
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Attribute-level sentiment element extraction aims to obtain the word pair < opinion target, opinion word > from texts, which mainly obtain fine-grained evaluation information in the attribute level. Due to the information fragmentation and semantic sparseness of product reviews, it is difficult to capture more comprehensive local information from unstructured texts, which leads to the incorrect extraction of some word pairs. Aimed at the problem, this paper proposes a framework for Attribute-Level Sentiment Element Extraction (ALSEE) towards product reviews. Firstly, a small amount of sample data is selected by random sampling, and multiple features (including part of speech, word distance, dependency relationship and semantic role) which are labelled. The labelled data are used as the training set. Then, the Condition Random Field (CRF) model is applied to extract opinion targets (OT) and opinion words (OW). The self-training strategy is used to achieve the semi-supervised learning of CRF model through iterative training. Finally, target-opinion word pairs with modifying relationship are obtained by dependency parsing. Compared with the existing methods, the proposed framework can effectively extract attribute-level sentiment elements though experimental results.
1. Introduction
With the e-commerce industry developing rapidly, the user-generated content in the interactive media of Internet consumption grows explosively (Da’U et al., Citation2020; Hu et al., Citation2017; Onan, Citation2020). Confronted with rich expressions in product reviews, users are more inclined to obtain the fine-grained evaluation information of product attributes (e.g. appearance and quality), which are attribute-level sentiment elements. Attribute-level sentiment elements include opinion targets and opinion words, and the opinion words can also be understood as sentiment words, which are the modifier of the opinion target. The extraction of attribute-level sentiment elements can provide data support for the sentiment analysis (Wang et al., Citation2021). Due to the information fragmentation and semantic sparseness of product reviews, it is difficult to capture more comprehensive local information from unstructured texts.
With regard to the research on information extraction from comments, in (Zhang, Hu et al., Citation2021), sentiment element word pairs are obtained based on syntactic dependency, and the “modification distance” is defined to measure the proximity of sentiment words and their modifier words. In Liu, Tang et al. (Citation2018), dependency syntax analysis and MHITS algorithm are combined to obtain product features. Different from the previous work, the paper focuses on the basic research of attribute-level sentiment element extraction towards product reviews, which can provide technical support for fine-grained opinion mining. The novelty of this paper mainly focuses on multi-feature fusion and the self-training of the CRF model, and then the CRF model can learn multiple local features more adequately, which contribute to improving the accuracy of sentiment element extraction. Based on the CRF model and dependency parsing, this paper constructs a framework for Attribute-Level Sentiment Element Extraction (ALSEE) towards product reviews.
Based on the above three considerations, we proposed a framework for Attribute-Level Sentiment Element Extraction (ALSEE) towards product reviews, as shown in Figure . The framework includes the following two aspects.
(1) Extracting opinion targets and opinion words. Firstly, multiple features (including part of speech, word distance, dependency relationship and semantic role) in sample data are labelled by the language technology platform (LTP), and the labelled data are taken as the training set of model. Then, CRF model is utilised to obtain the text sequences annotated with opinion targets (OT) and opinion words (OW).
(2) Extracting target-opinion word pairs. Firstly, text sequences with annotation are divided into individual sentences, and dependency parsing is performed on sentences with the help of a dependency parser. Then, target-opinion word pairs with modifying relationship can be extracted according to the results of dependency parsing.
Figure 1. System framework.
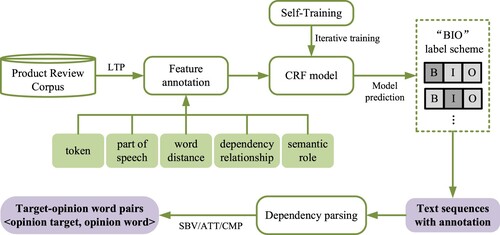
In this paper, the framework of attribute-level sentiment element extraction is constructed in two parts. In the part of extracting opinion targets and opinion words, the data annotated with multiple features are input into the CRF model for training. The advantage of multi-feature information fusion is that the CRF model can learn the feature information more adequately. The self-training algorithm is applied to achieve the semi-supervised learning of the CRF model by iterative training. The introduction of self-training can reduce the amount of data annotation and improve the accuracy of model prediction. The dependency parsing technique is used to find the word pairs with modifying relationship. The advantage of this method is that it can consider the syntactic structure of sentences and can better analyse the dependency relationship between words in the sentence.
The organisation structure of the paper is as follows. Section 2 introduces the related works. Section 3 describes the specific process of obtaining opinion targets and opinion words with the help of the CRF model. Section 4 explains how to obtain sentiment element word pairs based on the relevancy detection method. Section 5 discusses the experimental design and the analysis of experimental results. Section 6 expresses the summary of conclusions and the future work.
2. Related works
The related research works of sentiment element extraction can be categorised into unsupervised learning methods and supervised learning methods.
2.1. Unsupervised learning methods
With regard to unsupervised learning, common methods include semantic rule mining, dependency parsing and so on. Zhuang et al. identified the dependency relationship of opinion targets and opinion words through dependency parsing (Zhuang et al., Citation2006). Mirtalaie et al. proposed a framework of sentiment analysis based on dependency relationship and used grammatical rules to extract features (Mirtalaie et al., Citation2018). Wang et al. used phrase structure grammar and syntax rules to extract target-opinion word pairs (Wang et al., Citation2019). Zhou et al. and Kang et al. used label propagation algorithm to extract features (Kang & Zhou, Citation2016; Zhou et al., Citation2016). Wu et al. extracted word pairs, composed of opinion targets and opinion words, by combining semantic and syntactic features, and constructed an opinion dictionary for targets (Wu et al., Citation2019). Rana et al. identified some domain-related aspects on the basis of dual rules (Rana & Cheah, Citation2017). Luo et al. used knowledge resources, such as WordNet and the new method, based on corpus statistics to extract the most appropriate aspect (Luo et al., Citation2019). Zhang et al. (Citation2016) extracted feature keywords by the ICTCLAS system, and proposed the associated semantic mining algorithm to mine the semantic relations among keywords. According to Aytuğ et al. (Citation2016), extracting keywords as features also plays an important role in subsequent text classification.
In addition, many scholars integrated deep learning into the research of sentiment element extraction. Zhang et al. and Poria et al. utilised the CNN model to extract aspects, which can learn information more accurately, which is better than the linear model (Poria et al., Citation2016; Zhang, Li et al., Citation2021). Liu et al. identified opinion targets by the proposed augmented recursive neural network model (OLSRNN), which adds a self-link to the output layer and captures the dependency relations in the output sequence (Liu, Wang et al., Citation2018). Fu et al. combined a multi-perspective attention framework based on BiLSTM and ASPE joint strategy for simultaneously extracting aspects and opinion pairs, which avoided the error propagation caused by step-by-step extraction (Fu et al., Citation2021). Yang et al. achieved a joint task of extracting aspects and classifying the polarity of aspects with the help of the proposed model LCF-atepc (Yang et al., Citation2021).
2.2. Supervised learning methods
With regard to supervised learning, Tang and Liu (Citation2019) applied the CRF model and the extended HITS algorithm (Zhang et al., Citation2010) based on dichotomy network to sort and select opinion-target word pairs. Liu et al. combined with graph-based collaborative sorting algorithm to select candidate words with high confidence, which captures the long-span viewpoint relationship more accurately and alleviates the problem of wrong parsing in informal texts effectively (Liu et al., Citation2015). Liao et al. obtained the domain vocabulary through implicit syntactic and semantic knowledge and combined domain vocabulary with opinion targets extracted from CRF (Liao et al., Citation2016). Yang et al. achieved the product feature extraction by combining local information and global context information (Yang et al., Citation2016). Agerri et al. incorporated shallow clustering features and proposed a language-independent system model to extract opinion targets (Agerri & Rigau, Citation2019). Li et al. extracted opinion targets from user-generated content, using a method based on rules and semantic role labelling (Li & Chang, Citation2019). He et al. trained the classifier based on BiLSTM networks to extract Chinese entity attributes (He et al., Citation2019). The extraction of sentiment elements can also provide data support for sentiment analysis (Dashtipour et al., Citation2020).
The method based on semantic rules requires setting some rules manually, and it is difficult to deal with all kinds of new words and language rules emerging on the Internet. Some methods based on CRF model only consider lexical features, do not mine the implicit syntactic and semantic knowledge, and need a great deal of annotated data to drive. On the basis of the existing research, we proposed a framework for attribute-level sentiment element extraction towards product reviews. The framework considers multiple valid features, and it does not need to annotate a large amount of data.
3. Extracting opinion targets and opinion words based on the CRF model
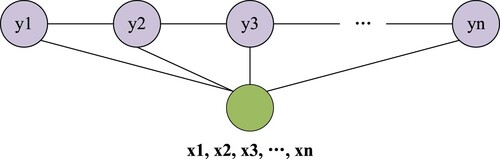
In this paper, the task of extracting OT and OW is treated as a problem of sequence labelling, which means that OT and OC in product reviews are annotated with some labels. Common models of sequence labelling include Conditional Random Field (CRF) (Shao et al., Citation2021 2]) and Hidden Markov Model (HMM). In this paper, the linear-chain CRF model proposed by (Lafferty et al., Citation2001) is chosen for sentiment element extraction, which is an undirected probability graph model (as illustrated in Figure ). It has the advantages of expressing long distance dependency and overlapping characteristics.
Figure 2. Linear-chain CRF model.
3.1. How to select features and define feature templates
For the CRF model, the selection of features (Aytuğ Citation2018; Onan & Korukoglu, Citation2017; Rout & Jagadev, Citation2018) and the definition of future templates make a critical difference in the extraction performance of OT and OW. This section mainly introduces feature selection and template definition in the CRF model. In this paper, the selected features are listed in Table .
(1) Token. The LTP tool (http://www.ltp-cloud.com/) is applied for word segmentation which is to split words into word strings. The result of word segmentation is directly used as a kind of feature of the CRF model. Because a lexical unit may directly reflect the characteristics and constitution rules of opinion targets or opinion words. Especially for some new cyber words or low-frequency words, the feature of token has a considerable influence on the extraction of OT and OW.
(2) Part of speech (POS). The LTP tool is also applied for part-of-speech tagging (POS Tagging). For example, “ This computer has a very clear screen (这款电脑的屏幕非常清晰)”, the result of POS Tagging is “这/r款/q电脑/n的/u屏幕/n非常/d清晰/a”. In product reviews, targets are mostly nouns or noun phrases (e.g. 屏幕), and opinion words are mostly adjectives (e.g. 清晰). Therefore, selecting POS, as one of the CRF model features, plays a remarkable role in the extraction of OT and OW.
(3) Word distance (WD). It was first proposed by Jakob et al. [35] to take word distance as one of the features of the CRF model. According to people’s language expression habits, the position distance between OT and OW is relatively close. In other words, the noun or noun phrase closest to the opinion word is likely to be an opinion target, and the adjective closest to the opinion target is also probably an opinion word. Especially for short review texts, when the model cannot obtain more features, the position feature of word distance can be applied to identify OT and OW effectively.
(4) Dependency Relationship (DR). The CRF model does not have the strict assumption of independence as HMM, so it is more flexible in feature selection and can take the distant dependency relationship into consideration. The LTP tool is used to perform dependency parsing and get the dependency relationship between words. Because there is a clear and direct dependency relationship between OT and OW in most cases, choosing dependency relationship as one of the features is beneficial for extracting OT and OW from product reviews. For example, “销量增加” represents the subject-verb relationship (SBV), “时尚的外观” represents the attribute relationship (ATT), and “拍照清晰” represents the complementary relationship (CMP). In addition, the coordinate relationship (COO) can help to obtain other opinion targets. As shown in Figure (a), given that “触感” is an opinion target, it can be judged that “瀑布屏” is also an opinion target via the coordinate relationship (COO).
(5) Semantic Role (SR). As one of the main implementation methods of shallow semantic parsing, Semantic Role Labelling (SRL) is performed with the help of LTP tool. SRL is to determine the semantic roles of some words (called “arguments”) according to the core predicate in the sentence. There are six core semantic roles: A0–A5. A0 usually represents the actor of action, A1 usually represents the recipient of action, and A2–A5 represents different semantic meanings according to the predicate verbs. There are also 15 additional semantic roles, such as LOC for place, TMP for time, and ADV for additional. Through large-scale corpus statistics, it could be found that the opinion target is usually the actor (A0) or the recipient (A1) of the predicate. As shown in Figure (b), the opinion targets “电脑配置” and “店铺销量” play the semantic roles of A0 and A1, respectively, in the sentence.
Figure 3. The visualisation of feature annotation.
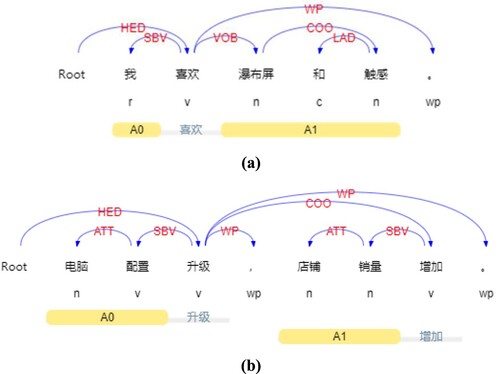
Table 1. Feature selection.
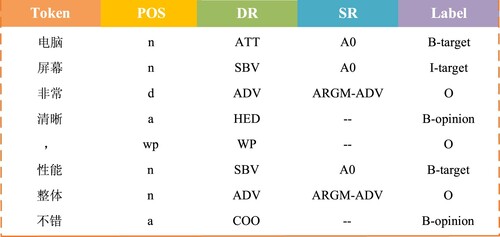
The data after feature annotation are organised together as training data. The training data are presented in the form of column. The first column represents the word string (Token) to be annotated, the last column outputs the BIO label, and other additional features are added to the middle columns. Figure illustrates the data format after feature annotation.
Figure 4. The data format after feature annotation.
Templates defined in the CRF model reflect the local features of words and the relationships between words. For the CRF model, there are two main types of feature templates: Unigram (indicates the feature that only associated with the label of the current node) and Bigram (represents the feature that is associated with the label of the previous node and the current node). Templates are used to control the size of the sliding window and the combination of different features, the design of which is particularly important. In this paper, the defined feature templates are described in Table .
Table 2. Defined feature templates.
3.2. The solution of the CRF model
The goal of this section is to solve the CRF model, so that the model can find the optimal output sequence corresponding to each initial text sequence. Firstly, given an observation sequence , the probability model is built for the conditional distribution
of output sequence
. Then, based on the training of labelled dataset, it is required to find an output sequence
that maximises
to annotate
.
In the CRF model, the probability of is the normalised form of the product of potential functions
, and the form of each factor is shown as formula (1).
(1)
(1) where transfer functions
depend on the current position and the previous position, which represents an estimate that the previous node
transferred from to the current node
in the
-th position of label sequence
. State functions
depend on the current position, which represents an estimate that the
-th position in label sequence
is labelled with
.
The concept of characteristic functions is introduced in the CRF model, and the expression form of characteristic function is .
is a unified description of the transition function and the state function. Therefore, the conditional distribution form of
of the CRF model is shown as formula (2).
(2)
(2) where
is the template serial number, and a feature template corresponds to a transfer function.
is the number of labels, and a label corresponds to a state function.
is the weight coefficient corresponding to the
-th characteristic function, which is also the parameter to be estimated and adjusted in each process of model training.
To describe the expression of conveniently, replace
with
. Then, the conditional distribution form of
is shown as formula (3).
(3)
(3) where
is the normalised factor, which is used as the denominator for the purpose of ensuring that the conditional probability sum of all possible output sequences is 1. The calculation form of normalised factor is shown as formula (4).
(4)
(4)
The solution goal of the CRF model is to find to maximise
, and the dynamic optimisation algorithms (e.g. Viterbi algorithm) can be applied for the solution. CRF is a discriminant model; and the parameter estimation method of Maximum Likelihood Estimation (MLE) is chosen in this paper to solve the optimal value of parameter
, by finding the logarithmic maximum of the probability formula of the CRF model, as shown in formula (5).
(5)
(5)
3.3. The self-training of the CRF model
Although the training effect of the CRF model is good, its training cost is high. Therefore, the self-training strategy is applied to achieve semi-supervised learning of the CRF model. Figure displays the self-training process of the CRF model.
Figure 5. The self-training process of the CRF model.
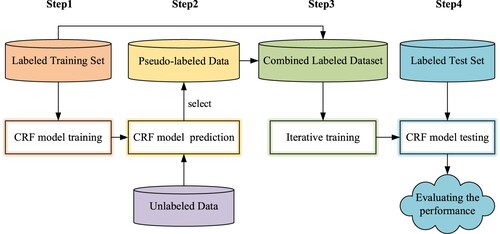
The essence of self-training (Gu, Citation2020) is to find a way to expand the labelled dataset with unlabelled data. As a method that can achieve semi-supervised learning, the self-training algorithm can not only lessen the laborious workload of annotating data manually, but also enhance the generalisation performance of the CRF model.
As shown in Figure , the specific steps of self-training are as follows.
Step1: CRF Model Training. Referring to the required data format, the data after feature annotation are organised as the training data. The labelled data are split into two parts: training set and test set. Based on the defined feature templates, the labelled training set is input into the CRF model for model training.
Step2: CRF Model Prediction. The trained CRF model obtained in the previous step is utilised to predict the label corresponding to the unlabelled data. Among all predicted results, the data with high confidence (called “pseudo-labeled data”) are selected, and the labels of which are called “pseudo labels”.
Step3: Iterative Training of the CRF Model. The pseudo-labelled data selected from model prediction results are merged into the correctly labelled training set. The combined dataset is used to retrain the CRF model iteratively. Until the predicted results in Step 2 no longer exceed the confidence threshold, or until there are no predictable unlabelled data, stop the iterative training.
Step4: Performance Evaluation. When the iteration stops, the final trained model testing is achieved by making prediction on the labelled test set. The performance of the CRF model is evaluated according to the predicted results.
4. Extracting target-opinion word pairs based on dependency parsing
The CRF model after training can output text sequence with annotation, which is annotated with opinion targets and opinion words. In this section, the goal is to find target-opinion word pairs with modifying relationships, also known as attribute-level sentiment elements.
Attribute-level sentiment elements contain opinion targets and opinion words, as shown in formula (6). The opinion target is the modified object of the opinion word, the opinion word is the modifier of the opinion target.
(6)
(6) where
is the opinion target,
is the opinion word.
is the set of attribute-level sentiment elements, the target-opinion word pairs.
Dependency parsing analysis can be used to analyse the dependency relationship between components in a sentence. Dependencies are represented by directed arcs; the arc of modifiers point to the word they modify. Two words connected by an arc have a direct relationship, but not necessarily a modifying relationship. According to the dependency parsing results of numerous product reviews, it is found that the word pairs with modifying relationship usually conform to several dependency relationships, such as SBV, ATT, CMP and VOB. Therefore, on the basis of obtaining text sequences with annotations, this paper will obtain target-opinion word pairs with modifying relationship through the following steps.
Divide the text sequence with annotations into individual sentences.
Dependency parsing (DP) is performed on each sentence using a dependency parser.
According to the results of dependency parsing, the dependency relationship between words in each sentence can be identified.
The opinion targets and opinion words with dependency relations (including SBV, ATT, CMP and VOB) were selected to form target-opinion word pairs.
Table shows some examples of word pairs based on dependency relationship.
Table 3. Examples of four dependencies.
5. Experiment and analysis of results
In this experiment, the CRF++0.58 open source toolkit was used to achieve the training and testing of the CRF model. The product review dataset crawled from JD Mall (JD.COM) was used in the experiment. The LTP tool (http://www.ltp-cloud.com/) was applied for multiple preparatory works (including word segmentation, part-of-speech tagging, dependency parsing and semantic role labelling).
5.1. Experimental data
In terms of experimental data preparation, the product review corpus was constructed by using product reviews crawled from JD Mall, including 10,000 “computer reviews” and 10,000 “cellphone reviews”, a total of 20,000 items. Among them, 20% of the review data were used for model training (called the Training Set), 20% for model testing (called the Test Set), and 60% for model prediction. The Training Set and the Test Set need to be labelled in advance. By random sampling, 4000 reviews were selected from the computer reviews and cellphone reviews. Multiple features in the review data were labelled by the LTP tool. Opinion targets (#OT), opinion words (#OW) and word pairs (#PAIRS) were labelled manually. Table displays the detailed distribution of the labelled dataset.
Table 4. Distribution of the labelled dataset.
5.2. Experimental performance evaluation index
In this paper, precision (P), recall (R), F-measure (F) are applied for the performance evaluation of the proposed framework, the calculation forms of which are as formula (10) ∼ (12), respectively.
(7)
(7)
(8)
(8)
(9)
(9) where
denotes the number of correct sentiment elements extracted by the framework,
denotes the number of all sentiment elements extracted by the framework,
denotes the number of sentiment elements manually labelled.
5.3. Experimental design
In the experiment, the “BIO” label scheme is adopted to label OT and OW in the text sequence. Where, “B-target” means the beginning word of opinion targets, “I-target” means the word at the other position of opinion targets, “B-opinion” means the beginning word of opinion words, “I-opinion” means the word at the other position of opinion words, and “O” means that the word at the corresponding position is neither OT nor OW. For example, “ This computer has a very sharp screen and overall good performance (这款电脑屏幕非常清晰,性能整体不错)”, the output sequence of the review is [O, O, B-target, I-target, O, B-opinion, B-target, O, B-opinion]. The visual form of BIO label scheme can be observed in Figure .
Figure 6. The visual form of BIO label scheme.

In this paper, the experimental design is mainly carried out from two perspectives as follows.
Analysing the influence of different feature combinations on the CRF model
For the purpose of analysing the influence of different feature combinations on the CRF model, we designed five kinds of feature combinations (as shown in Table ) and conducted comparative experiments on two categories of product review datasets: “computer” and “cellphone”.
Table 5. Five feature combination.
Combination 1 (C1) is the basic template, which only considers two features of token and part of speech. In Combinations 2∼4 (C2∼C4), word distance, dependency relationship and semantic role are added respectively, which is conducive to compare the impact of each feature on the extraction results. In Combination 5 (C5), five features are comprehensively considered to investigate whether the feature combination can improve the extraction effect of opinion targets and opinion words.
Comparing the framework with other existing methods
For the purpose of verifying the effectiveness of the proposed framework (ALSEE), a variety of methods will be used to conduct comparative experiments on the same product review dataset. Methods 1∼3 are the three existing methods, and Method 4 is the framework proposed in this paper.
Method 1 (Dependency) (Zhuang et al., Citation2006): Firstly, the dependency parsing is performed for review texts and some external constraint rules are set. Then, target-opinion word pairs with certain modifying relationships are extracted.
Method 2 (Syntactic-Rules) (Wang et al., Citation2019): Firstly, opinion targets are extracted through the phrase structure analysis with the help of Stanford parser model, and opinion words are extracted from opinioned sentences. Then, target-opinion word pairs that conform to the syntactic rules are obtained.
Method 3 (CRF+ HITS) (Tang & Liu, Citation2019): Firstly, the CRF model is applied to get OT and OW. Then, the feature-sentiment dichotomy network is constructed, and the extended HITS algorithm, based on dichotomy network, is used to sort and select opinion-target word pairs.
Method 4 (CRF+ Dependency): Firstly, the CRF model joint with self-training algorithm is used to extract OT and OW. Then, dependency parsing is applied to obtain target-opinion word pairs.
5.4. Experimental results and analysis
The experimental results and analysis are presented from the two perspectives of the experimental design.
Analysing the influence of different feature combinations on the CRF model
For extracting OT and OW, five groups of feature combinations are used to carry out comparative experiments on two categories of product review datasets. The comparative results of different feature combinations on two categories of datasets are given in Table . Furthermore, the F-measure variation trend of different feature combinations on computer and cellphone product review datasets is shown in Figure .
Figure 7. F-measure variation trend of different feature combinations.
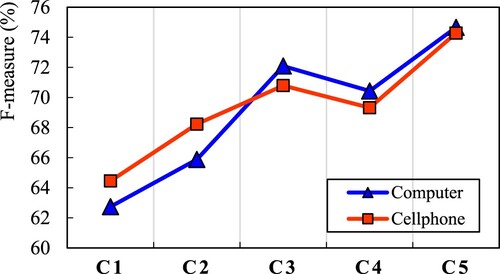
Table 6. Comparative results of different feature combinations.
According to Table , the following analysis can be made.
(1) Integrating multiple features (Token + POS + WD + DR + SR) into the CRF model, the CRF model performed best. The reason is that multiple effective features can provide more comprehensive local information for the CRF model, and the model can learn the feature information of OT and OW more fully. Compared with Combination 1 (Token + POS), the F-measure of Combination 5 on computer and cellphone review dataset increased by 11.92% and 10.83%, respectively. It is proved that the combination of five features selected in the model in this paper can help the model to extract OT and OW effectively.
(2) The introduction of dependency relationship feature has a more positive impact than the semantic role feature. Compared with Combination 2, when the feature of dependency relationship was added, the F-measure of the CRF model extraction results on computer and cellphone review datasets increased by 5.21% and 4.56%, respectively. When the feature of semantic role was added, the F-measure of the CRF model extraction results increased by 3.55% and 2.09%, respectively. The reason is that dependency relationships between OT and OW are relatively clear, but for some opinion targets, semantic roles are neither A0 nor A1.
As can be seen from Figure , for different types of datasets, F-measure on different feature combinations showed an upward trend, indicating that the introduction of features (e.g. word distance, dependency relationship and semantic role) has an improving effect on the CRF model. At the same time, the generality of the model in the product review field is also verified.
Comparing the framework with other existing methods
Table lists some examples of attribute-level sentiment elements extracted by the framework ALSEE. It is observed that most of attribute-level sentiment elements are extracted correctly, including multiple attributes and opinion words of products, which explained that the proposed framework can effectively extract attribute-level sentiment elements.
Table 7. Examples of attribute-level sentiment elements.
Table shows the experimental results of four methods on computer and cellphone review datasets. Figure displays the average performance of four methods on two review datasets.
Figure 8. The average performance of four methods on two review datasets.
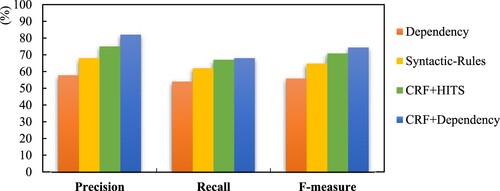
Table 8. Experimental results of four methods on two review datasets.
According to Table and Figure , the framework (ALSEE) achieved better performance on the extraction task of sentiment elements, the precision, recall and F-measure are improved. The specific analysis is as follows.
(1) The CRF model can improve the extraction effect of target-opinion word pairs. Compared with that of Method 1, the average F-measure of Method 4 increased by 18.51% after using the CRF model. Because the CRF model can learn multiple feature information to extract OT and OW more comprehensively, thus ensuring the accuracy of subsequent extraction of word pairs.
(2) The framework of ALSEE is superior to other four existing methods in precision and F-measure. Compared with those of Method 3, the average results of Method 4 increased by 7.06% (P), 0.95(R) and 3.56% (F), respectively. The precision and F-measure increased because the self-training strategy is introduced, which enhanced the classification accuracy and generalisation performance of the CRF model.
Generally speaking, among the three existing methods, the overall performance of ALSEE is best. Therefore, the framework of ALSEE can enhance the effect of the sentiment element extraction task to a certain extent.
6. Conclusions
Due to the information fragmentation and semantic sparseness of product reviews, traditional methods are difficult to capture the local information of texts comprehensively. Hence, we proposed a framework for Attribute-Level Sentiment Element Extraction (ALSEE) towards product reviews. To sum up, the major contributions can be concluded as the following three aspects.
Multiple features are considered to realise the feature fusion. The fusion of multiple features can help the model to capture local information and long distance dependencies in texts more comprehensively, and improve the recall of the extraction of OT and OW.
The self-training algorithm was applied to realise the semi-supervised learning of the model. The introduction of self-training algorithm reduced the amount of data annotation and improved the classification accuracy and generalisation performance of the model.
The dependency parsing technique is used to find the word pairs with modifying relationship. It considers the syntactic structure information and can better analyse the dependency relationship between words.
In the future work, we will continue to explore how to combine attribute-level sentiment elements to carry out fine-grained opinion mining. As a small branch of natural language processing, the research will realise the automatic processing of user’s attribute description information, which has a potential application value in intelligent services such as product recommendation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Agerri, R., & Rigau, G. (2019). Language independent sequence labelling for opinion target extraction. Artificial Intelligence, 268, 85–95. https://doi.org/10.1016/j.artint.2018.12.002
- Aytuğ, O. (2018). An ensemble scheme based on language function analysis and feature engineering for text genre classification. Journal of Information Science, 44(1), 28–47. https://doi.org/10.1177/0165551516677911
- Aytuğ, O., Serdar, K., & Hasan, B. (2016). Ensemble of keyword extraction methods and classifiers in text classification. Expert Systems with Applications, 57, 232–247. https://doi.org/10.1016/j.eswa.2016.03.045
- Dashtipour, K., Gogate, M., Li, J., Jiang, F., Kong, B., & Hussain, A. (2020). A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing, 380, 1–10. https://doi.org/10.1016/j.neucom.2019.10.009
- Da’U, A., Salim, N., Rabiu, I., & Osman, A. (2020). Recommendation system exploiting aspect-based opinion mining with deep learning method. Information Sciences, 512, 1279–1292. https://doi.org/10.1016/j.ins.2019.10.038
- Fu, Y., Liao, J., Li, Y., Wang, S., Li, D., & Li, X. (2021). Multiple perspective attention based on double BiLSTM for aspect and sentiment pair extract. Neurocomputing, 438, 302–311. https://doi.org/10.1016/j.neucom.2021.01.079
- Gu, X. (2020). A self-training hierarchical prototype-based approach for semi-supervised classification. Information Sciences, 535, 204–224. https://doi.org/10.1016/j.ins.2020.05.018
- He, Z., Zhou, Z., Gan, L., Huang, J., & Zeng, Y. (2019). Chinese entity attributes extraction based on bidirectional LSTM networks. International Journal of Computational Science and Engineering (IJCSE), 18(1), 65–71. https://doi.org/10.1504/IJCSE.2019.096988
- Hu, Y., Chen, Y., & Chou, H. (2017). Opinion mining from online hotel reviews - a text summarization approach. Information Processing & Management, 53(2), 436–449. https://doi.org/10.1016/j.ipm.2016.12.002
- Kang, Y., & Zhou, L. (2016). Rube: Rule-based methods for extracting product features from online consumer reviews. Information & Management, 54(2), 166–176. https://doi.org/10.1016/j.im.2016.05.007
- Lafferty, J., Mccallum, A., & Pereira, F. (2001, June 28). Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Proceedings of International Conference on Machine Learning (ICML), Williamstown, USA (pp. 282–289).
- Li, G., & Chang, C. (2019). Semantic role labeling for opinion target extraction from Chinese social network. IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Vancouver, Canada (pp. 1042–1047).
- Liao, C., Feng, C., Yang, S., & Huang, H. (2016). A hybrid method of domain lexicon construction for opinion targets extraction using syntax and semantics. Journal of Computer Science and Technology, 31(3), 595–603. https://doi.org/10.1007/s11390-016-1649-z
- Liu, C., Tang, L., & Wei, S. (2018). An extended HITS algorithm on bipartite network for features extraction of online customer reviews. Sustainability, 10(5), 1425–1440. https://doi.org/10.3390/su10051425
- Liu, K., Xu, L., & Zhao, J. (2015). Co-extracting opinion targets and opinion words from online reviews based on the word alignment model. IEEE Transactions on Knowledge and Data Engineering, 27(3), 636–650. https://doi.org/10.1109/TKDE.2014.2339850
- Liu, Y., Wang, J., & Wang, X. (2018). Learning to recognize opinion targets using recurrent neural networks. Pattern Recognition Letters, 106, 41–46. https://doi.org/10.1016/j.patrec.2018.02.017
- Luo, Z., Huang, S., & Zhu, K. Q. (2019). Knowledge empowered prominent aspect extraction from product reviews. Information Processing & Management, 56(3), 408–423. https://doi.org/10.1016/j.ipm.2018.11.006
- Mirtalaie, M. A., Hussain, O. K., Chang, E., & Hussain, F. K. (2018). Extracting sentiment knowledge from pros/cons product reviews: Discovering features along with the polarity strength of their associated opinions. Expert Systems with Application, 114, 267–288. https://doi.org/10.1016/j.eswa.2018.07.046
- Onan, A. (2020). Sentiment analysis on product reviews based on weighted word embeddings and deep neural networks. Concurrency and Computation: Practice and Experience, e5909. https://doi.org/10.1002/cpe.5909
- Onan, A., & Korukoglu, S. (2017). A feature selection model based on genetic rank aggregation for text sentiment classification. Journal of Information Science, 43(1), 25–38. https://doi.org/10.1177/0165551515613226
- Poria, S., Cambria, E., & Gelbukh, A. (2016). Aspect extraction for opinion mining with a deep convolutional neural network. Knowledge-Based Systems, 108, 42–49. https://doi.org/10.1016/j.knosys.2016.06.009
- Rana, T. A., & Cheah, Y. N. (2017). A two-fold rule-based model for aspect extraction. Expert Systems with Applications, 89, 273–285. https://doi.org/10.1016/j.eswa.2017.07.047
- Rout, K., & Jagadev, K. (2018). Elitism-based multi-objective differential evolution with extreme learning machine for feature selection: A novel searching technique. Connection Science, 30(4), 362–387. https://doi.org/10.1080/09540091.2018.1487384
- Shao, Y., Lin, C., Srivastava, G., Jolfaei, A., Guo, D., & Hu, Y. (2021). Self-attention-based conditional random fields latent variables model for sequence labeling. Pattern Recognition Letters, 145, 157–164. https://doi.org/10.1016/j.patrec.2021.02.008
- Tang, L., & Liu, C. (2019). Extraction of feature and sentiment word pair based on conditional random fields and HITS algorithm. Computer Technology and Development, 29(7), 71–75. https://doi.org/10.3969/j.issn.1673-629X.2019.07.014
- Wang, Q., Zhu, G., Zhang, S., Li, K., Chen, X., & Xu, H. (2021). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Wang, Y., He, W., Jiang, M., Huang, Y., & Qiu, P. (2019). Chopinionminer: An unsupervised system for Chinese opinion target extraction. Concurrency and Computation Practice and Experience, 32, 7. https://doi.org/10.1002/cpe.5582
- Wu, S., Wu, F., Chang, Y., Wu, C., & Huang, Y. (2019). Automatic construction of target-specific sentiment lexicon. Expert Systems with Applications, 116, 285–298. https://doi.org/10.1016/j.eswa.2018.09.024
- Yang, H., Zeng, B., Yang, J., Song, Y., & Xu, R. (2021). A multi-task learning model for Chinese-oriented aspect polarity classification and aspect term extraction. Neurocomputing, 419, 344–356. https://doi.org/10.1016/j.neucom.2020.08.001
- Yang, L., Liu, B., Lin, H., & Lin, Y. (2016). Combining local and global information for product feature extraction in opinion documents. Information Processing Letters, 116(10), 623–627. https://doi.org/10.1016/j.ipl.2016.04.009
- Zhang, J., Li, F., Zhang, Z., Xu, G., Wang, Y., Wang, X., & Zhang, Y. (2021). Integrate syntax information for target-oriented opinion words extraction with target-specific graph convolutional network. Neurocomputing, 440, 321–335. https://doi.org/10.1016/j.neucom.2020.07.152
- Zhang, L., Liu, B., Lim, S. H., & O’Brien-Strain E. (2010, August 23). Extracting and ranking product features in opinion documents. Processing of the 23rd International conference on computational linguistics, Beijing, China (pp. 1462–1470).
- Zhang, S., Hu, Z., Zhu, G., Jin, M., & Li, K. C. (2021). Sentiment classification model for Chinese micro-blog comments based on key sentences extraction. Soft Computing, 25(1), 463–476. https://doi.org/10.1007/s00500-020-05160-8
- Zhang, S., Yin, W., Zhang, S., & Zhu, G. (2016). Building associated semantic representation model for the ultra-short microblog text jumping in big data. Cluster Computing, 19(3), 1399–1410. https://doi.org/10.1007/s10586-016-0602-9
- Zhou, X., Wan, X., & Xiao, J. (2016). Cminer: Opinion extraction and summarization for Chinese microblogs. IEEE Transactions on Knowledge and Data Engineering, 28(7), 1650–1663. https://doi.org/10.1109/TKDE.2016.2541148
- Zhuang, L., Jing, F., & Zhu, X. (2006, November 6). Movie review mining and summarization. Proceedings of the 15th ACM international conference on information and knowledge management (CIKM-2006), New York, USA (pp. 43–50).