
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Entity and relation extraction has been widely studied in natural language processing, and some joint methods have been proposed in recent years. However, existing studies still suffer from two problems. Firstly, the token space information has been fully utilized in those studies, while the label space information is underutilized. However, a few preliminary works have proven that the label space information could contribute to this task. Secondly, the performance of relevant entities detection is still unsatisfactory in entity and relation extraction tasks. In this paper, a new model GANCE (Gated and Attentive Network Collaborative Extracting) is proposed to address these problems. Firstly, GANCE exploits the label space information by applying a gating mechanism, which could improve the performance of the relation extraction. Then, two multi-head attention modules are designed to update the token and token-label fusion representation. In this way, the relevant entities detection could be solved. Experimental results demonstrate that GANCE has better accuracy than several competitive approaches in terms of entity recognition and relation extraction on the CoNLL04 dataset at 90.32% and 73.59%, respectively. Moreover, the F1 score of relation extraction increased by 1.24% over existing approaches in the ADE dataset.
1. Introduction
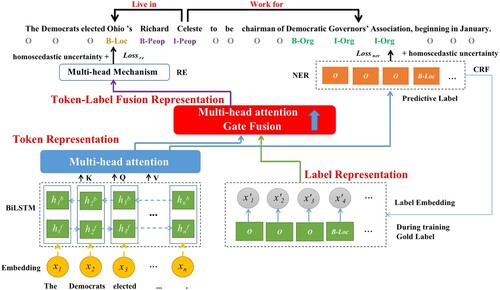
Entity recognition (NER) (Yang et al., Citation2018) and relation extraction (RE) (Liu et al., Citation2015; Zhao et al., Citation2021a) are two important tasks in text mining. When a sentence is given, the entities and their types are detected first by entity recognition. Take the sentence in Figure as an example, “Richard” and “Celeste” are two entities with type People(Peop), and “Ohio” is another entity with type Location(Loc). Then, the semantic relationships between the entities will be determined by relation extraction. For example, there is a “Live in” relation between entities in Figure . In this way, the relationship structure of entities in unstructured texts can be obtained automatically (Liu et al., Citation2019; Sharma et al., Citation2020; Zhao et al., Citation2020). Accordingly, entity recognition and relation extraction play essential roles in information extraction (IE). Besides, they are enablers for other natural language processing tasks, such as knowledge base population (Viswanathan et al., Citation2015), information retrieval (Chen et al., Citation2015), and question answering (Yih et al., Citation2016).
Figure 1. An sentence example from the CoNLL04 dataset.

At first, NER and RE are generally organised as two successive subtasks. A major disadvantage of such an approach is that errors can propagate and spread across subtasks. Specifically, errors generated in NER could be propagated to RE (Li et al., Citation2017). Another disadvantage is that the correlations between two subtasks are ignored, while these correlations may benefit the coordination between these two subtasks. Recently, joint models have been put forward to realise NER and RE simultaneously (Li et al., Citation2017; Nayak & Ng, Citation2020; Xiao et al., Citation2020), which merge these two subtasks into an individual task. In other words, for an input, joint models extract the entities and relations in the input text simultaneously. Therefore, the above two disadvantages can be eliminated in the joint models. Such models have achieved gratifying results. Miwa and Bansal (Citation2016), Katiyar and Cardie (Citation2017), Bekoulis et al. (Citation2018a), Nguyen and Verspoor (Citation2019) and Eberts and Ulges (Citation2019). However, we notice that two limitations still exist in those models:
Little work has been done to utilise label information in the joint model. However, the entity types contained in the label information play an important role in RE. To our best knowledge, few studies make sufficient use of label space information in their joint model. Some exceptions are Miwa and Bansal (Citation2016), Bekoulis et al. (Citation2018a) and Wan et al. (Citation2021), which fuse label space information in their model by simple feature concatenation. Those works are beneficial attempts that prove the positive contribution of label information to the joint extraction task.
Several RNN- and CNN-based models, such as tree-LSTM structured model (Miwa & Bansal, Citation2016) and globally normalised CNN-model (Adel & Schütze, Citation2017), are proposed to realise the joint extraction task. Furthermore, Bekoulis et al. (Citation2018a) regards the joint extraction as a multi-head selection problem and proposes a multi-head model. Wadden et al. (Citation2019) extract global features of context to extend graph neural network (GNN) for the joint task. In these models, all entities in the sentence are treated equally. However, the importance of each entity in the joint extraction task is different. In this case, noises will likely be introduced into the model if all entities are used indiscriminately, especially for the multi-head model.
To address these two limitations, a novel end-to-end joint entity and relation extraction model, called Gated and Attentive Network Collaborative Extracting (GANCE), is proposed in this paper.
Firstly, the label information is exploited in GANCE, and then a gating mechanism is applied to fuse token and label information dynamically. In this way, the entity types in label information are utilised by GANCE and benefit the performance of relation extraction.
Secondly, a multi-head attention module is designed to capture the attention weight between tokens. Then, another multi-head attention module is used to refine the attention weight after the label information is integrated by gating. Based on these two-layer multi-head attention modules, the relevance of the entities can be extracted and the potential relevant entities can be detected. Since the relevant entities could conduce to the RE task (Zhao et al., Citation2021a), it is anticipated that GANCE could achieve better performance on RE than the existing models.
Finally, the correctness and feasibility of the proposed GANCE are validated based on two public datasets, i.e, CoNLL04 and ADE. Furthermore, the comparison results between several competitive approaches and GANCE show that GANCE could achieve better performance.
2. Related work
2.1. Entity and relation extraction
Early entity and relation extraction are mostly configured as two subtasks. Then two models (NER model and RE model) are designed to solve the two subtasks in pipeline way (Chan & Roth, Citation2011; Miwa et al., Citation2009; Nadeau & Sekine, Citation2007). Yang and Cardie (Citation2013) and Miwa and Sasaki (Citation2014) propose the joint extraction model. However, early joint models involve non-trivial feature engineering and rely heavily on NLP tools.
Recently, with the development of deep learning, joint models tend to adopt RNN-based and CNN-based structures to skip feature engineering (Alberto, Citation2018; Chiang et al., Citation2019; de Jesús Rubio, Citation2009; de Rubio, Citation2020; Furlán et al., Citation2020; Islas et al., Citation2021; Lin et al., Citation2020; Shen et al., Citation2021). Miwa and Bansal (Citation2016) design a bidirectional tree-structured RNNs model, which makes full use of dependency tree and word sequence information to extract relationships between entities. Wang et al. (Citation2016) propose multi-level attention CNNs to extract relations. Similarly, Katiyar and Cardie (Citation2017) introduce a traditional attention model to extract relations. Li et al. (Citation2019) design a multi-round problem method for entity and relation extraction. This method applies BERT as the core model and achieves promising performance on multiple datasets. Bekoulis et al. (Citation2018b) propose a multi-head mechanism to predict multiple relationships. However, it requires manual feature extraction and the assistance of external tools. Bekoulis et al. (Citation2018b) encode the whole sentence by a BiLSTM. Then the output is fed into a multi-head mechanism.
2.2. Label space information
The information extraction problem can be regarded as a sequence labelling problem, which will generate label space information (label information for short). Sequence labelling aims to give a label to each element in the sequence. In general, in NLP, a sequence refers to a sentence, and an element refers to a word in the sentence. Named Entity Recognition (NER) is a subtask of information extraction, which needs to locate and classify elements. For NER, its label information includes the locations and types of elements. In this paper, the BIO joint tagging method is used to tag each element with “B-X”, “I-X”, or “O”. Where “B-X” indicates the beginning of the element of type X, “I-X” indicates the middle position of the element of type X, and “O”indicates that the element does not have a type. As the entity “Richard Celeste” shown in Figure , “Richard” is labelled as “B-Peop” since it is the first element of the entity with the type name. Then “Celeste” is labelled as “I-Peop”. Since “Celeste” is followed by a word labelled “O”, it can be inferred that “Celeste” is the end boundary of this entity.
Some studies have proved that label space information does play a positive role in entity relation extraction. To facilitate zero-shot learning, label space information is first applied to computer vision (Zhang & Saligrama, Citation2016). Recently, label information has been widely used in other NLP tasks. Yu et al. (Citation2019) apply label space information to text classification task, Bekoulis et al. (Citation2018b) and Miwa and Bansal (Citation2016) has utilised the label information by simple feature concatenation in their RE model, Wang et al. (Wang et al., Citation2021) proposes a new method to eliminate the different treatment on the two sub-tasks' (i.e. entity detection and relation classification) label spaces, and a unified label space is used for entity relation extraction. Previous studies have proved that label space information plays a positive role in entity relation extraction.
2.3. Relevant entity
In other words, the stronger the correlation between two entities, these two entities are more likely to be relevant entities, which further indicates there may be a relationship between them. For example, assuming A is an entity with type “Location”, B is an entity with type “people”, and C is an entity with type “ organisation”. Compared with A and C, A and B would have a stronger correlation for the “Live in” relationship than that of A and C. Therefore, there is a greater possibility of A and B having a “Live in” relationship in one sentence.
Based on this observation, we use the attention mechanism to capture the correlation between entities and potential relevant entities, which is helpful to our entity relation extraction. In addition, the traditional neural network model can only learn the close-distance relevant entities, it is difficult to capture long-distance relevant entities. Hence, a multi-head attention mechanism is used in GANCE to solve this problem.
3. The GANCE model
This section provides the detailed design of GANCE. The overall flowchart of GANCE is illustrated in Figure . Firstly, token representation is obtained by a BiLSTM and a multi-head attention module (Section 3.1.1). Then, a low-dimension label representation is obtained by randomly initialised vectors (Section 3.1.2). Next, a gating mechanism and another multi-head attention module are carefully designed to fuse and update the token and label representation (Section 3.2). Meanwhile, conditional random field (CRF) (Lafferty et al., Citation2002) and multi-head mechanism (Bekoulis et al., Citation2018a) are employed as the decoding module for NER and RE, respectively (Section 3.3). Lastly, the training and inference processes are described (Section 3.4).
Figure 2. The overall flowchart of GANCE. Token representation is first obtained by a BiLSTM and a multi-head attention module. Then, a low-dimension label representation is obtained by embedding. Next, a gating mechanism and another multi-head attention module are carefully designed to fuse token and label information.
3.1. Token and label representation
3.1.1. Token representation
Word-level Encoder: Recently, distributed feature representation has been widely used in NLP, especially for the deep learning methods (Luo et al., Citation2018). Based on distributed feature representation, the discrete words in a sentence can be mapped into continuous input embeddings. In this paper, word embedding, character embedding, and ELMO embedding (Peters et al., Citation2018) are utilised and concatenated as the final embedding. Accordingly, given a sentence as a sequence of tokens, each token
is mapped into a real-valued embedding
. This embedding representation implies the semantic and syntactic meanings of the token. Therefore, the sequence W is transformed into a set of embedding vectors. Then, a BiLSTM is utilised to encode those embedding vectors. Denote the embedding vectors of sequence W as
, where
is the length of the sentence. The BiLSTM takes X as input, as shown in Equations (Equation1
(1)
(1) )–(Equation2
(2)
(2) ).
(1)
(1)
(2)
(2) Afterwards, the outputs of the forward and backward LSTM at each timestep are concatenated as the output H of the BiLSTM, as shown in equation(3).
(3)
(3) Multi-head attention: Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. In this paper, our attention layers are both based on the multi-head attention formulation (Vaswani et al., Citation2017). One critical advantage of multi-head attention is its ability to model the long-range dependency, which is beneficial for extracting relevant entities. A scaled dot product is chosen for the compatibility function in multi-head attention. Compared with the standard additive attention mechanism (Bahdanau et al., Citation2014), which is implemented using a one-layer feed-forward neural network, scaled dot product enables efficient computation. Given a matrix of n query vectors
, keys vectors
and value vectors
. The multi-head attention is calculated as Equations (Equation4
(4)
(4) )–(Equation6
(6)
(6) ):
(4)
(4)
(5)
(5)
(6)
(6) where
refers to the ith head of multi-head attention.
,
, and
are trainable parameter matrices.
For simplicity, the above multi-head attention module is defined as Equation (Equation7(7)
(7) ):
(7)
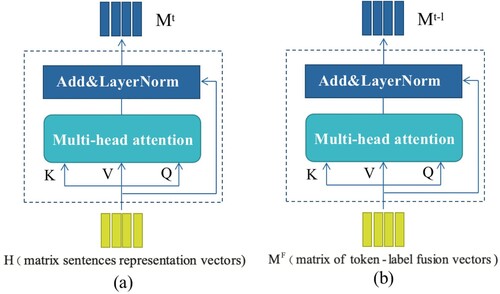
(7) As shown in Figure (a) and Equation (Equation8
(8)
(8) ), the output H of the BiLSTM is regarded as queries, keys and values matrices and is fed into the multi-head attention. Finally, the token representation is generated, which denotes as
. For the parallel attention heads in GANCE,
is employed.
(8)
(8)
Figure 3. Two multi-head attention modules with different types of inputs. One multi-head attention module takes features H as input and output the token representation . Another multi-head attention takes features
as input and output the token-label representation
.
3.1.2. Label representation
As illustrated in Figure , the label with BIO (Beginning, Inside, Outside) format is used in this paper for NER (Zhao et al., Citation2021a, Citation2021b). Motivated by Miwa and Bansal (Citation2016), each label is represented by a randomly initialised embedding vector, whose size denotes as . After the fine-tune during the training, the generated vector sequence
is used as the label representation. Note that gold labels are used only during training. For inference, predicted labels are utilised. In other words, the entity labels predicted by the NER model (CRF) are used in the process of relation inference.
3.2. Token-Label fusion representation
To further exploit the token and label information, it is necessary to fuse the token representation and label representation. Instead of using naive fusion ways such as simple concatenation or , a gating mechanism and a multi-head attention module are applied for representations fusion and update in GANCE. The motivation behind this design is that the importance of the representations should be determined by the specific context. Hence the fusion should be implemented in a dynamic form, which could be realised by the gate and multi-head attention mechanism.
At first, gating is used to fuse the token and label representation as Equations (Equation9(9)
(9) )–(Equation10
(10)
(10) ):
(9)
(9)
(10)
(10) where
is element-wise multiplication.
Then, a multi-head attention module takes as its input and outputs the updated token-label representation. As shown in Figure (b), the multi-head attention component feeds
as queries, keys, and values matrices by using different linear projections. Finally, the fused token-label representation
is computed as Equation(11) :
(11)
(11)
3.3. Decoder layer
NER: To identify the entities, a CRF layer is added in GANCE. It takes token representation as input. As Equations (Equation12
(12)
(12) )–(Equation13
(13)
(13) ) show, the output of the CRF layer is a sequence of predicted tagging label probabilities
:
(12)
(12)
(13)
(13) where
and
are model parameters.
RE: A multi-head mechanism is utilised for RE, and token-label fusion representation is the input. Suppose C is a set of relation labels. The multi-head mechanism aims to give a value for each tuple
, where
is the head token,
is the tail token, and
denotes the rth relation between
and
. There are multiple heads in each pair of tokens
,
, and each head computes a value for one relation. Given a relation label
using a single layer neural network, the score s
of word
is computed as Equation (Equation14
(14)
(14) ), which is further used as the head of
:
(14)
(14) where
, and z is the width of the layer. The probability that token
and token
have a
relationship can be calculated by Equations (Equation15
(15)
(15) )–(Equation16
(16)
(16) ):
(15)
(15)
(16)
(16) where σ is the sigmoid function. During inference, the most probable candidate tuple
are selected using threshold-based prediction.
3.4. Training and inference
During the training process, the parameters are optimised to maximise the conditional likelihood in Equation (Equation17(17)
(17) ) for NER (Zhao et al., Citation2021a):
(17)
(17) For RE, the cross-entropy
is calculated as shown in Equation (Equation18
(18)
(18) ):
(18)
(18) where o is the number of relations (heads).
The objective of the joint entity and relation extraction task is set as Equation (Equation19(19)
(19) ) shows, where w and θ denote tokens and model parameters, respectively.
(19)
(19) Similar to Kendall et al. (Citation2018), we combine NER and RE objectives using homoscedastic uncertainty to learn relative weights from the data. We proceed here directly to the loss that is in our case given as
instead of Equation (Equation19
(19)
(19) ). Where,
(20)
(20)
(21)
(21)
4. Experiments and result analysis
4.1. Dataset
Public benchmarks CoNLL04 (Roth & Yih, Citation2004) and ADE (Gurulingappa et al., Citation2012) are used to validate the effectiveness of the proposed method. CoNLL04 consists of 910/243/288 instances for training/validation/testing. Besides, 10-fold cross-validation are adopted on the ADE dataset. Three commonly used evaluation metrics in machine learning are used to evaluate the model, including Precision (P), Recall (R), and F1 score (F).
4.2. Implementation details
There are 3 BiLSTM layers in GANCE, and the size of hidden layer d and label embeddings are set as 64 and 25, respectively. The optimiser is Adam, with learning rate is set as 0.0005. The size of character embeddings, word embeddings and ELMO (Peters et al., Citation2018) are set as 128, 128, and 1024 respectively. Lastly, the training takes 180 epochs for convergence.
4.3. Performance on benchmarks
The performance comparison of different models on two datasets are provided and analysed as follows.
CoNLL04: The performance of different models on CoNLL04 is shown in Table . It can be seen that the proposed GANCE achieves the best results on NER and RE among the existing models. Compared with SpERT (Eberts & Ulges, Citation2019), which mainly relies on pre-trained language model(BERT) to obtain span representation, our model achieves substantial improvements on both NER (+1.38%) and RE (+2.12%). Moreover, our model achieves greater performance improvement (NER (+6.71%) and RE (+11.64%)) compared with Multi-head + AT (Bekoulis et al., Citation2018a). Note that Multi-head + AT uses feature concatenation to capture label-space information. It indicates that the effectiveness of our method GANCE for capturing information on multiple entity types and relation types from a sentence. Furthermore, we can observe that our method GANCE with ELMO and SpERT (Eberts & Ulges, Citation2019) with BERT have significant improvement both on entities and relations. The reason is that the pre-training method is useful in NLP tasks.
Table 1. Comparison of results with previous papers on the CoNLL04 dataset.
ADE: Table shows the performance of different models on dataset ADE. Again our method obtains the state-of-the-art performance. GANCE achieves better performance on NER and RE compared with the latest Table-Sequence model. Particularly, the F1 score of RE of GANCE increase by 1.24% over that of Table-Sequence model.
Table 2. Comparison of results with previous papers on the ADE dataset.
4.4. performance against entity distance
For two entities, their entity distance refers to the absolute character offset between the last character of the entity that appears first and the last character of the entity that appears second. The distance between related entities influences the effect of relationship extraction, and capturing long-distance entity dependencies is always a difficult problem in relation to extraction. To evaluate the impact of the entity distance on the performance of GANCE, experiments are conducted on the CoNLL04 dataset.
According to different entity distance (i.e. , 9-19, 0-9), the CoNLL04 dataset is divided into three parts (Zhao et al., Citation2021a). Multi-head + AT (Bekoulis et al., Citation2018a) is set as the baseline because the same decoding layer is used in it as GANCE. Under different entity distances, the performance of GANCE and the baseline is depicted in Figure . It can be seen from Figure that GANCE outperforms the baseline under all different entity distances. Moreover, the performance of the GANCE is much better than the baseline when the distance between entities exceeds 20 characters. Specifically, GANCE leads by 15.59% in the F1 score for RE. In conclusion, GANCE could maintain remarkable performance even though a long entity distance exists. This is in line with expectations since GANCE can detect relevant entities by learning attention weights between the entities in the sentence.
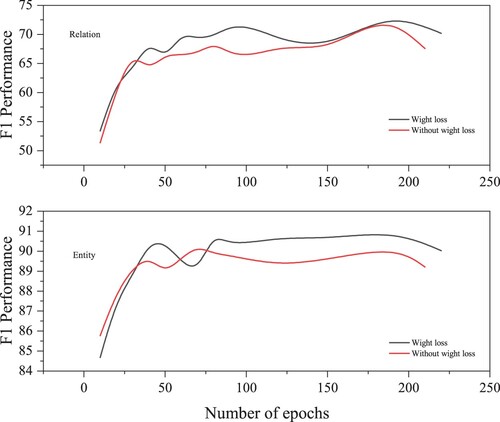
4.5. Effect of homoscedastic uncertainty
The effect of loss with and without homoscedastic uncertainty is further analysed in this section. As shown in Figure , GANCE based on the loss with homoscedastic uncertainty realises better performance on the dataset CoNLL04. Specifically, the F1 score of GANCE with weight loss is 0.8% and 1.08% higher than that of GANCE without weight loss for NER and RE, respectively. This is reasonable since homoscedastic uncertainty could capture the correlation confidence between NER and RE. Therefore, the model based on the loss with homoscedastic uncertainty could learn to balance the weights optimally. Moreover, as seen in Figure , the performance of the two models (Weight loss and Without weight loss) have similar trends. It can be observed that the performance of both models is closer to the maximum even from the early training epochs.
Figure 4. The performance comparison of the baseline and GANCE under different entity distances on dataset CoNLL04. Multi-head + AT is set as the baseline. (a) RE and (b) NER.
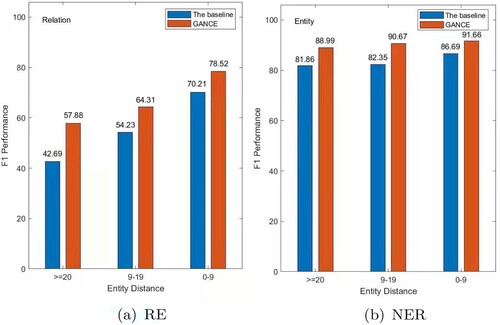
Figure 5. F1 score of GANCE with weighting loss and without it on the dataset CoNLL04. Weight loss indicates that the model adopts homoscedastic uncertainty to weight loss.
4.6. Ablation study
To further assess the impact of different modules on the performance of GANCE, an ablation study is designed and executed on the dataset CoNLL04. Three modules (the gate module and two multi-head attention modules) are evaluated in the following four ways, and the results are summarised in Table .
The gate module. The gate module is replaced with a simple feature addition scheme (
). It is found that the
Multi-head attention module in token representation. This multi-head attention module is ablated in both tasks. After the ablation, the performance of GANCE significantly decreases on NER and RE. Specifically, the F1 score decreases by 2.1% and 1.93% on NER and RE, respectively. These results prove that the applied multi-head module does benefit from capturing self-correlations among tokens.
Multi-head attention module in token-label fusion representation. This multi-head attention module is deleted and
Both multi-head attention modules. After removing both attention modules, worse results on NER (−4%) and RE (−3.48%) are caused, which demonstrates that the proposed attention modules play a vital role in enhancing character representations.
Table 3. Ablation evaluation on the dataset CoNLL04.
4.7. Extraction cases analysis
To gain further insights about GANCE, an error analysis is provided as Table shows. For case1, it can be observed that “Rocky Mountains ”, “ Montana” and “Livingston” can be correctly detected as Location entities. Besides, GANCE identifies the two “Located_ In” relations between these entities. For case2, GANCE cannot recognise that there is a “ Live_in” relationship between “ Peter Murtha” and “U.S.”. Besides, the “OrgBased_In” relation between ‘Justice Department” and ‘U.S.” is also omitted. The reason is that “Justice Department” and “ Peter Murtha” are involved in more than one relation.
Table 4. Extraction cases of GANCE on dataset CoNLL004. True entities are highlighted in bold.
5. Concluding remarks
In this paper, we propose a Gated and Attentive Network Collaborative Extracting (GANCE) for the task of joint entity relation extraction. GANCE consists of a gating mechanism and two multi-head attention modules. Besides, homoscedastic uncertainty to weight losses is introduced between the two tasks. Compared with existing joint methods, GANCE provides a new way to utilise label-space information and detect relevant entities. Experimental results on two benchmarks demonstrate that GANCE could effectively improve the performance of NER and RE by fusing label-space information and detecting relevant entities effectively.
For future work, text-based entity and relationship extraction can be used in more related research fields in the Internet of Things, such as relationship prediction, link mining, image recognition (Liang, Long, et al., Citation2021), attack detection (Kang, Citation2020), QoS prediction and anti-attack protection (Liang, Li, et al., Citation2021), security defense (Liang, Ning, et al., Citation2021), IP circuit protection (Liang et al., Citation2020), etc. Besides, it can be combined with many new technologies, such as Blockchain (Liang et al., Citation2020), big data (Chen, Liang, Zhou, et al., Citation2021), service recommendation (Chen, Liang, Xu, et al., Citation2021), Security Risk Assessment (Kang et al., Citation2020), etc. In addition, related research on entity representation, text mining, and relation extraction can be conducted based on images, videos, and audios. which would have theoretical significance and application value for the Intelligent Internet of Things (IIoT) development.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Adel, H., & Schütze, H. (2017). Global normalization of convolutional neural networks for joint entity and relation classification. arXiv preprint arXiv:1707.07719.
- Alberto, M. (2018). On the estimation and control of nonlinear systems with parametric uncertainties and noisy outputs: graphical abstract. IEEE Access, 6, 31968–31973. https://doi.org/10.1109/ACCESS.2018.2846483
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Bekoulis, G., Deleu, J., Demeester, T., & Develder, C. (2018a). Adversarial training for multi-context joint entity and relation extraction. arXiv preprint arXiv:1808.06876.
- Bekoulis, G., Deleu, J., Demeester, T., & Develder, C. (2018b). Joint entity recognition and relation extraction as a multi-head selection problem. Expert Systems with Applications, 114(2), 34–45. https://doi.org/10.1016/j.eswa.2018.07.032
- Chan, Y. S., & Roth, D. (2011). Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th annual meeting of the Association for Computational Linguistics: Human language technologies (pp. 551–560).
- Chen, X., Liang, W., Xu, J., Wang, C., Li, K. C., & Qiu, M. (2021). An efficient service recommendation algorithm for cyber-physical-social systems. IEEE Transactions on Network Science and Engineering, 1–1. https://doi.org/10.1109/TNSE.2021.3092204
- Chen, X., Liang, W., Zhou, X., Jiang, D., Kui, X., & Li, K. C. (2021). An efficient transmission algorithm for power grid data suitable for autonomous multi-robot systems. Information Sciences, 572(3), 543–557. https://doi.org/10.1016/j.ins.2021.05.033
- Chen, Y., Xu, L., Liu, K., Zeng, D., & Zhao, J. (2015). Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd annual meeting of the Association for Computational Linguistics and the 7th international joint conference on natural language processing (Vol. 1: Long papers, pp. 167–176). Association for Computational Linguistics (ACL).
- Chi, R., Wu, B., Hu, L., & Zhang, Y. (2019). Enhancing joint entity and relation extraction with language modeling and hierarchical attention. In Asia-Pacific Web (APWEB) and web-age information management (WAIM) joint international conference on web and big data (pp. 314–328). Springer Verlag.
- Chiang, H. S., Chen, M. Y., & Huang, Y. J. (2019). Wavelet-based EEG processing for epilepsy detection using fuzzy entropy and associative petri net. IEEE Access, 7, 103255–103262. https://doi.org/10.1109/Access.6287639
- Crone, P. (2020). Deeper task-specificity improves joint entity and relation extraction. arXiv preprint arXiv:2002.06424.
- de Jesús Rubio, J. (2009). SOFMLS: online self-organizing fuzzy modified least-squares network. IEEE Transactions on Fuzzy Systems, 17(6), 1296–1309. https://doi.org/10.1109/TFUZZ.91
- de Rubio, J. J. (2020). Stability analysis of the modified Levenberg-Marquardt algorithm for the artificial neural network training. IEEE Transactions on Neural Networks and Learning Systems, 32(8), 3510–3524. https://doi.org/10.1109/TNNLS.2020.3015200
- Eberts, M., & Ulges, A. (2019). Span-based joint entity and relation extraction with transformer pre-training. arXiv preprint arXiv:1909.07755.
- Furlán, F., Rubio, E., Sossa, H., & Ponce, V. (2020). CNN based detectors on planetary environments: a performance evaluation. Frontiers in Neurorobotics, 14, 85. https://doi.org/10.3389/fnbot.2020.590371
- Gurulingappa, H., Rajput, A. M., Roberts, A., Fluck, J., Hofmann-Apitius, M., & Toldo, L. (2012). Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. Journal of Biomedical Informatics, 45(5), 885–892. https://doi.org/10.1016/j.jbi.2012.04.008
- Islas, M. A., Rubio, J.d.J., Muñiz, S., Ochoa, G., Pacheco, J., J. A. Meda-Campaña, & Zacarias, A. (2021). A fuzzy logic model for hourly electrical power demand modeling. Electronics, 10(4), 448. https://doi.org/10.3390/electronics10040448
- Kang, W. (2020). Two attacking strategies of coordinated cyber-physical attacks for cascading failure analysis in smart grid. In International conference on 5G for future wireless networks (pp. 384–396). Springer Science and Business Media Deutschland GmbH.
- Kang, W., Deng, J., Zhu, P., Liu, X., Zhao, W., & Hang, Z. (2020). Multi-dimensional security risk assessment model based on three elements in the IoT system. In 2020 IEEE/CIC international conference on communications in China (ICCC) (pp. 518–523). Institute of Electrical and Electronics Engineers Inc.
- Katiyar, A., & Cardie, C. (2017). Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th annual meeting of the Association for Computational Linguistics (Vol. 1: Long papers, pp. 917–928). Association for Computational Linguistics (ACL).
- Kendall, A., Gal, Y., & Cipolla, R. (2018). Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7482–7491). IEEE Computer Society.
- Lafferty, J., McCallum, A., & Pereira, F. C. (2002). Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of ICML. https://doi.org/10.1109/ICIP.2012.6466940
- Li, F., Zhang, M., Fu, G., & Ji, D. (2017). A neural joint model for entity and relation extraction from biomedical text. BMC Bioinformatics, 18(1), 1–11. https://doi.org/10.1186/s12859-016-1414-x
- Li, F., Zhang, Y., Zhang, M., & Ji, D. (2016). Joint models for extracting adverse drug events from biomedical text. In Ijcai (Vol. 2016, pp. 2838–2844). International Joint Conferences on Artificial Intelligence.
- Li, X., Yin, F., Sun, Z., Li, X., Yuan, A., Chai, D., Zhou, M., & Li, J. (2019). Entity-relation extraction as multi-turn question answering. arXiv preprint arXiv:1905.05529.
- Liang, W., Li, Y., Xu, J., Qin, Z., & Li, K. (2021). QoS prediction and adversarial attack protection for distributed services under dlaas. IEEE Transactions on Computers, 1–14. https://doi.org/10.1109/TC.2021.3077738
- Liang, W., Long, J., Li, K. C., Xu, J., Ma, N., & Lei, X. (2021). A fast defogging image recognition algorithm based on bilateral hybrid filtering. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 17(2), 1–16. https://doi.org/10.1145/3391297
- Liang, W., Ning, Z., Xie, S., Hu, Y., Lu, S., & Zhang, D. (2021). Secure fusion approach for the internet of things in smart autonomous multi-robot systems. Information Sciences, 579(1), 468–482. https://doi.org/10.1016/j.ins.2021.08.035
- Liang, W., Zhang, D., Lei, X., Tang, M., Li, K. C., & Zomaya, A. (2020). Circuit copyright blockchain: Blockchain-based homomorphic encryption for IP circuit protection. IEEE Transactions on Emerging Topics in Computing.
- Lin, Y., Ji, H., Huang, F., & Wu, L. (2020). A joint neural model for information extraction with global features. In Proceedings of the 58th annual meeting of the Association for Computational Linguistics (pp. 7999–8009). Association for Computational Linguistics (ACL).
- Liu, F., Tang, G., Li, Y., Cai, Z., Zhang, X., & Zhou, T. (2019). A survey on edge computing systems and tools. Proceedings of the IEEE, 107(8), 1537–1562. https://doi.org/10.1109/PROC.5
- Liu, Y., Wei, F., Li, S., Ji, H., Zhou, M., & Wang, H. (2015). A dependency-based neural network for relation classification. arXiv preprint arXiv:1507.04646.
- Luo, L., Yang, Z., Yang, P., Zhang, Y., Wang, L., Lin, H., & Wang, J. (2018). An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics (Oxford, England), 34(8), 1381–1388. https://doi.org/10.1093/bioinformatics/btx761
- Miwa, M., & Bansal, M. (2016). End-to-end relation extraction using lstms on sequences and tree structures. arXiv preprint arXiv:1601.00770.
- Miwa, M., & Sasaki, Y. (2014). Modeling joint entity and relation extraction with table representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1858–1869). Association for Computational Linguistics (ACL).
- Miwa, M., Sætre, R., Miyao, Y., & Tsujii, J. (2009). A rich feature vector for protein-protein interaction extraction from multiple corpora. In Proceedings of the 2009 conference on empirical methods in natural language processing (pp. 121–130). Association for Computational Linguistics (ACL).
- Nadeau, D., & Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1), 3–26. https://doi.org/10.1075/li
- Nayak, T., & Ng, H. T. (2020). Effective modeling of encoder-decoder architecture for joint entity and relation extraction. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, pp. 8528–8535). AAAI press.
- Nguyen, D. Q., & Verspoor, K. (2019). End-to-end neural relation extraction using deep biaffine attention. In European Conference on information retrieval (pp. 729–738). Springer Verlag.
- Peters, M., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. arXiv 2018. arXiv preprint arXiv:1802.05365 12.
- Roth, D., & Yih, W t. (2004). A linear programming formulation for global inference in natural language tasks (Tech. Rep.). Urbana-Champaign Department of Computer Science, Illinois University.
- Sharma, R., Morwal, S., Agarwal, B., Chandra, R., & Khan, M. S. (2020). A deep neural network-based model for named entity recognition for Hindi language. Neural Computing and Applications, 32(20), 16191–16203. https://doi.org/10.1007/s00521-020-04881-z
- Shen, Y., Ma, X., Tang, Y., & Lu, W. (2021). A trigger-sense memory flow framework for joint entity and relation extraction. In Proceedings of the web conference 2021 (pp. 1704–1715). Association for Computing Machinery, Inc.
- Tran, T., & Kavuluru, R. (2019). Neural metric learning for fast end-to-end relation extraction. arXiv preprint arXiv:1905.07458.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998–6008). Neural information processing systems foundation.
- Viswanathan, V., Rajani, N. F., Bentor, Y., & Mooney, R. (2015). Stacked ensembles of information extractors for knowledge-base population. In Proceedings of the 53rd annual meeting of the Association for Computational Linguistics and the 7th international joint conference on natural language processing (Vol. 1: Long papers, pp. 177–187). Association for Computational Linguistics (ACL).
- Wadden, D., Wennberg, U., Luan, Y., & Hajishirzi, H. (2019). Entity, relation, and event extraction with contextualized span representations. arXiv preprint arXiv:1909.03546.
- Wan, Q., Wei, L., Chen, X., & Liu, J. (2021). A region-based hypergraph network for joint entity-relation extraction. Knowledge-Based Systems, 228(10), 107298. https://doi.org/10.1016/j.knosys.2021.107298
- Wang, J., & Lu, W. (2020). Two are better than one: Joint entity and relation extraction with table-sequence encoders. arXiv preprint arXiv:2010.03851.
- Wang, L., Cao, Z., De Melo, G., & Liu, Z. (2016). Relation classification via multi-level attention CNNS. In Proceedings of the 54th annual meeting of the Association for Computational Linguistics (Vol. 1: Long papers, pp. 1298–1307). Association for Computational Linguistics (ACL).
- Wang, Y., Sun, C., Wu, Y., Zhou, H., Li, L., & Yan, J. (2021). UniRE: A unified label space for entity relation extraction. arXiv preprint arXiv:2107.04292.
- Xiao, Y., Tan, C., Fan, Z., Xu, Q., & Zhu, W. (2020). Joint entity and relation extraction with a hybrid transformer and reinforcement learning based model. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, pp. 9314–9321). AAAI press.
- Yang, B., & Cardie, C. (2013). Joint inference for fine-grained opinion extraction. In Proceedings of the 51st annual meeting of the Association for Computational Linguistics (Vol. 1: Long papers, pp. 1640–1649). Association for Computational Linguistics (ACL).
- Yang, J., Liang, S., & Zhang, Y. (2018). Design challenges and misconceptions in neural sequence labeling. arXiv preprint arXiv:1806.04470.
- Yih, W t., Richardson, M., Meek, C., Chang, M. W., & Suh, J. (2016). The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th annual meeting of the Association for Computational Linguistics (Vol. 2: Short papers, pp. 201–206). Association for Computational Linguistics (ACL).
- Yu, Z., Yu, J., Cui, Y., Tao, D., & Tian, Q. (2019). Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA (pp. 6281–6290). IEEE Computer Society.
- Zhang, Z., & Saligrama, V. (2016). Zero-shot learning via joint latent similarity embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 6034–6042). IEEE Computer Society.
- Zhao, S., Hu, M., Cai, Z., & Liu, F. (2021a). Dynamic modeling cross-modal interactions in two-Phase prediction for entity-relation extraction. IEEE Transactions on Neural Networks and Learning Systems, 1–10. 10.1109/TNNLS.2021.3104971
- Zhao, S., Hu, M., Cai, Z., & Liu, F. (2021b). Modeling dense cross-modal interactions for joint entity-relation extraction. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence (pp. 4032–4038). International Joint Conferences on Artificial Intelligence.
- Zhao, W., Gao, H., Chen, S., & Wang, N. (2020). Generative multi-task learning for text classification. IEEE Access, 8, 86380–86387. https://doi.org/10.1109/ACCESS.2020.2991337