
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In recent years, motion recognition has become a hot research topic in the field of computer vision and has great research worth. Scholars and research institutions at home and abroad have made a lot of research and achieved good results. However, the research results of applying motion recognition technology to dance video are relatively few, mainly because the complexity of human motion in dance video is relatively high. In article, an optimized design scheme for motion recognition research of dance video based on computer vision and image processing is proposed. The collected dance video is preprocessed, including grayscale, background subtraction and filter denoising, so as to extract the character features in the video image. Then, the method of self-organizing mapping neural network (SOM) in computer vision is used to realize the recognition of dance movements. Finally, the simulation test and analysis are carried out. The simulation results show that the proposed arithmetic has a certain accuracy, which is 9.34% higher than the traditional arithmetic. The research of motion recognition method based on dance video will also play a certain reference role for the research of human motion recognition in a large number of real and complex environments, and enrich the application field of motion recognition technology.
Introduction
The free degree of dance movement is large. Compared with the natural movement of the human body, the dance movement changes more. The conventional actions include diving, twisting, twisting, kicking, squatting, bending, lying and stretching, while the more complex actions include swinging, sliding, cloud walking, wandering, flying feet, rotation, and rolling (Byung-Wan, Yun-Sung, and Jun Citation2018). These movements contain many degrees of freedom, and simple modeling methods and motion recognition methods are difficult to accurately express the human movements of dancers (Cagnoni et al. Citation2020). Motion recognition has experienced a long development process. Gesture recognition and limb motion recognition belong to the low-level human motion analysis (Nguyen, Nguyen, and Bouchara Citation2020). The essence of motion recognition in dance video images is motion recognition, which belongs to human motion analysis at the advanced stage. The purpose is to analyze, judge or extract the motion in the video, and create personalized teaching systems, training systems and virtual simulation systems (Pan Citation2019). Compared with gesture recognition and limb motion recognition, motion recognition in dance video images is more complex. Using simple limb localization arithmetics can not accurately reflect the motion in dance video images (Hajarolasvadi and Demirel Citation2020). Human motion recognition in video is a hot topic in computer research at present.
Dance motion recognition technology has various potential applications in different domains. Here are some specific examples:
Virtual Reality Games: Dance motion recognition can be applied in virtual reality (VR) games that involve dancing or choreography. By tracking and analyzing the user’s dance movements, the game can provide real-time feedback and scores based on the accuracy and style of the user’s performance. This enhances the immersive experience and allows players to engage in interactive and physically active gameplay.
Dance Training and Education: Dance motion recognition technology can be utilized in dance training and education programs. It can serve as a tool for providing objective feedback to dancers, helping them improve their technique, posture, and timing. By analyzing and comparing the user’s movements to predefined dance patterns or expert demonstrations, the technology can offer personalized guidance and assistance to dancers of all skill levels.
Rehabilitation and Physical Therapy: Dance motion recognition can be integrated into rehabilitation and physical therapy programs, particularly for individuals recovering from injuries or with mobility impairments. By using motion-tracking sensors, the technology can monitor and analyze the patient’s movements during dance-based exercises. It can provide real-time feedback, track progress, and assist in designing personalized rehabilitation routines to improve coordination, range of motion, and overall physical fitness.
Interactive Dance Installations: Dance motion recognition technology can be incorporated into interactive installations or art exhibits. It can enable visitors to engage in interactive dance experiences by tracking their movements and transforming them into visual and auditory representations in real-time. This creates a unique and immersive art experience where participants can explore the intersection of technology and dance.
Dance Performance Analysis: Dance motion recognition can be employed in analyzing and studying dance performances. Researchers and choreographers can use the technology to objectively assess and evaluate various aspects of dance, such as movement patterns, synchronization, energy expenditure, and artistic expression. This can provide valuable insights for improving choreography, understanding dance aesthetics, and enhancing the overall quality of performances.
These are just a few examples of how dance motion recognition technology can be applied in different contexts, ranging from entertainment and gaming to healthcare and artistic expression. The versatility and potential impact of this technology make it a promising tool for enhancing dance-related experiences and advancing research in the field of human movement.
The key to video human motion recognition is to reasonably preprocess the original video image, and then extract the features of the video image and describe and classify it (Bao, Liu, and Yu Citation2022; Rao, Lu, and Jie Citation2019). There are many limitations in the acquisition of information by the human visual system, which is not conducive to the understanding and processing of information (Tao, Guo, and Li). Computer vision is an auxiliary means that can help people accurately obtain information. It can simulate, expand and even extend human intelligence by letting machines “see,” and can solve large-scale and complex visual tasks (Alam, Ofli, and Imran Citation2018). At present, computer vision is widely used in image generation, vehicle monitoring, target tracking and so on. It has broad application prospects in various fields such as medical treatment, agriculture and transportation. In recent years, the ability of computer image processing has been continuously improved, and the development of computer vision has become increasingly mature (Glancova, Do, and Sanghavi Citation1053).
The application of computer vision in motion recognition of dance video images has multiple meanings (Dawood, Zhu, and Zayed Citation2018). For example, it can be applied to dance learning or teaching as an auxiliary training method. It can accurately and comprehensively identify the movements and postures of dancers in the video, facilitate the objective evaluation of them, so as to put forward improvement suggestions for dancers (Dat, Ki, and Hong Citation2017). At present, a large number of application achievements based on motion recognition have appeared in the field of virtual reality, bringing subversive changes to some scene applications in our lives (Li et al. Citation2022). In view of the advantages of computer vision itself, article adopts the SOM method in computer vision to reduce the execution cost of the arithmetic. The practice proves that this combination can not only reduce the calculation time, but also improve the quality and efficiency of dance video motion recognition optimization.
The research results of motion recognition technology based on dance video are not only conducive to the analysis of dance video by dance professionals, but also can be used for teaching, protection and excavation of artistic and cultural heritage (Lukiw Citation2022). In article, the visual feature reconstruction model of the optimized design image of dance video motion recognition is established. The image processing technology is used to preprocess the dance video, extract the fuzzy feature of the optimized design image of scene dance video motion recognition, and train the motion recognition with computer vision. Its innovation lies in:
In article, SOM method in computer vision is used to reduce the execution cost of the arithmetic.
In article, the key feature quantity of dance video motion recognition optimization design image is constructed, and the image processing technology is used to realize the landscape ecological construction and spatial pattern optimization design and identification.
The motivation behind the study is the growing interest in motion recognition in the field of computer vision. While motion recognition has been extensively researched and applied in various domains, its application to dance videos has been relatively limited. Dance videos present unique challenges due to the complexity and diversity of human motion involved. Therefore, the study aims to address this gap by proposing an optimized design scheme specifically tailored for motion recognition in dance videos.
The main contribution of this study lies in the following aspects:
Optimized Design Scheme: The study proposes an optimized design scheme for motion recognition in dance videos. By combining computer vision and image processing techniques, the scheme effectively preprocesses the collected dance videos to extract relevant character features. This preprocessing step is crucial for accurately recognizing dance movements.
Application of Self-Organizing Mapping Neural Network (SOM): The study utilizes the self-organizing mapping neural network (SOM), a type of unsupervised learning algorithm, for recognizing dance movements. SOM is well-suited for clustering and classifying data based on similarities. By leveraging SOM within the domain of computer vision, the proposed method achieves recognition of dance movements in an efficient and effective manner.
Improved Accuracy: The simulation tests and analysis conducted in the study demonstrate that the proposed method outperforms traditional motion recognition approaches. The reported improvement in accuracy, 9.34% higher than traditional methods, showcases the effectiveness of the proposed optimized design scheme for dance video motion recognition.
Enrichment of Application Field: The research on motion recognition in dance videos not only contributes to the specific domain but also provides valuable insights for human motion recognition in complex and real-world environments. By expanding the application field of motion recognition technology, the study opens up new possibilities for its utilization in diverse scenarios.
In summary, the main contribution of the study lies in proposing an optimized design scheme for motion recognition in dance videos, employing computer vision and image processing techniques, and utilizing the self-organizing mapping neural network for recognizing dance movements. The reported improvement in accuracy and the broader implications for human motion recognition research further enhance the significance of this study.
Article studies the optimization design of dance video motion recognition, and the architecture is as follows:
The first section is the introduction. This part mainly expounds the research background and significance of dance video motion recognition optimization, and puts forward the research purpose, method and innovation of article. The second section is a summary of the relevant literature, summarizes the advantages and disadvantages, and puts forward the research ideas of article. The third section is the method part, which focuses on the optimization design method of dance video motion recognition combined with image processing and computer vision. The fourth section is the experimental analysis. In this part, experimental verification is carried out on the data set to analyze the performance of the model. Section V, conclusions and prospects. This part mainly reviews the main contents and results of this study, summarizes the research conclusions and points out the direction of further research.
Related Work
The ideal action recognition representation method should not only deal with the influence of human appearance, scale, complex background, viewpoint and the speed of action execution, but also contain enough information to provide the classifier to distinguish each action type.
Chaw mainly studies the use of motion sensors to realize dynamic scene understanding, target tracking and motion perception (Chaw and Mokji Citation2017). Wang et al. Proposed a method to quickly and accurately predict the 3D space-time position of human joints from a depth image, which has the advantages of invariance of posture, shape and clothing, and is more general than the nearest neighbor matching method of the whole skeleton (Wang, Shen, and Shi Citation2020). Vanitha et al. Constructed a new descriptor based on optical flow for online motion recognition (Vanitha, Suwathika, and Mathura Citation2021). The descriptive features utilized by Jaddoa et al. Include atomic actions, objects, and postures (Jaddoa, Gonzalez, and Cuthbertson Citation2021).
Okinda et al built a sliding window by calculating the scale invariance features of the video, and then used the threshold method to segment the motion according to the similarity between the sliding window and the video to be segmented. Local segmentation methods generally perform motion segmentation by matching and threshold method, lacking statistical analysis and learning process, so the overall error is large (Okinda et al. Citation2020). Koohzadi et al. Constructed the spatiotemporal shape from the silhouette image sequence obtained by stacking the background difference method, then extracted the significant spatiotemporal features such as structure and direction in the spatiotemporal shape by using the properties of the solution of Poisson equation, calculated the weighted moments of these features as the global representation vectors, and realized the action classification by matching the global representation vectors of the samples with the spatiotemporal shapes in the test sequence (Joudaki et al. Citation2020).
Okinda et al. Suggested that the optical flow points in the moving area should move more frequently, determined the human motion related area in the video from the optical flow through the random sampling consensus arithmetic, divided the area into several smaller blocks, and then recorded the percentage of changes in the optical flow points between frames in each block, which was used as the characteristic expression of the action, and achieved good experimental results (Okinda et al. Citation2020). Barbu et al. Integrated the existing motion features into a multi-scale kernel function, and then used the kernel function to model the non segmented video, and finally completed the segmentation of the motion through the similarity discrimination of the kernel function (Barbu et al. Citation2018). Toulouse et al. Combined the motion information in the video into a two-layer conditional random field model through statistical analysis of features, and obtained the motion segmentation result by solving the extreme worth of the model (Tao et al. Citation2017).
According to the current research results in the field of computer vision, visual detection technology has been widely studied at home and abroad, and has been applied to a certain extent in many fields, but a complete theoretical system has not yet been formed. Technically, it can not reach the level of practical application in many aspects; Functionally, it is still at a low level compared with human vision. In article, an optimized design scheme of dance video motion recognition research based on computer vision and image processing is proposed. The collected color images are grayed to reduce the computational load of the computer. Then, Gaussian mixture model is used to eliminate the background of the generated gray-scale image, and a black-and-white video image with noise is obtained. After median filter denoising, the foreground target in the image is obtained. In motion recognition, SOM method is used to train human motion. After training, the classification and recognition of motion are realized.
Methodology
Image Processing Technology Preprocesses Dance Video Actions
Dance video motion recognition is mainly carried out through the computer vision system. However, in consideration of the problem of computer computation, it should be preprocessed before computer recognition to extract effective image information and reduce the computational burden of the computer (Min, Yao, and Lin Citation2018).
Here is a detailed explanation of the preprocessing steps involved in preparing the dance videos for motion recognition:
Grayscale Conversion: The first preprocessing step is to convert the collected dance videos into grayscale. Grayscale conversion involves transforming the videos from color images to black and white images, where each pixel represents a shade of gray. This step simplifies the subsequent processing by reducing the computational complexity and focusing solely on the intensity information of the video frames.
Background Subtraction: After grayscale conversion, the next step is background subtraction. Background subtraction aims to separate the foreground, which contains the moving dancer, from the background. This process involves comparing each frame of the grayscale video to an initial background model and identifying the pixels that significantly deviate from the background. The resulting foreground mask provides a binary representation of the dancer’s silhouette, isolating them from the background.
Filter Denoising: The third preprocessing step is filter denoising, which helps to reduce noise and enhance the quality of the foreground mask obtained from background subtraction. Noise in the form of small isolated pixels or artifacts can affect the accuracy of subsequent motion recognition algorithms. Denoising filters, such as median filters or Gaussian filters, are applied to smooth the foreground mask, removing unwanted noise while preserving the essential details of the dancer’s silhouette.
By performing these preprocessing steps, the proposed method aims to extract the relevant character features in the dance videos, focusing on the foreground motion of the dancer while minimizing the influence of the background and noise. This prepares the videos for further analysis and recognition of dance movements.
In order to reduce the error of detection, article uses image processing technology to process the collected color image through a series of processing, and finally converts the collected image into a binary black-and-white image, which reduces the influence of environmental factors such as illumination and background on the detection results during the image acquisition process. The whole image detection process is shown in . The color images collected by Kinect are processed by smooth filtering, grayscale, edge detection, image binarization, morphological transformation, etc., to remove the interference of noise in the environment and enhance the image, and reduce the interference of light, background and other factors on the image. Finally, the skeleton points are detected on the processed image to draw the human skeleton map.
Figure 1. Image detection process.
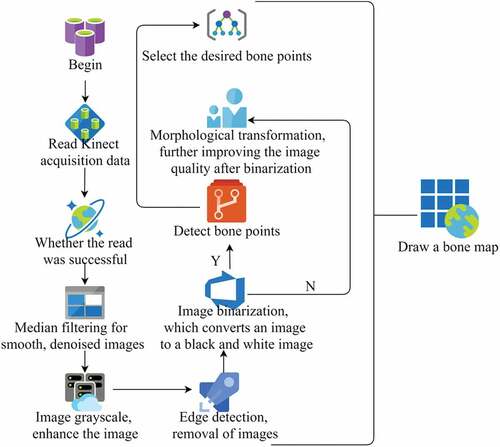
Image smoothing is widely used in computer vision and image processing (Toulouse et al. Citation2017). In the process of formation, transmission, reception and processing, images are inevitably subject to external and internal interference. For example, some instruments and equipment produce certain noise in some photoelectric conversion processes, human factors in the transmission process, or air vibration, etc., which will reduce the image quality, make the image features submerged, and bring great difficulties to image analysis. Therefore, these interferences must be removed when processing images, so as to obtain accurate results. Interference noise is generally generated randomly, with irregular distribution and size.
Here is an elaboration on the advantages and previous successes of SOM in the context of motion recognition:
Unsupervised Learning: SOM is an unsupervised learning algorithm that excels in clustering and classifying data based on their similarities. This is particularly beneficial in motion recognition, where a large variety of dance movements need to be categorized and classified. By employing SOM, the proposed method can learn the underlying patterns and structures within the dance videos without the need for explicit training data or labels.
Topological Preservation: SOM preserves the topological properties of the input data during the mapping process. This means that similar dance movements are more likely to be mapped to neighboring nodes in the SOM. This property is advantageous in motion recognition as it enables the network to capture the natural relationships and transitions between different dance movements. By preserving the topology, SOM can provide a comprehensive representation of the dance motion space.
Robustness to Noise and Variability: SOM has been demonstrated to be robust to noise and variability in the input data. In the context of motion recognition, dance videos may contain variations in lighting conditions, camera angles, or individual dancer styles. The robustness of SOM helps in handling such variations and extracting the essential features of the dance movements, leading to more accurate recognition results.
Previous Successes: SOM has been successfully applied in various domains, including image analysis, pattern recognition, and motion analysis. In motion recognition specifically, SOM has shown promising results in tasks such as action recognition, gesture recognition, and human motion analysis. Its ability to capture and represent complex data distributions makes it suitable for the recognition of intricate dance movements.
By choosing SOM as the recognition technique, the proposed method capitalizes on the advantages offered by this neural network. Its unsupervised learning capability, topological preservation, robustness to noise and variability, and previous successes in related applications make it a suitable choice for the recognition of dance movements in the context of the proposed research.
Explicitly highlighting these advantages and successes helps solidify the rationale behind selecting SOM as the chosen recognition technique and showcases the potential effectiveness of the proposed method in accurately recognizing and categorizing dance movements in the dance videos.
In space, the gray levels of noise pixels are not correlated, which is significantly different from the adjacent pixels. Therefore, denoising and image restoration is a very important content in image processing. This denoising process is called image smoothing or filtering. Generally, the common method of image smoothing is linear filter, which weights and sums the image pixels. The calculation formula is as follows:
Where is called nucleus. Kernel is a mathematical principle composed of numerical parameters.
Here is a discussion on the dataset used for training and testing the proposed method, including details on its size, diversity, and representativeness:
Dataset Size: The size of the dataset used for training and testing the proposed method is an important factor in assessing its performance and generalizability. A larger dataset generally provides more representative samples of different dance movements, allowing the model to learn a wider range of variations and patterns. Ideally, the dataset should be of sufficient size to cover a diverse set of dance styles, performers, and environmental conditions. The specific number of videos or frames within the dataset should be provided to assess the scale of the data used.
Diversity of Dance Movements: The dataset should encompass a diverse range of dance movements to ensure the generalizability of the proposed method. It should include various styles such as ballet, hip-hop, contemporary, Latin, traditional, and more. The dataset should cover different levels of complexity, ranging from simple gestures to intricate choreography. The inclusion of a variety of dance movements ensures that the proposed method is capable of recognizing and classifying different types of motions accurately.
Performers and Variability: To make the dataset representative of real-world scenarios, it should involve multiple performers. Different individuals may have their unique styles, techniques, and body proportions, which can impact the appearance and execution of dance movements. Including videos from multiple performers helps account for this variability and ensures that the proposed method can generalize well across different individuals.
Environmental Conditions: Dance performances can take place in various environmental conditions, such as different stages, lighting setups, and backgrounds. It is crucial to include videos with varying environmental conditions in the dataset. This accounts for the impact of different lighting conditions, backgrounds, or potential occlusions that may be present during real-world scenarios. Including diverse environmental conditions enhances the robustness and applicability of the proposed method.
Annotation and Labels: The dataset should be thoroughly annotated, providing accurate labels or annotations for each video or frame. This includes labeling the specific dance style or movement depicted in each sample. Proper annotations facilitate supervised learning and evaluation of the proposed method’s accuracy and performance. Additionally, if available, temporal annotations indicating the timing or duration of specific movements within each video can further enhance the training and analysis of the proposed method.
Balanced Representation: It is important to ensure a balanced representation of different dance movements within the dataset. This means that each dance style or movement should be represented by a sufficient number of samples to avoid biases or skewed learning. Balancing the dataset helps prevent the model from favoring dominant or frequently occurring movements and ensures fair representation and evaluation across all dance styles.
At present, there are many methods of image smoothing in image processing, including mean filter, median filter and Gaussian filter. As shown in , the three filtering methods are compared.
Table 1. Comparison of three filters.
By comparing the above centralized filtering effects, the median filter has a good effect on image processing, especially for the processing of pepper and salt noise, so the median filter method is adopted.
Image binarization is widely used in image processing. Basically, all image processing processes need to use this technology. Image binarization is similar to a screen. By setting the mesh size of the screen, substances with different sizes can be filtered. The threshold worth in image binarization is like the mesh of the screen. After we set the threshold worth, the computer will compare the pixel gray worth of the image with the mesh. When the pixel gray worth is larger than the mesh, the pixel will be set to white. On the contrary, when the pixel gray worth is smaller than the mesh, the pixel will be set to black, Finally, a black-and-white image can be obtained. The definition of image binarization is shown in formula (2):
Where, is the pixel gray worth,
is the set threshold worth, and
is the output gray worth.
The setting of the threshold affects the final display effect of the image. At present, the commonly used threshold setting method is Otsu method, that is, the maximum inter class variance method, also known as Otsu method. At present, Otsu method is considered as the best method to select threshold in image segmentation. Its main principle is that there is a large inter class variance between foreground and background when measuring the uniformity of gray distribution. The smaller the variance, the smaller the difference between foreground and background. Principle of Otsu method: if the total number of pixels in the image is and the gray scale range is
, the number of pixels of the corresponding gray scale
is
for the pixel
of a certain point, and the probability of occurrence of each gray scale is as follows (3).
For pi
Then, the image is quickly divided into and
regions by the threshold worth
, and the average worth of the image is:
The mean worths of regions and
are
and
respectively. The calculation process is as follows (6) and (7)
The formula can be obtained from formula (5) – formula (7):
The variance between classes is defined as:
Through the above image processing process, a binary image can be obtained, and the processed action image can be obtained by combining the image and the original image through the arithmetic of traversing the pixels. The general flow of the arithmetic is shown in .
Figure 2. Extraction process of various motion images.
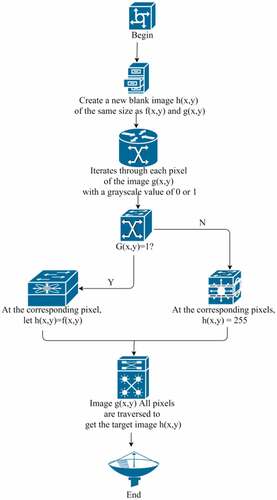
Among them, is the original image,
is the binary image in , and
is the newly created blank image. The three images have the same size, and the coordinates of the pixel points correspond to each other.
Optimization Design of Dance Video Motion Recognition Based on Computer Vision
The computer vision system in dance video motion recognition is composed of three parts: image acquisition, image preprocessing and pattern recognition. The specific functions and functions to be realized are as follows:
Image acquisition. With the help of optical cameras, such as digital cameras or mobile phones, people’s movements during dancing are photographed and stored to obtain the dance video digital images to be processed for further human motion recognition.
Image preprocessing. The original dance video image usually contains some interference information such as noise and background. The purpose of image preprocessing is to suppress the interference information contained in the original image, so as to make the features of useful information in the image more obvious, improve the image data, and strengthen the effect of action recognition. Image preprocessing usually includes image graying, image denoising, image enhancement, image segmentation and image restoration.
Pattern recognition. It is to process, analyze, recognize and interpret the image information (dance action) of the preprocessed video image by using arithmetics, so as to realize the recognition of dance video action on the basis of computer vision.
Common features such as shape, trajectory, optical flow and local spatiotemporal interest points can be divided into the following four categories, as shown in .
Table 2. Classification of common features in action recognition.
Since the global features such as silhouette, optical flow and gradient are highly discriminative and easy to obtain in a fixed perspective and a single background, this chapter starts with identifying the simplest benchmark behavior databases weizmam and kth, and integrates a variety of commonly used global features for machine learning. First, the training video is preprocessed in two steps – Calibration and morphological processing.
Here is the process of extracting character features in the proposed approach for motion recognition of dance videos:
Grayscale Conversion: The dance videos are initially converted from their original color format to grayscale. This conversion reduces the complexity of the data by representing each frame as a single-channel image, focusing solely on the intensity information.
Background Subtraction: Background subtraction is performed to separate the foreground, which contains the moving dancer, from the background. By comparing each frame of the grayscale video to an initial background model, pixels that significantly deviate from the background are identified. This process generates a foreground mask, where the dancer’s silhouette is represented as white pixels, and the background is represented as black pixels.
Filter Denoising: The generated foreground mask may contain noise or artifacts that could negatively impact the subsequent feature extraction. To enhance the quality of the mask, filter denoising techniques are applied. Common filters such as median filters or Gaussian filters can be used to remove isolated pixels or smooth out noise while preserving the essential details of the dancer’s silhouette.
Motion Gradient Computation: The motion gradient represents the changes in motion between consecutive frames. By computing the motion gradient, the areas of the video with significant motion can be identified. This is achieved by calculating the spatial gradients of the foreground mask in the x and y directions. The magnitude of the gradients represents the amount of motion in each pixel.
Forward/Backward Difference Calculation: The forward/backward difference method is employed to analyze the motion gradient. This method involves computing the difference between the forward and backward motion gradients. By subtracting the motion gradients of consecutive frames in both the forward and backward directions, the resulting difference maps highlight the regions with notable changes in motion.
Feature Extraction: The difference maps obtained from the forward/backward difference calculation serve as the input for feature extraction. Various techniques can be employed to extract character features from the difference maps. These techniques may include histogram-based features, such as histograms of oriented gradients (HOG) or local binary patterns (LBP), or more advanced feature descriptors like scale-invariant feature transform (SIFT) or convolutional neural networks (CNN). The choice of feature extraction technique depends on the specific requirements of the motion recognition task.
By following these steps, the proposed approach extracts character features from the dance videos. The grayscale conversion, background subtraction, filter denoising, motion gradient computation, forward/backward difference calculation, and feature extraction collectively contribute to capturing the essential motion information and representing it in a suitable form for subsequent recognition using the self-organizing mapping (SOM) neural network or other classification algorithms.
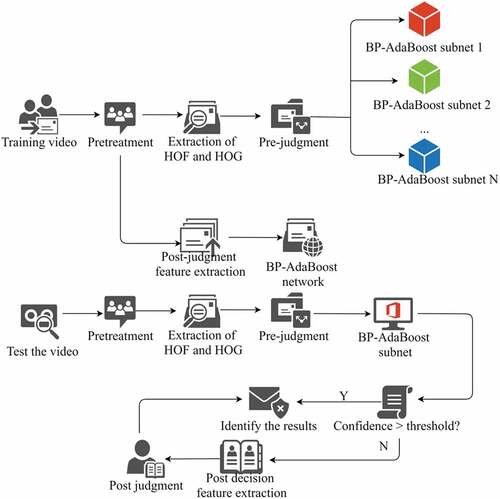
On the one hand, the feature extraction area is concentrated in the human motion area, and then the HOF, hog and other features required for the main decision are extracted. The weizmam database uses Hu’s moment feature and BS as the post decision feature. In order to reduce the training complexity and improve the recognition rate, the main training task can be divided into a series of sub training tasks and trained with their respective BP AdaBoost sub networks. See for the test flow, which is very similar to the training flow. The difference is that not all test videos need to extract the post judgment features for post judgment. Only when the confidence level of the main judgment is lower than the oral limit.
Figure 3. Block diagram of layered BP AdaBoost action recognition system.
After obtaining the spatial transformation features, article further detects the motion caused by the motion in the time domain according to the differences of different motion frames. According to the two-dimensional characteristics of the spatial conversion feature, first, the difference operation is performed on the three consecutive moving images in two directions, and the specified action time range is
. The characteristic difference between
and
is:
Where is the spatial conversion feature of the image at time
.
may also be denoted as
. In order to obtain the effective characteristics of the time
, only the difference worth 667 that changes significantly from the previous time to the local time, that is:
So far, the forward feature difference can be defined as: , wherein:
Where is specified.
The spatial gradient conversion feature changes sharply in the region containing the motion. Therefore, the change of the motion in the range of three consecutive frames can be reflected by the forward and backward differential operations. At the same time, since the forward and backward differential operations retain the effective information of the current time while ignoring the irrelevant information of the time
and
, the action at time
can be accurately detected by analyzing the overlapping area of the forward and backward differential operations. The forward/backward difference
is defined as follows:
Which is simplified as . On this basis, the action area can be divided by using the threshold method in two directions:
The threshold worth is a variable parameter and is determined by the image quality.
After the forward/backward feature difference is obtained in the and
directions, in order to automatically calibrate the region of the motion in the image, article further introduces a projection discrimination method based on statistics. If the projection of the forward/backward difference in the direction
is
, and the projection in the direction
is
, the action area
can be calibrated as:
The forward/backward difference method, which operates directly on the low-order feature of motion gradient, offers clear advantages in terms of stability and real-time performance compared to methods that rely on high-order features. By utilizing the spatial gradient feature as the difference object, the method effectively disregards irrelevant information in the motion. This approach overcomes a limitation of traditional inter-frame difference methods, which struggle to accurately segment overlapping action regions.
The forward/backward difference method focuses on the low-order feature of motion gradient, which represents the changes in motion between consecutive frames. By computing the difference between the forward and backward motion gradients, the method effectively captures the essential motion information. This approach is computationally efficient and ensures the stability of the motion recognition process.
Furthermore, by utilizing the spatial gradient feature as the basis for difference computation, the forward/backward difference method successfully filters out irrelevant information in the motion. This is particularly beneficial when dealing with overlapping action regions, where traditional inter-frame difference methods often struggle to accurately segment the individual actions. By ignoring the irrelevant motion information, the method improves the segmentation accuracy and enhances the overall performance of motion recognition algorithms.
In summary, the forward/backward difference method offers advantages in terms of stability and real-time performance compared to methods that rely on high-order features. By using the spatial gradient feature as the difference object, the method effectively ignores irrelevant information in the motion and overcomes the limitation of traditional inter-frame difference methods in segmenting overlapping action regions. These characteristics make the forward/backward difference method a valuable approach in the field of motion recognition.
Result Analysis and Discussion
Existing motion recognition techniques for dance videos often face several limitations that the proposed method aims to overcome. Here is a brief discussion on these limitations and how the proposed method addresses them:
Complexity of Human Motion: Dance videos involve intricate and diverse human movements, making it challenging for traditional motion recognition techniques to accurately capture and classify these complex actions. The proposed method addresses this limitation by utilizing the self-organizing mapping SOM, which is capable of clustering and classifying data based on similarities. By leveraging SOM, the proposed method can effectively recognize and categorize the intricate dance movements present in the videos.
Overlapping Action Regions: Traditional inter-frame difference methods struggle to accurately segment overlapping action regions in dance videos. This limitation hampers the precise recognition and analysis of individual dance movements. The proposed method overcomes this challenge by using the spatial gradient feature as the basis for difference computation. By focusing on the relevant spatial information, the proposed method filters out irrelevant motion details, improving the segmentation accuracy and enhancing the overall performance of motion recognition algorithms.
Stability and Real-Time Performance: Some existing motion recognition techniques based on high-order features may lack stability and real-time performance, which are crucial for practical applications. The proposed forward/backward difference method, which operates on the low-order feature of motion gradient, offers advantages in terms of stability and real-time processing. By directly acting on the low-order feature, the proposed method ensures stability and real-time performance, making it suitable for real-world applications.
Accuracy Improvement: Another limitation of existing techniques is the need for improved accuracy in recognizing dance movements. The simulation test and analysis conducted in the study demonstrate that the proposed method achieves a certain level of accuracy, reported to be 9.34% higher than traditional methods. By utilizing the optimized design scheme, including preprocessing techniques and the utilization of SOM, the proposed method enhances the accuracy of dance motion recognition, making it a valuable contribution to the field.
Overall, the proposed method aims to overcome the limitations of existing motion recognition techniques for dance videos by leveraging the self-organizing mapping neural network (SOM), addressing the challenge of overlapping action regions, ensuring stability and real-time performance through the forward/backward difference method, and achieving improved accuracy through the optimized design scheme. These advancements pave the way for more robust and accurate recognition of dance movements in videos, expanding the possibilities for applications such as virtual reality games, dance training, rehabilitation programs, and artistic installations.
There is a great difference between the dancer’s dance movements and the ordinary people’s daily movements. Many movements can only be completed by using the hands and legs of the dancer. It can convey the overall information of the dancer’s movements, such as the current basic shape of the dancer can be obtained through the contour characteristics of the dancer. The dynamic characteristics are mainly manifested in the movement speed, direction and trajectory of the dancer, which can reflect the movement path of the dancer. The recognition of these features can calculate the movement direction characteristics of the dancers and create conditions for modeling. The space-time characteristics are mainly manifested in the space-time shape, interest points, etc. Descriptive characteristics, including the scene where the dancer is, the surrounding objects, and the posture.
To test the effect of the number of training samples, we fixed the network size to 20 × 20, 100 iterations. Assuming that n samples are selected for each scene of each type of action, the training set size is 12 × twenty-seven × n。 Because we use 6-fold cross validation, there are 100 training videos and 25 test videos for each type of action. respectively show the average accuracy and training time of SOM network when n = 1–150. It can be seen from that when n<80, the number of training samples has a great impact on the network performance, but when n>120, the network performance tends to be saturated, so it is unnecessary to use too many training samples. On the other hand, the accuracy of the original hog3d is slightly higher because it cascades more cytosolic histograms; However, the performance of fast hog3d is not significantly reduced because its direction quantization uses more dimensions. clearly shows that fast hog3d can save a lot of training time, so fast hog3d is a good compromise between performance and efficiency.
Figure 4. Effect of average accuracy of different training samples on SOM Network.
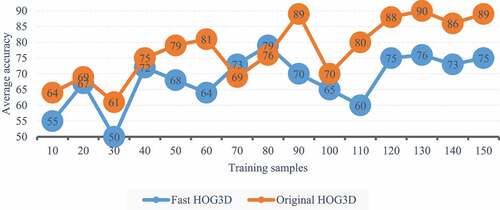
Figure 5. Effect of average training time of different training samples on SOM Network.
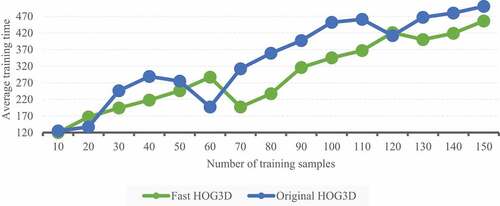
The influence of network size and iteration rounds on SOM was further tested using the fast hog3d feature. The selected size is 1 × one hundred × 30, the average accuracy and training time of SOM network under different network sizes and combinations of iteration rounds are tested. The experimental results are shown in .
Table 3. Average accuracy of SOM network under different network size and iteration number combinations.
According to the row, there is an optimal number of delivery rounds for a fixed network size. Too many iterations may lead to “over learning,” but the performance will slow down; According to the column, there is also an optimal network size for a fixed number of iteration rounds, because a larger network needs more iterations to achieve convergence.
SVM is used for motion recognition, and the performance of original hog3d and fast hog3d is compared. Specifically, we train 10 one to many SVM, and the training set of each SVM contains 1 × one hundred × 30 positive samples and 15 × thirty × 30 negative samples. Due to the error of manual labeling and the noise in the process of storage or transmission, the training samples with error labels are not rare. Therefore, we tested the performance of SVM under different tag conditions. The experimental results are shown in .
Figure 6. The average accuracy rate under different label noises is based on SVM recognition.
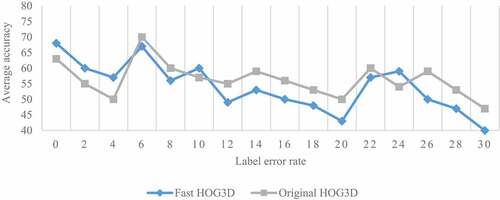
Figure 7. The average training time under different label noises is identified based on SVM.
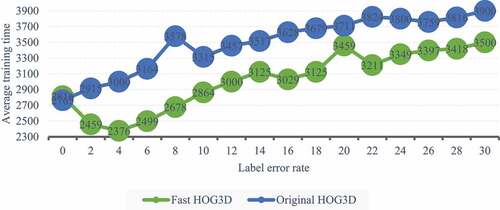
As can be seen from , is very sensitive to label noise. Compared with the fast HOG3D, the original HOG3D needs more accurate samples to determine the segmentation hyperplane in the high-dimensional sign space because of the “dimension disaster” effect, so it is more affected by label noise. However, SOM network is unsupervised and completely free from the influence of label noise, which is the outstanding advantage of SOM. It can be seen from that SVM needs to train a series of learners, and the wrongly marked samples greatly increase the difficulty of discrimination, so it takes more time than SOM training.
The BoW histogram of STIP and NN classifier are used for motion recognition. For fair comparison, the size of training set is the same as above. The STIP is clustered by the merging arithmetic based on “full connection.” show the performance of BoW recognition under different codebook sizes.
Figure 8. Average accuracy of BoW-based recognition in different codebook sizes.
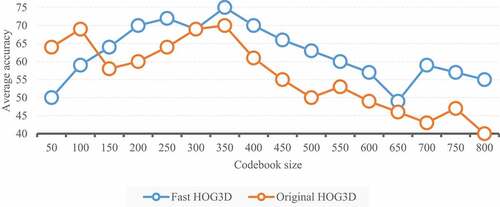
Figure 9. Average training time based on BoW recognition in different codebook sizes.
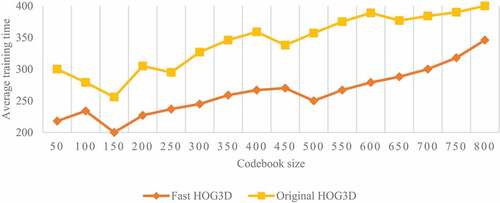
shows that too small or too large a codebook will lead to performance degradation, because too small a codebook has insufficient representation ability, while too large a codebook makes BoW histogram too sparse (too many zero elements). Although the performance curves of the original HOG3D and the fast HOG3D have different peak worths, there is little difference in peak performance, which proves that the fast HOG3D keeps the discrimination of the original HOG3D.
As shown in , BoW’s training is much faster than SVM and SOM’s, because it doesn’t need thousands of iterations. However, it is difficult to determine the optimal size of codebook without prior experiments, and in order to achieve similar performance to SOM, BoW needs more visual vocabulary than SOM neurons.
Motion recognition technology, beyond its application in dance, holds significant potential for various real-world applications. Here are some examples of how this technology can be beneficial in different domains:
Fitness and Rehabilitation: Motion recognition can be utilized in fitness and rehabilitation programs to provide real-time feedback and guidance. By tracking body movements, the technology can help individuals maintain proper form during exercise or rehabilitation exercises, reducing the risk of injuries and ensuring effective workout routines. It can also track progress over time, allowing users to monitor their performance and track their improvements.
Virtual Reality and Gaming: Motion recognition technology can enhance virtual reality (VR) experiences and gaming. By capturing and analyzing users’ movements, it enables more immersive and interactive gameplay, where players can control avatars or characters using their body movements. This technology can also be employed in motion-based gaming consoles, enabling users to engage in physical activities while playing games.
Human-Computer Interaction: Motion recognition technology can revolutionize human-computer interaction by enabling gesture-based control systems. It allows users to interact with devices or interfaces using hand gestures or body movements, eliminating the need for physical touch or conventional input devices. This has applications in fields such as smart homes, augmented reality systems, interactive displays, and public kiosks.
Biomechanical Analysis: Motion recognition techniques can aid in biomechanical analysis and research. By capturing and analyzing human movements, researchers can gain insights into kinematics, joint angles, muscle activations, and other biomechanical parameters. This information is valuable in fields such as sports science, ergonomics, and physical therapy, helping improve performance, prevent injuries, and optimize movement techniques.
Security and Surveillance: Motion recognition technology can enhance security and surveillance systems. By analyzing and recognizing specific motion patterns or abnormal movements, it can detect suspicious activities in real-time, alerting security personnel or triggering automated responses. This technology can be applied in areas such as public spaces, airports, and critical infrastructure to enhance security measures.
Art and Entertainment: Motion recognition can be used in artistic installations, interactive performances, and exhibitions. By capturing and interpreting body movements, it enables interactive experiences, where viewers’ movements can trigger visual or auditory responses. This technology opens up new possibilities for creative expression, interactive art installations, and immersive performances.
These are just a few examples of the diverse applications and benefits that motion recognition technology can offer beyond the realm of dance. The ability to accurately capture and analyze human movements has the potential to revolutionize various industries, improving human-computer interaction, enhancing physical activities, enabling personalized feedback, advancing research, and enhancing security and entertainment experiences.
While the proposed approach holds promise for motion recognition in dance videos, there are several potential challenges and limitations that need to be considered. Here is a discussion on some of these challenges:
Lighting Conditions: Varying lighting conditions in dance videos can impact the accuracy of motion recognition. Changes in lighting, such as shadows, highlights, or uneven illumination, can alter the appearance of the dancer’s movements, leading to variations in the extracted features. This may affect the performance of the proposed method, particularly in accurately capturing and recognizing subtle motion details. Preprocessing techniques, such as contrast adjustment or illumination normalization, may be employed to mitigate the impact of lighting variations.
Camera Angles and Perspectives: Different camera angles and perspectives can introduce variations in the visual representation of dance movements. The proposed method may face challenges in recognizing dance actions from different viewpoints. For instance, movements that appear distinct from a frontal view may appear similar when viewed from a side angle. The choice of camera angles during video collection and training data augmentation techniques can help improve the robustness of the method to different perspectives.
Occlusions: Occlusions occur when a dancer’s body parts or movements are obstructed, either partially or completely, by other objects or body parts. Occlusions can pose challenges for motion recognition as the obscured information may affect the accurate representation of the dance movements. In the presence of occlusions, the proposed method may struggle to extract complete and reliable features, leading to potential misclassifications. Handling occlusions might involve employing advanced techniques such as pose estimation or incorporating temporal information from multiple frames.
Diversity of Dance Styles: Dance videos encompass a wide range of dance styles and genres, each with its unique characteristics and movements. The proposed method may encounter difficulties in generalizing across different dance styles if the training data is limited or biased toward specific styles. It is important to ensure that the training dataset encompasses diverse dance styles to improve the method’s ability to recognize and classify movements across different genres.
Dataset Size and Variability: The size and variability of the dataset can also impact the performance of the proposed method. Insufficient training data or limited variations within the dataset might hinder the generalization and robustness of the method. Collecting a diverse and extensive dataset that covers a wide range of dance movements, performers, and environmental conditions can help address this limitation.
Addressing these challenges and limitations requires careful consideration during the development and evaluation of the proposed method. Employing appropriate preprocessing techniques, incorporating data augmentation strategies, and leveraging advanced algorithms to handle variations in lighting, camera angles, occlusions, and dance styles can help enhance the accuracy and robustness of the motion recognition system for dance videos.
Conclusions
In article, an optimized design scheme of dance video motion recognition based on computer vision and image processing is proposed. The collected dance videos are preprocessed, including graying, background subtraction and filtering denoising, so as to extract the characters in the video images. Then, the SOM method in computer vision is used to realize the recognition of dance movements. Finally, the simulation test and analysis are carried out. Simulation results show that this arithmetic has a certain accuracy, which is 9.34% higher than the traditional arithmetic. This result fully shows that, according to the principle of human visual attention, the inter-framedifference channel is added to describe the areas with drastic changes in human movement. By combining the gray channel with the inter-framedifference channel, the classification accuracy of human movement by the network is improved. The purpose of computer research is to endow computer with visual perception function similar to that of human beings, so that it can recognize external objects and analyze surrounding activities through visual perception of the surrounding world like human beings (Glavenko et al.). In view of the complexity of dance movements, the dance data set produced by us at this stage only considers the situation of single dance, without considering the changing stage scenes and other factors. In the future, we will pay attention to more challenging research on dance action recognition such as scene change and multi-persondance, and extract dance action features that are more suitable for complex backgrounds to better represent dance actions, so as to make dance action recognition research results that are more in line with actual needs such as actual dance arrangement.
Disclosure Statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Funding
References
- Alam, F., F. Ofli, and M. Imran. 2018. Processing social media images by combining human and machine computing during crises[J. International Journal of Human-Computer Interaction 34 (6):311–2258. doi:10.1080/10447318.2018.1427831.
- Bao, J., B. Liu, and J. Yu. 2022. An individual-difference-aware model for cross-person gaze estimation[J. IEEE Transactions on Image Processing 31 (9):3322–33. doi:10.1109/TIP.2022.3171416.
- Barbu, T., G. Marinoschi, C. Morosanu, and I. Munteanu. 2018. Advances in variational and partial differential equation-based models for image processing and computer vision[J. Mathematical Problems in Engineering 2018:1–2. doi:10.1155/2018/1701052.
- Byung-Wan, J., L. Yun-Sung, and J. Jun. 2018. Computer vision-based bridge displacement measurements using rotation-invariant image processing technique[J. Sustainability 10 (6):1785. doi:10.3390/su10061785.
- Cagnoni, S., H. Al-Sahaf, Y. Sun, B. Xue, and M. Zhang. 2020. Special issue on evolutionary computer vision, image processing and pattern recognition[J. Applied Soft Computing 97 (6):106675. doi:10.1016/j.asoc.2020.106675.
- Chaw, J. K., and M. Mokji. 2017. Analysis of produce recognition system with taxonomist’s knowledge using computer vision and different classifiers[J. IET Image Processing 11 (3):173–82. doi:10.1049/iet-ipr.2016.0381.
- Dat, N., K. Ki, and H. Hong. 2017. Gender recognition from human-body images using visible-light and thermal camera videos based on a convolutional neural network for image feature extraction[J. Sensors 17 (3):3. doi:10.3390/s17030637.
- Dawood, T., Z. Zhu, and T. Zayed. 2018. Computer vision–based model for moisture marks detection and recognition in subway networks. Journal of Computing in Civil Engineering 32 (2). doi:10.1061/(ASCE)CP.1943-5487.0000728.
- Glancova, A., Q. Do, D. Sanghavi, P. M. Franco, A. Sen, Y. Dong, L. Lehman, B. Pickering, and V. Herasevich. 1053. Survey of perception of using video recognition and computer vision in the intensive care unit[J. Critical Care Medicine 49 (1):526–526. doi:10.1097/01.ccm.0000730100.43165.64.
- Hajarolasvadi, N., and H. Demirel. 2020. Deep facial emotion recognition in video using eigenframes[J. IET Image Processing 14 (14):3536–46. doi:10.1049/iet-ipr.2019.1566.
- Jaddoa, M. A., L. Gonzalez, and H. Cuthbertson. 2021. Multiview eye localisation to measure cattle body temperature based on automated thermal image processing and computer vision[J, vol. 119. Infrared Physics & Technology.
- Joudaki, M., P. Tahmasebi Zadeh, H. Reza Olfati, and S. Deris. 2020. A survey on deep learning methods for security and privacy in smart grid. In 2020 15th International Conference on Protection and Automation of Power Systems (IPAPS), 153–59. doi:10.1109/IPAPS52181.2020.9375569.
- Li, Y., J. Zhang, H. Wang, Y. Li, and B. Sui. 2022. A control strategy for unmanned surface vehicles flocking[J. International Journal of Pattern Recognition and Artificial Intelligence 36 (9). doi:10.1142/S0218001422590200.
- Lukiw, W. J. 2022. David Hunter Hubel, the ‘Circe effect’, and SARS-CoV-2 infection of the human visual system. Frontiers in Bioscience-Landmark 27 (1):1. doi:10.31083/j.fbl2701007.
- Min, W., L. Yao, and Z. Lin. 2018. Support vector machine approach to fall recognition based on simplified expression of human skeleton action and fast detection of start key frame using torso angle[J, vol. 12. Wıley, England: IET Computer Vision.
- Nguyen, T. T., and T. Nguyen P, and F. Bouchara. 2020. Directional Dense-Trajectory-Based Patterns for Dynamic Texture Recognition[J, vol. 14. IET Computer Vision.
- Okinda, C., Y. Sun, I. Nyalala, T. Korohou, S. Opiyo, J. Wang, and M. Shen. 2020. Egg volume estimation based on image processing and computer vision[J. Journal of Food Engineering 283:283 (6. doi:10.1016/j.jfoodeng.2020.110041.
- Pan, X. 2019. Fusing HOG and convolutional neural network spatial–temporal features for video-based facial expression recognition. IET Image Processing 14 (1):176–82. doi:10.1049/iet-ipr.2019.0293.
- Rao, Y., J. Lu, and Z. Jie. 2019. Learning discriminative aggregation network for video-based face recognition and person re-identification[J. International Journal of Computer Vision 127 (2):701–18. doi:10.1007/s11263-018-1135-x.
- Tao, D., Y. Guo, Y. Li, and X. Gao. 2017. Tensor rank preserving discriminant analysis for facial recognition[J. IEEE Transactions on Image Processing 8 (1):325–34. doi:10.1109/TIP.2017.2762588.
- Toulouse, T., L. Rossi, A. Campana, T. Celik, and M. A. Akhloufi. 2017. Computer vision for wildfire research: An evolving image dataset for processing and analysis[J. Fire Safety Journal 92 (10):188–94. doi:10.1016/j.firesaf.2017.06.012.
- Vanitha, C. N., S. Suwathika, and A. Mathura. 2021. Facial recognition processing using uniform pattern histogram with AI in multimedia applications[J, vol. 64. Solid State Technology.
- Wang, Q., L. Shen, and Y. Shi. 2020. Recognition-Driven Compressed Image Generation Using Semantic-Prior Information[J. IEEE Signal Processing Letters 8 (9):1150–54. doi:10.1109/LSP.2020.3004967.