
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Semantic segmentation is a crucial method for recognizing and classifying objects in high-resolution remote sensing images (HRRSIs). However, due to the problems of varying target scale and difficulty in determining the edges of small-scale targets in remote sensing images, traditional semantic segmentation models perform poorly. To address this issue, we propose a multi-scale feature enhancement network (MFENet) to improve the segmentation accuracy of small-scale objects in HRRSIs. MFENet considers the differences between objects of different scales and selects more suitable receptive fields to enhance the extraction of multi-scale semantic features. We propose a composite atrous multi-scale feature fusion (CAMFF) module to enhance the extraction of spatial detail and semantic information of features at different scales. In addition, we propose an improved composite atrous spatial pyramid pooling (C-ASPP) module to enhance the network feature extraction capability across multiple scales. We also propose a network structure that combines the C-ASPP module with the efficient channel attention (ECA) module in parallel, which performs better to extract contextual information. Our experimental evaluations on the Potsdam and Vaihingen datasets demonstrate the effectiveness of our Network, It F1 score reaching 93.33% and 94.66% respectively.
1. Introduction
Semantic segmentation of remote sensing images is a classic yet challenging problem in the field of computer vision. This task requires precise classification and annotation of each pixel in an image, with the goal of interpreting the semantic information of each pixel and assigning them specific semantic labels (Guo et al. Citation2018). Remote sensing images obtained through satellite optical imaging sensors can provide a wealth of information about the conditions of the Earth’s surface, which is crucial for environmental monitoring (Alzu’bi and Alsmadi Citation2022), land cover classification (Wang et al. Citation2021), resource exploration (Rajesh Citation2004), road extraction (Zhang, Liu, and Wang Citation2018), scene understanding (Zhao et al. Citation2017, Citation2018 in ECCV Psanet.), and many other fields.
However, remote sensing images are very different from ordinary natural images, and they have unique characteristics. Firstly, the background of remote sensing images is very complex, as shown in , the car and its surrounding environment are coupled to varying degrees. In order to correctly classify them, the network needs to combine contextual semantic information to classify each pixel point. Secondly, the size difference between different objects in remote sensing images is very large, as shown in , the building occupies nearly one-third of the entire image, while the size of the car only occupies dozens of pixels. In order to obtain enough semantic information, the network needs to use an appropriate receptive field to obtain the image features of small-scale objects. It is this complexity that has led to widespread attention on semantic segmentation of remote sensing images and has become a research hotspot.
Figure 1. The remote sensing image samples from the ISPRS potsdam dataset and their corresponding ground truth label maps.

The proposal of the Fully Convolutional Network (FCN) (Long et al. Citation2015; Sun and Wang Citation2018) has pioneered the use of deep learning methods to complete semantic segmentation tasks. The FCN is an improvement of the classification network. Compared with traditional convolutional neural networks, the FCN replaces the fully connected layer with a convolutional layer, allowing the network to handle images of any size. However, as features are extracted continuously, the size of the feature map will continue to decrease, which will lead to the loss of spatial detail information and context information of the image. To address this issue, some scholars use global non-uniform pooling to reduce the loss of contextual information between different regions, while others use spatial pyramid pooling to aggregate semantic information at different scales. For example, GPINet (Li et al. Citation2023 in IEEE 2023b.) utilizes an interaction module to facilitate interaction between CNN features and Transformer features, in order to alleviate the loss of global contextual information. SSCNet (Li et al. Citation2023 in Remote Sensing.) employs a spectral-spatial cooperative attention mechanism to capture global contextual information. DASSN_RSI (Li et al. Citation2021 in International Journal of Remote Sensing.) leverages SLSAM to enhance low-level feature extraction and DLCAM to optimize high-level semantic features, thereby aiding the network in better utilizing semantic information at different scales. SPANet (Li et al. Citation2023 in IEEE 2023a.) simultaneously models spatial and channel correlations, and hierarchically deploys synergistic attention modules between the encoder and decoder to aggregate encoded and decoded features. However, these methods, like FCN, all have the problem of reducing the size of the feature map. Since the network needs enough semantic information, downsampling operations are indispensable. To alleviate this contradiction, existing semantic segmentation networks mainly have two methods: one is to recover the size of the feature map through an decoder, and the other is to alleviate the reduction of the feature map size and ensure the size of the receptive field through dilated convolution.
Therefore, in light of the characteristics of remote sensing images, this paper proposes a multi-scale feature enhancement network (MFENet) that combines these two methods. The MFENet effectively acquires global context information and spatial details information and helps the multi-scale objects being well recognized. We employ a deep convolutional neural network (DCNN) (Krizhevsky et al. Citation2012) with an encoder-decoder structure. Firstly, in the encoder, we use the composite atrous multi-scale feature fusion (CAMFF) module to extract the spatial detail information and semantic information of multi-scale objects (Zhou et al. Citation2019; Tao et al. Citation2020; Gu et al. Citation2022). Second, based on the atrous spatial pyramid pooling (ASPP)(Sullivan and Lu Citation2007) module, the composite atrous spatial pyramid pooling (C-ASPP) module is proposed to better capture the contextual information at multiple scales. Third, we propose a network structure that is parallel to the efficient channel attention (ECA) (Wang et al. Citation2020) module and C-ASPP module. This network structure uses the feature map of the last one of the backbone as input, and then channel fusion the feature maps extracted by the two modules. The ECA module is based on a non-dimension reduction local cross-channel interaction strategy, which effectively avoids the impact of dimension reduction on the learning effect of channel attention. Appropriate cross-channel interaction can significantly reduce the complexity of the model while maintaining performance. In the decoder, we choose the feature map extracted by the CAMFF module as the shallow feature, and use pointwise convolution to adjust the number of channels to reduce the computational burden. In addition, we perform bilinear interpolation and upsampling on the feature maps output by the parallel network structure. Finally, the semantic consistency of the network is enhanced by aggregating the semantic contextual information with low-level feature information.
The main contributions of this paper are as follows:
(1) This parallel network structure can reduce the amount of network parameters and computational complexity while allowing the network to comprehensively consider the relationships between channels and the feature information of different scale targets, thereby improving the network’s performance in handling complex scenes and its ability to capture global contextual information.
(2) We propose a CAMFF module to capture spatial detail information. CAMFF first uses a parallel multi-branch structure with different receptive fields to extract semantic information from feature maps at different stages. Considering the potential feature misalignment issues in the transformed features, we employ skip connections to aggregate low-level features and enhance precise positional information.
(3) We propose an improved C-ASPP module and conduct experiments on two large-scale datasets, Postdam and Vaihingen, from ISPRS. The experimental results demonstrate that our method outperforms other semantic segmentation methods.
2. Related works
Our work for high-resolution remote sensing image semantic segmentation is based on a deep learning multi-scale feature fusion network structure. Therefore, in this section, we will first introduce the mainstream methods of semantic segmentation. Then we will introduce the attention mechanism related to deep learning, and finally, we will introduce the related work of multi-scale feature fusion.
2.1. Methods of semantic segmentation
Thanks to the introduction of FCN, semantic segmentation has achieved remarkable progress in the field of computer vision. Many researchers have explored more complex network structures and training strategies based on this foundation. These methods integrate operations such as feature extraction, upsampling, and downsampling into a single network, enabling end-to-end training and prediction, further improving the accuracy of semantic segmentation. For instance, Yu and Koltun (Citation2015) designed a new convolutional module for dense prediction, which systematically captures multi-scale contextual information without losing resolution. Badrinarayanan et al. (Citation2017) proposed the SegNet model, which builds a encoder-decoder symmetric structure on top of the FCN framework to achieve end-to-end pixel-level image semantic segmentation. The novelty of the model is that the decoder part uses a pooling index corresponding to the encoder, which saves the positional information of the pooling operation and uses it for the up-sampling operation of the decoder. Cheng et al. (Citation2017) proposed a convolutional network with edge-aware capabilities by constructing an edge detection network and a semantic segmentation network based on the SegNet network. The network uses the semantic segmentation network to extract semantic feature information at different scales for the training of the edge detection network, and then uses the edge map in the edge detection network to fine-tune the network. Zhang et al. (Citation2022) designed a collaborative network that can simultaneously solve super-resolution semantic segmentation and super-resolution image reconstruction. The network takes low-resolution images as input and obtains high-resolution segmented images in a simple and efficient way that can replace different branches with most state-of-the-art models.
In addition, due to the large intra-class differences in HRSI, Sang et al. (Citation2020) proposed a FRF-Net network model based on two types of attention mechanisms, which can achieve a complete receptive field to capture long-range semantic information. Liu et al. (Citation2021) proposed a lightweight remote sensing image semantic segmentation network based on an encoder-decoder architecture with an attention mechanism module. The model can not only perform multi-scale feature fusion, but also capture global semantic information through the attention mechanism module. Xu et al. (Citation2020) proposed a feature enhancement feature pyramid (FEFP) structure to integrate contextual information of different scales. (Dong et al. Citation2022) proposed an integrated semantic segmentation network including multi-scale feature fusion and feature enhancement.
The aforementioned methods can effectively extract semantic information and enhance global contextual information. However, they still struggle to handle feature extraction for multi-scale objects, leading to poor segmentation performance for small-scale targets.
2.2. Attention mechanism Related to deep learning
The receptive field (Luo et al. Citation2016) of the convolution operation is limited by the size of the convolution kernel, which only considers local areas, making it difficult to perform global modeling. However, global information is essential for semantic segmentation. In order to solve this problem, numerous existing semantic segmentation methods introduce attention mechanism to compensate for the shortcomings of convolutional neural network, so as to improve the accuracy of semantic segmentation.
Ding et al. (Citation2021) proposed an embedded local attention mechanism that enhances contextual information and incorporates local focus in high-level features, thereby enriching the semantic information of low-level features. Based on the idea of non-local mean filtering operation, Wang et al. (Citation2018) proposed a non-local operation operator that can be directly embedded in the current network, which can capture the long-distance dependencies of the deep neural network, thereby increasing the receptive field of the network. Zhang and Yang (Citation2021) proposed a replacement attention mechanism. This method is based on spatial attention and channel attention, and introduces channel replacement in the feature grouping domain to obtain an ultra-lightweight attention mechanism. Yuan et al. (Citation2023) added a channel attention mechanism optimization module and a fusion module to the decoder to enhance the overall feature information in different dimensions. Zhong et al. (Citation2020) proposed a method that considers two salient features of segmented pixel-group attention and pixel-wise prediction by utilizing an effective squeeze and attention module to efficiently account for the correlation of spatial channels.
2.3. Semantic segmentation with multi-scale feature fusion
Due to the inherent characteristics of convolutional neural network (CNN) (Gu et al. Citation2018; Li et al. Citation2021 in IEEE.), the final output features usually contain a significant amount of semantic information, commonly referred to as’ deep features’. However, these ‘deep features’ have lower resolution and retain less spatial detail information, resulting in subpar segmentation performance for small-scale objects. To address this issue, the concept of multi-scale feature fusion has emerged, which can be achieved through two main modes: image pyramid and feature pyramid.
In the image pyramid mode, different resolution sub-images of the original image are processed to extract features with diverse receptive fields. These features are then fused to complement the spatial detail information missing in the output. For instance, Zhao et al. (Citation2018) proposed a lightweight real-time semantic segmentation network, which introduced a cascade feature fusion unit that progressively restores and refines segmentation using low-level and deep features at a lower computational cost. Liu et al. (Citation2020) fuses low spatial detail information and supplement it into the main network to balance the rich semantic information of deep features with spatial detail information. However, these methods fail to deliver satisfactory performance on small objects. Pang et al. (Citation2019) effectively generate a feature pyramid in a single-stage detection framework, enabling detection across a range of scales.
While image pyramid effectively utilizes various information in remote sensing images, it incurs significant computational overhead due to multi-scale transformations, leading to substantial memory consumption. Thus, the feature pyramid mode was proposed, aiming to fuse features from different resolution levels. This approach handles multi-scale variations with minimal additional computation. He et al. (Citation2015) introduced spatial pyramid pooling, which performs pooling with different stride sizes on the last layer’s feature map before feature fusion, enhancing the model segmentation capabilities for objects of various scales. Lin et al. (Citation2017) proposed the feature pyramid network (FPN), which downsamples the image multiple times and performs predictions at the last layer, but it may not perform well for small object segmentation. Liu et al. (Citation2018) enhances the entire feature hierarchy by adding a bottom-up pathway to the top-down pathway in FPN. Liang et al. (Citation2018) develop a new two-stage detector, at the region proposal stage, they adopt the feature pyramid architecture with lateral connections, which makes the semantic feature of small-scale objects more sensitive.
3. Proposed method
In this section, we introduce the basic framework of MFENet, and then detail our proposed composite atrous multi-scale feature fusion module and the selected attention module.
3.1. The MFENet basic framework
The overall structure of MFENet is shown in , which consists of an encoder and a decoder (the upper and lower dashed boxes in the figure represent the encoder and decoder, respectively).
Figure 2. The MFENet network model framework.
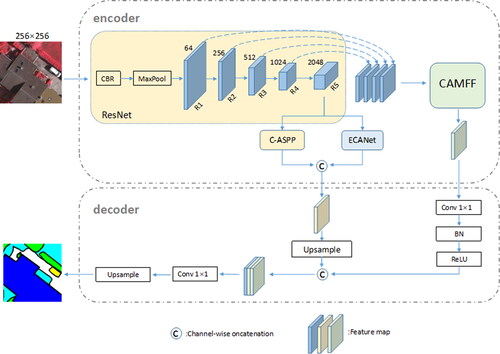
We use ResNet-101 as the main network and remove its pooling layers and all fully connected layers. The five layers of features extracted from the main network are denoted as Ri (i = 1, 2, 3, 4, 5), with the number of channels from the first to the fifth layers being 64, 256, 512, 1024, and 2048, respectively. During encoding, we divide into two branches: one branch uses the CAMFF module to connect adjacent layer features for cross-layer fusion, and the other branch uses the ECA and C-ASPP parallel network structures to enhance global context information. During decoding, we use pointwise convolutions on the output of the CAMFF module to reduce computational burden and for regularization and ReLU activation. Then, we aggregate the output with the parallel network structure. Finally, we use convolution and up-sampling to process the aggregated feature map, adjusting the resolution and the number of channels to serve as the final output of the network.
3.2. The composite atrous multi-scale feature fusion (CAMFF) module
Multi-scale feature fusion involves the extraction of image features using different receptive fields to effectively enhance network performance. Currently, there are mainly two design paradigms for multi-scale feature networks: one employs the skip connection network structure of deep convolutional neural networks (DCNNs) (e.g. MFFTNet), and the other utilizes a parallel multi-branch network structure (e.g. SAPNet).
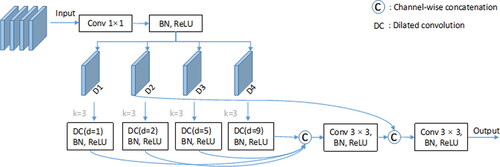
As shown in , based on the parallel multi-branch network structure, we propose the Compound Asymmetric Multi-scale Feature Fusion (CAMFF) module. Before fusing multi-scale features, we use a 1 × 1 convolutional layer combined with Batch Normalization (BN) and ReLU to pre-process the features extracted from ResNet-101, which aims to achieve a unified number of output channels and reduce the number of network parameters. The dilation rate used for dilated convolutions in each branch is denoted as Di(i = 1, 2, 5, 9). In each branch, we employ dilated convolutions with a kernel size of 3 × 3 and combine them with BN and ReLU activation. Then, we connect the outputs of each branch together. Additionally, to enhance the network’s spatial detail information, we use skip connections to fuse low-level and high-level features with the same resolution.
Figure 3. The composite atrous multi-scale feature fusion (CAMFF) module.
3.3. The efficient channel attention (ECA) module
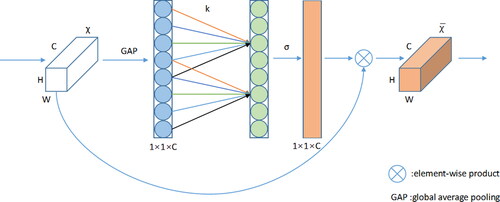
In neural network learning (Hinton Citation1992), it is generally acknowledged that a model with more parameters possesses a stronger expressive ability. However, this also results in an increased number of parameters, which can lead to information overload. To address this issue, the attention mechanism is introduced (Niu et al. Citation2021), focusing on the more critical information of the current task among the numerous input information, while reducing attention to other information or filtering some irrelevant information, which can solve the problem of model parameters, and at the same time can improve the efficiency and accuracy of resistant models. In response to this problem, Wang et al. proposed the ECA channel attention module based on the SE attention mechanism (Hu et al. Citation2018). In the SE attention mechanism, channel compression (Liang et al. Citation2020) is first performed on the input feature information, and such compression and dimensionality reduction have a very adverse effect on learning the dependencies between channels. Therefore, the ECA attention mechanism uses 1D convolution to efficiently realize local cross-channel interaction, and extracts dependencies between channels to avoid dimensionality reduction.
It can be seen from that ECA first performs a global average pooling (GAP) operation on the input feature information, and then uses a one-dimensional convolution operation with a convolution kernel size of 3 × 3, and obtains the weight w of each channel through the Sigmoid activation function, as defined by (1).
(1)
(1)
where CID stands for one-dimensional convolution, and then the weight is multiplied by the element corresponding to the original input feature information to obtain the final output feature information.
Figure 4. The efficient channel attention (ECA) module.
3.4. The CompoundAtrous space pyramid pooling (C-ASPP) module
Hybrid Dilated Convolution (HDC) is a technique in computer vision tasks designed to enhance a network’s ability to learn features at different scales. Its core idea involves incorporating dilated convolutions with varying expansion rates into the convolutional operations, allowing the network to capture finer-grained and longer-range feature information without increasing parameters or computational complexity. In HDC, the expansion rates of consecutive dilated convolutions are set according to the constraints defined by EquationEquation 3(3)
(3) , thereby eliminating the issue of pixel loss that can occur with the consecutive use of dilated convolutions in traditional networks.
(2)
(2)
where Mi is the maximum distance between two non-zero elements in the i-th layer, which represents the maximum dilation rate. ri is the dilation rate of the i-th layer.
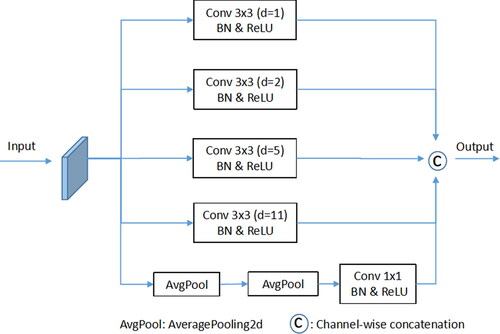
Inspired by HDC, we have proposed an improved C-ASPP module based on the ASPP module, as shown in . The C-ASPP module employs five parallel branches to extract feature information from the image, with the first branch using a 1 × 1 dilated convolution and the remaining four branches using 3 × 3 dilated convolutions. Unlike the ASPP module, we set the expansion rates of the dilated convolutions in the first four branches to 1, 2, 5, and 11, respectively, to enhance the network’s capability to extract features of objects at different scales and to avoid unnecessary interference. Additionally, before the dilated convolution in the last branch, we apply two rounds of average pooling operations. These multiple average pooling operations allow for a more refined capture of the average features of the input data across different dimensions, enabling the network to better understand the distribution of image features.
Figure 5. The compound hole space pyramid pooling (C-ASPP) module.
4. Experimental results
To demonstrate the superiority of the proposed MFENet in semantic segmentation of high-resolution remote sensing images, the Vaihingen and Potsdam datasets of the ISPRS International Society for Photogrammetry and Remote Sensing are used in our experiments. We conduct ablation experiments on the Vaihingen dataset and compare MFENet with other state-of-the-art semantic segmentation networks on the Potsdam and Vaihingen datasets.
4.1. Datasets introduction
Both the Potsdam and Vaihingen datasets label the six most common land cover (land use) categories, including impervious surface (Imp. Sur.), building, low vegetation (Low veg.), tree, car, and clutter. The details of these two datasets are shown in .
Table 1. Datasets settings.
4.1.1. The Potsdam dataset
The Potsdam dataset is a high-resolution airborne image dataset collected over the city of Potsdam, which is a typical historical city with many large buildings. It contains 38 aerial images with an image size of 6000 × 6000 pixels, and the ground sampling distance of each image is 5 cm. Like the Vaihingen dataset, the Potsdam dataset also provides TOP and DSM. Similarly, we only use TOP images, and use the sliding window cropping method to cut the 24 images into slices with a size of 512 × 512 pixels, of which 4/5 are used as training sets and 1/5 are used as test sets. With an overlap of 256 pixels when cropping, the last 10156 and 2397 slices are used for training and testing, respectively.
4.1.2. The Vaihingen dataset
The Vaihingen dataset recorded a relatively small village, which has many individual buildings. The dataset contains 33 aerial images of different sizes, and the image size ranges from 1996 × 1995 to 3816 × 2550 pixels. The ground sampling distance of the real image TOP (including IR (infrared), R (red), and G (green)) is 9 cm. In addition, the digital surface model (DSM) used to measure the distance between the object surface and the camera is also included in this dataset. In this experiment, due to hardware limitations, we use the sliding window cropping method to crop the 12 aerial images in TOP into slices with a size of 256 × 256 pixels. In addition, in order to avoid the problem of overfitting (the model is highly dependent on the training set and does not perform well on the test set) (Ying Citation2019), the data set is divided into a training set and a test set, and the division ratio is 5:1. In order to avoid the influence of cropping operation, an overlap of 128 pixels is used when cropping. Finally, 10113 and 2529 slices are obtained for training and testing respectively.
4.2. Experiment settings and evaluation metrics
Our network model and other comparative experiments (shown ) run on high performance computing (HPC) resource NVIDIA GTX 1080Ti GPU (11 GB RAM) and use Cuda 11.5 for accelerated computation by applying Pytorch (Paszke et al. Citation2017) deep learning framework. The network is divided into two phases during operation: the freezing phase and the unfreezing phase. During the freezing stage, the weights of the backbone network, which is ResNet-101, are fixed. This means that only the training is conducted on the proposed MEFNet network (excluding the backbone network), which helps prevent overfitting and save computing resources. In the thawing stage, all parameters of the MFENet network, including the weights of the backbone network, will be updated, thereby enhancing the network’s performance on the target task. In addition, the maximum number of iterations of the model is 100, and the learning rate (Loshchilov and Hutter Citation2016) update strategy is defined by (3).
(3)
(3)
Table 2. Experiment settings.
Where nt represents the learning rate, nmax represents the maximum learning rate of 5e-4, nmin represents the minimum learning rate of 5e-6, Tcur and Tmax represent the current number of iterations and the maximum number of iterations, respectively. We use the Adam optimizer (Zhang Citation2018) with momentum = 0.9 to train the model.
We use common evaluation metrics in semantic segmentation, including precision, recall, F1 score, and Mean intersection over Union (mIoU), to evaluate the performance of our proposed method.
(4)
(4)
(5)
(5)
(6)
(6)
(7)
(7)
(8)
(8)
where TP (True Positive) indicates that the actual pixel is positive, and the prediction is also positive, that is, the prediction is correct. TN (True Negative) means that the actual is negative, and the prediction is also negative. FN (False Negative) means that the prediction was false, but it was actually true. FP (False Positive) means that the prediction was positive, but it was actually negative.
4.3. Experimental results and analysis
In this section, we evaluate the effectiveness of the proposed MFENet method and present experimental results of the method on two datasets from ISPRS. In addition, compare with FCN-8s, DeepLab-V3 (Chen et al. Citation2017), LRASPP (Howard et al. Citation2019), SegNet, DANet (Fu et al. Citation2020), CMTFNet (Wu et al. Citation2023), DeepLab-V3plus and other networks. At the same time, for a fair comparison, all methods compared in this paper were re-run experiments using the hyperparameters listed in the study to ensure that the purpose of the control variable experiment was achieved. For ease of analysis, the best results in the table below are highlighted in bold.
4.3.1. Numerical results
The quantitative results of the experiments are shown in and . It can be observed from these tables, it can be observed that our proposed method achieves significant performance improvement compared to existing semantic segmentation methods. On the Potsdam dataset, our model MFENet achieves F1 and mIoU scores of 93.33% and 87.60% respectively, which are 0.80% and 1.34% higher than the best-performing CMTFNet method. Moreover, on the Vaihingen dataset, MFENet shows even more significant improvement compared to other methods. MFENet achieves F1 and mIoU scores of 94.66% and 90.12% respectively, which are 0.89% and 1.69% higher than the best-performing CMTFNet. This demonstrates that our model effectively enhances the ability of the network in global contextual information extraction and spatial detail information retention through the jump-connected multi-scale feature fusion technique, which significantly improves the semantic segmentation performance of the model.
Table 3. Results evaluated by recall (%), precision (%), F1 (%) and mIoU(%) on the Potsdam dataset.
Table 4. Results evaluated by recall (%), precision (%), F1 (%) and mIoU(%) on the Vaihingen dataset.
and represent the IoU accuracy of each method in each category on the Potsdam and Vaihingen datasets, respectively. It can be observed from the tables that the category Building performs better in accuracy among each method. However, due to the continuous downsampling operations in traditional semantic segmentation models, the spatial details of small-scale objects are lost, leading to poor segmentation results for irregularly shaped and similarly colored small-scale objects such as cars, trees, and low vegetation. The use of the lightweight MobileNet as the backbone network in LRASPP leads to a weaker feature extraction capability, making it difficult to effectively extract semantic information about small-scale targets. As a result, the network achieves a relatively low IoU score of only 39.86% on the vehicle category in the Vaihingen dataset, indicating its shortcomings in small object segmentation. In the Vaihingen dataset, although our MFENet model achieved an IoU score of only 76.54% on the Car category, which is 6.43% lower than CMTFNet, our method outperformed CMTFNet on the Imp. Sur, Building, Tree, and Low veg categories, especially achieving a 6.24% higher IoU score on the Low veg category. This indicates that the MFENet model is overly focused on the feature information of multi-scale targets, while the extraction of contextual information for occluded targets (e.g. vehicles obscured by trees) is insufficient, thus affecting the segmentation performance. In our future work, we plan to further optimize the MFENet model to better balance the extraction of multi-scale target feature information and contextual information, thereby improving the segmentation performance for occluded targets.
Table 5. IoU Scores (%) of each category on the Potsdam dataset.
Table 6. IoU Scores (%) of each category on the Vaihingen dataset.
4.3.2. Visual results
In order to observe the segmentation results of different methods for these two data sets more intuitively, we selected 4 images from the validation sets of Potsdam and Vaihingen for evaluation, and each image was sent to our proposed method and other comparison models. The predicted results are shown in and , respectively.
Figure 6. The visualization of comparing methods on the potsdam dataset.(the white circles emphasise the most significant differences.).
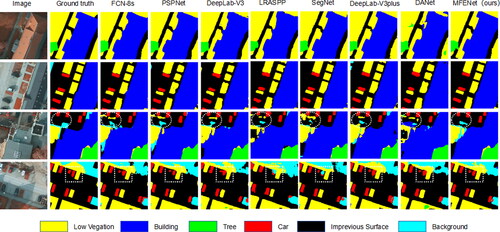
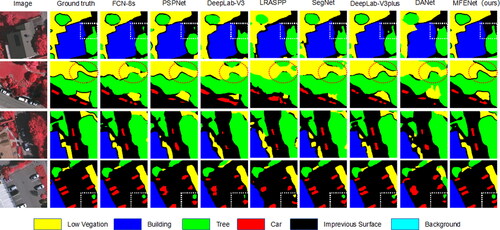
Figure 7. The visualization of comparing methods on the vaihingen dataset.(the red circles and white boxes emphasise the most significant differences.).
shows the visualization of different models for Potsdam dataset segmentation. From the figure, we can observe that different models have the better segmentation effect for the Building category. This is because most buildings have neater boundaries and are therefore easier to identify and segment. It is worth noting that our proposed method performs the best in segmenting small-scale objects and is closer to the ground truth label map. Careful observation shows that MFENet can better segment the boundary and shape of Car. Additionally, many models are indistinguishable for the two due to occlusion by buildings and the fact that low vegetation grows mostly around impervious surfaces. Moreover, due to the irregularity of the low-vegetation boundary, this undoubtedly increases the difficulty of the semantic segmentation model for this category. In the visualization result image of the third row in , as indicated by the white circle, our proposed method performs better on low vegetation, it does not misclassify impervious surfaces as low vegetation compared to other methods.
presents the visualization results of different models on the Vaihingen dataset. From the Image column of the figure, it can be observed that due to many cars parked under trees, the leaves obstruct the recognition of cars, making it more challenging for the model. As shown in the red circles in the figure, our method performs better than other methods in road extraction, effectively distinguishing low vegetation from trees. In the white box in the bottom right corner, we can see that the visualisation results of our model in the category of cars are extremely similar to the state-of-the-art algorithm CMTFNet, except that there are still some gaps in the prediction of the boundaries, but it performs better than the rest of the algorithms in terms of prediction results. This also shows that our model is able to identify multi-scale targets effectively by focusing on global contextual information as well as jump connection fusion of shallow feature information, but there is still room for improvement in edge prediction.
4.4. Ablation experiments
In order to further demonstrate the effectiveness of our proposed network model and modules, we conducted ablation experiments on the Vaihingen dataset. The experiment employs F1 and mIoU as evaluation metrics to quantitatively analyze the effectiveness of each module. There are three components: composite atrous spatial pyramid pooling (C-ASPP) module, enhanced channel attention (ECA) module and composite atrous multi-scale feature fusion (CAMFF) module. We adopted DeepLab-V3plus with a ResNet101 backbone as the baseline. Based on this, we validated the effectiveness of each module by individually or simultaneously adding them. The results of the ablation experiment are shown in .
Table 7. The ablation experiment results on the vaihingen dataset using mIoU(%) and F1(%) as metrics.
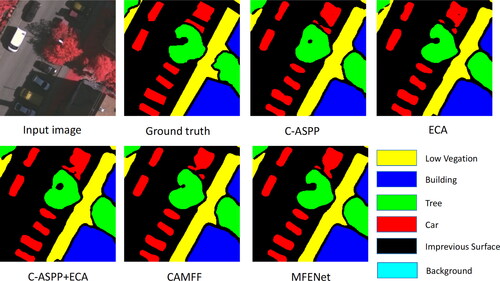
From , it can be observed that the performance of the baseline network improves after incorporating the three modules. Compared with the baseline, when only using the C-ASPP module, mIoU and F1 increased by 0.72% and 0.43% respectively. When only using the ECA module in parallel with ASPP, compared with the baseline, mIoU and F1 increased by 1.19% and 0.72% respectively. When the two modules are integrated, the mIoU score increased by 1.44%, and the F1 score increased by 0.87%. The collaborative work of the C-ASPP and ECA modules is more beneficial to the improvement of model performance. When only using the CAMFF module, the model performance significantly improved, the mIoU score increased by 2.1%, and the F1 score increased by 1.27%. Compared to the parallel network structure using the high-performance C-ASPP and ECA modules, the mIoU score of the network using only the CAMFF module increased by 0.66%. This is because the C-ASPP and ECA modules mainly focus on enhancing global contextual information, while the CAMFF module effectively extracts semantic information of objects at different scales through its multi-branch structure and performs cross-scale feature fusion to better handle multi-scale objects. Therefore, the combination of the CAMFF module with the C-ASPP and ECA modules in a parallel network structure, known as the MFENet method, can integrate global contextual information and semantic information of multi-scale objects, further improving semantic segmentation performance. In addition, we visualize the results of the above ablation experiments, as shown in .
Figure 8. The visualization of ablation experiment on the Vaihingen dataset.
4.4.1. Composite atrous spatial pyramid pooling module
To evaluate the effectiveness of different expansion rates of hole convolution based on the HDC principle in the C-ASPP module, we conducted experiments based on DeepLab-V3plus. From , it can be observed that when the expansion rate is (1, 2, 5, 11), it is the most suitable receptive field for multi-scale object feature extraction, achieving the best performance with an mIoU score of 87.87% and an F1 score of 93.34%. As the expansion rate gradually increases or decreases, the network performance deteriorates. Therefore, the adopted expansion rate for hole convolution in the C-ASPP module is (1, 2, 5, 11).
Table 8. The ablation experiment evaluated the C-ASPP module with different dilation rates on the vaihingen dataset using mIoU(%) and F1(%) as metrics(in square brackets is expansion rate of C-ASPP).
4.4.2. Enhanced channel attention module
shows the parallel and serial structures of ECA with the ASPP module. To evaluate the performance of these two structures, we conducted experiments based on DeepLab-V3plus. From , it can be observed that both the parallel and serial structures of ECA with ASPP have a positive impact on the performance of the baseline (mIoU score of 87.15% and F1 score of 92.91%). The serial structure has a minimal improvement, with only a 0.26% increase in mIoU and a 0.1% increase in F1 score compared to the baseline. In contrast, the parallel structure shows better performance in improving the baseline, with a 1.19% increase in mIoU and a 0.72% increase in F1 score.Therefore, the network structure of ECA and ASPP in parallel helps the network to understand the global semantic information and the dependencies between the channels, and avoids the problem of double computation caused when they are connected in series.
Figure 9. The parallel (a) and serial (b) structures of ECA with the ASPP module.
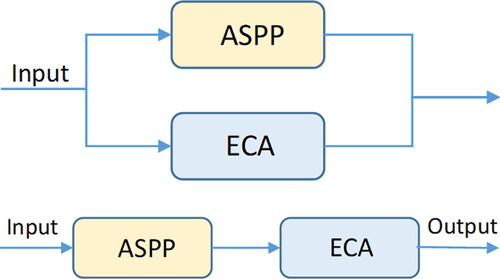
Table 9. The ablation experiment evaluated the ECA module on the vaihingen dataset using mIoU(%) and F1(%) as metrics.
5. Conclusions
In this paper, we propose MFENet for semantic segmentation of high-resolution remote sensing images, which is a -multiscale feature fusion model based on the architecture of FCN. Considering the characteristics of high-level and low-level features, we propose CAMFF to fully learn global features and fuse spatial detail information. Then, we propose C-ASPP to learn the semantic feature information of multi-scale targets. In addition, we introduce ECA and concatenate it with the C-ASPP module to reduce the impact of redundant information on the model and to improve the understanding of the global semantic information.Extensive results on the ISPRS Vaihingen and Potsdam datasets confirm that the proposed MFENet achieves excellent performance compared to state-of-the-art segmentation methods.
Although the proposed MFENet achieves a good acquisition ability of semantic context and spatial detail information, there is still room for improvement. At present, the input features of the CAMFF module are large, which makes the computing cost of our proposed method high. In addition, there should be a more effective combination of spatial detail information of multi-scale targets and semantic information of deep features. Therefore, our future work will focus on further optimizing the CAMFF module, reducing model parameters while maintaining its performance, and explore the possibilities of multimodal fusion. We will attempt to fuse data from other modalities, such as LiDAR and SAR, with optical remote sensing images to enhance the model’s comprehensive understanding of the scene.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alzu’bi A, Alsmadi L. 2022. Monitoring deforestation in Jordan using deep semantic segmentation with satellite imagery. Ecol Inf. 70:101745. doi: 10.1016/j.ecoinf.2022.101745.
- Badrinarayanan V, Kendall A, Cipolla R. 2017. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell. 39(12):2481–2495. doi: 10.1109/TPAMI.2016.2644615.
- Chen L-C, Papandreou G, Schroff F, Adam H. 2017. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:170605587.
- Cheng D, Meng G, Xiang S, Pan C. 2017. FusionNet: edge aware deep convolutional networks for semantic segmentation of remote sensing harbor images. IEEE J Sel Top Appl Earth Observations Remote Sensing. 10(12):5769–5783. doi: 10.1109/JSTARS.2017.2747599.
- Ding L, Tang H, Bruzzone L. 2021. LANet: local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans Geosci Remote Sensing. 59(1):426–435. doi: 10.1109/TGRS.2020.2994150.
- Dong Z, An S, Zhang J, Yu J, Li J, Xu D. 2022. L-unet: a landslide extraction model using multi-scale feature fusion and attention mechanism. Remote Sensing. 14(11):2552. doi: 10.3390/rs14112552.
- Fu J, Liu J, Jiang J, Li Y, Bao Y, Lu H. 2020. Scene segmentation with dual relation-aware attention network. IEEE Trans Neural Netw Learn Syst. 32(6):2547–2560. doi: 10.1109/TNNLS.2020.3006524.
- Gu J, Kwon H, Wang D, Ye W, Li M, Chen Y-H, Lai L, Chandra V, Pan DZ. 2022. Multi-scale high-resolution vision transformer for semantic segmentation. https://openaccess.thecvf.com/content/CVPR2022/html/Gu_Multi-Scale_High-Resolution_Vision_Transformer_for_Semantic_Segmentation_CVPR_2022_paper.html
- Gu J, Wang Z, Kuen J, Ma L, Shahroudy A, Shuai B, Liu T, Wang X, Wang G, Cai J, et al. 2018. Recent advances in convolutional neural networks. Pattern Recognit. 77:354–377. doi: 10.1016/j.patcog.2017.10.013.
- Guo Y, Liu Y, Georgiou T, Lew MS. 2018. A review of semantic segmentation using deep neural networks. Int J Multimed Info Retr. 7(2):87–93. doi: 10.1007/s13735-017-0141-z.
- He K, Zhang X, Ren S, Sun J. 2015. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell. 37(9):1904–1916. doi: 10.1109/TPAMI.2015.2389824.
- Hinton GE. 1992. How neural networks learn from experience. Sci Am. 267(3):144–151. doi: 10.1038/scientificamerican0992-144.
- Howard A, Sandler M, Chu G, Chen L-C, Chen B, Tan M, Wang W, Zhu Y, Pang R, Vasudevan V, et al. 2019. Searching for mobilenetv3. https://openaccess.thecvf.com/content_ICCV_2019/html/Howard_Searching_for_MobileNetV3_ICCV_2019_paper.html
- Hu J, Shen L, Sun G. 2018. Squeeze-and-excitation networks. https://openaccess.thecvf.com/content_cvpr_2018/html/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.html
- Krizhevsky A, Sutskever I, Hinton GE. 2012. Imagenet classification with deep convolutional neural networks. Adv Neural Inform Process Syst. 25.
- Li X, Xu F, Liu F, Lyu X, Tong Y, Xu Z, Zhou J. 2023. A synergistical attention model for semantic segmentation of remote sensing images. IEEE Trans Geosci Remote Sensing. 61:1–16. doi: 10.1109/TGRS.2023.3243954.
- Li X, Xu F, Lyu X, Gao H, Tong Y, Cai S, Li S, Liu D. 2021. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int J Remote Sens. 42(9):3583–3610. doi: 10.1080/01431161.2021.1876272.
- Li X, Xu F, Yong X, Chen D, Xia R, Ye B, Gao H, Chen Z, Lyu X. 2023. SSCNet: a spectrum-space collaborative network for semantic segmentation of remote sensing images. Remote Sensing. 15(23):5610. doi: 10.3390/rs15235610.
- Li Z, Liu F, Yang W, Peng S, Zhou J. 2021. A survey of convolutional neural networks: analysis, applications, and prospects. IEEE Trans Neural Netw Learn Syst. 33(12):6999–7019. doi: 10.1109/TNNLS.2021.3084827.
- Liang J, Zhang T, Feng G. 2020. Channel compression: rethinking information redundancy among channels in CNN architecture. IEEE Access. 8:147265–147274. doi: 10.1109/ACCESS.2020.3015714.
- Liang Z, Shao J, Zhang D, Gao L. 2018. Small object detection using deep feature pyramid networks. https://link.springer.com/chapter/10.1007/978-3-030-00764-5_51
- Lin T-Y, Dollr P, Girshick R, He K, Hariharan B, Belongie S. 2017. Feature pyramid networks for object detection. https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html
- Liu S, Cheng J, Liang L, Bai H, Dang W. 2021. Light-weight semantic segmentation network for UAV remote sensing images. IEEE J Sel Top Appl Earth Observations Remote Sensing. 14:8287–8296. doi: 10.1109/JSTARS.2021.3104382.
- Liu S, Qi L, Qin H, Shi J, Jia J. 2018. Path aggregation network for instance segmentation. https://openaccess.thecvf.com/content_cvpr_2018/html/Liu_Path_Aggregation_Network_CVPR_2018_paper.html
- Liu Z, Gao G, Sun L, Fang L. 2020. IPG-net: image pyramid guidance network for small object detection. https://openaccess.thecvf.com/content_CVPRW_2020/html/w69/Liu_IPG-Net_Image_Pyramid_Guidance_Network_for_Small_Object_Detection_CVPRW_2020_paper.html
- Long J, Shelhamer E, Darrell T. 2015. Fully convolutional networks for semantic segmentation. https://openaccess.thecvf.com/content_cvpr_2015/html/Long_Fully_Convolutional_Networks_2015_CVPR_paper.html
- Loshchilov I, Hutter F. 2016. Sgdr: stochastic gradient descent with warm restarts. arXiv preprint arXiv:160803983.
- Luo W, Li Y, Urtasun R, Zemel R. 2016. Understanding the effective receptive field in deep convolutional neural networks. Adv Neural Inform Process Syst. 29.
- Niu Z, Zhong G, Yu H. 2021. A review on the attention mechanism of deep learning. Neurocomputing. 452:48–62. doi: 10.1016/j.neucom.2021.03.091.
- Pang Y, Wang T, Anwer RM, Khan FS, Shao L. 2019. Efficient featurized image pyramid network for single shot detector.
- Paszke A, Gross S, Chintala S, Chanan G, YE, DeVito Z, Lin Z, Desmaison A, Antiga L, Lerer A. 2017. Automatic differentiation in pytorch.
- Rajesh HM. 2004. Application of remote sensing and GIS in mineral resource mapping-An overview. J Mineral Petrol Sci. 99(3):83–103. doi: 10.2465/jmps.99.83.
- Sang Q, Zhuang Y, Dong S, Wang G, Chen H. 2020. FRF-Net: land cover classification from large-scale VHR optical remote sensing images. IEEE Geosci Remote Sensing Lett. 17(6):1057–1061. doi: 10.1109/LGRS.2019.2938555.
- Sullivan A, Lu X. 2007. ASPP: a new family of oncogenes and tumour suppressor genes. Br J Cancer. 96(2):196–200. doi: 10.1038/sj.bjc.6603525.
- Sun W, Wang R. 2018. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci Remote Sensing Lett. 15(3):474–478. doi: 10.1109/LGRS.2018.2795531.
- Tao A, Sapra K, Catanzaro B. 2020. Hierarchical multi-scale attention for semantic segmentation. arXiv preprint arXiv:200510821.
- Wang J, Zheng Z, Ma A, Lu X, Zhong Y. 2021. LoveDA: a remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv preprint arXiv:211008733.
- Wang P, Chen P, Yuan Y, Liu D, Huang Z, Hou X, Cottrell G. 2018. Understanding convolution for semantic segmentation. https://ieeexplore.ieee.org/abstract/document/8354267
- Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. 2020. ECA-Net: efficient channel attention for deep convolutional neural networks. https://openaccess.thecvf.com/content_CVPR_2020/html/Wang_ECA-Net_Efficient_Channel_Attention_for_Deep_Convolutional_Neural_Networks_CVPR_2020_paper.html
- Wang X, Girshick R, Gupta A, He K. 2018. Non-local neural networks. https://openaccess.thecvf.com/content_cvpr_2018/html/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.html
- Wu H, Huang P, Zhang M, Tang W, Yu X. 2023. CMTFNet: CNN and multiscale transformer fusion network for remote sensing image semantic segmentation. IEEE Trans Geosci Remote Sensing. 61:1–12. doi: 10.1109/TGRS.2023.3314641.
- Xu Z, Zhang W, Zhang T, Li J. 2020. HRCNet: high-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sensing. 13(1):71. doi: 10.3390/rs13010071.
- Ying X. 2019. An overview of overfitting and its solutions. https://iopscience.iop.org/article/10.1088/1742-6596/1168/2/022022/meta
- Yu F, Koltun V. 2015. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:151107122.
- Yuan M, Ren D, Feng Q, Wang Z, Dong Y, Lu F, Wu X. 2023. MCAFNet: A multiscale channel attention fusion network for semantic segmentation of remote sensing images. Remote Sensing. 15(2):361. doi: 10.3390/rs15020361.
- Zhang Q, Yang G, Zhang G. 2022. Collaborative network for super-resolution and semantic segmentation of remote sensing images. IEEE Trans Geosci Remote Sens. 60:1–12. doi: 10.1109/TGRS.2021.3099300.
- Zhang Q-L, Yang Y-B. 2021. Sa-net: shuffle attention for deep convolutional neural networks. https://ieeexplore.ieee.org/abstract/document/9414568
- Zhang Z. 2018. Improved adam optimizer for deep neural networks. https://ieeexplore.ieee.org/abstract/document/8624183
- Zhang Z, Liu Q, Wang Y. 2018. Road extraction by deep residual u-net. IEEE Geosci Remote Sensing Lett. 15(5):749–753. doi: 10.1109/LGRS.2018.2802944.
- Zhao H, Qi X, Shen X, Shi J, Jia J. 2018. Icnet for real-time semantic segmentation on high-resolution images. https://openaccess.thecvf.com/content_ECCV_2018/html/Hengshuang_Zhao_ICNet_for_Real-Time_ECCV_2018_paper.html
- Zhao H, Shi J, Qi X, Wang X, Jia J. 2017. Pyramid scene parsing network. https://openaccess.thecvf.com/content_cvpr_2017/html/Zhao_Pyramid_Scene_Parsing_CVPR_2017_paper.html
- Zhao H, Zhang Y, Liu S, Shi J, Loy CC, Lin D, Jia J. 2018. Psanet: point-wise spatial attention network for scene parsing. http://openaccess.thecvf.com/content_ECCV_2018/html/Hengshuang_Zhao_PSANet_Point-wise_Spatial_ECCV_2018_paper.html
- Zhong Z, Lin ZQ, Bidart R, Hu X, Daya IB, Li Z, Zheng W-S, Li J, Wong A. 2020. Squeeze-and-attention networks for semantic segmentation. http://openaccess.thecvf.com/content_CVPR_2020/html/Zhong_Squeeze-and-Attention_Networks_for_Semantic_Segmentation_CVPR_2020_paper.html
- Zhou Z, Siddiquee MMR, Tajbakhsh N, Liang J. 2019. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans Med Imaging. 39(6):1856–1867. doi: 10.1109/TMI.2019.2959609.