
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Lane detection is an indispensable technology for environmental perception and is a function of autonomous vehicles. Although many researchers have applied deep learning to lane detection and achieved good results, their application scenarios were relatively simple. When a lane is blocked, lost, or met with other challenges, the accuracy of lane detection decreases tremendously. This paper proposes a novel semantic segmentation network for lane detection that includes IBN-Net, an attention module, and an encoder-decoder structure called IAED. IBN-Net improves the modelling and generalisation capability with little computational complexity. The attention module can better capture context information and improve the performance of the network. We evaluated the performance of the proposed method, which improved by 6.3% over ResNet34 on the TuSimple datasets. Tests on the CULane datasets showed that our method is at least 3% better than existing methods. Experimental results showed that the proposed method has strong robustness under complex conditions such as insufficient illumination and shadow occlusion.
1. Introduction
Thousands of people worldwide lose their lives in traffic accidents every year, and more than 90% of these losses are caused by driver distraction. An advanced driving assistance system (ADAS) can reduce the incidence of traffic accidents by calculating some form of feedback by taking inputs from sensors around the vehicle and providing assistance to the driver. A lane keeping system and lane departure warning system are important components of the ADAS and ensure that vehicles do not deviate from the lane.
In research on the autonomous navigation of driverless vehicles, vision-based lane line detection is one of the important aspects. It is the key to achieving autonomous navigation of driverless vehicles by obtaining location information on a road through the fast and accurate detection of lane lines. The correct detection of lane lines guarantees the safe driving of driverless vehicles. The method proposed in this paper saves on costs and is effective.
Traditional lane detection methods require considerable manual marking and postprocessing, which lead to a large amount of calculation. Lane line detection based on manual features generally utilises colour features, structure tensors, strip filters, ridge features (Chiu & Lin, Citation2005; Loose et al., Citation2009; Teng et al., Citation2010), etc. However, these traditional methods have poor robustness and are easily affected by illumination, weather, shielding, and other factors, which are not conducive to their application expansion in changeable road scenarios.
In 2012, Geoffrey and his student Alex won the competition in ImageNet by establishing the significance of deep learning in computer vision (Krizhevsky et al., Citation2012). Recently, many researchers on lane line detection have adopted the method of deep learning (Wang, Sun, et al., Citation2022; Duan et al., Citation2021; Ghafoorian et al., Citation2018; Gurghian et al., Citation2016; Yu et al., Citation2022; Lu et al., Citation2021; Zhang & Mahale, Citation2018). This process can be divided into three categories: image classification (Cai, Liu, et al., Citation2021; Chougule et al., Citation2018; Wang, Wang, et al., Citation2022; Qin, Wang, et al., Citation2020; Zhang, Li , et al., Citation2021; Yoo et al., Citation2020 ), target detection (Qi et al., Citation2021; Huang et al., Citation2018; Huval et al., Citation2015; Lee et al., Citation2017; Ning, Duan, et al., Citation2020), and semantic segmentation (Ning, Gong, et al., Citation2020; Wang et al., Citation2021; Chen et al., Citation2018; Neven et al., Citation2018). The method based on image classification cannot accurately represent lanes, nor can it detect a relatively high number of lanes. The method based on target detection is complex in data collection and requires a large amount of computation. At present, the method based on semantic segmentation is the most widely used. However, this technology cannot capture the global context information, which reduces the performance of lane line detection, and most of the methods are completed under sunny conditions. Therefore, the lane detection performance decreased sharply when the test was carried out on cloudy days, poorly lit days, rainy days, and in shaded conditions.
Recently, many scholars have found that the attention mechanism can emphasize feature maps and improve the network representation ability. By introducing a spatial transformer module, Max (Ning et al., Citation2021) made corresponding spatial changes to the image spatial domain information to accurately determine the regions that need to be considered in the image information and extract the key information. Hu (Zhang, Sun, Yu, Dong, et al., Citation2021) proposed a squeeze and excite module (SeNet) that enables the network to focus on the relationship between channels and helps the model to automatically learn the importance of different channel characteristics. Based on the literature (Zhang, Sun, Yu, Dong, et al., Citation2021), Woo et al. (Niu et al., Citation2021) expanded and proposed the CBAM module, which successively integrates the channel attention module and spatial attention module. The performance of CBAM was superior to that of SENET, and all of these methods achieved excellent performance in image classification by introducing an attention mechanism. This mechanism can improve the robustness of lane detection under complex weather and model the specific context information of the road to determine whether the pixels belong to the lane. This helps to improve the accuracy of lane detection.
IBN-Net is composed of instance normalization (IN) and batch normalization (BN) to enhance its learning ability and generalisation ability. IN enables the model to learn features that are invariant to appearance changes, while BN speeds up convergence and preserves content-related information.
Lane detection relies heavily on global information because of its slender appearance, strong perspective relationship, and obvious mutual constraints between different targets. Therefore, to make the network not completely dependent on the appearance feature under the condition of lane occlusion and insufficient light, this paper focuses on modelling the specific context information of the road and uses the appropriate context information for inference. In this paper, we consider introducing a novel encoder-decoder network (called IAED) with IBN-Net and attention modules to meet the above requirements. IAED is an effective semantic segmentation neural network that uses U-Net as the backbone and combines the advantages of jump connections, residual blocks and codec structures. IBN-Net can not only learn the colour and style of lane lines but also retain the features related to texture (Pan, Luo, et al., Citation2018). The spatial attention and channel attention modules are added to the encoder-decoder architecture to obtain the characteristic dependencies on spatial and channel dimensions separately, and the output of the two attention modules is fused to further improve the learning and generalisation ability of the network. The two modules of IBN-Net and attention modules can improve the accuracy of semantic segmentation. We combine the advantages of these two modes to improve the performance of the network. A more accurate lane segmentation result can be obtained by obtaining rich context dependencies. The purpose of this paper is to enhance the performance of lane line detection, which is verified in the TuSimple and CULane datasets.
Our main contributions are as follows:
We propose a new framework, IAED, which fully utilises the superficial appearance feature information and deep semantic information of the neural network and aggregates more global information.
IBN-Net is added to ResNet, which improves the generalisation ability and learning ability of the network structure with only a small amount of calculation.
The attention module is appended to the encoder-decoder architecture and can overcome lane occlusion by using context information, which improves the feature representation ability of the lane detection network structure.
The new architecture is adopted to improve the computational efficiency while maintaining accuracy. The experiment verifies the effectiveness and high performance of our study.
The paper is organised as follows. In Section 2, some recent excellent lane line detection algorithms and attention mechanisms are introduced in detail. The method of this paper is proposed in Section 3. In Section 4, the method proposed in this paper is verified by experiments and discussed. Finally, conclusions are given in Section 5.
2. Related work
2.1. Lane detection
The continuous development of semantic segmentation networks has improved the performance of lane detection (Zhang, Lu, Zhang, Xue, et al., Citation2021). Because lane lines have the characteristics of slender structure space and regular correlation of position, many scholars have proposed different network structures according to these characteristics. Pan and others proposed SCNN (Pan, Shi, et al., Citation2018), which extends the deep convolution neural network to a rich spatial level. The obtained spatial information can be propagated on the neurons of the same layer to enhance the spatial information, which is particularly effective for recognising structured objects. This method improves the accuracy of lane line detection, but it requires orderly stacking convolution, which greatly reduces the efficiency of the algorithm. Considering that vehicles or pedestrians often block lane boundaries and local characteristics of lane boundaries are not obvious, Fan et al. (Citation2019 ) proposed a new rotational convolutional layer and a new parameterised lane branch to detect lane boundaries from a global perspective. The feature maps in the convolutional module rotate at different angles to collect more information about the entire lane boundary in multiple directions. However, these two methods require a large amount of computation, and there are too many lane lines to detect, which is difficult to apply in practice. To solve the problem of lane line changes, Neven (Neven et al., Citation2018) proposed LaneNet, which is composed of a lane line splitting branch and a lane line embedding branch. This network can learn the structure of lane line marking from multiple angles and carry out end-to-end training. This method is a multibranch network structure that can detect any number of lane lines and has good robustness. However, this method is very time-consuming in clustering, and it is difficult to meet the requirements of real-time in practical engineering applications.
Zou (Zou et al., Citation2019) used multiple frames of continuous driving scenes for lane detection and proposed a hybrid depth structure combining CNN and RNN. Although this method can guarantee accuracy in the case of occlusion, the calculation is very complex. To solve the problem of colour distortion in rainy and low-light conditions, an improved lane line detection method based on vanishing point location was proposed by Seokju (Lee et al., Citation2017 ). However, the postprocessing cost of this method is very high.
To retain internal data and avoid the loss of useful information in the subsampling, Shao (Chen et al., Citation2018) embedded three dilated convolution layers between the encoder and decoder based on VGG to increase the receptive field without losing road information. However, the effect of dilated convolution is not obvious for lane structures with slender appearances. Some attention mechanism methods are applied to the lane detection algorithm to establish a large global receptive field. Xiao (Xiao et al., Citation2020) added an attention module to the network structure. This module can effectively capture the global background. To obtain better lane line detection results, Xiao placed the two modules in parallel. Although this method achieves the same level of performance as SCNN and has higher efficiency, it still does not solve the fundamental problem of complex SCNN computation. Lee et al. (Citation2022 ) added expanded self-attention (ESA), which uses the confidence of lane line prediction results to indicate the clarity of lane lines to the network. ESA enhances the network’s attention to the blocked lane line and improves the lane line detection effect. Hou, Ma, & Liu (Citation2019) proposed the self-attention distillation (SAD) method, which allows models to study themselves and achieve materiality improvements without increasing computation time and without any additional supervision or labelling. This method uses a lighter backbone to achieve high performance while maintaining real-time efficiency.
The lane detection method based on object detection has achieved excellent results, and anchor-based methods in lane detection are widely used. LaneATT (Torres et al., Citation2020 ) uses a new anchor-based attention mechanism that can aggregate global information. SGNet (Su et al., Citation2021) uses a top-down vanishing point guidance anchoring mechanism to generate strong anchors to effectively capture various lane lines and improve lane perception by using multilevel structural constraints. CondLaneNet (Liu et al., Citation2021) has a conditional lane detection strategy based on conditional convolution and row formulas for lane instance level discrimination. UFLD (Qin, Wang, et al., Citation2020) regards the process of lane detection as a row-based selection problem using global features, thus reducing computational cost but sacrificing accuracy. CLRNet (Zheng et al., Citation2022) utilises a linear RoI extraction operator based on bilinear sampling and constructed the overall dimension of the lane IoU loss to constrain the regression quality of the overall lane line.
2.2. Attention mechanisms
The study of attention mechanisms comes from the study of human vision, which selectively pays attention to part of all information and ignores other visible information. The attention mechanism will not process all information but only key parts of information to improve the efficiency of information processing. In recent years, some scholars (Cai, Zhai, et al., Citation2021; Wang et al., Citation2017; Wang et al., Citation2018; Yuan et al., Citation2018; Bai et al., Citation2021) introduced the attention mechanism of the spatial domain and the domain channel to improve the performance of the model. Max et al. added spatial transformer networks to the CNN networks, making the model have powerful performance. This keeps translation, rotation and scaling unchanged, aiming to improve the accuracy of classification. Hu proposed the squeeze and exclusion module (SeNet), which models the relationship between feature channels and can automatically learn the importance of different channel features. According to the importance degree, the important features are enhanced, while unusable features are suppressed. This method adopts global average pooling (GAP), which is simple and efficient, but it is easy to ignore the useful input information. Fair regards nonlocal operations as a generic family of building blocks to capture long-term dependencies. Woo et al. proposed CBAM, which added a channel attention module based on SeNet, and its performance was better than that of SeNet. On the basis of references, Fu et al. (Citation2019) and others proposed Danet to adaptively integrate local features and global dependencies. Two types of attention modules were extended FCN to simulate the semantic interdependence in the spatial and channel dimensions. Yuan (Yuan et al., Citation2018) proposed OCNet, which is basically the same as DaNet’s method and achieves accurate results in image segmentation. The accuracy of the segmentation results of these two algorithms has been effectively improved, but the time consumption also increases. Based on references, Huang et al. (Citation2019) proposed a cross-attention module that enables each pixel to capture the long dependence of all pixels on it. Compared with the references, the calculation time is reduced by 85%, but the accuracy of segmentation results is sacrificed (Wang et al., Citation2018). Qin proposed FcaNet (Qin, Zhang, et al., Citation2020), which is a multispectral channel attention method. In the channel attention mechanism, a discrete cosine transform (DCT) is used to compress the channel, and multiple but limited frequency components of DCT are used as the channel attention mechanism. This does not increase the amount of calculation, and the effect is better than the baseline SeNet. In our article, the attention channel is also improved based on SeNet. The simplicity of the global average pool (GAP) makes it difficult to capture the complex information of various inputs well. Following the example of CBAM, we further use the global maximum pool and the global standard difference pool to enhance the performance of GAP.
Based on the segmentation method, lane line detection is modelled as a per-pixel classification problem, and each pixel is classified as a lane area or background. Our approach is to model long-term correlations between pixels and create correlations between feature maps. Therefore, the generalisation ability of the method is improved by capturing context information.
3. Method
Due to the simple structure of lane lines, position information is more important than shape information in complex environments such as occlusion and low light. Therefore, the lane detection task relies heavily on global context information. This study has two main objectives: to use a space and channel attention module to obtain global context information and improve the accuracy of lane detection in complex environments such as occlusion and low light, and to increase the IBN network to improve network generalisation ability and reduce the amount of computation.
3.1. Architecture
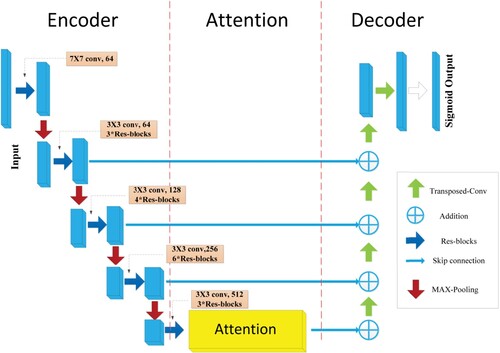
Inspired by the literature (Huang et al., Citation2019), different types of encoder and decoder combinations can increase the computational efficiency on the premise of ensuring the accuracy of the reference frame. The main structure of the U-Net (Ronneberger et al., Citation2015) network consists of an encoder, decoder, and bottleneck layer, in which the encoding and decoding are symmetric and skip connection is used. In our study, ResNet34 is used as the encoder module, which gives up average pooling and a fully connected layer retaining the first four feature extraction blocks. The main reason for this is that a shortcut mechanism is introduced by using ResNet34. This avoids gradient disappearance and accelerates network convergence. In the encoder phase, IBN networks are added to ResNet34 to improve network performance without additional computation. The attention mechanism is introduced at the connection between the encoding stage and decoding stage to refine the result of deconvolution by jump connection. The feature map of the attention layer in the encoder is fused with the result of the corresponding deconvolution layer, the structure of which is shown in Figure .
Figure 1. Based on ResNet34-UNet network structure, IBN-NET is added to encoding stage, and attention mechanism is added to encoding and decoding stages. Each blue rectangular block represents a multichannel feature map. Left part of network is encoder. Right part of network is decoder. Middle part of network is attention mechanism, which obtains context information.
3.2. IBN-Net
Instance normalization (IN) is more commonly used in style transformations and similar tasks, which allow instance-specific contrast information to be filtered out of the content as they attempt to change the appearance of the image while preserving the content. During the IN statistics calculation, all elements of a single sample and a single channel are considered in the normalisation statistics. Therefore, IN can provide visual and appearance invariance (Ulyanov et al., Citation2016).
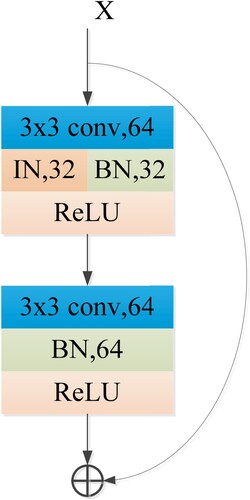
BN, which retains texture-related attributes, is more often applied to the tasks of image classification and semantic segmentation. The traditional deep neural network only standardises the input data before the input layer. The main reason why the gradient disappears is that when the number of neural network layers increases, the weight between layers closer to the input layer cannot be effectively corrected. The disappearance of the gradient causes the deeper neural network to update slowly and even stagnate in the hidden layer close to the input layer. BN normalises the input data of each layer and reduces the scale difference of the input characteristic values, which enlarges the gradient of the network and avoids the problem of gradient disappearance. Therefore, BN can accelerate the convergence speed of model training and make the model training process more stable. According to the literature (Pan et al., Citation2018), the shallow layer of a neural network expresses more appearance feature information, while the deep layer expresses more semantic information. Therefore, IN is used in the shallow layer, BN is used in the deep layer of the network, and BN is also retained in the shallow layer due to its great role. In this paper, the BN layer is reserved as the feature in the deep layer and is replaced by the IN layer as half the feature in the shallow layer of ResNet34. The other half of the feature is the BN layer. IBN-Net integrates IN and BN as building blocks, which retains their advantages and enhances the learning and generalisation ability of the network, as shown in Fig. .
Figure 2. Instance-batch normalization (IBN) block. In first convolution layer, we apply half the IN and BN in channel. In second convolution layer, we apply only BN in channel.
3.3. Attention module
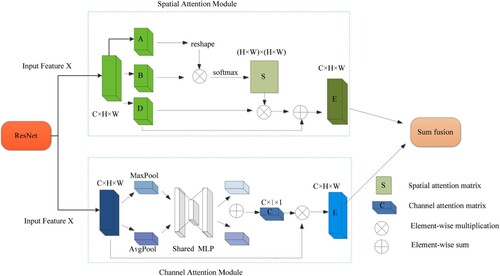
Although most lane detection models adopt a convolution operation, they cannot obtain long-distance context information, which results in incorrect lane detection classification. However, the addition of an attention mechanism has achieved good results (Zhang et al., Citation2019 ). The structure of a lane line is simple, and its distribution has regularity and continuity, so channel and space information is important. When lane lines are mostly occluded, the local context cannot adequately infer pixel attributes. In this case, the channel attention module and spatial attention module can capture rich context and solve the problem of lane occlusion. In this paper, we combine the channel attention module of the CBAM with the spatial attention module of Danet. To enhance the presentation capability of the network, this paper extends the presentation of each pixel by aggregating the representation of context pixels and considers the relationship between pixels. As shown in Figure , the attention module in this paper has two submodules: the spatial attention module and the channel attention module.
Figure 3. Overview of attention module, which consists of two parallel submodules: channel attention module and spatial attention module.
3.3.1. Spatial attention module
The IAED-Net proposed in this paper retains the spatial attention module of DANet, which combines local features with their global dependencies to infer the information of the lane line occlusion area. Rich context relationship models are built on local features, which enhances the presentation capability of the network and improves the accuracy of lane detection. As shown in Figure , input features , A, and B are two new feature maps of X, where
. Then, we perform a matrix multiplication between the transpose of A and B and apply a softmax layer to compute the spatial attention map S:
(1)
(1) where
measures the
position’s impact on the
position. The more similar feature representations of the two positions contribute to greater correlation between them. The final output is as follows:
(2)
(2) where
is initialised as 0 and gradually learns to assign more weight. The resulting feature
for each location is the weighted sum of all the location features and the original features of the lane line. Therefore, the resulting feature has a global context view of lane lines and selectively aggregates contexts based on a spatial attention map.
3.3.2. Channel attention module
Channel attention can more accurately identify lane lines because each channel in the feature map is regarded as a feature detector. Lane detection should take advantage of the interdependencies between channel maps rather than just checking the context on a single channel. Each channel performs a certain function; for example, some channels that should be given special attention play a very important role in the pixel recovery of occluded areas. CBAM computes the spatial information of the feature map, aggregates the spatial information of the feature map by means of the average pool and maximum pool operations, and generates a global context vector, which is input into the multilayer perceptron (MLP). The channel attention is computed as follows:
(3)
(3) where
denotes the sigmoid function,
, and
.
and
represent evaluation pooling characteristics and maximum pooling characteristics, respectively. The MLP weights
and
are shared for both inputs, and the ReLU activation function is followed by
. The final output is
(4)
(4)
3.3.3. Combination of spatial attention module and combination of modules
To take advantage of the remote context information, we combine the characteristics of the two attention modules. Generally, there are two ways to combine the two modules: sequential connection and parallel connection. In this paper, we use a parallel connection that sums the elements to complete feature fusion to obtain a better representation of lane line features. Finally, the final prediction diagram is generated by the convolution layer. To reduce the GPU calculation burden, no cascading process is used in this research.
3.4. Loss function
The choice of loss function directly affects the performance of the deep learning network model, which is used to solve and evaluate models by minimising loss functions. We have to choose or design a proper loss function for a particular problem rather than a fixed loss function. The cross entropy based on softmax shows remarkable performance in various lane line detection tasks. However, it cannot clearly guide network learning with highly distinguishing characteristics, resulting in the neglect of the difference in false labels (Tang et al., Citation2021). To overcome this shortcoming, L-Softmax enables the learned feature distribution to be highly clustered within classes and the distance between classes to be large enough, which enables the model to have a certain ability to prevent overfitting. The literature (Zhang et al., Citation2018) proposes a boundary perception loss function for lane detection. The formula is shown as follows:
(5)
(5)
4. Experiment
To evaluate the proposed method, we carry out extensive lane detection experiments on the TuSimple and CULane datasets. We use PyTorch as the deep learning framework, and all models are trained on 2 NVIDIA 3080 GPUs with 16 GB memory.
4.1. Dataset
The Tusimple database consists of 3626 training images and 2782 test images. Each image provides the first 19 frames of the image, which are unmarked. The dataset was taken on American highways at different times of the day with good weather conditions. This dataset is relatively simple because the roads were not crowded.
Culane was collected by different drivers with cameras on traffic roads in Beijing. The dataset is divided into 88,880 training sets, 9675 verification sets, and 34,680 test sets. The data include many challenging driving scenarios such as overcast days, insufficient light, rainy days, and shaded roads. It has more diversified traffic conditions and more complex scenes than the Tusimple database.
4.2. Evaluation metrics
In the field of image processing, there are many indices used to evaluate the performance of a model, including true positive (TP), true negative (TN), false-positive (FP) and false negative (FN), precision, recall, and accuracy. Accuracy is the proportion of data (TP + TN) correctly judged by the model in the total data and is the most intuitive evaluation index. The recall rate is the proportion of positive cases (TP) correctly judged by the model to all positive cases (TP + FN) in the dataset. Then, the calculation formulas are as follows:
(6)
(6)
(7)
(7) where N represents the total number of ground truth lane points.
It is not accurate to only use recall or precision to measure the detection of lane markings. The F1 score considers both precision and recall, and is an indicator to measure the accuracy of two types of models in statistics:
(8)
(8) To determine whether a lane mark is successfully detected, we treat the lane mark as a line with a width of 30 pixels and calculate the cross union (IoU) between the ground truth and the predicted value.
4.3. Implementation details
In this paper, we choose ResNet-34 as our backbone. The images of TuSimple and CULane are resized to 360 × 640 and 288 × 800, respectively. We use SGD to train our model, and the learning rate is set to 0.01. We trained 70 and 16 periods for TuSimple and CULane, respectively, with a batch size of 8. All models were trained and tested using PyTorch, the CPU is an Intel Core i9-10900 K, and the GPUs are 2 NVIDIA 3080s with 16 GB memory. To verify the advantages and disadvantages of the proposed method, different test conditions are used such as night, cloudy, and sunny scenes. In our experiments, except for the improved methods in this paper, other methods are from the literature (Pan et al., Citation2018), and the evaluation metrics are the same.
4.4. Results
4.4.1. Experiment on TuSimple dataset
To demonstrate that ResNet-UNet and IBN-Net can effectively improve lane detection capability, we compared them with the baseline in the TuSimple database. Table shows that the accuracy of ResNet34-UNet is better than that of UNet and ResNet34, indicating that the improvement in performance comes from the effective design of the network structure. The UNet method of incremental upsampling within the network provides the best accuracy. The experimental results show that the accuracy is improved by 2.3% when we add IBN-Net to ResNet34-UNet. Therefore, when IN is added moderately, content-related information can be well-preserved.
Table 1. Results of lane detection with baseline and IBN-Net in TuSimple datasets.
To prove that IBN-Net not only has better lane detection ability but also stronger modelling ability than ResNet34, we compare it with other ResNet families on the TuSimple dataset. The results are listed in Table . IBN-Net achieves better results than the other ResNet series, indicating that it has better modelling capabilities. IBN-NET does not introduce any more parameters.
Table 2. Results of IBN-Net over other ResNet families on TuSimple datasets.
To verify the attention module’s ability to improve lane detection, we compared our model with the baseline in the TuSimple database. Table shows that the accuracy of ResNet34-UNet + IBN with the attention module is 91.6%, which is 1.8% higher than that of ResNet34-UNet + IBN. The results show that attention modules bring great benefits to lane detection.
Table 3. Results of attention over baseline on TuSimple datasets.
We use ResNet34 as our baseline. The experiment shows in Table that our model, which is the same as ResNet34-UNet, is faster than the baseline. This finding indicates that the ResNet-UNet structure improves speed while maintaining accuracy, and our model has little increase in computational costs even when additional parameters are introduced.
Table 4. Runtimes of Baseline, ResNet34-UNet, and our model. Runtimes of ResNe34t, ResNet34-UNet, and our model CPU are from Intel Core i9-10900K, and GPUs are 2 NVIDIA 3080s with 16 GB memory.
4.4.2. Experiment on CULane dataset
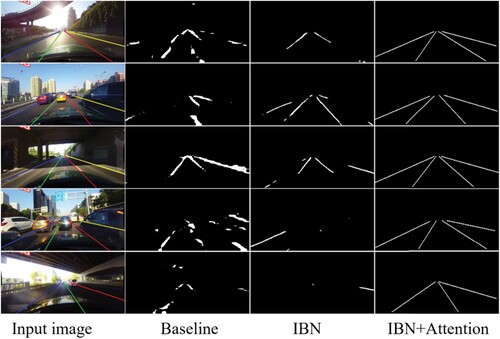
To prove the effectiveness of IAED, we compared it with a series of baselines under different scenarios in the CUlane dataset. As shown in Figure , which presents the visualisations, the performance of lane detection with IAED is better than ResNet34 and Resnet34-UNet + IBN in the case of shadows, dazzling light, crowding, and so on. Our attention network, which captures long-range contextual information effectively, achieves outstanding performance consistently on five challenging driving scenarios.
Figure 4. Comparison between baseline and our model. First line: strong light. Second line: moderate crowding. Third line: moderate shadows. Fourth line: heavily crowded. Fifth line: heavy shadows.
We compared the approach proposed in this paper with a series of ResNet34 methods in CUlane datasets that contain several challenging driving scenarios. It can be seen from Table that the approach proposed in this paper is better than other methods in lane detection under normal conditions, but the performance difference is not obvious. This is because the image marking of the middle lane line under normal conditions is relatively simple and easy. In some complex cases, the performance of our method in lane line detection is slightly reduced. However, other methods cannot transfer the long-range dependence between pixel and channel dependence, making the performance decrease sharply, which reduces the lane detection ability. Therefore, the proposed method has better generalisation ability compared with other methods. The results show that IBN-Net and the attention module in the encoder-decoder network have excellent lane detection capability in the CUlane datasets. IBN-Net unifies instance normalisation and batch normalisation layers to increase modelling and generalisation capabilities. The attention module combines local features with global information to effectively capture remote context information, which gives accurate lane line detection results to make the network more robust.
Table 5. Results of Attention over baseline on CULane datasets in different scenarios. Experimental evaluation standard is F1.
The method proposed in this paper is compared with the existing methods, which proves the excellent effect of the network structure. All other experimental results in Table are from reference (Pan et al., Citation2018), and all experimental settings remain consistent. It can be seen from Table that our method improves by 3.4% and 4.5% compared with ResNet-50 and MRFN, respectively, in normal scenarios, which is similar to the SCNN. However, in complex cases, the method in this paper is better than the other three methods. The results show that our method can provide more accurate lane line detection results than the existing methods and has better generalisation ability and robustness.
Table 6. Comparison with state-of-the-art methods on CULane datasets in different scenarios. Experimental evaluation standard is F1.
To illustrate the advantages of our proposed method more intuitively, we use Acc on the CULane Datasets to compare with other existing methods. As shown in Table , our method achieves the best results with the highest Acc.
Table 7. Comparison with state-of-the-art methods on CULane datasets in different scenarios.
At the end of the experiment, we compared the performance and efficiency of our method with those of the SCNN. As seen from Table , taking F1 as the evaluation criterion, our proposed method is slightly superior to the SCNN. For a more detailed comparison with the SCNN, we use the mean IoU to evaluate the performance of the two models. The results listed in Table indicate that our method achieves significantly better performance.
Table 8. Comparison between our model and SCNN using mIoU evaluation criteria.
To compare our model with the efficiency of the SCNN, we calculate their runtime experimentally. In the fair comparison case, the input size is modified to be the same as that in the SCNN, and both methods are tested on a GPU. The results show that our model is faster than the SCNN in Table . This is because the SCNN requires a high number of convolution operations.
Table 9. Runtimes of our model and SCNN. CPU is Intel Core i9-10900K, and GPUs are 2 NVIDIA 3080s with 16 GB memory.
5. Conclusion
This paper proposed a semantic segmentation network IAED for lane detection. This network can retain the details and effectively capture remote context information to deal with the performance degradation of lane detection in complex environments such as occlusion and low light. IBN-net increased modelling and generalisation capabilities. The spatial attention module and channel attention module can effectively capture the global background and judge whether the pixel is in the lane line sign, providing accurate lane line detection results. Our proposed network consistently delivers superior performance in the TuSimple and CULane datasets, especially in complex environments where this approach outperforms previous approaches.
Since lane line detection based on the segmentation method models the lane line as a pixel classification problem rather than a specified line shape, the lane is not regarded as a whole unit. In the future, we want to use rowwise detection methods for lane line detection. We hope to use data enhancement to improve the generalisation ability of the model and consider transformers to improve the detection accuracy of the model.
Author contributions
Conceptualization, Y. S., and L.-Y.W.; formal analysis, investigation, methodology, and validation, Y. S.; software, Y. S., and H.-D.W.; writing – original draft preparation, Y. S.; writing – review and editing, Y. S. and L.-Y.W.; supervision, L.-Y.W. All authors have read and agreed to the published version of the manuscript.
Acknowledgments
The authors would like to acknowledge the technical and administrative support from Key Laboratory of Modern Measurement and Control Technology members throughout the data collections and data calibration.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Bai, X., Wang, X., Liu, X., Liu, Q., Song, J., Sebe, N., & Kim, B. (2021). Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments. Pattern Recognition, 120, 108102. https://doi.org/10.1016/j.patcog.2021.108102
- Cai, W., Liu, D., Ning, X., Wang, C., & Xie, G. (2021). Voxel-based three-view hybrid parallel network for 3D object classification. Displays, 69, 102076. https://doi.org/10.1016/j.displa.2021.102076
- Cai, W., Zhai, B., Liu, Y., Liu, R., & Ning, X. (2021). Quadratic polynomial guided fuzzy C-means and dual attention mechanism for medical image segmentation. Displays, 70, 102106. https://doi.org/10.1016/j.displa.2021.102106
- Chen, P. R., Lo, S. Y., Hang, H. M., Chan, S. W., & Lin, J. J. (2018, November). Efficient road lane marking detection with deep learning. In 2018 IEEE 23rd international conference on digital signal processing (DSP) (pp. 1–5). IEEE.
- Chiu, K. Y., & Lin, S. F. (2005, June). Lane detection using color-based segmentation. In IEEE proceedings. Intelligent vehicles symposium, 2005 (pp. 706–711). IEEE.
- Chougule, S., Koznek, N., Ismail, A., Adam, G., Narayan, V., & Schulze, M. (2018). Reliable multilane detection and classification by utilizing CNN as a regression network. In Proceedings of the European conference on computer vision (ECCV) workshops.
- Duan, Z., Chen, Y., Yu, H., Hu, B., & Chen, C. (2021). RGB-fusion: Monocular 3D reconstruction with learned depth prediction. Displays, 70, 102100. https://doi.org/10.1016/j.displa.2021.102100
- Fan, R., Wang, X., Hou, Q., Liu, H., & Mu, T. J. (2019). Spinnet: Spinning convolutional network for lane boundary detection. Computational Visual Media, 5(4), 417–428. https://doi.org/10.1007/s41095-019-0160-1
- Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., & Lu, H. (2019). Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 3146–3154). IEEE.
- Ghafoorian, M., Nugteren, C., Baka, N., Booij, O., & Hofmann, M. (2018). El-gan: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the European conference on computer vision (ECCV) workshops (pp. 38–45). ECCV workshops.
- Gurghian, A., Koduri, T., Bailur, S. V., Carey, K. J., & Murali, V. N. (2016). Deeplanes: End-to-end lane position estimation using deep neural networksa. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops (pp. 38–45). IEEE.
- Hou, Y., Ma, Z., Liu, C., & Loy, C. C. Supplementary material of learning lightweight lane detection CNNs by self attention distillation.
- Hou, Y., Ma, Z., Liu, C., & Loy, C. C. (2019). Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 1013–1021). IEEE.
- Huang, Y., Chen, S., Chen, Y., Jian, Z., & Zheng, N. (2018, May). Spatial-temproal based lane detection using deep learning. In IFIP international conference on artificial intelligence applications and innovations (pp. 143–154). Springer.
- Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., & Liu, W. (2019). Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 603–612). IEEE.
- Huval, B., Wang, T., Tandon, S., Kiske, J., Song, W., Pazhayampallil, J., Andriluka, M., Rajpurkar, P., Migimatsu, T., Cheng-Yue, R., Mujica, F., Coates, A., & Ng, A. Y. (2015). An empirical evaluation of deep learning on highway driving. arXiv preprint arXiv:1504.01716.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25.
- Lee, M., Lee, J., Lee, D., Kim, W., Hwang, S., & Lee, S. (2022). Robust lane detection via expanded self attention. In Proceedings of the IEEE/CVF winter conference on applications of computer vision (pp. 533–542). IEEE.
- Lee, S., Kim, J., Shin Yoon, J., Shin, S., Bailo, O., Kim, N., Lee, T.-H., Hong, H. S., Han, S.-H., & So Kweon, I. (2017). Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE international conference on computer vision (pp. 1947–1955). IEEE.
- Liu, L., Chen, X., Zhu, S., & Tan, P. (2021). Condlanenet: A top-to-down lane detection framework based on conditional convolution. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 3773–3782). IEEE.
- Loose, H., Franke, U., & Stiller, C. (2009, June). Kalman particle filter for lane recognition on rural roads. In 2009 IEEE intelligent vehicles symposium (pp. 60–65). IEEE.
- Lu, B., Sun, L., Yu, L., & Dong, X. (2021). An improved graph cut algorithm in stereo matching. Displays, 69, 102052. https://doi.org/10.1016/j.displa.2021.102052
- Neven, D., De Brabandere, B., Georgoulis, S., Proesmans, M., & Van Gool, L. (2018, June). Towards end-to-end lane detection: An instance segmentation approach. In 2018 IEEE intelligent vehicles symposium (IV) (pp. 286–291). IEEE.
- Ning, X., Duan, P., Li, W., & Zhang, S. (2020). Real-time 3D face alignment using an encoder-decoder network with an efficient deconvolution layer. IEEE Signal Processing Letters, 27, 1944–1948. https://doi.org/10.1109/LSP.2020.3032277
- Ning, X., Gong, K., Li, W., & Zhang, L. (2021). JWSAA: Joint weak saliency and attention aware for person re-identification. Neurocomputing, 453, 801–811. https://doi.org/10.1016/j.neucom.2020.05.106
- Ning, X., Gong, K., Li, W., Zhang, L., Bai, X., & Tian, S. (2020). Feature refinement and filter network for person re-identification. IEEE Transactions on Circuits and Systems for Video Technology, 31(9), 3391–3402. https://doi.org/10.1109/TCSVT.2020.3043026
- Niu, C., Nan, F., & Wang, X. (2021). A super resolution frontal face generation model based on 3DDFA and CBAM. Displays, 69, 102043. https://doi.org/10.1016/j.displa.2021.102043
- Pan, X., Luo, P., Shi, J., & Tang, X. (2018). Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 464–479). ECCV.
- Pan, X., Shi, J., Luo, P., Wang, X., & Tang, X. (2018, April). Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI conference on artificial intelligence (Vol. 32, pp. 45–57). AAAI.
- Qi, S., Ning, X., Yang, G., Zhang, L., Long, P., Cai, W., & Li, W. (2021). Review of multi-view 3D object recognition methods based on deep learning. Displays, 69, 102053–102067. https://doi.org/10.1016/j.displa.2021.102053
- Qin, Z., Wang, H., & Li, X. (2020, August). Ultra fast structure-aware deep lane detection. In European conference on computer vision (pp. 276–291). Springer.
- Qin, Z., Zhang, P., Wu, F., & Li, X. (2020). FcaNet: Frequency channel attention networks.
- Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation. In International conference on medical image computing and computer-assisted intervention (pp. 234–241). Springer.
- Su, J., Chen, C., Zhang, K., Luo, J., Wei, X., & Wei, X. (2021). Structure guided lane detection. arXiv preprint arXiv:2105.05403.
- Tang, J., Li, S., & Liu, P. (2021). A review of lane detection methods based on deep learning. Pattern Recognition, 111, 107623. https://doi.org/10.1016/j.patcog.2020.107623
- Teng, Z., Kim, J. H., & Kang, D. J. (2010, October). Real-time lane detection by using multiple cues. In ICCAS 2010 (pp. 2334–2337). IEEE.
- Torres, L. T., Berriel, R. F., Paixão, T. M., Badue, C., De Souza, A. F., & Oliveira-Santos, T. (2020). Keep your eyes on the lane: Attention-guided lane detection. CoRR .
- Ulyanov, D., Vedaldi, A., & Lempitsky, V. (2016). Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022.
- Wang, C., Wang, X., Zhang, J., Zhang, L., Bai, X., Ning, X., Zhou, J., & Hancock, E. (2022). Uncertainty estimation for stereo matching based on evidential deep learning. Pattern Recognition, 124, 108498. https://doi.org/10.1016/j.patcog.2021.108498
- Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., Wang, X., & Tang, X. (2017). Residual attention network for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156–3164).
- Wang, G., Li, W., Zhang, L., Sun, L., Chen, P., Yu, L., & Ning, X. (2021). Encoder-x: Solving unknown coefficients automatically in polynomial fitting by using an autoencoder. IEEE Transactions on Neural Networks and Learning Systems, (99), 1–13.
- Wang, M., Sun, T., Song, K., Li, S., Jiang, J., & Sun, L. (2022). An efficient sparse pruning method for human pose estimation. Connection Science, 34(1), 960–974. https://doi.org/10.1080/09540091.2021.2012423
- Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7794–7803). IEEE.
- Xiao, D., Yang, X., Li, J., & Islam, M. (2020). Attention deep neural network for lane marking detection. Knowledge-based Systems, 194, 105584. https://doi.org/10.1016/j.knosys.2020.105584
- Yoo, S., Lee, H. S., Myeong, H., Yun, S., Park, H., Cho, J., & Kim, D. H. (2020). End-to-end lane marker detection via row-wise classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 1006–1007.
- Yu, Z., Li, S., Sun, L., Liu, L., & Haining, W. (2022). Multi-distribution noise quantisation: An extreme compression scheme for transformer according to parameter distribution. Connection Science, 34(1), 990–1004 .
- Yuan, Y., Huang, L., Guo, J., Zhang, C., Chen, X., & Wang, J. (2018). Ocnet: Object context network for scene parsing. arXiv preprint arXiv:1809.00916.
- Zhang, H., Goodfellow, I., Metaxas, D., & Odena, A. (2019, May). Self-attention generative adversarial networks. In International conference on machine learning (pp. 7354–7363). PMLR.
- Zhang, J., Xu, Y., Ni, B., & Duan, Z. (2018). Geometric constrained joint lane segmentation and lane boundary detection. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 486–502). ECCV.
- Zhang, L., Li, W., Yu, L., Sun, L., Dong, X., & Ning, X. (2021). Gmface: An explicit function for face image representation. Displays, 68, 102022. https://doi.org/10.1016/j.displa.2021.102022
- Zhang, L., Sun, L., Yu, L., Dong, X., Chen, J., Cai, W., Wang, C., & Ning, X. (2021). ARFace: Attention-aware and regularization for face recognition with reinforcement learning. IEEE Transactions on Biometrics, Behavior, and Identity Science, 30–42.
- Zhang, W., & Mahale, T. (2018). End to end video segmentation for driving: Lane detection for autonomous car. arXiv preprint arXiv:1812.05914.
- Zhang, Y., Lu, Z., Zhang, X., Xue, J. H., & Liao, Q. (2021). Deep learning in lane marking detection: A survey. IEEE Transactions on Intelligent Transportation Systems, PP(99), 1–17. https://doi.org/10.1109/TITS.2021.3070111
- Zheng, T., Huang, Y., Liu, Y., Tang, W., Yang, Z., Cai, D., & He, X. (2022). CLRNet: Cross layer refinement network for lane detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 898–907). IEEE.
- Zou, Q., Jiang, H., Dai, Q., Yue, Y., Chen, L., & Wang, Q. (2019). Robust lane detection from continuous driving scenes using deep neural networks. IEEE Transactions on Vehicular Technology, 69(1), 41-54. https://doi.org/10.1109/TVT.2019.2949603