
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Safety control is a fundamental problem in policy design. Basic reinforcement learning is effective at learning policy with goal-reaching property. However, it does not guarantee safety property of the learned policy. This paper integrates barrier certificates into actor-critic-based reinforcement learning methods in a feedback-driven framework to learn safe policies for dynamical systems. The safe reinforcement learning framework is composed of two interactive parts: Learner and Verifier. Learner trains the policy to satisfy goal-reaching and safety properties. Since the policy is trained on training datasets, the two properties may not be retained on the whole system. Verifier validates the learned policy on the whole system. If the validation fails, Verifier returns the counterexamples to Learner for retraining the policy in the next iteration. We implement a safe policy learning tool SRLBC and evaluate its performance on three control tasks. Experimental results show that SRLBC achieves safety with no more than 0.5× time overhead compared to the baseline reinforcement learning method, showing the feasibility and effectiveness of our framework.
1. Introduction
The synthesis of control policies for heating, ventilation and air conditioning systems, autonomous vehicles, and robotics is a fundamental problem for cyber-physical systems (Lin et al., Citation2018; Wei et al., Citation2017; Xu et al., Citation2018). Researchers have demonstrated that reinforcement learning is effective at learning policies to achieve goal-reaching property to solve complex tasks, i.e. controlling the system to obtain the expected long-term reward (Dong et al., Citation2020; Haarnoja et al., Citation2018). However, basic reinforcement learning methods do not provide safety guarantees and face the threat of unsafe behaviours, which is an obstacle to the use of reinforcement learning in safety-critical fields (Berkenkamp et al., Citation2017; Fulton & Platzer, Citation2018).
There is some recent work towards safe reinforcement learning, which tries to deal with the possible risk of unsafe behaviours (Garcıa & Fernández, Citation2015; Yang, Vamvoudakis, et al., Citation2020). A category of work takes into account uncertainty and applies appropriate risk measure costs to the reward, reducing the probability of unsafe behaviours by minimising the expectation of safety violations (Stooke et al., Citation2020; Thananjeyan et al., Citation2021). However, because safety is specified through safety costs, these methods only reduce safety violations and do not eliminate them (Srinivasan et al., Citation2020; T. Y. Yang et al., Citation2020).
To completely avoid unsafe behaviours, another category of work integrates external safety techniques, including control barrier functions, control Lyapunov functions, and safe backup policies into reinforcement learning (Alshiekh et al., Citation2018; Cohen & Belta, Citation2020; Ohnishi et al., Citation2019). These works propose sufficient conditions to guarantee safety property. However, the limitation of these methods is that the control barrier functions, control Lyapunov functions and safe backup policies usually need to be provided manually, or some prior knowledge is required (Bastani, Citation2019; Ravanbakhsh & Sankaranarayanan, Citation2019).
To guarantee safety property without relying on prior knowledge, this work integrates barrier certificates into actor-critic-based reinforcement learning methods in a feedback-driven framework to learn safe policies for dynamical systems. The barrier certificate guarantees that the system trajectories will not cross its zero level set to enter the unsafe states (Prajna & Jadbabaie, Citation2004). Therefore, the existence of a barrier certificate is a sufficient condition for system safety property. The insight of the proposed framework is that the barrier certificate is represented by a neural network, which is simultaneously learned along with the policy. Therefore, safety is naturally considered in the policy learning process and it does not need prior knowledge.
The framework of our approach is composed of two interactive parts: Learner and Verifier, as shown in Figure . Learner simultaneously trains three neural networks: the actor network, the critic network and the barrier network. The actor network represents the control policy; the critic network guides the actor to satisfy goal-reaching property; the barrier network is used as the barrier certificate to guarantee safety property. Since neural networks are trained on training datasets, the goal-reaching and safety properties that the actor satisfies on training datasets may not be retained on the whole system. Therefore, Verifier validates the two properties on the whole system. If the validation succeeds, the actor is a safe policy satisfying goal-reaching and safety properties. Otherwise, Verifier returns some failure experience or counterexamples to Learner to retrain the networks in the next iteration.
Figure 1. Framework of the feedback-driven approach.
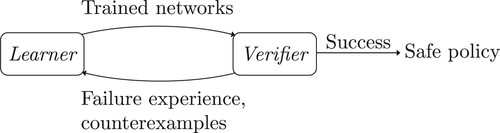
The main contributions of the paper are summarised as follows:
We propose a novel feedback-driven framework, which integrates barrier certificates into actor-critic-based reinforcement learning methods to learn safe policies for dynamical systems.
We introduce how to synthesise safe policies without prior knowledge based on iterations between Learner and Verifier. The proposed workflow and techniques enable the policy to be trained and verified efficiently.
We implement a safe policy learning tool SRLBC based on the deep deterministic policy gradient (DDPG) method, which only focuses on goal-reaching property for the learned policy. SRLBC is evaluated on three control tasks: Continuous Mountain Car, Pendulum, and CartPole. Experimental results show that SRLBC achieves both goal-reaching and safety properties with no more than 0.5× time overhead compared to DDPG, showing the feasibility and effectiveness of our framework.
The rest of this paper is organised as follows. Section 2 introduces some notions and definitions used in the paper. Section 3 shows how Learner trains the policy to satisfy goal-reaching and safety properties. Section 4 presents how Verifier validates the two properties. Experiments are displayed in Section 5. Section 6 discusses related work. Finally, Section 7 concludes the paper.
2. Preliminaries
This section briefly introduces the feedforward neural network, dynamical system, reinforcement learning and the definitions of goal-reaching and safety properties, followed by the introduction of the barrier certificate. Let denote the field of real number.
2.1. Feedforward neural network
This paper focuses on the control policies that are represented by feedforward neural networks. A feedforward neural network with n + 1 layers (from the 0-th layer to the n-th layer) is a tuple
defined as follows:
is a set of neuron outputs of each layer;
ϕ is the activation function.
Let denote the neuron outputs in the kth layer before applying activation function ϕ, and the network forward propagation is defined as follows:
(1)
(1) A feedforward neural network (hereinafter referred to as neural network for simplicity) receives the external input as the input layer neuron value
. The output of neural network
is the value of the output layer neuron, i.e.
2.2. Dynamical system
A dynamical system is composed of a plant model and a control policy, which consists of a tuple
defined as follows:
f denotes the local Lipschitz continuous vector field, representing the system evolution;
g denotes the observation model of the system such as the observation output
The system considered in the paper is continuous and modelled by the ordinary differential equation as follows:
(2)
(2) where
is the control signal produced by the control policy π. The control policy π receives the observation of real-time system state x and outputs the signal
to control the system
. It is assumed that the system variables are directly exported to the observation model, which means g is an identical function, i.e.
. Then, the output of the control policy is determined as
.
For a dynamical system , a neural network
serves as the control policy π, receiving system state
as input to output the control signal
. Figure displays a dynamical system controlled by a neural network policy.
Figure 2. A dynamical system controlled by a neural network policy.
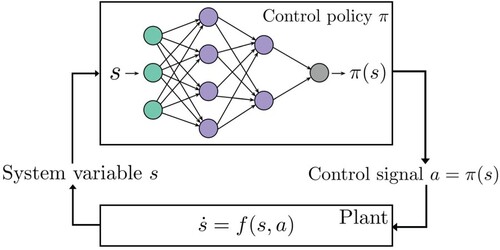
2.3. Reinforcement learning
A reinforcement learning system consists of an agent interacting with the environment in continuous or discrete-time steps, represented as a Markov decision process (MDP). A MDP is defined as follows:
It is assumed that the MDP starts from a set of initial states
and the environment is fully observed to the agent.
The behaviour of the agent is determined by a policy π, which maps system states to a probability distribution over the actions. This paper considers deterministic policies, so the policy maps a state to a deterministic action. At each time step t, the agent receives an observation of state
, chooses and then performs action
. The agent transits to the next state
and the environment returns the reward
about this transition. The goal of the system is to learn a policy π for the agent that maximises the expected long-term reward
, which is defined as follows:
(3)
(3) where
is the accumulative discounted reward from time step 0 to t, and
denotes the discount factor.
The proposed safe reinforcement learning method in this paper is model-based. That is, we know the accurate dynamics and constraints of the system. In addition, to enable reinforcement learning to be used to learn control policies on continuous-time dynamical systems, we divide the time steps into small pieces by discrete sampling and approximate the behaviours of continuous-time systems.
2.4. Goal-reaching and safety properties
This paper considers two properties of the learned policy: goal-reaching and safety. Goal-reaching property requires that the learned policy can control the agent to obtain the expected long-term reward, while safety property requires that the agent must not run into unsafe states.
Definition 2.1
Goal-reaching
For the initial state , goal-reaching property requires learning a policy π to control the agent to obtain the accumulative reward
not less than the given reward threshold
in some time step t:
(4)
(4)
Definition 2.2
Safety
For the given unsafe states U, when the agent starts from the initial states I, safety property requires learning a policy π to control the agent not to enter U in any time step t:
(5)
(5)
2.5. Barrier certificate
Before introducing barrier certificates, we introduce the Lie derivative first. Given a continuously differentiable function , the Lie derivative of
with respect to vector field
is defined as the inner product of
and f:
(6)
(6) where
and
denote the ith elements of
and
, respectively.
A barrier certificate is a continuously differentiable function of system states, preventing system trajectories from passing it and invading the unsafe states. A continuously differentiable function becomes a barrier certificate of a dynamical system if it satisfies the following conditions (Prajna & Jadbabaie, Citation2004):
Theorem 2.3
Barrier certificate conditions
Given a dynamical system with unsafe states U, the following conditions guarantee that the function
is a barrier certificate:
(7)
(7)
In Theorem 2.3, the first and second conditions require to separate unsafe states and initial states with positive and nonpositive values, respectively. The third condition guarantees that
cannot become positive from a nonpositive state when the system evolves. If all three conditions are satisfied,
is a barrier certificate of
, and the safety of
is certified.
3. Learner: training policies with goal-reaching and safety properties
Given a dynamical system , our approach learns a safe policy π with goal-reaching and safety properties to control the system. The framework consists of two interactive parts: Learner and Verifier. The former trains the policy on training datasets, while the latter validates whether the trained policy satisfies the two properties on the whole system.
This section introduces how Learner works. To learn safe policy π, the key idea of Learner is to simultaneously train three neural networks based on the two training datasets. Figure shows the workflow of Learner. In Learner, actor represents the policy π to be learned. Critic
guides the policy to meet goal-reaching property. Barrier
guarantees the policy to satisfy safety property. The following subsections introduce how to define neural network structures, generate training datasets and construct loss functions to train three networks. Finally, the algorithm of Learner is presented.
Figure 3. Workflow of Learner.
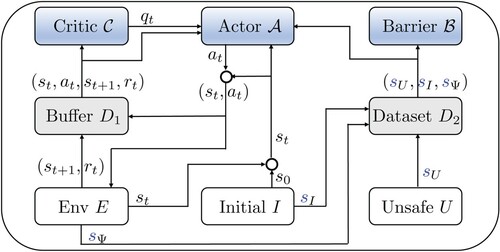
3.1. Defining neural network structures
The structures of actor , barrier
and critic
are predefined and not changed during the training process. Actor
receives the current state
and outputs the action
to control the agent. For dynamical system
, the value of state
is that of system state x. Therefore, the number of neurons in the input layer is the same as the dimension of system variables. The number of neurons in the output layer is the same as the dimension of action
. The hidden layers can contain an arbitrary number of layers and neurons.
Barrier receives system state
and outputs value
. Therefore, the neuron number of the input layer is the same as the system variable number, and the output layer contains one neuron. The number of hidden layers and neurons has no limitation.
Critic receives the current state
and the action
to output evaluation
to quantify the chosen action
. Therefore, the neuron number of the input layer is the same as the sum dimensions of state
and action
. The output layer contains one neuron. Also, there is no limitation on hidden layers and neurons.
3.2. Generating training datasets
3.2.1. Sampling data for experience replay buffer
Experience replay buffer is used to train actor
and critic
to satisfy goal-reaching property. The data in experience replay buffer
are in the form called a transition:
. Before starting network training, actor
is randomly initialised, and noise μ is added to action
, i.e.
. By choosing a time bound T and time interval
between two time steps, a sequence of transitions is sampled:
where
During network training, the agent continues to explore the environment and produce new transitions, which are added to
to replace old ones.
3.2.2. Sampling data for state point dataset
State point dataset is used to train barrier
to be a real barrier certificate for the system controlled by actor
. According to Theorem 2.3, if barrier
satisfies the barrier certificate conditions, safety property is guaranteed.
To satisfy the first barrier certificate condition, we randomly sample data points from unsafe states U and construct the dataset
. When training barrier
with data points in
, the expected outputs should be positive, i.e.
. Similarly, to satisfy the second condition,
contains the data points sampled from initial states I. The expected outputs of barrier
on
should be nonpositive. To satisfy the third condition, we need to sample data points
. However, during network training, the parameters of barrier
continue to update, so the data points belonging to
are constantly changing. In addition, the constraint
is too strict to be satisfied due to the errors in floating-point computation. Instead, the data points are sampled from system space Ψ and tested at run-time to pick suitable points. Let
and
be small positive numbers,
is relaxed as
.
The state point dataset is composed of the above three parts:
.
3.3. Constructing loss functions
3.3.1. Constructing loss functions for goal-reaching property
The optimisation for goal-reaching property involves actor and critic
. Actor
chooses the action
, and critic
evaluates how much rewards the agent will obtain after this transition by
. The goal of training for actor
is to make the selected action
obtain higher estimation
. For critic
, the goal is to make its evaluation
more accurate.
This paper adopts the temporal difference (TD) algorithm (Sutton et al., Citation2008) to update critic . As
is the estimation of future reward at time step t, it is considered that
is not as accurate as the TD target
computed as follows:
(8)
(8) where
denotes the discount factor. The updating of critic
is to reduce the difference between the estimation
and TD target
. Let
denote the parameters of critic
, critic
is trained by minimising the following loss function
:
(9)
(9) To update actor
, the policy gradient technique (Silver et al., Citation2014) is used. The goal of actor
is to make
higher. Let
denote the parameters of actor
; its gradient is computed as follows by applying the chain rule
(10)
(10) Then, let
be the step length of gradient ascent, and
is updated as follows:
(11)
(11)
3.3.2. Constructing loss functions for safety property
Then we consider safety property of actor , which is guaranteed by the simultaneously trained barrier
. The goal is to train barrier
as a real barrier certificate, satisfying the barrier certificate conditions in Theorem 2.3. Therefore, the expected outputs for three parts in state point dataset
are characterised as follows:
(12)
(12) Then, let
be a small positive number, and the following sub-loss functions are designed to meet the constraints in Equation (Equation12
(12)
(12) ):
(13)
(13) Let
denote the coefficients among
, and
denote the parameters of
, and the network training is processed by minimising the following loss function
:
(14)
(14) Note that the Lie derivative
involves actor
and barrier
, so the optimisation of
is over
and
. If
is minimised to 0, barrier
is a barrier certificate on
, and actor
satisfies safety property.
3.4. Algorithm of Learner

The algorithm of Learner is presented in Algorithm 1. Learner trains a policy π with goal-reaching and safety properties. Before training the policy, networks ,
,
and datasets
,
are initialised. In each episode, the agent explores the environment from a random initial state
with the noise μ. For each step, it performs action
based on the current state
and noise
, then steps into next state
and obtains reward
. The transitions are stored in
. Then Learner updates the networks
,
and
according to Equations (Equation11
(11)
(11) ), (Equation14
(14)
(14) ) and (Equation9
(9)
(9) ).
Algorithm 1 terminates when reaching the maximum episode or learning a policy with goal-reaching and safety properties on training datasets. During network training, if the average reward of 100 consecutive episodes is greater than the threshold, the learned policy is considered stable, satisfying goal-reaching property. If the loss in Equation (Equation14
(14)
(14) ) is 0 for 10 consecutive episodes, the learned policy is considered to satisfy safety property. When goal-reaching and safety properties are both satisfied, Algorithm 1 terminates early and returns
,
and
. Since
is trained on training datasets, goal-reaching and safety properties may not be retained on the whole system
. The following section introduces how to validate whether actor
satisfies the two properties on the whole system.
4. Verifier: validating safe policies using simulations and verification
This section validates whether the learned policy, i.e. actor , satisfies goal-reaching and safety properties on the whole system using large-scale simulations and formal verification before presenting the algorithm of Verifier.
4.1. Validating goal-reaching property using large-scale simulations
This work carries out large-scale simulations to ensure that actor satisfies goal-reaching property (Wang et al., Citation2019). The basic idea is to determine whether the agent can obtain the expected long-term reward by repeatedly simulating. The simulation steps are presented in Algorithm 2.

Algorithm 2 returns failure experience dataset . If
is empty, actor
is considered to satisfy goal-reaching property. Otherwise, actor
does not meet goal-reaching property at some initial states. In this situation, Verifier returns
to the experience replay buffer
in Learner to retrain actor
.
4.2. Validating safety property using formal verification
If actor is validated to satisfy goal-reaching property, the next step is to check whether it meets safety property. As introduced in Section 2.5, for a dynamical system, if there is a barrier certificate satisfying the three conditions in Theorem 2.3, the system is safe. In the last section, Learner trains a barrier
as the barrier certificate of the system controlled by actor
. This subsection checks whether
is a real barrier certificate on the whole system.
If satisfies the barrier certificate conditions in Theorem 2.3, it is a real barrier certificate and guarantees safety property of
. In our previous work (Zhao et al., Citation2022), we propose an optimisation problem solving-based method to verify safety property. The key idea is to transform the verification of barrier certificate conditions into corresponding optimisation problems to perform validation. The following briefly introduces the method. For more details, please refer to our former paper.
4.2.1. Validating the first barrier certificate condition
We first consider the first barrier certificate condition . Assume barrier
is a n + 1 layer (from the 0-th layer to the n-th layer) neural network. For any state
as the network input
, i.e.
, if the output layer neuron value
, the first barrier certificate condition is verified to be satisfied. Based on Equation (Equation1
(1)
(1) ), the verification of the first barrier certificate condition is transformed into an optimisation problem about the minimum value of the barrier output layer neuron on the unsafe states, which is formalised as follows:
(15)
(15) It is observed that if the global minimum of Problem (Equation15
(15)
(15) ) is > 0,
satisfies the first barrier certificate condition. To solve Problem (Equation15
(15)
(15) ), we utilise the optimiser Gurobi 9.5 (Gurobi Optimization, Citation2022) to find the global optimum. However, it is difficult to find the global optimum exactly due to the nonlinearity, nonconvexity and floating-point error. The following introduces how to get a formally guaranteed solution based on the current optimum returned by the optimiser.
4.2.2. Getting formally guaranteed solutions
When optimising Problem (Equation15(15)
(15) ), the basic idea to handle the nonlinearity is using the piece-wise linear approximation to transform nonlinear constraints into piece-wise linear ones. However, the transformed problem may be nonconvex. Since the transformed problem is composed of piece-wise linear constraints, it can be split into a group of sub-problems that are convex. (Note that the linear approximation and splits are done by the optimiser automatically.) To bound the error about linear approximation and floating-point computation, the optimiser in real-time returns a current optimum p and an error bound ξ, which measures the maximum relative error between the current optimum p and the real global optimum
, satisfying:
(16)
(16) For Equation (Equation16
(16)
(16) ), assuming
, there are
It can be found if
,
, which means the sign of
can be inferred based on p and ξ.
Theorem 4.1
When optimising Problem (Equation15(15)
(15) ), let p be a current optimum,
be the global optimum, ξ be the error bound, if
,
. Then, barrier
is proven to satisfy the first barrier certificate condition.
4.2.3. Validating the second barrier certificate condition
The verification of the second barrier certificate condition is isomorphic with the first one, except for the region of and the optimisation direction. We transform it into a problem optimising for the maximum of
on initial states I, which is defined as follows:
(17)
(17)
Theorem 4.2
When optimising Problem (Equation17(17)
(17) ), let p be a current optimum,
be the global optimum, ξ be the error bound, if
,
. Then, barrier
is proven to satisfy the second barrier certificate condition.
4.2.4. Validating the third barrier certificate condition
The third barrier certificate condition requires that once a system trajectory reaches the zero level set of barrier , i.e.
, it travels along or is rebounded from the curve. The requirement involves the constraint that the Lie derivatives of those states are
. By transforming the Lie derivative as the inner product form in Equation (Equation6
(6)
(6) ) and denoting the layered representations of the two neural networks
and
, the optimisation problem corresponding to the third barrier certificate condition is formalised as follows:
(18)
(18) In Problem (Equation18
(18)
(18) ), t is an intermediate variable denoting the Lie derivative.
and
are the weight matrix and the bias vector of barrier
, respectively. Actor
is assumed to be a m + 1 layer (from the 0-th layer to the m-th layer) neural network.
denotes the layer output of actor
.
and
are the weight matrix and the bias vector of actor
, respectively.
and
are activation functions of barrier
and actor
, respectively. If the maximum of Problem (Equation18
(18)
(18) ) is
, the third barrier certificate condition is verified to be satisfied.
Then we consider the encoding of . Based on Equation (Equation1
(1)
(1) ) and the fact that
,
is computed as
(19)
(19)
Theorem 4.3
When optimising Problem (Equation18(18)
(18) ), let p be a current optimum,
be the global optimum, ξ be the error bound, if
,
. Then, barrier
is proven to satisfy the third barrier certificate condition.
When solving Problems (Equation15(15)
(15) ), (Equation17
(17)
(17) ) or (Equation18
(18)
(18) ), if the optimiser gets a current optimum p with an unexpected sign and the error bound
, e.g.
for Problem (Equation15
(15)
(15) ), the optimisation variable configuration of p corresponds to a counterexample. In this situation,
is not a real barrier certificate, and safety property of
is not guaranteed. Then Verifier returns the counterexample to the state point dataset
in Learner to retrain actor
.
4.3. Algorithm of Verifier

The algorithm of Verifier is presented in Algorithm 3. Verifier validates whether learned actor satisfies goal-reaching and safety properties on the whole dynamical system. To check goal-reaching property, Verifier repeatedly performs simulations. For safety property, Verifier constructs three optimisation problems and verifies them. If the simulations and verification both succeed,
is a safe policy satisfying goal-reaching and safety properties. Otherwise, Verifier exits and returns the failure experience or counterexamples to Learner to retrain actor
.
5. Implementation and experiments
This section first introduces the implementation of our safe policy learning tool SRLBC. Then we demonstrate the application of SRLBC by treating three control tasks selected from the OpenAI gym environment (Brockman et al., Citation2016) and compare it with the baseline method DDPG (Lillicrap et al., Citation2016).
5.1. Implementation

Algorithm 4 presents our Safe Reinforcement Learning method using Barrier Certificates, called SRLBC. SRLBC can be applied to any actor-critic-based reinforcement learning method to provide safety guarantees for them. This work implements SRLBC based on DDPG, which focuses on learning policies with goal-reaching property. Note that our framework is also suitable for other actor-critic-based methods such as soft actor-critic (SAC), asynchronous advantage actor-critic (A3C) and proximal policy optimization (PPO).
SRLBC combines Learner with Verifier to learn safe policies for dynamical systems. SRLBC is not complete, since it cannot guarantee to learn a safe policy before reaching the maximum iteration. On the one hand, SRLBC is sound for the verification of safety property. However, on the other hand, it cannot provide formal guarantees for the simulations of goal-reaching property.
The computational complexity of SRLBC consists of those about Learner and Verifier. Learner's complexity is approximately related to the number of training episodes, while the Verifier's complexity is related to the learned policy, i.e. Actor . For actors using ReLU activation functions, the complexity is exponentially related to the number of neurons in the worst case.
SRLBC is implemented on top of TensorFlow 2.0 (Abadi et al., Citation2016) and invokes optimiser Gurobi 9.5 (Gurobi Optimization, Citation2022) to solve optimisation problems on a workstation running Ubuntu 18.04 with 320 GB RAM, two 3.20 GHz Intel Xeon Gold 6146 CPUs, and three NVIDIA TITAN V GPUs. The default settings of the hyperparameters are ,
,
,
and
. Besides, there are some hyperparameters that vary significantly among different dynamical systems due to special characteristics, such as the time bound T, time interval
, the neural network structures, etc. These hyperparameters are set heuristically according to the specific examples.
5.2. Case studies
5.2.1. Continuous Mountain Car
Figure (a) shows the Continuous Mountain Car environment. The goal is to drive the car up the right mountain. The car's state is described by two features: position
and velocity
. The position of the success flag is 0.45. In exploring, the maximum time is 999, and the time step for each transition is 0.01.
Figure 4. Continuous Mountain Car environment. (a) Original. (b) Safety constrained.
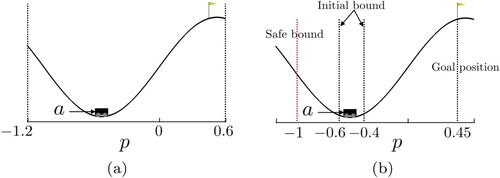
The evolution of the car's state is formulated as follows:
This paper limits the car's trajectories with some safety constraints. As shown in Figure (b), we mark the position p<−1 as unsafe states. The reward for SRLBC is set as follows:
The success threshold for the average reward of 100 consecutive explorations is 90. For DDPG, we use the default reward settings.
Figure (a) compares SRLBC with DDPG on goal-reaching property, which is evaluated by the average rewards of 100 consecutive episodes. SRLBC converges at 133rd episode using 114.23 s, while DDPG converges at the 108th episode using 82.19 s. After 220 episodes, SRLBC obtains the same level of reward as DDPG and remains stable.
Figure 5. Evaluation of goal-reaching and safety properties on each episode for Continuous Mountain Car environment.
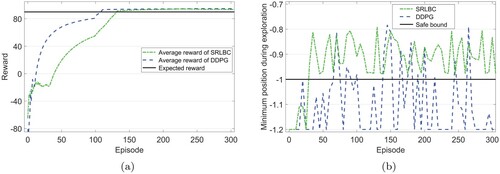
Figure (b) displays the evaluation of safety property, which is quantified by the minimum position during the car's exploration. The safe bound is p = 1. At the beginning of training, both SRLBC and DDPG will control the car to enter unsafe states. After the 31st episode, the car controlled by SRLBC no longer enters unsafe states. However, for the car controlled by DDPG, it does not satisfy safety property and will often enter unsafe states.
5.2.2. Pendulum
Figure (a) shows the Pendulum swing-up problem. The goal is to learn a policy applying a torque a to the pendulum to swing it up so it stays upright. The pendulum's state is described by two features: the angle of the pendulum
and the angular velocity of the swing
. In exploration, the maximum time is 200, and the time step for each transition is 0.005. This paper marks
as unsafe states and limits the initial angle
, as shown in Figure (b). The reward for this system is set as follows:
The success threshold for the average reward of 100 consecutive explorations is
.
Figure 6. Pendulum environment. (a) Original. (b) Safety constrained.
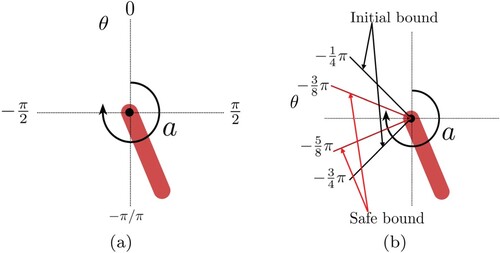
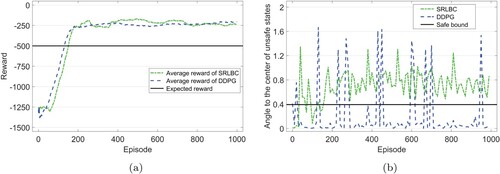
Figure shows the performance of SRLBC compared with DDPG. As displayed in Figure (a), SRLBC learns a stable policy with goal-reaching property at the 153rd episode using 42.15 s, while DDPG learns the policy at the 129th episode using 37.63 s. Figure (b) illustrates the minimum angle of the pendulum to the centre of unsafe states . The safe bound is
. At the 161st episode, SRLBC successfully learns a policy with safety property that controls the pendulum to stand up without entering the unsafe states on training datasets. For DDPG, the policy learned by it does not satisfy safety property.
Figure 7. Evaluation of goal-reaching and safety properties on each episode for Pendulum environment.
5.2.3. CartPole
Figure shows the CartPole environment. The system consists of a cart moving along the horizontal direction and a pendulum connected with the cart. The pendulum starts upright, and the goal is to learn a policy controlling the force a applied to the cart to prevent the pendulum from falling over. The system's state is described by four features: the cart's position
, the moving speed of the cart
, the angle of the pendulum θ and the angular velocity of the pendulum
. In exploring, the maximum time is 200, and the time step for each transition is 0.005. If the angle of the pendulum is too large, i.e.
, the exploration is considered failed. Besides, this paper constrains the cart's movement area
and marks the remaining states as unsafe. The reward for SRLBC is set as follows:
The success threshold for the average reward of 100 consecutive explorations is 195.
Figure 8. CartPole environment. (a) Original. (b) Safety constrained.
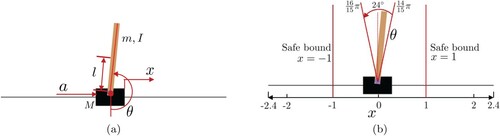
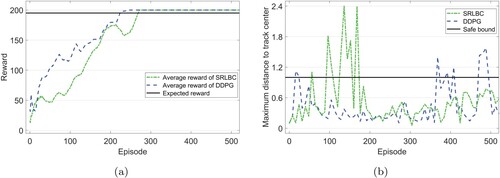
Figure shows the performance of SRLBC compared with DDPG on goal-reaching and safety properties. As shown in Figure (a), SRLBC learns a policy to obtain the expected long-term reward at the 270th episode using 232.90 s, while DDPG learns at the 225th episode using 190.46 s. Figure (b) displays the maximum distance of the cart to the track centre. The safe bound of maximum distance is 1. It can be found that the policy learned by SRLBC controls the car not to cross the safe bound after the 179th episode. For the policy learned by DDPG, it does not provide safety, and the cart may enter unsafe states.
Figure 9. Evaluation of goal-reaching and safety properties on each episode for CartPole environment.
5.3. Performance evaluation
Table shows the performance evaluation of SRLBC and DDPG. In Table , the structures of actor , barrier
and critic
are displayed. For DDPG, the column ‘Goal-reaching’ denotes the average episode and running time of five runs to achieve goal-reaching property, in the form of
. For SRLBC, the columns ‘Goal-reaching’ and ‘Safety’ denote the stage to satisfy goal-reaching and safety properties in the network training process, respectively. The column ‘Validation’ denotes the average running time when SRLBC successfully validates the learned policy.
Table 1. Experimental results.
Observing Table , it can be found that SRLBC can learn actor networks with 3–6 layers. The layers of barrier networks span from 3 to 5. For goal-reaching property, the episode and running time of DDPG are smaller than those of SRLBC. This is because SRLBC simultaneously trains three networks, which affects the speed of network training. In addition, SRLBC guarantees safety property of learned actor , which is not considered by DDPG. The training of actor
to satisfy safety property also influences the convergence speed of goal-reaching property.
When SRLBC successfully learns a policy with goal-reaching and safety properties on training datasets, it calls Verifier to validate it. For Continuous Mountain Car and CartPole, SRLBC iterates once to learn safe policies. For Pendulum, it iterates four times due to the dissatisfaction of safety property. The average running time of SRLBC to learn safe policies for three cases is 147.99 s. Compared with DDPG's 103.43 s, SRLBC achieves safety with no more than 0.5× time overhead, showing the feasibility and effectiveness of our framework.
6. Related work
This work is related to the literature about safety verification and control of dynamical systems.
6.1. Safety verification of dynamical systems
Intuitively, the safety property can be directly checked by computing the exact system reachable set or its overapproximation (Akametalu et al., Citation2014; Clavière et al., Citation2020; Hu et al., Citation2020). To address the computational difficulty arising from neural network control policies (also called controllers), some methods construct a new system approximating the original one and then adopt its reachable set in safety verification (Huang et al., Citation2019; Ivanov et al., Citation2020; Sun et al., Citation2019; Xiang et al., Citation2020). However, the approximation of dynamical systems and control policies will bring errors. As the reachable set is computed step by step, the errors accumulate quickly.
Another type of method is to separate neural network control policies from dynamical models and analyse each of them individually, where safety verification leads to the problem of output range evaluation of neural network with respect to a given input region (Julian & Kochenderfer, Citation2019). Many techniques including input refinement (Katz et al., Citation2017), abstract interpretation (Anderson et al., Citation2020), interval arithmetic (Wang et al., Citation2018), abstract domain (Singh et al., Citation2019), linear approximations (Wong & Kolter, Citation2018) and mixed integer programming (Dutta et al., Citation2018b) are proposed to handle the problem.
Recently, neural networks have been adopted as barrier certificates in verifying the safety property of dynamical systems. Zhao et al. (Citation2020) introduce networks with Bent-ReLU activation functions as barrier certificates and rely on the satisfiability modulo theories (SMT) solver iSAT3 (Winterer, Citation2017) to identify real barrier certificates. Peruffo et al. (Citation2021) propose a counterexample-based, formal, and automated sequential loop to synthesise candidate barrier certificates, and use the SMT solvers dReal (Gao et al., Citation2013) and Z3 (De Moura & Bjørner, Citation2008) to certify them. The disadvantage of the above methods is that they only provide safety verification but do not participate in the construction of safe systems.
6.2. Safety control of dynamical systems
The existing methods to learn safe policies based on supervised learning have been widely studied. Dutta et al. (Citation2018a) present an approach to learning and formally verifying feedback laws for data-driven models of neural networks. Taylor et al. (Citation2020) develop a machine learning framework utilising control barrier functions to reduce model uncertainties. The shortcoming of these methods is that they only consider the safety property of the learned policy, but cannot achieve the goal-reaching property. Instead, Jin et al. (Citation2020) construct an optimisation objective and minimise it to learn policies for dynamical systems. Limited to the characteristics of supervised learning, it is not as effective as the methods using reinforcement learning when learning policies to achieve the goal-reaching property.
Towards safe reinforcement learning, many model-free or model-based methods have been proposed (Yang, Ding, et al., Citation2020; Yang et al., Citation2021; Yang, Vamvoudakis, et al., Citation2020). Radac and Precup (Citation2019) propose a neural network-based control scheme in an adaptive actor-critic learning framework designed for output reference model tracking. Ma et al. (Citation2022) propose a model-based safe reinforcement learning framework to account for potential modelling errors by capturing and exploiting model uncertainty. There have been several surveys on safe reinforcement learning (Garcıa & Fernández, Citation2015; Gu et al., Citation2022; Thomas, Citation2015), and this paper briefly introduces the two common categories.
A line of work applies risk measure costs into the reward to design constrained policy optimisation formulation to ensure safety in expectation. Stooke et al. (Citation2020) propose a new set of constrained reinforcement learning solutions for Lagrangian methods utilising derivatives of the constraint functions. Tamar et al. (Citation2016) present the sampling-based algorithms for optimisation under a coherent-risk objective using two new policy gradient style formulas. Thananjeyan et al. (Citation2021) present the recovery reinforcement learning algorithm to effectively balance task performance and constraint satisfaction when learning policies. However, since these methods specify the possible risk of unsafe behaviours through the costs, the safety property is guaranteed by probability and they cannot completely avoid safety violations.
Another line of work utilises external safety techniques to avoid unsafe behaviours, which are sufficient conditions to guarantee the safety property in the exploration process. Deshmukh et al. (Citation2019) propose a verification-in-the-loop training algorithm to synthesise neural network controllers under the safety provided by the control barrier function. Berkenkamp et al. (Citation2017) extend the theoretical results of the control Lyapunov function to safely optimise policies based on statistical models of the dynamics. Cheng et al. (Citation2019) propose an end-to-end architecture for safe reinforcement learning that combines the model-free reinforcement learning-based controller, model-based controller and online learning of unknown system dynamics. Luo and Ma (Citation2021) explore safe reinforcement learning with zero training-time safety violations for the discrete-time system based on a safe initial policy. The limitation of these methods is that the control barrier functions, control Lyapunov functions and safe backup policies usually need to be manually provided, or some prior knowledge is required. Compared with the above work, the approach proposed in this paper simultaneously learns the policy with a barrier certificate, which provides formal safety guarantees for the learned policy and does not need any prior knowledge.
7. Conclusion
This paper proposes a feedback-driven framework to learn safe policies for dynamical systems, which integrates barrier certificates into actor-critic-based reinforcement learning methods to provide safety guarantees. The learned policy satisfies goal-reaching and safety properties. The framework of the approach is composed of two interactive parts: Learner and Verifier. Learner learns a policy with goal-reaching and safety properties on training datasets, while Verifier validates the two properties on the whole system using large-scale simulations and formal verification. We implement a safe policy learning tool SRLBC based on DDPG and evaluate its performance on three control tasks. Experimental results demonstrate that SRLBC achieves safety with no more than 0.5× time overhead compared to DDPG, showing the feasibility and effectiveness of our framework.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., & Kudlur, M. (2016). Tensorflow: A system for large-scale machine learning. In 12th {USENIX} symposium on operating systems design and implementation ({OSDI}16) (pp. 265–283).
- Akametalu, A. K., Fisac, J. F., Gillula, J. H., Kaynama, S., Zeilinger, M. N., & C. J. Tomlin (2014). Reachability-based safe learning with Gaussian processes. In 53rd IEEE conference on decision and control (pp. 1424–1431).
- Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., & Topcu, U. (2018). Safe reinforcement learning via shielding. In Thirty-second AAAI conference on artificial intelligence.
- Anderson, G., Verma, A., Dillig, I., & Chaudhuri, S. (2020). Neurosymbolic reinforcement learning with formally verified exploration. Advances in Neural Information Processing Systems, 33, 6172–6183. https://dl.acm.org/doi/abs/10.5555/3495724.3496242
- Bastani, O. (2019). Safe reinforcement learning via online shielding. Preprint arXiv:1905.10691, 288, 289.
- Berkenkamp, F., Turchetta, M., Schoellig, A. P., & Krause, A. (2017). Safe model-based reinforcement learning with stability guarantees. Preprint arXiv:1705.08551.
- Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., & Zaremba, W. (2016). Openai gym. Preprint arXiv:1606.01540.
- Cheng, R., Orosz, G., Murray, R. M., & Burdick, J. W. (2019). End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, pp. 3387–3395).
- Clavière, A., Asselin, E., Garion, C., & Pagetti, C. (2020). Safety verification of neural network controlled systems. Preprint arXiv:2011.05174.
- Cohen, M. H., & Belta, C. (2020). Approximate optimal control for safety-critical systems with control barrier functions. In 2020 59th IEEE conference on decision and control (CDC) (pp. 2062–2067).
- De Moura, L., & Bjørner, N. (2008). Z3: An efficient SMT solver. In International conference on tools and algorithms for the construction and analysis of systems (pp. 337–340).
- Deshmukh, J. V., Kapinski, J. P., Yamaguchi, T., & Prokhorov, D. (2019). Learning deep neural network controllers for dynamical systems with safety guarantees. In 2019 IEEE/ACM international conference on computer-aided design (ICCAD) (pp. 1–7).
- Dong, K., Luo, Y., Yu, T., Finn, C., & Ma, T. (2020). On the expressivity of neural networks for deep reinforcement learning. In International conference on machine learning (pp. 2627–2637).
- Dutta, S., Jha, S., Sankaranarayanan, S., & Tiwari, A. (2018a). Learning and verification of feedback control systems using feedforward neural networks. IFAC-PapersOnLine, 51(16), 151–156. https://doi.org/10.1016/j.ifacol.2018.08.026
- Dutta, S., Jha, S., Sankaranarayanan, S., & Tiwari, A. (2018b). Output range analysis for deep feedforward neural networks. In Nasa formal methods symposium (pp. 121–138).
- Fulton, N., & Platzer, A. (2018). Safe reinforcement learning via formal methods: Toward safe control through proof and learning. In Proceedings of the AAAI conference on artificial intelligence (Vol. 32).
- Gao, S., Kong, S., & Clarke, E. M. (2013). dReal: An SMT solver for nonlinear theories over the reals. In International conference on automated deduction (pp. 208–214).
- Garcıa, J., & Fernández, F. (2015). A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1), 1437–1480. https://dl.acm.org/doi/10.5555/2789272.2886795
- Gu, S., Yang, L., Du, Y., Chen, G., Walter, F., Wang, J., Yang, Y., & Knoll, A. (2022). A review of safe reinforcement learning: Methods, theory and applications. Preprint arXiv:2205.10330.
- Gurobi Optimization, I. (2022). Gurobi optimizer reference manual. Retrieved from https://www.gurobi.com
- Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic algorithms and applications. Preprint arXiv:1812.05905.
- Hu, H., Fazlyab, M., Morari, M., & Pappas, G. J. (2020). Reach-sdp: Reachability analysis of closed-loop systems with neural network controllers via semidefinite programming. In 2020 59th IEEE conference on decision and control (CDC) (pp. 5929–5934).
- Huang, C., Fan, J., Li, W., Chen, X., & Zhu, Q. (2019). Reachnn: Reachability analysis of neural-network controlled systems. ACM Transactions on Embedded Computing Systems (TECS), 18(5s), 1–22. https://doi.org/10.1145/3358228
- Ivanov, R., Carpenter, T. J., Weimer, J., Alur, R., Pappas, G. J., & Lee, I. (2020). Verifying the safety of autonomous systems with neural network controllers. ACM Transactions on Embedded Computing Systems (TECS), 20(1), 1–26. https://doi.org/10.1145/3419742
- Jin, W., Wang, Z., Yang, Z., & Mou, S. (2020). Neural certificates for safe control policies. Preprint arXiv:2006.08465.
- Julian, K. D., & Kochenderfer, M. J. (2019). A reachability method for verifying dynamical systems with deep neural network controllers. Preprint arXiv:1903.00520.
- Katz, G., Barrett, C., Dill, D. L., Julian, K., & Kochenderfer, M. J. (2017). Reluplex: An efficient SMT solver for verifying deep neural networks. In International conference on computer aided verification (pp. 97–117).
- Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., & Wierstra, D. (2016). Continuous control with deep reinforcement learning. In ICLR (poster).
- Lin, L., Gong, S., Li, T., & Peeta, S. (2018). Deep learning-based human-driven vehicle trajectory prediction and its application for platoon control of connected and autonomous vehicles. In The autonomous vehicles symposium (Vol. 2018).
- Luo, Y., & Ma, T. (2021). Learning barrier certificates: Towards safe reinforcement learning with zero training-time violations. In Thirty-fifth conference on neural information processing systems.
- Ma, Y. J., Shen, A., Bastani, O., & Dinesh, J. (2022). Conservative and adaptive penalty for model-based safe reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence (Vol. 36, pp. 5404–5412).
- Ohnishi, M., Wang, L., Notomista, G., & Egerstedt, M. (2019). Barrier-certified adaptive reinforcement learning with applications to brushbot navigation. IEEE Transactions on Robotics, 35(5), 1186–1205. https://doi.org/10.1109/TRO.8860
- Peruffo, A., Ahmed, D., & Abate, A. (2021). Automated and formal synthesis of neural barrier certificates for dynamical models. In International conference on tools and algorithms for the construction and analysis of systems (pp. 370–388).
- Prajna, S., & Jadbabaie, A. (2004). Safety verification of hybrid systems using barrier certificates. In Proceedings of the 7th international workshop on hybrid systems: Computation and control (HSCC) (pp. 477–492). Springer.
- Radac, M. B., & Precup, R. E. (2019). Data-driven model-free tracking reinforcement learning control with VRFT-based adaptive actor-critic. Applied Sciences, 9(9), 1807. https://doi.org/10.3390/app9091807
- Ravanbakhsh, H., & Sankaranarayanan, S. (2019). Learning control Lyapunov functions from counterexamples and demonstrations. Autonomous Robots, 43(2), 275–307. https://doi.org/10.1007/s10514-018-9791-9
- Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., & Riedmiller, M. (2014). Deterministic policy gradient algorithms. In International conference on machine learning (pp. 387–395).
- Singh, G., Gehr, T., Püschel, M., & Vechev, M. (2019). An abstract domain for certifying neural networks. Proceedings of the ACM on Programming Languages, 3(POPL), 1–30. https://doi.org/10.1145/3290354
- Srinivasan, K., Eysenbach, B., Ha, S., Tan, J., & Finn, C. (2020). Learning to be safe: Deep rl with a safety critic. Preprint arXiv:2010.14603.
- Stooke, A., Achiam, J., & Abbeel, P. (2020). Responsive safety in reinforcement learning by PID Lagrangian methods. In International conference on machine learning (pp. 9133–9143).
- Sun, X., Khedr, H., & Shoukry, Y. (2019). Formal verification of neural network controlled autonomous systems. In Proceedings of the 22nd ACM international conference on hybrid systems: Computation and control (pp. 147–156).
- Sutton, R. S., Szepesvári, C., & Maei, H. R. (2008). A convergent O(n) temporal-difference algorithm for off-policy learning with linear function approximation. In Nips.
- Tamar, A., Chow, Y., Ghavamzadeh, M., & Mannor, S. (2016). Sequential decision making with coherent risk. IEEE Transactions on Automatic Control, 62(7), 3323–3338. https://doi.org/10.1109/TAC.2016.2644871
- Taylor, A., Singletary, A., Yue, Y., & Ames, A. (2020). Learning for safety-critical control with control barrier functions. In Learning for dynamics and control (pp. 708–717).
- Thananjeyan, B., Balakrishna, A., Nair, S., Luo, M., Srinivasan, K., Hwang, M., Gonzalez, J. E., Ibarz, J., Finn, C., & Goldberg, K. (2021). Recovery rl: Safe reinforcement learning with learned recovery zones. IEEE Robotics and Automation Letters, 6(3), 4915–4922. https://doi.org/10.1109/LRA.2021.3070252
- Thomas, P. S. (Doctoral Dissertations, 2015). Safe reinforcement learning. https://doi.org/10.7275/7529913.0
- Wang, S., Pei, K., Whitehouse, J., Yang, J., & Jana, S. (2018). Formal security analysis of neural networks using symbolic intervals. In 27th {USENIX} security symposium ({USENIX} security 18) (pp. 1599–1614).
- Wang, T., Qin, R., Chen, Y., Snoussi, H., & Choi, C. (2019). A reinforcement learning approach for UAV target searching and tracking. Multimedia Tools and Applications, 78(4), 4347–4364. https://doi.org/10.1007/s11042-018-5739-5
- Wei, T., Wang, Y., & Zhu, Q. (2017). Deep reinforcement learning for building HVAC control. In Proceedings of the 54th annual design automation conference 2017 (pp. 1–6).
- Winterer, F. (2017). iSAT3. Retrieved from https://projects.informatik.uni-freiburg.de/projects/isat3
- Wong, E., & Kolter, Z. (2018). Provable defenses against adversarial examples via the convex outer adversarial polytope. In International conference on machine learning (pp. 5286–5295).
- Xiang, W., Tran, H. D., Yang, X., & Johnson, T. T. (2020). Reachable set estimation for neural network control systems: A simulation-guided approach. IEEE Transactions on Neural Networks and Learning Systems, 32(5), 1821–1830. https://doi.org/10.1109/TNNLS.2020.2991090
- Xu, J., Hou, Z., Wang, W., Xu, B., Zhang, K., & Chen, K. (2018). Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks. IEEE Transactions on Industrial Informatics, 15(3), 1658–1667. https://doi.org/10.1109/TII.2018.2868859
- Yang, T. Y., Rosca, J., Narasimhan, K., & Ramadge, P. J. (2020). Accelerating safe reinforcement learning with constraint-mismatched policies. Preprint arXiv:2006.11645.
- Yang, Y., Ding, D. W., Xiong, H., Yin, Y., & Wunsch, D. C. (2020). Online barrier-actor-critic learning for H∞ control with full-state constraints and input saturation. Journal of the Franklin Institute, 357(6), 3316–3344. https://doi.org/10.1016/j.jfranklin.2019.12.017
- Yang, Y., Gao, W., Modares, H., & Xu, C. Z. (2021). Robust actor-critic learning for continuous-time nonlinear systems with unmodeled dynamics. IEEE Transactions on Fuzzy Systems, 30(6), 2101–2112. https://doi.org/10.1109/TFUZZ.2021.3075501
- Yang, Y., Vamvoudakis, K. G., Modares, H., Yin, Y., & Wunsch, D. C. (2020). Safe intermittent reinforcement learning with static and dynamic event generators. IEEE Transactions on Neural Networks and Learning Systems, 31(12), 5441–5455. https://doi.org/10.1109/TNNLS.5962385
- Zhao, H., Zeng, X., Chen, T., & Liu, Z. (2020). Synthesizing barrier certificates using neural networks. In Proceedings of the 23rd international conference on hybrid systems: Computation and control (pp. 1–11).
- Zhao, Q., Chen, X., Zhao, Z., Zhang, Y., Tang, E., & Li, X. (2022). Verifying neural network controlled systems using neural networks. In 25th ACM international conference on hybrid systems: Computation and control (pp. 1–11).