
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Biometric authentication methods, representing the ”something you are” scheme, are considered the most secure approach for gaining access to protected resources. Recent attacks using Machine Learning techniques demand a serious systematic reevaluation of biometric authentication. This paper analyzes and presents the Fast Gradient Sign Method (FGSM) attack using face recognition for biometric authentication. Machine Learning techniques have been used to train and test the model, which can classify and identify different people’s faces and which will be used as a target for carrying out the attack. Furthermore, the case study will analyze the implementation of the FGSM and the level of performance reduction that the model will have by applying this method in attacking. The test results were performed with the change of parameters both in terms of training and attacking the model, thus showing the efficiency of applying the FGSM.
Introduction
The transition of most physical processes in the form of the electronic application, starting from personal data storage to banking, has forced the requirement of authentication whenever you need to access them. Almost every modern computer or mobile device offers a large number of authentication forms to increase security. Emphasizing that face recognition is one of the most common forms of authentication that we use efficiently daily, attacking processes that use this way of authentication is dangerous. The range in which facial recognition is used starts from tagging photos on social networks and opening personal devices to access high-security areas. The risk of malfunctioning facial recognition systems can be severe and significant damage. As attacks on authentication processes are becoming more and more inevitable, work is actively underway to identify vulnerabilities in the models created for this process and improve the vulnerabilities that have already been made known in advance.
According to Andress (Citation2011), authentication, in terms of information security is the set of methods we use to verify whether an identity is genuine. It should be noted that authentication only determines whether the claim of the instance’s identity is correct. This is not related to the access offered subsequently to the authenticated party and what it is allowed to do because it falls under the responsibility of the authorization process. Several methods can be used for authentication that is categorized by reference to a factor. In trying to validate an identity claim the more factors used, the more positive the results are. When we authenticate, factors can be something we know, something we are, or something we have. Authentication is the act of proving that someone is whom they claim to be. By focusing on something we are, we can categorize the relatively unique physical attributes of an individual, such as biometric characteristics.Biometrics summarizes measurements and calculations of human characteristics. Biometric authentication is used in computer science as a form of identification and verification. Biometric identifiers are distinctive, measurable features used to label and describe individuals. Biometric identifiers are often categorized as physiological or behavioral characteristics.
A biometric system recognizes a person by determining authentication by using different features of his body such as fingerprints, face, iris, retina scanning, signature, hand geometry, voice, etc. These features can be divided based on the level of security, user acceptance, cost, performance, etc. Biometrics is a growing technology, which has been widely used in forensics, access and physical security (Gill et al. Citation2019).
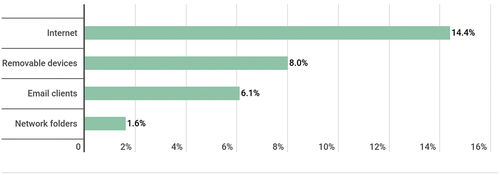
Despite the benefits, biometrics is prone to some security threats, such as presentation attacks (spoofing), biometric data processing attacks, software, and networking vulnerabilities. According to Kaspersky (Citation2019), in 2019, of all threats on biometric data processing systems were internet-related threats (malicious and phishing websites), followed by removable media (
) and network folders (
), as presented in .
Figure 1. Threats for biometric data processing and storage systems (Kaspersky Citation2019).
Being aware of the importance of the authentication process and the consequences of its performance may have, any attack carried out on the process is a threat to many instances that exploit it. If the airport authentication system was attacked, people wanted by the police could be allowed to travel without any problems. In cases where authentication is used in automotive, a vehicle could be used by unauthorized persons or even cause improper functioning by confusing driver’s preferences. In high-security buildings, any malfunction of authentication systems could lead to unauthorized persons having access to areas they are not supposed to be in. In schools, the safety of students could be endangered. In banking systems there is the possibility of card theft and misuse of large sums of money by deceiving an identity identification system.
We chose FGSM because it is a white-box approach, as it requires access to the internals of the classifier being attacked. As mentioned in Xue, Yang, and Jing (Citation2019), FGSM image perturbation algorithm is to disturb images at the classification layer, and it needs to be considered that the size of the disturbance factor is determined, resulting in the false classification effect of face recognition is not obvious. In addition, FGSM is compared with other attack methods in Rao et al. (Citation2020). They use the area under curve (AUC) as an evaluation metric. The value of AUC ranges from 0 to 1. A perfect model would approach 1 while a poor model would approach 0. For single models, FGSM has higher AUC than other methods such as PGD, MIFGSM, DAA, DII-FGSM, in the white box attacks.
The contribution of this paper is toward of using human images with FGSM, which represents an alternative approach to other traditional methods mentioned previously (PGD, MIFGSM, DAA, DII-FGSM).
Therefore the objectives of this study are:
Measuring the performance of a model based on different training characteristics.
Implementing attack with the FGSM method.
Determining the level of vulnerability of the model depending on the training characteristics.
Determining the effectiveness of the attack on the model with different performances.
The rest of the paper is structured as follows. Section 2 gives an overview of related work, Section 3 describes the Fast Gradient Sign Method (FGSM), Section 4 presents the experimental setup and data analysis. Experimental results are provided in Section 5, and lastly, Section 6 rounds off the paper with a discussion and indication of future work.
Related Work
Face Recognition
Since the face is considered to be the most important part of the human body, it plays a key role in identifying and validating a person, due to which it can be used for multiple applications in daily life. As studied in (Zulfiqar et al. Citation2019) the face recognition system is trending across the globe as it offers safe and reliable security solutions. It is the fastest biometric technology that identifies a person without involving him. It does not add any unwanted delay as it automatically captures the image of a person from a certain distance or takes a snippet from a video, processes that image, and recognizes that person. From (Mori, Matsugu, and Suzuki Citation2005), (Li et al. Citation2020) it can be seen that for the creation of a system that performs the function of face recognition, ML techniques are used, specifically artificial neural networks. Neural networks that have been created specifically for such tasks and that have shown efficiency in performing them when it comes to image processing, analysis, and comparison are convolutional neural networks (CNN) (Albawi, Mohammed, and Al-Zawi Citation2017). This type of network was also used in the case of our study.
Transfer Learning
While using Machine Learning, if a model is trained with a certain dataset and labels, it responds only to the classification of images in the respective labels. With the increasing use of models and the extremely large addition of domains treated as training subjects of these models, training from the beginning becomes costly and unnecessary to be repeated. From this came the creation of the concept of Transfer Learning. From the name itself, it is understood that the transferred learning is related to the transfer of prior knowledge acquired by a trained model with a certain dataset, to another model that will be trained with a different dataset but which belongs to the same domain. The main pillar of the trained model used in this study is precisely transfer learning. Deep Learning and Convolutional Machine Learning algorithms are designed to work in isolation. These algorithms are trained to solve specific tasks and models must be constructed from the beginning when the spatial distribution of features changes. Transfer learning is the idea of overcoming the paradigm of isolated learning and utilizing the knowledge gained while solving one task to solve another complicated task. Some of the architectural types of CNN networks developed in advance, which are used for the further development of AI models are: LeNet (Lecun et al. Citation1998), AlexNet (Krizhevsky, Sutskever, and Hinton Citation2012), VGGNet (Simonyan and Zisserman Citation2014), GoogLeNet (Szegedy et al. Citation2015), ResNet (He et al. Citation2016).
Adversarial Attacks
With the beginning of the integration of ML and DL methods in facial recognition, techniques have also been developed to threaten and to lead to failure of the systems that use these methods. Quite a lot of techniques have been developed which deceive ML models not only by changing their operation but by modifying the inputs to change the factors that the model takes into account when analyzing them. The development of these techniques has been studied extensively both from the analytical point of view and from that of their practical implementation and efficiency in realization in (Ren et al. Citation2020). Methods have also been developed to detect and prevent these attacks by teaching models through examples of how to spot a real input and a modified one by the attacker and not fall prey to scams (Massoli et al. Citation2021).
Attacks such as Adversarial Attacks have room for use in many delicate areas which can bring fatal results. With the daily publication of content as textual as well as those in the form of images on the Internet, many machine learning instances have been developed to deal with the evaluation of this content to avoid threatening or uncensored content. Adversarial examples can be used to trick models into faking the contents of photos, which can be used to promote child pornography or spread images with threatening content, without being detected by systems and without being censored. One such system which is exposed to adversarial attacks is content classification on Instagram.
According to Yuan et al. (Citation2019) adversarial attacks are divided into many different types depending on their characteristics. These attacks based on prior knowledge about the system are divided into:
White-box attacks – the attacker has access to the ML model, including the model structure and its parameters.
Black-box attacks – the attacker has no access to the model, but only to its results.
Adversarial attacks based on the intent of the attacker can belong to two main types (Yuan et al. Citation2019):
Targeted attack – develops algorithms that modify the input in such a way that the output is a predefined value, different from the correct one.
Untargeted attack – develops algorithms that modify the input in such a way that the output has a different value from the correct one, but not a predefined value.
In Goodfellow, Shlens, and Szegedy (Citation2014), methods for generating perturbation are presented that modify the input images of the model and deceive it. It explains how models that are easily optimized can be easily fooled as well. Linear models lack the ability to resist perturbation in images, and only structures with a hidden layer need to be trained to resist adversarial patterns. According to Massoli et al. (Citation2021) adversarial examples are a serious threat to DL models, as they place a significant constraint especially on the use of learning models in sensitive applications where such a threat should be avoided. In addition to adversarial training, one approach that enhances the resilience of AI-based systems to such threats is the detection of intrusive inputs. The adversarial attack on systems that use ML methods to recognize people’s faces on the basics learned from similar work will be addressed in the case study.
In Goswami et al. (Citation2018), experimental evaluation demonstrates that the performance of deep learning based face recognition algorithms can suffer greatly in the presence of by commonly observed distortions in the real world that are well handled by shallow learning methods along with learning based adversaries. That deep CNNs are vulnerable to adversarial examples, which can cause fateful consequences in real-world face recognition applications with security-sensitive purposes is also proved in Dong et al. (Citation2019).
George et al. (Citation2019) proposed a multi-channel Convolutional Neural Network based approach for face presentation attack detection (PAD), as well as, authors introduced the new Wide Multi-Channel presentation Attack (WMCA) database for face PAD. The proposed method was compared with feature-based approaches and found to outperform the baselines.
Furthermore, Wang et al. (Citation2020) proposed a new framework of palmprint false acceptance attack with a deep convolutional generative adversarial network (DCGAN). It has been proven that DCGAN provides better accuracy and significant improvements over the existing classical methods.
Fast Gradient Sign Method – FGSM
According to Goodfellow, Shlens, and Szegedy (Citation2014), in many cases the accuracy of an individual input feature is limited. An example of this is the fact that digital images often use only 8 bits per pixel which makes them ignore the information below the dynamic range 1/255. Because the precision of this feature is limited, it is not rational for a classifier(model) to respond differently to an entry and a modified entry
every element of the
is smaller than the precision of the feature. For an example with well-separated classes, we expect the model to show the same class for both
and
while
If we consider the scalar product of a weight vector w and an adversarial example
as follows:
adversarial perturbation causes activation to increase by . This increase can be maximized at the maximum rate limit in
, expressing
as
. If
has
dimensions and the average size of a vector element
is
, then the activation would increase by
. According to this flow, a linear model would be forced to follow the signal that most closely matches its weights even if multiple signals are present and the other signals have larger amplitudes. The purpose of the FGSM method is to add noise to the image whose direction is the same as the gradient of the loss function in relation to the input data analyzed at the pixel level. FGSM has been used as the targeted and untargeted method and the mathematical difference is explained below.
Targeted FGSM
The targeted FGSM method, which aims to modify the image so that the model has the desired output, defines the modified image based on the formula:
where, adversarialImage is the modified image, cleanImage is the clean image to be modified of the tensor format (width, length, depth), the label identifies the class which is intended to be the output value when the model receives the modified image input and is different from the correct output of the model when the input is the pure image, is the coefficient on which the amount of noise added to the image depends and is triggered,
is the cross-entropy loss function and
are the model parameters.
Untargeted FGSM
The method aims to modify the image so that only if the model has an incorrect output, the modified image is defined by the formula:
where, the label in this case is the correct output of the model when the input is the clean image. In both types of methods the noise that is added to the image is defined by the following formula:
Creating a finite optimal perturbation linearizes the loss function around the values of the parameters . As discussed in Goodfellow, Shlens, and Szegedy (Citation2014), the fact that such simple and inexpensive algorithms can generate erroneously classified examples serves as evidence in favor of interpreting adversarial examples as results of linearity. Algorithms are useful to accelerate adversarial loss training to analyze trained networks.
Experimental Setup
Since the application of the attack requires the creation and training of a model with machine learning techniques through artificial neural networks and the most suitable network for training models aimed at classifying images, recognizing images or even detecting objects is the convolutional neural network (CNN), the steps to be followed to achieve training should be devised.
Creating the Model for Authentication
Data Collection
To train the artificial neural network, the model, it is necessary to possess a large set of data, in our case pictures of different persons to have the appropriate relevant material from which the model can learn. The sie of the dataset depends on the classification task and the built up model. CNN models require datasets with thousands of images, but since we use transfer learning the dataset can be much smaller. The dataset we used is the public “5 Celebrity Faces Dataset”Footnote1 DanB (Citation2017) which contains pictures of 5 different people. This is a small database dedicated to experiment with computer vision techniques. For each person in the files, there are 14–20 pictures, structured in respective folders, while in the evaluation files there are 5 photos for each.
Two main techniques that are used during data collection and preparation are:
Data processing which refers to transformations that must be applied to data before they can be used. Data processing is a technique used to convert raw data into a clean data set. In other words, whenever data is collected from different sources it is collected in raw formats, which is not possible for analysis.
Data augmentation process which is used to add data by transforming current data without applying new data collection. This process is very useful in DL because in cases when it is necessary to collect a very large amount of data, adding them in such a form is very efficient. It enables better learning due to the increase of the training dataset and allows the algorithm to learn from different states. The main operations of this process that we have used are: scaling (ensures that the input is in the range [0, 1]), rotation, zoom, shift, and flip.
Defining Model Architecture
The architecture of the model should be defined by specifying the layers to which the data should be passed to ensure the most efficient training of the model. The specific characteristics of each neural network model are the number and type of layers, the number of neurons, and the type of activation functions. These characteristics must be tested and assigned so that the performance of the model is satisfactory and achieves the level of acceptability for the function it is to perform. Due to the limitation of the topic in analyzing attacks on the authentication process based on facial recognition features, the type of neural network that has been elaborated and implemented is CNN using the convolution operation. The advantage of CNN is obvious considering that it is dedicated to the problems related to computer vision and our related problem.
As documented in Simonyan and Zisserman (Citation2014), VGGNet is the CNN network architecture proposed by Karen Simonyan and Andrew Zisserman from Oxford University in 2014. The VGG network inputs are RGB images with 224 × 224 dimensions. In the VGG16 type architecture, there are 3 fully connected layers and 13 constituent layers, while the VGG19 type has 16 such layers. There are small filters with 3 × 3 dimensions but with more depth instead of large filters. In both types of architecture, two fully connected layers have 4096 channels while the third layer has 1000 channels to predict 1000 labels. The last fully connected layer uses the softmax activation function to perform the classification. The VGG16 model with pre-trained weights in ImageNet was used as the base model for our trained model. This model supports both image formats with color channel dimensions as “channels_first” and “channels_last.”
Our model, as presented in , utilizes the features of the VGG16 model and develops on it. The constructed model is a sequential model which by its name is understood to be a sequential set of layers. The number of layers is set so that the network is strong enough to solve the problem for which it is created. Each layer accepts a tensor as input and also has an output tensor. The output of the previous layer is the input of the next layer and by applying this idea to our model we would have a functional structure as follows:
Figure 2. Model architecture.
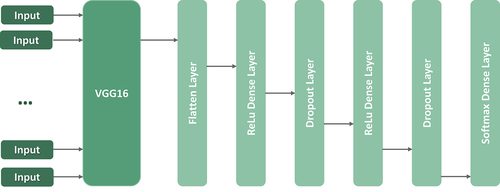
The VGG16 has the input shape as and the output shape as
. The output shape of each VGG16 layer is represented in . Initially the flatten layer is used to flatten the output of the base model VGG16, which was referred to in the previous formula as entry and is the input for the flatten layer. The function of the flatten layer is to transform a multidimensional tensor into a one dimensional tensor. Since the output of the previous layer is of shape
, flatten layer unstacks all the tensor values into a tensor of shape
. In the Dense layer the end result is passed through a fuction called activation function, on our case the used activation function is Rectified Linear Unit (ReLU). This fuction returns 0 for any negative input value and returns the value back for any positive value. This layer specifies the unit value which represents the output size of the layer. The set value is 4096 in both used Dense layers. Droupout layer is used to prevent the model from overfitting. As mentioned in Srivastava et al. (Citation2014) the Neural Networks (NN) with a large number of parameters are very powerful and also slow to use, which makes it difficult to deal with overfitting. Dropout is a technique for addressing this problem by randomly droping units along with their connections, from the NN during training. This prevents units from co-adapting too much. The fraction of the input units to be dropped is set to
. The last layer is the Dense layer with Softmax activation function, which is used in classification networks because the result could be interpreted as a probability distribution. This activation function converts the input tensor to a tensor of categorical probabilities, thus dividing the probability of 5 classes. The output shape of each model layer is represented in .
Table 1. Output shapes of VGG16 layers
Table 2. Output shapes of the model layers
Model Training and Evaluation
To measure the performance of the classification model we use cross-entropy loss. Cross-entropy loss increases as the predicted probability diverges from the actual label. Since we have more than two labels to predict, it is required to use categorical crossentropy. Optimization algorithms in ML aim at minimizing the loss function. We use RMSprop optimizer on our model. Model training through the epochs has lasted about per epoch because image processing requires more time and the structure of the model layers is more complicated. At the end of each epoch, the levels of accuracy and losses during training and validation were recorded.
FGSM Implementation
The explanation of FGSM in Simonyan and Zisserman (Citation2014) has been the basis of realization in the case study. Fast Gradient Sign Method is a method which aims at incorrect classification of images. To achieve such a goal, since it is white box attack, one must know the structure of the model. For this reason, it has been explained in advance how the model that we will use as a target of the attack was constructed. Attack methods have been implemented based on formulas (2) and (3).
Results
The constructed model we used was trained according to the steps outlined and several tests were performed to observe changes in accuracy and vulnerability spaces when training characteristics change. Five cases have been tried, when the model is trained with and
epochs. By applying the FGSM method to create modified images, cases have been tried where the value of
has changed from the range
and
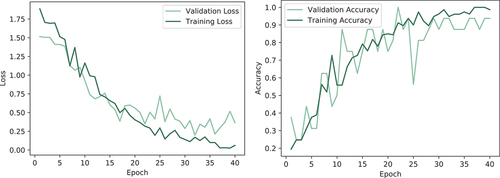
and always taking into account whether the method is targeted or untargeted. Thus, five tests were performed with the change of parameters both in terms of training and in terms of attacking the model, where in each test as input were used 5 identically randomly selected images, a photo of each of five people for whose identification the model is trained. A graphical presentation of the losses and accuracy of the model, using 40 epochs, during the training and validation phase is presented in the . The spike in shows that the better performance is achieved with 20 and 30 epochs rather than with 25 epochs.
Figure 3. The graphical presentation of the losses and accuracy of the proposed model.
Moreover, these tests have served to build the relationship between the parameters and the impact that their change has on the efficiency of applying the FGSM method in the corresponding model.
From the test results presented in one can conclude that the performance of a model which aims to identify and classify five different people depends on the number of epochs assigned for training. The model that has had the highest degree of accuracy is the one trained with epochs, which has achieved an average of
confidence in estimation. Hence, this comparison is made by calculating the average level of security accumulated by a large number of test inputs as it is presented as a differentiating value given that other parameters such as maximum security are not efficient at this level as in all three cases when the model trained in
and
epochs, the maximum safety achieved at the exit is
.
Table 3. Model test results
Statistically, the cases when the method failed to generate modified images were collected and those images did not represent the desired result from the model. From the analysis of the attack efficiency the highest accuracy is achieved in the application of the untargeted attack in the trained model with epochs, where it has not resulted in any case of failure and the accuracy of the attack measured with the test samples is
. Such a percentage of accuracy is evident even in the untargeted attack on the 50-epochs trained model. In both cases the successful or unsuccessful execution of the attack has not been affected by
, but it can only be argued that its small values has generated noise that has not changed the images much. With the increase of
from
to
in most cases it can be noticed that the picture does not have the original quality. Attacks that have had the highest level of inaccuracy are the targeted attack on the
epochs trained model that achieves
inaccuracy and the targeted attack on the
epochs trained model that achieves
inaccuracy. In addition to achieving the goal of deceiving a model through modified inputs to have the desired output, the level of security that these unrealistic outputs have should also be discussed. The lowest level of security of the model output evaluation was measured in the unsaturated attack on the trained model with
epochs and with a value of
with a certainty of
, while the highest security value is recorded in the unsaturated attack on trained model with
epochs and with value of
that has
certainty.
From the performed tests it is noticed that there are fluctuations of accuracy in different numbers of epochs. This happens for two reasons, the first because with the change of the number of model epochs the way model fits also changes, facing overfitting or underfitting, while the second is the determination of attack characteristics as epsilon. The ideal number of epochs turned out to be the one that had the highest accuracy, reflecting the change in the accuracy of the adversarial attack.
Conclusion
The FGSM method was mathematically clarified, which was successfully implemented in the case study. From the test results one can conclude that practically this method had a relatively high percentage of accuracy and had the right effect in most cases.
The results showed that untargeted attacks are more effective and have better performance, with fewer failures and a higher value of security accuracy in estimation. Such an analysis leads us to two choices of adequate conditions. The most effective targeted attack is the trained model’s attack with epochs and
. In comparison, the most effective non-targeted attack is the attack on the trained model with
epochs and
. Achieving such percentages of security in image identification is entirely satisfactory when viewed from the application and well-functioning ML algorithms. Still, the amount of space created for erroneous classifications in delicate processes is intolerable.
Finally, the achieved results could be used in any biometric aware application, with facial images in the database, where security and authentication is a primary issue, such as access to high security facilities of any kind.
Acknowledgments
Authors would like to thank you the Department of Computer Engineering from University of Prishtina and the Department of Informatics at the University of Oslo for support and cooperation.
Notes
References
- Albawi, S., T. A. Mohammed, and S. Al-Zawi. 2017. Understanding of a convolutional neural network. In 2017 International Conference on Engineering and Technology (ICET), 1–6.
- Andress, J. 2011. Chapter 2 - identification and authentication. In The basics of information security, ed. J. Andress, 17–31. Boston: Syngress.
- DanB. 2017. 5 celebrity faces dataset. https://www.kaggle.com/dansbecker/5-celebrity-faces-dataset
- Dong, Y., H. Su, B. Wu, Z. Li, W. Liu, T. Zhang, and J. Zhu. 2019. Efficient decision-based black-box adversarial attacks on face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR): 7706-7714. doi:https://doi.org/10.1109/CVPR.2019.00790.
- George, A., Z. Mostaani, D. Geissenbuhler, O. Nikisins, A. Anjos, and S. Marcel. 2019. Biometric face presentation attack detection with multi-channel convolutional neural network. IEEE Transactions on Information Forensics and Security 15: 42-55. doi:https://doi.org/10.1109/TIFS.2019.2916652.
- Gill, R., A. Pandey, H. Gill, and V. Gupta. 2019. Security of message transmission using hand biometric features. International Journal of Computer Engineering and Applications (IJCEA). Volume XII, Special Issue, April- ICITDA 18, pp.1-4.
- Goodfellow, I., J. Shlens, and C. Szegedy. 2014. Explaining and harnessing adversarial examples. arXiv 1412.6572. December.
- Goswami, G., N. Ratha, A. Agarwal, R. Singh, and M. Vatsa. 2018. Unravelling robustness of deep learning based face recognition against adversarial attacks. Proceedings of the AAAI Conference on Artificial Intelligence 32(1):6829-6836. https://ojs.aaai.org/index.php/AAAI/article/view/12341/12200.
- He, K., X. Zhang, S. Ren, and J. Sun. 2016. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, doi:https://doi.org/10.1109/CVPR.2016.90.
- Kaspersky. (2019). Biometric data processing and storage system threats.
- Krizhevsky, A., I. Sutskever, and G. Hinton. 2012. Imagenet classification with deep convolutional neural networks. Neural Information Processing Systems 25. January, pp. 1097–1105.
- Lecun, Y., L. Bottou, Y. Bengio, and P. Haffner. 1998. Gradient-based learning applied to document recognition. Proceedings of the IEEE 86:2278–324. December. doi:https://doi.org/10.1109/5.726791.
- Li, Y., Z. Wang, Y. Li, X. Zhao, and H. Huang. 2020. Design of face recognition system based on cnn. Journal of Physics: Conference Series 1601:052011. August.
- Massoli, F. V., F. Carrara, G. Amato, and F. Falchi. 2021. Detection of face recognition adversarial attacks. Computer Vision and Image Understanding 202:103103. January. doi:https://doi.org/10.1016/j.cviu.2020.103103.
- Mori, K., M. Matsugu, and T. Suzuki. 2005. Face recognition using SVM fed with intermediate output of CNN for face detection. In Proceedings of the IAPR Conference on Machine Vision Applications (IAPR MVA 2005), 410–13. Tsukuba Science City, Japan, May 16-18
- Rao, C., J. Cao, R. Zeng, Q. Chen, H. Fu, Y. Xu, and M. Tan. 2020. A thorough comparison study on adversarial attacks and defenses for common thorax disease classification in chest x-rays. ArXiv abs/2003.13969.
- Ren, K., T. Zheng, Z. Qin, and X. Liu. 2020. Adversarial attacks and defenses in deep learning. Engineering 6 (3):346–60. doi:https://doi.org/10.1016/j.eng.2019.12.012.
- Simonyan, K., and A. Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv 1409.1556. September.
- Srivastava, N., G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research 15 (56):1929–58.
- Szegedy, C., W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. 2015. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 1–9.
- Wang, F., L. Leng, A. B. J. Teoh, and J. Chu. 2020. Palmprint false acceptance attack with a generative adversarial network (gan). Applied Sciences 10 (23):8547. doi:https://doi.org/10.3390/app10238547.
- Xue, J., Y. Yang, and D. Jing. 2019. Deceiving face recognition neural network with samples generated by deepfool. Journal of Physics: Conference Series 1302 022059. August.
- Yuan, X., P. He, Q. Zhu, and X. Li. 2019. Adversarial examples: Attacks and defenses for deep learning. IEEE Transactions on Neural Networks and Learning Systems 30 (9):2805–24. doi:https://doi.org/10.1109/TNNLS.2018.2886017.
- Zulfiqar, M., F. Syed, M. Khan, and K. Khurshid. 2019. Deep face recognition for biometric authentication. In 2019 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), pp. 1-6, doi: https://doi.org/10.1109/ICECCE47252.2019.8940725.