
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In recent years, one of the prominent research areas in the complex network field has been the Influence Maximization Problem. This problem focuses on selecting seed sets to achieve optimal information propagation across networks. Practical networks often encounter challenges like node or link failures due to internal issues or external disturbances. Addressing this, researchers emphasize seed robustness against potential interferences, framing it as the robust influence maximisation problem. However, current approaches to this problem are incomplete, leaving several challenges unaddressed. On one hand, existing methods primarily handle seed selection under isolated disruptions, neglecting the simultaneous threats posed by both node-based and link-based attacks. On the other hand, prevailing algorithms fail to capture information synergy from multiple scenarios during the solution process. To bridge these gaps, this study integrates the multi-tasking optimisation theory into robust influence maximisation, introducing an evolutionary algorithm called DMFEA. DMFEA concurrently addresses multiple optimization scenarios, leveraging synergy between tasks while emphasizing information diversity. Experimental results demonstrate DMFEA's competitive edge over existing methods. This research significantly advances collaborative optimization for robust influence maximisation under multi-scenario disruptions, offering a reliable solution for robust information diffusion in complex environments.
1. Introduction
Complex systems of all shapes and sizes widely exist in nature and human society. It tends to be difficult to analyze the dynamics of networked systems due to their complicated features and diverse uncertainties. The complex network theory has been taken as one of the most effective approaches for analyzing and understanding systems (Kurant & Thiran, Citation2006). A typical network consists of nodes and links that are connected to them, where each node represents a certain actual individual and each link represents the relationship between them. For example, a social network can be considered a network formed by contact connections between different users, and a neuro system can be considered a network formed by connections between different neurons through nerve fibres. Similarly, in reality, various networked systems such as power networks, the Internet, and transportation networks are common. Driven by many scholars, increasing attention has been paid to employing complex network theory to solve the analytic dilemmas of complicated systems. In recent years, research on complex networks has focused on problems including community detection (Bai et al., Citation2021), influence maximisation (Bond et al., Citation2012; Wang & Tan, Citation2022a, Citation2022b), robustness (Schneider et al., Citation2011), and graph neural networks (Zhu et al., Citation2021).
In the field of complex networks, the influence maximisation problem is one research hotspot(Li et al., Citation2023; Samir et al., Citation2021; Zhu et al., Citation2019). This problem is to find a small number of influential nodes from the network that have remarkable propagation performance. These influential nodes can disseminate more information than other nodes, and their influence can quickly activate a majority of nodes in the network. The application of the influence maximisation problem can be found in many fields. For example, with the popularity and rise of the Internet in the past decade, social network platforms have become a necessity of human society, and their efficient information dissemination and plentiful users have made online marketing an efficient way for businesses to advertise. However, due to financial constraints, it is impossible for manufacturers to target every user to market their products. There are often influential “seed” users in social networks, and manufacturers can manage to dig out these users as marketing targets to maximise their marketing effects under considerable budgets. The study of the maximisation problem is significant in reality and may present important guidance for solving social puzzles. Also, in the traffic network, some traffic hub intersections may become traffic jams caused by unexpected events, and the transit on streets adjacent to these intersections is also likely to be blocked; in this manner, the transportation path inside a city gets interrupted and can lead to large-scale traffic paralysis. The influence of traffic intersections is demonstrated in (Ren et al., Citation2013), and policymakers can design reliable transportation hubs to achieve safe and efficient urban traffic operations.
The information dissemination rule between nodes is the key to the influence maximisation problem, which is defined by the propagation model. Several possible propagation models have been proposed including the independent cascade model (IC model) (Kempe et al., Citation2003), the weight cascade model (WC model) (Chen et al., Citation2009), and the linear threshold model (LT model) (Rahimkhani et al., Citation2015). Among them, the IC model simulates the information diffusion process between seeds and their neighbours and becomes one of the most widely used models. Kempe et al. (Kempe et al., Citation2003) pointed out that the influence maximisation problem is essentially an NP-hard optimisation problem and proposed a greedy algorithm to solve the problem. Recent years witnessed an enormous interest in the influence maximisation problem, and many effective solutions have emerged. Several optimisation solvers are designed, like population-based search methods (Huang et al., Citation2022), heuristic-based optimisation methods (Gong et al., Citation2016), and community-based methods (Gong et al., Citation2016). In addition, methods based on network structural properties (Qiu et al., Citation2019; Xianli et al., Citation2020; Yang & Liu, Citation2017) also achieve good results. These methods provide powerful reference solutions for the problem and contribute to excavating in-depth information on networks.
In the field of complex networks, robustness usually refers to its ability to tolerate internal failures and external disturbances. It has been demonstrated (Wang & Liu, Citation2017) that the interactive behaviours in networks can also be affected by changes in the topology. Therefore, the selection of seeds with high influence propagation performance when the network structure is impaired is critical in the current research related to the influence maximisation problem and the robustness optimisation, i.e. the robust influence maximisation problem (RIM). The robustness of seeds and corresponding optimisation methods are necessary for achieving a stable influence diffusion process. Currently, several pilot studies are focusing on the robustness of seeds under structural perturbances. An evaluation factor to assess the robustness when the network is under attack has been proposed in (Schneider et al., Citation2011); in (Huang et al., Citation2022), a numerical measure is proposed to evaluate the performance of seeds under link removals. These studies explore the field of network robustness and promote the application of the complex network theory to information propagation tasks.
Progresses have been made in the modelling of diffusive behaviours and evaluating network robustness performance. However, several deficiencies remain to be addressed, preventing further application towards practical systems Firstly, in practice, networks are often damaged by internal components or subject to external attacks, either by removing nodes or links that can cause serious damage to structural connections and the quality. Most previous studies are limited to considering a single case of link or node attacks, and optimisation methods for solving the robust influence maximisation problem are usually designed in a single-objective way considering a single damage type. Although such an approach is effective, drawbacks are also distinct from two perspectives, it may be of low convergence and easy to fall into local optimal; meanwhile, the seeds obtained from a single optimisation are only applicable towards a certain case of a determinate type of attack. Secondly, the evolutionary algorithm (EA) is effective in solving the influence maximisation problem, but traditional EA only performs genetic processes including initialisation, crossover, mutation, and selection operations, and little attention has been paid to the gene information maintained in the whole population. Poor population diversity may hinder searchability, and the diversity of the population still requires deliberations to improve search efficiency. To obtain the optimal solution, the algorithm is expected to construct the population with a wide distribution in the solution space. Last but least, in the RIM problem, expected outputs towards multiple attack categories are specific sets of seeds selected from the network. Nodes with considerable influential ability tend to show similarity in terms of structural properties, as indicated in previous studies (Qiu et al., Citation2019; Xianli et al., Citation2020; Yang & Liu, Citation2017). In this manner, the potential synergy may exist in the optimisation procedure towards multiple targets, which has not been thoroughly studied yet. Briefly, until now, how to solve the problem of maximising the robust influence ability of seeds under multiple attacks and providing effective seeds to achieve reliable and robust propagation is still pending resolution.
To address the above deficiencies of current research, this paper systematically investigates the robust influence maximisation problem from the perspective of structural perturbances. First, based on several related studies, multiple damage scenarios are handled simultaneously. To utilise valuable cross-task information in the optimisation process, a knowledge transfer operator has been developed to exchange optimal information found by multiple individuals. Secondly, a multi-factorial evolutionary algorithm considering diversity concerns, DMFEA, is proposed to determine seeds with robust influential ability. The algorithm employs the multi-tasking optimisation theory and intends to explore the solution space of each task parallelly. Applying the implicit parallelism across multiple tasks, polygenetic information is exploited to guarantee population diversity. Experimental results on both synthetic and real-world networks validate that DMFEA outperforms existing approaches focusing on the RIM problem.
Contributions of this paper are summarised as follows.
For the network performance evaluation task, we have employed two distinct robust influence evaluation metrics, taking into account both node-based and link-based attacks, thereby providing a more comprehensive assessment of seeds’ performance. Unlike previous studies that primarily focused on single-objective optimisation, our work explores the implicit relationship between these metrics. Experimental results indicate there exists a correlated optimisation pattern between the two metrics, laying the foundation for co-optimisation and revealing the underlying information within the network structure.
For the solver of network-related problems, we have developed a multi-tasking optimisation algorithm aimed at addressing the robust influence maximisation problem. This algorithm leverages the inherent correlation between the aforementioned two evaluation metrics to efficiently utilise genetic information. The structural information has been exploited in the search process, which provides possible solvers to address the network-related problem with discrete decision variables.
For the multi-tasking optimisation theory, the diversity information has been incorporated into the multi-tasking search process, encompassing individual diversity, gene diversity, probability diversity, learning space diversity, and inheritance diversity. This comprehensive approach balances exploration and exploitation in the solution space, ensuring effective search capability towards the optimisation of multiple objectives. Compared with existing single-objective and multitasking optimisation algorithms, the proposed DMFEA shows superiority in detecting robust and influential seeds for diffusion tasks under multiple structural perturbances.
The paper is structured as follows, Section 2 briefly describes the related work on the influence maximisation problem. Section 3 presents the robustness measure and operators to finish multi-tasking explorations. Section 4 gives details of the DMFEA algorithm. Section 5 shows the corresponding experimental results. Finally, Section 6 summarises the whole paper.
2. Background
In general, a networked system can be modelled as graph G: where is the set of different individuals in this system and
is the set of interrelationships between different individuals, and the description of networks in this paper follows the above definition.
The content of this section consists of four parts, the first part introduces the related work on the influence maximisation problem. The second part introduces the commonly used propagation models and influences performance evaluation methods in the influence maximisation problem. The third part presents related work on the robustness of complex networks and the robust influence maximisation problem. The last part briefly introduces evolutionary computation and multi-task evolutionary algorithms.
2.1. Influence maximisation issues and related work
As mentioned in Section 1, the influence maximisation problem is closely related to daily life. The influence maximisation problem is how to select a given number of nodes from the network as a seed set such that these seeds can reach the maximal influence propagation range in the network following a specific diffusion propagation model. Plenty of methods have been proposed to find nodes with the maximal influence propagation performance in the network. Leskovec et al. (Leskovec et al., Citation2007) proposed CELF, where they formed a delay procedure in selecting new seeds, which uses the submodularity of the diffusion function to reduce the number of function evaluations. Goyal et al. (Goyal et al., Citation2011) proposed CELF++ based on CELF, which further addresses the efficiency problem. A method based on simulated annealing was proposed in (Buesser et al., Citation2011), which simulates the solid annealing principle in physics and combines the probabilistic burst jump property with the randomly selected solution under the objective function. Wang et al. (Wang et al., Citation2010) proposed a community-based greedy algorithm called CGA. This method reduces the search space of affected nodes from the whole graph narrowed down to communities, uses dynamic programming methods to select the communities with the largest influential growth, and implements the MixGreedy algorithm (Chen et al., Citation2009) to select the influential seeds. In addition, Wang et al. (Huang et al., Citation2022) considered the situation when the network structure is damaged and proposed an improved genetic algorithm with a local search operator to solve the influence maximisation problem. All these methods provide effective references for subsequent research in this field.
2.2. Diffusion propagation model and influence performance assessment method
There are two concepts to be focused on in the influence maximisation problem. The first one is the information diffusion model. In the process of spreading information from seeds outwards, the diffusion model defines the rules of dissemination processes. Several propagation models have been proposed in previous work considering different scenarios. Three models have attracted attention including the independent cascade model (IC model) (Kempe et al., Citation2003), the weight cascade model (WC model) (Chen et al., Citation2009), and the linear threshold model (LT model) (Rahimkhani et al., Citation2015). A brief description is given as follows. First, nodes in the network are defined as two states, i.e. active and inactive. If a node is active, then this node has received the information and can spread it through the connected links; otherwise, if a node is inactive, it has not received information and can accept the propagation from active ones at a certain probability. It is important to note that the activation state of a node can only transform from inactive to active, but not vice versa.
The propagation process defined by the IC model is as follows. In the initial state (), a given number of nodes are selected as the seed set and preserved in the set of activated nodes, i.e.
. When time
, each node n in the set of activated nodes
attempts to activate the neighbouring inactive neighbour nodes m at a probability of
, and if the activation operation is successful, these activated nodes are preserved into a temporary set
and the set of activated nodes is updated as
. Note that when multiple active nodes are trying to activate the same inactive node, these activation processes do not interfere with each other. The influence propagation process ends when all activated nodes have completed the diffusion propagation operation, but are still empty at time
. The maximal propagation range
of the seed set S is determined by the size of the final set of activated nodes
. The difference between the WC model and the IC model is that in the IC model, the propagation probability of activated nodes is generally set as a constant (usually 0.1 or 0.01, depending on the characteristics of the network); while in the WC model, the propagation probability is mainly determined by the degree difference between nodes. In the LT model, each node has a predefined influence threshold, and the node becomes activated only when its received influence from neighbouring nodes reaches the predefined threshold. The propagation end rules of the above two models are the same as that of the IC model, i.e. when
is empty
. In previous studies, the IC model has received intensive attention (Gong et al., Citation2016; Lee & Chung, Citation2014; Leskovec et al., Citation2007; Wang et al., Citation2019) for its practical value, this work thus employs the IC model to study the influence maximisation problem (Figure ).
Figure 1. Illustration of IC model diffusion, with initial activated nodes S0 = a, b. The blue colour is the seed node in the activated state. In each round, a node in the activation state activates a neighbouring node with probability p (each edge has a propagation probability p).
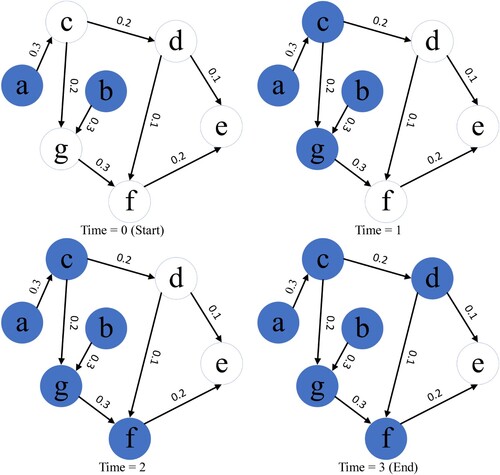
The second one is the influence assessment method. Taking the IC model as an example, calculating the exact influence propagation range of S () is an NP-hard problem, and the Monte Carlo simulation (Chen et al., Citation2009; Kempe et al., Citation2003) is a possible manner. However, as the size of the network increases, the runtime of the Monte Carlo process becomes non-negligible and the computational budget may be prohibitive. The reverse influence sampling (RIS) evaluation method proposed in (Borgs et al., Citation2014; Tang et al., Citation2014; Tang et al., Citation2015) requires less budget by avoiding redundant traversal computations but is still threatened by the high cost when generating the reverse reachable set of massive nodes. (Lee & Chung, Citation2014) proposed a fast approximation of the influence, which limits the influence propagation to 2-hop instead of all nodes in the network, and considers the potential overlapping influence between seeds. The specific definition is shown below.
(1)
(1) where
represents all neighbours within the 1-hop range of node s,
is the propagation probability from node s to c,
the scale of the 1-hop neighbours of node c, and χ represents the 2-hop overlapping influence of the newly activated node concerning the original seeds, as defined in the literature (Lee & Chung, Citation2014), defined as
. The first term of this equation represents the sum of the 2-hop influences of all nodes within the set of nodes S, and the second and third terms are the compensation for the overlapping influences between these nodes. The results show that this fast method is not only able to reliably estimate the seed influence range, but also considerably improves the previous time-consuming drawbacks of Monte Carlo, at a much lower computational cost. This method can thus be used to guide the search process on networks (Gong et al., Citation2016; Wang et al., Citation2019).
2.3. Robustness of networks and influence diffusion processes
Network robustness is an important issue in the field of complex networks. Real-world network systems are often exposed to complicated application environments, and the functionality may be disturbed by internal failures or external attacks. As mentioned above, structural failures affect the information dissemination process of seeds. The robustness is significant to the stability of networks’ function; therefore, it is necessary to quantify the tolerance (i.e. robustness) of a networked system towards perturbations. (Schneider et al., Citation2011) proposed a numerical measure R to evaluate network robustness, which considers the structural changes during the damage process, defined as follows,
(2)
(2)
is the maximum connected cluster of the network after removing Q nodes, N is the total number of nodes in the network, and 1/N is a normalisation factor to ensure that different networks can be compared fairly. The evaluation of network robustness can be summarised as follows: each node is ranked by degree value first, and the maximum degree node in the current network is selected to be removed with all the connected links; then the maximum connected cluster at this point is calculated. These steps are repeated until the network collapses. A normalising of the summation is operated to obtain the evaluation result. The larger the R value of a network, the better it can maintain robustness against attacks.
Based on the above study, (Zeng & Liu, Citation2012) designed an extended version Rl, which differs from R in that it focuses on the damages caused by link removals, and its corresponding removal process is changed to the link with the largest degree at each attack attempt (here the degree of the link is defined as ). It is defined as follows.
(3)
(3)
is the maximum cluster of connections in the network after removing P links, M is the total number of links in the network, and 1/M is a normalisation factor to ensure that different networks can be compared fairly.
Experiments in the related literature demonstrate (Schneider et al., Citation2011; Wang & Liu, Citation2019) that the above two evaluation factors can achieve good results when evaluating networks’ robustness. These metrics mainly focus on the change of network connectivity after suffering attacks and cannot be directly applied to the influence maximisation problem, but they can still provide valuable references to the design of robust influence evaluation metrics on seeds.
Networked systems are often exposed to complicated environments, and prone to be disturbed by structural damage. For example, social networks are fragile to external attacks that disconnect the structure and interfere functionality of the system such as sabotage from hackers. In general, hackers attack social networks in two ways, i.e. by stealing a user’s social account and disconnecting the user from all other ones; or by cutting certain links with important functions. Many networks show the scale-free property (Barabási & Albert, Citation1999) (i.e. only a small number of nodes possess significant structural importance), including social networks. Hackers usually attack those nodes or links with importance, and both of these attacks are bound to hurt social networks. In this context, the robust influence maximisation problem intends to investigate how to select seeds that are robust and influential under the condition that the network is threatened by structural failures, which is the key problem studied in this work. The evaluation of the robust propagation performance of seeds is the key to the robust influence maximisation problem, which will be discussed in Section 3.
2.4. Evolutionary computing and multitasking optimisation
Evolutionary computation is an effective method for solving network-related optimisation puzzles like the influence maximisation problem. This technique is inspired by Darwin's idea of “survival of the fittest” and draws on the evolutionary operations of living organisms in nature. Generally, evolutionary algorithms start with a population of individuals, each of which is a feasible candidate in the solution space. The population undergoes computational simulations including coding, sexual reproduction, and genetic mutation to produce the next generation of populations. The process continues iteratively, with superior individuals surviving and inferior ones being eliminated. The next generation population consists of those individuals with better fitness values. Currently, algorithms related to evolutionary computation have been widely applied to various optimisation problems in diversified fields like parameter optimisation, resource allocation, and complex network analysis.
In literature (Gupta et al., Citation2015), multifactorial optimisation (MFO) and the multifactorial evolutionary algorithm (MFEA) have been devised. Multifactorial optimisation is the study of solving multiple optimisation problems (tasks) simultaneously and improving the performance of tasks independently. Another optimisation approach is the multi-objective optimisation (Srinivas & Deb, Citation1994). The difference lies in that these objective functions do not conflict with each other in multi-tasking optimisation, and the improvement of one sub-objective brings reference information to the other sub-objectives. Each sub-objective can thus be jointly optimised. The aim of the multifactorial evolutionary algorithm (MFEA) is to solve multiple optimisation tasks with a single population, exploiting the implicit parallelism via knowledge transfer across tasks. The implicit connections between different tasks are explored to speed up the convergence of optimisation processes.
In the growing field of multifactorial optimisation, a variety of methods have emerged that have proven to have potential for real-world applications (Gupta et al., Citation2022; Shen & Zhang, Citation2022; Wei et al., Citation2021; Wu et al., Citation2023). For example, in the bipolar controller design problem, the problem can be solved efficiently by leveraging solution knowledge (Da et al., Citation2019; Liaw & Ting, Citation2019). In the area of fuzzy control systems, the application of the MFO framework to simultaneously optimise a T1 system and an IT2 fuzzy system has yielded significant results (Karafotias et al., Citation2014). In addition, in the area of fuzzy cognitive mapping learning, the MFO framework successfully solves the empirical risk minimisation problem and the sparse constraint problem (Shen et al., Citation2020), which provides strong support for research and application in this area.
In addition, multifactorial optimisation has achieved a wide range of applications in the field of complex networks. (Wang et al., Citation2023) introduced a multi-factor evolutionary algorithm aimed at enhancing network robustness against multiple damages. (Wu et al., Citation2021) expanded multi-factor optimisation to the realm of multilayer networks and proposed corresponding solution approaches. Additionally, (Wang et al., Citation2021) presented a knowledge transfer multi-factor optimisation algorithm that utilises anomaly detection. Experimental results have demonstrated the effectiveness of these methods in their respective domains, providing valuable insights for further research in these fields.
However, the existing optimisation methods have not been able to effectively address the robust influence maximisation problem. This paper aims to fill this gap by applying the theory of multi-factor optimisation to tackle the robust influence maximisation problem.
3. Multi-task optimisation for robust influence maximisation problem
The design of a problem-oriented multitasking algorithm to find influential seeds from the network requires clarifying two issues. The first one is what the optimisation tasks are, and the second one is how to model the optimisation problem. To address these issues, this work presents discusses, and gives possible solutions based on related research.
3.1. A robust influence performance evaluation method for seed sets under link attacks
In the robust influence maximisation problem, a reliable evaluation factor is necessary to provide an effective measure of the robust propagation performance of the selected seed set. This evaluation factor needs to be frequently invoked by the algorithm to guide the optimisation process. Therefore, a low-cost and efficient evaluation method is expected. As mentioned above, the direct simulation of the diffusion process by the Monte Carlo process shows remarkable accuracy, but its huge computational cost makes it prohibitive to be applied in large-scale optimisation problems. For the seed selection problem under structural failures, an effective numerical measure to record the performance change of seeds during damage processes is required. Wang et al. (Huang et al., Citation2022) designed a robustness influence evaluation metric based on
(Equation 1) and
(Equation 3). This metric develops
, which employs the approximation of the performance evaluating criterion, and can be used to approximate the robust influential ability of seeds under link attacks. Here, similar to the degree of the node, the degree of the link (defined in the same way as 2.3) can also reflect its importance, which is adopted to assess the importance of the link. The evaluation process is as follows: the attacker selects the link with the maximum degree to conduct the removal operation, and the influential ability of the seed set in the current network is evaluated; a normalisation process is conducted to get the final output. The specific definition is as follows.
(4)
(4) M is the total number of links in the current network, Per is the number of links successfully attacked by the intruder and
is the approximated 2-hop influence propagation value of the seed set S on the network after removing P links. In this paper, we assume that the intruder attacks all links, i.e. Per = 1.
3.2. A robust influence performance evaluation method for seed sets under node attack
Depending on the attack preferences of the intruder, the network may be subject to node attacks. In this case, it may not be accurate to directly use (Equation 4) to evaluate the robust influential ability of seeds, and a metric that can effectively evaluate the performance of nodes under node attacks is needed. Similar to
(Equation 4), we can develop a metric to evaluate the robustness and influence of seeds under node attacks based on
(Equation 1) and R (Equation 2). The specific definition is as follows.
(5)
(5) N denotes the number of nodes in the current network and
is the 2-hop influence propagation value of the seed set S on the network after removing the Q nodes. Similar
, the evaluation process follows that the attacker selects the node with the largest degree for each attack, and the influential ability of the seed set on the current network is evaluated, and the evaluation results are obtained after normalisation.
Aiming at link attack and node attack, the two evaluation factors consider the robustness of the seeds under different types of attacks, respectively, and provide feasible solutions to evaluate the seeds’ robust influence propagation performance.
3.3. Modelling for multitasking optimisation
The above two evaluation metrics guide selecting influential nodes under network impairments. For solving the influence maximisation problem under a single-attack approach (single-objective problem), many effective methods have been proposed in previous studies. Although the performance of their models and methods on single-objective problems have been emphasised, they may not be comprehensive in the context of multiple attacks. Optimisation problems for real network systems are often in complicated applicable environments and faced with potential threats of multiple attacks. The intruder is often difficult to determine a specific attack method, and an experienced hacker would selectively attack links or nodes based on the characteristics of the network structure. If seeding is done only for a single attack method for links or nodes, these seeds may not perform well under another kind of attack. For robust influence maximisation problems under a single attack method, previous population-based approaches guided by or
have been able to achieve considerable results. However, these approaches have not touched upon the multitasking optimisation theory, i.e. solving multiple optimisation problems simultaneously using a single population of evolved individuals.
To address the shortcomings and deficiencies of the current study, we introduce the concept of multitasking optimisation into the influence maximisation problem and intend to employ the possible implicit association between and
to provide additional guidance for the search procedures. To verify the possible relationship between
and
, a plain genetic algorithm is implemented to select seeds under the guidance of
(i.e. using
as the fitness function of the genetic algorithm) and analyze the trend of
and
. The parameters of the genetic algorithm are set as follows: the number of genetic iterations is set as 60, the population size is set as 30, the probability of both crossover and mutation is set as 0.05, the information diffusion process is simulated using the IC model, and the activation probability is set as 0.01.
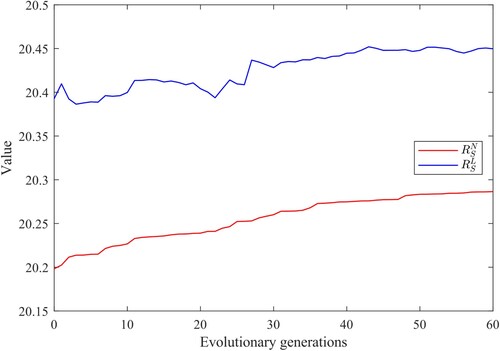
Experiments are conducted on a scale-free network with power-law degree distribution (Barabási & Albert, Citation1999) (SF network) and a small-world network (Strogatz, Citation2001) (WS network), both with a node size of 200 and an average degree of 4. The results are shown in Figures and .
Figure 2. Performance trends on the SF network.
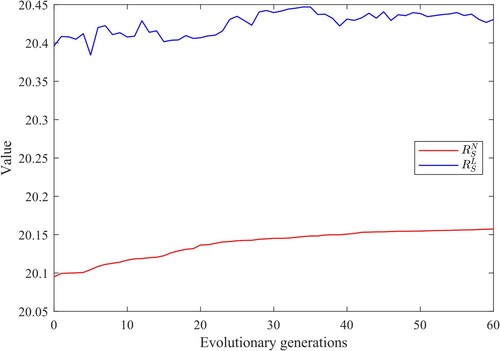
Figure 3. Performance trends on the WS network.
As shown in Figures and , and
show similar upward trends in the optimisation process. In statistics, the Pearson correlation coefficients can reflect the correlative relation between variables. The Pearson correlation coefficients of the data in Figures and reach 0.7791 and 0.9528, respectively, which can be considered a strong correlation.
Even from the definition, it is clear that they are not independent. is based on link attack, where the link with the largest degree is removed at each attack attempt;
is based on node attack, where the node with the largest degree is removed at each attach attempt. Both
and
evaluate the seeds under network impairments, employing the same influence propagation estimator
, and both results are the superposition of the influence propagation range of the seed set S in the network destruction process.
From the above analysis, it can be concluded that and
are closely correlated with each other. According to the definition of multitasking optimisation, assuming that useful knowledge exists when solving a certain task, such knowledge may help to solve other related tasks. We can use the relevance between
and
to generate valuable knowledge to guide the subsequent search procedures, and improve the optimisation efficiency on both the two targets.
4. Dmfea
To address the shortcomings of previous studies, this paper introduces the multitasking optimisation theory into the robust influence maximisation problem. In this section, details of the DMFEA algorithm are presented. The algorithm incorporates and
simultaneously has optimisation tasks, considering diverse genetic information, and aims to solve the robust influence maximisation problem. First, the preparation and overall framework of the algorithm are introduced, and then procedures of the initialisation operator, crossover operator, mutation operator, task-oriented learning operator, gene-oriented learning operator, and selection operator are given.
4.1. Preparation
The encoding format of individuals in DMFEA is demonstrated as follows: S = 26, 44, 59, 63, 76. In this representation, 26, 44, and other values correspond to nodes within the network. The relevant operations of DMFEA will be conducted within a population composed of multiple individuals.
To design a multitasking solver for the robust influence maximisation problem, this paper defines a set of attributes for each individual to evaluate the performance in the multitasking environment based on (Gupta et al., Citation2015). Here, the specific optimisation tasks are referred to and
, respectively. The subsequent definitions follow this description. The details are as follows.
Definition 1 (Factor cost): The current individual is evaluated using
and
, and its corresponding value is the factor cost of the individual on tasks
and
, which are denoted as
and
.
Definition 2 (Factor rank): The factor levels of the individual on tasks
and
are defined as the individual's rank in the population, which is determined according to the order of the individual's factor cost in an increasing order.
Definition 3 (Fitness scalar): The fitness scalar of an individual
is defined as the sum of the reciprocals of the factor ranks of that individual on each task, i.e.
.
Definition 4 (Skill factor): The skill factor of an individual
is the index of the task on which the individual performs best on all tasks, i.e.
, where
. When the ranking of this individual is the same on all tasks, the value is assigned to the index of a random task in which it excels.
4.2. Algorithm framework
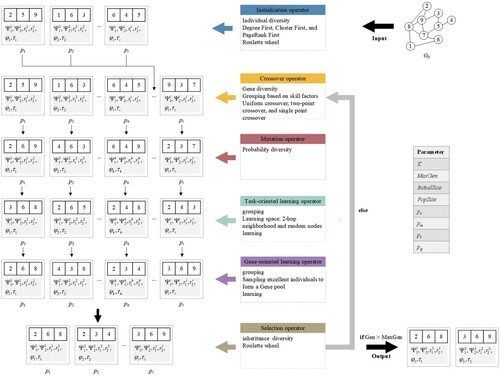
The execution steps of DMFEA are summarised below. (1) The initialisation operator is executed that combinates three strategies of Degree-first, PageRank-first, and Clustering-first (Degree (Qiu et al., Citation2019), PageRank (Xianli et al., Citation2020), and Clustering (Watts & Strogatz, Citation1998) are all assessment metrics for measuring the importance of nodes. The specific operations of Degree-first, PageRank-first, and Clustering-first are as follows: nodes in the network are selected as genes for individuals based on the magnitudes of their Degree, PageRank, and Clustering values using a roulette wheel method) to generate several individuals with InitialSize to form the initial population; (2) The crossover operator is executed to exchange genetic materials to facilitate cultural exchanges between multiple tasks. This operator incorporates the idea of diversity and generates a series of new individuals based on the probability of crossover until the population size reaches PopSize; (3) The mutation operator is executed on each individual in the population at a certain probability. The execution probability of the mutation operator is based on the fitness scalar of the individual, and the higher the fitness scalar, the higher the execution probability, which helps the algorithm to jump out of the local optimum, expect for the current best individual; (4) The task-oriented learning operator is executed. This operator learns the tasks that individuals are directed at according to their skill factors, which can significantly improve the performance of the population; (5) The gene-oriented learning operator is performed. This operator selects a certain number of superior individuals in the population according to their factor cost and fitness scalar, and a gene pool is generated. Other individuals learn information from this pool to improve their performance; (6) Finally, the selection operator is executed, which implements an elitism strategy to update the population obtained in each iteration depending on the performance of individuals in the population. The above steps are repeated until a predefined termination condition is satisfied. The optimal solutions for tasks that emerge during the whole evolution process are the ultimate outputs. the procedure of DMFEA is summarised in Algorithm 1 and Figure .
4.3. Initialisation operator
In evolutionary computation, the role of the initialisation operator is to generate a set of possible candidates uniformly distributed in the solution space. As mentioned in Section 1, the algorithmic performance is closely correlated with the population diversity. In previous studies, most EA-based methods have been designed considering only a single initialisation approach with insufficient population diversity. To find the best set of seeds, DMFEA follows the principle of “individual diversity” to improve the efficiency of the initialisation operator. Specifically, three strategies are considered including Degree-first, Clustering-first, and PageRank-first to initialise the first 1/3, middle 1/3, and remaining 1/3 individuals of the population. The roulette is utilised to select a given number of nodes as genes of individuals. This strategy ensures the diverse distribution of seeds in the solution space, and guarantees the performance of these initial individuals.
Figure 4. An intuitive framework of DMFEA. A network containing nine nodes is taken as input and two tasks ( and
) are processed. The algorithm consists of six parts: including initialisation, crossover, mutation, task-oriented learning, gene-oriented learning, and selection. Guided by the two performance metrics and the best information of
and
, strong seeds are expected to be the output results.
4.4. Crossover operator
Similar to the reproduction phenomenon in nature, the crossover operator can enrich the diversity of the population and generate more individuals to expand the population size. In previous studies, evolutionary algorithms are usually implemented to deal with single-objective problems, where the designed crossover operators are only considered to deal with single-objective cases and are not suitable for multi-task problems. To fully explore the implicit association between different tasks, the crossover operator is redesigned. This operator follows the principle of “gene diversity”, in which a specific process of the crossover operator is presented in Algorithm 2. It is important to note that if duplicate gene nodes may appear within an individual during the crossover process, then a correction operation is performed. The correction operation is as follows: a node in the initial network is randomly selected to replace the duplicate node in the individual until there is no duplicate node.
4.5. Mutation operator
In evolutionary computation, premature maturation (i.e. falling into a local optimum solution) causes barriers to the optimisation process. The mutation operator can randomly change the genes in an individual to form a new individual. Detailed operation follows the principle of “ probability diversity” and dynamically adjusts the probability of mutation according to the individual fitness scalar. For each individual in the population, the mutation operator is executed at the probability of (
is the current individual fitness scalar,
is the sum of all individual fitness scalars), replacing one node in the individual with another node in the network stochastically. Similarly, if the same node appears redundantly within an individual, the correction operation mentioned above is executed.
4.6. Task-oriented learning operator
Table
The task-oriented learning operator in DMFEA greatly improves the optimisation efficiency of the algorithm. Targeted learning and optimisation are considered for different tasks, and parallel searches for individuals with high robustness and high propagation performance under different attacks are achieved. Meanwhile, the algorithm follows the principle of “learning space diversity”, which dramatically promotes the abundance of the population. Additionally, only new individuals that are helpful for influence propagation are retained. Although such a search is time-consuming, it can directly promote the performance of the current individual and the entire population, and accelerate the convergence of the algorithm.
4.7. Gene-oriented learning operator
Table
First, the operator will divide the population into two groups according to individuals’ skill factors. Two outstanding individuals are selected from each group based on their factor ranks, and a gene pool is created to store the nodes of these two individuals. To reduce the computational cost, not all genes of these outstanding individuals are preserved in the gene pool, but a sampling operation is adopted. The number of gene pools is 0.1 × N (N is the number of all nodes in the current network). Here, the sampling operation selects a given number of nodes from all genetic nodes of these outstanding individuals by the roulette method.
Each individual in the population learns nodes in the gene pool according to a certain probability. The learning operation here is the same as that in Section 4.6, i.e. nodes are replaced with nodes in the search space stochastically. The replacement operation is accepted if the seed set after generating the replacement shows a better factor cost.
The learning operation towards superior individuals helps individuals within the population evolve rapidly, which contributes to the performance promotion of the whole population, and the sampling strategy contributes to reducing the required computational cost.
4.8. Selection operator
The role of the selection operator is to inherit better individuals to the next generation to keep the competitiveness of the population. The selection operator designed in this work considers the common knowledge among tasks and follows the principle of “inheritance diversity” by adopting multiple strategies. The specific steps are as follows. (1) First, the selection operator inherits two individuals with factor rank = 1 from the current population to the next generation so that the population avoids degenerating; (2) Second, the roulette wheel method is used to select 1/3InitialSize individuals from individuals with skill factor 1 and skill factor 2 into the child population; (3) Finally, for the remaining part of the child population, individuals are selected into the next generation using the roulette method according to the adaptation scalar of the other chosen individuals in the population.
4.9. Algorithm complexity analysis
The DMFEA algorithm can be mainly divided into the following parts: (1) Initialisation operator, which initialises PopSize individuals with a complexity of O(InitialSize) and is executed only once; (2) Crossover operator, which requires expanding the population size to PopSize, resulting in a complexity of O(MaxGen * (PopSize - InitialSize)) throughout the entire iteration; (3) Mutation operator, executed up to PopSize times per iteration, resulting in a complexity of O(PopSize * MaxGen) over the entire iteration; (4) Task-oriented learning operator, executed up to PopSize times per iteration, with each execution requiring a complexity of O(0.5 * K * (0.1 * N + <k > * )) (<k > is the average degree of the network), resulting in a complexity of O(PopSize * MaxGen * K * <k > * <k > + PopSize * MaxGen * K * N) over the entire iteration. (5) Gene-oriented learning operator, executed up to PopSize times per iteration, with each execution requiring a complexity of O(0.5 * K * (0.1 * N)), resulting in a complexity of O(PopSize * MaxGen * K * N) over the entire iteration. (6) Selection operator, which selects InitialSize individuals to enter the next generation, resulting in a complexity of O(MaxGen * InitialSize) over the entire iteration.
In conclusion, the overall time complexity of the DMFEA algorithm is O(PopSize * MaxGen * K * <k > * <k > + PopSize * MaxGen * K * N).
5. Experiment
In this section, the performance of DMFEA is verified on a variety of networks. The first part is the comparison of DMFEA with other single-objective optimisation algorithms. The second part is the comparison of DMFEA with other multi-tasking optimisation algorithms. Finally, the performance of DMFEA and other methods are compared on real-world networks.
5.1. DMFEA performance on synthetic networks
In previous studies on robust influence maximisation (Gong et al., Citation2016; Gong et al., Citation2016; Huang et al., Citation2022), single-objective optimisation techniques have been employed to identify seeds with robust influence ability. DMFEA introduces the multitasking mechanism to handle the robust influence maximisation problem by considering operators with knowledge transferring across multiple tasks ( and
). The effectiveness of DMFEA over single-objective optimisation methods is first demonstrated. For comparison, the single-objective optimisation methods implemented here are: (1) the population-based optimisation method MA-RIM (Huang et al., Citation2022); (2) the plain genetic algorithm (GA) (Wang & Liu, Citation2021); (3) the heuristic-based optimisation method simulated annealing (SA) (Buesser et al., Citation2011);
Similar to the experiments in Section 3, we adopt the IC model to simulate the information diffusion process, and the activation probability is set as 0.01. The parameters of the DMFEA algorithm are configured as follows: the initial population size InitialSize is set as 30, the population size PopSize as 50, the crossover probability as 0.5, the mutation probability
as 0.05, the execution probability of the task-based learning operator
as 0.5, the execution probability of gene-based learning operator
as 0.5, and the maximum number of evolution MaxGen as 150. Other algorithms are configured based on the parameters suggested in their original papers. In this work, experiments are conducted on three synthetic networks with node size N = 200 and averaged degree 〈k〉 = 4, namely, a scale-free network with power-law degree distribution (Barabási & Albert, Citation1999) (SF network), an Erdős–Rényi (ER network) (Erds & Rényi, Citation1961) with Poisson degree distribution, and a small-world network (Strogatz, Citation2001) (WS network) with close neighbouring connections. Experiments were considered for optimisation with different seed sizes K, lying in the range of 5, 10, 20. The best result is highlighted for each test scenario. We performed a t-test at a significance level of 0.002, using the results obtained from DMFEA as the baseline, to verify if there are significant performance differences among the results obtained from different methods, “-” indicates that the compared algorithm is inferior to DMFEA, “+” indicates the compared algorithm outperforms DMFEA, while “≈” means the two algorithms show no significant difference. Subsequent experiments follow the same label.
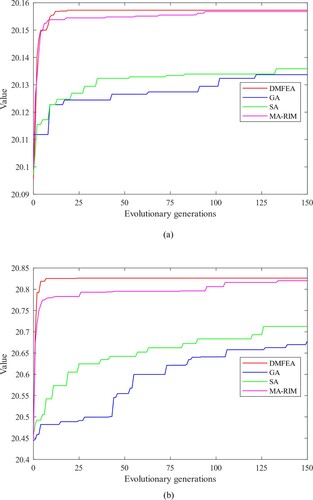
As shown in Tables and . As a classical method to solve the influence maximisation problem, GA includes information exchange between different individuals and mutation operations, which can solve the above problems to a certain extent, but the effect is still relatively unsatisfactory. The advantage of SA is its low space complexity, which allows it to be used as a component of EAs like (Wang & Liu, Citation2019), but may not be suitable for solving the influence maximisation problem alone. Compared with other single-objective optimisation methods, MA-RIM obtains better results. The reason is that MA-RIM includes a local search operator that has been verified to be effective for solving the robust influence maximisation problems, but requires a huge computational cost. When K is small, DMFEA, MA-RIM, SA, and GA can achieve similar optimisation performance, and seeds’ propagation performance lies at a similar level. However, as K increases, the number of key nodes in the network is limited to carry out all propagation tasks, and the overlapping phenomenon may cause difficulties when selecting suitable seeds. In this context, DMFEA tends to show competitiveness over other solvers, and the obtained seed set can achieve the best performance.
Table 1 The values of the seeds obtained by different algorithms when
is the optimisation task.
Table 2 The values of the seeds obtained by different algorithms when
is the optimisation task.
These traditional single-objective optimisation methods, GA, SA, and MA-RIM, have limitations in solving the multi-tasking optimisation problem between and
. First, the possible implicit correlations among tasks is completely ignored, leading to less competitive optimisation-seeking ability and unsatisfactory results. Second, the computational budget is high and only a single optimisation task can be solved at an iteration, which can only tackle a specific attack (node attack or link attack). Figure shows the convergence curves of each algorithm when seed size K = 20. It can be concluded that for both optimizations on
and
, the seeds obtained by DMFEA can achieve better influence propagation performance under structural failures at the same genetic budgets. This is due to the multi-task processing mechanisms embedded in crossover, task-oriented learning, and gene-oriented learning operators of DMFEA. These operators solve multiple optimisation tasks parallelly and enable cross-task knowledge available for the whole search process. The convergence is accelerated and high-quality solutions can be produced. These seeds contribute to admirable dissemination tasks in the original network and show resistance against structural failures. The influential ability and robustness are guaranteed to the diffusion task.
Figure 5. Convergence analysis of DMFEA with other single-objective optimisation methods using SF network as an example with seed size K = 20. (a) Convergence curves of different algorithms when is taken as the optimisation task. (b) Convergence curves of different algorithms when
is taken as the optimisation task.
Experimental comparison with the single-objective method demonstrates the effectiveness of the multitasking mechanism in dealing with multiple optimisation problems. Several existing multi-task optimisation algorithms are implemented to provide comparisons against DMFEA, including basic MFEA in (Gupta et al., Citation2015), SREMTO in (Zheng et al., Citation2019), and MFDE in (Gong et al., Citation2019). These algorithms are mainly used to handle optimisation problems with continuous variables (Gupta et al., Citation2015, Citation2016; Zhang et al., Citation2015) and cannot be directly applied to optimisation problems on networks with discrete data shapes. In our experiments, frameworks of these algorithms are implemented to cooperate with network-directed operators. The parameter settings are the same as before, and the experiments are performed on three synthetic networks, SF, ER, and WS, and the seed sizes are set to K = 5, K = 10, and K = 20.
The experimental results are shown in Tables and , and Figure . In these multi-task optimisation algorithms, the seeds selected by DMFEA still exhibit superior or
values. These seeds tend to keep considerable spreading ability even under node-based and link-based attacks. The experimental results show that MFDE performs poorly in the experiments due to the adopted differential evolution (DE) search mechanism. Such a search mechanism performs better in continuous variable problems (Gong et al., Citation2021), but may not be suitable for discrete problems. For SREMTO and MFEA, although they also implement the multitasking optimisation theory, these algorithms are not directed for discrete problems related to networks, which lack problem-orientated operators and thus show only less competitive performance.
Figure 6. Convergence analysis of DMFEA with other multitasking optimisation methods using SF network (N = 200) as an example with seed size K = 20. (a) Convergence curves of different algorithms when is used as the optimisation task (b) Convergence curves of different algorithms when
is used as the optimisation task.
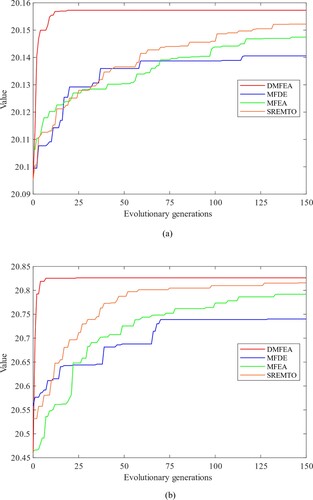
Table 3 The values of the seeds obtained by different algorithms when
is the optimisation task.
Table 4 The values of the seeds obtained by different algorithms when
is the optimisation task.
As the complexity of the problem increases, operators are required to guarantee the quality of obtained candidate seeds. The decision variables of the robust influence maximisation problem are highly discrete nodes, and efficient strategies are necessary to explore the network-based solution space. The design of a reasonable knowledge transfer strategy is the key to designing MFEA, which requires elaborate utilisation of relevant knowledge shared among multiple tasks, and also manages to avoid of extensive transfer of negative knowledge. DMFEA contains a unique task-oriented learning operator and gene-oriented learning operator to reach fast convergence across tasks. Moreover, DMFEA considers the diverse gene information, where several operators enhance the diversity of the population to prevent the algorithm from falling into local optimal solutions. In this manner, a remarkable optimisation ability is achieved.
Furthermore, we substantiate the DMFEA's performance on the SF network of 500 nodes. Building upon prior findings, we select the top-performing methods, namely MFDE, MFEA, SREMTO, and MA-RIM, and maintain the same parameter settings as in the previous experiments, for comparative analysis with DMFEA. The and
performance metrics of the seed sets acquired through different approaches are presented in Table and Figure . According to the analysis, the algorithm proposed in this paper demonstrates significant advantages over alternative solutions in large-scale networks, far surpassing them, and concurrently exhibits remarkable scalability. As the scale of the network continues to expand, the increased accumulation of information within its structural framework presents a greater challenge in selecting seed nodes that manifest robustness. Through the utilisation of
and
guidance, the DMFEA algorithm attains a more steadfast solution for propagation performance.
Figure 7. Convergence analysis of DMFEA with other optimisation methods using SF network (N = 500) as an example with seed size K = 20. (a) Convergence curves of different algorithms when used as the optimisation task (b) Convergence curves of different algorithms when taken as the optimisation task.
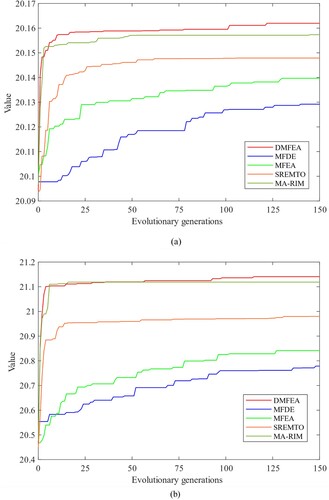
Table 5 The values of the seeds obtained by different algorithms.
5.2. Ablation experiment
To comprehensively analyze the impact of different components of the algorithm on its performance, we conducted a series of ablation experiments. In these experiments, we selectively removed two critical components of DMFEA: the task-oriented learning operator and the gene-oriented learning operator. We evaluated the contributions of these components to propagation performance. In the ablation experiments, we maintained consistent parameter settings and datasets as previously used (SF network, N = 200). The specific results are presented in Figure . (DMFEA-NG denotes the removal of the gene-oriented learning operator, DMFEA-NT denotes the removal of the task-oriented learning operator).
Figure 8. Ablation experiment with K = 20. (a) Convergence curves of different algorithms when taken as the optimisation task (b) Convergence curves of different algorithms when taken as the optimisation task.
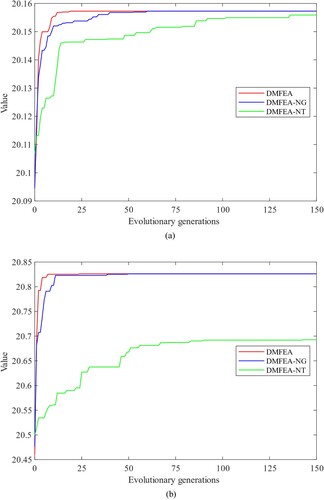
Compared with other multi-task optimisation methods, DMFEA-NG can still reach the possible inter-task synergy in the population and maintain a competitive convergence performance. As mentioned in Section 4.7, the gene-oriented learning operator is aimed at accelerating convergence without consuming much computational cost. The experimental results confirm this presupposition. and the convergence of the algorithm with the gene-specific learning operator reaches significant improvement. The effectiveness of the gene-oriented learning operator is thus validated. At the same time, DMFEA-NT performed poorly in the task, especially in the task of optimising . The possible reasons are as follows: as the complexity of the optimisation task gradually increases, it is likely to be disturbed by the local optimum if learning procedures are limited in individuals with better performance. Moreover, task-oriented learning dominates the search process due to the relatively large space when optimising
. Without such a strategy, DMFEA-NT performs poorly in the task. Thus, gene-oriented learning operators may not be suitable for implementing stand-alone optimisation, but rather for combining with other powerful operators (e.g. task-oriented learning operators).
5.3. Parameter selection
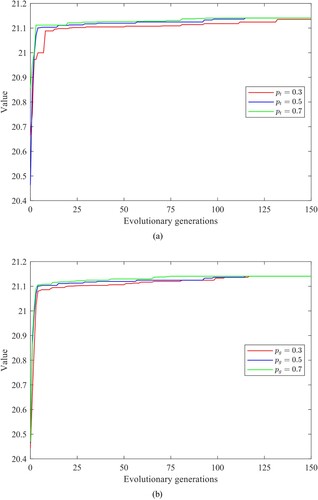
To substantiate the rationality of the designed experimental parameters, we compared the convergence curves of the algorithm under different pt and pg parameter settings on a Scale-Free network with 500 nodes. Here, we take the optimisation of as an example. The experimental results reveal that both pt and pg exert a substantial influence on the outcomes. Smaller values of pt and pg can effectively reduce the execution frequency of the operators, thus diminishing the computational cost of the algorithm. However, this reduction is accompanied by a certain degree of performance trade-off. Conversely, excessively high values of pt and pg introduce additional computational overhead, with limited contributions to search performance enhancement. Optimal parameter settings enable a harmonious equilibrium between search effectiveness and computational expenditure. Through experimental validation, we confirm the rationality and efficacy of the employed parameter configuration. Moreover, in practical applications, parameter selection can be flexibly tailored based on distinct performance requirements and resource constraints. (Figure )
Figure 9. Algorithm convergence curves for different parameter settings on SF network (N = 500) with K = 20 for example. (a) pt (b) pg.
5.4. Evaluation of the cost test
Furthermore, we conducted a comprehensive performance analysis among distinct methodologies while maintaining uniform evaluation costs. In this context, the evaluation cost refers to the frequency of algorithmic employment of or
for individual assessments. We established a predefined ceiling of 5,000 evaluations to meticulously observe the efficacy of diverse algorithms. Consistent with our prior experimental protocols, we employed identical parameter configurations. The experimental network was structured as an ER network, comprising 200 nodes. The detailed outcomes of these evaluations are succinctly presented in the ensuing table (Table ).
Table 6 Performance of different algorithms for different numbers of evaluations.
In addition, we also tested the actual running time of the algorithm. The experimental environment is as follows: CPU: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz, RAM: 16GB. the dataset is an SF network with 500 nodes, and the parameter settings are the same as in Section 5.1. The actual running time is shown in Table .
Table 7 Comparison of time used by different optimisation algorithms in hours.
The experimental results show that a higher performance solution can be obtained using DMFEA at the same evaluation cost, which is due to the multi-tasking mechanism adopted within DMFEA, which can make the individuals between different tasks get sufficient information exchange, thus improving the performance of the whole population. This is due to the multi-tasking mechanism within DMFEA, which can make the individuals between different tasks get sufficient information exchange, thus improving the performance of the whole population. It can be seen that the multitasking mechanism within DMFEA is effective.
5.5. DMFEA performance on real networks
The synthetic networks described above have distinct structural features, including small-world properties, connection randomness, and power-law degree distributions. However, in real networks these features may be randomly distributed, and it is possible that these features co-exist in a network and do not show a distinct distribution pattern. Therefore, the performance test of DMFEA on several real networks is necessary. Two networks are considered. The first one is a robot communication network (Robot network) collected from the database of Sun Yat-sen University, containing 200 nodes and 555 links, each node representing a different robot and each link representing a communication relationship between them. The second network is the Berlin regional logistics and transport network (Frid network) presented in (Farid, Citation2015), containing 224 nodes and 376 links, each node representing a different freight transfer station and each link representing a different transport route. According to the experimental results in Sections 5.1 and 5.2, DMFEA, MFEA, MA-RIM, MFDE, and SREMTO, which have better performance on the synthetic network, are implemented to provide comparisons. The algorithmic parameters are the same as above.
Tables and show the results obtained with different seed selection schemes, and the convergence performance curves of the different methods are drawn in Figures and . It can be seen that DMFEA still achieves competitive results on real networks, and the obtained seed nodes maintain superior propagation capability under network structure disruption over other approaches. Furthermore, we present the distribution of seed nodes in both the Frid network and the Robot network (Figures and ), with K = 20. In the figures, the nodes highlighted in red represent the set of nodes that exhibit the best performance on task T1 (evaluated using as the metric). The nodes highlighted in blue, on the other hand, represent the set of nodes that excel in task T2 (evaluated using
as the metric). The yellow nodes indicate the overlapping portions between these two sets.
Figure 10. Convergence analysis of DMFEA with other optimisation methods using Frid network as an example with seed size K = 20 (a) Convergence curves of different algorithms when is taken as the optimisation task (b) Convergence curves of different algorithms when
is taken as the optimisation task.
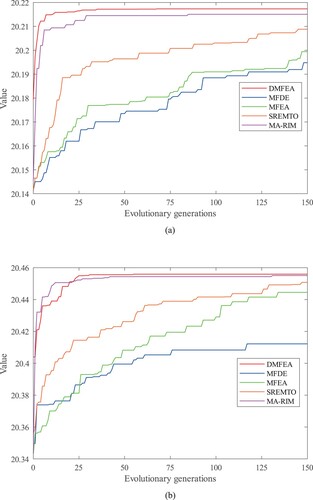
Figure 11. Convergence analysis of DMFEA with other optimisation methods using Robot network as an example with seed size K = 20 (a) Convergence curves of different algorithms when is taken as the optimisation task (b) Convergence curves of different algorithms when
is taken as the optimisation task.
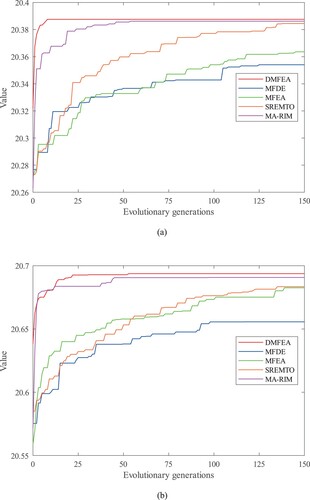
Figure 12. The distribution of seeds in the Frid network.
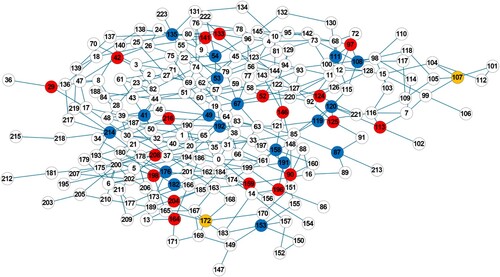
Figure 13. The distribution of seeds in the Robot network.
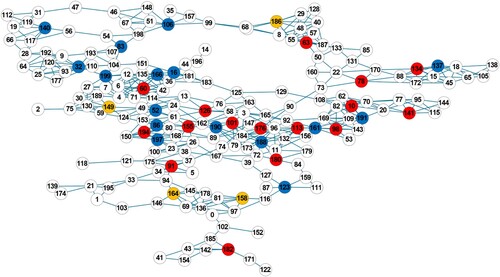
Table 8 The values of the seeds obtained by different algorithms when
is the optimisation task.
Table 9. The values of the seeds obtained by different algorithms when
is the optimisation task.
The experimental results obtained here can serve as potential solutions for decision-makers to solve practical operational dilemmas. For example, the results on the Frid network show that these candidate seeds are key staging points in the logistics network, and these staging points show robustness against connective losses. Based on this, decision-makers can make selections as alternatives to logistic transit centres, and a responsive impact on nearby transport nodes is expected even if attacks happen. The transport efficiency of the whole system can be improved (Chen et al., Citation2016; Farid, Citation2015). For the Robot network, the selected seeds are generally backbones in the robotic communication system, through which decision-makers can quickly spread control commands or deliver important information at a small communication cost, thus enhancing the control effect over the entire system. The seeds selected by DMFEA can maintain robust information dissemination ability under the condition of intrusions. In summary, the designed DMFEA can provide effective solutions to the robust influence maximisation problem, and feasible candidates are provided on both synthetic and real-world networks.
6. Concluding remarks
In this paper, the multitasking optimisation theory has been introduced into the influence maximisation problem. The network is subject to various types of attacks in practical applications, and both node attacks and link attacks are considered. This paper reveals the possible relationship between the optimisation towards link-based and node-based attacks, and a multitasking optimisation model of two related performance indicators is constructed. Based on this, a multi-factorial evolutionary algorithm, DMFEA, considering diverse gene information is designed to find robust and influential seeds. The algorithm fully considers the diverse information of the whole population and can optimise multiple tasks simultaneously utilising the implicit parallelism between multiple tasks. Seeds obtained by DMFEA on synthetic and real networks show competitiveness over existing methods, providing reliable candidates to accomplish diffusion tasks on networked systems under structural risks.
How to effectively mine the information in the network is still a challenging problem to be studied, and we will consider the application of graph embedding techniques to achieve a fast information mining approach or enhance the influence of seeds using structural adjustment in the following research. At the same time, the existing algorithms can obtain satisfactory results, but still require a certain amount of computational cost, and how to improve the efficiency is also the focus of future research. In addition, how to solve the robust influence maximisation problem in large-scale networks, multilayer networks, and directed networks with more complicated structures is also a challenging task at present, and we will continue to focus on the future.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The raw/processed data required to reproduce these findings cannot be shared at this time as the data also forms part of an ongoing study.
Additional information
Funding
References
- Bai, M., Tan, Y., Wang, X., Zhu, B., & Li, G. (2021). Optimized algorithm for skyline community discovery in multi-valued networks. IEEE Access, 9, 37574–37589. https://doi.org/10.1109/ACCESS.2021.3063317
- Barabási, A.-L., & Albert, R. (1999). Emergence of scaling in random networks. Science, 286(5439), 509–512. https://doi.org/10.1126/science.286.5439.509
- Bond, R. M., Fariss, C. J., Jones, J. J., Kramer, A. D., Marlow, C., Settle, J. E., & Fowler, J. H. (2012). A 61-million-person experiment in social influence and political mobilization. Nature, 489(7415), 295–298. https://doi.org/10.1038/nature11421
- Borgs, C., Brautbar, M., Chayes, J., & Lucier, B. (2014). Maximizing social influence in nearly optimal time. Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms.
- Buesser, P., Daolio, F., & Tomassini, M. (2011). Optimizing the robustness of scale-free networks with simulated annealing. International Conference on Adaptive and Natural Computing Algorithms.
- Chen, W., Lin, T., Tan, Z., Zhao, M., & Zhou, X. (2016). Robust influence maximization. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Chen, W., Wang, Y., & Yang, S. (2009). Efficient influence maximization in social networks. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/1599272
- Da, B., Gupta, A., & Ong, Y. S. (2019). Curbing negative influences online for seamless transfer evolutionary optimization. IEEE Transactions on Cybernetics, 49(12), 4365–4378. https://doi.org/10.1109/TCYB.2018.2864345
- Erds, P., & Rényi, A. (1961). On the evolution of random graphs. Publication of the Mathematical Institute of the Hungarian Academy of Sciences.
- Farid, A. M. (2015). Symmetrica: Test case for transportation electrification research. Infrastructure Complexity, 2(1), 1–10. https://doi.org/10.1186/s40551-015-0012-9
- Gong, M., Song, C., Duan, C., Ma, L., & Shen, B. (2016). An efficient memetic algorithm for influence maximization in social networks. IEEE Computational Intelligence Magazine, 11(3), 22–33. https://doi.org/10.1109/MCI.2016.2572538
- Gong, M., Tang, Z., Li, H., & Zhang, J. (2019). Evolutionary multitasking with dynamic resource allocating strategy. IEEE Transactions on Evolutionary Computation, 23(5), 858–869. https://doi.org/10.1109/TEVC.2019.2893614
- Gong, M., Yan, J., Shen, B., Ma, L., & Cai, Q. (2016). Influence maximization in social networks based on discrete particle swarm optimization. Information Sciences, 367-368, 600–614. https://doi.org/10.1016/j.ins.2016.07.012
- Gong, Y., Liu, S., & Bai, Y. (2021). Efficient parallel computing on the game theory-aware robust influence maximization problem. Knowledge-Based Systems, 220, 106942. https://doi.org/10.1016/j.knosys.2021.106942
- Goyal, A., Lu, W., & Lakshmanan, L. V. (2011). Celf++ optimizing the greedy algorithm for influence maximization in social networks. Proceedings of the 20th International Conference Companion on World Wide Web.
- Gupta, A., Ong, Y.-S., & Feng, L. (2015). Multifactorial evolution: Toward evolutionary multitasking. IEEE Transactions on Evolutionary Computation, 20(3), 343–357. https://doi.org/10.1109/TEVC.2015.2458037
- Gupta, A., Ong, Y.-S., Feng, L., & Tan, K. C. (2016). Multiobjective multifactorial optimization in evolutionary multitasking. IEEE Transactions on Cybernetics, 47(7), 1652–1665. https://doi.org/10.1109/TCYB.2016.2554622
- Gupta, A., Zhou, L., Ong, Y.-S., Chen, Z., & Hou, Y. (2022). Half a dozen real-world applications of evolutionary multitasking, and more. IEEE Computational Intelligence Magazine, 17(2), 49–66. https://doi.org/10.1109/MCI.2022.3155332
- Huang, D., Tan, X., Chen, N., & Fan, Z. (2022). A memetic algorithm for solving the robust influence maximization problem on complex networks against structural failures. Sensors, 22(6), 2191. https://doi.org/10.3390/s22062191
- Karafotias, G., Hoogendoorn, M., & Eiben, ÁE. (2014). Parameter control in evolutionary algorithms: Trends and challenges. IEEE Transactions on Evolutionary Computation, 19(2), 167–187. https://doi.org/10.1109/TEVC.2014.2308294
- Kempe, D., Kleinberg, J., & Tardos, É. (2003). Maximizing the spread of influence through a social network. Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Kurant, M., & Thiran, P. (2006). Layered complex networks. Physical Review Letters, 96(13), 138701. https://doi.org/10.1103/PhysRevLett.96.138701
- Lee, J.-R., & Chung, C.-W. (2014). A fast approximation for influence maximization in large social networks. Proceedings of the 23rd International Conference on World Wide Web.
- Leskovec, J., Krause, A., Guestrin, C., Faloutsos, C., VanBriesen, J., & Glance, N. (2007). Cost-effective outbreak detection in networks. Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Li, Q., Cheng, L., Wang, W., Li, X., Li, S., & Zhu, P. (2023). Influence maximization through exploring structural information. Applied Mathematics and Computation, 442, 127721. https://doi.org/10.1016/j.amc.2022.127721
- Liaw, R. T., & Ting, C. K. (2019). Evolutionary manytasking optimization based on symbiosis in biocoenosis. Proceedings of the AAAI Conference on Artifical Intelligence.
- Qiu, L., Jia, W., & Fan, X. (2019). Influence maximization algorithm based on overlapping community. Data Analysis Knowledge Discovery, 3(7), 94–102.
- Rahimkhani, K., Aleahmad, A., Rahgozar, M., & Moeini, A. (2015). A fast algorithm for finding most influential people based on the linear threshold model. Expert Systems with Applications, 42(3), 1353–1361. https://doi.org/10.1016/j.eswa.2014.09.037
- Ren, Z. M., Shao, F., Liu, J. G., Guo, Q., & Wang, B. H. (2013). Node importance measurement based on the degree and clustering coefficient information. ActaPhysica Sinica, 62(12), 522–526.
- Samir, A. M., Rady, S., & Gharib, T. F. (2021). LKG: A fast scalable community-based approach for influence maximization problem in social networks. Physica A: Statistical Mechanics and its Applications, 582, 126258. https://doi.org/10.1016/j.physa.2021.126258
- Schneider, C. M., Moreira, A. A., Andrade, J. S., Havlin, S., & Herrmann, H. J. (2011). Mitigation of malicious attacks on networks. Proceedings of the National Academy of Sciences, 108(10), 3838–3841. https://doi.org/10.1073/pnas.1009440108
- Shen, C., & Zhang, K. (2022). Two-stage improved Grey Wolf optimization algorithm for feature selection on high-dimensional classification. Complex Intelligent Systems, 1–21.
- Shen, F., Liu, J., & Wu, K. (2020). Evolutionary multitasking fuzzy cognitive map learning. Knowledge-Based Systems, 192, 105294. https://doi.org/10.1016/j.knosys.2019.105294
- Srinivas, N., & Deb, K. (1994). Multiobjective function optimization using nondominated sorting genetic algorithms. Evolutionary Computation, 2(3), 1301–1308. https://doi.org/10.1162/evco.1994.2.3.221
- Strogatz, S. H. (2001). Exploring complex networks. Nature, 410(6825), 268–276. https://doi.org/10.1038/35065725
- Tang, Y., Shi, Y., & Xiao, X. (2015). Influence maximization in near-linear time: A martingale approach. Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data.
- Tang, Y., Xiao, X., & Shi, Y. (2014). Influence maximization: Near-optimal time complexity meets practical efficiency. Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data.
- Wang, C., Liu, J., Wu, K., & Wu, Z. (2021). Solving multitask optimization problems with adaptive knowledge transfer via anomaly detection. IEEE Transactions on Evolutionary Computation, 26(2), 304–318. https://doi.org/10.1109/TEVC.2021.3068157
- Wang, S., Jin, Y., & Cai, M. (2023). Enhancing the robustness of networks against multiple damage models using a multifactorial evolutionary algorithm. IEEE Transactions on Systems, Man, Cybernetics: Systems.
- Wang, S., & Liu, J. (2017). A multi-objective evolutionary algorithm for promoting the emergence of cooperation and controllable robustness on directed networks. IEEE Transactions on Network Science and Engineering, 5(2), 92–100. https://doi.org/10.1109/TNSE.2017.2742522
- Wang, S., & Liu, J. (2019). Designing comprehensively robust networks against intentional attacks and cascading failures. Information Sciences, 478, 125–140. https://doi.org/10.1016/j.ins.2018.11.005
- Wang, S., & Liu, J. (2021). A memetic algorithm for solving the robust influence maximization problem towards network structural perturbances. Chinese Journal of Computers, 44(6), 1153–1167.
- Wang, S., Liu, J., & Jin, Y. (2019). Finding influential nodes in multiplex networks using a memetic algorithm. IEEE Transactions on Cybernetics, 51(2), 900–912. https://doi.org/10.1109/TCYB.2019.2917059
- Wang, S., & Tan, X. (2022a). Determining seeds with robust influential ability from multi-layer networks: A multi-factorial evolutionary approach. Knowledge-Based Systems, 246, 108697. https://doi.org/10.1016/j.knosys.2022.108697
- Wang, S., & Tan, X. (2022b). Solving the robust influence maximization problem on multi-layer networks via a Memetic algorithm. Applied Soft Computing, 121, 108750. https://doi.org/10.1016/j.asoc.2022.108750
- Wang, Y., Cong, G., Song, G., & Xie, K. (2010). Community-based greedy algorithm for mining top-k influential nodes in mobile social networks. Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature, 393(6684), 440–442. https://doi.org/10.1038/30918
- Wei, T., Wang, S., Zhong, J., Liu, D., & Zhang, J. (2021). A review on evolutionary multitask optimization: Trends and challenges. IEEE Transactions on Evolutionary Computation, 26(5), 941–960. https://doi.org/10.1109/TEVC.2021.3139437
- Wu, K., Wang, C., & Liu, J. (2021). Evolutionary multitasking multilayer network reconstruction. IEEE Transactions on Cybernetics, 52(12), 12854–12868. https://doi.org/10.1109/TCYB.2021.3090769
- Wu, Y., Ding, H., Xiang, B., Sheng, J., Ma, W., Qin, K., … Gong, M. (2023). Evolutionary multitask optimization in real-world applications: A survey. Journal of Artificial Intelligence Technology, 3(1), 32–38.
- Xianli, Z., Jianxin, T., & Laicheng, C. (2020). Influence maximization algorithm based on reverse PageRank. Journal of Computer Applications, 40(1), 96.
- Yang, J., & Liu, J. (2017). Influence maximization-cost minimization in social networks based on a multiobjective discrete particle swarm optimization algorithm. IEEE Access, 6, 2320–2329. https://doi.org/10.1109/ACCESS.2017.2782814
- Zeng, A., & Liu, W. (2012). Enhancing network robustness against malicious attacks. Physical Review E, 85(6), 066130. https://doi.org/10.1103/PhysRevE.85.066130
- Zhang, H., Nguyen, D. T., Zhang, H., & Thai, M. T. (2015). Least cost influence maximization across multiple social networks. IEEE/ACM Transactions on Networking, 24(2), 929–939. https://doi.org/10.1109/TNET.2015.2394793
- Zheng, X., Qin, A. K., Gong, M., & Zhou, D. (2019). Self-regulated evolutionary multitask optimization. IEEE Transactions on Evolutionary Computation, 24(1), 16–28. https://doi.org/10.1109/TEVC.2019.2904696
- Zhu, J., Ghosh, S., & Wu, W. (2019). Group influence maximization problem in social networks. IEEE Transactions on Computational Social Systems, 6(6), 1156–1164. https://doi.org/10.1109/TCSS.2019.2938575
- Zhu, Q., Yang, C., Xu, Y., Wang, H., Zhang, C., & Han, J. (2021). Transfer learning of graph neural networks with ego-graph information maximization. Advances in Neural Information Processing Systems, 34, 1766–1779.