
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Traffic density monitoring is an important method to predict road traffic conditions, which can bring some convenience to people's travel in daily life. The common method of traffic density monitoring is to collect and process the location information uploaded by vehicles, but the information of these vehicle location contains a large amount of personal privacy information of vehicle owners, and there is a risk of privacy disclosure. In this paper, we propose a traffic density monitoring system by adding a pseudonym server and a location anonymisation server; the identity information and location information of the vehicles are saved separately. The system can protect both the location privacy of vehicles and the query privacy of users. To prevent dummy locations from being filtered, we calculate the probability distribution of historical location service requests to generate location anonymous sets, which can improve the success rate of anonymity. The location anonymisation server uses the location anonymous set instead of the real location of the vehicle to send to the location-based service provider, which can increase the location privacy security of the vehicle. According to the experimental results of this paper, compared with SimpMaxMinDistds algorithm and MMDS algorithm, our system has better location anonymous set generation efficiency and location privacy protection level.
1. Introduction
As a major part of the development of smart city, smart transportation can effectively improve the work efficiency of urban traffic management and then effectively alleviate the urban traffic congestion. Traffic density monitoring is the basis and premise of developing intelligent transportation. Urban roads and their topological structures are becoming more and more complex, and the amount of real-time traffic data is increasing. Therefore, it is necessary to acquire the urban traffic running conditions quickly and accurately.
With the rapid development of mobile Internet, location-based services have brought some convenience to people's lives, such as location navigation and traffic density monitoring. The general method of traffic density monitoring is to collect and process the real-time location uploaded by a single vehicle (Jain et al., Citation2019). However, the location information of the vehicle is directly related to the personal privacy of the vehicle owner, which the malicious attacker can infer. Through continuously gathering the location information of the vehicle, malicious attackers can infer the owner's privacy information. Malicious attackers can infer information such as the owner's home address, company address and social relationships through the location frequented by the vehicle, which can seriously reduce the owner's motivation to upload the vehicle's location. Nair et al. (Citation2020) used two algorithms, k-means clustering and k-nearest neighbour classification, to implement traffic detection. Sakai et al. (Citation2019) proposed a new remote sensing method for wide-range traffic density monitoring based on small-satellite remote sensing.
In recent years, cloud computing has become popular because of its high storage capacity and strong computing power. Cloud computing makes it convenient for enterprises and individuals to outsource and share their data (Ge et al., Citation2019, Citation2021b). We have also realised that there are significant challenges in data security and privacy information protection (Gu et al., Citation2020; Kong et al., Citation2018; Moses et al., Citation2019). In Ge et al. (Citation2020), they proposed a CPAB-KSDS mechanism that can support attribute-based data sharing. In Ge et al. (Citation2021a), they proposed a VF-ABPRE scheme that supports verifiability and fairness. Fog computing is an extension of cloud computing (Chen et al., Citation2020), because of its security of local data, it has attracted extensive attention of scholars.
The common methods of location privacy protection include location encryption, k-anonymity and dummy location anonymity (Ren & Tang, Citation2019). During traffic density monitoring, the vehicle does not need to upload its exact location to the location server, and it simply needs to submit its fuzzy location to the server. Using the method of location encryption to encrypt the location information of each vehicle will lead to low encryption efficiency, thus reducing the efficiency of the location server, for instance, homomorphic encryption (Gentry, Citation2009; Gupta & Rao, Citation2017a), which can generate the searching results of encrypted states, suffers from some efficiency problems. In Lin et al. (Citation2019), they proposed an SELS scheme that uses smartphones to encrypt location-based data and then outsources them to a cloud centre. In Shen et al. (Citation2017), the user's location is encrypted by using the method of order preserving encryption, and the encrypted location data is orderly. The anonymous server only knows the size relationship between the locations, but the real location of the users cannot be identified, and the location privacy information of the users can be secured. In the area with fewer vehicles, the hidden area required by the k-anonymity method may be very large (Gruteser & Grunwald, Citation2003; Wang et al., Citation2009), because the vehicle itself and at least k−1 other vehicles need to be included, so it cannot be directly applied to location privacy protection. The performance of these methods is poor when they are attacked by background knowledge. As an important means of location privacy protection, dummy location anonymity (Andrés et al., Citation2013; Liu, Citation2007; Parmar & Rao, Citation2020) has been widely concerned by scholars. The dummy location anonymity algorithm is to use dummy location instead of the real location of the vehicle to initiate service requests, can protect the location of the vehicle privacy. Du et al. (Citation2019) proposed an Enhanced-DLP scheme, which can also resist edge information attacks. It is a challenge to achieve accurate and efficient traffic density monitoring without revealing the privacy of vehicle location. All in all, protecting the privacy and safety of vehicle locations and scientifically and reasonably monitoring traffic density are of great significance to traffic management, service control and vehicle manufacturing.
In our paper, we propose a traffic density monitoring system based on location privacy protection. By adding a pseudonym server, the private information of vehicles is stored separately, that is, the pseudonym server only knows the real identity of the vehicle, while the location anonymisation server only knows the real location of the vehicle. We calculate the historical request probability distribution based on the real location service request data, which can select effective dummy locations and improve the anonymity effect. While realising traffic density monitoring, it can also protect the query privacy of the user. Our system can protect both the vehicle's location privacy and the user's query privacy, thereby improving the security of the system.
Our contributions are:
The traffic density monitoring system of this paper uses pseudonym server to store the vehicle's identity and location information separately, which can prevent the attacker from obtaining the complete privacy information of the vehicle and improve the location privacy protection of the vehicle.
In this paper, we calculate the probability distribution of historical queries to select effective dummy locations, and the selected dummy locations have a high degree of location dispersion, which can resist the attacker single point attack and can further improve the privacy protection degree of the vehicle location.
Our system can also protect the user's query privacy. When the user's query information is encrypted, the attacker cannot infer the user's privacy information from the user's historical query information, so it can improve the security of the system.
2. Related work
The Internet and 5G technology are developing rapidly, and Location Based Service (LBS) is being extensively applied. In daily life, LBS has gradually become an indispensable service due to its wide coverage, high positioning accuracy, easy operation and wide application (Shin et al., Citation2012). Location-based services mean that users use their own location information to access location-related information and services, such as route planning for travel, Point of Interest (POI), access to current location and route navigation, etc. The architecture of location-based services (Mitton et al., Citation2012; Mokbel et al., Citation2007) generally consists of four components: mobile terminal, positioning system, communication network and location-based service provider. Users' location information is generally obtained through GPS, and China's self-developed BeiDou Navigation Satellite System (BDS) has gradually started to be applied in geolocation-based related services (Alsaawy et al., Citation2019; Zhao et al., Citation2018), which provides a strong technical guarantee for the development of LBS. In people's daily travel, LBS can provide various conveniences, such as searching the hotel near a tourist attraction, searching the nearby public toilet or searching the nearest service area on the highway. The installation of the positioning system for taxis, buses and other vehicles can effectively manage traffic roads, monitor traffic accidents in real time, respond in a timely manner and ensure the smooth flow of roads. For the elderly and children, smart bracelets can be worn to quickly locate them in the event of getting lost. While LBS brings convenience, it also brings the risk of user privacy leakage. In Gupta and Rao (Citation2017b), they analyse existing techniques for location privacy protection based on centralised and distributed approaches, bringing new thinking to address privacy issues in LBS.
Privacy in LBS is generally divided into two categories (Aloui et al., Citation2020; Chow & Mokbel, Citation2011), the first category is the location privacy, which means the privacy information directly or indirectly relevant to the location where the user has been and the current location. In order to protect location privacy in LBS, Gupta and Rao (Citation2019) proposed a VIC-PRO scheme. The second category is the query privacy, which means the privacy information related to the query information, and the attacker can use the query information to infer the user's interests, hobbies, identity, etc. Zhang et al. (Citation2021) combined blockchain and public-key cryptography technique to realise the privacy protection of user query. In Tang et al. (Citation2019), they proposed an efficient location-based service scheme for content protection. The leakage of any type of privacy will cause the leakage of user's information and threaten the privacy security of users.
Currently, location privacy protection system architecture can be generally classified into three types (To et al., Citation2017), which are stand-alone architecture, central server architecture and distributed peer-to-peer architecture.
The standalone architecture usually refers to a client/server (C/S) structure consisting of a client and a location server (Li et al., Citation2011; Wang et al., Citation2019), where the mobile terminal has positioning function, computing power and anonymous processing capability. In the C/S structure, the mobile terminal first acquires its own location information using the positioning device, and then needs to complete the anonymous processing work by itself and send it to the location server using the processed location instead of its real location. In this structure, the calculation and anonymous processing operations are performed at the user terminal, and the user terminal has a heavy burden.
The centralised server architecture is usually a centralised architecture formed by adding the trusted anonymous server (AS) to the mobile terminal and the location server (Memon et al., Citation2017), and in the centralised architecture of the trusted third party (TTP), the anonymous server anonymises the location information submitted by the user, sends query requests to the location server on behalf of the user and filters the query results. This centralised architecture moves the computing operations on the user side to the anonymous server, and the amount of computing on the user side is greatly reduced. In order to ensure the privacy and security of users, requiring third-party anonymous servers is completely credible, but in practice this is difficult to achieve. Anonymous servers may become the performance bottleneck and attack point of the system. The number of anonymous servers is generally not large, and when the number of location requests from user terminals is too large, it can easily become the performance bottleneck of the system. The anonymous server stores a large number of user's query requests and location privacy information, which is easy to become the target of attackers.
The distributed peer-to-peer (P2P) architecture refers to the architecture consisting of mobile user groups and location servers (Chow et al., Citation2006), where the distributed peer-to-peer architecture of user collaboration does not require anonymous servers, mobile terminals can collaborate with each other to complete anonymous processing, and each mobile terminal is equipped with computing power and the ability to store information. In the distributed peer-to-peer architecture, the user communicates with other neighbouring users through the communication network, and when the user initiates a location service request, the user and the other k−1 users found collaborate with each other to form a user group, and a user within the user group is selected as a representative to forward the query requests of other users, so that the user in contact with the location server is not the direct user of the query request.
The anonymous processing operations of this architecture depend on the user group and can reduce the computational overhead of the users, but the users communicate with each other over the network, thus increasing the network communication overhead. When forming a user group, if there are fewer users around, the risk of user privacy leakage is greatly increased. When the communication network environment is poor, the transmission of information between users is hindered and the efficiency of anonymous processing is low. The architecture also requires that the members in the user group are honest and trustworthy, and if a user is malicious, it will lead to the malicious user leaking private information about members of the user group.
The dummy location anonymity method has received widespread attention from scholars because of its simple deployment and the advantages of not affecting the quality of service.
The dummy location anonymity method was first proposed by Kido et al. (Citation2005), which is a stand-alone architecture in which the mobile terminal generates multiple dummy locations through a certain dummy location generation algorithm and then sends current location to the location server along with multiple dummy locations. This method has a high quality of service, but a relatively low degree of privacy protection, a long service waiting time in the dummy location generation process, and requires a mobile terminal with strong computing and storage capabilities.
Lu et al. (Citation2008) proposed the PAD method, which generates a certain number of dummy locations by virtual grid and circle based, and the user's real location and these dummy locations together form an anonymous set as a way to cover the user's real location, this method also considers the problem of uneven distribution of dummy locations, too scattered dummy locations are easily filtered out by attackers, so this method adopts the method of uniformly generating dummy locations. In 2016, Zha et al. (Citation2016) presented a Cir-Dummy algorithm based on virtual circles and Grid-Dummy algorithm based on virtual grids on the basis of PAD, which further improved the level of location privacy protection.
Zhang et al. (Citation2018) proposed the TPLO method, which obtains the obfuscated location based on the location prediction mechanism and the dummy location selection mechanism, then obfuscated location is sent to the anonymous server along with the user's real location and forms an anonymous domain, and then sends the anonymous domain to the location server for querying, which enhances the privacy protection of the user's trajectory and also solves the performance bottleneck problem of a single anonymous server.
Niu et al. (Citation2014) proposed a DLS scheme that generates reasonable dummy locations based on the historical query probability of each location, making it difficult for an attacker to reduce the degree of location privacy protection by filtering unreasonable dummy locations and also introducing location entropy to measure the degree of privacy protection of dummy locations.
3. Preliminary
3.1. Attacker single point attack model
The attacker single point attack means that the attacker can infer privacy information of the user through obtaining the single location service request, the main attack methods include side information attack and location homogeneity attack.
Side information attack refers to the attacker according to the side information to analyse and filter out the dummy location, and then reduce the anonymity. For example, when the attacker filters dummy locations out of the k−1 selected dummy locations, the k-anonymity requirement is not satisfied, and the location privacy protection level will decline.
Location homogeneity attack means that the attacker analyses the dummy locations in the anonymous set. If the distance between the dummy locations is very close, although the k-anonymity requirement is met, the anonymous area is too small, and the user's location privacy cannot be well protected.
Definition 3.1
The attacker single point attack model can be described as follows:
(1)
(1)
where h is the attacker's operation and is the number of dummy locations filtered out by the attacker through h. The purpose of single point attack is to maximise
under the given h condition.
In this paper, for the attacker single point attack, we use a History based Cloaking Location Selection algorithm (HCLS) (Xia et al., Citation2019) to select the desired dummy locations and generate location anonymous set.
3.2. Dummy location technology
The basic idea of location privacy protection method based on dummy location technology is that users select dummy locations according to their own privacy needs and ensure that the dummy locations have the maximum authenticity. This method sends these dummy locations along with the real location to the location-based service provider, making it impossible for attackers to identify the user's real location information.
3.3. Privacy metrics
Definition 3.2
Probability of Exposing Real Location (PERL), the probability of exposing the real location of the vehicle is used in the article to measure the level of privacy protection of the dummy location, the calculation method is as follows:
(2)
(2) where k is the anonymity degree and
is the number of locations that can be filtered out by the attacker.
The more dummy locations are filtered out by the attacker, the larger the PERL is, and the greater the probability that the real location of the vehicle will be exposed. The opposite is true for the opposite.
Definition 3.3
Product of Distances (PD), the degree of dispersion of dummy locations in the anonymous set is obtained by calculating the sum of the distances of two locations in the anonymous set, and the calculation process is shown in Equation (Equation3(3)
(3) ):
(3)
(3)
In general, the higher the PD, the larger the coverage of the anonymous set and the better the anonymisation effect will be.
4. Privacy-preserving traffic density monitoring system
4.1. System architecure
According to the shortcomings of the current location privacy protection framework, this paper designs a privacy protection system architecture, as shown in Figure , which is mainly composed of the following five parts:
Figure 1. System model.
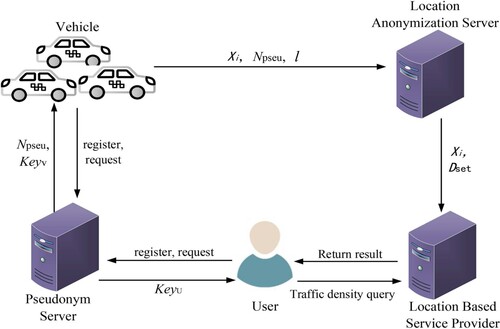
Users. The user initiates the location service request through the mobile terminal when needed.
Vehicles. Vehicles refer to vehicles installed with smart devices with positioning capabilities and vehicle clients as location data providers.
Pseudonym server (PS). The PS generates the corresponding pseudonym and encryption key for the vehicle and returns the pseudonym and encryption key to the vehicle. The PS only acts as the pseudonym and encryption key provider, so the PS does not keep the pseudonyms and keys locally.
Location anonymisation server (LAS). The LAS hides the real location of the vehicle according to the corresponding location anonymisation algorithm and generates the location anonymous set.
Location based service provider (LBSP). The LBSP returns the corresponding service result according to the user's query request.
In our paper, we assume that the PS, LAS and LBSP are honest and curious, do not disrupt the protocol flow, can do their jobs according to the protocol, and they only collect and analyse the data within their area of responsibility. What's more, suppose PS, LAS and LBSP can't collude with each other, they can't be controlled by an attacker at the sametime.
Figure shows the architecture of our system, the clients are divided into two groups, one is the vehicle client with intelligent devices and the other is the user client who wants to query the traffic density. In our system, the vehicle client as the data provider, we want to ensure both the location privacy security of the vehicle and the availability of the data. The user client as the location service requester, we want to ensure the privacy and security of the user's query information. LBSP are used to collect location information of vehicles, then process them and return the query results to the user when the user queries. In brief, our system process includes the following steps: first, the vehicle requests a pseudonym and encryption key from the PS. Second, the vehicle uses the encryption key to encrypt the area number, then the vehicle sends its pseudonym, the encrypted area number and real location to the LAS. Third, the LAS processes the vehicle's location, generates a location anonymous set and sends the location anonymous set to the LBSP. Finally, the LBSP returns the corresponding query result based on the user's query request.
4.2. Our proposed system
When we consider traffic density monitoring, what we need to collect is not the exact location of vehicles, an approximate location is enough for us to monitor traffic density. In our privacy protection system, we convert the entire region into a series of discrete regions and then use the set of locations in each region to represent the locations of vehicles located in that region. In the whole region large area, we divide the whole region into Φ regions equally and number each region . The specific traffic density monitoring process is as follows:
4.2.1. Initialisation
PS is used to generate global system parameters and issue certificates for entities in the system. At the beginning of initialisation, a security parameter λ is entered and PS generates the system parameters through the following steps:
Choose the multiplicative cyclic group
of order prime p, where the generating element of
Randomly select a number
PS publicly generated system parameters (
4.2.2. Registration
In order to apply incentives and prevent malicious data uploads, we authenticate all participants and assign identifiers to each participant. Vehicles and users are required to generate their public–private key pairs and register with PS to obtain certificates. The specific steps are as follows:
For vehicle
For user
Based on the identity information of the entities (vehicles and users) in the system, the PS issues certificates for them using the system master key and signing scheme.
4.2.3. Vehicle pseudonym and key generation
Before uploading the vehicle location, the vehicle with positioning function first requests the PS, The PS generates the corresponding pseudonym and encryption key
for the vehicle. The vehicle uses the encryption key
to encrypt the area number
and calculates
. The vehicle sends its pseudonym
, the encrypted area number
and the current exact location l to the LAS.
The detailed process is shown in Table . The PS generates a random pseudonym for the vehicle through a pseudorandom generator. The PS randomly selects a number
and then computes
. Within the limited time
(If the limited time is 1 min, the calculation result is the traffic density of the area within 1 min, and the limited time can be set according to the specific requirements), for multiple requests for service from vehicles at the same location, vehicles will only apply for a pseudonym and encryption key once. when the limited time expires, the vehicle will apply for new pseudonym and encryption key again.
Table 1. Vehicle pseudonym and key generation.
4.2.4. Location anonymisation
After receiving the information from the vehicle, the LAS protects the real location l of the vehicle according to the corresponding location anonymity algorithm, generates the location anonymous set , and sends the encrypted area number
of the vehicle and the location anonymous set
to the LBSP.
For the attacker single point attack, we use a History-based Cloaking Location Selection algorithm (HCLS). The specific flow of the algorithm is as follows:
Calculating the probability distribution of historical location service requests.
The algorithm first grids each region, with each grid corresponding to a location, and the total number of grids in each area is n.
Because the location anonymisation server can obtain all the location service requests of vehicles, based on the historical request data of vehicles, the algorithm can calculate the probability of launching location service requests at each location m, which meets the following conditions:
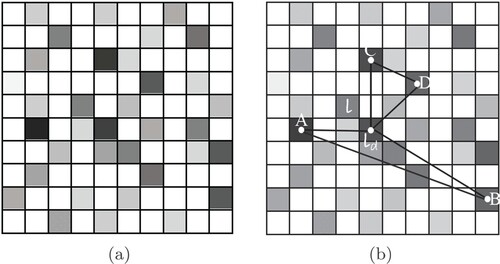
Figure (a) shows the location probability distribution of vehicle historical location service requests, each grid in the figure corresponds to a location, the depth of the color indicates the size of the location service request probability, the darker the color indicates a higher probability, the lighter the color indicates a lower probability, the white location indicates that the vehicle has not performed location request service here, so these white locations may be rivers, wastelands and other locations that can be easily identified by malicious attackers.
Select the offset location
Location offset refers to the reduction of location accuracy by adding noise to reduce the chance of the vehicle location being identified. HCLS algorithm protects the location privacy of the vehicle by selecting an offset location instead of the real location of the vehicle into the anonymous set.
After obtaining the location probability distribution of the historical service request data, HCLS algorithm selects the nearest x−1 locations of
Selecting dummy location set
In the whole grid space,
In order to prevent the locations in the anonymous results are too concentrated, HCLS algorithm has to optimise the dummy location candidate set
The dummy location selection process is shown in Figure (b), l is the real location of the vehicle,
Obtaining location anonymous set
By step (3), the HCLS algorithm selects k−1 dummy locations, which then together with the offset locations
Figure 2. Location probability distribution and dummy location selection process: (a) location probability distribution and (b) dummy location selection process.
The algorithm process of HCLS is shown in Table . HCLS algorithm uses the historical location service request data of the vehicle, which can select the effective dummy location, so as to achieve the hiding of the real location of the vehicle. The algorithm solves the problem of attackers filtering dummy locations and also avoids the problem of over-concentration of dummy locations.
Table 2. History based Cloaking Location Selection algorithm.
The HCLS algorithm can effectively resist the attacker's single point attack, but it cannot completely against the attacker's inference attack, assuming that the attacker has some background knowledge, using the learned location privacy protection mechanism, combined with the anonymous algorithm, to speculate the probability that each location in the anonymous set is the real location of the vehicle, it can make the inference attack more accurate. Therefore, this approach has some limitations for scenarios with higher privacy protection requirements.
4.2.5. Traffic density statistics
When a user queries traffic density, he first requests an encryption key from the PS (in the same limited time
, the encryption key sent by the PS to the vehicle and the user is the same), then encrypts the location area number
he wants to query and sends it to the LBSP. The LBSP will compare the encrypted location area number
sent by the user with the encrypted location area number
sent from the LAS, select the anonymous set with the same area number and finally perform statistics to derive the traffic density monitoring results and return them to the user.
5. Security and availability
5.1. Security analysis
In this paper, the system sets up that the PS, LAS and LBSP are honest and curious, and will not be controlled by one attacker at the same time. In this setting, the following theorems are proved to illustrate the security of the overall system.
Theorem 5.1
After the attacker obtains the anonymous set , the probability of obtaining the real location of the vehicle through single point attack is negligible.
Proof.
Assuming that the number of dummy locations in the anonymous set is k, thus the probability of an attacker inferring an offset location from the anonymous set is
. Suppose the number of locations in the vehicle history distribution is n, and it is a possible event for the attacker to identify the real location of the vehicle by the offset location, but there exists a small probability function
such that the probability
of the attacker identifying the real location of the vehicle satisfies
. Then the probability of obtaining the exact vehicle location information in the case of known
is
.
Theorem 5.2
When the attacker attacks the PS, the probability of obtaining the vehicle identity, pseudonym and encryption key is negligible.
Proof.
The PS in this paper only acts as a provider of pseudonyms and keys, and does not save the pseudonyms and encryption keys locally. The pseudonym assignment at the PS is dynamic and requests for the same vehicle at different time periods will correspond to different pseudonyms. The PS can complete its own work according to the protocol. When an attacker attacks the PS to obtain the pseudonym and encryption key of the vehicle, further locating the vehicle identity is a small probability event .
Theorem 5.3
When the attacker attacks the LAS, the probability of obtaining the pseudonym, real location and anonymous set of the vehicle is negligible.
Proof.
The information obtained by the LAS communicating with the vehicle includes . Suppose that the attacker has attacked the LAS, the probability that the attacker obtains the vehicle location l is
. From Theorem 5.2, the probability that the attacker obtains the vehicle identity and the corresponding pseudonym is
. It follows that the probability that the LAS obtains the vehicle identity and the true location is
. Therefore, the probability that the attacker obtains both the vehicle identity and the real location is negligible.
Theorem 5.4
When the attacker attacks the LBSP, the probability of obtaining the vehicle identity, real location and anonymous set of the vehicle is negligible.
Proof.
The information obtained by the LBSP includes , the probability that the attacker obtains the anonymous set is
and the probability that the attacker obtains the vehicle identity is
. From Theorem 4, the probability of the attacker identifies the real location of the vehicle is
. Therefore, the probability that the attacker obtains the vehicle identity, real location and anonymous set simultaneously is
.
Theorem 5.5
When the attacker attacks two or three servers, the probability of obtaining vehicle identity and key privacy information is negligible.
Proof.
According to the protocol requirements of the PS, the assignment of pseudonyms is dynamic and the pseudonyms are not saved locally. When the attacker successively attacks the PS and the LAS, even though the attacker obtains some pseudonyms from the PS, the obtained pseudonyms are no longer valid due to time and the attacker cannot locate the vehicle. When the attacker successively attacks the PS and the LBSP, for the same reason, the obtained pseudonyms are no longer valid and the attacker cannot match the anonymous set with the vehicle; Finally, when the three-party server is compromised, the attacker cannot locate the vehicle and obtain the complete private information of the vehicle due to the pseudonyms.
5.2. Availability analysis
On the PS side, the system mainly allows the PS to provide the pseudonym and key for the vehicle, which takes a constant level of time, denoted by .
On the LAS side, the system mainly allows the LAS to complete the location anonymous operation of the vehicle, so the computation time mainly depends on the computational complexity of the HCLS algorithm. The computational complexity is , and k is the degree of location anonymity.
On the LBSP side, the system mainly allows the LBSP to search the corresponding location anonymous set based on the user's query request, and the search speed depends on the number of locations k searched, denoted by .
As a result, the overall computing time of the system will not exceed the polynomial complexity, and the maximum is .
6. Experimental analysis
6.1. Experimental data set
This experiment uses the order data of Didi Taxi, which was released during the 2016 Didi Di-Tech Algorithm Competition, The data set gives data information for a city for 3 consecutive weeks in 2016, which include information such as order number, driver number, passenger number and specific order time.
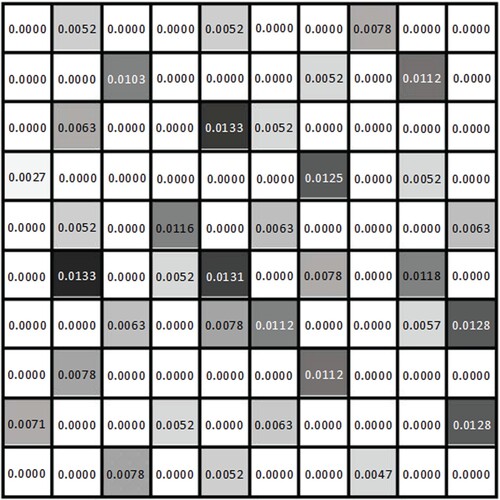
In this paper, the experiments are carried out based on the location probability distribution of vehicle historical location service requests, and we need to preprocess the dataset first. We divide the location space into 10*10 grids for each region according to the region number, calculate the total number of orders in each region and then calculate the probability of vehicle initiating location request in each grid by using Equation (Equation6
(6)
(6) ):
(6)
(6) where
denotes the number of orders in the i grid and Tnum denotes the total number of orders in the region.
6.2. HCLS algorithm evaluation
As shown in Figure , the location probability distribution of vehicle service requests in an region during a certain time period. The depth of the colour indicates the probability of location service request, the darker the colour indicates the greater the probability, the lighter the colour indicates the smaller the probability. The later experiments were performed based on this type of probability distribution plot.
Figure 3. Location request probability distribution.
In order to verify the effectiveness of the algorithm, the method of randomly selecting anonymous set is compared with HCLS method, and the specific distribution of the locations in the anonymous set is shown in Figures (a,b).
Figure 4. Comparison of the location distribution: (a) random dummy location selection result and (b) HCLS dummy location selection result.
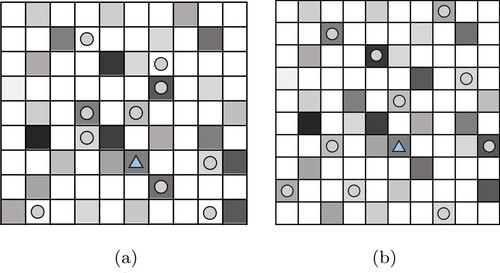
In Figures (a,b), the grid areas marked with triangles represent the real locations of the vehicles, and the grid areas marked with circles represent of selected dummy locations of the vehicles. Figure (a) shows the randomly selected dummy locations, which can be seen to be easily selected in blank grids, which are easily filtered out by the attacker. Figure (b) shows the dummy locations selected by HCLS, and it can be seen that the set of selected dummy locations is relatively scattered and will not be selected in the blank grids.
In this paper, the SimpMaxMinDistDS algorithm (Chen & Shen, Citation2016) and MMDS algorithm (Wang et al., Citation2020) are used for experimental comparison, from the generation time of location anonymous set, PD and PERL to verify the effectiveness of HCLS algorithm. The location anonymous set generated by the SimpMaxMinDistDS algorithm and the MMDS algorithm includes the real location of the user, while the location anonymous set generated by the HCLS algorithm does not include the real location of the user, but replaces the real location of the user with the offset location.
Location anonymous set generation efficiency
The SimpMaxMinDistDS algorithm, MMDS algorithm and HCLS algorithm generate the average generation time of location anonymous set as shown in Table . Figure shows the comparison results of the generation time of the dummy location sets of these three algorithms, where the value of k ranges from 2 to 8.
As shown in Figure , the time to generate the location anonymous set increases for all three algorithms as the value of k increases, moreover, with the increase of k value, the time of HCLS algorithm is always less than MMDS algorithm. When the value of k is less than 5, the time required by the HCLS algorithm is larger than that of the SimpMaxMinDistDS algorithm, and when the value of k is greater than 5, the time required by the HCLS algorithm is smaller than that of the SimpMaxMinDistDS algorithm. We can conclude that when the value of k is greater than 5, the increase amplitude of HCLS algorithm is smaller than that of MMDS algorithm and SimpMaxMinDistDS algorithm, the generation time of HCLS algorithm is the shortest.
PD
PD refers to the dispersion degree of dummy locations in anonymous set. The larger the distance between the dummy locations, the more scattered the dummy locations are. In this paper, we measure the PD of dummy locations by calculating the sum of the distances of any two locations in the anonymous set. In general, the higher the PD, the wider the coverage of anonymous set, and the better the effect of anonymity.
As shown in Figure , through the experimental comparison, it can be seen that with the increase of k value, the PD of the three algorithms is increasing. The PD of the HCLS algorithm is consistently higher than the PD of the SimpMaxMinDistDS algorithm and the MMDS algorithm. Moreover, with the increase of k value, the increased magnitude of the HCLS algorithm will be larger and larger. We can conclude that HCLS algorithm can select more scattered dummy locations.
PERL
PERL refers to the probability of location exposure and can be used to indicate the degree of protection of the vehicle's real location. The more dummy locations are filtered by the attacker, the greater the probability that the vehicle's real location will be exposed.
The experimental comparison shows that the PERL decreases continuously as the value of k increases, indicating that the larger the value of k, the better the level of privacy protection of the algorithm. As shown in Figure , with the increase of k value, the PERL of HCLS algorithm is consistently lower than SimpMaxMinDistDS algorithm and MMDS algorithm. In addition, the PERL of HCLS algorithm tends to be stable, and the HCLS algorithm has a better level of privacy protection. Because the HCLS algorithm filters out dummy locations with a probability of 0, it is difficult for attackers to filter out the invalid dummy locations, so it has a better level of privacy protection.
Figure 5. Comparison of the generation time of location anonymous set.
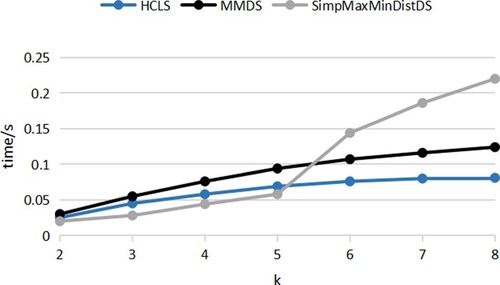
Figure 6. Comparison of PD.
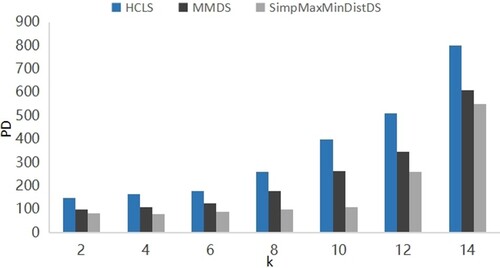
Figure 7. Comparison of PERL.
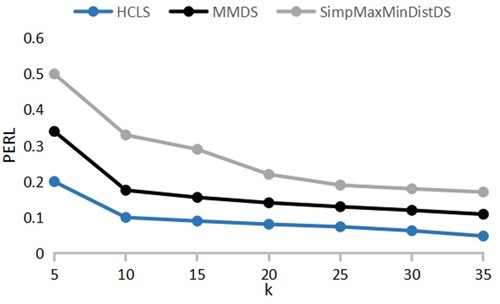
Table 3. Average generation time of location anonymous set.
7. Conclusion
In this paper, we investigate the architecture of existing location privacy protection systems and analyse their advantages and disadvantages. In our traffic density monitoring system, we use location offset and dummy location technology to protect the location privacy of vehicles. The HCLS algorithm selects appropriate dummy locations to form the location anonymous set, and the location anonymous set does not contain the real location of the vehicle, thereby improving the level of location privacy protection of the vehicle. The experiment in this paper compares the SimpMaxMinDistDS algorithm and the MMDS algorithm from the three aspects of location anonymous set generation efficiency, PD and PERL.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Aloui, A., Kazar, O., Bourekkache, S., & Omary, F. (2020). An efficient approach for privacy-preserving of the client's location and query in M-business supplying LBS services. International Journal of Wireless Information Networks, 27(3), 433–454. https://doi.org/10.1007/s10776-020-00478-4
- Alsaawy, Y., Alkhodre, A., Eassa, F. A., & Abi Sen, A. A. (2019, March 13–15). Triple cache approach for preserving privacy and enhancing performance of LBS. 6th International conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India. IEEE.
- Andrés, M. E., Bordenabe, N. E., Chatzikokolakis, K., & Palamidessi, C. (2013, November). Geo-indistinguishability: Differential privacy for location-based systems. Proceedings of the 2013 ACM SIGSAC conference on Computer & Communications Security, CCS '13 (pp. 901–914). ACM. https://doi.org/10.1145/2508859.2516735
- Chen, S., Chen, N., Tang, J., & Wang, X. (2020). Cognitive fog for health: a distributed solution for smart city. International Journal of Computational Science and Engineering, 22(1), 30–38. https://doi.org/10.1504/IJCSE.2020.107267
- Chen, S., & Shen, H. (2016, August 23–26). Semantic-aware dummy selection for location privacy preservation. IEEE Trustcom/BigDataSE/ISPA, Tianjin, China (pp. 752–759). IEEE Press. https://doi.org/10.1109/TrustCom.2016.0135
- Chow, C. Y., & Mokbel, M. F. (2011). Trajectory privacy in location-based services and data publication. ACM SIGKDD Explorations Newsletter, 13(1), 19–29. https://doi.org/10.1145/2031331.2031335
- Chow, C. Y., Mokbel, M. F., & Liu, X. (2006, November). A peer-to-peer spatial cloaking algorithm for anonymous location-based service. Proceedings of the 14th annual ACM international symposium on Advances in Geographic Information Systems, GIS6 (pp. 171–178). ACM. https://doi.org/10.1145/1183471.1183500
- Du, Y., Cai, G., Zhang, X., Liu, T., & Jiang, J. (2019). An efficient dummy-based location privacy-preserving scheme for internet of things services. Information, 10(9), 278. https://doi.org/10.3390/info10090278
- Ge, C. P., Liu, Z., Xia, J. Y., & Fang, L. M. (2019, February). Revocable identity-Based broadcast proxy re-encryption for data sharing in clouds. IEEE Transactions on Dependable and Secure Computing, 18(3), 1214–1226. https://doi.org/10.1109/TDSC.2019.2899300
- Ge, C. P., Susilo, W., Baek, J., Liu, Z., Xia, J. Y., & Fang, L. M. (2021a, April). A verifiable and fair attribute-based proxy re-encryption scheme for data sharing in clouds. IEEE Transactions on Dependable and Secure Computing. https://doi.org/10.1109/TDSC.2021.3076580
- Ge, C. P., Susilo, W., Baek, J., Liu, Z., Xia, J. Y., & Fang, L. M. (2021b, March). Revocable attribute-based encryption with data integrity in clouds. IEEE Transactions on Dependable and Secure Computing. https://doi.org/10.1109/TDSC.2021.3065999
- Ge, C. P., Susilo, W., Liu, Z., Xia, J. Y., Szalachowski, P., & Fang, L. M. (2020, January). Secure keyword search and data sharing mechanism for cloud computing. IEEE Transactions on Dependable and Secure Computing. https://doi.org/10.1109/TDSC.2020.2963978
- Gentry, C. (2009, May). Fully homomorphic encryption using ideal lattices. Proceedings of the forty-first annual ACM symposium on Theory of Computing (pp. 169–178). https://doi.org/10.1145/1536414.1536440
- Gruteser, M., & Grunwald, D. (2003, May). Anonymous usage of location-based services through spatial and temporal cloaking. Proceedings of the 1st international conference on Mobile Systems, Applications and Services (pp. 31–42). ACM. https://doi.org/10.1145/1066116.1189037
- Gu, W., Yang, C., & Yi, Y. (2020, May). An access model under cloud computing environment. International Journal of Computational Science and Engineering, 22(2/3), 328–334. https://doi.org/10.1504/IJCSE.2020.107355
- Gupta, R., & Rao, U. P. (2017a, June). A hybrid location privacy solution for mobile lbs. Mobile Information Systems, 2017, 2189646. https://doi.org/10.1155/2017/2189646
- Gupta, R., & Rao, U. P. (2017b, May). An exploration to location based service and its privacy preserving techniques: A survey. Wireless Personal Communications, 96(2), 1973–2007. https://doi.org/10.1007/s11277-017-4284-2
- Gupta, R., & Rao, U. P. (2019, April). VIC-PRO: vicinity protection by concealing location coordinates using geometrical transformations in location based services. Wireless Personal Communications, 107(2), 1041–1059. https://doi.org/10.1007/s11277-019-06316-y
- Jain, N. K., Saini, R. K., & Mittal, P. (2019). A review on traffic monitoring system techniques. In K. Ray, T. Sharma, S. Rawat, R. Saini, & A. Bandyopadhyay (Eds.), Soft computing: Theories and applications. Advances in intelligent systems and computing (Vol. 742). Springer.
- Kido, H., Yanagisawa, Y., & Satoh, T. (2005, July 11–14). An anonymous communication technique using dummies for location-based services. Proceedings of the ICPS5 international conference on Pervasive Services, Santorini, Greece (pp. 88–97). IEEE. https://doi.org/10.1109/PERSER.2005.1506394
- Kong, W., Lei, Y., & Ma, J. (2018). Data security and privacy information challenges in cloud computing. International Journal of Computational Science and Engineering (IJCSE), 16(3), 215–218. https://doi.org/10.1504/IJCSE.2018.091772
- Li, W., Li, G., & Liu, C. (2011, December 3–4). Query-aware anonymization in location-based service. 7th international conference on Computational Intelligence and Security, Sanya, China (pp. 741–745). IEEE. https://doi.org/10.1109/CIS.2011.168
- Lin, J. P., Niu, J. W., Li, H., & Atiquzzaman, M. (2019). A secure and efficient location-based service scheme for smart transportation. Future Generation Computer Systems, 92(2019), 694–704. https://doi.org/10.1016/j.future.2017.11.030
- Liu, L. (2007, September 23–28). From data Privacy to location privacy: Models and algorithms. Proceeding of the 33rd international conference on Very Large Data Bases, Vienna, Austria (pp. 1429–1430). VLDB Endowment.
- Lu, H., Jensen, C. S., & Man, L. Y. (2008, June). PAD: Privacy-area aware, dummy-based location privacy in mobile services. Proceedings of the 2008 ACM international workshop on Data Engineering for Wireless and Mobile Access (pp. 16–23). ACM. https://doi.org/10.1145/1626536.1626540
- Memon, I., Ali, Q., Zubedi, A., & Mangi, F. A. (2017). DPMM: dynamic pseudonym-based multiple mix-zones generation for mobile traveler. Multimedia Tools and Applications, 76(22), 24359–24388. https://doi.org/10.1007/s11042-016-4154-z
- Mitton, N., Papavassiliou, S., Puliafito, A., & Trivedi, K. S. (2012). Combining cloud and sensors in a smart city environment. EURASIP Journal on Wireless Communications and Networking, 2012, 247. https://doi.org/10.1186/1687-1499-2012-247
- Mokbel, M. F., Chow, C., & Aref, W. G. (2007, April 15–20). The new Casper: A privacy-aware location based database server. IEEE 23rd international conference on Data Engineering, Istanbul, Turkey (pp. 1499–1500). IEEE. https://doi.org/10.1109/ICDE.2007.369052
- Moses, J. S., Nirmala, M., & Raj, E. D. (2019). A security ensemble framework for securing the file in cloud computing environments. International Journal of Computational Science and Engineering, 18(4), 413–423. https://doi.org/10.1504/IJCSE.2019.099080
- Nair, S. C., Elayidom, M. S., & Gopalan, S. (2020). Call detail record-based traffic density analysis using global K-means clustering. International Journal of Intelligent Enterprise, 7(1/2/3), 176–187. https://doi.org/10.1504/IJIE.2020.104654
- Niu, B., Li, Q., Zhu, X., Cao, G., & Li, H. (2014, April 27–May 2). Achieving k-anonymity in privacy-aware location-based services. Proceedings of the 2014 IEEE conference on Computer Communications, Toronto, ON (pp. 754–762). IEEE. https://doi.org/10.1109/INFOCOM.2014.6848002
- Parmar, D., & Rao, U. P. (2020). Towards privacy-preserving dummy generation in location-based services. Procedia Computer Science, 171(2020), 1323–1326. https://doi.org/10.1016/j.procs.2020.04.141
- Ren, W., & Tang, S. (2019). EGeoIndis: An effective and efficient location privacy protection framework in traffic density detection. Vehicular Communications, 21(2020), 100187. https://doi.org/10.1016/j.vehcom.2019.100187
- Sakai, K., Seo, T., & Fuse, T. (2019, October 27–30). Traffic density estimation method from small satellite imagery: Towards frequent remote sensing of car traffic. IEEE Intelligent Transportation Systems conference, Auckland, New Zealand (pp. 1776–1781). IEEE. https://doi.org/10.1109/ITSC.2019.8916990
- Shen, N., Jia, C. F., Liang, S., Li, R. Q., & Liu, Z. L. (2017). Approach of location privacy protection based on order preserving encryption of the grid. Journal on Communications, 38(7), 78–88. https://doi.org/10.11959/j.issn.1000-436x.2017146
- Shin, K. G., Ju, X. E., Chen, Z. G., & Hu, X. (2012). Privacy protection for users of location-based services. Wireless Communications, IEEE, 19(1), 30–39. https://doi.org/10.1109/MWC.7742
- Tang, S. Y., Liu, S. L., Huang, X. Y., & Liu, Z. Q. (2019). Privacy-preserving location-based service protocols with flexible access. International Journal of Computational Science and Engineering (IJCSE), 20(3), 412–423. https://doi.org/10.1504/IJCSE.2019.103946
- To, H., Ghinita, G., Fan, L., & Shahabi, C. (2017). Differentially private location protection for worker datasets in spatial crowdsourcing. IEEE Transactions on Mobile Computing, 16(4), 934–949. https://doi.org/10.1109/TMC.2016.2586058
- Wang, J., Cai, Z., Li, Y., Yang, D., Li, J., & Gao, H. (2009). Protecting query privacy with differentially private k-anonymity in location-based services. Personal and Ubiquitous Computing, 22(3), 453–469. https://doi.org/10.1007/s00779-018-1124-7
- Wang, J., Wang, C. R., Ma, J. F., & Li, H. T. (2020). Dummy location selection algorithm based on location semantics and query probability. Journal on Communications, 41(3), 53–61. https://doi.org/10.11959/j.issn.1000-436x.2020061
- Wang, N., Fu, J., Li, J., & Bhargava, B. K. (2019). Source-location privacy protection based on anonymity cloud in wireless sensor networks. IEEE Transactions on Information Forensics and Security, 15, 100–114. https://doi.org/10.1109/TIFS.2019.2919388
- Xia, X. Y., Bai, Z. H., Li, J., & Yu, R. Y. (2019). A location cloaking algorithm based on dummy and Stackelberg game. Chinese Journal of Computers, 42(10), 2216–2232. https://doi.org/10.11897/SP.J.1016.2019.02216
- Zha, H., Xiaoling, Y. I., & Wan, J. L. (2016). Privacy-area aware all-dummy-based location privacy algorithms for location-based services. Proceedings of the 2016 international conference on Network and Communication Security (pp. 1–10). DEStech Transactions on Computer Science and Engineering.
- Zhang, S., Yao, T., Sandor, V., Weng, T., Wei, L., & Su, J. (2021). A novel blockchain-based privacy-preserving framework for online social networks. Connection Science, 33(3), 555–575. https://doi.org/10.1080/09540091.2020.1854181
- Zhang, S. B., Liu, Q., & Wang, G. J. (2018, May). Trajectory privacy protection method based on location obfuscation. Journal on Communications, 39(7), 81–91. https://doi.org/10.11959/j.issn.1000−436x.2018119
- Zhao, P., Li, J., Zeng, F., Xiao, F., Wang, C., & Jiang, H. (2018, January). ILLIA: enabling k-anonymity-based privacy preserving against location injection attacks in continuous LBS queries. IEEE Internet of Things Journal, 5(2), 1033–1042. https://doi.org/10.1109/JIOT.2018.2799545