Abstract
This study investigates how more advanced joint attentional mechanisms, rather than only shared attention between two agents and an object, can be implemented and how they influence the results of language games played by these agents. We present computer simulations with language games showing that adding constructs that mimic the three stages of joint attention identified in children's early development (checking attention, following attention, and directing attention) substantially increase the performance of agents in these language games. In particular, the rates of improved performance for the individual attentional mechanisms have the same ordering as that of the emergence of these mechanisms in infants’ development. These results suggest that language evolution and joint attentional mechanisms have developed in a co-evolutionary way, and that the evolutionary emergence of the individual attentional mechanisms is ordered just like their developmental emergence.
1. Introduction
An important prerequisite of a successful conversation is the participants’ ability to engage in joint attention in order to understand each other. This is not a coincidence. For young children, the ability to share attention with an adult concerning a third object or actor is a very important step in their language development. Tests like the Intentionality Detector or the Eye Direction Detector, which examine various aspects of joint attention, have shown that infants acquire joint attention skills at approximately the same age as they start to learn their first words (Baron-Cohen Citation1995). According to Tomasello Citation(1999), the ability to engage in joint attention may have been the crucial mechanism for cultural learning, enabling mankind to rise from stone age to modern culture and technology in a relatively short time. The ability to engage in joint attention may also be a crucial prerequisite for language evolution.
In the literature on child development, the term joint attention refers to a set of skills that can be categorised into three distinct stages: checking attention, following attention, and directing attention (Carpenter, Nagell and Tomasello 1998). These three stages mainly differ in the way joint attention is initiated: checking attention involves a natural sharing of attention without a clear initiator, following attention involves the caregiver directing the attention of the infant to an object, and directing attention involves the infant directing the attention of the caregiver to an object. They also differ in the way objects are brought into the scope of attention: in checking attention, the attended object is already in the scope of attention, in following attention and directing attention, the attended object is explicitly brought into the scope of attention. Carpenter et al. Citation(1998) found that the order in which the three stages arise is: checking attention (month 9–10), followed by following attention (month 10.5), and finally directing attention (month 12.6). This ordering has been confirmed in other studies for autistic children (Carpenter, Pennington and Rogers Citation2002) and healthy children (Mundy et al. Citation2007). Moreover, the frequency with which children use these three attentional mechanisms between 9 and 18 months of age predicts how well these children perform at language development tests at 24 months (Mundy et al. Citation2007).
In this paper we address three questions: (1) How can we model these three joint attentional mechanisms with respect to other models of language evolution? (2) To what extent do the different attentional skills contribute to language emergence in language game models? (3) Why do we find exactly this ordering in the emergence of attentional skills and not another? We assume that joint attentional skills are used to reduce the uncertainty with which the meanings of words can be inferred and that the different skills contribute differently in reducing this uncertainty. Assuming a cross-situational learner (Siskind Citation1996), we know that the more uncertainties there are in the learning situations, the longer it takes to learn a set of word-meaning mappings (Smith, Smith, Blythe and Vogt Citation2006). Although the ordering of emergence in attentional skills may be accounted for by different factors (e.g. complexity of the required skill), we will assume that those skills that contribute most to language development are most likely to have evolved first. If they have evolved first phylogenetically, it is not unlikely that they also develop first ontogenetically.
The computer model used for the current study is based on the language game model that investigates how agents (either robots or software agents) can develop a common lexicon, i.e. how they can develop a shared set of word-meaning mappings (e.g. Oliphant Citation1999; Steels Citation2001; Steels and Kaplan Citation2002; Vogt and Coumans Citation2003; Smith Citation2005; Vogt and Divina Citation2007). In these language games, a population of agents, situated in a common but changing environment, repetitively exchange utterances for concepts (like shape or colour) present in the current environment, until a common lexicon for these concepts has emerged. The hard problem that the agents have to solve is the social symbol grounding problem (Cangelosi Citation2006; Vogt and Divina Citation2007): how can a (large) group of agents arrive at a shared set of symbols? Various studies have shown that a one-to-one bias towards word-meaning mappings is required for learning them, i.e. learning mechanisms acquiring word-meaning mappings seem to require a pressure towards assuming one-to-one mappings (Oliphant Citation1999; Smith Citation2004). The question remains how such a bias is implemented, and to what extent this bias is strict (i.e. using it as a fixed constraint, rather than as a tendency)? Seeing such a bias as a strict one could be wrong, because words can have different meanings and letting agents learn only one-to-one mappings would not allow this. The bias should rather be seen as pressure or tendency towards words having one meaning and vice versa.
In (virtual) robotic experiments, agents communicate typically in situations containing many different objects and events, which after categorisation lead to even more meanings (see, e.g. Steels Citation2005; Vogt Citation2006, for overviews). Various strategies to reduce the complexity of the situations have been investigated. These include either sharing attention by means of pointing to the subject of the communication (Vogt Citation2000), using corrective feedback regarding the interpretation of hearers (Steels and Kaplan Citation2002, Vogt Citation2003), a combination of sharing attention and corrective feedback (Steels, Kaplan, McIntyre and van Looveren Citation2002), or neither pointing nor feedback, but cross-situational learning (Vogt Citation2000; Smith Citation2005; De Beule, De Vylder and Belpaeme Citation2006). Comparisons of various methods indicate that joint attention is very beneficial in terms of speed, that corrective feedback improves the quality of the emerging lexicon and that cross-situational learning only works under certain conditions (Vogt Citation2000; Vogt and Coumans Citation2003; Vogt Citation2005; Vogt and Divina Citation2007). One problem is that many of these implementations assume that sharing attention or corrective feedback hands over the meaning (sense) of a word almost explicitlyFootnote1, for instance, by assuming a whole object bias in which the meaning is assumed to be the meaning relating to the whole object (or referent) as in Vogt Citation(2000). Although the whole object bias is realistic (Macnamara Citation1982), children do not use it continuously. Moreover, it does not allow one to learn the meaning of, for instance, adjectives referring to features such as colours or shapes.
In the current study, we will assume that cross-situational learning is the core learning mechanism that allows agents to infer the meaning of a word from the statistical co-variance of the word with its meaning. The speed with which agents can learn an idealised language using cross-situational learning is proportional to the complexity of the situation in which the agents communicate (Smith et al. Citation2006). Although under ideal circumstances cross-situational learning works well, a reduction of complexity in learning situations is required in more complex worlds (e.g. Vogt and Coumans Citation2003). We investigate how the three joint attentional stages can be implemented to reduce the complexity of the situations. By doing so, we investigate how the different stages influence the emergence of lexicons and why the stages come in the ordering with which they emerge in children.
Although we only consider a small aspect of language development, namely the establishment of a common lexicon in a very simplified simulation setting, the findings can be used as indirect evidence for language evolution. Steels Citation(1999) argued that the kind of simulations such as those presented here provides valuable evidence, because the emerging structures (in this case, the common lexicon) are based on the properties and dynamics of a population of autonomous agents. According to Steels Citation(1999):
In such investigations, it becomes quite natural to study language evolution. For example, one can test whether agents with a particular architecture enabling them to construct and acquire a lexicon, indeed arrive at a shared lexicon, whether this lexicon is resistant to changes in the population, whether it scales up to large numbers of meanings and agents, under what conditions shifts in meaning might occur, etc. (p. 8)
If there are large differences in the effects of basic cognitive social skills (such as the different joint attentional skills) on the outcome of these language games, it is plausible that similar effects play a role in language evolution. For instance, if checking attention is indeed a crucial prerequisite for the establishment of a common lexicon in language games (for instance, when without checking attention, lexicon establishment is found to be far less successful), this suggests that early hominids needed to have these capabilities before more advanced language usage could emerge.
In the following section, we further discuss the concepts of Theory of Mind (ToM), joint attention, and their development in children. Next, Section 3 discusses how joint attention relates to language evolution and language development. In Section 4, we describe the model and method used in this study. Results are presented in Section 5, followed by a discussion in Section 6. Finally, we formulate some conclusions in Section 7.
2. ToM and joint attention
What abilities separate mankind from other species? Among other suggestions, like bipedalism and tool fabrication, the ability to use and master a complex language and the possession of a Theory of Mind (Premack and Woodruf Citation1978) are proposed as being unique to mankind. Having a ToM (i.e. the capacity for ‘mind reading’ or ‘mentalising’) means that one sees other actors as intentional agents like oneself, with comparable beliefs, desires, and intentions, and that one can understand what other actors are thinking. While having a ToM is necessary to engage in complex communicative behaviours, it has been shown that very young children do not have a full-blown ToM. For example, children only pass ToM indicators like the False Belief Test (Wimmer and Perner Citation1983) and the Opaque Context Test (Robinson and Apperlyb Citation2001) after approximately four and five years of age, respectively. At this age, children know a considerable number of words (Bloom Citation2000).
Using tests like the Intentionality Detector or the Eye Direction Detector that evaluate various aspects of joint attention, it has been shown that infants acquire joint attention skills, like gaze following and joint engagement, at approximately the same age as they start to learn their first words (Baron-Cohen Citation1995). They know hundreds of words at 24 months of age, long before the False Belief Test or Opaque Context Test indicate the existence of a workable ToM, as shown in , which is adapted from Reboul Citation(2004). As Reboul concluded from these data, a child needs some sort of joint attention skills in order to acquire a vocabulary, although from this perspective ToM and language acquisition develop in parallel rather than serially. It is clearly not the case that a workable ToM is required before the child starts to acquire a vocabulary. Nevertheless, the development towards a ToM in the first years – for example, the ability to view other persons as intentional agents, demonstrated by complex social skills as social referencing or imitative learning (Tomasello Citation1995) – undoubtedly facilitates further vocabulary development.
Table 1. Age, Language development and ToM development.
On the basis of these developmental data, Reboul suggests that language evolution and evolutionary ToM development follow the same pattern. They develop in a co-evolutionary way, rather than serially (specifically: ToM preceding language evolution). Basic joint attentional skills are necessary prerequisites for both ToM development and language evolution. Malle Citation(2002) also suggests that ToM and language have evolved ‘coincidentally concurrent’, as mutual escalations utilising advances from either side, or driven by a third factor. The hypothesis that ToM and language evolved as mutual escalations is supported by another observation in language acquisition. Although names of simple objects that play a role in the infant's life are learned during the first years, children only use deictic relationsFootnote2 correctly at the age of three or four years, depending on whether the speaker's or the listener's perspective was taken (Pan and Gleason Citation2004). Furthermore, various studies suggest that autistic children are particularly impaired in this domain (Tager-Flusberg Citation1981). This suggests that the usage of these more advanced language constructs could emerge only after some sort of ToM evolved.
The term joint attention describes a compound set of skills and interactions that emerge in infants of about nine months of age. Normally, at this age children begin to follow the gaze of their caregivers and engage with them in more complex social interactions that involve joint attention. The most prominent feature in these skills and interactions is that they are triadic: whereas younger children typically either pay attention to a toy or their caregiver, the interactions of older children are usually more sophisticated and involve both the object and the other person (Baron-Cohen Citation1995; Tomasello Citation2000).
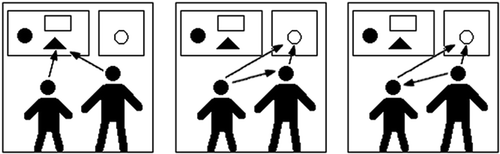
Carpenter et al. Citation(1998) categorised various forms of joint attention (like joint engagement, gaze following, and point following) into three distinct stages, namely checking attention, following attention, and directing attention. depicts these three stages. In the checking attention stage, both child and adult share attention to the black triangle and to each other. In the following attention stage, the child follows the attention of the adult to the white circle, and in the directing attention stage the child directs the attention of the adult to the white circle. While the following and directing stages differ in the passive versus active role of the child, the differences between checking attention and following or directing attention are subtler. Carpenter et al. Citation(1998) describedFootnote3 these three stages as follows:
Checking attention: By definition, all joint attentional skills involve infants sharing attention with a partner in some manner. We are concerned here, however, with relatively extended episodes of joint attentional engagement in which adult and infant share attention to an object of mutual interest over some measurable period of time (at least a few seconds). The prototypical example of an episode of joint attentional engagement is a situation in which adult and infant are playing with a toy and the infant looks from the toy to the adult's face and back to the toy. (…) Minimally, the infant must be engaged with an object on which the adult is also focused, then demonstrate her awareness of the adult's focus by looking to her face, and then return to engagement with the object. (p.5)
Following attention: It is difficult to know what infants understand of their social partners as intentional agents when they are looking to them and engaging with them in these extended periods of joint engagement. But when infants begin to follow into the attention or behaviour of others in certain specific ways, a much more compelling case can be made that they understand something about the other person as an intentional agent. In particular, infants may follow into the attention of others by following the direction of their visual gaze or manual pointing gesture to an outside object. (p.8)
Directing attention: Human infants demonstrate their understanding of adults as intentional agents, not only by following into their attention and behaviour, but also by attempting to direct their attention and behaviour to outside entities through acts of intentional communication. (p.17)
Figure 1. Checking attention (a), following attention (b) and directing attention(c).
These descriptions imply that in the checking stage, the ‘third object’ is already within the scope of the two agents (like child and adult), for example, because it was physically given to the child by the adult to hold it in its hands, whereas in the following and directing stages, the third object is brought into scope by the adult or the child. In , the difference between checking and directing attention is sketched. In the initial stage, the child and the adult share attention to the objects in the box on the left, which is the current scope of their shared attention (the encircled objects in . Through directing attention, the scope is extended when the infant directs the adult's attention to the circle in the box on the right (. The adult, being able to understand the child as an intentional agent, follows the attention of the visual gaze of the infant, bringing the circle into the scope of their shared attention (encircled objects . Normally, the child will check to see if the adult has followed its direction of attention, so both participants are aware that they share attention. The difference between following and checking attention is similar to the disparity between directing and checking, except that the initiative of shifting attention is taken by the adult instead of the child.
Figure 2. Scope of the agents in checking versus directing attention.
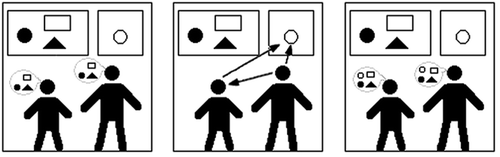
Note that, in order for this scope extension to succeed, both agents must be able to employ joint attentional capabilities. One cannot direct if the other cannot follow, and vice versa. In normal development, the child will – after having acquired checking attention – first acquire following attention, and later on, directing attention capabilities.
3. Joint attention and language development
Research has indicated that using joint attentional skills correlates well with children's language development. It has been shown experimentally that children who learn new words in a joint attentional setting do better than children who learn them without a joint attentional setting (Tomasello and Todd Citation1983). Autistic children, who reveal a different development of joint attentional skills than non-autistic children show correlated differences in language development (Dawson et al. Citation2004). Even regarding the various stages in joint attention, there appears to be a measurable correlation between the use of these stages of joint attention between 9 and 18 months old infants and the level of language competence at 24 months of age (Mundy et al. Citation2007). An interesting issue is how joint attention influences language development in children, i.e. what makes joint attention a mechanism that influences the ability to learn language.
The obvious possibility, which we will explore here, is that joint attention allows individuals to reduce the number of hypothetical meanings when learning a word's meaning. According to Quine Citation(1960), each unfamiliar word that we learn can, in principle, mean an infinite number of things (the word ‘gavagai’ expressed when a rabbit scurries by can mean ‘rabbit’, ‘undetached rabbit parts’, ‘running furry animal’, ‘dinner’, ‘it will rain’, and so on). So, in order to learn the meaning of a word, one must be able to reduce the number of possible hypotheses substantially. Various mechanisms have been proposed of which joint attention is just one (Bloom Citation2000). Others include, for instance, mutual exclusivity (Markman Citation1989), the principle of contrast (Clark Citation1993), and the whole object bias (Macnamara Citation1982). Even though the various mechanisms are not necessarily mutually exclusive, they will tend to fail in minimising the hypothesis set to one.
All these principles and constraints assume an underlying mechanism that stores and manages the associations between words and meanings. Various mechanisms have been proposed, but the most straightforward mechanism is associative – Hebbian – learning. In essence, this associative learning mechanism strengthens the associations between a word and all meanings that apply in a certain situation (or context). When applied over varying situations, a word's meaning tends to co-occur with that word, and the learning mechanism eventually boils out all competing hypotheses. This mechanism, also known as cross-situational learning (Siskind Citation1996), has long been considered to be an impossible learning mechanism (see, e.g. Bloom Citation2000, for a discussion). However, there is increasing evidence that children can and do use cross-situational learning as a mechanism for learning word-meaning mappings (Akhtar and Montague Citation1999; Klibanoff and Waxmann Citation2000; Mather and Schafer Citation2004; Houston-Price, Plunkett and Harris Citation2005; Smith and Yu 2007).
Despite Quine's referential indeterminacy, it has been shown mathematically that cross-situational learning is very robust against context size (i.e. the ratio between context size and lexicon size can be very high), though the time it takes to learn a lexicon increases super linear with increasing context sizes (Smith et al. Citation2006). However, these results were achieved with idealised assumptions concerning the input to the learner; in particular it was assumed that there is a strict one-to-one mapping between word and meaning in the input lexicon, the input for the learner is consistent and comes from one source, such that each utterance always co-occurs with the intended meaning (or feature), and the input is presented to the learner with a uniform distribution.
When one deviates from these idealised assumptions, cross-situational learning appears to be much harder, although not infeasible. When cross-situational learning is applied in multi-agent simulations of language evolution and where the number of agents in which the lexicon develops is larger than two, then assumptions 1 and 2 are violated. In such simulations, multiple agents invent different words for a meaning early during the simulation, after which the population needs to converge on a single convention (Baronchelli, Felici, Caglioti, Loreto and Steels Citation2006). Several simulations have shown that cross-situational learning alone does not provide a sufficiently powerful one-to-one bias for the lexicon to converge (Vogt and Coumans Citation2003; Vogt and Divina Citation2007). Adding extra one-to-one biases, such as mutual exclusivity (Smith Citation2005) or the mechanism of synonymy damping proposed by De Beule et al. Citation(2006), can overcome this problem. A yet unpublished study by Vogt has shown that when the input to a learner follows a non-uniform Zipfian distribution (Zipf Citation1949) through which assumption 3 is violated, the time required to learn – even a small – lexicon runs beyond control when the average context size increases.
In sum, although under ideal circumstances cross-situational learning can work well in situations containing large numbers of hypotheses, under more realistic circumstances the context size from which individuals learn must be well limited. In this study, we will assume that all agents have three joint attentional skills based on those proposed by Carpenter et al. to reduce the context size. Based on previous studies (Smith et al. Citation2006), we predict that each mechanism has a positive effect on the rate with which lexicons are acquired in the population. The question is which skill yields better performances and whether there are optimal combinations of mechanisms those agents can use.
4. Model and methods
The model is based on the language game model introduced by Steels Citation(1996) in which a population of agents tries to develop a shared lexicon using communicative actions in a particular environment (e.g. a whiteboard with coloured geometrical objects) by engaging in a series of language games. Such language games are typically played between two agents; one of them (the speaker) tries to produce a word expressing a feature (or meaning) of an object in its scope of attention, while the other (the hearer) tries to identify this feature based on this uttered word. When the speaker does not know a word, it invents a new random string. When the hearer does not know a word, it acquires the word. When the hearer knows the word, it strengthens the co-occurrence frequencies between the word and the features (or meanings) in the context using cross-situational learning mechanisms. The various joint attentional mechanisms are used to construct the context from which the hearers acquire the word-meaning mappings.
Simulations were run with a population containing 10 agents, each starting with an empty lexicon. The agents were situated in a virtual world containing 64 objects, each characterised as a three-dimensional vector with four different values in each dimension. Each position in one dimension is called a feature of the particular object and could be interpreted as, for instance, a colour, a shape, or a size. So, in total, there are 43=64 different objects in this world, constructed from the 3×4=12 possible features in total (or meanings m j ). Note that we assume that each feature corresponds directly to one meaning, e.g. the feature ‘colour-of-object-1’ could correspond to the meaning ‘red’.
Each agent is equipped with a private lexicon represented as an association matrix that associates words w
i
with meanings m
j
. Initially, each agent has an empty lexicon; the lexicons are constructed while playing language games. Each association is given a weight ω
ij
that is calculated as the a posterior co-occurrence probability as follows:
In all simulations, each time a language game is played, two agents are selected from the population at random, one is randomly assigned the role of speaker, the other the role of hearer. Four objects are selected arbitrarily with a uniform distribution from the world to form the situation S. The context C S of this situation is defined as the set of all features f j of all objects O i ∈S. The speaker selects one random object O t ∈S from this context as the topic and from this object, it selects one arbitrary feature f t ∈O t to form the target. The speaker then tries to produce an utterance by searching its lexicon for a word that has the highest weight with the target meaning. If no such word is found, the speaker invents a new word as a random string, adds the form – target pair to its lexicon and utters the new word.
In turn, the hearer tries to interpret the uttered word by searching its lexicon for the association of which the meaning is consistent with one of the potential meanings available in the context C S and that has the highest weight. Depending on the type(s) of joint attention mechanism(s) that agents use in a language game, the context C S is adjusted to form the learning context C L. The hearer adapts its lexicon by increasing the co-occurrence frequencies u ij between the word w i and all meanings m j in the learning context C L by 1. If an association between word and meaning does not exist, it is added to the lexicon before updating its co-occurrence frequency.
As mentioned, we use the joint attentional mechanisms to reduce the complexity of the learning situation, i.e. these mechanisms are used to construct the learning context C L. So, how can we translate the joint attentional skills proposed by Carpenter et al. Citation(1998) into the abstraction of the model? Although in the simulations all agents are equally old, we will assume that in the language games, the speaker takes up the role of the adult and the hearer the role of the child. The following explains how we propose that the joint attention mechanisms can change the learning context:
4.1 Checking attention
With checking attention, the object is already in the agents’ scope of attention, so we assume it precedes the exchange of the verbal utterance, which means that both agents share attention to the topic right from the start of the interaction, i.e. . If no further attentional mechanism is used, the learning context is also set to the topic, i.e.
. Note that in the model, the speaker selects the topic. The definition of checking attention assumes that the object is already in the scope of both agents’ attention, but, because the topic selection is random, it does not matter when the topic is selected.
4.2 Following attention
With following attention, the object is brought into the child's scope of attention by the adult. We assume that this occurs after the hearer has interpreted the utterance based on the situation's context C
S. The speaker then selects a random object O
r
from the situation S that contains the same feature as the target, i.e. f
t
∈O
r
and that is different from the topic (i.e. O
r
≠O
t
). This object is then brought into the hearer's scope of attention and – in case there was no prior joint attention in the game – the features describing this object construct the learning context, i.e. . If there was prior joint attention – checking attention – then the learning context is constructed as the cross-section of the topic and this additional object, i.e.
. If no object is found that contains the intended feature and unequal to the topic, then no attention is modelled and the hearer takes the context of the whole situation as learning context (i.e.
. We realise that this is not entirely realistic compared with what humans do (the adult will probably point to the topic), but we decided that a different object is brought into the scope of attention, rather than the topic. We made this choice, because if the speaker can bring the topic into the scope of attention, the mechanism would essentially reduce to checking attention when it comes to learning.
4.3 Directing attention
With directing attention, the object is brought into the adult's scope of attention by the child. Again, we assume that this occurs after the hearer has interpreted the utterance. The hearer then selects a random object O
h
from the situation S that contains the same feature as the interpreted meaning, i.e. f
I
∈O
h
and brings this object into the speaker's scope of attention. The speaker then provides feedback by signalling whether or not this object contains the intended target, i.e. whether f
t
∈O
h
. We assume that the hearer can use this information to construct the learning context. If the speaker signalled a success, the hearer constructs the learning context C
L as this novel object, i.e. . If the speaker signals that the object does not contain the target, then the context is refined by taking the complement of the original context C
S and the new object, i.e.
. (In the cases where checking attention and/or following attention preceded directing attention in the same language game, yielding a learning context C′
L
, then
or
.)
It is important to note that we assume that checking attention precedes the verbal interaction, whereas following attention and directing attention occur as a response to an interaction (i.e. occur afterwards). So, checking attention has an impact on interpretation as in the current model: agents interpret an utterance with a meaning that is in the context (i.e. in the scope of attention). For following attention and directing attention, the scope is initially the entire context C S, used for interpretation, but learning (i.e. adapting the weights) is carried out on C L after joint attention has been achieved. This distinction is important, because the simulations are measured based on the ability to interpret an utterance.
4.4 An example
To explain the basics of the model, consider the following example. A mother and child are playing with four toy dogs. One is red, striped, and furry; the second is green, striped, and furry; the third is red, dotted, and plastic; and the fourth is yellow, striped, and plastic. Suppose that the mother wants to talk about furry things. Further suppose, for the sake of the example, that the child understands phrases like ‘That is …’ and that she knows the word for dog, but has never heard any of the words for the colours, textures or materials. So, let us assume that the context of the whole game is limited to red, green, yellow, striped, dotted, furry, and plastic. When the child would hear the word ‘furry’ in this context, she has no clue, other than to associate this word with all these seven properties.
Now suppose that the child starts playing with the red striped furry dog and the mother says, following her child's attention, ‘That is furry, isn't it?’ Mother and child are checking attention and the child, knowing that her model shares her attention to the dog, reduces the learning context to red, striped, and furry. The child looks as if she does not understand her mother, which is true because she still does not know whether ‘furry’ means red, striped, or furry. In response, the mother draws the child to a green striped furry dog and says ‘Look, another furry thing!’ The child, following attention, realises that ‘furry’ does not mean red, but either striped or furry. The child guesses that it means striped, and verifies this by directing the mother's attention to the yellow striped plastic dog while saying ‘furry?’ The mother responds ‘No, that's not furry.’ Now the child can infer the meaning of ‘furry’. Because the child already decided that ‘furry’ means either striped or furry, the object she pointed to was a striped plastic dog and given the negative response, she can infer that ‘furry’ must mean furry.
In this example, all three joint attention stages were used shortly one after another and in the order of emergence. We model such an interaction as if it is one language game. However, in reality and in the model the joint attentional mechanisms may be used separately. We have carried out eight series of simulations where we varied the different joint attention mechanisms available to the agents. The eight simulation series correspond to eight different combinations of having none, one or more of the attention mechanisms available, as shown in . During a simulation, all agents use only one and the same strategy. In the different conditions, each language game used all available mechanisms in the order as proposed by Carpenter et al. Citation(1998), i.e. used in the order checking attention > following attention > directing attention, as in the above example. Only after the joint attention mechanisms are applied does the hearer adapt the co-occurrence frequencies of the utterance with the meanings that remain in the learning context C L. (Note that the speaker always increments the co-occurrence frequency of the utterance and the target.)
Table 2. The eight different simulation series and the attention mechanisms switched off (−) or on (+). The final column shows how the learning context C L is constructed.
We realise that the simulations carried out are still far from reality, as humans do not learn by applying only one type of interaction that uses none, one, or all possible strategies available to them. Instead, humans use different strategies in different interactions, constrained by what is available to them. Moreover, children learn from hearing complex multiword utterances rather than from one word utterances, and they understand a whole range of privately acquired concepts, rather than a limited set of pre-defined meanings. Nevertheless, the current set up of the experiment allows us to investigate – on the basis of the proposed model – the effects of different joint attention mechanisms on the emergence of a lexicon.
It is instructive to note a number of differences between the models of the current paper and those studied before. All current models are based on cross-situational learning. That means that all co-occurrence frequencies between a word and the meanings in the context are increased. In the observational games (e.g. Oliphant Citation1999; Vogt Citation2000; Vogt and Coumans Citation2003), the attended object is the meaning, so the update only strengthens the correct association and weakens incorrect ones. The same holds for the guessing games (e.g. Steels and Kaplan Citation2002; Vogt Citation2003; Vogt and Coumans Citation2003), most closely resemble models containing following and/or directing attention and no checking attention (i.e. xfx, xxd, and xfd). The essential difference is that in terms of learning the guessing game reduces to checking attention as the speaker informs the hearer what the topic was in case the hearer guessed wrong (so, the learning context becomes the topic). In following attention, the information is not always given in case no alternative object could be found (if we would allow the speaker to bring the topic into the scope, then following attention xfx would effectively become the guessing game). With directing attention, the hearer uses the information of its own interpretation, the situation and the speaker's response to construct the learning context, rather than that the speaker provides this as in the guessing game. The learning context may therefore be larger than necessary. In combination with following attention, directing attention can use the additional information to further reduce the learning context size, which does not occur in the guessing game.
5. Results
Series of simulations were run with each of these different game models, where each language game model was run 100 times with different random seeds for 100,000 language games or until communicative accuracy reached 100% for 10 language games in a row. Communicative accuracy is defined as the number of correctly played games averaged over the final 100 games. A game was played correctly if the hearer guessed the target meaning (i.e. feature) intended by the speaker based on the interpretation.
We also measured the hearer's learning context size, which we define as the number of features (or meanings) in the learning context (C L). Furthermore, we measured time of convergence as the number of games for communicative accuracy to become equal to 1 for 10 games in a row. When this condition was not reached within 100,000 games, then time of convergence was set to 100,000. The means and standard deviations of communicative accuracy, context size, and time of convergence are presented in . Communicative accuracy and time of convergence for the different conditions are also shown in and .
Figure 3. Average time of convergence.
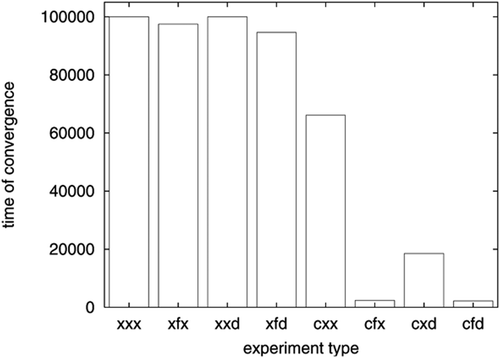
Figure 4. Average communicative accuracy.
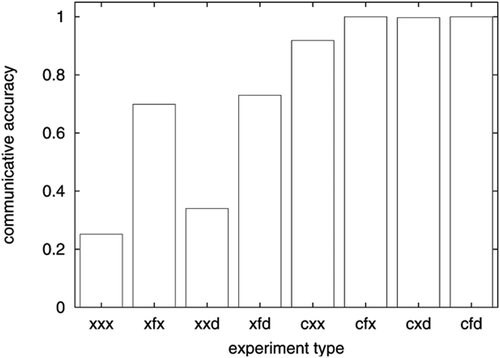
Table 3. Means and standard deviation of communicative accuracy, context size, and time of convergence.
Between the various language game models, communicative accuracy differed significantly (F(7, 792)=1473, P<0.0001), as was the case for time of convergence (, P<0.0001). To compare the effects of the checking attention mechanism with more advanced mechanisms, we submitted the convergence time scores of the language games to a two-factor ANOVA, with checking attention (yes/no) and following/directing attention (none/following/directing/following and directing) as the between-subject variables. The most interesting significant result here was the interaction between having or lacking a check attention mechanism, and having or lacking following and directing attention mechanisms (
, P<0.0001). In the conditions without checking attention mechanisms, the communicative accuracy of most simulations did not converge to 1 within 100,000 games (only the xfx and xfd models converged occasionally). Nevertheless, the communicative accuracy was much lower in the xxx model (0.25) than in the xfd model (0.73). On the other hand, in the conditions with checking attention mechanisms, the communicative accuracy of most games converged to 1 within 100,000 games, but the time of convergence was much slower in the cxx model (66,147) compared with the cfx (2403) and cfd (2223) models, and – to a lesser extent – to the cxd model (18,546). The differences between these models are significant (
, P<0.001).
The learning context size differed significantly between the language game models (, P<0.0001). While the xxx-game model had an average context size of 8.3252, all game models, which used some kind of joint attention mechanism, were able to decrease the context size, to an average ranging from 4.5641 (xfx) to 2.0650 (cfd). The differences between the context sizes of the games with combined joint attention mechanisms having checking attention (the cfx, cxd, and cfd) were, however, not significant (
, P>0.5). The value of 3 for the cxx mode can be understood by realising that the learning context is set to the three features of the topic. Only when attention is further refined through following attention and/or directing attention does the context size become lower.
The strategy that yielded lowest context size (i.e. the one containing all attentional stages) also yielded best performance in terms of communicative accuracy and time of convergence, which is consistent with our prediction. But if we compare the results between following and directing attention (both in combination with checking attention, i.e. cfx and cxd), then the following attention strategy yielded the best performance on all indicators, despite insignificant differences in context sizes for both models.
When comparing the models that contain only one of the three mechanisms (cxx, xfx, and xxd) with each other in terms of improvement on the model without any joint attention (xxx), the differences between the three models are most apparent. Clearly, checking attention shows the largest improvement, as it consistently reduces the context size to three. Following attention, which is second best, only does so when there is another object than the topic that has the target feature (recall that this is an artefact of the model, not necessarily realistic). Directing attention comes third and only yields context sizes of three when the guessed object contains the target meaning.
6. Discussion
The simulations showed dramatic improvements in performance for two of the attention mechanisms: checking attention and following attention. When the checking attention mechanism was absent, none of the conditions yielded a communicative accuracy near 100%. Nevertheless, following attention and (to a lesser extent) directing attention yielded significant improvements relative to the simulations where either is absent. When the checking attention mechanism was available, all four conditions (nearly) converged to 100% communicative accuracy. Here, following and (to a much lesser extent) directing attention affected the time of convergence drastically from around 66,000 language games for checking attention alone to about 18,000 games for directing attention and 2500 games for following attention.
In general, the improvements in performance correlate well with the decreases in context size. The differences in context size between the simulations that included checking attention and following attention and/or directing attention were not significant, while their differences in performance were. This can be explained as follows: in the directing attention simulation (cxd), the child directs the attention. Early in development, the child makes relatively many mistakes, after which the learning context becomes the difference in features between topic and guessed object, which tends to be larger than one (the chance that two objects have one feature in common is larger than the chance they have two features in common). Later on, when the child's language improves, she will more often guess correctly, thus reducing the learning context more frequently to one. In the following attention model (cfx), the learning context is constructed from the intended objects (topic and additional object) throughout the entire simulation, so the chances to learn from a context size 1 is larger. However, in this model the context size can only be reduced in games when an additional object can be found. On average, the context sizes do not differ enough to be significant, but the development in time of their sizes does have an impact on the learning speed.
From our results, it is clear that the use of these joint attentional enhancements, in particular checking and follow attention, have a large impact on these language games. Moreover, the results suggest that the ability to check attention is more crucial than the ability to follow attention, which in turn is more crucial than the ability to direct attention. Sharing attention is – of course – better than not sharing attention, because this narrows down the context size. With checking attention, both participants are aware what the focus of attention is (by definition), so the verbal communication is typically relevant, i.e the utterance refers to the object of attention. To understand the different effects of the three attentional models, let us consider – as a possible interpretation of the model – that following attention is a response of the adult to a child's inability to understand a word's meaning so that the child cannot share attention based on the language alone. The adult will sometimes respond, but not always. When the adult responds, it will draw the child's attention to an object that has the intended meaning, but otherwise the child's ‘learning context’ remains as uncertain as it was. However, in case that the child is directing attention, it may be to an object that does not have the intended meaning (in which case the child has to learn from an uncertain situation). So, it is easy to understand that, in terms of context size, checking attention has the largest effect, then following attention, and finally directing attention, which – in turn – results in the same ordering regarding the effectiveness of language development.
This conclusion is in line with the developmental data from Reboul Citation(2004) and other data suggesting a clear link between joint attention and language development (e.g. Mundy et al. Citation2007). Whereas infants knew only a few to a couple of dozen words at the moment, they were developing their joint attentional skills (from 9 to 18 months of age), this number rapidly increased to over 300 in the following half year, when they were able to use these skills. The catalyst in this rapid increase is thus not just caused by checking attention – which is typically acquired after 9–12 months of age – but also the ability to follow and direct attention, acquired after 11–15 months of age (Carpenter et al. Citation1998). The so-called word spurt occurs between 18 and 24 months, which has likely to do with the further refinement of joint attentional skills, an increased frequency of usage (Mundy et al. Citation2007) and the applicability of them to language learning, though other factors may play a role too. For instance, the accumulation of linguistic knowledge allows children to use the pragmatics of the language to focus attention.
Given the parallel ordering of effectiveness and skill emergence in children, it is tempting to suggest a relation here. Let us examine a possible reflection of an ontogenetic ordering of these skills in a phylogenetic ordering of them. Since checking attention has revealed the largest improvement in language development, it is quite possible that such a skill would have evolved first. Had we run a genetic algorithm selecting for the three skills, then the fitness landscape would have seen the largest increase for a population using checking attention and the second largest increase for following attention. One could therefore expect the three skills to evolve in the order checking attention > following attention > directing attention. However, other effects on fitness, such as the ease with which the different skills can be performed (checking attention appears easier than following attention and directing attention appears most difficult), could significantly influence the evolutionary process. Another issue concerns the possible prediction that – if there are other species than humans that have some form of joint attention – checking attention would be the most likely form to find among them, followed by following attention. However, whether this can be verified is questionable, because the most likely candidates (chimpanzees) do not seem to have joint attentional skills. Even though they jointly engage in certain behaviours and can follow eye gaze and even occasionally point to objects, they miss the aspect of understanding that the other has similar intentions (Tomasello and Carpenter Citation2007). Nevertheless, this concerns a much discussed issue in which new discoveries are to be expected that may turn out to be relevant to the prediction formulated here.
Additional research into the nature of these three joint attentional skills, the influence of their subcomponents (e.g. declarative pointing, gaze following, joint engagement, showing etcetera), as well as more advanced components of ToM on language development and language evolution could shed more light into a better understanding of our ability to learn and use language. Ideally, a model should be built in which all aspects of joint attention are available to agents. This model should then search a whole space of possible frequency distributions with which the different skills are used at different moments in development. The setting that uses frequency distributions and development that most closely resembles those of humans, should reveal a language development similar to that observed in humans. If not, the underlying model of language learning is probably wrong. If it is, the model is a very likely model for human language learning. Such an endeavour would require a combined effort from computer modellers and developmental psychologists. At the moment, there are insufficient empirical data on frequency distributions and development of joint attentional skills available to build such an integrated model (although the data from Mundy et al. Citation2007, comes close).
Another type of approach in which it is possible to continue studying the evolution of joint attentional skills in many interesting aspects (possibly even on their ontogenetic and phylogenetic emergence), is currently investigated in the context of the NEW TIES project, which aims to study the evolution of an artificial cultural society (Gilbert et al. Citation2006).Footnote4 In this project, large populations of virtual robots (i.e. virtually embodied and situated agents who are – to some extent – autonomous) operate in an environment containing various objects (such as food sources) with various features about which the agents communicate and develop a shared vocabulary. In this environment, the visual context can be rather large, so establishing joint attention is required to achieve communicative accuracy. The model currently uses checking attention and following attention skills (directing attention is being constructed) that allow agents to acquire language that allows them to learn rules required to survive in their environment (Vogt and Haasdijk Citation2007). It would, for instance, be interesting to let the model evolve the three attentional mechanisms in order to investigate which one tends to evolve first.
7. Conclusions
In this study, we have investigated how we can implement the three stages of joint attentional skills found with children (checking attention, following attention, and directing attention) in the language game model and how this affects language development. We argue that the crucial distinction between these three stages of joint attention concerns the scope of the shared attention. While the objects of shared attention in checking attention are physically ‘put’ into scope (e.g. by giving a toy to an infant to hold it in its hands), the scope can be extended in later stages by initiative of the adult (the child following attention) or by the child (directing the attention of the adult). We modelled this scope extension by augmenting the agents in the language games with a ‘toolbox’ of methods that typically require follow attention (the speaker brings another object, also having the desired property, into scope) or direct attention (the hearer inquires whether a specific object also has this property).
This scope extension can (and typically does) reduce the context in which hearers learn word-meaning mappings. Learning word-meaning mappings in the model is achieved by cross-situational learning, whose performance is known to be correlated with context size. As a result, our simulations yield substantial improvements in performance when one of the joint attentional mechanisms is added to the language game model. We found that checking attention yields the largest improvement, following attention the second largest, and directing attention comes last. Exactly in this ordering, the analogues mechanisms tend to emerge for human children (Carpenter et al. Citation1998). We argue that the ordering in performance increase is an indicator for fitness of the various joint attentional stages. Assuming that the most effective mechanism evolved first, we suggest that checking attention may have evolved first, following attention second, and directing attention last in human evolution.
As a final note, the child's growing participation in more complex social interactions provides an important illustration of the embeddedness of cognition. According to a recent approach in cognitive science, addressed under a variety of labels (e.g. situated cognition, enactive cognition, embodied embedded cognition), an organism's bodily interaction with the environment can significantly determine the nature of the cognitive tasks it has to fulfil (van Dijk, Kerkhofs, van Rooij and Haselager Citation2008). Specifically, by creating and/or using structure in the environment many cognitive tasks can be simplified or changed radically in character (e.g. when one does not want to forget posting a letter, one could put it next to one's shoes, thereby changing a memory task into a perceptual one). Such cognition-aiding structures are sometimes referred to as scaffolds (Clark Citation1997). Although research into scaffolds often focuses on physical structure, other actors in a social environment provide extremely useful scaffolds for the developing child (Vygotsky Citation1978). This investigation can be taken as an illustration of how a developing capacity to use available social scaffolds may help to enhance a child's growing shared lexicon.
Notes
1. In many simulations the meanings actually are transferred explicitly (Steels, Citation1996; Oliphant, Citation1999; Vogt & Coumans, Citation2003).
2. Deictic relations are relations whose referents depend on the speakers’ perspective, like ‘X is behind Y’. Children typically have difficulties specifying relations as they are experienced by another person, for example ‘to my right, and left for those of you watching at home…’.
3. It should be pointed out, that in Carpenter et al. the term joint (attentional) engagement, rather then checking attention, is used to refer to the interactive form of sharing attention as described in this citation. We will use the more common term checking attention to describe this behaviour.
4. The software running the NEW TIES project, including the code implementing checking attention, following attention and directing attention, can be downloaded and used from http://www.new-ties.org.
References
- Akhtar , N. , Montague and L . 1999 . Early Lexical Acquisition: The Role of Cross-situational Learning . First Language , 19 : 347 – 358 .
- Baronchelli , A. , Felici , M. , Caglioti , E. , Loreto , V. and Steels , L. 2006 . Sharp Transition Towards Shared Lexicon in Multi-agent Systems . Journal of Statistical Mechanics , : P06014
- Baron-Cohen , S. 1995 . Mindblindness: An Essay on Autism and Theory of Mind , Cambridge, MA : MIT Press .
- Bloom , P. 2000 . How Children Learn the Meanings of Words , Cambridge, MA : MIT Press .
- Carpenter , M. , Nagell , K and Tomasello , M. 1998 . Social Cognition, Joint Attention, and Communicative Competence from 9 to 15 Months of Age . Monographs of the Society for Research in Child Development , 63
- Carpenter , M. , Pennington , B. F. and Rogers , S. J. 2002 . Interrelations Among Social-cognitive Skills in Young Children with Autism and Developmental Delays . Journal of Autism and Developmental Disorders , 32 : 91 – 106 .
- Cangelosi , A. 2006 . The Grounding and Sharing of Symbols . Pragmatics and Cognition , 14 : 275 – 285 .
- Clark , A. 1997 . Being There , Cambridge, MA : MIT Press .
- Clark , E. V. 1993 . The Lexicon in Acquisition , Cambridge, , UK : Cambridge University Press .
- Dawson , G. , Toth , K. , Abbott , R. , Osterling , J. , Munson , J. , Estes , A. and Liaw , J. 2004 . Early Social Attention Impairments in Autism: Social Orienting, Joint Attention, and Attention to Distress . Developmental Psychology , 40 : 271 – 283 .
- De Beule , J. , De Vylder , B. and Belpaeme , T. 2006 . “ A Cross-situational Learning Algorithm for Damping Homonymy in the Guessing Game ” . In ALIFE X. Tenth International Conference on the Simulation and Synthesis of Living Systems , Edited by: Rocha , L. M. , Yaeger , L. S. , Bedau , M. A. , Floreano , D. , Goldstone , R. L. and Vespignani , E. Cambridge, MA : MIT Press .
- van Dijk , J. , Kerkhofs , R. , van Rooij , I. and Haselager , W. F.G. 2008 . Can There be such a Thing as Embodied Embedded Cognitive Neuroscience? . Theory & Psychology , 18 (in press)
- Gilbert , N. , den Besten , M. , Bontovics , A. , Craenen , B. G.W. , Divina , F. , Eiben , A. E. , Griffioen , R. , Hévízi , G. , Lõrincz , A. , Paechter , B. , Schuster , S. , Schut , M. C. , Tzolov , C. , Vogt , P. and Yang , L. 2006 . Emerging Artificial Societies Through Learning . Journal of Artificial Societies and Social Simulation , 9
- Houston-Price , C. , Plunkett , K. and Harris , P. 2005 . Word-Learning Wizardry’ at 1;6 . Journal of Child Language , 32 : 175 – 189 .
- Klibanoff , R. S. and Waxman , S. R. 2000 . Basic Level Object Categories Support the Acquisition of Novel Adjectives: Evidence from Preschool-aged Children . Child Development , 7 : 649 – 659 .
- Macnamara , J. 1982 . Names for Things: A Study of Human Learning , Cambridge, MA : MIT Press .
- Malle , B. F. 2002 . “ The Relation Between Language and Theory of Mind in Development and Evolution ” . In The Evolution of Language Out of Pre-language , Edited by: Givón , T. and Malle , B. F. 265 – 284 . Amsterdam : Benjamins .
- Markman , E. M. 1989 . “ Categorization and Naming in Children: Problems of Induction ” . Cambridge, MA : MIT Press .
- Mather , E. and Schafer , G. 2004 . “ Object-label Covariation: A Cue for the Acquisition of Nouns? ” . In Poster presented at the meeting of the International Society of Infant Studies Chicago
- Mundy , P. , Block , J. , Delgado , C. , Pomares , Y. , Vaughan Van Hecke , A. and Venezia Parlade , M. 2007 . Individual Differences and the Development of Joint Attention in Infancy . Child Development , 78 : 938 – 954 .
- Oliphant , M. 1999 . The Learning Barrier: Moving from Innate to Learned Systems of Communication . Adaptive Behavior, , 7 : 371 – 384 .
- Pan , B. A. and Gleason , J. B. 2004 . “ Semantic Development: Learning the Meaning of Words ” . In The Development of Language , 6 , Edited by: Gleason . Needham Heights, MA : Allyn & Bacon/Pearson Education .
- Premack , D. G. and Woodruf , G. 1978 . Does the Chimpanzee have a Theory of Mind? . Behavioral and Brain Sciences , 1 : 515 – 526 .
- Quine , W. V.O. 1960 . Word and Object , Cambridge, MA : MIT Press .
- Reboul , A. 2004 . Evolution of Language from Theory of Mind or Coevolution of Language and Theory of Mind? . Issues in Coevolution of Language and Theory of Mind , http://www.interdisciplines.org/coevolution/papers/1 (Retrieved 20 September 2007)
- Robinson , E. J. and Apperlyb , I. A. 2001 . Children's Difficulties with Partial Representations in Ambiguous Messages and Referentially Opaque Contexts . Cognitive Development , 16 : 595 – 615 .
- Siskind , J. M. 1996 . A Computational Study of Cross-situational Techniques for Learning Word-to-Meaning Mappings . Cognition , 61 ( 1–2 ) : 39 – 91 .
- Smith , A. D.M. 2005 . “ Mutual Exclusivity: Communicative Success Despite Conceptual Divergence ” . In Language Origins: Perspectives on Evolution , Edited by: Tallerman , M. Oxford, , UK : Oxford University Press .
- Smith , K. 2004 . The Evolution of Vocabulary . Journal of Theoretical Biology , 228 : 127 – 142 .
- Smith , K. , Smith , A. D.M. , Blythe , R. and Vogt , P. 2006 . “ Cross-situational Learning: A Mathematical Approach ” . In Symbol Grounding and Beyond: Proceedings of Emergence and Evolution of Linguistic Communication III, LNAI 4211 , Edited by: Vogt , P. , Sugita , Y. , Tuci , E. and Nehaniv , C. Berlin : Springer .
- Smith , L. B. and Yu , C. 2008 . Infants Rapidly Learn Word-referent Mappings via Cross-situational Statistics . Cognition , 106 : 1558 – 1568 .
- Steels , L. 1996 . “ Emergent Adaptive Lexicons ” . In From Animals to Animats 4: Proceedings of the Fourth International Conference on Simulating Adaptive Behavior , Edited by: Maes , P. Cambridge, MA : MIT Press .
- Steels , L. 1999 . The Puzzle of Evolution . Kognitionswissenschaft , 8 : 143 – 150 .
- Steels , L. 2001 . Language Games for Autonomous Robots . IEEE Intelligent Systems , 16 : 16 – 22 .
- Steels , L. 2005 . The Emergence and Evolution of Linguistic Structure: From Lexical to Grammatical Communication Systems . Connection Science , 17 : 213 – 230 .
- Steels , L. and Kaplan , F. 2002 . “ Bootstrapping Grounded Word Semantics ” . In Linguistic Evolution Through Language Acquisition: Formal and Computational Models , Edited by: Briscoe , T. Cambridge, , UK : Cambridge University Press .
- Steels , L. , Kaplan , F. , McIntyre , A. and van Looveren , J. 2002 . “ Crucial Factors in the Origins of Word-meaning ” . In The Transition to Language , Edited by: Wray , A. Oxford, , UK : Oxford University Press .
- Tager-Flusberg , H. 1981 . On the Nature of Linguistic Functioning in Early Infantile Autism . Journal of Autism and Developmental Disorders , 11 : 45 – 56 .
- Tomasello , M. 1995 . “ Joint Attention as Social Cognition ” . In Joint Attention: Its Origins and Role in Development , Edited by: Moore , C. and Dunham , P. Mahwah, NJ : Lawrence Erlbaum Associates .
- Tomasello , M. 1999 . The Cultural Origins of Human Cognition , Cambridge, MA : Harvard University Press .
- Tomasello , M. 2000 . The Item Based Nature of Children's Early Syntactic Development . Trends in Cognitive Sciences , 4 : 156 – 163 .
- Tomasello , M. and Carpenter , M. 2007 . Shared Intentionality . Developmental Science , 10 : 121 – 125 .
- Tomasello , M. and Todd , J. 1983 . Joint Attention and Lexical Acquisition Style . First Language , 12 : 197 – 211 .
- Vogt , P. 2000 . Bootstrapping Grounded Symbols by Minimal Autonomous Robots . Evolution of Communication , 4 : 89 – 118 .
- Vogt , P. 2003 . Anchoring of Semiotic Symbols . Robotics and Autonomous Systems , 43 : 109 – 120 .
- Vogt , P. 2005 . The Emergence of Compositional Structures in Perceptually Grounded Language Games . Artificial Intelligence , 167 : 206 – 242 .
- Vogt , P. 2006 . “ Language Evolution and Robotics: Issues in Symbol Grounding and Language Acquisition ” . In Artificial Cognition Systems , Edited by: Loula , A. , Gudwin , R. and Queiroz , J. Hershey, PA : Idea Group .
- Vogt , P. and Coumans , H. 2003 . Investigating Social Interaction Strategies for Bootstrapping Lexicon Development . Journal of Artificial Societies and Social Simulation , 6
- Vogt , P. and Divina , F. 2007 . Social Symbol Grounding and Language Evolution . Interaction Studies , 8 : 31 – 52 .
- Vogt , P. and Haasdijk , E. 2007 . “ Social Learning of Skills and Language ” . In Proceedings of International Workshop on Social Learning in Embodied Agents Edited by: Acerbi , A. , Marocco , D. and Vogt , P. (CD-ROM)
- Vygotsky , L. S. 1978 . Mind in Society , Cambridge, MA : Harvard University Press .
- Wimmer , H. and Perner , J. 1983 . Beliefs About Beliefs: Representation and Constraining Function in Wrong Beliefs in Young Children's Understanding Of Deception . Cognition , 13 : 103 – 128 .
- Zipf , G. K. 1949 . Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology , Cambridge, MA : Addison-Wesley .