
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The finite volume neural network (FINN) is an exception among recent physics-aware neural network models as it allows the specification of arbitrary boundary conditions (BCs). FINN can generalize and adapt to various prescribed BC values not provided during training, where other models fail. However, FINN depends explicitly on given BC values and cannot deal with unobserved parts within the physical domain. To overcome these limitations, we extend FINN in two ways. First, we integrate the capability to infer BC values on-the-fly from just a few data points. This allows us to apply FINN in situations, where the BC values, such as the inflow rate of fluid into a simulated medium, are unknown. Second, we extend FINN to plausibly reconstruct missing data within the physical domain via a gradient-driven spin-up phase. Our experiments validate that FINN reliably infers correct BCs, but also generates smooth and plausible full-domain reconstructions that are consistent with the observable data. Moreover, FINN can generate precise predictions orders of magnitude more accurate compared to competitive pure ML and physics-aware ML models – even when the physical domain is only partially visible, and the BCs are applied at a point that is spatially distant from the observable volumes.
Introduction
Physics-informed machine learning approaches incorporate physical knowledge as inductive bias (Battaglia et al. Citation2018). When applied to corresponding physical domains, they yield improvements in generalization and data efficiency when contrasted with pure machine learning (ML) systems (Karlbauer et al. Citation2021; Raissi, Perdikaris, and Karniadakis Citation2019). Moreover, inductive biases often help ML models to play down their “technical debt” (Sculley et al. Citation2015), effectively reducing model complexity while improving model explainability. Several recently proposed approaches augment neural networks with physical knowledge (Le Guen and Thome Citation2020; Li et al. Citation2020; Long et al. Citation2018; Seo, Meng, and Liu Citation2019; Sitzmann et al. Citation2020).
But these models do neither allow including – or structurally capturing – explicitly defined physical equations, nor do they generalize to unknown initial or boundary conditions (Raissi, Perdikaris, and Karniadakis Citation2019). The recently introduced finite volume neural network (FINN) (Karlbauer et al. Citation2022; Praditia et al. Citation2021, Citation2022) accounts for both: it combines the learning abilities of artificial neural networks with physical and structural knowledge from numerical simulations by modeling partial differential equations (PDEs) in a mathematically compositional manner. So far, FINN is the only physics-aware neural network that can handle boundary conditions that were not considered during training. Nonetheless, boundary conditions (BCs) need to be known and presented explicitly. But not even FINN can predict processes where unknown boundary conditions apply. In realistic application scenarios, however, a quantity of interest is measured for a specific, limited region only. The amount of the quantity that flows into the observed volumes through boundaries is notoriously unknown and hitherto impossible to predict. On top of that, the available systems are not able to expand their predictions beyond the boundaries of the observable volumes. One example of relevance is weather forecasting: a prediction system observes, e.g., precipitation or cloud density for a limited area. Incoming weather dynamics from outside of the observed region that strongly control the processes inside the domain cannot be incorporated, turning into one of the main error sources in numerical simulations.
Here, we expand on previous work by Can Horuz et al. (Citation2022), which presented an approach to infer the explicitly modeled BC values of FINN on-the-fly, while observing a particular spatiotemporal process. The approach is based on the retrospective inference principle (Butz et al. Citation2019; Otte, Karlbauer, and Butz Citation2020), which applies a prediction error-induced gradient signal to adapt the BC values of a trained FINN model. Only very few data points are required to find boundary conditions that best explain the recently observed process dynamics and, moreover, to predict the observed process with high accuracy in closed-loop. We compare the quality of the inferred boundary conditions and the prediction error of FINN with two state-of-the-art architectures, namely, DISTANA (Karlbauer et al. Citation2020) and PhyDNet (Le Guen and Thome Citation2020).
The distributed spatiotemporal graph artificial neural network architecture (DISTANA) is a hidden state inference model for time-series prediction. It encodes two different kernels in a graph structure: First, the prediction kernel (PK) network predicts the dynamics at each spatial position while being applied to each node of the underlying mesh. Second, the transition kernel (TK) network coordinates the lateral information flow between PKs, thus allowing the model to process spatiotemporal data. The PKs consist of feed-forward neural networks combined with long short-term memory (LSTM) units (Hochreiter and Schmidhuber Citation1997). Similar to Karlbauer et al. (Citation2020), we use just linear mappings as TKs in this work since the data considered here is represented on a regular grid and does not require a more complex processing of lateral information. All PKs and TKs share weights. DISTANA has been shown to perform better compared to convolutional neural networks (CNN), recurrent neural networks (RNN), convolutional LSTM, and similar models (Karlbauer et al. Citation2020, Citation2021). The model’s performance and its applicability to spatiotemporal data makes it a suitable pure ML baseline for this paper.
PhyDNet is a physics-aware encoder-decoder model. First, it encodes the input at time step . Afterward, the encoded information is disentangled into two separate networks, PhyCell and ConvLSTM-Cell. Inspired from physics, PhyCell implements spatial derivatives up to a desired order and can approximate solutions of a wide range of PDEs, e.g., heat equation, wave equation, and the advection-diffusion equation. Moreover, the model covers the residual information that is not subsumed by the physical norms. Concretely, the ConvLSTM-Cell complements the PhyCell and approximates the residual information in a convolutional deep learning fashion. The outputs of the networks are combined and fed into a decoder in order to generate a prediction of the unknown function at time
(Le Guen and Thome Citation2020). PhyDNet is a state-of-the-art physics-aware neural network, which is applicable to advection-diffusion equations and was therefore selected as a physics-aware baseline in this study.
Our results indicate that FINN is the only architecture that reliably infers BC values and outperforms all competitors in predicting non-linear advection-diffusion-reaction processes when the BC values are unknown. As an extension to Can Horuz et al. (Citation2022), we additionally hide 40% of the data that connect the boundaries with the simulation domain and demonstrate FINN’s ability to accurately infer this hidden information in agreement with the boundary condition.
Finite Volume Neural Network
The finite volume neural network (FINN) introduced in (Karlbauer et al. Citation2022; Praditia et al. Citation2021) is a physics-aware neural network model that combines the well-established finite volume method (FVM) (Moukalled, Mangani, and Darwish Citation2016) as an inductive bias with the learning abilities of deep neural networks. FVM discretizes a continuous partial differential equation (PDE) spatially into algebraic equations over a finite number of control volumes. These volumes have states and exchange fluxes via a clear mathematical structure. The enforced physical processing within the FVM structure constrains FINN to implement (partially) known physical-laws, resulting in an interpretable, well-generalized, and robust method.
Architecture
FINN solves PDEs that express non-linear spatiotemporal advection-diffusion-reaction processes, formulated in Karlbauer et al. (Citation2022) as
where is the unknown function of time
and spatial coordinate
, which encodes a state. The objective of a PDE solver (if the PDE was fully known) is to find the value of
in all time steps and spatial locations. However, EquationEquation 1
(1)
(1) is composed of three, often unknown functions, which modify
, i.e.,
,
, and
.
is the diffusion coefficient, which controls the equilibration between high and low concentrations,
is the advection velocity, which represents the movement of concentration due to the bulk motion of a fluid, and
is the source/sink term, which increases or decreases the quantity of
locally.
These unknown functions are approximated by neural network modules, which imitate the structure of EquationEquation 1(1)
(1) while applying it to a set of spatially discretized control volumes. and EquationEquation 2
(2)
(2) illustrate how FINN models the PDE for a single control volume
. The first- and second-order spatial derivatives
, for example, can be approximated with a linear layer,
, aiming to learn the FVM stencil, i.e., the exchange terms between adjacent volumes. In the current work, the first-order flux multiplier (i.e., advection velocity) is approximated by neural networks which take
as input. This applies to both Allen–Cahn and Burgers’ benchmarks and the networks have the size
, which makes 420 parameters (422 if BCs are learnt in the training as in Section 4.2).
Figure 1. The composition of the modules to represent and learn different parts of an advection-diffusion equation. Red lines indicate gradient flow during training and retrospective inference. Figure from Karlbauer et al. (Citation2022).
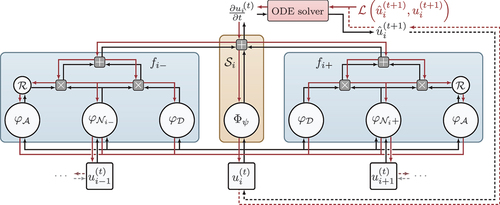
Furthermore, and in order to account for the structure of EquationEquation 1(1)
(1) , FINN introduces two kernels that are applied to each control volume with index
; similar to how convolution kernels are shifted over an input image. First, the flux kernel
models both the diffusive
and the advective flux
, respectively, via the feedforward network modules
and
. Second, the state kernel
models the source/sink term
for each volume. All modules’ outputs are summed up to conclude in
, which results in a system of ODEs with respect to time that is solved by NODE (Chen et al. Citation2018). Accordingly, FINN predicts
in time step
, that is
, and the error is computed via
, where
corresponds to the discretized spatial control volume index and
is the mean squared error. FINN operates entirely in a closed-loop manner, i.e., only the initial condition
is fed into the model to unroll a prediction
into the future, with sequence length
. Note that learning the diffusive flux has been demonstrated in earlier studies (Karlbauer et al. Citation2022; Praditia et al. Citation2021) and is not part of this work. Therefore, instead of approximating
by a neural network
, we set it to the actual value used for data generation.
The connection scheme of different kernels and modules ensures compliance with fundamental physical rules, such that advection can spatially propagate exclusively to the left or to the right ( in ). Note that we only consider one-dimensional problems in this work, although FINN can also be applied to higher-dimensional equations. The reader is referred to Karlbauer et al. (Citation2022) and Praditia et al. (Citation2021) for an in-depth depiction of the model.
Boundary Condition Inference
The specification of boundary conditions (BCs) is required to obtain a unique solution of a PDE. Common BCs are Dirichlet (fixed values for ), periodic (any quantity leaving the field on one side enters on the opposing side), or Neumann (the derivative of
is specified at the boundary). In contrast to state-of-the-art physics-aware neural networks (Le Guen and Thome Citation2020; Long et al. Citation2018; Raissi, Perdikaris, and Karniadakis Citation2019; Yin et al. Citation2021), FINN allows the explicit formulation of a desired BC. Thus, FINN can deal with not only simple boundary conditions (Dirichlet or periodic) but also more complicated ones such as Neumann (Karlbauer et al. Citation2022).
FINN uses the boundary conditions strictly. The solid implementation of a BC type (Dirichlet, periodic, Neumann) enables the model to read out unknown/unseen BC values of a given dataset. So far, however, it was necessary to use explicit BCs for solving a PDE. However, due to the explicit integration of BCs into the formulation of FINN, it is predestined to learn which BC values best describe a specific dataset – during both training and prediction. Here, we show that it is possible to infer not only BC values in a much larger range via retrospective inference, but also to recover parts of the simulation domain that were unavailable to the model during training.
From a broader perspective, the need for BCs is often a modeling artifact for real-world problems – simply because we do not have the means to simulate an entire system but need to restrict ourselves to a bounded subdomain. Even if these boundaries do not exist in the original system, our resulting model needs to identify their conditions for accurate forecasting. Our aim is to infer appropriate BCs and their values quickly, accurately, and reliably. Technically, a BC value is inferred by setting it as a learnable parameter and projecting the prediction error over a defined temporal horizon onto this parameter. Intuitively, the determination of the BC values can thus be described as an optimization problem where, instead of the network weights, the BC values are subject to optimization.
Benchmark PDEs
We performed experiments on two different PDEs and will first introduce these equations and later report the respective experiments and results.
Burgers’ Equation
Burgers’ equation is frequently used in different research fields to model, e.g., fluid dynamics, nonlinear acoustics, or gas dynamics (Fletcher Citation1983; Naugolnykh et al. Citation2000). It offers a useful toy example formulated as a 1D equation in this work as
where is the unknown function and
is the advective velocity, which is defined as an identity function
here. The diffusion coefficient
is set to
for data generation. During training, Burgers’ equation has constant values on the left and right boundaries defined as
. However, these were modified to take different symmetric values at inference in order to assess the ability of the different models to cope with such variations. The initial condition is defined as
.
Allen–Cahn Equation
Allen–Cahn is chosen and also defined as a 1D equation that could have periodic or constant boundary conditions. It is typically applied to model phase-separation in multi-component alloy systems and has also been used by Raissi, Perdikaris, and Karniadakis (Citation2019) to analyze the performance of their physics-informed neural network (PINN). The equation is defined as
where the reaction term takes the form . The diffusion coefficient is set to
, which is significantly higher than in Karlbauer et al. (Citation2022), where it was set to
. The reason for this decision is to scale up the diffusion relative to the reaction, such that the effects of the BCs are more apparent.
Experiments
We have conducted three different experiments. First, the ability to learn BC values during training is studied in Section 4.1. Afterward, we analyze the ability of the pre-trained models to infer unknown BC values in Section 4.2. Finally, in Section 4.3, we investigate the ability of the models to reconstruct 40% of the simulation domain while still inferring the BC of the dataset. Data were generated by numerical simulations using the Finite Volume Method, similarly to Karlbauer et al. (Citation2022).
Learning with Fixed Unknown Boundary Conditions
This experiment is conducted in order to discover whether it is possible for the model to approximate the boundary conditions of the given dataset. It can be utmost useful in real-world scenarios to determine the unknown BC values during training, where the model determines the BC values according to the data without depending on prior assumptions.
The shape of the generated training data was , where
specifies the discretized spatial locations and
the number of simulation steps. To train the models, we used the first 30 time steps of the sequence. The extrapolation data (remaining 226 time steps) is used to compute the test error. The learnt BC values are shown in that neither DISTANA nor PhyDNet can deduce reasonable BC values.
Table 1. Comparison of the training error, test error, and the learnt BC values of all models. For each trial, the average results over 5 repeats are presented. Burgers’ dataset BC and Allen–Cahn dataset BC
.
The results imply that the complex nature of the equations combined with large ranges of possible BC values indeed yields a challenging optimization problem, in which gradient-based approaches can easily get stuck in local minima. For example, the fact that FINN uses NODE (Chen et al. Citation2018) to integrate the ODE may lead to the convergence into a stiff system and, hence, unstable solutions. Moreover, as FINN employs backpropagation through time (BPTT), it can easily produce vanishing/exploding gradients. During preliminary studies, however, we realized that FINN benefits from shorter sequences in this regard. Thus, only the first 30 time steps of the data are employed. As a result, FINN identifies the correct BCs and – although this was not necessarily the goal – even yields a lower test error.
Neither PhyDNet nor DISTANA provide the option to meaningfully represent boundary conditions. Accordingly, the BCs are fed explicitly into the model on the edges of the simulation domain. The missing inductive bias of how to use these BC values, however, seemed to prevent the models to determine the correct BC (c.f. ). Nevertheless, both PhyDNet and DISTANA can approximate the equation fairly accurately (albeit not reaching FINN’s accuracy), even when the determined BC values deviate from the true values. The learnt BC values by the two models do not converge to any point and persist around the initial values, which are for Burgers’ and
for Allen–Cahn. Similarly, they remain around 0 when we set the initial BC values to
. We conclude that PhyDNet and DISTANA do not seem to consider the BC values.
On the other hand, FINN appears to benefit from the structural knowledge about BCs when determining their values. The BC values in converged from to
, well maintaining them for the rest of the training (c.f. first row of ). As it can be seen on the second row of , FINN also manages to infer BC values for Allen–Cahn in a larger range. In , FINN demonstrates an accurate determination of the true BCs without under- or overestimating their actual values once the gradients converged to zero. Note that we know the true BC values since we generated our own synthetic data. However, it would be possible to trust FINN, even when the BC values are unknown to the researcher. During training, the gradients of the boundary conditions converge to 0, maintaining the correctly learnt BC (see the right plots of ).
Figure 2. Convergence of the boundary conditions and their gradients during training in FINN. The dataset for Burgers’ on the first row. On the second row for Allen–Cahn with
.
![Figure 2. Convergence of the boundary conditions and their gradients during training in FINN. The dataset BC=[1.0,−1.0] for Burgers’ on the first row. On the second row for Allen–Cahn with BC=[−6.0,6.0]..](/cms/asset/4d9f62f7-056a-4f6a-ab71-95ef88e465fe/uaai_a_2204261_f0002_oc.jpg)
Boundary Condition Inference with Trained Models
The main purpose of this experiment is to investigate the possibility to infer an unknown BC value after having trained a model on a different BC value. The trained models are evaluated for their ability to infer the underlying BC values of the test data (generated by the same equation as the training data). Consequently, only the BCs are set as learnable parameters, which results in two parameters. The models infer the values for left- and right-boundary conditions through gradient-based optimization. Accordingly, we examined two different training algorithms while applying the identical inference process when evaluating the BC inference ability of the trained models.
Multi-BC Training and Inference
Ten different sequences with randomly sampled BC values from the ranges for Burgers’ and
for Allen–Cahn’s equation were used as training data. The sequences were generated with
,
and
. As the BCs of each sequence are different, the models have the opportunity to learn the effect of different BC values on the equation, allowing the weights to be adjusted accordingly.
During inference, the models had to infer BC values outside of the respective training ranges (up to for Burgers’ and
for Allen–Cahn in our studies) when observing 30 simulation steps only. The rest of the dataset, that is, the remaining 98 time steps, was used for simulating the dynamics in closed-loop depicted in as test error. As can be seen in , FINN is superior in this task compared to DISTANA and PhyDNet. All three models have small training errors, but DISTANA and PhyDNet mainly fail to infer the correct BC values as well as to predict the equations accurately. FINN, however, manages to find the correct BC values with high precision and exceptionally small deviations. After finding the correct BC values, FINN manages to predict the equations correctly.
Table 2. Comparison of multi-BC training and prediction errors along with the inferred BC values by the corresponding models. The experiments were repeated 5 times for each trial and the average results are presented. Burgers’ dataset BC and Allen–Cahn dataset BC
.
shows how the prediction error changes in different models as the BC range drifts away from the BC range of the training set. On the other hand, depicts the predictions of the multi-BC trained models after inference, highlighting once again the precision of FINN.
Figure 3. Average prediction errors of 5 multi-BC trained models for Allen–Cahn-Equation. As the BC-range grows larger, the error and the standard deviation (SD) increases. This phenomenon applies to FINN as well (SD range from to
). However, due to the scale of the plot, it is not possible to see this shift.
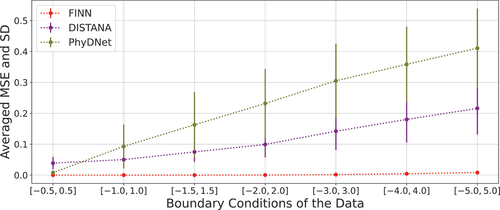
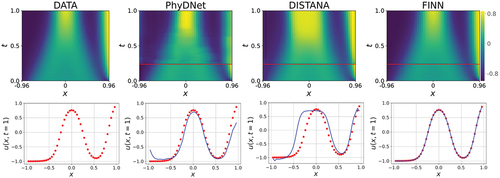
Figure 4. The predictions of the multi-BC trained Allen–Cahn dynamics after inference. First row shows the models’ predictions over space and time. Areas below the red line are the 30 simulation steps that were used for inference and filled with data for visualization. Test error is computed only with the upper area. Second row shows the predictions over and
, i.e.,
in the last simulation step. Data is represented by the red dots and the predictions by the blue line. Best models are used for the plots.
Single-BC Training and Inference
In this experiment, the models receive only one sequence with ,
and
in training. The BC values of the dataset are constant and set to
. Hence, the models do not see how the equations behave under different BC values. This is substantially harder compared to the previous experiment, as clearly reflected in the results (see and ). Despite low training errors, DISTANA and PhyDNet fail to infer correct BC values. The prediction errors when testing in closed-loop after BC inference also indicate that these models have difficulties solving the task. Although FINN manages to capture the correct BC values, its prediction error increases significantly when compared to the training error, particularly in the case of Burgers’ equation. Nonetheless, FINN produces the lowest test error by orders of magnitude for both equations. These results demonstrate that FINN significantly benefits from sequences with various BC values, enabling it to infer and predict the same equations over a larger range of novel BCs. Due to space constraints, we only report the results of one set of boundary conditions for each experiment. We observed similar results in experiments with several other BC values.
Figure 5. The predictions of the single-BC trained Burgers’ dynamics after inference. First row shows the models’ predictions over space and time. Areas below the red line are the 30 simulation steps that were used for inference and filled with data for visualization. Test error is computed only with the upper area. Second row shows the predictions over and
, i.e.,
in the last simulation step. Data is represented by the red dots and the predictions by the blue line. Best models are used for the plots.
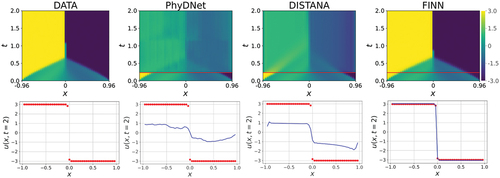
Table 3. Comparison of single-BC training and prediction errors along with the inferred BC values by the corresponding models. The experiments were repeated 5 times for each trial and the average results are presented. Burgers’ dataset BC and Allen–Cahn dataset BC
.
Physical Domain Reconstruction
Our final experiment differs from the previous two in that not only the BCs were inferred, but also a large part of the simulation domain itself. The training process is similar to Section 4.2.1. Ten sequences are created with ,
and
(compared to 49 earlier). In analogy to Section 4.2.1, we train the models on a variety of different BC values randomly sampled from the same range as before, that is,
and
for Burgers’ and Allen–Cahn’s equation, respectively. The inference dataset is generated with
and the outside-of-training-range BCs are set to
for Burgers’ and
for Allen–Cahn. At inference, the models’ field of view remains restricted to the 29 out of 49 spatial data points. Moreover, the BCs are also unknown to the models. Intuitively, the inference process could correspond to the situation where the models obtain data only from Germany. However, they need to predict the weather not only for Germany but also for the whole of Central Europe. Needless to say that the models need to infer reasonable BC values for the larger domain as well.
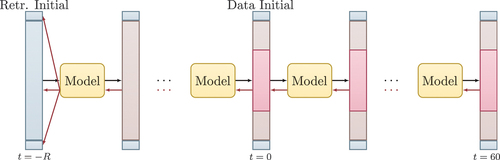
In order to approach this problem, we applied active tuning (AT, Otte, Karlbauer, and Butz Citation2020). Technically, along with retrospectively inferring unknown values, that is, BCs and unobserved domain sections, AT involves forward passing cycles to incrementally clean its current solution and make it consistent with the model dynamics before generating predictions. The latter can be regarded as a repeatedly applied spin-up phase known from physics simulations. The algorithm and task are visualized in .
Figure 6. Active tuning algorithm. corresponds to the retrospective tuning horizon as stated in Otte, Karlbauer, and Butz (Citation2020). The blue column represents the retrospective initial state and the BCs, which are optimized depending on the gradient-signal. The red areas in the middle of the columns are so-called seen areas from which the models receive information and that provide the error signal. The brown areas are called unseen area and models need to reconstruct the equation, i.e., the
values for the entire domain. Black and red arrows represent the model forward and backward passes, respectively. The gradient information (red arrows) is used to infer the BCs.
As our approach is a gradient-based optimization procedure, the weight updates and error minimization are realized on the basis of the error signal (we apply the mean squared error). However, the error signal does not represent the internal state of the models. That is, a predicted and
(i.e., two adjacent volumes) can differ meaningfully, but still yield a small error when unrolling the model into the future. Notwithstanding, such large local differences are not a realistic scenario. In fact, FINN’s internal state can provide a measure for such nonrealistic states, as the adjacent volumes are computed with respect to each other in the underlying FVM. Therefore, we optimize and search for an arbitrary solution at
and recruit the model’s simulation output at
(starting from
) as initial state. A visualization of how the model tunes its predictions in the past is provided in for
. Although the optimized retrospective initial states at
are ragged, FINN smooths its prediction during the forward pass and thus produces an initial state at
that is consistent with the model’s physics and has been cleared from all implausible artifacts. The initial state prediction of all models can be seen in DISTANA and PhyDNet neither manage to predict how the equation would unfold for the seen domain after inference (i.e., time steps between
), nor can they reconstruct the unseen domain. clearly shows how DISTANA can make use of the information it receives as it predicts well inside the seen data boundaries. However, DISTANA is incapable of reconstructing the areas from which it receives no information. We see this as further evidence for the importance of incorporating physical inductive biases, which are not present in DISTANA.
Figure 7. Retrospective state inference. The red lines at show the ground truth, i.e., the initial state of the dataset. The brownish faces indicate the seen area. Best models are used.
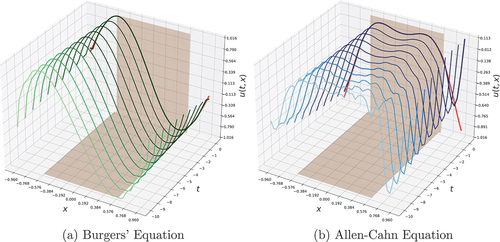
Figure 8. Initial state inference. Figures depict the initial state prediction of the models for trials. Each light blue line corresponds to one trial. Dataset BC are [1.5, −1.5]. BC-Errors are computed as root mean squared error and are depicted as red lines showing the deviation from the red dots which represent the actual BC values. The plots correspond to the results reported in .
![Figure 8. Initial state inference. Figures depict the initial state prediction of the models for 5 trials. Each light blue line corresponds to one trial. Dataset BC are [1.5, −1.5]. BC-Errors are computed as root mean squared error and are depicted as red lines showing the deviation from the red dots which represent the actual BC values. The plots correspond to the results reported in Table 4.](/cms/asset/26956f28-6175-41f1-8729-f510310e0e18/uaai_a_2204261_f0008_oc.jpg)
Table 4. Comparison of seen domain and whole-domain prediction errors along with the inferred BC values by the corresponding models. The experiments were repeated times for each trial and the average results are presented. Burgers’ dataset BC
and Allen–Cahn dataset BC
. R =
. As 60 data points were used in this experiment (compared to 30 time steps in the previous ones) an error comparison with the other experiments is not possible.
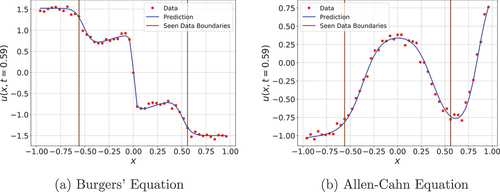
The quantitative results depicted in demonstrate, once again, clear superiority of FINN compared to DISTANA and PhyDNet. The seen domain error corresponds to the error for the time steps after the inference and within the domain from which the models obtained information during inference. The whole domain error, on the other hand, subsumes the seen domain error while also including the reconstruction error from the unseen domain. The larger whole-domain error over the seen domain error of FINN for Burgers’ Equation is likely caused by the high non-linearity of Burgers’ equation in the middle of the spatial domain, compared to more linear dynamics on the edges (c.f. ). Another interesting point is the inferred BC values of FINN. Despite the significant increase in task complexity and the availability of less data compared to the previous experiments, FINN still achieves accurate BC predictions. However, this is not the case for the right BC in Allen–Cahn. The predicted value stays consistently below the true BC. This might result from arbitrary and nonrealistic BC values chosen for inference data. Furthermore, the BCs contravene with the initial state. As depicted in at , the right edge of the data’s initial state (red line) is as low as
. The gradients reaching the spatial domain push the prediction to fit the initial state. On the contrary, gradients going to the boundary conditions drive the prediction upward because the right BC is
. This is evident in , where the predictions of the right-hand side tend to raise toward the BC. FINN's reaction to this nonrealistic contradiction, however, underlines its strive to find a most plausible and overall consistent explanation. Note that this situation does not occur in the left BC because both the domain and the BC have a higher match.
Physical Domain Reconstruction with Noise
In this section, we tested the performance of the models to reconstruct the missing spatial data and infer unknown boundary conditions from noisy data. The noise robustness of FINN has formerly been demonstrated in Karlbauer et al. (Citation2022). Therefore, the same trained models as in Section 4.3 are used. However, at inference, the models now receive the masked and noisy data.
Data is generated with the same parameters besides that normal-distributed noise with standard deviation is added, following the experimental setup in Karlbauer et al. (Citation2022). gives an idea how strong the noise is in relation to the signal’s magnitude. As it is harder to realize the underlying structure of the equation with noisy data, a longer sequence was needed to make FINN generate meaningful predictions. Thus, we used
time steps instead of
in the previous section. The inference length and data noise are the only differences in the experiment design. The test sequence, i.e., the remaining
time steps from the whole sequence, does not contain any noise.
Figure 9. FINN prediction with noisy data. The red dots show the data and the blue line is the prediction of the model. The area between brown lines indicates the seen area. Best models are used.
The results in support the previous indications. FINN’s robust and adaptable architecture allows to extract an accurate structure from noisy data, whereas the other two models fail to generate meaningful predictions. Notwithstanding, noisy data brings its challenges and this can also be seen in FINN’s performance. In particular, the standard deviations of the inferred BCs are relatively high compared to the results in .
Table 5. Comparison of seen domain and whole-domain prediction errors along with the inferred BC values by the corresponding models inferred on noisy data. The experiments were repeated times for each trial and the average results are presented. Burgers’ dataset BC
and Allen–Cahn dataset BC
. R =
. As 80 data points were used in this experiment (compared to 30 and 60 time steps in the previous ones) a direct error comparison with the other experiments is not possible.
Discussion
The aim of our first experiment (see Section 4.1) was to assess whether FINN, DISTANA, and PhyDNet are able to learn the fixed and unknown Dirichlet BC values of data generated by Burgers’ and Allen–Cahn equations. This was achieved by setting the value of the BC as a learnable parameter to optimize it along with the models’ weights during training. The results, as detailed in , suggest two conclusions: First, all models can satisfactorily approximate the equations by achieving error rates far below . Second, only FINN can infer the BC values underlying the data accurately. Although DISTANA and PhyDNet simulate the process with high accuracy, they apparently do not exhibit an explainable and interpretable behavior. Instead, they treat the BC values in a way that does not reflect their true values and physical meaning. This is different in FINN, where the inferred BC values can be extracted and interpreted directly from the model. This is of great value for real-world applications, where data often come with an unknown BC, such as in weather forecasting or traffic forecasting in a restricted simulation domain.
In the second experiment (see Section 4.2), we addressed the question of whether the three models can infer an unknown BC value when they have already been trained on (a set of) known BC values. Technically, this is a traditional test for generalization. The results in suggest that both DISTANA and PhyDNet decently learn the effect of the different BC values on the data when being trained on a range of BC values. Once the models are trained on one single BC value only (c.f. ); however, the inferred BC values of DISTANA and PhyDNet are far off the true values. This is different for FINN: although the test error on Burgers’ drops considerably, FINN still determines the underlying BC values in both cases accurately, even when trained on one single BC value only.
In the third experiment (see Section 4.3), we extended the BC inference and examined the ability of the models to simultaneously reconstruct a solid amount of data surrounding the simulation domain. Indeed, shows that FINN is able to reconstruct a physical spatial domain while only receiving information from a small domain. In order to achieve this goal, a temporal gradient-based algorithm, Active Tuning (Otte, Karlbauer, and Butz Citation2020), was applied to optimize domain and BC values in the past. Afterward, these optimized values were employed as initial conditions such that the model could tune its prediction solely depending on its own internal dynamics. With this method, FINN reaches a smooth initial state on the basis of which it starts its prediction at (see ). A key advantage of FINN compared to DISTANA and PhyDNet is recognized in the physical knowledge it has about the equations (i.e., Burgers’ and Allen–Cahn). In the last experiment (see Section 4.4, we created a more challenging task and added noise to the data. We used essentially the same experimental design (except for longer inference sequences) and showed FINNs’ robustness in noisy-data regimes.
Our main aim was to infer physically plausible, interpretable BC values and reconstruct a spatial domain. Although FINN is a well-tested model and has been compared with several models such as ConvLSTM, TCN, and CNN-NODE in Karlbauer et al. (Citation2022), we applied FINN to 1D equations in this work only. However, since the same principles underlie in higher dimensional equations, we anticipate the applicability of the proposed method to higher dimensional problems and leave it as an interesting topic for future research.
Conclusion
In a series of experiments, we found that the physics-aware finite volume neural network (FINN) is the only model – among DISTANA (a pure spatiotemporal processing ML approach) and PhyDNet (another physics-aware model) – that can determine an unknown boundary condition value of data generated by two different PDEs with high accuracy. While finding the correct BC values, FINN can also deal with missing data and reproduce around of the spatial domain. So far, the universal pure ML models stay too general to solve the problem studied in this work. State-of-the-art physics-aware networks, e.g., in Le Guen and Thome (Citation2020) or Em Karniadakis et al. (Citation2021) are likewise not specific enough. Instead, this work suggests that a physically structured model, which can be considered as an application-specific inductive bias, is indispensable and should be paired with the learning abilities of neural networks. FINN integrates these two aspects by implementing multiple feedforward modules and mathematically composing them to satisfy physical constraints. This structure allows FINN to determine unknown boundary condition values both during training and inference, which, to the best of our knowledge, is a unique property among physics-aware ML models. Besides, setting BC values in the form of hyper-parameters on real-world data is an undesirable situation for researchers. Therefore, we interpret this latest component as valuable contribution to the spatiotemporal modeling scene. Moreover, FINN offers explanations of the modeled process, including BC and substance properties, which need to be explored in further detail.
In future work, we will investigate how different BC types (Dirichlet, periodic, Neumann, etc.) – and not only their values – can be inferred from data. Moreover, an adaptive and online inference scheme that can deal with dynamically changing BC types and values is an exciting direction to further advance the applicability of FINN to real-world problems. Our long-term aim is to apply FINN to a variety of real-world scenarios of a larger scale, such as to local weather forecasting tasks, and to extend previous work by Praditia et al. (Citation2022). We expect that FINN will be able to generate complete model simulations from sparse data and potentially unknown BCs.
Acknowledgement
This work was partially funded by the Deutsche Forschungsgemeinschaft [EXC 2075 – 390740016] and [EXC 2064 – 390727645]. We acknowledge the support provided by the Stuttgart Center for Simulation Science (SimTech). Matthias Karlbauer was supported by the International Max Planck Research School for Intelligent Systems and the Deutscher Akademischer Austauschdienst. Sebastian Otte was supported by a Feodor Lynen fellowship from the Alexander von Humboldt-Stiftung.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Battaglia, P. W., J. B. Hamrick, V. Bapst, A. Sanchez-Gonzalez, V. Zambaldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner, et al. 2018. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261.
- Butz, M. V., D. Bilkey, D. Humaidan, A. Knott, and S. Otte. 2019. Learning, planning, and control in a monolithic neural event inference architecture. Neural Networks 117:135–1375. doi:10.1016/j.neunet.2019.05.001.
- Can Horuz, C., M. Karlbauer, T. Praditia, M. V. Butz, S. Oladyshkin, W. Nowak, and S. Otte. 2022. Inferring boundary conditions in finite volume neural networks. In International Conference on Artificial Neural Networks (ICANN), Bristol, United Kingdom, 538–49. Springer Nature Switzerland. doi:978-3-031-15919-0.
- Chen, R. T. Q., R. Yulia, J. Bettencourt, and D. Duvenaud. 2018. Neural ordinary differential equations. Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY, USA. Curran Associates Inc., 6572–6583.
- Em Karniadakis, G., I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang. 2021. Physics-informed machine learning. Nature Reviews Physics 3 (6):422–440. doi:10.1038/s42254-021-00314-5.
- Fletcher, C. A. 1983. Generating exact solutions of the two-dimensional burgers’ equations. International Journal for Numerical Methods in Fluids 3 (3):213–216. doi:10.1002/fld.1650030302.
- Hochreiter, S., and J. Schmidhuber. 1997. Long short-term memory. Neural Computation 9 (8):1735–1780. doi:10.1162/neco.1997.9.8.1735.
- Karlbauer, M., T. Menge, S. Otte, H. P. A. Lensch, T. Scholten, V. Wulfmeyer, and M. V. Butz. 2021. Latent state inference in a spatiotemporal generative model. In International Conference on Artificial Neural Networks (ICANN), Bratislava, Slovakia, 384–95. Springer International Publishing. doi:978-3-030-86380-7.
- Karlbauer, M., S. Otte, H. P. A. Lensch, T. Scholten, V. Wulfmeyer, and M. V. Butz. 2020 October. A distributed neural network architecture for robust non-linear spatio-temporal prediction. In 28th European Symposium on Artificial Neural Networks (ESANN), 303–08, Bruges, Belgium.
- Karlbauer, M., T. Praditia, S. Otte, S. Oladyshkin, W. Nowak, and M. V. Butz. 2022. Composing partial differential equations with physics-aware neural networks. In International Conference on Machine Learning (ICML), Baltimore, USA.
- Le Guen, V., and N. Thome. 2020. Disentangling physical dynamics from unknown factors for unsupervised video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11474–84.
- Li, Z., N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar. 2020. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895.
- Long, Z., Y. Lu, X. Ma, and B. Dong. 2018. Pde-net: Learning PDEs from data. In International Conference on Machine Learning, Stockholm, Sweden, 3208–16. PMLR.
- Moukalled, F., L. Mangani, and M. Darwish. 2016. The Finite Volume Method In Computational Fluid Dynamics : An Advanced Introduction With OpenFOAM and Matlab. In Fluid Mechanics and Its Applications, vol. 113. Cham: Springer International Publishing. doi:10.1007/978-3-319-16874-6.
- Naugolnykh, K. A., L. Ostrovsky, O. A. Sapozhnikov, and M. F. Hamilton. 2000. Nonlinear wave processes in acoustics. The Journal of the Acoustical Society of America 108 (1):14–15. doi:10.1121/1.429483.
- Otte, S., M. Karlbauer, and M. V. Butz. 2020. Active tuning. arXiv preprint arXiv:2010.03958.
- Praditia, T., M. Karlbauer, S. Otte, S. Oladyshkin, M. V. Butz, and W. Nowak. 2021. Finite volume neural network: Modeling subsurface contaminant transport. In International Conference on Learning Representations (ICRL) – Workshop Deep Learning for Simulation.
- Praditia, T., M. Karlbauer, S. Otte, S. Oladyshkin, M. V. Butz, and W. Nowak. 2022. Learning groundwater contaminant diffusion-sorption processes with a finite volume neural network. Water Resources Research 58 (12). doi:10.1029/2022WR033149.
- Raissi, M., P. Perdikaris, and G. E. Karniadakis. 2019. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics 378:686–707. doi:10.1016/j.jcp.2018.10.045.
- Sculley, D., G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J.F. Crespo, and D. Dennison. 2015. Hidden technical debt in machine learning systems. In Proceedings of the 28th International Conference on Neural Information Processing Systems 2(15): 2503–11, Cambridge, MA, USA: MIT Press.
- Seo, S., C. Meng, and Y. Liu. 2019. Physics-aware difference graph networks for sparsely-observed dynamics. In International Conference on Learning Representations, New Orleans, USA.
- Sitzmann, V., J. Martel, A. Bergman, D. Lindell, and G. Wetzstein. 2020. Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems 33:7462–7473.
- Yin, Y., V. Le Guen, J. Dona, E. de Bézenac, I. Ayed, N. Thome, and P. Gallinari. 2021. Augmenting physical models with deep networks for complex dynamics forecasting. Journal of Statistical Mechanics: Theory and Experiment 20210 (12):124012. doi:10.1088/1742-5468/ac3ae5.