
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In an intelligent edge network, data owners encrypt data and outsource it to the edge servers to prevent the leakage of data and user information. It is a research issue to achieve efficient search and data update of the ciphertext stored in the edge servers. For the above problems, we construct a fuzzy multi-keyword search scheme based on a two-level tree index, where the first-level tree index stores keyword tags and the second-level stores encrypted file identifiers and counting bloom filters (CBFs). By constructing a two-level tree index, efficient multi-keyword search is realised, and it also has obvious time advantages when performing the single-keyword search. In addition, the proposed scheme supports index updating by introducing the CBF, and it can realise fuzzy search by calculating the inner product between the CBF in index and search trapdoor. At last, the proposed scheme is proved to be semantically secure under the known ciphertext attack model. Theoretical analysis and simulation test indicate that the proposed scheme spends lower computation overhead than other related schemes, especially in the search phase; as the number of matching files or query keywords grows, it costs less time, at around 2–10 ms.
1. Introduction
As mobile devices and the Internet of Things develop, mobile communications have brought huge storage and computing pressure to cloud servers, and some new server models have sprung up, such as an intelligent edge network. Information perception has mushroomed into mobile devices and the Internet of Things. It is a hot point to store and calculate large amounts of data in the intelligent edge network (Hu et al., Citation2021; Mao et al., Citation2017; Zhao et al., Citation2021). Intelligent edge computing can solve the data processing problems of the cloud centre and edge servers, which relieves the computing and storage pressure of the cloud server, but privacy leakage has also become an urgent problem for the intelligent edge (Zhang et al., Citation2021).
In some scenarios, the edge server is honest but curious, so the private data and identity information outsourced to the semi-honest edge servers can not be guaranteed security. Edge servers can process the data as required, but these edge servers are able to record and analyze private information. Data encryption technology has become a common method that can effectively prevent privacy leakage (Ji et al., Citation2021; Zhang et al., Citation2021). However, it cannot support the exact retrieval operation on ciphertext in edge servers. The proposed searchable encryption technology (Dawn et al., Citation2002) realises the purpose of protecting data privacy, and supports authorised users to search for ciphertext in the cloud server.
The data and tasks are processed by the edge server that is close to the data source on the edge computing, and the edge server may be any entity from the data to the data source. The data owner outsources the encrypted data to the edge centre, and the nearest edge server receives the requests and processes the requests locally, which can reduce the computational burden of the edge centre. Besides reducing the processing pressure on the edge centre, problems with data storage can also reduce the possibility of information leakage, namely, storing only secure indexes on the edge servers. In recent years, many researchers have done some excellent work on searchable encryption, which focuses not only on security and efficiency, but also on functionality, especially in the multi-keyword fuzzy search.
We propose a multi-keyword fuzzy search scheme supporting dynamic updates in the intelligent edge network, which solves the problems of encrypted data retrieval and dynamic data updates. The query request is submitted and processed by the nearest edge server, which would reduce the time and avoid information leakage in the transmission process. In addition, our scheme provides secure search services to edge computing, while edge computing speeds up query processing and relieves the pressure on the edge centre. As follows, there are three main contributions to our paper.
We develop a novel two-level tree index based on counting bloom filter (CBF). We put the file identifiers containing the same keyword under the leaf node and generate the CBF for each file identifier node. With the two-level tree index, the proposed scheme can provide a more efficient search service for multi-keywords. In particular, when searching for a single keyword, the proposed scheme only needs to search the first-level index to obtain the results.
We use CBF to realise multi-keyword fuzzy search, what is more, users can set the threshold to control the accuracy of the fuzzy search. Due to the changeability of CBF, we can realise the addition and deletion of CBF in the index. In order to demonstrate that the proposed scheme supports a dynamic update, the correctness of the add and delete operation is proved.
It can be proved that the proposed scheme is semantically secure under the known ciphertext and background models. Moreover, theoretical analysis and simulation results indicate that the proposed scheme has a low overhead in the search phase.
The remainder of this paper is organised as follows. Section 2 introduces the related works. Section 3 gives some preliminaries including 2-gram, Locality-Sensitive Hashing and CBF. Section 4 shows the system model and the security model. Then, we present the details of the proposed scheme in Section 5, and prove the correctness and security of the proposed scheme in Section 6. Section 7 analyzes the performance through theory and experiment. Section 8 presents the conclusions of our scheme.
2. Related work
There are two main methods to achieve fuzzy search at present. One is to pre-generate a set of fuzzy keywords for each keyword, the other is to quantify the similarity of keywords. Xue et al. propose a fuzzy search scheme, which constructs a fuzzy keyword set for each keyword by introducing the cuckoo filter (Xue & Chuah, Citation2015). Ge et al. construct a linked list as the secure index, which generates a fuzzy set for each index vector (Ge et al., Citation2018). Although these two schemes achieve higher search accuracy and search efficiency, the required time and the storage of index generation are huge.
In order to reduce the generation time and storage overhead of indexes, some schemes have been proposed that are dedicated to quantifying the similarity between keywords. These schemes have not only improved the performance in efficiency, but also better performance in security. Chen et al. propose mapping keywords into Bloom Filter, and then calculating the inner product of keywords to quantify the similarity (Chen et al., Citation2020). In addition, the scheme constructs forward and inverted indexes and stores the keywords by Bloom Filter, which improves the search efficiency but does not support dynamic updates. Zhang et al. propose using Tanimoto distance to quantify the similarity between keywords, which employs the word2vec algorithm to construct a fuzzy matching model, but it is only suitable for small data sets (Zhang et al., Citation2020). In addition, Guo et al. propose a similarity search scheme over encrypted non-uniform datasets, which has a higher recall and precision and improves the security by hiding the distribution of the query set (Guo et al., Citation2020). Zhang et al. propose measuring the degree of keywords similarity by edit distance, which controls accurate search results by threshold (Zhang et al., Citation2021). However, Zhang’s scheme needs a private cloud to rank the search result. Liu et al. realise the approximate keyword matching by exploiting the indecomposable property of primes and the extended scheme realises the semantic search by calculating the matrix multiplication between keywords (Liu et al., Citation2021). Because this scheme constructs an index matrix for each document, it cost a lot in the index generation.
In order to resolve the dynamic update, Liu et al. propose a verifiable searchable encryption and construct a two-keyword index to realise a dynamic update (Liu et al., Citation2018). However, this scheme needs to determine the authorised user set in the initialisation and cannot authorise users in subsequent phases. Wang et al. propose a fuzzy searchable encryption that constructs a dynamic index by pseudo-random padding and realise fuzzy search by extended fuzzy Bloom Filter, which realises querying in high-dimensional data (Wang et al., Citation2018). Wang et al. put forward a dynamic and verifiable search scheme, which achieves dynamic updates by adding and deleting tree-index nodes and constructs Merkle tree to check the completeness and correctness of results (Wang et al., Citation2020). However, the establishment and updating of the Merkle tree entail much time. Li et al. propose a dynamic searchable symmetric scheme, in which the original documents’ index needs no change during the update processes so that the cost of updating process is constant (Li et al., Citation2020). However, this scheme requires a re-encryption operation, which takes up a certain amount of overhead.
In short, the existing fuzzy multi-keyword search schemes are difficult to achieve dynamic updates under the premise of ensuring high efficiency and security. Subsequently, we develop an efficient multi-keyword fuzzy search scheme that supports a dynamic update.
3. Preliminaries
3.1. 2-gram
is a technique for dividing a given string into sequences of segments of length (Gervás, Citation2016; Lavanya et al., Citation2020). Our scheme chooses
,which cuts the keyword into strings of 2 characters long. For example, for the keyword “search”, the
sequence is
. Then, store the sequence in an array of size
.
The first and second bits of each element in the sequence, according to the alphabetical order, set the corresponding row and column of the matrix to 1. Finally, the binary sequence is converted into a dimensional matrix. For example, in the element “se”,
is the nineteen in alphabetical order and
is the fifth; then we set the nineteen row and the fifth column of the matrix to 1. Following the method, a keyword is converted into a matrix.
3.2. Locality-sensitive hashing
Locality-sensitive hashing (LSH) (Wong et al., Citation2009) is a text similarity measurement algorithm that can select a similar element from a lot of elements. LSH is able to map similar parameters into the same bucket quite probabilistically. A LSH hash function family is
and is defined as follows:
If ,
;
If ,
.
where denotes the distance between
and
,
and
denote distance thresholds, and
and
denote probability thresholds. LSH has many application scenarios, such as
distribution. Our scheme uses a
distribution LSH, and it is defined as follows:
(1)
(1) where
is a vector and
is randomly selected from
,
. The
LSH family puts similar vectors into the same bucket, then realises separating similar vectors from other vectors.
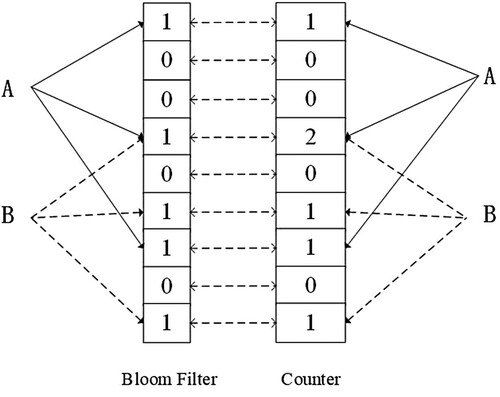
3.3. Counting bloom filter
Bloom filter (BF) (Lavanya et al., Citation2020) is a set composed of m-bit array, which is used to detect whether an item belongs to the group by mapping it to the binary vector via hash functions. As shown in Figure , CBF (Lavanya et al., Citation2020; Wu et al., Citation2021) is a data structure based on the Bloom Filter, which expands a counter for each bit in the BF. To determine whether an item belongs to the group, the item needs to be processed by
hash functions. As long as the values of the corresponding position are not all 1, the element does not belong to the set. If the values of the corresponding position are all 1, there are two cases: the item belongs to the group or it is a false positive problem. The probability of the false positive case is approximately
, where
represents the number of hash functions,
represents the number of inserted keywords and
represents the number of bits of Bloom filter. As shown in Figure , when an item
is inserted, if
and
are mapped to the same position by hash functions, the value of the corresponding position counter is increased by 1. When an element is deleted, the value of the corresponding position counter is decreased by 1.
Figure 1. Counting bloom filter.
4. Problem formulation
4.1. System model
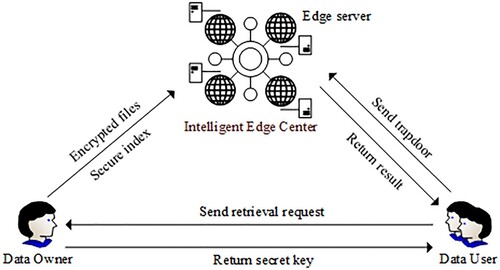
Figure shows the system model; the system is composed of three different entities: data owner, data user and the edge network. First, the data owner extracts the keyword set from the file set and encrypts the local files, then outsources them to the edge centre. At the same time, the data owner constructs a secure index of keywords and files and uploads it to the edge network. Second, the data user submits the search trapdoor to the nearest edge server, and the edge server performs the search operation. Then, the edge server requests the corresponding encrypted documents from the edge centre to send to the data user. Finally, the data user uses the symmetric key to decrypt the ciphertext result returned by the edge server.
Figure 2. System model of the intelligent edge server.
4.2. Security model
It is assumed that in the scenario, the edge server is honest but curious, which means that the edge server will honestly execute every step of the algorithm, but it would record and leak file content, keywords and other information. In view of the need for privacy protection, two main threat models are analyzed as follows (Qi et al., Citation2020).
Known ciphertext model: The edge server can only know and record encrypted files, secure indexes, search trapdoors and search results.
Known background model: The edge server can obtain additional background information, such as the correlation of two search trapdoors. Through analyzing the correlation relationship on a large scale, the edge server can infer the keywords in a query.
When the adversary knows the size of the file set
, the number of keywords
, the inner product of the search trapdoor and the index and the encrypted file
, a simulated game between a simulator
and an adversary
is used to prove that the scheme is secure. We define a leakage function to describe the leakage situation and the leakage function is defined as
. As follows, the simulation game is defined.
: Challenger
initialises the system, then adversary
sends file set
to the challenger
. According to the encryption algorithm, the challenger
generates the security index
and the encrypted file
, then sends them to
. Adversary
performs a polynomial number of queries
, and then the challenger
generates a trapdoor
for each query
and sends them to
. Finally, adversary
outputs
,
and
, where
.
: The adversary
outputs file set
and gives a leak function
. The simulator
generates indexes
and encrypted file set
, then sends them to the adversary
. When receiving
and
,
performs a polynomial number of queries
. Based on the leak function
, the simulator
returns the corresponding search trapdoor
for each query
, and sends them to the adversary
. Finally, adversary
outputs
,
and
, where
.
5. Construction of the scheme
5.1. Overview
In this section, we construct a multi-keyword fuzzy search scheme with a dynamic update, which is based on a two-level tree and CBF. In addition, the files uploaded by the data owner are encrypted by symmetric encryption. We encrypt the files by the AES encryption algorithm with a 256-bit key, which ensures that the encrypted files are secure.
5.2. Scheme detail
Our scheme is constructed by six polynomial-time algorithms, i.e. ,
,
,
,
, and
. The detailed structure of the scheme is as follows.
: The data owner generates two random invertible matrices
For each keyword
If
If
If
If
Choose threshold
If , it means the match is successful. For each
, the edge server decrypts
to gain the file identifier
by
, i.e.
and returns the encrypted file to the set
in line with
. Finally, the edge server returns
to the data user.
Figure 3. Two-level tree index.
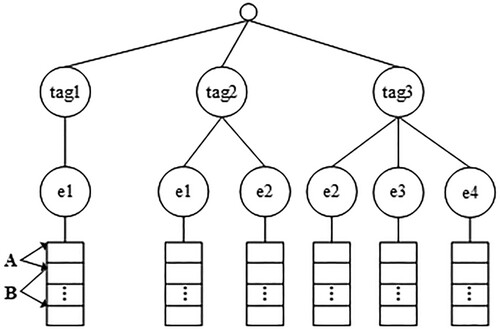
Analogously, when deleting the file , the data owner extracts keywords
from
, where
represents the keyword set only existing in
and
means the keyword set existing in several files. For each
, the data owner deletes all the child nodes which belong to the keyword tag
converted from
. For each
, the data owner deletes
and the corresponding CBF which is under
converted from
. Similarly, the edge server deletes the index generated by deletion operation from the existing index and then obtains the new index.
6. Theoretical analysis
6.1. Correctness analysis
Since CBF is used when constructing the index and the search trapdoor, it can well support the keyword update. Taking the adding operation as an example, the index that is generated by adding operation is added to the leaf nodes of the two-level tree index to generate an updated encrypted index. Here, it is proved that CBF supports keywords update. The specific analysis process is as follows.
(3)
(3)
If , then
,
,
, and then
(4)
(4)
If , then
,
,
, so
, and then
(5)
(5)
is the result of mapping updating keywords and existing keywords to CBF, which is equal to the index of the updated CBF. It can be deduced that traversing
, the final result is
.
Similarly, it can be proved that when the data owner deletes the file, the result is also true. It can be seen that the index constructed by CBF can realise the addition and deletion of keywords.
6.2. Security analysis
Theorem 6.1:
Since is a secure pseudo-random function, the proposed scheme is semantically secure under the known ciphertext model. The edge server only knows the number of keywords and files, as well as the inner product of the search trapdoor and the secure index and encrypted files. Except for these, the edge server cannot obtain other information.
Proof:
In order to prove Theorem 6.1, we imitate a simulator that cannot be distinguished from the actual scheme. As follows, the secure game between adversary
and challenger
is defined under the known ciphertext model.
Simulated encrypted file set
Simulated secure index
Initialised
For each
For each
Simulated search trapdoor
As tries to analyze the ciphertext, index, and search trapdoor to win the game,
represents the advantage of
to distinguish between encrypted files and simulated encrypted files,
represents the advantage of
to distinguish between the real index and simulated indexes, and
represents the advantage of
to distinguish between real search trapdoors and simulated search trapdoors. The probability advantage that
can win the game is defined as follows.
(6)
(6)
Let , then get
. Since
,
and
are negligible,
is negligible. For an arbitrary polynomial-time adversary, because
and
are indistinguishable, the scheme meets the semantic security under the known ciphertext model.
Theorem 6.2:
Since is a secure pseudo-random function and KNN encryption is secure, the proposed scheme is semantically secure under the known background model.
Proof :
Under the known background model, we allow the edge servers to record and analyze some query trapdoors. Edge servers analyze the connection between trapdoors by observing the trapdoors that have been collected. When the user submits the same query twice, there is a high probability of selecting different keywords to generate keyword tags, which will cause the different values of CBF generated by the two queries. In addition, in the trapdoor generation phase, the different random values will be chosen for KNN encryption, so the different trapdoors for the same query will be generated. Any PPT adversary cannot perform linear analysis of the KNN encryption algorithm. Therefore, the trapdoors cannot be linkable, which ensures that edge servers cannot analyze whether the queries are identical or not (Xiao et al., Citation2020). It is demonstrated that the proposed scheme is semantically secure under the known background model.
7. Performance analysis
7.1. Theoretical analysis
As shown in Table , we compare the proposed scheme with Chen's scheme, Fu's scheme and Zhong's scheme in function realisation and the computation cost (Chen et al., Citation2020; Fu et al., Citation2017; Zhong et al., Citation2020). Chen's scheme can support fuzzy search, but not realise dynamic updates. Fu's and Zhong's schemes implement fuzzy search and dynamic update, but the efficiency is lower than the proposed scheme.
Table 1. Function and performance comparison.
In the comparison of the computation cost, indicates the number of files,
represents that all files are traversed once,
represents the number of keywords extracted from each file,
represents the time of LSH operation,
represents the time used to execute symmetric encryption once and
represents the time used to establish a Bloom Filter.
denotes the time required to establish CBF once, where
is slightly larger than
.
denotes the average number to perform a depth-first search.
represents the time used to calculate the correlation of a keyword and a file,
represents the time used to calculate the inner product once,
denotes the number of query keywords, and
denotes the average value of files containing the same keyword,
.
In the index generation, Fu's scheme requires LSH to deal with all keywords, computes the relevance score of each keyword and the files, and then generates one Bloom Filters for each file. Chen's scheme uses LSH to generate keyword tags for each keyword, and all tags should execute symmetric encryption, and then it needs to generate Bloom Filter for each file. For Zhong's scheme, it needs to calculate the relevance of keywords and documents to realise top-k search, which consumes some extra time of index generation. Our scheme is similar to Chen's, but we use CBF in the index generation stage. As is slightly larger than
, the cost of our scheme's index is slightly larger than Chen's. However, CBF supports a dynamic update, so it is worth sacrificing less time overhead to get the update function.
In generating search trapdoors, both Fu's and Zhong's schemes perform LSH operations on each query keyword, map the query to BF, and calculate the relevance score for the query keyword. In Chen's scheme, if a user queries a single keyword, the scheme only needs to generate a keyword tag for that keyword; if the user queries multiple keywords, the scheme needs to perform LSH operations on all keywords and generate a BF. Our scheme is similar to Chen's scheme, except that we utilise CBF instead of BF.
In the search phase, Fu's scheme needs to compute the inner product of the trapdoor's BF and all files that require a large computational cost. Chen's scheme requires times symmetric decryption operation in the first level of the index, and traverses
times to find the corresponding file identifier, and then performs the inner product calculation of the trapdoor's BF and the index's BF. Zhong's scheme computes the inner product of trapdoor's BF and index's according to the depth-first strategy. In the proposed scheme, when querying a single keyword, the edge server searches all file identifiers under the tag, and the calculation cost is constant. When querying multiple keywords, the edge server only needs to calculate
times the inner product of the index's CBF and trapdoor's CBF.
In the update phase, Fu's and Zhong's schemes need to perform LSH operations for the keywords that are added or deleted from the file and calculate the correlation score between keywords and the file. Our scheme needs to perform LSH operation for the keywords of adding or deleting files, generating CBF and encrypting the file identifier of the file. Therefore, the calculation cost of the update phase of our scheme is lower than that of Fu's scheme.
In summary, from the five aspects of index generation, trapdoor generation, search phase, dynamic update, and function, there exist obvious advantages for the proposed scheme in functionality and efficiency.
7.2. Experimental analysis
7.2.1. Efficiency
Through the above-mentioned theoretical analysis, the proposed scheme has obvious advantages in the comprehensive performance of function and efficiency. To assess the efficiency more accurately, we compare our scheme with Fu's scheme, Chen's scheme and Zhong's scheme in aspects of index generation, trapdoor generation and search phase.
The data set used in the experiment contains 129,000 abstracts describing the NSF basic research awards from 1990 to 2003. Total 3000 abstracts are selected as experimental data; moreover, stop words are moved by using the NLTK library. Extract the most frequent keywords from each file, and repeat each experiment 10 times, and then take the average of each result as the final experimental result. The scheme simulation in our paper is implemented by Pycharm. The experimental results are obtained by using Python language on a Windows10 server with a Core12 CPU running at 3.0 GHz.
Figure (a) shows the changing trend of index generation time with the number of files. We extract 10 keywords from each file because the time of the index construction is related to the number of extracted keywords. It is shown that under the same number of files, our scheme spends less time to build an index than Fu's and Zhong's schemes. In addition, when the number of files increases, the rate of increase in index generation time is much slower than that of Fu's and Zhong's schemes. Note that although the cost of index generation in our scheme is slightly higher than Chen's, we implement the dynamic update of files in the edge server.
Figure 4. Time consumption of index generation, trapdoor generation and search. (a) Index generation time. (b) Trapdoor generation time. (c) The search time of different sizes of files. (d) The search time of different sizes of keywords. (e) The search time of different sizes of extracted keywords. (f) The search time of different sizes of files under a single keyword.
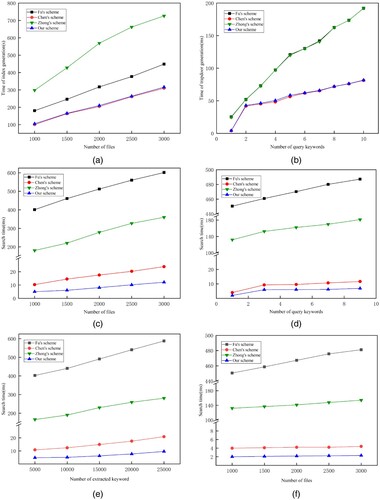
Figure (b) shows the changing trend of trapdoor generation with the number of query keywords. Fu's and Zhong's schemes need to generate BF for query keywords, perform LSH operation, and calculate the relevance score of each keyword, which costs large amounts of time. Our scheme and Chen's are extremely efficient when generating single-keyword trapdoors. As the number of query keywords increases, the time-consuming growth of our scheme is slow, but the time of Fu's scheme is growing rapidly. Especially when the user queries 10 keywords, the trapdoor generation process takes over three-fourths less time than Fu’s scheme.
Since our scheme is based on the two-level tree index generated by all files, the elements affecting the search time include the number of files, query keywords and extracted keywords, so these factors are respectively analyzed by experiments. Figure (c) shows the changing trend of search time with the number of files. Each file extracts 10 keywords and queries 3 keywords. Fu's scheme spends about 400 ms, when the number of files is 1000. As to Zhong's scheme, it spends about 180 ms by depth-first search. When searching the same number of files, Chen's scheme needs 10 ms, while our scheme only takes about 5 ms. What is more, in our scheme, as the number of files grows, the search time increases very slowly. Figure (d) shows the search time with the changing trend of the query keywords; 1500 files are searched, and 10 keywords are extracted from each file. When searching a single keyword, Fu's and Zhong's schemes follow a multi-keyword approach, while Chen's scheme needs about 4 ms and our scheme only takes about 2 ms. When searching multi-keywords, the search time of our scheme remains relatively stable, despite the increase in search keywords. Figure (e) shows the search time with the increase of extracted keywords. As the number of extracted keywords increases, the results matched to the first-level index will also increase. It can be clearly seen that the search time of our scheme grows linearly and slowly. In addition, the search time of our scheme is much lower than that of Fu's and Zhong's schemes, and grows slower than Chen's scheme. Figure (f) presents the search time when querying a single keyword. The search time of our scheme is constant and hardly affected by the number of files. Compared with Chen's scheme, the efficiency of our scheme is higher, because it does not need decryption after the first-level index.
Based on the above analysis, the actual performance of our scheme is consistent with the theoretical performance analysis. Compared with Fu's and Zhong's schemes, our scheme has higher efficiency in index generation, trapdoor generation, search phase and update phase. Compared with Chen's scheme, although index generation efficiency is not dominant, our scheme has more advantages in terms of search efficiency, which is demonstrated by the experiment above. In addition, the extra time consumed in the index generation is worth it, because it reserves space for building CBF to enable dynamic updates. Therefore, the proposed scheme has obvious advantages in aspects of the function and performance.
7.2.2. Result accuracy
Since the proposed scheme supports fuzzy search, we have to consider the accuracy of search results. The precision is used to represent the accuracy of search results and
, where
represents the true positive and
represents the false positive. To obtain fuzzy keywords, some keywords are selected randomly and modified.
For the proposed scheme, there are two factors that affect the result accuracy. One is the number of query keywords, and the other is the threshold in the trapdoor. We set
, where
represents the number of hash functions and
represents the number of query keywords. Figure shows the precision of search results. For exact search, when the number of query keywords is from 1 to 10, the precision gradually declines slightly from 100% to 93% due to the occurrence of false positives. For fuzzy search, when searching one keyword, the precision can reach up to 91% which is higher than that of multi-keyword, because it is not affected by the false positive. When two keywords are searched, the precision decreases because of the dual effect of false positives and LSH mapping. When the number of query keywords is from 2 to 10, the precision slowly increases from about 85% to 89%. Because as the number of query keywords increase, the impact of the false positive generated by fuzzy keywords will decrease.
Figure 5. The precision of the different number of query keywords.
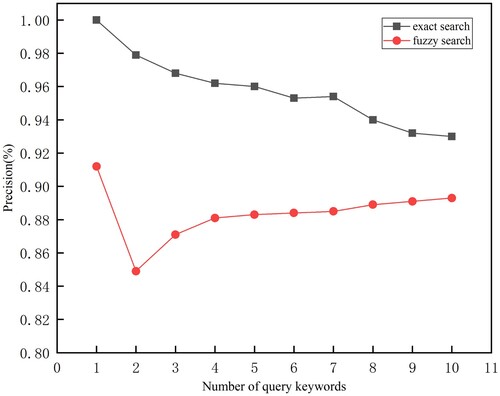
Based on the above analysis, the proposed scheme could meet the precision demand of searching in an intelligent edge network.
8. Conclusion
In the paper, we focus on how to realise multi-keyword fuzzy search in the case of data encryption protection in an intelligent edge server. First of all, based on the existing technology, we construct a two-level tree index and CBF, which not only realises multi-keyword fuzzy search, but also guarantees the search efficiency and supports the dynamic update of the edge server. Secondly, we prove the correctness and security under the honest and curious edge server model. Finally, we make comparisons in terms of the function and efficiency, and then carry out simulation to prove that our scheme has certain advantages.
Acknowledgements
The authors would like to thank the various Funding Agencies for their strong financial support. In addition, the authors would like to thank the editors and the reviewers of connection science for providing such an opportunity.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chen, J., He, K., Deng, L., Yuan, Q., Du, R., Xiang, Y., & Wu, J. (2020). EliMFS: Achieving efficient, leakage-resilient, and multi-keyword fuzzy search on encrypted cloud data. IEEE Transactions on Services Computing, 13(6), 1072–1085. https://doi.org/10.1109/TSC.2017.2765323
- Dawn, X., Wagner, D., & Perrig, A. (2002). Practical techniques for searches on encrypted data. IEEE Symposium on Security & Privacy.
- Fu, Z., Wu, X., Guan, C., Sun, X., & Ren, K. S. (2017). Toward efficient multi-keyword fuzzy search over encrypted outsourced data with accuracy improvement. IEEE Transactions on Information Forensics and Security, 11(12), 2706–2716. https://doi.org/10.1109/TIFS.2016.2596138
- Ge, X., Yu, J., Hu, C., Zhang, H., & Hao, R. (2018). Enabling efficient verifiable fuzzy keyword search over encrypted data in cloud computing. IEEE Access, 6, 45725–45739. https://doi.org/10.1109/ACCESS.2018.2866031
- Gervás, P. (2016). Constrained creation of poetic forms during theme-driven exploration of a domain defined by an N-gram model. Connection Science, 28(2), 111–130. https://doi.org/10.1080/09540-091.2015.1130024
- Guo, C., Liu, W., Liu, X., & Zhang, Y. (2020). Secure similarity search over encrypted Non-uniform datasets. IEEE Transactions on Cloud Computing, PP(99), 1–1. https://doi.org/10.1109/TCC.2020.300-0233
- Hu, J., Liang, W., Hosam, O., Hsieh, M.-Y., & Su, X. (2021). 5GSS: A framework for 5G-secure-smart healthcare monitoring. Connection Science, 1–23. https://doi.org/10.1080/09540091.2021.1977243
- Ji, H., Zhang, H., Shao, L., He, D., & Luo, M. (2021). An efficient attribute-based encryption scheme based on SM9 encryption algorithm for dispatching and control cloud. Connection Science, 33(4), 1094–1115. https://doi.org/10.1080/09540091.2020.1858757
- Lavanya, V., Ramasubbareddy, S., & Govinda, K. (2020). Fuzzy keyword matching using N-gram and cryptographic approach over encrypted data in cloud. Embedded Systems and Artificial Intelligence.
- Li, H., Yang, Y., Dai, Y., Yu, S., & Xiang, Y. (2020). Achieving secure and efficient dynamic searchable symmetric encryption over medical cloud data. IEEE Transactions on Cloud Computing, 8(2), 484–494. https://doi.org/10.1109/TCC.2017.2769645
- Liu, Q., Peng, Y., Wu, J., Wang, T., & Wang, G. (2021). Secure multi-keyword fuzzy searches with enhanced service quality in cloud computing. IEEE Transactions on Network Service Management, PP(99), 1–1. https://doi.org/10.1109/TNSM.2020.3045467
- Liu, X., Yang, G., Yi, M., & Deng, R. (2018). Multi-user verifiable searchable symmetric encryption for cloud storage. IEEE Transactions on Dependable and Secure Computing, 17, 1322–1332. https://doi.org/10.1109/TDSC.2018.2876831
- Mao, Y., You, C., Zhang, J., Huang, K., & Letaief, K. B. (2017). A survey on mobile edge computing: The communication perspective. IEEE Communications Surveys & Tutorials, 19, 2322–2358. https://doi.org/10.1109/COMST.2017.2745201
- Qi, C. A., Kai, F. A., Kz, B., Hw, A., Hui, L. A., & Yy, C. J. C. C. (2020). Privacy-preserving searchable encryption in the intelligent edge computing. Computer Communications, 164, 31–41. https://doi.org/10.1016/j.comcom.2020.09.012
- Wang, H., Fan, K., Li, H., & Ya Ng, Y. (2020). A dynamic and verifiable multi-keyword ranked search scheme in the P2P networking environment. Peer-to-Peer Networking and Application, 13(1), 16. https://doi.org/10.1007/s12083-018-0715-4
- Wang, Q., He, M., Du, M., Chow, S., Lai, R., & Zou, Q. J. I. T. o. D. (2018). Searchable encryption over feature-rich data. IEEE Transactions on Dependable & Secure Computing, 15(3), 496–510. https://doi.org/10.1109/TDSC.2016.2593444
- Wong, W., Cheung, D., Kao, B., & Mamoulis, N. (2009). Secure kNN computation on encrypted databases. ACM Sigmod International Conference on Management of Data, Rhode Island, USA, June 29 - July 2, 2009.
- Wu, X., Gao, J., Ji, G., Wu, T., Tian, Y., & Al-Nabhan, N. (2021). A feature-based intelligent deduplication compression system with extreme resemblance detection. Connection Science, 33(3), 576–604. https://doi.org/10.1080/09540091.2020.1862058
- Xiao, T., Han, D., He, J., Li, K. C., & Mello, R. J. C. S. (2020). Multi-keyword ranked search based on mapping set matching in cloud ciphertext storage system. Connections: A Journal of Language, Media and Culture, 1(1), 1–18. https://doi.org/10.29173/connections10
- Xue, Q., & Chuah, M. C. (2015). Cuckoo-filter based privacy-aware search over encrypted Cloud data. 2015 11th International Conference on Mobile Ad-hoc and Sensor Networks (MSN), Shenzhen, China, 16-18 Dec. 2015.
- Zhang, H., Zhao, S., Guo, Z., Wen, Q., Li, W., & Gao, F. (2021). Scalable fuzzy keyword ranked search over encrypted data on hybrid clouds. IEEE Transactions on Cloud Computing, 1–1. https://doi.org/10.1109/TCC.2021.3092358
- Zhang, M., Chen, Y., & Huang, J. (2020). SE-PPFM: A searchable encryption scheme supporting privacy-preserving fuzzy multikeyword in cloud systems. IEEE Systems Journal, 15, 2980–2988. https://doi.org/10.1109/JSYST.2020.2997932
- Zhang, S., Yao, T., Arthur Sandor, V. K., Weng, T.-H., Liang, W., & Su, J. (2021). A novel blockchain-based privacy-preserving framework for online social networks. Connection Science, 33(3), 555–575. https://doi.org/10.1080/09540091.2020.1854181
- Zhao, H., Yao, L., Zeng, Z., Li, D., Xie, J., Zhu, W., & Tang, J. (2021). An edge streaming data processing framework for autonomous driving. Connection Science, 33(2), 173–200. https://doi.org/10.1080/09540091.2020.1782840
- Zhong, H., Li, Z., Cui, J., S, Y., & Liu, L. (2020). Efficient dynamic multi-keyword fuzzy search over encrypted cloud data. Journal of Network and Computer Applications, 149(1), 102469. https://doi.org/10.1016/j.jnca.2019.102469