
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
A popular chatbot can generate natural and human-like responses, and the crucial technology is the ability to understand and appreciate the emotions and demands expressed from the perspective of the user. However, some empathetic dialogue generation models only specialise in commonsense and neglect emotion, which can only get a one-sided understanding of the user's situation and makes the model unable to express emotion better. In this paper, we propose a novel affective feature knowledge interactive model named AFKI, to enhance response generation performance, which enriches conversation history to obtain emotional interactive context by leveraging fine-grained emotional features and commonsense knowledge. Furthermore, we utilise an emotional interactive context encoder to learn higher-level affective interaction information and distill the emotional state feature to guide the empathetic response generation. The emotional features are to well capture the subtle differences of the user's emotional expression, and the commonsense knowledge improves the representation of affective information on generated responses. Extensive experiments on the empathetic conversation task demonstrate that our model generates multiple responses with higher emotion accuracy and stronger empathetic ability compared with baseline model approaches for empathetic response generation.
1. Introduction
Humans have the special ability to convey subtle emotions in a more natural communication way. Most neural conversation models (J. Li, Galley, Brockett, Gao, et al., Citation2016; Shang et al., Citation2015; Vinyals & Le, Citation2015; Wolf et al., Citation2019) successfully generate fluent and relevant responses grounded in the given user inputs. However, these models only focus on semantic understanding and the quality of generated responses, while ignoring the empathetic ability in conversations. This ability is called emotional transference in psychology. Empathetic responding refers to the natural and human-like utterances generated by the system through understanding and appreciating both the emotions and demands expressed by them from the perspective of users. In other words, the most critical communication skill of the empathetic conversation system is to recognise the user's emotions and understand the user's feelings, and then generate appropriate responses related to the user's emotions through emotional associations. We show a conversation from the EmpatheticDialogues dataset in Table .
Table 1. A conversation from the EmpatheticDialogues dataset, where the speaker stands for user and the listener stands for the system mentioned in this paper.
A grouping body of studies has shown that empathetic conversations can improve users' satisfaction and availability in lots of fields (Brave et al., Citation2005; Wright & McCarthy, Citation2008; L. Zhou et al., Citation2020). For example, K. K. Liu and Picard (Citation2005) denotes that embedding empathy into human-computer interactive systems, namely conscious empathy systems, plays a crucial role in building a good user experience. Recent research (Ma et al., Citation2020) has been attracted to how to give the ability of empathetic responses to the conversation system. However, numerous studies (Hasegawa et al., Citation2013; Ruan & Ling, Citation2021; Song et al., Citation2019; H. Zhou et al., Citation2018; X. Zhou & Wang, Citation2018) are based on an externally given emotion label to generate the response with a specific emotion. These methods generate emotional responses to some extent, but they are not conducive to improving the emotional content quality of generated responses and are not necessarily empathetic to the user either. Meanwhile, some recent works (Lin et al., Citation2019; Lin, Xu, et al., Citation2020; Majumder et al., Citation2020; Rashkin et al., Citation2019) have focussed on improving the ability of conversation models to understand the emotions expressed by the user, which makes models somewhat more empathetic. Therefore, one of the challenges faced by open-domain conversation systems is how to better understand the user's emotions and make the corresponding empathetic responses without specifying emotion labels.
We mainly focus on the basic research of the empathetic conversation generation model in open-domain dialogue systems. A conscious empathetic conversation system built by embedding empathy into human-computer interaction systems can not only improve user satisfaction but also play a crucial role in natural language processing. Therefore, how to give the ability of empathetic responses to the conversation system is the focus of our research. However, there are still some issues in most existing research: despite conversation generation models have made great progress in semantic understanding (Lin et al., Citation2019; Rashkin et al., Citation2019) and response generation (Majumder et al., Citation2020; Welivita & Pu, Citation2020), there are still great challenges in improving the quality of empathetic response generation by leveraging both emotional features and commonsense knowledge. In this paper, the purpose of training our model is to generate empathetic responses similar to the user's emotions by extracting the emotional state feature from the context that combines emotional features and commonsense knowledge.
Toward this end, we propose a new framework for conversation generation of affective feature knowledge interactive model, named AFKI, which is a Transformer-based empathetic response generation model and leverages multi-head attention to learn higher-level affective interaction information. AFKI model is composed of three components. (1) The emotional interactive context is obtained from the interaction of emotional features, conversation history, and commonsense knowledge, which is the expression of conversation history enriched by affective information and enhances the system's understanding of emotional knowledge in semantic information. (2) The emotional interactive context encoder is used to encode the interactive context to obtain the vector representation of the emotional interactive context information, and we extract the emotional state feature to guide the empathetic response generation. (3) The emotional response decoder can effectively inject the emotional state feature into the model training to generate appropriate empathetic responses. In this paper, the emotional state feature is injected into each decoding layer so that the multi-attention mechanism can effectively capture the affective information and enhance the system's empathy expression in response generation.
The main contributions in this work are summarised as:
We extract the contextual emotional features and retrieve the external concepts, which can help the system well capture the subtle differences in the user's emotional expression and improve the expression of affective information in the conversation history.
We obtain the vector representation of emotional interactive context information utilising the proposed emotional interactive context encoder and extract the emotional state feature to guide the target response generation.
Extensive experimental evaluations containing automatic and human evaluations indicate that AFKI is superior to several competing baseline models based on the EmpatheticDialogues dataset.
The remainder of this paper is arranged as follows: the related work is described in Section 2, Section 3 describes our proposed model in detail, Section 4 presents the experiments, and our paper is summarised in Section 5.
2. Related work
In this section, we introduce the related work of diverse response generation, emotional response generation, and empathetic response generation in open-domain conversation systems.
2.1. Diverse response generation
Open-domain conversation systems (Serban et al., Citation2015, Citation2016; Shang et al., Citation2015; Vinyals & Le, Citation2015; Weizenbaum, Citation1966; Wolf et al., Citation2019) have been extensively studied. The researchers noted that responses generated by the encoder-decoder models tended to be generic and repetitive, like “I don't know”. Some recent work (J. Li, Galley, Brockett, Gao, et al., Citation2016; J. Li, Galley, Brockett, Spithourakis, et al., Citation2016; Lin, Winata, et al., Citation2020; Serban et al., Citation2017; Zhang et al., Citation2018; T. Zhao et al., Citation2017) utilised different means including modifying the learning objective, introducing additional information, or integrating random potential variables to improve the diversity of generated responses. The enhancement of diversity can enrich the generated responses. Due to the lack of emotion, the responses of the system can only confirm to user's idea, but cannot give an affirmation to the user and fail to express the desire to accompany the user.
2.2. Emotional response generation
Human beings are rich in emotions, and all kinds of emotions show up in conversations. To address the issue that open-domain conversation systems cannot control the emotional expression of the generated responses, the emotional conversation models (Hasegawa et al., Citation2013; Ruan & Ling, Citation2021; Shen & Feng, Citation2020; Song et al., Citation2019; Zhong et al., Citation2021; H. Zhou et al., Citation2018; X. Zhou & Wang, Citation2018) which can improve the users' satisfaction and experimental results came into being X. Zhou & Wang (Citation2018) constructed a large-scale annotated emotion dataset using Twitter data labelled with emojis, then adopted several neural models and generated emotional responses grounded in arbitrarily specific emotions. To express a designated emotion naturally in the target response, CitationH. Zhou et al. proposed a sequence-to-sequence language model with an internal memory and an external memory to generate emotional sentences according to a given sentence and affective categories. CitationSong et al. utilised lexicon-based attention to extend the sequence-to-sequence model and guided the target response generation process by applying an emotion classifier. CitationZhong et al. leveraged commonsense and emotion to generate more accurate and commonsense-aware responses with desired emotions. However, most parts of emotional conversation models produce specific emotional responses conditioned on designated emotion labels. Although these generated responses are emotional, they still cannot produce natural and meaningful responses through real emotions. In other words, these responses are not necessarily empathetic.
2.3. Empathetic response generation
Early studies on emotional response generation were limited to sentiment labels annotated by a small number of humans. Hence, X. Zhou & Wang (Citation2018) introduced a large-scale labelled Twitter dataset naturally annotated with emojis. Rashkin et al.(Citation2019) presented a novel benchmark for generating empathetic conversations. EmpatheticDialogues is a new publicly available dialogue dataset based on specific emotional situations with 25k conversations, where the speaker feels a given emotion label and the listener responds to the speaker. The development of empathetic conversations benefits not only from conversation corpora with emotion labels but also from empathetic conversation models. Previous research on emotional conversation generation is devoted to generating specific emotional responses according to designated affective categories. In recent years, more and more researchers have paid increasing attention to the field of empathetic conversation generation (Casas et al., Citation2021; Gao et al., Citation2021; Q. Li, Chen, et al., Citation2020; Lin et al., Citation2019; Lin, Xu, et al., Citation2020; Majumder et al., Citation2020; Rashkin et al., Citation2019; Zandie & Mahoor, Citation2020; Zeng et al., Citation2021). CitationRashkin et al. promoted empathetic response generation by constructing new models from existing models and generated more empathetic responses by identifying the users' emotions. The model designed by CitationLin et al. first identified the user's emotions and then fused the emotion distribution information from multiple decoders to generate an empathetic response. Majumder et al. (Citation2020) introduced the method of emotion grouping and emotion mimicry to produce more empathetic responses, in which emotion mimicry was used to mimic the user's emotion. Q. Li, Li et al. (Citation2020) facilitated empathetic response generation by enriching conversation history with multi-type knowledge. Recently, Zeng et al. (Citation2021) designed an effective method named affective decoding and added the auxiliary dual emotion encoder for more empathetic responses.
3. The proposed model
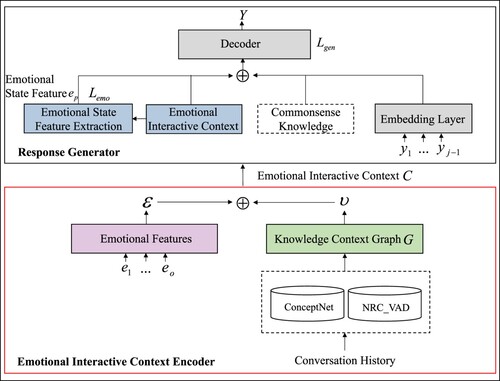
In this section, we present the proposed AFKI model, which is built on the standard Transformer (Vaswani et al., Citation2017), as shown in Figure . According to most of the previous work on neural response generation, we leverage an encoder-decoder architecture to construct the AFKI model. The input of the encoder is the emotional interactive context, which is connected by the emotional features and knowledge context graph. Among them, emotional features are retrieved from conversation history, and the knowledge context graph G is composed of conversation history and external concepts obtained from the commonsense knowledge base ConceptNet. The attentional mechanism selectively weights different parts of the sentence during decoding, so that the decoder is used to decode the emotional features and the knowledge context graph differently.
Figure 1. In our proposed framework, emotional feature extraction is first carried out for the given conversation history to obtain the emotional feature matrix. Then, we extract the commonsense knowledge using the commonsense knowledge base ConceptNet and obtain the emotional interactive context by interacting with the emotional features, commonsense knowledge, and conversation history. Finally, the emotional state feature extracted from the emotional interactive context is used to guide the model to produce more empathetic responses.
3.1. Task definition
Given a conversation history consisting of a set of utterances, the ith utterance is made up of
tokens, i.e.
, where a and
are the number of utterances in the conversation history and the number of tokens in the ith utterance, respectively. The ath and bth utterances belong to the user and the system, respectively, where a represents the even number and b represents the odd number. Following the MoEL (Lin et al., Citation2019), the utterances in
are flattened into a single token sequence
. Besides, we add a token before the sequence to get
. The emotional words
are extracted from conversation history with the emotion lexicon NRC_VAD (Mohammad, Citation2018), where o is the number of emotional words selected by sorting emotional words in descending order. We also add a emotion token before the sequence to get
. Our task can be expressed as follows: given a conversation history
, the general knowledge base ConceptNet (Speer et al., Citation2017), the emotion lexicon NRC_VAD and the emotional words
, the system generates a natural and emotionally appropriate empathetic response.
3.2. Knowledge context graph
Inspired by Q. Li, Li et al. (Citation2020), we utilise the emotion lexicon NRC_VAD and the general knowledge base ConceptNet as knowledge data sources in the proposed AFKI model to enrich conversation history.
NRC_VAD is an emotion lexicon that is a list of over 20k English words and their corresponding VAD scores. It gives human ratings of English words for valence (a.k.a V), arousal (a.k.a A), and dominance (a.k.a D). The affective intensity of words
is calculated by using VAD values as shown below:
(1)
(1) where
,
,
represents
norm,
and
are the valence value and arousal value of word
in the VAD vector, respectively. If
is not in NRC_VAD, we set both
and
to 0.5.
ConceptNet is an open large-scale knowledge graph representing relations between words. Edges in a knowledge graph (D. Zhao et al., Citation2022) are knowledge units that connect one vertex to another. In our knowledge context graph G, we set edges to 1. We succinctly denote an assertion as a triple of its start vertex, a relation label, and an end vertex, i.e. “a monkey has a mouth” can be expressed as (monkey, HasA, mouth). Each (start concept, relation, end concept) triple denotes an assertion, and each assertion has a confidence score. Therefore, we represent each triplet and its corresponding confidence as a tuple of non-stop word
. ConceptNet contains 5.9 million assertions, 3.1 million concepts, and 38 relations in English. Usually, the confidence score s of each assertion belongs to
. We scale s between 0 and 1 by using min-max normalisation:
(2)
(2) where
,
.
For the token sequence , we retrieve a set of tuples of non-stopword token
from ConceptNet:
,
,…,
, where
is the relation between token
and concept
,
is the
th concept connected with token
,
is the confidence of the
th concept, respectively. To better enrich the conversation history with external knowledge, we perform the following operations on knowledge: First, the concepts and candidate tuples whose confidence values
are below the minimum threshold α are filtered. Second, we perform relational filtering to filter out the tuples that belong to the list
of unrelated relations. Third, the affective intensity
of the concept
and cosine similarity
between token
and concept
are calculated, and we finally sum them with
to obtain the combined score
of each candidate tuple:
(3)
(3) The tuples are sorted in descending order of combined scores
, and the top
candidate tuples
are taken as the emotional knowledge of per token
. Then the knowledge retrieved from the emotion lexicon NRC_VAD and the knowledge base ConceptNet is applied to enrich conversation history. Finally, vertices
in the enriched conversation history consist of a CLS token, the words
, and concepts
of the words
.
3.3. Encoder
Our encoder is built on L identical and independently parameterised Transformer layer blocks, where L is the number of blocks. Each Transformer encoder block is composed of a graph attention mechanism, a multi-head self-attention mechanism, and a fully connected feed-forward network model.
In a multi-turn conversation, it is essential to ensure that the model can distinguish vertices in different utterances. Therefore, we incorporate a conversation state embedding for each vertex. And we employ three different ways of embedding in the vector representation of vertex
. The vertex
is finally represented as:
(4)
(4) where
,
,
, d is the embedding dimension.
,
, and
denote the word embedding, the position embedding, and the conversation state embedding, respectively.
Next, each vertex contextualises itself by focussing on other neighbouring vertices connected to it in the knowledge context graph. We employ the N-headed graph attention mechanism and obtain the new representation vector of each vertex
with the local context to model the vertex interactions.
denotes a self-attention mechanism module of the nth head, as shown below:
(5)
(5)
(6)
(6)
(7)
(7) where
. N denotes the number of self-attention heads, ∥ denotes the concatenation of N heads,
represents the neighbourhood of
in the adjacency matrix
,
represents the neighbouring vertex of
,
,
,
.
To obtain the emotional interactive context and make the generated responses more appropriate and empathetic, we introduce emotional words into the enriched conversation history. The emotion lexicon NRC_VAD is utilised to extract emotional words from conversation history, and the emotional features are ranked in descending order according to affective intensity values. Then, we select top-o words as the emotional words for each conversation history and add an emotion token to infer the emotional state of the conversation context, i.e. , where
. Finally, we employ three different ways of embedding in the vector representation of the word
. The word
is finally represented as:
(8)
(8) where
denotes the conversation state embedding. We concatenate the emotional word vector
and the vertex representation vector
obtained previously as the emotional interactive context vector:
(9)
(9) where
,
denotes the concatenation operator, t is the total number of vertices and emotional words. The remaining operators are to utilise the transformer layer to optimise all the tokens
, which will serve as input to the transformer model shown in Figure . We apply the residual connection (He et al., Citation2016) around each multi-head attention mechanism and feed-forward network, followed by the layer normalisation (Ba et al., Citation2016):
(10)
(10)
(11)
(11) where
. MHAtt is the multi-head attention with N attention heads, LayerNorm is the layer normalisation, and FFN is a position-wise and simple fully connected feed-forward network model. Each layer of the encoder contains a fully connected feed-forward network model consisting of two linear transformation layers with an activation function ReLu in the middle.
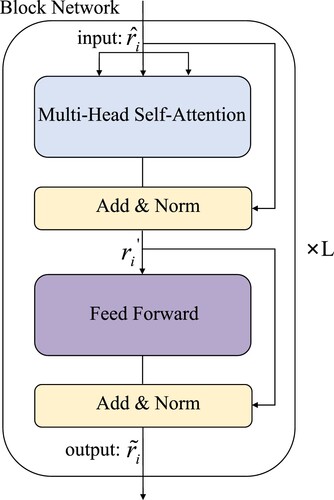
Figure 2. In our Transformer encoder, the obtained emotional interactive context vector is input into the encoder for encoding.
To facilitate the generation of empathetic responses, the emotional state feature is extracted from the vector representations of the fusion of knowledge context graph G and emotional words. We first compute the affective intensity value of
in C according to Equation (Equation1
(1)
(1) ) and take the weighted sum of all the vector representations that are outputs of the encoder to obtain the emotionally augmented context representation
. We then apply a linear transformation to
to obtain the emotional state feature
that will be input into the decoder to facilitate the generation of empathetic responses, and the representation
is fed into the emotional category distribution
to promote the generation of empathetic responses:
(12)
(12)
(13)
(13)
(14)
(14) where
and
denote the learnable weights and the learnable bias for the linear transformation layer, respectively. q is the number of affective categories, and d is the embedding dimension.
3.4. Decoder
Our decoder is built on L independently parameterised Transformer layer blocks, where L is the number of blocks. Each Transformer decoder block consists of a multi-head self-attention mechanism, a multi-head attention mechanism, and a fully connected feed-forward network model. The middle layer of the decoder performs multi-head attention by attending to the output of the encoder stack.
The vector representation is the connection between emotion vector
and the embeddings of the previously generated
words
, where
, emotion vector
is transformed from
by using a linear transformation. The vector representation Y is fed into the decoder.
The decoder of the proposed model is grounded in the Transformer layers. The emotional words, conversation history, and external concepts are concatenated with special tokens as inputs to the decoder. We adopt the multi-headed attention mechanism with N attention heads to calculate the cross sentiment context vector from the fusion of emotional features and knowledge context graph G.
is calculated using the multi-headed attention contextualised by
:
(15)
(15)
(16)
(16) where N is the number of self-attention heads, ∥ denotes the concatenation of N heads,
is the projection of the outputs of the previous decoder layer, and
is the projection of the outputs of the interactive Transformer encoder.
denotes the self-attention module of the nth head as shown below:
(17)
(17) We construct the final emotional context vector by concatenating the cross sentiment context vector
with the emotion vector
to enhance the empathetic ability of the target response. Each layer of the decoder contains a fully connected feed-forward network model FFN consisting of two linear transformation layers with a ReLu activation function in the middle:
(18)
(18)
(19)
(19)
(20)
(20) where
denotes the concatenation operator and
.
3.5. Response generator
The decoder generates tokens one by one that makes up the target response . We utilise the obtained sequence of tokens as the context to predict the next token. The softmax function is used as a readout to calculate the vocabulary probability distribution
of the next token
generated by the response generator:
(21)
(21) CitationGu et al. introduced the copying mechanism and proposed CopyNet, which can not only generate words regularly but also copy appropriate segments of the input sequence. Later, See et al. (Citation2017) proposed a hybrid pointer-generator network, which is similar to CopyNet. By using external concepts and emotional words to generate empathetic responses, we calculate the probability
of copying a word from vertices
using the sigmoid function in a way similar to See et al. (Citation2017) and calculate the final probability distribution
of eventually predicting the next token. Next, the standard maximum likelihood estimator (MLE) is used as the loss function
to optimise the response prediction, and
is computed as follows:
(22)
(22)
(23)
(23)
(24)
(24) where vector
and scalar
are learnable parameters.
is used to generate a word from the vocabulary which is sampled from
, and
is used to copy a word from the knowledge-enriched conversation context by sampling from the attention probability distribution
.
is the concatenation of attention scores, i.e.
. During training, we adopt the negative log-likelihood (NLL) loss between the golden label
of the conversation history and the emotional category distribution
to optimise the weights:
(25)
(25) Finally, we jointly optimise the two objectives of A prediction and B prediction. The total loss function
is:
(26)
(26) where α and β are hyper-parameters that we utilise to balance the two losses. During our training, we set both α and β to 1.
4. Experiments
In this part, we mainly introduce the public dataset, evaluation metrics, baseline models, results and analysis, and settings, which are related to the following experiments.
4.1. Dataset
We evaluate our model on the first large-scale multi-turn empathetic dialogue dataset, namely EmpatheticDialogues (Rashkin et al., Citation2019). Table presents the statistics of the EmpatheticDialogues dataset used in the experiments. This dataset is obtained from the Amazon Mechanical Turk platform, containing 25k one-to-one open-domain conversations. The dataset provides 32 emotion labels, which are evenly distributed. As shown in Table , we divide 32 emotions into two categories: positive emotions and negative emotions.
Table 2. The statistics of the EmpatheticDialogues dataset.
Table 3. Two categories of 32 emotion labels.
4.2. Evaluation metrics
In terms of the evaluation metrics, we utilise automatic and human evaluations to evaluate the models on the EmpatheticDialogues dataset.
4.2.1. Automatic metrics
We evaluate all models using two automatic metrics. Perplexity (Serban et al., Citation2015): Perplexity indicates the inverse likelihood of predicting the responses on the test set. Accuracy: The emotion classification accuracy of the responses measured by our emotion classifier is used to evaluate the model at the emotional level.
4.2.2. Human evaluations
We also conduct three human evaluation metrics rated on a Likert scale (1: not at all, 3: somewhat, 5: very much) (Alexandrov, Citation2010; Ji et al. Citation2022; Rashkin et al. Citation2019) to evaluate the models. Specifically, we randomly sample 112 instances and ask five participants to compare responses generated by our model and baseline models with those ground truth responses to judge their Empathy, Relevance, and Fluency. The scores of 112 samples and five participants are averaged to get the final human ratings. Empathy: The replies express whether the system understands or cares about the feelings expressed by the user. Relevance: The responses are whether consistent with the conversation and on-topic. Fluency: You are whether understand the generated responses, and the responses are whether accurate.
4.3. Baselines
To conduct a comprehensive performance evaluation, we compare our model over the following typical baselines.
Transformer (Vaswani et al., Citation2017): is trained by using a Maximum Likelihood Estimation (MLE) loss.
EmoPrepend-1 (Rashkin et al., Citation2019): is a Transformer-based model with an external supervised classifier. It leverages the top-1 predicted emotion label trained from the emotion classifier as a prepended token which is added to the beginning of the token sequence as the input of the encoder.
MoEL (Lin et al., Citation2019): consists of an emotion tracker, emotion-aware listeners, and a meta listener. The model uses a decoder for each emotion, referred to as the listener, optimised to respond to one type of emotion. The meta listener gently combines the output representations of these decoders and produces a response.
EmpDG (Q. Li, Chen, et al., Citation2020): is an extension of the Transformer model, which utilises an empathetic generator and interactive discriminators to enhance the performance of empathetic response generation. Interaction discriminators consist of a semantic discriminator and an emotional discriminator. The semantic discriminator ensures that the generated responses are contextual, while the emotional discriminator ensures that the generated responses are empathetic.
MK-EDG (Q. Li, Li, et al., Citation2020): is another extension of the Transformer model, which incorporates an emotional context graph, a multi-type knowledge-aware context encoder, and a multi-type knowledge-aware response generator. The framework exploits multiple types of knowledge to understand and express appropriate emotions in the generation of empathetic conversation.
4.4. Results and analysis
In this section, we discuss the automatic evaluation results, human evaluation results, and case study respectively.
4.4.1. Automatic evaluation results
We present the evaluation results of the automatic evaluation indicators for the baseline models and our AFKI model in Table . The EmpDG model has the lowest accuracy among the baseline models, while it obtains slightly lower perplexity than Transformer. The Emoprepend-1 model and MoEL model achieve slightly better accuracy, however their perplexity increases. Compared with other baseline models, the accuracy of the MK-EDG model increases slightly and perplexity decreases slightly, suggesting that commonsense knowledge is helpful in improving emotion accuracy and reducing perplexity. Compared with all the baseline models, our AFKI model scores the highest in the evaluation results of emotional accuracy, and the perplexity is equivalent to that of the best baseline model, which illustrates that our model is effective in empathy expression.
Table 4. Results of automatic evaluations and human evaluations between multiple models on EmpatheticDialogues dataset.
4.4.2. Human evaluation results
We list the evaluation results of human evaluations, including Empathy, Relevance, and Fluency, in Table . According to the human evaluation results, we observe that the proposed AFKI model significantly outperforms baseline models in terms of empathy and relevance, indicating that both emotional features and commonsense knowledge contribute to the system's understanding of implicit emotions and the generation of more empathetic responses. Furthermore, it is easily observed from Table that the fluency results of the response generated by all models remain basically stable despite the change of models, which can be explained by the excellent fluency of the Transformer model. Both the baseline models and our model are based on the Transformer, thus they have a steady fluency.
4.4.3. Case study
To intuitively display the expression of emotion in the generated responses, we provide three samples generated by the baseline models and our model in Table . In the first sample, our model can express empathy similar to that of the user based on the user's utterance. The generated utterance not only expresses the same joy when the user gets the job he wants but also expresses the system's blessing that he hopes the user will get a raise soon. Our model produces richer, more empathetic, and more consistent content than other baseline models. For the second example, the responses generated by our model are coherent and more contextually consistent, whereas the responses generated by the baselines are less relevant, that is, the baselines fail to generate responses that are more context-appropriate based on semantic content. For the third sample, our model can follow the emotional context and advise the owner to fix the cat, whereas the baseline models can express similar empathy but produce meaningless responses. These samples indicate that the AFKI model is superior to the baselines in the emotional and content balance of context.
Table 5. Examples generated by the baselines and the proposed AFKI model.
4.5. Settings
We train all models in PyTorch (Paszke et al., Citation2017) with a batch size of 16 and initialise the word embedding using 300-dimensional pre-trained Glove vectors (Pennington et al., Citation2014). The hidden size for all respective components is set as 300. The maximum values of external concepts introduced into each conversation and each token are set to 10 and 5, respectively. All models are implemented on a single GPU of NVIDIA-SMI 430.40 and CUDA Version 10.1. Early stopping is a technique applied when training.
5. Conclusion
In this paper, through studying the problem of empathetic response generation, we propose a novel affective feature knowledge interactive model named AFKI, which can integrate emotional features and commonsense knowledge into the conversation context. At the same time, the emotional interactive context encoder is utilised to learn an emotional interactive context and distill the emotional state feature to guide the empathetic response generation. Experimental results on automatic evaluation and human evaluation tasks demonstrate that our work outperforms the baselines in Accuracy, Empathy, and Relevance. Our proposed approach can improve the empathy ability of chatbots. Under the background of the application of deep learning technology (Huan et al., Citation2022; X. Liu & Qi, Citation2021; Wei et al., Citation2022; Zhang et al., Citation2021), the proposed model can be applied in the field of customer service to improve user satisfaction and relieve the service pressure of human customer service. However, the current method still has limitations, such as the introduction of emotional features is not conducive to improving the diversity of empathetic response generation. In future work, we will leverage maximum mutual information as the objective loss function and integrate random potential variables to promote diversity in generated responses.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alexandrov, A. (2010). Characteristics of single-item measures in Likert scale format. Journal of Polymer Research, 8(1), 1–12.
- Ba, L. J., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. CoRR, abs/1607.06450.
- Brave, S., Nass, C., & Hutchinson, K. (2005). Computers that care: Investigating the effects of orientation of emotion exhibited by an embodied computer agent. International Journal of Human-Computer Studies, 62(2), 161–178. https://doi.org/10.1016/j.ijhcs.2004.11.002
- Casas, J., Spring, T., Daher, K., Mugellini, E., Khaled, O. A., & Cudré-Mauroux, P. (2021, September 14–17). Enhancing conversational agents with empathic abilities. In IVA '21: ACM international conference on intelligent virtual agents (pp. 41–47). ACM.
- Gao, J., Liu, Y., Deng, H., Wang, W., Cao, Y., Du, J., & Xu, R. (2021, November 16–20). Improving empathetic response generation by recognizing emotion cause in conversations. In Findings of the association for computational linguistics: EMNLP 2021 (pp. 807–819). Association for Computational Linguistics.
- Gu, J., Lu, Z., Li, H., & Li, V. O. K. (2016, August 7–12). Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th annual meeting of the association for computational linguistics, ACL 2016, Volume 1: Long papers. The Association for Computer Linguistics.
- Hasegawa, T., Kaji, N., Yoshinaga, N., & Toyoda, M. (2013, August 4–9). Predicting and eliciting addressee's emotion in online dialogue. In Proceedings of the 51st annual meeting of the association for computational linguistics, ACL 2013, Volume 1: Long papers (pp. 964–972). The Association for Computer Linguistics.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016, June 27–30). Deep residual learning for image recognition. In 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016 (pp. 770–778). IEEE.
- Huan, H., Guo, Z., Cai, T., & He, Z. (2022). A text classification method based on a convolutional and bidirectional long short-term memory model. Connection Science, 34(1), 2108–2124. https://doi.org/10.1080/09540091.2022.2098926
- Ji, T., Graham, Y., Jones, G. J. F., Lyu, C., & Liu, Q. (2022, May 22–27). Achieving reliable human assessment of open-domain dialogue systems. In S. Muresan, P. Nakov, & A. Villavicencio (Eds.), Proceedings of the 60th annual meeting of the association for computational linguistics (Volume 1: Long papers), ACL 2022 (pp. 6416–6437). Association for Computational Linguistics.
- Li, J., Galley, M., Brockett, C., Gao, J., & Dolan, B. (2016, June 12–17). A diversity-promoting objective function for neural conversation models. In NAACL HLT 2016, the 2016 conference of the North American chapter of the association for computational linguistics: Human language technologies (pp. 110–119). The Association for Computational Linguistics.
- Li, J., Galley, M., Brockett, C., Spithourakis, G. P., Gao, J., & Dolan, W. B. (2016, August 7–12). A persona-based neural conversation model. In Proceedings of the 54th annual meeting of the association for computational linguistics, ACL 2016, Volume 1: Long papers. The Association for Computer Linguistics.
- Li, Q., Chen, H., Ren, Z., Ren, P., Tu, Z., & Chen, Z. (2020, December 8–13). Empdg: Multi-resolution interactive empathetic dialogue generation. In Proceedings of the 28th international conference on computational linguistics, COLING 2020 (pp. 4454–4466). International Committee on Computational Linguistics.
- Li, Q., Li, P., Chen, Z., & Ren, Z. (2020). Towards empathetic dialogue generation over multi-type knowledge.https://doi.org/10.48550/arXiv.2009.09708
- Lin, Z., Madotto, A., Shin, J., Xu, P., & Fung, P. (2019, November 3–7). Moel: Mixture of empathetic listeners. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing, EMNLP-IJCNLP 2019 (pp. 121–132). Association for Computational Linguistics.
- Lin, Z., Winata, G. I., Xu, P., Liu, Z., & Fung, P. (2020). Variational transformers for diverse response generation. CoRR, abs/2003.12738.
- Lin, Z., Xu, P., Winata, G. I., Siddique, F. B., Liu, Z., Shin, J., & Fung, P. (2020, February 7–12). Caire: An end-to-end empathetic chatbot. In The thirty-fourth AAAI conference on artificial intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020 (pp. 13622–13623). AAAI Press.
- Liu, K. K., & Picard, R. W. (2005). Embedded empathy in continuous, interactive health assessment. In CHI Workshop on HCI Challenges in Health Assessment.
- Liu, X., & Qi, F. (2021). Research on advertising content recognition based on convolutional neural network and recurrent neural network. International Journal of Computational Science and Engineering, 24(4), 398–404. https://doi.org/10.1504/IJCSE.2021.117022
- Ma, Y., Nguyen, K. L., Xing, F. Z., & Cambria, E. (2020). A survey on empathetic dialogue systems. Information Fusion, 64, 50–70. https://doi.org/10.1016/j.inffus.2020.06.011
- Majumder, N., Hong, P., Peng, S., Lu, J., Ghosal, D., Gelbukh, A. F., Mihalcea, R., & Poria, S. (2020, November 16–20). MIME: Mimicking emotions for empathetic response generation. In Proceedings of the 2020 conference on empirical methods in natural language processing, EMNLP 2020 (pp. 8968–8979). Association for Computational Linguistics.
- Mohammad, S. (2018, July 15–20). Obtaining reliable human ratings of valence, arousal, and dominance for 20, 000 english words. In Proceedings of the 56th annual meeting of the association for computational linguistics, ACL 2018, Volume 1: Long papers (pp. 174–184). Association for Computational Linguistics.
- Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., Devito, Z., Lin, Z., Desmaison, A., Antiga, L., & Lerer, A. (2017). Automatic differentiation in pytorch.
- Pennington, J., Socher, R., & Manning, C. D. (2014, October 25–29). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing, EMNLP 2014, A meeting of SIGDAT, a special interest group of the ACL (pp. 1532–1543). ACL.
- Rashkin, H., Smith, E. M., Li, M., & Boureau, Y. (2019, July 28–August 2). Towards empathetic open-domain conversation models: A new benchmark and dataset. In Proceedings of the 57th conference of the association for computational linguistics, ACL 2019, Volume 1: Long papers (pp. 5370–5381). Association for Computational Linguistics.
- Ruan, Y. P., & Ling, Z. (2021). Emotion-regularized conditional variational autoencoder for emotional response generation. IEEE Transactions on Affective Computing, PP, 1–1. https://doi.org/10.1109/T-AFFC.5165369
- See, A., Liu, P. J., & Manning, C. D. (2017, July 30–August 4). Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th annual meeting of the association for computational linguistics, ACL 2017, Volume 1: Long papers (pp. 1073–1083). Association for Computational Linguistics.
- Serban, I. V., Lowe, R., Charlin, L., & Pineau, J. (2016). Generative deep neural networks for dialogue: A short review. CoRR, abs/1611.06216.
- Serban, I. V., Sordoni, A., Bengio, Y., Courville, A. C., & Pineau, J. (2015). Hierarchical neural network generative models for movie dialogues. CoRR, abs/1507.04808.
- Serban, I. V., Sordoni, A., Lowe, R., Charlin, L., Pineau, J., Courville, A. C., & Bengio, Y. (2017, February 4–9). A hierarchical latent variable encoder-decoder model for generating dialogues. In Proceedings of the thirty-first AAAI conference on artificial intelligence (pp. 3295–3301). AAAI Press.
- Shang, L., Lu, Z., & Li, H. (2015, July 26–31). Neural responding machine for short-text conversation. In Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing of the asian federation of natural language processing, ACL 2015, Volume 1: Long papers (pp. 1577–1586). The Association for Computer Linguistics.
- Shen, L., & Feng, Y. (2020, July 5–10). CDL: Curriculum dual learning for emotion-controllable response generation. In Proceedings of the 58th annual meeting of the association for computational linguistics, ACL 2020 (pp. 556–566). Association for Computational Linguistics.
- Song, Z., Zheng, X., Liu, L., Xu, M., & Huang, X. (2019, July 28–August 2). Generating responses with a specific emotion in dialog. In Proceedings of the 57th conference of the association for computational linguistics, ACL 2019, Volume 1: Long papers (pp. 3685–3695). Association for Computational Linguistics.
- Speer, R., Chin, J., & Havasi, C. (2017, February 4–9). Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the thirty-first AAAI conference on artificial intelligence (pp. 4444–4451). AAAI Press.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017, December 4–9). Attention is all you need. In Advances in neural information processing systems 30: Annual conference on neural information processing systems 2017 (pp. 5998–6008).
- Vinyals, O., & Le, Q. V. (2015). A neural conversational model. CoRR, abs/1506.05869.
- Wei, S., Zhu, G., Sun, Z., Li, X., & Weng, T. (2022). GP-GCN: Global features of orthogonal projection and local dependency fused graph convolutional networks for aspect-level sentiment classification. Connection Science, 34(1), 1785–1806. https://doi.org/10.1080/09540091.2022.2080183
- Weizenbaum, J. (1966). Eliza – a computer program for the study of natural language communication between man and machine. communications of the acm 9(1), 36-45. Communications of the ACM, 9(1), 36–45. https://doi.org/10.1145/365153.365168
- Welivita, A., & Pu, P. (2020, December 8–13). A taxonomy of empathetic response intents in human social conversations. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020 (pp. 4886–4899). International Committee on Computational Linguistics.
- Wolf, T., Sanh, V., Chaumond, J., & Delangue, C. (2019). Transfertransfo: A transfer learning approach for neural network based conversational agents. CoRR, abs/1901.08149.
- Wright, P. C., & McCarthy, J. C. (2008, April 5–10). Empathy and experience in HCI. In Proceedings of the 2008 conference on human factors in computing systems, CHI 2008 (pp. 637–646). ACM.
- Zandie, R., & Mahoor, M. H. (2020, May 17–20). Emptransfo: A multi-head transformer architecture for creating empathetic dialog systems. In Proceedings of the thirty-third international florida artificial intelligence research society conference, Originally to be held in North Miami Beach (pp. 276–281). AAAI Press.
- Zeng, C., Chen, G., Lin, C., Li, R., & Chen, Z. (2021). Affective decoding for empathetic response generation. In Proceedings of the 14th international conference on natural language generation (pp. 331–340). Association for Computational Linguistics.
- Zhang, S., Dinan, E., Urbanek, J., Szlam, A., Kiela, D., & Weston, J. (2018, July 15–20). Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th annual meeting of the association for computational linguistics, ACL 2018, Volume 1: Long papers (pp. 2204–2213). Association for Computational Linguistics.
- Zhang, S., Zhang, Z., Chen, Z., Lin, S., & Xie, Z. (2021). A novel method of mental fatigue detection based on CNN and LSTM. International Journal of Computational Science and Engineering, 24(3), 290–300. https://doi.org/10.1504/IJCSE.2021.115656.
- Zhao, D., Wang, X., & Luo, X. (2022). Path embedded hybrid reasoning model for relation prediction in knowledge graphs. International Journal of Embedded Systems, 15(1), 44–52. https://doi.org/10.1504/IJES.2022.122058
- Zhao, T., Zhao, R., & Eskénazi, M. (2017, July 30–August 4). Learning discourse-level diversity for neural dialog models using conditional variational autoencoders. In Proceedings of the 55th annual meeting of the association for computational linguistics, ACL 2017, Volume 1: Long papers (pp. 654–664). Association for Computational Linguistics.
- Zhong, P., Wang, D., Li, P., Zhang, C., Wang, H., & Miao, C. (2021, February 2–9). CARE: Commonsense-aware emotional response generation with latent concepts. In Thirty-fifth AAAI conference on artificial intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021 (pp. 14577–14585). AAAI Press.
- Zhou, H., Huang, M., Zhang, T., Zhu, X., & Liu, B. (2018, February 2–7). Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18) (pp. 730–739). AAAI Press.
- Zhou, L., Gao, J., Li, D., & Shum, H. (2020). The design and implementation of xiaoice, an empathetic social chatbot. Computational Linguistics, 46(1), 53–93. https://doi.org/10.1162/coli_a_00368
- Zhou, X., & Wang, W. Y. (2018, July 15–20). Mojitalk: Generating emotional responses at scale. In Proceedings of the 56th annual meeting of the association for computational linguistics, ACL 2018, Volume 1: Long papers (pp. 1128–1137). Association for Computational Linguistics.