
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Data clustering is an important data analysis and data mining tool in many fields such as pattern recognition and image processing. The goal of data clustering is to optimally organize similar objects into clusters. Grey wolf optimizer is a newly introduced optimization algorithm with inspiration from the social behavior of gray wolves. In this work, we propose a modified gray wolf optimizer to tackle some of the challenges in meta-heuristic algorithms. These modifications include a balanced approach to the exploration and exploitation stages of the algorithm as well as a local search around the best solution found. The performance of the proposed algorithm is compared to seven other clustering methods on nine data sets from the UCI machine learning laboratory. Experimental results demonstrate the competence of the proposed algorithm in solving data clustering problems. Overall, the intra-cluster distance of the proposed algorithm is lower than other algorithms and gives an average error rate of 11.22% which is the lowest among all.
Introduction
Data clustering which is the practice of organizing a set of objects into groups of objects is one of the most important and common analysis tools for data statistics in many fields of engineering such as machine learning, image processing, signal processing, pattern recognition, and data mining (Jacques and Preda Citation2014; Mai, Cheng, and Wang Citation2018; Shirkhorshidi et al. Citation2014). The goal of clustering is to group data objects into clusters such that the closeness of members belonging to the same group are maximized while closeness of members from different groups is minimized.
Generally, clustering techniques can be divided into two categories of hierarchical clustering and partitional clustering (Celebi Citation2014; Murtagh and Contreras Citation2012; Nanda and Panda Citation2014). One method of hierarchical clustering is to start with assigning each data member to individual clusters and combining more similar clusters into a larger cluster at each step and the other method is to start with the total set of data as one big cluster and breaking it down into smaller clusters until no further improvement is feasible. Partitional clustering, which is the technique utilized in this paper, attempts to divide a set of data objects into a set of non-overlapping clusters without the nested structure. The center of a cluster is called centroid and each data object is initially assigned to the closest centroid and then centroids are updated based on current assignment and by optimizing some criterion (Reynolds et al. Citation2006).
One of the most popular and widely used partitional clustering algorithms is k-means algorithm which is a fast and simple algorithm that minimizes the average squared distance (Hartigan and Wong Citation1979). However, k-means efficiency is not only reliant on the initial values of cluster centers but it is also vulnerable to local optimum convergence. Later, k-means++ was proposed to address the sensitivity issue of the standard algorithm to the initial centers (Arthur and Vassilvitskii Citation2007). However, it failed to solve the problem of convergence to a local optimum (Jain, Murty, and Flynn Citation1999). In order to overcome this convergence issue and reducing the risk of getting trapped in local optima, we use a meta-heuristic approach to solve the data clustering problem.
In the last few decades, meta-heuristic algorithms have been commonly used to solve NP-hard problems and data clustering falls into the category of NP-hard problems. Several meta-heuristic algorithms have been developed, such as Particle Swarm Optimization (PSO) (Kennedy Citation2011), Firefly Algorithm (FA) (Yang Citation2009), Artificial Bee Colony (ABC) algorithm (Karaboga and Basturk Citation2007), Gravitational Search Algorithm (GSA) (Rashedi, Nezamabadi-pour, and Saryazdi Citation2009), Simulated Annealing (SA) (Van Laarhoven and Aarts Citation1987), and Ant Colony Optimization (ACO) (Dorigo and Birattari Citation2011). A tabu search based method to avoid convergence to local optima in clustering problem was developed which improved k-means by using a tabu search strategy (Lu et al. Citation2018). Shelokar, Jayaraman, and Kulkarni in 2004 used ACO which mimics the way real ants find the shortest path from their nest to the food source and back to propose an approach to the clustering problem. Artificial bee colony-based algorithm (Zhang, Ouyang, and Ning Citation2010), particle swarm optimization-based algorithm (Cura Citation2012), a hybrid of k-means, Medler-Mead simplex, and PSO (Kao, Zahara, and Kao Citation2008) and a hybrid of PSO and SA (Niknam et al. Citation2009) are also among the approaches of solving the clustering problem using meta-heuristic algorithms.
Recently, a meta-heuristic technique named gray wolf optimizer (GWO) (Mirjalili, Mirjalili, and Lewis Citation2014) is used to solve many problems such as load dispatch problem (Kamboj, Bath, and Dhillon Citation2016), feature subset selection (Emary et al. Citation2015), concept-based text mining (Thilagavathy and Sabitha Citation2017), task allocation (Gupta, Ghrera, and Goyal Citation2018), transmission network expansion planning (Khandelwal et al. Citation2018), and image segmentation (Mostafa et al. Citation2016). The promising results of the mentioned literature motivated the authors of this paper to apply a modified version of the GWO algorithm to the data clustering problem.
The remainder of this paper is organized as follows. A summary of data clustering is described in Section “Data Clustering.” Introduction of GWO and the proposed improvements are described in Section “Methodology.” Experimental results on benchmark problems are provided in Section “Experimental Results.” Conclusion of the work is discussed in Section “Conclusion.”
Data Clustering
Extracting information from extensive amounts of data is the main objective of data mining methods. These methods identify compelling patterns in large data sets using data analysis methods. Data analysis methods include clustering, classification, anomaly detection, deviation detection, summarization, and regression. Data clustering is the process of organizing a set of data into subsets such that members of each subset have a high intensity of resemblance while having low resemblance to data in other subsets. The similarity between members of a subset is measured by distance metrics such as Euclidean distance, Chord distance, and Jaccard index. Generally speaking, based on how data is managed and how clusters are formed, clustering methods fall into two main categories: hierarchical and partitional.
In hierarchical clustering, without any advance knowledge of the number of clusters or dependency on the initial condition, a tree which represents a series of clusters is formed (Leung, Zhang, and Xu Citation2000). However, they are static and an object that belongs to a cluster cannot be assigned to other clusters. This is the primary weakness of hierarchical algorithms. Also, the lack of foresight about the number of clusters may lead to ineffective grouping of overlapping clusters (Jain, Murty, and Flynn Citation1999). Conversely, partitional clustering separates objects into clusters with a predefined number of clusters. Many partitional clustering algorithms attempt to decrease the dissimilarity between objects within each cluster while increasing the dissimilarity of members assigned to different clusters (Frigui and Krishnapuram Citation1999).
Problem Formulation
To mathematically formulate the data clustering problem, a set of objects is represented by
. Then,
is a vector representing the
data object and
is representing the
attribute of
. The objective of clustering is to assign each object in
to one of
clusters,
,
,
,
, such that all clusters contain at least one object
, no object is assigned to more than one cluster
and all objects are assigned to a cluster
(Zhang, Ouyang, and Ning Citation2010) while minimizing the objective function.
Methodology
Grey wolf optimizer and modifications made to improve its efficiency are presented in this section.
Grey Wolf Optimizer
By taking inspiration from the natural behavior of gray wolves while hunting for prey, a new optimization algorithm called Grey Wolf Optimizer was introduced (Mirjalili, Mirjalili, and Lewis Citation2014). In this section, the mathematical models for the four stages of this algorithm called surrounding, hunting, searching, and attacking are introduced.
All gray wolves fall into four categories: alpha (), beta (
), delta (
), and omega (
). Alpha wolves which are the decision-makers represent the best solution. The second best solution is represented by beta wolves which provide assistance to alpha wolves. The third best solution is represented by delta wolves, and the remaining solutions are omegas.
The hunting step in GWO is carried out by alpha, beta, and delta wolves while the omega wolves follow their lead. However, before starting to hunt, gray wolves surround the prey. The surrounding operation is modeled by the following equations:
where marks the current iteration,
and
are coefficient,
represents the position of the prey, and
represents the position of a gray wolf.
and
are worked out by:
where is lowered from 2 to 0 over the course of time in a linear manner. Random vectors
and
are in the range of [0, 1]. Using EquationEq. (1)
(1)
(1) and EquationEq. (2
(2)
(2) ), a gray wolf can move to a new random location in the area around the prey. shows multiple possible positions for a gray wolf based on the position of prey. Coordinates of a gray wolf and the prey are, respectively,
and
and different values of
and
affect the movement direction of a gray wolf.
Figure 1. Possible next positions of a gray wolf
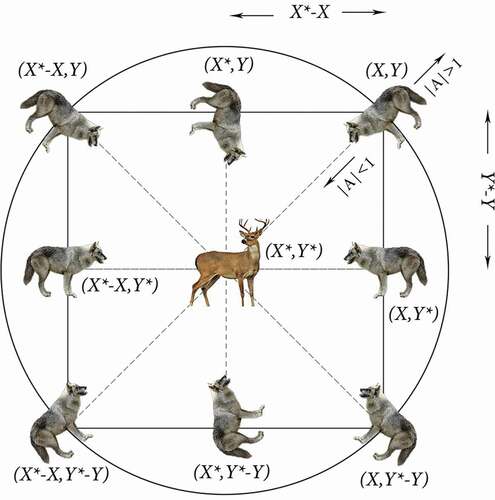
Grey wolves approximate the position of the prey. After all, the position of the prey is unknown, but we can expect that the alpha, beta, and delta wolves to be the nearest to the prey among all wolves. Hence, the position of other wolves is calculated based on the best solutions found so far using the following equations which models the hunting operation:
EquationEqs. (5)(5)
(5) -(Equation7
(7)
(7) ) calculate the distance between the prey and alpha, beta, and delta wolves. EquationEqs. (8)
(8)
(8) -(Equation10
(10)
(10) ) calculate the new position of alpha, beta, and delta wolves while EquationEq. (11)
(11)
(11) calculates the position of the prey.
The exploration of search space or searching for prey is accomplished when which commands the gray wolves to move away from the prey. The coefficient
also assists in the searching step. The value of
is randomly chosen between 0 and 2 which increases or decreases the impact of prey on distance calculation.
The exploitation of search space or attacking the prey is accomplished when is in the range of −1 and 1. With
the new position of a gray wolf is in any place within its current position and the position of prey, which forces gray wolves to move toward the prey.
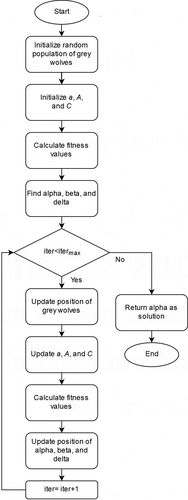
depicts the flowchart of gray wolf optimizer. It begins by generating a set of random solutions as the initial population. Best, second best, and third best solutions are chosen as alpha, beta, and delta wolves and the position of each remaining wolf is calculated based on the approximated position of the prey. In conclusion, alpha is returned as the ultimate solution.
Figure 2. Flowchart of gray wolf optimizer
Modified Grey Wolf Optimizer (MGWO)
Exploration and exploitation are two common stages in most optimization algorithms. Exploration is the process of probing the search space. First iterations of an algorithm scan the search space with the hope of finding more fitting solutions. This process allows searching agents to avoid local optima while scanning throughout the search space. Gradually, exploration declines and exploitation rises, so the algorithm can converge to an optimum solution which is the exploitation stage of an algorithm. Finding a proper balance between these two stages is critical to the performance of the algorithm. Hence, proposing a new approach is desirable.
In GWO these two stages are controlled using the parameter . As mentioned in the previous section, this parameter is decreased linearly. In earlier iterations of the algorithm, there is more emphasis on exploration and in the later iterations of the algorithm, exploitation is carried out. By changing the linear behavior of
we can change the power of exploration and exploitation and come up with a balanced approach between these two stages. Our new control parameter is as followed:
where indicates the current iteration,
is the total number of iterations, and
is a constant. Here the parameter
is still decreased from 2 to 0 but in a non-linear manner. For the values of
between 0 and 1, the emphasis will be on exploitation; however, the quality of searching capability might suffer. For values of more than 1, search space will be thoroughly explored and then the algorithm moves on to exploitation. A suitable value for
should be found by trial and error.
We expect to improve the performance of GWO by the non-linear reduction of the control parameter; however, there is still room for further improvement. In order to make up for the decreased number of iterations that exploit the search space, we use a mapping method to carry out a local search around the best solution. This method maps the best gray wolf position to a new position and if it results in better fitness, the gray wolf will be moved to that place. The new position is calculated as:
where and
are the upper and lower boundaries,
is the center, and
is the mapping parameter which gets updated at each iteration:
The modified GWO is expressed by the following pseudo-code.
Algorithm 1. MGWO
Random generation of gray wolves:
Setting initial values of ,
, and
= total number of iterations
Fitness evaluation of each gray wolf
: the best solution
: second best solution
: third best solution
while do
for each in
do
Update the position of
end for
Update ,
, and
Evaluate the fitness of all gray wolves
Map a new position for and move it there if it’s improved
Update ,
, and
end while
return as the solution
Solution Encoding and Fitness Function for Data Clustering
Solution encoding is a key step in any meta-heuristic algorithm. Each solution (gray wolf) represents all the cluster centers. Initially, these solutions are generated randomly. However, at each iteration of the GWO, the best solutions (alpha, beta, and delta) guide the rest of the gray wolves. Each solution is an array of size , where
is the total number of clusters in the data set and
is the total number of attributes for each data object. A population of gray wolves representing the solutions is shown in .
Figure 3. Example of solution encoding

We use the sum of the intra-cluster distance as the objective function. To find optimal cluster centers with MGWO, the objective function should be minimized. Achieving a lower sum of intra-cluster distances is desired. Cluster center is defined in EquationEq. (15)(15)
(15) and distances between cluster members are defined in EquationEq. (16)
(16)
(16) .
Here, is the center of cluster
,
is the
member of a cluster. The total number of attributes is represented by
,
is the number of members in cluster
and
are the members of cluster
.
Experimental Results
In this section, the quality of MGWO performance is evaluated. First, simulations are carried out on unimodal and multimodal benchmark functions where minimization is the goal and then data clustering using MGWO is performed. In both experiments, a comparison with other algorithms is presented.
Performance Evaluation of MGWO Algorithm
MGWO is tested on 23 standard test problems (-
) used by many researchers (Mirjalili and Lewis Citation2016; Mirjalili, Mirjalili, and Lewis Citation2014; Rashedi, Nezamabadi-pour, and Saryazdi Citation2009). These functions have different types of modality and complexity as presented in . D is the dimension of a function, R is the range of a function’s search space, and
is the minimum of a function. To evaluate the competitiveness of MGWO, it is compared to the standard Grey Wolf Optimizer (GWO) (Mirjalili, Mirjalili, and Lewis Citation2014), Particle Swarm Optimization (PSO) (Kennedy Citation2011), Gravitational Search algorithm (GSA) (Rashedi, Nezamabadi-pour, and Saryazdi Citation2009), and Whale Optimization Algorithm (WOA) (Mirjalili and Lewis Citation2016). The objective in these test functions is minimization.
Table 1. Definition of standard test functions
The total number of search agents is 30 and the total number of iterations is set to 500. Parameters and
are, respectively, set to 0.15 and 2. The stopping criterion is reaching the total number of iterations. Our algorithm is independently run 30 times on each test function, mean, and standard deviation results are reported in . Results show that the overall MGWO gives better results and is superior to the other methods.
Table 2. Results of test problems to
Exploitation ability of meta-heuristic algorithms is evaluated by unimodal functions since they only have one global minimum. It can be seen from the results that MGWO is the best performing algorithm for functions
,
,
, and
while being the second best performing algorithm for functions
and
which is an indication of excellent exploitation of MGWO.
To evaluate the exploration capability of algorithms, multimodal functions are selected which unlike unimodal functions include multiple local minima. In all multimodal functions but
, MGWO is the best or the second best performing algorithm. GWO is the best algorithm for function
, PSO gives the best result for
and
, GSA outperforms other algorithms for
and WOA is superior for
,
, and
. Overall the results of the proposed algorithm indicate efficient exploration and exploitation capabilities.
Data Clustering Using MGWO Algorithm
We used nine benchmark data sets from the UCI databases (Blake Citation1998) which are commonly used in cluster analysis literature. The chosen data sets have a different number of data objects, number of classes, and number of attributes. Three-quarter of data objects in each data set is chosen randomly for training and the remainder is used for testing. Properties of these data sets are provided in .
Table 3. Characteristics of UCI data sets
Heart data set obtained from the Cleveland Heart Clinic database includes 303 objects with 35 attributes. The individuals are grouped into two classes.
E. Coli data set includes information about Escherichia Coli bacterium. Classes with a low number of instances have been removed from this data set. The remaining data has 327 objects and 5 classes.
Horse data set is used for predicting the health situation of a horse with colic disease. Horses are divided into three groups. This data set includes 364 objects and 58 attributes.
Dermatology data set is based on the examination of skin diseases. This data set consists of 366 objects, 34 attributes, and 6 classes.
Cancer data set obtained from the Wisconsin-Diagnostic database groups breast tumors into two classes of mild and deadly. This data set includes 569 objects and 30 attributes.
Balance data set is formed from psychological tests. Each member is classified into one of the three classes: balanced, tip to the left, and tip to the right. This data set includes 625 objects and 4 attributes.
Credit data set is used for the evaluation of credit card applicants in Australia. Data objects in this data set are classified into 2 groups using 15 attributes.
Cancer-Int data set is similar to the Cancer data set but includes 699 objects and 9 attributes instead.
Diabetes data set is the diagnosis of diabetes for patients. A total of 768 objects with 8 attributes are classified into 2 groups of positive and negative.
The total number of search agents is 30 and the total number of iterations is set to 500. Parameters and
are, respectively, set to 0.15 and 2. The stopping criterion is reaching the total number of iterations. Results are compared to GSA (Bahrololoum et al. Citation2012), k-means (Nanda and Panda Citation2014), PSO (De Falco, Della Cioppa, and Tarantino Citation2007), K-PSO (Kao, Zahara, and Kao Citation2008), K-NM-PSO (Kao, Zahara, and Kao Citation2008), and Firefly Algorithm (Senthilnath, Omkar, and Mani Citation2011).
Results obtained from these methods are compared based on the sum of intra-cluster distances as well as the error rate. The error rate is the percentage of misclassified data objects in each data set.
Intra-cluster distances obtained from the eight algorithms are provided in . The values are the average of the sums of intra-cluster distances over 25 runs.
Table 4. Intra-cluster distances of each algorithm on data sets
In Credit, Cancer-Int, and Diabetes data sets which have the highest number of data objects, MGWO outperforms all algorithms while PSO, KPSO, and K-NM-PSO have the worst results. Dermatology data set has the highest number of classes which is six classes. Again, our proposed algorithm gives substantially better result on this data set while PSO and FA have the worst results. The only data sets where MGWO doesn’t outperform other algorithms are Horse and Balance. For the Horse data set, PSO gives the best answer followed by GSA, K-PSO, and our proposed algorithm. For Balance data set, MGWO has the second best answer after K-PSO.
shows the mean error rate of each algorithm on each data set over 25 simulation runs. For Heart and E. Coli data sets, MGWO has the lowest error rate among all algorithms and k-means, PSO and K-NM-PSO are the worst performing algorithms. For Horse and Dermatology data sets, the mean error rate of K-NM-PSO is the smallest, although, MGWO obtains lower intra-cluster distances for these data sets. It is worth mentioning that since the data distribution in these data sets is not a normal distribution, intra-cluster distance and error rate are not comparable and a lower error rate does not imply a smaller distance.
Table 5. Mean error rate (%) of each algorithm on data sets
The mean error rate of MGWO is the lowest for Cancer data set which is slightly better than K-PSO. For Balance and Credit data sets, FA and GSA, respectively, have the lowest error rate and K-PSO has the highest error rate in both data sets. For Cancer-Int and Diabetes data sets, K-PSO is the superior algorithm, although MGWO obtains better intra-distances in these instances.
Although MGWO in some data sets does not provide the lowest error rate, it never obtains the highest error rate and the average error rate of MGWO over all data sets is 11.22% which is the lowest and puts it at rank number 1 followed by GSA, GWO, and PSO. k-means and K-NM-PSO have a significantly higher error rate compared to other algorithms.
Conclusion
In this work, we introduced a modified version of a new meta-heuristic optimization method named gray wolf optimizer. The modification is mainly on the importance of the exploration and exploitation aspects of meta-heuristic algorithms and finding a suitable balance between these two stages. The performance of the proposed algorithm was evaluated on well-known benchmark functions and after establishing its superiority compared to PSO, GSA, GWO, and WOA, it was evaluated in terms of intra-cluster distances and error rate on commonly used data clustering benchmark data sets. The results showed that it is overall the better performing algorithm.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
References
- Arthur, D., and S. Vassilvitskii. 2007. k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, New Orleans, Louisiana, 1027–35. January.
- Bahrololoum, A., H. Nezamabadi-pour, H. Bahrololoum, and M. Saeed. 2012. A prototype classifier based on gravitational search algorithm. Applied Soft Computing 12 (2):819–25. doi:https://doi.org/10.1016/j.asoc.2011.10.008.
- Blake, C. 1998. UCI repository of machine learning databases. http://www.ics.uci.edu/~mlearn/MLRepository.html.
- Celebi, M. E. 2014. Partitional clustering algorithms. Switzerland: Springer International Publishing.
- Cura, T. 2012. A particle swarm optimization approach to clustering. Expert Systems with Applications 39 (1):1582–88. doi:https://doi.org/10.1016/j.eswa.2011.07.123.
- De Falco, I., A. Della Cioppa, and E. Tarantino. 2007. Facing classification problems with Particle Swarm Optimization. Applied Soft Computing 7 (3):652–58. doi:https://doi.org/10.1016/j.asoc.2005.09.004.
- Dorigo, M., and M. Birattari. 2011. Ant colony optimization. In Sammut C., Webb G.I. (Eds.), Encyclopedia of machine learning, 36–39. Boston, MA: Springer.
- Emary, E., H. Zawbaa, C. Grosan, and A. Hassenian. 2015. Feature Subset Selection Approach by Gray-Wolf Optimization. Advances In Intelligent Systems And Computing 1–13. doi:https://doi.org/10.1007/978-3-319-13572-4_1.
- Frigui, H., and R. Krishnapuram. 1999. A robust competitive clustering algorithm with applications in computer vision. IEEE Transactions On Pattern Analysis And Machine Intelligence 21 (5):450–65. doi:https://doi.org/10.1109/34.765656.
- Gupta, P., S. Ghrera, and M. Goyal. 2018. QoS Aware Grey Wolf Optimization for Task Allocation in Cloud Infrastructure. Proceedings Of First International Conference On Smart System, Innovations And Computing 875–86. doi:https://doi.org/10.1007/978-981-10-5828-8_82.
- Hartigan, J., and M. Wong. 1979. Algorithm AS 136: A K-Means Clustering Algorithm. Applied Statistics 28 (1):100–08. doi:https://doi.org/10.2307/2346830.
- Jacques, J., and C. Preda. 2014. Functional data clustering: A survey. Advances In Data Analysis And Classification 8 (3):231–55. doi:https://doi.org/10.1007/s11634-013-0158-y.
- Jain, A., M. Murty, and P. Flynn. 1999. Data clustering: A review. ACM Computing Surveys 31 (3):264–323. doi:https://doi.org/10.1145/331499.331504.
- Kamboj, V., S. Bath, and J. Dhillon. 2016. Solution of non-convex economic load dispatch problem using Grey Wolf Optimizer. Neural Computing And Applications 27 (5):1301–16. doi:https://doi.org/10.1007/s00521-015-1934-8.
- Kao, Y., E. Zahara, and I. Kao. 2008. A hybridized approach to data clustering. Expert Systems with Applications 34 (3):1754–62. doi:https://doi.org/10.1016/j.eswa.2007.01.028.
- Karaboga, D., and B. Basturk. 2007. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. Journal Of Global Optimization 39 (3):459–71. doi:https://doi.org/10.1007/s10898-007-9149-x.
- Kennedy, J. 2011. Particle swarm optimization. In Sammut C, Webb G (Eds.), Encyclopedia of machine learning, 760–66. Boston, MA: Springer.
- Khandelwal, A., A. Bhargava, A. Sharma, and H. Sharma. 2018. Modified Grey Wolf Optimization Algorithm for Transmission Network Expansion Planning Problem. Arabian Journal For Science And Engineering 43 (6):2899–908. doi:https://doi.org/10.1007/s13369-017-2967-3.
- Leung, Y., J. S. Zhang, and Z. B. Xu. 2000. Clustering by scale-space filtering. IEEE Transactions On Pattern Analysis And Machine Intelligence 22 (12):1396–410. doi:https://doi.org/10.1109/34.895974.
- Lu, Y., B. Cao, C. Rego, and F. Glover. 2018. A Tabu search based clustering algorithm and its parallel implementation on Spark. Applied Soft Computing 63:97–109. doi:https://doi.org/10.1016/j.asoc.2017.11.038.
- Mai, X., J. Cheng, and S. Wang. 2018. Research on semi supervised K-means clustering algorithm in data mining. Cluster Computing 1–8. doi:https://doi.org/10.1007/s10586-018-2199-7.
- Mirjalili, S., and A. Lewis. 2016. The Whale Optimization Algorithm. Advances in Engineering Software 95:51–67. doi:https://doi.org/10.1016/j.advengsoft.2016.01.008.
- Mirjalili, S., S. Mirjalili, and A. Lewis. 2014. Grey Wolf Optimizer. Advances in Engineering Software 69:46–61. doi:https://doi.org/10.1016/j.advengsoft.2013.12.007.
- Mostafa, A., A. Fouad, M. Houseni, N. Allam, A. Hassanien, H. Hefny, and I. Aslanishvili. 2016. A Hybrid Grey Wolf Based Segmentation with Statistical Image for CT Liver Images. Advances In Intelligent Systems And Computing 846–55. doi:https://doi.org/10.1007/978-3-319-48308-5_81.
- Murtagh, F., and P. Contreras. 2012. Algorithms for hierarchical clustering: An overview. Wiley Interdisciplinary Reviews: Data Mining And Knowledge Discovery 2 (1):86–97. doi:https://doi.org/10.1002/widm.53.
- Nanda, S., and G. Panda. 2014. A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm And Evolutionary Computation 16:1–18. doi:https://doi.org/10.1016/j.swevo.2013.11.003.
- Niknam, T., B. Amiri, J. Olamaei, and A. Arefi. 2009. An efficient hybrid evolutionary optimization algorithm based on PSO and SA for clustering. Journal Of Zhejiang University-SCIENCE A 10 (4):512–19. doi:https://doi.org/10.1631/jzus.a0820196.
- Rashedi, E., H. Nezamabadi-pour, and S. Saryazdi. 2009. GSA: A Gravitational Search Algorithm. Information Sciences 179 (13):2232–48. doi:https://doi.org/10.1016/j.ins.2009.03.004.
- Reynolds, A., G. Richards, B. de la Iglesia, and V. Rayward-Smith. 2006. Clustering Rules: A Comparison of Partitioning and Hierarchical Clustering Algorithms. Journal Of Mathematical Modelling And Algorithms 5 (4):475–504. doi:https://doi.org/10.1007/s10852-005-9022-1.
- Senthilnath, J., S. Omkar, and V. Mani. 2011. Clustering using firefly algorithm: Performance study. Swarm And Evolutionary Computation 1 (3):164–71. doi:https://doi.org/10.1016/j.swevo.2011.06.003.
- Shelokar, P., V. Jayaraman, and B. Kulkarni. 2004. An ant colony approach for clustering. Analytica chimica acta 509 (2):187–95. doi:https://doi.org/10.1016/j.aca.2003.12.032.
- Shirkhorshidi, A., S. Aghabozorgi, T. Wah, and T. Herawan. 2014. Big Data Clustering: A Review. Computational Science And Its Applications – ICCSA 2014:707–20. doi:https://doi.org/10.1007/978-3-319-09156-3_49.
- Thilagavathy, R., and R. Sabitha. 2017. Using cloud effectively in concept based text mining using grey wolf self organizing feature map. Cluster Computing. doi:https://doi.org/10.1007/s10586-017-1159-y.
- Van Laarhoven, P. J. M., and E. H. L. Aarts. 1987. Simulated annealing. Simulated Annealing: Theory And Applications 37:7–15. doi:https://doi.org/10.1007/978-94-015-7744-1_2.
- Yang, X. S. 2009. Firefly Algorithms for Multimodal Optimization. Stochastic Algorithms: Foundations And Applications 5792:169–78. doi:https://doi.org/10.1007/978-3-642-04944-6_14.
- Zhang, C., D. Ouyang, and J. Ning. 2010. An artificial bee colony approach for clustering. Expert Systems with Applications 37 (7):4761–67. doi:https://doi.org/10.1016/j.eswa.2009.11.003.