1. Introduction
Rather long ago, Newell (Citation1973) wrote a prophetic paper that can serve as a rallying cry for this special issue of JETAI: ‘You Can't Play 20 Questions with Nature and Win’. This paper helped catalyse both modern-day computational cognitive modelling through cognitive architectures (such as ACT-R, Soar, Polyscheme, etc.) and AI's – now realised, of course – attempt to build a chess-playing machine better at the game than any human. However, not many know that in this article Newell suggested a third avenue for achieving machine intelligence, one closely aligned with psychometrics. In the early days of AI, at least one thinker started decisively down this road for a time (Evans Citation1968); but now the approach, it may be fair to say, is not all that prominent in AI. The paper in the present issue, along with other work in the same vein, can be plausibly viewed as resurrecting this approach, in the form of what is called Psychometric AI, or just PAI (rhymes with ‘π’).
The structure of what follows is this: First (Section 2), I briefly present Newell's call for (as I see it) PAI in his seminal ‘20 Questions’ paper. Section 3 provides a naïve but serviceable-for-present-purposes definition of PAI in line with Newell's call. I end with some brief comments about the exciting papers in this special issue.
2. Newell and the neglected route toward machine intelligence
In the ‘20 Questions’ paper, Newell (Citation1973) bemoans the fact that, at a symposium gathering together with many of the greatest psychologists at the time, there is nothing whatsoever to indicate that any of their work is an organised, integrated program aimed seriously at uncovering the nature of intelligence as information processing. Instead, Newell perceives a situation in which everybody is carrying out work (of the highest quality, he cheerfully admits) on his or her own specific little part of human cognition. In short, there is nothing that, to use Newell's phrase, ‘pulls it all together’. He says: ‘We never seem in the experimental literature to put the results of all the experiments together.’ (Newell Citation1973: 298) After making clear that he presupposes that ‘man is an information processor’, and that therefore from his perspective the attempt to understand, simulate and replicate human intelligence is by definition to grapple with the challenge of creating machine intelligence, Newell offers three possibilities for addressing the fragmentary nature of the study of mind as computer.
The first possibility Newell calls ‘Complete Processing Models’. He cites his own work (with others; e.g. Simon; the two, of course, were to be a dynamic duo in AI and computational cognitive science for many decades to come) based on production systems, but makes it clear that the production-system approach is not the only way to go. Of course, today's cognitive architectures [e.g. SOAR (Rosenbloom, Laird, and Newell Citation1993); ACT-R (Anderson Citation1993; Anderson and Lebiere Citation1998; Anderson and Lebiere Citation2003); Clarion (Sun Citation2001); and Polyscheme (Cassimatis Citation2002; Cassimatis, Trafton, Schultz, and Bugajska Citation2004)] can be traced back to this first possibility.
The second possibility is to ‘Analyze a Complex Task’. Newell sums it up as follows.
A second experimental strategy, or paradigm, to help overcome the difficulties enumerated earlier is to accept a single complex task and do all of it … the aim being to demonstrate that one has a significant theory of a genuine slab of human behavior. … A final example [of such an approach] would be to take chess as the target super-task. (Newell Citation1973: 303–304)
This second possibility is one most people in computational cognitive science and AI are familiar with. Though Deep Blue's reliance upon standard search techniques having little cognitive plausibility perhaps signalled the death of the second avenue, there is no question that, at least for a period of time, many researchers were going down it.
The third possibility, ‘One Program for Many Tasks’, is the one many people seem to have either forgotten or ignored. Newell described it this way:
The third alternative paradigm I have in mind is to stay with the diverse collection of small experimental tasks, as now, but to construct a single system to perform them all. This single system (this model of the human information processor) would have to take the instructions for each, as well as carry out the task. For it must truly be a single system in order to provide the integration we seek. (Newell Citation1973: 305)
For those favourably inclined toward the test-based approach to AI, it's the specific mold within Newell's third possibility that is of acute interest. We read:
A … mold for such a task is to construct a single program that would take a standard intelligence test, say the WAIS or the Stanford-Binet. (Newell Citation1973: 305)
I view this remark as a pointer to PAI and to an explication of this brand of AI we now turn.
3. What is Psychometric AI?
What is AI? I would be willing to wager that many of you have been asked this question – by colleagues, reporters, friends and family and others. Even if by some fluke you have dodged the question, perhaps you have asked it yourself, maybe even perhaps (in secret moments, if you are a practitioner) to yourself, without an immediate answer coming to mind. At any rate, AI itself repeatedly asks the question – as the first chapter of many AI textbooks reveals. Unfortunately, many of the answers standardly given do not ensure that AI tackles head on the problem of human-level, integrated cognition.Footnote1 My answer, however, is one in line with Newell's third possibility and one in line with a perfectly straightforward response to the ‘What is AI?’ question.
To move toward my answer, note first that presumably the ‘A’ part of ‘AI’ is not the challenge: we seem to have a fairly good handle on what it means to say that something is an artefact or artificial.Footnote2 It's the ‘I’ part that seems to throw us for a bit of a loop. What is intelligence? This is the big, and hard, question. Innumerable answers have been given, but many outside the test-based approach to AI seem to forget that there is a particularly clear and straightforward answer available, courtesy of the field that has long sought to operationalise the concept in question; that field is psychometrics. Psychometrics is devoted to systematically measuring psychological properties, usually via tests. These properties include the one most important in the present context: intelligence. In a nutshell, then, the initial version of a psychometrics-oriented account of intelligence is simply this: some agent is intelligent if and only if it excels at all established, validated tests of intelligence.
I anticipate that some will insist that intelligence tests, even broad ones, are still just too narrow, when put in the context of the full array of cognitive capacities seen in Homo sapiens. But one can understand intelligence, from the standpoint of psychometrics, to include many varied tests of intellectual ability. Accordingly, one can work on the basis of a less naïve definition of PAI:
Psychometric AI is the field devoted to building information-processing entities capable of at least solid performance on all established, validated tests of intelligence and mental ability, a class of tests that includes not just the rather restrictive IQ tests, but also – and this is important given the tests on which the papers in the present special issue are focused – tests of artistic and literary creativity, mechanical ability, and so on.
This definition, when referring to tests of mental ability, is pointing to much more than IQ tests. For example, following Sternberg (Citation1988), someone with much musical aptitude would count as brilliant even if their scores on tests of ‘academic’ aptitude (e.g. on the SAT, GRE, LSAT, etc.) were low. Nonetheless, even if, hypothetically, one were to restrict attention in PAI to intelligence tests, a large part of cognition would be targeted. Along this line, in choosing the Wechsler Adutt Intelligent Scale (WAIS), Newell knew what he was doing.
To see this, we begin by going back to the early days of AI, specifically to a time when Psychometric AI was at least implicitly entertained. For example, in the mid-1960s, the largest Lisp program on earth was Evans' (Citation1968) ANALOGY program, which could solve problems like those shown in . Evans himself predicted that systems able to solve such problems would ‘be of great practical importance in the near future’, and he pointed out that performance on such tests is often regarded to be the ‘touchstone’ of human intelligence. Unfortunately, ANALOGY simply has not turned out to be the first system in a long-standing, comprehensive research program (Newellian or otherwise): after all, we find ourselves, at present, trying to start that very program. What went wrong? Well, certainly Psychometric AI would be patently untenable if the tests upon which it is based consist solely of geometric analogies. This point is entailed by such observations as this one from Fischler and Firschein (Citation1987):
If one were offered a machine purported to be intelligent, what would be an appropriate method of evaluating this claim? The most obvious approach might be to give the machine an IQ test. … However, [good performance on tasks seen in IQ tests would not] be completely satisfactory because the machine would have to be specially prepared for any specific task that it was asked to perform. The task could not be described to the machine in a normal conversation (verbal or written) if the specific nature of the task was not already programmed into the machine. Such considerations led many people to believe that the ability to communicate freely using some form of natural language is an essential attribute of an intelligent entity. (Fischler and Firschein Citation1987, p. 12)
Figure 1. Sample problem solved by Evan's (Citation1968) ANALOGY program. Given sample geometric configurations in blocks A, B and C, choose one of the remaining five possible configurations that completes the relationship: A is to B as C is to …?
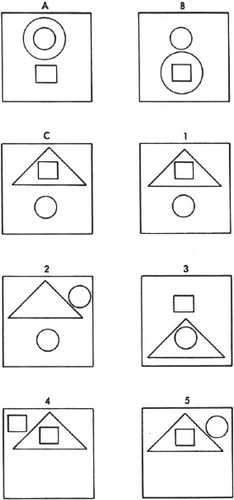
Unfortunately, while this quote helps explain why ANALOGY in and of itself did not ignite a research program to drive AI, Fischler and Firschein apparently are familiar with only what we call narrow, as opposed to broad, intelligence tests that Newell had in mind. Arguably, this distinction goes back to Descartes' (Citation1911, p. 116) claim that while a machine could in the future pass any test for a particular mental power (including, before Turing was born, the test that now bears his name), no machine could pass a test for any mental power whatsoever. This rather speculative claim can be seen to be cashed out in two different and longs-tanding views of intelligence within psychology: Thurstone's (Citation1938) and Spearman's (Citation1927). In Thurstone's view (put barbarically), intelligence consists in the capacity to solve a broad range of problems, e.g. verbal analogies, geometric analogies, digit recall, story understanding, commonsense reasoning, arithmetical calculation and so on. In Spearman's view (again, put roughly), intelligence is a specific, narrow, underlying capacity (notoriously) referred to as g, summoned up to the highest degree when solving highly focussed and abstract problems like those ANALOGY solved. The most famous set of ‘g-relevant’ problems is the tightly guarded and much-used Raven's (Citation1962) Progressive Matrices, or just ‘RPM.’
Psychological Corporation's popular WAIS, the very test Newell cited, is a paradigmatic example of a broad intelligence test that includes the full array of ‘Thurstonean’ subtests (the complete array is enumerated in Baron Citation2001). and , taken from (Baron Citation2001), summarise the wide array of tasks on the WAIS. It should be clear that when Newell described the third possibility as one program for many tasks, and pointed at the WAIS, he was making good sense. It is clear as well that Fischler and Firschein's criticism of simplistic versions of Psychometric AI certainly evaporates in the face of the WAIS. That this is so follows from the subtest on the WAIS known as ‘Comprehension’, in which, in ordinary conversation, subjects are asked fiendishly tricky ‘general-knowledge’ questions. For example, examinees might be asked to explain why the tyres on automobiles are made of rubber, rather than, say, plastic.
Table 1. Performance subtests of the WAIS.
Table 2. Verbal subtests of the WAIS.
4. The current state of PAI
The papers in this special issue of JETAI together paint an informative, impressive picture of the current state of PAI. Here now to conclude, a very brief preview of each of these papers.Footnote3
| 1. | Cassimatis and Bignoli embrace a test-based approach to AI aimed at reaching human-level intelligence, and specifically recommend a version of this approach based on the concept of a microcosm, a suitably configured simulated environment. The tests discussed in the paper are fascinating ones aimed at child cognition. The paper includes a powerful analogical argument based on the aviary domain; the conclusion of the argument is that AI should shun the ‘model-fit imperative’ (unfortunately prevalent in computational cognitive science) in favour of testing in microcosms. | ||||
| 2. | Klenk et al. explain how an expansion of the impressive Companion cognitive architecture and a specific advance in analogical processing (which is central to Companion, and hence taken to be central to human-level intelligence by the research group in question) allows a Companion to score quite respectably on a challenging subtest of the Bennett Mechanical Comprehension Test. This success is achieved without the pre-installation of a complete formalisation of the domain. | ||||
| 3. | Chapin et al. report on a hybrid approach to story arrangement, a subtest on the aforementioned WAIS test. This hybrid approach is distinguished by the pursuit of a bottom-up approach (specifically to change detection), designed to complement the top-down approach to story arrangement taken previously by one of the authors (Schimanski). | ||||
| 4. | Turney too notes that analogy is at the very heart of cognition, and he can therefore be seen as providing, via his PairClass system, which tackles proportional analogies, a significant advance for AI and computational cognitive science (and, needless to say, for the narrower PAI field as characterised above). PairClass' performance on seven tests used to measure the performance of humans is truly impressive. For example, on the TOEFL synonym test, PairClass' performance exceeds that of the average human. Perhaps most impressive is the fact that PairClass is a learning system that succeeds without the kind of hand-coding-in-advance so often seen in AI systems. (As the reader will already have noted, there are some striking commonalities between the Klenk et al. and Turney papers.) | ||||
Notes
1. E.g. Russell and Norvig (Citation2002) characterise AI in a way (via functions from percepts to actions; they call these functions intelligent agents) that, despite its many virtues, does not logically entail human-level, integrated cognition.
2. We can ignore here conundrums arising from self-reproducing systems, systems that evolve without human oversight, etc.
3. Of course, a full account of the current state of PAI would consider work beyond the papers in this special issue. For example, Project Halo I (Friedland et al. Citation2004) was devoted to the attempt to build an AI system able to do well on the US Chemistry AP exam, and it is not unreasonable to say that considerable success was achieved.
References
- Anderson , JR . 1993 . Rules of Mind , Hillsdale, NJ : Lawrence Erlbaum .
- Anderson , JR and Lebiere , C . 1998 . The Atomic Components of Thought , Mahwah, NJ : Lawrence Erlbaum .
- Anderson , J and Lebiere , C . 2003 . The Newell test for a theory of cognition . Behavioral and Brain Sciences , 26 : 587 – 640 .
- Baron , R and Kalsher , M . 2001 . Psychology , , 5th , Boston, MA : Allyn and Bacon .
- Cassimatis , N . (2002), ‘Polyscheme: A Cognitive Architecture for Integrating Multiple Representation and Inference Schemes’, PhD thesis, Massachusetts Institute of Technology (MIT)
- Cassimatis , N , Trafton , J , Schultz , A and Bugajska , M . 2004 . “ Integrating Cognition, Perception and Action Through Mental Simulation in Robots ” . In Proceedings of the 2004 AAAI Spring Symposium on Knowledge Representation and Ontology for Autonomous Systems , Edited by: Schlenoff , C and Uschold , M . 1 – 8 . Menlo Park : AAAI .
- Descartes , R . 1911 . The Philosophical Works of Descartes , Vol. 1 , translated by E.S. Haldane . Cambridge, UK: Cambridge University Press
- Evans , G . 1968 . “ A program for the Solution of a Class of Geometric-analogy Intelligence-test Questions ” . In Semantic Information Processing , Edited by: Minsky , M . 271 – 353 . Cambridge, MA : MIT Press .
- Fischler , M and Firschein , O . 1987 . Intelligence: The Eye, the Brain, and the Computer , Reading, MA : Addison-Wesley .
- Friedland , N , Allen , P , Matthews , G , Witbrock , M , Baxter , D , Curtis , J , Shepard , B , Miraglia , P , Angele , J , Staab , S , Moench , E , Oppermann , H , Wenke , D , Israel , D , Chaudhri , V , Porter , B , Barker , K , Fan , J , Chaw , SY , Yeh , P , Tecuci , D and Clark , P . 2004 . Project Halo: Towards a Digital Aristotle . AI Magazine , 25 : 29 – 47 .
- Newell , A . 1973 . “ You can't play 20 questions with nature and win: Projective comments on the papers of this symposium ” . In Visual Information Processing , Edited by: Chase , W . 283 – 308 . New York : Academic Press .
- Raven , JC . 1962 . Advanced Progressive Matrices Set II London, , UK H K. Lewis. (Distributed in the United States by The Psychological Corporation Inc., San Antonio, Texas)
- Rosenbloom , P . Laird, J., and Newell, A., (eds.) (1993), The Soar Papers: Research on Integrated Intelligence, Cambridge, MA: MIT Press
- Russell , S and Norvig , P . 2002 . Artificial Intelligence: A Modern Approach , Upper Saddle River, NJ : Prentice Hall .
- Spearman , C . 1927 . The Abilities of Man , New York, NY : MacMillan .
- Sternberg , R . 1988 . The Triarchic Mind: A New Theory of Human Intelligence , New York, NY : Viking .
- Sun , R . 2001 . Duality of the Mind , Mahwah, NJ : Lawrence Erlbaum Associates .
- Thurstone , L . 1938 . Primary Mental Abilities , Chicago, IL : University of Chicago Press .