
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper presents a heterogeneous ensemble classifier for price trend prediction of a stock, in which the prediction results are subsequently used in trading recommendation. The proposed ensemble model is based on Support vector machine, Artificial neural networks, Random forest, Extreme gradient boosting, and Light gradient boosting machine. A feature selection is performed to choose an optimal set of 45 technical indicators as input attributes of the model. Each base classifier is executed with an extensive hyperparameter tuning to improve performance. The prediction results from five base classifiers are aggregated through a modified majority voting among three classifiers with the highest accuracies, to obtain final prediction result. The performance of proposed ensemble classifier is evaluated using daily historical prices of 20 stocks from Stock Exchange of Thailand, with 3 overlapping datasets of 5-year intervals during 2014–2020 for different market conditions. The experimental results show that the proposed ensemble classifier clearly outperforms buy-and-hold strategy, individual base classifiers, and the ensemble with straightforward majority voting in terms of both trading return and Sharpe ratio.
Introduction
Stock trend prediction is very valuable for investment management. Accurate prediction makes it possible for investors to decide a proper moment to buy or sell a stock, to achieve the goal to beat the market and make profits (Ding and Qin Citation2020). However, stock trend prediction is really challenging due to the high volatility in the stock market. The trend prediction in stock market has drawn a lot of research attention for many decades using both statistical and computing approaches including artificial intelligence. Recent approaches focus more on machine learning with both regression and classification techniques. Regression techniques aim to predict the future value of the stock price (Wang et al. Citation2011), while classification techniques aim to predict the trend of stock price movement (Deng et al. Citation2021; Kim and Han Citation2016; Nobre and Neves Citation2019; Olson and Mossman Citation2003; Zhang et al. Citation2018, Citation2021).
Broadly speaking, there are two approaches in analyzing financial market: fundamental analysis and technical analysis. Fundamental analysis studies the economic factors and financial factors of the firm to predict its price or trend. Technical analysis approach believes that the historical data of the firm’s prices can be mathematically analyzed for predicting the trend. Technical analysis has been widely used for short-term trading, in a range of weeks to hours (Hu et al. Citation2015; Lorenzo Citation2013).
This work aims to apply five well-known classification algorithms, namely, support vector machine, artificial neural network, random forest, extreme gradient boosting (or XGBoost), and light gradient boosting machine (or LightGBM) for trend prediction. The aim is to propose a heterogeneous ensemble classifier from such five base algorithms to predict trend of stock price for trading recommendation. Performance of the algorithms will be evaluated with the investment returns and risks from trading simulation using the predicted trend results.
Specifically, in the first step, the classifiers are trained to build a trend prediction model from a daily dataset. The experiment uses publicly available data of open, high, low, close, and volume of stock prices. These raw data are used to compute a set of technical indicators which are widely used by technical analysts. The computed technical indicators are fed into the process of building the prediction models. However, up to now, there is no known set of technical indicators most suitable for a dataset. A feature (or attribute) selection method is adopted in the data preprocessing to automatically choose the optimal technical indicators as model inputs. The models are used for predicting daily trends of the corresponding testing (or unseen) data, which will further be used for trading simulation in the second step. Moreover, choosing the optimal classification algorithm and its hyperparameter for a given data often requires expertise and amount of effort (Elshawi, Maher, and Sakr Citation2019). Hyperparameters are parameters of the algorithm itself that need to be set to suitable values to obtain good performance for a given data. Most of the time they are left to using default values, which unfortunately often lead to performance much lower than of the hyperparameter tuning. Thus in this work, performance and optimum parameters for a given algorithm are explored by using grid search method.
Most works on classification algorithm usually compare the performance with common classification metrics such as accuracy. However, there are usually inconsistencies between model’s performance and profitability. Classification metrics like accuracy do not take into account the profit information. The model with optimal metric value cannot guarantee the optimal profitability (Guang and Wang Citation2019; Teixeira and De Oliveira Citation2010). Therefore, an ensemble method is used to aggregate the results from base classifiers to arrive at a collaborated decision (Tsai et al. Citation2011).
In the second step, the predicted trend results are employed in a trading recommendation system – that is to buy, to sell, or to do nothing if the predicted trend is positive, negative, or very small, respectively. The investment returns from trading simulation with the testing data are calculated. Performance of the proposed model is evaluated using trading return and Sharpe ratio. Sharpe ratio is a measure of risk-adjusted return, describing how much excess return received for the volatility (or risk) of holding a riskier asset (Sharpe Citation1994). The returns and Sharpe ratios are to be compared with the trading using prediction results from individual classifier as well as with two other cases – one is the buy and hold (B&H) and the other is if we know the future (KF).
This research contributes to (1) construct a heterogeneous ensemble classifier that aggregates results from different base classifiers, each of which using an extensive hyperparameter tuning. Inputs of each base classifier are various commonly used technical indicators automatically chosen with a feature selection method. In addition, we also (2) propose a trading recommendation system based on the trend prediction result from the ensemble classifier.
The remaining of this article is organized as following. The next section reviews related literature about technical analysis and financial trend prediction using classification algorithms. Then the proposed ensemble classifier will be described, and its performance is evaluated and discussed. Finally, the last section concludes this work with its limitations and future works.
Related Works
Technical Analysis and Indicators
In financial markets, technical analysis develops technical indicators and several charts from historical prices and uses them to predict trends or provide trading signals (Hu et al. Citation2015; Lorenzo Citation2013). There are hundreds of technical indicators developed for the past decades, but the most popular ones are limited to fewer than 20 of them. Technical indicators can be classified into four types – trend, momentum, volume, and volatility (Hu et al. Citation2015). First, trend indicators tell us which direction the price is moving in, upward, downward, or sideway – there is no trend. Simple Moving Average (SMA) and Exponential Moving Average (EMA) are the most popular examples of trend indicators. Second, momentum indicators evaluate the velocity of price change and judge whether a reversal is about to happen. Common momentum indicators are Moving Average Convergence Divergence (MACD), Stochastic Oscillator (%K and %D), and Relative Strength Index (RSI). Third, volume indicators measure the strength of a trend or confirm a trading direction based on some form of averaged volume traded. A popular volume indicator is On Balance Volume (OBV). Fourth, volatility indicator measures the range of price movement and can be used to identify level of support and resistance. Common volatility indicator includes Bollinger Band (BB) (Hu et al. Citation2015; Lorenzo Citation2013).
Trend Prediction with Classification Techniques
Classification algorithms try to classify data into a given number of classes. Classification algorithms can be employed straightforwardly for prediction of the trend or direction of stock returns into positive or negative, for example. During the past two decades, the widely used classification algorithms with proved performance are support vector machine, artificial neural networks, and random forest. More recently, tree-ensembled methods have significantly improved performance and are increasingly accepted as state-of-the-art. Among them are extreme gradient boosting (or XGBoost) and light gradient boosting machine (or LightGBM).
Support vector machine (SVM) is a statistical learning technique that constructs a hyperplane as the decision surface that maximized the margin of separation of different classes (Cortes and Vapnik Citation1995). Given a set of training examples (xi,yi), i = 1, 2, …, l. Where xi ∈ Rn and yi ∈{-1, 1} is the label of xi, a standard SVM model is formulated as s.t. yi (<w, xi> +b) ≥ 1, i = 1, 2, …, l; where w is the normal vector of hyperplane, b is a bias value, and <p, q> is the inner product of vectors p and q. The goal of SVM to maximize the margin of separation of different classes is to minimize
.
SVM is one of the early successful algorithms for trend prediction. Huang, Nakamori, and Wang (Citation2005) investigated the predictability of weekly movement direction of NIKKEI 225 index with SVM. Their experiment results showed SVM outperformed Linear Discriminant Analysis, Quadratic Discriminant Analysis and Elman Backpropagation Neural Networks. Ni, Ni, and Gao (Citation2011) proposed an SVM model with fractal feature selection of 19 technical indicators and a grid search method using fivefold cross validation to predict direction of Shanghai stock index. Luo et al. (Citation2017) improved their integrated piecewise linear representation and weighted support vector machine (PLR-WSVM) for trading 20 China stock. Their SVM model with relative technical indicators and automatic threshold has improved performance in classification of turning points and ordinary points for making more profitable trading decision.
Artificial Neural Network (ANN) is biologically inspired computing models which can be used to find knowledge, patterns, or models from a large amount of data (Bose and Liang Citation1996). ANN consists of connected computational units or nodes, called neurons, arranged in several layers. Each neuron combines its inputs, each of which is multiplied with a weight, and then passes it through an activation function, which can be a linear or nonlinear filter (such as sigmoid or tanh functions). Then the neuron sends its output to other neurons or to be output of the network. The interconnection of all neurons forms different types of architectures designed for various functions. The most widely used architecture is called feed-forward multilayer perceptron (MLP) which generally used back-propagation (BP) learning algorithm to adjust its weights for supervised learning. BP works in an iteration of three steps. The first step is propagating inputs forward through the hidden layers to the output nodes. The second step is to propagate the errors backward through the network starting from output layer. And the final step is to update the weight and biases using approximate steepest descent rule. Such three steps repeat until reaching the maximum iterations allowed with the aim to minimize the errors of output during the training.
ANN has demonstrated promising results in predictions of stock price trends during the past two decades. Olson and Mossman (Citation2003) compared the forecasts of one-year-ahead Canadian stock returns using ANN, logistic regression and ordinary least squares. The results demonstrated that ANN outperformed the other two algorithms. O’Connor and Madden (Citation2006) included some external indicators, such as currency exchange rates, in predicting movements in the Dow Jones Industrial Average index using ANN models. Kara, Boyacioglu, and Baykan (Citation2011) predicted the direction of stock price movement in the Istanbul Stock Exchange using ANN and SVM with ten technical indicators as inputs. The empirical results demonstrated that their ANN model performed better than SVM model. Chen, Leung, and Daouk (Citation2003) applied probabilistic neural network to predict the direction of return on Taiwan Stock Exchange and found that their model demonstrated a more predictive power than generalized methods of moments with Kalman filter and random walk.
Random forest (RF) is an efficient learning algorithm for classification that is constructed from many unpruned decision trees (DT) from random subsets of features using bootstrapped training data (Breiman Citation2001). The accuracy (or probability of correct prediction) of a single tree may not be high, but the combination of many trees, forming the forest, results in a higher accuracy. Construction of RF mainly includes two stages. The first stage is the generation of forest, in which the training samples are divided into many samples at random, construct CART (Classification and Regression Tree) decision trees. When creating partitions to a feature, the goodness of a partition is measured by purity. If a partition is pure, for each sub-branch of this node, its instances belong to the same class (Zhang et al. Citation2018). The second stage is to determine the classification results from the forest. For a classification task, the result combination can be as simple as majority voting (Breiman Citation2001). This ensemble method enhances the accuracy of RF over the single DT, while the problem of overfitting is controlled simultaneously.
Zhang et al. (Citation2018) proposed a model using random forests, imbalance learning, feature selection and clipping for prediction of both stock price movement and its interval of growth (or decline) rate. Using more than 70 technical indicators as inputs, the model classified prediction targets into 4 classes: up, down, flat, and unknown. The model was evaluated using more than 400 stocks in Shenzhen Market and the results revealed that it outperforms ANN, SVM and K-Nearest Neighbors in terms of accuracy and return per trade. Thakur and Kumar (Citation2018) applied RF to discover the optimal feature subset from a large set of technical indicators from daily data of five index futures for trading. Kim and Han (Citation2016) predicted the direction of movement of stock index using a modified random forest where bootstrap also determined the weights based on the degree of Korea composite stock index change. The experimental results confirmed that their enhanced random forest outperformed the classical random forest with statistical significance.
XGBoost (eXtreme Gradient Boosting) is an efficient ensemble machine learning system, developed by Chen and Guestrin in 2016 (Chen and Guestrin Citation2016). XGBoost improves Friedman’s gradient boosting technique (Friedman Citation2001) that employs DT as base learners to fit the training data and use a tree ensemble model to sum the score of each tree to get the final prediction. The objective function of the XGBoost is to combine the standard penalty term with the loss function term to obtain the optimal solution. XGBoost uses regularization to control the flexibility of the learning task and to obtain models that generalize better to unseen data. In addition, its loss function is optimized by second-order Taylor expansion to help avoid overfitting.
Due to its efficiency and fast operation, XGBoost has been widely applied in financial applications. For example, Nobre and Neves (Citation2019) applied XGBoost for binary classifier for predicting trend of five different financial time series for trading simulation. Hyperparameters of their XGBoost are optimized with multiobjective genetic algorithm. The empirical results showed that their system can outperform the Buy and Hold (B&H) strategy in three of the five analyzed financial markets. Chen et al. (Citation2021) proposed a novel portfolio construction approach based on XGBoost for stock price prediction. Hyperparameters of XGBoost are optimized using an improved firefly algorithm. Their experiment demonstrated that this approach yielded the best results in terms of returns and risks. Deng et al. (Citation2021) proposed a novel hybrid method of XGBoost with bagging and regrouping particle swarm optimization (RPSO) for direction forecasting of a high-frequency future trading simulation. A bagging method is incorporated to solve overfitting problem while the RPSO is for optimizing hyperparameters of XGBoost. The empirical results reveal that their hybrid model outperforms SVM, RF and buy-and-hold with many evaluation criteria. Yun, Yoon, and Won (Citation2021) proposed a hybrid model of XGBoost and genetic algorithm with an extensive feature engineering process on more than 60 technical indicators for stock market predictions. Their hybrid model can outperform LSTM models in terms of both performance and interpretability.
LightGBM is also a gradient learning tree-based framework with boosting technique to integrate results from weak learners to enhance performance (Ke, Menget al. Citation2017). Its main difference from the XGBoost model is that it uses Gradient-based One Side Sampling (GOSS) and automated feature selection with Exclusive Feature Bundling (EFB). With GOSS, LightGBM uses histogram algorithm to discretize continuous floating-point eigenvalues into many bins. Histogram algorithm does not need extra storage of presorted results and thus greatly reduces memory consumption without scarifying the accuracy of the model. EFB reduces the optimal bundling of exclusive features to a graph coloring problem and solves it by a greedy algorithm with a constant approximation ratio. Both GOSS and EFB makes LightGBM lighter and efficient. In addition, LightGBM uses leaf-wise tree growth strategy, which effectively finds the leaves with the highest branching gain each time from all the leaves, and then goes through the branching cycle. Therefore, it can reduce more errors and obtain better precision with the same number of times of segmentation. A maximum depth limit is set to prevent overfitting while ensuring high efficiency.
With high prediction accuracy, fast computational speed and preventing of overfitting, LightGBM has been widely applied in many fields. Zhang et al. recently propose a smart contract Ponzi scheme identification method based on the improved LightGBM algorithm (Zhang et al. Citation2021). Experiments are conducted on the real Ethereum data set which is imbalanced. The results prove that their proposed method has highly improved accuracy, F-score and the area under the receiver operating characteristics curve (AUC) metrics compared with XGBoost and RF. Slezak, Butler, and Akbilgic (Citation2021) preoperatively predict risk of postoperative readmission for total joint replacement surgery among older persons. The dataset has 22 predictor variables and is highly imbalance. The experimental results indicate that LGBM outperforms XGboost, RF, and Logistic Regression using AUC obtained in the holdout data. Oram et al. (Citation2021) proposed a LGBM-based phishing e-mail detection model using phisher websites’ features of mimic URLs. Their experimental result show that LGBM outperforms XGBoost, AdaBoost, RF, and many other classical classification algorithms in terms of accuracy and F1 score.
Issues Related to Classification
Unfortunately, using machine learning algorithms is not an easy task. There are three common issues for thorough considerations: (i) feature selection, (ii) hyperparameter tuning, and (iii) no free lunch theorem and ensemble.
Feature Selection
First, one major question is how to choose a proper set of attributes, called features, to be inputs of the model. Feature selection methods become an important step of data preprocessing for the classification algorithm. Feature selection approaches fall into three categories: filter based, wrapper based, and embedded (Li et al. Citation2018; Xue et al. Citation2016).
Filter-based methods uses statistical data dependency techniques to find the subset of features.
Wrapper-based methods evaluate candidate subsets by a learning algorithm and thus itself requires parameter tuning.
Embedded methods incorporate knowledge about the specific structure of the algorithm while selecting features in the training process (Cai et al. Citation2018). Thus, they are generally applicable to only specific classification algorithms (Nguyen, Xue, and Zhang Citation2020).
Both wrapper-based and embedded methods are computing intensive. The filter-based approach is usually considered efficient in most cases since it does not involve any learning process, and is chosen for use in this work.
Hyperparameter Tuning
Second, building an effective classification model is a complex and time-consuming process that involves tuning its hyperparameters (Nguyen, Xue, and Zhang Citation2020; Yang and Shami Citation2020). Tuning hyperparameters is considered a key component of building an effective machine learning model, especially for tree-based or neural-based models like RF and ANN, which have many hyperparameters. Accurate results for ANN highly depend on a careful selection of its hyperparameters such as number of hidden layers, number of nodes in each layer the learning rate, input variables, etc. (Hussain et al. Citation2008). Unfortunately, manual tuning of hyperparameters not only requires expertise but also is prone to getting lower performance.
Grid search is one of the most commonly used methods to explore hyperparameter configuration space. It involves exhaustively search that evaluates all the hyperparameter combinations given to a grid of configurations (Nguyen, Xue, and Zhang Citation2020; Yang and Shami Citation2020). In this work, we use grid search for hyperparameter tuning of all selected classification algorithms for an optimal performance. Although this approach is time consuming, this work does not aim to run in a real-time environment.
No Free Lunch Theorem and Ensemble
Third, there are several algorithms available for a given problem class and there is no definite guideline to select the algorithm best fit the problem. According to well-known No Free Lunch theorem (Wolpert and Macready Citation1997), no single method may outperform others in all situations. Classification algorithms are not exceptions. No one can foretell which algorithm will outperform in all tested datasets. Ensemble learning is an approach to overcome this challenge by combining multiple classifiers, forming committee to improve prediction, and is believed to perform better than single classifiers. Ensemble techniques have been applied in several application domains including energy and financial prediction, which can be briefly reviewed as following.
Khairalla et al. (Citation2018) proposed a stacking multilearning ensemble model with support vector regression, ANN, and linear regression, for prediction of oil consumption. The experimental results demonstrated that their ensemble model outperforms classical models for both 1-ahead and 10-ahead horizon prediction, in terms of error rate, similarity, and directional accuracy. Nti, Adekoya, and Weyori (Citation2020a) performed an extensive comparative analysis of different ensemble methods such as bagging, boosting, stacking, and blending for stock market prediction. They constructed 25 different ensemble regressors and classifiers using DT, MLP, and SVM for stock indexes from four countries. The obtained result revealed that the stacking technique outperformed boosting, bagging, blending, and simple maximum in stock market prediction. Nti, Adekoya, and Weyori (Citation2020b) proposed a homogeneous ensemble classifier based on Genetic Algorithm for feature-selection and optimization of SVM parameters for predicting 10-day-ahead price movement on the Ghana stock exchange. They employed a simple majority voting ensemble method to combine results from 15 different SVM models using 14 technical indicators as inputs. Their empirical results showed that their ensemble model provided a higher prediction accuracy of stock price movement as compared with DT, RF, and NN. Ampomah, Qin, and Nyame (Citation2020) compared the effectiveness of different tree-based ensemble models including RF, XGBoost, Bagging Classifier, AdaBoost, Extra Trees Classifier, and Voting Classifier in forecasting the direction of stock price movement. Eight different stock data from three stock exchanges (NYSE, NASDAQ, and NSE) were used for the study. They employed principal component analysis to do feature selection of 45 inputs including 40 technical indicators. The empirical results revealed that Extra Trees classifier outperformed the other models in all the rankings.
In general, ensemble methods can be divided into homogeneous and heterogeneous approaches (Polikar Citation2006). In homogeneous ensemble, all base classifiers are from the same family (e.g. tree-based), whereas in heterogeneous ensemble, we construct the ensemble model from the classifiers having different learning strategies. The heterogeneous classifier ensembles offer slightly better performance than the homogeneous ones (Tsai et al. Citation2011). The common ensemble strategies are majority voting, bagging (Breiman Citation1996) and boosting (Breiman Citation2001). However, it might be inconclusive to identify which strategy clearly outperforms the others. This work employs an ensemble classification model that works on the modified majority voting of results of five classifiers.
The Proposed Model
This work proposes an ensemble classifier built from SVM, RF, ANN, XGBoost, and LightGBM to develop trend prediction models for stock prices. The trend prediction results will be used to recommend trading decisions (to long, to short, or to do nothing) in a trading simulation using the testing data. The returns obtained from the simulation will be compared. This work is developed using Python 3.8 platform on Windows 10 and 16-core Intel Core i9 processor running 2.50 GHz. The whole process of trend classification for trading is shown in . It includes five stages of process including data collection and preparation, feature selection, base classification, ensemble with majority voting approach, and trading simulation as explained below.
Figure 1. Process.
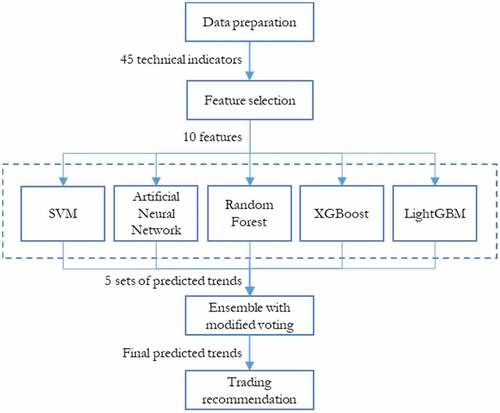
Data Collection and Preparation
The prediction in this work is based on technical analysis approach. Inputs to the process are daily open, high, low, close and volume data downloaded from web finance.yahoo.com. The input data are used for computing 45 technical indicators listed in . All these indicators, forming attribute, or feature set of the classifiers, are commonly used by the technical practitioners in stock markets. Their descriptions and formulas can be found in Hu et al. (Citation2015) and Lorenzo (Citation2013). Some of them e.g. RSI, DISP, and ROC use varying periods to deal with uncertainty. Then every feature is normalized to range [0, 1] before further processing.
Table 1. Technical indicators used
Feature Selection
However, some features might be redundant features providing similar information for the learning task while others might be irrelevant providing misleading information that deteriorates the learning performance. A filter-based approach feature selection is chosen in this work to remove redundant or irrelevant features. The filter-based methods evaluate feature subsets using their intrinsic properties (Xue et al. Citation2016) such as correlation, information, distance, etc. In this work, we use a univariate filter-based method that removes all but the highest Chi-square scoring features.
Base Classification
The model aims to predict the trend of closing price at day d + 2 (closed + 2) compared to the opening price on the next day d + 1 (opend + 1). Specifically, output of the model, called classd ∈{-1, 0, 1}, represents direction of δd or percentage change of day d as of the following equation:
where and
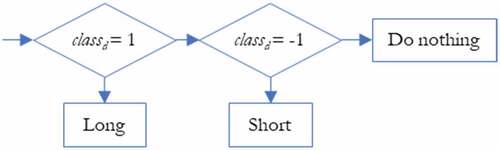
are the closing price and opening price of day d. The value of classd is determined by comparing δd with a decision threshold θ as in . That is classd is 0 if the percentage change δd is between -θ and θ. Otherwise classd will be −1 or 1 if δd is less than -θ or greater than θ respectively. The sign of the class value indicates short-term direction, i.e. positive is uptrend and negative is downtrend. Class 0 implies that the change is so small that the potential profit is difficult to beat transaction fee.
Figure 2. Determining classd from δd.

Hyperparameter Tuning
As discussed in previous section, performance of any classifiers highly depends on its hyperparameter setting. Grid search method is employed in this work to explore hyperparameter configuration space. It exhaustively evaluates all the hyperparameter combinations (Yang and Shami Citation2020) of all five base classifiers as following.
SVM
kernel[‘rbf,’ ‘poly’]
C[0.01, 0.1, 1, 10, 100]
gamma[1, 0.1, 0.01, 0.001]
ANN
solver[‘adam,’ ‘sgd’]
activation[‘tanh,’ ‘relu’]
learning_rate[‘invscaling,’ ‘adaptive’]
learning_rate_init[0.01, 0.001]
hidden_layer_sizes[(20,), (40,), (60,), (40, 40)]
RF
criterion[‘gini,’ ‘entropy’]
n_estimators[100, 400]
max_depth[5, 9, 13]
min_samples_split[2, 6]min_samples_leaf [1, 5]
XGBoost
max_depth[4, 8]
learning_rate[0.0005, 0.01]gamma [0.1, 1.0]
subsample[1.0, 0.7]
min_child_weight[0.02, 1, 5.]
LightGBM
max_depth[5, 10, 15]
learning_rate[0.005, 0.05]num_leaves [20, 40, 60]
max_bin[100, 200, 300]
Performance of SVM depends upon the selected kernel function, regularization parameter C, and gamma. The kernel function defines the hyperplane used for separating data into different classes. Regularization parameter controls the trades off between error minimization and margin maximization. The parameter gamma specifies the desired curvature for the radial basis function kernel.
Performance and complexity of an ANN mainly depend upon the number of hidden layers and the number of nodes in each layer. We choose three different number of nodes for one hidden-layer configuration plus a two-hidden-layer configuration for grid search to explore. In addition, we choose two solvers for weight optimization: a classical stochastic gradient descent (sgd) and Adam, an improved stochastic gradient optimizer (adam). Different combinations of learning rate and its adaptation are also varied in the experiment.
For RF, two probably most important hyperparameters are depth of each tree and the number of trees in the forest for taking a vote. A better performance can be expected from a higher number of trees with the cost of computing time. A deeper tree may capture more information about the data but is prone to overfitting and fail to generalize the findings for new data. Two splitting criteria are chosen here for the RF, i.e. Gini impurity index and entropy. The Gini index measures impurity of a node, while entropy, or information gain, is the difference between uncertainty of the starting node and weighted impurity of the child nodes.
Performance of the XGBoost (called XGB from now on) depends on several hyperparameters. Like RF, deeper trees (high maximum depth) can model more complex relationships by adding more nodes to learn from specific training samples but is prone to overfitting. Parameter min_child_weight allows the algorithm to create children that correspond to fewer samples, thus allowing for more complex trees, but again, more likely to overfit. The eta (or learning rate) is shrinkage of the weights associated to features after each round. The lower value of eta is better but again is time consuming and prone to overfitting. Parameter subsample denotes the fraction of observations to be randomly samples for each tree. Lower values make the learning more conservative and prevents overfitting but too small values might lead to underfitting. Parameter gamma specifies the minimum loss reduction required to make a split, and its values highly depends on the loss function.
For LightGBM (called LGB from now on), we choose four hyperparameters that most impact performance of LGB. Parameters max_depth and learning_rate control the complexity and the accuracy the model like in XGB. Parameter num_leaves controls the number of decision leaves in a single tree. Parameter max_bin controls the maximum number of bins that features will bucketed into. Large values of num_leaves and max_bin increase accuracy of the training set but also are prone to overfitting.
Result Ensemble
The proposed model in this work employs five base classifiers, namely SVM, ANN, RF, XGB, and LGB. Each of which runs independently using the same input data of the selected features. However, the trend prediction results from base classifiers might be different. Therefore, they are further aggregated using a modified majority voting for a final trend prediction for the proposed ensemble model. Since there are five base classifiers, we propose two following ensemble methods for comparison:
For each stock prediction, two base classifiers with the lowest accuracy values are ignored. Then the prediction results of remaining three classifiers are considered with a majority voting scheme summarized in . Last three rows are for the cases that results of all three base classifiers are mutually different; then the final results will be from the one with highest accuracy value. Let us call algorithm using this ensemble scheme as T3.
A straightforward majority voting. If there is a tie (e.g. [1, 1, −1, −1, and 0]), the result will come from the classifier pair with a greater sum of accuracy values. Let us call algorithm using this ensemble scheme as E5.
Table 2. Final decision of trend prediction results
Trading Recommendation
After the ensemble of prediction results, all predicted classd values are employed in the recommendation of trading one stock as in . That is if classd = 0, then do nothing in response to the uncertainty in direction of price change. If classd = 1, then take a long position (or buy) of the stock with a proportion ρ of the current available cash. If classd = – 1, then take a short position (or sell) of the stock for a proportion ρ of the current amount of in-hand stock.
Figure 3. Trading recommendation based on classd.
Parameters ρ represents proportion of number of stocks for selling (or short) or amount of cash for buying (long) stocks on the day, thus ρ ∈ (0, 1]. The value of ρ helps control the risk of investment; the lower value of ρ, the more risk averse the investor takes by buying a smaller portion of the current cash and selling a smaller portion of in-hands stocks.
All buying and selling transactions are subjected to transaction fees of rate f. This means that when buying n stocks at price p, we have to pay for n × p × (1 + f). When selling n stocks at price p, our cash will increase only n × p × (1 – f). The trading recommendation and simulation can be summarized as algorithm in . The trading decision threshold θ should be greater than the fee rate f to avoid loss from the excessive transaction fee. Note that the proposed algorithm is to be run at the end of day d, and buying or selling transactions as recommended are at the opening price on the next day (opend+1).
Figure 4. Algorithm for trading recommendation.

Experimentation
Data in the experiment are historical daily prices of 20 stocks from Stock Exchange of Thailand (SET). They are among top largest stocks and are randomly selected from leaders of different major industries including energy, telecommunication, banking, foods, infrastructure, property, etc. To study the performance in varying market situations, the datasets are taken from the following three different periods:
2014-1-2 to 2018–12-28
2015-1-5 to 2019–12-30
2016-1-4 to 2020–12-30
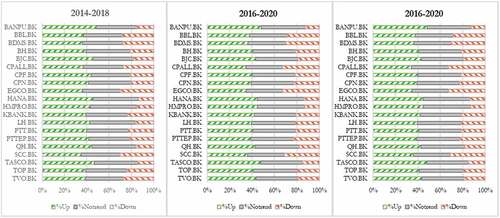
Each dataset ranges 5 years or about 1220 days and is split into 80:20 proportion for training and testing. The training set is for constructing the classification models whose performance will be compared using the testing set. The characteristics of the stocks are summarized in . Column Sign Diff? indicates that the direction of change in training set is different to the direction of change in testing set. Such different patterns of training set and testing set makes it more difficult to generalize the classification models. illustrate charts of the closing prices of all stocks for the three datasets. It can be seen from both and the figures that the tested stocks have various characteristics: uptrend, downtrend, fluctuation, and sideway, during the training and testing periods for evaluating the proposed models under varying market situations. illustrates proportion of classd (or direction of price change) for testing set of each stock. Set {%Up, %Notrend, %Down} maps to {1, 0, −1}. The shows that the classification problem in this work is not imbalance.
Table 3. Characteristics of stocks used in the experiment
Figure 5. Price charts of all stocks in dataset A (2014–2018). Training and testing datasets are shown in green and blue colors.
Figure 6. Price charts of all stocks in dataset B (2015–2019). Training and testing datasets are shown in green and blue colors.
Figure 7. Price charts of all stocks in dataset C (2016–2020). Training and testing datasets are shown in green and blue colors.
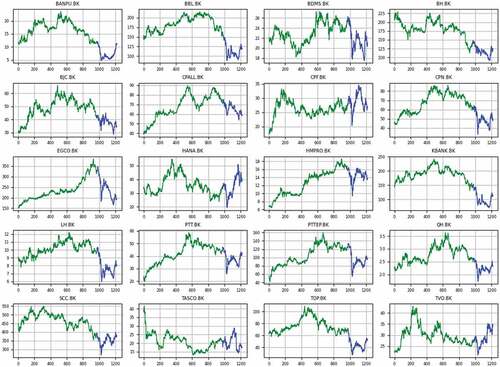
Figure 8. Proportions of % price changes.
Experimentation Setup
Details of the experimentation are as following (see ):
Data Acquisition and Preparation: The downloaded data, including open, high, low, close and volume, are used to calculate 45 technical indicators (whose descriptions are in ) with Python’s TA-Lib library. They forms attributes or features of the dataset. For each dataset range, the downloaded data actually begin at the prior 100 days for necessary calculation of some technical indicators that require historical data; e.g. DISP100 requires data of prior 100 days. Then every feature is normalized to range [0, 1] before further processing.
Feature Selection: A filter-based feature selection is employed to pick a subset of 10 optimal features (from the existing 45 attributes) having the highest Chi-square score. We’ve also tried with 8 and 12 features and the results are not significantly different.
Training with Hyperparameter Tuning: After feature selection, four base classifiers are trained using the training set. We use Python scikit learn’s gridsearchcv function to exhaustively search for the optimal hyperparameter set of SVM, ANN, RF, XGB, and LGB as reported in subsection 3.4.
Prediction and Result Ensemble: After training, five base classifiers are independently used for prediction of daily classd of the testing set. Their results are then ensembled using algorithm in subsection 3.5 to obtain the prediction results of T3 and E5.
Trading Simulation to Observe Performance: The prediction results of all 7 classifiers are further used for simulation using trading recommendation described in subsection 3.5 for comparison. In the simulation, the initial fund is 1,000,000 baht. Note that the amount of initial fund does not matter in this experiment since the performance is based on the investment return R for whole testing period, and R is calculated as following.
where valued = cashd + onhandd × closed, and subscripts i and f denote the initial day and the final day. Term onhandd denotes the number of stocks held in portfolio on day d. The predicted classd will be used to make trading decision on day d + 1 as described earlier.
Parameter Setting for Trading Simulation
All buy and sell transactions are subjected to 0.15% commission fee. The decision threshold θ is set to 0.5%. The trading proportion parameter ρ is set to 0.8. These trading parameters are set the same for all trading scenarios for a fair comparison. In fact, we have tested the model with ρ ∈ [0.4, 0.6, 0.8, 1.0]. The results are not significantly different, but the configuration with ρ = 0.8 offers the best results.
Performance Comparison
The above simulation is performed using seven classifiers independently. After the trading simulation, the returns RSVM, RANN, RRF, RXGB, RLGB, RT3, and RE5 are to be compared with the returns from the Buy and hold (B&H) strategy, RBH, as baseline. The return RBH in this case is computed from the closing price of the last day (closef) and the opening price of first day (openi) of the testing dataset, as following:
The main metrics for comparison are return surplus and Sharpe ratio. Return surplus (Δ) is difference of the return from algorithm and the return from B&H strategy, i.e. ΔT3 = RT3 – RBH. A positive surplus means that using the algorithm obtains a higher return than using B&H strategy, and of course the higher Δ achieved, the better the algorithm is.
To measure the volatility or risk of trading, Sharpe ratio (Sr) is the average return earned in excess of the risk-free rate per unit of volatility, represented by the standard deviation σp. For good return/risk ratio, Sr should be higher than 1.0. Sr is calculated by
where Rp is return rate from investment and Rf or risk-free rate is the return of an investment with risk-free asset, i.e. short-term government treasury bills. In this experiment, Rf is set to 2%, 2% and 0.1% for datasets A, B, and C respectively; these are average values obtained from web Interest Rate of Bank of Thailand (https://www.bot.or.th/English/Statistics/FinancialMarkets/InterestRate/Pages/InterestRate.aspx).
It’s also interesting to observe the case of If we know the future (KF). The return RKF is computed based on the formulae which is similar to the case of prediction. However, the trading decision (buying, selling or do-nothing) is based on the actual class values, as if we know the future closing prices.
Obviously, if we know the future, the return from trading (RKF) is very high. This is confirmed from the column RKF in . It unquestionably beats other trading strategies for every stock and thus is regarded as the ideal case. Therefore, we here will focus on only the cases of seven classifiers compared with B&H strategy.
Table 4. Results of accuracy values and returns of trading
In addition, we investigate the relationship of return of proposed ensemble model and accuracy metric. Accuracy (Ac) is the total number of correct predictions divided by the total number of predictions made for a dataset.
Results and Discussions
lists accuracies of predictions and returns of trading from seven classifiers using the same testing dataset (A, B, and C separately). For a better comparison, reports the return surpluses (Δ) of all 7 classifiers. Then their averages, together with average Sharpe ratios (Sr) and average accuracies (Ac), are displayed in . The higher Δ indicates more profit given by such algorithm, whereas the higher Sr reflects a better excess return per risk. As a baseline reference, reports the averages of returns from B&H (RBH). To identify the superior performance among 7 classifiers, their returns are ranked from 1 (best) to 7 (worst) for 20 stocks. Next, those 20 ranks are averaged for each classifier and listed in as average rank. reports the correlation coefficients (Cor) of return and accuracy of all classifiers. illustrates the comparative returns of all classifiers over testing periods for some largest stocks in different sectors.
Figure 9. Comparative returns for some largest stocks.
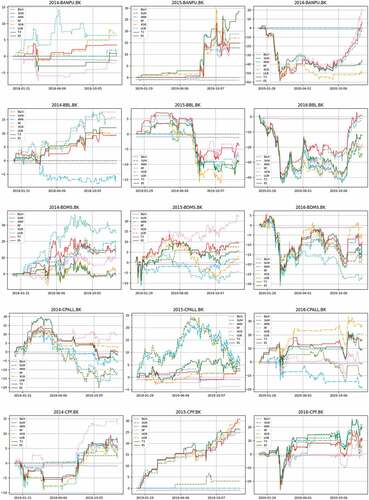
Figure 9. Continued.
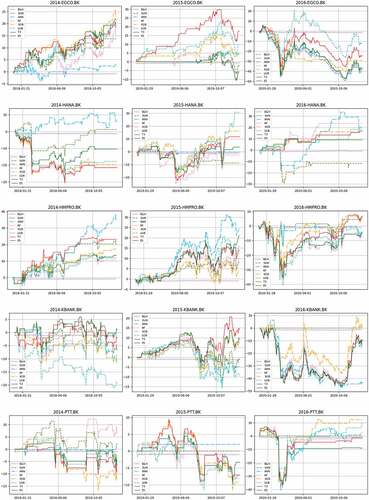
Table 5. Return Surpluses ΔX = RX – RBH
Table 6. Averages of return surplus (ΔX = RX – RBH), Sharpe ratios (Sr), and accuracy (Ac)
Table 7. Averages of returns from B&H (RBH)
Table 8. Average ranks of return
Table 9. Correlation coefficients (Cor) of return and accuracy
Here are the observations from to 9.
(1) In , all average Δs are greater than 0, indicating that on average the proposed trading recommendation provides a more profitable return than B&H.
(2) Among three datasets: A, B & C, T3 outperforms all base classifiers, except in dataset A (ΔT3 = 12.375 < ΔRF = 12.720). In addition, E5 outperforms all base classifiers, except in dataset C (ΔE5 = 15.466 < ΔLGB = 15.696).
(3) T3 and E5 defeat all individual base classifiers in terms of the average of three datasets:
T3 = 13.513 (the highest),
E5 = 11.993 (the second best), with ranking as
T3 >
E5 >
LGB >
XGB >
RF >
ANN >
SVM.
(4) Majority of average Sr are below 1.0, corresponding to the fluctuated downtrend or sideway of price charts in and confirmed by the averages of RBH in . Considering those Sr > 1.0 (bold font), both T3 and E5 can achieve the highest on average.
(5) In , T3 achieves the best average rank (lowest value) in all three datasets.
(6) Based on above discussions, modern ensemble-based classifiers (XGB and LGB) outperform classical SVM, ANN, and RF. And more importantly, the proposed T3 and E5 outperform all base classifiers on average in terms of both return and Sharpe ratio.
The following are discussions on accuracies and returns.
(7) In , T3 and E5 defeat all individual base classifiers in terms of average accuracies of 3 datasets: T3 = 0.467 (the highest),
E5 = 0.461 (the second), with ranking as
T3 >
E5 >
RF >
LGB >
XGB >
SVM =
ANN.
(8) In , LGB, T3 and E5 have average values of Cor greater than 0.40, which are higher than other classifiers. A higher positive value of Cor signifies a stronger relationship between return and accuracy achieved by the classifier. T3 achieves the highest Cor value in this case, and LGB ranked second. Considering this together with (in ) and average rank of return (in ), we can observe that the selective majority voting scheme of T3 clearly helps improve the accuracy and return.
(9) In summary, the proposed T3 with majority voting of the 3 (out of 5) classifiers with the highest accuracy outperforms the E5 with straightforward majority voting as well as other base classifiers.
Conclusion and Future Works
This work brings together five widely used classifiers for trend prediction. The proposed ensemble classifier T3 combines the results from base classifiers with a selective majority voting by dropping out the results from two classifiers with lowest accuracies. Hyperparameters of each base classifier are tuned with an exhaustive grid search method. The prediction results are further used for recommendation (to buy, to sell, or to do nothing) in a single-stock trading simulation. Performance of all classifiers are compared using historical daily prices of 20 leading stocks in Stock Exchange of Thailand (SET). The inputs of classifiers are 45 technical indicators calculated and taken through a feature selection process. Empirical results reveal that the proposed ensemble T3 model clearly achieves a higher trading return and Sharpe ratio than B&H strategy, all individual base classifiers, and the ensemble with straightforward majority voting (E5). In addition, novel ensemble-based classifiers like XGBoost and LightGBM have better performance than more classical classifiers in this experiment.
Limitations and future works: However major limitations of this work are (i) do not support short-selling which is in a roadmap of full adoption world-wide and in SET, (ii) do not incorporate stop-loss mechanism, (iii) trading recommendation is limited to a single stock. Future works shall support short-selling, multistock trading recommendation with stop-loss mechanism and using other classifiers with profitability-concerned metrics, more advanced ensemble methods, feature selection methods. Other data sources including fundamentals and online news should also be considered.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Ampomah, E. K., Z. Qin, and G. Nyame. 2020. Evaluation of tree-based ensemble machine learning models in predicting stock price direction of movement. Information 11 (6):226. doi:10.3390/info11060332.
- Bose, N. K., and P. Liang. 1996. Neural network fundamentals with graphs, algorithms, and applications. In McGraw-Hill series in electrical and computer engineering, ed. S. W. Director. 1-30. New York: McGraw-Hill.
- Breiman, L. 1996. Bagging predictors. Machine Learning 24:123–257. doi:10.1007/BF00058655.
- Breiman, L. 2001. Random forests. Machine Learning 45 (1):5–32. doi:10.1023/A:1010933404324.
- Cai, J., J. Luo, S. Wang, and S. Yang. 2018. Feature selection in machine learning: A new perspective. Neurocomputing 300:70–79. doi:10.1016/j.neucom.2017.11.077.
- Chen, A.-S., M.-T. Leung, and H. Daouk. 2003. Application of neural networks to an emerging financial market: Forecasting and trading the Taiwan Stock Index. Computer and Operation Research 30 (6):901–23. doi:10.1016/S0305-0548(02)00037-0.
- Chen, T., and C. Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining August 13 - 17, 2016 San Francisco, California, 785–94. doi:10.1145/2939672.2939785.
- Chen, W., H. Zhang, M. K. Mehlawat, and L. Jia. 2021. Mean–variance portfolio optimization using machine learning-based stock price prediction. Applied Soft Computing 100:106943. doi:10.1016/j.asoc.2020.106943.
- Cortes, C., and V. Vapnik. 1995. Support-vector networks. Machine Learning 20 (3):273–97. doi:10.1007/BF00994018.
- Deng, S., X. Huang, Z. Qin, Z. Fu, and T. Yang. 2021. A novel hybrid method for direction forecasting and trading of Apple Futures. Applied Soft Computing 110:107734. doi:10.1016/j.asoc.2021.107734.
- Ding, G., and L. Qin. 2020. Study on the prediction of stock price based on the associated network model of LSTM. International Journal of Machine Learning and Cybernetics 11:1307–17. doi:10.1007/s13042-019-01041-1.
- Elshawi, R., M. Maher, and S. Sakr. 2019. Automated machine learning: State-of-the-art and open challenges. arXiv Preprint arXiv:1906.02287, 1–26. http://arxiv.org/abs/1906.02287 .
- Friedman, J. H. 2001. Greedy function approximation: A gradient boosting machine. The Annals of Statistics 29 (5):1189–232. doi:10.1214/aos/1013203451.
- Guang, L., and X. Wang. 2019. A new metric for individual stock trend prediction. Engineering Applications of Artificial Intelligence 82:1–12. doi:10.1016/j.engappai.2019.03.019.
- Hu, Y., K. Liu, X. Zhang, L. Su, E.-W.-T. Ngai, and M. Liu. 2015. Application of evolutionary computation for rule discovery in stock algorithmic trading: A literature review. Applied Soft Computing 36:534–51. doi:10.1016/j.asoc.2015.07.008.
- Huang, W., Y. Nakamori, and S.-Y. Wang. 2005. Forecasting stock market movement direction with support vector machine. Computers & Operations Research 32:2513–22. doi:10.1016/j.cor.2004.03.016.
- Hussain, A. J., A. Knowles, P. J. G. Lisboa, and W. El-Deredy. 2008. Financial time series prediction using polynomial pipelined neural networks. Expert Systems and Applications 35 (3):1186–99. doi:10.1016/j.eswa.2007.08.038.
- Kara, Y., M. A. Boyacioglu, and Ö. K. Baykan. 2011. Predicting direction of stock price index movement using artificial neural networks and support vector machines: The sample of the Istanbul stock exchange. Expert Systems with Applications 38 (5):5311–19. doi:10.1016/j.eswa.2010.10.027.
- Ke, G. et al, 2017. Lightgbm: A highly efficient gradient boosting decision tree. Advances in Neural Information Processing Systems 30:3149–54.
- Khairalla, M. A., X. Ning, N. T. AL-Jallad, and M. O. El-Faroug. 2018. Short-term forecasting for energy consumption through stacking heterogeneous ensemble learning model. Energies 2018 (11):1–21. doi:10.3390/en11061605.
- Kim, H., and S.-T. Han. 2016. The enhanced classification for the stock index prediction. Procedia Computer Science 91:284–86. doi:10.1016/j.procs.2016.07.077.
- Li, J., K. Cheng, S. Wang, F. Morstatter, R. P. Trevino, J. Tang, and H. Liu. 2018. Feature Selection: A data perspective. ACM Computing Survey (CSUR) 50 (6):94. doi:10.1145/3136625.
- Lorenzo, R. D. 2013. Basic Technical analysis of financial markets: A modern approach. Heidelberg: Springer Milan.
- Luo, L., S. You, Y. Xu, and H. Peng. 2017. Improving the integration of piece wise linear representation and weighted support vector machine for stock trading signal prediction. Applied Soft Computing 56:199–216. doi:10.1016/j.asoc.2017.03.007.
- Nguyen, B. H., B. Xue, and M. Zhang. 2020. A survey on swarm intelligence approaches to feature selection in data mining. Swarm and Evolutionary Computation 54:100633–49. doi:10.1016/j.swevo.2020.100663.
- Ni, L. P., Z. W. Ni, and Y. Z. Gao. 2011. Stock trend prediction based on fractal feature selection and support vector machine. Expert Systems with Applications 38 (5):5569–76. doi:10.1016/j.eswa.2010.10.079.
- Nobre, J., and R. Neves. 2019. Combining principal component analysis, discrete wavelet transform and XGBoost to trade in the financial markets. Expert Systems with Applications 125:181–94. doi:10.1016/j.eswa.2019.01.083.
- Nti, I. K., A. F. Adekoya, and B. A. Weyori. 2020a. A comprehensive evaluation of ensemble learning for stock-market prediction. Journal of Big Data 7 (20). doi:10.1186/s40537-020-00299-5.
- Nti, I. K., A. F. Adekoya, and B. A. Weyori. 2020b. Efficient stock-market prediction using ensemble support vector machine. Open Computer Science 10 (1):153–63. doi:10.1515/comp-2020-0199.
- O’Connor, N., and M. G. Madden. 2006. A neural network approach to predicting stock exchange movements using external factors. Knowledge Based Systems 19 (5):371–78. doi:10.1016/j.knosys.2005.11.015.
- Olson, D., and C. Mossman. 2003. Neural network forecasts of Canadian stock returns using accounting ratios. International Journal of Forecasting 19 (3):453–65. doi:10.1016/S0169-2070(02)00058-4.
- Oram, E., P.-B. Dash, B. Naik, J. Nayak, S. Vimal, and S. K. Nataraj. 2021. Light gradient boosting machine-based phishing webpage detection model using phisher website features of mimic URLs. Pattern Recognition Letters 152:100–06. doi:10.1016/j.patrec.2021.09.018.
- Polikar, R. 2006. Ensemble based systems in decision making. IEEE Circuits and Systems Magazine 6:21–45. doi:10.1109/MCAS.2006.1688199.
- Sharpe, W. F. 1994. The Sharpe Ratio. The Journal of Portfolio Management 21 (1):49–58. doi:10.3905/jpm.1994.409501.
- Slezak, J., L. Butler, and O. Akbilgic. 2021. The role of frailty index in predicting readmission risk following total joint replacement using light gradient boosting machines. Informatics in Medicine Unlocked 25:100657–62. doi:10.1016/j.imu.2021.100657.
- Teixeira, L. A., and A. L. I. De Oliveira. 2010. A method for automatic stock trading combining technical analysis and nearest neighbor classification. Expert Systems with Applications 37 (10):6885–90. doi:10.1016/j.eswa.2010.03.033.
- Thakur, M., and D. Kumar. 2018. A hybrid financial trading support system using multi-category classifiers and random forest. Applied Soft Computing 67:337–49. doi:10.1016/j.asoc.2018.03.006.
- Tsai, C.-F., Y.-C. Lin, D.-C. Yen, and Y.-M. Chen. 2011. Predicting stock returns by classifier ensembles. Applied Soft Computing 11 (2):2452–59. doi:10.1016/j.asoc.2010.10.001.
- Wang, J.-Z., -J.-J. Wang, Z.-G. Zhang, and S.-P. Guo. 2011. Forecasting stock indices with back propagation neural network. Expert Systems with Applications 38 (11):14346–55. doi:10.1016/j.eswa.2011.04.222.
- Wolpert, D.-H., and W.-G. Macready. 1997. No free lunch theorems for search. IEEE Transactions on Evolutionary Computation 1:67–82. doi:10.1109/4235.585893.
- Xue, B., M. Zhang, W. Browne, and X. Yao. 2016. A survey on evolutionary computation approaches to feature selection. IEEE Transactions on Evolutionary Computation 20:606–26. doi:10.1109/TEVC.2015.2504420.
- Yang, L., and A. Shami. 2020. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 415:295–316. doi:10.1016/j.neucom.2020.07.061.
- Yun, K. K., S. W. Yoon, and D. Won. 2021. Prediction of stock price direction using a hybrid GA-XGBoost algorithm with a three-stage feature engineering process. Expert Systems with Applications 186:115716. doi:10.1016/j.eswa.2021.115716.
- Zhang, J., S. Cui, Y. Xu, Q. Li, and T. Li. 2018. A novel data-driven stock price trend prediction system. Expert Systems with Applications 97:60–69. doi:10.1016/j.eswa.2017.12.026.
- Zhang, Y., W. Yu, Z. Li, S. Raza, and H. Cao. 2021. Detecting ethereum Ponzi schemes based on improved LightGBM algorithm. IEEE Transactions on Computational Social Systems. doi:10.1109/TCSS.2021.3088145.