
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
As deep learning takes off, monocular depth estimation based on convolutional neural networks (CNNs) has made impressive progress. CNNs are superior at extracting local characteristics from a single image; however, they are unable to manage long-range dependence and thus have a substantial impact on the performance of monocular depth estimation. In addition to this, as architectures based on CNNs frequently utilize down sampling operations, numbers of pixel-level features, which are extremely crucial for dense prediction tasks, are lost in the encoder phase. Unlike CNNs, ViT is capable of capturing global feature information, but it requires numbers of parameters and data augmentation owing to its lack of inductive bias. To address the aforementioned difficulties, in this study, we propose a Dilated Self Attention Block (DSAB) as well as a Local and Global Feature Extraction (LGFE) module. The former resolves the inference speed issue of standard ViT models, and we accomplish this by limiting the number of self-attention computations among tokens. The latter combines the advantages of CNNs and ViT, first extracting local representation information in low-dimensional space through standard convolution and then mapping the input tensor to high-dimensional space to capture global information, achieving the simultaneous extraction of global and local characteristics.
Introduction
Monocular depth estimation is one of the classical problems in computer vision, which can be applied to several computer vision tasks, including 3D reconstruction, autonomous driving, augmented reality and virtual reality, etc. Traditional sensor-based methods of acquiring depth information can yield high-quality depth images, but the equipment is extremely expensive, so there is still a long way to go from large-scale marketization. Compared to binocular cameras, monocular cameras have advantages such as low cost, high popularity and convenient image acquisition, etc. Therefore, monocular depth estimation is currently a more popular and challenging technology.
With the development of deep learning, the ability of CNNs to capture features from a single RGB image has been validated in multiple computer vision tasks, including depth estimation, object detection, semantic segmentation, etc. However, CNNs have obvious drawbacks. Firstly, due to the large number of down sampling operations, the network loses numerous pixel-level features at the encoder edge, and these features cannot be recovered at the decoder stage, which can considerably degrade the performance of monocular depth estimation. Secondly, although the spatial induction bias of CNNs enables them to capture characteristics with lower parameters in diverse visual tasks, it is spatially local and unable to capture global representations, since its ability to withdraw features can only be limited to a fixed convolutional kernel size, such as 33 or 5
5.
Recently, the emergence of vision transformer has had a profound impact in the area of computer vision. It compensates for the aforementioned shortcomings of CNNs. Unlike CNNs, vision transformer can capture global features effectively by employing the MSA mechanism, which is shown in .
Figure 1. Multi-head self-attention mechanism.
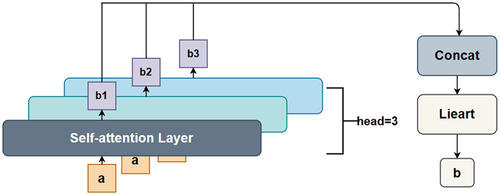
The output vectors b1, b2, b3 are generated from the input token a processed by the self-attention layer (here we take 3 heads for instance), then the vectors are concatenated and linearly transformed to get b. The same process is done for the other inputs in the sequence and all of them share the weight parameters.
The MSA mechanism enables the network to learn cross-relations between patches for a better understanding of the global characteristics of a single image. Compared with the self-attention mechanism, which is defined as Equationequation (1)(1)
(1) , where Q, K, V are query, key, and value. The MSA mechanism supports process parallelization, thereby boosting computational performance and guarding against overfitting. However, the MSA mechanism lacks the inductive bias of CNNs, resulting in vision transformer that
requires tremendous parameters and high computation as well as extensive data augmentation. Although the performance of the network is boosted, the cost comes in the form of model size and latency, therefore, deploying the model to edge devices is challenging.
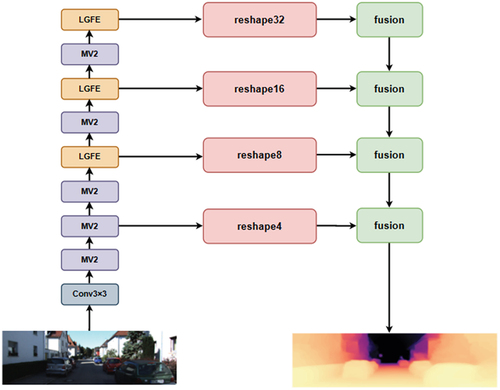
In this paper, we propose a lightweight and efficient monocular depth estimation model that can capture more pixel-level features with fewer parameters. The network as a whole employs an encoder-decoder architecture that is suitable for dense prediction tasks. The encoder consists of the Dilated Self-Attention Block (DSAB) module as well as the MobilenetV2 (Sandler et al. Citation2018) module that extracts global and local features, respectively. The decoder side employs a multi-scale fusion module, which can extract multi-scale features from images in a coarse-to-fine process. The network architecture is shown in .
Figure 2. Overview of the proposed MobileDepth.
This paper is organized as follows. Section 2 introduces some related research works. In Section 3, we will illustrate our network architecture in detail. Section 4 will describe our experimental procedures and results. Section 5 is the conclusion of this paper.
Related Work
CNNs Based Monocular Depth Estimation
Monocular depth estimation is an ill-posed problem. A single RGB image may corresponds to a variety of real scenes, but there are no stable cues in the image to constrain these possibilities. Therefore, it is difficult to capture depth information directly from a single image. In recent years, researchers have proposed several methods to extract depth information from a single RGB image (Fu et al. Citation2018; Kim Citation2014; Long, Shelhamer, and Darrell Citation2015). Eigen et al. (Citation2014) used neural networks for the first time to obtain depth maps. They integrated local and global characteristics to predict the depth map, first design a coarse network to emphasize the global features, and then using a fine network to enhance the quality of the depth map. Soon after, Li et al. (Citation2015) adopted regression of deep convolutional neural networks and conditional random fields for post-processing refinement to address the issue of unpredictable surface normal to monocular images. Fu et al. (Citation2018) introduced a ranking mechanism in their model to estimate the depth images more accurately. Specifically, they first pre-divided the truth depth into many sub-intervals according to interval increments method and designed a pixel-to-pixel ordered regression loss function to model the ordered relationship between these depth sub-intervals. Unlike traditional encoder-decoder architectures, they employed dilated convolution network to better extract multi-scale features. Liu et al. (Citation2015) proposed a model that does not require geometric prior knowledge and can be applied in general scenarios, which aims to jointly explore the capabilities of deep CNNs and continuous conditional random fields, proposing an equivalent model based on fully CNNs and a novel super-pixel merging method. Different from Liu et al., Gan et al. (Citation2018) exploited the prior knowledge, and they introduced vertical pooling in the proposed model to aggregate the features in the vertical direction and improve the accuracy of depth prediction. Considering that the ground truth collected by radar is generally sparse, they also utilized a stereo matching network that takes left and right paired images as input to obtain a high-quality dense depth map. In 2019, Kaur et al. introduced attention to tools for enhancer prediction working on common features of enhancer (Kaur, Chauhan, and Aggarwal Citation2019). Soon, discovered the importance of the loss function and they proposed Monodepth2 Godard et al. (Citation2018), which used the minimum reprojection loss function to handle the occlusion problem and the auto-masking loss function to ignore training pixels that violate the camera motion assumption and filter pixels that are stationary and relatively stationary.
Transformer Based Monocular Depth Estimation
Although the above-mentioned CNNs-based methods have achieved promising performance in the domain of monocular depth estimation, the limitation of these networks is that they are unable to extract global features well. Recently, transformer has made a significant breakthrough in natural language processing. The model discards the traditional recurrent neural network and convolutional neural network and purely utilizes the attention mechanism, addressing the issue of long-distance dependency of input sequences. Vision transformer was the first model to introduce transformer into computer vision. Experiments have shown that the ability of vision transformer to extract image features is quite promising. In the domain of monocular depth estimation, researchers have also employed vision transformer as a backbone network for encoders, and have achieved strong performance. (Bhat et al. Citation2020). proposed AdaBins, a transformer-based model that divides the depth range into multiple units. The central value of each unit is estimated adaptively for each image, and the final depth value of the image is estimated as a linear combination of the units. Vision Transformers for Dense Prediction (DPT) employs a traditional encoder-decoder architecture suitable for dense prediction tasks Ranftl et al. (Citation2021), the encoder side utilizes transformer as the backbone to extract the global features of the image. Compared to fully convolutional neural networks, DPT eliminates the down sampling operation and vision transformer provides finer-grained and more globally consistent predictions. After DPT was proposed, Bae et al. (Citation2022) proposed the MonoFormer. They observed that transformer has a strong shape bias, while the CNN exhibits a sharp texture bias. Compared to models that heavily rely on texture bias, models based on shape bias shows better generalization performance in terms of monocular depth estimation. Based on these observations, they designed a hybrid CNN-Transformer network with a multi-level adaptive feature fusion module, which enhances the shape bias by transformer while compensating for the weak local bias of Transformer by adaptively fusing multi-level representations. MonoViT Zhao et al. (Citation2022), proposed by Zhao et al., is a brand-new framework combining the global reasoning enabled by ViT models with the flexibility of self-supervised monocular depth estimation. It achieves SOTA performance on the KITTI dataset by virtue of the combination of the local detail-awareness capability of CNN and the global long-range feature extraction capability of Transformer. It can be seen that Transformer plays an increasingly important role in the field of monocular depth estimation. However, due to the excessive use of the transformer layers that include many fully connected layers, the inference speed of transformer-based model is still an issue. To address the matter, Ibrahem et al. proposed RT-ViT (Ibrahem, Salem, and Kang Citation2022), which has different combinations composed of four ViT-based encoder architectures and four different CNN-based decoder architectures. This main architecture of the proposed method consists of a vision transformer encoder and a convolutional neural network decoder. They started by training the base vision transformer with 12 transformer layers then they reduced the transformer layers to six layers, and four layers, to obtain real-time processing. It is not the only case. In 2023, investigated the effective combination of CNN and Transformer and proposed a hybrid architecture named Lite-Mono Zhang et al. (Citation2023) They proposed a Consecutive Dilated Convolution (CDC) module and a Local-Global Features Interaction (LGFI) module. The former is used to extract abundant multi-scale local features, and the latter encodes long-range global information into the feature map by utilizing self-attention mechanism. Experiments show that Lite-Mono greatly outperforms Monodepth2 in terms of accuracy, and the trainable parameters are reduced by about 80%.
Compared to the methods mentioned above, we take full advantage of the ability of transformer to capture long-distance dependencies and compensate for the disadvantage of transformer which lacks the capacity to extract local features with MobileNetV2 (Sandler et al. Citation2018). Furthermore, our method utilizes extremely fewer parameters to achieve stronger performance so that it can be deployed on edge devices, which greatly contributes to the development and popularity of MDE.
Method
Design Motivation
Several papers have demonstrated that vision transformer achieves better performance in dense prediction tasks. Employing vision transformer as an encoder can extract more effective features from a single image than CNNs, and therefore get better performance on the decoder side. We investigated several vision transformer-based monocular depth estimation models and found that they provide a significant performance improvement over traditional CNNs. (See details in ). However, there are two sides to everything. The significant performance improvement comes at the cost of a large model and a huge computational effort that results in their inability to apply on edge devices. DPT-large contains amazingly 343 M parameters, and even DPT-base with 112 M parameters, which makes it difficult to deploy on mobile devices. Compared to CNNs-based models, parameters of transformer are tremendous. Taking Monodepth2-Res18 for example, it only takes 14.3 M parameters.
Table 1. Comparison of CNNs-based models and transformer-based models.
Therefore, how to make the model smaller while maintaining its existing performance is a topic worth investigating. To solve the above problems, in this paper, by taking full advantage of the ability of vision transformer to capture long-distance relations and compensate for the shortcomings of vision transformer in local feature extraction through MobileNetV2 (Sandler et al. Citation2018), we designed a lightweight encoder–decoder network architecture. Experiments demonstrate that our performance outperforms traditional CNNs-based monocular depth estimation models, at the same time, the parameters of our method are drastically reduced compared to the vision transformer-based model.
Architecture
The network employs an encoder-decoder architecture in general. The encoder consists of the MobileNetV2 block (MV2) and the Local and Global Feature Extraction (LGFE), which are responsible for capturing short-distance relationship and extracting global features, respectively. The decoder is composed of a reshape block, which is responsible for transforming the feature map generated from the encoder into multiple scales, as well as a fusion block, which is designed to fuse the rich hierarchical features and generate a high-resolution depth map.
Dilated Self-Attention Block
In order to fine-tune the global properties of a single image and decrease the parameters of the vision transformer, we propose the Dilated Self-Attention Block (DSAB). The traditional vision transformer, which approach consists generally of the following steps that are shown in . (1) Split the input image into many patches. Taking ViT-B/16 as an example, it divides the input image, whose resolution is 224 224, into many patches of 16
16 size, generating 196 patches. (2) Each patch is processed through the embedding layer, which maps the three-dimensional matrix of each patch into one-dimensional vector that is called a token. The length of each token is 768. (3) Position encoding operation for all tokens so that the input token has position information. (4) Input each layer-normalized token to the MSA layer. It can be found that the MSA layer of traditional vision transformer requires each token to perform self-attention operation with all other tokens, including itself, as illustrated in . Although features of images can be extracted better, it will consume tremendous computation resources.
Figure 3. Processing of vision transformer.
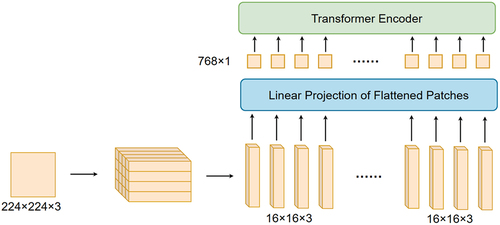
Figure 4. Dilated self-attention block (Dsab)(top) and standard self-attention block(bottom).
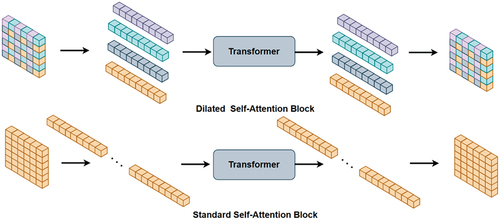
Inspired by MobileViT (Lyu et al. Citation2020), we reduce parameters by limiting the amount of self-attention calculations between tokens, as there are enormous redundant pixels in RGB images, especially for images with high resolution. Furthermore, since there is not much feature variation between adjacent pixels, calculating self-attention among all tokens is both superfluous and highly expensive. Specifically, we first split the tokens into groups, and then the tokens in the same position of each group perform self-attention computation, as shown in . In this method, it not only drastically decreases parameters by three quarters but also enhances the performance of global learning of the network.
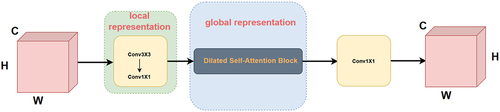
Local and Global Feature Extraction (LGFE)
LGFE is designed to extract local and global features of single image with smaller parameters, as illustrated in . The input image is first processed by the convolution layer; here we use the standard n × n convolution to extract the local features of the image. Then the input tensor is projected into a high-dimensional space by 1 × 1 convolution. Long-distance dependencies on feature points can be effectively handled by DSAB. The feature maps obtained by convolution layer are fed to the DSAB module so that the purpose of global modeling can be achieved. Finally, projecting the feature map from high-dimension into raw image through point-wise convolution. The whole module makes good use of inductive bias property of CNNs (short distance) and global feature extraction capability of vision transformer (long-distance dependency) at a small cost in parameters.
Figure 5. Local and global feature extraction block (LGFE).
MobileNetv2 Block
MobileNetV2 (Sandler et al. Citation2018), which is proposed by Howard et al., is a lightweight network architecture that can be applied to edge devices, as shown in . Compared to traditional convolutional neural networks, MV2 considerably reduces parameters and the number of computations of model in the price of a tiny drop in accuracy. Firstly, the input feature map is raised to a higher dimension by pointwise convolution, which aims to prevent missing characteristic information, and here the Relu6 activation function is used. Then, instead of standard convolution, MV2 uses depth-wise convolution to extract the features of each channel. Finally, the feature map is reverted to the original dimension through pointwise convolution.
Figure 6. MobileNetV2 block.

Fusion Block
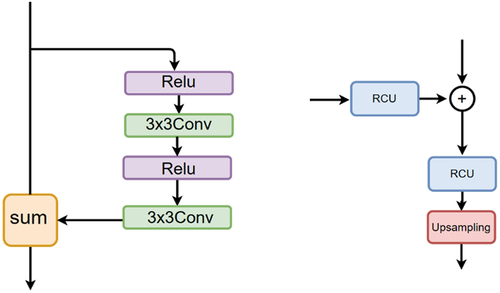
In the decoder end, we use fusion block based on RefineNet (Lin et al. Citation2016) to progressively fuse features from different scale layers so that we can generate high-resolution images. The Fusion block consists mainly of the residual convolution unit (RCU), as shown in . This module is similar to Resnet in design philosophy, which enables the network to capture more hierarchical features. After RCU, feature maps of hierarchical layers are progressively up-sampled by twice the size, and here we use bilinear interpolation. Finally, the bottom layer is processed by the output head to generate the final prediction.
Figure 7. Residual convolution unit (RCU)(left) and fusion block(right).
Scale-And-Shift Invariant Trimmed Loss
Mixing multiple datasets in training can improve the performance of monocular depth estimation. Because it is challenging to obtain dense ground truth maps in different scenes, this results in many datasets with different characteristics and biases. The depth range is inconsistent across datasets, for instance, the ground truth depth values for ETH3D, KITTI, NYU, and TUM are within 72, 80, 10, and 10 m respectively. However, although the depth range varies in the datasets, the distribution of depth values is similar. Therefore, it is important to keep the scale and shift consistent. In this paper, we design the following loss function to address this problem.
where are the aligned predicted depth values and ground truth, respectively; M denotes the number of valid ground truth depth values; ρ denotes specific loss function, here we use MSE_Loss, see equation 3.
,
is calculated by least squares method, see equation 4.
where d, denotes predicted depth value and ground truth, ensuring the consistency of the scale and distribution. Due to the direction of MSE gradient update is easily affected by outliers, it is not robust. Therefore, we add a robust loss function, and here we take the gradient descent loss, see equation 5.
denotes the difference of the depth map at k scales, where k = 4,and halve image resolution at each scale. Ultimately, the loss function takes the following form:
The loss function supports training on different datasets and can quantify the values of existing depth estimation datasets, exploring the best strategy for mixed datasets during training. Compared to the traditional L1 and L2 loss function, it converges faster and possesses stronger generalization and robustness.
Experiment
Datasets
KITTI is the largest monocular depth estimation evaluation dataset currently, which is captured by mobile vehicles equipped with four cameras,3D lidar and GPU/IMU. It contains multiple scenes, such as road, city, residential, campus, person. We use the raw data of the city, residential, and road scenes to train the model. Following Eigen split, we use 29K images for training, 4424 images for validation, and 697 images for testing. The resolution of the original RGB images is around 1242 375, while the corresponding ground truth depth image captured by lidar is sparse. When evaluating, we limit the predicted depth image to [0,80] meters and use NYU Depth Toolbox to complete the predicted depth image to ground truth resolution.
The NYU dataset, created by researchers from the Tandon School of Engineering at New York University (NYU), is an open dataset widely used in the field of computer vision. The main purpose of this dataset is to promote and drive research on computer vision and deep learning algorithms. It is mainly composed of the NYU Depth V2 dataset, which contains numbers of RGB images and corresponding depth maps of indoor scenes, covering multiple scenes such as the living room, bedroom, and kitchen. RGB images provide visible surface information about the scene, while depth maps provide distance information from each pixel to the nearest surface in the scene, providing a foundation for studying depth perception and 3D understanding.
Metric and Relative Depth
Monocular depth estimation is categorized into metric depth estimation and relative depth estimation, as shown in , and the former can predict the realistic ground depth. Relative depth estimation, which is unable to represent realistic depth information, merely predicts the relative depth discrepancy among pixels. Metric depth estimation obtains the distance between camera and target object via Lidar, binocular camera, TOF, and it is usually measured in meters. Compared to relative depth estimation, absolute depth estimation is more useful in downstream tasks such as navigation, 3D modeling, and object recognition. In our experiments, we use the KITTI raw dataset, which consists of sparse absolute depth maps obtained by Lidar, to estimate metric depth information.
Figure 8. (a) Input RGB image (b) Relative depth map predicted by Monodepth2 (c) Metric depth map predicted by MobileDepth.

Evaluation Methodology
In our experiments, our evaluation method follows the standard approach of previous work on monocular depth estimation (Eigen et al. Citation2014). It mainly includes the following six evaluation criteria. (1) Absolute Relative error (Abs Rel), which normalize per-pixel errors, reducing the effect of large errors with distance. (2) Square Relative error (Sq Rel), the squared penalizes for larger depth error. (3) Root Mean Squared error (RMSE), a traditional method for measuring regression errors. (4) Root Mean Squared logarithm error (), the logarithm makes this error relative, reducing the effect of large errors with the distance. We also use accuracy under thresholds (
).
Implementation Details
We build the entire network using PyTorch, and experiments are deployed on Nvidia RTX 3090 GPUs. In our experiments, we take batch size as 4, and the entire model achieves convergence after 50 rounds of training, which takes about 35 hours. To take advantage of the features pre-trained on ImageNet (Deng et al. Citation2009), we use two optimizers to train the model. Specifically, we optimize the network parameters from scratch with optimizer and optimize our backbone network with
optimizer, where
and
are both Adam optimizers, but the learning rates are
and
respectively, and for a better weight initialization, the momentum is set to be 0.9.
Date Augmentation
In order to enhance robustness of the model, following Ranftl et al. (Citation2021), we apply a random horizontal flipping (70%) and a random rotation (20%, with a maximum angle value of ) as well as a random cropping (10%).
Experimental Results and Discussions
We evaluated the proposed model and existing lightweight networks on the KITTI test set and conducted both qualitative and quantitative comparisons. shows the qualitative comparison results, where we compared the depth map predicted by our model with the ground truth. As shown in the figure, the model can perfectly duplicate ground truth map and effectively predict the metric depth information in detail as well. In , the proposed model is compared quantitatively with existing works in recent years. It can be clearly seen that our model not only outperforms traditional CNNs-based models but also outperforms transformer-based networks with much fewer parameters. shows the quantitative results obtained from the NYU dataset. In , we compared our model with the existing models mainly in terms of parameters and the Floating-Point Operations (FLOPs). The results show that our model achieves outstanding improvements in terms of number of parameters, and simultaneously, the performance has been enhanced as well. For instance, compared to MonoFormer-VIT (Bae et al. Citation2022), which is transformer-based and needs 138 M parameters, our model only consumes 17.65 M parameters and achieves better performance. As can be noticed, the parameters have decreased by approximately 87.8%.
Figure 9. Qualitative comparison with ground truth.
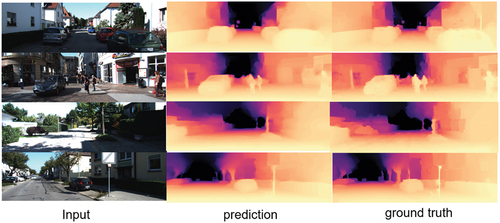
Table 2. Quantitative results. Compare our method to existing methods on KITTI.
Table 3. Quantitative results. Compare our method to existing methods on NYU.
Table 4. Comparison of MobileDepth with existing models in parameters.
Table 5. Complexity of models.
Moreover, we introduce the FLOPs to measure model complexity, which is often used as an indirect measure of model speed. It should be pointed out that the MACs (Multiply-Accumulate Operations), which are often confused with the concept of FLOPs, are actually twice as many as FLOPs. The result can be found in , in comparison to MonoFormer-VIT, FLOPs of MobileDepth are just 15.22 G, an 84.24% reduction in operations. Furthermore, Inference time is an important indicator for evaluating the response speed of a model in practical applications. MobileDepth leads all other models at a speed of 9 ms, which is 25% faster than the second fastest model R-MSFM6 at 12 ms. This is crucial for applications that require quick response, such as autonomous driving and intelligent navigation. In terms of accuracy, at a threshold size of δ < , the accuracy of MobileDepth is 0.996, which is a significant improvement compared to other models. For example, compared to PackNet Sfm’s 0.982, MobileDepth has increased by approximately 1.4%, indicating that MobileDepth can more accurately predict depth. In summary, the MobileDepth model has achieved significant efficiency improvements with minimal accuracy loss. While maintaining high accuracy, it significantly reduces the demand for computing resources and inference time, making it very suitable for use on mobile and embedded devices, especially those applications that have strict requirements for real-time performance and energy consumption.
Ablation Study
To check the effectiveness of the proposed model, we performed ablation experiments on some modules of the architecture. We adjusted and replaced some modules to meet our purpose. Furthermore, we performed quantitative and qualitative ablation comparisons on the KITTI dataset, as shown in and , respectively.
Table 6. Ablation study for components and loss function.
Figure 10. Quantitative ablation comparison experiments. (a) The input image. (b) The ground truth. (c) The predicted depth map using MSE loss function. (d)The predicted depth map via full model. (e) The predicted depth map without DSAB block. (f) The predicted depth map without MV2 block.
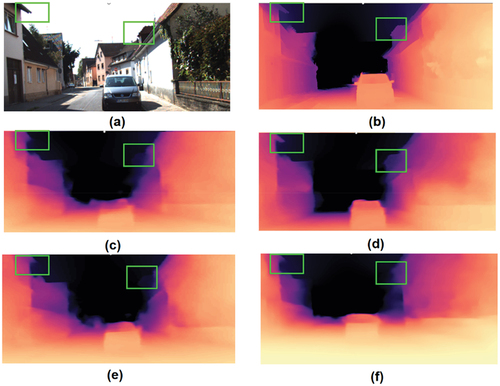
Impact of MobileNetv2
When we remove the MV2 block and only employ the DSAB module to extract features from a single image, we see that the number of parameters increases and the model cannot predict the depth information in the image details. According to the findings, we believe that the MV2 module is essential for the entire architecture because it compensates well for the DSAB module, which lacks the ability to extract local characteristics, so that depth information on the image details can be recovered.
Impact of DSAB Block
In the DSAB module, we attempt to set the size of each group to 1. In other words, the DSAB module was replaced with the standard self-attention block. It turns out that without the DSAB module not only the number of parameters in the model increases significantly (17 M vs. 320 M) but also the accuracy drops. Consequently, when compared to the standard self-attention block, the DSAB module considerably enhances global learning ability of the model by decreasing self-attention computation between redundant pixels in the image, and more importantly, the number of parameters is substantially reduced as a result.
Impact of Loss Function
In this paper, we use the scale-and-shift-invariant trimmed loss function, which aims to improve the performance of the model when training on mixed datasets. When we replace our loss function with others, such as MSE and SGD, the performance suffers as well. This is because the depth range is inconsistent across datasets. When training on a mixed dataset, the scale and shift must be kept consistent, which is extremely critical for the training results. Furthermore, even within the same dataset, the scenes differ, for example, KITTI contains road, city, residential, campus, and human scenes; therefore, there is bias in the characteristics among different scenes. The proposed loss function addresses this problem well and updates the weights of the model wonderfully via back propagation.
Conclusion
We suggest MobileDepth, a novel and lightweight monocular depth estimation model. From a single image, our method can effectively extract both local and global features. On the encoder side, we combine the advantages of CNN and vision transform, fully exploiting the inductive bias property of CNN and the ability to handle long-distance dependencies of vision transformer. Furthermore, we propose the Dilated Self-Attention Block (DSAB) to shrink the model by reducing the redundant self-attention computation operations among patches of vision transformer. MobileDepth can predict high-resolution metric depth maps that are helpful for downstream tasks and can be deployed on edge devices. Experiments demonstrate that MobileDepth improves monocular depth estimation significantly with a small number of parameters. In the future, we will concentrate on lightweight monocular depth estimation based on self-supervised method, which is one of the urgent improvements in this paper. Compared with supervised learning, self-supervision has gradually become one of the research hotspots in recent years for its easy training and low cost.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Bae, J.-H., S. Moon, and S. Im. 2022. MonoFormer: Towards generalization of self-supervised monocular depth estimation with transformers. arXiv Preprint arXiv: 150302531 2 (37): 11083.
- Bhat, S., I. Alhashim and P. Wonka. 2020. AdaBins: depth estimation using adaptive bins. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 4008–20. Nashville, TN, USA. June 10–25, 2021.
- Deng, J., W. Dong, R. Socher, Li, L.J., Li, K. and L. Fei-Fei. 2009. Imagenet: A large-scale hierarchical image databaseC. In 2009 IEEE conference on computer vision and pattern recognition, 248–55. IEEE: Miami, FL, USA. June 20–25, 2009.
- Eigen, D., C. Puhrsch, and R. Fergus. 2014. Depth map prediction from a single image using a multi-scale deep network. NIPS 27. http://arxiv.org/abs/1406.2283.
- Fu, H., M. Gong, C. Wang, K. Batmanghelich and D. Tao. 2018. Deep ordinal regression network for monocular depth estimation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2002–11. Salt Lake City, UT, USA. June 18–22, 2018.
- Gan, Y., X. Xu, W. Sun and L. Lin. 2018. Monocular depth estimation with affinity, vertical pooling, and label enhancement. In European Conference on Computer Vision, Munich, Germany. September 8–14, 2018.
- Godard, C., O. Mac Aodha, M. Firman and G.J. Brostow. 2018. Digging into self-supervised monocular depth estimation. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 3827–37. Seoul, Korea (South), Oct 27–Nov 2, 2019.
- Guizilini, V. C., R. Ambrus, S. Pillai, A. Raventos and A. Gaidon. 2019. 3D Packing for self-supervised monocular depth estimation. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2482–91. Seattle, WA, USA. June 13–19, 2020.
- Ibrahem, H., A. Salem, and H.-S. Kang. 2022. RT-ViT: Real-time monocular depth estimation using lightweight vision transformers. Sensors (Basel, Switzerland) 22 (10):3849. doi:10.3390/s22103849.
- Kaur, A., A. P. S. Chauhan, and A. K. Aggarwal. 2019. Machine learning based comparative analysis of methods for enhancer prediction in genomic data C. In 2019 2nd International Conference on Intelligent Communication and Computational Techniques (ICCT), 142–45. IEEE: Jaipur, India. September 28–29, 2019.
- Kim, Y. 2014. Convolutional neural networks for sentence classification. In Conference on Empirical Methods in Natural Language Processing, Doha, Qatar. October 25–29, 2014.
- Kundu, J. N. 2018. AdaDepth: Unsupervised content congruent adaptation for depth estimation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2656–65. Salt Lake City, UT, USA. June 18–22, 2018.
- Lee, J.H., M.K. Han, D.W Ko, and I.H Suh. 2019. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv Preprint arXiv: 1907 abs/1907.10326: 10326. http://arxiv.org/abs/1907.10326.
- Lin, G., A. Milan, C. Shen and I. Reid. 2016. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5168–77. Honolulu, HI, USA. July 21–26, 2017.
- Li, B., C. Shen, Y. Dai, A. Van Den Hengel and M. He. 2015. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1119–27. Boston, MA, USA. June 7–12, 2015.
- Liu, F., C. Shen, G. Lin, and I. Reid. 2015. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38:2024–39. NW Washington, DC, United States.
- Long, J., E. Shelhamer, and T. Darrell. 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA. June 7–12, 2015.
- Lyu, X., L. Liu, M. Wang, X. Kong, L. Liu, Y. Liu, X. Chen, and Y. Yuan. 2020. HR-Depth: High resolution self-supervised monocular depth estimation. arXiv Preprint arXiv: 1503025312 35: 07356.
- Poggi, M., F. Tosi, and S. Mattoccia. 2018. Learning monocular depth estimation with unsupervised trinocular assumptions. In 2018 International Conference on 3D Vision (3DV), 324–33. Verona, ltaly. September 5–8, 2018.
- Ranftl, R., A. Bochkovskiy and V. Koltun. 2021. Vision transformers for dense prediction. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV) ,12159–68. Montreal, Canada. Oct 10–17, 2021.
- Sandler, M., A. Howard, M. Zhu, A. Zhmoginov and L.C. Chen. 2018. MobileNetV2: Inverted residuals and linear bottlenecks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–20. Salt Lake City, UT, USA. June 18–22, 2018.
- Wang, C., J.M. Buenaposada, R. Zhu and S. Lucey. 2017. Learning depth from monocular videos using direct methods. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022–30. Salt Lake City, UT, USA. June 18–22, 2018.
- Wang, L., J. Zhang, O. Wang, Z. Lin and H. Lu. 2020. Sdc-depth: Semantic divide-and-conquer network for monocular depth estimation C. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 541–50. Seattle, WA, USA. June 13–19, 2020.
- Xu, D., E. Ricci, W. Ouyang, X. Wang and N.Sebe. 2017. Multi-scale continuous crfs as sequential deep networks for monocular depth estimationC. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5354–62. Honolulu, HI, USAJuly 21–26, 2017.
- Yan, J., H. Zhao, P. Bu, and Y. Jin. 2021. Channel-wise attention-based network for self-supervised monocular depth estimation. In 2021 International Conference on 3D Vision (3DV), 464–73. December 1–3, 2021.
- Zhan, H., R. Garg, C.S. Weerasekera, K. Li, H. Agarwal and I. Reid. 2018. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstructionC. In Proceedings of the IEEE conference on computer vision and pattern recognition, 340–49. Salt Lake City, UT, USA. June 18–22, 2018.
- Zhang, N., F. Nex, G. Vosselman, and N. Kerle. 2023. Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation C. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18537–46. Vancouver, Canada. June 18–22, 2023.
- Zhao, C., Y. Zhang, M. Poggi, Tosi, F., Guo, X., Zhu, Z., Huang, G., Tang, Y. and S. Mattoccia. 2022. Monovit: Self-supervised monocular depth estimation with a vision transformer C. In 2022 International Conference on 3D Vision(3DV), 668–78. IEEE: Prague, CZ. September 12–16, 2022.
- Zhou, T., M. Brown, N. Snavely and D.G Lowe. 2017. Unsupervised learning of depth and ego-motion from video. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6612–19. Honolulu, HI, USA. July 21–26, 2017.
- Zhou, Z., X. Fan, P. Shi, and Xin Y. 2021. R-msfm: Recurrent multi-scale feature modulation for monocular depth estimating C. In Proceedings of the IEEE/CVF international conference on computer vision, 12777–86. Montreal, Canada. Oct. 10–17, 2021