
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Distributed denial of service (DDoS) attacks constitute a rapidly evolving threat in the current Internet. Multiagent Router Throttling is a novel approach to defend against DDoS attacks where multiple reinforcement learning agents are installed on a set of routers and learn to rate-limit or throttle traffic towards a victim server. The focus of this paper is on online learning and scalability. We propose an approach that incorporates task decomposition, team rewards and a form of reward shaping called difference rewards. One of the novel characteristics of the proposed system is that it provides a decentralised coordinated response to the DDoS problem, thus being resilient to DDoS attacks themselves. The proposed system learns remarkably fast, thus being suitable for online learning. Furthermore, its scalability is successfully demonstrated in experiments involving 1000 learning agents. We compare our approach against a baseline and a popular state-of-the-art throttling technique from the network security literature and show that the proposed approach is more effective, adaptive to sophisticated attack rate dynamics and robust to agent failures.
1. Introduction
One of the most serious threats in the current Internet is posed by distributed denial of service (DDoS) attacks, which target the availability of a system (Douligeris & Mitrokotsa, Citation2004). A DDoS attack is a highly coordinated attack where the attacker takes under his control a large number of hosts, called the botnet (network of bots), which start bombarding the target when they are instructed to do so. Such an attack is designed to exhaust a server's resources or congest a network's infrastructure, and therefore renders the victim incapable of providing services to its legitimate users or customers. Beyond the financial loss caused by DDoS attacks, victims also suffer loss to their reputation which results in customer or user dissatisfaction and loss of trust.
To tackle the distributed nature of these attacks, a distributed and coordinated defence mechanism is required, where many defensive nodes, across different locations cooperate in order to stop or reduce the flood. Router Throttling (Yau, Lui, Liang, & Yam, Citation2005) is a popular approach to defend against DDoS attacks, where the victim server sends throttle signals to a set of upstream routers to rate-limit traffic towards it. Similar techniques to throttling are implemented by network operators (Douligeris & Mitrokotsa, Citation2004).
Multiagent Router Throttling (Malialis and Kudenko, Citation2013, Citation2015) is a novel throttling approach where multiple reinforcement learning agents are installed on the set of upstream routers and learn to throttle or rate-limit traffic towards the victim server. The approach has been demonstrated in the offline learning setting to perform well against DDoS attacks in medium-scale network topologies, but suffers from the “curse of dimensionality” (Sutton & Barto, Citation1998) when scaling-up. The main focus of this paper is on online learning and scalability, and we propose a novel design that resolves this problem. Our contributions in this paper are the following.
There is an extensive literature regarding the application of machine learning to intrusion detection, specifically anomaly detection where no action is performed beyond triggering an intrusion alarm when an anomalous event is detected. Our work investigates the applicability of multiagent systems and machine learning to intrusion response. In this paper we are interested in distributed rate-limit approaches to defend against DDoS attacks.
We use task decomposition, team rewards and a form of reward shaping called difference rewards, and demonstrate that the proposed system learns remarkably fast, thus being suitable for online learning. Furthermore, its scalability is successfully demonstrated in experiments involving 1000 learning agents. A strong result is obtained as it is empirically shown that the system performance remains unaffected by the addition of new learning agents.
One of the novel characteristics of the proposed system is that it provides a decentralised coordinated response to the DDoS problem, thus being resilient to DDoS attacks themselves. We compare our approach against a baseline and a popular state-of-the-art throttling technique from the network security literature and show that the proposed approach is more effective as it consistently outperforms them. The proposed approach is also shown to be adaptive to sophisticated attack rate dynamics and robust to agent failures.
2. Background
2.1. Reinforcement learning
Reinforcement learning is a paradigm in which an active decision-making agent interacts with its environment and learns from reinforcement, that is, a numeric feedback in the form of reward or punishment (Sutton & Barto, Citation1998). The feedback received is used to improve the agent's actions. The problem of solving a reinforcement learning task is to find a policy (i.e. a mapping from states to actions) which maximises the accumulated reward.
When the environment dynamics (such as the reward function) are available, this task can be solved using dynamic programming (Sutton & Barto, Citation1998). In most real-world domains, the environment dynamics are not available and therefore the assumption of perfect problem domain knowledge makes dynamic programming to be of limited practicality.
The concept of an iterative approach constitutes the backbone of the majority of reinforcement learning algorithms. These algorithms apply so called temporal-difference updates to propagate information about values of states, , or state-action,
, pairs. These updates are based on the difference of the two temporally different estimates of a particular state or state-action value. The SARSA algorithm is such a method (Sutton & Barto, Citation1998). After each real transition,
, in the environment, it updates state-action values by the formula:
(1)
(1) where α is the rate of learning and γ is the discount factor. It modifies the value of taking action a in state s, when after executing this action the environment returned reward r, moved to a new state
, and action
was chosen in state
.
The exploration-exploitation trade-off constitutes a critical issue in the design of a reinforcement learning agent. It aims to offer a balance between the exploitation of the agent's knowledge and the exploration through which the agent's knowledge is enriched. A common method of doing so is ε-greedy, where the agent behaves greedily most of the time, but with a probability ε it selects an action randomly. To get the best of both exploration and exploitation, it is advised to reduce ε over time (Sutton & Barto, Citation1998).
Applications of multiagent reinforcement learning typically take one of two approaches; multiple individual learners or joint action learners (Claus & Boutilier, Citation1998). The former is the deployment of multiple agents each using a single-agent learning algorithm. The latter is a group of multiagent specific algorithms designed to consider the existence of other agents; in this setting an agent observes the actions of the others or each agent communicates its action to the others.
Multiple individual learners assume any other agents to be a part of the environment and so, as the others simultaneously learn, the environment appears to be dynamic as the probability of transition when taking action a in state s changes over time. To overcome the appearance of a dynamic environment, joint action learners were developed that extend their value function to consider for each state the value of each possible combination of actions by all agents. The consideration of the joint action causes an exponential increase in the number of values that must be calculated with each additional agent added to the system. Therefore, as we are interested in scalability and minimal communication between agents, this work focuses on multiple individual learners and not joint action learners.
To reduce the impact of scalability and deal with large and continuous state and action spaces, function approximation is used to reduce an agent's exploration (Sutton & Barto, Citation1998). Tile coding is one of the most common techniques which partitions the state space into a number of tilings and tiles where state feature values are grouped into.
2.2. Difference rewards
Difference rewards are introduced to tackle the multiagent credit assignment problem encountered in reinforcement learning. Typically, in a multiagent system an agent is provided with a reward at the global level. This reward signal is noisy due to the other agents acting in the environment. This is because an agent may be rewarded for taking a bad action, or punished for taking a good action. The reward signal should reward an agent depending on its individual contribution to the system objective.
Difference rewards is a shaped reward signal that helps an agent i to learn the consequences of its actions on the system objective by removing a large amount of the noise created by the actions of other agents active in the system (Wolpert, David, & Tumer, Citation2000). It is defined as:
(2)
(2) where z is a general term representative of either states or state-action pairs depending on the application,
is the reward function used, and
is
for a theoretical system without the contribution of agent i.
Difference rewards exhibit the following two properties. Firstly, any action taken that increases simultaneously increases R. Secondly, since difference rewards only depend on the actions of agent i,
provides a cleaner signal with reduced noise. These properties allow for the difference reward to significantly boost learning performance in a multiagent system.
The challenge for deriving the difference rewards signal is obviously how to calculate the second term of the equation which is called the counterfactual. From the literature, there are typically three ways to calculate the counterfactual.
In particular domains, the counterfactual is possible to be directly calculated (Devlin, Yliniemi, Tumer, & Kudenko, Citation2014). In other cases, difference rewards can be calculated by introducing the term
, which represents a constant action of agent i, which is (theoretically) executed in order to eliminate the contribution of agent i and evaluate the system performance without it (HolmesParker, Agogino, & Tumer, Citation2013). The difference rewards
signal is then given by:
(3)
(3)
Alternatively, in cases where this is not possible, it has been demonstrated that difference rewards can be estimated (Tumer & Agogino, Citation2007). Difference rewards have been applied in different domains such as air traffic management (Tumer & Agogino, Citation2007) and distributed sensor networks (Colby & Tumer, Citation2013).
2.3. DDoS attacks
A DDoS attack is a highly coordinated attack; the strategy behind it is described by the agent-handler model (Douligeris & Mitrokotsa, Citation2004; Mirkovic & Reiher, Citation2004). The model consists of four elements, the attacker, handlers, agents and victim. A handler (or master) and the agent (or slave or zombie or daemon) are hosts compromised by the attacker, which constitute the botnet. Specifically, the attacker installs a malicious software on vulnerable hosts to compromise them, thus being able to communicate with and control them. The attacker communicates with the handlers, which in turn control the agents in order to launch a DDoS attack.
The basic agent-handler model can be extended by removing the handlers layer and allowing communication between the attacker and agents via Internet Relay Chat (IRC) channels. A more recent extension occurs at the architectural level, where the centralised control is replaced by a peer-to-peer architecture. Moreover, an attacker can use IP spoofing, that is, hiding his true identity by placing a fake source address in the IP packet's source address. These extensions make the DDoS problem orders of magnitude harder to tackle because they offer limited botnet exposure, a high degree of anonymity and they provide robust connectivity.
The DDoS threat is challenging for many reasons (Mirkovic & Reiher, Citation2004), including the following. Firstly, the traffic flows originate from agent machines spread all over the Internet, which they all aggregate at the victim. Furthermore, the volume of the aggregated traffic is really large which is unlikely to be stopped by a single defence point near the victim. Also, the number of compromised agent machines is large, thus making an automated response a necessary requirement. Moreover, DDoS packets appear to be similar to legitimate ones, since the victim damage is caused by the total volume and not packet contents. A defence system cannot make an accurate decision based on a packet-by-packet basis. It requires the defender to keep some statistical data in order to correlate packets and detect anomalies, for example, “all traffic directed towards a specific destination address”. Lastly, it is very difficult to traceback, that is, to discover even the agent machines, let alone the actual attackers, firstly because of the agent-handler model's architecture, and secondly because of IP spoofing.
It is evident that, to combat the distributed nature of these attacks, a distributed and coordinated defence mechanism is necessary where many defensive nodes across different locations cooperate in order to stop or reduce the flood.
3. Network model and assumptions
We adopt the network model used by Yau et al. (Citation2005). A network is a connected graph
, where V is the set of nodes and E is the set of edges. All leaf nodes are hosts and denoted by H. Hosts can be traffic sources and are not trusted because they can spoof traffic, disobey congestion signals etc. An internal node represents a router, which forwards or drops traffic received from its connected hosts or peer routers. The set of routers are denoted by R, and they are assumed to be trusted, that is, not to be compromised. This assumption is realistic since it is much more difficult to compromise a router than an end host or server, because routers have a limited number of potentially exploitable services (Keromytis, Misra, & Rubenstein, Citation2002). The set of hosts
is partitioned into the set of legitimate users and the set of attackers. A leaf node denoted by S represents the victim server. Consider for example the network topology shown in Figure . It consists of 20 nodes, these are, the victim server denoted by S, 13 routers denoted by
and
and six end hosts denoted by
, which are traffic sources towards the server.
Figure 1. Network topology showing defensive routers.
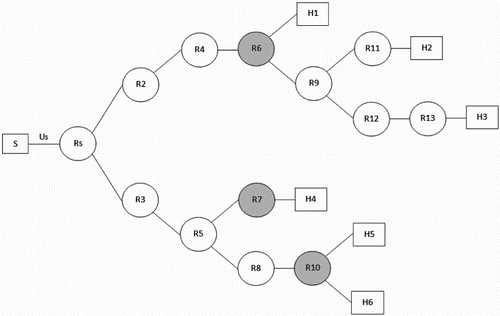
A legitimate user sends packets towards the server S at a rate , and an attacker at a rate
. We assume that the attacker's rate is significantly higher than that of a legitimate user, that is,
(dropping traffic based on source addresses can be harmful because, as mentioned, hosts cannot be trusted). This assumption is based on the rationale that if an attacker sends at a similar rate to a legitimate user, then the attacker must recruit a considerably larger number of agent hosts in order to launch an attack with a similar effect (Yau et al., Citation2005). A server S is assumed to be working normally if its load
is below a specified upper boundary
, that is,
(this includes cases of weak or ineffective DDoS attacks). The rate
of a legitimate user is significantly lower than the upper boundary, that is,
, where
can be determined by observing how users normally access the server.
4. Multiagent router throttling
4.1. Basic design (MARL)
The basic multiagent reinforcement learning (MARL) design is based on Malialis and Kudenko (Citation2013). We adopt the selection method used by Yau et al. (Citation2005). Reinforcement learning agents are installed on locations that are determined by a positive integer k, and are given by .
is defined as the set of routers that are either k hops away from the server, or less than k hops away but are directly attached to a host. The effectiveness of throttling increases with an increasing value of k, provided that routers in
must belong to the same administrative domain, for example, an Internet Service Provider (ISP) or collaborative domains.Footnote1 Consider the network topology shown in Figure . Learning agents are installed on the set
, which consists of routers
and
. Router
is included in the set
, although it is only 4 hops away from the server, because it is directly attached to the host
.
The aggregate is defined as the traffic that is directed towards a specific destination address, that is, the victim (Mahajan et al., Citation2002). In the basic design, each agent's state space consists of a single state feature, which is its aggregate load. The aggregate load is defined as the aggregate traffic arrived at the router over the last T seconds, which is called the monitoring window. The monitoring window should be set to be about the maximum round trip time between the server S and a router in (Yau et al., Citation2005). The time step of the learning algorithm is set to be the same as the monitoring window size.
Each router applies throttling via probabilistic packet dropping. For example action means that the router will drop (approximately)
of its aggregate traffic towards the server, thus setting a throttle or allowing only
of it to reach the server. The action is applied throughout the time step. Completely shutting off the aggregate traffic destined to the server is prohibited, that is, the action
(which corresponds to
drop probability) is not included in the action space of any of the routers. The reason is that the incoming traffic likely contains some legitimate traffic as well, and therefore dropping all the incoming traffic facilitates the task of the attacker, which is to deny server access to its legitimate users (Mahajan et al., Citation2002).
Global (G) reward: With a global (G) reward function each agent receives the same reward or punishment. The system has two important goals, which are directly encoded in the reward function. The first goal is to keep the server operational, that is, to keep its load below the upper boundary . When this is not the case, the system receives a punishment in the range
. The second goal of the system is to allow as much legitimate traffic as possible to reach the server during a period of congestion. In this case, the system receives a reward of
, where L denotes the proportion of the legitimate traffic that reached the server during a time step. We consider that legitimate users are all of equal importance, therefore there is no prioritisation between them. The global reward function is shown in Algorithm 1.

Difference rewards: The difference rewards for any agent i require the calculation of the global (G) reward without the contribution of agent i. To calculate the counterfactual we need to introduce the term
, which represents a constant action of agent i which is taken to eliminate its contribution from the system. As we will later demonstrate in Section 5.1, a suitable value is
, that is, to drop no traffic. Difference rewards are then calculated using the formula below. We will refer to the combination of MARL with difference rewards as D_MARL.
(4)
(4)
Let us now discuss the availability of L in the online learning setting, that is, when the system is trained directly in a realistic network. If the detection mechanism is accurate enough to derive attack signatures (i.e. known characteristics) then the problem can be simply solved by filtering the attack traffic. However, we are interested in cases where the detection mechanism cannot precisely characterise the attack traffic, that is, when attack signatures cannot be derived. Inevitably, in such cases L can only be estimated.
There are different ways to measure legitimate traffic, for example by observing the behaviour or habits of customers and regular users of the victim's services and detect deviations. Another example is by observing the IP addresses that have been seen in the past, as this suggests that they are likely legitimate (Jung, Krishnamurthy, & Rabinovich, Citation2002). Another way is by observing whether IP packets have appeared before or after the DDoS impact, as the latter suggests that they are likely illegitimate (Hussain, Heidemann, & Papadopoulos, Citation2003).
4.2. Coordinated team learning
The coordinated team learning (CTL) approach is based on Malialis and Kudenko (Citation2015). As it is later demonstrated the basic MARL approach suffers from the “curse of dimensionality” and fails to scale-up in large scenarios. To scale-up we propose a number of mechanisms based on the divide-and-conquer paradigm. Generally, the divide-and-conquer paradigm breaks down a large problem into a number of sub-problems which are easier to be solved. The individual solutions to the sub-problems are then combined to provide a solution to the original problem.
The first step towards scalability is to form teams of agents as shown in Figure (a). Dashed lines do not necessarily represent nodes with a direct connection. The structure of the team is shown in Figure (b). Each team consists of its leader and the throttling routers which are k hops away from the server. Participating routers belong to the same administrative domain, for example, an ISP. In case of collaborative domains, each team can belong to a different administrative domain. The number of teams and their structure depend on the underlying topology and network model.
Figure 2. Teams of learning agents. (a) team formation and (b) team structure.
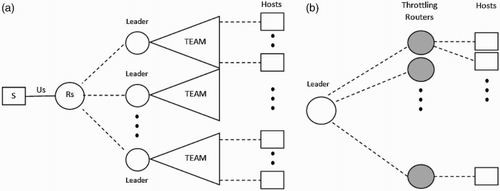
To scale-up we use task decomposition and team rewards. For task decomposition, it is now assumed that instead of having a big DDoS problem at the victim, there are several smaller DDoS problems where the hypothetical victims are the team leaders.Footnote2 The hypothetical upper boundary of each leader depends on its traffic sources. Assuming a defence system of homogeneous teams, with respect to their traffic sources (i.e. host machines), the hypothetical upper boundary for each team leader is given by
.
Moreover, agents are now provided with rewards at the team level rather than the global level, that is, agents belonging to the same team receive the same reward or punishment. In this section we propose the coordinated team (CT) reward function as follows:
CT rewards: This approach involves coordination between the teams of agents by allowing a team's load to exceed its hypothetical upper boundary as long as the victim's router load remains below the global upper boundary. The CT reward function of each learning agent is shown in Algorithm 2.

Difference rewards: The difference rewards signal for any agent i belonging to team j requires the calculation of the team
reward without the contribution of agent i. To calculate the counterfactual we use the same
as defined earlier. Difference rewards can now be calculated using the formula below. We will refer to the combination of CTL with difference rewards as D_CTL.
(5)
(5)
We assume that each learning agent calculates its own difference rewards signal. To achieve that, the victim and team leaders need to communicate to the learning agents the relevant information at each time step (this information is the victim's aggregate load, leader's aggregate load and leader's estimate of legitimate load – see CT reward function). It is emphasised that communication is performed in a hierarchical team-based fashion and no information exchange between the learning agents takes place (i.e. decentralised coordination). This constitutes a simple and minimal communication scheme and the introduced overhead is not restrictive for a real-world deployment. To eliminate this overhead completely, an approximation of difference rewards may be possible, but this is subject to future work.
Lastly, the throttling agents start learning, that is, responding to an attack only when an attack is detected, that is, when the victim experiences congestion/overloading. In practise, it is expected that the victim will send an activation or “wake-up” signal to the defensive system, informing it about the need for protection.
5. Experiments and results
To conduct experiments we have developed a network emulator which serves as a testbed for demonstrating the effectiveness of our proposed approach. The emulator has been introduced in order to allow us to study our learning-based techniques in large-scale scenarios. This is achieved by moving to a higher level of abstraction and omitting details that do not compromise a realistic evaluation. Specifically, the emulator treats the internal model of a network as a black box and mimics the observable behaviour of the network by only considering inputs and outputs of the model. It is important to note that this is adequate to demonstrate the functionality of throttling approaches. Also, we can still re-produce realistic conditions such as the introduction of traffic loss, measurement noise and agent failures.
Our experimental setup is similar to the one by Yau et al. (Citation2005). As a convention, bandwidth and traffic rates are measured in Mbit/s. The bottleneck link has a limited bandwidth of
, which constitutes the upper boundary for the server load. The rest of the links have an infinite bandwidth. Legitimate users and attackers are evenly distributed, specifically each host is independently chosen to be a legitimate user with probability p and an attacker with probability
. Parameters p and q are set to be
and
, respectively. Legitimate users and attackers are chosen to send UDP traffic at constant rates, randomly and uniformly drawn from the range
and
Mbit/s, respectively (except where otherwise is stated). We refer to an episode, as an instance of the network model just described.
Our approach uses a linearly decreasing ε-greedy exploration strategy (initial ε values are given later for each individual experiment) and the learning rate is set to . We discretise the continuous action space into 10 actions:
which correspond to
traffic drop probabilities (recall that action
is prohibited). We use function approximation, specifically tile coding (Sutton & Barto, Citation1998), for the representation of the continuous state space. The state feature (router load) of a router that sees a low, medium and high amount of traffic is split into 6, 12 and 18 tiles per tiling, respectively; as a note, in practise, the network administrator is aware of the nodes that typically experience a substantial amount of traffic. In all three cases, the number of tilings is 8.
Due to the nature of the domain, the current network state has not necessarily been entirely affected by the actions taken by the agents at the previous time step. This is because the domain is highly probabilistic and exhibits unpredictable behaviour for example, at any time a DDoS attack can be initiated or stopped, more attackers can join or withdraw during an attack, attackers can alter their strategy which may be known or unknown to the network operator, legitimate users can start or quit using the victim's service, legitimate users can also alter their behaviour, routers can fail, network paths can change, etc. For this reason we are only interested in immediate rewards, that is, the agents learn a reactive mapping based on the current sensations. Therefore we set the discount factor to . Moreover, we use the popular SARSA (Sutton & Barto, Citation1998) algorithm; Q-values are initialised to zero and each agent uses the following update formula:
(6)
(6)
For the purposes of our experiments we use tree network topologies consisting of homogeneous teams of agents. Notice that our proposed approach is not restricted to tree network topologies; the proposed defensive architecture constitutes an overlay network, that is, atop of the underlying network topology. Therefore, parent–child relationships can still be obtained even if the underlying topology is not tree-structured.
Each team of agents contains six throttling routers (i.e. six learning agents) and 12 host machines. A throttling router can have behind it a different number of host machines; we have varied this to be from 1 to 3. The victim's upper boundary depends on the topology size and is set to be equal to (except where otherwise is stated). For example, for the network topology consisting of 2 teams the upper boundary is given by
.
Lastly, we compare our proposed system against a baseline and the popular state-of-the-art (additive-increase/multiplicative-decrease) AIMD throttling techniques from the network security literature (these are described in Section 6). Their control parameters are configured based on values or range of values recommended by their authors (Yau et al., Citation2005).
5.1. Parameter tuning
Default action for difference rewards: The counterfactual can be calculated by introducing the term
, which represents a constant action of agent i, which is (theoretically) executed in order to eliminate the contribution of agent i from the system. This experiment aims at determining which action is suitable for
.
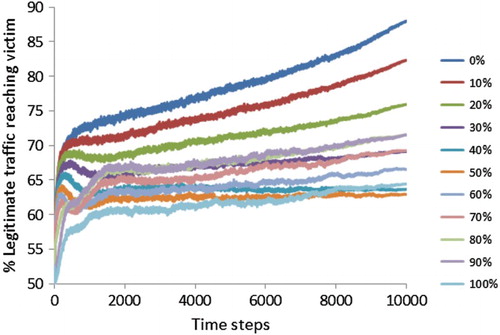
Figure shows how the performance of D_MARL varies with different dropping probabilities of the constant action . The topology contains 30 learning agents that use an initial
and a decrease rate
. The values are averaged over 500 episodes. Clearly, the best result is when
; in other words, an agent (theoretically) executes action
or drops
of its aggregate traffic in order to eliminate its contribution from the system.
Figure 3. Default action for difference rewards.
Effect of exploration strategy: Contrary to the offline learning setting where the quality of the learnt behaviour is the main objective, for online learning the learning speed is equally critical. After observing from Figure that the difference rewards method is applicable to our domain, we have investigated the linearly and exponentially decreasing ε-greedy strategies, and examined different values for the initial ε parameter and the decrease/decay rate δ. Results have revealed that the approaches perform better when linearly decreasing ε-greedy is used. The parameter values for which the best performance is obtained are the following. For MARL and CTL we use a decrease rate . For D_MARL and D_CTL it is set to
. All approaches use an initial
.
5.2. Scalability
This series of experiments aims at investigating the scalability of our proposed approaches. Figure (a) shows the performance of MARL when applied to topologies including up to 102 learning agents. The values are averaged over 500 episodes and error bars showing the standard error around the mean are plotted. As expected, the basic design MARL fails to scale-up; its performance declines as the number of learning agents increases. Specifically, its performance declines by when the number of learning agents is increased from 12 to 102.
Figure 4. Scalability of the approaches. (a) MARL, (b) CTL, (c) D_MARL and (d) D_CTL.
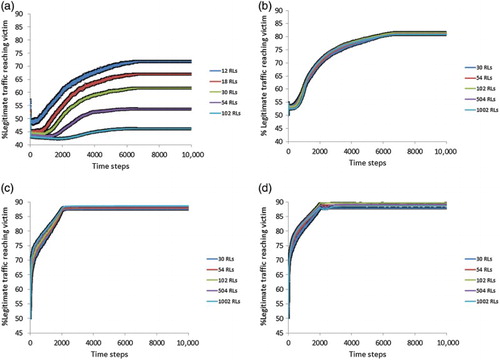
Figure (b) shows the performance of CTL when applied to topologies including up to 1002 learning agents. A very strong result is obtained from this experiment. Our proposed approach is shown to be scalable since its performance remains unaffected by the addition of new teams of learning agents. Strictly speaking, although not visible in the graph, there is a 0.7% difference in legitimate traffic reaching victim between the highest performance (102 RLs) and the lowest performance (1002 RLs).
Figure (c) shows the behaviour of D_MARL when applied to topologies including up to 1002 learning agents. The D_MARL approach is also shown to be scalable as its performance remains unaffected by the addition of new learning agents. Strictly speaking, although not visible in the graph, there is a 1.2% difference in legitimate traffic reaching victim between the highest performance (1002 RLs) and the lowest performance (30 RLs).
Learnability of a reward signal is defined as the signal-noise ratio. As more agents are added into a multiagent system, the learnability of the global reward goes down, that is, the global reward signal becomes more noisy because an agent is responsible for less of the system performance. This could explain the behaviour of the basic MARL approach (Figure (a)). Difference rewards avoid this problem because they provide a high learnability signal with large numbers of agents, that is, they dampen this growth in noise as more agents are added (Agogino & Tumer, Citation2008).
Lastly, Figure (d) shows the behaviour of our proposed approach D_CTL when applied to topologies including up to 1002 learning agents. The D_CTL approach is highly scalable as well as its performance remains unaffected by the addition of new learning agents. Strictly speaking, although not visible in the graph, there is a 1.85% difference in legitimate traffic reaching victim between the highest performance (102 RLs) and the lowest performance (30 RLs).
Noteworthy are the two small “valleys” that are observed in the case of 504 and 1002 agents. This is attributed to the fact that the exploration parameter ε becomes zero at the start point of the “valley”. This phenomenon is often experienced in multiagent learning domains where the system performance starts declining when exploration hits zero. However, after a while the performance is again improved until it finally converges as learning continues even without exploration. The phenomenon is not observed when we stop decreasing the exploration parameter ε in order to reach a value close to zero, but not zero.
To further investigate how the individual approaches compare to each other the following experiment is conducted. Figure shows how the approaches MARL, CTL, D_MARL and D_CTL compare to each other for the topology involving 102 learning agents. The values are averaged over 500 episodes and error bars showing the standard error around the mean are plotted.
Figure 5. Online learning for 102 RLs.
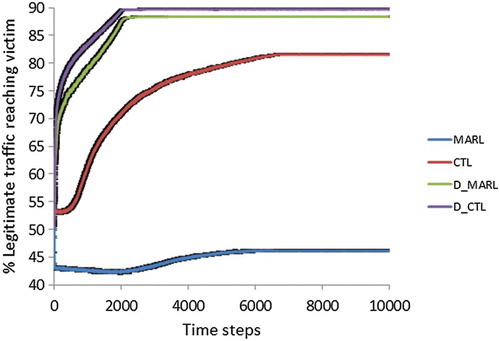
It is demonstrated that the basic MARL approach achieves a performance of . Our proposed CTL achieves
thus outperforming MARL by
. D_MARL is shown to perform even better; it achieves
and outperforms MARL by
. Our proposed D_CTL combines the benefits of both CTL and D_MARL and is shown to achieve
thus outperforming the basic MARL by
, but more importantly it learns faster than D_MARL.
We are particularly interested in the learning speed. As mentioned, contrary to offline learning where the quality of the learnt behaviour is the main objective, for online learning the learning speed is equally critical. This is particularly the case for a real-world application like DDoS response. Beyond the financial loss caused by DDoS attacks, victims also suffer loss to their reputation which results to customer or user dissatisfaction and loss of trust. It is demonstrated that our proposed approach D_CTL learns faster than D_MARL.
5.3. Performance
At this point we concentrate on D_CTL since it can better scale-up. This experiment aims at investigating how the D_CTL approach compare against the baseline and the popular AIMD throttling approaches (Yau et al., Citation2005). It further investigates their learning speed and examines the extent to which the proposed approach is deployable.
Figure (a) shows how the three approaches perform in the topology involving 102 learning agents for the constant-rate attack scenario. All approaches use an upper boundary for the victim of and the Baseline and AIMD also use a lower boundary of
. The values are averaged over 500 episodes and error bars showing the standard error around the mean are plotted.
Figure 6. Performance. (a) % legitimate traffic and (b) aggregate load.
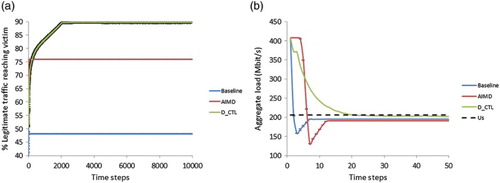
The AIMD approach outperforms the Baseline as expected. D_CTL and AIMD achieve a performance of and
, respectively. In other words, D_CTL outperforms AIMD by 14%. The D_CTL requires about 200 time steps to equalise the performance of AIMD, and about 2000 to reach its maximum performance.
For the same experiment, we show in Figure (b) how the aggregate load at the victim behaves for the three approaches. Recall from Section 3 that the server is assumed to be operating normally if its load is below the upper boundary, that is, . All three approaches do what they are intended to do, that is, to bring down the aggregate load to acceptable levels, that is,
and
for the learning and non-learning approaches respectively. Specifically, the AIMD and D_CTL require 12 and 19 time steps, respectively, to bring down the aggregate load to acceptable levels.
D_CTL learns quickly to avoid punishments, that is, to bring the victim's load below its operational limit (Figure (b)). However, to achieve an effective response is more challenging, requires the coordination of actions of all learning agents, and it therefore needs more learning time (Figure (a)).
The question now is what all these figures mean in practise about the learning speed. Since we use a network emulator and also due to the lack of an actual ISP topology we can only provide an estimate of the learning speed. Recall from Section 4.1 that the monitoring window or time step of the throttling algorithms should be about the maximum round trip time between the victim server S and a router in . Assuming a maximum round trip time of 100–200 ms means that the AIMD approach would require a few seconds to bring the aggregate load to acceptable levels (Figure (b)) and the same time to reach its maximum value (Figure (a)); this is consistent with experiments in Yau et al. (Citation2005).
The D_CTL approach would require a few more seconds to bring the aggregate load below the upper boundary (Figure (b)). It would also require less than a minute to overcome the performance of AIMD and it will reach its maximum performance in 3–7 min (Figure (a)). We state that the figures just mentioned constitute estimates in order to provide an indication of the learning speed.
Taking into consideration that 88% of DDoS attacks last for less than an hour (Anstee, Cockburn, & Sockrider, Citation2013), this powerful result suggests that our proposed D_CTL approach can potentially be deployed in a realistic ISP network. We will now run more experiments to stress test our reinforcement learning-based approach.
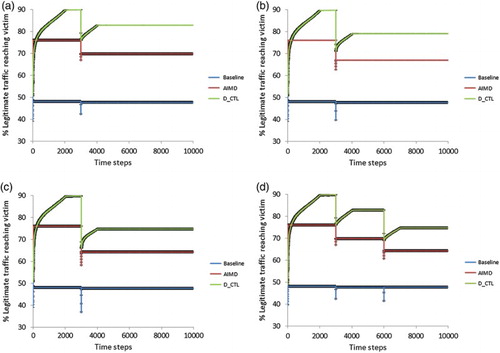
5.4. Performance with agent failures
A deployable system must be robust to router failures. A router fails when it drops all of its incoming traffic (i.e. it executes action 1.0), thus not forwarding any traffic at all to the victim server. Figure (a)–(c) shows how the system performance for 102 learning agents (17 teams) is affected when 2, 3 and 4 teams of agents fail at time step 3000. This corresponds approximately to 12%, 18% and 24% of the total number of agents. At time step 3001 the exploration parameter is resetFootnote3 to and the system re-trains for 1000 episodes to make up for the loss. Figure (d) shows the performance when 4 teams fail gradually; specifically, 2 teams fail at time step 3000 and another 2 teams at time step 6000. The values are averaged over 500 episodes and error bars showing the standard error around the mean are plotted. All three approaches are affected and show signs of performance degradation when the failures occur. However, it is demonstrated that agents in D_CTL are capable of adapting and can recover to make up for the loss. In all scenarios, D_CTL outperforms AIMD by 11–14%. Interestingly, the system even with almost a quarter of agents failing, it achieves a performance of
, which is very similar to AIMD's performance without failures (
).
Figure 7. Agent failures. (a) 2 Teams (≈ 12% agents), (b) 3 teams (≈ 18% agents), (c) 4 teams (≈ 24% agents) and (d) 4 teams gradually.
5.5. Performance with variable-rate attack dynamics
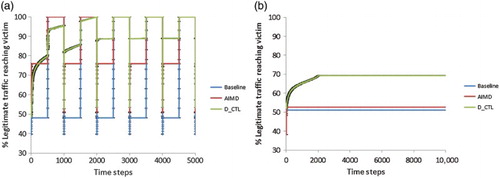
The majority of DDoS attacks use a constant-rate mechanism where agent machines generate traffic at a steady rate (Mirkovic & Reiher, Citation2004). The DDoS impact is rapid but the large and continuous flood can be easily detected. It is also the most cost-effective method for the attacker. However, the attacker can also deploy a variable rate mechanism to delay or avoid detection and response.
Figure (a) shows how the approaches behave against a pulse DDoS attack for 102 learning agents. The values are averaged over 500 episodes and error bars showing the standard error around the mean are plotted. The attack rate oscillates between the maximum rate and zero, and the duration of the active and inactive periods is the same and set to 500 time steps, that is, about 50–100 seconds (assuming a time step of 100–200 ms). For example, the first attack pulse starts at time step 0 and stops at 500. The second pulse starts at time step 1000 and stops at 1500. It is shown that D_CTL outperforms AIMD during the active periods of the pulse attack; furthermore, agents in D_CTL learn not to rate-limit any traffic during the inactive periods of the attack.
Figure 8. Pulse attack and “Meek” attackers.
5.6. Performance with “meek” attackers
We have assumed so far that agent or zombie machines are aggressive, that is, their sending rate is significantly higher than that of a legitimate user. Indeed, that is a realistic assumption since in the case of “meek” attackers, that is, when a zombie machine sends at a similar rate to a legitimate user, this would require the attacker to compromise a considerably larger number of machines in order to launch an attack with a similar effect.
Both legitimate users and attackers send traffic at constant rates, randomly and uniformly drawn from the range Mbit/s (recall that the range for aggressive attackers used to be
). Figure (b) shows the performance of Baseline, AIMD and D_CTL in the presence of “meek” attackers. The values are averaged over 500 episodes and error bars showing the standard error around the mean are plotted. All approaches use an upper boundary for the victim of
and the Baseline and AIMD also use a lower boundary of
.
It is observed that the Baseline and AIMD approaches have now a similar performance. This is expected as their authors (Yau et al., Citation2005) admit that
… our approach is most useful under the assumption that attackers are significantly more aggressive than regular users. [Otherwise] our solution is then mainly useful in ensuring that a server under attack can remain functional within the engineered load limits.
Although the D_CTL approach is heavily affected as well, it achieves a system performance of 69%, allowing 17% of legitimate traffic more than AIMD to reach the victim server.
To more effectively tackle the “meek” attackers problem it would require the designer to enrich the state feature space, that is, to introduce more statistical features other than the router load. This would be helpful because in the case of “meek” attackers, the system cannot differentiate between legitimate and attack traffic by just taking into account the traffic volume.
6. Related work on DDoS response
Response mechanisms aim at mitigating the DDoS impact on the victim, while keeping collateral damage levels to a minimum. Collateral damage occurs when legitimate traffic is punished along with the attack traffic.
Traceback mechanisms aim at identifying the agent machines responsible for the attack. Probabilistic Packet Marking (Savage, Wetherall, Karlin, & Anderson, Citation2000) is a popular traceback technique, where upstream routers probabilistically mark IP packets so the attack route can be reconstructed.
Traceback can be very expensive though and it is virtually impossible to trace due to the large number of attack paths. It is also questionable whether it is useful to spend large amounts of resources to traceback and identify individual zombies when the actual attackers continue to operate unnoticed and uninhibited (Papadopoulos, Hussain, Govindan, Lindell, & Mehringer, Citation2003).
Reconfiguration mechanisms alter the topology of the network in order to add more resources or isolate the attack traffic. XenoService (Yan, Early, & Anderson, Citation2000) is a content replication mechanism and works as follows. A number of ISPs install Xenoservers that offer web hosting services. A website is monitored and if reduction in the quality of service is experienced due to a surge in demand, the website is replicated to other Xenoservers. The attacker needs to attack all replication points in order to deny access to the legitimate users.
Replication techniques have the following limitations (Keromytis et al., Citation2002). They are not suitable in cases where information requires to be frequently updated (especially during an attack) or it is dynamic by nature (e.g. live audio or video stream). In case of sensitive information security being a major concern; engineering a solution that replicates sensitive information without any “leaks” is very challenging.
Rate limiting mechanisms drop some fraction of the suspicious network traffic. These mechanisms are typically used when the detection mechanism cannot precisely characterise the attack traffic, that is, when attack signatures cannot be derived.
One of the first and most influential work in the field is the aggregate-based congestion control (ACC) and Pushback mechanisms by Mahajan et al. (Citation2002). The authors view the DDoS attacks as a router congestion problem. The aggregate is defined as the traffic that is directed towards a specific destination address, that is, the victim (note that source addresses cannot be trusted because hosts can spoof traffic, disobey congestion signals etc). A local ACC agent is installed on the victim's router which monitors the drop history. If the drop history deviates from the normal,Footnote4 the local ACC reduces the throughput of the aggregate by calculating and setting a rate-limit.
Pushback is a cooperative mechanism. The local ACC can optionally request from adjacent upstream ACC routers to rate limit the aggregate according to a max–min fashion, a form of equal-share fairness, where bandwidth allocation is equally divided among all adjacent upstream routers. Rate limiting of the aggregate recursively propagates upstream towards its sources in a hierarchical fashion.
The major limitation of Pushback is that it causes collateral damage, that is, when legitimate traffic is rate limited along with the attack traffic. This is because the resource sharing starts at the congested point, where the traffic is highly aggregated and contains a lot of legitimate traffic within it.
Another popular work is the original Router Throttling mechanism by Yau et al. (Citation2005); this is the method tested against our approach. The authors view the DDoS attacks as a resource management problem and they adopt a server-initiated approach. According to Douligeris and Mitrokotsa (Citation2004), similar techniques to throttling are used by network operators. Router Throttling is described as follows. When a server operates below an upper boundary , it needs no protection (this includes cases of weak or ineffective DDoS attacks). When the server experiences heavy load, it requests from upstream routers to install a throttle on the aggregate. In case the server load is still over the upper boundary
, the server asks from upstream routers to increase the throttle. If the server load drops below a lower boundary
, the server asks the upstream routers to relax the throttle. The goal is to keep the server load within the boundaries
during a DDoS attack. Router Throttling, unlike Pushback, is more of an end-to-end approach initiated by the server and therefore collateral damage is significantly reduced. Yau et al. (Citation2005) present the Baseline throttling approach in which all upstream routers throttle traffic towards the server, by forwarding only a fraction of it. This approach penalises all upstream routers equally, irrespective of whether they are well behaving or not. The authors then propose the AIMD throttling algorithm, which installs a uniform leaky bucket rate at each upstream router that achieves the level-k max–min fairness among the routers
. These are the two throttling techniques tested against our approach.
7. Discussion and conclusion
7.1. Advantages
Effectiveness has two aspects; these are learning speed and final performance. The performance is the percentage of the legitimate traffic that reached the victim server. It was demonstrated that D_CTL achieves a high performance, consistently outperforming AIMD. For instance, in the topology involving about 100 learning agents, D_CTL achieves a system performance of , outperforming AIMD by
. We further examined the case of a more sophisticated attack strategy with variable rate dynamics, specifically a pulse attack, where similar results are obtained. Moreover, although our approach and AIMD are more useful under aggressive attackers, D_CTL achieves a
performance, outperforming AIMD by
. Also, as far as the AIMD approach is concerned, performing throttling becomes challenging as the range
becomes smaller.
The learning speed is critical for online learning. If the learning speed is slow, the system may be practically useless to the victim, even if it eventually achieves a high performance. If D_CTL was deployed, we have estimated that it would require a few seconds to bring the aggregate load below its upper boundary, thus allowing the victim to remain functional during the DDoS attack. Furthermore, it would require less than a minute to overcome AIMD and about 3–7 min to reach its maximum performance. This is a powerful result suggesting that D_CTL is suitable for online learning.
The scalability of our proposed system D_CTL is successfully demonstrated in experiments involving up to 1000 learning agents. A very strong result is obtained as it is empirically shown that the system performance remains unaffected by the addition of new teams of learning agents. D_CTL's remarkable learning speed and high scalability lay the foundations for a potential real-world deployment.
One of the core advantages of reinforcement learning is its capability for online learning. Online learning relaxes the assumption of prior knowledge availability required for offline learning. Offline learning can also be expensive and time consuming. Moreover, online learning allows a system to adapt to new situations. This is particularly useful for a defensive system since not only do attackers change their strategy, but legitimate users can also change their behaviour.
In real-world deployment network component failures do and will occur. Therefore, a system must be robust to these failures. This is particularly the case for our approach and AIMD which are router-based. We have shown that our D_CTL approach is robust to router failures. When routers fail, the remaining active learning agents adapt and recover to make up for the loss. Specifically, we have demonstrated that even when almost a quarter of the defending routers fail, the remaining active learning agents recover and achieve an impressive system performance of ,
more than AIMD.
The original AIMD throttling approach is victim-initiated, that is, the victim controls and sends the throttle signals to the upstream routers. However, it is based on the assumption that either the victim remains operational during a DDoS attack or that a helper machine is introduced to deal with the throttle signalling. The first assumption can be violated in a real-world scenario. As far as the second assumption is concerned, the helper machine can also become a target of the attack. In essence, the problem may arise because the existing throttling approach is victim-initiated, that is, it has a single point of control. In other words, although it offers a distributed response, it is still a centralised approach. Our proposed approach has a decentralised architecture and provides a decentralised coordinated response to the DDoS problem, thus being resilient to the attacks themselves.
7.2. Deployment issues
The proposed D_CTL approach performs minimum levels of communication conducted in a hierarchical team-based fashion required for activating the defensive system, for instructing the system to explore more and for calculating the difference rewards (for the latter, a good approximation of difference rewards may be possible but this is subject to future work).
However, in real-world deployment we need to ensure a reliable and secure delivery of the communicated information. In practise, our proposed system will require the designer to include mechanisms like message authentication, priority transmission and retransmission in case of losses. Notice that this also applies to the case of the AIMD approach in order to have a reliable and secure delivery of the throttle signals (Yau et al., Citation2005).
For the selection of upstream defensive routers we have adopted the same method by Yau et al. (Citation2005). However, in practise there are hundreds of potential victims and it is unlikely that for each victim i, an ISP would support the proposed functionality on a separate set of defensive routers . This holds true for the AIMD approach as well. It is expected that in real-world deployment an ISP will support the defensive functionality on distributed fixed locations, that is, routers which see a significant amount of network traffic. As long as the majority of the DDoS traffic passes through these points our proposed approach would still be effective.
Acknowledgements
The authors would like to thank Logan Yliniemi and Kagan Tumer for their invaluable suggestions.
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes
1. Collaboration between different administrative domains is desirable but the motivation for deployment is low.
2. An ISP backbone or core router, like a team leader, is able to handle large amounts of traffic therefore it is unlikely to become a victim itself.
3. In practice, it is expected that the victim will instruct the activated system to start exploring if the victim observes a rapid decline in its performance or a decline over a period of time. Alternatively, it is reasonable to expect that the network administrator is aware of any router failures, therefore he can manually instruct the system to start exploring.
4. The authors distinguish between typical congestion levels (e.g. observed during peak times) and unusual or serious congestion levels caused by DDoS attacks (although serious congestion can occur due to other reasons as well, e.g. a fibre cut).
References
- Agogino, A. K., & Tumer, K. (2008). Analyzing and visualizing multiagent rewards in dynamic and stochastic domains. Autonomous Agents and Multi-Agent Systems, 17(2), 320–338. doi: 10.1007/s10458-008-9046-9
- Anstee, D., Cockburn, A., & Sockrider, G. (2013). Worldwide infrastructure security report (Technical report). Arbor Networks.
- Claus, C., & Boutilier, C. (1998). The dynamics of reinforcement learning in cooperative multiagent systems. AAAI conference on artificial intelligence, Madison, Wisconsin, USA.
- Colby, M., & Tumer, K. (2013). Multiagent reinforcement learning in a distributed sensor network with indirect feedback. Proceedings of the 12th international joint conference on autonomous agents and multiagent systems, Saint Paul, Minnesota, USA.
- Devlin, S., Yliniemi, L., Tumer, K., & Kudenko, D. (2014). Potential-based difference rewards for multiagent reinforcement learning. Proceedings of the 13th international conference on autonomous agents and multiagent systems, Paris, France.
- Douligeris, C., & Mitrokotsa, A. (2004). Ddos attacks and defense mechanisms: classification and state-of-the-art. Computer Networks, 44(5), 643–666. doi: 10.1016/j.comnet.2003.10.003
- HolmesParker, C., Agogino, A., & Tumer, K. (2013). Combining reward shaping and hierarchies for scaling to large multiagent systems. Knowledge Engineering Review.
- Hussain, A., Heidemann, J., & Papadopoulos, C. (2003). A framework for classifying denial of service attacks. Proceedings of the 2003 conference on applications, technologies, architectures, and protocols for computer communications, Karlsruhe, Germany.
- Jung, J., Krishnamurthy, B., & Rabinovich, M. (2002). Flash crowds and denial of service attacks: Characterization and implications for cdns and web sites. Proceedings of the 11th international conference on World Wide Web, Honolulu, Hawaii, USA.
- Keromytis, A. D., Misra, V., & Rubenstein, D. (2002). Sos: secure overlay services. Proceedings of ACM SIGCOMM, Pittsburgh, Pennsylvania, USA.
- Mahajan, R., Bellovin, S. M., Floyd, S., Ioannidis, J., Paxson, V., & Shenker, S. (2002). Controlling high bandwidth aggregates in the network. Computer Communication Review, 32(3), 62–73. doi: 10.1145/571697.571724
- Malialis, K., & Kudenko, D. (2013). Multiagent router throttling: Decentralized coordinated response against ddos attacks. Proceedings of the 25th conference on innovative applications of artificial intelligence (AAAI / IAAI), Bellevue, Washington, USA.
- Malialis, K., & Kudenko, D. (2015). Distributed response to network intrusions using multiagent reinforcement learning. Engineering Applications of Artificial Intelligence. Retrieved from http://dx.doi.org/10.1016/j.engappai.2015.01.013
- Mirkovic, J., & Reiher, P. L. (2004). A taxonomy of ddos attack and ddos defense mechanisms. Computer Communication Review, 34(2), 39–53. doi: 10.1145/997150.997156
- Papadopoulos, C., Hussain, A., Govindan, R., Lindell, R., & Mehringer, J. (2003). Cossack: Coordinated suppression of simultaneous attacks. DARPA information survivability conference and exposition, Arlington, Virginia, USA.
- Savage, S., Wetherall, D., Karlin, A., & Anderson, T. (2000). Practical network support for ip traceback. ACM SIGCOMM Computer Communication Review, 30(4), 295–306. doi: 10.1145/347057.347560
- Sutton, R. S., & Barto, A. G. (1998). Introduction to Reinforcement Learning. Cambridge, MA: MIT Press.
- Tumer, K., & Agogino, A. (2007). Distributed agent-based air traffic flow management. Proceedings of the 6th international joint conference on autonomous agents and multiagent systems, Honolulu, Hawaii, USA.
- Wolpert, K. R. W., David, H., & Tumer, K. (2000). Collective intelligence for control of distributed dynamical systems. Europhysics Letters, 49(6), 708. doi: 10.1209/epl/i2000-00208-x
- Yan, J., Early, S., & Anderson, R. (2000). The xenoservice-a distributed defeat for distributed denial of service. Proceedings of the information survivability workshop, Boston, Massachusetts, USA.
- Yau, D. K. Y., Lui, J. C. S., Liang, F., & Yam, Y. (2005). Defending against distributed denial-of-service attacks with max-min fair server-centric router throttles. IEEE/ACM Transactions on Networking (TON), 13(1), 29–42. doi: 10.1109/TNET.2004.842221