
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Aiming at the problems of few detecting samples, deformable target sizes and overlapping among targets in the detection of headdresses and seats of Thangka Yidam, we propose an optimised few shot Thangka detection method based on the ResNet and deformable convolution. Firstly, the optimised deep residual network is designed to address the problem of few categories and complicated composition in Thangka images. Then, we replace the 3×3 convolution of the optimised deep residual network with deformable convolution. By introducing the offset of deformable convolution, the receptive field can adapt to the different sizes and shapes of the detection target of Thangka Yidam. Finally, the box regression is achieved through the multi-relation detector, where DT-NMS is proposed to reduce the missed and repeated detection target. Experimental results show that the proposed method has better performance than the SOTA on the COCO dataset. In addition, the AP of 2-way 5-shot on the Thangka dataset is 33.3%, and the AP50 reaches 71.2%, which increases by 4.7% and 5.3%, respectively.
1. Introduction
As a unique 1300-year-old scroll painting, Thangka was embodied in the intangible cultural heritage of the United Nations in 2006 (Ge, Citation2018). The subject matter and content of Thangka are extremely rich, including Eikon,Footnote1 Mandala, Biography, Architectural Attraction, Tibetan Medical Calendar and so on. The Eikon is the most representative type, accounting for about 80%. When people initially understand the Thangka art, they are often shocked by the rich layout and the strong artistic tension of Thangka. However, a lot of religious knowledge is required for sake of identifying semantic objects and understanding image contents. For instance, Lord Sakyamuni Buddha with a blue mitral and a high bun holds an alms bowl in the left hand and a flower in the right hand, and sits on the padmasana, as shown in Figure . The alms bowl and the flower symbolise different wishes and merits of the divine statues. By identifying the mitral and the padmasana, we can determine that the Thangka Yidam is Sakyamuni Buddha. A key point in computer vision is how to analyse static images to achieve the purpose of scene understanding. Through the detection of key objects in the Thangka images, we can obtain important semantic information about Thangka images, and interpret image contents and experience the Tibetan living culture.
Figure 1. The Sakyamuni Buddha.

The traditional object detection technology was usually realised by statistical learning methods (Chen et al., Citation2021; Rama et al., Citation2018; Saha et al., Citation2021; Li et al., Citation2018). All of those algorithms were trained by a manual design feature, resulting in the high time complexity and the poor robustness. To this end, some efficient detection algorithms with convolutional neural networks (CNNs) were proposed. According to different training methods, object detection algorithms based on CNNs can be divided into two types: the single-stage detection algorithm (Kim, Citation2020; Bochkovskiy et al., Citation2020; Liu et al., Citation2021) and two-stage detection algorithm (Girshick et al., Citation2015; Girshick, Citation2015; Ren et al., Citation2017). However, all of them require a large amount of training data with accurate border annotations. The collected Thangka images show unbalance categories and few samples problems. We will face greater challenges when we directly apply the data-driven detection model to the detection of Thangka images with few samples.
To address few samples problem, the domestic and foreign scholars proposed a new kind of machine learning theory: few shot learning, which can be learned from limited data. With the excellent achievements in few shot image classification (Gidaris & Komodakis, Citation2018; Dvornik et al., Citation2019; Cai et al., Citation2018), few shot object detection algorithms have also been developed rapidly. However, recent works for few-shot object detection (Kang et al., Citation2019; Yan et al., Citation2019; Sun et al., Citation2021; Zhu et al., Citation2021) all require fine tuning and cannot be directly applied on novel categories. To address this problem, Fan et al. (Citation2020) proposed a Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector (FSOD) model, which introduces the attention mechanism and the data information of support set in RPN. In addition, FSOD integrates the features of query image and support image to guide the network to generate more bounding boxes related to query images and suppress irrelevant bounding boxes. It can achieve the significant detection performance without fine tuning. Therefore, we perform Thangka image detection based on the FSOD model.
However, Thangka images have the characteristics of complex composition, few detection categories, different detection shapes and sizes and so on. It is not ideal to directly transplant Thangka images into the FSOD model, which is easy to cause poor generalisation ability, high missed detection rate and repeated rate. Therefore, we propose an improved method based on the FSOD and named it RD-FSOD, where R represents the improved ResNet and D represents the deformable convolution. Our contributions are follows:
Proposed the improve backbone network to extract Thangka features, which addresses the problem of complicate Thangka images and few categories, thus effectively improving the detection performance of the model.
Introduced the deformable convolution (DC) (Dai et al., Citation2017) according to the geometric deformation characteristics of the seats in Thangka Yidam. We replace the 3×3 convolution of the improve backbone network with the deformable convolution.
Proposed the double thresholds non-maximum suppression (DT-NMS) algorithm to solve overlapping among objects problem. By comparison under different threshold combinations, we choose Nt = 0.45 and Nd = 0.90 as the final threshold. Experiments show that the performance of our proposed method is better than the FSOD model in the detection for headdresses and seats of Thangka Yidam.
The rest of this article is arranged as follows: Section 2 introduces the related work of few shot object detection and the FSOD model. Section 3 is the detailed design and implementation of the model. In Section 4, the datasets and the experimental environment are introduced first. Then we carry out the comparison and ablation experiments, and explain and analyse the results. Section 5 is the conclusion.
2. Related work
2.1. Few shot object detection method
Few shot object detection refers to learning a better detection performance model from few labelled samples. Karlinsky et al. (Citation2019) converted the region of interest (RoI) into the feature vector as the input of the distance metric learning sub-network. The posterior probability of each RoI is calculated to achieve the detection and cognition of few samples by comparing the distance between the embedded feature vector and the representation vector of each target. In LSTD (Chen et al., Citation2018) based on fine tuning, the authors proposed a novel few shot object detection network that can transfer knowledge from one large dataset to another smaller dataset, by minimising the gap of classifying posterior probability between the source domain and the target domain. Singh et al. (Citation2020) also adopted the fine-tuning method to obtain the detection results by fine-tuning the pre-training model in the target domain. However, these methods ignore that potential bounding boxes can easily miss unseen categories and falsely detect images in the background. Aiming at this problem, Fan et al. proposed the FSOD model, which proposed a general few-shot object detection model that can be applied to detect novel objects without retraining and fine-tuning.
2.2. FSOD method
FSOD is a ‘few shot object detection’ model based on the model structure. Given a support image with a close-up of the target and a query image
which potentially contains objects of the support category c, central to the FSOD is to find all the objects belonging to the support category in the query and label them with the bounding boxes. If the support set contains N categories and K examples for each category, the problem is dubbed N-way K-shot detection.
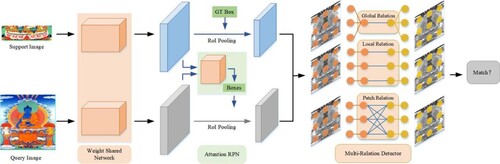
Figure shows the overall architecture of FSOD. Fan et al. build a weight shared framework consisting of multiple branches, where one branch is for the query set and the others are for the support set. The model first extracts features of sc and qc through the residual network (ResNet), and then performs the bounding box regression and localisation in the query branch. The query branch is the Faster R-CNN network containing RPN and detector. This framework is utilised to learn the matching relationship between support features and query features, so that the network can learn common features among same categories. Since RPN only classifies anchor boxes between foreground and background, all foreground anchor boxes are given high confidence, and the ROI sent to the next stage contains many categories unrelated to the support image. Therefore, the authors introduce a novel Attention-RPN and detector with multi-relation modules to produce an accurate parsing between support and potential boxes in the query.
Figure 2. The overall network architecture of FSOD.
3. Proposed method
3.1. Few shot object detection for headdresses and seats in Thangka Yidam based on ResNet and deformable convolution
Our research objects have the characteristics of complicated composition, few detection categories, different detection shapes and sizes and overlapping between detection objects. However, the detection object of FSOD is natural images, which makes the FSOD model unable to be directly applied to the detection of Thangka images. Therefore, we propose the RD-FSOD model based on the FSOD model in accordance with the above characteristics, as shown in Figure .
Figure 3. The overall network architecture of RD-FSOD.
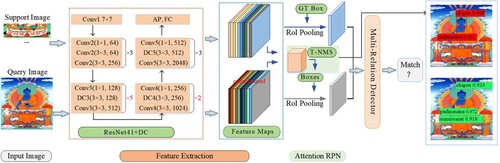
Firstly, according to complex composition and few detection categories, we improve the ResNet50 to focus on the shallow features and decrease feature loss. In this work, we adjust the convolution layers of the conv3_x stage from 12 to 15 and the conv4_x stage from 18 to 6. Secondly, DC is introduced to the improved ResNet50 to address the problem of different detection shapes and sizes. We replace the 3×3 convolution of the improved ResNet50 with DC. By introducing the offset of DC, the receptive field can adapt to the different sizes and shapes of the detection target of Thangka Yidam, so as to achieve better detection results. In addition, we propose a DT-NMS algorithm to solve overlapping among objects problem in the bounding box regression stage.
3.2. Adjustment and optimisation of convolution layer structure
As a kind of deep network, ResNet can effectively address the gradient dispersion problem when the conventional network is stacked to a certain depth, and achieve a better feature extraction effect.
Thangka, as a unique religious art works, pays particular emphasis to colour application and composition, making it difficult to extract the feature of Thangka images. In addition, the character attributes in Thangka images are only six categories. The Thangka images and character attributes are shown in Figure . In order to obtain the maximum extraction of Thangka images and improve the detection accuracy, the improved ResNet50 is designed.
Figure 4. The Thangka image and character attributes.

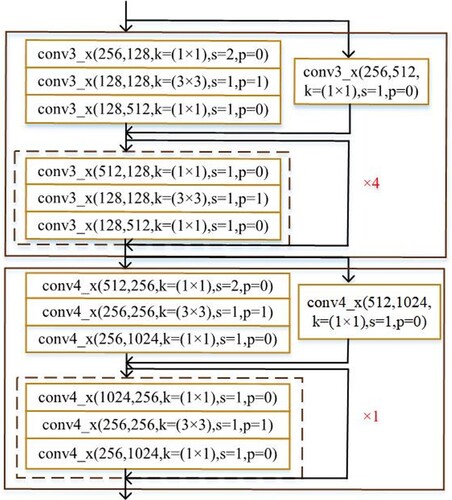
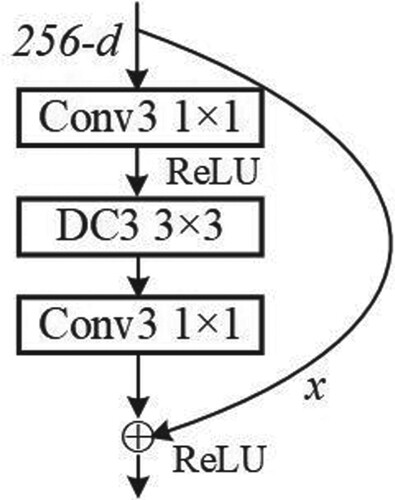
The existing researches (Lu, Citation2021; Shah et al., Citation2020) show that the shallow network has a small receptive field, which can contain more image details and improve the detection accuracy. On the contrary, the deep network extracts more abstract features and pays more attention to the semantic information of images, which is conducive to the detection of targets (Xu & Zhang, Citation2020). Therefore, we adjust the number of convolution layers of ResNet50 to better extract Thangka image features. We appropriately reduce the number of convolution layers of the deep network and add the number of convolution layers of the shallow network. The improved network pays more attention to image details information and decreases image feature loss and network computing. We reduce the network layers from 50 to 41, namely ResNet41: the convolution layers of the conv3_x stage are added to 15 layers and the convolution layers of the conv4_x stage are reduced to 6 layers. The adjusted ResNet41 structure is shown in Figure . The conv3_x and conv4_x represent 3th and 4th stages of ResNet, respectively. In the conv(256,128, k = (1×1), s = 2, p = 0), k is the size of the convolution kernel, s is the stride, p is the padding, 256 is the number of convolution kernel channels, and 128 is the number of channels output by the upper convolution layer.
Figure 5. The Optimized ResNet50 network structure. "×4" indicates the number of repeated layers of optimized network.
3.3. Introduction of deformable convolution
In the 2D convolution, for each location on the output feature map, the calculation formula of the feature value is
(1)
(1) Among them, i = 1, … , N, N = |F|, ω represents the weight of convolution kernel, f is the input feature map, F represents the output feature map which defines a 3×3 kernel with dilation 1, p0 represents central location and pi enumerates the location in the F.
Figure shows the images of seats in Thangka Yidam. It can be seen that the appearance of seats is variable and the size is different. Therefore, it is necessary to address the problem of the target geometric deformation in the detection of the Thangka image. However, according to Equation (1), the traditional convolution operation does not have scale invariance and rotation invariance. To this end, Dai et al. proposed a deformable convolution network which enhances the ability of feature extraction by introducing the offset of the sampling position. In the DC, the regular grid F is augmented with offsets , where N = |F|. Equation (1) becomes
(2)
(2) where
represents the input eigenvalue of the sampling offset location.
Figure 6. The image data of seats in Thangka Yidam.

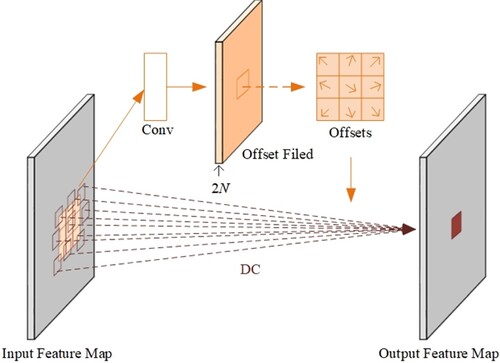
DC uses a parallel convolution layer to learn the offset so that the sampling points of the convolution kernel on the input feature map are offset, that is, a direction vector is added to each sampling point, as shown in Figure . Numerous studies (Wei et al., Citation2020; Xu et al., Citation2020) have indicated that the DC has excellent performance in the field of object detection. The application of DC can obtain position information of detection targets through continuous learning and extract more exact features of detection targets of Thangka Yidam.
Figure 7. Illustration of 3×3 deformable convolution.
We introduce DC into all 3 × 3 convolution layers of conv3, conv4 and conv5 of ResNet41 to enhance the detection accuracy for Thangka images. Figure shows the stacking sequence of conv3. By introducing deformable convolution layers, the model can obtain sampling points of more extensive hierarchical features, so that the network as a whole has the ability to learn the spatial support region more precisely.
Figure 8. The stacking sequence of conv3.
3.4. Double threshold non-maximum suppression
Non-maximum suppression (NMS) (Neubeck & Van Gool, Citation2006) is a key post-processing process in many computer vision filed. In object detection, it is utilised to convert a response map which activates many imprecise object windows in a single bounding-box for each detection object. The NMS is a greedy algorithm. It greedily selects high confident score detection, and deletes less confident score detection adjacent to high confident bounding box to avoid the same object being repeated detection. The fractional reset function is
(3)
(3) where Bmax represents the bounding box with the highest confidence and Bi is the ith bounding box.
is the Intersection-over-Union (IoU) ratio between the rest of bounding boxes and the bounding boxes with the highest confidence. Nt is the preset threshold of NMS. si is the confidence.
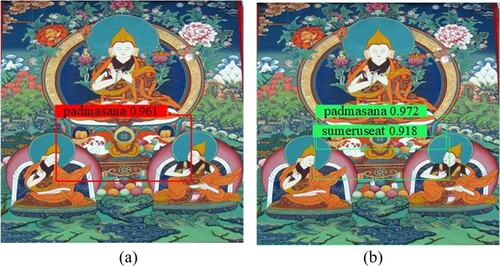
However, when two detection objects are adjacent in the image, the bounding box with lower confidence is likely to be directly suppressed, resulting in missed detection. As shown in Figure (a), the sumeruseat is close to the padmasana in the Thangka images. The NMS algorithm will take sumeruseat and padmasana as the same detection object. The padmasana bounding box with the highest score is retained, but the sumeruseat is missed.
Figure 9. Comparison of the detection results of NMS and Soft-NMS on Thangka images.
The soft non-maximum suppression (soft-NMS) (Bodla et al., Citation2017) adopts the ‘weight punish’ strategy to address the missed detection problem. The specific method is shown in Equation (4).
(4)
(4) where the symbol is the same as in Equation (3).
The soft-NMS algorithm designs an attenuation function in the overlapping part of the adjacent bounding box between detection objects. It re-scores recursively according to the current confident score rather than directly suppresses the adjacent bounding boxes with lower scores, thus retaining the detection bounding boxes of adjacent targets. Figure (b) shows the detection result of the soft-NMS algorithm, where sumeruseat and the padmasana were identified simultaneously.
However, as the number of bounding boxes increases, the probability of target misclassification and repeated detection increases. To this end, we propose the DT-NMS algorithm combining the advantages of the NMS and the Soft-NMS. The fractional reset function is shown in Equation (5).
(5)
(5) where the symbol is the same as in Equation (3).
We add a threshold Nd on the basis of soft-NMS algorithm and set Nt<Nd. When the IoU(Bmax, Bi) is higher than Nd, we delete the bounding boxes. This is because if IoU(Bmax, Bi) is too large, Bmax and Bi are very likely to be the same target, which will increase the probability of repeated detection. If , a ‘weight punish’ strategy the same as soft-NMS is given as a new score si. If
, the overlap area between
and Bmax is small, and the original score is retained.
The proposed DT-NMS algorithm can filter the bounding boxes again while decreasing the repeated detection rate. In the threshold selection process, we follow the 2-way 5-shot evaluation protocol to evaluate our DT-NMS. Table shows the ablation study of our proposed under the naive 2-way 5-shot training strategy on the Thangka dataset. We adopt the same evaluation setting hereafter for all ablation studies on the Thangka dataset.
Table 1. Comparison of AP (%) under different threshold combinations.
We choose Nt = 0.45 and Nd = 0.90 as the final threshold, which makes the AP reach the highest 33.34%.
4. Experiment
In the experiments, we compare our approach with other state-of-the-art (SOTA) methods on different datasets. For fair comparison, we adopt the same train/test setting as these methods. In these cases, we use a multi-way few-shot training in the fine-tuning stage with more details to be described. At the same time, we carry out ablation experiments to verify the effectiveness of each component of the RD-FSOD model.
4.1. Experimental setting
The experiment employs the pytorch framework, and is carried out in Ubuntu 16.04 system. All experimental platforms are: Intel(R) Core(TM) 5-1035G1, the main frequency is 1.19 GHz, and the memory is 16 GB. GPU is used to accelerate the calculation.
4.2. Datasets
4.2.1. Thangka dataset
Research objects, headdresses and seats in Thangka Yidam are from the Institute of Thangka, School of Art, Northwest University for Nationalities. All of six categories are padmasana, chignon, cushion, mitral, sumeruseat and coronet, as shown in Figure .
Figure 10. The detection categories of Thangka Yidam.

According to the existing research, padmasanas have a high probability of appearing in any Thangka images. Hence, we need to balance the dataset by means of data augmentation to further improve the detection accuracy. Table shows the number of categories before and after the Thangka image augmentation.
Table 2. The number distribution of categories before and after Thangka image augmentation.
4.2.2. MS COCO dataset
MS COCO (Lin et al., Citation2014) dataset is constructed by Microsoft, which contains more than 800 thousand pictures and 80 classes. It is mainly used for the task of detection and segmentation in natural scenes. MS COCO contains a complex image background, a large number of instances and small target size, so it is reasonable to verify the effectiveness of the proposed method on the COCO dataset.
4.3. Main results
4.3.1. Dataset split and results analysis
In order to verify the effectiveness of the method on the Thangka dataset, the experiments are carried out on the Thangka images with six categories. It is noted that padmasanas, cushions, coronets and mitrals are used as training sets, and chignons, sumeruseats as testing sets, which ensure that the training set and testing set belong to the same conceptual domain. Dataset partitions are shown in Table .
Table 3. Experimental instructions for the Thangka data.
We train respectively sumeruseats, cushions, coronets and mitrals on the FSOD model and our model. In the experiment, we set the learning rate as 10−4, the number of iterations as 70,000, and the batch size as 4, and then evaluate the performance of the model on the new testing set. We adopt AP and AP50 for evaluation.
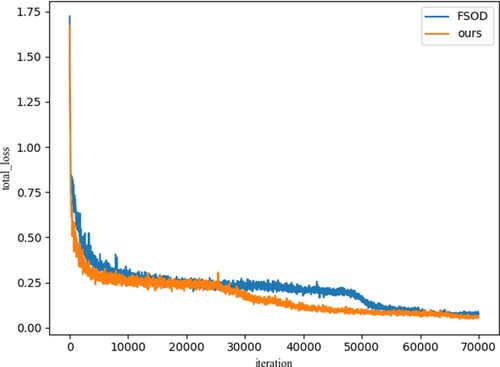
Figure shows the change curve of loss value during the model training. The training loss values of the two models show a decreasing trend and the model gradually converges in the training process. The total_loss of our method slowly drops after 30,000 iterations, tends to be stable after 50,000 iterations and finally stabilises at 0.5–0.6, while the total_loss of the FSOD model suddenly drops after 50,000 iterations and finally stabilises at 0.7–0.8, which fully proves that the performance of our model outperforms the FSOD model.
Figure 11. The loss curve of the training model.
We construct the few shot learning regime of the 2-way K-shot for the training of few shot data, where K∈{1,5}. In the few shot testing stage, a batch of samples extracted from chignons and sumeruseats are sent to the network to obtain the predicted results. Results for the Thangka dataset are shown in Table .
Table 4. The evaluation results of Thangka image detection.
It can be seen from the experimental results in Table that our model achieves 28.5% and 33.3% AP on 2-way 1-shot and 2-way 5-shot, with up to 4.7% and 7.1% above FSOD respectively. And the AP50 of our model is higher than that of the FSOD model in the Thangka dataset, which fully proves the effectiveness of our method in the few shot object detection. We will further analyse the impact of our improved parts on model performance in the Thangka dataset and COCO dataset in Section 4.3.2. Figure shows the detection result on the 2-way 1-shot task. Two images on the left side are the new class and the image on the right side is the class to be tested.
Figure 12. The test results of 2-way 1-shot.

The network model has a certain influence on the performance. In Table , we compare our results with those of the state-of-the-art (SOTA) on the COCO dataset based 20-way 10-shot detection task. We adopt the same data split as their method and follow their evaluation protocol: we set the 60 categories as training categories in MS COCO, and use the rest 20 categories as novel categories for evaluation. In addition, we use the same backbone network for the SOTA model to carry out comparative experiments. The experimental analysis shows our model with the same MS COCO training dataset outperforms SRR by 1.1%/2.2% on AP/AP50 metrics. This indicates that our model obtains enough high-level features when ResNet41 and DC are utilised as backbone networks. At the same time, the application of T-NMS algorithm in the regression stages avoids missed or repeated detection between adjacent targets, thus increasing the detection accuracy.
Table 5. The comparison results on the MS COCO dataset for 20-way 10-shot.
4.3.2. Ablation experimental analysis
Based on the RD-FSOD model, we carry out the ablation experiment on the Thangka and COCO dataset under the different evaluation tasks. Table shows the ablation experiment result.
Table 6. The ablation experiment results for key components on the Thangka dataset and COCO dataset.
When combining ResNet41 and DC, we obtain better performance than that of other combination type. When the ResNet41 structure is not introduced, the AP on the Thangka dataset is significantly lower than that on the COCO dataset, which further indicates that strengthening shallow features is useful for the detection of complex Thangka images. However, DT-NMS has the most obvious effect on the detection of the Thangka dataset. We believe that the occlusion among Thangka targets makes the DT-NMS algorithm more efficient. By combining all components, we achieve best performance.
5. Conclusion
Thangka Yidam includes various characteristic attributes, such as seats, headdresses and handheld. The detection of headdresses and seats can not only promote the development of the image understanding field of Thangka Yidam, but also has a certain significance for the spread of Tibetan culture.
In order to address the problems of minority categories, different sizes and overlapping between target objects in Thangka image detection, we improve the FSOD model as follows:
A ResNet-based backbone network is designed to address the few categories and complicate composition problem in Thangka images. The ablation experimental results verify the effectiveness of the improved ResNet in Thangka Yidam detection.
The deformable convolution is adopted in the improved ResNet to expand the receptive field of Thangka feature maps, which effectively strengthen the ability of extracting effective Thangka feature.
In the border regression process, a DT-NMS algorithm is proposed to address the problem of the overlapping between seats.
The experimental results show that the proposed method has higher detection accuracy than the STOA model on the MS COCO dataset. In addition, we also carried out ablation experiments, and the three improvements are carried out to further prove the effectiveness of our method.
In future, the effectiveness of our method will be further verified with the expansion of the Thangka categories, such as books and bottles in handheld objects.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Thangka with the theme of all kinds of Buddha, Bodhisattva, Buddha Mother, Rohana, Fawang, Yidam, Guardian, Monk Tai Tak and historical figures of Tibetan Buddhism.
References
- Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). Yolov4: Optimal speed and accuracy of object detection. arXiv Preprint ArXiv:2004, 10934.
- Bodla, N., Singh, B., Chellappa, R., & Davis, L. S. (2017). Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE international conference on computer vision (pp. 5561-5569).
- Cai, Q., Pan, Y., Yao, T., Yan, C., & Mei, T. (2018). Memory matching networks for one-shot image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4080-4088).
- Chen, H., Wang, Y., Wang, G., & Qiao, Y. (2018, April). Lstd: A low-shot transfer detector for object detection. In Proceedings of the AAAI conference on artificial intelligence (Vol. 32, No. 1).
- Chen, W. S., Ge, X., & Pan, B. (2021). A novel general kernel-based non-negative matrix factorisation approach for face recognition. Connection Science, 1–26. https://doi.org/10.1080/09540091.2021.1988904
- Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., & Wei, Y. (2017). Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision (pp. 764-773).
- Dvornik, N., Schmid, C., & Mairal, J. (2019). Diversity with cooperation: Ensemble methods for few-shot classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 3723-3731).
- Fan, Q., Zhuo, W., Tang, C. K., & Tai, Y. W. (2020). Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4013-4022).
- Ge, J. F. (2018). From temple to exhibition Hall: Reconstruction of tangka viewing mechanism under the transformation of space. Journal Of Lanzhou University(Social Sciences, 46(2), 74–80. https://doi.org/10.13885/j.issn.1000-2804.2018.02.010
- Gidaris, S., & Komodakis, N. (2018). Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4367-4375).
- Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440-1448).
- Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2015). Region-based convolutional networks for accurate object detection and segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(1), 142–158. https://doi.org/10.1109/TPAMI.2015.2437384
- Kang, B., Liu, Z., Wang, X., Yu, F., Feng, J., & Darrell, T. (2019). Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8420-8429).
- Karlinsky, L., Shtok, J., Harary, S., Schwartz, E., Aides, A., Feris, R., … Bronstein, A. M. (2019). Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5197-5206).
- Kim, S. D. (2020). Situation-cognitive traffic light control based on object detection using YOLO algorithm. International Journal of Computational Vision and Robotics, 10(2), 133–142. https://doi.org/10.1504/IJCVR.2020.105682
- Li, Z. H., Yang, C., & Liang S, H. (2018). Adaboost moving-target detection algorithm based on superpixel segmentation and mixed weight. Electronics Optics & Control, 25(02|2), 33–37. https://doi.org/10.0.15.129/j.issn.1671-637X.2018.02.007
- Lin, T. Y., Maire, M., Belongie, S., Hays, J., & Zitnick, C. L. (2014, September). Microsoft coco: Common objects in context. In European conference on computer vision (pp. 740–755). Springer.
- Liu, D., Gao, S., Chi, W., & Fan, D. (2021). Pedestrian detection algorithm based on improved SSD. International Journal of Computer Applications in Technology, 65(1), 25–35. https://doi.org/10.1504/IJCAT.2021.113643
- Lu, T. C. (2021). CNN convolutional layer optimisation based on quantum evolutionary algorithm. Connection Science, 33(3), 482–494. https://doi.org/10.1080/09540091.2020.1841111
- Neubeck, A., & Van Gool, L. (2006, August). Efficient non-maximum suppression. In 18th International Conference on Pattern Recognition (ICPR'06) (Vol. 3, pp. 850-855). IEEE.
- Rama, M. C., Mahendran, D. S., & Kumar, T. R. (2018). A hybrid colour model based land cover classification using random forest and support vector machine classifiers. International Journal of Applied Pattern Recognition, 5(2), 87–100. https://doi.org/10.1504/IJAPR.2018.092517
- Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence , 39(6), 1137–1149. https://doi.org/10.1109/tpami.2016.2577031
- Saha, M., Naskar, M. K., & Chatterji, B. N. (2021). Human skin ringworm detection using wavelet and curvelet transforms: A comparative study. International Journal of Computational Vision and Robotics, 11(3), 245–263. https://doi.org/10.1504/IJCVR.2021.115158
- Shah, S. K., Mishra, R., Mishra, B. S. P., & Pandey, O. (2020). Prediction of abnormal hepatic region using ROI thresholding based segmentation and deep learning based classification. International Journal of Computer Applications in Technology, 64(4), 382–392. https://doi.org/10.1504/IJCAT.2020.112685
- Singh, P., Varadarajan, S., Singh, A. N., & Srivastava, M. M. (2020, June). Multi-domain Document Layout Understanding Using Few-Shot Object Detection. In International Conference on Image Analysis and Recognition (pp. 89-99). Springer, Cham.
- Sun, B., Li, B., Cai, S., Yuan, Y., & Zhang, C. (2021). FSCE: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7352-7362).
- Wei, R., Song, Y., & Zhang, Y. (2020). Enhanced faster region convolutional neural networks for steel surface defect detection. ISIJ International, 60(3), 539–545. https://doi.org/10.2355/isijinternational.ISIJINT-2019-335
- Xu, X., Yu, T., Hu, X., Ng, W., & Heng, P. A. (2020). Salmnet: a structure-aware lane marking detection network. IEEE Transactions on Intelligent Transportation Systems, PP(99), 1-12.
- Xu, Z., & Zhang, W. (2020). Hand segmentation pipeline from depth map: An integrated approach of histogram threshold selection and shallow CNN classification. Connection Science, 32(2), 162–173. https://doi.org/10.1080/09540091.2019.1670621
- Yan, X., Chen, Z., Xu, A., Wang, X., Liang, X., & Lin, L. (2019). Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9577-9586).
- Zhu, C., Chen, F., Ahmed, U., Shen, Z., & Savvides, M. (2021). Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8782-8791).