
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In order to resist malicious attacks and improve recommendation accuracy, this paper proposes a collaborative filtering recommendation algorithm based on fuzzy subjective trust based on the subjectivity and fuzziness of trust. Firstly, the trust matrix is constructed by calculating the trust degree between users based on fuzzy subjective trust model and set of trusted users. Then, based on the traditional collaborative filtering recommendation algorithm, the user hybrid recommendation matrix is obtained through user similarity matrix and trust matrix to form recommendations for target users. Experimental results show that this method can effectively improve the resistance to malicious attacks and improve the accuracy of the recommendation system.
1. Introduction
In recent years, with the rapid development of social networks such as Facebook, Twitter, Weibo, WeChat, QQ, etc., various social applications and services have penetrated into many fields such as instant messaging, e-commerce and consumer recommendation. Social networking has become one of the main ways for people to communicate and obtain information (Arora & Taneja, Citation2021; Meeker, Citation2017; Shen et al., Citation2020). As the main body of the social network platform, users have established complex and diverse social networks based on their actual needs, real social relationships and activities. On social networks, people are no longer satisfied to communicate with friends they know in the real world, but hope that social networks can recommend them more new users with common interests and hobbies, continue to expand their social relationships and learn more useful information. How to provide users with service recommendations safely, quickly and accurately has become one of the hotspots of social network service research (Bushra & Yousef, Citation2020). Traditional recommendation systems are mostly based on collaborative filtering algorithms (Liu et al., Citation2020), content data filtering algorithms, and hybrid recommendation algorithms (Bushra & Yousef, Citation2020; Zhang, Citation2019; Zhu, Citation2020). Among them, the collaborative filtering algorithm is one of the most widely used personalised recommendation algorithms, but the algorithm has problems such as cold start (Li et al., Citation2022), data sparseness, forgery of scoring data, and inaccurate recommendation accuracy (Chen et al., Citation2016; Jia et al., Citation2019; Nassira et al., Citation2020; Yu, Chen, et al., Citation2020).
With the continuous deepening of social networks, trust has gradually been introduced into the research of collaborative filtering algorithms. Trust is the foundation of the entire social formation and is of paramount importance in social networks. It has been found that, similar to real social life, items recommended by friends trusted by users in social networks are more easily accepted by users (Ive & Tatiane, Citation2021; Lv, Citation2020; Tong et al., Citation2017). Therefore, the research of collaborative filtering algorithm based on trust relationship is in line with the actual construction characteristics of social networks. It provides a new idea to solve the problems of data sparseness and cold start in traditional collaborative filtering algorithms and improve the accuracy of social network recommendation (Nassira et al., Citation2020; Wang et al., Citation2019).
At present, some achievements have been made in the research of trust-based recommendation methods in social networks. Guo Lei et al. (Citation2021) mined trust relationships from social behaviours, measured user trust from both explicit and implicit aspects, and proposed a joint matrix factorisation social recommendation algorithm based on trust mechanism and social behaviours. Experimental results show that the proposed algorithm can significantly improve the recommendation accuracy and top-K recommendation ability. Zou Yang et al. (Citation2020) calculated the trust degree of social network users based on the behaviour of social network users, and proposed a recommendation algorithm combining improved fill method and multi-weight similarity degree. The algorithm obtained neighbour users and recommended goods to target users according to the similarity degree. Experimental results show that the MAE of the proposed algorithm is superior to other recommendation methods in the case of data sparsity and personalised recommendation. Ju Chunhua et al. (Citation2021) proposed a recommendation method combining users’ social relationship and trust relationship, which calculates trust degree based on the trust relationship of friends and the reputation of users, and effectively combines similar relationship with trust relationship. Experimental results show that the proposed application recommendation method can effectively improve the validity and accuracy of application recommendation. Yu Shengjie et al. (Citation2020) integrated the trust model of user preference and trust–distrust relationship, and proposed a recommendation algorithm based on joint probability matrix decomposition. The experimental results show that the algorithm has better recommendation accuracy than the traditional collaborative filtering algorithm based on fusion trust and the existing trust-enhanced matrix decomposition recommendation method. Sheng Liqun et al. (Citation2022) mined the implicit trust relationship matrix between users by using known user rating information, and proposed an improved SoRec model based on the obtained trust information. Experimental verification shows that the model can improve the accuracy of the recommendation algorithm. Hu Yun et al. (Citation2017) proposed a social recommendation algorithm for comprehensive scoring and trust relationship. This method used the probability matrix decomposition method to study the trust relationship, and solved the problem of accurate construction of users feature vectors and trust transfer. The experimental results show that the proposed algorithm has a significant performance improvement over the traditional social network recommendation algorithm. Tang Xiaobo et al. (Citation2015) proposed a social media friend recommendation model based on complex trust network. Based on the social relationship of social media users, this model combined the trust measurement and delivery method to construct the user’s trust network system. The experimental results show that the proposed algorithm alleviates the cold start problem of the friend recommendation system and improves the accuracy of the friend recommendation result. Guo Lei et al. (Citation2013) proposed a sensitive social recommendation algorithm to strengthen the trust relationship. The experimental results show that this method can achieve better recommendation results, and the strength of the trust relationship derived by it can further improve the performance of existing recommendation algorithms. Using the concept of a friend of a Friend (FOAF), Dionisis et al. (Citation2020) proposed the CFfoaf algorithm, which was evaluated under eight widely used sparse datasets and two widely used collaborative filtering correlation metrics, and proved to be particularly effective. However, in the existing trust-based collaborative filtering algorithm research, most of the trust is based on the probability model. The definition of trust is too strict, and the subjectivity, uncertainty and fuzziness of trust itself are not considered. Therefore, the true trust relationship in the social network cannot be correctly reflected. Trust is an important foundation for the formation of social networks. Establishing a reasonable and efficient trust model is a prerequisite for the accurate study of social recommendation algorithms.
Therefore, this paper proposes a collaborative filtering recommendation algorithm based on fuzzy subjective trust, which uses fuzzy subjective trust model to dynamically describe the trust relationship between users in social networks. After removing malicious attack users, the set of trusted users is constructed, and the trust degree among trusted users in the social trust network is calculated based on this set. In this way, the user trust matrix is constructed, and the traditional CF algorithm is improved based on the similarity of user preferences, and finally the recommendation to target users is formed.
2. Collaborative filtering recommendation algorithm based on fuzzy subjective trust (FST-CF)
2.1. Algorithm process
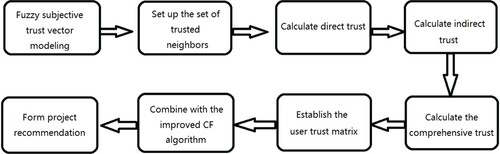
Fuzzy subjective trust model is the core of FST-CF algorithm, including the establishment of fuzzy subjective trust vector, the establishment of trusted users set (TUS) and the calculation of trust degree between users. Considering the subjectivity and fuzziness of trust in social networks, this paper uses fuzzy membership theory to objectively describe the trust evaluation among users in social networks, and completes the construction of fuzzy subjective trust vector. In the calculation of trust degree between users, the calculation of direct trust degree between users is the basis of trust measurement, which determines the accuracy and rationality of indirect trust degree between users. The direct trust degree and indirect trust degree between users will directly affect the construction of user trust matrix. In order to prevent the shilling attacks behaviour of malicious users, the algorithm adds the trusted users to the set of trusted users by judging the behaviour of users, and calculates the direct and indirect trust degree of users based on the set of trusted users. Finally, the user trust matrix is constructed and the target user is recommended by the improved CF algorithm.
FST–CF algorithm process is shown in Figure .
Figure 1. FST-CF algorithm process.
2.2. Trust
Under the social network, users form a circle of friends because of mutual trust, and they constantly update and strengthen trust through social interaction. Once trust is established, the social relationships between users are gradually spread. Therefore, the key to the research on trust-based recommendation algorithms in social networks is to give a formal description of trust network after analyzing and defining trust-related attributes (Gan et al., Citation2012; Gan et al., Citation2015).
X.509 v4 (2000 version) (International Telecommunications Union, Citation2000) defines trust as follows: “In general, if an entity assumes another entity will be strictly in accordance with the it would expect action, then call it trust that entity”. The concept of trust defined here contains a relationship between the two parties and an expectation of the relationship. In social networks, trust is the subjective behaviour between two entities in the network. It is a complex network relationship with characteristics of otherness, fuzziness, transitivity, asymmetry, compositionality and dynamicity.
Definition 2.1:
Let R be a collection of user entities in the social network, ,
and
. The relationship between entities is represented by
, and the trust value is represented by
. The trust relationship between users can be formally defined as formula (1).
(1)
(1)
2.3. Formal description of the trust network
This paper uses a trust network to express the trust relationship between users in social networks and the recommendation environment of the social network.
Definition 2.2:
Trust Network. It is formally represented by a directed weighted graph G composed of nodes representing users and trust relationship between nodes, denoted as G = (V, E, R). The set of vertices of the trust network is represented by V, the set of edges between the vertices is represented by E, and the set of trust values between the nodes is represented by R.
2.4. The establishment of fuzzy subjective trust vector
Suppose is the problem domain studied by fuzzy subjective trust, and
is the subject of the problem domain under study.
Definition 2.3:
If problem domain is a non-empty set and
is an element in
, the following mapping relationship holds for
:
(2)
(2) Then the set
is called the fuzzy subset on
. We call
the membership of
to the fuzzy subset A, call the mapping
the membership function of the fuzzy subset A, and call
the set of all fuzzy subsets A in the problem domain
.
Definition 2.4:
Definition is a trust type with different trust degrees, and a discrete value
is used to describe the level of trust of the user subject.
Definition 2.5:
Let be a subset with different levels of trust, subject
be an element in
, and take the vector formed by the membership degree
of
to each
as the trust vector.
In social networks, users can be characterised by historical credibility, social identity, social status, transaction evaluation and other parameters of the user subject (Zhang, Citation2006). Then, the finite number of fuzzy parameters is used to describe the vector
formed by the feature values of each user subject as the trust vector of the subject
. In this way, the fuzzy membership theory is used to objectively describe the trust evaluation of other users to a certain user in the social network, and the construction of fuzzy subjective trust vector is completed.
2.5. The establishment of trusted users set
In the collaborative filtering recommendation system, the system generates a recommendation list for each user according to the evaluation information of his neighbour, so the shilling attacks behaviour of malicious users will affect the final result of the recommendation. As the shilling attacks method has the characteristics of score difference, symmetry, camouflage and infectivity (Zhang & Huang, Citation2020), in order to determine whether a user is a malicious user, four parameters are defined to determine whether a user is a shilling attack user according to the characteristics of trusted users, so as to establish a set of trusted users in the trust network.
2.5.1. Degree of trust clustering (DTC)
This clustering degree describes the degree to which users in a trust network trust each other in a “cluster”. Because the trust relationship between normal users is usually asymmetrical, there is not much overlap between trusted users. However, shilling attacks users’ symmetry features, resulting in trust relations between each other to form certain cluster characteristics, which are defined as follows:
(3)
(3) In formula (3),
indicates the set of users trusted by user A, and
indicates the set of users trusted by user
.
2.5.2. Proportion of trusted projects (PTP)
Due to the random attack characteristics of shilling attacks, it can be concluded that the number of scoring items of shilling attacks users is almost the same and the number of scoring items is large. In the actual recommendation scenario, it is precisely because users rate fewer items that data sparseness appears in the scoring matrix. Using this feature of shilling attacks users, it is defined as follows:
(4)
(4) In formula (4),
represents the scoring item of user
,
represents the scoring item of user A,
represents the number of scoring items of user A.
2.5.3. Trust similarity (TS)
In the trust network, there is usually not too much item score between normal users, resulting in low similarity between them. Due to the mutual trust behaviour of the shilling attacks users and the similar attack behaviour of the shilling attacks, there is a high degree of similarity between the two users in the trust relationship. Using this feature of shilling attacks users, it is defined as follows:
(5)
(5) In formula (5),
is cosine similarity of user A and user T,
represents the number of scoring items of user A.
2.5.4. Degree of global consistency (DGC)
Users of partial shilling attacks randomly attack the system without adding trust information. In order to increase the robustness of the system against this kind of shilling attacks, the global consistency degree is proposed and defined as follows:
(6)
(6) In formula (6),
is user A’s rating of project
,
is the average of all ratings of project
, and
represents the number of scoring items of user A.
Because the users of shilling attack adopt the same attack mode, the global consistency obtained by the final calculation is stable around a certain value. According to this feature, the trusted users without added trust information can be found by calculating the global consistency in the TUS.
2.5.5. Trusted users set
The TUS is built as follows:
Part one: shilling attacks user judgment in trust network.
Firstly, DTC, PTP and TS of the trusted network are calculated, and the users whose values of these three parameters are greater than a certain threshold are added to the set of shilling attacks users. After being added, users in the set of shilling attacks users meet the following conditions: the user with a large “cluster” in the trust relationship, a large number of items commented and a large number of items jointly scored by the users in the trust relationship and a user with a high degree of similarity with himself in the trust relationship can be considered as a shilling attack user with added trust information, and added to the shilling attacks users set, and conversely, added to the TUS.
The second part: shilling attacks user judgment without added trust information.
The average value of DGC is calculated by the set of shilling attacks users in the trusted network. At this time, users without added user trust information can determine whether they are shilling attacks users by calculating their DGC, so that the trusted users are added to the TUS.
After the above two steps, the TUS in the trust network is established. The calculation of direct and indirect trust in social trust networks is based on the interaction between trusted users.
2.6. Direct trust degree
Research shows (Huang et al., Citation2018) that popular item ratings cannot better describe and represent the similarity relationship between users, while the similarity behaviour of rare item ratings can better explain the similarity between users. Therefore, the number of evaluated projects is sorted, and the m projects that rated the most by users are eliminated, and the remaining projects are regarded as “rare project set”. According to the number and difference of items jointly scored by users and trusted neighbours belonging to the TUS, the similarity of items (RIS) is calculated as follows:
(7)
(7) In formula (7),
and
are rare items rated by user u and user
respectively,
is the user u’s rating of the project i,
is the average score of user u.
The closer and more rare items are evaluated by the trusted neighbours and the users, the higher the similarity between the trusted neighbours and the users. Set the minimum number of rare items in common evaluation m, and only when the number of rare items in common evaluation of trusted neighbours is greater than or equal to M, they will participate in the screening of trusted neighbours. Take n trusted neighbours with large RIS values and calculate the weight of trusted neighbours as follows:
(8)
(8) In formula (8),
is a set of n trusted neighbours with the maximum RIS value of user u,
is the user in
,
is RIS of rare item similarity of user u and user
.
The direct trust degree of user u to user can be calculated as:
(9)
(9) In formula (9),
is the fuzzy subjective trust evaluation of user u to user
,
is the fuzzy subjective trust evaluation of user
by user u’s trusted neighbour
and α is the weight factor.
2.7. Indirect trust degree
According to the transitivity and attenuation characteristics of trust and TidalTrust algorithm, the shorter path has higher trust. Combined with the “six dimensions of space” theory in social networks, this paper introduces the maximum propagation length and sets the value of
as 6. For the scoring item set of source and target trusted users, the number of scoring times of all trusted users on the path is added to this item set, so that the smaller the scoring difference of trust path between users is, the more scoring items are, and the trust value of the trust path with shorter path length is larger.
The way we define the path item differences (PID) for each path is calculated as follows:
(10)
(10) In formula (10),
and
are set of scoring items of source trusted user u and target trusted user
, respectively, and
is all users on a path between source trusted user u and target trusted user
,
indicates the predicted or actual score of item i of user T on the path, and
indicates the average score of item i of all users.
After obtaining multiple trust paths between users, the paths are sorted according to the PID, and m paths with the smallest PID value are taken to calculate the path trust weight (PTW) of each path as follows:
(11)
(11) In formula (11),
is the set of m paths with the smallest PID value between source trusted user u and target trusted user
and
is the path item difference of path i in
.
The indirect trust degree between trusted users is calculated as follows:
(12)
(12) In formula (12),
is the direct trust degree of all users on the path of
, and
is the weight of path trust degree of
.
2.8. The comprehensive trust degree of fuzzy subjective trust
Combining direct trust degree and indirect trust degree, the fuzzy subjective trust degree of user u to user can be expressed as:
(13)
(13)
In formula (13), β is the weight factor of direct trust degree and indirect trust degree. According to the real characteristics of social networks, users are more willing to trust their direct interaction experience, so the weight of direct trust degree is generally higher.
2.9. Steps of collaborative filtering recommendation algorithm based on fuzzy subjective trust (FST–CF)
The above trust method is applied to the traditional CF algorithm, and a collaborative filtering recommendation algorithm based on fuzzy subjective trust is constructed. The specific steps are described as follows:
Step 1: Establish a user scoring matrix, and convert the user's explicit, implicit scores, evaluation behaviours, etc. to a numerical score according to certain rules to form a user item scoring matrix.
Step 2: Calculate the similarity between users using the improved Pearson correlation coefficient formula (Li et al., Citation2018; Wu & Jiang, Citation2019). The traditional Pearson correlation coefficient formula is:
(14)
The traditional Pearson correlation coefficient is inaccurate in calculating user similarity. However, in social networks, the trust relationship between users not only includes the similarity relationship between them, but also the number of items they jointly score in history. The greater the number of users, the higher the trust value. Therefore, an improved Pearson similarity coefficient can be proposed by integrating the number of jointly scored items and Pearson similarity coefficient, as shown in the following model:
(15)
(15) In formula (15),
represents the number of historical common scoring items between users
and
,
represents the set of scoring items for user
.
Step 3: According to formula (9) and (12), the direct trust degree
Step 4: Calculate the user's comprehensive trust degree
Step 5: Determine the threshold
Step 6: According to the number and range of trust neighbour users selected in Step 5, calculate the user similarity in combination with Step 2, and establish a user similarity matrix
Step7: Combine the user trust matrix
Step 8: The first L users with the highest mixing similarity with the target user in the mixing matrix S are selected as the set of the most recent trusted neighbours.
Step 9: According to the selected nearest neighbour user and its score record, the recommended value of the target user for the predicted item can be calculated. In this paper, the user similarity in the prediction formula of the classical user-based collaborative filtering algorithm is changed to the mixed similarity to calculate the recommended value:
3. Experiment and analysis
3.1. Experimental data
The Movielens data set collected by the GroupLens project team of the University of Minnesota was selected for this experiment. This data set contains 86,432 real ratings of 1546 movies by 1043 users, with the scoring criteria ranging from 1 to 5. After calculation, the sparsity reached 93.7%. In addition, the data set also contains the user’s characteristic attribute information, which meets the evaluation requirements of trust relationship in this paper. In this paper, 80% of the Movielens dataset was randomly selected as the training set and 20% as the test set.
3.2. Experimental evaluation criteria
The Mean Absolute Error (MAE) is used to measure the recommendation accuracy of the recommendation system by calculating the absolute error between the user’s actual score in the test set and the score predicted by the recommendation algorithm. The smaller MAE value is, the higher the accuracy of the recommendation result is; otherwise, the lower the accuracy of the recommendation result is (Meng et al., Citation2020). The MAE calculation formula is as follows:
(20)
(20) In formula (20),
is the user’s predicted score for the target item,
is the actual score for the target item,
is the user test set and
is the number of user test set.
The root mean square error (RMSE) measures the recommendation accuracy of the recommendation system by calculating the arithmetic square root of the mean square error between the user's actual score in the test set and the score predicted by the recommendation algorithm. The smaller the RMSE value is, the higher the accuracy of the recommendation result is; otherwise, the lower it is (Wu, Yu, et al., 2013). The RMSE calculation formula is as follows:
(21)
(21) In formula (21),
is the user’s predicted score for the target item,
is the actual score for the target item,
is the user test set and
is the number of user test set.
In order to better measure the recommendation effect, influence indicator parameter is introduced (Zhou et al., Citation2018), as shown below:
(22)
(22)
This parameter is the harmonic value of MAE and RMSE. The smaller the value is, the better the recommendation accuracy is.
3.3. Experimental results and analysis
Experiment 1: Influence of weight factor on FST-CF algorithm.
When calculating the direct trust degree of users, the weight factor determines the weight distribution of fuzzy subjective trust evaluation of user by user
and fuzzy subjective trust evaluation of user
by trusted neighbours of user
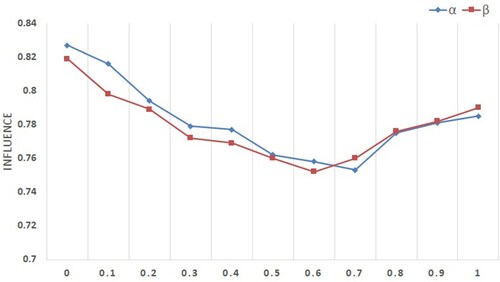
. When calculating the comprehensive trust degree of users, the weight factor determines the weight distribution of direct trust degree and indirect trust degree. Figure shows the value of the parameter influence obtained by changing the weight factor respectively while keeping other variables of the FST-CF algorithm unchanged, so as to measure the influence of the weight factor on the FST-CF algorithm.
Figure 2. The influence of and
on FST-CF algorithm.
As can be seen from Figure , influence achieves the minimum value when it is 0.7, because the fuzzy subjective trust evaluation of user by user
reflects the real trust relationship between users. Therefore, when calculating the user’s trust degree, direct trust degree will occupy a large weight. In addition, it can be seen that influence gets the minimum value when it is 0. 6. This indicates that in real social trust networks, users are more willing to trust their direct interaction experience, so the weight of direct trust degree is generally higher. Therefore, the values of α and β are set to 0.7 and 0.6, respectively in the experiments described below.
Experiment 2: The Comparison of recommended accuracy under no shilling attacks.
Shilling attack is a common attack method in which malicious users improve the similarity between themselves and the target users by simulating the project score of the target users, and then recommend the deceptive project to the target users, thus causing the interests of the target users to be damaged. This experiment compares the collaborative filtering recommendation algorithm based on FST-CF, the traditional collaborative filtering recommendation algorithm (CF), the social recommendation algorithm combining score and trust relationship (TSR) and the cooperative filtering algorithm integrating traditional trust relationship (TUBCF). In the case of no shilling attacks, the experimental comparison results obtained by these four recommended methods are shown in Figure .
Figure 3. Comparison of recommendation accuracy under different trusted neighbour number k values.
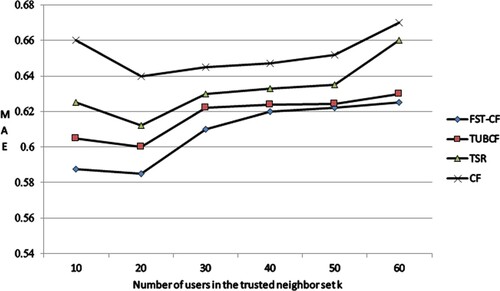
Analysis of the experimental results in Figure shows that the recommendation accuracy of the recommendation algorithm is the highest when the number of users k in the trusted neighbour set is 20. In addition, the FST-CF algorithm designed in this paper achieves the lowest MAE value, indicating that the algorithm has a high recommendation accuracy. When the number of trusted neighbour users is 10, FST-CF algorithm is 11%, 6% and 2.89% higher than CF algorithm, TSR algorithm and TUBCF algorithm, respectively. When the number of trusted neighbour users is 20, FST-CF algorithm improves by 8.2%, 4% and 2.08% compared with CF algorithm, TSR algorithm and TUBCF algorithm respectively. This shows that trust relationships in social networks can improve the accuracy of recommendations. In particular, the FST-CF algorithm in this paper is based on real trust relationships in social networks to make the selection of trusted neighbours more accurate, thus effectively improving the accuracy of recommendations.
Experiment 3: The comparison of recommendation accuracy under shilling attacks.
Assuming that there is no shilling attacks in the original data set, this experiment simulates the shilling attacks behaviour of malicious users, Experimental comparison was made between the collaborative filtering recommendation algorithm based on FST-CF, the CF, the TSR and the TUBCF. In this experiment, MAE values of the four algorithms are compared when the number of trusted neighbour users k is set to 20, the artificial injection of random attack, mean attack and popular attack each account for 1/3, the filling rate is 5%, and the attack scale is 1%, 3% and 5%. The experimental results are shown in Figure .
Figure 4. Comparison of recommended accuracy of four algorithms under mixed attack.
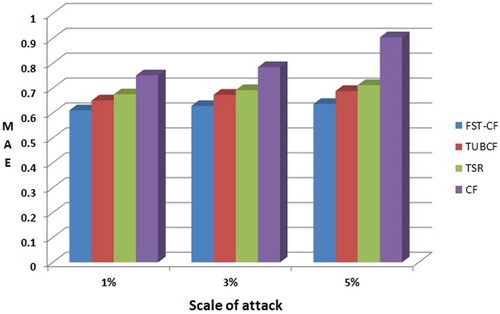
It can be seen from the experimental results that MAE of the four recommendation algorithms increases to varying degrees with the increase of attack scale, which indicates that the recommendation accuracy of the recommendation algorithm will decrease with the increase of the profile of the attacker user. However, the FST-CF algorithm in this paper achieves the minimum MAE value under different support attack scales, which reflects the strong anti-attack ability. This shows that the trust measurement method proposed in this paper can accurately calculate the trust degree among users in social networks, so as to effectively isolate attacks from trusted neighbours and improve the anti-attack capability of the recommendation algorithm.
4. Conclusion
This paper proposes a collaborative filtering recommendation algorithm based on fuzzy subjective trust for the lack of trust evaluation in the current social network recommendation system. This method is based on fuzzy subjective trust model and measures the trust value of users in social networks correctly by constructing the set of trusted users. Combined with the improved traditional collaborative filtering recommendation algorithm, the target user recommendation is finally formed. Experimental results show that compared with the traditional collaborative filtering algorithm, the new algorithm can effectively improve the accuracy and anti-attack ability of the recommendation system, thus providing a new idea for the research of trust-based collaborative filtering algorithm. However, in future studies, it is necessary to comprehensively consider all user information in similarity calculation, including user active time, user active location, user usage time, etc. At the same time, more factors need to be weighed to alleviate the problem of data sparsity. The algorithm also needs to better balance the requirements of real-time and accuracy of the algorithm, so that the algorithm can be improved in both real-time and accuracy.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Arora, A., & Taneja, A. (2021). Research issues, innovation and associated approaches for recommendation on social networks. International Journal of Performability Engineering, 17(12), 1027–1036. https://doi.org/10.23940/ijpe.21.12.p7.10271036
- Bushra, A., & Yousef, K. (2020). The recommender system: A survey. International Journal of Advanced Intelligence Paradigms, 15(3), 229–251. https://doi.org/10.1504/IJAIP.2020.105815
- Chen, T., Zhu, Q., Zhou, M., & Wang, S. (2016). A trust-based recommendation algorithm in social network environment. Journal of Software, 28(3), 721–731. https://doi.org/10.13328/j.cnki.jos.005159
- Dionisis, M., & Costas, V. (2020). Improving collaborative filtering's rating prediction coverage in sparse datasets by exploiting the 'friend of a friend' concept. International Journal of Big Data Intelligence, 7(1), 47–57. https://doi.org/10.1504/IJBDI.2020.106178
- Gan, Zaobin, Zeng, Can, Ma, Yao, Lu, Hongwei, (2015). C2C e-commerce trust algorithm based on trust network. Journal of Software, 26(8), 1946–1959. https://doi.org/10.13328/j.cnki.jos.004690
- Gan, Z. B., Zeng, C., Li, K., & Han J.-J. (2012). Construction and optimization of trust network in e-commerce environment. Chinese Journal of Computers, 35(1), 27–37. https://doi.org/10.3724/SP.J.1016.2012.00027
- Guo, L., Ma, J., & Chen, Z. (2013). A socialized recommendation algorithm based on the strength of trust relationship. Journal of Computer Research and Development, 50(9), 1805–1813. CNKI:SUN:JFYZ.0.2013-09-003
- Guo, L., Yu, W.-S., & Wu, Q.-S. (2021). Simulation of joint matrix factorization recommendation algorithm integrating trust relationship. Computer Simulation, 38(2), 378–382. https://doi.org/10.3969/j.issn.1006-9348.2021.02.081
- Hu, Y., Li, H., & Shi, W. (2017). Socialized recommendation algorithm combining score and trust relationship. Journal of Computer Applications, 37(3), 791–795. https://doi.org/10.11772/j.issn.1001-9081.2017.03.791
- Huang, Liwei, Jiang, Bitao, Lv, Shouye, et al. (2018). Survey on deep learning based recommender systems. Chinese Journal of Computers, 41(7), 1619–1647. https://doi.org/10.11897/SP.J.1016.2018.01619
- International Telecommunications Union. (2000). ITU_T Recommendation X.509 ISO/IEC 9594-8: Information Technology-Open Systems Interconnection-The Directory Public-key and Attribute Certificate Frameworks[S]. ITU-T,2000.
- Ive, A. D. S. T., & Tatiane, N. R. (2021). FACF: Fuzzy areas-based collaborative filtering for point-of-interest recommendation. International Journal of Computational Science and Engineering, 24(1), 27–41. https://doi.org/10.1504/IJCSE.2021.113636
- Jia, R., Li, R., & Gao, M. (2019). Study on data sparsity in social network-based recommender system. International Journal of Computational Science and Engineering, 20(1), 15–20. https://doi.org/10.1504/IJCSE.2019.103245
- Ju, C., Gu, Q., & Li, J. (2021). Research on application recommendation method integrating user social relationship and trust relationship. Journal of Systems Science and Mathematical Sciences, 41(12), 144–161. https://doi.org/10.12341/jssms14101
- Li, Tianyuan, Su, Xin, Liu, Wei, Liang, Wei, Hsieh, Meng-Yen, Chen, Zhuhui, Liu, XuChong, Zhang, Hong, et al. (2022). Memory-augmented meta-learning on meta-path for fast adaptation cold-start recommendation. Connection Science, 34(1), 301–318. https://doi.org/10.1080/09540091.2021.1996537
- Li, Y., Chen, L., Shi, C., & Lan, X. (2018). Enhanced collaborative filtering algorithm adopting trust network. Application Research of Computers, 35(1), 117–120. https://doi.org/10.3969/j.issn.1001-3695.2018.01.024
- Liu, N., Lu, Y., Tang, X.-J., Li, M.-X., & Wang, C. (2020). Improved user-based collaborative filtering algorithm with topic model and time tag. International Journal of Computational Science and Engineering, 22(2-3), 181–189. https://doi.org/10.1504/IJCSE.2020.107340
- Lv, C.-S. (2020). Anti-Attack social recommendation algorithm based on multiple implicit trust relationship. Operations Research and Management Science, 29(1), 69–77. CNKI:SUN:YCGL.0.2020-01-010
- Meeker, M. (2017). Internet trends 2017 reports [EB/OL].2017-12-10. http://www.kpcb.com/internet-trends
- Meng, H., Gao, C., Wang, S., Zhang, L.-L., & Liu, N. (2020). User clustering collaborative filtering recommendation algorithm combined with trust relationship. Computer Systems & Applications, 29(8), 224–229. https://doi.org/10.15888/j.cnki.csa.007561
- Nassira, C., Ilyes, C., Souham, M., Badreddine, C., Didier, S., Mohamed, B., & Amel, Z. (2020). SCOL: Similarity and credibility-based approach for opinion leaders detection in collaborative filtering-based recommender systems. International Journal of Reasoning-Based Intelligent Systems, 12(1), 34–50. https://doi.org/10.1504/IJRIS.2020.105006
- Shen, J., Zhou, T., & Chen, L. (2020). Collaborative filtering-based recommendation system for big data. International Journal of Computational Science and Engineering, 21(2), 219–225. https://doi.org/10.1504/IJCSE.2020.105727
- Sheng, L., & Song, Y. (2022). An improved social recommendation model based on implicit trust information. Journal of Chinese Computer Systems, 43(2), 306–311. https://doi.org/10.20009/j.cnki.21-1106/TP.2020-0870
- Tang, X., & Sun, F. (2015). Research on social media friends recommendation based on complex trust network. Information Studies Theory & Practice, 38(11), 96–102. https://doi.org/10.16353/j.cnki.1000-7490.2015.11.019
- Tong, X.-R., Jiang, X.-X., Wang, Y.-J., & Zhang, N. (2017). Research on the systems. Journal of Chinese Computer Systems, 38(1), 92–98. CNKI:SUN:XXWX.0.2017-01-018
- Wang, H., Yu, X., Zhao, J., & Zheng, Y. (2019). Detecting sparse rating spammer for accurate ranking of online recommendation. International Journal of Computational Science and Engineering, 19(1), 121–131. https://doi.org/10.1504/IJCSE.2019.099646
- Wu, H., Bian, Y., Zhao, Z., & Ma, R.-M. (2014). Collaborative filtering algorithm based on trust. Computer Systems & Applications, 24(7), 131–135. https://doi.org/10.3969/j.issn.1003-3254.2014.07.025
- Wu, H., & Jiang, H. (2019). Collaborative filtering recommendation based on potential social trust model. Computer Engineering and Applications, 55(20), 114–121. https://doi.org/10.3778/j.issn.1002-8331.1807-0043
- Yu, D., Chen, R., & Chen, J. (2020). Video recommendation algorithm based on knowledge graph and collaborative filtering. International Journal of Performability Engineering, 16(12), 1933–1940. https://doi.org/10.23940/ijpe.20.12.p9.19331940
- Yu, S., Xiong, L., & Wang, L. (2020). A social recommendation method based on user preference and trust-trust relationship. Journal of Chinese Computer Systems, 41(12), 2529–2535. 1000-1220041:012<2529:YZRHYH>2.0.TX;2-E
- Zhang, S. (2006). Research on Fuzzy Trust Model and national PKI system. Sichuan: Chengdu. Southwest Jiaotong University. https://doi.org/10.7666/d.y884767
- Zhang, T. (2019). Research on collaborative filtering recommendation algorithm based on social network. International Journal of Internet Manufacturing and Services, 6(4), 343–356. https://doi.org/10.1504/IJIMS.2019.103874
- Zhang, X., & Huang, G. (2020). Trust-based shilling attacks user detection algorithm. Computer Applications and Software, 37(11), 286–291. https://doi.org/10.3969/j.issn.1000-386x.2020.11.046
- Zhou, Ya, Chai, Wang, Han, Junyang, Zhang, Guoliang (2018). Recommendation algorithm based on user comprehensive trust degree and community trust propagation. Computer Engineering, 44(12), 294–300. CNKI:SUN:JSJC.0.2018-12-049
- Zhu, A. (2020). Personalised recommendation algorithm for social network based on two-dimensional correlation. International Journal of Autonomous and Adaptive Communications Systems, 13(2), 195–209. https://doi.org/10.1504/IJAACS.2020.109807
- Zou, Y., Wu, H., Jiang, Y., & Zhao, Y. (2020). Recommendation algorithm based on filling method and multi-weight similarity. Application Research of Computers, 37(12), 3578–3581. https://doi.org/10.19734/j.issn.1001-3695.2019.09.0541