Abstract
We propose here a new computational method for the information-theoretic method, called the greedy network-growing algorithm, to facilitate a process of information acquisition. We have so far used the sigmoidal activation function for competitive unit outputs. The method can effectively suppress many competitive units by generating strongly negative connections. However, because methods with the sigmoidal activation function are not very sensitive to input patterns, we have observed that in some cases final representations obtained by the method do not necessarily faithfully describe input patterns. To remedy this shortcoming, we employ the inverse of distance between input patterns and connection weights for competitive unit outputs. As the distance becomes smaller, competitive units are more strongly activated. Thus, winning units tend to represent input patterns more faithfully than in the previous method with the sigmoidal activation function. We applied the new method to artificial data analysis and animal classification. Experimental results confirmed that more information can be acquired and more explicit features can be extracted by our new method.
1. Introduction
In this paper, we propose a novel computational method for the network-growing algorithm. The network-growing algorithm is called ‘greedy network-growing’, because a network with this algorithm grows while acquiring as much information as possible from the outside (Kamimura et al. Citation2002, Kamimura Citation2003c). Our new computational method is proposed to overcome the shortcomings of previous greedy network-growing algorithms (Kamimura et al. Citation2002, Kamimura Citation2003c). The shortcomings of the previous methods can be summarized by two points: (1) difficulty in acquiring sufficient information; and (2) an unclear relation between our method and conventional competitive learning.
First, we have seen that the previous methods fail to acquire information for some problems. In our network-growing methods, information acquisition processes correspond to competition processes. Competition is realized by using the standard sigmoidal activation function (Kamimura et al. Citation2002, Kamimura Citation2003c). The sigmoidal activation function seems to be very powerful to realize competitive processes, because multiple negative connections are generated in the course of information maximization. These negative connections can be used to turn off the majority of competitive units except for a few winning ones. However, we have so far observed that in some cases the methods failed to acquire information on input patterns. This means that information acquisition is sometimes very low, and competition processes are not sufficiently simulated. One problem is that the sigmoidal function is less sensitive to input patterns when the magnitude of input patterns is larger. The sigmoidal function is good at extracting overall features, but it has difficulty in extracting detailed features in complex input patterns. Thus, the greedy algorithm with the sigmoidal activation function has failed to extract important features in the later stages of learning. In this context, there is an urgent need to develop a method to facilitate information acquisition.
Second, our method with the sigmoidal activation was proposed to simulate competitive processes independently of conventional competitive learning. Thus, the relation between our information-theoretic competitive learning and conventional competitive learning is unclear, and sometimes final representations obtained by our method and by conventional methods are completely different from each other. This means that it is difficult to evaluate the performance of our method in the framework of competitive learning. In our new approach, we use Euclidean distance between input patterns and connection weights for the activation function (Kamimura Citation2003b). This means that our method is fundamentally equivalent to conventional competitive learning. When information is supposed to be completely maximized, our method realizes a winner-take-all process in which a winner tends to represent most faithfully a set of input patterns in terms of Euclidean distance. When information is less, several competitive units tend to be simultaneously activated. At this point, our method can realize soft competition. Thus, the new algorithm is fundamentally the same as conventional competitive learning (Rumelhart and Zipser, Citation1986, Grossberg Citation1987) and is an extension of conventional competitive learning to more flexible competitive learning.
2. Growing network
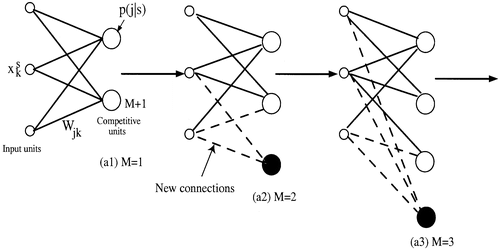
In the greedy network-growing algorithm, we suppose that a network attempts to acquire as much information as possible from the outer environment. shows a process of growing by the greedy network-growing algorithm. represents an initial state of information maximization, in which only two competitive units are used. We need at least two competitive units because our method aims to make neurons compete with each other. First, information is increased as much as possible with these two competitive units. When it becomes difficult to increase information, the first cycle of information maximization is finished. In this case, just one unit wins the competition, while the other loses. Then, a new competitive unit is added, as shown in . These processes continue until no more increase in information content is possible.
Figure 1. A process of network growing by the greedy network-growing algorithm. Black circles denote newly recruited neurons, and dotted lines show connection weights into the new neurons.
Now, we can compute information content in a neural system. We consider information content stored in competitive unit activation patterns. For this purpose, let us define information to be stored in a neural system. Information stored in the system is represented by decrease in uncertainty (Gatlin Citation1972). Uncertainty decrease, that is, information I(t) at the tth epoch, is defined by
![]() where p(j; t), p(s) and p(j | s; t) denote the probability of the jth unit in a system at the tth learning cycle, the probability of the sth input pattern and the conditional probability of the jth unit, given the sth input pattern at the tth epoch, respectively.
where p(j; t), p(s) and p(j | s; t) denote the probability of the jth unit in a system at the tth learning cycle, the probability of the sth input pattern and the conditional probability of the jth unit, given the sth input pattern at the tth epoch, respectively.
Let us present update rules to maximize information content at every stage of learning. For simplicity, we consider the Mth growing cycle, and t denotes the cumulative learning epochs throughout growing cycles. As shown in , a network at the tth epoch is composed of input units ![]() and competitive units
and competitive units ![]() . An output from the jth competitive unit can be computed from
. An output from the jth competitive unit can be computed from
![]() where L is the number of input units, and w
jk
denotes connections from the kth input unit to the jth competitive unit. In the previous models (Kamimura et al., Citation2002, Kamimura Citation2003c), we used the sigmoidal activation function instead of this inverse Euclidean distance function. The output is increased as connection weights come closer to input patterns. The conditional probability p(j|s;t) at the tth epoch is computed from
where L is the number of input units, and w
jk
denotes connections from the kth input unit to the jth competitive unit. In the previous models (Kamimura et al., Citation2002, Kamimura Citation2003c), we used the sigmoidal activation function instead of this inverse Euclidean distance function. The output is increased as connection weights come closer to input patterns. The conditional probability p(j|s;t) at the tth epoch is computed from
![]() where M denotes the Mth growing cycle. Since input patterns are supposed to be given uniformly to networks, the probability of the jth competitive unit is computed by
where M denotes the Mth growing cycle. Since input patterns are supposed to be given uniformly to networks, the probability of the jth competitive unit is computed by
 where S is the number of input patterns. Information I(t) is computed from
where S is the number of input patterns. Information I(t) is computed from
![]()
As information becomes larger, specific pairs of input patterns and competitive units become strongly correlated. Differentiating information with respect to input-competitive connections w
jk
(t), we have
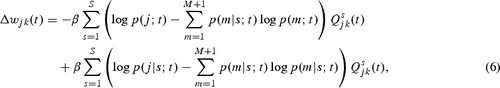
where β is the learning parameter, and
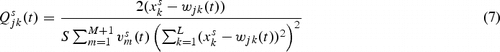
As has been already mentioned, we used the sigmoidal function: ![]() , where f ( u) = 1/ ( 1 + exp ( − u) ). When we increase information, the sigmoidal activation function produces negative connection weights by which the majority of competitive units are suppressed. Because negative connection weights are generated independently of input patterns, representations faithful to input patterns are not obtained.
, where f ( u) = 1/ ( 1 + exp ( − u) ). When we increase information, the sigmoidal activation function produces negative connection weights by which the majority of competitive units are suppressed. Because negative connection weights are generated independently of input patterns, representations faithful to input patterns are not obtained.
3. Artificial data analysis
In the first experiment, we attempt to show that a problem cannot be solved by the conventional greedy network-growing algorithm. In the problem, we have 30 input patterns, shown in . The number of competitive units is increased gradually up to 20, with 19 growing cycles. The number of input units is 30. The learning parameter β is unity for the previousFootnote1 and the new method. In learning, the momentum is used with the parameter value 0.8 to speed up and stabilize learning. To make the difference between the two methods clearer, input patterns were adjusted to have zero mean and unity standard deviation, because the previous method with the sigmoidal activation function could not classify input pattern into appropriate classes with this normalization.
Figure 3. Competitive unit activation patterns p (j|s) and connection weights w jk by: (a) the conventional; and (b) the novel method. In competitive unit activations (left), black squares represent normalized competitive unit activations p (j|s), and their size denotes the strength of activations. In connection weights (right), we used the Hinton diagram (Hinton and Sejnowski Citation1986) in which black and white squares represent positive and negative connections, and their size shows the strength of connections.

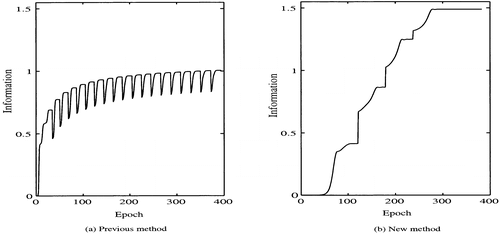
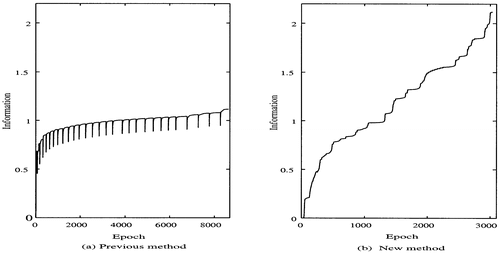
shows information as a function of the number of epochs by the conventional greedy network-growing method. Information is rapidly increased in the first growing cycle, and then increase in information in the later growing cycles is significantly small. This means that it becomes difficult to extract features by the conventional method. On the other hand, shows information as a function of the number of epochs by the new method. As shown in the figure, information is significantly increased during different learning cycles and reaches its stable point in about 300 epochs. In addition, we can see that information is significantly larger than that achieved by the previous model.
Figure 2. Information by: (a) the conventional greedy algorithm; and (b) the novel algorithm.
shows competitive unit activations p(j|s) and connection weights w jk from the first to the third growing cycle by the previous method. In the first and the second growing cycle, features are gradually extracted. However, from the third growing cycle, no additional features can be observed in competitive unit activations as well as connection weights. shows competitive unit activations and connection weights from the first to the fourth growing cycles by the new method. As can be seen in the figure, distinct features are gradually extracted. When we see connection weights, five features are clearly separated ().
4. Animal classification
The new greedy network-growing algorithm was applied to animal classification in the UCI machine learning data set.Footnote2 We used this database because the animal data set is well known and the target information on explicit classes is well documented in the database. In the database, animals are classified into seven groups: No. 1 (41,animals), No. 2 (20 animals), No. 3 (five animals), No. 4 (13 animals), No. 5 (four animals), No. 6 (eight animals) and No. 7 (10 animals). These animals are classified based upon 16 attributes. One attribute (No. 13) has numeric values ranging between zero and eight. All the other attributes are Boolean. Thus, we adjusted the data set to one with zero mean and one variance. In addition, we can expect a clearer difference between the new method and the previous method by adjusting the data. When the data are adjusted, networks must cope with more subtle input values, because the data do not take an explicit one or zero (Boolean data). In our networks, the number of input units is 16, corresponding to the 16 attributes, and the number of competitive units is increased from two to 30.
As a problem becomes more complex, it becomes more difficult to acquire information in the later stages of learning. Thus, the stopping criterion is changed to acquire as much information as possible. The stopping criterion ϵ(M) at the Mth growing cycle is defined by
![]() where M represents the Mth growing cycle and α is a constant. As the number of growing cycles increases, the stopping criterion becomes more severe, and so more information can be obtained. In the actual experiment, the parameter α was set to 0.0005. shows information as a function of the number of epochs by: (a) the previous method, and (b) the new method. As can be seen in , by the previous method, information rapidly increases for the first several growing cycles, and then information increase is significantly small. On the other hand, by the new method, shown in , information is constantly increased throughout different growing cycles. This means that by using the previous method, it is difficult to obtain additional information for this problem in the later stages of learning.
where M represents the Mth growing cycle and α is a constant. As the number of growing cycles increases, the stopping criterion becomes more severe, and so more information can be obtained. In the actual experiment, the parameter α was set to 0.0005. shows information as a function of the number of epochs by: (a) the previous method, and (b) the new method. As can be seen in , by the previous method, information rapidly increases for the first several growing cycles, and then information increase is significantly small. On the other hand, by the new method, shown in , information is constantly increased throughout different growing cycles. This means that by using the previous method, it is difficult to obtain additional information for this problem in the later stages of learning.
Figure 4. Information as a function of the number of epochs by: (a) the previous method; and (b) the new method.
shows competitive unit activations p (j|s) and the corresponding connection weights w jk by the previous method. In the first cycle (), animals are classified into two groups. In the second growing cycle, the second competitive unit responds to animals corresponding only to the first class composed of the first 41 animals. In the third cycle, the first and the fourth competitive units produce similar output patterns. From the fourth cycle, similar output patterns, shown in , were recurrently generated.
Figure 5. Competitive unit activation patterns by the previous method and the new method. Black squares in the competitive unit activations represent normalized competitive unit activations p (j|s), and their size denotes the strength of outputs. In connection weights, we used the Hinton diagram in which black and white squares represent positive and negative connections, and their size denotes the strength of connections.
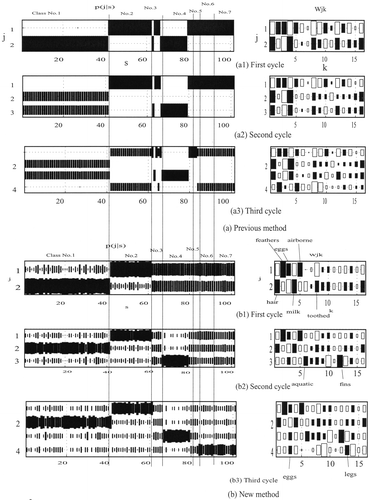
shows competitive unit activations p(j|s) and the corresponding connection weights p(j|s) by the new method. As can be seen in , after the first growing cycle, two classes, that is, class Nos 1 and 2, are clearly separated. In addition, the other classes are represented by the intermediate levels of activations. The first competitive unit responds to class No. 2. By examining the corresponding connection weights on the right-hand side, we can see that the second class is represented by features such as feathers, eggs and airborne. The second class is composed of birds, such as chicken, crow, dove and so on. The second competitive unit represents class No. 1, with features such as hair, milk, toothed and so on. Class No. 1 is composed of mammals, such as antelope, bear and boar. In the second growing cycle (), class No. 4 is clearly extracted. The features extracted in the cycle are aquatic and fins. Thus, this class represents fish, such as bass and carp. In the third growing cycle, class Nos 6 and 7 are separated (). The feature extracted is legs, meaning that there are animals with many legs in these classes. For example, lobster and octopus are those with many legs. Even when the number of growing cycles is larger, we have observed that networks try to classify animals into appropriate classes.
These results clearly show that our new method can extract salient features gradually. When growing stages are higher, more specific features to a smaller number of input patterns can be extracted.
5. Conclusion
We have proposed a new computational method to improve the feature extraction performance of the greedy network-growing algorithm. In the new method, the inverse of distance between input patterns and connection weights is used instead of the sigmoidal activation function to produce competitive unit outputs. This ensures that winning neurons faithfully represent input patterns. We have applied the new method to the artificial data analysis and the animal classification of the machine-learning database. In the artificial data problem, we could observe that, while the previous methods could not increase information sufficiently, the new method made it possible to increase information to a sufficiently high level. In addition, the new methods could completely extract the original five classes, while the previous methods could find just two or three classes. In the animal classification problem, by using the previous method, information reached a saturated point in the very early stage of learning. On the other hand, the new method could increase information to a sufficiently high point. In addition, the previous method could not extract appropriate classes, while the new method succeeded in extracting appropriate classes. Thus, we can say that the new method can extract features more explicitly and classify input patterns more appropriately.
For further development of our method, it is necessary to mention the following three points. First, the performance of our new method should be tested on more large-scale problems. Second, we adapted a stopping criterion that changed during the course of learning. However, more subtle changes in the stopping criterion will be needed to extract features specific to some input patterns. Finally, networks should be extended to multilayered networks, because networks with one competitive layer certainly cannot deal with more complex problems (Kamimura Citation2003a, Citationd). Though some improvement will be needed for practical applications, this new method certainly opens up a new perspective in the network-growing approach in neural networks.
Acknowledgement
The author is very grateful to two reviewers, Taeko Kamimura and Mitali Das, for their valuable comments and suggestions.
Notes
The previous method means a greedy network-growing algorithm with the sigmoidal activation function in which all connection weights are updated (Kamimura Citation2003c).
UCI Machine Learning Repository, http://www.ics.uci.edu/∼mlearn/MLRepository.html
References
- Gatlin LL 1972 Information Theory and Living Systems New York Columbia University Press
- Grossberg , S . 1987 . Competitive learning: from interactive activation to adaptive resonance . Cognitive Science , 11 : 23 – 63 .
- Hinton GE Sejnowski TJ 1986 Learning and relearning in Boltzmann Machines In D. E. Rumelhart, J. L. McClelland and the PDP Research Group (eds) Parallel Distributed Processing: Explorations in the Microstructure of Cognition 1 Foundations Cambridge MA MIT Press
- Kamimura , R . 2003a . Information theoretic competitive learning in self-adoptive multi-layered networks . Connection Science , 13 ( 4 ) : 323 – 347 .
- Kamimura , R . 2003b . Information-theoretic competitive learning with inverse Euclidean distance . Neural Processing Letters , 18 : 163 – 184 .
- Kamimura , R . 2003c . Progressive feature extraction by greedy network-growing algorithm . Complex Systems , 14 ( 2 ) : 127 – 153 .
- Kamimura , R . 2003d . Teacher-directed learning: information-theoretic competitive learning in supervised multi-layered networks . Connection Science , 15 ( 2–3 ) : 117 – 140 .
- Kamimura , R , Kamimura , T and Takeuchi , H . 2002 . Greedy information acquisition algorithm: a new information theoretic approach to dynamic information acquisition in neural networks . Connection Science , 14 ( 2 ) : 137 – 162 .
- Rumelhart DE Zipser D 1986 Feature discovery by competitive learning In D. E. Rumelhart, J. L. McClelland and the PDP Research Group (eds) Parallel Distributed Processing 1 Cambridge MA MIT Press pp. 151–193