Abstract
In this article we present our system for scalable, robust, and fast city-scale reconstruction from Internet photo collections (IPC) obtaining geo-registered dense 3D models. The major achievements of our system are the efficient use of coarse appearance descriptors combined with strong geometric constraints to reduce the computational complexity of the image overlap search. This unique combination of recognition and geometric constraints allows our method to reduce from quadratic complexity in the number of images to almost linear complexity in the IPC size. Accordingly, our 3D-modeling framework is inherently better scalable than other state of the art methods and in fact is currently the only method to support modeling from millions of images. In addition, we propose a novel mechanism to overcome the inherent scale ambiguity of the reconstructed models by exploiting geo-tags of the Internet photo collection images and readily available StreetView panoramas for fully automatic geo-registration of the 3D model. Moreover, our system also exploits image appearance clustering to tackle the challenge of computing dense 3D models from an image collection that has significant variation in illumination between images along with a wide variety of sensors and their associated different radiometric camera parameters. Our algorithm exploits the redundancy of the data to suppress estimation noise through a novel depth map fusion. The fusion simultaneously exploits surface and free space constraints during the fusion of a large number of depth maps. Cost volume compression during the fusion achieves lower memory requirements for high-resolution models. We demonstrate our system on a variety of scenes from an Internet photo collection of Berlin containing almost three million images from which we compute dense models in less than the span of a day on a single computer.
1. Introduction
City models from aerial imagery have recently been made freely accessible via online mapping sites. The biggest limitation is that when observed from the ground the texture and geometry have very limited resolution. The next generation of 3D models will need to employ ground-based imagery to overcome this limitation. To obtain those models, we have proposed the first real-time 3D reconstruction system, which collects ground reconnaissance video Citation(1) in the range of multiple million frames for small cities and computes 3D models. Alternatively, researchers proposed to use crowdsourced Internet photo collections (IPC) to avoid the image collection effort required for city-scale 3D modeling Citation(2 –Citation 5). These IPC typically include several million images for a city and cover the sites of interest in the city. The major challenge added compared with video is there no information about the spatial ordering of the views is provided, that is, there is no information about which views overlap with each other. The massive amount of unordered image data requires one to solve the overlap search efficiently to obtain a highly scalable 3D reconstruction system that meets the demands of 3D modeling from millions of ground reconnaissance images.
In this article, we discuss our system for city-scale 3D reconstruction from crowdsourced photo collections, which can compute city-scale 3D models from three million images on a single personal computer (PC) in less than the span of a day. Our method is designed to reduce the computational complexity of the reconstruction problem to close to linear for the most expensive parts of the reconstruction pipeline. We achieve this by jointly using geometric constraints and recognition-based constraints allowing for a highly efficient method. In contrast to most other crowd-based 3D modeling algorithms, our system efficiently solves the high-resolution dense reconstruction problem by exploiting the redundancy in the estimated multiview geometries enforcing surface and free-space constraints. Additionally, the proposed method is able to use readily available geo-registered street view imagery (e.g. those provided by Google StreetView) to automatically scale and geo-reference the computed 3D city models. In summary, our method is currently outperforming the state of the art methods in crowdsourced 3D reconstruction by three orders of magnitude in performance, while in contrast to those methods also solving the dense reconstruction problem.
2 Related work
There are currently two main classes of city-scale reconstruction algorithms, the first uses bag of words methods to identify scene overlap, which is then used to bootstrap large-scale structure from motion registration delivering camera registration and sparse 3D point clouds of the scene Citation(2 , Citation 5). Even with a cloud computer of 62 CPUs, these methods only scale to the registration of a few hundred thousand images within 24 h, not meeting the demand of true Internet-scale photo collections. The second class of methods uses appearance-based image grouping followed by epipolar geometry verification to identify overlapping images. A set of identified characteristic views (iconics) is afterwards exploited to bootstrap the efficient image registration through structure from motion Citation(3 , Citation 4). These methods can scale to the processing of a few million images on a single PC within 24 h as shown in our work Citation(3).
Bag of words methods typically provide a higher degree of resulting 3D model completeness in the reconstruction than the appearance clustering approaches. In order to achieve higher completeness, they compromise the computational complexity of the method. The first approach in this category was the seminal Photo Tourism Citation(5) method, which deployed exhaustive search for the overlap search. Agarwal et al. Citation(2) employed feature-based recognition and query expansion to improve the computational complexity of the overlap detection, scaling to the processing of a few hundred thousand images on a cloud computer (62 CPUs). In contrast, our method scales to millions of images on a single PC, while maintaining model quality and producing dense 3D models.
Appearance-based clustering has the strong advantage of scalability, which has been shown in our work Citation(3) to outperform the most efficient bag of word approach Citation(2) by at least three orders of magnitude. This is a result of the close to linear computational complexity of the method introduced in Citation(3). Additionally, we deliver the largest so far obtained 3D models from IPCs.
After the appearance grouping for overlap search, both types of methods use traditional structure from motion techniques to solve for camera registration Citation(6 , Citation 7). They exploit error mitigation through increasingly larger bundle adjustment, which optimizes the 3D structure simultaneously with the pose of the cameras Citation(2 –Citation 4 , Citation 8). This step is one of the remaining performance bottlenecks in the large-scale reconstruction systems, despite the recent progress in the computational performance of bundle adjustment through parallelization Citation(9) or hierarchical processing as proposed by Ni et al. Citation(10). Alternatively, Crandall et al. Citation(11) proposed to use a discrete continuous method to limit the number of bundle adjustments. However, it requires a computationally expensive discrete optimization partially executed on a 200 core cluster to initialize the continuous optimizer. Using this method limits the drift drastically and allows for large-scale reconstruction. Snavely et al. Citation(8) propose to construct a minimal set of views for reconstruction (skeletal set), which provides the same reconstruction accuracy. The major drawback for the computational complexity with the skeletal set is that it still requires a full pairwise matching of the image connection graph. In contrast, our approach utilizes high-level appearance information to reduce the inherent redundancy in the data by obtaining an iconic scene representation of the photo collection Citation(3 , Citation 4).
Goesele et al. Citation(12) use a patch growing to obtain a dense 3D model from IPC data. They start from the sparse structure from motion point cloud. Then, the participating views for each patch are carefully selected based on resolution, color, and viewing direction. Furukawa et al. Citation(13) proposed another view selection approach for the computation of the dense 3D point cloud. Both Goesele et al. Citation(12) and Furukawa et al. Citation(13) are computationally highly demanding compared with our method. We extend our previous approach from Gallup et al. Citation(14), which achieves scalable reconstruction for a limited number of views by decoupling the reconstructions in two of the three dimensions of the 3D space. Our extension overcomes the limitation of Gallup et al. Citation(14) to only be able to use a limited number of views for the dense computation.
3 Scalable crowdsourced modeling
Our 3D modeling technique consequently limits the computational complexity of each step of the system. This leads to an overall computational complexity that is close to linear in the initial registration process, which involves millions of images for a typical city-scale reconstruction. An overview of the steps of our method is shown in Figure . We evaluate the method on an IPC from Berlin that contains approximately 2.8 million images downloaded from Flickr. All reported execution times are on our PC with dual quad core Xeon 3.33 Ghz processors, four NVidia 295GTX commodity graphics cards, and 48 GB RAM.
3.1 Appearance-based grouping (Steps 1–2)
Our approach uses appearance clustering for determining overlapping views. To facilitate the clustering, we exploit the gist-descriptor Citation(15) to obtain a compact 368 dimensional vector describing each image. This descriptor mostly depends on the edge structure of the image, the texture roughness of the image, and the global color distribution in the image. Hence, it will not change with small viewpoint changes but it will significantly change for scene changes and wide baseline viewpoints. Using this insight, our method clusters the gist descriptors of the images, which equates to a viewpoint clustering. For the Berlin dataset, we obtain about 4 GB of descriptors compared to the IPC of approximately 650 GB.
Figure 1 Overview of the processing steps.
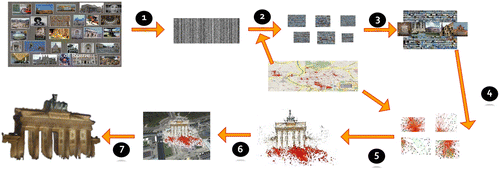
Given that clustering is an inherently parallel problem, it would be optimal to execute it on commodity graphics hardware (GPUs), which are highly parallel. Even the 4 GB of gist descriptors exceed the memory of typical graphics hardware. To obtain a more compressed representation, we apply a random basis projection followed by a binarization Citation(16). This guarantees that with an increasing number of bits the Hamming distance approximates the Euclidian distance of the original descriptors. The best trade-off between approximation accuracy and memory usage for our datasets was found at 512 bits. To cluster using the Hamming distance we employ a k-medoids algorithm on GPU, which is a k-means for non-metric spaces.
For a better cluster initialization, we approximate the spatial distribution of the geo-tagged images with our cluster initialization. As shown in our work Citation(3), this increases the number of registered cameras by 20% compared with a random initialization. Figure illustrates an example viewpoint cluster. The advantage of our appearance clustering approach is that it has in practice linear complexity in the number of images.
Figure 2 Left: Appearance cluster from the Berlin dataset. Right: Geometrically verified cluster from Berlin dataset.
3.2 Geometric cluster verification (Step 3)
Due to the coarseness of the 512 bit binary descriptors, the above appearance clustering leads to noisy clusters. To remove the unrelated views, we enforce valid epipolar geometry between the images of a cluster. A naive verification strategy would evaluate all view pairs within a cluster, which is of quadratic complexity in the number of images. To avoid the combinatorial explosion, our method first identifies a set of n mutually consistent views (n = 3 for all results in the study). Then, it selects the iconic view as the view that has the most correspondences to the other views. All remaining images are only verified against the iconic. For high verification performance, we exploit Universal RANSAC (USAC), a fast RANSAC scheme Citation(17) leading to verification rates of approximately 450 Hz. Figure shows the verified clusters. The iconic of each cluster is then used in the following computation to represent the cluster for the initial registration.
3.3 Camera registration (Steps 4–5)
After identifying all iconic views, our method establishes the registration between the different iconics. Li et al. Citation(4) introduced the iconic scene graph to represent the relationships between the iconic views. The graph has an edge between two iconics if there is a valid epipolar geometry between the two images. We take the concept of the iconic scene graph, which was designed for landmarks where all iconics show the landmark and extend it to city-scale modeling by establishing local iconic scene graphs for each separate site in the dataset. To compute the local iconic scene graph, we test for mutual overlap between the iconics by enforcing the epipolar geometry with USAC Citation(17). To avoid the quadratic complexity of an exhaustive test, we use the binary descriptors from step 1 by testing each iconic for potential overlap with the k = 10 nearest neighbors in the binary descriptor space. To foster further connections, we exploit the spatial location of the cluster by verifying potential connections to other iconics in the spatial vicinity. The location of the iconic is obtained through kernel voting using the geo-located images within the cluster.
Then, we perform structure from motion combined with bundle adjustment for each local iconic scene graph. Next, all images of all clusters will be registered into the reconstruction. Example registrations and iconics are shown in Figure .
Figure 3 Example iconics and registered cameras for three different sites in Berlin: Brandenburg Gate, Berlin Dome, Ishtar Gate.

3.4 Geo-registration (Step 6)
Given the inherent scale ambiguity for structure from motion, we propose a scale estimation and geo-registration. We empirically observed that typically there are very few precisely geo-localized photos in the IPC, which often prohibits accurate geo-registration except for some large-scale models as shown by Kaminsky et al. Citation(18). Hence, we exploit the embedded tags (automatic and user clicked) only to obtain a rough position through kernel voting, where each geo-localized image casts a Gaussian distributed vote with σ = 8.3 m and a three σ cutoff distance. The rough estimate for the model location is then obtained as the center of gravity of the largest connected component. In the rare case of no registered geo-located images in the IPC, we propose to use the text tags of the IPC images to obtain a rough geo-location through a search on Google maps.
To support more accurate geo-location, our algorithm employs ubiquitously available Google StreetView panoramas in the model’s vicinity, which have high accuracy geo-location and orientation.Footnote 1 Given that our obtained camera registration is in a Euclidean space, we transform the latitude/longitude coordinates of the StreetView panoramas into the Universal Transverse Mercator (UTM) grid, which provides a Euclidean space too and allows the use of Euclidean distances during the alignment optimization.
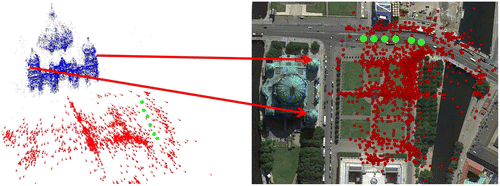
Next, we perform a feature-based registration of the StreetView panoramas into our 3D model using essentially the registration process of step 5 with a viewing ray-based panorama registration. After the registration of the panoramas into the 3D model, we can utilize their coordinates in the 3D model and their known UTM coordinates to estimate the transformation between the 3D model coordinate system and the UTM coordinate system with USAC. Figure illustrates a geo-registered reconstruction.
Figure 4 Geo-registered cameras for the Berlin dome. StreetView panoramas in green and IPC cameras are in red.
3.5 Dense scene modeling (Step 7)
After obtaining the geo-registered cameras, our method computes a dense 3D model for each site. The major challenge for IPCs is the varying appearance of the scene in the different views, which poses significant challenges for the image-based correlation. We exploit our gist-based clustering to overcome this challenge as it groups the images not only by viewpoint but also by color. Hence, the resulting clusters are similar in color and allow for a GPU-based normalized cross-correlation plane sweeping stereo algorithm to be executed. Example cluster images and their depth maps are shown in Figure . As a result of the varying appearance, the resulting depth maps contain significant noise. To combat the noise for the final 3D model, we use the redundancy of the depth maps by fusing them into a mutually consistent 3D model.
Figure 5 Example cluster images used for stereo computation and their depth maps.

Our fusion method Citation(14 , Citation 19) uses a volumetric representation for the scene to enable the fusion of a large variety of viewpoints. Volumetric methods have the inherent cubic memory complexity, which prohibits high-resolution models. In contrast to traditional volumetric models, our fusion Citation(19) only exercises quadratic memory complexity. Hence, it is able to fuse the depth maps of each site into a high-quality 3D model representation.
Our heightmap fusion Citation(14 , Citation 19) takes as input a set of depth maps along with the best estimates for each camera’s external and internal parameters. From the camera parameters, we automatically extract the ground plane using a technique similar to Szeliski’s method Citation(20), which fits a plane through the x-axes of the landscape mode cameras and the y-axes of the portrait mode cameras. The ground plane then serves as a basis for the heightmap representation with the height direction along the normal of the estimated ground plane. We chose a quantization grid for the ground plane to effectively define the ground sampling distance of our obtained model. Given that our model is correctly scaled, we can set the ground sampling distance directly in units of meter. We typically chose a value between 5 and 30 cm.
For each column (volume above the area of a ground sampling point), we then perform a voting process for its occupancy in the height direction using the same quantization as the ground sampling distance. In the voting, each pixel in each depth map votes for an occupied cell (voxel in the column) at the depth of the observed surface. For cells between the camera and the occupied cell, it votes for empty and for all cells behind the observed surface its vote exponentially declines from occupied to a indecisive vote. After the votes of a column have been accumulated, our technique determines the occupied segments within the column using a regularization to minimize the number of occupied segments (for more details please see Gallup et al. Citation(14)). Please note that our method not only uses the surface constraints in the voting but also enforces free space constraints, which we found to be highly efficient to suppress noise in the fused model. We execute this process on commodity graphics hardware to exploit its given parallelism. This fusion process Citation(14) is limited by the memory, that is, it can only fuse a limited number of depth maps per column. Naively this can be overcome by either streaming all the depth maps from the hard disk for each column, which is prohibitively expensive in time due to disk bandwidth, or alternatively the cost volume has to be kept in memory to avoid streaming the depth maps. The latter is prohibitive for high resolution models due to the cubic memory complexity.
To enable the fusion of all available depth maps, our method Citation(19) exploits Haar-wavelet compression for the cost volume, which accurately preserves the transitions between occupied and empty segments along the column. This enables the algorithm to present the cost function of each column to be represented with a constant number of coefficients k. We empirically found k = 30 to perform well and used this for all our experiments. Accordingly, the memory to store the cost function only grows quadratically with the ground sampling distance allowing our method to perform high-resolution 3D modeling on commodity graphics hardware using all available depth maps as described in Zheng et al. Citation(19). Figure shows some of the resulting models for the Berlin dataset. The overall processing time of the IPC was 23 h and 35 min.
Figure 6 Fused 3D models.

4 Conclusion
In this article, we discussed our algorithm for the computation of geo-registered dense 3D models from IPC, which outperforms any existing method for reconstruction of sparse models by at least three orders of magnitude. The performance and scalability of our system result from a consequent reduction in computational complexity using geometric and recognition constraints. Our technique also solves the automatic geo-registration by exploiting the readily available StreetView imagery along with its precise location information. Our novel depth map fusion is able to fuse the information from all available depth maps of a site and hence allows us to obtain highly detailed dense noise free 3D scene models.
Notes on contributors
Jan-Michael Frahm is an assistant professor at the UNC Chapel Hill where he heads the 3D computer vision group. He received his PhD in Computer Science from the Christian-Albrechts-University Kiel, Germany in 2005. He has co-authored over 80 articles in peer-reviewed journals and conferences. He is also one of the editors in chief of the Elsevier journal of Image and Vision Computing.
Jared Heinly is a PhD candidate in the Computer Science Department at UNC Chapel Hill. His research focuses on structure from motion and feature detection and description.
Enliang Zheng is a PhD candidate in the Computer Science Department at UNC Chapel Hill. His research focuses on 3D stereo, depth map computation and fusion, and virtual view synthesis.
Enrique Dunn is a research assistant professor at UNC Chapel Hill in the 3D computer vision group. He received his PhD in 2006 from the CICESE Research Center in Mexico. Dr Dunn has published over 25 peer-reviewed publications.
Pierre Fite-Georgel is a principal engineer at Deko Inc. He received his PhD in Computer Science in 2011 from the Technical University Munich, Germany. He published over 20 peer-reviewed papers in conferences and journals.
Marc Pollefeys is a full professor at ETH Zurich where he heads the Visual Computing group. He received his Ph.D. in Computer Science from Katholieke Universiteit Leuven in Belgium in 1999. He co-authored over 160 peer-reviewed publications. Dr Pollefeys is/was on the Editorial Board of the IEEE Transactions on Pattern Analysis and Machine Intelligence, the International Journal of Computer Vision, Foundations and Trends in Computer Graphics and Computer Vision and several other journals. He is an IEEE Fellow.
Notes
1The panoramas are automatically downloaded through the Google StreetView API (http://code.google.com/apis/maps/index.html)
References
- Pollefeys, M.; Nistér, D.; Frahm, J.M.; Akbarzadeh, A.; Mordohai, P.; Clipp, B.; Engels, C.; Gallup, D.; Kim, S.J.; Merrell, P.; Salmi, C.; Sinha, S.; Talton, B.; Wang, L.; Yang, Q.; Stewénius, H.; Yang, R.; Welch, G.; Towles, H. Detailed real-time urban 3D reconstruction from video. Int. J. Comput. Vision 2008, 78 (2), 143–167.
- Agarwal, S.; Snavely, N.; Simon, I.; Seitz, S.M.; Szeliski, R. Building Rome in a Day. IEEE International Conference on Computer Vision, Kyoto, Japan, 2009.
- Frahm, J.M.; Georgel, P.F.; Gallup, D.; Johnson, T.; Raguram, R.; Wu, C.; Jen, Y.H.; Dunn, E.; Clipp, B.; Lazebnik, S.; Pollefeys, M. Building Rome on a Cloudless Day. European Conference on Computer Vision, Crete, Greece, 2010.
- Li, X.; Wu, C.; Zach, C.; Lazebnik, S.; Frahm, J.M. Modeling and Recognition of Landmark Image Collections Using Iconic Scene Graphs. European Conference on Computer Vision, Marseille, France, 2008.
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo Tourism: Exploring Photo Collections in 3D. ACM International Conference on Computer Graphics and Interactive, Techniques, Boston, MA, 2006.
- Pollefeys , M. , Van Gool , L. , Vergauwen , M. , Verbiest , F. , Cornelis , K. , Tops , J. and Koch , R. 2004 . Visual Modeling with a Hand-Held Camera . Int. J. Comput. Vision , 59 ( 3 ) : 207 – 232 .
- Hartley , R. and Zisserman , A. 2004 . Multiple View Geometry in Computer Vision , 2nd ed. , Cambridge : Cambridge University Press .
- Snavely, N.; Seitz, S.M.; Szeliski, R. Skeletal Graphs for Efficient Structure from Motion. IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, 2008.
- Wu, C.; Agarwal, S.; Curless, B.; Seitz, S.M. Multicore Bundle Adjustment. IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, 2011.
- Ni, K.; Steedly, D.; Dellaert, F. Out-of-core Bundle Adjustment for Large-scale 3D Reconstruction. IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 2007.
- Crandall, D.; Owens, A.; Snavely, N.; Huttenlocher, D. Discrete-Continuous Optimization for Large-Scale Structure from Motion. IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, 2011.
- Goesele, M.; Snavely, N.; Curless, B.; Hoppe, H.; Seitz, S.M. Multi-View Stereo for Community Photo Collections. IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 2007.
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Towards Internet-scale Multi-view Stereo. IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, 2010.
- Gallup, D.; Pollefeys, M.; Frahm, J.M. 3D Reconstruction Using an n-layer Heightmap. DAGM conference on Pattern recognition, Darmstadt, Germany, 2010.
- Oliva , A. and Torralba , A. 2001 . Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope . Int. J. Comput. Vision , 42 ( 3 ) : 145 – 175 .
- Raginsky, M.; Lazebnik, S. Locality Sensitive Binary Codes from Shift-Invariant Kernels. Conference on Neural Information Processing Systems, Vancouver, BC, 2009.
- Raguram, R.; Chum, O.; Pollefeys, M.; Matas, J.; Frahm, J.M. USAC: A Universal Framework for Random Sample Consensus. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012.
- Kaminsky, R.S.; Snavely, N.; Seitz, S.M.; Szeliski, R. Alignment of 3D Point Clouds to Overhead Images. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami Beach, FL, 2009.
- Zheng, E.; Dunn, E.; Raguram, R.; Frahm, J.M. Efficient and Scalable Depthmap Fusion. British Machine Vision Conference, Guildford, UK, 2012.
- Szeliski , R. 2006 . Image Alignment and Stitching: A tutorial . Foundations and Trends in Computer Graphics and Computer Vision , 1 ( 2 ) : 1 – 104 .