
Abstract
This study proposes a variation immunological system (VIS) algorithm with radial basis function neural network (RBFN) learning for function approximation and the exercise of industrial computer (IC) sales forecasting. The proposed VIS algorithm was applied to the RBFN to execute the learning process for adjusting the network parameters involved. To compare the performance of relevant algorithms, three benchmark problems were used to justify the results of the experiment. With better accuracy in forecasting, the trained RBFN can be practically utilized in the IC sales forecasting exercise to make predictions and could enhance business profit.
INTRODUCTION
Traditionally, time series forecasting dominates financial market prediction, which tries to create linear prediction models to trace patterns in historic data (Zhang, Wang, and Zhao Citation2007). Although autoregressive (AR) integrated moving average (MA; ARIMA) models (Box and Jenkins Citation1976) are quite flexible in that they can represent several different types of time series (i.e., pure AR, pure MA, and combined AR and MA (ARMA) series), their major limitation is the preassumed linear form of the model. Therefore, it is very important for decision makers to focus on alternative models when movement and nonlinearity play a significant role in the forecasting (Sattari, Yurekli, and Pal Citation2012).
In the presence of complexity and nonlinearity of the input dataset, neural networks (NNs) are more likely to outperform other popular forecasting methods as the nature of the input dataset gets fuzzier (Azadeh et al. Citation2012). Further, the radial basis function (RBF) neural network (RBFN) is the most suitable for a complex structure because the adaptive learning capability can approximate the nonlinear system. The transfer function of the hidden layer is generally a nonlinear Gaussian function. It has been shown that the RBFN can estimate any continuous function mapping with a reasonable level of accuracy (Wu and Liu Citation2012). However, a drawback of the RBFN is that its learning strategy randomly selects from input datasets the RBF centers to be in the hidden layer, and such a mechanism is not adequate for building more ideal RBFNs (Liao Citation2010).
The bioinspired optimization methods of atomic structures have become very popular in the last few years (Mrozek, Kuś, and Burczyński Citation2015). Among the most popular nature-inspired approaches, when the task is optimization within complex domains of data or information, are those methods representing successful animal and microorganism team behavior (Marinakis, Marinaki, and Dounias Citation2011) such as artificial immune system (AIS) algorithm schemes that mimic the characteristics of biological immune systems (De Castro and Timmis Citation2002). Moreover, we found that no effort has been made to integrate the AIS algorithm with trained RBFN, for which there is room for improvement in terms of the fitting accuracy on function approximation and a practical sales forecasting exercise. Accordingly, this study proposes a variation immunological system (VIS) algorithm for training RBFN.
LITERATURE REVIEW
Most of the traditional methods for dealing with the forecasting problems include simple regression, multivariate regression, time series analysis, and NNs, etc. (Chu Citation2008). NNs have been broadly applied to many forecasting problems because of their capability in discovering hidden relationships in data (Azadeh et al. Citation2012). To improve forecasting nonlinear time series events, researchers have developed alternative modeling approaches (Ghiassi, Saidane, and Zimbra Citation2005). The emergence of various NN topologies and efficient learning algorithms have led to a wide range of successful applications in forecasting (Beliaev and Kozma Citation2007). This section will briefly introduce the background related to this study.
RBFN for Forecasting
An NN is essentially a nonlinear modeling approach that provides a fairly accurate universal approximation to any function. Therefore, an NN can be trained to predict the future values of a dependent variable (Rojas et al. Citation2008), the main reason being that NN models can capture more nonlinear patterns hidden in the data, thus leading to performance improvement (Yu et al. Citation2010). Moreover, RBFNs have a number of advantages compared with other types of NNs, such as better prediction accuracy, simpler network structure, and faster learning process (Tian, Li, and Chen Citation2010). Accordingly, we are confident to conclude that the RBFN has been recognized as a good approach for forecasting.
The RBFN was proposed by Duda and Hart (Citation1973); it exhibits good approximation, learning ability, and it is easy to train (Maqsood et al. Citation2005). The design of RBFN can be viewed as a curve-fitting problem in a high-dimensional space. The mathematical justification for the network is based on the approximation or simulation in the higher-dimensional space through a nonlinear process that is more likely to be linearly separable (Chen and Yan Citation2008). Furthermore, once an RBFN is determined and well trained, it can easily calculate the results for any new input vectors (Yao et al. Citation2006). In addition, Chen, Wu, and Luk (Citation1999) have employed the orthogonal least squares (OLS) algorithm for training and configuring the RBFN (i.e., RBFN-OLS algorithm). The hidden units are allocated one by one, based on an error reduction ratio (Omidvar Citation2004). Once the centers and widths of the RBFs are determined, each weight (), used in the approximation may be determined either by direct numerical least-squares methods such as singular-value decomposition or by iterative methods such as the least mean square (LMS) algorithm (Widrow and Hoff Citation1960).
In the field of prediction, RBFN has received a considerable degree of attention recently due to its universal approximation properties and its ability to estimate simple parameters (Zemouri, Racoceanu, and Zerhouni Citation2003). RBFNs have the ability to rapidly learn complex patterns and tend to present data and then adapt to changes quickly (Guerra and Coelho Citation2008). For example, Yu et al. (Citation2008) proposes an RBFN-ensemble forecasting model to obtain accurate prediction results and improve prediction quality further. Also, an RBFN model was developed to forecast the total ecological footprint (TEF) from 2006 to 2015 (Li et al. Citation2010). All of these represent the capability of RBFN for making good predictions in a wide variety of applications.
AIS-Based Algorithm
Among optimization methods, evolutionary algorithms (EAs), which are generally known as general purpose optimization algorithms, are capable of finding the near-optimal solution to the numerical real-valued test problems for which exact and analytical methods do not produce the optimal solution within a reasonable computation time (Karaboga and Basturk Citation2008). In the field of immune optimization computing, more and more researches indicate that, compared with EAs, AIS algorithms can maintain better population diversity, and thus, they do not easily fall in local optima (Qi et al. Citation2015). Further, AIS is a new type of computational system inspired by theoretical immunology and observed immune functions, principles, and models. In recent years, AIS has received a significant amount of interest from researchers and industrial sponsors (Qi et al. Citation2015).
The immunological algorithm (IA), or AIS, inspired by the theory of immunology (Khilwani et al. Citation2008), is one of the recently developed evolutionary techniques (Kuo, Chiang, and Chen Citation2014). The clonal selection (CS) principle (De Castro and Von Zuben Citation2002) is utilized to design the IAs because of its self-organizing and learning capability when solving combinatorial optimization problems (Khilwani et al. Citation2008). After that, the modus operandi associated with the CS principle can be explained, in simple terms, as follows. Every molecule that can be recognized by the immune system (IS) is an antigen. When a person is exposed to an antigen, the B-cells produce a population of antibody molecules whose aim is to recognize and bind to the antigen. The higher the antibodies’ ability to recognize the antigen is, the higher is their affinity. In simple terms, the antigenic stimulus causes a proliferation and maturation (controlled mutation) of B-cells capable of producing high affinity antibodies, followed by a natural selection mechanism to preserve the most adapted individuals, which compose the group of memory cells (Silva et al. Citation2015).
Also, the class of IAs used for numerical and combinatorial optimization is based on the CS principle. Further, the CS algorithm (CSA) is based on two principles (Ozsen and Yucelbas Citation2015): (1) only cells that recognize the antigen are selected for proliferation; (2) selected and proliferating cells increase their sensitivity to the antigen through a maturation process (Ozsen and Yucelbas Citation2015). Such CSAs have been applied in various fields of computation in the literature, such as function approximation (Diao and Passino Citation2002), machine learning, EA and programming, generation, and emergent behavior (Dasgupta and Gonzalez Citation2002), etc. In addition, biological systems have provided the inspiration for a number of novel biologically inspired computational approaches such as NNs (Twycross and Aickelin Citation2010). For example, Diao and Passino (Citation2002) proposed an immune-based algorithm for the RBFN structure and adjustment of parameters. Furthermore, Chen and Mahfouf (Citation2006) proposed a novel population-adaptive-based immune algorithm (PAIA) using CS and immune network theories for solving multiobjective optimization problems.
AISs are based on the ISs of vertebrates and derive from various immunological theories, among those, the CS principle, negative selection, immune networks, and danger theory. Even though anomaly detection and classification are the most natural applications for AISs, they are also often applied to the problem of optimization (Jansen and Zarges Citation2011), because the CSA is capable of optimizing multimodal problems and keeping a varied set of local optimal solutions along a single run (De Castro and Von Zuben Citation2002). However, in the process of evolution, the CSA is easily trapped in the local optimum and lacks the global search capability (Tien and Li Citation2012). As such, this study proposes an immunological-based algorithm with RBFN learning for adjusting the network parameters involved and applied to function approximation.
METHODOLOGY
Compared to other metaheuristics, the advantages of AIS are as follows (Zhang, Su, et al. Citation2015):
AIS can incorporate many properties of natural ISs, including diversity, distributed computation, error tolerance, and dynamic learning in the evolutionary process (Aickelin, Dasgupta, and Gu Citation2014).
AIS performs hypermutation to effectively prevent premature convergence.
AIS is easy to implement and adjust with a small number of parameters (Zhang, Su, et al. Citation2015).
As such, this study focuses on training and adjusting the relevant parameters for RBFN. Then, the best solution of the parameter values set can be obtained through the proposed VIS algorithm and used in the RBFN to solve the problem for function approximation. The objective is to obtain the maximum of a fitness function with respect to the parameters of the RBFN (i.e., the hidden node center, width, and weight between the hidden and output layers). The inverse of the root mean squared error (1/RMSE) is used as a fitness function (DelaOssa, Gamez, and Puetra Citation2006). The fitness values for relevant measured algorithms in the experiment are computed by maximizing the fitness function (i.e., 1/RMSE) (Lee Citation2008) defined as Equation (1):
Moreover, the nonlinear function that the RBFN hidden layer adopted is the Gaussian function. Next, a typical hidden node in an RBFN is characterized by its center, which is a vector with dimension equal to the number of inputs to the node. The Gaussian basis functions are the most frequently used RBFs (Feng Citation2006), and the generalized Gaussian function (i.e., ) can be defined as:
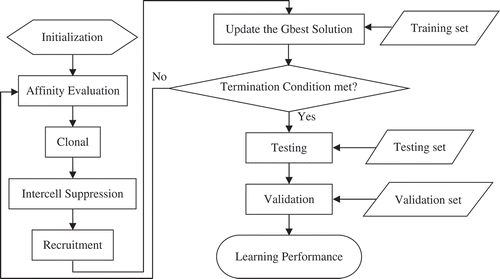
FIGURE 1 The flowchart of the proposed VIS algorithm.
The Detailed Description of the Proposed VIS Algorithm
When the CSA is applied to optimization, each element of the search space (i.e., each possible solution) corresponds to the structure of an antibody, and the objective function for this antibody represents its affinity with a certain antigen (Silva et al. Citation2015). The learning algorithm with respect to training the RBFN with approaches based on the immunological algorithm will be described in the following section. In addition, the pseudocode for the VIS algorithm is illustrated in . Furthermore, a detailed description of how the evolutionary procedure for the VIS algorithm was performed and summarized follows.
FIGURE 2 The pseudocode for the proposed VIS algorithm.

Step 1. Initialization:
Generate a population that has a random number of antibodies. Each antibody exists as its own center point.
With the averaged distance from itself to the center points of all the other antibodies, adjust the width of the center point in each antibody through Equation (3) as below:
where the default width is a constant that exists dependent on the resolution of the problem in this initialization stage. Additionally, the range of the width value is between one to two times the default width. Once the width value is set according Equation (3), it could then ensure that the antibodies are able to maintain a proper distance and avoid the autoimmune response in between.(3)
Resolve the value of the weight parameter for each antibody through the LMS method proposed by Widrow and Hoff (Citation1960).
Step 2. Affinity Evaluation:
In immunology, affinity is the fitness measurement of an antibody (Peng and Lu Citation2015). Usually the antibody with high affinity is more likely to be retained (Qi et al. Citation2015). As such, Equation (4) is used to calculate the fitness value of each antibody in the population. Next, once each antibody is calculated through Equation (4), the global best (Gbest) solution can be gradually achieved.
Step 3. Clonal:
The main idea of CS theory lies in the phenomenon that the antibody can selectively react to the antigen. When an antigen is detected, the antibodies that can best recognize such antigen will proliferate by cloning. The newly cloned antibodies undergo hypermutations in order to increase their receptor population (Peng and Lu Citation2015). Thus, through Equation (5), we can generate a clone number to inherit the fitness value of each antibody in the parent population and have it as the initial local best (Lbest) solution.
Step 4. Intercell Suppression:
During the clonal expansion and mutation process of antibodies, the average antibody affinity increases for the antigen that makes the immune response more effective. This phenomenon is called affinity maturation (Qiu and Lau Citation2014). Afterward, the antibody will be suppressed when the affinity between two antibodies is less than the suppression threshold. Meanwhile, the antibody with the highest fitness value will be kept to recognize the exhibition of the data character. This process is similar to the mechanism of the memory cells in a biological immune system. As long as the antibody recognizes the specific data character, there will be more antibodies generated around where the syndrome is more severe and they will be used to destroy the antigen.
Step 5. Recruitment:
CSA is a population-based search and optimization design imitating the learning and affinity maturation processes deployed by B-cells for solving a particular problem (Zhang, Yen, and He Citation2014). After that, to increase the diversity in the new generated population, a certain percentage of antibodies will be randomly generated through Equation (6) and then will be added into the initial population.
Step 6. Update the Gbest Solution:
The adaptability of the immune response to an antigen can be conceptually formulated as a global optimization search with the antibodies being candidate solutions in the decision space and the antigen being the optima sought for (Zhang, Yen, and He Citation2014). As such, within the randomly generated population in the proposed VIS algorithm, the relevant evolutionary procedures would recruit more antibodies to where the data character has the largest RMSE in order that the Gbest solution can be gradually resolved. This process is similar to the secondary immune response in an immune system: when the antibody meets the similar antigen that it has encountered before, it is able to faster generate more antibodies with the assistance of the memory cells to rapidly destroy the antigen and lower the probability of pathogenesis.
Step 7. Termination:
The VIS algorithm will not stop returning to Step 2 until a specific number of generations have been achieved.
This study focuses on training and adjusting the relevant parameters for the RBFN. The objective is to obtain the maximum of a fitness function (i.e., RMSE−1) with respect to the parameters of the network. As shown, it is promising to conclude that the proposed VIS algorithm can significantly increase the diversity of population-based solutions during the process of evolution and, thus, increase the possibility of solving the global optimal solution. Then, the best solution of the parameter values set can be obtained and used in the VIS algorithm with the network to further solve the exercise for sales forecasting.
EXPERIMENT RESULTS
This section focuses on training and adjusting the relevant parameters with the RBFN for the function approximation problem. The objective is to obtain the maximum of a fitness function with respect to the parameters of the network and to solve the proper values of the parameters from the setting domain in the experiment. The proposed VIS algorithm will gradually be able to train and, thus, obtain a solution to the parameter values set. Finally, the solution is validated by using the validation set, which has not been utilized throughout the entire training and testing procedures thus far.
Benchmark Continuous Test Functions
Several benchmark continuous test functions have so many local minima that they are challenging enough for performance evaluation (Tsai, Chou, and Liu Citation2006). This study applies three continuous test functions that are frequently used in the literature to be the comparative benchmark of relevant measured algorithms. The experiment involves the following three benchmark problems: Rosenbrock, Griewank, and B2 continuous test functions (Shelokar et al. Citation2007), which are defined in .
Next, there are several parameter values within the RBFN that must be set up in advance to perform training for function approximation. The VIS algorithm is better than the trial-and-error method reported in the literature in that it determines the appropriate parameter values from the verified domain to train the RBFN. Relevant measured algorithms start with the selection of the parameters settings for three continuous test functions shown in .
TABLE 1 Three Continuous Test Functions Used in This Experiment
TABLE 2 Parameters Setup for Three Continuous Function Testing Experiments
Parameters Setup for the VIS Algorithm
In this study, all parameter settings for the proposed VIS algorithm are obtained according to the related literatures (De Castro and Timmis Citation2002). Subsequently, according to the Taguchi’s orthogonal arrays (Taguchi, Chowdhury, and Wu Citation2005), the setting of parameter values for the VIS algorithm are obtained. The VIS algorithm starts with the selection of the parameter settings shown in to ensure consistency in the experiment. The maximum number of generations is set at 1000 as the termination condition in the experiment.
TABLE 3 The Setting of Parameters in the Proposed VIS Algorithm
Performance Evaluation and Comparison
The advantage of NNs over other models is their ability to model a multivariable problem, given the complex relationships between the variables, and they can extract the implicit nonlinear relationships among these variables by means of learning with training data (Yao et al. Citation2006). After that, the relevant algorithms will carry out learning on several RBFN parameters’ solutions that are generated by the population during the operation of the evolutionary procedure in the experiment.
Accordingly, once an RBFN is determined and well trained, it can easily calculate the results for any new input vectors (Yao et al. Citation2006). Thus, Looney (Citation1996) recommends 65% of the parent database to be used for training, 25% for testing, and 10% for validation. This technique helps ensure that the training, testing, and validation datasets are statistically representative of the same population in order that a fair comparison of the models developed can be made (Bowden et al. Citation2006). Consequently, we use the VIS algorithm to solve the Gbest solution of the RBFN parameter values set, and VIS algorithm randomly generates an unrepeated 65% of the training set from 1000 generated data and inputs the set to RBFN for learning. Then, with the same method, VIS algorithm randomly generates an unrepeated 25% testing set to verify the individual parameter’s solution in the population and calculates the fitness value. So far, the RBFN has used 90% of the dataset in the learning stage. After 1000 generations in the evolutionary process have progressed, the best RBFN parameter’s solution will have been obtained. Finally, the algorithm randomly generates an unrepeated 10% validation set to prove how each individual parameter’s solution approximates the three benchmark problems and records the RMSE values to confirm the learning situation of the RBFN.
Once the data processing steps presented here have been completed, relevant algorithms are ready to run. Finally, the VIS algorithm randomly generates an unrepeated 10% validation set to prove how the individual parameters’ solutions approximate three benchmark problems and records the RMSE values to justify the learning situation of RBFN. The learning and validation stages mentioned herein were implemented 50 times before the average RMSE values were calculated. The values of the average RMSE and standard deviation (SD) for the three algorithms are shown in .
TABLE 4 Result Comparison Among Three Algorithms Used in This Experiment
PRACTICAL EXERCISE FOR SALES FORECASTING
This research tries studies the sales data of the industrial computer (IC) product provided by one manufacturer of the IC industry in Taiwan. It then adopts the proposed VIS algorithm for sales data forecasting verification analysis and compares its accuracy against other algorithms in the literature. The analysis has assumed that the influence of external experimental factors does not exist, and the sales trend of the IC product is not interrupted by any special events. The sales data of the IC product from 2008 to 2009 are used in this exercise.
The experiment of this study was performed on a PC with Intel XeonTM CPU, running at 3.40GHz symmetric multiprocessing, with 2GB of RAM. Simulations were programmed on the Java 2 Platform, Standard Edition (J2SE) 1.5. In addition, software EViewsTM 6.0 and SPSSTM 16.0 were also used in the analysis of Box–Jenkins models to calculate the numerical results.
Building the Box–Jenkins Models
This research carries out sales forecasting for the IC product based on the modeling strategy of an ARIMA model followed by Box–Jenkins methodology through the identification, estimation, diagnostic checking, and forecasting stages (Shukur and Lee Citation2015); the implementation of each stage is elaborated as follows.
Identification
This research precedes the data identification of ARIMA models through augmented Dickey–Fuller (ADF) testing (Dickey and Fuller Citation1981). The results reveal that the sales data for the IC product are stationary and, thus, differencing is not necessary. Thus, it can adopt ARIMA (p, 0, q) models to precede estimation and forecasting of sales data.
Estimation
The data eliminate the coefficient of each parameter item that is insignificantly different from zero, and then sequentially sift the candidate ARMA models out. Next, the Akaike information criteria (AIC) (Akaike Citation1974) are employed to sift the optimal model out (Engle and Yoo Citation1987). Thus, it infers that the AIC value (i.e., 14.8533) of ARMA (2, 1) mode is the smallest (R-square = 0.1347, adjusted R-square = 0.0981) among all candidate ARMA models, revealing that the ARMA (2, 1) mode is the optimal model and, thus, the most appropriate for the sales forecasting exercise.
Diagnostic Checking
This study adopts the Ljung–Box statistic (Kmenta Citation1986) to measure the residual values of ARMA models for white noise. The results of model diagnosis reveal that the values of the Ljung–Box statistic are greater than 0.05 in the result of the ARMA (2, 1) mode; the result is serial noncorrelation and it was suitably fitted.
Forecasting
This study adopted the ARMA (2, 1) mode to project forecasting on historical daily sales data for the IC product.
Parameters Setup for the Sales Forecasting Exercise
In this study, several parameter settings with respect to the VIS algorithm are obtained according to De Castro and Timmis (Citation2002). Next, according to the Taguchi’s orthogonal arrays (Taguchi, Chowdhury, and Wu Citation2005), the setting of parameter values for the proposed VIS algorithm are obtained. The VIS algorithm starts with the selection of the parameters setting shown in to ensure consistent basis in the experiment.
TABLE 5 The Setting of Parameters in the Proposed VIS Algorithm
The Performance Evaluation for the Sales Forecasting Exercise
The approximation performance of the RBFN prediction is examined with the 10% validation set. This study elaborates how data is input to RBFN for forecasting through relevant algorithms in comparison with the ARMA (2, 1) mode. Consequently, the following predicted values were generated in turn by the moving window method: the first 90% of the observations were used for model estimation and the remaining 10% (Zou et al. Citation2007) were used for validation and one-step-ahead forecasting. Further, there are 227 observations of which 204 (90%) and 23 (10%) observations are for learning and forecasting, respectively. In addition, the RMSE, mean absolute error (MAE), and mean absolute percentage error (MAPE) are applied to evaluate the forecasting accuracy (Zhang, Zhang, and Zhang Citation2015) in this study. Afterward, three criteria were used to compare the sale forecasting performance of the VIS algorithm against other algorithms and were presented in . Among relevant algorithms, the results of the VIS algorithm have the smallest values. Next, the forecasting verification and the paired sample test (t-test) results among relevant algorithms are shown in .
TABLE 6 The Error Comparison of Relevant Algorithms
In , it is shown that the ARMA (2, 1) mode and VIS algorithm without statistical significance (p-value larger than 0.05, i.e., there is no significant deviation between the predicted values and actual values) are better in forecasting accuracy than RBFN-OLS (Chen, Cowan, and Grant Citation1991) and AIS-based (Diao and Passino Citation2002) algorithms.
TABLE 7 The Statistical Results for Paired Sample Test (t-test) Among Relevant Algorithms in This Exercise
CONCLUSIONS
This research adopted certain immunological-based algorithms and was applied on RBFN to provide the settings of network parameters such as node center, width, and weight. Consequently, further verification analysis and comparison among the relevant mentioned algorithms were executed as well. The evolutionary learning mechanism of the proposed VIS algorithm can be used to train and determine the optimal network parameters within the solution space of the individually generated population in RBFN. Additionally, this study attempts to verify the forecasting results on the sales data of the IC product provided by an international IC manufacturer in Taiwan. With better accuracy in forecasting, the proposed VIS algorithm for the trained RBFN can be practically utilized in the IC sales forecasting exercise to make predictions and could enhance business profit.
In the future, other EAs, such as ant colony optimization and artificial bee colony algorithms can be applied to further improve the accuracy for general forecasting problem. Additionally, the product characteristics in the IC industry have high variety, but each product has limited quantity with high customization. These characteristics increase the degree of variety in general product sales forecasting. Next, perhaps the sales data in the short term would be more stable and could be more beneficial toward improving prediction accuracy. Therefore, the accuracy of forecasting in product sales data within shorter periods could be further compared in the future. In addition, it is common to have significant fluctuation and change in general sales forecasting, and it could be the result of exogenous variables or unexpected variances such as sales force, promotional campaign, and exposure in international exhibitions. These exogenous variables were not considered in this study and thus could be considered in future work.

REFERENCES
- Aickelin, U., D. Dasgupta, and F. Gu. 2014. Artificial immune systems, search methodologies, 187–211. Springer.
- Akaike, H. 1974. A new look at the statistical model identification. IEEE Transactions on Automatic Control 19 (2):716–23. doi:10.1109/TAC.1974.1100705.
- Azadeh, A., M. Moghaddam, M. Khakzad, and V. Ebrahimipour. 2012. A flexible neural network-fuzzy mathematical programming algorithm for improvement of oil price estimation and forecasting. Computers & Industrial Engineering 62 (2):421–30. doi:10.1016/j.cie.2011.06.019.
- Beliaev, I., and R. Kozma. 2007. Time series prediction using chaotic neural networks on the CATS benchmark. Neurocomputing 70 (13–15):2426–39. doi:10.1016/j.neucom.2006.09.013.
- Bowden, G. J., J. B. Nixon, G. C. Dandy, H. R. Maier, and M. Holmes. 2006. Forecasting chlorine residuals in a water distribution system using a general regression neural network. Mathematical and Computer Modelling 44 (5–6):469–84. doi:10.1016/j.mcm.2006.01.006.
- Box, G. E. P., and G. Jenkins. 1976. Time series analysis, forecasting and control. San Francisco, CA, USA: Holden-Day.
- Chen, C. H., and W. Yan. 2008. An in-process customer utility prediction system for product conceptualisation. Expert Systems with Applications 34 (4):2555–67. doi:10.1016/j.eswa.2007.04.019.
- Chen, J., and M. Mahfouf. 2006. A population adaptive based immune algorithm for solving multiobjective optimization problems. In ICARIS, ed. H. Bersini, and Carneiro, Vol. 4163, 280–93. LNCS. Berlin Heidelberg: Springer-Verlag.
- Chen, S., C. F. N. Cowan, and P. M. Grant. 1991. Orthogonal least squares learning algorithm for radial basis function networks. IEEE Transactions on Neural Networks 2 (2):302–09. doi:10.1109/72.80341.
- Chen, S., Y. Wu, and B. L. Luk. 1999. Combined genetic algorithm optimization and regularized orthogonal least squares learning for radial basis function networks. IEEE Transactions on Neural Networks 10 (5):1239–43. doi:10.1109/72.788663.
- Chu, F. 2008. Analyzing and forecasting tourism demand with ARAR algorithm. Tourism Management 29:1185–96. doi:10.1016/j.tourman.2008.02.020.
- Dasgupta, D., and F. Gonzalez. June 2002. An immunity-based technique to characterize intrusions in computer networks. IEEE Transactions on Evolutionary Computation 6 (3):1081–88. doi:10.1109/TEVC.2002.1011541.
- De Castro, L. N., and J. Timmis. 2002. Artificial immune systems: A new computational approach. London, UK: Springer-Verlag.
- De Castro, L. N., and F. J. Von Zuben. 2002. Learning and optimization using the clonal selection principle. IEEE Transactions on Evolutionary Computation 6 (3):239–51. doi:10.1109/TEVC.2002.1011539.
- DelaOssa, L., J. A. Gamez, and J. M. Puetra. July 2006. Learning weighted linguistic fuzzy rules with estimation of distribution algorithms. IEEE Congress on Evolutionary Computation, Vancouver, BC, Canada, 900–07. doi:10.1109/CEC.2006.1688407.
- Diao, Y., and K. M. Passino. 2002. Immunity-based hybrid learning methods for approximator structure and parameter adjustment. Engineering Applications of Artificial Intelligence 15:587–600. doi:10.1016/S0952-1976(03)00003-4.
- Dickey, D. A., and W. A. Fuller. July 1981. Likelihood ratio statistics for autoregressive time series with a unit root. Econometrica 49 (4):1057–72. doi:10.2307/1912517.
- Duda, R. O., and P. E. Hart. 1973. Pattern classification and scene analysis. New York, NY, USA: John Wiley & Sons.
- Engle, R. F., and B. Yoo. 1987. Forecasting and testing in cointegrated systems. Journal of Econometrics 35 (1):143–59. doi:10.1016/0304-4076(87)90085-6.
- Feng, H.-M. 2006. Self-generation RBFNs using evolutional PSO learning. Neurocomputing 70:241–51. doi:10.1016/j.neucom.2006.03.007.
- Ghiassi, M., H. Saidane, and D. K. Zimbra. 2005. A dynamic artificial neural network model for forecasting time series events. International Journal of Forecasting 21:341–62. doi:10.1016/j.ijforecast.2004.10.008.
- Guerra, F. A., and L. D. S. Coelho. 2008. Multi-step ahead nonlinear identification of Lorenz’s chaotic system using radial basis neural network with learning by clustering and particle swarm optimization. Chaos, Solitons & Fractals 35:967–79. doi:10.1016/j.chaos.2006.05.077.
- Jansen, T., and C. Zarges. 2011. Analyzing different variants of immune inspired somatic contiguous hypermutations. Theoretical Computer Science 412:517–33. doi:10.1016/j.tcs.2010.09.027.
- Karaboga, D., and B. Basturk. 2008. On the performance of artificial bee colony (ABC) algorithm. Applied Soft Computing 8:687–97. doi:10.1016/j.asoc.2007.05.007.
- Khilwani, N., A. Prakash, R. Shankar, and M. K. Tiwari. 2008. Fast clonal algorithm. Engineering Applications of Artificial Intelligence 21:106–28. doi:10.1016/j.engappai.2007.01.004.
- Kmenta, J. 1986. Elements of econometrics, 2nd ed. New York, NY, USA: Macmillan.
- Kuo, R. J., N. J. Chiang, and Z.-Y. Chen. 2014. Integration of artificial immune system and k-means algorithm for customer clustering. Applied Artificial Intelligence 28 (6):577–96.
- Lee, J., and M. Verleysen. 2005. Generalization of the Lp norm for time series and its application to self-organizing maps. Paper presented at Proceedings of the Workshop on Self-Organizing Maps (WSOM), Paris, France, September 5–8, 2005.
- Lee, Z.-J. 2008. A novel hybrid algorithm for function approximation. Expert Systems with Applications 34 (1):384–90. doi:10.1016/j.eswa.2006.09.006.
- Li, X. M., R. B. Xiao, S. H. Yuan, J. A. Chen, and J. X. Zhou. 2010. Urban total ecological footprint forecasting by using radial basis function neural network: A case study of Wuhan city, China. Ecological Indicators 10:241–48. doi:10.1016/j.ecolind.2009.05.003.
- Liao, C.-C. 2010. Genetic k-means algorithm based RBF network for photovoltaic MPP prediction. Energy 35 (2):529–36. doi:10.1016/j.energy.2009.10.021.
- Looney, C. G. 1996. Advances in feed forward neural networks: Demystifying knowledge acquiring black boxes. IEEE Transactions on Knowledge and Data Engineering 8 (2):211–26. doi:10.1109/69.494162.
- Lu, J., H. Hu, and Y. Bai. 2015. Generalized radial basis function neural network based on an improved dynamic particle swarm optimization and AdaBoost algorithm. Neurocomputing 152:305–15. doi:10.1016/j.neucom.2014.10.065.
- Maqsood, I., M. R. Khan, G. H. Huang, and R. Abdalla. 2005. Application of soft computing models to hourly weather analysis in southern Saskatchewan, Canada. Engineering Applications of Artificial Intelligence 18:115–25. doi:10.1016/j.engappai.2004.08.019.
- Marinakis, Y., M. Marinaki, and G. Dounias. 2011. Honey bees mating optimization algorithm for the Euclidean traveling salesman problem. Information Sciences 181:4684–98. doi:10.1016/j.ins.2010.06.032.
- Mrozek, A., W. Kuś, and T. Burczyński. 2015. Nano level optimization of graphene allotropes by means of a hybrid parallel evolutionary algorithm. Computational Materials Science 106:161–69. doi:10.1016/j.commatsci.2015.05.002.
- Omidvar, A. E. 2004. Configuring radial basis function network using fractal scaling process with application to chaotic time series prediction. Chaos, Solitons & Fractals 22 (4):757–66. doi:10.1016/j.chaos.2004.03.008.
- Ozsen, S., and C. Yucelbas. 2015. On the evolution of ellipsoidal recognition regions in artificial immune systems. Applied Soft Computing 31:210–22. doi:10.1016/j.asoc.2015.03.014.
- Peng, Y., and B.-L. Lu. 2015. Hybrid learning clonal selection algorithm. Information Sciences 296 (1):128–46. doi:10.1016/j.ins.2014.10.056.
- Qi, Y., Z. Hou, M. Yin, H. Sun, and J. Huang. 2015. An immune multi-objective optimization algorithm with differential evolution inspired recombination. Applied Soft Computing 29:395–410. doi:10.1016/j.asoc.2015.01.012.
- Qiu, X., and H. Y. K. Lau. 2014. An AIS-based hybrid algorithm for static job shop scheduling problem. Journal of Intelligent Manufacturing 25:489–503. doi:10.1007/s10845-012-0701-2.
- Rojas, I., O. Valenzuela, F. Rojas, A. Guillen, L. J. Herrera, H. Pomares, L. Marquez, and M. Pasadas. 2008. Soft-computing techniques and ARMA model for time series prediction. Neurocomputing 71:519–37. doi:10.1016/j.neucom.2007.07.018.
- Sattari, M. T., K. Yurekli, and M. Pal. 2012. Performance evaluation of artificial neural network approaches in forecasting reservoir inflow. Applied Mathematical Modelling 36:2649–57. doi:10.1016/j.apm.2011.09.048.
- Shelokar, P. S., P. Siarry, V. K. Jayaraman, and B. D. Kulkarni. 2007. Particle swarm and ant colony algorithms hybridized for improved continuous optimization. Applied Mathematics and Computation 188 (1):129–42. doi:10.1016/j.amc.2006.09.098.
- Shukur, O. B., and M. H. Lee. 2015. Daily wind speed forecasting through hybrid KF-ANN model based on ARIMA. Renewable Energy 76:637–47. doi:10.1016/j.renene.2014.11.084.
- Silva, D. G., J. Montalvão, R. Attux, and L. C. Coradine. 2015. An immune-inspired, information-theoretic framework for blind inversion of Wiener systems. Signal Processing 113:18–31. doi:10.1016/j.sigpro.2015.01.010.
- Taguchi, G., S. Chowdhury, and Y. Wu. 2005. Taguchi’s quality engineering handbook. Hoboken, NJ, USA: Wiley.
- Tian, J., M. Li, and F. Chen. 2010. Dual-population based coevolutionary algorithm for designing RBFNN with feature selection. Expert Systems with Applications 37:6904–18. doi:10.1016/j.eswa.2010.03.031.
- Tien, J. P., and T. H. S. Li. 2012. Hybrid Taguchi-chaos of multilevel immune and the artificial bee colony algorithm for parameter identification of chaotic systems. Computers & Mathematics with Applications 64 (5):1108–19. doi:10.1016/j.camwa.2012.03.029.
- Tsai, J.-T., J.-H. Chou, and T.-K. Liu. 2006. Tuning the structure and parameters of a neural network by using hybrid Taguchi-genetic algorithm. IEEE Transactions on Neural Networks 17 (1):69–80. doi:10.1109/TNN.2005.860885.
- Twycross, J., and U. Aickelin. 2010. Information fusion in the immune system. Information Fusion 11:35–44. doi:10.1016/j.inffus.2009.04.008.
- Widrow, B., and M. E. Hoff. 1960. Adaptive switching circuits. In WESCON Convention Record, 96–104. New York, NY, USA:Institute of Radio Engineers.
- Wu, J.-D., and J.-C. Liu. 2012. A forecasting system for car fuel consumption using a radial basis function neural network. Expert Systems with Applications 39 (2):1883–88. doi:10.1016/j.eswa.2011.07.139.
- Yao, Y., Z. Lian, Z. Hou, and W. Liu. 2006. An innovative air-conditioning load forecasting model based on RBF neural network and combined residual error correction. International Journal of Refrigeration 29:528–38. doi:10.1016/j.ijrefrig.2005.10.008.
- Yu, L., K. K. Lai, and S. Wang. 2008. Multistage RBF neural network ensemble learning for exchange rates forecasting. Neurocomputing 71 (16):3295–302. doi:10.1016/j.neucom.2008.04.029.
- Yu, L., S. Wang, K. K. Lai, and F. Wen. 2010. A multiscale neural network learning paradigm for financial crisis forecasting. Neurocomputing 73:716–25. doi:10.1016/j.neucom.2008.11.035.
- Zemouri, R., D. Racoceanu, and N. Zerhouni. 2003. Recurrent radial basis function network for time-series prediction. Artificial Intelligence 16:453–63.
- Zhang, J.-L., Y.-J. Zhang, and L. Zhang. 2015. A novel hybrid method for crude oil price forecasting. Energy Economics 49 (C):649–59. doi:10.1016/j.eneco.2015.02.018.
- Zhang, L., Z. Wang, and S. Zhao. 2007. Short-term fault prediction of mechanical rotating parts on the basis of fuzzy-grey optimising method. Mechanical Systems and Signal Processing 21 (2):856–65. doi:10.1016/j.ymssp.2005.09.013.
- Zhang, W., G. G. Yen, and Z. He. Feb. 2014. Constrained optimization via artificial immune system. IEEE Transactions on Cybernetics 44 (2):185–98. doi:10.1109/TCYB.2013.2250956.
- Zhang, Z., S. Su, Y. Lin, X. Cheng, K. Shuang, and P. Xu. 2015. Adaptive multi-objective artificial immune system based virtual network embedding. Journal of Network and Computer Applications 53:140–55. doi:10.1016/j.jnca.2015.03.007.
- Zou, H. F., G. P. Xia, F. T. Yang, and H. Y. Wang. 2007. An investigation and comparison of artificial neural network and time series models for Chinese food grain price forecasting. Neurocomputing 70:2913–23. doi:10.1016/j.neucom.2007.01.009.