
ABSTRACT
The design of an experiment can always be considered at least implicitly Bayesian, with prior knowledge used informally to aid decisions such as the variables to be studied and the choice of a plausible relationship between the explanatory variables and measured responses. Bayesian methods allow uncertainty in these decisions to be incorporated into design selection through prior distributions that encapsulate information available from scientific knowledge or previous experimentation. Further, a design may be explicitly tailored to the aim of the experiment through a decision-theoretic approach using an appropriate loss function. We review the area of decision-theoretic Bayesian design, with particular emphasis on recent advances in computational methods. For many problems arising in industry and science, experiments result in a discrete response that is well described by a member of the class of generalized linear models. Bayesian design for such nonlinear models is often seen as impractical as the expected loss is analytically intractable and numerical approximations are usually computationally expensive. We describe how Gaussian process emulation, commonly used in computer experiments, can play an important role in facilitating Bayesian design for realistic problems. A main focus is the combination of Gaussian process regression to approximate the expected loss with cyclic descent (coordinate exchange) optimization algorithms to allow optimal designs to be found for previously infeasible problems. We also present the first optimal design results for statistical models formed from dimensional analysis, a methodology widely employed in the engineering and physical sciences to produce parsimonious and interpretable models. Using the famous paper helicopter experiment, we show the potential for the combination of Bayesian design, generalized linear models, and dimensional analysis to produce small but informative experiments.
Introduction
Design of experiments is an a priori activity, taking place before data has been collected, and hence the Bayesian paradigm is a particularly appropriate approach to take. Bayesian methods allow available prior information on the model to be incorporated into both the design of the experiment and the analysis of the resulting data, and produce posterior distributions that are interpretable by scientists. They also reduce reliance on unrealistic assumptions and asymptotic results that may be inappropriate for small- to medium-sized experiments. The Bayesian approach to design enables realistic and coherent accounting for the substantial model and parameter uncertainties that usually exist before an experiment is performed and it is also a natural framework for sequential inference and design.
An important problem where Bayesian methods can have substantial impact is optimal design for nonlinear modelling, which relies on some prior information being available about the unknown values of the model parameters (see Atkinson et al., Citation2007, Ch. 17). A Bayesian approach relaxes the requirement of locally optimal design criteria to specify particular values of the parameters. Fully Bayesian design, predicated on using the posterior distributions for inference as outlined below, is also less reliant on the asymptotic assumptions that underpin most classical design for nonlinear models.
A decision-theoretic Bayesian optimal design is found through minimization of the expectation of a loss function that is chosen to encapsulate the aims of the experiment. Suppose that we require a design for q variables in n points, with the ith point defined as . The choice of design space
determines the quality of design that can be found and should be chosen in conjunction with the statistical model. For a linear model composed of only first-order terms and interactions, a discrete design space containing only the corner points of, for example, the unit cube will suffice for finding an optimal design. For the more complex nonlinear models considered in this article, a continuous design space is needed to allow an optimal design to be found.
Let be the loss function for a design
producing data
. Assume a statistical model defined via likelihood
, with parameters
having prior density
. The vector
may include parameters defining both the mean and variance of y. Then an optimal design ξ⋆ is defined as
[1] For further details, see the landmark review article of Chaloner and Verdinelli (Citation1995].
There are a number of challenges in calculating the expected loss in [Equation1[1] ]:
| (a) | the evaluation of l itself is potentially non-trivial, as it may depend on the posterior distribution and only be available numerically; | ||||
| (b) | the integrals in [Equation1 | ||||
| (c) | evaluation of the joint density | ||||
Common choices for l include (i) the self-information loss log , and (ii) the squared-error loss between (a function of)
and its posterior expectation. If the prior density does not depend on the design, minimization of the expected self-information loss is equivalent to maximisation of the expected Kullback-Leibler (KL) divergence between the prior and posterior distributions (see MacKay, Citation2003, Ch. 2; Sebastiani and Wynn, Citation2000). For some experiments, bespoke loss functions may be required. For example, it may be necessary or desirable to incorporate the cost of each run of the experiment. We demonstrate results using both expected self-information loss (SIL), defined as
[2] and the expected squared-error loss (SEL) for the prediction of the mean response μ(x),
[3] We refer to a design minimizing [Equation2
[2] ] or [Equation3
[3] ] as SIL-optimal or SEL-optimal, respectively.
Until very recently, optimal Bayesian design has not evolved far from the methods reviewed by Chaloner and Verdinelli (Citation1995). Development and application of methods for Bayesian design have lagged behind the progress made in inference and modelling due to the additional complexity introduced by the need to integrate over the (as yet) unobserved responses, in addition to unknown model parameters. Hence, methodology has been restricted to simple models and fully sequential, one-point-at-a-time, procedures (Ryan et al., Citation2016).
In this article, we focus on experiments for multi-variable generalized linear models and present new results for optimal design for dimensional analysis. In Section 2 we introduce the generalized linear models for which optimal designs will be sought and use Box’s helicopter experiment to introduce and demonstrate the concepts of dimensional analysis. In Section 3, we then review the main approaches to overcoming challenges (a)–(c) that have been proposed in the literature. A major focus is the approximate coordinate exchange methodology proposed by Overstall and Woods (Citation2016b). In Section 4 we use approximate coordinate exchange to find Bayesian optimal designs for three examples, including the helicopter experiment. We finish with a short discussion in Section 5, highlighting issues that may hinder the adoption of Bayesian design in practice, and propose some potential remedies.
Experiments with generalized linear models
Generalized linear models (GLMs; McCullagh and Nelder, Citation1989) are an important class of models for scientific and industrial experiments whose response cannot be well described by a normal-theory linear model (see Myers et al., Citation2010). In addition to standard linear regression, the class of GLMs includes models for binary and count data. A GLM has three components:
| 1. | a distribution for the univariate response y(x) taken from the exponential family; | ||||
| 2. | a linear predictor | ||||
| 3. | a link function g(μ(x)) = η(x) relating x to the mean E{y(x)} = μ(x). | ||||
The variance of y(x) takes the form Var{y(x)} = φV{μ(x)}, with φ > 0 a dispersion parameter and the form of the function V dependent on the selected exponential family distribution.
Atkinson and Woods (Citation2015) reviewed the upsurge in the development of design methodology for GLMs that has taken place over the last 10 years or so. Key to frequentist, and much Bayesian, optimal design for GLMs is the Fisher information matrix for , which for an n-run experiment takes the form
[4] with X an n × p model matrix with ith row equal to
and W an n × n diagonal matrix with ith entry
In general, the information matrix depends on the values of the unknown model parameters through the matrix W. A notable exception is for the linear regression model.
Below we discuss two classes of models: (i) GLMs for discrete responses; and (ii) a GLM for a continuous response with a linear predictor that incorporates physical principles via dimensional analysis.
Experiments with discrete responses
Perhaps the most common examples of optimal design for GLMs involve discrete responses, for example binary, binomial or count data. Woods et al. (Citation2006) and Woods and van de Ven (Citation2011) described examples from chemistry, food technology and engineering with binary (success/fail) responses. In particular, the potato-packing experiment from Woods et al. (Citation2006) involved measuring the formation, or not, of moisture in a protected atmosphere package. The treatments consisted of the settings of three variables: vitamin concentration in the pre-packing dip and the levels of two gases in the atmosphere. A suitable GLM here might be a logistic regression. Let y(xi) ∼ Bernoulli{ρ(xi)} be the response from the ith run of the experiment, with variable settings xi and
[5] where β0, …, β3, β11, β12, …, β33 are unknown parameters to be estimated. Here, μ(xi) = ρ(xi) and the variance function is given by V{μ(xi)} = ρ(xi)[1 − ρ(xi)] with φ = 1. To illustrate some Bayesian design concepts, Atkinson and Woods (Citation2015) assumed the following independent prior distributions for the parameters:
[6]
For multi-variable experiments, most theoretical progress on optimal design has been made for Poisson distributed responses, see, for example, Russell et al. (Citation2009). Poisson regression is often employed in industrial experiments counting numbers of defects (Wu and Hamada, Citation2009, Ch. 14) or in environmental and biological experiments where the response is the count of animal numbers or cell growth. Let y(xi) ∼ Poisson{μ(xi)}, with V{μ(xi)} = μ(xi) and φ = 1. McGree and Eccleston (Citation2012) and Atkinson and Woods (Citation2015) presented theoretical constructions of optimal designs robust to the values of the model parameters for log-linear models with linear predictors of the form
[7] The latter authors illustrated the construction methods for experiments with q = 5 variables with uniform prior distributions assumed for each βj,
[8] with α > 0. The intercept β0 = 0 was assumed known.
In Section 4.1, we find, assess and compare Bayesian optimal designs for both the logistic and log-linear models.
Dimensional analysis
Dimensional analysis (DA) is a methodology commonly used by engineers and physical scientists to produce parsimonious and dimensionally consistent models (Sonin, Citation2001). A base set of dimensionless variables are identified via (nonlinear) transformations of the explanatory variables and related to a similarly transformed response variable via a, typically nonlinear, regression model. The model thus formed will satisfy Buckingham’s Π theorem (Buckingham, Citation1914, Citation1915a, Citation1915b), which states that physically meaningful relationships must be dimensionally homogeneous. In addition to performing a priori dimension reduction of the input variables, DA provides the possibility of obtaining models that are scale-free and hence, for example, applicable to a range of manufacturing processing scales from lab to production.
Reviews of DA from a statistician’s perspective are provided by the recent articles from Albrecht et al. (Citation2013) and Shen et al. (Citation2014). The latter authors applied DA to Box’s paper helicopter experiment (Box and Liu, Citation1999), and we will use this example to demonstrate the potential of the combination of DA, GLMs, and Bayesian design.
We use a standard paper helicopter pattern and consider three independent variables: rotor width, rotor length, and tail length; see . The ranges of these three variables, and other dimensions, are taken from http://www.paperhelicopterexperiment.com and are given in , along with settings of other physical parameters.
Figure 1. Paper helicopter pattern.
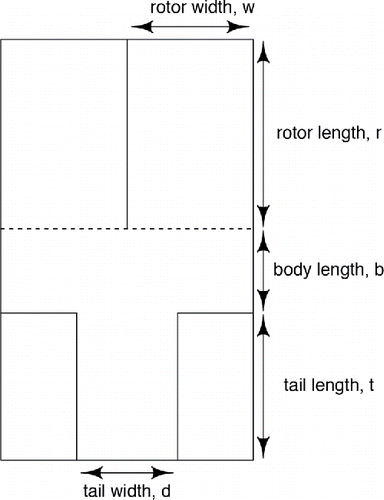
Table 1. Variable ranges and physical parameter settings (in SI units) for the paper helicopter experiment. Flight time is the measured response.
Shen et al. (Citation2014) identified the base quantities
and fitted a regression model for flight time on the log scale with
[9] Equation[Equation9
[9] ] follows a power law and is consistent with Bridgman’s principle of absolute significance of relative magnitude (Bridgman, Citation1931), another fundamental theorem of DA.
In common with Shen et al. (Citation2014), we consider experiments with n = 4 runs but adapt these authors’ study in two ways.
| 1. | We assume the density of the paper is fixed, and hence helicopter mass (m) is a varying function of the three controllable variables rotor width, rotor length and tail length. Relabeling T = y(x) and r = x1, w = x2 and t = x3 for consistency, Eq. [Equation9 | ||||
| 2. | Rather than assume additive normal errors on the log scale, we model flight time as a Gamma distributed random variable and assume a GLM with log link and linear predictor [Equation10 | ||||
We assume prior distributions
[11] The prior means of the physical parameters are equal to estimates from Shen et al. (Citation2014); we set the prior variances equal to 2.5 times the estimated variances from Shen et al. (Citation2014) to obtain more diffuse prior distributions. For the dispersion parameter, our choice of prior leads to the variance of y(x) being between 75% and 125% of the value of μ(x)2.
In Section 4.2, we find, assess and compare Bayesian optimal designs for this Gamma regression model.
A review of approaches to Bayesian design
In this section, we provide an overview of some of the most common approaches to Bayesian design in the literature. We focus on (i) analytical and computational approximations to the expected loss in [Equation1[1] ], and (ii) optimization methods for multi-variable experiments.
Asymptotic approximations
For experiments with large n, the inverse of the expected Fisher information matrix is an asymptotic approximation to the posterior variance-covariance matrix of the parameters
. Use of this approximation leads to pseudo-Bayesian “alphabetic” optimality criteria (Atkinson et al., Citation2007, Ch. 10). For example, under pseudo-Bayesian D-optimality, a design is selected to minimize
[12] The integral with respect to
is usually of low dimension and amenable to deterministic approximation. Such an approximation to the objective function can then be minimized using a conditional algorithm such as point or coordinate exchange; see, for, example, Gotwalt et al. (Citation2009). For a point prior density on
, which is equivalent to assuming known parameter values, minimization of [Equation12
[12] ] leads to a locally D-optimal design.
Simulation-based optimization
In general, the expected loss can be approximated via Monte Carlo integration (e.g., Gentle, Citation2003, Ch. 7) as
with
a random sample drawn from the joint distribution of parameters
and responses y. Typically, this is obtained by sampling
from the prior density
and then sampling y from the conditional density
. The loss
often itself requires numerical approximation, necessitating a nested, double-loop, Monte Carlo simulation; see Ryan (Citation2003). Direct optimization of this approximation requires large B to generate a suitably precise approximation to the objective function and/or expensive stochastic algorithms (e.g., simulated annealing or genetic algorithms), see, for example, Hamada et al. (Citation2001) and Huan and Marzouk (Citation2013) who employed polynomial chaos approximations to facilitate sampling from
. Alternatively, the optimization can be embedded within a Markov chain simulation scheme, and an optimal design identified by sampling from an artificial joint distribution for the design, model parameters and data, and then finding the mode of the marginal distribution of the design (Müller, Citation1999, Müller et al., Citation2004, Amzal et al., Citation2006). Typically, an annealing step is employed to enable easier identification of the optimal design. This approach is most effective for small experiments (few variables and runs). Recent extensions to this algorithm have allowed designs to be found for (i) models with intractable likelihoods using Approximate Bayesian Computation (see Drovandi and Pettitt, Citation2013, and Hainy et al., Citation2013 for other ABC design methods) and (ii) dynamic models with numerous sampling times using dimension reduction (Ryan et al., Citation2014), importance sampling, and Laplace approximations (Ryan et al., Citation2015).
Sequential design
Most experiments are part of a sequence, where a Bayesian approach, with sequential updating from prior to posterior distributions, is natural. For point-sequential designs, with one point at a time added to the design, approximation of the expected loss is greatly simplified by the resulting reduction in the dimension of the integral. Recent methods have been suggested for estimation of, and discrimination between, nonlinear models, see Drovandi et al. (Citation2013, Citation2014). A growing area is Bayesian optimization of expensive black-box functions (e.g., in computer experiments), using Gaussian process surrogates to reduce the number of required function evaluations, following the seminal work of Jones et al. (Citation1998). The computational efficiency of sequential design can be greatly aided through the use of sequential Monte Carlo for the necessary inference (see Gramacy and Polson, Citation2011).
Smoothing-based optimisation
Smoothing-based design methods (Müller and Parmigiani, Citation1996) evaluate a computationally expensive, typically Monte Carlo, approximation to the expected loss [Equation1[1] ] for a limited number of designs and then smooth these approximated losses to generate a surrogate function which can then be optimized in place of the true expected loss. Recent research includes (i) extension of such methods to employ Gaussian process smoothing and Bayesian optimization (Weaver et al., Citation2016) and (ii) use of surrogates to enable Bayesian D-optimal design for generalized linear mixed models (Waite and Woods, Citation2015).
A key challenge for the application of smoothing-based methods to design problems with large numbers of runs or variables is the high-dimensional smoothing that is required. An extension that addresses this challenge using conditional smoothing and optimization is described in the next section.
Approximate coordinate exchange
Overstall and Woods (Citation2016b) proposed the first general purpose methodology for high-dimensional, multi-variable Bayesian design that does not rely on normal approximations to the posterior density. Their approximate coordinate exchange (ACE) algorithm is a conditional optimization algorithm that makes use of surrogates, or emulators, for the expected loss as a function of a single design coordinate (i.e., the value of a single variable for a particular run).
In the field of computer experiments (Sacks et al., Citation1989), an emulator is a statistical model built to approximate the output from an expensive computer model or code. The most common emulator is a Gaussian process model (GP; see, for example, Rasmussen and Williams, Citation2006), which nonparametrically smooths or interpolates the computer model output. In the ACE algorithm, GP models are used to smooth the Monte Carlo approximation to the expected loss.
Algorithm 1 gives the basic steps of ACE. Let be a Monte Carlo approximation to the expected loss for design ξ with ijth coordinate replaced by
(i = 1, …, n; j = 1, …, q). Here,
is the projection of the design space
onto the jth dimension. The algorithm steps through each coordinate of the design, and for each coordinate constructs a one-dimensional emulator,
, for
. The value of x that minimises this emulator is found, and an accept/reject step performed in order to decide whether to swap the current design coordinate with this proposed coordinate. This accept/reject step is described in Algorithm 2.
The ACE algorithm would typically be repeated multiple times (perhaps exploiting parallel computing) to avoid local optima. Overstall and Woods (Citation2016b) gave more details of the implementation and application of the algorithm, including its combination with a point-exchange algorithm to consolidate clusters of similar design points.
A GP model is employed in line 9 of Algorithm 1. The emulator is given by the posterior mean function of the GP
[13] with
,
,
a Q-vector having kth entry equal to the standardised approximate expected loss
and ζij = {x1ij, …, xQij} being points from a one-dimensional space-filling design in
(see Algorithm 1). Under the common assumption of a squared exponential correlation structure, the correlation between the responses at two points is inversely proportional to the exponential of the squared difference between the points, leading to the Q-vector
and Q × Q matrix A having entries
where
is the indicator function and η > 0 is the nugget. Adding η to the diagonal elements of the correlation matrix ensures the emulator will smooth, rather than interpolate, the stochastic Monte Carlo approximation
, and improves the numerical stability of the emulator (Gramacy and Lee, Citation2012). We estimate ρ and η via maximum likelihood.
The minimization in line 10 of Algorithm 1 is subject to both Monte Carlo error and emulator error. To remove the emulator error when making the decision whether to accept the exchange, the steps in Algorithm 2 are performed using independent Monte Carlo samples to assess the improvement in the design. Algorithm 2 essentially describes a Bayesian t-test based on simulated data from the existing and proposed designs (cf. Wang and Zhang, Citation2006). If the assumption of normality that underpins this test is invalid, a nonparametric procedure may be used instead.
Convergence in Algorithm 1 is assessed graphically, in a similar spirit to convergence diagnostics for Markov chain Monte Carlo; see Overstall and Woods (Citation2016b) for examples.
Bayesian designs for generalized linear models
In this section, we find Bayesian optimal designs for the three GLMs outlined in Section 2. The new designs are found using ACE, with B = 1000 and Q = 20 in Algorithm 1 and in Algorithm 2, unless otherwise stated, and assessed against various competitors from the literature.
Optimal design for experiments with discrete response
We now demonstrateBayesian design for logistic and Poisson regression. As most previous design work for these models has focussed on D-optimality, we find SIL-optimal designs and compare with Pseudo-Bayesian D-optimal designs. These latter designs are an asymptotic approximation to the SIL-optimal designs (see Overstall and Woods, Citation2016b).
Logistic regression
We start by finding n = 16 run SIL-optimal designs for logistic regression, minimising a Monte Carlo approximation to [Equation2[2] ] and using Q = 10 in Algorithm 1, with linear predictor [Equation5
[5] ],
and prior distribution [Equation6
[6] ]. The choice of design space
allows comparison to an orthogonal central composite design (CCD) with n = 16 points. The CCD is a common design for a linear model with a second-order linear predictor (see Dean and Voss, Citation1999, Ch. 16). a gives two-dimensional projections of the SIL-optimal design, along with the CCD and a pseudo-Bayesian D-optimal design with n = 16 points that minimizes a quadrature approximation to [Equation12
[12] ]. The main qualitative difference between the SIL-optimal and D-optimal designs is the greater concentration of points at the extremes of the design region for the SIL-optimal design, especially for x3. These differences in the distribution of the design points can be clearly seen in , which shows histograms of the one-dimensional projections of the three designs. The concentration of points at the extremes of x3 for both optimal designs is consistent with literature results on locally optimal design with parameter values that are small in absolute value (see Cox, Citation1988); here, E(β3) = 0.
Figure 2. Logistic regression example: (a) Two-dimensional projections of the SIL-optimal, pseudo-Bayesian D-optimal and central composite designs. (b) Boxplots of 20 Monte Carlo approximations of the expected self-information loss [Equation2[2] ] using B = 20, 000 simulations for the SIL-optimal, Pseudo-Bayesian D-optimal and central composite designs.
![Figure 2. Logistic regression example: (a) Two-dimensional projections of the SIL-optimal, pseudo-Bayesian D-optimal and central composite designs. (b) Boxplots of 20 Monte Carlo approximations of the expected self-information loss [Equation2[2] ] using B = 20, 000 simulations for the SIL-optimal, Pseudo-Bayesian D-optimal and central composite designs.](/cms/asset/acc7bb86-12ce-4dd2-8898-cb8f683adabc/lqen_a_1246045_f0002_b.gif)
Figure 3. Logistic regression example: One-dimensional projections of the SIL-optimal, pseudo-Bayesian D-optimal, and central composite designs.
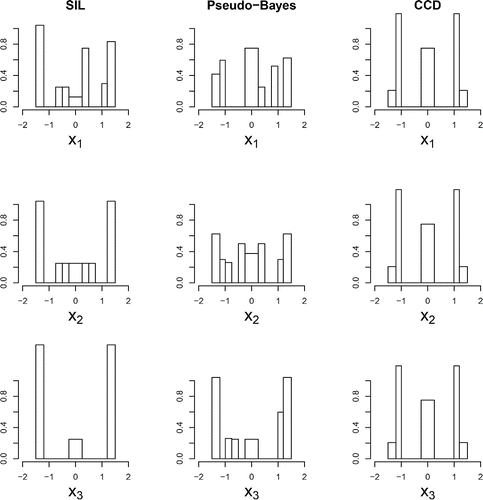
To quantitatively compare the three designs, we performed 20 repeated Monte Carlo approximations of [Equation2[2] ], each using B = 20, 000. Boxplots of these results are given in b. The SIL-optimal design naturally performs best, and has around 10% lower negative expected KL divergence compared to the pseudo-Bayesian design. Both are substantially better than the central composite design, which of course makes no use of prior information and should only be employed for the estimation of a second-order response surface model which is linear in the unknown parameters.
Poisson regression
McGree and Eccleston (Citation2012) and Atkinson and Woods (Citation2015) presented analytical construction methods for pseudo-Bayesian optimal designs for log-linear regression with linear predictor [Equation7[7] ]. The resulting designs minimize [Equation12
[12] ] among the class of minimally supported designs, that is, designs for which the number of distinct design points is equal to the number of parameters in the linear predictor. The construction method uses the algorithm of Russell et al. (Citation2009). For − 1 ⩽ xij ⩽ 1 (i = 1, …, q + 1; j = 1, …, q) and |E(βj)| > 1, the unreplicated minimally supported pseudo-Bayesian D-optimal (MSPBD) design has points xi = c − 2ei/E(βi) for i = 1, …, q and xq + 1 = c, where ei is the ith column of the q × q identity matrix and c = (c1, …, cq)T with ci = 1 if E(βi) > 0 and ci = −1 if E(βi) < 0. The minimally supported optimal design for q = 5 variables and prior distribution [Equation8
[8] ] is given in .
Table 2. Log-linear regression example: Minimally supported Pseudo-Bayesian D-optimal design under uniform prior distribution [Equation8[8] ]; γ = 0.6 for α = 0.5 and γ = 0.455 for α = 0.75.
Using ACE, we find SIL-optimal designs, again minimising a Monte Carlo approximation to [Equation2[2] ], with n = q + 1 = 6 design points under prior distribution [Equation8
[8] ]. The designs are given in a and b for α = 0.5 and α = 0.75, respectively. These designs have the same structure as the MSPBD-optimal design, with each variable only taking two values, one value with xij = ±1 and one value with − 1 < xij < 1. Unlike the MSPBD-optimal designs, this latter value is not constant in absolute value across the variables, although it does always have the same sign as the corresponding value in the MSPBD-optimal design.
Table 3. Log-linear regression example: SIL-optimal designs under uniform prior distribution [Equation8[8] ] for (a) α = 0.5 and (b) α = 0.75.
A quantitative comparison of the designs is given in a for α = 0.5 and b for α = 0.75, which display 20 repeated Monte Carlo approximations of [Equation2[2] ], each using B = 20, 000. The expected loss is lower for the less diffuse prior distribution (α = 0.5). For both values of α, the SIL-optimal and MSPBD-optimal designs perform very similarly, showing that the asymptotic approximation [Equation12
[12] ] is considerably more effective for this problem than for the binary response example, even though the experiment size n is smaller. This finding is unsurprising as the normal distribution, from which [Equation12
[12] ] is derived, is a more effective approximation to the Poisson distribution than it is to the Bernoulli distribution.
Figure 4. Log-linear regression example: Boxplots of 20 Monte Carlo approximations of the expected self-information loss [Equation2[2] ] using B = 20, 000 simulations for the SIL-optimal and minimally supported Pseudo-Bayesian D-optimal designs (MSPBD) under uniform prior distributions [Equation8
[8] ] for (a) α = 0.5 and (b) α = 0.75.
![Figure 4. Log-linear regression example: Boxplots of 20 Monte Carlo approximations of the expected self-information loss [Equation2[2] ] using B = 20, 000 simulations for the SIL-optimal and minimally supported Pseudo-Bayesian D-optimal designs (MSPBD) under uniform prior distributions [Equation8[8] ] for (a) α = 0.5 and (b) α = 0.75.](/cms/asset/aa636d4c-804b-4740-93bf-f9e0b4df3fe9/lqen_a_1246045_f0004_b.gif)
Optimal designs for dimensional analysis
For the paper helicopter experiment, we find a SEL-optimal design, minimising a Monte Carlo approximation to [Equation3[3] ], for the Gamma regression model with linear predictor [Equation10
[10] ] and prior distribution [Equation11
[11] ]. The integral with respect to x in [Equation3
[3] ] is approximated by summation across a 43 grid of values constructed from x1, x3 ∈ {0.07, 0.087, 0.103, 0.12} (rotor and tail length) and x2 ∈ {0.03, 0.05, 0.07, 0.09} (rotor width). The design is given in a in terms of both the original three variables and the base quantity, Π1 ∈ [ − 1.903, 0.351]. Clearly, any design that results in the same values of Π1 will have the same expected posterior variance. A goal of equally weighted prediction over
leads to greater weight being given to smaller values of Π1, leading to the design including only points with smaller values of the base quantity.
Table 4. Helicopter experiment: (a) SEL-optimal and (b) V-optimal designs.
We compare the SEL-optimal design to four competitors.
A V-optimal design: the Fisher information matrix for
for Gamma regression with the log link is equivalent to that for a linear model. Hence, classical optimal designs for the linear model (Atkinson et al., Citation2007, Ch. 10) can be employed with this example. A V-optimal design, that minimizes the average prediction variance, has equally replicated design points with − log Π1 = −1.904 and − log Π1 = 0.351. One such design is given in b.
The two regular n = 23 − 1 fractional factorial designs with defining relation I = x1x2x3.
A maximin Latin hypercube (LH) design (Santner et al., Citation2003, Ch. 5) with n = 4 points: 20 such designs were generated algorithmically using different starting designs. Each will be an approximation to the (globally) optimal maximin LH design.
A quantitative comparison of these designs is given in which displays boxplots from 20 Monte Carlo approximations to [Equation3[3] ] for the SEL-optimal, V-optimal, fractional factorial, and LH designs. The SEL-optimal design has a performance advantage over all the other designs, having average expected posterior variance around 8% smaller than the V-optimal design, 11–12% smaller than the fractional factorial designs, and 11–17% smaller than the LH designs.
Figure 5. Helicopter experiment: Boxplots of 20 Monte Carlo approximations of the average expected posterior variance [Equation3[3] ] from B = 20, 000 simulations.
![Figure 5. Helicopter experiment: Boxplots of 20 Monte Carlo approximations of the average expected posterior variance [Equation3[3] ] from B = 20, 000 simulations.](/cms/asset/b84c9381-25e8-4b74-852f-4b99e37b3d23/lqen_a_1246045_f0005_b.gif)
Discussion
Optimal Bayesian design is challenging for high-dimensional problems with multi-variable models and/or many design points and there are few literature examples of such designs being used in practice. Reasons for this include the lack of scaleable algorithms for design selection, the complexity of available software for Bayesian design, an occasional unwillingness to “bias” designs through the use of prior information (that is, to focus design performance on a certain set of parameter scenarios or models) and, in many application areas, a lack of appreciation that design of experiments can go beyond standard factorial designs. However, Bayesian design is a powerful tool for a variety of experiments. Here, we have focused on using new methodology to find designs for generalized linear models where some prior information is necessary to design informative experiments. We have also demonstrated for the first time how algorithmic Bayesian design can combine empirical and physical modelling principles via generalized linear models and dimensional analysis.
Methodology such as ACE removes some of the barriers to the implementation of Bayesian design, both by widening the scope of models and experiments that can be addressed, and by facilitating the provision of greater evidence for the effectiveness of the methods through rigorous scientific studies. Although the methodology is still computationally challenging for larger examples, an increase in statistical efficiency that allows even slightly smaller experiments to be run can lead to considerable cost savings in expensive industrial experimentation. These savings will often more than offset the additional computational time and resource used to find the designs.
Clearly, in practice it is not always sensible to choose a design based solely on a one-number summary of design performance, particularly if it is obtained from a generic loss function that may not capture the aims of the experiment. However, being able to find optimal, or near-optimal, designs under suitable loss functions enables a short-list of competing designs to be compared on other merits. The methodology demonstrated in this article allows the experimenter to understand any trade-offs resulting from the incorporation of other practical considerations.
More details of the methodology demonstrated in this article can be found in Overstall and Woods (Citation2016b) and also in Overstall et al. (Citation2015) who discussed optimal designs for uncertainty quantification of physical models, an application area of increasing importance. We demonstrated ACE using straightforward Monte Carlo approximations to the expected loss. However, the methodology can be applied with a variety of different approximations to the loss function, including asymptotic approximations to find pseudo-Bayesian designs. The ACE algorithm has been implemented in R package acebayes (Overstall and Woods, Citation2016a).
About the authors
David C. Woods is Professor of Statistics at the University of Southampton. His research interests are in the statistical design of experiments and the modeling of the resultant data, particularly with scientific and industrial application. He is a past winner of the ASQ Youden prize, and is an Associate Editor for Technometrics.
Antony M. Overstall is an Associate Professor in the Southampton Statistical Sciences Research Institute and Mathematical Sciences at the University of Southampton.
Maria Adamou is a Research Fellow at the University of Southampton. She received her PhD from Southampton in 2014. Her research focuses on the Bayesian design of experiments for computational modeling and spatial data, motivated by problems from science and industry.
Timothy W. Waite is a Lecturer in Statistics at the University of Manchester. His research interests are in statistical design of experiments, especially the development of design methodology that facilitates efficient fitting of various models including discrete response empirical models and science-based computational models, and methodology that is robust to model misspecification.
Acknowledgments
We are grateful to a reviewer for comments that improved the article.
Funding
Woods was supported by Fellowship EP/J018317/1 from the UK Engineering and Physical Sciences Research Council.
References
- Albrecht, M. C., C. J. Nachtsheim, T. A. Albrecht, and R. D. Cook. 2013. Experimental design for engineering dimensional analysis (with discussion). Technometrics 55:257–295.
- Amzal, B., F. Y. Bois, E. Parent, and C. Robert. 2006. Bayesian optimal design via interacting particle systems. Journal of the American Statistical Association 101:773–785.
- Atkinson, A. C., A. N. Donev, and R. D. Tobias. 2007. Optimum experimental design, with SAS. 2nd ed. Oxford: Oxford University Press.
- Atkinson, A. C., and D. C. Woods. 2015. Designs for generalized linear models. In Handbook of Design and Analysis of Experiments, eds. A. M. Dean, M. D. Morris, J. Stufken, and D. R. Bingham, Boca Raton, FL: Chapman & Hall/CRC.
- Box, G. E. P., and P. Y. T. Liu. 1999. Statistics as a catalyst to learning by scientific method part I - an example. Journal of Quality Technology 31:1–15.
- Bridgman, P. 1931. Dimensional analysis. 2nd ed. New Haven, CT: Yale University Press.
- Buckingham, E. 1914. On physically similar systems; illustrations of the use of dimensional equations. Physical Review 4:345–376.
- Buckingham, E. 1915a. Model experiments and the forms of empirical equations. Transactions of the American Society of Mechanical Engineers 37:263–296.
- Buckingham, E. 1915b. The principle of similitude. Nature 96:396–397.
- Chaloner, K., and I. Verdinelli. 1995. Bayesian experimental design: a review. Statistical Science 10:273–304.
- Cox, D. R. 1988. A note on design when response has an exponential family distribution. Biometrika 75:161–164.
- Dean, A. M., and D. T. Voss. 1999. Design and analysis of experiments. New York: Springer.
- Drovandi, C. C., J. M. McGree, and A. N. Pettitt. 2013. Sequential Monte Carlo for Bayesian sequentially designed experiments for discrete data. Computational Statistics and Data Analysis 57:320–335.
- Drovandi, C. C., J. M. McGree, and A. N. Pettitt. 2014. A sequential Monte Carlo algorithm to incorporate model uncertainty in Bayesian sequential design. Journal of Computational and Graphical Statistics 23:3–24.
- Drovandi, C. C., and A. N. Pettitt. 2013. Bayesian experimental design for models with intractable likelihoods. Biometrics 69:937–948.
- Gentle, J. E. 2003. Random number generation and Monte Carlo methods. 2nd ed. New York: Springer.
- Gotwalt, C. M., B. A. Jones, and D. M. Steinberg. 2009. Fast computation of designs robust to parameter uncertainty for nonlinear settings. Technometrics 51:88–95.
- Gramacy, R. B., and H. K. H. Lee. 2012. Cases for the nugget in modeling computer experiments. Statistics and Computing 22:713–722.
- Gramacy, R. B., and N. G. Polson. 2011. Particle learning of Gaussian process models for sequential design and optimization. Journal of Computational and Graphical Statistics 20:102–118.
- Hainy, M., W. G. Müller, and H. P. Wynn. 2013. Approximate Bayesian computational design (ABCD), an introduction. In MODA 10 - Advances in model-oriented design and analysis, D. Ucinski, A. Atkinson, and M. Patan, eds. Springer.
- Hamada, M., H. F. Martz, C. S. Reese, and A. G. Wilson. 2001. Finding near-optimal Bayesian experimental designs via genetic algorithms. The American Statistician 55:175–181.
- Huan, X., and Y. M. Marzouk. 2013. Simulation-based optimal Bayesian experimental design for nonlinear systems. Journal of Computational Physics 232:288–317.
- Jones, D., M. Schonlau, and W. Welch. 1998. Efficient global optimization of expensive black-box functions. Journal of Global Optimization 13:455–492.
- MacKay, D. J. C. 2003. Information theory, inference, and learning algorithms. Cambridge: Cambridge University Press.
- McCullagh, P., and J. A. Nelder. 1989. Generalized linear models. 2nd ed. London: Chapman and Hall.
- McGree, J. M., and J. A. Eccleston. 2012. Robust designs for Poisson regression models. Technometrics 54:64–72.
- Müller, P. 1999. Simulation-based optimal design. In Bayesian statistics 6, eds., J. M. Bernardo, M. J. Bayarri, J. O. Berger, A. P. Dawid, D. Heckerman, and A. F. M. Smith, Oxford.
- Müller, P., and G. Parmigiani. 1996. Optimal design via curve fitting of Monte Carlo experiments. Journal of the American Statistical Association 90:1322–1330.
- Müller, P., B. Sanso, and M. De Iorio. 2004. Optimal Bayesian design by inhomogeneous Markov chain simulation. Journal of the American Statistical Association 99:788–798.
- Myers, R. H., D. C. Montgomery, G. G. Vining, and T. J. Robinson. 2010. Generalized linear models with applications in engineering and the sciences. 2nd ed. Hoboken, NJ: Wiley.
- Overstall, A. M., and D. C. Woods. 2016a. acebayes: Optimal Bayesian experimental design using the ACE algorithm. R package version 1.3.
- Overstall, A. M., and D. C. Woods. 2016b. Bayesian design of experiments using approximate coordinate exchange. Technometrics In press. doi: 10.1080/00401706.2016.1251495
- Overstall, A. M., D. C. Woods, and B. M. Parker. 2015. Bayesian optimal design for ordinary differential equation models. arXiv:1509.04099.
- Rasmussen, C. E., and C. K. I. Williams. 2006. Gaussian processes for machine learning. Cambridge, MA.: MIT Press.
- Russell, K. G., D. C. Woods, S. M. Lewis, and J. A. Eccleston. 2009. D-optimal designs for Poisson regression models. Statistica Sinica 19:721–730.
- Ryan, E. G., C. C. Drovandi, J. M. McGree, and A. N. Pettitt. 2016. A review of modern computational algorithms for Bayesian optimal design. International Statistical Review 84:128–154.
- Ryan, E. G., C. C. Drovandi, and A. N. Pettitt. 2015. Fully Bayesian experimental design for pharmacokinetic studies. Entropy 17:1063–1089.
- Ryan, E. G., C. C. Drovandi, M. H. Thompson, and A. N. Pettitt. 2014. Towards Bayesian experimental design for nonlinear models that require a large number of sampling times. Computational Statistics and Data Analysis 70:45–60.
- Ryan, K. J. 2003. Estimating expected information gains for experimental designs with application to the random fatigue-limit model. Journal of Computational and Graphical Statistics 12:585–603.
- Sacks, J., W. J. Welch, T. J. Mitchell, and H. P. Wynn. 1989. Design and analysis of computer experiments (with discussion). Statistical Science 4:409–435.
- Santner, T. J., B. J. Williams, and W. I. Notz. 2003. The design and analysis of computer experiments. New York: Springer.
- Sebastiani, P., and H. P. Wynn. 2000. Maximum entropy sampling. Journal of the Royal Statistical Society B 62:145–157.
- Shen, W., T. Davis, D. K. J. Lin, and C. J. Nachtsheim. 2014. Dimensional analysis and its applications in statistics. Journal of Quality Technology 46:185–198.
- Sonin, A. A. 2001. The physical basis of dimensional analysis. 2nd ed. Cambridge, MA.: Department of Mechanical Engineering, Massachusetts Institute of Technology.
- Waite, T. W., and D. C. Woods. 2015. Designs for generalized linear models with random block effects via information matrix approximations. Biometrika 102:677–693.
- Wang, L., and L. Zhang. 2006. Stochastic optimization using simulated annealing with hypothesis test. Applied Mathematics and Computation 174:1329–1342.
- Weaver, B. P., B. J. Williams, C. M. Anderson-Cook, and D. M. Higdon. 2016. Computational enhancements to Bayesian design of experiments using Gaussian processes. Bayesian Analysis 11:191–213.
- Woods, D. C., S. M. Lewis, J. A. Eccleston, and K. G. Russell. 2006. Designs for generalised linear models with several variables and model uncertainty. Technometrics 48:284–292.
- Woods, D. C., and P. van de Ven. 2011. Blocked designs for experiments with non-normal response. Technometrics 53:173–182.
- Wu, C. F. J., and M. Hamada. 2009. Experiments: planning, analysis and optimization. 2nd ed. Hoboken, NJ: Wiley.