
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The Zipf-Mandelbrot distribution serves as a mathematical model for ranked frequencies in many areas of scientific research, including linguistics. Many linguistic units, like e.g., words or word n-grams, follow this distribution. However, in some cases, such as for graphemes in linguistics or species abundance and diversity data in biology, the parameters of the Zipf-Mandelbrot distribution are virtually uninterpretable, as their values strongly depend on the precision of numerical methods used to estimate them (values from several tens to several hundreds are not uncommon). It is shown in the paper that these values can be explained by the convergence to the geometric distribution, which forces both parameters of the Zipf-Mandelbrot distribution to increase to infinity while their ratio converges to a constant. Some examples which illustrate this limit behaviour are presented.
1. Introduction and Motivation
The Zipf-Mandelbrot distribution (see e.g. Wimmer & Altmann, Citation1999, p. 666, the ZM distribution henceforward) was suggested by Mandelbrot (Citation1953). It is defined as
with c being a normalization constant, i.e.
Its non-truncated version,
is known also as the Hurwitz distribution (in that case, is the Hurwitz zeta function, see Johnson et al., Citation2005, p. 530). The ZM distribution is a generalization of the famous Zipf distribution. Its mathematical properties and statistical inference on its parameters are discussed e.g. in F. Izsák (Citation2006a), J. Izsák (Citation2006b), Young (Citation2013), and Adil Khan et al. (Citation2019). Families of related discrete probability distributions are presented in Zörnig and Altmann (Citation1995) and in Kemp (Citation2010).
The ZM distribution is used very often as a model for ranked frequencies in many areas of scientific research. As examples, we mention scientometrics (Ausloos, Citation2014; Silagadze, Citation1997), economics (Wu, Citation2007), medicine (Berclaz et al., Citation2012), and computer science (Wu et al., Citation2008). In biology, it is one of standard models for species abundance and diversity (Bach et al., Citation1988; Do et al., Citation2014; Huang & Zhan, Citation2014; J. Izsák & Pavoine, Citation2012; Juhos & Vörös, Citation1998; Wilson, Citation1991).
In linguistics, the ZM distribution serves most often as a model for word frequencies (see e.g. Bentz et al., Citation2014; Koplenig, Citation2018; Popescu et al., Citation2009), but it can be applied also to many other linguistic units. Thus, Egghe (Citation1999) used it to model frequencies of multi-word phrases, and Ha et al. (Citation2009) frequencies of word n-grams. Frequencies of word length motifs conform to the ZM distribution as well (Köhler & Naumann, Citation2008; Mačutek, Citation2009). On the opposite side, i.e. considering lower level linguistic units, syllable frequencies (Radojičić et al., Citation2019) and character frequencies (Riyal et al., Citation2016) were also shown to follow the model. Even word-like units in programming languages display the same behaviour (Zhang, Citation2008).
Attempts to use the ZM distribution also as a model for ranked grapheme frequencies in some Slavic languages can be found in Grzybek et al. (Citation2004, Citation2006) and in Grzybek and Kelih (Citation2005a). It seems that graphemes in alphabetsFootnote1 are one of a few exceptions among basic language units where the ZM distribution does not turn out to be a model with a satisfactory fit in generalFootnote2 (although it fits the data well for some languages, as will be shown in Section 3).
In principle, the ZM distribution has two free parameters, a and b, while the normalization constant c is uniquely determined by their values. However, several papers report a strong correlation between the parameter values when the distribution is fitted to data. According to J. Izsák (Citation2006b, p. 114), [t]he parameters of the ZM distribution frequently correlate, and Koplenig (Citation2018, p. 21) writes that both ZM parameters are strongly correlated. Wilson (Citation1991, p. 43) writes that his fitting procedure does not converge with some datasets within a reasonable time, as the value of one parameter is becoming very large, with balancing changes in the other.Footnote3 As a result, the fit improves only slightly and the parameters attain unrealistic values.Footnote4
2. Convergence to the Geometric Distribution
Problems reported by Wilson (Citation1991), i.e. very large and ever increasing values of the parameters, their correlation, and a very slow improvement of the fit, make the ZM distribution ‘suspicious’ in the sense that, in such cases, the distribution could converge to another one. Indeed, for the ZM distribution we have
and provided that
and
i.e. if both parameters of the ZM distribution increase to infinity, but their ratio converges to a constant, for every fixed we obtain the limit
In other words, the ratio of two neighbouring probabilities and
does not depend on
, i.e. it is a constant. We thus proved that, under the conditions mentioned above, the ZM distribution converges to the geometric distribution with
,
which is the only discrete probability distribution with this property. In this case, it holds
This proof is mathematically very simple, but, to our best knowledge, it has not appeared in the explicit form in the literature. We note that neither Wimmer and Altmann (Citation1999), nor Johnson et al. (Citation2005), i.e. none of the two probably most comprehensive books on discrete distributions, mentions this convergence, although they present many relations among discrete probability distributions, including limit distributions for special values of parameters. Some hints towards this limit behaviour can be found e.g. in Malacarne and Mendes (Citation2000) and in Montemurro (Citation2001). These two papers use a continuous approach, and thus speak about a convergence to the exponential function – it is a well-known fact that the exponential distribution is a continuous analogue of the geometric distribution.
Curiously enough, already Sigurd (Citation1968, pp. 1–2) wrote that the ZM distribution, which he calls the Mandelbrot’s formula, has the disadvantage of having more parameters, which makes it more complicated to characterize the phoneme frequencies of a language (we remind that he compared it with the Zipf’s formula, but the comparison is true, with respect to the number of parameters, also for the geometric distribution). Some pages later (p. 13), he suggested that [a]s an alternative to Mandelbrot’s formula, geometric series may be used. No frequencies, only percentages rounded to one or two decimal places are presented in that paper, hence we cannot present exact results of fitting. However, given the convergence proved above, and the supposed similarity between grapheme and phoneme rank-frequency distributions, it could be said that the geometric distribution is not an alternative to the ZM distribution, but that from the limit point of view the two distributions coincide.
The convergence provides also a mathematical explanation why the parameters of the ZM distribution explode in some cases (like e.g. when the distribution is fitted to ranked frequencies of graphemes). Suppose that the ZM distribution is used as a model for such data. Given that the geometric distribution is its limit distribution, the parameters a and b are in theory ‘forced’ to tend to infinity. Their actual estimated values depend on the choice of software, programming language, optimization algorithm etc., but they are usually very high. The values increase with the increasing desired precision of optimization algorithms used to obtain them, while their ratio fluctuates around a constant.
3. Examples
Ranked grapheme frequencies in Bulgarian and Slovene (see ; data were taken from Koščová et al., Citation2016) are used here to exemplify the limit behaviour of the ZM distribution which is described in Section 2. The goodness of fit of the models is evaluated in terms of the discrepancy coefficient , with
indicating an acceptable fit (see Mačutek & Wimmer, Citation2013, for details). The parameters were estimated by the minimum
method, i.e. their values minimize the
statistic. They were computed in the R statistical software environment. A short R script, which uses the function optim with the default choice of the function arguments, was created by the author of this paper.
Table 1. Grapheme rank-frequency distributions in Bulgarian and Slovene (data – observed frequencies, ZM – expected frequencies from the right truncated ZM distribution, geom – expected frequencies from the right truncated geometric distribution).
We emphasize that Bulgarian and Slovene were chosen as examples because both the ZM distribution and the geometric distribution fit the data from these two languages sufficiently well, and our aim was to demonstrate the limit behaviour of the ZM distribution on real linguistic data. We do not claim that either of the two distributions is a general mathematical model for ranked grapheme frequencies.Footnote5
It is obvious that fitting the ZM and the geometric distribution results in very similar numbers. In addition, the value of the parameter p of the geometric distribution is very close to (where a, b are the parameters of the ZM distribution) for both languages (Bulgarian: p = 0.1086,
0.1099; Slovene: p = 0.1027,
0.1037), which is a consequence of the convergence from Section 2.
The convergence of the ZM distribution to the geometric distribution under the conditions stated on Section 2 is demonstrated in , where the ZM distribution is fitted to the Bulgarian and Slovene data again, but now the maximum number of iterations in the R function optim is controlled (the default maximum is set to the value of 500). With the increasing numbers of iterations, the values of parameters a and b increase rapidly. The value of gets closer to the optimized value of parameter p of the geometric distribution from , and the fit improves, but only to a very slight extent. We thus ‘copied’ the behaviour of the ZM distribution parameters reported by Wilson (Citation1991, p. 43). The only noticeable difference – namely, all our fitting procedures were performed in a very short time – can be attributed to enormous advances in computer technology in the last 30 years.
Table 2. Convergence of the ZM distribution to the geometric distribution (max – the maximum number of iterations in the function optim; a, b – optimized parameters of the ZM distribution).
The similarity between the two models is highlighted also in for Slovene (the Bulgarian data give basically the same picture).
Figure 1. Rank-frequency distribution of graphemes in Slovene (white – observed frequencies, grey – expected frequencies from the right truncated ZM distribution, black – expected frequencies from the right truncated geometric distribution).
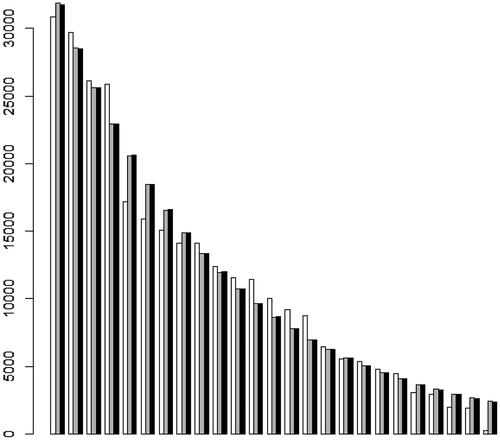
Grapheme frequencies in several other languagesFootnote6 behave similarly, i.e. if one fits the data with the ZM distribution, the parameters a and b attain large values and the value of is close to the optimized parameter p of the geometric distribution. The same is true for some data from individual texts in Russian, Slovak, and Ukrainian (see Grzybek et al., Citation2004, Citation2006; Grzybek & Kelih, Citation2005a, respectively). We note that in most of these cases the ZM distribution (as well as the geometric distribution) does not achieve a sufficiently good fit (i.e.
), and Bulgarian and Slovene data from are, in this respect, more an exception than a rule.
4. Conclusion and Discussion
Understanding and explanations of linguistic phenomena belong to the aims of theoretical research in quantitative linguistics (see e.g. Altmann, Citation1993). It is obvious that a mathematical model with a good fit alone, without a linguistic interpretation of its parameters, does not contribute to the achievement of these aims. If one fits data with the ZM distribution and the estimated parameter values get unrealistically large, and, in addition, if the values strongly depend on the precision of numerical methods used, the parameters are virtually uninterpretable. If the conditions for the convergence from Section 2 are satisfied (i.e. if the ratio of the two parameters of the ZM distribution is stable in spite of the increase of the two particular values), the geometric distribution is a better model. Its goodness of fit is approximately the same under these conditions, and, moreover, it has only one parameter p with an obvious interpretation – it is the relative frequency of the most frequent item from the inventory of the linguistic units under study.
It remains an open question why graphemes and phonemes are exceptional among basic language units in the sense that their ranked frequencies do not follow the ZM distribution, and, instead, the negative hypergeometric distribution is a strong candidate for a general model. A relatively small grapheme inventory size (if compared with syllables, words, word n-grams, etc.) can be one of the reasons, as in such a case the tail of the rank-frequency distribution can be too short to be able to display ‘typical Mandelbrot’ properties, and the optimized parameter values suggest that the data be modelled with the geometric distribution rather than with the ZM distribution. We remind that according to the study by Riyal et al. (Citation2016) mentioned in Section 1, ranked frequencies of charactersFootnote7 in the Garhwali language can be modelled by the ZM distribution. However, this language uses the Devanagari script, which is an abugida (see Daniels, Citation1996). As such, it has a substantially larger character inventory than an alphabet. A character inventory of an abugida is similar – although not necessarily equal – to an inventory of syllables.
Specifically for grapheme frequency data, the two free parameters of the ZM distribution seem to depend on each other in such a way that only their ratio has an influence on the model. In other words, there remains only one free parameter, which makes the model less flexible. On the other hand, the negative hypergeometric distribution also has two free parameters, K and M. It seems they are strongly mutually correlated as well, however, there is a crucial difference between the mutual parameter relations in the ZM and the hypergeometric distributions. According to Grzybek (Citation2007), there is a linear relation between K and M, i.e. , with
depending, again linearly, on the inventory size
(i.e.
). These mathematically formulated links between the parameters of the model contribute to the explanation of the model, as they specify the character of the mutual relations between the parameters. But here, as opposed to fitting the grapheme and phoneme rank-frequency data with the ZM distribution, the number of free parameters does not decrease. Grzybek (Citation2007) suggests that M depends on K, and indirectly also on the inventory size, but new parameters, those of the linear functions, appear. Thus, the negative hypergeometric distribution remains flexible enough to achieve a satisfactory goodness of fit.
If a too short tail of the rank-frequency distribution is indeed the cause why the ZM distribution with the optimized parameter values converges to the geometric distribution with only one free parameter, and consequently fails to achieve a good fit in general, the same could be expected to be observed also in other areas of linguistics if the inventory size of the phenomena under study is relatively small (such as several units or tens, but not hundreds of items). These numbers are typical for inventory sizes of some grammatical categories, e.g. for cases. Frequencies of grammatical cases in Czech from Mačutek and Čech (Citation2013, p. 65) confirm this conjecture, the optimized parameters of the ZM distribution behave analogously to the ones in models from Section 3. However, more studies from this field are required, and for the time being we have only a single observation which does not have to represent a general tendency.
Disclosure Statement
No potential conflict of interest was reporter by the author.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
Notes
1. Probably also in abjads. See Daniels (Citation1996) for definitions of writing systems.
2. The same is most probably true also for phonemes. Grzybek and Kelih (Citation2005b) and Grzybek and Rusko (Citation2009) demonstrate similarities among rank-frequency distributions of letters, graphemes, and phonemes.
3. This formulation hints, in fact, at their correlation, although without using this term.
4. Unfortunately, according to personal communication with J.B. Wilson, those datasets are not available anymore.
5. Given the current state of research (see e.g. Wilson & Mačutek, Citation2020, and the references therein), the negative hypergeometric distribution (Wimmer & Altmann, Citation1999, pp. 465–468) seems to be the general model.
6. See e.g. data from the Slavic languages in Koščová et al. (Citation2016), and from the Celtic languages in Wilson and Mačutek (Citation2020). In both papers data from corpora, as opposed to individual texts, are presented.
7. Riyal et al. (Citation2016) do not provide a definition of a character in their paper. See Köhler (Citation2008) for a discussion on slightly differing definitions of a grapheme.
References
- Adil Khan, M., Pečarić, Ð., & Pečarić, J. (2019). On Zipf-Mandelbrot entropy. Journal of Computational and Applied Mathematics, 346, 192–204. https://doi.org/10.1016/j.cam.2018.07.002
- Altmann, G. (1993). Science and linguistics. In R. Köhler & B. B. Rieger (Eds.), Contributions to quantitative linguistics (pp. 3–10). Kluwer.
- Ausloos, M. (2014). Zipf-Mandelbrot-Pareto model for co-authorship popularity. Scientometrics, 101(3), 1565–1586. https://doi.org/10.1007/s11192-014-1302-y
- Bach, P., Amanieu, M., Lam Hoai, T., & Lasserre, G. (1988). Application du modèle de distribution d’abondance de Mandelbrot á l’estimation des captures dans l’étang de Thau. Journal du Conseil International pour l’Exploration de la Mer, 44(3), 235–246. https://doi.org/10.1093/icesjms/44.3.235
- Bentz, C., Kiela, D., Hill, F., & Buttery, P. (2014). Zipf’s law and the grammar of languages: A quantitative study of Old and Modern English parallel texts. Corpus Linguistics and Linguistic Theory, 10(2), 175–211. https://doi.org/10.1515/cllt-2014-0009
- Berclaz, C., Goulley, J., Villiger, M., Pache, C., Bouwens, A., Martin-Williams, E., Van de Ville, D., Davison, A. C., Grapin-Botton, A., & Lasser, T. (2012). Diabetes imaging – Quantitative assessment of islets of Langerhans distribution in murine pancreas using extended-focus optical coherence microscopy. Biomedical Optics Express, 3(6), 1365–1380. https://doi.org/10.1364/BOE.3.001365
- Daniels, P. T. (1996). The study of writing systems. In P. T. Daniels & W. Bright (Eds.), The world’s writing systems (pp. 3–17). Oxford University Press.
- Do, Y., Lineman, M., & Joo, G. J. (2014). Carabid beetles in green infrastructures: The importance of management practices for improving the biodiversity in a metropolitan city. Urban Ecosystems, 17(3), 661–673. https://doi.org/10.1007/s11252-014-0348-1
- Egghe, L. (1999). On the law of Zipf-Mandelbrot for multi-word phrases. Journal of the American Society for Information Science, 50(3), 233–241. https://doi.org/10.1002/(SICI)1097-4571(1999)50:3<233::AID-ASI6>3.0.CO;2-8
- Grzybek, P. (2007). On the systematic and system-based study of grapheme frequencies: A re-analysis of German letter frequencies. Glottometrics, 15, 82–91.https://www.ram-verlag.eu/wp-content/uploads/2018/08/g15zeit.pdf
- Grzybek, P., & Kelih, E. (2005a). Graphemhäufigkeiten im Ukrainischen. Teil I: Ohne Apostroph (‘). In G. Altmann, V. Levickij, & V. Perebyinis (Eds.), Problems of quantitative linguistics (pp. 159–179). Ruta.
- Grzybek, P., & Kelih, E. (2005b). Häufigkeiten von Buchstaben/Graphemen/Phonemen: Konvergenzen des Rangierungsverhaltens. Glottometrics, 9, 62–73. https://www.ram-verlag.eu/wp-content/uploads/2018/08/g9zeit.pdf
- Grzybek, P., Kelih, E., & Altmann, G. (2004). Graphemhäufigkeiten (Am Beispiel des Russischen). Teil II: Modelle der Häufigkeitsverteilung. Anzeiger für Slavische Philologie, 32, 25–54. https://static.uni-graz.at/fileadmin/gewi-institute/Slawistik/Dokumente/00_Inhalt_Anz2004.pdf
- Grzybek, P., Kelih, E., & Altmann, G. (2006). Graphemhäufigkeiten im Slowakischen. Teil II: Mit Digraphen. In R. Kozmová (Ed.), Sprache und Sprachen im mitteleuropäischen Raum. Vorträge der Internationalen Linguistik-Tage, Trnava 2005 (pp. 641–664). Filozofická fakulta, Univerzita sv. Cyrila a Metoda v Trnave.
- Grzybek, P., & Rusko, M. (2009). Letter, grapheme and (allo-)phone frequencies: The case of Slovak. Glottotheory, 2(1), 30–48. https://doi.org/10.1515/glot-2009-0004
- Ha, L. Q., Hanna, P., Ming, J., & Smith, F. J. (2009). Extending Zipf’s law to n-grams in large corpora. Artificial Intelligence Review, 32(1–4), 101–113. https://doi.org/10.1007/s10462-009-9135-4
- Huang, B., & Zhan, R. (2014). Species-abundance models for brachiopods across the Ordovician-Silurian boundary of South China. Estonian Journal of Earth Sciences, 63(4), 240–243. https://doi.org/10.3176/earth.2014.25
- Izsák, F. (2006a). Maximum likelihood estimation for constrained parameters of multinomial distributions – Application to Zipf-Mandelbrot models. Computational Statistics & Data Analysis, 51(3), 1575–1583. https://doi.org/10.1016/j.csda.2006.05.008
- Izsák, J. (2006b). Some practical aspects of fitting and testing the Zipf-Mandelbrot model. A short essay. Scientometrics, 67(1), 107–120. https://doi.org/10.1007/s11192-006-0052-x
- Izsák, J., & Pavoine, S. (2012). Links between the species abundance distribution and the shape of the corresponding rank abundance curve. Ecological Indicators, 14(1), 1–6. https://doi.org/10.1016/j.ecolind.2011.06.030
- Johnson, N. L., Kemp, A. W., & Kotz, S. (2005). Univariate discrete distributions. Wiley.
- Juhos, S., & Vörös, L. (1998). Structural changes during eutrophication of Lake Balaton, Hungary, as revealed by the Zipf-Mandelbrot model. Hydrobiologia, 369, 237–242. https://doi.org/10.1023/A:1017006128228
- Kemp, A. W. (2010). Families of power series distributions, with particular reference to the Lerch family. Journal of Statistical Planning and Inference, 140(8), 2255–2259. https://doi.org/10.1016/j.jspi.2010.01.021
- Köhler, R. (2008). Quantitative analysis of writing systems: An introduction. In G. Altmann & F. Fengxiang (Eds.), Analyses of script. Properties of characters and writing systems (pp. 3–9). de Gruyter.
- Köhler, R., & Naumann, S. (2008). Quantitative text analysis using L-, F- and T-segments. In C. Preisach, H. Burkhardt, L. Schmidt-Thieme, & R. Decker (Eds.), Data analysis, machine learning and applications (pp. 637–645). Springer.
- Koplenig, A. (2018). Using the parameters of the Zipf-Mandelbrot law to measure diachronic lexical, syntactical and stylistic changes – A large-scale corpus analysis. Corpus Linguistics and Linguistic Theory, 14(1), 1–34. https://doi.org/10.1515/cllt-2014-0049
- Koščová, M., Mačutek, J., & Kelih, E. (2016). A data-based classification of Slavic languages: Indices of qualitative variation applied to grapheme frequencies. Journal of Quantitative Linguistics, 23(2), 177–190. https://doi.org/10.1080/09296174.2016.1142327
- Mačutek, J. (2009). Motif richness. In R. Köhler (Ed.), Issues in quantitative linguistics (pp. 51–60). RAM-Verlag.
- Mačutek, J., & Čech, R. (2013). Frequency and declensional morphology of Czech nouns. In I. Obradović, E. Kelih, & R. Köhler (Eds.), Methods and applications of quantitative linguistics (pp. 59–68). Beograd: Akademska Misao.
- Mačutek, J., & Wimmer, G. (2013). Evaluating goodness-of-fit of discrete distribution models in quantitative linguistics. Journal of Quantitative Linguistics, 20(3), 227–240. https://doi.org/10.1080/09296174.2013.799912
- Malacarne, L. C., & Mendes, R. S. (2000). Regularities in football goal distributions. Physica A. Statistical Mechanics and Its Applications, 286(1–2), 391–395. https://doi.org/10.1016/S0378-4371(00)00363-0
- Mandelbrot, B. (1953). An information theory of the statistical structure of language. In W. Jackson (Ed.), Communication theory (pp. 486–502). Butterworths.
- Montemurro, M. A. (2001). Beyond the Zipf-Mandelbrot law in quantitative linguistics. Physica A. Statistical Mechanics and Its Applications, 300(3–4), 567–578. https://doi.org/10.1016/S0378-4371(01)00355-7
- Popescu, I.-I., Altmann, G., Grzybek, P., Jayaram, B. D., Köhler, R., Krupa, V., Mačutek, J., Mehler, A., Pustet, R., Uhlířová, L., & Vidya, M. N. (2009). Word frequency studies. de Gruyter.
- Radojičić, M., Lazić, B., Kaplar, S., Stanković, R., Obradović, I., Mačutek, J., & Leššová, L. (2019). Frequency and length of syllables in Serbian. Glottometrics, 45, 114–123.https://www.ram-verlag.eu/wp-content/uploads/2020/09/g45zeit.pdf
- Riyal, M. K., Rajput, N. K., Khanduri, V. P., & Rawat, L. (2016). Rank-frequency analysis of characters in Garhwali text: Emergence of Zipf’s law. Current Science, 110(3), 429–434. https://doi.org/10.18520/cs/v110/i3/429-443
- Sigurd, B. (1968). Rank-frequency distributions for phonemes. Phonetica, 18(1), 1–15. https://doi.org/10.1159/000258595
- Silagadze, Z. K. (1997). Citations and the Zipf-Mandelbrot law. Complex Systems, 11(6), 487–499. https://content.wolfram.com/uploads/sites/13/2018/02/11-6-4.pdf
- Wilson, A., & Mačutek, J. (2020). A classification of the Celtic languages based on grapheme frequencies. In E. Kelih & R. Köhler (Eds.), Words and numbers. In memory of Peter Grzybek (1957–2020) (pp. 53–68). RAM-Verlag.
- Wilson, J. B. (1991). Methods for fitting dominance/diversity curves. Journal of Vegetation Science, 2(1), 35–46. https://doi.org/10.2307/3235896
- Wimmer, G., & Altmann, G. (1999). Thesaurus of univariate discrete probability distributions. Stamm.
- Wu, C. H., Chiang, K., Yu, R. J., & Wang, S. D. (2008). Locality and resource aware peer‐to‐peer overlay networks. Journal of the Chinese Institute of Engineers, 31(7), 1207–1217. https://doi.org/10.1080/02533839.2008.9671475
- Wu, Q. (2007). Analysis of global manufacturing top 200: Applications of Zipf-Mandelbrot law and its transposing type. In: IEEE International Conference on Industrial Engineering and Engineering Management (pp. 397–401). IEEE.
- Young, D. S. (2013). Approximate tolerance limits for Zipf-Mandelbrot distributions. Physica A. Statistical Mechanics and Its Applications, 392(7), 1702–1711. https://doi.org/10.1016/j.physa.2012.11.056
- Zhang, H. (2008). Exploring regularity in source code: Software science and Zipf’s law. In: Proceedings of the 2008 15th Working Conference on Reverse Engineering (pp. 101–110). IEEE.
- Zörnig, P., & Altmann, G. (1995). Unified representation of Zipf distributions. Computational Statistics & Data Analysis, 19(4), 461–473. https://doi.org/10.1016/0167-9473(94)00009-8