
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Human cognition is the result of an interaction of several complex cognitive processes with limited capabilities. Therefore, the primary objective of human cognitive augmentation is to assist and expand these limited human cognitive capabilities independently or together. In this study, we propose a glass-type human augmented cognition system, which attempts to actively assist human memory functions by providing relevant, necessary and intended information by constantly assessing intention of the user. To achieve this, we exploit selective attention and intention processes. Although the system can be used in various real-life scenarios, we test the performance of the system in a person identity scenario. To detect the intended face, the system analyses the gaze points and change in pupil size to determine the intention of the user. An assessment of the gaze points and change in pupil size together indicates that the user intends to know the identity and information about the person in question. Then, the system retrieves several clues through speech recognition system and retrieves relevant information about the face, which is finally displayed through head-mounted display. We present the performance of several components of the system. Our results show that the active and relevant assistance based on users' intention significantly helps the enhancement of memory functions.
1. Introduction
From the information-processing theory perspective, cognition generally refers to the process of acquiring and reorganising a large amount of information or experiences obtained from the surroundings and manipulating them via a memory system in the brain. In other words, cognition can be seen as a complex interaction of several processes with limited capacities. Augmented cognition, which is also referred to as intelligence amplification, aims to improve the performance of these limited cognitive processes, independently or together through the means of several interventions such as information technology.
In this article, we propose an augmented cognition system, which is developed to actively assist and enhance users' memory functions by constantly assessing their intention. We focus on memory because it plays an important role in human cognition. Several studies in last few decades have shown the limitations of human memory and the effect of its limitation on overall cognition. For instance, Miller (Citation1956) has shown that short-term memory, which is critical for reasoning and making sense of immediate world, can store only seven chunks regardless of the units. This is famously known as magic number seven. Similarly, Cowan (Citation2001) showed this number to be around four chunks in young population. Moreover, memory is a two-way process. Apart from storage, there exists a mechanism to retrieve stored information, which also faces a limitation in the form of a phenomenon called forgetting. Ebbinghaus (Citation1913) showed the effect of forgetting on memory. On the other hand, it has been claimed that context in which the information is stored plays a critical role in its retrieval. For example, Bransford and Johnson (Citation1972) in their experiments showed that humans usually understand and memorise a piece of information as the combination of several concepts from a part of a series of individual experiences. This implies that a piece of information is not saved in isolation but for a smooth retrieval, whenever needed, it is stored with a proper context, which further exaggerates the problem of memory storage capacity. Therefore, memory storage enhancement has been a major focus in last few years and with the availability of external storage, this problem has been solved, albeit partially.
To assist the memory storage, several smart devices have been released. In fact, most smart devices, in principle, are a form of the augmented cognition system, which attempts to assist one or more cognitive function(s). For example, phonebook in a smart or normal mobile device is a very basic memory storage enhancement system. In addition, with the growth of wireless network environment, it is now possible for smart device users to store and access large amount of information remotely on a device through a wireless network anytime and anyplace. Taking these devices on an advanced level, several ubiquitous and wearable devices or services have been proposed (Kim, Citation2003; Ryoo & Bae, Citation2007). Despite the introduction of novelties, in terms of service platform, the procedure for obtaining information is still passive. Which means that information is retrieved only through interactions with a users' explicit key press, touch, voice, head motion, etc. This interaction is typical of human–machine interaction, which does not provide two-way communication as it happens in human-to-human interaction. Some companies and researchers have attempted to develop novel interaction methods but by and large the process still remains passive.
We assume that an augmented cognition device, particularly a wearable device, is more useful if it is active rather than passive and provide necessary, relevant and intended information. For an active interaction of system with humans, it is important that machines become intelligent in terms of understanding subtle human clues, which is critical for any successful communication. In this regard, human “intention” plays an important role, as it is the fundamental premise of human-to-human communication. Human beings have a capacity to empathise with other humans and predict the state of mind of the other by understanding their intentions. Human intention is either “explicit” or “implicit”. Explicit intentions are represented through language, facial expression, etc. Implicit intentions, on the other hand, are represented through subtle clues such as body posture, change in bio-features such as change in pupil size and eye-blink. Therefore, an assessment of these implicit intentions is the key to improve human-to-machine interaction. By assessing these subtle clues, machines can become active and provide more relevant services.
Hence, instead of bombarding users with abundant unnecessary and irrelevant information, which may be irritating and sometime may defeat the purpose, the augmentation system must proactively attempt to understand the need and requirement of its users in a given environment and provide assistance accordingly. Our proposed system “actively” assesses the intention of the user, determines the nature and need of the information in the context and then provides it on the basis of users’ intention to assist their memory functions. To determine the intention of the user, our system exploits the selective attention mechanism. That is, in a given environment, the system determines the users’ area of interest by gaze point detection and assesses the users’ “navigational” and “informational” intention by analysing their pupil dilation. Based on this analysis, the system determines if the user intends to know about the object in question in a visual scene or just browsing through it. Then, it accesses its external large database and retrieves necessary and only relevant information. Moreover, the system also determines the relevancy of the needed information by analysing keywords acquired from speech recognition. Although our system can be used in several real-world scenarios, in this paper, we present the experimental results of our system in a person identity scenario.
The remainder of this paper is organised as follows: in Section 2, we review relevant psychological aspects that play an important role in memory assistance. Section 3 presents the overall system architecture of the proposed system. A performance evaluation of various components of the system is given in Section 4. Finally, Section 5 describes our conclusions as well as future research directions.
2. Related works
In this section, we review important cognitive functions such as memory, selective attention and intention that are important for our system.
2.1. Human memory
Human memory plays a very important role in human cognition. Different mechanisms of memory functions store as well as retrieve information, whenever necessary. In general, human memory has been divided into three parts, namely perceptual memory, short-term (working) memory and long-term memory. Perceptual and short-term memory have limitations and are critical in functioning of daily life. The capacity of long-term memory, which permanently stores the information, is still debated. Miller (Citation1956) proposed that humans store information in chunks and the working memory (short-term) capacity of a young person is around seven chunks regardless of the units. This is famously known as magic number seven. In the same vein, Cowan (Citation2001) proposed that the working memory capacity of a young person is around four chunks. In addition, Ebbinghaus (Citation1913) introduced memory forgetting and spacing effect based on experimental studies.
Moreover, memory is a two-way process. Apart from storage, there exists a mechanism to retrieve stored information. Several studies have claimed that context in which the information is stored plays a critical role in its retrieval. Studies have shown that humans usually understand and memorise one remembrance as the combination of several concepts from a part of a series of individual experiences (Bransford & Johnson, Citation1972). Bransford and Johnson illustrated the effects of a priori knowledge in series of experiments. They found that the recall process improved when the title of an experimental passage was given in advance.
These experimental studies indicate the limitations of human memory and also point to aspects that can help in memory functions. Therefore, an augmented cognition system must be able to use a large amount of external repository and permanently retain most information, alleviating human short-term and long-term memory capacity limitations and it should be capable of providing needed information when it is required without causing extra cognitive load.
2.2. Human attention
According to James (Citation1890), attention is possession of the mind, in a clear and vivid form, by one out of the several simultaneously present objects or trains of thoughts. Attention also refers to the processing or selection of some information at the expense of other information (Pashler, Citation1998). One of the reasons for selective attention mechanism in a human is that there is always more information in a scene than can be processed by human perceptual system. Some of that are redundant, non-changing, while some are relevant, but keep changing. The attention mechanism, which some argue affect the early perceptual processing (Mangun & Hillyard, Citation1991), helps in filtering out relevant information and avoid unnecessary over-processing (see also Jeong, Ban, & Lee, Citation2008). Moreover, the attention mechanism is multimodal. However, we focus on visual modality in our system.
We concentrate on human eyeball movement to determine visual selective attention in the proposed system. We use gaze point detection to recognise what the user is looking at and focusing on. This information is crucial for determining the interest of the user in a given environment and to provide relevant information. This is in contrast to those systems that provide uncontrolled flow of information.
2.3. Human memory and selective attention
It is argued that short-term memory and visual attention are tightly coupled. The key to perform any task depends critically on the ability to retain task relevant information in an accessible state over time (short-term memory) and to selectively process information in the environment (attention). For instance, consider a walk through an unfamiliar city. In order to get to the destination, directions have to be retained and kept in short-term memory. In addition, we must be able to selectively attend to the relevant objects because there is always more information to process. If the directions stored in short-term memory instructs us to turn right after a red building, then attention may be guided towards objects that resemble a red building. Similarly, the attention marks the area of interest and the short-term memory encodes it as a mark for turning right. Although the exact relationship between memory and attention is not fully understood, contents of memory and attention are often assumed to be the same (Awh, Vogel, & Oh, Citation2006; Miyake & Shah, Citation1999). That is, attention selects the information to be encoded into memory.
In our proposed system, we make use of this overlapping relation between the short-term memory and selective attention to determine the area of interest of the user about which he/she may be interested to know or attempting to retrieve information from.
2.4. Human intention
In cognitive psychology, intention refers to an idea or plan of what an individual wants to do. According to the Theory of Mind (ToM; Premack & Woodruff, Citation1978), human beings have a natural way to predict, represent and interpret intention of others. Intentions are divided into two kinds: explicit and implicit. Explicit intentions are comparatively easy to recognise as they are represented through speech, body movements and so on. However, implicit intentions are represented through subtle facial expressions, changes in bio-features such as pupil dilation and so on. Implicit human intention recognition is crucial for an efficient and smooth human–computer interaction. As we mentioned earlier, to improve machine-to-human interaction, it is important for an augmentation system to understand human intentions. Recently, intention modelling and recognition are being researched in psychology and cognitive science so as to create a new paradigm of human–computer interface and human–robot interaction (Breazeal, Citation2004; Wong, Park, Kim, Jung, & Bien, Citation2006). Furthermore, intention recognition is widely used in Web applications (Chen et al., Citation2002). In this study, we redefine and present following classification (Jang, Lee, Mallipeddi, Kwak, & Lee, Citation2011) of human intention:
Navigational search intent: This refers to a human's idea of finding interesting objects in a visual input without any particular motivation.
Informational search intent: This refers to a human's aspiration to find a particular object of interest, or to behave with motivation.
We use several features related to implicit intention, including fixation length and count as well as pupil size variation (Privitera, Renninger, Carney, Klein, & Aguilar, Citation2008). shows heat maps representing the fixation length of eyeballs for a given visual stimulus. The image on the left side of is the heat map of the navigational search intention result. The image on the right side of is the informational search intention result. Notice that given the scan path and fixation points, navigation and informational intention can be clearly distinguished.
Figure 1. Heat maps of human eyeball movement for visual stimulus: (a) navigational intent and (b) informational intent.

An augmented cognition system must capture the start and the end points of the duration of informational intention in order to actively offer needed information. In our system, we assess the intention of the user through eyeball movement patterns and pupil size variations, which are strongly related to human cognitive processes (Liversedge & Findlay, Citation2000).
3. System design and architecture
Our proposed glass-type human augmented cognition system has been developed to actively assist users' memory functions to expand their overall cognitive capability. We choose glass-type platforms because they, unlike conventional handheld devices, are easy to interact with. They are convenient and allow fast information exchange. Moreover, the most critical and novel aspect of our system is its proactive assessment of users' intention. The system attempts to provide necessary, relevant and intended information by assessing the intention of the user. This section covers the architecture and functions of different components of the proposed system.
3.1. Overall system architecture
The proposed human augmented cognition system consists of hardware, an internal processing system and external data storage with computing power, as shown in . The hardware consists of a glass-type wearable platform composed of two tiny complementary metal oxide semiconductor cameras, two microphones, a head-mounted display (HMD) and an embedded system for distributed processing. The internal system consists of several function blocks that are sequentially executed for the processing of sensory data. The internal system in contains functions for face/object detection and recognition as well as acoustic source localisation (Kim & Park, Citation2010). The system manipulates the buffered information to filter redundant information that has been retrieved from the external repository, and it modulates the information flow according to users' intention. The external storage stores and retrieves the information related to the recognised faces/objects or user experience such as dialogue and location history. Furthermore, it is constructed in an ontological form from domain-specific Web documents as well as user log data collected by the device.
Figure 2. Overall architecture of the human augmented cognition system.
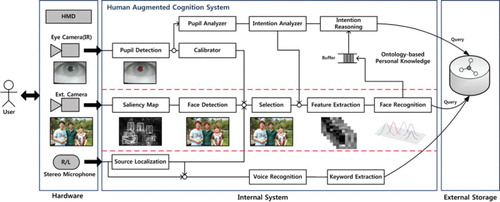
The overall process of the proposed system is described in . First, two images are captured by cameras mounted inside and outside of the glasses (see ). One image is used to analyse users' intention by detecting the gaze point as well as pupil dilation. The other camera is for face/object detection and recognition. In a visual scene, these two cameras together determine users' area of interest and corresponding intention in a given scenario. Particularly in a person identification scenario, one of the cameras captures the outside visual scenes and faces. The second camera measures the gaze point and change in pupil size. The gaze point helps in determining the face of interest in the scene. Pupil dilation helps to determine if the user is interested to know about the face, or trying to remember the identity and details of the person in question (Jang et al., Citation2011). Intention reasoning attempts to extract specific information according to implicit or explicit user intention. A buffer is required to determine the user's implicit or explicit intention from the quantity of information, which is collected as clues as to what human users are interested in. Finally, the retrieved relevant information is provided to the user through the HMD.
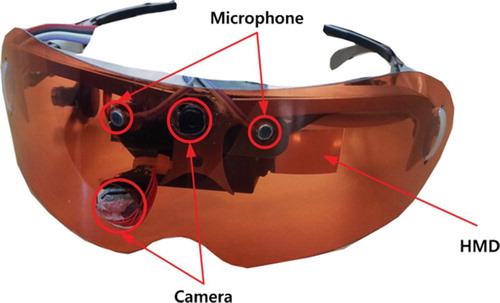
Figure 3. Prototype platform of the human augmented cognition system.
3.2. Face detection
In a person identification scenario, to recognise a face in a natural visual scene, a skin-colour preferable selective attention model is applied to localise face candidate regions prior to face detection (Kim, Ban, & Lee, Citation2008). This preprocessing requires less computation time and has a lower false-positive detection rate compared to AdaBoost face detection algorithm. In order to robustly localise candidate regions of a face, a skin-colour intensified saliency map (SM), which is constructed using a selective attention model reflecting skin-colour characteristics, is implemented. A skin-colour preferable SM is generated by integrating three different feature maps (intensity, edge and colour opponent). Applying a labelling-based segmentation process localises face candidate regions. The localised face regions are subsequently categorised as final face candidates using the Haar-like form feature-based AdaBoost algorithm.
In addition, an incremental two-dimensional kernel principal component analysis (I2DKPCA) approach is developed for feature extraction (Choi, Ozawa, & Lee, Citation2014). This incremental feature extraction algorithm has advantages in implementing a real-time face recognition system, including the reduction of computational load and memory occupation. PCA is one of the most widely used feature extraction algorithms and is used in various domains such as pattern recognition and computer vision. However, most conventional PCAs should be prepared for all training samples prior to the testing process. If new sample data need to be added, a conventional PCA must keep all data to update the eigenvector. Hence, we used the I2DKPCA for human face recognition (Choi et al., Citation2014).
3.3. Users' selective attention
The most significant aspect of the system is that it should select a face based on users' attention from several faces in the visual scene. For this, a technique that can track pupil centre in real time is applied using a small infrared (IR) camera with IR illuminations. In this case, it needs to match the pupil centre coordinate corresponding to the attention point on the outside view image. A simple second-order polynomial transformation is used to obtain the mapping relationship between the pupil vector and the outside view image coordinate.
A user's selective attention point can be calculated by gaze point detection using the pupil centre position (Jang et al., Citation2011). There are two general types of eye movement detection techniques: bright pupil and dark pupil. The difference between them is based on the location of the illumination source with respect to the optics. If the illumination is coaxial with the optical path, then the eye acts as the light reflector off the retina, creating a bright pupil effect similar to the red eye. If the illumination source is offset from the optical path, then the pupil appears dark since the retro-reflection from the retina is directed away from the camera. According to the natural response, the darkest region can be considered to be the pupil region. Therefore, the pupil detection method can be applied by using IR light with small IR illuminators to detect the point the regions where the user focuses.
In addition, the pupil becomes smaller or constricts in response to bright light levels, whereas it enlarges or dilates in response to low or dim light, which is collectively referred to pupillary reflex. Therefore, the primary function of the pupil is to regulate the amount of light entering the eye by dilation or contraction in response to changes in incident illumination (Lowenstein & Loewenfeld, Citation1962; Young & Biersdorf, Citation1954). On the other hand, under the conditions of constant illumination, the pupil size varies systematically in relation to a range of physiological and psychological factors, such as fatigue and level of mental effort (Goldwater, Citation1972).
3.4. Users' intention recognition
To retrieve relevant information about the face that is selected by gaze point detection from the external storage, the information should depend on the user's intention for the human augmented cognition system. That is whether the user is interested to know about the person in question. For this reason, user intention recognition is an important part of the proposed system. A probabilistic approach is used to select one of the various predefined user intentions. By using the naïve Bayes classifier, such a system can infer the user's intention in a specific situation. Our previous research demonstrated reasonable intention recognition performance in similar situations (Hwang, Jang, Mallipeddi, & Lee, Citation2012). The naïve Bayes classifier is based on conditional probabilities and uses Bayes' theorem with a strong independence assumption. Equation (1) describes the naïve Bayes classifier used in this study (Zhang, Citation2004)
(1)
(1)
where
is n number of recognised object classes in historical data and C is a predefined user intention class. Only one intention class with maximum probability is selected among all possible probabilities among specific user intentions.
3.5. Speech recognition
To provide relevant and contextual information, we also used speech recognition. Basically, the idea is to recognise keywords from the conversation and retrieve information based on present and past conversations and location. In our system, we use two microphones to capture sound streams from frontal scene. Captured sound streams include not only human voice, but also environmental sounds such as wind, car, ringtone and so on. To recognise the human voice properly, we need to reduce noise from the captured sound streams. We reduce sound noise by using minimum mean-square error-based speech power estimation and extension of degenerate unmixing estimation technique-based noise power estimation. The extracted filtered sound streams are then put into Google voice recognition service to retrieve corresponding text. These texts are called “clues” and are input to keyword extraction module for relevant information retrieval, which is automatically fed by the system.
3.6. Information retrieval by clue
After face recognition based on users' selective attention and intention, the internal system sends the recognised results as clue information to the external storage in order to retrieve the information related to the results. All visual and speech recognition results are continuously stacked into the external storage and then automatically constructed in a form of dependency graph. The external repository is equipped with a Web crawler in order to automatically collect specific domain knowledge such as electronic product information, public figure and so on. from the formally structured Web text data. This storage is designed based on graph-based ontology to manage the user experience (Son, Kim, Park, Noh, & Go, Citation2011). It has two kinds of ontology: situation ontology and domain ontology. Situation ontology stores several types of situations that occur with events responding to “when”, “where”, “what” and “how” questions, whereas the domain ontology contains a great number of triples with detailed information on diverse objects in real life. The data that come out from the speech recognition are converted into sentences in natural language so that general natural language processing can be used.
When the recognised results are put into the external repository, the retrieval system searches and select several keywords among the suitable candidates according to relative importance assigned by the TextRank algorithm (Mihalcea & Tarau, Citation2004) and presented to user. Consequently, the user may become aware of the individual relationship between the recognised results and user through the information retrieval system based on user experience. This information, which is relevant in the context, assists the user to recall from past memory.
3.7. Information presentation
The final result, considered being relevant information, is sent to the HMD for the presentation to the user. The HMD is organised into two parts: real screen and transparent screen. The real screen is in the black box and displays the result, and the real screen does not display as it blocks user's eyesight. Thus, we installed transparent screen, which reflects the image of real screen. Hence, the screen does not block user's eyesight as well as displays information to the user.
3.8. Prototype hardware platform implementation
A prototype hardware platform was implemented as shown in . Two mono-microphones were adopted for sound source localisation and voice recognition. One of the two cameras was used to recognise the environment, including faces and objects, whereas the other was used to measure gaze points and pupil variation. The HMD was used to immediately display the retrieved information corresponding to the recognised result from the external storage.
The prototype hardware platform was based on a standard personal computer (PC). However, some computationally intensive signal processing parts of the visual processing was assigned to a high-performance embedded digital signal processor (DSP) in order to distribute high computational load.
4. Experimental results
Our architecture consists of three major parts: (1) hardware, (2) internal system and (3) external storage. The internal system can be roughly subdivided into three sections: (1) selective attention and intention recognition, (2) visual processing and (3) acoustic processing, as shown in . Every component in the internal system is executed in parallel and most of the computation power consumption comes from the visual processing components. To test the performance of various components in the system, we conducted preliminary experiments. We mainly tested performance of face recognition, retrieval of information based on intention recognition and effect of the overall memory enhancement through assistance. All experiments were conducted in controlled indoor environment.
4.1. Face recognition and memory capacity expansion
According to psychological research, human short-term memory capacity has limitations in terms of quantity and time. Therefore, we performed a primary short-term memory capacity limitation test. We included 7 participants and a total of 30 faces in this experiment. First, the 30 faces were shown, 1 face at a time, in 2-s intervals. After a 30 s break time, randomly selected 15 faces were shown, 1 face at a time, in 2-s intervals. Finally, all participants were asked to choose the 15 memorised faces among the 30 faces. We measured the average of the difference between true positive and false positive as well as precision. The experimental results are shown in .
Table 1. Results of short-term memory capacity limitation.
In order to improve the limited capacity of memory storage for human faces, we implemented face detection and an incremental face recognition system. The proposed system requires feature extraction algorithm in order to reduce computational load in terms of the length of the human attention span. I2DKPCA feature extraction algorithm was used for face recognition (Choi et al., Citation2014), which is one of the key components of the proposed system. Incremental feature extraction algorithm can remarkably reduce the computation load for face recognition so that it allows the whole process to perform in real time even though the quantity of face data increases. In order to evaluate the classification, we used three face databases: ORL (Samaria & Harter, Citation1994), YaleA (Georghiades, Citation1997) and Extended YaleB (Lee, Ho, & Kriegman, Citation2005). These databases include various rotations, glass occlusion and emotions for each individual. The ORL face database consists of 400 frontal images of 40 subjects. For each subject, 10 images were taken with a few movements. The YaleA face database consists of 165 frontal images of 15 subjects. For each subject, 11 images were taken with different emotions, luminance and glass occlusions (wearing glass). In the experimental result with ORL and YaleA face databases, we randomly chose half of the images for each subject. Remaining half of the images were used for testing. The Extended YaleB face database consists of over 2200 frontal images of 38 subjects. For each subject, over 58 images were taken with different illuminations and the same position. In the experiment, we randomly chose only 10 images of each subject. Remaining images were used for testing. For experiments, the images were down-sampled to a resolution of 32 × 32 due to memory and computational load problems. We checked the performance of the proposed method in terms of accuracy. For the test data, each algorithm was repeated 10 times using different training sample sequences. presents the recognition performance comparison between the proposed incremental feature extraction algorithm and PCA-based methods based on accuracy and number of coefficients. In , accuracy means how many faces were successfully recognised for test data.
Table 2. Performance comparison using ORL, YaleA and YaleB database.
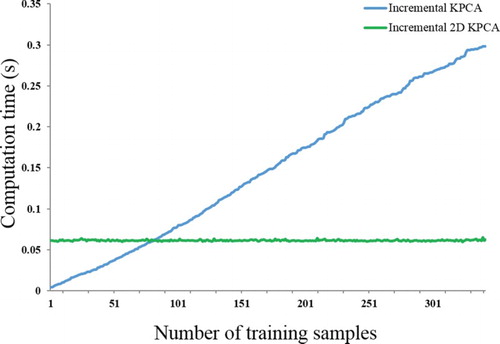
The computation time comparison between PCA-based incremental feature extraction algorithms is shown in . Notice that the computation time of the proposed algorithm is not very sensitive to the increased number of training samples, whereas the computation time of incremental kernal principle component analysis dramatically increases along with the amount of sample data.
Figure 4. Comparison of computation time between incremental methods (in color online).
4.2. Pupil analysis for intention-based information retrieval
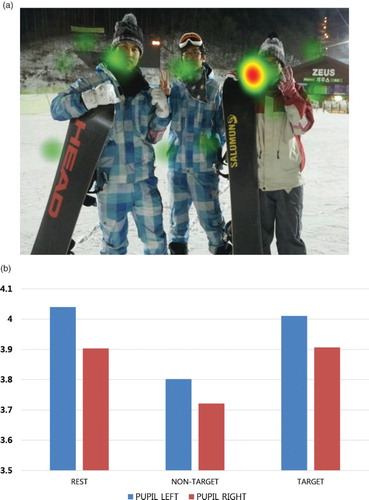
As discussed in Section 2, our proposed system recognises users' informational search intention to retrieve relevant and necessary information within the context. The system uses pupil size variation as a feature that can be measured from participants during performing an experimental visual task in order to verify discrimination between navigational search intention and informational search intention (Jang, Mallipeddi, Lee, Kwak, & Lee, Citation2012). Testing the system outdoors is currently not possible as the system uses IR camera to detect pupil. This experiment was conducted within a controlled indoor environmental condition. To eliminate the effect of other factors on pupil dilation such as illumination, angle and so on, we used the method applied in Jang et al. (Citation2012). In other words, the proposed human augmented system treats only the data within the duration of informational search intent. shows experimental results of pupil size and gradient of pupil size variation during navigational search intention and information search intention. The point bars are obtained by averaging the pupillary responses and the standard deviations of all subjects while viewing different visual stimuli. Using the average of pupil size and gradient of average of pupil size, the pupil analyser successfully identifies the instances of navigational search intention and informational search intention as well as changes in informational search intention for generation, maintenance and disappearance. shows the change in pupil dilation in the area of interest.
Figure 5. Experimental result of pupil size and gradient of pupil size variation during several types of human implicit intentions.
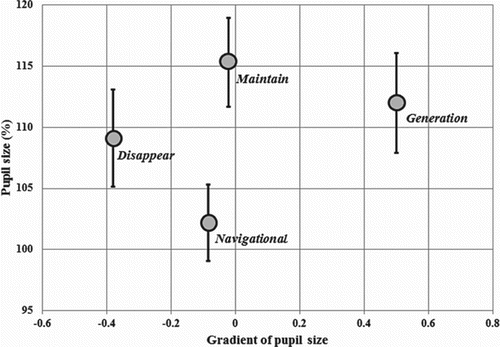
Figure 6. Experimental result of selective attention and change in pupil dilation for informational intention (in color online).
4.3. Relevancy of clue information
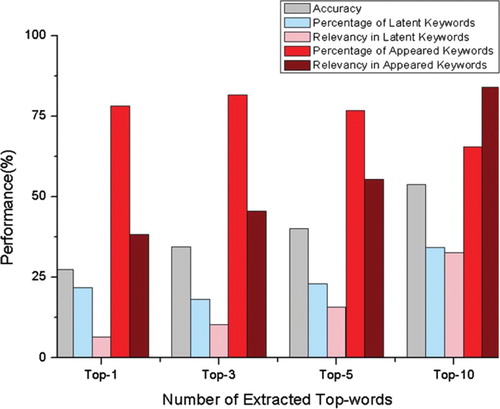
One of the most significant points of the information processing system of proposed human augmented cognition system is relevancy of the information retrieved from the repository. In other words, the information retrieval system has to extract acceptable clue information from the repository and offer it to the user. The retrieved information plays a role in this system as a clue to recall from user's past memories and experiences. The keyword extraction based on TextRank is effective to retrieve relevant text-based information related to the input query.
The result of keyword extraction performance is shown in . The relevance of keywords was calculated by comparing human and system-based keyword extraction methods. Thus, user and system extracted 10 keywords for a given document in order of importance. We checked and calculated a concordance rate between two sets of results. The results show that accuracy increases as the number of extracted top-words increases.
Figure 7. Relevance of the extracted top-words (in color online).
4.4. Computation time for assistance
From a service platform point of view, the augmented cognition system should meet requisite conditions such as the processing time of a single whole cycle due to the limited human attention span to make the information relevant. Therefore, whole execution time can be measured from hot spots, which means that data transfer between the embedded system with the proposed wearable glasses, the PC and the external storage system consume a large percentage of a program's total execution time. This experiment was performed on two types of platforms: PC and embedded systems. Embedded platform has the ultimate purpose of computing resource distribution and compact system design with easy mobility. However, in our system, the embedded system did not perform all visual processing functions due to its limited computing power. Hence, we use the embedded system only for face detection function, which can provide high-efficiency processing of face recognition. Then, localised face areas are transmitted to the PC through wireless LAN, and the face recogniser in PC identifies them. The recognised results are returned to the embedded platform through the wireless LAN. Finally, the HMD provided the recognised results to participants using our glass-type system.
Image streams are used for this experiment, with 320 × 240 pixels and 24 frames/s as shown in . shows the experimental conditions of the platforms for performance measurement. The AdaBoost algorithm combined with a face colour preferable SM was applied for face detection (Kim et al., Citation2008).
Figure 8. Sampled image from video clip (320 × 240, 24 fps).

Table 3. Experimental conditions of the platform.
The computational load of PC and the embedded platform are shown in Tables and , respectively. The maximum processing time for visual processing and information retrieval in a PC system is 446 ms and minimum-processing time is 320 ms. Note that the communication delay time is not included in the processing time result, even though the experiment was performed in an environment with wireless LAN. This is because network environmental conditions are out of control while doing an experiment. In the case of embedded platform, DSP was in charge of the computational load distribution so that the device using both advanced RISC machine (ARM) and DSP showed performance with a small average processing time, as shown in . Notice that computation time for the whole process is less than about 1 s, even if the whole process is performed on embedded system. This indicates that our system can provide appropriate information retrieved from the external storage within the time limit of 2 s (which is usually well below the average attention span of a normal human being) (Dukette & Cornish, Citation2009).
Table 4. Average processing time for each function.
Table 5. Average performance of face detection on embedded system.
4.5. Overall effect of the augmentation system on memory function enhancement
Finally, to evaluate the overall performance of our augmentation system on memory function enhancement, we compared person identification results between human and human with augmented device. We present the result of 15 participants in three following tests:
Test 1:
− Participants learn 15 faces in database.
− Participants test 15 faces (8 faces were from database, 7 faces were not from database).
− Participants learn again for failed recognition case.
Test 2:
− Participants test 15 faces.
− The augmented cognition device also learns faces in database.
Test 3:
− Participants with the augmented device.
− The augmented cognition device recognises faces and displays the necessary information
via the HMD only when participant's answer is vague.
− Participants test 15 faces.
Task:
− Participant sees a face and answer with known, unknown and vague.
− Participant knows both face and name: Know.
− Participant does not know both face and name: Unknown.
− Participant knows face but does not knows name: Vague.
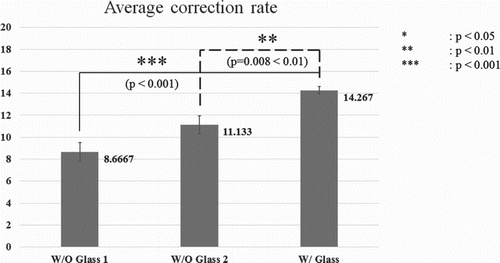
In this experiment, we measured three categories (known, unknown and vague) for the participants. Each category represents, learned face, unlearned face, learned face but cannot remember the name. We measured 15 participants' scores of three groups (TEST1, TEST2 and TEST3). For statistical relevance levene's test (Levene, Citation1960) was applied for checking equality of variance (p = .024 < .05). According to the p-value, ANalysis Of Variance could not be applied because equality of variance was not met. So we applied Dunnett T3 post hoc test (Dunnett, Citation1955). represents average of each group with standard error and significance value p. The results show that the proposed glass-type cognitive augmentation device significantly enhances users' memory and assists overall cognitive experience.
Figure 9. The comparison between human and human with augmented device.
5. Conclusion and future works
We proposed a glass-type human augmented cognition system. Although, the system can be used in various scenarios, in this study, we focused on the performance of the system in person identification scenario. Our system, unlike other passive systems, actively provides only relevant, necessary and intended information by constantly assessing the intention of the user. For this, the system analyses users' attention in a visual scene through eyeball movement and intention through change in pupil size variation. It also compliments the relevancy of the retrieved information through clues acquired from speech recognition. Finally, the information deemed relevant in the context is presented on the HMD to the user.
We tested various components of our system in different experiments and found that our proposed glass-type human augmented cognition system considering human selective attention and informational intention can provide appropriate information well below 1-s time. Further, it showed good results of face recognition performance as well as retrieval of relevant information according to users' intention and need. We also found significant effect of the system on the overall enhancement of memory functions.
We also believe that such augmentations can change the brain structure, as the brain is plastic and susceptible to modifications. Therefore, to check the effect of memory assistance though relevant information on brain functioning pattern and structure, we intend to use electroencephalography and functional near-infrared spectroscopy during cognitive function tests in our future work. Furthermore, wireless transmission technology of image streams with low power and compact design are also under investigation for commercialisation of the glass-type human augmented system.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Awh, E., Vogel, E. K., & Oh, S. H. (2006). Interactions between attention and working memory. Neuroscience, 139(1), 201–208. doi: 10.1016/j.neuroscience.2005.08.023
- Bransford, J. D., & Johnson, M. K. (1972). Contextual prerequisites for understanding: Some investigations of comprehension and recall. Verbal Learning and Verbal Behavior, 11, 717–726. doi: 10.1016/S0022-5371(72)80006-9
- Breazeal, C. (2004). Social interactions in HRI: The robot view. IEEE Transactions on Systems, Man, and Cybernetics – Part C: Applications and Reviews, 34(2), 181–186. doi: 10.1109/TSMCC.2004.826268
- Chen, Z., Lin, F., Liu, H., Liu, Y., Ma, W.-Y., & Liu, W. (2002). User intention modeling in Web applications using data mining. World Wide Web – Internet and Web Information Systems, 5, 181–192.
- Choi, Y., Ozawa, S., & Lee, M. (2014). Incremental two-dimensional kernel principal component analysis. Neurocomputing, 134, 280–288. doi: 10.1016/j.neucom.2013.08.045
- Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24, 87–114. doi: 10.1017/S0140525X01003922
- Dukette, D., & Cornish, D. (2009). The essential 20: Twenty components of an excellent health care team. Pittsburgh, PA: RoseDog Books.
- Dunnett, C. W. (1955). A multiple comparison procedure for comparing several treatments with a control. Journal of the American Statistical Association, 50, 1096–1121. doi: 10.1080/01621459.1955.10501294
- Ebbinghaus, H. (1913). Memory: A contribution to experimental psychology. New York, NY: Teachers College, Columbia University.
- Georghiades, A. (1997). Yale face database, center for computational vision and control at Yale University. Retrieved from: http://cvc.cs.yale.edu/cvc/projects/yalefaces/yalefaces.html
- Goldwater, B. C. (1972). Psychological significance of pupillary movements. Psychological Bulletin, 77(5), 340–355. doi: 10.1037/h0032456
- Hwang, B., Jang, Y.-M., Mallipeddi, R., & Lee, M. (2012). Probabilistic human intention modeling for cognitive augmentation. International conference on system, man, and cybernatics (SMC 2012), Seoul, pp. 2580–2584.
- James, W. (1890). The principles of psychology (Vol. 1). New York, NY: Henry Holt.
- Jang, Y.-M., Lee, S., Mallipeddi, R., Kwak, H.-W., & Lee, M. (2011, November 13–17). Recognition of human's implicit intention based on an eyeball movement pattern analysis. International Conference on Neural Image Processing (ICONIP 2011), Serial Vol. 7062, Shanghai, China, 138–145.
- Jang, Y.-M., Mallipeddi, R., Lee, S., Kwak, H.-W., & Lee, M. (2012). Human implicit intent transition detection based on pupillary analysis. IEEE World Congress on Computational Intelligence – IJCNN, Brisbane, pp. 2144–2150.
- Jeong, S., Ban, S.-W., & Lee, M. (2008). Stereo saliency map considering affective factors and selective motion analysis in a dynamic environment. Neural Networks, 21, 1420–1430. doi: 10.1016/j.neunet.2008.10.002
- Kim, B., Ban, S.-W., & Lee, M. (2008). Improving AdaBoost based face detection using face color preferable selective attention. Intelligent Data Engineering and Automated Learning (IDEAL2008), Series Vol. 5326, Daejeon, pp. 88–95.
- Kim, J. B. (2003). A personal identity annotation overlay system using a wearable computer for augmented reality. IEEE Transactions on Consumer Electronics, 49(4), 1457–1467. doi: 10.1109/TCE.2003.1261254
- Kim, J.-S., & Park, H.-M. (2010). Target speech enhancement based on degenerate unmixing and estimation technique for real-world applications. IET Electronics Letters, 46(3), 245–247. doi: 10.1049/el.2010.3033
- Lee, K.-C., Ho, J., & Kriegman, D. J. (2005). Acquiring linear subspaces for face recognition under variable lighting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(5), 684–698.
- Levene, H. (1960). Robust tests for equality of variances. Ingram Olkin, Suchish G. Ghurye, Wassily Hoeffding, William G. Madow, & Henry B. Mann (Eds.), Contributions to probability and statistics: Essays in honor of Harold Hotelling (pp. 278–292). Stanford: Stanford University Press.
- Liversedge, S. P., & Findlay, J. M. (2000). Saccadic eye movement and cognition. Trends in Cognitive Science, 4(1), 6–14. doi: 10.1016/S1364-6613(99)01418-7
- Lowenstein, O., & Loewenfeld, I. E. (1962). The pupil. The Eye, 3, 231–267.
- Mangun, G. R., & Hillyard, S. A. (1991). Modulations of sensory-evoked brain potentials indicate changes in perceptual processing during visual–spatial priming. Journal of Experimental Psychology: Human Perception and Performance, 17(4), 1057–1074.
- Miller, G. A. (1956). The magical number seven, plus minus two: Some limits on out capacity for processing information. Psychological Review, 63, 81–97. doi: 10.1037/h0043158
- Mihalcea, R., & Tarau, P. (2004, July 25–26). TextRank: Bring order into texts. Conference on Empirical Methods in Natural Language Processing (EMNLP 2004), Barcelona, Spain, pp. 404–411.
- Miyake, A., & Shah, P. (Eds.). (1999). Models of working memory: Mechanisms of active maintenance and executive control. Cambridge: Cambridge University Press.
- Pashler, H. E. (Ed.). (1998). Attention. Cambridge: Psychology Press.
- Premack, D., & Woodruff, G. (1978). Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences, 1(4), 515–526. doi: 10.1017/S0140525X00076512
- Privitera, C. M., Renninger, L. W., Carney, T., Klein, S., & Aguilar, M. (2008). The pupil dilation response to visual detection. Human vision and electronic imaging XIII/SPIE-IS&T, San Jose, 6806, 68060T-68060T-11.
- Ryoo, D.-W., & Bae, C. (2007). Design of the wearable gadgets for life-log services based on UTC. IEEE Transaction on Consumer Electronics, 53(4), 1477–1482. doi: 10.1109/TCE.2007.4429240
- Samaria, F. S., & Harter, A. C. (1994, December 5–7). Parameterization of a stochastic model for human face identification. Proceedings of the 2nd IEEE Workshop on Applications of Computer Vision, Sarasota, FL, pp. 138–142.
- Son, J.-W., Kim, S., Park, S.-B., Noh, Y., & Go, J.-H. (2011). Expanding knowledge source with ontology alignment for augmented cognition. International Conference on Neural Information Processing, 7063, 316–324.
- Wong, F., Park, K.-H., Kim, D.-J., Jung, J.-W., & Bien, Z. (2006). Intention reading towards engineering applications for the elderly and people with disabilities. International Journal of Assistive Robotics and Mechatronics, 7(3), 3–15.
- Young, F. A., & Biersdorf, W. R. (1954). Pupillary contraction and dilation in light and darkness. Journal of Comparative and Physiological Psychology, 47(3), 264–268. doi: 10.1037/h0057928
- Zhang, H. (2004). The optimality of naive bayes. In V. Barr & Z. Markov (Eds.), Proceedings of the seventeenth international Florida Artificial Intelligence Research Society conference (FLAIRS 2004). Miami: AAAI Press.