
Abstract
Chinese short comment texts have the characteristics of feature sparseness, interlacing, irregularity, etc., which makes it difficult to fully grasp the overall emotional tendency of users. In response to such problem, the text proposes a new method based on ELECTRA and hybrid neural network. This method can more accurately capture the emotional features of the text, improve the classification effect, enhance the evaluation feedback mechanism, and facilitate user decision-making. First, in the embedding layer, ELECTRA model is used to replace BERT model, which can avoid the inconsistency of the mask training and fine-tuning process of the traditional pre-training model. Then, in the training layer, the self-attention mechanism and the BiLSTM are selected to obtain the fine-grained semantic representation information of the review text more comprehensively. Finally, in the output layer, the softmax classifier classifies the input corpus according to the sentiment characteristics of the Chinese short text. The experimental results show that the proposed model has an efficiently improvement in accuracy and there are some discoveries about the training effect of the pre-training model on text sentiment analysis tasks.
1. Introduction
Excavating the subjective emotional tendencies in people’s comments has important meaning (Cambria, Citation2016; Dai et al., Citation2020) and value for politics, business, advertising, and marketing. Most approaches toward sentiment analysis involve feature engineering in order to enhance the predictive performance (Peng et al., Citation2021). However, the length of each Chinese short text comment is short, so it contains less effective information. This results in sparse sample features, and it is difficult to extract accurate and key sample features from it for classification learning.
In response to such problem, this text proposes a method based on ELECTRA and hybrid neural network. Regarding to the research on text sentiment analysis, a previous work proposed a method of using genetic algorithm to aggregate multiple features to obtain more effective sub-features (Onan & Korukoglu, Citation2017). Different from this method based on machine learning, the proposed method in this paper is based on deep learning, which first obtains the text language features, and then obtains the text emotional features. A previous work proposed a method based on an optimised weighted voting scheme, which assigns an appropriate weight value to the classifier and each output class according to the prediction performance of the classification algorithm (Onan et al., Citation2016). Different from this method, the method in this paper focuses on the embedding layer. It learns the vectorised representation and text features of the text through the ELECTRA model.
ELECTRA model is a pre-trained language model used in this paper to optimise the extraction process of text emotional features. In recent years, affected by transfer learning, pre-training models represented by BERT model combined with deep learning technology have been widely used in various research fields of natural language processing. However, the BERT-based text sentiment analysis model still has following problems. Most of the pre-trained models are prepared for downstream tasks, and in actual applications, some initial parameters of the model need to be fine-tuned. The general pre-training model will add [MASK] as a noise training model in the pre-training process, and it will not be used in the fine-tuning stage. Therefore, the traditional pre-training model will be inconsistent in the process of covering training and fine-tuning. This inconsistency will affect the accuracy of the learning of text emotion features by the downstream model. In addition, the traditional text sentiment analysis training model based on word segmentation embedding will be affected by the degree of dependence on the accuracy of word segmentation. For example, the word2Vec and GloVe word segmentation embedding methods (Onan, Citation2019) in NLP can convert words into meaningful vectors. However, these two methods ignore the emotional information of the text and rely on the text library to train and generate accurate vectors. With the improvement of language model feature extraction capabilities, traditional word segmentation methods are no longer necessary, and word-level feature learning can be incorporated into internal features for context-to-context representation learning. However, the model represented by BERT only learns the partially covered input token, and lacks a more fine-grained vector representation of Chinese characters and words. Therefore, the BERT-based text sentiment analysis model has limited ability to relieve the degree of dependence on the accuracy of word segmentation. In summary, optimising the embedding layer of the classification model is one of the keys to enhancing the prediction performance in feature engineering.
Considering the above problems and one of the key points, this paper proposes a sentiment classification method for Chinese short comment texts based on ELECTRA. This is a new method of text sentiment classification based on the concept of transfer learning to capture the emotional features of short texts. Different from our previous method of text sentiment analysis based on sentiment dictionary (Zhang et al., Citation2018; Wang, Zhu et al., Citation2020), the method proposed in this paper is based on pre-training language model and deep learning technology for text sentiment analysis. In the choice of pre-training language model, unlike Zheng Jianzhong et al.’s method of sentiment analysis based on BERT (Zheng, Chen Citation2020), the proposed method is to choose ELECTRA model instead of BERT model at the embedding layer. The advantages of this replacement is that it can optimise the process of embedding layer feature learning and avoid some problems. In the training layer, the self-attention mechanism is used to capture the context information of the keywords in the comment sentence. This process strengthens the weight of emotional words. BiLSTM is used to obtain bidirectional sequence information in the corpus. This process can obtain the fine-grained semantic representation information of the review text more comprehensively. In the output layer, according to the text emotion features learned in the above three processes, softmax is selected for sentiment classification. Our work mainly includes the following two aspects:
Improving the embedding layer of sentiment analysis model. At the embedding layer, ELECTRA is selected to replace BERT when performing sentiment analysis on short text comments. In the embedding layer, a more detailed vectorised representation of text features is carried out through ELECTRA. Optimise the text feature learning process of Chinese short texts through ELECTRA to prepare for the next stage of emotional feature extraction.
Mining the emotional feature of shot text. Text features are obtained through ELECTRA. Emotional semantic information is obtained through attention mechanism and BiLSTM. Then, the text emotion feature vector is mined through emotion semantic information and text feature.
The advantage of using the method proposed in this paper is that it can improve the classification effect, strengthen the evaluation feedback mechanism, and facilitate user decision-making. Regardless of the size of the data set, the method in this paper has obvious advantages in classification accuracy. Compared with other methods, the limitation of using the method proposed in this paper is that as the number of training rounds increases, the advantage of the algorithm in classification accuracy will become smaller. At the same time, it is difficult to explain which text emotion features are learned by this method.
The rest of this paper is organised as follows. Section 2 presents related works of existing text sentiment analysis. The specific implementation process of the proposed method is described in section 3. The experiment of this paper is described in section 4. The conclusions of the main research content are made in section 5.
2 Related works
In this section, we review three categories of methods for sentiment analysis and two hot techniques in natural language processing.
2.1 Research method based on sentiment dictionary
In recent years, some scholars have combined sentiment dictionaries with other technologies to build text sentiment analysis models. Using the sentiment dictionary, word polarity can be considered when word embedding (Naderalvojoud & Sezer, Citation2020). For the sentiment dictionary in a specific field, the rules of language features in a specific situation can be determined (Phu et al., Citation2018). The basic sentiment dictionary is difficult to meet the needs of more fine-grained research, so some text sentiment classification tasks include the subtask of the expansion of the sentiment dictionary (Wang et al., Citation2021). The expansion of the emotional dictionary can be combined with Naive Bayes, attention model, and the introduction of emotional symbols to calculate the score of new emotional words (Kiichi et al., Citation2019; Li, Li, & Jin Citation2020). By considering emotion analysis elements such as emojis and sentence patterns (Huang et al., Citation2018) to expand multiple emotion dictionaries (Tago & Jin, Citation2018), more fine-grained emotion expressions are recognised (Cao et al., Citation2021; Wang & Guo, Citation2020). These methods all use sentiment lexicon to give sentiment features and then perform sentiment analysis. Their advantage lies in the interpretability of the features, but the limitation is that the effect of sentiment analysis depends on the selected sentiment words.
2.2 Research methods based on machine learning
Whether it is a model based on multi-core SVM (Peng et al., Citation2017; Peng et al., Citation2019), or training an SVM model with a multi-dimensional data set (Aurangzeb et al., Citation2021), or using SVM to fuse samples of different types of voice and text (Atmaja & Akagi, Citation2021), SVM is adopted as the core of these methods. Asghar et al. (Citation2020) evaluated the considerable gains of SVM on the performance of text sentiment classification in machine learning on the benchmark sentiment data set. Research methods based on machine learning rely on the selection of emotional features such as text features (Halim et al., Citation2020) and emoticons (Ullah et al., Citation2020). Machine learning can cascade machine learning functions (TF, TF-IDF) and vocabulary functions (positive and negative words, connotation) to improve the accuracy of sentiment analysis (Keerthi et al., Citation2019). Combining multiple basic classifiers (Ghanbari-Adivi & Mosleh, Citation2019) can improve the classification effect of the model output layer. The advantage of these methods is that they can expand the emotional characteristics of the text, filter out the main characteristics and have interpretability. Its limitation is that the selection and extraction of its features is a relatively independent process. Subsequent classification work relies on the prior knowledge of the emotional features of the text. Considering the irregularity of Chinese short text features, this paper did not choose a method based on machine learning.
2.3 Research methods based on deep learning
Massive data has promoted the development of sentiment analysis technology based on neural networks (Liu & Shen, Citation2020; Ronran et al., Citation2020). Many scholars use LSTM as the core to build sentiment analysis models, including dynamic decomposition on the cloud and distributed systems to achieve fast LSTM (You et al., Citation2020), LSTM, or BiLSTM combined with CNN to build a hybrid model (Jang et al., Citation2020; Wu et al., Citation2021). LSTM combined with the user’s topic preference helps to analyze the user’s personality and emotional characteristics (Zhao, Dalin et al., Citation2020), combined with regional CNN helps to predict the dimensional emotional level of the text (Wang, Yu et al., Citation2020), combined with CRF helps to identify the components of regular entities and irregular entities (Li et al., Citation2018). Research methods based on deep learning need to automatically learn feature vectors and feature vectors (Lin et al., Citation2021) can be scored and filtered by comparing them with label vectors. The advantage of these methods is that they do not rely on the prior knowledge of the emotional features of the text, and they can grasp the emotional semantics in the text while training the data through the neural network. The disadvantage is that they are all black-box models, and it is difficult to explain the learned text emotional characteristics. Different from these methods, this paper uses pre-trained language models to strengthen the learning process of text features.
2.4 Attention mechanism
Attention mechanism can enhance the dependence between emotional elements, such as multi-head self-attention mechanism combined with word-level embedding (Zhang, Xu et al., Citation2020), self-attention mechanism based on word interaction gating (Fu & Liu, Citation2021), introducing pseudo-sentence hierarchical attention mechanism (Zinovyeva et al., Citation2020) can recognise some important words and establish the relationship between words. The attention mechanism combined with RNN (Cheng et al., Citation2019), or combined with neural networks such as BiLSTM (Yu et al., Citation2020), can shorten the training time of the neural network according to the relationship between emotional elements and prior knowledge (Wang, Li et al., Citation2020), and form a multi-layer attention network (Feng & Zeng, Citation2019), build a multi-granular sentiment analysis model. Attention mechanism can introduce position information to further strengthen the connection between words (Zheng, Huang et al., Citation2020). The combination of attention mechanism and CNN can make full use of the features of convolution (Xu et al., Citation2020; Su, Chen et al., Citation2020). Considering these methods, this paper combines the attention mechanism with the hybrid neural network to enhance the learning of text emotional features.
2.5 Pre-trained model
How to better obtain text features through language models is a hot spot in today’s research. Using the pre-training model can overcome the contextual information interaction problems in traditional embedding methods (Cong et al., Citation2020), eliminate the ambiguity of named entities (Ji et al., Citation2020), and extract keywords (Zhao, You et al., Citation2020; Sun et al., Citation2020). A model pre-trained on a specific corpus can perform vector representation learning for a specific domain language (Zhang, Wu et al., Citation2020; Lee et al., Citation2020) and obtain its text features. The pre-training language model can be combined with the capsule network (Su, Yu et al., Citation2020) to represent word vectors in a more fine-grained manner (Rezaeinia et al., Citation2019) to improve the accuracy of word embedding in sentiment analysis pre-training tasks. Commonly used pre-training language models include GPT and BERT (Zhang, Fan et al., Citation2020; Li, Li, & Ji, Citation2020).
Based on the research of the above-related works, it is feasible that the approach combining pre-training model, attention mechanism, and neural network to strengthen the learning process of text emotional features. First, word vectorisation and text features extraction are carried out through the pre-training model. Then, text emotion feature vectors are extracted by attention mechanism and neural network. Finally, comments are classified according to these text sentiment feature vectors. The innovation of this paper is to build a new hybrid neural network based on the ELECTRA model to strengthen the learning process of shot text emotional features.
3 Model based on ELECTRA and integrated emotional semantics
In this section, the proposed model is divided into four layers. This new method is based on ELECTRA and strengthens the acquisition of Chinese short text features.
3.1 Model architecture
The proposed model is mainly composed of three parts, ELECTRA pre-training language model (Clark et al., Citation2020), attention mechanism, BiLSTM. ELECTRA model is used to replace BERT model in the embedding layer. In this process, text features are extracted.
Emotional semantic information is acquired through attention mechanism and BILSTM. According to the text feature and the emotion semantic information, the model trains the emotion feature vector. According to the trained feature vectors, the proposed model selects softmax classifier in the output layer for sentiment classification.
Selecting the ELECTRA model to replace the BERT model in the embedding layer can avoid the problems caused by the inconsistency of the BERT model in the pre-training process and the fine-tuning phase. And this replacement can effectively alleviate the dependence on the accuracy of word segmentation in traditional text sentiment analysis methods, and reduce the cost of training costs. This paper proposes the model architecture as shown below Figure .
Figure 1. Model architecture diagram based on ELECTRA.
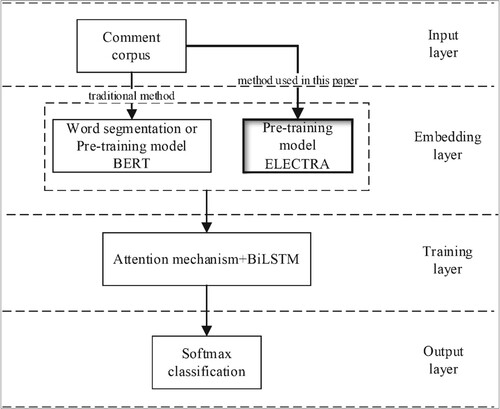
3.2 Input layer and embedding layer
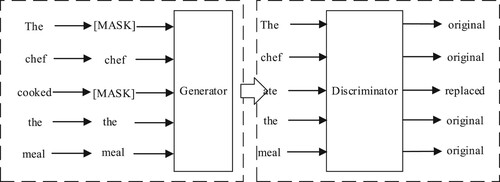
The input layer of the proposed model includes preprocessing of the corpus. Replace the result of BERT training with embedding trained by ELECTRA. ELECTRA model handles some existing language model problems by using pre-trained text encoders as identifiers. For example, as a pre-trained model based on masked language modeling (MLM), BERT mainly uses [MASK] to replace part of the token in the input sequence, and then trains a model to repair the original token. Compared to embedding methods such as word2vec, this approach can reflect some good results in downstream NLP tasks. The ELECTRA language model uses a more efficient pre-training method which is a replacement mask detection method. The characteristic of the approach is that instead of masking part of the input token, it uses a small generator to generate samples to replace the [MASK] in the input. BERT is used to train a model to predict the original marker replaced by the [MASK]. ELECTRA trains a discriminant model to predict whether each token in the input is replaced by a sample generated by the generator. The main task of ELECTRA is to learn how to distinguish between the real input token and the plausible but generated replacement token. ELECTRA model learns and understands vocabulary and text feature in this process. Its training task is defined on all input tokens, not just on a subset of the masked ones. That is, the discriminator of ELECTRA will calculate the loss value on all tokens. When calculating the loss value of BERT, the unmasked tokens were ignored. Therefore, ELECTRA’s training will be more efficient than BERT’s. The main difference between the ELECTRA model and its variants is the size of the training corpus. In theory, the larger the corpus, the better the model trained on reading comprehension and sentence pair classification tasks. Considering these factors, The ELECTRA model chosen in this paper is the Chinese version of ELECTRA-180G-large. Existing data point out that ELECTRA-180G significantly exceeds the effect of the original ELECTRA in Chinese reading comprehension and sentence pair classification tasks.
The ELECTRA model mainly trains two neural networks, which are a generator and a determiner. The encoder maps the input sequence to the corresponding vector and selects a part of the data sequence as a token to the generator. For each given position, the generator replaces some of the masked tokens, and then uses the discriminator to detect whether the vector at each position has been replaced. In this process, ELECTRA’s replacement mask detection method is shown in Figure below.
Figure 2. Replacement mask detection.
3.3 Training layer and output layer
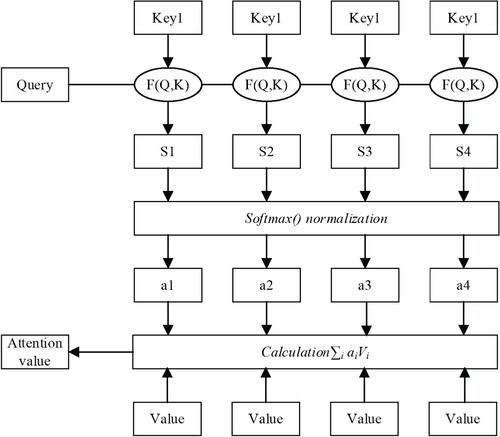
The training layer of the ELECTRA + atten + BiLSTM model is a BiLSTM neural network layer combined with the attention mechanism. Since the target corpus of this paper is short Chinese sentences, it is necessary to obtain the dependencies and internal structure of the sentences. Therefore, this paper chooses the self-attention mechanism in the transformation as an integral part of the model. Self-attention is an attention mechanism that can enhance the weight of important components in a sentence. The computational process of self-attention can be divided into three steps. First, calculate the similarity between Query and Key. Then a softmax is used to normalise the values. Finally, the value is weighted and summed by the weight value of attention. The weight calculation method of self-attention is shown in Figure . Among them, Query, key, and value are all obtained by different linear transformations after the words in the input sentence are transformed by embedding. Its weight calculation method is shown in Figure below.
Figure 3. Self-attention weight calculation process.
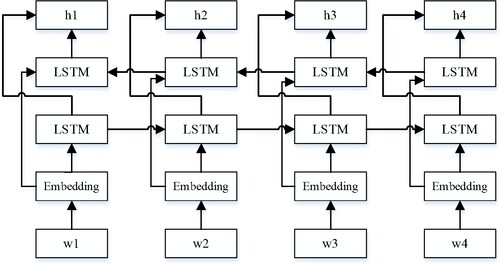
Due to the characteristics of the threshold structure designed by LSTM, it can solve the problems of gradient disappearance and gradient explosion. It is widely used in the modelling of text data. However, in a more fine-grained classification, the one-way LSTM cannot well capture the interaction between emotional words, degree words, and negative words. BiLSTM is a combination of forward LSTM and backward LSTM, so it can better capture the two-way semantic dependence. Combining the attention mechanism and BiLSTM helps to transform the text feature vector, and extract the emotional feature vector to classify short text comments. As shown in Figure below, for sentiment classification tasks, BiLSTM will obtain the semantic and structural information between the components of the sentence from two directions, and finally perform the splicing.
Figure 4. BiLSTM structure.
The output layer of the proposed model is a softmax classifier. The training process of ELECTRA + atten + BiLSTM model is shown in Algorithm 1.
In Algorithm 1, steps 1–2 are the process of selecting the ELECTRA model to replace the BERT model. Steps 5–6 are the process of calculating the attention value. Then, steps 8–10 are the process of calculating the values of the three gates of BiLSTM. Finally, steps 14–24 are the process of iteratively calculating the weight matrix W and deviation matrix b. Assuming that the value of epoch is k, there are a total of m sentences, and the maximum number of words in each sentence is n. The time complexity of this algorithm is O(kmn). The space complexity of this algorithm is O(mn).4 Experiments
In this section, the paper analyzes and explores the rules through the training effects of 6 groups of models on 2 data sets.
4.1 Experimental data and environment construction
This experiment includes two sets of experimental data, both from online user comment data sets. Among them, data set 1 is the data corpus of user reviews of food and beverage delivery crawled from Meituan Takeaway (a food delivery platform in China). Octopus was chosen as the crawler tool for data capture. Data set 1 is divided into a training set and a test set. The training set has a total of 9600 short comment data and the test set has 2386 corpus data. In the training set, there are 3200 positive corpus comments and 6400 negative corpus comments, with a positive–negative ratio of 1:2. Data set 2 is the user comment corpus of car sales shared by user bigboNed3 on Github in the chinese_text_cnn file (Link: https://github.com/bigboNed3/chinese_text_cnn). Its training set contains 56700 review corpus, and the test set contains 6299 review corpus. Its training set corpus includes 28,425 positive data reviews and 28,275 negative data reviews, and the test set corpus includes 3156 positive data reviews and 3143 negative data reviews. Data set 1 is a small-scale data test designed for experiments to test the application effect of the experimental model proposed in this paper on a small-scale data set. Data set 2 is a medium-to-large-scale data test designed by the experiment to test the application effect of the experimental model of this paper on the medium-to-large-scale data set. The setup of the experimental data set is shown in Table below.
Table 1. Experimental data.
This paper selects the python development environment and downloads torch, sklearn and other toolkits through Anaconda. And adjust the pre-training weights of BERT and ELECTRA. Among them, BERT’s attention layer dropout probability is 0.1. Its activation function is gelu, hidden layer dropout probability is 0.1, hidden layer size is set to 768, initial range is 0.02, intermediate size is 3072. The dictionary word size is 21128. Correspondingly, the relevant parameter settings of ELECTRA and BERT are kept as consistent as possible. The ELECTRA model chosen in this paper is the Chinese version of ELECTRA-180G-large. The values of these hyperparameters refer to the weight values trained on the 180G corpus.
4.2 Experimental evaluation index
The evaluation index of this paper selects the accuracy rate and its mean value. The accuracy of the model can reflect the correctness of the model’s prediction. The goal of this paper is to build a model that can predict the emotional tendency of user reviews faster and more accurately after simple training. In the era of big data, shortening the training cost of the model can save a lot of training resources. Therefore, the evaluation criteria select the respective mean values of the accuracy rate.
Among them, the higher the accuracy curve, the better the performance of model classification. The greater the mean accuracy rate, the more accurate the model prediction.
4.3 Experimental design and result analysis
The text experiment sets up six sets of controlled experiments in the same environment to verify the superiority of the ELECTRA + atten + BiLSTM combined model proposed in this paper.
According to different combinations of two natural language preprocessing models (BERT, ELECTRA) and two neural network models (LSTM, BILSTM), four combined models can be obtained:
BERT + atten + BiLSTM
BERT + atten + LSTM
ELECTRA + atten + LSTM
ELECTRA + atten + BiLSTM
In the comparison of model classification accuracy, this paper also arranges two sets of controlled experiments that do not use pre-trained language models:
FastText + BiRNN
TextCNN
Among them, ELECTRA + atten + BiLSTM is the model proposed in this paper. Each model has undergone 10 epochs of neural network iterative training to verify the effects of each model on small-scale, moderately large-scale data sets. After each epoch of iterative training, the accuracy of the model trained in this epoch will be calculated through the test set test.
Using the data set 1(food delivery user review corpus), the accuracy rates of several models trained are shown in Table below.
Table 2. The accuracy of the model trained by each model on the data set 1.
As Table shows, by calculating the mean accuracy of each model after 10 epochs of iterative training, it can be intuitively seen that the ELECTRA + atten + BiLSTM model proposed in this paper has obvious advantages in the accuracy of the model. The mean accuracy of the BERT + atten + BiLSTM model is 91.064%, the mean accuracy of the BERT + atten + LSTM model is 91.968%, the mean accuracy of the ELECTRA + atten + LSTM model is 94.24%, and the mean accuracy of the ELECTRA + atten + BiLSTM model is 94.657%. The mean accuracy of the model proposed in the text has increased by 3.6% compared with the BERT + atten + BiLSTM model, increased by 2.7% compared with the BERT + atten + LSTM model, increased by 0.4% compared with the ELECTRA + atten + LSTM model. In order to facilitate comparison, the mean accuracy of each model is shown in Figure , and the accuracy curve is shown in Figure .
Figure 5. mean accuracy trained by each model on data set 1.
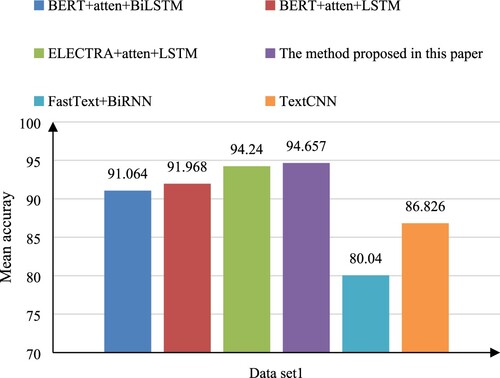
Figure 6. Line graph of classification accuracy trained by each model on data set 1.
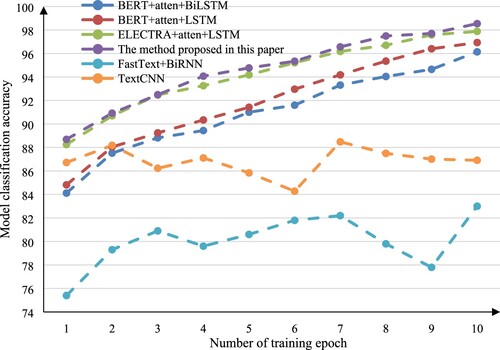
It can be clearly seen from Figure that on a small-scale data set, the pre-training model can effectively improve the accuracy of text sentiment classification. In the face of small-scale data sets, the model proposed in this paper has an advantage in average accuracy. This shows that the model based on ELECTRA has learned the emotional characteristics of Chinese text well.
It can be seen from the figure that after the iterative training of the neural network of each model, these accuracy curves of the combined model based on pre-trained model show a rising trend. However, the ELECTRA + atten + BiLSTM model proposed in this paper is always on top of each model. At the same time, it can be seen that the model based on ELECTRA and LSTM saves the cost of training resources in the field of natural language processing text sentiment analysis, and can also achieve better accuracy than the model based on BERT and LSTM. On this data set, the combined model based on the pre-training model is obviously superior to the combined model combined without the pre-training model.
In order to better explore the experimental effects of various combination models on different data sets and verify the effectiveness of the model proposed in this paper, this paper designs an experimental study on the data set 2 (car sales review data set). Considering that the ratio of positive and negative corpus in data set 1 food delivery review corpus is 1:2, and the ratio of positive and negative corpus in data set 2 is set to 1:1, and then the possible imbalance of positive and negative review corpus is eliminated. For each model The impact of forecasting results.
In dataset 2 (car sales user reviews), each model has undergone 10 epochs of neural network iterative training, and the accuracy of the model trained in each round is shown in Table below. Calculating the mean of the accuracy of each model after 10 rounds of iterative training, it can be seen that the ELECTRA + atten + BiLSTM model proposed in this paper is still superior in the accuracy of the model when facing medium and large-scale data sets. The mean accuracy of the BERT + atten + BiLSTM model is 87.602%, the mean accuracy of the BERT + atten + LSTM model is 89.198%, the mean accuracy of the ELECTRA + atten + LSTM model is 92.416%, and the mean accuracy of the ELECTRA + atten + BiLSTM model is 93.713%. The mean accuracy of the proposed model has increased by 6.111% compared with the BERT + atten + BiLSTM model, increased by 4.515% compared with the BERT + atten + LSTM model, increased by 1.297% compared with the ELECTRA + atten + LSTM model. TextCNN shows good performance on large-scale data sets. The comparison results of all models are based on the condition of 10 epochs.
Table 3. The accuracy of the model trained by each model on the data set 2.
In order to facilitate comparison, the mean accuracy of each model is shown in Figure , and the accuracy curve is shown in Figure below. It can be seen from the figure that the accuracy curve of the combined model based on ELECTRA and BiLSTM proposed in this paper is always above the other models. Although after 10 epochs, each combination model based on the pre-trained language model can improve the accuracy between 90%-96%, but the model based on ELECTRA is obviously more advantageous than the model based on BERT. In combination with BiLSTM, ELECTRA showed a positive combination effect, while BERT showed a negative combination effect. In addition, the accuracy curve of the combined model of BERT and LSTM or BiLSTM fluctuates greatly in 10 epochs. At the same time, the accuracy of the combined model of ELECTRA and LSTM or BiLSTM fluctuates relatively stable in the 10 epochs.
Figure 7. Mean accuracy trained by each model on data set 2.
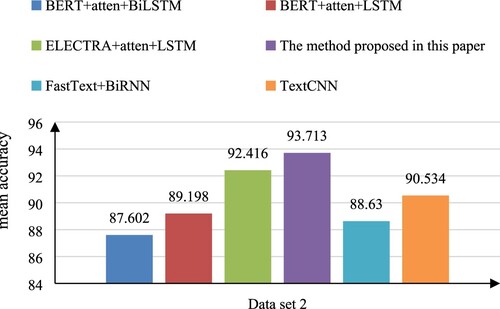
Figure 8. Line graph of classification accuracy trained by each model on data set 2.
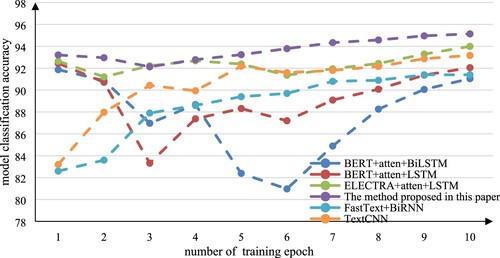
It can be seen from Figure that the hybrid neural network based on ELECTRA has obvious advantages in the average accuracy of classification. This shows that the hybrid neural network based on ELECTRA can grasp the features of Chinese short texts more accurately and effectively.
Due to the relatively large data size of data set 2 (the user review corpus of automobile sales), the changes in the F1 value of four pre-training combination models after each round of training were also calculated during the experiment, as shown in Table below. Calculating the F1 mean value of each model after 10 epochs of iterative training, it can be seen that the ELECTRA + atten + BiLSTM model proposed in this paper is still superior in the F1 mean value when facing medium and large-scale data sets. Among them, the F1 mean value of the BERT + atten + BiLSTM model is 86.822%, the F1 mean value of the BERT + atten + LSTM model is 89.338%, the F1 mean value of the ELECTRA + atten + LSTM model is 89.891%, and the F1 mean value of the ELECTRA + atten + BiLSTM model is 91.515%. Compared with the BERT + atten + BiLSTM model, the F1 mean value of the proposed model has increased by 4.7%, the F1 mean value increased by 2.2% compared with the BERT + atten + LSTM model, increased by 1.6% compared with the ELECTRA + atten + LSTM model.
Table 4. F1 value of the model trained by each model on data set 2.
In order to better reflect the size and change of the F1 value of each model on data set 2, the data in the table is shown in the form of Figure .
Figure 9. F1 value line chart of each model on data set 2.
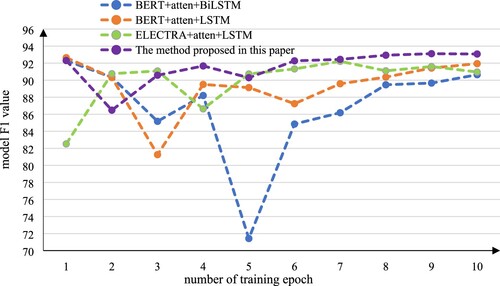
It can be seen from the figure that the F1 value curve of the combined model based on ELECTRA and BiLSTM proposed in this paper is basically above the other models. Moreover, the combination model based on ELECTRA shows less volatility than the combination model based on BERT and is significantly more stable. By analyzing the experimental data, the following experimental results can be found:
Facing the task of Chinese short comment text sentiment classification, when using BiLSTM or LSTM to build a model, after simple training, the model based on ELECTRA shows better accuracy than the model based on BERT.
Facing the task of Chinese short comment text sentiment classification, after simple training, unlike the model based on ELECTRA, the model built by BERT combined with BiLSTM is not as good as the model built by BERT combined with LSTM.
It can be inferred that the model proposed in this paper still has advantages (advantages in classification accuracy) compared to some combined models that do not combine pre-training models. This advantage is obvious on small-scale data sets, but on large-scale data sets, the advantage will be relatively small.
5 Conclusions
In order to strengthen the evaluation feedback mechanism and facilitate user decision-making, the sentiment analysis of short text evaluation needs to grasp the characteristics more accurately. According to the current concept of transfer learning, this method builds a hybrid neural network around the ELECTRA model to provide a new method of text emotional feature learning and classification. Our contribution includes three aspects:
Proposing a new method. This paper has constructed an emotional classification model for Chinese short comments that combines ELECTRA, attention mechanism, and BiLSTM. Compared with other models, the proposed model gives an effective gain in the accuracy of classification. This is because the method in this paper can capture more accurate emotional features in short text review tasks. The experiment proved this.
Giving a new discovery through experiment. The pre-trained language model combined with the BiLSTM hybrid neural network may not necessarily be better than the classification effect of the LSTM hybrid neural network.
Giving a new guess through experiment. In text sentiment analysis tasks, if it is a small data scale, the advantage of using a pre-trained language model will be very prominent. If it is a large data scale, the advantage of using a pre-trained language model is very small, or even nonexistent. This point is only based on the conditions of 10 epochs and requires further experimental verification.
This paper has proposed a new text sentiment classification model based on ELECTRA for Chinese short comment texts. The experimental process can provide a basis for studying the transfer effects of different pre-trained language models in the field of text sentiment analysis. Future work includes further analysis of the transfer effect of different pre-trained language models on Chinese text sentiment analysis tasks. For example, follow-up work can study the migration effects of different ELECTRA variants, and explore the possibility of combining LEME (Local Interpretable Model-Agnostic Explanations) and SHAP models with pre-training models to deal with NLP problems.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Asghar, M. Z., Subhan, F., Imran, M., Kundi, F. M., & Khan, A. (2020). Performance evaluation of supervised machine learning techniques for efficient detection of emotions from online content. CMC-Computers Materials & Continua, 63(3), 1093–1118. https://doi.org/10.32604/cmc.2020.07709
- Atmaja, B. T., & Akagi, M. (2021). Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM. Speech Communication, 126, 9–21. https://doi.org/10.1016/j.specom.2020.11.003
- Aurangzeb, K., Ayub, N., & Alhussein, M. (2021). Aspect based multi-labeling using SVM based ensembler. IEEE Access, 9, 26026–26040. https://doi.org/10.1109/ACCESS.2021.3055768
- Cambria, E. (2016). Affective computing and sentiment analysis. IEEE Intelligent Systems, 31(2), 102–107. https://doi.org/10.1109/MIS.2016.31
- Cao, Z. X., Zhou, Y. M., Yang, A. M., & Peng, S. C. (2021). Deep transfer learning mechanism for fine-grained cross-domain sentiment classification. Connection Science. Advance online publication. https://doi.org/10.1080/09540091.2021.1912711
- Cheng, Y., Ye, Z., Wang, M., & Zhang, Q. (2019). Document classification based on convolutional neural network and hierarchical attention network. Neural Network World, 29(2), 83–98. https://doi.org/10.14311/NNW.2019.29.007
- Clark, K., Luong, M. T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: Pre-training text encoders as discriminators rather than generators. International Conference on Learning Representation 2020. Advance online publication. https://arxiv.org/abs/2003.10555
- Cong, F., Yuan, R., Ambreen, N., Wu, L., & Long, H. (2020). Pre-trained language embedding-based contextual summary and multi-scale transmission network for aspect extraction. Procedia Computer Science, 174, 40–49. https://doi.org/10.1016/j.procs.2020.06.054
- Dai, Y. H., Wang, Y., Xu, B., Wu, Y. Y., & Xian, J. (2020). Research on image of enterprise after-sales service based on text sentiment analysis. International Journal of Computational Science and Engineering, 22(2–3), 346–354. https://doi.org/10.1504/IJCSE.2020.107367
- Feng, X., & Zeng, Y. (2019). Multi-level fine-grained interactions for collaborative filtering. IEEE Access, 7, 143169–143184. https://doi.org/10.1109/ACCESS.2019.2941236
- Fu, Y., & Liu, Y. (2021). CGSPN: Cascading gated self-attention and phrase-attention network for sentence modeling. Journal of Intelligent Information Systems, 56(1), 147–168. https://doi.org/10.1007/s10844-020-00610-z
- Ghanbari-Adivi, F., & Mosleh, M. (2019). Text emotion detection in social networks using a novel ensemble classifier based on Parzen Tree estimator (TPE). Neural Computing & Applications, 31(12), 8971–8983. https://doi.org/10.1007/s00521-019-04230-9
- Halim, Z., Waqar, M., & Tahir, M. (2020). A machine learning-based investigation utilizing the in-text features for the identification of dominant emotion in an email. Knowledge-Based Systems. Advance online publication https://doi.org/10.1016/j.knosys.2020.106443
- Huang, W., Wang, Q., & Cao, J. (2018). Tracing public opinion propagation and emotional evolution based on public emergencies in social networks. International Journal of Computers Communications & Control, 13(1), 129–142. https://doi.org/10.15837/ijccc.2018.1.3176
- Jang, B., Kim, M., Harerimana, G., Kang, S. U., & Kim, J. W. (2020). Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Applied Sciences. Advance online publication. https://doi.org/10.3390/app10175841
- Ji, Z., Dai, L., Pang, J., & Shen, T. (2020). Leveraging concept-enhanced pre-training model and masked-entity language model for named entity disambiguation. IEEE Access, 8, 100469–100484. https://doi.org/10.1109/ACCESS.2020.2994247
- Keerthi, K., Harish, B. S., & Darshan, H. K. (2019). Sentiment analysis on IMDb movie reviews using hybrid feature extraction method. International Journal of Interactive Multimedia and Artificial Intelligence, 5(5), 109–114. https://doi.org/10.9781/ijimai.2018.12.005
- Kiichi, T., Kosuke, T., Seiji, K., & Jin, Q. (2019). Analyzing influence of emotional tweets on user relationships using Naive Bayes and dependency parsing. World Wide Web, 22(3), 1263–1278. https://doi.org/10.1007/s11280-018-0587-9
- Lee, J., Yoon, W., Kim, S., Kim, D., & Kim, S. (2020). BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics (Oxford, England), 36(4), 1234–1240. https://doi.org/10.1093/bioinformatics/btz682.
- Li, F., Zhang, M., Tian, B., Chen, B., & Fu, G. (2018). Recognizing irregular entities in biomedical text via deep neural networks. Pattern Recognition Letters, 105(1), 105–113. https://doi.org/10.1016/j.patrec.2017.06.009.
- Li, L., Li, C., & Ji, D. (2020). Deep context modeling for multi-turn response selection in dialogue systems. Information Processing & Management. Advance online publication. https://doi.org/10.1016/j.ipm.2020.102415
- Li, Z., Li, R., & Jin, G. (2020). Sentiment analysis of Danmaku videos based on Naive Bayes and sentiment dictionary. IEEE Access, 8, 75073–75084. https://doi.org/10.1109/ACCESS.2020.2986582
- Lin, Z., Wang, L., Cui, X., & Gu, Y. (2021). Fast sentiment analysis algorithm based on double model fusion. Computer Systems Science and Engineering, 36(1), 175–188. https://doi.org/10.32604/csse.2021.014260
- Liu, N., & Shen, B. (2020). ReMemNN: A novel memory neural network for powerful interaction in aspect-based sentiment analysis. Neurocomputing, 395, 66–77. https://doi.org/10.1016/j.neucom.2020.02.018
- Naderalvojoud, B., & Sezer, E. A. (2020). Sentiment aware word embeddings using refinement and senti-contextualized learning approach. Neurocomputing, 405(10), 149–160. https://doi.org/10.1016/j.neucom.2020.03.094.
- Onan, A. (2019). Topic-enriched word embeddings for sarcasm identification. In R. Silhavy (Ed.), Software engineering methods in intelligent algorithms. CSOC 2019. Advances in intelligent systems and computing (p. 984). Springer. https://doi.org/10.1007/978-3-030-19807-7_29
- Onan, A., & Korukoglu, S. (2017). A feature selection model based on genetic rank aggregation for text sentiment classification. Journal of Information Science, 43(1), 25–38. https://doi.org/10.1177/0165551515613226
- Onan, A., Korukoglu, S., & Bulut, H. (2016). A multiobjective weighted voting ensemble classifier based on differential evolution algorithm for text sentiment classification. Expert Systems with Applications, 62(15), 1–16. https://doi.org/10.1016/j.eswa.2016.06.005.
- Peng, H., Cambria, E., & Hussain, A. (2017). A review of sentiment analysis research in Chinese language. Cognitive Computation, 9(4), 423–435. https://doi.org/10.1007/s12559-017-9470-8
- Peng, H., Ma, Y., Poria, S., Li, Y., & Cambria, E. (2021). Phonetic-enriched text representation for Chinese sentiment analysis with reinforcement learning. Information Fusion, 70, 88–99. https://doi.org/10.1016/j.inffus.2021.01.005
- Peng, Z., Hu, Q., & Dang, J. (2019). Multi-kernel SVM based depression recognition using social media data. International Journal of Machine Learning and Cybernetics, 10(1), 43–57. https://doi.org/10.1007/s13042-017-0697-1
- Phu, V. N., Chau, V. T. N., Tran, V. T. N., & Dat, N. D. (2018). A Vietnamese adjective emotion dictionary based on exploitation of Vietnamese language characteristics. Artificial Intelligence Review, 50(1), 93–159. https://doi.org/10.1007/s10462-017-9538-6
- Rezaeinia, S. M., Rahmani, R., Ghodsi, A., & Veisi, H. (2019). Sentiment analysis based on improved pre-trained word embeddings. Expert Systems with Applications, 117(1), 139–147. https://doi.org/10.1016/j.eswa.2018.08.044.
- Ronran, C., Lee, S., & Jang, H. J. (2020). Delayed combination of feature embedding in bidirectional LSTM CRF for NER. Applied Sciences, 10(21), 7557–3417. https://doi.org/10.3390/app10217557
- Su, J., Yu, S., & Luo, D. (2020). Enhancing aspect-based sentiment analysis with capsule network. IEEE Access, 8, 100551–100561. https://doi.org/10.1109/ACCESS.2020.2997675
- Su, Y. J., Chen, C. H., Chen, T. Y., & Cheng, C. C. (2020). Chinese microblog sentiment analysis by adding emoticons to attention-based CNN. Journal of Internet Technology, 21(3), 821–829. https://doi.org/10.3966/160792642020052103019
- Sun, Y., Qiu, H., Zheng, Y., Wang, Z., & Zhang, C. (2020). SIFRank: A New baseline for unsupervised keyphrase extraction based on pre-trained language model. IEEE Access, 8, 10896–10906. https://doi.org/10.1109/ACCESS.2020.2965087
- Tago, K., & Jin, Q. (2018). Influence analysis of emotional behaviors and user relationships based on twitter data. Tsinghua Science and Technology, 23(1), 104–113. https://doi.org/10.26599/TST.2018.9010012
- Ullah, M. A., Marium, S. M., Begum, S. A., & Dipa, N. S. (2020). An algorithm and method for sentiment analysis using the text and emoticon. ICT Express, 6(4), 357–360. https://doi.org/10.1016/j.icte.2020.07.003
- Wang, C., Li, H., Li, X., Hou, F., & Hu, X. (2020). Guided attention mechanism: Training network more efficiently. Journal of Intelligent & Fuzzy Systems, 38(2), 2323–2335. https://doi.org/10.3233/JIFS-191257
- Wang, J., Yu, L. C., Lai, K. R., & Zhang, X. (2020). Tree-structured regional CNN-LSTM model for dimensional sentiment analysis. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 581–591. https://doi.org/10.1109/TASLP.2019.2959251
- Wang, Q. Y., Zhu, G. L., & Zhang, S. X. (2020). Building sentimental word Lexicon for Chinese Movie comments. Advances in Intelligent Systems and Computing, 1017, 1414–1422. https://doi.org/10.1007/978-3-030-25128-4_173
- Wang, Q. Y., Zhu, G. L., Zhang, S. X., Li, K. C., & Chen, X. (2021). Extending emotional lexicon for improving the classification accuracy of Chinese film reviews. Connection Science, 33(2), 153–172. https://doi.org/10.1080/09540091.2020.1782839
- Wang, Z., & Guo, Y. (2020). Empower rumor events detection from Chinese microblogs with multi-type individual information. Knowledge and Information Systems, 62(9), 3585–3614. https://doi.org/10.1007/s10115-020-01463-2
- Wu, S. T., Liu, Y. L., Zou, Z. R., & Weng, T. H. (2021). S_I_LSTM: Stock price prediction based on multiple data sources and sentiment analysis. Connection Science. Advance online publication. https://doi.org/10.1080/09540091.2021.1940101
- Xu, S., S, E., & Yang, X. (2020). Enhanced attentive convolutional neural networks for sentence pair modeling. Expert Systems with Applications. Advance online publication. https://doi.org/10.1016/j.eswa.2020.113384
- You, Y., He, Y., Rajbhandari, S., Wang, W., & Demmel, J. (2020). Fast LSTM by dynamic decomposition on cloud and distributed systems. Knowledge and Information Systems, 62(11), 4169–4197. https://doi.org/10.1007/s10115-020-01487-8
- Yu, X. M., Feng, W. Z., Wang, H., Chu, Q., & Chen, Q. (2020). An attention mechanism and multi-granularity-based Bi-LSTM model for Chinese Q&A system. Soft Computing, 24(8), 5831–5845. https://doi.org/10.1007/s00500-019-04367-8
- Zhang, G., Wu, J., Tan, M., Yang, Z., & Cheng, Q. (2020). Learning to predict US policy change using New York times corpus with Pre-trained language model. Multimedia Tools and Applications, 79(45–46), 34227–34240. https://doi.org/10.1007/s11042-020-08946-y
- Zhang, L., Fan, H., Peng, C., Rao, G., & Cong, Q. (2020). Sentiment analysis methods for HPV vaccines related tweets based on transfer learning. Healthcare. Advance online publication. https://doi.org/10.3390/healthcare8030307
- Zhang, S. X., Wei, Z. L., Wang, Y., & Liao, T. (2018). Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Generation Computer Systems, 81, 395–403. https://doi.org/10.1016/j.future.2017.09.048
- Zhang, Y. J., Xu, B., & Zhao, T. J. (2020). Convolutional multi-head self-attention on memory for aspect sentiment classification. IEEE/CAA Journal of Automatica Sinica, 7(4), 1038–1044. https://doi.org/10.1109/JAS.2020.1003243
- Zhao, J., Dalin, Z., Xiao, Y., Che, L., & Wang, M. (2020). User personality prediction based on topic preference and sentiment analysis using LSTM model. Pattern Recognition Letters, 138, 397–402. https://doi.org/10.1016/j.patrec.2020.07.035
- Zhao, S., You, F., & Liu, Z. Y. (2020). Leveraging Pre-Trained language model for summary generation on short text. IEEE Access, 8, 228798–228803. https://doi.org/10.1109/ACCESS.2020.3045748
- Zheng, J. Z., Chen, X. L., Du, Y. J., Li, X. Y., & Zhang, J. B. (2020). Short text sentiment analysis of micro-blog based on BERT. Electrical Engineering, 590, 390–396. https://doi.org/10.1007/978-981-32-9244-4_56
- Zheng, Z., Huang, S., Weng, R., Dai, X., & Chen, J. (2020). Improving Self-Attention networks with sequential relations. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 1707–1716. https://doi.org/10.1109/TASLP.2020.2996807
- Zinovyeva, E., Hardle, W. K., & Lessmann, S. (2020). Antisocial online behavior detection using deep learning. Decision Support Systems. Advance online publication. https://doi.org/10.1016/j.dss.2020.113362