
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Finding relevant information from biological data is a critical issue for the study of disease diagnosis, especially when an enormous number of biological features are involved. Intentionally, the feature selection can be an imperative preprocessing step before the classification stage. Equilibrium optimizer (EO) is a recently established metaheuristic algorithm inspired by the principle of dynamic source and sink models when measuring the equilibrium states. In this research, a new variant of EO called general learning equilibrium optimizer (GLEO) is proposed as a wrapper feature selection method. This approach adopts a general learning strategy to help the particles to evade the local areas and improve the capability of finding promising regions. The proposed GLEO aims to identify a subset of informative biological features among a large number of attributes. The performance of the GLEO algorithm is validated on 16 biological datasets, where nine of them represent high dimensionality with a smaller number of instances. The results obtained show the excellent performance of GLEO in terms of fitness value, accuracy, and feature size in comparison with other metaheuristic algorithms.
Introduction
One of the most common challenges in biological data sets is the existence of a large number of variables, which are often called features. The complexity of biological data is gradually growing due to advances in measuring devices (Li et al. Citation2020; Yamada et al. Citation2018). Conventionally, the immense amounts of data not only makes the process of classifying them challenging but also increases the complexity (Mafarja et al. Citation2019). Besides, biological data contain many irrelevant and redundant features, which may adversely degrade the processing accuracy. To remove the noisy information and define the most significant features, the feature selection (FS) process should be considered as a pre-processing step before employing the classifiers to a dataset (Pashaei and Aydin Citation2017; Zhang et al. Citation2015).
There are two types of FS in the literature: filter and wrapper. The filter approaches point out the relevant features independently of the learning model. That is, they rank the attributes using the properties of the data and remove all features that do not perceive an adequate score (Hu et al. Citation2018; Sayed et al. Citation2019). The wrapper approaches rank the features using a pre-determined learning model, which can select the feature sub-set with a high evaluation measure (Kashef and Nezamabadi-pour Citation2015). Although the filter is computationally less expensive, the wrapper FS can often produce better results. In wrapper, the FS is known as NP-hard optimization problem (Lu, Yan, and de Silva Citation2015; Zhang, Shan, and Wang Citation2017). Hence, many approaches based on metaheuristic algorithms, such as genetic algorithm (Krömer et al. Citation2018), ant colony optimization (Aghdam, Ghasem-Aghaee, and Basiri Citation2009), and particle swarm optimization (Chuang et al. Citation2008) have proposed to assess the efficient solution.
(Kaur, Saini, and Gupta Citation2018) proposed a parameter-free bat algorithm to find an optimal set of features when classifying brain tumor MR images. The proposed method selected significant features by minimizing the weighted distance between different groups. (Li Zhang et al. Citation2018) integrated the chaotic attractiveness movement, simulated annealing, and scattering strategies into the firefly algorithm for FS. In their study, the proposed method can often accelerate the convergence and improve the weak solutions, which overtook other conventional algorithms in classification and regression tasks. (Emary, Zawbaa, and Hassanien Citation2016) developed a novel binary gray wolf optimization for dimensionality reduction. In this approach, a modified sigmoid function was implemented, and it enabled the wolves to conduct the search around the binary feature space. Moreover, (Sindhu et al. Citation2017) proposed an advanced sine cosine algorithm to tackle the high-dimensional FS in medical datasets. The proposed method utilized elitism strategy to replace the worst agents with quality agents, which ensured high-quality search. The authors in (Too and Abdullah Citation2020b) proposed a fast rival genetic algorithm in which the competition concept was integrated to boost the performance of the algorithm in FS tasks. Besides, (Amoozegar and Minaei-Bidgoli Citation2018) developed a multi-objective particle swarm optimization to rank the importance of features by considering the frequency in the archive set. Furthermore, an improved binary dragonfly algorithm was proposed in (Hammouri et al. Citation2020) for feature selection problems. The authors modified the five main coefficients to overcome the randomness of the algorithm in the diversification and intensification process. More FS studies can be found in (Banka and Dara Citation2015; Barani, Mirhosseini, and Nezamabadi-pour Citation2017; Bhadra and Bandyopadhyay Citation2015; Too and Abdullah Citation2020a; Wang et al. Citation2017).
A new metaheuristic algorithm, named Equilibrium Optimizer (EO), has been developed by Faramarzi et al. in 2020 (Faramarzi et al. Citation2020). Details about the mathematical model and inspiration of the EO is provided in Section 2. Among the early work, EO has shown its superiority against conventional metaheuristic algorithms in several benchmark function tests. However, the EO algorithm has the limitation of restricting the local optimal. Due to the insufficient results and few engineering applications of the EO when compared to other algorithms, this article introduces a new variant of EO, namely general learning equilibrium optimizer (GLEO), to resolve the problem of feature selection in biological data classification. In GLEO, a general learning strategy is proposed to evolve the capability of EO in discovering promising solutions. Unlike EO, GLEO enables the particle to learn from different candidates in multi-dimensions, which is beneficial in preventing the particles from being trapped in the local optimal. Sixteen biological datasets are collected from Arizona State University (ASU) and UCI repository to investigate the usefulness of proposed GLEO in this work. The performance of GLEO is further compared with other six well-known FS algorithms. The experimental results disclose the ascendancy of GLEO not only in higher processing accuracy but also in smaller feature sizes.
The main contributions are summarized as follows:
A variant version of standard EO is proposed and named GLEO by using a general learning strategy to improve the capability of the EO in exploring the promising regions and escaping the local optimal.
The proposed GLEO is validated on 16 biological datasets. GLEO overtook other FS algorithms (EO, BOA, GWO, PSO, SCA, and RF).
The proposed GLEO proved its efficacy based on the obtained solutions and offered excellent results.
Equilibrium Optimizer
Equilibrium optimizer (EO) is a recently established physics-based metaheuristic algorithm in 2020. The EO is inspired by the concept of dynamic source and sink models in measuring equilibrium states (Faramarzi et al. Citation2020). Like other metaheuristic algorithms, EO generates an initial population of stochastic solutions to start the optimization process. In EO, an initial population of N particles is computed as follows:
where X is the position of the particle, N represents the number of particles, D is the number of dimensions, and rand is a random vector between [0, 1]. The Xmax and Xmin are the maximum and minimum values for the dimensions. After generating the initial population, the particles are evaluated with a specific fitness function, and the equilibrium candidates were identified.
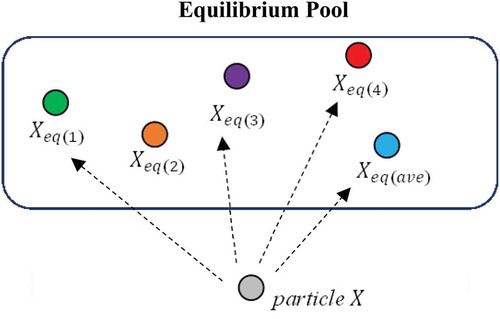
Equilibrium Pool and Candidates
In EO, there is an equilibrium pool to store promising candidates. Correspondingly, four best-so-far particles and their average are stored in the equilibrium pool and will be used for the updating process. These four best-so-far candidates can assist the EO to explore the untried areas, which ensures a high exploration. On the one hand, the average of these candidates can help to exploit the areas near the best solution to find the global optimum. Following this line of thoughts, the equilibrium pool is constructed as follows:
where Xeq,pool is the equilibrium pool, Xeq(1), Xeq(2), Xeq(3), and Xeq(4) are the four best-so-far candidates. The Xeq(ave) is the average of four best-so-far candidates. In each iteration, the particles update their positions with random selection among these five candidates (same probability).
Exponential Term
The exponential term is an important factor that will help EO to maintain a proper balance between global and local searches. The exponential term is defined as follows:
where λ is a random vector between [0, 1], t is the time that can be computed as below:
where Iter is the current iteration, MaxIter is the maximum number of iterations, and α is a constant used to control the local search behavior. On the other hand, t0 is a parameter used to manage exploration and exploitation as follows:
where r is a random vector between [0, 1], and β is a constant used to manage the exploration capability. As given in EquationEquation (6)(6)
(6) , the larger the value of β, the better the exploration capability. According to (Faramarzi et al. Citation2020), α and β are equal to 1 and 2, respectively. By substituting the EquationEquation (6)
(6)
(6) into EquationEquation (4)
(4)
(4) , the final version of the exponential term can be redefined as below:
Generation Rate
Another important factor in EO is the generation rate. Intuitively, the generation rate helps the EO to explore the search domain. In EO, the generation rate (G) is formulated as follows:
where r1 and r2 are two random vectors between [0, 1], respectively. The GCP is the generation rate control parameter, and it is computed using EquationEquation (10)(10)
(10) . Eventually, the updating rule of EO is defined as:
where F is the exponential term, G is the generate rate, Xeq is a random candidate from equilibrium pool, and V is a constant unit with a value equal to 1 (Faramarzi et al. Citation2020).
Memory Saving
In EO, a mechanism resembles the pbest concept in particle swarm optimization is implemented. If the fitness value attained by the particle in the present iteration is better than the previous iteration, then the particle with better fitness will be saved and stored in pbest. The pseudocode of the EO algorithm is displayed in Algorithm 1.
General Learning Equilibrium Optimizer
Generally speaking, EO has the benefits and advantages of being casual, adaptable, and flexible, as compared to other metaheuristic optimization algorithms (Faramarzi et al. Citation2020). However, the performance of EO is still far from perfect. Besides, EO has the limitation of restricting the local optimal. As given in EquationEquation (11)(11)
(11) , the particles are guided by Xeq to move toward the global optimum. Recall that Xeq is a random candidate selected from the equilibrium pool. It means that each particle is learning from a randomly selected candidate in the updating process. The particle might have the difficulty of searching the promising regions if the selected candidate is trapped in the local optimal.
In this article, a new variant of EO, namely general learning equilibrium optimizer (GLEO) is proposed to promote the performance of the EO algorithm. The main idea of general learning is originated from (Liang et al. Citation2006). The GLEO utilizes a general learning strategy (see ) that enables the particles to learn from the potential candidates in different dimensions, which can assist the algorithm to escape the local optimal and explore more promising regions.
Figure 1. Basic concept of general learning strategy
General Learning Strategy
In this general learning strategy, the particle is updated as follows:
where feq = [feq(1), feq(2), …,feq(D)] defines which candidate the particle should follow. The Xdfeq(d) can be the corresponding dth dimension of any candidate in the equilibrium pool. Unlike EO, the candidates of each particle are selected randomly for each dimension. In an alternative word, the particle is learning from different candidates to explore the promising regions.
All the Xfeq can generate new positions in the search space using the information offered by different candidates in the equilibrium pool. Therefore, to ensure the particle learns from good candidates and prevents poor direction, the feq will be refreshed only when the fitness value obtained by the current particle is worse than its pbest. With a general learning strategy, it is believed that the search capability and diversity of GLEO can be dramatically enhanced. The pseudocode of GLEO is presented in Algorithm 2.
Proposed GLEO for Feature Selection
illustrates the block diagram of the proposed GLEO for biological data classification. In the first stage, the biological features are collected from the biological dataset to construct the feature set. Due to the high dimensionality of the biological feature set, the Pearson correlation coefficient is used to remove and filter some unwanted features . Then, the GLEO is employed to identify the most informative feature sub-set.
Figure 2. Block diagram of proposed GLEO for biological data classification
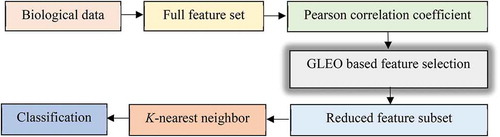
The GLEO starts the FS by creating a set of initial solutions with size (N × D), where N is the number of particles, and D is the number of features. In the population, each vector represents the indices of corresponding features. A threshold of 0.5 is employed to determine whether the feature is selected or not.
As given in EquationEquation (14)(14)
(14) , if the value of the vector is greater than 0.5, then the corresponding feature is selected. Otherwise, the feature is considered an unselected feature. In GLEO, each particle is evaluated by a fitness function. The fitness function is expressed as follows:
where CE is the classification error, |R| is the length of reduced feature sub-set, |F| is the number of features, and γ is a control parameter. As given in EquationEquation (15)(15)
(15) , the first term measures the prediction power, whereas the second term estimates the ratio of feature size. Iteratively, the proposed GLEO will evolve the initial solutions to find the global best solution (Optimal feature subset), as shown in Algorithm 2. Last but not least, the reduced feature sub-set is fed into the k-nearest neighbor (KNN) for the performance validation process.
Results and Discussions
Biological Data and Performance Metrics
Sixteen biological datasets are collected from ASU and UCI repository to evaluate the effectiveness of proposed GLEO algorithm. depicts the detailed of 16 utilized biological datasets. As can be seen, the datasets were made up of various numbers of instances, features, and classes, which can examine the efficacy of the proposed GLEO in different perspectives. From , one can see that nine datasets consisted of very high dimensions (number of features >1000). The dataset with a larger number of features is more complex and represents a real challenge.
Table 1. Detail of 16 utilized biological datasets
Four different statistical measurements are used to investigate the efficacy of proposed GLEO in biological data FS and classification. These performance metrics are fitness value, accuracy, feature size, and running time (Emary, Zawbaa, and Hassanien Citation2016; Kashef and Nezamabadi-pour Citation2015).
Comparison of Proposed GLEO with EO Algorithm
In this section, the performance of the GLEO is evaluated and compared to the EO algorithm. The environment settings of the experiment are population size = 10, maximum number of iterations = 100, and the lower and upper boundaries are set at 0 and 1, respectively (Faris et al. Citation2018). According to (Aljarah et al., Citation2018; Faris et al. Citation2018), the γ is set at 0.99 because the classification accuracy is the most important measurement. Each dataset is assessed using stratified K-fold cross-validation. To evaluate the fitness of each solution, the k-nearest neighbor (KNN) is employed, which is one of the best classifier as also investigated in (Aljarah et al., Citation2018; Ibrahim et al. Citation2019). Due to the stochastic of metaheuristic algorithms, for each algorithm, the experiment is running for G times. Lastly, the average results obtained from all the simulations are recorded and reported. The K and G are at 10 and 20, respectively.
demonstrates the convergence curves of the GLEO and EO algorithms. As can be seen, GLEO offered a very high diversity. As compared to EO, GLEO can often converge faster to find the global optimum, thus resulting in an optimal feature subset. The cardinal cause for the improved efficacy of the GLEO is that it enables the particle to learn from potential candidates in different dimensions. Hence, in the case of immature convergence, the GLEO can effectively prevent converging to inferior locations.
Figure 3. Convergence curves of GLEO and EO algorithms
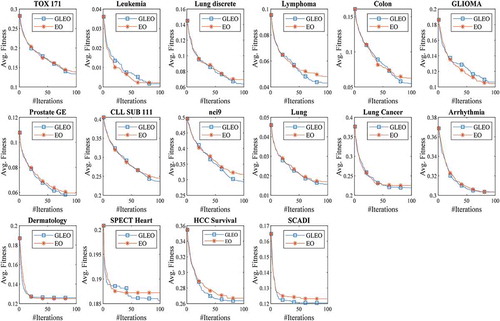
Figure 4. Boxplot of different algorithms
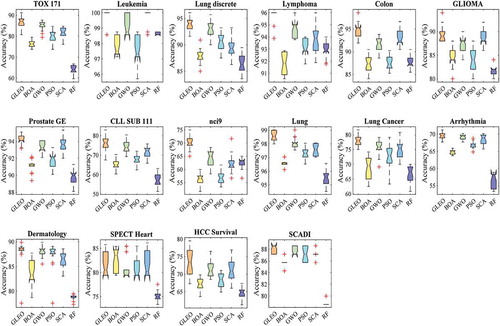
presents the results of the GLEO and EO algorithms. From , GLEO yielded the best fitness value in most cases. Besides, GLEO scored the highest accuracy in at least 14 datasets. Taking dataset 8 (CLL_SUB_111) and dataset 9 (nci9) as the examples, GLEO achieved the optimal accuracies of 76.27% and 70.50%, which proves its superiority in solving the high-dimensional FS problem. Owing to the general learning strategy, GLEO can be capable to avoid local optimal and can effectively get the best solution in this work.
Table 2. Experimental results of GLEO and EO algorithms
In terms of feature size, GLEO and EO can often remove a large quantity of irrelevant and redundant features from the original datasets. The results affirm the supremacy of GLEO and EO in feature reduction. As for computation time, it is seen that the processing speed of GLEO and EO algorithms were very closed. Based on the results obtained, it can be inferred that GLEO not only offered great prediction power but also excellent in selecting a smaller number of informative features.
Comparison of Proposed GLEO with Other Well-known Algorithms
In this section, the performance of GLEO is further compared with butterfly optimization algorithm (BOA) (Arora and Singh Citation2018), grey wolf optimizer (GWO) (Mirjalili, Mirjalili, and Lewis Citation2014), particle swarm optimization (PSO) (Kennedy Citation2011), sine cosine algorithm (SCA) (Mirjalili Citation2016) and ReliefF algorithm (RF) (Kira and Rendell Citation1992). outlines the parameter settings of comparison algorithms.
Table 3. Parameter settings of comparison algorithms
depicts the result of the average fitness value. From , GLEO achieved the best fitness value in most datasets (14 datasets), followed by BOA and GWO (one dataset). In a nutshell, GLEO retained very good convergence behavior compared to BOA, GWO, PSO, and SCA methods.
Table 4. Results of the fitness value
outlines the result of the accuracy. Based on the result obtained, GLEO outperformed other algorithms on around 87.5% of the datasets. The result reveals that GLEO worked very well in defining the informative features, especially on high-dimensional datasets. , exhibits the boxplot of the accuracy. As can be observed, GLEO obtained the highest median value in most datasets, which contributed better classification performance than BOA, GWO, PSO, SCA, and RF algorithms. GLEO’s superior performance is due to high ability to escape local solutions and avoid immature convergence with the general learning mechanism.
Table 5. Results of the accuracy
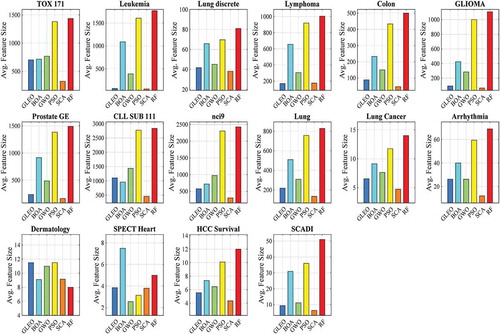
shows the result of the feature size. It is seen that SCA yielded the smallest number of selected features in 13 datasets, followed by GLEO, GWO, and RF (one dataset). Although GLEO is not the best algorithm in feature reduction; however, GLEO can often select the descriptive features that can best describe the target class. Hence, GLEO has attained higher accuracies in this work.
Figure 5. Feature size of different algorithms
exhibits the p-values obtained from the Wilcoxon signed-rank test for the pair-wise comparison of the best accuracy achieved from whole iterations with a 5% significance level. Inspecting the result, the performance of GLEO was significantly better than other algorithms in this work. On the whole, GLEO can be inferred as a valuable FS tool in biological data classification.
Table 6. Results of the Wilcoxon test with p-value
Conclusion and Future Works
FS is an important pre-processing step before applying the classifier to the datasets. That is, the wrapper-based FS method helps to select the informative features, which is an extremely challenging task in high-dimensional datasets. In this article, a new FS method called GLEO has been developed to solve the FS issue in biological data classification tasks. The integration of general learning strategy within GLEO made it highly capable of searching the promising regions, which can effectively eliminate the redundant and irrelevant information. The experimental results of GLEO implied this algorithm perceived the highest accuracy with the reduced feature sub-set for most of the datasets. The efficacy of GLEO has been proven by verifying the results with EO, BOA, GWO, PSO, SCA, and RF algorithms. Ultimately, GLEO can be considered as a powerful tool in the classification of medical and biological datasets. In the future, GLEO can be hybridized with the other metaheuristic algorithms to further enhance its optimization behavior. Furthermore, the implementation of the general learning strategy as a new mechanism for other metaheuristic algorithms can be investigated in future studies.
Ethical approval
This article does not contain any studies with human participants or animals performed by
any of the authors.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Aghdam, M. H., N. Ghasem-Aghaee, and M. E. Basiri. 2009. Text feature selection using ant colony optimization. Expert Systems with Applications 36 (3,Part 2):6843–53. doi:10.1016/j.eswa.2008.08.022.
- Aljarah, I., M. Mafarja, A. A. Heidari, H. Faris, Y. Zhang, and S. Mirjalili. 2018. Asynchronous accelerating multi-leader salp chains for feature selection. Applied Soft Computing 71:964–79. doi:10.1016/j.asoc.2018.07.040.
- Amoozegar, M., and B. Minaei-Bidgoli. 2018. Optimizing multi-objective PSO based feature selection method using a feature elitism mechanism. Expert Systems with Applications 113:499–514. doi:10.1016/j.eswa.2018.07.013.
- Arora, S., and S. Singh. 2018. Butterfly optimization algorithm: A novel approach for global optimization. Soft Computing. doi:10.1007/s00500-018-3102-4.
- Banka, H., and S. Dara. 2015. A Hamming distance based binary particle swarm optimization (HDBPSO) algorithm for high dimensional feature selection, classification and validation. Pattern Recognition Letters 52 (SupplementC):94–100. doi:10.1016/j.patrec.2014.10.007.
- Barani, F., M. Mirhosseini, and H. Nezamabadi-pour. 2017. Application of binary quantum-inspired gravitational search algorithm in feature subset selection. Applied Intelligence 47 (2):304–18. doi:10.1007/s10489-017-0894-3.
- Bhadra, T., and S. Bandyopadhyay. 2015. Unsupervised feature selection using an improved version of Differential Evolution. Expert Systems with Applications 42 (8):4042–53. doi:10.1016/j.eswa.2014.12.010.
- Chuang, L.-Y., H.-W. Chang, C.-J. Tu, and C.-H. Yang. 2008. Improved binary PSO for feature selection using gene expression data. Computational Biology and Chemistry 32 (1):29–38. doi:10.1016/j.compbiolchem.2007.09.005.
- Emary, E., H. M. Zawbaa, and A. E. Hassanien. 2016. Binary grey wolf optimization approaches for feature selection. Neurocomputing 172:371–81. doi:10.1016/j.neucom.2015.06.083.
- Faramarzi, A., M. Heidarinejad, B. Stephens, and S. Mirjalili. 2020. Equilibrium optimizer: A novel optimization algorithm. Knowledge-Based Systems 191:105190. doi:10.1016/j.knosys.2019.105190.
- Faris, H., M. M. Mafarja, A. A. Heidari, I. Aljarah, A. M. Al-Zoubi, S. Mirjalili, and H. Fujita. 2018. An efficient binary Salp Swarm Algorithm with crossover scheme for feature selection problems. Knowledge-Based Systems 154:43–67. doi:10.1016/j.knosys.2018.05.009.
- Hammouri, A. I., M. Mafarja, M. A. Al-Betar, M. A. Awadallah, and I. Abu-Doush. 2020. An improved Dragonfly Algorithm for feature selection. Knowledge-Based Systems 203:106131. doi:10.1016/j.knosys.2020.106131.
- Hu, L., W. Gao, K. Zhao, P. Zhang, and F. Wang. 2018. Feature selection considering two types of feature relevancy and feature interdependency. Expert Systems with Applications 93:423–34. doi:10.1016/j.eswa.2017.10.016.
- Ibrahim, R. A., A. A. Ewees, D. Oliva, M. Abd Elaziz, and S. Lu. 2019. Improved salp swarm algorithm based on particle swarm optimization for feature selection. Journal of Ambient Intelligence and Humanized Computing 10 (8):3155–69. doi:10.1007/s12652-018-1031-9.
- Kashef, S., and H. Nezamabadi-pour. 2015. An advanced ACO algorithm for feature subset selection. Neurocomputing 147:271–79. doi:10.1016/j.neucom.2014.06.067.
- Kaur, T., B. S. Saini, and S. Gupta. 2018. A novel feature selection method for brain tumor MR image classification based on the Fisher criterion and parameter-free Bat optimization. Neural Computing and Applications 29 (8):193–206. doi:10.1007/s00521-017-2869-z.
- Kennedy, J. 2011. Particle Swarm Optimization. In Encyclopedia of Machine Learning, ed. Claude S., Geoffrey I. W.,760–66. Boston, MA: Springer. doi:10.1007/978-0-387-30164-8_630.
- Kira, K., and L. A. Rendell. 1992. The feature selection problem: Traditional methods and a new algorithm. Proceedings of the Tenth National Conference on Artificial Intelligence, San Jose, California, 129–34.
- Krömer, P., J. Platoš, J. Nowaková, and V. Snášel. 2018. Optimal column subset selection for image classification by genetic algorithms. Annals of Operations Research 265 (2):205–22. doi:10.1007/s10479-016-2331-0.
- Li, C., X. Luo, Y. Qi, Z. Gao, and X. Lin. 2020. A new feature selection algorithm based on relevance, redundancy and complementarity. Computers in Biology and Medicine 119:103667. doi:10.1016/j.compbiomed.2020.103667.
- Liang, J. J., A. K. Qin, P. N. Suganthan, and S. Baskar. 2006. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Transactions on Evolutionary Computation 10 (3):281–95. doi:10.1109/TEVC.2005.857610.
- Lu, L., J. Yan, and C. W. de Silva. 2015. Dominant feature selection for the fault diagnosis of rotary machines using modified genetic algorithm and empirical mode decomposition. Journal of Sound and Vibration 344:464–83. doi:10.1016/j.jsv.2015.01.037.
- Mafarja, M., I. Aljarah, H. Faris, A. I. Hammouri, A. M. Al-Zoubi, and S. Mirjalili. 2019. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Systems with Applications 117:267–86. doi:10.1016/j.eswa.2018.09.015.
- Mirjalili, S. 2016. SCA: A Sine Cosine Algorithm for solving optimization problems. Knowledge-Based Systems 96:120–33. doi:10.1016/j.knosys.2015.12.022.
- Mirjalili, S., S. M. Mirjalili, and A. Lewis. 2014. Grey Wolf Optimizer. Advances in Engineering Software 69:46–61. doi:10.1016/j.advengsoft.2013.12.007.
- Pashaei, E., and N. Aydin. 2017. Binary black hole algorithm for feature selection and classification on biological data. Applied Soft Computing 56:94–106. doi:10.1016/j.asoc.2017.03.002.
- Sayed, S., M. Nassef, A. Badr, and I. Farag. 2019. A Nested Genetic Algorithm for feature selection in high-dimensional cancer Microarray datasets. Expert Systems with Applications 121:233–43. doi:10.1016/j.eswa.2018.12.022.
- Sindhu, R., R. Ngadiran, Y. M. Yacob, N. A. H. Zahri, and M. Hariharan. 2017. Sine–cosine algorithm for feature selection with elitism strategy and new updating mechanism. Neural Computing and Applications 28 (10):2947–58. doi:10.1007/s00521-017-2837-7.
- Too, J., and A. R. Abdullah. 2020a. Opposition based competitive grey wolf optimizer for EMG feature selection. Evolutionary Intelligence. doi:10.1007/s12065-020-00441-5.
- Too, J., and A. R. Abdullah. 2020b. A new and fast rival genetic algorithm for feature selection. The Journal of Supercomputing 1–31. doi:10.1007/s11227-020-03378-9.
- Wang, M., Y. Wan, Z. Ye, and X. Lai. 2017. Remote sensing image classification based on the optimal support vector machine and modified binary coded ant colony optimization algorithm. Information Sciences 402:50–68. doi:10.1016/j.ins.2017.03.027.
- Yamada, M., J. Tang, J. Lugo-Martinez, E. Hodzic, R. Shrestha, A. Saha, H. Ouyang, D. Yin, H. Mamitsuka, C. Sahinalp, et al. 2018. Ultra high-dimensional nonlinear feature selection for big biological data. IEEE Transactions on Knowledge and Data Engineering 30 (7):1352–65. doi:10.1109/TKDE.2018.2789451.
- Zhang, L., K. Mistry, C. P. Lim, and S. C. Neoh. 2018. Feature selection using firefly optimization for classification and regression models. Decision Support Systems 106:64–85. doi:10.1016/j.dss.2017.12.001.
- Zhang, L., L. Shan, and J. Wang. 2017. Optimal feature selection using distance-based discrete firefly algorithm with mutual information criterion. Neural Computing and Applications 28 (9):2795–808. doi:10.1007/s00521-016-2204-0.
- Zhang, Y., D. Gong, Y. Hu, and W. Zhang. 2015. Feature selection algorithm based on bare bones particle swarm optimization. Neurocomputing 148:150–57. doi:10.1016/j.neucom.2012.09.049.