
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Bi-level optimization is a challenging research area that has received significant attention from researchers to model enormous NP-hard optimization problems and real-life applications. In this paper, we propose a new evolutionary bi-level algorithm for Flexible Job Shop Problem with Sequence-Dependent Setup Time (SDST-FJSP) and learning/deterioration effects. There are two main motivations behind this work. On the one hand, learning and deterioration effects might occur simultaneously in real-life production systems. However, there are still ill posed in the scheduling area. On the other hand, bi-level optimization was presented as an interesting resolution scheme easily applied to more complex problems without additional modifications. Motivated by these issues, we attempt in this work to solve the FJSP variant using the bi-level programming framework. We suggest firstly a new bi-level mathematical formulation for the considered FJSP; then we propose a bi-level evolutionary algorithm to solve the problem. The experimental study on well-established benchmarks assesses and validates the advantage of using a bi-level scheme over the compared approaches in this research area to solve such NP-hard problem.
Introduction
Job shop scheduling problem (JSSP) is considered as the most active research field with the area of combinatorial optimization problems (Garey, Johnson, and Stockmeyer Citation1976). This problem holds a set of jobs that should be processed on
specified machines. Each job consists of a specific set of operations, which must be processed according to a given order. Introduced by Nuijten and Aarts (Citation1996), the FJSP is a generalization of the above-described definition, where each operation could be processed by a set of resources with a processing time that depends on the used resource. However, most classical FJSPs studied in the literature consider the known job processing times as a constant over time, which is not appropriate for many realistic situations, where the actual processing time of a job might increase or decrease regarding its normal processing time if it is scheduled later. This dynamic nature of job processing time may be the result of two situations: (1) The first one is where employees and machines execute the same job several times. They learn how to perform such operation more efficiently. In other words, the productivity is getting continuously better by performing similar tasks repeatedly. Accordingly, the processing time of a given job will be smaller if it is scheduled later in the sequence. In the literature, this phenomenon is known as learning effects (Wright Citation1936). Empirical studies in several industries have demonstrated that the learning effects have a significant impact on manufacturing systems. This phenomenon takes place mainly when the workers are able to perform setup, deal with both machine operations and software, such as read data or handle raw materials. The learning theory confirmed that the time needed to produce a single unit is in decreasing at a uniform rate. This latter is restrainedly related to the manufacturing process being observed. In this context, several works were suggested, for instance, the work of Wang and Cheng (Citation2007), and Hosseini and Tavakkoli-Moghaddam (Citation2013), etc. For more details, we refer the readers to the recent survey on scheduling problems with learning effects (Azzouz, Ennigrou, and Ben Said Citation2018). (2) The dynamic nature of the processing time is the result of a second situation in which it is called deterioration effects. It occurs when machines lose their performance during their execution times. In this case, the job that is processed later consumes more time than another one processed earlier. Scheduling in such environments is known as scheduling with deteriorating jobs, and it is first introduced by Gupta and Gupta (Citation1988). The authors assumed that the processing time of all jobs is a function of their starting time. Since then, deterioration effects have widely studied in connection with scheduling problem.
Besides, bi-level programming problems are a special class of optimization problems with two levels of optimization tasks. These problems have been widely studied in the literature (Colson, Marcotte, and Savard Citation2007); and often appear in many practical problem solving tasks (Bard Citation2013). In practice, a bi-level scenario commonly occurs when a set of decision variables in an (upper level) optimization task is considered physically or functionally acceptable, only when it is a stable point or a point in equilibrium or a point satisfying certain conservation principles, etc. The satisfaction of one or more of these conditions is usually posed as another optimization task (lower level). Consequently, the bi-level scheme was presented as a new paradigm able to successfully solve a number of hierarchically NP-hard problems.
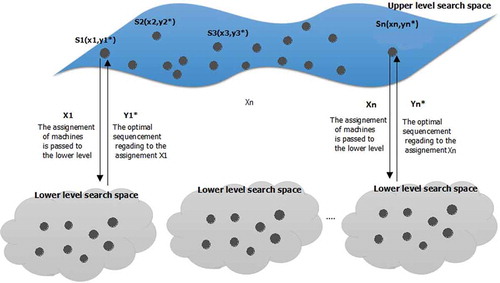
The particular structure of these optimization problems facilitates the formulation of several practical problems that involve a nested decision-making process. Motivated by this issue, we present in this paper, a new bi-level approach able to minimize the makespan criteria of the SDST-FJSP with learning/deterioration considerations. So far, we knew no other research was reported till date, where any variant of FJSP was addressed with bi-level optimization algorithm. Most of the researchers solved the problem as a single level optimization task. However, the nature of the problem fits quite well with the bi-level framework. To this end, we present in this work, a hierarchical structure of the problem such as a leader decision focuses on the assignment of jobs to machines, while a follower level is interested by the sequencement of operations. In other words, the leader assigns the jobs to machines and the follower sequences the jobs assigned to each machine. The main contributions of this paper are summarized as follows:
Proposing, a new bi-level evolutionary algorithm that we call (Bi-GTS) to solve SDST-FJSP with learning/deterioration effects.
Proposing a new mathematical bi-level formulation of the SDST-FJSP with learning/ deterioration effects, which will be evaluated using the bi-level proposed scheme.
Demonstrating the out-performance of our Bi-GTS over some of the most representative approaches with this research area which are VNS, TS, GA, and GTS on different commonly used benchmark problems from the literature.
FJSP Related Works
In recent years, FJSP has been highly studied by researchers. The problem could be decomposed into two sub-tasks: a routing sub-problem, which consists of assigning each operation to the available machine, and a scheduling sub-task, which consists in sequencing the assigned operations on all selected machines in order to optimize such considered objective function. Two kinds of approaches have been used to solve the problem: the hierarchical approach and the integrated one. Considering the first category, the routing sub-problem and the scheduling sub-problem are treated separately. The basic idea of this approach is to decomposing the original problem in order to reduce its complexity. Brandimarte (Citation1993) used, for the first time, this approach for solving FJSP. He treated the routing sub-problem using several dispatching rules and then he solved the scheduling sub-problem using a tabu search algorithm. According to Brandimarte, the hierarchical scheme can be further expressed by information flow among the two sub-problems: in a one-way scheme, a routing problem is firstly solved, and then a sequencing problem is solved; alternatively, there is an iteration between the two steps, but the two tasks are evolved separately using then a correction stage. Following this architecture, Zribi, Kacem, and El Kamel (Citation2004) solve the assignment problem using an heuristic algorithm and they apply a Genetic Algorithm (GA) to deal with the sequencing task. Another work in this field was reported by Saidi-Mehrabad and Fattahi (Citation2007). Alternatively, the integrated architecture were used by considering assignment and scheduling at the same time. During the last few years, successful results have been achieved within integrated architecture such as the work of Ziaee (Citation2014) and Azzouz, Ennigrou, and Ben Said (Citation2017), etc.
The majority of researchers on scheduling assume that the setup time is negligible or is a part of the processing time. However, machine setup time is an important factor for production scheduling in several manufacturing systems; it may consume more than 20 of available machine time (Pinedo Citation1995). In this way, there are two types of setup time: sequence-independent and sequence-dependent. In the first case, the setup time depends only on the job itself. However, in the second one, the setup time is not only dependent on the job but also on the previous job that ran on the same machine. Despite the relevance of the flexible job shop in real manufacturing systems, there is not many papers that consider both sequence-dependent setup-times and flexible job shop environments. We cite just the work of Saidi-Mehrabad and Fattahi (Citation2007) which presented a TS for solving the SDST-FJSP to minimize the makespan. Moreover, Bagheri and Zandieh (Citation2011) proposed a variable neighborhood search based on integrated approach to minimize an aggregate objective function (AOF) where
and
denote the weight given, respectively, to makespan
and mean tardiness
. The most recent comprehensive survey of scheduling problem with setup times is given by Allahverdi (Citation2015).
Bi-level Optimization: Basic Definition
As we mentioned previously, bi-level optimization is an important research area of mathematical programming (Dempe Citation2002). This type of problem has emerged as an important area for progress in handling many real-life problems in different domains, e.g.,, optimal control, process optimization, game-playing strategy development, transportation problems (Chaabani, Bechikh, and Said Citation2015b). The first formulation of bi-level programming was proposed in 1973 by Bracken and McGill (Citation1973). After that, Candler and Norton (Citation1977) are the first authors who use the designation of bi-level and multi-level programming with optimization problem. The decision variables of a bi-level optimization problem (BOP) are split into two groups that are controlled by two decision makers called leader (on the upper level) and follower (on the lower level). Both decision makers have an objective function of their own and a set of constraints on their variables. Furthermore, there are coupling constraints that connect the decision variables of leader and follower. The nested structure of the overall problem requires that a solution to the upper level problem may be feasible only if it is an optimal or near-optimal solution to the lower level problem.
Using this description, we present in the following the bi-level SDST-FJSP with learning and deterioration consideration formulation. Then, we describe the bi-level evolutionary algorithm to solve the problem.
A New Bi-level Mathematical Model for SDST-FJSP with Learning and Deterioration Considerations
The SDST-FJSP with learning and deterioration effects consists on performing jobs on
machines. The set of machines is noted
. Each job
consists on a sequence of
operations (routing). Each routing has to be performed to complete a job. The execution of each operation
of a job
noted (
), requires one machine out of a set of a given machines
(i.e.,
is the set of machines available to execute
). The problem is to define a sequence of operations together with the assignment of start times and machines for each operation. It is noteworthy that the following assumptions are considered in this paper:
• Jobs are independent of each other;
• Machines are independent of each other;
• One machine can process at most one operation at a time;
• No preemption is allowed;
• All jobs are available at time zero;
• The applied time deterioration rate is as follows:
where is the actual processing time for
on
machine and
is a normal processing time,
is the starting time of the operation and
is a non-negative deterioration index.
• Setup times are dependent on the sequence of jobs. When one of the operations of a job is processed before one of those of job
on machine
, the sequence depend setup time is
.
• The applied position based learning effect is defined as follows:
where corresponds to the actual SDST for
jobs on
machine and
is the normal SDST. We should mention here that the standard FJSP can be classified into two main categories: (1) the Total-FJSP (T-FJSP), and (2) the Partial-FJSP (P-FJSP) (Kacem, Hammadi, and Borne Citation2002). In T-FJSP, each operation can be processed by all machines. However, in P-FJSP, at least one operation may not be processed on all machines. Several researches pointed out that the P-FJSP is more general and complex as compared to T-FJSP on the same scale. In this paper, we consider the P-FJSP.
According to this description, we present in the following a hierarchical structure of the SDST-FJSP problem with learning/deterioration effects taking into account the presented assumptions and constraints. In fact, a leader decision level focuses on the assignment of jobs to machines, while a follower is interested by the sequencement of operations. In this regard, the leader’s objective depends only on its’ variables. (cf. ). However, the feasibility of a solution depends on the follower’s response as well. It is important to note that the main motivation behind the design of SDST-FJSP as a bi-level model is the possibility to well accelerate the diversity and the convergence of the search by exploring more job assignments in the upper level search space and then concentrates on one fixed assignment at each way, in order to found the corresponding optimal job sequencement. We seek then to enhance the search ability on the SDST-FJSP decision space in order to improve the quality of solutions. We give in the following, the used parameters and the decision variables used in our formulation:
the number of jobs,
the number of machines,
index for jobs where
,
,
index for operations of job
,
index of machines where
,
the set of jobs,
the set of machines,
the set of operations of a job
,
the
operation of job
,
takes value 1 if machine i is eligible for
and 0 otherwise,
the set of alternative machines in which operation
can be processed, (
),
the set of machines by which operations
and
can be processed,
the normal sequence-dependent setup time (SDST) of operation
on machine
,
the actual SDST of operation
on machine
,
the completion time of a job
,
the completion time of an operation
on machine
,
maximum completion time over all jobs (makespan),
the position of operation in the sequence,
learning index where
,
the normal processing time of operation
on machine
,
the actual processing time of operation
on machine
,
the deterioration rate
a large number.
The proposed mathematical model is defined as follows:

Decision variables
The upper level constraints are defined as follows: constraint (1) describes that each operation should be assigned to only one machine. Secondly, they specify that each operation is assigned to one of its eligible machines (on constraint (2)). Regarding to the lower level part, we consider eight constraints related to the sequencement of jobs on the different machines. Constraint (3) ensures that every operation could have at most one succeeding operation. Constraint (4) ensures that the dummy operation is the first one on machines. Constraint (5) assures that each operation has exactly one preceding operation on the same machine. Constraints (6) and (7) define the learning and deterioration formulas taken into consideration in this model. Constraint (8) guarantees that one machine cannot process two different operations simultaneously. In other words, the difference between the completion times of two consecutive operations on one machine should be greater than the setup time plus the processing time of the operation processed later. In fact, the constraint (9) ensures that the precedence relationships between operation
and
of a job should be satisfied. Thus, operation
cannot start before the operation
terminates its processing. The constraint (10) defines the completion times of the jobs, and finally, constraint (11) establishes the makespan parameter.
Figure 1. SDST-FJSP problem with learning effect formulated as bi-level optimization problem.
Bi-GTS Basic Scheme
As we have mentioned previously, the two main goals of this work are: (1) modeling SDST-FJSP with learning/deterioration effects problem using the bi-level optimization programming and, (2) designing a bi-level evolutionary strategy able to improve the resolution efficiently of this problem. In this work, we handle two types of meta-heuristics: a local optimization method based on Tabu Search (TS) with a global optimization approach based on GA, at both levels. The GA was applied in the upper level in order to better explore the whole search space and then to direct the algorithm into the region representing the best assignment vector. Our choice of the GA relies on the fact that this latter represents an evolutionary based algorithm, simple and powerful, able to solve complex combinatorial problem such as scheduling problem. In fact, the lower level problem was handling using the TS method, accentuating then the convergence rate of the procedure in the lower level space. The TS determines the optimal scheduling of the jobs on the
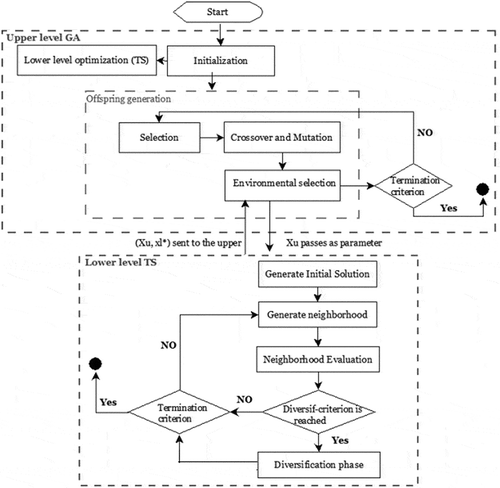
machines according to the upper decision variables (i.e., optimized assignment). To this end, the bi-level decision-making process is performed as follows. First, the GA process makes his decision and fixes the values of his upper variables (i.e., by applying selection, recombination, and mutation operators which are presented in the following subsections). After that, the follower reacts by setting his variables according to the ones fixed by the GA in the upper level. The leader has perfect knowledge of the follower’s scenario (objective function and constraints) and also of the follower’s behavior. The follower observes the leader’s action (the generated assignment), and then optimizes his own objective function subject to the decisions made by the leader (and subject to the imposed constraints). As the leader’s objective function depends on the follower’s decision, the leader must take the follower’s reaction into account (cf. ). To more understand the bi-level process, we present in the following the step-by-step procedure of our proposed algorithm.
Figure 2. Bi-GLS basic scheme.
Upper Level Optimization Procedure
Step 1 (Initialization Scheme): We generate an initial parent population of assignments randomly. Then, the lower level optimization procedure is executed to identify the optimal sequencements according to such generated affectation. In fact, the upper level fitness is assigned based on both upper level function value and constraints since the lower level problem appears as a constraint to the upper level one. In this paper, the upper solution is coded using a binary matrix proposed by Azzouz, Ennigrou, and Jlifi (Citation2015) where the rows represent the job operations and the columns correspond to the used machines as described in .
Step 2 (Upper level parent selection): We choose members from the parent population using tournament selection operator.
Step 3 (Variation at the upper level): We perform crossover and mutation operators in order to create the upper offspring population. In this way, we use the crossover operator order 1 (Davis Citation1985) which consists on selecting randomly two positions and
in the parent 1. Subsequently, the middle part is copied to the first offspring. The rest of this child is filled from the parent 2 starting with position
, and jumping elements that are already presented in the offspring 1. The same steps are repeated for the second offspring by starting with the parents 2. shows an example of this technique. Till now to the mutation operator, we use the mutation technique proposed by Pezzella, Morganti, and Ciaschetti (Citation2008) in which, we select one operation with the maximum workload (i.e. the maximum amount of work that a machine produces in a specified time period). Then we assign to the machine the minimum workload it if possible.
Step 4 (Lower level optimization): We solve the lower level optimization problem for each generated offspring using the tabu search algorithm (cf. the following subsection).
Step 5 (Offspring evaluation): We combine both upper level parents (the assignments in our case) and the upper level children into an population and we evaluate them based on the upper level objective function and the constraints.
Step 6 (Environmental selection): We fill the new upper level population using a replacement strategy. The new upper level population is formed with the best solutions of
set. If the stopping criterion is met then return the best upper level solution; otherwise, return to Step 2.
Lower Level Optimization Procedure
The tabu search strategy is considered as an intensification procedure able to guide the search in order to explore the solution space beyond local optimality. It has achieved widespread success in solving practical optimization problem. In this paper, we opt to use such algorithm in order to optimize the sequencement of operation jobs according to the passed assignment upper solution. The step-by-step procedure of the lower level TS algorithm is described as follows:
Step 1 (Initial solution): We need to generate firstly an initial solution. This latter is created based on the passed upper level solution structure. In this way, we conserve the same upper solution representation, while considering now the operation order in the matrix as the scheduling of operation on the machines.
Step 2 (Generate neighborhood): In this step, we determine the neighborhood of the current solution. Then, we define two types of moves: (1) the swap of two critical operations, and (2) the reassignment of an operation. Denote that a critical path is the longest path in the schedule composed of operations related either by precedence or disjunctive constraints. We determine then, the neighborhood of the current solution and we evaluate it to be able to choose the best non-tabu neighbor satisfying the aspiration criterion. It is important to note here that the best solution will be stored in an elite list. Then, any solution belongs to the neighborhood of the current one that obeys the following condition (if the difference costs between the current and the best one is less than or equal to such as
), will be stored in a secondary elite list.
Figure 3. A sample chromosome encoding by our representation.

Figure 4. Order 1 crossover operator with and
.

Step 3 (Neighborhood evaluation): In a tabu search method, the best non-tabu neighbor belonging to the current solution neighborhood will be selected for the next iteration. Hence, all neighbors must be evaluated in order to determine the best one. However, a global evaluation, i.e. computation of all start times of all operations, of each neighbor will need a considerable time. For this reason, we propose an estimation method in which only a subset of operations will be taken into account and to which start times will be recalculated. These operations are the ones effectively concerned by the move executed. Once the current neighbor was chosen, the move will be stored in the tabu list. Thereafter, the corresponding selected move is applied to the offspring solution that will be stored as elite solution. Subsequently, the lower level fitness is assigned based on the lower level objective function and constraints.
Step 4 (Diversification technique): In order to avoid that a large region of the search space remains completely unexplored, it is important to diversify the search during the optimization process. For this reason, we use three diversification techniques as follows:
Select randomly a solution among the elite solution list,
Select randomly a solution from the secondary elite solution list, or
Create a new solution by re-sequencing the operations of one job selected randomly.
Each of them is executed when the number of iterations performed after the last diversification phase or the last improving iteration exceeds a predefined threshold (the diversification probability).
Step 6 (Stop criterion): If the stopping criterion is met then we send the best found lower level solution to the upper level problem; otherwise, return to Step 2.
Experimental Study
The main motivation of this paper is to investigate the performance of the bi-level scheme with both problems (1) the SDST-FJSP with the learning effects and (2) the SDST-FJSP with learning/deterioration effects. Thus, two parts are considered in this experimental study. In the first one, we will try to evaluate the performance and the superiority of our Bi-GTS regarding four different schemes within this research area that are:
Variable Neighborhood Search (VNS) which explores distant neighborhoods based on a variable neighborhood changes proposed by Bagheri and Zandieh (Citation2011);
Tabu search (TS) algorithm which is a based-intensification technique proposed by Ennigrou and Ghedira (Citation2008);
Genetic algorithm which is an evolutionary method proposed by Azzouz, Ennigrou, and Said (Citation2016);
Hybrid genetic algorithm coupled with VNS algorithm (GTS) (Azzouz, Ennigrou, and Ben Said Citation2017).
The second part of this experimental study focus on evaluating our Bi-GTS on the SDST-FJSP with learning and deterioration effects. We should mention here that only the work of Tayebi Araghi and Rabiee (Citation2014) was reported to solve this problem. For this reason, we will use the same experimental framework presented in this latter to access the performance of our proposal. To this end, the second part focus mainly on a comparative study of the Bi-GTS algorithm to the following methods:
GA version adapted to the SDST-FJSP with learning and deterioration effects proposed by Pezzella, Morganti, and Ciaschetti (Citation2008),
VNS which version adapted to the SDST-FJSP with learning and deterioration effects proposed by Amiri et al. (Citation2010), and
GVNSWAF which is an hybrid algorithm based on GA coupled with VNS search strategy with affinity function proposed by Tayebi Araghi and Rabiee (Citation2014).
We note that all simulations are performed on the same machine (Intel Core i5-3230 CPU 2.6 GHz and 6 GB RAM). The remaining of this section is organized as follows: Subsection 5.1 presents the used benchmarks and metrics used in this study. The second subsection devoted the parameter tuning and settings. Then, we report the comparative results with (1) SDST-FJSP with learning effects, and (2) SDST-FJSP with learning and deterioration effects.
Used Benchmarks and Metrics
In this subsection, we describe the different benchmark problems used in our experimental study. In fact, we choose commonly used test problems within the community that allow assessing the performance of any used algorithm with respect to different kinds of difficulties. Thus, two kinds of benchmarks are adopted: The first one is adopted to evaluate the SDST-FJSP with learning effects which is denoted (González, Rodriguez Vela, and Varela Citation2013). It contains
instances derived from the first
instances of the FJSP benchmarks proposed by Hurink, Jurisch, and Thole (Citation1994). Each instance was created by adding to the original instance one setup time matrix
for each machine
. The same setup time matrix was considered for all benchmark instances. Each matrix has a size of
, and the
value indicates the setup time needed to reconfigure the machine
when it switched from job
to job
. These setup times are sequence dependent and they fulfill the inequality triangle. The second set of benchmarks consists on
instances proposed by Tayebi Araghi and Rabiee (Citation2014). For each job, three combinations of maximum operation (
) and machines are considered. summarizes the characteristics of the used benchmarks. To evaluate now the generated results and to compare the performance of the used algorithms, we use two kinds of metrics: (1) the first one is the makespan parameter which denotes the completion time of the last operation and (2) the second performance measure is the relative percentage deviation (RPD) which is calculated as follows:
Table 1. Description of Tayebi Araghi et al., instances (Tayebi Araghi and Rabiee Citation2014).
where is the makespan of each algorithm and
is the best solutions obtained for each instance after ten iterations.
Parameter Tuning and Settings
It is well known that the performance of an algorithm is heavily dependent on the setting of control parameters. Most research use fixed parameter values after some preliminary experiment or with reference to values of the previous similar literature. In this context, the most popular-used approach is the full factorial experiment (Ruiz, Maroto, and Alcaraz Citation2006). This later is usually used when the number of factors and their levels are small. Consequently, the major inconvenient of this method exists when the number of factors and their level are large. In such situation, it’s well difficult to calculate all possible combinations. Thus, the Taguchi's design of experiment (TDOE) approach was represented as an interesting alternative able to reduce the number of required tests. TDOE suggests the use of orthogonal arrays to organize the parameters affecting the process and the levels at which they should be varying. Orthogonal arrays can be used to accomplish optimal experimental designs by considering a number of experimental situations (Roy Citation2001). Moreover, the Taguchi method uses the signal-to-noise ratio (SNR), instead of the average value to interpret the data (experimental results). SNR can reflect both the average and the variation of the quality characteristic. In this way, the Taguchi’s method classifies the objective functions into three groups: (1) the smaller-the-better type, (2) the larger-the-better type and (3) the nominal-is-the best type. Since almost all objective functions in scheduling are categorized in the smaller the-better type, its corresponding SNR is expressed as follows:
Before the calibration of the Bi-GTS, the algorithm is subjected to some preliminary tests to obtain the proper parameter levels to be tested in the fine-tuning process. In order to achieve more accurate and stable results for our proposed algorithm, we considered five parameters for tuning. These parameters are ,
,
,
and
. These parameters with their levels are shown in . The corresponding orthogonal array with five factors and three levels in Taguchi method is
. By analyzing all of experimental results using Taguchi method, the average SNR and average maximum completion time were obtained for the considered experiments. displays the obtained results. In this way, the optimal levels are A(2), B(3), C(3), D(3) and E(2) (cf.). Furthermore, results computed in terms of mean makespan in Taguchi experimental analysis confirmed the optimal levels obtained using SNR values (see ). exhibits the effectiveness rank of parameters in minimizing makespan.
Figure 5. The SNR plot for experiments in Taguchi methodology.
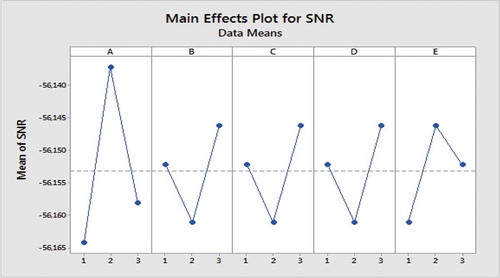
Figure 6. The plot of means of makespan for experiments in Taguchi methodology.
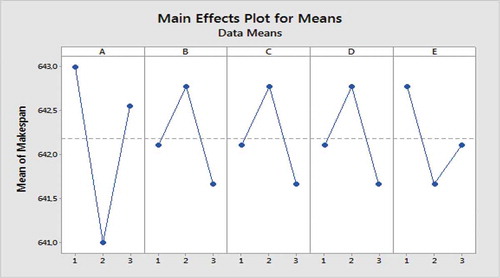
Table 2. Parameters and their levels.
Table 3. SNR table for experiments.
Table 4. Makespan values of Bi-GTS, VNS, TS, GA and GTS on SDST-HUdata benchmarks. The symbol ” + ” means that is rejected while the symbol ” – ” means the opposite. The best values are highlighted in bold.
Adopted Statistical Methodology
In order to compare between the algorithms, we choose to use the Wilcoxon rank sum test in a pairwise fashion (Derrac, García, Molina, and Herrera Citation2011). It allows to verify whether the results are statistically different or not between samples. Thus, we perform runs for each couple (algorithm, problem) with different random seeds (i.e.,
different randomly generated populations). Once the results are obtained, we use the MATLAB ranksum function in order to compute the p-value of the following hypothesis: (1)
: median (Algorithm1) = median (Algorithm2) and (2)
: median (Algorithm 1)
median (Algorithm 2) for a confidence level of 95%, if the p-value is found to be less or equal than
, we reject
and we accept
. In this way, we can say that the medians of the two algorithms are different from each other and that one algorithm outperforms the other viewpoint the used metric. However, if the p-value is found to be greater than
, then we accept
and we cannot say that one algorithm is better than the other nor the opposite.
Comparative Results of the SDST-FJSP with Learning Effects
In order to validate the advantage of the bi-level scheme in solving the SDST-FJSP with learning effects, we compared our model regarding four mono-level different schemes. The simulation results are summarized in . The instance names are listed in the first column, the second column shows the size of each instance. The remaining columns report the obtained results of the used algorithms. We observe from that Bi-GTS presents the best performance on the majority of test problems. It outperforms GTS, GA, TS, and VNS on
benchmark problems. This fact can be explained by the driving force of Bi-GTS in manipulating both diversity and convergence under the search space. In this way, the bi-level scheme was able at first to explore more possible assignments in the upper level search space. Then, the algorithm accentuates the search in the lower level regarding all possible generated assignments in the other level to be able to generate good bi-level solution qualities.
Table 5. RPD values of Bi-GTS, VNS, TS, GA and GTS on SDST-HUdata benchmarks.
In addition to the empirical simulation presented to access the performance of the different approaches, we use Relative Percentage Deviation (RPD) as a common performance metric to measure the algorithm stability. reports the generated results of the algorithms. In fact, we deduce that the proposed Bi-GTS outperforms the other algorithms in instances with an average RPD value of
. The worst performance is then observed with the TS algorithm which presents an average RPD value of
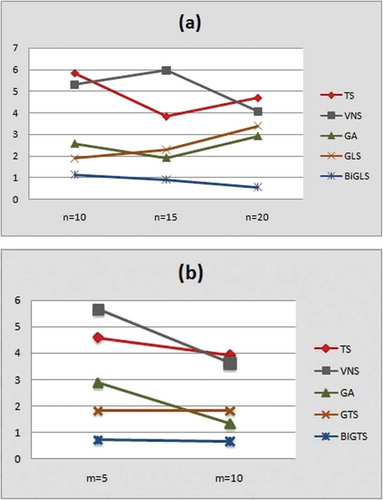
To further evaluate the performance of our algorithm, we study the interaction between the performance of the algorithm regarding the problem dimension. presents a plot describing the average RPD trace of the used approaches regarding to the number of jobs and machines, respectively. According to this Figure, we remark that Bi-GTS seems competitive regarding to other approaches. In fact, it generates the better RPD values on small, average, and large-scale problems. As well, we observe from these figures that the other approaches are sensitive to the number of machines. They represent a bad RPD values regarding to a variation on the machine numbers. Thus, we can deduce that the Bi-GTS keeps its robust performance in different problem sizes and especially with large-scale problem instances.
Table 6. Makespan values of Bi-GTS, GTS, GAVNS, GA and VNS on Tayebi benchmarks. The best values are highlighted in bold.
Comparative Results of SDST-FJSP with Learning and Deterioration Effects
In this second part, we are interesting to compare our bi-level algorithm mainly to the GVNSWAF work since it is the only one that is proposed to handle the same problem interest. shows the obtained results in terms of makespan values. In particular, we indicate that the instance problem names follow the formula in which
represents job number,
is the maximum operation number considered for each jobs and the
value defines the number of machines detained by the problem. We observe from this Table that our Bi-GTS outperforms also the other algorithms on fourteen/eighteen instances. The second best value is observed by the GVNSWAF and GTS which they outperform the other algorithms (GA and VNS) in nine instances. Thus, we can properly say that the hierarchical scheme allows to generate good solutions which confirms that this scheme is more adapted to solve the SDST-FJSP with learning and deterioration considerations than the other compared approaches.
Figure 7. The average RPD vaues of the used algorithms regarding to (a) the number of jobs and (b) the number of machines respectively.
Conclusion and Future Works
In this paper, we consider two realistic assumptions with the flexible job shop problem (FJSP), namely, the sequence-dependent setup times (SDST) and the learning/deterioration effects. We have suggested, for the first time, a bi-level evolutionary algorithm to solve this problem. The experimental results revealed that Bi-GLS is very competitive with respect to the considered algorithms. As part of our future work, we plan firstly to improve the proposed bi-level scheme by testing other meta-heuristic approaches. Secondly, the obtained results are promising, thus it would be a challenging perspective to investigate the dynamic SDST-FJSP with learning/deterioration effects, in order to reflect as closely as possible the reality of the actual flexible manufacturing systems.
References
- Allahverdi, A. 2015. The third comprehensive survey on scheduling problems with setup times/costs. European Journal of Operational Research 246:345–78. doi:10.1016/j.ejor.2015.04.004.
- Amiri, M., M. Zandieh, M. Yazdani, and A. Bagheri. 2010. A variable neighbourhood search algorithm for the flexible job-shop scheduling problem. International Journal of Production Research 48 (19):5671–89. doi:10.1080/00207540903055743.
- Azzouz, A., M. Ennigrou, and L. Ben Said. 2017. A hybrid algorithm for flexible job-shop scheduling problem with setup times. International Journal of Production Management and Engineering 5 (1):23–30. doi:10.4995/ijpme.2017.6618.
- Azzouz, A., M. Ennigrou, and L. Ben Said. 2018. Scheduling problems under learning effects: Classification and cartography. International Journal of Production Research 56 (4):1642–61. doi:10.1080/00207543.2017.1355576.
- Azzouz, A., M. Ennigrou, and B. Jlifi. 2015. Diversifying ts using ga in multi-agent system for solving flexible job shop problem. Proceedings of the 12th International Conference on Informatics in Control, Automation and Robotics (ICINCO), France, vol. 1, 94–101.
- Azzouz, A., M. Ennigrou, and L. B. Said. 2016. Flexible job-shop scheduling problem with sequence-dependent setup times using genetic algorithm. 18th International Conference on Enterprise Information Systems (ICEIS), Italy, vol. 2, 47–53.
- Bagheri, A., and M. Zandieh. 2011. Bi-criteria flexible job-shop scheduling with sequence-dependent setup times—variable neighborhood search approach. Journal of Manufacturing Systems 30 (1):8–15. doi:10.1016/j.jmsy.2011.02.004.
- Bard, J. F. 2013. Practical bilevel optimization: Algorithms and applications, vol. 30. Springer Science & Business Media.
- Bracken, J., and J. T. McGill. 1973. Mathematical programs with optimization problems in the constraints. Operations Research 21 (1):37–44. doi:10.1287/opre.21.1.37.
- Brandimarte, P. 1993. Routing and scheduling in a flexible job shop by tabu search. Annals of Operations Research 41 (3):157–83. doi:10.1007/BF02023073.
- Candler, W., and R. Norton. 1977. Multilevel programming. Technical Report 20, World Bank Development Research, Washington, D. C.
- Chaabani, A., S. Bechikh, and L. B. Said. 2015b. A co-evolutionary decomposition-based algorithm for bi-level combinatorial optimization. 2015 IEEE Congress on Evolutionary Computation (CEC), IEEE, Japan, 1659–66.
- Colson, B., P. Marcotte, and G. Savard. 2007. An overview of bilevel optimization. Annals of Operations Research 153 (1):235–56. doi:10.1007/s10479-007-0176-2.
- Davis, L. D. 1985. Applying adaptive algorithms to epistatic domains. In Proc. International Joint Conference on Artificial Intelligence, USA. 162–64.
- Dempe, S. 2002. Foundations of bilevel programming. Springer Science & Business Media.
- Derrac, J., S. Garca, D. Molina, and F. Herrera. 2011. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm and Evolutionary Computation 1 (1):3–18. doi:10.1016/j.swevo.2011.02.002.
- Ennigrou, M., and K. Ghedira. 2008. New local diversification techniques for flexible job shop scheduling problem with a multi-agent approach. In Autonomous Agents and Multi-Agent Systems 17 (2):270–87. doi:10.1007/s10458-008-9031-3.
- Garey, M. R., D. S. Johnson, and L. Stockmeyer. 1976. Some simplified np-complete graph problems. Theoretical Computer Science 1 (3):237–67. doi:10.1016/0304-3975(76)90059-1.
- González, M. A., C. Rodriguez Vela, and R. Varela. 2013. An efficient memetic algorithm for the flexible job shop with setup times. InTwenty-Third International Conference on Au-tomated Planning and Scheduling, Italy. 91–99.
- Gupta, J. N., and S. K. Gupta. 1988. Single facility scheduling with nonlinear processing times. Computers & Industrial Engineering 14 (4):387–93. doi:10.1016/0360-8352(88)90041-1.
- Hosseini, N., and R. Tavakkoli-Moghaddam. 2013. Two meta-heuristics for solving a new two-machine flowshop scheduling problem with the learning effect and dynamic arrivals. The International Journal of Advanced Manufacturing Technology 65:771–86. doi:10.1007/s00170-012-4216-y.
- Hurink, J., B. Jurisch, and M. Thole. 1994. Tabu search for the job shop scheduling problem with multi-purpose machines. Operations-Research-Spektrum 15 (4):205–15. doi:10.1007/BF01719451.
- Kacem, S., I. Hammadi, and P. Borne. 2002. Approach by localization and multiobjective evolutionary optimization for flexible job-shop scheduling problems. Syst IEEE Syst Man Cybern 32 (1):1–13.
- Nuijten, W. P., and E. H. Aarts. 1996. A computational study of constraint satisfaction for multiple capacitated job shop scheduling. European Journal of Operational Research 90 (2):269–84. doi:10.1016/0377-2217(95)00354-1.
- Pezzella, F., G. Morganti, and G. Ciaschetti. 2008. A genetic algorithm for the flexible job-shop scheduling problem. Computers & Operations Research 35 (10):3202–12. doi:10.1016/j.cor.2007.02.014.
- Pinedo, M. 1995. Scheduling theory, algorithms, and systems. New York: Springer-Verlag.
- Roy, R. K. 2001. Design of experiments using the Taguchi approach: 16 steps to product and process improvement. John Wiley & Sons.
- Ruiz, R., C. Maroto, and J. Alcaraz. 2006. Two new robust genetic algorithms for the flowshop scheduling problem. Omega 34 (5):461–76. doi:10.1016/j.omega.2004.12.006.
- Saidi-Mehrabad, M., and P. Fattahi. 2007. Flexible job shop scheduling with tabu search algorithms. The International Journal of Advanced Manufacturing Technology 32 (5–6):563–70. doi:10.1007/s00170-005-0375-4.
- Tayebi Araghi, M. F., . J., and M. Rabiee. 2014. Incorporating learning effect and deterioration for solving a sdst flexible job-shop scheduling problem with a hybrid meta-heuristic approach. International Journal of Computer Integrated Manufacturing 27 (Iss):8. doi:10.1080/0951192X.2013.834465.
- Wang, X., and T. Cheng. 2007. Single-machine scheduing with deteriorating jobs and learning effects to minimize the makespan. European Journal of Operational Research 178:57–70. doi:10.1016/j.ejor.2006.01.017.
- Wright, T. P. 1936. Factors affecting the cost of airplanes. Journal of the Aeronautical Science 3 (2):122–28. doi:10.2514/8.155.
- Ziaee, M. 2014. A heuristic algorithm for solving flexible job shop scheduling problem. The International Journal of Advanced Manufacturing Technology 71:519. doi:10.1007/s00170-013-5510-z.
- Zribi, N., I. Kacem, and A. El Kamel. 2004. Hierarchical optimization for the flexible job shop scheduling problem. IFAC Proceedings Volumes 37 (4):479–84. doi:10.1016/S1474-6670(17)36160-8.