Abstract
In this paper, we propose a method to enhance activity recognition in complex environments, where problems like occlusions, outliers and illumination changes occur. In order to address the problems induced by the dependency on the camera's viewpoint, multiple cameras are used in an endeavor to exploit redundancies. We initially examine the effectiveness of various information stream fusion approaches based on hidden Markov models, including Student's t-endowed models for tolerance to outliers. Following, we introduce a neural network-based readjustment mechanism that fits these fusion schemes and aims at dynamically correcting erroneous classification results for image sequences, thus improving the overall recognition rates. The proposed approaches are evaluated under complex real life activity recognition scenarios, and the acquired results are compared and discussed.
INTRODUCTION
The field of event recognition and human activity modeling has been the focal point of researchers from various communities. The main reason that justifies this trend lies in the wide variety of applications linked with event detection and behavior recognition. In this paper, we focus on monitoring visually complex environments, such as the production line of an automobile manufacturer. Computer vision and machine learning algorithms attempting to effect activity recognition in complicated environments are confronted with visibility problems, occlusions, outliers, and, in some cases, low intra class and high interclass similarity of the observed activity classes. Industrial environments pose additional difficulties ranging from background clutter, frequent illumination changes, and welding flare to camera shaking and target deformations. Figure depicts typical key frames from the complex industrial environment of our use case, highlighting the challenges posed. Typical object-based methods cannot cope with the aforementioned challenges. Testing a tracker and a popular person detector both led to failure in our industrial dataset. In particular, the tracker was based on standard particle filtering and the employed features were the color histogram and the edges of the blobs corresponding to the human figure (for details, see our previous work Makris et al. Citation2007); the experiments showed that the tracker was losing the target very often. We also tested the Histogram of Oriented Gradients (HOG) person detector (Dalal and Triggs Citation2005), which achieved a maximum accuracy of 56.42% in some of the least challenging sequences of our dataset. However, despite the visually complex environment, the observed activities in the production line remain structured to a certain extent, thus making it reasonable to expect that they can be modelled using machine-learning methods.
FIGURE 1 Sequences from our industrial environment dataset. Object tracking as well as activity recognition is extremely challenging due to occlusions, low resolution, and high intraclass and low interclass variance. The first two rows depict two different activities that are executed during the production cycle: their resemblance is so high, that they would be difficult to distinguish even for the human eye; the third row shows some example frames of occlusions, outliers, sparks, abnormalities, etc. (Figure is provided in color online.)

In this context, the need arises to bypass the error-prone detection and tracking algorithms (Doulamis Citation2010) by relying on appropriate holistic features for scene representation. Moreover, exploiting the wider scene coverage provided by multiple viewpoints (which are often available in monitoring applications) may conduce to occlusion solving; on the other hand, endowing time series classifiers with outlier-tolerant characteristics can increase robustness. Finally, exploiting an expert user's feedback on a small part of the video sequences through a relevance feedback-inspired approach can minimize classification error.
Considering the above, our work contributes to the solution of activity recognition by proposing an approach for further improving the supplied results after holistic scene representation, robust classification based on outlier-tolerant hidden Markov models (HMMs), and multi-camera fusion; this method allows interaction with the user, who may provide relevance feedback in part of the data. The proposed approach is based on a neural network and early, as well as late, fusion feedback schemes are investigated.
The remainder of this paper is structured as follows. After discussing related work regarding activity recognition as well as relevance feedback, the paper focuses on robust multi-camera HMM based activity modeling. Following that, we analyze the neural network-based rectification mechanism, which readjusts the classification probabilities provided by the HMM, and we introduce a novel “fusion” approach. Subsequently, the experimental validation is detailed, and results are reported and discussed. Finally, the paper concludes with a summary of the findings.
RELATED WORK
Event detection, as well as human action and activity recognition have been the focus of interest of the computer vision community for years. A variety of methods has addressed these problems, including semilatent topic models (Wang and Mori Citation2009), spatial-temporal context (Hu et al., Citation2010), optical flow and kinematic features (Ali and Shah Citation2010), and random trees and Hough transform voting (Yao, Gall, and Vangool 2010). Wada and Matsuyama (Citation2000) employ a nondeterministic finite automaton as a sequence analyzer to present an approach for multiobject behavior recognition based on behavior-driven selective attention. Other works focus on more specific domains, e.g., event detection in sports (Huang and Hsieh 2008), retrieving actions in movies (Laptev and Perez Citation2007), and automatic discovery of activities (Hamid et al. Citation2007). Models might be previously trained and kept fixed (Wang et al. Citation2008; Antonakaki, Kosmopoulos, and perantonis Citation2009) or adapt over time (Breitenstein, Grabner, and Van Gool 2009) to cope with changing conditions. A broad variety of image feature extraction methods are used, such as global scene 3D motion (Padoy et al. Citation2009), object trajectories (Johnson and Hogg Citation1996) or other object-based approaches (Fusier et al. Citation2007), which require accurate detection and tracking. Other machine learning and statistical methods that have been used for activity recognition include clustering (Boiman and Irani Citation2005) and density estimation (Johnson and Hogg Citation1996). A very popular approach is HMMs (e.g., Ivanov and Bobick Citation2000; Padoy et al. Citation2009), due to the fact that they can efficiently model stochastic time series at various time scales. An alternative approach to the HMM for the analysis of complex dynamical systems is the Echo State Networks (ESNs) (see, e.g., Jaeger, Maass and Principe 2007). ESNs have been recently used for industrial activity recognition in workflows using part of the same dataset that we are using (Veres et al. Citation2010). A limitation of ESNs is that all significant variations of activity order in a given workflow have to be learnt in order to provide good classification results. As will be shown in the experimental section through comparisons, our approach outperforms ESN-based methods. Other approaches for industrial activity recognition have also been proposed, involving sensors and wearable computing (e.g., Stiefmeier et al. Citation2008). A recent comprehensive literature review regarding action and activity recognition can be found in (Poppe Citation2010).
As far as multiple cameras are concerned, the work that investigates fusion of time series resulting from holistic image representation is limited. Some typical approaches seek to solve the problem of position or posture extraction in 3D or on ground coordinates (see, e.g., Antonakaki, Kosmopoulos, and Perantonis 2009; Lao Citation2009). However, camera calibration or homography estimation is required, and in most cases there is still dependency on tracking or on extraction of foreground objects and their positions, which can be easily corrupted by illumination changes and occlusions. Later in the paper, several fusion schemes using HMMs are discussed, and their applicability to our scenario is scrutinized.
The neural network-based rectification framework has been inspired by relevance feedback. Relevance feedback is a common approach for automatically adjusting the response of a system with regard to information taken from the user's interaction (Doulamis and Doulamis Citation2006). Originally, it had been developed in traditional information retrieval systems (Rocchio Citation1971), but it has now been extended to other applications, such as surveillance systems (Oerlemans, Rijsdam, and Law 2007; Zhang et al. Citation2010). Relevance feedback is actually an online learning strategy that reweights important parameters of a procedure in order to improve its performance. Reweighting strategies can be linear or nonlinear relying either on heuristic or optimized methodologies. Linear and heuristic approaches usually adjust the degree of importance of several parameters that are involved in the selection process. On the contrary, nonlinear methods adjust the applied method itself using function approximation strategies (Doulamis Citation2005). In this direction, neural network models have been introduced as nonlinear function approximation systems (Doulamis, Doulamis, and Kollias Citation2000). A comprehensive review regarding algorithms of relevance feedback in image retrieval has been provided in (Zhou and Huang Citation2003). In this paper, the authors lay emphasis on comparing different techniques of relevance feedback with respect to the type of training data, the adopted organization strategies, the similarity metrics used, the implemented learning strategies, and the effect of negative samples in the training performance. However, such approaches have been applied mostly in information retrieval systems instead of event recognition or surveillance applications. In information retrieval systems, a query object (image) is compared against a set of stored objects (images), and the time dimension is not present, whereas activity recognition is accomplished by taking into consideration the “time variation” of the features of several image frames.
ACTIVITY MODELING VIA HIDDEN MARKOV MODELS AND MULTI-CAMERA FUSION
On the basis of the activity recognition framework lies the extraction of holistic visual features at the image level; these features are further used to associate events and activities with temporal patterns. The extracted information is modeled by employing HMMs, which constitute a popular methodology for sequential data modeling (Rabiner Citation1989), while also offering the possibility to exploit redundancies stemming from multiple streams through the utilization of HMM-based information fusion schemes.
Visual Observations
As was already mentioned, using holistic image-based features, we obviate the need for successful detection and tracking, which are particularly difficult in complex environments. The features we used are calculated as follows: First we perform backgroundsubtraction. We use the foreground regions to represent the multiscale spatio-temporal changes at pixel level, using the pixel change history (PCH), which is defined as (Xiang and Gong Citation2006):
To represent the resulting PCH images, we propose use of Zernike moments. The complex Zernike moments of order p (see, e.g., Mukundan and Ramakrishnan Citation1998) are defined as:
Using HMMs for Activity Modeling
An HMM entails a Markov chain comprising a number of N states, with each state being coupled with an observation emission distribution. An HMM defines a set of initial probabilities for each state, and a matrix A of transition probabilities between states; each state is associated with a number of observations o (input vectors). Gaussian mixture models are typically used for modeling the observation emission densities of the hidden states. Typically, HMMs are trained under the maximum-likelihood framework, by means of the Expectation-Maximization (EM) algorithm (Rabiner Citation1989). The HMM model size, i.e., the number of constituent states and mixture components, can affect model performance and efficiency; for this reason, several criteria have been proposed for the purpose of data-driven HMM model selection, (e.g., Ostendorf and Singer Citation1997). However, for systems that are expected to operate in nearly realtime, small models are generally preferable, because of their low number of parameters, hence easier learning, and considerably less computational burden for sequential data classification.
Outliers are expected to appear in model training and test datasets obtained from realistic monitoring applications as a result of illumination changes, unexpected occlusions, unexpected task variations, etc., and could seriously corrupt training results. For this, we propose the integration of the Student's t-distribution in our models. The probability density function (pdf) of Student's t-distribution with mean vector μ, positive definite inner product matrix Σ, and ν degrees of freedom is given by:
Modifying ν enables including outliers in the pdf without corrupting the model. This additional degree of freedom can model heavier tails, which is not possible for the Gaussian, which is a special case of Student's t for ν → ∞. A detailed presentation on how to learn ν as well as experimental argumentation for the robustness of Student's t-distribution-based HMM can be found in Chatzis, Kosmopoulo, and Varvaridgou 2009).
Exploiting Redundancies via Multicamera Fusion
In the cases of complex environments, which are examined in this paper, the vulnerability to occlusions is significant, thus highlighting the dependency on the camera viewpoint. Deploying multiple cameras with partly overlapping views and exploiting the redundancies can help solve occlusions and increase robustness. Each camera input provides a different stream of observations. These streams can be combined by means of information fusion techniques, to exploit the complementarity of the different views. Here we will examine the most popular HMM fusion approaches, analyze their characteristics and applicability (which will be experimentally verified in the HMM-Based Recognition Results subsection), and propose certain adaptations to increase tolerance to outliers.
In the state-synchronous HMM (Dupont and Luettin Citation2000; Figure (a)); the streams are assumed to be synchronised. Each stream is modeled using an individual HMM; the postulated streamwise HMMs share the same state dynamics (identical states, state priors, transition matrices, component priors). Then, the likelihood for one observation is given by the product of the observation likelihood of each stream c raised to an appropriate positive stream weight r c (Dupont and Luettin Citation2000):
FIGURE 2 HMM-based fusion approaches for streams. Symbols s and o stand for states and observations, respectively. The first index indicates the stream and the second the time. (Figure is provided in color online.)
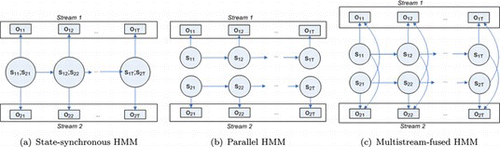
Nevertheless, the assumption of synchronized data can be rather confining when attempting activity recognition in real-world applications. The parallel HMM (Vogler and Metaxas Citation1999; Figure (b)) is an alternative that assumes that the streams are independent of each other. A separate HMM for each stream can be therefore trained in the typical way. The parallel HMM can be applied to cameras or other sensors that may not necessarily be synchronized and may operate at different acquisition rates. Similar to the synchronous case, each stream c may have its own weight r
c
, depending on the reliability of the source. Classification is performed by selecting the class that maximizes the weighted sum of the classification probabilities from the streamwise HMMs, i.e., class assignment is conducted by picking the class with
, where λ
cl
are the parameters of the postulated streamwise HMM of the c
th
stream that corresponds to the l
th class. As can be inferred by the described architecture, a major drawback that plagues the parallel HMM lies in its tendency to neglect any dependencies on the state level between the observation streams.
To this end, several architectures attempting to address this issue have been proposed in the literature, such as the coupled HMM (Nefian et al. Citation2002; Brand, Oliver, and Pentland Citation1997) and the multistreamed fused HMM (Zeng et al. Citation2008). Brand, Oliver, and Pentland (1997) couple the current state of one stream with the previous of the other (assuming two streams), while Zeng et al. (Citation2008) couple the current state of one stream to the current of the other, which is a stronger and more intuitive condition and unlike Brand, Oliver, and Pentland Citation1997) does not necessitate approximations, which inevitably sacrifice some crucial information. Focusing on multistream fused HMM (Figure (c)), the connections between the component stream-wise HMMs of this model are chosen based on a probabilistic fusion model, which is optimal according to the maximum entropy principle and a maximum mutual information criterion for selecting dimension-reduction transforms. Specifically, if we consider a set of multistream observations with
and
, the multistream-fused HMM models this data based on the fundamental assumption:
Similar to the case of parallel HMMs, the class that maximizes the weighted sum of the log-likelihoods over the streamwise models is the winner. Experimental verification of the suitability of the described fusion schemes for activity recognition, as wellas related comparisons will be discussed in a following section.
A RECTIFICATION SCHEME BASED ON A FEEDFORWARD NEURAL NETWORK
In this section, we propose a rectification scheme that exploits the expert user's feedback on the classification provided by the HMM framework in part of the footage, so as to enhance future classification results.
Let us denote as S a set that contains the selected samples by the expert user. The set S = { … (p
i
, d
i
) … } contains pairs of the form (p
i
, d
i
), where, as p
i
, we indicate the observation probability vector, generated by the HMM, the elements of which express the probability of the corresponding frame to belong to one of the, say, M available classes. Vector d
i
indicates the ideal probabilities for the i
th
sample. Variable d
i
is an indicator vector, meaning that all its elements will be zero apart from one, which is equal to one. This element indicates the class that this task belongs to. Assuming the existence of a nonlinear function able to correct the erroneous classifications of the HMM, we can derive: d
i
=
f
(p
i
) where
f
(·) is an unknown vector function indicating the nonlinear relationship between p
i
and d
i
. The nonlinear relationship dynamically changes under different conditions and camera system modifications. To address the aforementioned difficulties, we introduce a feedforward neural network model that is able to accurately approximate the unknown vector function
f
(·) with a certain degree of accuracy. In this case, the previous equation is now written as: . The difference between the two equations is the introduction of the vector weight w. This means that different parameters (weights) of the network yield different performances of the adaptable classifier. Vector w includes all the parameters (weights) of the nonlinear neural network-based classifier.
To estimate the weights w, we need to apply a training algorithm that actually minimizes the mean square error among all data (task sequences) selected from the expert user and the respective output of the network when a particular set of weights is applied. That is, .
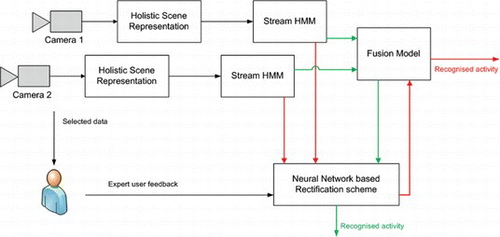
The back propagation algorithm can provide a solution to this nonlinear minimization problem. In our experiments, we select a small neural network structure of few hidden neurons and one hidden layer. In this case, we try to minimize the number of neural networks parameters, i.e., the size of weight vector w. It is clear that the samples of the training set S should be greater than the number of neural network parameters, that is, the dimension of the weight vector w. Nevertheless, because the size of the neural network is small, few training samples are required. The readjusted probabilities extracted as output of the neural network testing process are used as a basis for enhanced activity recognition by means of selecting the activity yielding the maximum probability in each case. The approach described here is graphically depicted by the green arrow path in Figure , which gives a schematic overview of the proposed framework. Here, the neural network rectifies the “combined” probabilities extracted from the fused HMM. In the following subsection we introduce a novel approach for integrating the neural network-based rectification mechanism into the fusion model.
FIGURE 3 Schematic overview: The neural network-based rectification mechanism is examined under two different approaches (corresponding to the green and red paths, respectively). The green approach rectifies the fused result produced by the fused HMM, whereas the red one performs streamwise rectification and in the sequel the rectified streams are fused (RDFHMM). (Figure is provided in color online.)
Integrating Neural Network-Based Rectification into the Fusion Model
In addition to utilizing the readjusted likelihoods provided by the neural network as the basis from which to select the winner class for every activity, we hereby propose an adaptation to the aforementioned parallel HMM fusion scheme, which incorporates the rectified probabilities. This approach corresponds to the red arrow path in Figure , where the neural network rectifies the streamwise probabilities, which are subsequently fused.
We assume that the probabilities extracted by the individual streamwise HMM frameworks are fed into the rectification mechanism. As a consequence, readjusted probabilities corresponding to the two streamwise models are generated. Let P
NN
(o
1 … o
T
|λ
cl
, n
c
)]) be the readjusted probability generated as output from the neural network, where λ
cl
are the parameters of the postulated streamwise HMM of the c
th
stream that corresponds to the l
th
class, and n
c
are the parameters of the neural network that corresponds to the c
th
stream. In this proposed rectification-driven fused HMM (RDFHMM) fusion model, class assignment is conducted by picking the class with:
EXPERIMENTAL VALIDATION
We experimentally validated the proposed methods with video sequences obtained from a real assembly line of an automobile manufacturer. The workflow on this line included picking several parts from racks and placing them on a designated welding cell. Each of the above activities/tasks was regarded as a class of behavioral patterns that had to be recognized. Two cameras with partially overlapping views were used. We evaluated the overall efficiency of the proposed system, as well as the framework's different alternative constituent components.
Experimental Setup
The workspace configuration and the cameras' positioning are depicted in Figure . According to the manufacturing requirements each workflow consists of the following seven activities/tasks, which are not necessarily executed sequentially:
Task 1: A part from Rack 1 (upper) is placed on the welding spot by worker(s). | |||||
Task 2: A part from Rack 2 is placed on the welding spot by worker(s). | |||||
Task 3: A part from Rack 3 is placed on the welding spot by worker(s). | |||||
Task 4: Two parts from Rack 4 are placed on the welding spot by worker(s). | |||||
Task 5: A part from Rack 1 (lower) is placed on the welding spot by worker(s). | |||||
Task 6: A part from Rack 5 is placed on the welding spot by worker(s). | |||||
Task 7: Worker(s) grab(s) the welding tools and weld the parts together. | |||||
FIGURE 4 Depiction of workcell together with the position of the cameras and racks #1–5. (Figure is provided in color online.)
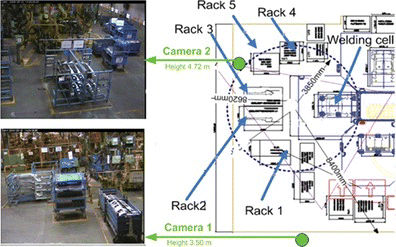
Two datasetsFootnote 1 (Voulodimos et al. Citation2011) were used for the experiments. Each dataset contains 20 segmented sequences representing full assembly cycles/workflows. In each workflow, all seven activities are performed, but not necessarily in the same order. The total number of frames was approximately 80,000 per camera for each dataset. Challenges of the two datasets include occlusions, visually complex background, similar colors, high intraclass and low interclass variance. In dataset-1, the assembly process was rather well structured and was performed strictly by two people. Noisy objects were present (other persons or vehicles) but not particularly often. In dataset-2 the assembly process was modified in that a third person was present quite often in the scene, performing tasks in parallel to the tasks executed by the other two workers. Dataset-2 is therefore far more challenging because the workers' body silhouettes got overlayed in a random fashion, thus making the motion signatures (i.e., the trajectories of their movements), much more difficult to model. Moreover, variable task durations and overlapping phenomena were far more exacerbated in comparison to dataset-1. The annotation of the datasets was done manually. Synchronization of the employed IP-cameras was approximate by exploiting the server-generated timestamps.
Holistic Scene Representation
We have used the Zernike moments up to sixth order (excluding four angles that were always constant), along with the center of gravity and the area, thus having a good scene reconstruction without too high a dimension (31). This choice provided a good trade-off between representation quality and real-time performance requirements (higher-order moments would require much more computational resources). Limiting the order of moments used was also justified by the fact that the details captured by higher-order moments have much higher variability and are more sensitive to noise. For capturing the spatio-temporal variations we have set the parameters at ς = 10 and τ = 70, which were defined by the duration of motion that we wanted to capture, and are application specific. Zernike moments have been calculated in rectangular regions of interest of approximately 15,000 pixels in each image, to limit the processing and allow real-time feature extraction. The processing was performed at approximately 50–60 fps.
Fused HMM-Based Classification
The models were trained using the EM algorithm. We used the typical HMM model for the individual streams as well as state-synchronous, parallel, and multistream-fused HMMs. We have experimented with the Gaussian and the Student's t-distribution. All experimental variations were performed on both dataset-1 and dataset-2, thus making a total of 20 different experimental setups. We used three-state HMMs with a single mixture component per state to model each of the seven tasks described above, which is a good trade-off between performance and efficiency. For the mixture model representing the interstream interactions in the context of the multistream-fused HMM, we used mixture models of two component distributions. Full covariance matrices were employed for the observation models. The stream weights r c in the fusion models, as well as the weights r cl in the case of RDFHMM, were selected according to the reliability of the individual streams, that is in proportion to the classification accuracy attained by the respective single-stream HMM. For each dataset, ten work cycles were used for training of the HMMs and the other ten were used for testing.
Neural Network-Based Rectification
In this phase an expert user selected a set of training samples. These samples were represented using the respective probability vector, as extracted by the HMM framework, and the targeted correct classification of this task. Following, a feed forward neural network model was trained so as to adjust the probabilities extracted by the HMM framework to minimize the erroneous classifications. The structure of the feed foward neural network was selected to be small. In particular, we selected a feed forward neural network with one hidden layer and 15 neurons in this layer. It had 7 input nodes and 7 output nodes (as many as the number of activities). The transfer function was the sigmoid. In these experiments of the second phase, the samples belonging to three work cycles were selected to form the training set, and the remaining were used for testing.
RESULTS
We evaluated the overall efficiency of the proposed system, as well as the framework's different alternative constituent components. For a quantitative evaluation, we used recall-precision metrics. Recall corresponds to the number of true positives divided by the total number of positives in the ground truth, whereas precision equals the number of true positives divided by number of true and false positives. The F-measure is the harmonic mean of these two measurements. The measurements presented were averaged across all test sequences per experimental setup.
HMM-Based Recognition
Table shows the obtained results from the HMM-based approaches for dataset-1 and dataset-2.
TABLE 1 Results Obtained from Dataset-1 and Dataset-2 Using (1) Individual HMMs to Model Information from Stream 1 (HMM1); (2) Individual HMMs to Model Information from Stream 2 (HMM2); (3) State-Synchronous HMMs (SYNC); (4) Parallel HMMs (PARAL); and (5) Multistream-Fused HMMs (MULTI) with (a) Gaussian and (b) Student's -distribution as Observation Likelihood
Dataset-1 vs. Dataset-2
As a first observation, the employed holistic features and HMM based frameworks represented rather well the assembly process. The classification rates attained in dataset-1 were very high, considering the complexity of the environment. The representation capability of PCH based features proved very satisfactory for dataset-1. As expected, success rates in dataset-2 were lower, which can be explained by the far more relaxed structure in the activities performed, the randomly overlayed silhouettes and all the special challenges described above. However, these results were still rather satisfactory for such a difficult dataset and constituted a good base for the rectification mechanism to follow.
Single Stream vs. Fusion Approaches
The results indicated that the individual HMM corresponding to camera 2 (HMM2) tended to yield better recognition rates than HMM1, which can be explained by the generally better viewpoint of the former. The confusion matrices in Figure display the impact of the complementarity of the views on the results as well as the successful exploitation of this fact in the case of multistream-fused HMM. For example, camera 2 offered a more favorable viewpoint for discerning task 1 from task 5, whereas camera 1 provided a better angle for recognizing task 4.
FIGURE 5 Confusion matrices from dataset-1 for (a) individual HMM for camera 1, (b) individual HMM for camera 2 and (c) multistream-fused HMM, using Student's t -distribution. (Figure is provided in color online.)
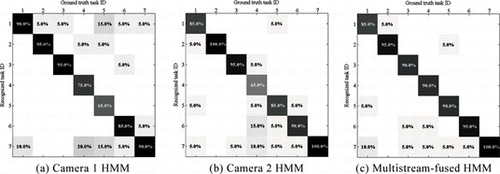
A careful evaluation of the results shown in Table leads to the conclusion that information fusion provides significant added value when implemented in the form of multistream-fused HMM. In all experimental setups, the multistream-fused approach outperformed the better of two individual streamwise models in terms of recall and precision by up to 6.2%. This improvement can be put down to the multistream-fused model's capability of capturing the state interdependencies, without assuming strict synchronicity. The parallel HMM approach provided slightly inferior or slightly superior success rates (depending on the experimental setup) in comparison to the best individual streamwise model. This approach considers the streams to be totally asynchronous and is thus unable to make use of state interdependencies. On the other hand, recall and precision rates deteriorated when assuming perfect synchronicity by employing the state-synchronous approach, reflecting the fact that our cameras were indeed not perfectly synchronized.
Gaussian vs. Student's t
Using Student's t-distribution instead of the conventional Gaussian as a predictive function of the HMMs additionally increased recognition rates to a certain extent (ranging from 1.4% up to 11.4%). The contribution was more apparent in the experiments of dataset-2 (Table ), where the amount of noise was greater, thus proving the usefulness of Student's t-distribution in enhancing the robustness to outliers in activity recognition from video streams.
Neural Network-Based Rectification Results
Table contains the results acquired after employing the rectification mechanism. Comparing the measures in Table with the respective results of Table , we notice that the proposed rectification scheme provides a substanstial improvement. Recall, precision, and F-measure were all significantly increased compared with the respective experimental setups when no neural network-based readjustment was performed. As expected, multistream-fused HMM supplemented with the rectification mechanism provided the best results among the approaches that rectify the fused results, because it was also the best performing approach when standing alone. However, we observe that our proposed RDFHMM, which first readjusts the streamwise probabilities before feeding them into the adapted fusion model, yielded the best results, slightly outperforming MFHMM+RM, with recall rates of up to 95% and 79.8% for datasets 1 and 2, respectively.
TABLE 2 Results Obtained from Dataset-1 and Dataset-2 After Applying the Rectification Mechanism (RM) Using (1) Individual HMMs to Model Information from Stream 1 (HMM1); (2) Individual HMMs to Model Information from Stream 2 (HMM2); (3) State-Synchronous HMMs (SYNC); (4) Parallel HMMs (PARAL); (5)Multistream-Fused HMMs (MULTI); and (6) Rectification-Driven Fused HMM (RDFHMM) with (a) Gaussian and (b) Student's -distribution as Observation Likelihood
Comparing our results with those of Veres et al. (Citation2010; the results presented therein concern camera 1 from dataset-1) we observe that the streamwise HMM1 (Student's t) method outperforms the ESN-based approach both in terms of recall and precision. The difference in performance increases when considering multistream fusion or rectification. We also experimented with ESN using the features described here, so as to compare the performance of our methods in both datasets. To this end, we used a network of 500 nodes, which was efficient for real-time execution and avoided over fitting. It had seven output nodes, each one corresponding to a predicted task. The median of the last 101 estimations was taken to ensure lower jitter in the output. We have used the Matlab toolbox provided by Jaeger, Maass, and Principe Citation2007) after parameters' optimization using trial and error. The F-measures were 80.3% and 82.6% (camera 1 and 2) for dataset-1, and 60.5% and 57.3% (camera 1 and 2) for dataset-2, i.e., comparable to the respective single-stream HMM. However, employing the existing HMM-based fusion schemes as well as exploiting user feedback through rectification (even better through RDFHMM) can lead to significant improvement of performance.
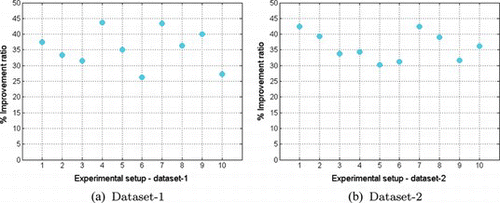
Figures (a) and 6(b) display the % classification error for all experimental setups with and without the rectification mechanism for datasets 1 and 2, respectively. The improvement ratio (in terms of % error decrease) in relation to the sole use of the HMM-based approaches is depicted in Figures (a) and 7(b). Clearly, rectification significantly enhanced the performance of the proposed framework, especially when implemented in the form of the proposed RDFHMM.
FIGURE 6 Classification error % with and without the rectification mechanism for all experimental setups: 1. HMM1-Gauss, 2. HMM1-Student-t, 3. HMM2-Gauss, 4. HMM2-Student-t, 5. SYNC-Student-t, 6. SYNC-Student-t, 7. PARAL-Gauss, 8. PARAL-Student-t, 9. MULTI-Gauss, 10. MULTI-Student-t, 11. RDFHMM-Gauss, 12. RDFHMM-Student-t, (11 & 12 have no corresponding nonrectified setup). (Figure is provided in color online.)
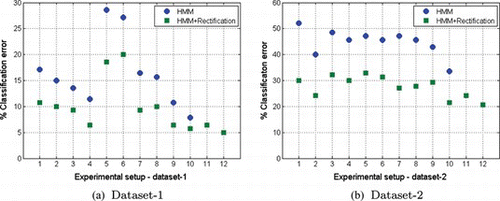
FIGURE 7 Improvement ratio % in terms of error for all experimental setups: 1. HMM1-Gauss, 2. HMM1-Student-t, 3. HMM2-Gauss, 4. HMM2-Student-t, 5. SYNC-Gauss, 6. SYNC-Student-t, 7. PARAL-Gauss, 8. PARAL-Student-t, 9. MULTI-Gauss, 10. MULTI-Student-t, (above mentioned 11 & 12 have no corresponding non-rectified set-up therefore no improvement rate can be calculated). (Figure is provided in color online.)
CONCLUSION
In this work, we have presented a framework for activity recognition in complex environments, such as the production line of an industrial plant, which, although visually complicated, remains a structured process. The extraction of holistic features to bypass tracking, the employment of Student's t-distribution and multicamera fusion can address the challenges involved. However, all these together may be further improved by a rectification mechanism. Inspired by relevance feedback, this mechanism is based on a nonlinear classification scheme that aims to readjust the probabilities of the stochastic models (such as the HMM and its fused versions) according to a set of data selected by an expert user through an interactive framework. The nonlinear rectification is accomplished using a feedforward neural network model that takes as input the classification probabilities of the stochastic models and generates as output the adjusted probabilities. We differentiate between two approaches. Inthe first, the rectification mechanism readjusts the probabilites stemming from the fused stochastic model and produces the final activity recognition decision; in the second, the rectification mechanism readjusts the streamwise probabilities and feeds its output to the proposed rectification driven fused HMM (RDFHMM), which fuses the readjusted probabilites and extracts the recognized activity.
We have tested the proposed methodology in very challenging datasets from a real production line of an automobile industry. esearch. The results illustrate significant improvement when applying the rectification mechanism, whereas the proposed RDFHMM yields the best recognition rates. Regarding the practical implications of our results, the demonstrated experiment concerns real industrial workflows without any sort of environment engineering. So far, no assumptions have been made about occlusions, illumination changes, or workers motion, etc., so the setting is very challenging. The recognition rate is not expected to be perfect using the proposed method under such conditions. For accuracy that approximates 100% we would need to apply some additional constraints in the monitored scene, e.g., controlled illumination, enforced paths to workers, controlled timing for tasks, etc. The application of such constraints is not unusual in production environments, and if they are adopted it would be realistic to expect nearly perfect performance because the repeatability of the tasks would be much higher.
As future research, we plan to exploit adaptive neural network models in order to recursively readjust the classification probabilities during the activity execution and to investigate dynamic methods for readjusting the learning process of the involved stochastic models.
Notes
The datasets are publicly available on http://www.scovis.eu.
REFERENCES
- Ali , S. , and M. Shah . 2010 . Human action recognition in videos using kinematic features and multiple instance learning . IEEE Transactions on Pattern Analysis and Machine Intelligence 32 ( 2 ): 288 – 303 .
- Antonakaki , P. , D. Kosmopoulos , and S. Perantonis . 2009 . Detecting abnormal human behaviour using multiple cameras . Signal Processing 89 ( 9 ): 1723 – 1738 .
- Boiman , O. , and M. Irani . 2005 . Detecting irregularities in images and in video. In Proceedings of the 10th IEEE international conference on computer vision (ICCV) 2005, Volume 1: 462–469.
- Brand , M. , N. Oliver , and A. Pentland . 1997 . Coupled hidden markov models for complex action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) 1997, 994–999.
- Breitenstein , M. , H. Grabner , and L. Van Gool . 2009 . Hunting nessie - real-time abnormality detection from webcams. In Proceedings of the 12th IEEE international conference on computer vision workshops (ICCV Workshops) 2009, 1243–1250.
- Chatzis , S. P. , D. I. Kosmopoulos , and T. A. Varvarigou . 2009 . Robust sequential data modeling using an outlier-tolerant hidden markov model . IEEE Transactions on Pattern Analysis and Machine Intelligence 31 ( 9 ): 1657 – 1669 .
- Dalal , N. , and B. Triggs . 2005 . Histograms of oriented gradients for human detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) 2005, 886–893.
- Doulamis , A. 2005. Knowledge extraction in stereo video sequences using adaptive neural networks. Intelligent multimedia processing with soft computing , 235–252. Springer Berlin : Heidelberg.
- Doulamis , A. 2010 . Dynamic tracking re-adjustment: A method for automatic tracking recovery in complex visual environments . Multimedia Tools and Applications 50 ( 1 ): 49 – 73 .
- Doulamis , N. , and A. Doulamis . 2006 . Evaluation of relevance feedback schemes in content-based in retrieval systems . Signal Processing: Image Communication 21 ( 4 ): 334 – 357 .
- Doulamis , N. , A. Doulamis , and S. Kollias . 2000 . Nonlinear relevance feedback: improving the performance of content-based retrieval systems. In Proceedings of the IEEE international conference on multimedia and expo (ICME) 2000, Vol. 1, 331–334.
- Dupont , S. , and J. Luettin . 2000 . Audio-visual speech modeling for continuous speech recognition . IEEE Transactions on Multimedia 2 ( 3 ): 141 – 151 .
- Fusier , F. , V. Valentin , F. Bremond , M. Thonnat , M. Borg , D. Thirde , and J. Ferryman . 2007 . Video understanding for complex activity recognition . Machine Vision and Applications 18 : 167 – 188 .
- Hamid , R. , S. Maddi , A. Bobick , and M. Essa . 2007 . Structure from statistics – unsupervised activity analysis using suffix trees. In Proceedings of the 11th IEEE international conference on computer vision (ICCV) 2007, 1–8.
- Hu , Q. , L. Qin , Q. Huang , S. Jiang , and Q. Tian . 2010 . Action recognition using spatial-temporal context. In Proceedings of the 20th international conference on pattern recognition (ICPR) 2010, 1521–1524.
- Hung , M. H. , and C. H. Hsieh . 2008 . Event detection of broadcast baseball videos . IEEE Transactions on Circuits and Systems for Video Technology 18 ( 12 ): 1713 – 1726 .
- Ivanov , Y. , and A. Bobick . 2000 . Recognition of visual activities and interactions by stochastic parsing . IEEE Transactions on Pattern Analysis and Machine Intelligence 22 ( 8 ): 852 – 872 .
- Jaeger , H. , W. Maass , and J. Principe . 2007 . Special issue on echo state networks and liquid state machines . Neural Networks 20 ( 3 ): 287 – 289 .
- Johnson , N. , and D. Hogg . 1996 . Learning the distribution of object trajectories for event recognition . Image and Vision Computing 14 ( 8 ): 609 – 615 .
- Lao , W. , H. J. D. W. P. 2009 . Automatic video-based human motion analyzer for consumer surveillance system . IEEE Transactions on Consumer Electronics 55 ( 2 ): 591 – 598 .
- Laptev , I. , and P. Perez . 2007 . Retrieving actions in movies. In Proceedings of the 11th IEEE international conference on computer vision (ICCV) 2007, 1–8.
- Makris , A. , D. Kosmopoulos , S. Perantonis , and S. Theodoridis . 2007 . Hierarchical feature fusion for visual tracking. In Proceedings of the IEEE international conference on image processing (ICIP) 2007, VI: 289–292.
- Mukundan , R. , and K. R. Ramakrishnan . 1998 . Moment functions in image analysis: Theory and applications . New York , NY : World Scientific .
- Nefian , A. , L. Liang , X. Pi , L. Xiaoxiang , C. Mao , and K. Murphy . 2002 . A coupled hmm for audio-visual speech recognition. In Proceedings of the IEEE international conference on acoustics, speech, and signal processing (ICASSP) 2002, Vol. 2, II –II.
- Oerlemans , A. , J. T. Rijsdam , and M. S. Lew . 2007 . Real-time object tracking with relevance feedback. In Proceedings of the 6th ACM international conference on image and video retrieval (CIVR) 2007, 101–104.
- Ostendorf , M. , and H. Singer . 1997 . HMM topology design using maximum likelihood successive state splitting . Computer Speech & Language 11 ( 1 ): 17 – 41 .
- Padoy , N. , D. Mateus , D. Weinland , M.-O. Berger , and N. Navab . 2009 . Workflow monitoring based on 3d motion features. In Proceedings of the 12th IEEE international conference on computer vision workshops (ICCV Workshops) 2009, 585–592.
- Poppe , R. 2010 . A survey on vision-based human action recognition . Image and Vision Computing 28 ( 6 ): 976 – 990 .
- Rabiner , L. R. 1989 . A tutorial on hidden Markov models and selected applications in speech recognition . Proceedings of the IEEE 77 ( 2 ): 257 – 286 .
- Rocchio , J. J. 1971 . Relevance feedback in information retrieval . In The smart retrieval system – Experiments in automatic document processing . Englewood Cliffs , NJ : Prentice-Hall .
- Stiefmeier , T. , D. Roggen , G. Troster , G. Ogris , and P. Lukowicz . 2008 . Wearable activity tracking in car manufacturing . IEEE Pervasive Computing 7 ( 2 ): 42 – 50 .
- Veres , G. , H. Grabner , L. Middleton , and L. V. Gool . 2010. Automatic workflow monitoring in industrial environments. In Proceedings of the Asian conference on computer vision (ACCV) 2010, 200–213.
- Vogler , C. , and D. Metaxas . 1999 . Parallel hidden Markov models for American sign language recognition. In Proceedings of the 7th IEEE international conference on computer vision (ICCV) 1999, 116–122.
- Voulodimos , A. , D. Kosmopoulos , G. Vasileiou , E. Sardis , A. Doulamis , V. Anagnostopoulos , C. Lalos , and T. Varvarigou . 2011 . A dataset for workflow recognition in industrial scenes. In Proceedings of the 18th IEEE international conference on image processing (ICIP) 2011, 3310–3313.
- Wada , T. , and T. Matsuyama . 2000 . Multiobject behavior recognition by event driven selective attention method . IEEE Transactions on Pattern Analysis and Machine Intelligence 22 ( 8 ): 873 – 887 .
- Wang , X. , K. T. Ma , G.-W. Ng , and W. Grimson . 2008 . Trajectory analysis and semantic region modeling using a nonparametric bayesian model. In IEEE conference on computer vision and pattern recognition (CVPR) 2008, 1–8.
- Wang , Y. , and G. Mori . 2009 . Human action recognition by semilatent topic models . IEEE Transactions on Pattern Analysis and Machine Intelligence 31 ( 10 ): 1762 – 1774 .
- Xiang , T. , and S. Gong . 2006 . Beyond tracking: modelling activity and understanding behaviour . International Journal of Computer Vision 67 : 21 – 51 .
- Yao , A. , J. Gall , and L. Van Gool . 2010 . A Hough transform-based voting framework for action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) 2010, 2061–2068.
- Zeng , Z. , J. Tu , B. Pianfetti , and T. Huang . 2008 . Audio-visual affective expression recognition through multistream fused HMM . IEEE Transactions on Multimedia 10 ( 4 ): 570 – 577 .
- Zhang , C. , W. B. Chen , X. Chen , L. Yang , and J. Johnstone . 2010 . A multiple instance learning and relevance feedback framework for retrieving abnormal incidents in surveillance videos . Journal of Multimedia 5 ( 4 ): 310 – 321 .
- Zhou , X. S. , and T. S. Huang . 2003 . Relevance feedback in image retrieval: A comprehensive review . Multimedia Systems 8 ( 6 ): 536 – 544 .