
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Intrusion detection systems (IDS) play a critical role in ensuring the security and integrity of computer networks. There is a constant demand for the development of powerful, novel, and generalized methods for IDS that can accurately detect and classify intrusions. In this study, we aim to evaluate the benefits of linear classifiers (LC) and nonlinear classifiers (NLC) in IDS. We employed ten machine learning (ML) classifiers, consisting of five LC and five NLC. These classifiers underwent cross-validation for performance evaluation, unseen analysis, statistical tests, and power analysis on measuring the minimum sample size. Four hypotheses were formulated and validated on five processed intrusion attack datasets. NLC outperformed LC, with a mean accuracy (ACC)/area-under-the-curve (AUC) increase of 22.26%/20.3% on the WUSTL-EHMS dataset, with improvements of ACC/AUC by 5.5%/2.3% on the UNSW-NB15 dataset. In the unseen analysis, NLC achieved an ACC/AUC increase of 21.9%/21.8% when trained on WUSTL-EHMS and tested on UNSW-NB15. Lastly, when using a mixed dataset of WUSTL-EHMS and UNSW-NB15, NLC demonstrated an ACC/AUC increase of 11.67%/5.5%. The model performed well in cross-validation protocols, and the statistical tests yielded significant p-values. NLC provides generalized and robust solutions to detect intrusion attacks, ensuring the integrity and security of computer networks.
Introduction
Intrusion detection refers to the process of monitoring and analyzing computer networks (Kizza, Kizza, and Wheeler Citation2013) or systems to identify and respond to unauthorized or malicious activities (Chakraborty Citation2013). It involves using specialized tools and techniques to detect suspicious behaviors, such as unauthorized access attempts, malware infections (Sapalo Sicato et al. Citation2019), or unusual network traffic patterns. There are two main types of intrusion detection (Zamani and Movahedi Citation2013): network-based (Ring et al. Citation2019) and host-based (Singh and Singh Citation2014). Network-based monitoring focuses on analyzing network traffic, while host-based monitoring focuses on individual systems or hosts. The benefits of intrusion detection encompass early detection and prevention of security breaches, timely response to incidents, protection of sensitive data and resources, and enhancement of overall system security. Intrusion detection is necessary because cyber threats (Abubakar et al. Citation2015) and attacks have become increasingly sophisticated and prevalent. Organizations and individuals need intrusion detection systems (IDS) to proactively identify and defend against potential threats (Rubio et al. Citation2017), safeguard their networks and systems, maintain data confidentiality and integrity, and ensure the smooth functioning of their operations.
In intrusion detection, various methods are utilized to identify and respond to malicious activities (Garcia-Teodoro et al. Citation2009). Signature-based detection (Kumar and Sangwan Citation2012) compares observed patterns against known attack signatures, while anomaly-based detection (Jyothsna, Prasad, and Prasad Citation2011) seeks deviations from normal behavior. Behavior-based detection (Khraisat et al. Citation2019) analyzes user and system behavior for suspicious activities (Waqas et al. Citation2022). Packet intrusion (Chen, Chen, and Lin Citation2010) involves monitoring network packets for signs of intrusions, such as unauthorized access or abnormal traffic (Devarajan and Rao Citation2021). White list and black list methods (Chauhan et al. Citation2013; Tiwari et al. Citation2009) maintain lists of trusted and malicious entities, respectively. In this study, ten machine learning (ML) classifiers are assessed, encompassing both linear classifiers (LC) and nonlinear classifiers (NLC). The analysis incorporates cross-validation, unseen analysis, statistical tests, and power analysis for sample size calculations. Due to the nonlinear nature of the intrusion dataset, it is anticipated that the NLC will outperform the LC. The objective is to evaluate the reliability and robustness of the system through rigorous testing and analysis.
Intrusion detection procedures can be time-consuming due to the volume of network traffic and the need for continuous updates. The emergence of evolving cyber threats, such as man-in-the-middle attacks (Mallik Citation2019) which exploit unknown vulnerabilities (Rauf et al. Citation2022), further complicates the detection process. Automation is essential to enable real-time monitoring and response. ML classifiers play a crucial role in analyzing network data, identifying anomalies, and detecting various types of attacks (Zhang, Hu, and Feng Citation2010). ML classifiers have the ability to adapt and learn, making them highly valuable in handling evolving intrusion attempts. By automating intrusion detection using ML classifiers (Pai and Adesh Citation2021), security, accuracy, and response time can be enhanced, effectively mitigating potential threats in modern networks.
In our study, we focused on analyzing the performance of both LC and NLC in the context of IDS. The results of our study supported the hypothesis that the intrusion dataset exhibits nonlinear characteristics, indicating the superiority of NLC over LC. To validate the reliability of the system, we conducted an unseen analysis, comparing the performance of LC and NLC on previously unseen intrusion patterns. The results confirmed the effectiveness of NLC in accurately detecting these unseen intrusion patterns. Additionally, we demonstrated the robustness of the system through statical tests, with a highly significant p-value below 0.0001. We emphasized the importance of sample size calculation for power analysis, emphasizing the need for larger sample sizes to ensure statistically significant results and enhance the reliability of our findings. By utilizing both LC and NLC, our study aims to achieve high detection accuracy and robustness against a wide range of cyber threats. We believe that our interdisciplinary approach contributes to the advancement of cybersecurity by providing effective solutions for network protection and addressing the evolving nature of cyber threats.
The paper follows a structured approach, where it begins with a literature overview in Section 2, while Section 3 presents the dataset description, data preprocessing techniques, class balancing methods, and cross-validation. Section 4 includes the experimental discussions, focusing on the performance of LC and NLC and presenting the hypothesis. The overall results of the LC and NLC on different dataset combinations are showcased in Section 5. Section 6 covers performance evaluations, validation methods, and statistical tests, and includes the presentation of the ROC curve. Section 7 consists of overall discussions, including key findings, benchmarking against previous studies, and strengths, weaknesses, and future research directions. Finally, Section 8 concludes the paper.
Literature Overview
Traditional intrusion detection methods (Viegas, Santin, and Abreu Citation2021) commonly rely on rule-based and signature-based approaches (Yang et al. Citation2013). Rule-based methods involve defining specific patterns or rules to detect known attacks, while signature-based methods utilize predefined signatures or patterns of known attacks for detection. However, these methods have limitations. They depend on static rules or signatures, making them less effective against novel or unknown attacks. Moreover, they may produce false positives or negatives, which hinder their accuracy and scalability (Naiping and Genyuan Citation2010).
In recent years, several research works have focused on intrusion detection using ML techniques, as presented in . Kilincer et al. (Kilincer, Ertam, and Sengur Citation2021) reviewed decision tree (DT), k-nearest neighbors (KNN), and support vector machine (SVM) models on datasets such as CSE-CIC-IDS-2018 (Leevy and Khoshgoftaar Citation2020), ISCX 2012 (Yassin et al. Citation2013), NSL-KDD (Dhanabal and Shantharajah Citation2015), CIDDS-001 (Ring et al. Citation2017), and UNSW-NB15 (Moustafa and Slay Citation2016). Although the models achieved high accuracy, precision, and recall values of 0.99, the absence of an unseen analysis to evaluate the generalizability of the results suggests potential over fitting. Sarker et al. (Citation2020), used a DT-based model, to classify normal and anomaly samples, achieving an accuracy, precision, recall, and F-score of 0.98. However, the study relied on traditional feature ranking methods (Chang and Lin Citation2008), indicating a limitation in the design of the IDS.
Table 1. Overview of existing studies.
Zhang et al. (Citation2023) developed a Many-Objective Optimization-Based intrusion detection system for securing in-vehicle networks, using an algorithm that adopts double evolutionary selections to optimize the detection model parameters. Bindra and Sood (Citation2019) focused specifically on DDoS attack detection (ParwANI et al. Citation2015). The study employed eight classifiers, including LR, KNN, Gaussian Naive Bayes (GNB), Random Forest (RF), Linear SVM, KNN, RF, and Linear Discriminant Analysis (LDA). Tu et al. (Citation2023) proposed an intrusion detection mechanism deployed in a fog environment using pseudo-siamese stacked autoencoders. To extract deep semantic features, unsupervised training was performed on the stacked autoencoders, followed by supervised learning with labels.
Federated learning based schemes have also been proposed for IDS systems. Mármol Campos et al. (Citation2024) designed a federated learning architecture for intelligent transportation systems using collaborative learning approach. Friha et al. (Citation2023). also proposed a similar approach using differentially private federated learning-based intrusion detection system for industrial IoT ecosystem. The system comprised of three components, a key exchange protocol, a differentially private gradient exchange scheme, and a decentralized federated learning approach.
Previous research in intrusion detection has limitations, including overfitting, lack of cross-validation, and inadequate methods for handling imbalanced class issues. In contrast, this proposed paper addresses these flaws by implementing rigorous quality control measures, validating hypotheses through unseen analysis, and conducting statistical tests. Emphasizing generalization and power analysis, the study calculates optimal sample sizes for training and testing models. By considering these factors, the proposed work aims to establish a reliable and robust IDS, overcoming the limitations observed in previous studies. Experimental and theoretical approaches are employed for validation, ensuring the credibility of the proposed hypotheses.
Materials and Methods
The research included the use of statistical ML models for the categorization to gain a deeper knowledge of the link between datasets and their associated features. The first step was to collect the dataset that would be used for classification. Next, it was important to perform data pre-processing tasks, the problem of missing values, scaling the data, over sampling the minority class, and using label encoder attributes encoding. Additionally, the performance measures are determined that would be used to access the models by computing features from the dataset. Acronyms and symbols used throughout the paper have also been declared in respectively.
Table 2. Acronyms used in the manuscript.
Table 3. Symbols used in the manuscript.
Dataset Description
We utilized five carefully selected datasets for intrusion detection, providing diversity in inspection and enabling validation of unseen scenarios. By utilizing these datasets, each with its unique network configurations, traffic patterns, and types of attacks, we aimed to capture a comprehensive representation of real-world intrusions. This approach helped us avoid biased results and improve the effectiveness of our intrusion detection algorithms. Moreover, using multiple datasets ensured the reliability of our system across diverse network environments.
Dataset 1: WUST-EHMS
The WUSTL-EHMS-2020 dataset (Tauqeer et al. Citation2022) is a unique collection derived from a real-time Enhanced Healthcare Monitoring System (EHMS) spoofing (Kim et al. Citation2020). The EHMS testbed includes medical sensors, a gateway, network components, and a control system with visualization. In the dataset, data flow starts from patient sensors, passes through the gateway, and is then sent to the server. However, this transmission is vulnerable to interception and modification attacks. The dataset focuses on man-in-the-middle attacks, specifically spoofing (Kim et al. Citation2020) and data injection attacks (Sayghe et al. Citation2020). Spoofing compromises patient data confidentiality, while data injection attacks compromise data integrity.
The IDS captures network flow traffic and detects abnormalities in both network flow and patient biometric data. It contains 44 features, with the Source MAC address (Tao, Li, and Sampalli Citation2008) used for labeling. Samples with the attacker’s laptop MAC addresses are labeled as 1, while the rest are labeled as 0. The dataset comprises 16,318 samples, including 14,272 normal samples and 2,046 attack samples.
Dataset 2: UNSW-NB15
The UNSW-NB15 dataset (Souhail Citation2019) is a comprehensive collection of network packets generated using the IXIA Perfect Storm tool in the Australian Centre for Cyber Security’s (ACCS) Cyber Range Lab. It offers a blend of real-world normal activities and synthetic contemporary attack behaviors. The dataset encompasses nine types of attacks, including Fuzzers, Backdoors, Analysis, Exploits, DoS, Generic, Shellcode, Reconnaissance, and Worms (Rashid Citation2020). The dataset was generated using tools like Argus and Bro-IDS, employing twelve algorithms that produced 49 features for each network packet. Class labels were assigned based on whether a sample represented an attack or normal activity, with attacks labeled as 1 and normal samples as 0. The dataset comprises 82,334 samples, including 37,000 normal samples and 45,332 attack samples.
Dataset 3: Unseen 1 – Train on WUSTL-EHMS and Test on UNSW-NB15
For our first unseen dataset analysis, we combined two datasets to train and test our IDS. The training dataset comprised a fusion of five datasets from WUSTL-EHMS, each containing 28,544 samples. The testing dataset encompassed ten datasets from UNSW-NB15, with each dataset containing 8,233 samples. Our primary goal was to enhance the performance and generalization capability of our IDS by leveraging multiple datasets. Additionally, we conducted an analysis of this unseen data to evaluate the system’s effectiveness in detecting and classifying previously unseen intrusion patterns. This comprehensive approach allowed us to assess the system’s reliability and robustness in real-world scenarios, where emerging types of attacks may pose a threat. Through the amalgamation of these datasets and thorough analysis, our research contributes to advancing intrusion detection techniques and fortifying computer network security against evolving cyber threats.
Dataset 4: Unseen 2 – Train on UNSW-NB15 and Test on WUSTL-EHMS
For our second unseen dataset analysis, we employed a combined dataset comprising UNSW-NB15 and WUSTL-EHMS to train and test our IDS. The training dataset encompassed five datasets from UNSW-NB15, totaling 90,664 samples and providing a substantial volume of network traffic data. On the other hand, the testing dataset consisted of ten datasets from WUSTL-EHMS, with each dataset containing 1,631 samples. By integrating both datasets, our aim was to capture a diverse range of network behaviors and intrusion patterns, thereby enhancing the system’s capability to detect and classify various types of attacks. Moreover, we conducted an analysis of previously unseen intrusion scenarios to assess the system’s performance, ensuring its robustness and reliability.
Dataset 5: Mix-Matching Using WUST-EHMS and UNSW-NB15 Datasets
We adopted a mix-matching approach to creating the last dataset for our unseen analysis. This dataset was formed by combining Dataset WUSTL-EHMS and Dataset UNSW-NB15 for training and testing purposes. By combining and mixing the data from multiple datasets, our intention was to introduce greater diversity and variability in the training and testing samples. This approach enables us to evaluate the performance and generalization capabilities of our IDS on unseen instances that may exhibit different characteristics or patterns compared to the original datasets. By utilizing this mixed dataset, we can effectively assess the system’s ability to detect and classify intrusions in real-world scenarios involving various attack types and network behaviors.
Quality Control
Quality control is crucial in IDS when using datasets like WUSTL-EHMS and UNSW-NB15, requiring careful validation through data pre-processing, including cleaning, normalization, and handling missing values. Feature selection eliminates irrelevant features, reducing complexity and noise, and improving system performance.
Data preprocessing (Davis and Clark Citation2011) plays a crucial role in working with the WUSTL-EHMS and UNSW-NB15 datasets, ensuring data quality and preparing it for analysis. For both datasets, thorough examination and processing of each attribute are conducted. Data cleaning (Alrowaily, Alenezi, and Lu Citation2019) is performed to handle missing values appropriately. Linear interpolation is applied to replace the missing values, estimating them based on a linear relationship between available data points. By employing linear interpolation on the four instances with missing values, the dataset is successfully completed, ensuring data integrity for further analysis. Unnecessary attributes that have minimal contribution to the analysis are eliminated through data reduction, reducing computational complexity. Data transformation techniques (Revathi and Malathi Citation2013), such as standard scaling, are implemented to normalize the data and bring it to a standard scale, facilitating comparability among different attributes. This is achieved by subtracting the minimum value and dividing by the range (Johri et al. Citation2022; Konstantonis et al. Citation2022). By standardizing the features using this method, the values are reduced, which expedites the training process for both ML models. To enable the application of ML algorithms, label encoding is utilized to convert categorical labels into numerical representations.
To address the class imbalance in the WUSTL-EHMS and UNSW-NB15 datasets, we applied data augmentation methods, specifically the Synthetic Minority Over-sampling Technique (SMOTE) (Tan et al. Citation2019). SMOTE generates synthetic samples for the minority class by interpolating between existing neighboring instances. It is particularly useful for nonlinear datasets with skewed instance distributions, as it helps balance the classes and prevent biased model training. By introducing synthetic samples, SMOTE increases the representation of the minority class, enhancing the classifier’s ability to accurately detect intrusions. This technique is crucial in intrusion detection, as it ensures that the model is not biased toward the majority class, enabling improved intrusion detection and maintaining a high level of system security.
Global Architecture
The computerized paradigm employed in this study is illustrated in . Pre-processing steps for the intrusion detection data involve interpolation, scaling, class balancing, and class encoding (Le, Oktian, and Kim Citation2022). The attributes within the data serve as feature inputs for the prediction module, which employs both LC and NLC to forecast the labels. In the performance evaluation stage, ROC curves are generated using ground truth tables to assess the predicted labels, and statistical tests are conducted to evaluate reliability and stability.
Figure 1. The overall architecture of our computerized system. ML: Machine Learning; DT: Decision Tree; LDA: Linear Discriminant Analysis; LR: Logistic Regression; RR: Ridge Regression; NB: Naive Bayes; PERPT: Perceptron; RF: Random Forest; GBM: Gradient Boosting Machine; KNN: K-Nearest Neighbours; XGB: Extreme Gradient Boosting.
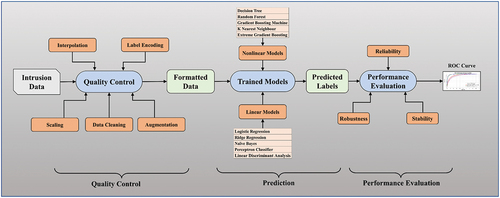
ML Classifiers
In this ML-based intrusion detection study, we employed a combination of both LC and NLC to achieve accurate and robust results. LC, including LR (Belavagi and Muniyal Citation2016), Ridge Regression (RR) (Ao Citation2021), Naive Bayes (NB) (Amor, Benferhat, and Elouedi Citation2004), Perceptron (PERPT) (Rahman et al. Citation2020), and LDA (Ibrahimi and Ouaddane Citation2017), are known for their simplicity and interpretability, making them suitable for detecting patterns in data with linear relationships. On the other hand, NLC such as DT (Bhavani, Rao, and Reddy Citation2019), RF (Bhavani, Rao, and Reddy Citation2019), Gradient Boosting Machine (GBM) (Khafajeh Citation2020), K-Nearest Neighbors (KNN) (Liu et al. Citation2022), and Extreme Gradient Boosting (XGB) (Jiang et al. Citation2020) excel at capturing complex patterns and relationships in the data, making them well-suited for datasets with nonlinear characteristics. Given that the WUSTL-EHMS and UNSW-NB15 datasets used in this study are likely to exhibit both linear and nonlinear patterns, it was necessary to combine both types of classifiers to effectively detect intrusions and improve overall detection performance. By leveraging the strengths of both LC and NLC, this approach aims to achieve higher accuracy and better performance in detecting various types of intrusions present in the datasets.
Performance Metrics
The proposed research model is evaluated for the classification of attack and normal samples in intrusion detection (Almseidin et al. Citation2017). The evaluation involves considering parameters such as true positive (TP), false positive (FP), true negative (TN), and false negative (FN). A TP occurs when an intrusion attempt is correctly detected, while a TN refers to correctly identifying a benign attempt as not an intrusion. On the other hand, an FP occurs when a benign event is mistakenly detected as an intrusion, and an FN is when an intrusion attempt is incorrectly identified as benign. Based on these parameters, the following performance evaluation (PE) metrics are derived: (i) Accuracy (η): It measures the model’s overall prediction’s correctness. (ii) Recall (): Also known as sensitivity, it measures the model’s ability to correctly classify positive instances. (iii) Precision (
): It quantifies the accuracy of positive predictions made by a model. (iv) F1 Score (F): The F1 score is a combined metric that is the harmonic mean of precision and recall, providing a balance between the two. (v) Specificity (S): It measures the model’s ability to correctly identify negative instances. (vi) Matthew’s Correlation Coefficient (MCC): MCC is a correlation coefficient that takes into account all four possible outcomes (TP, TN, FP, FN). It assesses the quality of binary classifications.
Experimental Protocols
To validate our hypotheses for intrusion detection, we collected two datasets: the WUSTLH-EHMS and the UNSW-NB15 dataset. We used these datasets for training as well as testing, specifically aimed at validating our first hypothesis. Additionally, we conducted unseen analysis by training with the WUSTL-EHMS dataset and testing with UNSW-NB15 dataset, as well as training with UNSW-NB15 dataset and testing with the WUSTL-EHMS dataset, to further validate our second hypothesis. We used the K10 protocol as a standard for our evaluation methodology. In this approach, the entire dataset is divided into 10 folds, with one fold randomly selected for testing while the remaining nine folds are used for training the data sets. This process ensures that each data point is utilized for both training and testing, contributing to a more comprehensive assessment of the algorithm’s performance (Jamthikar et al. Citation2021; Srivastava, Singh, and Suri Citation2019). Since the process of training is conducted 10 times, the process takes all 10 combinations for evaluation of the performance evaluation (Biswas et al. Citation2018; Kuppili et al. Citation2017; Srivastava, Singh, and Suri Citation2020; Suri and Rangayyan Citation2006). Additionally, we implemented nested cross-validation to manage parameter tuning independently from the outer loop of the K10 protocol, preventing over fitting and enhancing the reliability of the performance metrics (Maniruzzaman et al. Citation2019; Teji et al. Citation2022), which gives the robust performance. Note that such applications are well suited for different healthcare applications and are very powerful leading to generalization (Araki et al. Citation2016; Shrivastava et al. Citation2017).
In further analysis, we utilized a combination of mix-match datasets for further unseen analysis. The supervised ML algorithms were categorized into LC and NLC. The LC category consisted of five models: LR (Belavagi and Muniyal Citation2016), RR (Ao Citation2021), NB (Amor, Benferhat, and Elouedi Citation2004), PERPT (Rahman et al. Citation2020), and LDA (Ibrahimi and Ouaddane Citation2017). The NLC category included five models: DT (Bhavani, Rao, and Reddy Citation2019), RF (Bhavani, Rao, and Reddy Citation2019), GBM (Khafajeh Citation2020), KNN (Liu et al. Citation2022), and XGB (Jiang et al. Citation2020). During the evaluation, various metrics were used: accuracy, sensitivity (recall), precision, F1 score, specificity, MCC, and AUC.
Experiment 1: NLC Vs. LC
The experiment aims to compare the effectiveness of LC and NLC in intrusion detection. The study involved training and testing ten classifiers, including five LC and five NLC, on two intrusion datasets (WUSTL-EHMS and UNSW-NB15). The dataset for intrusion detection encompasses various elements that interact nonlinearly, including user behaviors, network traffic patterns, and attack characteristics. The performance of each classifier was evaluated using the K10 protocol setup. The results were averaged to obtain the final performance metrics, which were used to compare the performance of the LC vs. NLC.
Experiment 2: Unseen Analysis of NCL Vs. LC
The purpose of this experiment was to validate the hypothesis that NLC outperform LC in intrusion detection, specifically under unseen analysis. The study involved training and testing ten classifiers, consisting of five LC and five NLC, on two unseen intrusion datasets. For the first scenario, the classifiers were trained on WUSTL-EHMS dataset and tested on UNSW-NB15 dataset. In the second scenario, the classifiers were trained on the UNSW-NB15 dataset and tested on the WUSTL-EHMS dataset. The performance of each classifier was evaluated using the K10 protocol setup, and the results were averaged to obtain the final performance metrics. These metrics were then used to compare the performance of LC versus NLC.
Experiment 3: NLC Vs. LC on Mix-Matching Dataset
This experiment aimed to further solidify the hypothesis that NLC outperform LC in intrusion detection, particularly under unseen analysis. To achieve this, an additional analysis was conducted using a combination of mix-match datasets. In this analysis, the fifth dataset was utilized to train and test ten classifiers, consisting of five LC and five NLC. The performance metrics obtained from these classifiers were averaged to compare the performance of LC and NLC.
Experiment 4: Effect of Training Data Size on Performance of LC and NLC
In order to validate the stability of the system, we employed four cross-validation protocols: K2, K4, K5, and K10. These protocols allowed us to modify the training data size for each ML model and observe the resulting performance drop that occurred as a result of reducing the training size. The Mix-Matching Dataset-5 was used with these partition protocols, and the results were averaged to illustrate the impact of data size on our models.
Results
We conducted experiments involving five combinations of datasets to analyze the performance of our models effectively and obtain reliable findings. The first combination involved training and testing our models on the WUSTL-EHMS dataset. The second combination involved training and testing on the UNSW-NB15 dataset. In the third combination, we trained on the WUSTL-EHMS dataset and tested on the UNSW-NB15 dataset. Conversely, in the fourth combination, we trained on the UNSW-NB15 dataset and tested on the WUSTL-EHMS dataset. Lastly, we created a fifth dataset by merging data from both the WUSTL-EHMS and UNSW-NB15 into combined training and testing datasets.
To perform our experiments, we utilized the Python sklearn module for ML models. The experiments were conducted on Google Colab. We employed the cross-validation technique with partition protocols K2, K4, K5, and K10. This process allowed us to assess the performance of our models comprehensively. By analyzing the models’ performance using these protocols, we obtained reliable findings for our study. The simulation environment parameters are presented in .
Table 4. Parameters used in simulation environment and hyperparameters used for in ML classifiers.
NLC vs. LC on Seen Dataset
To validate the hypothesis that NLC exhibits superior performance compared to LC in the context of intrusion detection, an experimental evaluation was conducted. The analysis involved comparing the performance of LC and NLC using two datasets: the WUSTL-EHMS dataset, which contains network flow metrics presented in , and the UNSW-NB15 dataset, consisting of network flow measurements presented in .
Table 5. ML model performance on WUSTL-EHMS dataset with K10 protocol.
Table 6. ML model performance on UNSW-NB15 dataset with K10 protocol.
The evaluation was conducted using performance metrics including accuracy, sensitivity (recall), precision, F1 score, specificity, MCC, and AUC to provide a comprehensive understanding of the classifiers’ effectiveness. The results, presented in , clearly demonstrate that NLC outperformed LC. The mean accuracy difference between the NLC and LC on WUSTL-EHMS dataset across all classifiers was 22.26%, while the mean AUC difference was 20.3%. Additionally, on the UNSW-NB15 dataset, the mean accuracy difference between the NLC and LC across all classifiers was 5.5%, while the mean AUC difference was 2.3%. These findings validate our hypothesis that NLC performs better due to the nonlinear nature of the intrusion dataset. NLC excel at capturing complex nonlinear relationships between input features and output labels. They achieve this by recursively splitting the data into smaller subsets, enabling them to make accurate predictions. This capability is crucial when dealing with intrusion datasets that exhibit nonlinear characteristics.
Unseen Analysis of NLC vs. LC
In order to validate the hypothesis that NLC outperforms LC and ensure the reliability of the IDS, two unseen analyses were conducted. The first part of the analysis involved training the classifiers on the WUSTL-EHMS dataset and testing them on the UNSW-NB15 dataset, with the results presented in . The second part of the analysis involved training the classifiers on the UNSW-NB15 dataset for training and the WUSTL-EHMS dataset for testing, with the results presented in .
Table 7. Model performance on unseen analysis-1 train on WUSTL-EHMS and test on UNSW-NB15 using K-10 protocols.
Table 8. Model performance on unseen analysis-2 train on UNSW-NB15 and test on WUSTL-EHMS with K10 protocol.
The evaluation was conducted using performance metrics including accuracy, sensitivity (recall), precision, F1 score, specificity, MCC, and AUC to provide a comprehensive understanding of the classifiers’ effectiveness. The results, presented in , clearly demonstrate that NLC outperformed LC. The mean accuracy difference between the NLC and LC in Unseen Analysis-1 across all classifiers was 21.9%, while the mean AUC difference was 21.8%. Additionally, in Unseen Analysis-2, the mean accuracy difference between the NLC and LC across all classifiers was 23.68%, while the mean AUC difference was 17.2%. These findings validate our hypothesis that NLC generalizes better over new dataset due to the nonlinear nature of the intrusion. NLC are robust enough in detecting previously unseen intrusion patterns. The results of this analysis provided valuable insights into the comparative performance of LC and NLC under unseen conditions, contributing to the enhancement of IDS and the overall reliability of the system.
NLC vs. LC on Mix-Matching Dataset
To further validate the hypothesis that NLC outperforms LC and ensure the reliability of the system, an additional analysis was conducted using a combination of mix-match datasets. The fifth dataset consisted of merging data from the WUSTL-EHMS and the UNSW-NB15 dataset, into separate training and testing data using the combined data. The objective of using this mix-match dataset was to evaluate the performance presented in , comparing NLC to LC under unseen analysis.
Table 9. Model performance on mix-matching dataset with K10 protocol.
The evaluation was conducted using performance metrics including accuracy, sensitivity (recall), precision, F1 score, specificity, MCC, and AUC to provide a comprehensive understanding of the classifiers’ effectiveness. The results, presented in , clearly demonstrate that NLC outperformed LC. The mean accuracy difference between the NLC and LC across all classifiers was 11.67%, while the mean AUC difference was 5.5%. These findings further validate our hypothesis that NLC generalizes better over new datasets due to the nonlinear nature of the intrusion. This analysis provided crucial insights into the comparative performance of LC and NLC in an unseen scenario, contributing to the validation of hypotheses and enhancing the reliability of IDS.
Effect of Training Data Size on the Performance of LC and NLC
To conduct the experiment, we investigated in depth how the size of the training data impacts the performance of our models. The results of our analysis, shown in , indicate a gradual decrease in performance metrics across multiple cross-validation protocols: K10 (default), K5, and K2. We computed the average mean accuracy and AUC for ten ML classifiers (Five LC and Five NLC) on Dataset-5 (MixMatching).
Table 10. Performance metrics of all ML models on different cross-validation protocols.
We observed that the mean accuracy dropped from 91.57% when using the K10 protocol to 86.12% when using the K2 protocol, representing a decrease of 5.45%. Similarly, the AUC decreased from 0.952 with the K10 protocol to 0.893 with the K2 protocol, signifying a decrease of 5.9%. However, even with a reduced training data size in the K2 (50:50) validation protocol, our ML model’s metrics did not decrease significantly, demonstrating the reliability of our approach. These findings validate that our framework can effectively train for intrusion detection, even when there is limited availability of training data.
Performance Evaluation
As part of the performance evaluation (PE), ROC curves were generated to visualize the performance of the classifier models, depicting their performance across different thresholds. The ROC curves offer a graphical representation of the model’s performance and are useful in assessing its strengths and weaknesses. This evaluation provides valuable insights and identifies areas for improvement in the system. To ensure the reliability and significance of the predicted data, various statistical tests were conducted. Furthermore, a power analysis was performed using our top XGB model to calculate the required sample size, which helps in measuring the precision of the system. This analysis aids in determining the system’s effectiveness and accuracy.
Receiver Operating Curves and Charts
The ROC curves provide a comprehensive analysis of the performance of the LC and NLC classifiers across different cross-validation protocols (K2, K4, K5, and K10). displays the ROC performance of LC, including LR, RR, NB, PERPT, and LDA. presents the ROC performance of NLC, such as DT, RF, GBM, KNN, and XGB. These ROC graphs validate the second hypothesis, demonstrating the effectiveness of training on one dataset and testing on another (WUSTL-EHMS and UNSW-NB15). Additionally, a mix-match operation was performed, combining both the datasets. Among the LC, LR achieved the highest AUC of 0.976, while XGB performed the best among the NLC with an AUC of 0.996, as shown in .
Figure 2. ROC curve for linear classifiers under unseen analysis.
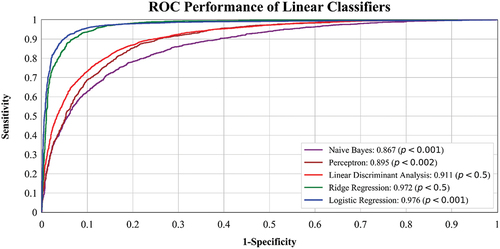
Figure 3. ROC curve for NLC under unseen analysis.
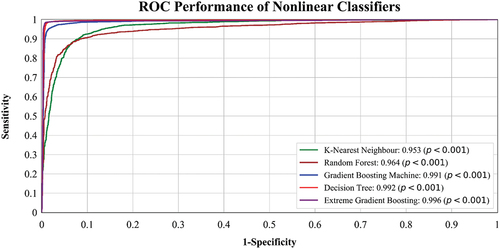
Furthermore, the statistical significance of the results was assessed by computing p-values for all nonlinear models, revealing p < .001. This indicates a high level of confidence in the observed differences between the models and strengthens the validity of the results. Bar charts are an effective visualization technique for presenting information from tables. In , the accuracy of both LC and NLC is depicted for the WUSTL-EHMS dataset.
Figure 4. Accuracy of LC and NLC models on WUSTL-EHMS dataset.
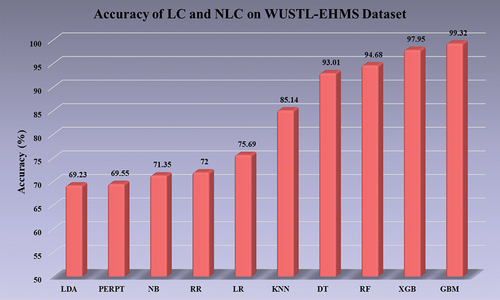
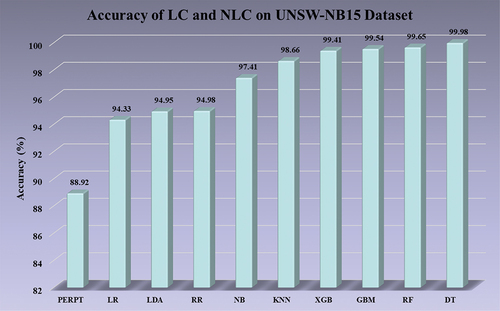
The accuracy values range from 69.23% for LDA to 99.32% for GBM, indicating significant improvements in model accuracy. Similarly, in , the accuracy of the models is displayed for the UNSW-NB15 dataset. The accuracy values range from 88.92% for PERPT to 99.98% for DT, demonstrating substantial increases in model accuracy. These bar charts provide a clear visual representation of the accuracy performance of the classifiers on the respective datasets.
Figure 5. Accuracy of LC and NLC models on UNSW-NB15 dataset.
Analysis of Reliability and Robustness Using Statistical Tests
The stability and reliability of the top-performing XGB model were evaluated across five datasets using five statistical tests: the Paired t-test, ANOVA test, Z-test, Friedman test, and Wilcoxon test. Paired t-test is a parametric statistical test that compares the mean difference between two paired samples to determine if it is statistically significant. It was used in this study to compare the performance of the XGB model in an unseen analysis. This comparison provided insights into the superiority of NLC. ANOVA test, (Analysis of Variance), is a statistical test that assesses the equality of means across multiple groups or datasets (Pathak and Pathak Citation2020). In this study, the ANOVA test was used to evaluate the significance of the performance metrics obtained from the XGB model across the different datasets. By monitoring the p-value of the ANOVA test, which needed to be less than 0.01 (p < .0001), the researchers ensured a high level of statistical significance. The Z-test is a standard statistical test used to validate if there is a statistically significant difference between a sample mean and a population mean. In this study, the Z-test (Elhamahmy, Elmahdy, and Saroit Citation2010) was employed to assess the statistical significance of the p-value obtained from the ANOVA test, providing further validation of the results. The Friedman test (Zhang and Liu Citation2022) is a non-parametric statistical test that compares the rankings of multiple related samples. It was used in this study to assess the significance of performance metrics across different datasets, taking into account the relative performance of the XGB model in a non-parametric manner.
Wilcoxon test (Silva et al. Citation2021), also known as the Wilcoxon signed-rank test, is a non-parametric statistical test used to determine if the median difference between two paired samples is statistically significant. In this study, the Wilcoxon test was employed to compare the performance of the XGB model in an unseen analysis, providing additional evidence of the superiority of NLC. The results of these tests, presented in , demonstrated the performance consistency of the XGB model and provided evidence of its stability as a reliable measure in intrusion detection. The statistical significance of these tests further confirmed the reliability and consistency of the XGB model across the different datasets.
Table 11. Statistical tests p-values of the XGB model using cross-validation protocol.
Power Analysis
In order to increase the data appropriately, we conducted a power analysis to identify the minimal sample size required for precisely predicting a population proportion. The sample size calculation formula, denoted by the symbol , is as follows:
Here, is the estimated percentage of the feature in the population,
denotes the Z-score associated with the chosen confidence level, and MoE denotes the margin of error. Half of the breadth of the confidence interval was used to compute the MoE. We settle on a percentage of 0.5 and a confidence interval of 95% for our experiment as shown in .
Table 12. Power analysis for five datasets using the XGB model.
The analysis of the intrusion detection datasets, namely WUSTL-EHMS and UNSW-NB15, involved a comprehensive examination of the calculated sample sizes on the best-performing XGB model. The results obtained indicated that the sample sizes utilized in the study surpassed the minimum sample size determined through power analysis. This observation signifies that the research incorporated an abundant number of observations to attain the desired level of statistical power and ensure precise classification during the intrusion detection process. By exceeding the required sample size, the study reinforces the strength and reliability of the findings, while enhancing the representativeness of the data, thereby enabling more accurate generalizations about the population.
In the context of intrusion detection, a larger sample size facilitates a more comprehensive analysis of network traffic patterns, user behaviors, and system logs, leading to a more dependable detection and classification of potential threats. Furthermore, a larger sample size helps reduce the margin of error and enhances the precision of statistical estimates. By ensuring that the sample size surpasses the calculated minimum value, the research study demonstrates a proactive approach toward achieving statistical significance and minimizing the likelihood of type II errors (false negatives). This ensures that the findings of the study are robust and reliable, thereby enhancing the overall quality and credibility of the intrusion detection analysis.
Discussions
Principal Findings
After conducting extensive research, we obtained valuable insights and reached conclusions related to our research problem: (i) To test our hypotheses, we developed a total of ten ML classifiers, consisting of five LC and five NLC. (ii) Our experimental analysis involved the use of five pre-processed datasets, which included two intrusion datasets, two unseen datasets, and one Mix-Match dataset. (iii) We implemented a novel quality control phase in our system to improve the classification of network data and detect intrusions more effectively. (iv) Our findings indicate that NLC outperformed LC, resulting in a significant increase in mean accuracy by 22.26% and a 20.3% increase in AUC on the WUSTL-EHMS dataset. Similarly, on the UNSW-NB15 dataset, NLC exhibited a substantial advantage over LC, with accuracy and AUC improvements of 5.5% and 2.3%, respectively. (v) In the unseen analysis, NLC demonstrated superior performance compared to LC, achieving a mean accuracy of 21.9% and an AUC of 21.8% when trained on WUSTL-EHMS and tested on UNSW-NB15. Additionally, when trained on UNSW-NB15 and tested on WUSTL-EHMS, NLC exhibited a significant mean accuracy increase of 23.68% and an AUC of 17.2%. (vi) Furthermore, when utilizing a mixed dataset of WUSTL-EHMS and UNSW-NB15, the NLC classifiers showed an average accuracy difference of 11.67% compared to LC, with a mean AUC difference of 5.5% across all classifiers. (viii) Finally, we evaluated the impact of training data size by implementing cross-validation protocols. (ix) To ensure the reliability and stability of our system, we subjected the classifiers to statistical tests. (x) To validate the precision of the AI system and assess its stability with smaller data sizes, we conducted a power analysis on the five pre-processed datasets.
Benchmarking: A Comparative Analysis
Numerous researchers have proposed various techniques and approaches for IDS. In the present research study, the chosen approach has undergone extensive analysis and validation to demonstrate the robustness and effectiveness of intrusion detection when employing NLC. Through rigorous examination and validation, it has been established that the adopted approach yields reliable results in detecting intrusions. By leveraging NLC, the study provides evidence of the approach’s capability to effectively identify and classify intrusions, further strengthening its credibility and demonstrating its superiority over existing methods.
presents a summary of ten studies that developed classifiers for intrusion detection. Teng et al. (Citation2018) constructed an Environments ‐ Classes, Agents, Roles, Groups, and Objects (E-CARGO) and Context Aware Intelligent Driver Model (CAIDM) model, which employs SVM and DT models in conjunction. These models were trained using the KDD-1999 dataset, resulting in the highest accuracy of 89.02%. Yihunie, Abdelfattah, and Regmi (Citation2019) employed five ML models for an IDS to assess performance based on precision, recall, and F1 score. However, the NSL-KDD dataset used in this study was not normalized, highlighting a flaw that requires further investigation. Hady et al. (Citation2020) proposed a research work that conducted a comparative analysis of ML models, emphasizing performance metrics such as accuracy and AUC values for model evaluation. The EHMS testbed was used for data collection, providing real-time data that facilitated further study. The WUSTL-EHMS-2020 dataset was employed for training and testing the ML models. Additionally, a 10-fold cross-validation methodology was used for experiment validation, demonstrating a certain level of reliability. Nonetheless, further research is still needed in this area.
Table 13. Benchmarking of studies conducted for intrusion detection.
Abrar et al. (Citation2020) conducted research on intrusion detection using a different set of attributes to train and test ML models, using the NSL-KDD dataset. The research included data pre-processing, which improved the dataset’s quality and aided ML models in better-identifying feature sets. Kilincer, Ertam, and Sengur (Citation2021) employed DT, KNN, and SVM models on various datasets, including CSE-CIS-IDS-2018, ISCX 2012, NSL-KDD, CIDDS-001, and UNSW-NB15. These models demonstrated impressive performance metrics, with accuracy, precision, and recall values of 0.99. However, the study lacked unseen analysis, which is essential for evaluating the models’ ability to generalize to new and unseen data. This raises concerns about the possibility of overfitting in the reported results. Rastogi et al. (Citation2022) proposed a research work that utilized the NSL-KDD dataset. The paper focused on transforming the data and performing performance evaluation based solely on accuracy as the measurement metric. However, the study lacked statistical analysis and validation of the dataset, which could impact the accuracy of measurements. Baich et al. (Citation2022) presented a comparative study between different ML models using the NSL-KDD dataset. The study employed accuracy, precision, recall, F1 score, and MCC as performance metrics for model evaluation. However, these studies lacked quality control, statistical tests, and comprehensive validation for robust model evaluation.
The proposed study aims to overcome the limitations of the aforementioned works. It conducts a comparative study between different ML classifiers and utilizes two datasets, WUSTL-EHMS-2020 and UNSW-NB15, for training and testing. The proposed work incorporates five LC and five NLC with good quality control applied to the datasets. The models are evaluated using accuracy (99.62%), sensitivity (recall) (0.99), precision (0.99), F1 score (0.99), specificity (0.99), MCC (0.99), and AUC (0.997) in nonlinear scenario on UNSW-NB15 dataset. These values are more efficient due to the statistical tests performed, considering a significance p-value <.001. The unseen analysis is conducted by training and testing on combinations of datasets and employing mix-matching techniques, making it unique in terms of evaluating ML classifiers. Additionally, K2, K4, K5, and K10 cross-validation methods are applied, and performance metrics are calculated for each cross-validation, providing an overall assessment of model performance.
By surpassing the limitations of previous research works and addressing the evaluation of ML classifiers in a unique and comprehensive manner, this study provides a reliable and robust system for intrusion detection.
Special Note on Nonlinear Classifier for Intrusion Detection
The advantage of implementing NLC for intrusion detection datasets arises from the complex and intricate relationships exhibited by cyber threats and network activities. Linear models are unable to effectively capture these relationships, given the nonlinear nature of intrusion data and logs. In intrusion detection, the dataset encompasses various factors, including network traffic patterns, user behaviors, and attack signatures, which interact in nonlinear ways. Consequently, LC fails to capture the intricate relationships and nonlinearity present in the data, resulting in limited detection capabilities.
NLC, on the other hand, are specifically designed to handle complex patterns and nonlinear relationships. By employing nonlinear decision boundaries and flexible modeling techniques, these classifiers can effectively capture and analyze the intricate dynamics of the intrusion detection dataset. Leveraging the capabilities of NLC enables IDS to improve their accuracy, sensitivity, and specificity in detecting various types of intrusions, including both known and unknown attacks. This advantage allows for more robust and comprehensive intrusion detection, enhancing the security and reliability of network environments.
Incorporating NLC in IDS enhances the system’s ability to accurately identify and classify anomalous activities, thereby strengthening the overall security of computer networks.
Strength, Weakness, and Extensions
The research findings demonstrate a novel approach to intrusion detection by utilizing ten ML models, comprising five LC and five NLC. The study successfully validates four novel hypotheses, focusing on linear and nonlinear aspects, unseen analysis, and the size of the training data. The approach proves effective in generalizing the models’ performance, showcasing superior results in unseen scenarios. Statistical tests conducted on the classifier’s outcomes and the calculation of sample size contribute to the generalization of the findings The approach significantly improves the performance of the models across all datasets, leading to a notable enhancement in classification accuracy within the IDS. These findings highlight the potential of the proposed approach to greatly improve the effectiveness and reliability of intrusion detection in various network environments.
However, the intrusion detection scheme we have developed may encounter challenges in classification accuracy and AUC when applied to a broader range of scenarios with a more complex network architecture. This is primarily due to the limited size of the training data available for our model. Furthermore, our intrusion detection scheme lacks feature extraction as it does not utilize DL models. This absence of feature extraction could limit the model’s capability to classify accurately and diminish its robustness and reliability.
In the future, the focus should be on utilizing feature extraction techniques to enhance the performance of ML models in intrusion detection. By employing these techniques, followed by proper training, testing, and validation of the models, it is possible to achieve better accuracy in detecting intrusions (Saheed et al. Citation2022; Singh et al. Citation2023; Yan and Han Citation2018). Additionally, collecting and incorporating a larger volume of data can further improve the system’s ability to learn and identify flaws more effectively. Cloud-based deep learning (DL) models (Saba et al. Citation2016, Citation2017; Suri Citation2020; Suri et al. Citation2022) that employ a federated learning-based paradigm, comprising a GUI, logic layer, and persistence layer, have shown promise in intrusion detection. Implementing such models as IDS (Modi et al. Citation2013; Roschke, Cheng, and Meinel Citation2009; Yassin et al. Citation2012) could yield positive results. The utilization of Explainable AI techniques (Zebin, Rezvy, and Luo Citation2022; Zhang et al. Citation2022) can also enhance interpretability in this paradigm. By employing these techniques, the IDS system becomes more transparent, allowing security professionals to better understand the decision-making processes of the models and providing insights into the detected intrusions. These advancements will contribute to more effective and reliable detection of intrusions in versatile network environments.
Conclusion
The proposed research work presents a novel approach to intrusion detection through the comprehensive utilization of machine learning models. Intrusions are classified using ten distinct models, comprising five LC and five NLC. Our findings demonstrate the superiority of NLC over LC in intrusion detection. Furthermore, we assess the generalizability of our scheme by evaluating the performance of the models in unseen analysis. To validate the reliability and significance of our approach, we conduct robust statistical tests and power analyses. In conclusion, the proposed scheme, with its utilization of machine learning models and the demonstrated superiority of nonlinear classifiers, offers a promising approach to effectively mitigate intrusions and enhance the security of computer networks.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
Due to its proprietary nature, supporting data cannot be made available openly.
References
- Abrar, I., Z. Ayub, F. Masoodi, and A. M. Bamhdi. 2020. A machine learning approach for intrusion detection system on NSL-KDD dataset. In 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India. IEEE.
- Abubakar, A. I., H. Chiroma, S. A. Muaz, and L. B. Ila. 2015. A review of the advances in cyber security benchmark datasets for evaluating data-driven based intrusion detection systems. Procedia Computer Science 62:221–34. doi:10.1016/j.procs.2015.08.443.
- Almseidin, M., M. Alzubi, S. Kovacs, and M. Alkasassbeh. 2017. Evaluation of machine learning algorithms for intrusion detection system. In 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia. IEEE.
- Alrowaily, M., F. Alenezi, and Z. Lu. 2019. Effectiveness of machine learning based intrusion detection systems. Security, Privacy, and Anonymity in Computation, Communication, and Storage: 12th International Conference, SpaCCS 2019, Atlanta, GA, USA. Springer.
- Amor, N. B., S. Benferhat, and Z. Elouedi. 2004. Naive Bayes vs decision trees in intrusion detection systems. In Proceedings of the 2004 ACM symposium on Applied computing, Nicosia, Cyprus.
- Ao, H. 2021. Using machine learning models to detect different intrusion on NSL-KDD. In 2021 IEEE International Conference on Computer Science, Artificial Intelligence and Electronic Engineering (CSAIEE), SC, USA. IEEE.
- Araki, T., N. Ikeda, D. Shukla, P. K. Jain, N. D. Londhe, V. K. Shrivastava, S. K. Banchhor, L. Saba, A. Nicolaides, S. Shafique, et al. 2016. PCA-based polling strategy in machine learning framework for coronary artery disease risk assessment in intravascular ultrasound: A link between carotid and coronary grayscale plaque morphology. Computer Methods and Programs in Biomedicine 128:137–58. doi:10.1016/j.cmpb.2016.02.004.
- Baich, M., T. Hamim, N. Sael, and Y. Chemlal. 2022. Machine learning for IoT based networks intrusion detection: A comparative study. Procedia Computer Science 215:742–51. doi:10.1016/j.procs.2022.12.076.
- Belavagi, M. C., and B. Muniyal. 2016. Performance evaluation of supervised machine learning algorithms for intrusion detection. Procedia Computer Science 89:117–23. doi:10.1016/j.procs.2016.06.016.
- Bhavani, T. T., M. K. Rao, and A. M. Reddy. 2019. Network intrusion detection system using random forest and decision tree machine learning techniques. In First International Conference on Sustainable Technologies for Computational Intelligence: Proceedings of ICTSCI 2019, Jaipur, Rajasthan, India. Springer.
- Bindra, N., and M. Sood. 2019. Detecting DDoS attacks using machine learning techniques and contemporary intrusion detection dataset. Automatic Control and Computer Sciences 53 (5):419–28. doi:10.3103/S0146411619050043.
- Biswas, M., V. Kuppili, D. R. Edla, H. S. Suri, L. Saba, R. T. Marinhoe, J. M. Sanches, and J. S. Suri. 2018. Symtosis: A liver ultrasound tissue characterization and risk stratification in optimized deep learning paradigm. Computer Methods and Programs in Biomedicine 155:165–77. doi:10.1016/j.cmpb.2017.12.016.
- Chakraborty, N. 2013. Intrusion detection system and intrusion prevention system: A comparative study. International Journal of Computing and Business Research (IJCBR) 4 (2):1–8.
- Chang, Y.-W., and C.-J. Lin. 2008. Feature ranking using linear SVM. In Proceedings of the Workshop on the Causation and Prediction Challenge at WCCI 2008, Hong Kong.
- Chauhan, H., V. Kumar, S. Pundir, and E. S. Pilli. 2013. A comparative study of classification techniques for intrusion detection. In 2013 International Symposium on Computational and Business Intelligence, New Delhi, India. IEEE.
- Chen, C.-M., Y.-L. Chen, and H.-C. Lin. 2010. An efficient network intrusion detection. Computer Communications 33 (4):477–84. doi:10.1016/j.comcom.2009.10.010.
- Davis, J. J., and A. J. Clark. 2011. Data preprocessing for anomaly based network intrusion detection: A review. Computers & Security 30 (6–7):353–75. doi:10.1016/j.cose.2011.05.008.
- Devarajan, R., and P. Rao. 2021. An efficient intrusion detection system by using behaviour profiling and statistical approach model. The International Arab Journal of Information Technology 18 (1):114–24.
- Dhanabal, L., and S. Shantharajah. 2015. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. International Journal of Advanced Research in Computer and Communication Engineering 4 (6):446–52.
- Elhamahmy, M., H. N. Elmahdy, and I. A. Saroit. 2010. A new approach for evaluating intrusion detection system. CiiT International Journal of Artificial Intelligent Systems and Machine Learning 2 (11):290–98.
- Friha, O., M. A. Ferrag, M. Benbouzid, T. Berghout, B. Kantarci, and K.-K. R. Choo. 2023. 2DF-IDS: Decentralized and differentially private federated learning-based intrusion detection system for industrial IoT. Computers & Security 127:103097. doi:10.1016/j.cose.2023.103097.
- Garcia-Teodoro, P., J. Díaz-Verdejo, G. Maciá-Fernández, and E. Vázquez. 2009. Anomaly-based network intrusion detection: Techniques, systems and challenges. Computers & Security 28 (1–2):18–28. doi:10.1016/j.cose.2008.08.003.
- Hady, A. A., A. Ghubaish, T. Salman, D. Unal, and R. Jain. 2020. Intrusion detection system for healthcare systems using medical and network data: A comparison study. Institute of Electrical and Electronics Engineers Access 8:106576–84. doi:10.1109/ACCESS.2020.3000421.
- Ibrahimi, K., and M. Ouaddane. 2017. Management of intrusion detection systems based-KDD99: Analysis with LDA and PCA. In 2017 International Conference on Wireless Networks and Mobile Communications (WINCOM), Rabat, Morocco. IEEE.
- Jamthikar, A. D., D. Gupta, L. E. Mantella, L. Saba, J. R. Laird, A. M. Johri, and J. S. Suri. 2021. Multiclass machine learning vs. conventional calculators for stroke/CVD risk assessment using carotid plaque predictors with coronary angiography scores as gold standard: A 500 participants study. The International Journal of Cardiovascular Imaging 37 (4):1171–87. doi:10.1007/s10554-020-02099-7.
- Jiang, H., Z. He, G. Ye, and H. Zhang. 2020. Network intrusion detection based on PSO-XGBoost model. Institute of Electrical and Electronics Engineers Access 8:58392–401. doi:10.1109/ACCESS.2020.2982418.
- Johri, A. M., K. V. Singh, L. E. Mantella, L. Saba, A. Sharma, J. R. Laird, K. Utkarsh, I. M. Singh, S. Gupta, M. S. Kalra, et al. 2022. Deep learning artificial intelligence framework for multiclass coronary artery disease prediction using combination of conventional risk factors, carotid ultrasound, and intraplaque neovascularization. Computers in Biology and Medicine 150:106018. doi:10.1016/j.compbiomed.2022.106018.
- Jyothsna, V., V. Prasad, and K. M. Prasad. 2011. A review of anomaly based intrusion detection systems. International Journal of Computer Applications 28 (7):26–35. doi:10.5120/3399-4730.
- Khafajeh, H. 2020. An efficient intrusion detection approach using light gradient boosting. Journal of Theoretical & Applied Information Technology 98 (5):825–35.
- Khraisat, A., I. Gondal, P. Vamplew, and J. Kamruzzaman. 2019. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2 (1):1–22. doi:10.1186/s42400-019-0038-7.
- Kilincer, I. F., F. Ertam, and A. Sengur. 2021. Machine learning methods for cyber security intrusion detection: Datasets and comparative study. Computer Networks 188:107840. doi:10.1016/j.comnet.2021.107840.
- Kim, K., S. Nalluri, A. Kashinath, Y. Wang, S. Mohan, M. Pajic, and B. Li. 2020. Security analysis against spoofing attacks for distributed UAVs. Workshop on Decentralized IoT Systems and Security (DISS) 2020, San Diego, CA, USA.
- Kizza, J. M., W. Kizza, and Wheeler. 2013. Guide to computer network security. Vol. 8.
- Konstantonis, G., K. V. Singh, P. P. Sfikakis, A. D. Jamthikar, G. D. Kitas, S. K. Gupta, L. Saba, K. Verrou, N. N. Khanna, Z. Ruzsa, et al. 2022. Cardiovascular disease detection using machine learning and carotid/femoral arterial imaging frameworks in rheumatoid arthritis patients. Rheumatology International 42 (2):215–39. doi:10.1007/s00296-021-05062-4.
- Kumar, V., and O. P. Sangwan. 2012. Signature based intrusion detection system using SNORT. International Journal of Computer Applications & Information Technology 1 (3):35–41.
- Kuppili, V., M. Biswas, A. Sreekumar, H. S. Suri, L. Saba, D. R. Edla, R. T. Marinhoe, J. M. Sanches, and J. S. Suri. 2017. Extreme learning machine framework for risk stratification of fatty liver disease using ultrasound tissue characterization. Journal of Medical Systems 41 (10):1–20. doi:10.1007/s10916-017-0797-1.
- Le, T. T. H., Y. E. Oktian, and H. Kim. 2022. XGBoost for imbalanced multiclass classification-based industrial internet of things intrusion detection systems. Sustainability 14 (14):8707. doi:10.3390/su14148707.
- Leevy, J. L., and T. M. Khoshgoftaar. 2020. A survey and analysis of intrusion detection models based on CSE-CIC-IDS2018 big data. Journal of Big Data 7 (1):1–19. doi:10.1186/s40537-020-00382-x.
- Liu, G., H. Zhao, F. Fan, G. Liu, Q. Xu, and S. Nazir. 2022. An enhanced intrusion detection model based on improved kNN in WSNs. Sensors 22 (4):1407. doi:10.3390/s22041407.
- Mallik, A. 2019. Man-in-the-middle-attack: Understanding in simple words. Cyberspace: Jurnal Pendidikan Teknologi Informasi 2 (2):109–34. doi:10.22373/cj.v2i2.3453.
- Maniruzzaman, M., M. Jahanur Rahman, B. Ahammed, M. M. Abedin, H. S. Suri, M. Biswas, A. El-Baz, P. Bangeas, G. Tsoulfas, J. S. Suri, et al. 2019. Statistical characterization and classification of colon microarray gene expression data using multiple machine learning paradigms. Computer Methods and Programs in Biomedicine 176:173–93. doi:10.1016/j.cmpb.2019.04.008.
- Mármol Campos, E., J. L. Hernández Ramos, A. González Vidal, G. Baldini, and A. Skarmeta. 2024. Misbehavior detection in intelligent transportation systems based on federated learning. Internet of Things.
- Modi, C., D. Patel, B. Borisaniya, H. Patel, A. Patel, and M. Rajarajan. 2013. A survey of intrusion detection techniques in cloud. Journal of Network and Computer Applications 36 (1):42–57. doi:10.1016/j.jnca.2012.05.003.
- Moustafa, N., and J. Slay. 2016. The evaluation of network anomaly detection systems: Statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set. Information Security Journal: A Global Perspective 25 (1–3):18–31. doi:10.1080/19393555.2015.1125974.
- Naiping, S., and Z. Genyuan. 2010. A study on intrusion detection based on data mining. In 2010 International Conference of Information Science and Management Engineering, Shaanxi, China. IEEE.
- Pai, V., and N. Adesh. 2021. Comparative analysis of machine learning algorithms for intrusion detection. In IOP Conference Series: Materials Science and Engineering, Bengaluru, India. IOP Publishing.
- ParwANI, D., A. Dutta, P. K. Shukla, and M. Tahiliyani. 2015. Various techniques of DDoS attacks detection & prevention at cloud: A survey. Oriental Journal of Computer Science and Technology 8 (2):110–20.
- Pathak, A., and S. Pathak. 2020. Study on decision tree and KNN algorithm for intrusion detection system. International Journal of Engineering Research 9 (5):376–81. doi:10.17577/IJERTV9IS050303.
- Rahman, M. A., A. T. Asyhari, L. S. Leong, G. B. Satrya, M. Hai Tao, and M. F. Zolkipli. 2020. Scalable machine learning-based intrusion detection system for IoT-enabled smart cities. Sustainable Cities and Society 61:102324. doi:10.1016/j.scs.2020.102324.
- Rashid, O. F. 2020. DNA encoding for misuse intrusion detection system based on UNSW-NB15 data set. Iraqi Journal of Science 3408–16. doi:10.24996/ijs.2020.61.12.29.
- Rastogi, S., A. Shrotriya, M. Kumar Singh, and R. V. Potukuchi. 2022. An analysis of intrusion detection classification using supervised machine learning algorithms on NSL-KDD dataset. Journal of Computing Research and Innovation (JCRINN) 7 (1):118–30. doi:10.24191/jcrinn.v7i1.274.
- Rauf, B., H. Abbas, M. Usman, T. A. Zia, W. Iqbal, Y. Abbas, and H. Afzal. 2022. Application threats to exploit northbound interface vulnerabilities in software defined networks. ACM Computing Surveys (CSUR) 54 (6):1–36. doi:10.1145/3453648.
- Revathi, S., and A. Malathi. 2013. A detailed analysis on NSL-KDD dataset using various machine learning techniques for intrusion detection. International Journal of Engineering Research & Technology (IJERT) 2 (12):1848–53.
- Ring, M., S. Wunderlich, D. Gruedl, D. Landes, and A. Hotho. 2017. Technical Report CIDDS-001 data set.
- Ring, M., S. Wunderlich, D. Scheuring, D. Landes, and A. Hotho. 2019. A survey of network-based intrusion detection data sets. Computers & Security 86:147–67. doi:10.1016/j.cose.2019.06.005.
- Roschke, S., F. Cheng, and C. Meinel. 2009. Intrusion detection in the cloud. In 2009 Eighth IEEE International Conference on Dependable, Autonomic and Secure Computing, Chengdu, China. IEEE.
- Rubio, J. E., C. Alcaraz, R. Roman, and J. Lopez. 2017. Analysis of intrusion detection systems in industrial ecosystems. In 14th International Conference on Security and Cryptography (SECRYPT 2017), Madrid, Spain.
- Saba, L., S. K. Banchhor, N. D. Londhe, T. Araki, J. R. Laird, A. Gupta, A. Nicolaides, and J. S. Suri. 2017. Web-based accurate measurements of carotid lumen diameter and stenosis severity: An ultrasound-based clinical tool for stroke risk assessment during multicenter clinical trials. Computers in Biology and Medicine 91:306–17. doi:10.1016/j.compbiomed.2017.10.022.
- Saba, L., S. K. Banchhor, H. S. Suri, N. D. Londhe, T. Araki, N. Ikeda, K. Viskovic, S. Shafique, J. R. Laird, A. Gupta, et al. 2016. Accurate cloud-based smart IMT measurement, its validation and stroke risk stratification in carotid ultrasound: A web-based point-of-care tool for multicenter clinical trial. Computers in Biology and Medicine 75:217–34. doi:10.1016/j.compbiomed.2016.06.010.
- Saheed, Y. K., A. Idris Abiodun, S. Misra, M. Kristiansen Holone, and R. Colomo-Palacios. 2022. A machine learning-based intrusion detection for detecting internet of things network attacks. Alexandria Engineering Journal 61 (12):9395–409. doi:10.1016/j.aej.2022.02.063.
- Sapalo Sicato, J. C., P. K. Sharma, V. Loia, and J. H. Park. 2019. VPNFilter malware analysis on cyber threat in smart home network. Applied Sciences 9 (13):2763. doi:10.3390/app9132763.
- Sarker, I. H., Y. B. Abushark, F. Alsolami, and A. I. Khan. 2020. Intrudtree: A machine learning based cyber security intrusion detection model. Symmetry 12 (5):754. doi:10.3390/sym12050754.
- Sayghe, A., Y. Hu, I. Zografopoulos, X. Liu, R. G. Dutta, Y. Jin, and C. Konstantinou. 2020. Survey of machine learning methods for detecting false data injection attacks in power systems. IET Smart Grid 3 (5):581–95. doi:10.1049/iet-stg.2020.0015.
- Shrivastava, V. K., N. D. Londhe, R. S. Sonawane, and J. S. Suri. 2017. A novel and robust Bayesian approach for segmentation of psoriasis lesions and its risk stratification. Computer Methods and Programs in Biomedicine 150:9–22. doi:10.1016/j.cmpb.2017.07.011.
- Silva, B. R., R. Silveira, M. Silva Neto, P. Cortez, and D. Gomes. 2021. A comparative analysis of undersampling techniques for network intrusion detection systems design. Journal of Communication and Information Systems 36 (1):31–43. doi:10.14209/jcis.2021.3.
- Singh, A. P., and M. D. Singh. 2014. Analysis of host-based and network-based intrusion detection system. International Journal of Computer Network and Information Security 6 (8):41–47. doi:10.5815/ijcnis.2014.08.06.
- Singh, J., K. Sharma, M. Wazid, and A. K. Das. 2023. SINN-RD: Spline interpolation-envisioned neural network-based ransomware detection scheme. Computers & Electrical Engineering 106:108601. doi:10.1016/j.compeleceng.2023.108601.
- Souhail, M. 2019. Network based intrusion detection using the UNSW-NB15 dataset. International Journal of Computing and Digital Systems 8 (5):477–87. doi:10.12785/ijcds/080505.
- Srivastava, S. K., S. K. Singh, and J. S. Suri. 2019. Effect of incremental feature enrichment on healthcare text classification system: A machine learning paradigm. Computer Methods and Programs in Biomedicine 172:35–51. doi:10.1016/j.cmpb.2019.01.011.
- Srivastava, S. K., S. K. Singh, and J. S. Suri. 2020. A healthcare text classification system and its performance evaluation: A source of better intelligence by characterizing healthcare text. Cognitive Informatics, Computer Modelling, and Cognitive Science 2:319–69.
- Suri, J. S. 2020. Low-cost preventive screening using carotid ultrasound in patients with diabetes. Frontiers in Bioscience-Landmark 25 (6):1132–71. doi:10.1274/4850.
- Suri, J. S., S. Agarwal, G. Chabert, A. Carriero, A. Paschè, P. Danna, L. Saba, A. Mehmedović, G. Faa, I. Singh, et al. 2022. COVLIAS 2.0-cXAI: Cloud-based explainable deep learning system for COVID-19 lesion localization in computed tomography scans. Diagnostics 12 (6):1482. doi:10.3390/diagnostics12061482.
- Suri, J. S., and R. M. Rangayyan. 2006. Breast imaging, mammography, and computer-aided diagnosis of breast cancer. Bellingham, WA, USA: SPIE.
- Tan, X., S. Su, Z. Huang, X. Guo, Z. Zuo, X. Sun, and L. Li. 2019. Wireless sensor networks intrusion detection based on SMOTE and the random forest algorithm. Sensors 19 (1):203. doi:10.3390/s19010203.
- Tao, K., J. Li, and S. Sampalli. 2008. Detection of Spoofed MAC Addresses in 802.11 Wireless Networks. In International Conference on E-Business and Telecommunications, Barcelona, Spain. Springer.
- Tauqeer, H., M. M. Iqbal, A. Ali, S. Zaman, and M. U. Chaudhry. 2022. Cyberattacks detection in IoMT using machine learning techniques. Journal of Computing & Biomedical Informatics 4 (1):13–20. doi:10.56979/401/2022/80.
- Teji, J. S., S. Jain, S. K. Gupta, and J. S. Suri. 2022. NeoAI 1.0: Machine learning-based paradigm for prediction of neonatal and infant risk of death. Computers in Biology and Medicine 147:105639. doi:10.1016/j.compbiomed.2022.105639.
- Teng, S., N. Wu, H. Zhu, L. Teng, and W. Zhang. 2018. SVM-DT-based adaptive and collaborative intrusion detection. IEEE/CAA Journal of Automatica Sinica 5 (1):108–18. doi:10.1109/JAS.2017.7510730.
- Tiwari, M., K. V. Arya, R. Choudhari, and K. S. Choudhary 2009. Designing intrusion detection to detect black hole and selective forwarding attack in WSN based on local information. In 2009 Fourth International Conference on Computer Sciences and Convergence Information Technology, Seoul, Korea (South). IEEE.
- Tu, S., M. Waqas, A. Badshah, M. Yin, and G. Abbas. 2023. Network intrusion detection system (NIDS) based on pseudo-siamese stacked autoencoders in fog computing. IEEE Transactions on Services Computing.
- Viegas, E., A. O. Santin, and V. Abreu. 2021. Machine learning intrusion detection in big data era: A multi-objective approach for longer model lifespans. IEEE Transactions on Network Science and Engineering 8 (1):366–76. doi:10.1109/TNSE.2020.3038618.
- Waqas, M., S. Tu, Z. Halim, S. U. Rehman, G. Abbas, and Z. H. Abbas. 2022. The role of artificial intelligence and machine learning in wireless networks security: Principle, practice and challenges. Artificial Intelligence Review 55 (7):5215–61. doi:10.1007/s10462-022-10143-2.
- Yan, B., and G. Han. 2018. Effective feature extraction via stacked sparse autoencoder to improve intrusion detection system. Institute of Electrical and Electronics Engineers Access 6:41238–48. doi:10.1109/ACCESS.2018.2858277.
- Yang, Y., K. McLaughlin, T. Littler, S. Sezer, and H. F. Wang 2013. Rule-based intrusion detection system for SCADA networks. In 2nd IET Renewable Power Generation Conference (RPG 2013), Beijing, China.
- Yassin, W., N. I. Udzir, Z. Muda, A. Abdullah, and M. T. Abdullah. 2012. A cloud-based intrusion detection service framework. Proceedings Title: 2012 International Conference on Cyber Security, Cyber Warfare and Digital Forensic (CyberSec), IEEE.
- Yassin, W., N. I. Udzir, Z. Muda, and M. N. Sulaiman. 2013. Anomaly-based intrusion detection through k-means clustering and naives Bayes classification. In Proceedings of the 4 th International Conference on Computing and Informatics, ICOCI 2013, Sarawak, Malaysia.
- Yihunie, F., E. Abdelfattah, and A. Regmi. 2019. Applying machine learning to anomaly-based intrusion detection systems. In 2019 IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA. IEEE.
- Zamani, M., and M. Movahedi. 2013. Machine learning techniques for intrusion detection. arXiv preprint arXiv:1312.2177.
- Zebin, T., S. Rezvy, and Y. Luo. 2022. An explainable ai-based intrusion detection system for dns over https (doh) attacks. IEEE Transactions on Information Forensics and Security 17:2339–49. doi:10.1109/TIFS.2022.3183390.
- Zhang, J., B. Gong, M. Waqas, S. Tu, and S. Chen. 2023. Many-objective optimization based intrusion detection for in-vehicle network security. IEEE Transactions on Intelligent Transportation Systems.
- Zhang, Q., G. Hu, and W. Feng. 2010. Design and performance evaluation of a machine learning-based method for intrusion detection. Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing 2010:69–83.
- Zhang, Y., and Q. Liu. 2022. On IoT intrusion detection based on data augmentation for enhancing learning on unbalanced samples. Future Generation Computer Systems 133:213–27. doi:10.1016/j.future.2022.03.007.
- Zhang, Z., H. Al Hamadi, E. Damiani, C. Y. Yeun, and F. Taher. 2022. Explainable artificial intelligence applications in cyber security: State-of-the-art in research. IEEE Access.