
ABSTRACT
Cardiotocographic (CTG) monitoring, consisting in analysis of the fetal heart rate, uterine contractions, and fetal movements is the primary noninvasive method for the fetal state assessment. The visual interpretation of the CTG signals is characterized by the large inter- and intraobserver disagreement. Hence, the automated methods supporting the diagnosis process are the topic of researches. In the presented study, the evaluation of the CTG signals, based on fuzzy clustering with pairs of prototypes, is described. The efficiency of the proposed method is verified using two benchmark datasets of the CTG signals (CTU-UHB and SisPorto), and the problems of the two- and three-class classification are considered. The obtained results show the improved quality of the automated fetal state assessment in accordance with the applied reference procedures: the fuzzy (c+p)-means clustering and the Lagrangian Support Vector Machines.
Introduction
Cardiotocographic (CTG) monitoring is the method for fetal state assessment during pregnancy and labour. It consists in simultaneous analysis of the fetal heart rate (FHR), uterine contractions, and fetal movements. The most popular method for the acquisition of the FHR signal is the noninvasive Doppler ultrasound technique (Jezewski et al. Citation2011). Because the visual assessment of the acquired signals is characterized by large inter- and intraobserver variability (Spilka et al. Citation2014), an automated analysis is used to support the diagnosis. The computer systems extract features, quantitatively describing the acquired signals (Wrobel, Matonia et al. Citation2015), which can be further analyzed by using computational-intelligence-based methods. Different classifiers were applied to support the automated fetal state assessment, including Support Vector Machines (SVMs), artificial neural networks (ANNs) and fuzzy systems. In Krupa et al. (Citation2011), FHR features extracted by using empirical mode decomposition were the inputs of the SVM, whereas the reference records assessments were provided by a clinical expert. The SVM with the modified criterion function was applied to predict the risk of the metabolic acidosis in Georgoulas, Stylios, and Groumpos (Citation2006). In Pedrinazzi, Magenes, and Signorini (Citation2004), the independent component analysis was used to preprocess the input data for the SVM classification. The comparison of classification methods including the SVM was presented in Magenes et al. Citation2014. The classification of the CTG signals using ANN was the topic of Magenes et al. (Citation2001), in which the multilayer perceptron was compared with other classification methods. The work by Georgoulas, Stylios, and Groumpos (Citation2005) shows the wavelet neural networks optimized with the particle swarm optimization procedure. The committee of ANNs applied for the prediction of birth asphyxia was described in Georgieva et al. (Citation2013). In Maeda et al. (Citation2015), the ANN was used as one of the components of the FHR monitoring system. The dataset representation influences the efficiency of the CTG signals’ classification when applying ANN. In Jezewski, Wrobel, Horoba, et al. Citation2007 and Jezewski, Wrobel, Labaj, et al. Citation2007 the relation between dataset’s representation and classification efficiency was studied. Several fuzzy-logic-based procedures were also proposed for the automated analysis of FHR signals (Czabanski et al. Citation2013, Citation2012; Signorini et al. Citation2000). In Czabanski et al. (Citation2013), several classification tasks concerning various datasets and various definitions of the fetal state were investigated. The two-step classification applying the fuzzy system and the ANN or the Lagrangian SVM was presented in Czabanski et al. (Citation2012). The classification of FHR signals using fuzzy systems was also described in Signorini et al. (Citation2000). A combination of neural networks and fuzzy systems leads to neurofuzzy systems. The assessment of the fetal state by applying the Artificial Neural Network Based on Logical Interpretation of fuzzy if-then Rules (ANBLIR) system with various learning algorithms based on deterministic annealing and ε-insensitive learning was examined in Czabanski et al. (Citation2008).
Antecedents of the rules defining the fuzzy classifiers can be determined using data clustering (Czabanski Citation2006; Jezewski, Leski, and Czabanski Citation2016; Leski Citation2015). Clustering consists in finding clusters (groups) of similar objects within a given dataset. Among clustering procedures, a group of fuzzy methods may be distinguished. The fuzziness of the methods is the application of a membership function, so a given object may partially belong to more than one cluster (with a given membership value within the range [0,1]). In contrast, the hard clustering considers only the full belonging to a given cluster. Hence, the fuzzy clustering might be better suited for real data, where groups or classes of objects might overlap. Moreover, the idea of the partial membership allows for selecting the objects that belong to a given cluster with the assumed level (i.e., satisfying the assumed membership threshold) for further processing. One of the most popular fuzzy clustering methods is the fuzzy c-means (FCM) method proposed by Bezdek (Citation1981). In that case, the clustering results are described by locations of prototypes (centers of clusters) and membership values (forming the partition matrix). The FCM prototypes are a weighted means of the clustered objects, with the weights defined as the normalized memberships of the objects to a given cluster. In this study, we applied clustering with pairs of prototypes (Jezewski et al. Citation2015) based on the FCM procedure to find the antecedents of the fuzzy classifier supporting the qualitative assessment of the fetal state. Two datasets of the CTG signals—SisPorto (Ayres-de-Campos et al. Citation2000) and CTU-UHB (Chudacek et al. Citation2014)—were used to verify the efficiency of the automated evaluation. The first (SisPorto) consists of sets with quantitative parameters describing the signals. The CTU-UHB contains the raw signals, so our investigation involved also the reanalysis of them and determination of the quantitative parameters.
Fuzzy classifier based on clustering with pairs of prototypes
The idea of the presented clustering procedure consists of introducing the additional prototypes—“prototypes in between” (PB), to those that were obtained separately in each of two classes ω1 and ω2 by the FCM method—“ordinary prototypes” (OP). All prototypes—PB and OP—are used to determine the antecedents of the rules defining the fuzzy classifier. The main idea behind definition of PB is to create rules of the fuzzy classifier allowing for more accurate assessment of the objects located near the border between two classes. In practice, however, the PB are not always located near that border. However, we suppose that introducing additional rules determined by using PB could improve the classification quality. The PB are new prototypes determined by pairs of the OP (one prototype from the ω1 class, and one from the ω2). The pairs are found by using the algorithm based on distances between prototypes and groups’ densities. A disadvantage of the basal FCM method is its sensitivity to noisy data and outliers, as a result, the obtained prototypes (OP and PB) might be located undesirably. However, the clustering with pairs of prototypes also could be based on robust clustering procedures. The clustering procedure is outlined in the following steps:
find OPs using FCM clustering,
find the appropriate pairs of the OP,
determine the PBs by using OP.
We presented two variations of the procedure (Jezewski et al. Citation2015), without and with the rejection of the OP based on the groups’ densities analysis.
The procedure starts with the FCM clustering of each of the two considered classes into the initial number of clusters per class (c). Consequently, 2c of OP are obtained in total. Each of the two classes is clustered with the same fuzziness degree (m, m > 1). If the same FCM prototypes in a given class are determined, only one remains for the further processing. If the same prototypes are found in both classes, then all are rejected. In case of variation with the rejection, there is the additional step of the prototypes’ rejection. We remove the prototypes that represent groups with densities lower than the assumed density threshold. The density is calculated using the objects with membership value greater than or equal to the assumed membership threshold. Three types of the density of the ith group of the jth class were applied:
where ,
,
denotes the number of ordinary prototypes (groups) of the jth class,
is the ith ordinary prototype of the jth class,
is the FCM membership of the object xk to the ith cluster of the jth class, and
denotes the number of objects with the membership value greater than or equal to the assumed threshold (
) in the ith cluster of the jth class. The sets
, and
define the indexes of these objects.
After each rejection, the partition matrix is updated; i.e., the appropriate rows of the matrix are removed and the objects with the zero summary memberships are excluded from further steps: finding the pairs, determining the PB, and calculating the clusters’ dispersions. After all rejections, finally, c(1) (c(2)) prototypes (
) in the ω1 (ω2) class remain.
The maximum number (Np) of the pairs of ordinary prototypes is equal to . The detailed algorithm finding the pairs is presented as follows:
Fix the “window” length W and the density type (Equation (1)).
Calculate the densities of the groups of ω1 and of ω2.
Sort the prototypes of the class with the smaller number of OP in descending order according to groups’ densities.
Set i = 1 and assume j = C, where C = max (c(1),c(2)).
If W > j, then set W = j, for the ith sorted prototype, find W nearest prototypes (using the Euclidean distance) of the class with the greater number of OP.
From the W nearest prototypes, choose the one that represents the group of the highest density. If there are more such prototypes, choose the nearest one. The prototypes found in Steps 5 and 6 form the pair.
Stop the algorithm if all (Np) possible pairs of prototypes are found, else set i = i + 1, j = j−1 and go to the Step 5. While finding W nearest prototypes (in Step 5), omit those previously chosen to form the pairs.
If c(1) = c(2), the algorithm is repeated twice, and the solution leading to the lower mean Euclidean distance between prototypes forming the pairs is chosen.
The expected number (c(b)) of PB was set as equal to . If the number of the determined pairs (Np) is greater than c(b), then c(b) nearest pairs are chosen, otherwise, all Np pairs are used. The PB are calculated as follows:
where: r and t denote the groups represented by the OP ( and
) forming the pair, the sets
and
include indexes of the objects satisfying the assumed membership threshold condition and were defined in the text following Equation (1).
The PB and OP form the set of K = c(1) + c(2) + c(b) prototypes (vi), defining the centers of the Gaussian membership functions of fuzzy sets Ak in the antecedents of the following rules defining the fuzzy classifier:
where: n is the number of features, denotes the p-feature of the object
, and
is the location of the singleton in the consequent, which is determined using the gradient method (Leski Citation2015). The rule base of the classifier can be interpreted as an ensemble of experts, each represented by a single fuzzy rule. Each rule defines the relationship between the input data and the class assessment. The weighted average of the assessments from all rules (experts) formulates the final interpretation of the fetal state, and the fuzzy antecedents provide soft switching between the local areas of expertise.
The final output value of such classifier is given as:
The parameter γ is used for scaling the dispersions skp of the Gaussian membership functions, which are calculated using Equation (6) for the OP, and Equation (7) for the PB:
The symbol (•2) denotes component-by-component squaring
. Dispersions
,
, and
form the set of
dispersions
.Defining
as the N × K matrix, where
denotes the class label (equals
or
) of the object
, and N is the number of objects in the clustered set, we can determine the fuzzy rules’ outputs
using the gradient method (Leski Citation2015) to minimize the Asymmetric SQuaRe (ASQR) loss function (Leski Citation2015):
where ,
for
, and
for
, where
,
denotes the iteration number, and 1 is a vector with all entries equal to one.
The classification procedure using prototypes obtained in the variation without (with) the rejection of the OP based on analysis of the groups’ densities was denoted as (
), where x represents the density type.
Research material
The efficiency of the automated fetal state assessment was verified using two sets of the CTG recordings: SisPorto (Ayres-de-Campos et al. Citation2000) and CTU-UHB (Chudacek et al. Citation2014; Goldberger et al. Citation2000).
The SisPorto database
The SisPorto dataset was obtained in August 2013 from the UCI Machine Learning Repository (Lichman Citation2013) and consisted of 2126 CTG signals, each described by 21 quantitative parameters. The reference signals’ assessments were provided by expert clinicians. As a result, 1655 recordings were labeled as normal, 295 as suspicious, and 176 as abnormal. We analyzed the three-class classification problem. Because the presented fuzzy classifier is a binary one, we used the class-class (one-against-one) approach. Consequently, three binary classifiers were defined as distinguishing cases: normal from suspicious (NS), normal from abnormal (NA), and suspicious from abnormal (SA) (Jezewski, Czabanski, and Leski Citation2015).
The CTU-UHB database
The CTU-UHB data is the set of raw 552 intrapartum CTG signals. In this case, the expert interpretation also can be used as the reference fetal state. However, due to a high level of the inter- and intraobserver disagreement (Spilka et al. Citation2014) we applied the retrospective analysis using fetal outcome attributes (the Apgar score, the percentile of the birth weight, and pH measurement of blood from the umbilical artery). Because only the raw CTG signals were available, the features that quantitatively describe the signals in the time domain were calculated by using the computerized fetal monitoring system (Wrobel, Jezewski et al. Citation2015). First, the fragments with the signal loss at the beginning or/and at the end of each recording were removed. Next, the possible artifacts were removed (Jezewski et al. Citation2010), and the signals were averaged using a moving window of 2.5 s width. Finally, 11 FHR signal parameters were analyzed:
The mean value of the FHR baseline [bpm] (Jezewski et al. Citation2010).
The fluctuation range of the FHR baseline [bpm], defined as the difference between the maximum and the minimum FHR baseline.
The number of identified acceleration patterns [1/h]. Acceleration was defined as the transient increase in FHR above the baseline by 15 bpm or more and lasting 15 s or more.
The number of deceleration patterns [1/h]. Deceleration was defined as the transient decrease in FHR below the baseline by 15 bpm or more and lasting 10 s or more.
Short-term variability (STV) [ms], defined as the mean of the differences
in the one-minute window, where Ti is the equivalent of the ith R-R interval from the fetal ECG (Kupka et al. Citation2004). The final value of the STV was calculated as the mean of all one-minute values.
Long-term variability (LTV) [ms], defined as the difference between the maximum and the minimum Ti intervals in the one-minute window, excluding the periods with recognized accelerations with the amplitude greater than 20 bpm and lasting longer than 30 s, and decelerations with the amplitude greater than 10 bpm and lasting longer than 1 minute. The final value of the LTV was calculated as the mean of all one-minute values.
The ratio of STV/LTV.
The duration of the reduced long-term variability (LTV) of the FHR signal, expressed as the percentage of the signal length.
The oscillation amplitude [bpm] defined as the difference between the maximum and the minimum FHR in the one-minute window. The final value of the oscillation amplitude was calculated as the mean of all one-minute values.
The percentage of silent oscillation (amplitude ≤ 5 bpm) in a whole signal.
The percentage of saltatory oscillation (amplitude ≥ 25 bpm) in a whole signal.
Additionally, the number of detected uterine contractions [1/h] was used. The above parameters were chosen, according to the expert suggestion, as having significance for the diagnosis support. All the applied signal features come from selected clinical criteria of CTG signals interpretation (e.g., FIGO guidelines, point scales).
In the further considerations we assumed the binary classification of the CTU-UHB data. As the reference assessment, we used the result of the retrospective fetal state evaluation using the pH measurements only (the pH lower than 7.2 was assumed as abnormal), and the approach where the fetal state was retrospectively considered as abnormal if at least one of the fetal outcome attributes was outside its physiological range (OR), i.e., pH < 7.2, Apgar score in the 1st minute < 7, or the percentile of the birth weight < 10. The percentiles of the birth weight were calculated in accordance to the newborn sex and the gestational age during the delivery. Due to one missing value of the birth weight, one recording was excluded from the presented analysis. Finally, we evaluated the set of 551 signals, with 177 indicating the abnormal fetal state according to the pH level and 228 in accordance with the OR approach.
Experiments
The assessment of the classification efficiency
The efficiency of binary classifiers was measured by using the classification accuracy (ACC) and four prognostic indexes: sensitivity (Se), specificity (Sp), positive predictive value (PPV), and negative predictive value (NPV). The Se describes the classification accuracy of the positive (abnormal) cases, whereas Sp describes the negative (normal) ones. The quality of the binary classification was evaluated with the quality index (QI) defined as the geometric mean of Se and Sp.
The efficiency of the three-class classification was measured by using the overall classification accuracy (ACC) and classification accuracies for each of the classes: ACCN, ACCS, and ACCA. The class accuracies were calculated as the percentage of the correctly classified cases in the given class. The mean class accuracy was introduced as well. Additionally, we defined QIm as being the mean value of the three QIs calculated for NS, NA, and SA classifiers by using their testing sets. In the case of the NS classifier, the “suspicious” class was denoted as positive, whereas for NA and SA, the “abnormal” class. The QIm describes the quality of binary classifiers used in the three-class classification and, hence, the quality of the three-class classification indirectly. All presented results are mean values and standard deviations calculated for 100 testing sets and are expressed in percents.
The learning procedures
The research material was 100 times randomly divided into training (50%) and testing (50%) parts to form training and testing sets maintaining the proportion between classes, the class ω1 included negative cases with class labels equal to +1, and the ω2 class contained positive cases with labels equal to −1. In the case of an odd number of cases, the additional case was added to the testing part. The obtained classification efficiency was compared with the efficiency of the classifier based on the fuzzy (c + p)-means clustering (Leski Citation2015) (for the ASQR loss function) and with the efficiency of the Lagrangian SVM (LSVM) (Mangasarian and Musicant Citation2001) with the Gaussian kernel
. The LSVM was chosen because it is characterized by higher computational efficiency than the classical SVM procedure. In LSVM, the quadratic programming was replaced with the iterative solution, providing comparable or better testing results (Mangasarian and Musicant Citation2001). The LSVM parameters (v and χ), providing the best classification quality, were searched within the set {10–5, 4·10–5, 7·10–5, 10–4, 4·10–4,…,7·104,105}, using 10 first pairs of training and testing sets. The remaining LSVM parameters were set to their default values. The LSVM input data were scaled to the range [–1, +1].
The ranges of the parameters for the fuzzy rule-based classifier with the proposed clustering (FCMpbx or FCMpbdx) were defined as follows:
the fuzziness degree in the FCM clustering m, searched within the set
the initial number of clusters per class c, changed from 2 to 16 with the step of
three density types: D1, D2, D3 (Equation (1)),
five values of the membership threshold: M0 (0, i.e., all objects were used), Mm (mean),
four values of the density threshold (only in the
the window length W changed from 1 to 5 with the step of 1,
the parameter γ, scaling the dispersions, changed from 0.2 to 1.6 with the step of 0.1.
Because the maximum initial number of clusters per class was established at , the maximum number of all obtained prototypes (
) was equal to
. If the numbers of prototypes were too small (i.e.,
or
) the clustering results were excluded from further analysis.
The clustering procedures (both the FCM and the -means) were initialized with prototypes selected from the boundary of the convex hull (Leski Citation2015) of the class being clustered. The clustering was performed as long as the absolute value of the difference between successive values of the criterion function was greater than or equal to
. The maximum number of iterations was established at 500, squared distances between objects and prototypes less than
were treated as equal to
, and then the relevant update of the partition matrix was conducted. The remaining specifications of the
-means were preserved as in (Leski Citation2015), however, we used
, and
scaling the dispersions (in the presented work denoted by
) changed from
to
with the step of
. If any of the components of the resulting dispersions were equal to
, we set them to
. If the summary activation level of the rules
was equal to
, then
for each rule was assumed.
To find the parameters of antecedents (centers and dispersions of the Gaussian membership functions), the first 10 training sets were merged into a single dataset and then clustered. The consequents (vector y) were determined separately for each of the first 10 training sets, and the parameters’ values providing the highest QI for the first 10 testing sets were chosen to calculate the final results. If the output value of any classifier was > 0 (≤ 0), then the ω1 (ω2) class was assigned.
Results and discussion
presents the results of the two-class classification of the CTU-UHB dataset. The methods always provided higher QI and ACC than the
procedures. For the
algorithms, we identified the
density as ensuring the highest values of QI and ACC for the pH reference assessment and
for the OR approach. compares in detail the results obtained using the proposed method with the LSVM and with the
-means clustering. Both (c + p)-means and the
outperformed the LSVM. Comparing the (c + p)-means and the
, we observed higher values for all classification efficiency measures for the OR approach. For the pH, we achieved higher values of Se and NPV, but lower of ACC, Sp, and PPV. However, the increase level of the Se was higher then the decrease of Sp, and hence, we obtained the improvement of the QI.
Table 1. The classification results for the CTU-UHB dataset using the presented clustering.
Table 2. Comparison of the results for the CTU-UHB dataset with the applied reference methods.
The statistical significance of the obtained results was verified using the paired-sample t-test. The proposed procedures were tested against the applied reference methods. In the case of CTU-UHB classification and the OR approach, all differences were statistically significant. The results for the pH are presented in , the symbol “+” denotes the difference that was statistically significant ( value < 0.05). The statistically insignificant differences were observed only in relation to (c + p)-means clustering.
Table 3. The classification results for the SisPorto dataset using the presented clustering.
Table 4. Comparison of the results for the SisPorto dataset with the applied reference methods.
Table 5. The binary classifiers in the three-class classification of the SisPorto dataset.
Table 6. Comparison of the classification results (from literature) for the SisPorto dataset.
Table 7. Statistical significance of the differences between the results for the pH approach; the symbol “+” denotes statistically significant difference (p-value < 0.05).
The classification results of the CTU-UHB dataset were also reported in Rotariu et al. (Citation2014) and Spilka et al. (Citation2013). Spilka et al. (Citation2013) used pH values as the reference, and the nearest mean classifier with adaboost was applied. From the presented cumulative confusion matrix, it is possible to calculate Se = 64.1% and Sp = 65.2%, whereas we achieved lower Se (47.6%) and higher Sp (85.6%). However, in Spilka et al. (Citation2013) the limiting value of pH indicating the abnormal fetal state was set to 7.05, which might result in increase of the Se. In Rotariu et al. (Citation2014), the CTG signals were classified as normal or abnormal based on accelerations and decelerations established in connection to the uterine contractions. The results were compared to the signals classification based on pH value and Apgar scores providing Se = 73.2% and Sp = 88.2%.
The quality of the three-class classification of the SisPorto dataset is summarized in . Similarly to the two-class classification, the methods provided higher mean values of the analyzed efficiency indexes. The best density type for the
may be indicated with respect to the highest value of the ACC (
) or
(
). With
the highest value of the
was obtained as well. compares in detail the three-class classification quality obtained using the presented procedure (
) with the applied reference methods. The LSVM achieved the highest ACC, however, it was characterized by lower values the
and the
when compared to the
-means and to the
. The
-means was characterized by the lowest value of the
, which results in the lowest ACC. We may conclude that the classification efficiency of the
is better in terms of the highest values of the
and
. The parameters and the results of the binary classifiers providing the best classification efficiency are shown in .
The statistical significance of the obtained results is shown in . The insignificant differences were noted between the and
-means methods only.
Table 8. Statistical significance of the differences between the results (ACC) for the SisPorto dataset, the symbol “+” denotes statistically significant difference (p-value < 0.05).
The three-class classification problem of the SisPorto dataset was also the topic of various researches (Das, Roy, and Saha Citation2013; Menai, Mohder, and Al-Mutairi Citation2013; Tomas et al. Citation2013; Yilmaz and Kilikcier Citation2013; Sundar, Chitradevi, and Geetharamani Citation2012), and the results are summarized in . In Tomas et al. (Citation2013) among three classifiers analyzed, the Random Forest was indicated as providing the best results: ACC = 93.7%, ,
,
. The classification procedure based on the least squares SVM and binary decision tree was presented in Yilmaz and Kilikcier Citation2013. The following results for the 10-fold cross-validation were obtained: ACC = 91.6%,
,
,
. In Sundar, Chitradevi, and Geetharamani Citation2012, the classification quality obtained by the ANN, applying 10 trials, was reported by the Recall measures: 99.1% (for normal class), 36.9% (suspicious) and 97.5% (abnormal). The Fuzzy Unordered Rule Induction Algorithm (FURIA) fuzzy-rule-based classifier used in Das, Roy, and Saha Citation2013 provided ACC = 94.6% and the following Recall measures: 90.3% (for normal class), 78.0% (suspicious), and 87.5% (abnormal) applying 5-fold cross-validation. In Menai, Mohder, and Al-Mutairi et al. Citation2013 the influence of four feature selection methods on the three- and ten-class classification quality was examined. In the case of the three-class classification, the best results were reported by the accuracy equals to 94.0% being the average across 100 trials. Comparing the efficiency of the proposed
classifier (ACC = 91.7%,
,
,
), we achieved higher value of
, once of ACC and twice of
. The presented classifier provided better classification accuracy for the class “suspicious,” however, improvement for two other classes is still needed.
The researches presented in Ocak and Ertunc (Citation2013) and Sahin and Subasi (Citation2015) describe the two-class classification of the SisPorto dataset (the “suspicious” class was excluded). In Ocak and Ertunc (Citation2013), the adaptive neurofuzzy inference system was applied, and the following classification accuracies for the testing set were reported: 97.2% for normal and 96.6% for abnormal cases. The evaluation of eight different machine-learning methods was presented in Sahin and Subasi (Citation2015), and the best results using the 10-fold cross-validation procedure were ACC = 99.2%, Se = 94.1%, and Sp = 99.7%. We can compare these results with the ACC = 98.8%, Se = 96.2%, and Sp = 99.1% provided by the binary classifier NA (). With the proposed method, we achieved lower Se and higher Sp compared to Ocak and Ertunc (Citation2013), and higher Se and lower Sp compared to Sahin and Subasi (Citation2015).
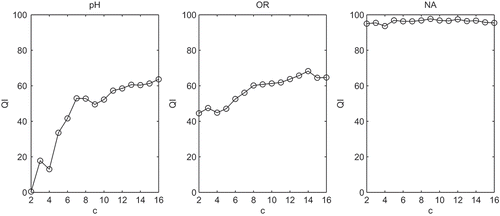
We investigated also the influence of the parameters’ values on the classification quality. We changed values of a given parameter while maintaining constant the remaining parameters. For each parameter, the range (rQI) of the QI was calculated as the difference between the maximum and minimum values (calculated as means for all 100 testing sets). The results of the CTU-UHB classification showed the highest influence of the initial number of clusters c (the rQI = 63.2% for pH and 23.8% for OR). For pH, we obtained rQI = 10.9%, 2.7%, 1.4%, and for OR approach rQI = 14.0%, 3.9% and 1.5%, respectively, for m, γ, W. With the increase of c, the increase of the QI was noticed also, but with higher m we got lower QI. In the case of the NA binary classifier for the SisPorto dataset, the highest rQI = 5.2% was observed for γ. In the case of m, c, and W, we got rQI = 4.5%, 4.0%, and 0.5%, respectively. The charts presenting the change of the classification quality with the change of the initial number of clusters per class are shown in .
Figure 1. The influence of the initial number of clusters per class (c) on the classification quality (QI).
Conclusions
In the presented work, we discuss the problem of fetal state assessment based on the analysis of the cardiotocographic signals. The classification procedure based on fuzzy clustering with pairs of prototypes was proposed to support the qualitative fetal state evaluation. To verify the efficiency of the fuzzy classifier, two benchmark sets (CTU-UHB and SisPorto) containing the cardiotocographic data were used. In the case of the CTU-UHB, it was difficult to compare the obtained classification efficiency with the results from the literature due to different inputs and outputs of the classifiers. However, improvement was achieved in relation to the applied reference methods. In the case of the three-class analysis of the SisPorto dataset, the increased classification quality was noticed when compared with the applied reference procedures; nevertheless, we did not improve the overall classification accuracy. When relating to other methods described in the literature, we got better classification accuracy of the “suspicious” class recognition, but improvement of the three-class analysis of the SisPorto CTG signals can still be achieved.
Funding
This work was partially supported by the Ministry of Science and Higher Education funding for statutory activities of young researchers (BKM-508/RAu-3/2016) and the Ministry of Science and Higher Education funding for statutory activities (BK-220/RAu-3/2016).
Additional information
Funding
References
- Ayres-de-Campos, D., J. Bernardes, A. Garrido, J. Marques-de-Sa, and L. Pereira-Leite. 2000. SisPorto 2.0: A program for automated analysis of cardiotocograms. Journal of Maternal-Fetal Medicine 9 (5):311–318.
- Bezdek, J. C. 1981. Pattern recognition with fuzzy objective function algorithms. New York, NY: Plenum Press.
- Chudacek, V., J. Spilka, M. Bursa, P. Janku, L. Hruban, M. Huptych, and L. Lhotska. 2014. Open access intrapartum CTG database. BMC Pregnancy and Childbirth 14 (16):1–12. doi:10.1186/1471-2393-14-16.
- Czabanski, R. 2006. Deterministic annealing integrated with ε-insensitive learning in neuro-fuzzy systems. In Proceedings of 8th international conference on artificial intelligence and soft computing (ICAISC 2006), ed. L. Rutkowski, R. Tadeusiewicz, L. A. Zadeh, and J. Zurada, 220–229, Lecture Notes in Artificial Intelligence 4029. Berlin Heidelberg: Springer-Verlag.
- Czabanski, R., J. Jezewski, K. Horoba, and M. Jezewski. 2013. Fetal state assessment using fuzzy analysis of fetal heart rate signals - Agreement with the neonatal outcome. Biocybernetics and Biomedical Engineering 33:145–155. doi:10.1016/j.bbe.2013.07.003.
- Czabanski, R., J. Jezewski, A. Matonia, and M. Jezewski. 2012. Computerized analysis of fetal heart rate signals as the predictor of neonatal acidemia. Expert Systems with Applications 39:11846–11860. doi:10.1016/j.eswa.2012.01.196.
- Czabanski, R., M. Jezewski, J. Wrobel, K. Horoba, and J. Jezewski. 2008. A neuro-fuzzy approach to the classification of fetal cardiotocograms. In 14th Nordic-Baltic conference on biomedical engineering and medical physics, ed. A. Katashev, Y. Dekhtyar, and J. Spigulis, 446–449, IFMBE Proceedings 20. Berlin Heidelberg: Springer-Verlag.
- Das, S., K. Roy, and C. K. Saha (2013). Application of FURIA in the classification of cardiotocograph. In IEEE-international conference on research and development prospects on engineering and technology (ICRDPET 2013) Vol. 4, 120–124. IEEE.
- Georgieva, A., S. J. Payne, M. Moulden, and C. W. G. Redman. 2013. Artificial neural networks applied to fetal monitoring in labour. Neural Computing and Applications 22:85–93. doi:10.1007/s00521-011-0743-y.
- Georgoulas, G., C. Stylios, and P. P. Groumpos 2005. Classification of FHR during the intrapartum period using wavelet neural networks trained by PSO. In The 3rd European medical and biological engineering conference (EMBEC’05), 1–5. IFMBE Proceedings 11 (1)CD-ROM edition (ISSN: 1727-1983).
- Georgoulas, G., C. D. Stylios, and P. P. Groumpos. 2006. Predicting the risk of metabolic acidosis for newborns based on fetal heart rate signal classification using support vector machines. IEEE Transactions on Biomedical Engineering 53 (5):875–884. doi:10.1109/TBME.2006.872814.
- Goldberger, A. L., L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. Ch. Ivanov, R. G. Mark, J. E. Mietus, et al. 2000. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 101 (23):e215–e220. doi:10.1161/01.CIR.101.23.e215.
- Jezewski, M., R. Czabanski, and J. Leski. 2015. An attempt to optimize the cardiotocographic signal feature set for fetal state assessment. Journal of Medical Imaging and Health Informatics 5 (6):1364–1373. doi:10.1166/jmihi.2015.1540.
- Jezewski, M., R. Czabanski, J. Leski, and K. Horoba. 2015. A new approach for the clustering using pairs of prototypes. Journal of Medical Informatics and Technologies 24:113–121.
- Jezewski, M., R. Czabanski, J. Wrobel, and K. Horoba. 2010. Analysis of extracted cardiotocographic signal features to improve automated prediction of fetal outcome. Biocybernetics and Biomedical Engineering 30 (4):29–47.
- Jezewski, M., J. M. Leski, and R. Czabanski. 2016. Classification based on incremental fuzzy (1+p)-means clustering. In Man-machine interactions 4, Advances in intelligent systems and computing, ed. A. Gruca, A. Brachman, S. Kozielski, and T. Czachorski, vol. 391, 563–572. Switzerland Cham: Springer International Publishing.
- Jezewski, J., D. Roj, J. Wrobel, and K. Horoba. 2011. A novel technique for fetal heart rate estimation from Doppler ultrasound signal. BioMedical Engineering OnLine 10 (1):1–17. doi:10.1186/1475-925X-10-92.
- Jezewski, M., J. Wrobel, K. Horoba, A. Gacek, N. Henzel, and J. Leski. 2007. The prediction of fetal outcome by applying neural network for evaluation of CTG records. In Computer recognition systems 2, Advances in soft computing, ed. M. Kurzynski, E. Puchala, M. Wozniak, and A. Zolnierek, vol. 45, 532–541. Berlin Heidelberg: Springer-Verlag.
- Jezewski, M., J. Wrobel, P. Labaj, J. Leski, N. Henzel, K. Horoba, and J. Jezewski 2007. Some practical remarks on neural networks approach to fetal cardiotocograms classification. In Proceedings of the 29th annual international conference of the IEEE engineering in medicine and biology society, pp. 5170–5173. IEEE.
- Krupa, N., M. A. MA, E. Zahedi, S. Ahmed, and F. M. Hassan. 2011. Antepartum fetal heart rate feature extraction and classification using empirical mode decomposition and support vector machine. BioMedical Engineering OnLine 10 (1):1–15. doi:10.1186/1475-925X-10-6.
- Kupka, T., J. Jezewski, A. Matonia, K. Horoba, and J. Wrobel. 2004. Timing events in Doppler ultrasound signal of fetal heart activity. In Proceedings of the 26th annual international conference of the IEEE engineering in medicine and biology society, 337–340. IEEE.
- Leski, J. M. 2015. Fuzzy (c+p)-means clustering and its application to a fuzzy rule-based classifier: Toward good generalization and good interpretability. IEEE Transactions on Fuzzy Systems 23 (4):802–812. doi:10.1109/TFUZZ.2014.2327995.
- Lichman, M. 2013. UCI Machine learning repository. Irvine, CA: University of California, School of Information and Computer Science. http://archive.ics.uci.edu/ml
- Maeda, K., Y. Noguchi, M. Utsu, and T. Nagassawa. 2015. Algorithms for computerized fetal heart rate diagnosis with direct reporting. Algorithms 8:395–406. doi:10.3390/a8030395.
- Magenes, G., R. Bellazzi, A. Fanelli, and M. G. Signorini. 2014. Multivariate analysis based on linear and non-linear FHR parameters for the identification of IUGR fetuses. In 36th Annual international conference of the IEEE engineering in medicine and biology society – EMBC 2014, 1868–1871. IEEE.
- Magenes, G., M. G. Signorini, R. Sassi, and D. Arduini. 2001. Multiparametric analysis of fetal heart rate: Comparison of neural and statistical classifiers. In 9th Mediterranean conference on medical and biological engineering and computing (MEDICON 2001), eds. R. Magjarevic et al., 360–363, IFMBE Proceedings 1, Zagreb, Croatia: University of Zagreb, Faculty of Electrical Engineering and Computing.
- Mangasarian, O. L., and D. R. Musicant. 2001. Lagrangian support vector machines. Journal of Machine Learning Research 1:161–177.
- Menai, M. E. B., F. J. Mohder, and F. Al-Mutairi. 2013. Influence of feature selection on naïve Bayes classifier for recognizing patterns in cardiotocograms. Journal of Medical and Bioengineering 2 (1):66–70.
- Ocak, H., and H. M. Ertunc. 2013. Prediction of fetal state from the cardiotocogram recordings using adaptive neuro-fuzzy inference systems. Neural Computing and Applications 23:1583–1589. doi:10.1007/s00521-012-1110-3.
- Pedrinazzi, L., G. Magenes, and M. G. Signorini. 2004. Support vector machine for cardiotocographic clustering. In Proceedings of the MEDICON conference ( IFMBE 2004), Milano, Italy: GHEDIMEDIA, 1–4.
- Rotariu, C., A. Pasarica, G. Andruseac, H. Costin, and D. Nemescu. 2014. Automatic analysis of the fetal heart rate variability and uterine contractions. In 2014 International conference and exposition on electrical and power engineering (EPE 2014), eds. M. Gavrilas et al., New York, USA: IEEE, 553–556.
- Sahin, H., and A. Subasi. 2015. Classification of the cardiotocogram data for anticipation of fetal risks using machine learning techniques. Applied Soft Computing 33:231–238. doi:10.1016/j.asoc.2015.04.038.
- Signorini, M. G., A. de Angelis, G. Magenes, R. Sassi, D. Arduini, and S. Cerutti. 2000. Classification of fetal pathologies through fuzzy inference systems based on a multiparametric analysis of fetal heart rate. Computers in Cardiology 27:435–438.
- Spilka, J., V. Chudacek, P. Janku, L. Hruban, M. Bursa, M. Huptych, L. Zach, and L. Lhotska. 2014. Analysis of obstetricians’ decision making on CTG recordings. Journal of Biomedical Informatics 51:72–79. doi:10.1016/j.jbi.2014.04.010.
- Spilka, J., G. Georgoulas, P. Karvelis, V. P. Oikonomou, V. Chudacek, C. Stylios, L. Lhotska, and P. Janku. 2013. Automatic evaluation of FHR recordings from CTU-UHB CTG database. In 4th International conference on information technology in bio- and medical informatics – (ITBAM 2013), ed. M. Bursa, S. Khuri, and M. E. Renda, 47–61, Lecture Notes in Computer Science 8060. Berlin Heidelberg: Springer-Verlag.
- Sundar, C., M. Chitradevi, and G. Geetharamani. 2012. Classification of cardiotocogram data using neural network based machine learning technique. International Journal of Computer Applications 47 (14):19–25. doi:10.5120/7256-0279.
- Tomas, P., J. Krohova, P. Dohnalek, and P. Gajdos. 2013. Classification of cardiotocography records by random forest. In 2013 36th International conference on telecommunications and signal processing (TSP), eds. N. Herencsar, K.Molnar, Brno, Czech Republic: Faculty of Electrical Engineering and Communication, Brno University of Technology. 620–623. Papers from this conference are available in IEEE Xplore Digital Library.
- Wrobel, J., J. Jezewski, K. Horoba, A. Pawlak, R. Czabanski, M. Jezewski, and P. Porwik. 2015. Medical cyber-physical system for home telecare of high-risk pregnancy: design challenges and requirements. Journal of Medical Imaging and Health Informatics 5 (6):1295–1301. doi:10.1166/jmihi.2015.1532.
- Wrobel, J., A. Matonia, K. Horoba, J. Jezewski, R. Czabanski, A. Pawlak, and P. Porwik. 2015. Pregnancy telemonitoring with smart control of algorithms for signal analysis. Journal of Medical Imaging and Health Informatics 5 (6):1302–1310. doi:10.1166/jmihi.2015.1533.
- Yilmaz, E., and C. Kilikcier. 2013. Determination of fetal state from cardiotocogram using LS-SVM with particle swarm optimization and binary decision tree. Computational and Mathematical Methods in Medicine 2013:1–8.