
ABSTRACT
Being a highly significant and complex function of management, decision making requires methods and techniques that simplify the process of selecting one choice among all available options. Decision making is therefore selection of that particular choice over any of several alternatives. Because of the process complexity, a continuous research and improvement of the methods and techniques modern decision making involves is required. One of many modern business challenges is to discover any possible improvement in the decision-making process managers shall use in making the right decision. Any decision made by managers directly impacts the realized profit, business, and company’s position on the market. The fact is that mankind faces the decision-making problem in each phase of its social development, which has resulted in increased need for learning more about it. In this work, both the significance and application of association rules will be analyzed on an example of car sales business. The research was conducted on a sample of 1728 transactions in order to recognize and establish the association rules and then determine their impact on the sales and profit. For the purpose of this research, a large car sales database was used as a source of information, which is also described in this work. Once these association rules were established, they were then used to create a better and more complete market supply. The main contribution of the paper is providing business intelligence model for performing association rules in real-term business settings.
Introduction
In this paper, one application of business intelligence techniques on a real business problem has been described. Some modern software architecture has been used for this purpose, namely Orange data mining software, which is a very popular data mining tool among managers, who use it massively to support themselves in decision making. The research problem shows the complexity and importance of managers’ decision-making process improved by the business intelligence tools. Having direct impact to the positioning of the company at the market and creation of the profit, it is very important to seek for the suitable long-term solutions of use of application rules that will provide expert support.
Scientist Agrawal was the first to establish association rules back in 1993 in order to perform the analysis of market basket. The market basket method has predominantly been used in sales analyses since, although its significance has been proved in other fields such as the analysis of credit card sales, identification of insurance companies committing a fraud, or analysis of telecommunication services. However, this method cannot be explicitely used in case of simultaneous events, but only in case of successive events, which may be very useful in marketing for instance. Since then, use of application rules has been highly appreciated and investigated in various fields of application.
Summary of contribution of this paper:
Theoretical framework section, where distinguished previous research on association rules application has been described, as well as the basic formalism of decision-making process;
Methodology section, where methodology of association rules used in the paper has been described in details;
Results and discussion section, where main results of the created model and contribution to the research problem have been described in systematic manner;
Conclusion section, where concluding remarks describe the main contribution of the paper, as well as the limitations and future research directions.
Theoretical framework
Catalog Sales is an example of a company that successfully applied the association rules method in marketing, which resulted in significant increase in their sales (Yang and Liu Citation2012). The application of this method revealed the need for creating catalogues that would contain specific groups of products to target different market segments.
This method was also used in solving a problem Colorful World of Colors co. had with their sales (Yang and Liu Citation2012). For example, the company reported decrease in sales of certain products, and it was necessary to determine if these products were to be sold together with other products or alone. Their research method included the analysis of preferences the first approach, that is, purchasing a combination of products from the two distinctive groups — popular (main) and non-popular products — would have over the other. The main group contained products bringing the highest sales profit. The research showed continued higher interest in purchasing the main group products while the sales of those other products kept the same level as before.
Another example of successful application of the association rules method is in the field of web browsing [25]. Here, the methods used to discover those web pages that had been accessed successively, and the information about users who had accessed pages A and B in order to access page C were then used for creating a suitable link (i.e., from A to C), which resulted in further analysis of e-business.
There has been research on how to approach the matter of discovering association rules in huge databases. One such approach has been derived from the conventional Apriori approach with assets in order to improve data searching. Numerous experiments were conducted in order to develop new algorithms, whose performance was then compared with the performance of the existing algorithms in the literature. The experimental results have proved a significant improvement this new approach brings regarding quick and effective search for data sets and association rules (AL-Zawaidah, Jbara, and AL-Abed Abu-Zanona Citation2011; Doko Citation2010; Fernando and Susanto Citation2011; Klepac and Mršić Citation2006).
One more example of successful application of the association rules method on a large database of sale items is described in (Venkatesh and Malthouse Citation2006; Verhoef et al. Citation2010). Amigo group co. has taken part in a project that involves searching for data in web-based databases. Here, FP-Growth algorhitm is used for the purpose of implementing association rules. This algorhitm uses its own rules to form a structure of data known as FP-Tree. The results obtained will then be used to help the company managers understand their customers’ purchase habits and analyze the items that are usually purchased together. Based on this, the managers will create a successful marketing strategy in order to increase the sale of such items.
Another important research regarding the application of the association rules method has been conducted in the field of intelligent transportation systems. These systems represent the next step in developing transportation systems, advanced information technologies as well as data transmission, e-sensor, control, and computer technologies. The use of the existing means of transportation could be made more efficient, the pollution they create could be reduced, and the safety of transport itself could be greatly improved, all that with the assistance of relating association rules. The research has presented one intelligent transportation system based on a set of association rules and models. Comparative analysis of the obtained results explains in detail and recommends the directions for further research. More information is available in (Čupić and Suknović Citation2008; Delibašić, Suknović, and Jovanović Citation2009; Drucker Citation2003).
All the examples above show how wide the application of the association rules methods in business can be. The researchers have drawn some significant conclusions based on which the right business decision can be taken. The methods proved to be most effective when applied to the market basket analysis, where association rules were used to identify patterns in purchasing products related to the car sales business.
Three dimensions determining complete development of this discipline need to be highlighted: qualitative, quantitative, and information-communication aspect. These three aspects of decision making completely satisfy all the concepts of modern decision making development, both theoretically and practically.
Quantitative approach in modern decision making defines the basic formalism of general decision-making problem (Suknović and Delibašić Citation2010). According to (Suknović Citation2001), the decision-making problem is a five-item problem (A, X, F, Θ, ≻) where:
A: represents a definite set of available alternatives (actions) ranked by a session participant in order to select the most acceptable one;
X: represents the set of possible outcomes as a consequence of selecting an alternative;
Θ: represents a set of world states and depends on the unknown state θ∈Θ because the consequences of selecting alternative a ∈A may differ;
F: A x Θ → X, for each world state ϖ and for each alternative a, determines the resulting consequence x = F (a,ϖ);
≻: weak order relation on X, i.e., a binary relation that satisfies the two following criteria:
Completeness: either x ≻ y or y ≻ x, ∀ x, y ∈ X;
Transitivity: if x ≻ y and y ≻ z then x ≻ z, ∀ x, y, z ∈ X.
Relation ≻ features the decision maker and is called a preference relation. Two other important relations can be derived from the preference relation. The first is the strict preference relation where x ≻ y if and only if both x ≥ y and not y ≥ x. The second is the indifference relation where x ~ y if and only if x ≥ y and y ≥ x. The most often way of solving decision-making problems is the transformation of weak order ≻ on X into normal order ≥ over the field of real numbers by the means of utility functions.
As the perfect solution rarely exists, a decision-making process will be deemed successful if it produces the most acceptable decision for given problem. As stated in (Suknović and Delibašić Citation2010), the moment of taking such a decision is unquestionably both the most creative and most critical moment in the complete process of decision making.
Methodology
Data mining is a process of analyzing large data sets in order to discover significant patterns and rules. As modern companies are constantly seeking for higher goals, which especially refers to their productivity, it becomes absolutely necessary to improve the functioning of their organization through better understanding of their customers’ needs. Data mining techniques and tools are widely used in various fields of application — law, astronomy, medicine, industrial process control, and so on. In fact, not a single data mining algorithm has been designed for any commercial use. Which combination of techniques will be used in research depends on the research task, available data, and also researcher’s skills and preferences. Data mining can be direct and indirect. Direct data mining tries to explain or categorize targeted items, such as money income for example; indirect data mining tries to recognize patterns or similarities between data sets without targeting specific items, collections of items, or predefined classes.
Data mining is mostly used in creating models. A model is either a simple algorithm or set of rules according to which a group of input elements (input) is interconnected with a group of output elements (goal). Most of the other techniques, such as regression, neural network technique or decision-making trees, are also model oriented. Under the right circumstances, a model can provide an explanation on how output elements of particular interest, such as precise order or unsuccessful paying of bills, are interconnected and how they can be predicted based on the available facts.
Association rules determine which items have been purchased together. According to (Davenport and Prusak Citation2000), the term association rules was first introduced by Agrawal. The task is to identify a set of rules that co-exist in some data set. According to (http://orange.biolab.si/), knowledge is a theoretical or practical understanding of facts and information, while wisdom is the synthesis of knowledge and experience that deepens our understanding of connections between different entities and uncovers some hidden message in their existence. If knowledge is considered tools, then wisdom can be considered a set of skills using knowledge as its tools. There is a case of association rules in the field of market basket (Chauhan and Cerpa. Citation2001), where these rules classify into groups the items purchased together in supermarkets.
Supermarket chains use association rules in order to place the items they sell on their shelves or put these items in their catalogues so that two items that are usually purchased together can be found on a shelf one next to the other. These rules are also used when assessing a chance for cross-selling, designing an attractive packaging, or grouping products or services. Here is a simple approach to create association rules from the available data. A pure fact is that the computer and the web camera are close to one another in any home most of their time. Therefore, it is possible to set the following association rules:
A customer who purchases a computer will purchase a web camera with probability P1;
A customer who purchases a web camera will purchase a computer with probability P2.
The quality of discovered association rules and therefore their importance is estimated based on two parameters — Support and Confidence. Confidence is defined as part of a sample to which certain association rule applies. It is given in percentage and describes how well this rule is established in the sample. If we now adopt that each sample consists of a number of cases, then Confidence determines what percentage of cases possessing attribute A also possesses attribute B. The greatest disadvantage of association rules is the lack of sufficient interconnectivity between them in most cases when large databases are analyzed, in which case their simplicity may lead to their inconsistency (Delibašić, Suknović, and Jovanović Citation2009).
Among many approaches used for identifying suitable association rules, Apriori algorithm distinguishes itself as the most basic one. This algorithm is based on the presumtion that if a number of items appears in a data set, in that case each item appears in the same data set as well (Agrawal, Imielinski, and Swami Citation1993). The way these association rules are applied can be observed by analyzing the relation between the number of computers and the number of anitivirus (AV) software copies sold in one computer shop. The information on customers who have purchased a computer and now want to purchase a copy of AV software can be presented by the following association rule:
Support = 2% means that 2% of all the purchase transactions completed in the computer shop indicate that the two products were purchased together. Confidence = 60% refers to 60% probability that a customer who has purchased a computer will also purchase a copy of AV software. Data mining process may have different tasks. Depending on the nature of data mining results, the tasks can be as follows:
Exploratory data analysis (EDA) — large databases consist of huge amounts of data. The task of EDA is, first, to find the knowledge required by the user and, second, to analyze data. These techniques are interactive and visible to consumers.
Descriptive modeling — describes all data and models all data probability distributions, also partitions a multi-dimensional space into groups, and creates models that define relations between variables.
Predictive modeling — is used to create models made up of variable factors that are likely to influence future behavior or results. Such a model predicts values of these relevant variables much better comparing to the known values of other variables.
Discovering patterns and rules — is a task primarily used for discovering hidden patterns and association rules in a cluster. Different cluster sizes are possible. The goal of this task is to determine the most efficient way of discovering these patterns. This goal can be achieved by using rule induction algorithms as well as many other data mining techniques. Such algorithms are called clustering algorithms.
Content analysis — is a task primarily used for discovering frequently accessed data sets based on their content, such as audio or video files and also images. This is a process of discovering patters in the targeted data set that are similar to those of particular interest.
Knowledge Discovery Process is a process used for discovering knowledge, and it includes both discovering raw data by exploiting the preferred data mining algorithms and processing of research results. Intelligent Discovery Assistants (IDA) are programs that can assist in discovering knowledge necessary to start research and complete its task. Users may benefit from these programs in the following three ways:
Systematic validation of Knowledge Discovery process
Effective ranking of valid processes according to different criteria, which helps in selecting the right option
Knowledge sharing infrastructure leading to the network externalization
The paper introduces a structure of data to be software processed. These data will then be further evaluated, and some significant information as to the problem specified will be extracted (Mihailović Citation2004). The knowledge is obtained by applying association rules as the result of decision-making process. The structure and the size of the research data sample as well as appropriate use of business intelligence tools will both contribute to the creation of an improved decision-making model.
According to (Suknović Citation2001), three aspects that determine the complete development of modern decision making are: qualitative, quantitative, and information-communication aspect. The research results will be shown in respect of all the three aspects of business decision making on the applicative level. The data will be shown quantitatively and process numerically. Appropriate business intelligence methods and techniques will be applied. Attributes, sub-attributes, and the research results will be described in order to ensure the qualitative aspect of modern decision making. Use of software architecture and visual data reviewing will ensure information-communication aspect of modern decision making. Data modifications will be possible in the course of research. Many authors described data mining approach (Delibašić, Suknović, and Jovanović Citation2009; Grob, Bensberg, and Kaderali Citation2004; Hornick, Marcade, and Venkayala Citation2007; Kriegel et al. Citation2007; Venkatesh and Malthouse Citation2006)
The data used for the purpose of this research are all car sales related. A total of 1728 transactions were processed. Attributes were assigned to shopping (very high, high, medium, and low rate of transactions), car maintenance (very high, high, medium, low level), number of car doors (two, three, four, or five), number of seats (two, three, four), trunk size (small, medium, large), and safety (low, medium, high). All the data were classified as: accurate, inaccurate, good, and very good.
Results and discussion
Orange is extremely handy and user-friendly software that contains numerous data mining options for data analysis, such as model integration, testing, data visualization, solution application, and so on. One of the most popular and well-proven technologies for data mining is CRISP-DM methodology. The CRISP-DM model consists of the following phases:
Business understanding
Data understanding
Data transformation
Modeling
Evaluation
Deployment
Each of these six CRISP-DM methodology phases is included in Orange.
As previously said, the paper describes a case of car sales business problem. To discover the association rules in a large database of car sales transactions, the data have been processed using Orange software. These association rules can provide customers with enough knowledge to make the right decision in respect of the most acceptable purchase, which may later contribute to improving future sales. The association rules can further help customers select a car to purchase by providing them with relevant sales data based on the information gathered from previous sales. Validation of both the obtained project solution and its application in practice has been made.
shows the desktop appearance of Orange software with its data search options. Underneath the menu bar, there is the tools menu with the main project functions. Data mining functions such as uploading data, visualization, classification, evaluation, or association rules are also available (Grabmeier and Lambe Citation2007; Saaty Citation1972; http://orange.biolab.si/). This is where the model of association rules applied to this research data was created. shows the data entry options of Orange software. For the purpose of identifying the association rules, a predefined data set has been used.
Figure 1. Desktop appearance of Orange software.
Figure 2. Data entry options of Orange software.
The first step was uploading the data file into the program. The Support and Confidence parameters were defined next. For this particular case, the lowest Support was initially set at 30%, and the lowest Confidence at 60%. As the research progressed, these parameters were altered in order to determine their impact on the final result of the association rules searching process.
shows the preview of obtained association rules. Considering the fact that the minimal Support had been set at relatively high 30%, only two association rules were obtained. The first association rule, with this parameter set at such a high value, was indicating that the two-seater car was classified as inaccurate. Moreover, 30% of all the car sales transactions for the two-seater car fell into this class. With the Support changed at 50%, if a customer was to purchase a car classified as inaccurate, there was 50% probability that a two-seater car would be purchased. The second association rule referred to the safety issue and established that the low safety cars were most often classified inaccurate.
Figure 3. Overview of created model of association rules.
Figure 4. Database characteristics.
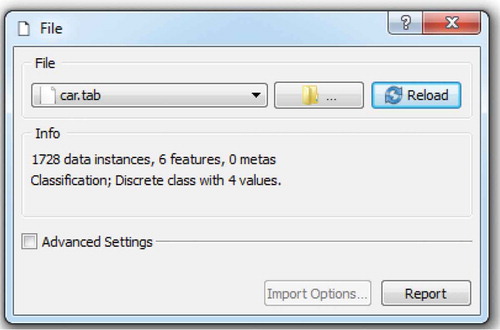
Figure 5. Start dialog box.
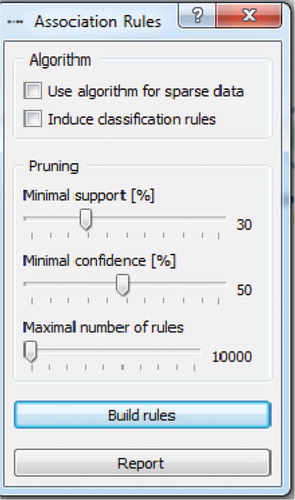
Figure 6. Association rules.
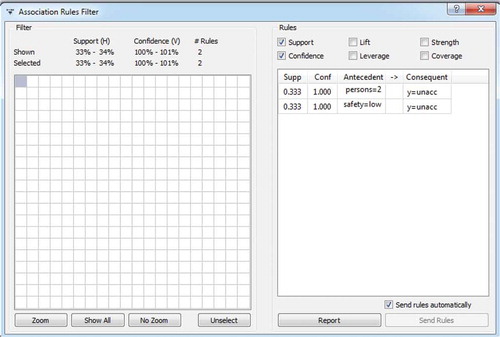
Orange has built in some excellent options for visual previewing of obtained results. A report will show both the number of obtained association rules and their description.
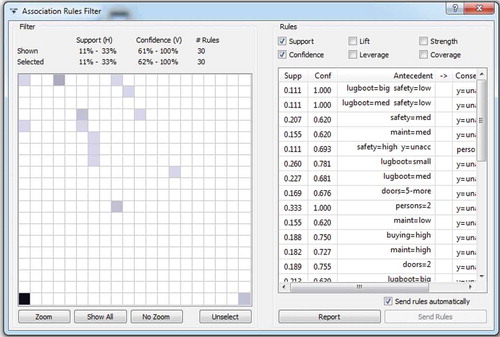
Different results were obtained when the minimal Support was reduced from 30% to 10%, and the minimal Confidence was increased from 50% to 60%. The number of discovered association rules consequently increased. There were 30 new association rules with the Support ranging from 11% to 33% and Confidence ranging from 62% to 100%. Further analysis of the obtained results revealed the purchasing patterns to be used in forming the optimal set of products in order to increase the sales rate and satisfy the customers to the furthest extent possible. shows these obtained association rules (the left-hand side of the window) together with their Support, Confidence, and description (the right-hand side of the window).
Figure 7. Example of association rules.
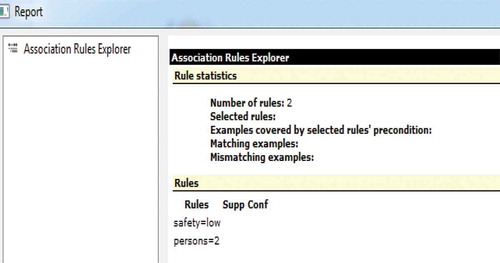
Figure 8. Support / Confidence parameters’ settings.
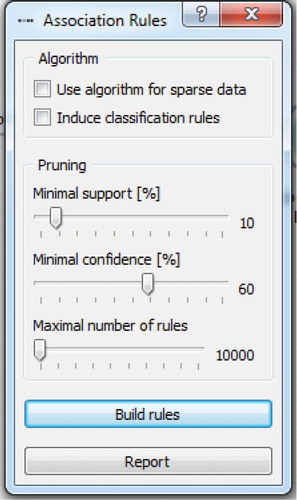
Figure 9. Example of obtained association rules.
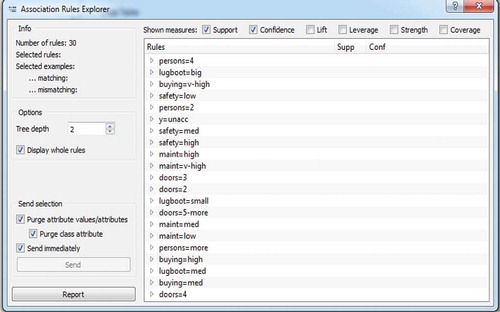
Figure 10. Obtained association rules with their parameters.
Highlighted is the association rule with the highest Support and Confidence, of 0.333 and 1, respectively. This rule says that if a customer purchases a two-seated car, he/she will most likely decide to purchase one classified as inaccurate. The analysis of each association rule showed precision in characteristics and patterns in the customers’ behavior. Yet another association rule, the one with the Support of 0.260 and Confidence of 0.781, distinguishes itself. This rule says that when smaller car interior space is preferred, a customer will most likely decide to purchase a car classified as inaccurate
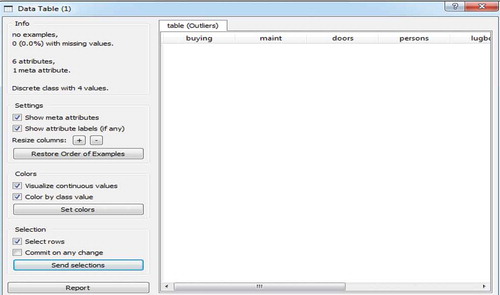
Nonstandard data may cause problems in creating a model. In statistics, such data are known as outliers. They occur rarely and are not subject to rules that apply to all other data from the same data set. They can either indicate errors or simply represent cases digressing abnormally from other, standard cases for some reasons. Because of all this, they could have various negative impacts on a model’s consistency in respect of data quality, making it very difficult for the model’s algorithms to discover regularities in the presence of such exceptions. Outliers node is used to identify and delete outliers from the program.
During the data preprocessing, the extent of the outliers’ presence in the sample was checked (). No nonstandard data that could affect the quality of the model were identified ().
Figure 11. Model for identifying outliers.

Figure 12. Report on outliers.
Apriori algorithm was next applied to the data, and a set of association rules was obtained. The rules were then checked, and those most important ones were selected for creating meta rules, in order to reduce redundancy and obtain the most acceptable solution.
The obtained solution may be used not only for discovering the original universal rule for improving car sales but also for improving sales of products in many other cases. With a proper and expert interpretation, the obtained results may be used for increasing the volume of sales and thus profits of automotive companies. Associations have been discovered between certain purchased products and characteristics of customers. Marketing campaigns can be planned based on the recommendations resulted from the knowledge revealed by appropriate business intelligence tools. Recommendation is also to provide prospective customers with a questionnaire containing questions about the most favorable car characteristics from the customer’s point of view.
Car attributes (characteristics) used for the purpose of this research were: price, maintenance costs, number of doors, number of seats, trunk size, and safety. The obtained association rules suggested that those customers interested in purchasing a low-safety two-seated car would most likely purchase a car classified as inaccurate. Marketing experts and experts from the sales sector are recommended to work to attract potential customers by evaluating their needs and offering them a suitable car with the highest probability of purchase. They are also recommended to organize suitable promotional activities for their existing and potential customer base, where it will be possible to purchase additional equipment together with a car. Furthermore, the obtained association rules also show that when a car is purchased, the car radio is commonly purchased as well being part of the car’s additional equipment. Therefore, any marketing strategy should be developed with respect to this information on order to be successful. For example, a big discount on the car radio will be offered to a customer who purchases a car. Or perhaps, if two cars are purchased together, then the customer gets both car radios for free.
Conclusion
The main advantage this research brings forth is its original approach in using business intelligence tools based on science. The main comparative advantage of the model created here lies in its wide applicability (car sales, banking, education, etc.). The main novelty of the paper is creating and explaining new model based on the obtained association rules developed to solve business problems in an easy and efficient manner. Simplified user interface and visual preview of the model provide a clear insight into each phase of decision-making process. The topic researched here is extremely challenging and provides extensive space for further elaboration of the association rules application. Certainly, by upgrading this model, that is, improving its characteristics, better results could be achieved, and completely new research course could be set. The obtained association rules were used to create better and more comprehensive market offer. Real-time settings and practical implication of the research provide it advantage compared to other similar researches. Some experienced business intelligence analysts were consulted concerning the research results.
By analyzing the current research work of various experts in the field of business intelligence, and despite the fact this field is relatively new in some segments of application, a great popularity and potential it carries have been proved. Therefore, it presents a challenge to researchers in those areas where further significant scientific and expert contribution can be expected. Any innovative research in the field of business intelligence is shaped with knowledge and creativity and conducted with the assistance of modern data mining software architectures. The obtained results have been analyzed using modern scientific methods, and several recommendations for the future research course have been made.
For the purpose of this research, a large car sales database has been used for extracting data and discovering association rules. The obtained association rules have been used to create better and more comprehensive market offer. The process of improving the car sales model has been presented having in mind that managers learn about their customers’ purchase habits through association rules. The market offer has been improved because of increased efficiency of the car sales management achieved by use of business intelligence techniques. The results of this successfully conducted research are higher sales rate and greater satisfaction of customers. A limitation of this research is that original database was used containing data from the region of South-East Europe. Therefore, interpreted results should relate to the above-mentioned region.
The primary motive for developing this model was to indicate the significance of association rules in the decision-making process of modern management. The developed model has indicated the significance of business intelligence methods and techniques in supporting business system management. This support reflects in finding the most acceptable solution with respect to profit maximization. The recommended direction of future research in this field will be creating a commercial decision-making model applicable to markets belonging to different business systems. The importance of business intelligence tools in creating a model that can increase the effectiveness of decision-making process has been emphasized. The application of association rules in research conducted in the field of business has some great potential. The significance of multidisciplinary approach has been explained — the dependence between decision making, business intelligence, human resource management, knowledge management, and modern ICT has been proved to be effective in the case of business system management.
References
- Agrawal, R., T. Imielinski, and A. Swami. 1993. Mining association rules between sets of items in large databases. In Proceeding 1993 ACM-SIGMOD, International Conference Management of Data, 207–16. Washington, DC.
- AL-Zawaidah, F. H., Y. H. Jbara, and M. AL-Abed Abu-Zanona. 2011. An improved algorithm for mining association rules in large databases. World of Computer Science and Information Technology Journal (WCSIT 1 (7):311–16. ISSN: 2221-0741.
- Chauhan, A., and N. Cerpa., “A comparison for procurement models for B2B Electronic Commerce”, Proceedings of the OPTIMA Conference, October 10-12, 2001, Curico, Chile.
- Čupić, M., and M. Suknović. 2008. Decision making. Belgrade: FOS.
- Davenport, T. H., and L. Prusak. 2000. Working knowledge: How organizations manage what they know. United States: Harvard Business Press.
- Delibašić, B., M. Suknović, and M. Jovanović. 2009. Algorhitms of machine learning for data mining. Belgrade: FOS.
- Doko, A. 2010. Automatic genesis of onthology and browsing the Web, Split. A.L.E.N., Croatia.
- Drucker, P. 2003. My view on management. Novi Sad: Adiges.
- Fernando, B., and B. Susanto. 2011. The implementation of association rules in analyzing the sales of Amigo group. Journal Informatika 7 (1):10.
- Grabmeier, J., and L. Lambe. 2007. Decision trees for binary classification variables grow equally with the Gini impurity measure and Pearson’s chi-square test. International Journal of Business Intelligence and Data Mining 2:213–26. doi:10.1504/IJBIDM.2007.013938.
- Grob, H., F. Bensberg, and F. Kaderali. 2004. Controlling open source intermediaries – a web log mining approach. In Proceedings of the 26th international conference on information technology interfaces, 233–42. Cavtat, Croatia, IEEE.
- Hornick, M., E. Marcade, and S. Venkayala. 2007. Java data mining: Strategy, standard, and practice. San Francisco: Elsevier.
- Klepac, G., and L. Mršić. 2006. Business intelligence through business cases. Zagreb: Lider Press, Tim Press.
- Kriegel, H.-P., K. M. Borgwardt, P. Kröger, A. Pryakhin, M. Schubert, and A. Zimek. 2007. Future trends in data mining. Data Mining and Knowledge Discovery 15 (1):87–97. doi:10.1007/s10618-007-0067-9.
- Mihailović, D. 2004. Methodology of scientific research. Belgrade: FOS.
- Saaty, T. 1972. An eigenvalue allocation model for priorization and planning. University of Pennsylvania, Pennsylvania, United States. http://orange.biolab.si/
- Suknović, M., Development of methodology of support to group decision making, PhD dissertation, FOS, Belgrade, 2001.
- Suknović, M., and B. Delibašić. 2010. Business intelligence and systems for support of decision making. Belgrade: FOS.
- Venkatesh, S., and E. Malthouse. 2006. Moving interactive marketing forward. Journal of Interactive Marketing 20:2–4. doi:10.1002/dir.20057.
- Verhoef, P. C., R. Venkatesan, L. McAlister, E. C. Malthouse, M. Krafft, and S. Ganesan. 2010. CRM in data-rich multichannel retailing environments: A review and future research directions. Journal of Interactive Marketing 24:121–37. doi:10.1016/j.intmar.2010.02.009.
- Yang, X. F., and Z. Liu. 2012. The application of association rules mining in building intelligent, transportation systems. Journal of Convergence Information Technology (JCIT) 7(20, November). doi: 10.4156/jcit.vol7.issue20.67.