDF. Ontology editors like Protégé,Footnote 2 from Stanford University typically organize terms in a tree-like visualization that represents the ontology backbone. However, inter-concept relations different from subsumption are usually rendered through an RDF graph, so specific OWL constructs are represented as categorial symbols, or in the best case, a general purpose representation like UML is used. In order to make user interaction easier, we defined a simple and intuitive graphical syntax for OWL–DL, namely, graphic OWL (GROWL), in which each OWL construct has its own stereotype.
First of all, each concept, that is, each class, is represented by an ellipse, just like in graph RDF representation. As shown in the upper-left of Figure , special diamond stereotypes are used to represent top and bottom concepts and class definitions can be related to each other through logical operators. OWL assertions about classes are represented by links, as shown in the upper left of Figure , like subsumption (⊑), equivalence, and disjointness. The upper right shows syntax for properties (or roles in description logics terminology). A property is represented by a bi-directional arrow with a double arrow on both sides. These arrows are to be taught as linking an object on its left to an object on its right. The presence of a single arrow on one side means that the property is functional in that direction. Finally, Figure shows the stereotypes for transitive and symmetric properties. To indicate the domain and range of a property it can be connected with incoming arrows from domain classes and out going arrows to range classes (see, for example, Figure ). The central part of Figure shows two of the many concept constructors: concept conjunction and existential quantification. The first describes the set of objects that belong both to C6 and C7 concepts (C6–C7 in DL syntax), while the second describes the set of individual with at least one r – successor, that is, instance of class C ( ∃ r.C in DL syntax).
FIGURE 2 Upper ontology: a LearningObject has some topics that are generic TeachableContents.
FIGURE 3 Principal elements of GrOWL syntax.
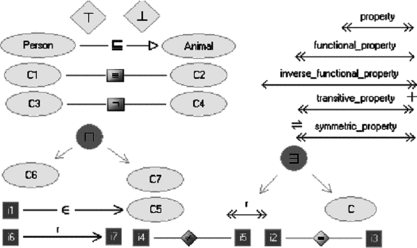
FIGURE 4 A tiny fragment of a repository that refers to a mathematics content ontology.
An individual can be connected to one or more classes by an instance – of (∊) link. A user can declare two objects to be aliases or explicitly different and can link two individuals with a role-labelled link, that is, the instance of a property.
LEARNING OBJECTS SEMANTIC METADATA
In this section, we discuss in more detail the ontological model, both describing resource ontology and addressing the problem of third-part content ontology integration. Finally, we use GrOWL syntax from a previous section to semantically query the joint ontological model.
Resource Taxonomies
First of all, learning objects are electronically reachable resources (Wiley Citation2000), but due to their content, they are particular resources with a didactic use. The relationship between a resource and its content has been addressed by the upper ontology; however, we have to classify resources themselves. VICE resource ontology is a multi-taxonomy, that is, the collection of three taxonomies used to classify learning objects with respect to different and orthogonal dimensions.
To a first approximation, we can consider a learning object merely as a generic electronic resource. The first taxonomy, namely, electronic resource taxonomy, considers the file type as the main characteristic of the resource, so a learning object can be classified as a video, a slide presentation, or a text. This information allows the teacher to take into account specific student abilities and course peculiarities. For example, if the teacher wants to make a class, he will prefer slide presentations and videos, while if he is building up the course notes he/she will look for texts. File classification is the basis for cognitive filtering. Particular care has been taken in disability aware filtering: if the student has a vision disability, the teacher can avoid videos and the system will look for audio contributions.
On the other side, we can consider a learning object as a pedagogical artifact, regardless of whether it is digital or not. Along this dimension, the classification is centered on didactic and pedagogical use of the resource. So we can distinguish between lessons and exercises, examples and introductions. This pedagogic taxonomy is fundamental in learning object selection, but is even more important if we want an artificial agent to automatically compose courses. In fact, pedagogic dimension allows the agent to articulate a class using a classic path like introduction-explanation-example-exercise.
The first two taxonomies describe the electronic and pedagogical aspects of resources. As shown by Wiley (Citation2001), the combination of the pedagogical value and the digital nature of the resource generates new issues, that are not characteristic of classic didactic material nor generic digital resources. Digital artifacts can interact with the user and modify the way the content is presented or even the content itself. Wiley taxonomy identifies five types of learning objects:
Single-type: resources that can be used atomically. | |||||
Combined-intact: a learning object composed of two or more components (for example, a photo and text). | |||||
Combined-modifiable: a combined resource that can dynamically choose and combine its components. | |||||
Generative-presentation: a resource capable of dynamically generating the content to be presented to the user. For example, an application that can generate a different example at each request. | |||||
Generative-instructional: a complete learning environment. | |||||
Resource ontology translates VICE metadata schema in an OWL T-Box using learning object metadata (LOM) (IEEE 2000) from IEEE as the starting point. Resource ontology metadata are of three different types:
-
– Taxonomy metadata allows a semantic module to classify learning objects in resource multi-taxonomy. A metadata editor has no access to semantic descriptions and is not able to manage type links. However, object classification can be related to special metadata from the resource taxonomy itself. For example, in the taxonomy we can say that CompositionalLO are exactly the learning object whose loType metadata assumes a specific value (see, for example, Figure ).
-
– Generic LOM metadata are metadata from a VICE platform with no special meaning for a semantic module. They can be used by a the user to further restrict query results.
-
– hasTopic metadata is the most expressive one. It not only assumes semantically-rich values, but possible values depend on the specific content domain. In order to make the user enter only correct values without making him browse the whole content for ontology, a keyword-based interface with a metadata editor was developed. The user can search by keyword for the intended topic. A textual description is returned for each compatible individual to support user choice.
Importing Content Ontologies
While resources are classified through a static ontology, content models have to be dynamic. The system can be tailored to work with learning objects about any knowledge domain, so the user must be able to define its own domain model and use such a model to tag resources. We allow the user to indicate a new domain ontology through a URI; the system recovers the new model as an OWL file. Therefore, a knowledge domain model can be assumed to be a generic OWL ontology.
FIGURE 5 Repository queries are expressed using content and resource ontologies. Content planning uses content ontology individuals with the mapping to pedagogic ontology. Finally, learning object selection uses resource ontology to select suitable objects.
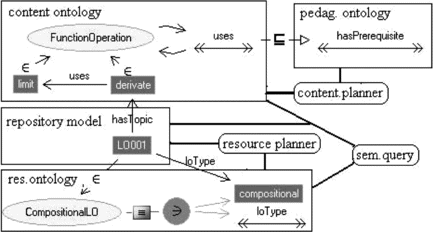
Unfortunately, such a flexible solution comes with a drawback. An ontology designed to represent the knowledge about a specific domain is usually not directly suitable for e-source metadata. In general an ontology engineer designs the ontology as a collection of concepts, more or less organized in taxonomies. Then he uses language constructs to further constraint ontology interpretations and finally he fills its ontology with some relevant individuals. The result is that some domain terms are used as concepts, while others are used as individuals. The level of this division largely depends on designer preference and is the specific goal the ontology is designed for. When the ontological model is imported in VICE and is used as the range of hasTopic role we must be able to link a specific resource to both individuals and concept names. In fact, a learning object can talk about any domain concept regardless of its abstraction level and without any commitment about subconcepts or individuals. We will say the topic relation does not distribute on concept instances nor through subsumption chains.
For example, let the imported ontology talk about mathematics. We could suppose Function to be a T-Box concept. GoniometricFunction could be a Function subconcept with an instance sin. Figure shows an example of a textual learning object that is an introduction and is Simple (as classified in Wiley taxonomy). If the introduction is about the specific function sin no problem arises, but what happens if the learning object is an introduction of the concept of function? In this case, the resource cannot be linked to any individual in the ontology. The easiest solution could be to link the resource directly to an intermediate node of function taxonomy; however, this should result in a second-order model since we have a link between an individual and a class and make any automatic reasoning unfeasible.
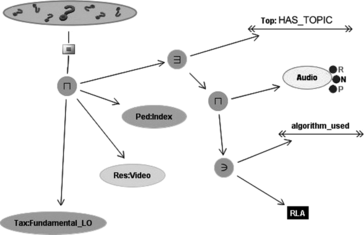
In order to obtain a first-order model, third part content ontology must be processed. We must guarantee that for each term in the ontology, an appropriate individual is available to be likened to resource descriptors. In order to accomplish this, we use a reification that adds some new individuals to the ontology as facets for classes. A reification module works with a very simple application ontology that contains only the concept for new generated objects, namely, Representant. The new imported ontology is processed; for each named concept C, a facet individual [ctilde] is added such that Representant ([ctilde]). It is then necessary to build new concepts to classify reified objects. For example (see Figure ), it lets the user it querying for learning objects about Functions; if the concept of Function is considered in the original ontology meaning, only resources about specific instances of Function concept will be found. If Function is interpreted in an extended meaning, that is, taking into account the reified objects, general introductions to the Function concept will be returned, as well as introductions to particular subconcepts like GonimetricFunction. So, starting from C a new extended concept, namely C +, is built adding [ctilde]:
FIGURE 6 Example of reification.

FIGURE 7 Ontology navigation-based query.
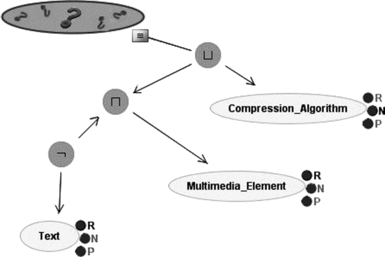
FIGURE 8 An example of content composition. Here the user is looking for a learning object about something that is a compression algorithm or a multimedia element that is not a text.
Finally, extended concepts must be organized in a taxonomy following original concepts one.
Ontology importing, therefore, consists of four phases:
-
connect imported ontology to VICE upper ontology, making each concept a subconcept of TeachableContent
-
reify each concept C in an individual [ctilde]
-
build extended concepts
-
organize extended concepts in a taxonomy.
After these steps each term has a corresponding individual and the user can take advantage of reification technique in ontological queries.
Unfortunately, import procedure makes the ontology grow to nearly double its original size. Even without this expansion handling, the whole repository description can be unfeasible for realistic databases. Since reasoning with expressive description logics is at least exponential (Horrocks Citation2002; Horrocks and Sattler Citation2001; Horrocks et al. Citation2000) ontological reasoning can be performed only on small databases. For this reason, a VICE semantic module clusters resources in islands. Each island contains learning objects that like to be accessed in the same context. So an island is simply the set of all the learning objects that refer to the same content ontology. When the user starts using a semantic module, he is asked to select a domain ontology so the system will load only the fragment repository about the chosen domain.
LEARNING OBJECTS RETRIEVAL
Once the ontological model has been built, the user can describe the learning object using all the available ontologies. An instance retrieval service from an ontology reasoner will then retrive all the resources from the repository that match user needs. In our experiments we used RACER (Haarslev and Moller Citation1999) as a description logic reasoner. Our platform is based on JenaFootnote 3 and the DIG (Bechhofer Citation2003) interface has been used to access reasoner services.
The more expressive power you give to the user, the more complex the query composition and the more skills are required to use the system. So in VICE, we developed three different query interfaces with different complexities.
Query Interfaces
The first and simplest query interface gives to the user the three resource taxonomies and the content ontology through a graph. The user selects concepts from resources taxonomies and navigates content ontology following subsumption links and properties. Reification is hidden by the application, the user analyses content domain exploring the original imported ontology. Concrete reified individuals and extended concepts are possible qualifications of desired content. Once the user has selected the node, he can indicate if he wants:
only the instances from original ontology, that is, the query for C concept instances | |||||
only the concept itself, that is, the individual [ctilde] | |||||
both plus any reification of C subconcepts, that is, extended concept C +. | |||||
In this first query, the user simply selects the right nodes inside an existing ontology. An ontological model allows for much more flexible uses. In fact, the user can use existent terminology to define its own concepts and describe a rich query. The second interface allows the user to manipulate content ontology, placing concepts and individuals on a blank table and building new concepts through GrOWL syntax. In this case each named concept from content ontology must be qualified with respect to the reification process.Footnote 4 The tool automatically composes the wanted concept and executes the instance retrieval on
Free composition of all the terminologies brings a strictly more expressive query language. In fact, the user can express logical contraints on resource parts of the ontology, for example, looking for any multimedia resource except video files and exercises. Furthermore, the explicit use of hasTopic role allows the user to express more than one possible content. For example, he could look for any video exercise about any GoniometricFunc-tion and about a substitution solving method; such a query cannot be expressed using the second interface. In fact the conjunction of GoniometricFunction and Substitution on the content side produces the query for a learning object which talks about a domain content that is, at the same time, both a function and a solving method. To ensure the system to return only learning objects, the system will perform the instance retrieval task on the concept.
Query Answering with Closure
When, the query is described using the simple or full graphic composition, a possible semantic problem is raised. In fact, in these cases the user is allowed to describe a rich query using virtually any valid OWL construct, including disjunction and free negation, so the result of the query changes if the system assumes the model to be complete or not. This is one of the main differences between ontological systems based on description logics, semantics (Horrocks and Patel-Schnider 2004) and classic database systems. In description logics, you usually have an open world assumption (OWA), that is, you assume the tour model to be incomplete and you admit that other assertions on the same resources can be done by other people in other parts of the world and your reasoning must be correct according to this vision. In a database system, on the other side, you assume your data to be complete, that is, everything you cannot read in your data is assumed to be false, so you work under a closed world assumption (CWA).
Description logic semantics is founded on classic Tarsky semantics over an interpretation domain Δ. In general, an interpretation I is a couple I = < ΔI, [sdot]I > where ΔI is the interpretation domain and İ is an interpretation function assigning a set of individuals to each atomic concept and a set of pairs of individuals to each role name. OWL-DL language is the DL based fragment of OWL; it is a syntactic variant of SHOIN description logic, whose concept constructors are listed in Table . A OWL-DL ontology can be reduced to a finite set of axioms in the form of C ⊏ D and R ⊏ S, where C and D are concepts and R and S are roles, forcing concepts (roles) to be interpreted as a subset of the other. An interpretation/is a model of an ontology if it satisfies all the axioms in the ontology.
TABLE 1 OWL-DL Basic Constructors Syntax and Semantics, Where C and D Are Concepts, R Is a Role and n Is a Natural Number
OWL-DL language is expressive enough to show the difference between OWA and CWA queries, since it allows concept-free negation and universal quantification over roles.
Obviously, when a user asks for objects in a repository, he assumes a CWA so he can obtain an unexpected behavior if the retrieval technique is based on DL reasoning, as in our case. In order to regain closed world semantics we can proceed in two different ways:
By implementing a new DL reasoner that works under CWA. This is a difficult way since most of the tableaux-based algorithm actually used to reason on DLs (Baader, Horrocks, and Sattler Citation2003b; Horrocks et al. Citation2000; Horrocks and Sattler Citation2001; Horrocks Citation2002) cannot be practically modified to take into account CWA. Furthermore, such a solution should make the system incompatible with the rest of semantic web solutions. | |||||
By forcing the closure at the ontology level, reformulating both the query and the ontology. This is a more practical solution since it does not require the implementation of new ontology reasoning stuff. | |||||
In general, if we call M(O) the set of models of O, we have that the evaluation of a query Q on the ontology O returns the set of individuals that are interpreted inside Q in any model of I:
Following the second approach, our goal is to evaluate a query Q on an ontology O that contains all the individuals from the repository obtaining a set of resulting individuals, namely, evalc(Q, O), such that x ∊ eval[Q, O) iff x ∊ Q
I in any I that is a model of O under a CWA. If we apply CWA, we have to change the instance retrieval on concepts in the forms , and < nR.
In our approach, starting from the query Q and the reference ontology O we want to build a new query Q′ and a new ontology O′ such that
A possible approach is to extend the semantics of the corresponding DL (SHOIN in our case) with an epistemic modal operator K. According to Fitting (Citation1993) epistemic extensions could not have a unique interpretation and the choice of a first-order semantic depends on application. An in-depth investigation of the properties of a modal description logic is beyond the focus of this article, however, we notice that since we use knowledge operator K to force a closure assumption in query evaluation, we can assume rigid designators, that is, there is an infinite set of designators and this is the interpretation domain for every world. This allows us to interpret an epistemic concept KC as the same set in every world extending to the modal setting the idea of interpreting concepts as sets (Donini et al. Citation1998). Instead of adding an explicit knowledge modal operator to OWL, it is possible to define a procedural semantic for K, adding to the ontology new axioms that fix the interpretation of K-closed concepts (that is, concepts in the form KC) and K-closed roles (in the form KR) according to their minimal interpretations, so
Given a query Q, let's call C(Q) and R(Q), respectively, the set of concept names and roles in Q. In order to evaluate Q under CWA, it is necessary to close the interpretation of all the roles and concepts in Q, this operation, namely, closure of concepts and roles consists in adding new K-closed versions of the concepts and roles:
set O′ = O | |||||
for every C ∊ C(Q) | |||||
for every R ∊ R(Q) | |||||
The second step is to modify the query to take into account the closed versions of both concepts and roles. Since OWL-DL is propositional closed, it is possible to express any concept in negate normal form (NNF) in linear time w.r.t. the size of the concept. A concept is in NNF id negation appears only in front of concept names (or enumerated concepts); we can push negation inside the formula in an inductive way w.r.t. the number of concept constructors using De Morgan laws and quantification rewriting rules (see Table ): Q′ can be obtained from the NNF of Q by substituting C with KC in any occurrence of subformula ¬ C and by substituting R with KR in any occurence of subformulas ∀ R.C, ≤nR, and = nR.
TABLE 2 NNF Rewriting Rules
LEARNING OBJECTS COMPOSITION
Course sequencing is the process that composes existent resources to build a more complex pedagogic entity, a course, which responds to student and teacher needs. In most cases a system is provided with an overlay model of the student, that is, the list of all the contents the student is assumed to know. The system must know the pedagogic goals too, that is, the final student model. This is another overlay model indicating all the contents the user is expected to know after the course.
Pedagogic planning requires the cooperation of different actors, each one with a specific competence:
-
domain expert is responsible for the correct formalization of the domain. He must have a complete and sound knowledge of the topics and of all the domain-specific relations between them. In principle, he could have no pedagogic skills at all.
-
domain pedagogist is a teacher specializing in the domain. It provides a pedagogic view of the domain structure. Can be less skilled in the domain than the domain expert, but has to integrate the global schema of the domain with a standard pedagogic view.
-
pedagogic-style expert knows the tactics to be implemented during teaching. In principle, can have no specific skills in the domain, since his contribution is largely domain-independent. He provides the knowledge about cognitive aspects of the learning process, at both the strategic and tactical level. At the strategic level, he defines some policies on how to use the pedagogic view of the domain to build a suitable curriculum, while at the tactical one he gives the rules to compose actual teaching units with actual learning objects.
Each actor has its own perspective on the teaching process and describes it in a task-specific language. In exploiting knowledge management techniques, it is possible to integrate the different contributions and coordinate the work of the actors to achieve the final goal. The main integration problem is in the schema level, that is, different experts describe the same domain using different terminologies, so formal ontologies can work as a bridge between different descriptions and as the glue of the whole system.
Course sequencing can be divided into two phases: content planning and delivery planning. Ontologies can be used in planning in three ways: translating an ontological model to another language, giving an operational semantic to a specific ontology through an ad-hoc planner, or reducing plan composition to an ontological reasoning task. In our work, we use the first approach for content planning and the second in delivery planning.
-
content planning First of all it is necessary to build a content plan, that is, the outline of the course, reporting a linear or nonlinear plan of content in the order they will be presented to the student. This phase uses initial and final student models to extract a plan from the domain ontology. Since it involves content structure, the skills of all the actors must be coordinated to achieve content-level planning: the modelling skills of the domain expert, the specific competences of domain pedagogist and the pedagogic-style expert with specific focus on strategic (that is content level) teaching approach.
-
delivery planning In the second phase, content plan is filled with actual resources from the repository. The system must use metadata from repository and resources ontology to organize learning objects according to teacher pedagogical preferences. Delivery planning is tightly related to the pedagogic style of the teacher, so the main actor involved is the pedagogic-style expert, with his specific competence on pedagogic tactics.
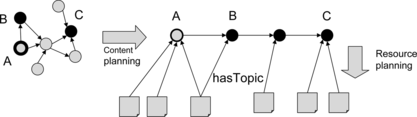
Figure shows a simple scenario. On the left we have the graph of content knowledge. Initial and final overlay models for the student are represented as empty bordered nodes (for the initial model) and filled nodes (for the final model). In general, a content plan could contain control structures like branches and loops. Some authors (Vassileva and Deters Citation1998; Peachey and McCalla Citation1986) argue that a linear plan is too restrictive and adds too many constraints to actual pedagogic models. However, we used LPG,Footnote 5 a linear planner from the University of Brescia. One of the main advantages of nonlinear planners is that a less-constrained content plan allows the successive resource planning phase a better chance to find a feasible learning object sequence. In VICE, we produce more than one possible outline, each one with a fitness measure that expresses the content cohesion. Learning object sequencing is performed on every proposed outline, starting from the best ones, until an outline can be filled with available resources. If the plan width is not sequential, but gives itself more possible paths, the ordering of plans with respect to global fitness should not guarantee that the resulting sequence will correspond to the best possible linear outline. In the bottom of Figure , the second phase has chosen some resources linked to outline contents through hasTopic role.
FIGURE 9 An example of free semantic query composition.
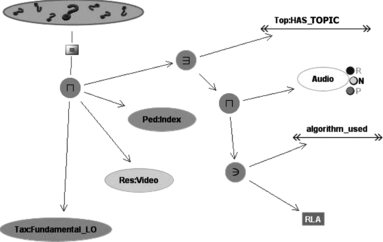
FIGURE 10 Two phase course composition through learning object sequencing.
Content Planning
The first planning phase, given the set of available domain concepts DOM, an initial overlay model I ⊆ DOM and a target overlay model T ⊆ DOM produces an outline as an ordered sequence O =〈[sdot][sdot]C i [sdot][sdot]〉 of selected nodes such that T ⊆ O and for each C i ∊ O, every [Ctilde] that is a prerequisite for C i is either [Ctilde] = C j ∊ O, j < i or [Ctilde] ∊ I.
Planning on content graphs, and in particular on conceptual graphs, gives rise to two problems:
Planning graph is not known a priori. Not only is its geometry unpredictable, but even the terminologies used to label its links cannot be forced at design time. In fact, content ontology can vary from one repository to another and can even be imported from the web in a semi-automatic way (Arrigoni Neri Citation2005). | |||||
Pedagogic approach, that is, the strategy on which links to follow during planning, is a fundamental teacher contribution to the planner and should be provided in an effective and simple way. | |||||
Such issues can be assessed exploiting terminological reasoning. Content planning must use a graph representation of content domain in which contents are connected by pedagogic relations. The first step is then the definition of a pedagogic ontology. Specific content ontologies can differ by the number and types of concepts and roles, but each domain must be mapped to a pedagogic planner model in order to be used in automatic course generation.
When the system administrator wants to enable automatic planning in a specific model, that is, on a specific content ontology, he maps domain models to pedagogic ontology; this mapping is carried out in two phases. First, some roles from the content ontology are mapped to pedagogic ones. For example, in a mathematics repository, the administrator could indicate uses Lemma to be a special case of hasStrongPrerequisite to indicate that the planner must check that each lemma are presented to the student before the theorem. In a second phase, the system administrator can browse content ontology and manually add specific pedagogic links between content individuals.
We stress that, once ontological mapping has been carried out, the planner has no need to access domain ontology, since any possible assertion has been translated in pedagogic links.
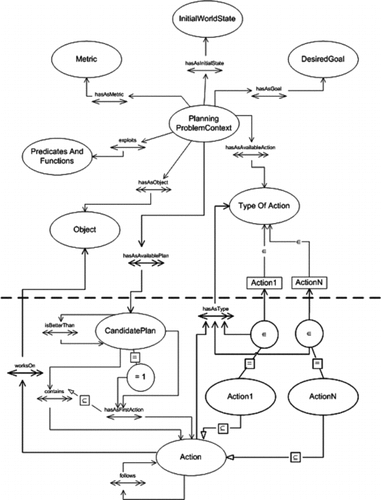
The planning problem is itself described through an ad-hoc ontology of problems and plans (Figure ). Problem description contains, among others, initial and desired student models and the description of the pedagogic approach to be applied. In the upper part of Figure the ontology describing the problem is reported, while in the lower part the terminology used to represent the composed plans is shown.
FIGURE 11 Problem and plan intermediate ontology. The planning problem description contains the set of possible action types, while the resulting plan is composed of actual tokens. Each one has an action from the problem as its type.
Starting from pedagogic ontology, PDDL translation is performed in two steps. In the first phase, the content composition is mapped to a planning problem described in the problem ontology. In the second phase, such a model is finally translated to PDDL. This intermediate translation allows a division from OWL and PDDL domain. In the first translation, the translation takes into account pedagogic specific problems, while the second phase is related to strictly syntactic mappings and handles all the language translating problems.
Pedagogic ontology basically contains two kinds of roles:
-
admissibility roles are roles that express constraints on the final plan. Typical example of admissibility roles is the strong prerequisite. No concept can be presented if a prerequisite cannot be assumed known by the student.
-
step roles are generic pedagogical roles that label the links between two contents. The planner follows these links to build a path from initial knowledge to final student status. An example of step roles is analogy, which can usually be followed to introduce new concepts.
The choice of the next step depends both on the goal knowledge and the type of links to follow. The user can give a weight to each pedagogic relation, so a low weight to the analogy role will make the planner prefer such links among others, while a high weight of falseAnalogy role will avoid presenting two interfering contents consecutively. So, a pedagogic approach, or pedagogic strategy is simply the weight assignment to each step role. Given the domain model expressed in pedagogic ontology and the model of the problem, VICE planner translates the problem in Planning domain definition language (PDDL) (AIPS, 1998), passes the obtained PDDL problem to an external planner and translates back the resulting plans in OWL filling the remaining part of the problem semantic model.Footnote 6 The resulting plans are ordered in global fitness descending order using the plan ontology is BetterThan role. The PDDL description of the problem is built assembling the following fragments:
-
student model in the translation, the overlay status of knowledge of the student is represented by a PDDL predicate “knows” that expresses the fact that, in a given planning world, the student knows a given topic. Planning actions modify such representation adding new acquired knowledge every time a new topic is scheduled by the planner. An initial partial world description is obtained from the initial overlay model, while a goal world is obtained enumerating each intended outcome.
-
pedagogic structure of the domain each pedagogic link that can be inferred by the ontology mapping must be translated in PDDL. The simplest solution is to foresee a binary predicate for each role in pedagogic ontology from Figure .
-
actions in a pure pedagogical vision, we should create an action for each content in the domain model. However, plans must be valid with respect to strong prerequisite structure. So our translator produces five basic PDDL actions, parametric with respect to actual content, each one considering different relations between the next topic and the current structure of the plan.
-
cost function all admissible plans must guarantee teaching all target contents following existing links only and respecting all strong prerequisite constraints. Furthermore, selected plans should be optimal with respect to a global cost. Cost function simply calculates the cost of a plan as the sum of link weight as indicated by pedagogic strategy.
The whole pipeline from domain description to PDDL plan problem description is shown in Figure and allows all the different actors to work together. In fact, the domain expert provides the initial domain fragment, domain pedagogist maps the fragment to the pedagogic ontology filling the gap from the domain and its pedagogic use, while the pedagogic expert gives the pedagogic strategy.
FIGURE 12 A fragment of VICE pedagogic ontology.
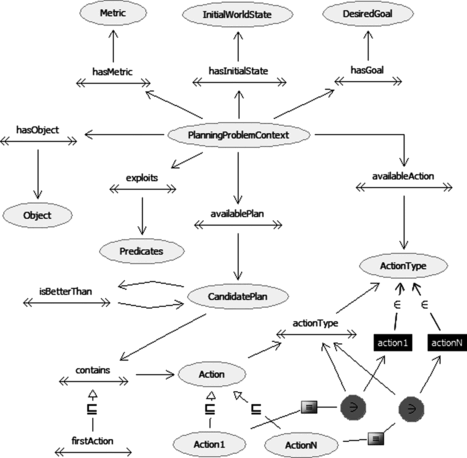
FIGURE 13 Content model to PDDL translation pipe.
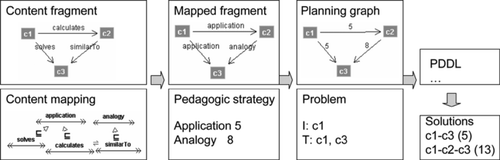
Ontologies for planning are not a new research topic. Specific ontologies for planning problems have been proposed for Darpa agent markup languageFootnote 7 (DAML), the OWL predecessor, and a DAML to PDDL translator has been developed.Footnote 8 However, our work is different. Our system generates a new planning problem from the pedagogic task description. We are evaluating any way to generate an intermediate OWL model for the generated plan and delegate to the DAML/PDDL converter the final translation.
Delivery Planning
The delivery planner fills the course outline from the previous phase with actual learning objects from the repository, obtaining a sorted set of learning objects ready to be delivered to the students. In this phase, tactical pedagogical choices must be done. The planner receives the course outline, that is, the ordered set of concepts plus the cost of each step from the planning graph; such costs will be considered proportional to the foreseen difficulty of the step. Once the set of topics is decided, as well as the order in which they must be presented, any teacher can express some rules to build “good” courses. A simple yet powerful way to express pedagogic tactics is through resource composition templates. Each template can apply to one or more consecutive concepts in the content plan and can describe the pattern of pedagogic types. For example, a classic template could be the triple 〈presentation, exercise, test〉. Each typed placeholder is a slot, so the example plan is composed of three slots.
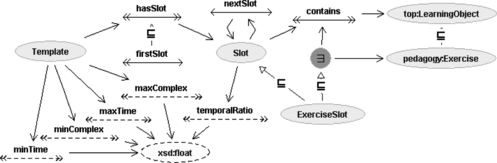
Figure shows the ontology used by the pedagogic-style exper to describe templates; it provides two main concepts:
FIGURE 14 Template ontology.
-
Template is the set of templates available during planning. Each template is applicable to a fragment of the course outline, that is, can cover one or more concepts, given that the global difficulty of the fragment is inside a given difficulty interval. Template difficulty interval expresses the teacher knowledge about the cognitive complexity the template can manage. Admissible interval is expressed by minComplex and maxComplex roles. Once a template has been allocated to one or more contents, it forces some temporal constraints on learning objects; the total amount of time the filling resources must be inside another interval expressed by minTime and maxTime.
-
Slot is the concept collecting specific slots that compose templates. Each slot covers a fraction of the time allocated for the template (role temporalRatio). Actually, a slot must provide information about the admissible pedagogic types of the learning objects; this can be expressed refining the Slot concept in a set of type bounded slots (see ExerciseSlot in Figure ).
The delivery planner composes the plan in the same order it will be executed using an A∗-like search algorithm. At each step, the planner chooses a template for the next concept or continues with a partially filled template.
When a template is assigned to a set of concepts, a slot expansion is necessary to take into account a multiple contents module and to manage time allocation through template inner structure. Figure shows a template Temp with two slots, S 1 and S 2 applied to the couple of contents C 1 − C 2. Temporal constraints are allocated to each slot using corresponding temporalRatio, that is, a slot S i has an admissible interval [t i = t[sdot]tr(S i );T i = T[sdot]tr(S i )]. Each slot is homogeneous w.r.t. resources type, but must be filled with resources about each content the template is applied to. Intercontents time allocation can exploit relative difficulties of each step in the content plan, allocating, the more time, the more difficult the content can be. So, for each slot S i and for each content C j , a subslot S ij is created to represent the resources inside S i that talk about C j . Subslot time constraints are calculated as follows:
FIGURE 15 Slots/subslots decomposition.
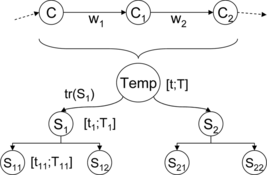
As soon as S 11 is completed, its actual allocated time t 11 can further constraint the remaining subslots reverting tree coefficients (with a tolerance δ greater than zero to preserve satisfiability).
Plan optimality must be evaluated w.r.t. a cost function in the form of f(x) = g(x) + h(x), where g(x) is the current partial plan cost and h(x) is an optimistic predictor for the rest of the plan. For simplicity we use learning time as a cost function, that is, the planner will try to reach pedagogic goals as quickly as possible. Under this assumption, g(x) is the learning time of already selected learning objects, while h(x) is the minimum time foreseen for the rest of the course. h(x) assumes each unfilled subslot S ij to be completed in t ij time units and all unmanaged content to be completed in the minimum time (calculated in a preprocessing phase combining each plan fragment with any possible template). Since f(x) is an optimistic approximation of actual time cost and is monotonic w.r.t. tree exploration it can be proven to be admissible and the planning process obtains an optimal solution.
Another issue is about learning object selection. Given that a delivery planner is working on the subslot S ij of pedagogic type P and about a content c, resource retrieval can rely on ontological reasoning executing an instance retrieval reasoning task on a query concept Q in the form Q ≡ PΠ ∃ hasTopic.{c}
CONCLUSIONS
We presented our contribution to the VICE project. Ontology engineering allows a modular design of the resource repository. A very simple application of upper ontology allows the inter-operation of the different components. Repository ontology is composed of a resource multi-taxonomy for learning object classification and a set of content ontologies that can be imported from the web. The joint ontological model is maintained, aligned with lower level data descriptions, and is used with different semantic query interfaces.
Another semantic-based service is learning object automatic sequencing. We proposed a two-level composition that works first at the content level, producing an outline of the course, and then at the resource level, filling the outline with actual resources. A massive use of semantic descriptions allows the mapping of specific domain concepts to a fixed pedagogic ontology that the planner can understand. All the actors involved in pedagogic planning have their soles in the system during content planning, while the resource planning is guided by the pedagogic-style expert only.
Notes
Content Object Reference Model http://www.imsglobal.org/
http://protege.stanford.edu/
http://jena.sourceforge.net/
Selecting N for original concept, P for the reification of the concept, and R for the whole extended concept.
http://zeus.ing.unibs.it/lpg/
Using problems and plan ontology.
Darpa agent markup language (DAML).
http://www.cs.yale.edu/homea/dvm/daml/pddldamltranslator l.html
REFERENCES
- Arrigoni Neri , M. 2005 . Ontology-based learning objects retrieval . In G. Richards , ed. Proceedings of World Conference on E-Learning in Corporate, Government, Healthcare, and Higher Education 2005 , pp. 2793 – 2798 , Vancouver , Canada . AACE .
- Arrigoni Neri , M. 2006 . Ontology-based learning objects sequencing . In Proceedings of World Conference on E-Learning in Corporate, Government, Healthcare, and Higher Education 2006 . Honolulu , Hawaii . AACE .
- Baader , F. , D. Calvanese , D. L. McGuinness , D. Nardi , and P. F. Patel-Schneider , ed. 2003a . The Description Logic Handbook: Theory, Implementation, and Applications , Cambridge : Cambridge University Press .
- Baader , F. , I. Horrocks , and U. Sattler . 2003b . Description logics as ontology languages for the semantic web . In: Festschrift in honor of Jörg Siekmann, Lecture Notes in Artificial Intelligence . eds. D. Hutter and W. Stephan , Springer, to appear .
- Bechhofer , S. 2003 . The DIG Description Logic Interface: DIG/1.1 .
- Berners-Lee , T. , J. Hendler , and O. Lassila . 2001 . The Semantic Web . Scientific American 284 ( 5 ): 34 – 43 .
- Donini , F. M. , M. Lenzerini , D. Nardi , A. Schaerf , and W. Nutt . 1998 . An epistemic operator for description logics . Artificial Intelligence 100 ( l–2 ): 225 – 274 .
- M. G. et al . 1998 . PDDL – The Planning Domain Definition Language . AIPS-98 Planning Competition Committee .
- Fischer , S. 2001 . Course and exercise sequencing using metadata in adaptive hypermedia learning systems . J. Educ. Resour. Comput. l:5. .
- Fitting , M. 1993 . Basic Modal Logics , Vol. 1 , pp. 365 – 448 . Oxford : Oxford Science Publications .
- Gruber , T. R. 1993 . Towards principles for the design of ontologies used for knowledge sharing . In: Formal Ontology in Conceptual Analysis and Knowledge Representation . eds. N. Guarino and R. Poli , The Netherlands , Kluwer Academic Publishers .
- Haarslev , V. and R. Moller . 1999 . RACE system description . In: Description Logics .
- Horrocks , I. 2002 . Reasoning with expressive description logics: Theory and practice . In: Proceedings of the 18th International Conference on Automated Deduction , pp. 1 – 15 . Springer-Verlag .
- Horrocks , I. and P. Patel-Schneider . 2004 . Reducing OWL entailment to description logic satisfiability . J. of Web Semantics.
- Horrocks , I. and U. Sattler . 2001 . Optimised reasoning for SHIQ. Technical Report LTCS-01-08, Germany. .
- Horrocks , I. , U. Sattler , and S. Tobies . 2000 . Reasoning with individuals for the description logic shiq . In: Proceedings of the 17th International Conference on Automated Deduction , pp. 482 – 496 . Springer-Verlag .
- W. C. http://www.w3.org/TR/owl ref/. OWL Web Ontology Reference. .
- IEEE . 2000 . Draft standard for learning object metadata. .
- Laurent Cimolino , A. M. and Judy Kay. 2003 . Incremental student modelling and reflection by verified concept-mapping . In: aied2003 .
- LTSC Leading technology standards committee website, http://ltsc.ieee.org, 2000. .
- Mohan , J. G. P. and G. McGalla . 2003 . Instructional planning with learning objects . In: Proc. the 18th International Joint Conference on Artificial Intelligence . Workshop on Knowledge Representation and Automated Reasoning for E-Learning Systems .
- Peachey , D. H. and G. I. McCalla . 1986 . Using planning techniques in intelligent tutoring systems . Int. J. Man-Mach, Stud. 24 ( l ): 77 – 98 .
- Sattler , U. 2003 . Description logics for ontologies . In: Proc. of the International Conference on Conceptual Structures (ICCS 2003) , Vol. 2746 : LNAI . Springer-Verlag .
- Vassileva , J. and R. Deters . 1998 . Dynamic courseware generation on the www . British journal of Educational Technologies , 1 ( 29 ): 5 – 14 .
- W3C World Wide Web Consortium . 2004 . RDF Primer. available at http://www.w3.org/TR/rdf-primer. .
- Wiley , D. A. 1999 . Learning objects and the new cai .
- Wiley , D. A. 2000 . Learning Object Design and Sequencing Theory . PhD thesis, Department of Instructional Psychology and Technology, Brigham Young University, Utah.
- Wiley , D. A. 2001 . Connecting learning objects to instructional design theory: A definition, a metaphor, and a taxonomy . In: ed. D. A. Wiley , The Instructional Use of Learning Objects , pp. 1 – 35 . Association for Educational Communications and Technology .