
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper delves into the analysis of card fraud within the banking system. Its aim is to gain a comprehensive understanding of fraud in the banking sector and explore effective detection techniques. The paper examines advanced techniques such as data analysis, automatic learning algorithms, and real-time monitoring systems to detect suspicious patterns, anomalies, and deviations from normal behavior with precision. To achieve this, the research methodology employs a combination of qualitative and quantitative analysis. Furthermore, empirical research is conducted to evaluate the effectiveness of Machine Learning-based decision tree algorithms in identifying card fraud using real-world datasets. By understanding the nature of fraud and implementing robust detection methods, banks can safeguard their operations, assets, and customers, and uphold trust in the banking system.
Introduction
A serious challenge in the field of finance is the detection and prevention of crimes committed through transactions that take place, particularly through electronic means. In recent decades, fraudulent financial transactions have been widely observed and therefore, fraud committed online and through other networks has become a cause for concern because of its expansion. For example, according to the Nilson Report, global losses from payment card fraud reached $27.85 billion in 2018 and have been growing ever since. To mitigate this problem, various techniques have been developed to detect fraudulent transactions (Nilson Report Citation2023).
Most fraud is discovered by accident or through tip-offs, usually through a hotline. In most cases, greater losses are incurred as a result of employees ignoring the obvious. Finding and reporting fraud and irregularities is the responsibility of all employees within an organization and it is equally important that it has adequate reporting mechanisms. It requires training and experience, awareness that fraud may exist in the institution, and professional alert should be maintained regarding potential fraud. In general, external auditors may not be as effective in detecting fraud as internal auditors. In addition, utilizing risk management procedures can aid in identifying fraud. Ideally, organizations should establish a robust internal audit team, if feasible, to oversee and offer guidance regarding risk management. Financial fraud detection techniques are split into two categories: a. statistical analysis techniques, i.e. time series analysis of time-dependent data; data pre-processing for validation, detection, error correction, detection and completion of missing or incorrect data; various parameters of statistical calculation, such as averages of performance values and probability distributions; probability distributions and models of various business activities; finding patterns and associations between groups of data through clustering and classification; and b. techniques that rely on Artificial Intelligence and Machine Learning. The latter relies on coding expertise for fraud detection; neural networks that would learn from datasets which are fraud attempts; pattern recognition to detect suspicious classes; groups or behavioral patterns; mining for data classification, clustering and segmentation and finding automatic associations and rules in data that signal interesting patterns, including those related to fraud. In this respect Plakandaras et al. (Citation2022) states that machine learning models are among the most prominent techniques in detecting illicit transactions.
Consequently, numerous methods of prevention have been suggested and experimented to help both financial institutions and their customers. First of all, knowing customers by storing their information (surname, name, personal numerical code, home address, phone number, e-mail address, etc.), helps to identify their identity and detect possible fraud quite swiftly when an uncharacteristic change is observed in the value of the amounts extracted from the accounts. Customers need to stay informed about the various types of fraud and how they are evolving, as well as the measures they can take to protect themselves. Secondly, there are also numerous software tools that a customer can use to prevent transactional fraud. A considerable number of fraud detection methods rely on analyzing transaction-related data and information about the individuals who conducted those transactions.
Motivated by the extending card fraud cases, the aim of the paper is to identify the importance of the attributes used in the training process of the Machine Learning algorithm based on decision trees. Such attributes help identify the most relevant and influential variables or characteristics that significantly contribute to distinguishing between fraudulent and legitimate transactions. Hence, the research question is to find the most important features regarding the detection of fraudulent card transactions. Secondly, we want to obtain a high performance in detection of card frauds. The relevance of our study is that we try to automate the process of fraud detection using digital data instead of interpreting the actual specific cases.
Based on Machine Learning experiments, we researched to distinguish between fraudulent and non-fraudulent transactions. The methodology involves two vast datasets and the Decision Tree Classifier algorithm from the sklearn (“scikit-learn: Machine Learning in Python,” Citationn.d.) library was used and implemented using the Python programming language. Our models have a 99% capability in detecting fraudulent transactions, rendering their outcomes both theoretically and practically feasible.
The research contributes to the literature as it provides a comprehensive perspective on the topic. Our model adds value to the existing literature, by highlighting the hierarchical significance of attributes in identifying fraudulent financial transactions. From a practical standpoint, this offers financial institutions a tool for detecting such activities in real time, thereby preventing any losses to clients and the institutions themselves.
The paper proceeds as follows: Literature review, presented in Section 2, refers to the theoretical advancements in the field of financial and card-related transactions; A brief statistical view on card fraud, in selected EU countries and the UK, is discussed in Section 3; The Machine Learning method in card fraud detection for which the data and research methodology are described in Section 4; Section 5 summarizes the main Results. The remainder of the paper is dedicated to Conclusions.
Literature review
Fraudulent financial activities have increased in recent years (West and Bhattacharya Citation2016). Therefore, to identify fraudulent losses, it is important to clearly define what constitutes fraud. Thus, fraud can be defined as corrupted truths to induce an individual to give up an asset or value that is legally owned or as an act of deception (Akers and Gissel Citation2006). Other experts define fraud broadly by stating that it encompasses all the means that an individual can use to gain a false advantage over another individual. Fraud involves surprise, deception, trickery, and unfair means by which a person is deceived (Albrecht Citation2003). To clarify the notion of fraud, researchers have proposed general definitions to cover as many situations as possible in which actions of a fraudulent nature can occur. Hence, fraud can be defined as: “Any act, expression, omission or concealment intended to deceive another to his disadvantage, especially, a misrepresentation or concealment concerning a fact important to a transaction which is made knowing its falsity; and or in reckless disregard of its truth or falsity with intent to defraud another and which reasonably relies on the other being injured thereby” (Manurung and Hadian Citation2017). At the same time, Ernst and Young (Ernst and Young Citation2009) define fraud as an act of deliberate action made by an entity, knowing that such action may lead to the possession of illegal benefits.
Reality shows that various categories of fraud and financial crime occur. For example, knowingly and materially misrepresenting financial statements constitutes financial statement fraud (Albrecht Citation2003). Banks can be considered more prone to fraud compared to other financial institutions, as a result of liquid cash and cash equivalent operations. Within them, fraud leads to financial, operational or psychological losses (Adetiloye, Olokoyo, and Taiwo Citation2016). Consequently, bank frauds bring much suffering to all stakeholders and the collapse of many banks is linked to the massive fraud experienced (Nwankwo Citation2013). And this is the main reason why the need for fraud detection and prevention is becoming more and more important.
The classification of financial fraud remains uncertain due to the diverse range of fraud types, which continues to grow. However, some studies categorize financial fraud based on the primary financial institution involved (West and Bhattacharya Citation2016). Arguably, mixed frauds are among the most common ones. They refer to cases where the staff of banking institutions conspire with customers to cause fraud through unauthorized loans, overdrafts, and fraudulent and false accounting procedures. It also involves the use of forgeries by operational personnel such as supervisors, officers, accountants, clerks and cashiers (Aljohani, Aljuaid, and Aljarboa Citation2021). Quite often, customer signatures are forged by non-customers with the consent of staff. Management fraud refers to frauds committed by bank employees at the top management level, which largely aim to defraud shareholders and to a considerable extent, auditors and regulators by deliberately presenting a false financial statement (Abiola and Idowu Citation2009). In addition, employee fraud refers to fraud committed by non-management employees. Unlike managerial fraud, employee fraud does not involve altering or misrepresenting financial statements or information, but rather misappropriating total bank assets or altering individual instruments such as checks for their benefits (Nabhan and Hindi Citation2009). Quite a large number of employee fraudulent acts occur after they have earned a position of trust and responsibility (Rahman and Anwar Citation2014). A considerably larger number of bank frauds are usually committed by non-management employees, most of whom are cashiers, clerks, accountants, etc.
After examining different instances of fraud, researchers have concluded that preventing fraud should be a priority. This approach is deemed more cost-effective and efficient than detecting fraud after it has already happened. Thus, Hoffmann and Birnbrich (Citation2012), argue that customers’ awareness related to prevention methods positively impacts their relationship with the bank while Enofe et al. (Citation2017) emphasize the importance of internal control, corporate governance and strong ethical principles in preventing bank fraud. Studies have demonstrated that once fraud is uncovered, it may be impossible to retrieve the lost money or the possibility of recovering the full amount becomes unlikely. In addition, investigating fraud is expensive and time-consuming, especially when it involves large-scale operations. Repousis, Lois, and Veli (Citation2019) studied fraud schemes in commercial banks listing the most common fraud channels: bribery, forgery, and money laundering. However, if the focus is on fraud prevention, time and effort to reconstruct the fraudulent transactions, find the perpetrator and recover the missing funds can be saved.
Several fundamental theories have attempted to explain the causes of fraud. Machado and Gartner (Citation2017) mention 1953 Cressey's hypothesis, the Triangle Theory of Fraud (TTF), and Wolfe and Hermanson’s (Citation2004) mention Fraud Diamond Theory (FDT) attempting to identify the determinants that lead perpetrators to commit fraud. Further on, we mention these theories, but we do not propose to test these concepts.Wolfe and Hermanson (Citation2004) considered that the former TTF needs to be expanded to improve both fraud prevention and detection by considering an additional element. They considered FDT, thus adding capability as a fourth element. The authors state that a fraud attempt can only be successful if the fraudster has the appropriate ability and skills to carry out every detail of the fraud. Capability shows fraudsters’ ability to evade internal controls within their companies, establish advanced diversionary tactics, and manipulate social conditions in their favor by persuading others to comply. At the same time, this is also applicable to online fraudsters who try to take advantage of the naivete of individuals to commit fraud that involves banking transactions. Numerous other researchers (Gbegi and F Citation2013; Omar and Mohamad Din Citation2010; Ruankaew Citation2013) have examined and discussed FDT. Their main conclusion was that FDT is an expanded and improved version of TTF.
In an extension of the FTT and the FDT, Crowe (Citation2015) constructed the Fraud Pentagon Theory (FPT). He mentions that an important element of fraud is the fraudster’s arrogance. Access to a broader range of information often leads to more sophisticated fraudulent behavior, as the fraudster may disregard legal policies in place. To address the issue of fraud, organizations must adopt effective strategies that reduce the factors that lead to fraudulent behavior, limit opportunities for fraud, and decrease the ability of fraudsters to rationalize their actions. It is crucial to tackle this problem comprehensively. Minimizing the temptation to commit fraud and reducing opportunities to commit fraud is the primary purpose of deliberate fraud.
Since it is equally important to be proactive rather than reactive in fraud prevention, the main components of an effective anti-fraud system are prevention, detection, deterrence, and response (Dzomira Citation2015). These four elements are closely related to each other and the connection between them plays a very important role in combating fraud. Using fraud detection measures serves as a warning to potential fraudsters that the institution is actively combating fraudulent activity. It also sends a message that procedures are in place to uncover any illegal activity that may have occurred. A would-be fraudster would resist committing the crime if there is a possibility of being caught. Dzomira (Citation2015) also demonstrates that the development of an organizational culture based on ethics and morality reduces the number of occurrences of fraud. At the same time, not sanctioning minor unethical practices such as cash theft and expense fraud would mean that larger frauds committed at senior management levels could also be treated in the same tolerant manner. Moreover, literature (Khanna and Arora Citation2009) highlights that fraudsters often look for loopholes in weak control systems before acting, while Tunji (Citation2013) argues that weak internal control systems lead to unethical behavior.
The literature cites various studies that evaluate the best methods to detect card fraud. In this respect, Al-Hashedi and Magalingam (Citation2021) analyze whether data mining is effective in detecting fraud based on a relevant number of articles. Bhasin (Citation2016) investigates to what extent banks can use technology to prevent fraud using network-based behavior and Ruankaew (Citation2013) states that, before making efforts to reduce fraud and proactively manage risk, it is important for business organizations to identify the drivers of fraudulent behavior by understanding who the fraudsters are, as well as, the reasons frauds are committed.
Bhattacharyya et al. (Citation2011) investigate the effectiveness of random forests and support vector machines, as data mining techniques, both being able to thoroughly detect card fraud. Chaudhary, Yadav, and Mallick (Citation2012) discuss various techniques to detect card fraud illustrating the advantages of neural networks, and confidence value calculation. Zhu (Citation2021) emphasizes that Machine Learning is an experience-based method translated into data accentuating the possibility of transforming data into learning models by using algorithms According to Athey (Citation2019), Machine Learning provides valuable assistance to the economic field as it deals with vast amounts of data. This significantly improves the accuracy of analyses.
On the other hand, Mullainathan and Obermeyer (Citation2017), in their analysis, bring forward measurement issues that can strain the used algorithm and Olaleye Ayorinde (Citation2021) shows that delayed or outdated data can lead to missed opportunities for fraud detection. Despite the potential shortcomings, Machine Learning methods have proven effective in detecting credit card fraud and are increasingly being used by financial institutions to improve their fraud detection (Mahesh Citation2020). However, there are also challenges associated with using these methods, such as the need for high-quality data (Olaleye Ayorinde Citation2021; Vonasek Citation2013).
Therefore, continued research is needed to refine and improve Machine Learning techniques for credit card fraud detection. Moreover, data quality is a critical factor in the correct analysis and modeling of financial transactions. Inaccurate or incomplete data can lead to incorrect insights and predictions, which can have significant consequences for financial institutions and their customers. Therefore, it is essential to ensure that the data used are of high quality and meet certain criteria (Hastie, Tibshirani, and Friedman Citation2009; Kotsiantis, Zaharakis, and Pintelas Citation2007). Authors Xuan, Liu, and Li (Citation2018) reach 96.77% accuracy in their paper 2018 for Random Forest II, respectively 97.76% in 2018 using data sets referring to an e-commerce company in China. The author Alraddadi (Citation2023) propose a perception on the credit card phenomenon discussing the results of the survey. In our work, we apply Decision Tree Algorithm to efficiently detect fraudulent transactions. Save et al. (Citation2017) suggest a system which detects fraud in credit card transaction a decision tree with combination of Luhn’s algorithm and Hunt’s algorithm. The authors mention a possibility to validate the card number without implementing the phases of pattern matching, Bayes theorem for fraud detection. In comparison, our solution is the practical one relying on a broad set of data. Our model could be integrated in such a system.
A brief statistical view on fraud in selected EU countries and the UK
Based on statistics, fraud related to cards appears to be a prevalent issue. In the aftermath of the recent pandemic, only four countries in the EU, i.e. Denmark, Sweden, the UK, and Hungary improved their card fraud performance, which is significant in the context of such economic uncertainty, while most countries either remained stable or experienced more fraudulent losses. The most notable are recorded in the Netherlands () and Portugal (), both with incremental losses exceeding + 15.
Figure 1. The evolution of various card-related fraud in the Netherlands during 2005–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
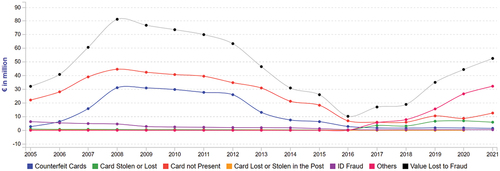
Figure 2. The evolution of various card-card fraud in Portugal during 2005–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
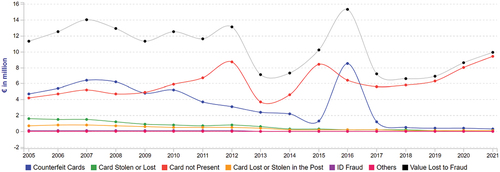
The UK and Scandinavian countries continue to lead Europe in both digital transformation and reducing fraud losses. Denmark () and Sweden () saw the largest percentage reductions in losses, with the UK () reducing fraud losses by £49.2 million.
Figure 3. The evolution of various card-related fraud in Denmark during 2005–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
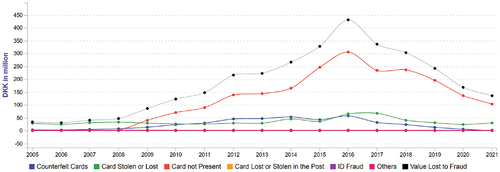
Figure 4. The evolution of various card-related fraud in Sweden during 2005–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
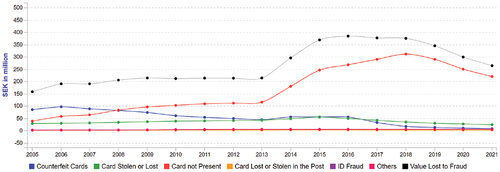
Figure 5. The evolution of various card-related fraud in the UK during 2005–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
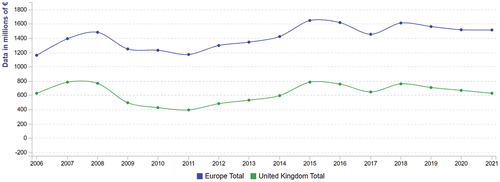
Payment fraud through digital channels has emerged as the leading fraud threat in many countries, surpassing card fraud losses. An analysis by the Fair Isaac Corporation (FICO Citation2023) mentions that the total level of fraud shows a polarized performance that maintains its general trend constant across Europe (). Total losses in Europe remained unchanged during 2020–2021, with decreases in the UK and Scandinavian countries offset by increases in losses across the region. In 2020, France, Poland and Germany saw increases of EUR 6 million, EUR 5 million and EUR 3 million respectively in losses due to bank fraud. However, in 2021, France maintained a steady trend, but Poland and Germany saw increases for the second consecutive year, with increases of €0.5 million and €2.4 million respectively in fraud losses. The Netherlands saw the biggest losses in relative value, coming in with an increase in losses of more than €8 million.
Figure 6. The evolution of total fraud in the EU and the UK during 2006–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
depicts an analysis of fraud threats in European countries, indicating the extent of fraud attacks in the region. FICO (Citation2023) propose a point-based fraud threat analysis across the European region. Point-based frauds are a standard measure of the severity of card fraud and can show how a bank or country compares to others. One basis point is equivalent to one cent per 100 EUR. It works the same in any currency and provides an indicator of the fraud-to-sales ratio.
Figure 7. Total fraud threats in selected European countries. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
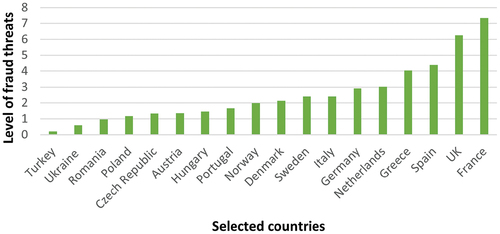
It seems that in 2021, there was a higher rate of attacks than in 2020. However, it is noteworthy that countries such as the UK, Denmark, and Sweden had the least amount of increase in card fraud threats. Denmark is the only country to see a decrease in threat levels (from 3.3 basis points in 2020 to 2.1 in 2021). Sweden saw a 14% increase and the UK’s threat level measured in basis points increased by 32% from 2020 to 2021 (FICO Citation2023). Although the UK and France had the highest fraud threat scores in both 2020 and 2021, the levels of fraud in other countries have risen dramatically over the past year, which is cause for concern. Point-based frauds in Germany, Greece and the Netherlands increased by 522%, 596% and 602% respectively. The Netherlands had the largest increase in losses in terms of relative value (€8 m+) in 2021; however, it’s commendable that damage was limited to only an 18% increase in light of the 600%+ increase in overall threats.
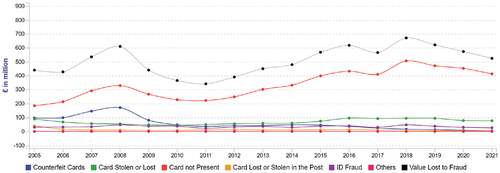
The overall trend of fraud threats in Europe may be unpredictable, but it seems that its level (the ratio of fraud losses to card sales) has doubled in 2021. Payment fraud is also growing exponentially, which further highlights the need for fraud management capabilities in addition to a cross-industry approach to prevent further escalating losses. Among these countries is Romania which was not immune to the problem of fraud. Statistics show that fraud has been increasing in Romania in recent years (). According to a report published by the National Institute of Statistics, the total number of frauds registered in Romania increased by 21.3% in 2020 compared to the previous year.
Figure 8. The evolution of various card-related fraud in the Romania during 2005–2021. Source: FICO (Citation2023), https://www.fico.com/europeanfraud/.
The machine learning method in fraud detection
The data
For the study, we have used the simulated dataset generated using the Sparkov tool that was created by Brandon Harris (dataset source: Kaggle Citation2020) and a dataset generated from a multi-agent virtual world simulation performed by IBM (dataset source: Kaggle Citation2021) First of all, we will discuss the dataset proposed by Brandon Harris. This dataset contains both legitimate and fraudulent credit card transactions between January 1, 2019, and December 31, 2020. The data includes 1,000 customers using credit cards transacting with a group of 800 merchants. As for the content of the used dataset, it includes approximately 1,300,000 data entries, each corresponding to a single transaction, based on which the Machine Learning algorithms can learn to make decisions about the nature of the transactions. At the same time, the dataset used contains 555,719 entries corresponding to transactions, based on which, the performance of the Machine Learning algorithms in identifying the type of transactions can be measured using the appropriate metrics. In total, the dataset accumulates 7506 entries corresponding to fraudulent transactions and 1,289,169 entries corresponding to non-fraudulent transactions. Each entry, in both the training dataset and the test dataset, contains the following information: transaction date and time, credit card number, merchant, transaction category, transaction amount, cardholder name and surname, cardholder gender, cardholder home address (street, city, country, zip code, latitude, longitude), the population of the city where the cardholder lives, occupation, date of birth, merchant location information (latitude, longitude), date and the time of the transaction, but also whether the transaction is a fraud and the category it falls under.
Figure 9. Category-based number of fraudulent transactions from the first dataset. Dataset source: Kaggle (Citation2020).
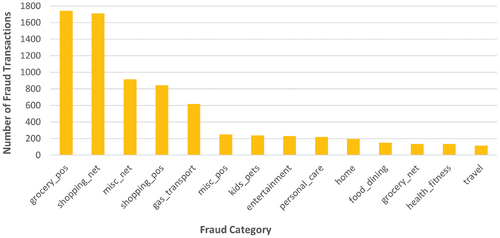
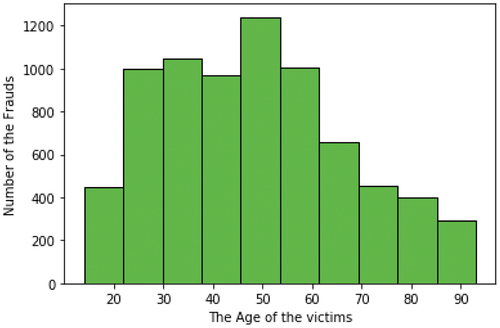
When analyzing the data, it becomes clear that the majority of fraudulent transactions happen when using a point of sale (POS) system to make daily purchases. However, it is also important to note that internet purchases are also a common target for fraud (). At the same time, at the opposite end of the list are frauds occurring during transactions made for travel and purchases related to health and sports activities. Regarding the number of frauds according to the gender of credit card holders, it can be stated that gender is not a factor in fraudulent actions. The number of frauds is approximately equal: 3771 for the male gender, and 3735 for the female gender. It is worth noting that the majority of fraud cases were reported among individuals employed in the fields of materials engineering, commercial standards officers, and naval architecture (). On the other hand, at the bottom of the ranking, with only two registered frauds are the occupations of contractor and English language teachers, respectively those with only three registered frauds with the occupations of health physicist and statistician. The distribution of fraud according to the age of credit card holders is also considered. In this case, the number of frauds is rather widespread among people aged between 20 and 60 compared to the number of younger and elderly (). It is important to note that individuals between the ages of 45 and 50 are at a higher risk for fraud compared to other age groups.
Figure 10. Number of fraud victims by age from the first dataset. Dataset source: Kaggle (Citation2020).
As already stated, in the analyzed dataset we find information that indicates the date and time when the transactions were made. A critical aspect of many datasets is the presence of date and time information which is crucial for several reasons. First, it enables temporal analysis, which is essential for understanding how phenomena evolve and change over time. Whether it is analyzing fluctuations in traded values, or anticipating potential fraud, the ability to capture and analyze temporal data is invaluable for drawing accurate conclusions and making informed decisions. Date and time information helps organize and structure data in a meaningful way. By associating specific timestamps with data points, sorting, filtering and aggregating information based on time criteria becomes easier. In this way, analysts can observe patterns and trends that might not be apparent when examining isolated data.
The analyzed dataset shows that most frauds usually occurred during March and May, closely followed by January and February, recording over 800 frauds each (). On the other hand, it can be seen how the month of July displays the lowest number of frauds, followed by November and August. Reporting by year, in 2019 more frauds were recorded compared to 2020 (). Finally, the exploratory analysis of the current dataset also involves reporting on transaction amounts for both fraudulent and non-fraudulent transactions. Thus, in the case of fraudulent transactions, the value of the transacted amounts largely varies compared to non-fraudulent transactions. In addition, in the case of fraudulent transactions, they do not exceed the amount of 1,500 monetary units, while in non-fraudulent transactions they reach values between 1,500 and 20,000 monetary units ().
Figure 11. Number of credit card frauds by occupation from the first dataset. Dataset source: Kaggle (Citation2020).
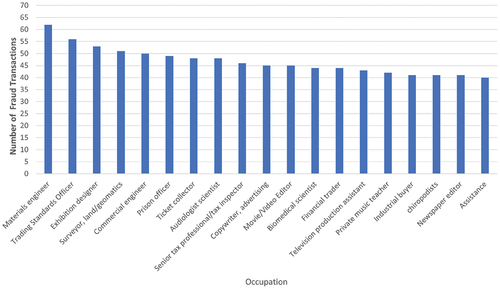
Figure 12. Number of credit card frauds by month from the first dataset. Dataset source: Kaggle (Citation2020).
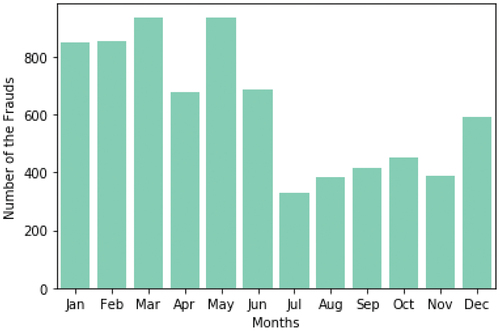
Figure 13. Number of credit card frauds by year from the first dataset. Dataset source: Kaggle (Citation2020).
Figure 14. Number of fraudulent transactions by amount from the first dataset. Dataset source: Kaggle (Citation2020).
Figure 15. Number of non-fraudulent transactions by amount from the first dataset. Dataset source: Kaggle (Citation2020).
Referring to the second dataset, the one proposed by IBM contains more than 24 million transactions covering 2000 (synthetic) consumers resident in the United States, but who traveled the world. The data covers decades of purchases and includes multiple cards from many of the consumers. Details regarding the data generation can be found at Altman (Citation2019). For each transaction, the dataset provides the card number, the exact time of the transaction (year, month, day, time), the amount, merchant information (name, city, state, zip code, category code), if there were registered errors during the transactions, respectively, the type of the transaction. From the entire dataset, approximately 30,000 transactions are classified as being fraudulent.
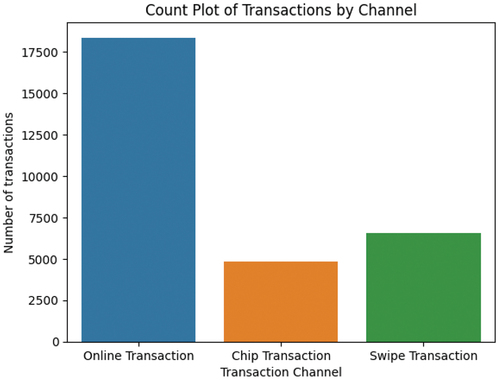
During our analysis, we observed that the values of the transacted amounts in the case of fraudulent transactions present a high similarity with the values of the transacted amounts of non-fraudulent transactions (). We also observed that most fraudulent transactions happened in December and August (), respectively during the years: 2010, 2008, 2016 and 2015 (). Moreover, we analyzed the types of transactions and observed that most of them were made through online channels ().
Figure 16. Number of fraudulent transactions by amount from the second dataset. Dataset source: Kaggle (Citation2021).
Figure 17. Number of fraudulent transactions by amount from the second dataset. Dataset source: Kaggle (Citation2021).
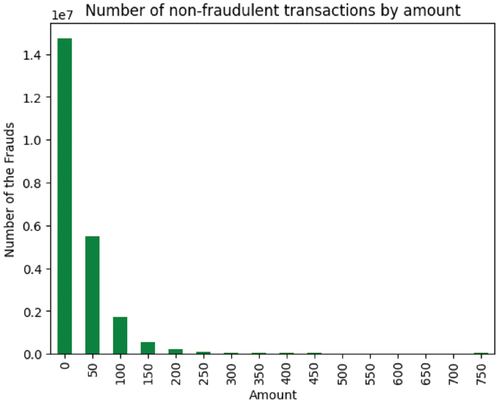
Figure 18. Number of fraudulent transactions by month from the second dataset. Dataset source: Kaggle (Citation2021).
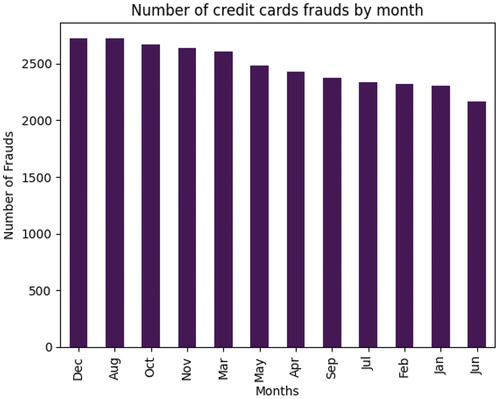
Figure 19. Number of fraudulent transactions by month from the second dataset. Dataset source: Kaggle (Citation2021).
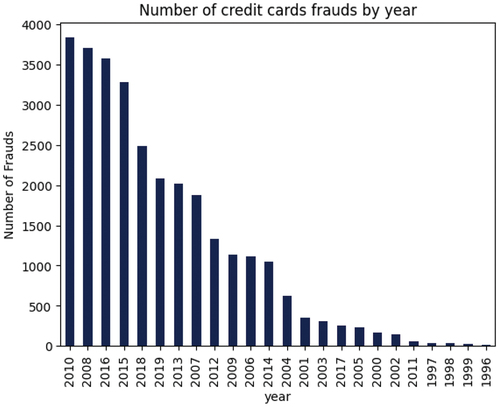
Figure 20. Transactions channels of fraudulent transaction. Dataset source: Kaggle (Citation2021).
Decision trees – identifying fraudulent transactions
Machine Learning algorithms have revolutionized various fields, enabling the automatic extraction of valuable information and patterns from large datasets. In the field of credit card fraud detection, Machine Learning techniques play a crucial role in identifying fraudulent transactions and minimizing financial losses for both cardholders and financial institutions. Among these algorithms, decision trees have gained significant attention due to their ability to achieve high performance in credit card fraud detection tasks.
Decision trees are a type of Machine Learning algorithm that utilizes a hierarchical structure consisting of nodes and branches to make decisions or classifications based on input features. Every node in the tree signifies an attribute or characteristic, while the branches outline potential outcomes or values. Through the recursive partitioning of data based on specific features, decision trees develop a model that can effectively classify new instances.
In credit card fraud detection, decision trees offer several advantages that contribute to their effectiveness. First, decision trees can handle both categorical and continuous features, making them suitable for various types of credit card transaction data. Whether categorical data such as transaction types or continuous data such as transaction amounts, decision trees can accommodate various input features commonly found in datasets containing credit card information.
Secondly, decision trees are inherently interpretable. The structure of a decision tree allows analysts to trace the decision-making process and understand the logic behind each classification. This inter-portability is crucial in fraud detection because it allows investigators to explain the reasons behind the model’s predictions, providing transparency and building trust in the decision-making process. Moreover, decision trees excel at capturing complex interactions and non-linear relationships between features. In credit card fraud detection, fraud patterns can be complicated and constantly evolving. Decision trees can detect and model these patterns by identifying combinations of features that indicate fraudulent activity. By considering multiple decision paths and evaluating different feature interactions, decision trees can accurately classify fraudulent transactions.
Considering all these arguments, but also the fact that decision trees are computationally efficient and scalable, we chose this Machine Learning algorithm to perform experiments on the dataset. Also, in our choice we took into account the fact that decision trees can be built efficiently and their classification process has a low computational cost, making them suitable for real-time fraud detection scenarios.
Therefore, the attributes that we have included in this classification are the following: the number of transactions carried out, the gender of the credit card holders, their age, the month in which the transaction took place, the year in which it took place, the location where the fraud took place, but also the type of fraud. To apply this algorithm, the Python programming language was used, and the implementation of the algorithm from the sklearn library called DecisionTreeClassifier. This implementation requires preparing the dataset beforehand. First, the algorithm must learn based on the training dataset and its performance evaluation must be performed on the test dataset.
Secondly, the data must be scaled. For data scaling, we used Standard- Scaler from the sklearn library. There are several reasons why applying StandardScaler can be beneficial: Different attributes in a dataset can have different scales or units of measure. For example, in a credit card fraud detection dataset, transaction amounts can vary from a few dollars to thousands of dollars, while the number of transactions can vary from a few per cent. These variable scales can cause certain features to dominate the learning process, leading to biased model performance. By applying the StandardScaler, all features are scaled to a common scale, smoothing out the impact of different magnitudes and allowing the model to learn from all features equally. On the other hand, many Machine Learning algorithms are sensitive to the scale of the input features. If the features are not on a similar scale, this can affect the performance of the model, leading to less good results.
Results
The results of the analysis focus on evaluating the performance and effectiveness of a decision tree model specifically trained to identify fraudulent transactions. Using two datasets, including fraudulent and legitimate transactions, two models were trained to discern patterns and characteristics that distinguish fraudulent from non-fraudulent activities. Through this process the decision tree-based algorithm has the potential to serve as a valuable tool for real-time fraud detection, helping organizations prevent financial losses and protect their customers’ interests.
The main objective of this analysis is to deepen the results obtained from the decision tree model and provide insights into its performance. By examining key metrics such as accuracy, precision, sensitivity, and F1 score, the overall effectiveness of the model can be assessed to correctly classify fraudulent transactions. In addition, important features identified by the model that significantly contribute to the classification process can be explored, shedding light on potential indicators of fraudulent activities.
Understanding the performance of the decision tree model is critical to evaluating its practical viability in real-world scenarios. By analyzing its strengths and weaknesses, the areas for improvement and fine-tuning can be identified, ultimately increasing the model’s accuracy and reliability. Furthermore, this analysis can inform decision-makers about the potential benefits and limitations of incorporating such a model into their fraud detection systems. Throughout this analysis, the results obtained from extensive testing procedures are deepened, ensuring the reliability and generalizability of the decision tree model performance. By examining its ability to accurately identify fraudulent transactions, we aim to provide useful information for prevention strategies.
As previously stated, in this analysis we used appropriate metrics to evaluate the model for identifying the nature of transactions. Firstly, to observe which of the attributes describing the transactions in the dataset influence the model’s decision more, a brief analysis of the importance of these attributes was performed. The importance of attributes plays a crucial role in credit card fraud detection, as it helps identify the most relevant and influential variables or characteristics that significantly contribute to distinguishing between fraudulent and legitimate transactions. Credit card transactions generate a large amount of data, including transaction amounts, merchant categories, time of day, location, and more. Feature importance analysis helps select the most relevant features for fraud detection, eliminating redundancy. By focusing on the most important features, organizations can improve the efficiency and effectiveness of their fraud detection models. Also, feature importance analysis can reveal the variables that have the greatest discriminating power in distinguishing between fraudulent and legitimate transactions. These important features can act as early warning indicators of potential fraud. By assigning higher weights or importance to these features, the model can improve its accuracy in detecting fraudulent transactions. This iterative feature selection process contributes to the continuous improvement of fraud detection systems.
The results regarding the importance of each attribute used in the training process are calculated by the algorithm. These are described in for the dataset generated using the instrument proposed by Brandon Harris, respectively in for the dataset proposed by IBM. In the case of the first dataset, the most important factor in deciding the nature of transactions is the transacted amount, with the rest of the attributes influencing only about 28% of the model’s decision. It can be seen how the age, the population of the city where the transaction took place, but also the type of certain transactions contribute to the decision in percentages of more than 2%. On the other hand, many other attributes, such as the year of the transaction and payments of purchases via POS, contribute only 1% in the identification of fraudulent transactions. In the case of the second dataset analyzed, the most significant attribute was the merchant name achieving approximately 50% importance. Moreover, the second importance value, of 10%, was obtained for the amount value of the transaction.
Regarding the transaction value, it is considered an important attribute in fraud detection for several reasons:
• Large transactions tend to have a more significant impact on individuals, businesses or financial institutions. Fraudulent activities involving substantial amounts can result in substantial financial losses.
• Unusual or abnormal transaction amounts may indicate fraudulent activity. Fraudsters often exploit system vulnerabilities to conduct transactions that deviate significantly from normal patterns.
• Certain types of fraud show consistent patterns in terms of transaction amounts. For example, fraudulent purchases often involve smaller transactions.
On the other hand, the merchant name is considered a very important attribute in fraud detection for several reasons:
• Merchant Reputation: The reputation of the merchant can provide valuable context. Fraudsters may target less reputable or new merchants. Monitoring transactions with unfamiliar or high-risk merchants can help flag potentially fraudulent activities.
• Transaction Patterns: Fraud detection systems often look for anomalies in transaction patterns. Knowing the merchant’s name can help identify unusual or unexpected transactions. For example, if a customer frequently shops at local stores and suddenly makes a large online purchase from a foreign merchant, it could be a red flag.
• Moreover, merchant names are often associated with Merchant Category Codes (MCC), which categorize businesses based on the types of products or services they provide. Certain MCCs may be associated with higher fraud risk. For example, online gambling or adult entertainment websites may have higher fraud rates than other categories.
Secondly, the performance evaluation of the model consists of analyzing the results of some of the most popular evaluation metrics for Machine Learning algorithms. In the context of credit card fraud detection, precision, accuracy, and F1 score are commonly used evaluation metrics to evaluate the performance of a fraud detection model.
In the context of credit card fraud detection, precision, accuracy, and F1 score are commonly used evaluation metrics to evaluate the performance of a fraud detection model. Each of these metrics provides insights into different aspects of the model’s effectiveness in identifying fraudulent transactions. The formulas of these metrics are based on the following notions:
• True positives (TP) – the number of fraudulent transactions correctly identified as fraudulent by the model.
• True negatives (TN) – represents the number of non-fraudulent transactions correctly identified as non-fraudulent by the model.
• False negatives (FN) occur when the model incorrectly predicts a transaction as non-fraudulent, but it is fraudulent according to the current classification.
• False positives occur when the model incorrectly predicts a transaction as fraudulent, but it is non-fraudulent according to the current classification.
Table 1. The importance of the attributes used in the training process of the machine learning algorithm based on decision trees for the first dataset analyzed.
Table 2. The importance of the attributes used in the training process of the machine learning algorithm based on decision trees for the second dataset analyzed.
The metrics for evaluating the performance of the model are as follows:
• precision is calculated as the ratio of true positives (TP) to the sum of true positives and false positives (FP): . A high precision value indicates that the model has a low rate of falsely identifying legitimate transactions as fraudulent. In credit card fraud detection, a high accuracy value is desirable because it minimizes the number of false alarms or incorrect fraud alerts.
• recall, is calculated as the ratio of true positives (TP) to the sum of true positives and false negatives (FN): . A high value of this indicates that the model has a low rate of misclassifying fraudulent transactions as non-fraudulent. In credit card fraud detection, a high sensitivity value is crucial because it ensures that the model can identify most fraudulent transactions, minimizing the risk of undetected fraud.
• accuracy, is calculated as the sum of true positives and true negatives divided by the sum of true positives, true negatives, false positives, and false negatives: . It should be considered alongside the value of precision and recall.
• the F1 score, combines precision and recall into a single metric, giving equal weight to both and is calculated as follows: . A higher F1 score indicates a better balance between precision and recall, suggesting a more reliable fraud detection model.
In this particular experiment, the decision tree-based model achieved good results in detection of frauds, as the values obtained for the evaluation show (). We managed to achieve a F1-Score of 97% and an accuracy of 99% when evaluated the model on the test dataset in case of the first data set. In case of the second data set, we achieved for both accuracy and F1-Score 99%. The obtained results indicate a good performance of the model showing that it also evolves well on new data, which were not included in the training set.
Table 3. Evaluation metrics values obtained in case of both datasets used.
Conclusion
The current paper discussed the prevalence of card fraud, which presents significant challenges and potential threats to banks, other financial institutions, customers and overall economic stability. This study explored the nature of card fraud and discussed different detection methods used to identify fraudulent transactions, both classical methods and new methods based on Artificial Intelligence and Machine Learning. These systems can promptly alert authorities to take appropriate action using rule-based models and anomaly detection techniques.
Fraudulent detection involves several layers of control. Enhanced know-your-customer procedures, such as identity verification, document authentication, and risk-based profiling, are implemented during the onboarding process to identify and flag potential fraudulent accounts. Regular reviews and audits of customer accounts, transactional data and unusual activity can help detect fraudulent behavior in existing accounts. In addition, collaboration and information sharing between financial institutions, law enforcement agencies and regulatory bodies play a crucial role in combating fraud. Sharing information about known fraudsters, suspicious transactions and emerging fraud trends enables proactive detection and prevention.
However, one of the limitations of our experimental study in terms of the automatic detection of fraudulent transactions is given by the datasets. They were generated by software tools, and in some cases, in reality, the data may have a different and much more complex structure. Moreover, the fraud theories mentioned in Literature Survey chapter are hard to be tested given the fact that the actions which lead to the specific fraud are unknown. Our work and results are based only on digital data.
Future research will continue this study by broadening the analysis based on the evolution of the level of fraud both at the European level and at the global level. We also aim to evaluate the performance of other Machine Learning algorithms in terms of fraud detection and to identify an automatic method for detecting fraudulent transactions. The research will also endeavor to integrate the best models of automatic fraud detection into a system readily available for financial institutions that could assist them more effectively in the fight against fraud.
uaai_a_2385249_sm7307.cls
Download (54 KB)uaai_a_2385249_sm7308.bst
Download (29.7 KB)uaai_a_2385249_sm7314.bib
Download Bibliographical Database File (17.8 KB)uaai_a_2385249_sm7313.bst
Download (37.5 KB)uaai_a_2385249_sm7309.bst
Download (34.9 KB)uaai_a_2385249_sm7305.bst
Download (143.7 KB)uaai_a_2385249_sm7311.bst
Download (62.6 KB)uaai_a_2385249_sm7315.bib
Download Bibliographical Database File (16.4 KB)uaai_a_2385249_sm7312.bst
Download (39.5 KB)uaai_a_2385249_sm7310.bst
Download (40.3 KB)uaai_a_2385249_sm7306.bst
Download (62.6 KB)Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data that support the findings of this study are openly available in Credit Card Transactions repository in Kaggle at https://www.kaggle.com/datasets/ealtman2019/credit-card-transactions. respectively in Credit Card Transactions Fraud Detection Dataset repository in Kaggle at https://www.kaggle.com/datasets/kartik2112/fraud-detection.
References
- Abiola and Idowu. 2009. An assessment of fraud and its management in Nigeria commercial banks. European Journal of Social Sciences 10 (4):628–26.
- Adetiloye, K. A., F. O. Olokoyo, and J. N. Taiwo. 2016. Fraud prevention and internal control in the Nigerian banking system. International Journal of Economics and Financial Issues 6:1172–79.
- Akers, M. D., and J. L. Gissel. 2006. What is fraud and who is responsible? Journal of Forensic Accounting 7 (1).
- Albrecht, W. S. 2003. Fraud examination. 3rd ed. South-Western College Pub.
- Al-Hashedi, K., and P. Magalingam. 2021. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Computer Science Review 40:1–23. doi:10.1016/j.cosrev.2021.100402.
- Aljohani, K., S. Aljuaid, and A. Aljarboa. 2021. Fraud prevention policies and strategies of banks in Saudi Arabia. Journal of Financial Crime 28 (1):200–15. doi:10.1108/JFC-09-2020-0151.
- Alraddadi, A. S. 2023. A survey and a credit card fraud detection and prevention model using the decision tree algorithm. Engineering, Technology & Applied Science Research 13 (4):11505–10. doi:10.48084/etasr.6128.
- Altman, E. R. 2019. Synthesizing credit card transactions. CoRR. doi: 10.1145/3490354.3494378.
- Athey, S. 2019. The impact of machine learning on economics. In The economics of artificial intelligence: An agenda, ed. A. Agrawal, J. Gans, and A. Goldfarb, 507–47. University of Chicago Press. Accessed July 20th, 2023. http://www.nber.org/chapters/c14009.
- Bhasin, M. 2016. The role of technology in combating bank frauds: Perspectives and prospects. Ecoforum Journal 5 (2):200–212.
- Bhattacharyya, S., S. Jha, K. Tharakunnel, and J. Westland. 2011. Data mining for credit card fraud: A comparative study. Decision Support Systems 50 (3):602–13. doi:10.1016/j.dss.2010.08.008.
- Chaudhary, K., J. Yadav, and B. Mallick. 2012. A review of fraud detection techniques: Credit card. International Journal of Computer Applications 45:39–44.
- Crowe, J. T. 2015. Fraud pentagon theory. Journal of Accountancy 220 (2):28–33.
- Dzomira, S. 2015. Fraud prevention and detection. Research Journal of Finance & Accounting 6:40–43.
- Enofe, A., T. Abilogun, A. Omoolorun, and E. Elaiho. 2017. International journal of academic research in business and social sciences. The International Journal of Academic Research in Business & Social Sciences 7 (7):110–21.
- Ernst and Young. 2009. Detecting financial statement fraud. Tech. rep. Ernst and Young.
- FICO. 2023. European fraud. Accessed April 9, 2023. https://www.fico.com/europeanfraud/.
- Gbegi, D. O., and A. J. F. 2013. The new fraud diamond model - how can it help forensic accountants in fraud investigation in Nigeria? European Journal of Accounting Auditing and Fiancé Research 1 (4):129–138.
- Hastie, T., R. Tibshirani, and J. Friedman. 2009. The elements of statistical learning: Data mining, inference, and prediction. New York, NY: Springer.
- Hoffmann, A., and C. Birnbrich. 2012. The impact of fraud prevention on bank-customer relationships: An empirical investigation in retail banking. International Journal of Bank Marketing 30 (5):390–407. doi: 10.1108/02652321211247435.
- Kaggle. 2020. Credit card transactions fraud detection dataset. Accessed May 11, 2023. https://www.kaggle.com/datasets/kartik2112/fraud-detection.
- Kaggle. 2021. Credit card transactions. Accessed September 24, 2023. https://www.kaggle.com/datasets/ealtman2019/credit-card-tran-sactions.
- Khanna, A., and B. Arora. 2009. A study to investigate the reasons for bank fraud and the implementation of preventive security controls in the Indian banking industry. International Journal of Business Science & Applied Management 4:3.
- Kotsiantis, S. B., I. D. Zaharakis, and P. E. Pintelas. 2007. Supervised machine learning: A review of classification techniques. Informatica 31 (3):249–68.
- Machado, M. R. R., and I. R. Gartner. 2017. Cressey hypothesis (1953) and an investigation into the occurrence of corporate fraud: An empirical analysis conducted in Brazilian banking institutions. https://api.semanticscholar.org/CorpusID:59024427.
- Mahesh, B. 2020. Machine learning algorithms - a review. International Journal of Science and Research 9 (1):381–86. doi:10.21275/ART2020399.
- Manurung, D. T. H., and N. Hadian. 2017. Detection fraud of financial statement with fraud triangle. International Journal of Business, Economics and Law 12 (4):31–34.
- Mullainathan, S., and Z. Obermeyer. 2017. Does machine learning automate moral hazard and error? The American Economic Review 107 (5):476–80. doi:10.1257/aer.p20171084.
- Nabhan, R., and N. Hindi. 2009. Bank fraud: Perception of bankers in the state of qatar. Academy of Banking Studies Journal 8:15–38.
- Nilson Report. 2023. Nilson report research publication. Accessed March 13, 2023.
- Nwankwo, O. F. 2013. Implications of fraud on commercial banks performance in nigeria. International Journal of Biometrics 8 (15):144. doi:10.5539/ijbm.v8n15p144.
- Olaleye Ayorinde, K. 2021. A methodology for detecting credit card Cornerstone: A Collection of Scholarly and Creative Works for Minnesota State University. Master’s thesis, Mankato.
- Omar, N. B., and H. F. Mohamad Din. 2010. Fraud diamond risk indicator: An assessment of its importance and usage. 2010 International Conference on Science and Social Research (CSSR 2010), 607–12. doi:10.1109/CSSR2010.5773853.
- Plakandaras, V., P. Gogas, T. Papadimitriou, and I. Tsamardinos. 2022. Credit card fraud detection with automated machine learning systems. Applied Artificial Intelligence 36 (1):2086354. doi:10.1080/08839514.2022.2086354.
- Rahman, R. A., and I. S. K. Anwar. 2014. Effectiveness of fraud prevention and detection techniques in Malaysian Islamic banks. Procedia - Social & Behavioral Sciences 145:97–102. doi:10.1016/j.sbspro.2014.06.015.
- Repousis, S., P. Lois, and V. Veli. 2019. An investigation of the fraud risk and fraud scheme methods in Greek commercial banks. Journal of Money Laundering Control 22 (1):53–61. doi:10.1108/JMLC-11-2017-0065.
- Ruankaew, T. 2013. The fraud factors. Accessed July 2023. https://oa.mg/work/2183440902.
- Save, P., P. Tiwarekar, K. N. Jain, and N. Mahyavanshi. 2017. A novel idea for credit card fraud detection using decision tree. International Journal of Computer Applications 161 (13):6–9. doi:10.5120/ijca2017913413.
- Scikit-learn: Machine learning in Python. n.d. https://scikit-learn.org/stable/.
- Tunji, S. 2013. Effective internal control system as an antidote for distress in the banking industry in nigeria. Journal of Economics and International Business Research 1 (5):106–21.
- Vonasek, J. 2013. Fraud detection in unlabeled payment card transactions. Bachelor’s Project, Czech Technical University in Prague, 1–63.
- West, J., and M. Bhattacharya. 2016. Intelligent financial fraud detection: A comprehensive review. Computers & Security 57:47–66. doi:10.1016/j.cose.2015.09.005.
- Wolfe, D. T., and D. R. Hermanson. 2004. The fraud diamond: Considering the four elements of fraud. The CPA Journal 74 (12):38–42.
- Xuan, S., G. Liu, and Z. Li. 2018. Refined weighted random forest and its application to credit card fraud detection. Computational Data and Social Networks: 7th International Conference, CSoNet 2018, 343–55, Shanghai, China, December 18–20, 2018, Proceedings 7.
- Zhu, Z.-H. 2021. Machine learning. Singapore: Springer Nature. doi: 10.1007/978-987-15-1967-3.