
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Conventional manual-programmable logic controller systems have confronted the problems of the unbalance load and the unreasonable bins allocation in industrial loading field. Furthermore, various optimisation models with multi-agent systems have been proposed for the single-layer scheduling and communicating, which results in either a high time cost or a difficult multi-target regression. In this paper, we propose a hierarchical-fuzzy bins allocation method and a multi-parameter adjustment values prediction model in the multi-agent collaborative control system. The method intuitively achieves topgallant and hierarchical bins allocation by different fuzzy rule bases. The multi-parameter adjustment values prediction model utilising parallel-multi LSTM(PM-LSTM) is located on the accurate multi-parameter prediction. First, new loading reference standards and an abnormal data procession method are adopted for the dataset collection. Second, the LSTM-1 is used to extract the time-series features in the loading process. Third, a two-dimensional and reconstructed matrix integrates comprehensive features with the feature crossover method. The matrix will be used as inputs to predict the adjustment value of multi parameters by the LSTM-2. Finally, the relationship model among multi parameter values is built and fitted. Experiment results show better effects for the reasonable bins allocation and balanced industrial loading.
1. Introduction
The manual-programmable logic controller system (MPLCs) provides some evident characteristics (i.e. anti-interference and high-reliability performance) convenient for workers (Jani et al., Citation2020; Krupa et al., Citation2021) while substantially increasing the possibility of manual intervention. It means that the referential operation metrics for daily loading control always rely on the manual experience, which has been applied in industrial material loading. The industrial loading field, aiming to achieve accurate and quantitative target loading, has attracted much attention from enterprises. However, the loading process based on MPLCs often suffers from the unbalanced load problem caused by the high error of various parameters (i.e. truck speed and belt conveyor flow) and requires reloading of the stopped truck. In addition, a real-time loading value is barely satisfied with selected bins pre-stored following a manual experience. Namely, the above problems will cause major losses and safety hazards to the enterprise. Hence, it is challenging to accurately reduce high errors of adjustment parameters to prevent unbalanced loading while making a reasonable bins allocation.
To the best of our knowledge, the related allocation issue can be solved with the target approximation. Che et al. (Citation2020) propose a coordinated optimal operation strategy for generation optimisation and coal management. Qiao et al. (Citation2020) present a novel partial repair rescheduling solution model to consider unexpected events and/or expanded performance criteria. However, the effective application results are only for discrete scenarios and single partial repair in the semiconductor system. Wang et al. (Citation2021) propose a genetic algorithm-back propagation neural network method to achieve single-target evaluation and optimise the back propagation neural network. In a word, these methods mentioned above cannot be well fitted with the actual bins allocation problem and are short of the ability of multi-layer recursive calculation for parameters.
Additionally, the multi-agent system has recently become a significant focus of industrial research. However, the existing scheduling/communicating methods that rely on the single-layer neural network strategy in multi-agent systems difficult to achieve multi-target regression (Han et al., Citation2020; Liang et al., Citation2021; Zhao et al., Citation2020). Fortunately, we have found that the long short-term memory (LSTM) based on the advantage of long-time series prediction ability can solve multi-parameter's high error problems. For example, Srivastava et al. (Citation2020) combine the convolution neural network with the LSTM to predict the power generated by wind turbines. Because the model composed of two layers processes the characteristic by characteristic in order, it cannot be well adapted to the multi-parameter feature matrix. Xue et al. (Citation2021) utilise a prediction of pedestrian paths-LSTM model to improve the potential destinations’ prediction accuracy. Mackenzie et al. (Citation2019), Mou et al. (Citation2019) provide optimal and long short-term memory models for short-term prediction of traffic flows. These models directly predict data based on initial feature items and are unable to further explore the hidden relationship between the multi-parameter. Thus, two critical targets should be considered. (1) How to achieve a better-balanced loading via a multi-output neural network, while the predicted and applied parameters of the network can fit the loading standards (e.g. the absolute value of height error for each loading area is less than 0.15 m). (2) what should be considered to optimise the rationality of the bins allocation strategy.
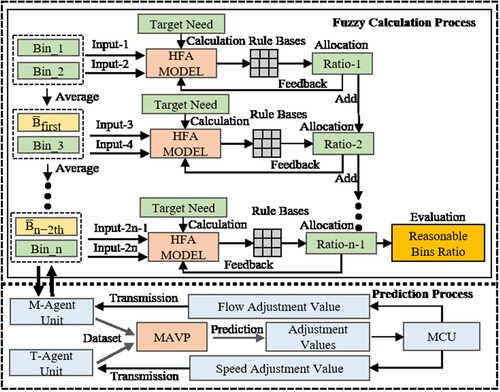
Based on the two considered objectives, we propose a hierarchical-fuzzy bin allocation (HFA) method and a multi-parameter adjustment values prediction (MAVP) model in the multi-agent collaborative control system (MACCs), which is shown in Figure . The HFA method is a hierarchical calculation method with different fuzzy rule bases, which is adopted for reasonable bins allocation. The MAVP model is used to collaborative control features extraction and accurate multi-parameter prediction. It is based on the parallel-multi long short-term memory (PM-LSTM) neural network and the feature crossover (FC) method. Further, the FC method is adopted to reconstruct extracted features to improve the multi-parameter prediction ability. The main contributions are summarised as follows.
The optimal strategy of material bins allocation on the hierarchical fuzzy calculation method. A novelty HFA method is proposed to actively obtain the topgallant and reasonable bins allocation ratio by different fuzzy rule bases in each fuzzy calculation layer.
The data procession process combines with the moment balance. The analysis of the moment balance for the objective carriage is to help to process abnormal data and to acquire the sample dataset. In addition, the related loading reference standards and deviation metrics are adopted to constrain the range of the sample dataset.
Accurate adjustment value prediction of multi parameters via parallel-multi deep learning model. The PM-LSTM for the MAVP model is adopted to solve the unbalanced loading problems. The parallel-multi neural network extracts the collaborative control features for its formidable extraction ability and accurately predicts the adjustment parameters based on regression characteristics for long-time series (He et al., Citation2019; Shu et al., Citation2021; Zhou & Xu, Citation2021). Further, the FC method expands the connection between hidden features as a two-dimensional reconstructed matrix to improve the feature extraction accuracy.
Multi parameters’ relationship model building and fitting based on neural networks. A relationship model among the parameters (i.e. the adjustment value of the truck speed and the flow of the belt conveyor) predicted by the MAVP model and target loading compensation is reasoned and built. The model aims to provide advanced adjustment values as a kind of reference. Further, we applied the model to the parameters’ adjusting in collaborative control of the industrial loading field.
Figure 1. The structure of the multi-agent collaborative control system.
The remainder of this paper is organised as follows: Section 2 introduces relevant model structures of the MACCs. Section 3 presents the experimental results and some comparative analysis. Finally, the conclusion and future works are given in Section 4.
2. The model construction via neural network and fuzzy allocation method
This section will introduce the optimal bins allocation ratio method and the accurate multi-parameter parallel prediction model.
2.1. The optimal bins allocation based on HFA method
Hierarchical fuzzy control is a kind of fuzzy control strategy that uses multiple fuzzy controllers of multi-input to accurately estimate the target value. It has been widely applied in the approximate logic coupling of the uncertain models (Sun & Huo, Citation2016; Yu et al., Citation2021). The hierarchical fuzzy calculation strategy can synthesise practical problems well to obtain the best results. Motivated by the idea, we propose a hierarchical-fuzzy bins allocation method for the material bins allocation optimisation. The method includes three critical steps: First, the allocation ratio of two random bins that considers the different kinds of fuzzy rulesets is obtained in the initial layer, shown in Figure . Second, both the average value of bins in the previous layer and the value of the new-selected bin will be added to calculate a relative allocation ratio in the next layer. Finally, according to the evaluation formula, the reasonable allocation ratio of all bins can be acquired in the final layer.
Figure 2. The process of bins allocation ratio in the initial layer.
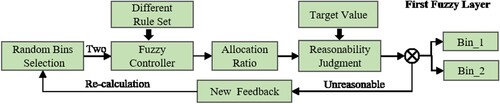
2.1.1. Bins allocation in initial fuzzy calculation layer
In this paper, let denotes the carriage's quantified storage value of each material bin, where
is the number of the material bins,
. In the initial allocation layer, we randomly select two bins
and
as the allocation input objects. The fuzzy sets of inputs and the outputs are virtually characterised by their membership functions. The degree of membership functions is shown in Figure (a), which is adopted to determine the degree of the membership (e.g. 1 denotes the highest degree, 0 denotes the lowest degree of membership). Figure (b) shows the outputs’ membership functions (i.e. three-trimf, one-smf, and one-zmf functions). Among them, the inputs’ membership functions are represented by five linguistic descriptions: low-low flag (LLF), low flag (LF), medium flag (MF), high flag (HF), high-high flag (HHF). Similarly, the outputs’ MFs include five linguistic descriptions: zero output (NO), low output (LO), small output (SO), medium output (MO), high output (HO).
Figure 3. (a) The MFs diagram of inputs (b) The MFs diagram of outputs.
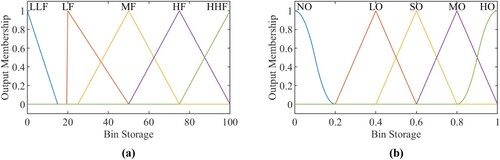
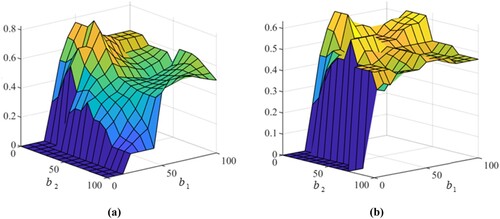
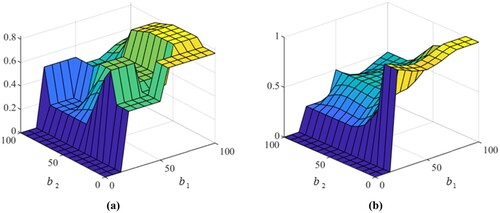
In the first layer, the domain of inputs and outputs are designed as [0,100] and [0,1] respectively, and the fuzzy rule bases in the first layer are described as ,
is the number of the fuzzy rule bases. The fuzzy rule base (
) is created for different bins allocation strategies. The surfaces of fuzzy rule bases are shown in Figure (a) and 4(b). Based on the above fuzzy rule bases, the general form of a fuzzy allocation rule is given as follows:
If is
and
is
, then
is
and
is
Figure 4. The fuzzy rule bases of the first layer.
The allocation ratios of the bins based on the different kinds of fuzzy rule bases can be described as , which is shown in Formula 1. If each bin satisfies
, the bins allocation ratio
will be selected as an element of the objective output in the first layer. Further, the average value (
), being used as an input to improve the bins allocation rationality and accuracy in the second layer, is shown in Formula 2.
(1)
(1)
(2)
(2) where the
denotes the selected allocation ratios in the first layer (e.g.
means that the allocation ratio of
and
are 0.45 and 0.55, respectively).
is the loading target value.
is the average function for each layer. The constraint of the first layer is
.
2.1.2. Bins allocation in other fuzzy calculation layers
The relevant inputs’ MFs in next each layer are the same as membership functions in the first layer. However, the outputs’ membership functions include seven linguistic descriptions: high-high allocation, high allocation, little-high allocation, medium allocation, low allocation, low-low allocation, none allocation, which is remarked as {1, 0.8, 0.6, 0.5, 0.4, 0.2, 0}. The fuzzy rule bases in each layer are described as .
In the second layer, we let and the new-added bin
as the inputs for the fuzzy calculation. The surface views of each fuzzy rule base (e.g.
,
) are shown in Figure (a) and (b), and the general form of a fuzzy allocation rule is given as follows:
If is
and
is
, then
is
and
is
Figure 5. The fuzzy rule bases of the second layer.
Based on the Formula (1) and (2) in the first fuzzy calculation layer, we can get the outputs of the second layer, which is shown as follows:
(3)
(3)
(4)
(4) where
denotes the objective output of the selected allocation set in the second layer.
is the number of reasonable allocation ratio schemes in the second fuzzy calculation layer.
is an allocation ratio of
and
.
is the average value of
and
.
is the multiolicative allocation ratio of the second layer. The constraint of the second layer is {
}.
Assumption 2.1:
It is assumed that the outputs with inputs
and fuzzy rule base
can be described as follows:
(6)
(6)
(7)
(7)
(8)
(8) where
is the average of
and
,
denotes the objective output of the selected allocation set in
layer, and
is a simple expression form of the
. The constraint of the
layer is {
}.
Corollary 2.1:
Under the condition of Assumption, the objective output of the last layer can be obtained with and the
/last layer inputs
,
, which is as follows:
(9)
(9)
(10)
(10) where
is the allocation ratio of the bin
in the last layer.
denotes the outputs of the selected allocation dataset in
layer, and
is the number of reasonable allocation ratio schemes in
layer.
is the multiplicative allocation ratio of
and
, under the basis of the calculation ratio in
layer.
is the allocation ratio sets of all bins in
layer.
is a simple expression form of the final output set. The constraint of the
layer is {
}.
Proof 1: Based on inductive synthesis, when,
. For convenience, we can easily get that the bins allocation output of the
layer satisfies the Formula (10). Thus, the uniform expression for each layer is shown in Formula (11).
(11)
(11) The final allocation ratio set for bins allocation is expressed in Formula (12). It can be well evaluated and selected by the final evaluation formula. The evaluation formula of the final bins allocation is given in Formula (13). The final objective of bins allocation strategy is shown in Formula (14).
Here, the time complexity of the allocation process in the initial fuzzy calculation layer based on the different kinds of fuzzy rule bases is
. Further, the time complexity of the process in the last layer is
. The total time complexity of the fuzzy bins allocation algorithm is
.
(12)
(12)
(13)
(13)
(14)
(14) where
is a kind of bins allocation ratio of the allocation ratio set
in the last layer, and
is the evaluation function of the bins allocation.
2.2. The accurate parallel prediction on MAVP model
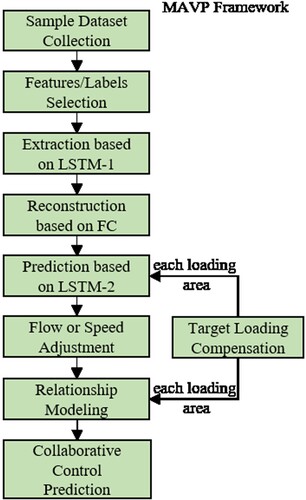
The long short-term memory can process and predict continuous time series with unknown sizes (Du et al., Citation2021; Wu et al., Citation2021). For the advantages, we propose a PM-LSTM neural network to achieve accurate parallel prediction. The framework includes three parts: sample dataset procession, multi-parameter adjustment value prediction via the PM-LSTM, and relationship model reasoning, which is shown in Figure .
Figure 6. The total framework of a parallel prediction model based on PM-LSTM.
2.2.1. Sample dataset procession
The industrial loading dataset usually has some high-error data because of discontinuous braking reload or parameters rough acquisition. To avoid adverse impacts and supplement the missing data of the raw dataset, we provide the new loading reference standards and an abnormal data procession method. The detailed process is described as follows:
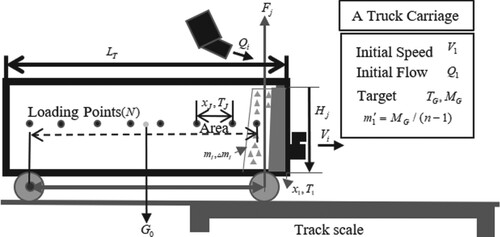
Let
represents the carriage wheelbase value, and
Let
Figure 7. The schematic diagram of parameters.
Based on the calculation of the Formula (18) to (21), the sample dataset for relevant parallel LSTM model training is obtained, such that:
(18)
(18)
(19)
(19)
(20)
(20)
(21)
(21) where
denotes the truck speed and
denotes the belt conveyor flow in
loading area.
and
are the target adjustment value of the parameters for
loading area.
2.2.2. Multi-parameter adjustment value prediction via the PM-LSTM
In this paper, the input data acquired by the above collection method contains seven features:
(22)
To eliminate the adverse data effect and accelerate gradient descent, we adopt a data normalisation method based on the Z-Score function. Further, we process the input features using the following procedure, which can be formulated as:
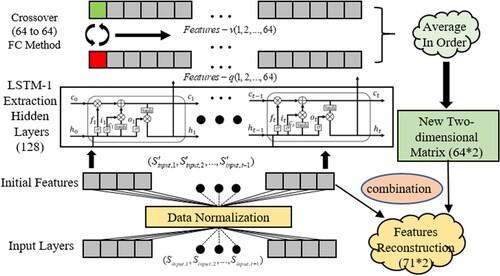
The PM-LSTM model includes an input layer, an extraction hidden layer (LSTM-1), an inference hidden layer (LSTM-2), three fully connected layers, and an output layer. Considering the repetitive sub-unit structure of the LSTM, the single-cell contains several gates (i.e. input gate, forget gate, and output gate) to track the time-series information (Çınar & Tuncer, Citation2021; Zhang, Yu, et al., Citation2021). The relative formulas of statue information updates are described in Formula (24).
Based on the time-series data processing capability of the LSTM-1 (Zhang, Yu, et al., Citation2021), the extracted features of multi-parameter (i.e.
The LSTM-2 is adopted to parallelly predict the adjustment values of multi-parameter, which is based on the reconstructed features with the FC method. Namely, the LSTM-2 uses the 71 feature elements in the first matrix row to predict the adjustment values of the speed parameter. The other features in the second matrix row is for the adjustment values of the flow parameter. Further, we adopt two general dense layers to reduce the data dimension. Also, we convert the data dimension to obtain the predicted outputs parallelly. The related prediction principle can also be described in Formula (24). The output of the model is described in Formula (27).
We use the Parallel Root Mean Square Error (PRMSE) to evaluate the proposed model. The evaluation metric measures the accuracy by the subtle deviation, which is defined as follows:
2.2.3. Relationship model derivation
Let denotes the target loading compensation of each loading area, the truck speed adjustment value is
, and the adjustment value of belt conveyor flow is
. The relationship among the
,
, and
presents a spatial linear relationship. When the relative parameters meet the condition of
and
, the relationship among these parameters can be described in Formula (29). Through the analysis of the time units for (
), we can find that the relationship among the flow adjustment value, the speed adjustment value, and the time interval can be expressed as
. Thus, we assume the time cost of each relative loading area satisfies
,
is a constant, the formula is shown in Formula (30). The final model expression is shown in Formula (31).
(29)
(29)
(30)
(30)
(31)
(31) where
denotes a spatial coefficient,
,
are the two-dimensional plane coefficients,
,
,
are constant coefficients. In addition, we adopt the prediction values via the PM-LSTM to fit the parameters
,
,
. Namely, the correctness of the model inference derivation can be verified by whether the real values can be calculated. Among them, we need to consider the relationship between coordination parameters under special conditions. when
,
, the time cost only depend on the speed parameter, we can assume that the relationship between speed adjustment value with the time cost satisfies
. Thus, the relationship formula can be described in Formula (32). Similarly, when
,
, and the time cost satisfies
, the relationship formula can be described in Formula (33). Further, we will verify the hypothesis by the Experiment 2.
(32)
(32)
(33)
(33) where
is a constant related to
.
,
,
,
,
,
are constant coefficients which need to be calculated by the prediction values.
Figure 8. The diagram of the features extraction process.
3. Experiments
3.1. Experiment 1: the material bins allocation method comparison
In this experiment, the relevant training dataset of daily bins allocation is collected from the Huaibei Coal Mine Co. Ltd in Anhui Province, China. To ensure the effectiveness of comparison, we use the same dataset for model training and fuzzy rule bases design, which comes from the daily bins allocation process. We compare the HFA model with the GA-BPNN (Wang et al., Citation2021), GA-SVR (Ji et al., Citation2021), and GA-LSTM (Kara, Citation2021) to verify the allocation effect. The number of bins is 4. The parameters of the proposed HFA method are as follows: The number of fuzzy rule bases in the first layer is 9. The number of the fuzzy rule bases in other layers is 6. The number of fuzzy rules in each base is 100. The weight of fuzzy rules is 1. The connection method of elements in rules is “and”. We select 100 data with different bin storages as the test dataset. The parameters of each neural model are listed in Table .
Table 1. Parameters setting of each neural network model.
where is the regression coefficient,
,
is the mean absolute error,
is the root mean square error,
is the target sum value of all bins,
is the predictive calculation value,
is the average calculation value.
Table indicates that the evaluation metrics of our proposed method are better than that of other models, the R2 value is about 0.932, the prediction loss of the proposed model is lowest (RMSE: 1.107, and MAE: 0.763). Table shows that our proposed-HFA can accurately achieve the target value while ensuring that the allocation of each bin is reasonable. The predicted calculation value can get 69.90 t. Namely, the material bins allocation can be well optimised in the industrial loading process. Further, the bins allocation value of each model with fixed storage value is shown in Table , which calculates for the different target values. The sum of calculation of the HFA method is highest among all listed models (i.e. HFA vs GA-BPNN: 1.035; HFA vs GA-SVR: 1.052; HFA vs GA-LSTM: 1.019).
Table 2. Comparison metrics results of all contrast models.
Table 3. Comparison results with the target value (70 ton) and different bins storage value.
Table 4. Detail bins allocation value with fixed storage value for the different target value.
3.2. Experiment 2: the accurate prediction effect of MAVP model
In this experiment, we take the 70(t)-capacity-carriage of the truck as the research object. The relative loading data collected from May 1st, 2020 to Dec 1st, 2020 are employed to run simulations. The loading reference standards are used to select the training dataset. The sample dataset selection standards for relevant parameters are shown in Table .
Table 5. The carriage parameters and dataset selection standards.
To verify the accuracy of the MAVP model based on PM-LSTM neural network, we use the Intel i7-8700 CPU, the NVIDIA GTX 1080ti, the 16GB of memory, and the training process runs in the Python 3.8 programming environment. The sample data is 20,000, the epoch value of the LSTM-1 is 500, the number of extractions hidden nodes is 128, the learning rate of the LSTM-1 is 0.001. The epoch value of the LSTM-2 is 1000, the batch size of the neural network is 50, the loss function in the PM-LSTM is MSE, the number of inference hidden nodes is 64/32, and the dropout value of the PM-LSTM is 0.2. The neuron numbers of the fully connected layers are 32/16/2. Figure (a) shows that all training loss-epoch curves with different initial learning rates for LSTM-2. Figure (b) is the Logarithmic curve fitting of Figure (a), which makes it smoother and intuitively reflects the average loss value of the training effect. Additionally, the results of the detailed comparison information are shown in Table .
Figure 9. (a) The results of training loss for each learning rate (b) The fitting curve of comparison results.
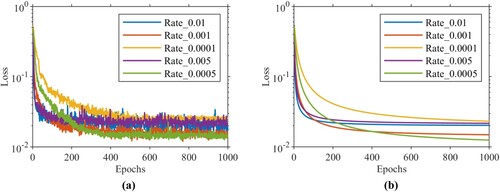
Table 6. The loss results of each initial learning rate for MAVP model.
Figure (a) and (b) show that both curve convergence range and training precision value with the learning rate (5e-4) are superior to others. The downward trend curve in the early 200 epochs is obvious and inconsistent because the training dataset has different adaptability to the training process of each learning rate. Further, Table provides the relevant loss value of the final epoch.
In the paper, we built the relationship model with the learning rate 5e-4. The detail and schematic diagram of the relationship model among ,
, and
are shown in Figure (a) and (b). To calculate the assumption parameter values in Formula 32 and 33, we fit the relationship model with the prediction data of the MAVP model. Thus, the function of the relationship model among the multi-parameter and the target loading compensation in Figure (a) is expressed as follows:
where boundary conditions satisfy as follows: when
and
,
, and when
and
,
.
Figure 10. (a) The diagram of the relationship model-1 (b) The diagram of the relationship model-2.
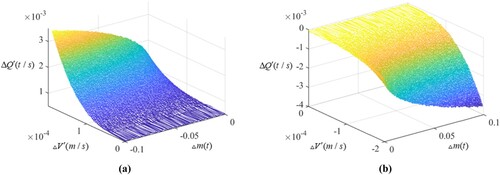
Concurrently, the function of the relationship model in Figure (b) is expressed as follows:
where boundary conditions satisfy as follows: when
and
,
, and when
and
,
.
3.3. Application results
In this paper, we apply the above-provided relationship model via the PM-LSTM in the MACCs and compare it with the conventional MPLC system to verify the superior performance in industrial loading. The primary configuration in the Huaibei coal mine is listed in Table , and actual loading diagrams of the system are shown in Figure (a) and (b).
Figure 11. (a) The diagram of the system console (b) The diagram of loading monitoring parameters.

Table 7. The major configuration of the industrial loading.
Based on the above configuration, we collected the material loading data of the selected 50 carriages from Jan 1st, 2021 to Jan 31th, 2021. The average metrics (i.e. actual material load, time consumption) of each carriage are shown in Figure (a) and (b). Table shows the load variance and average capacity of each loading group. The results indicate that all carriages’ material loading effect is nearly 69 t, and the average time consumption of the loading process is close to 235 s. It means that the industrial loading process based on the MACCs can get good performance.
Figure 12. (a) The effect of actual material loading (b) The effect of actual time consumption.
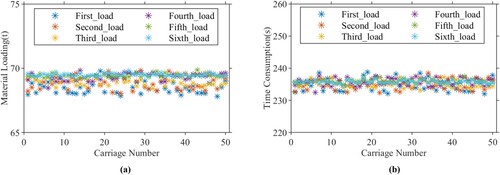
Table 8. The variance and mean value of actual material loading and time consumption in each group.
The historical data of the carriage (i.e. No.1653599) from Dec 1st, 2020 to Dec 31th, 2020 is collected from the coal mine. The comparison results of actual loading based on the MAVP model and conventional MPLC system are shown in Figure . The MACC system outperforms the conventional MPLC system, and the actual material loading capacity based on the MACCs is more stable and accurate, about 69.4 t. The time consumption is about 230 s, which is significantly less than the contrast system.
Figure 13. (a) The actual loading comparison results of systems (b) The loading time consumption results of systems.
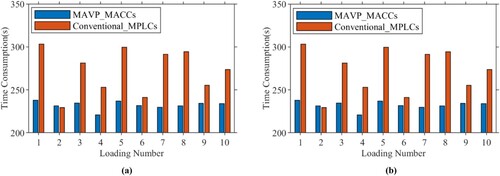
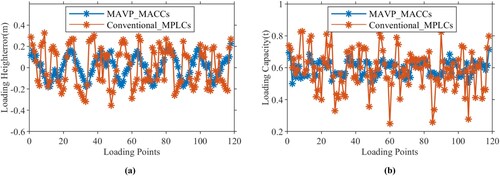
Figure (a) and (b) show that the comparison results of loading height error and loading capacity in a continuous process. The loading height-error and loading capacity of the MACCs for each loading area satisfy the indicators in Table (i.e. Area Loading Height-error and Area Loading Capacity). Namely, the loading capacity of each loading point belongs to [0.493, 0.693 t], and the absolute value of the loading height-error is less than 0.2 m. Namely, the optimised industrial loading based on MACCs has a good effect. In addition, the material loading balance compared with the conventional MPLCs is increased (i.e. absolute average height-error: 0.092 m vs 0.169 m, the standard deviation of loading capacity: 0.057 t vs 0.113 t).
Figure 14. (a) Height errors of each loading point (b) Capacity errors of each loading point.
3.4. Discussion and analysis
In this paper, the discussion and analysis of the experimental and applicational results are as follows:
The HFA method indicates better bins allocation ability for industrial loading. Because the fuzzy toolbox has a strong logic inference and calculation ability, we can use our proposed HFA method to optimise the bins allocation ratio and reduce allocation time consumption. The hierarchical fuzzy allocation guarantees the accuracy of the target loading value, and the evaluation formula further selects the most reasonable bins allocation ratio. The reason is that the different kinds of fuzzy rule bases in each layer can promote the fuzzy approximation target value within the allowance range. During the fuzzy calculation process in each layer, adding a single bin at a time can simplify the logic or time complexity.
The MAVP model based on PM-LSTM and FC method can further achieve regression accuracy and robustness for the long time series. Because of the memory cell accumulator and formidable extraction ability, the forward neural network LSTM-1 can be adopted as a feature extractor to sequence inputs. It means that the LSTM extracts subsequent features of the sequence and selectively merges them with the initial time features (Duguma et al., Citation2021; Zhang, Zhang, et al., Citation2021). With the help of the FC method, the hidden and comprehensive relationship among the adjustment parameters can be described as a two-dimensional feature matrix. Due to the method orderly adopting the average feature value substitution to integrate and reconstruct the multi-parameter independent features, the LSTM-2 can predict the multi-target parameters with low loss value.
The relationship among target loading compensation and multi parameters can be well fitted. Based on the theoretical derivation and proof of the relationship model, we can get the collaborative relationship between the adjustment values of multi-parameter and the target compensation value, which is first mentioned in the industrial loading field. Because of the high-precision prediction of adjustment parameters via the MAVP model, the relationship model's coefficients can be accurately calculated.
4. Conclusion
This paper proposes a HFA method and the MAVP model applied in the MACCs for optimising the bins allocation ratio and achieving accurate parameters prediction. In addition, the relationship model among the target loading compensation and adjustment values of multi parameters are derived and well built. Experimental and applicational results demonstrate that the MACCs can significantly solve the industrial loading problems of conventional MPLCs (i.e. unreasonable bin allocation strategy and dangerous eccentric load). It also can dramatically improve the loading efficiency and reduce the workload of the coal mining workers. However, the HFA method has the limitation in that the computational complexity of the strategy and the number of rule sets will suddenly increase with the increase of bins number. In the future, we will combine the resource scheduling algorithm with the HFA method to optimise computational consumption. Further, we want to explore the application of the more precisive MAVP model in the rail-mounted industrial loading field for collaborative control.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Che, P., Liu, Y., Che, L., & Lang, J. (2020). Co-Optimization of generation Self-Scheduling and coal supply for Coal-Fired power plants. IEEE Access, 8, 110633–110642. https://doi.org/10.1109/access.2020.2989514
- Çınar, A., & Tuncer, S. A. (2021). Classification of normal sinus rhythm, abnormal arrhythmia and congestive heart failure ECG signals using LSTM and hybrid CNN-SVM deep neural networks. Computer Methods in Biomechanics and Biomedical Engineering, 24(2), 203–214. https://doi.org/10.1080/10255842.2020.1821192
- Du, J., Vong, C., & Chen, C. L. P. (2021). Novel efficient RNN and LSTM-like architectures: Recurrent and gated broad learning systems and their applications for text classification. IEEE Transactions on Cybernetics, 51(3), 1586–1597. https://doi.org/10.1109/TCYB.2020.2969705
- Duguma, D. G., Kim, J., Lee, S., Jho, N., Sharma, V., & You, I. (2021). A lightweight D2D security protocol with request-forecasting for next-generation mobile networks. Connection Science, 1–25. https://doi.org/10.1080/09540091.2021.2002812
- Han, Y., Li, C., Zhang, W., & Ahmad, H. G. (2020). Impulsive consensus of multiagent systems with limited bandwidth based on encoding–decoding. IEEE Transactions on Cybernetics, 50(1), 36–47. https://doi.org/10.1109/TCYB.2018.2863108
- He, Z., Zhou, Z., Gan, L., Huang, J., & Zeng, Y. (2019). Chinese entity attributes extraction based on bidirectional LSTM networks. International Journal of Computational Science and Engineering, 18(1), 65. https://doi.org/10.1504/IJCSE.2019.096988
- Jani, M., Garg, P., & Gupta, A. (2020). Performance analysis of a mixed cooperative PLC–VLC system for indoor communication systems. IEEE Systems Journal, 14(1), 469–476. https://doi.org/10.1109/JSYST.2019.2911717
- Ji, Y., Xu, K., Zeng, P., & Zhang, W. (2021). GA-SVR algorithm for improving forest above ground biomass estimation using SAR data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14, 6585–6595. https://doi.org/10.1109/JSTARS.2021.3089151
- Kara, A. (2021). Multi-step influenza outbreak forecasting using deep LSTM network and genetic algorithm. Expert Systems with Applications, 180, 115153. https://doi.org/10.1016/j.eswa.2021.115153
- Krupa, P., Limon, D., & Alamo, T. (2021). Implementation of model predictive control in programmable logic controllers. IEEE Transactions on Control Systems Technology, 29(3), 1117–1130. https://doi.org/10.1109/TCST.2020.2992959
- Liang, H., Liu, G., Zhang, H., & Huang, T. (2021). Neural-network-based event-triggered adaptive control of nonaffine nonlinear multiagent systems with dynamic uncertainties. IEEE Transactions on Neural Networks and Learning Systems, 32(5), 2239–2250. https://doi.org/10.1109/TNNLS.2020.3003950
- Mackenzie, J., Roddick, J. F., & Zito, R. (2019). An evaluation of HTM and LSTM for short-term arterial traffic flow prediction. IEEE Transactions on Intelligent Transportation Systems, 20(5), 1847–1857. https://doi.org/10.1109/TITS.2018.2843349
- Mou, L., Zhao, P., Xie, H., & Chen, Y. (2019). T-LSTM: A long short-term memory neural network enhanced by temporal information for traffic flow prediction. IEEE Access, 7, 98053–98060. https://doi.org/10.1109/ACCESS.2019.2929692
- Qiao, F., Ma, Y., Zhou, M., & Wu, Q. (2020). A novel rescheduling method for dynamic semiconductor manufacturing systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 50(5), 1679–1689. https://doi.org/10.1109/TSMC.2017.2782009
- Shu, X., Zhang, L., Sun, Y., & Tang, J. (2021). Host–parasite: Graph LSTM-in-LSTM for group activity recognition. IEEE Transactions on Neural Networks and Learning Systems, 32(2), 663–674. https://doi.org/10.1109/TNNLS.2020.2978942
- Srivastava, T., Vedanshu, & Tripathi, M. M. (2020). Predictive analysis of RNN, GBM and LSTM network for short-term wind power forecasting. Journal of Statistics and Management Systems, 23(1), 33–47. https://doi.org/10.1080/09720510.2020.1723224
- Sun, L., & Huo, W. (2016). Adaptive fuzzy control of spacecraft proximity operations using hierarchical fuzzy systems. IEEE/ASME Transactions on Mechatronics, 21(3), 1629–1640. https://doi.org/10.1109/TMECH.2015.2494607
- Wang, L., Zhou, H., Yang, J., Xiong, Y., She, J., & Chen, W. (2021). A decision support system for tobacco cultivation measures based on BPNN and GA. Computers and Electronics in Agriculture, 181, 105928. https://doi.org/10.1016/j.compag.2020.105928
- Wu, S., Liu, Y., Zou, Z., & Weng, T. (2021). S_I_LSTM: Stock price prediction based on multiple data sources and sentiment analysis. Connection Science, 1–19. https://doi.org/10.1080/09540091.2021.1940101
- Xue, H., Huynh, D. Q., & Reynolds, M. (2021). PoPPL: Pedestrian trajectory prediction by LSTM with automatic route class clustering. IEEE Transactions on Neural Networks and Learning Systems, 32(1), 77–90. https://doi.org/10.1109/TNNLS.2020.2975837
- Yu, R., Chen, Y., Han, B., & Zhao, H. (2021). A hierarchical control design framework for fuzzy mechanical systems with high-order uncertainty bound. IEEE Transactions on Fuzzy Systems, 29(4), 820–832. https://doi.org/10.1109/TFUZZ.2020.2965913
- Zhang, S., Yu, H., & Zhu, G. (2021). An emotional classification method of Chinese short comment text based on electra. Connection Science, 1–20. https://doi.org/10.1080/09540091.2021.1985968
- Zhang, S., Zhang, Z., Chen, Z., Lin, S., & Xie, Z. (2021). A novel method of mental fatigue detection based on CNN and LSTM. International Journal of Computational Science and Engineering, 24(3), 290. https://doi.org/10.1504/IJCSE.2021.115656
- Zhao, Z., Liu, S., Zhou, M., Guo, X., & Qi, L. (2020). Decomposition method for new single-machine scheduling problems from steel production systems. IEEE Transactions on Automation Science and Engineering, 17(3), 1–12. https://doi.org/10.1109/TASE.2019.2953669
- Zhou, Z., & Xu, H. (2021). Large-scale multiagent system tracking control using mean field games. IEEE Transactions on Neural Networks and Learning Systems, 32(5), 1–9. https://doi.org/10.1109/TNNLS.2021.3071109