
ABSTRACT
This note starts with a retrospective view of the CDM model [Crépon, Bruno, Emmanuel Duguet, and Jacques Mairesse. 1998. “Research, Innovation and Productivity: An Econometric Analysis at the Firm Level.” Economics of Innovation and New Technology 7 (2): 115–158.] as an econometric framework for studying innovation and growth. A narrative interpretation of CDM describes the chain from innovative activity at firms to increases in welfare and makes links to the policy environment. Filling in missing pieces of the innovation to productivity puzzle has a heavy data burden. The paper makes use of the micro moments database (MMD) that allows observing micro-level behavior and macro-level impacts of innovation and production in a large selection of European countries. Two examples are given of research using the MMD. First, we estimate a simplified system of innovation and production equations that can be applied to average firm choices and outcomes, as well as to industry or aggregate outcomes. We find that innovative activity contributes to aggregate productivity even while the average effect at the firm level is insignificant. Next, a cross-country exploration is made that shows heightened productivity effects of combined use by firms of various enterprise-level information and communications technologies.
Introduction
Economists have been whittling away at the unknown drivers of productivity growth, leaving the process of innovation at the core. That is not to say that everything is known about capital accumulation, demography, education, and institutions, but much remains to be learned by exploring the many facets of innovation. In this issue of EINT, many papers display the progress made in our understanding of innovation since the seminal contribution of Crépon, Duguet, and Mairesse (Citation1998), henceforth CDM. The paper of Broström and Karlsson (Citation2016), for example, delves more deeply into the antecedents of CDM, providing a nice history of innovation in the study of innovation economics. In this paper, we broaden the scope of research using the CDM framework in two directions. First, we expand the use of CDM to make statements not just about firm-level impacts of innovation, but also about aggregate impacts. Next, we expand the definition of innovative activity by exploring innovative aspects of enterprise usage of information and communication technology (ICT). These two types of analysis have become possible through use of the novel Micro Moments Database (MMD) that has information built up from confidential linked firm-level surveys on production, innovation, and ICT usage for a set of 14 European countries.
The CDM model has proven to be a robust framework for empirical applications, but also can be seen as a narrative for describing the chain through which societies allocate resources to innovative activities in exchange for ultimate contributions to welfare that derive from improved products and production processes made possible by innovative output. In this guise, the CDM model can serve, with appropriate data, as a method to evaluate policy that impacts upon the various links in the innovation chain.
The long chain of events from decisions to undertake innovative activity to future benefits provides a treasure trove of research questions for economists. The main one, however, is simply stated: What are the social returns to innovative activity (Jones and Williams Citation1998)? For Crépon, Duguet, and Mairesse (Citation1998), who use firm-level information on innovation inputs, throughputs, and output, the main questions were: What is the return to innovative activity at the firm level? Related, what are the determinants and impediments to conducting innovative activity at the firm level? In this paper, with these questions in mind, we will describe the myriad causal links that make answering these questions difficult. We will attempt to answer the questions using a novel dataset that combines information from confidential firm-level data from multiple countries in a way that allows tracking micro-level innovative actions and macro outcomes.
Typically, the CDM approach looks at firm-level decisions, providing estimates of production functions, factor input decisions, innovative activity, and choice of technology. These decisions however take place in a market environment: the firm has interactions with other firms in own, downstream, and upstream sectors, and interactions on labor and capital markets, all taking place given a local institutional and policy environment. The aggregate outcomes of innovative activity undertaken at the firm-level thus depend not only on what innovative output the firm produces, but more importantly how the market rewards the innovation compared with other possible suppliers. This market selection mechanism itself is likely to play an important role in firm-level decisions. The data used in this paper, the MMD, contain information on average firm behavior as well as indicators of resource allocation needed to track firm decisions and macro outcomes.
The organization of this paper is as follows. First, we provide a narrative of the CDM model, along with the features of each equation of the model system. We also describe which questions are answered, and which are more difficult to address. The paper provides two examples of empirical research in the spirit of CDM that can be undertaken with the MMD. In the first example, we explore innovation and productivity from firms and industries in a cross-country context. Next, we look at complementarity between different enterprise ICT strategies. We conclude with some reflections on our remaining ignorance.
CDM: an innovative narrative
The steps in the innovation chain are depicted in .Footnote1 The first step – using innovative inputs to conduct innovative activity – is shown on the left side. This is captured in the innovative activity or innovation adoption equations of the CDM model. After having a vision that something is missing in the stock of knowledge, some people do some heavy lifting to complete the picture. The activity is preceded by a decision on which innovative activities to undertake or in which type of intangible assets to invest. R&D spending on technical innovation has been the focus of the earliest literature (Griliches Citation1979), but the scope of activities that are thought to build knowledge stocks that provide flows of service to future production has been expanded. For example, intangible investments in the System of National Accounts include software and databases, and recent authors (Corrado and Hulten Citation2010) propose considering business organization, design, marketing, and customer support as innovative activities.
Figure 1. The CDM approach.
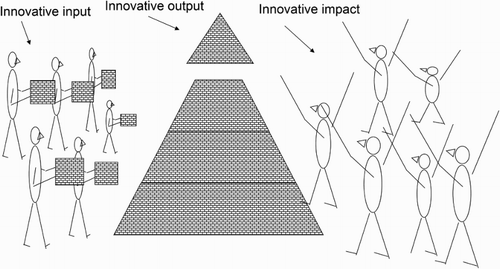
From the point of view of the entity undertaking the innovative activity, many further questions remain after deciding in which intangibles to invest. First, a decision needs to be made how much to invest, based upon balancing private costs and benefits. For benefits, the investor needs to have an opinion about the distribution of technological outcomes of the investment. Next, conditional on technological outcome a calculation must be made of the value of the stream of benefits. On the cost side, the market for skilled workers and the availability and price of financing (Mohnen et al. Citation2008; Hall and Lerner Citation2009) play a role.
Finally, even if we have a good understanding of the private decision making for innovative activity, the non-rival nature of intangible capital potentially generates a wedge between public and private returns. First, public returns may outstrip private returns because the use of the innovation by others may not be fully appropriable by the investor. Next, the stock may provide intertemporal spill-overs in the sense that future innovators may have a higher marginal product owing to earlier knowledge. Conversely, it may become more difficult to generate innovations if the existing stock is high. Another source of negative externalities may come from ‘stepping on toes’, where firms attempt to achieve first mover advantage or lock-in effects by socially excessive R&D or patent races.Footnote2
The role of demand has been underexposed in the innovation literature until recently. The main question of optimality of innovative investment requires a metric to measure innovative output. As shown in the middle of , the pyramid is no more than a pile of stones unless it is appreciated by customers or users, on the right-hand side. From an economist’s point of view, the invention of a technologically advanced widget that is not used does not generate any marginal benefit.Footnote3 In the CDM framework, the output of the innovative investment is measured by patent counts or by the share of sales from innovative products. The latter thus captures whether the innovation has led to something that customers want to buy. With the patent counts, the value of the innovation can be proxied by the willingness of firms to pay the patent application and/or renewal fee (Griliches, Hall, and Pakes Citation1991).
In the CDM approach, the drivers of innovative output are captured by an equation that explains either the count of patents or share of innovative sales. The explanatory variables usually are the latent ‘innovativeness’ from the innovative input equation and the variables for demand pull and technology push, but exclude information on market share and diversification that were included in the innovative activity equation.
The overall impact of innovative activity is shown on the right side of . Once the innovative output is in place, the production function takes over and uses the knowledge to either improve the efficiency through which primary inputs are turned into desired goods and services, or to improve the value that users attach to the goods and services, or both. The workhorse specification is the augmented production function, as described in the production function equation of the original CDM paper. The ultimate impact is thus measured by estimating whether on average firm-level productivity is higher for firms with more (predicted) innovative output.
Much of the novelty in the CDM approach was in the econometric methods used to estimate the complete system of equations. Known issues of selection bias and endogeneity of factor inputs have been dealt with in the past 15 years. More recently, progress is being made on the mismeasurement of impact of innovation through changes in mark-ups. As mentioned by Hall and Mairesse (Citation2006), estimates of the impact of process innovation often are insignificant because positive benefits may pass to the demand side through lower mark-ups and thus result in lower measured revenue-productivity. Based on work by Klette and Griliches (Citation1996), Martin (Citation2008), and De Loecker (Citation2011), effort is being made to estimate mark-ups along with typical output elasticities.
Single-country firm-level panels have been used with considerable success in the literature to estimate the system of equations of the CDM model. One drawback with single-country panels is that it is difficult to find sufficient exogenous variation to estimate the effect of policy changes, for example, a change in R&D subsidies. Identification requires defining appropriate control groups, for example through regression discontinuity owing to thresholds built into subsidy rules, or through finding valid instruments. Identification of the effect of policy shifts becomes easier with country-industry panels, such as EUKLEMS (www.euklems.net), but then one loses the ability to track the mechanisms in the innovation chain at the firm level. By contrast, the basic CDM framework together with a dataset incorporating firm-level and industry-level information for a selection of countries over time could be used to answer many of the open questions. For understanding firm incentives to conduct innovative activity, one could look at firm specific variables, but also at market conditions and country-specific institutional and regulatory environment, where the cross-country variation in timing of policy changes can help identification. For measuring private returns, one can look at firm performance while controlling for industry and country conditions. Finally, cross-country firm-level panel data can help inform how aggregate industry performance depends on innovative activity at all firms and on market selection of successful innovations. However, such cross-country firm-level data are not available, for reasons of confidentiality. The difficulty in analyzing cross-country firm-level data in conjunction with the corresponding industry and macro time-series is what has led to the creation of the methodology of distributed micro-data analysis, and the publication of the MMD.
Micro moments database
Setting up firm-level datasets for multi-country research is difficult and costly because most of the firm-level information that is collected by national statistical agencies is confidential. This means that the legal framework protecting the data does not allow for direct analysis on a merged cross-country firm-level dataset. In the past decade, several projects have been using the method of distributed micro-data analysis as developed by Bartelsman, Haltiwanger, and Scarpetta (Citation2009) to conduct cross-country research using firm-level information. In this approach, depicted in , a common protocol is used to extract information from each countries’ harmonized firm-level datasets. This involves the assembly of micro-data by participating national statistical offices (NSO), and the running of the same program code in each country to retrieve the indicators and statistical moments or to conduct statistical analyses. By proceeding in this way, a cross-country MMD containing harmonized indicators of underlying distributions and correlations can be made public without breaking national rules of confidentiality.
Figure 2. Distributed micro-data analysis.
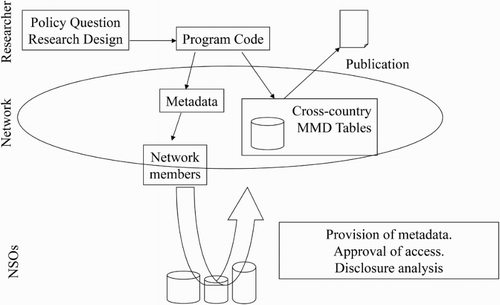
The MMD has been created through international collaborative projects of NSO.Footnote4 The description below summarizes the technical documentation by Bartelsman, Hagsten, and Polder (Citation2013). The projects harmonized the firm-level linking in each country of the Community Innovation Surveys, (below called IS), the Survey on ICT usage and e-commerce in enterprises (EC), the Structural Business Survey or Production Survey (PS) and the underlying business register (BR). Using the linked firm-level sources, each statistical agency ran common computer code, the results of which were ultimately combined into a cross-country datasets at a medium-level of industry disaggregation that include measures of ICT usage and innovative activity together with measures of business performance and industry dynamics. These measures include typical aggregates, such as sums and means, but also higher moments of distributions of variables of interest, as well as joint moments from multivariate distributions. Further, information is aggregated not just over firms in an industry, but also over subsets of firms in an industry, for example by size or age, or by innovation characteristics.
The distributed micro-data methodology and the resulting MMD is not the only way to allow cross-country analysis of firm-level data. Commercially available sources, such as ORBIS from Bureau van Dijk are sourced from Chamber of Commerce or mandatory filings of publically traded firms. However, the coverage and sources vary significantly across countries and it is costly to combine these data with other firm-level indicators. Another option is to generate public use versions of the data where individual firms have been made anonymous. In a recent project, the U.S. Census has created a synthetic BR that not only allows outside users to run their own analysis, but allows validation of the results against the confidential Longitudinal Business Database (http://www2.vrdc.cornell.edu/news/data/lbd-synthetic-data/). Finally, remote execution of analysis at multiple NSO sites may provide an option for cross-country firm-level data analysis. In fact, the research infrastructure built during the ESSLimit and ESSLait project provides a way to run analytical modules in multiple countries, but does not give real time access, as remote access does.
The MMD is composed of a set of related cross-country tables. There are tables that provide meta-data and coverage information about the underlying datasets, tables with firm demographics (birth, death, size, and age) based on the BR, tables of summary statistics from each underlying survey, PS, EC, and IS, and combined survey samples (e.g. PS–EC or PS–EC–IS), a table with industry dynamics indicators, and a set of tables with detailed information on distributions and joint distributions of variables.
The main data of the MMD used in the current paper come from the summary statistics tables. The variables for which summary statistics are generated include the main survey concepts, usually numeric variables, or Booleans, but also derived variables such as productivity or ICT intensity. Not only are the summary statistics created for all the firms in each survey, but also for combined samples, such as PS–EC or PS–EC–IS. Further, the table splits industries into sub-groups, such as size-class, age, or multinational status, ICT intensity, and export status, so that users can compare panels of country-industry-time panels built up from firms that are ICT intensive or not, or that export or not. For the empirical applications in this paper, it is important to note that the summary statistics provided not only are sums or means of the firm-level variables, but also weighted sums or means, usually with employment weights. Associated with the ‘stat’ tables are the ‘jointstat’ tables, that look at shares of firms in an industry that jointly use two or three ‘technologies’ or innovation modes from the EC or IS, such as mobile internet and process innovation. Together with shares of firms using each technology separately, statements can be made about possible complementarity of the technologies.
The table on industry dynamics contains indicators related to (re)allocation of resources and competition. The indicators include productivity decompositions, covariance of productivity and size, measures of market share churn, and simple versions of profit-elasticity measure of competition. The main indicator related to the efficiency of resource allocation used in this paper is the covariance of labor productivity and firm size, as used by Bartelsman, Haltiwanger, and Scarpetta (Citation2013).
The tables with distributional information provide means and standard deviations of variables for each country, industry, year, but also by quartile of the distribution within each industry. Related files provide joint distributions of two variables by providing means and standard deviations of a variable by quartile group of the other variable. For each country, industry, year, there are thus 10 moments for each variable, which should be sufficient to provide ways to back out the parameters for the underlying firm-level distributions. In this paper, we show that the productivity dispersion across firms increases with intensity of ICT use.
CDM using MMD
A few stylized facts have emerged from the limited analysis done with the MMD to date (see for more information, Bartelsman, Hagsten, and Polder Citation2013). To start, R&D, innovation, ICT usage, and high levels of human capital, generally are correlated in a cross-section of firms. Of course, particular ICT technologies are more strongly correlated with certain types of innovation, for example the use of Customer Relation Management software and conducting marketing innovation. Some firms persistently outperform others with respect to innovation and productivity. We explore this further in our second empirical example. Next, there is quite a bit of variation across countries in most innovation related indicators, even when controlling for industry and time, and some countries persistently outperform others with respect to innovation and productivity. Further, the variance of firm-level outcomes is larger for firms that intensively use ICT. This finding suggests an interesting hypothesis that will be explored in the first empirical example. On average, individual firms may have a relatively low innovation-output elasticity, but the aggregate impact nonetheless may be large. This can happen when the variance of performance increases with innovation intensity and market selection increases the size of firms with successful outcomes.
The descriptive findings provide some interesting stylized facts and narratives on the links between innovation and economic outcomes and point to a possible role of country-specific regulatory and institutional settings. In the following paragraphs, we will analyze the MMD using the framework inspired by CDM. To start, we will use the CDM framework and the MMD to look at the effect of innovative activity on average and aggregate performance. Next, we will look at the issue of substitutability or complementarity of different types of innovative activities using CDM in a manner very similar to that used for firm-level data. In both sets of analysis, moving the CDM framework from firm-level to industry-level requires some attention to aggregation of information on innovative activity.
In firm-level datasets on innovation, innovative activity usually is reported as a binary measure. This can be accommodated in the innovation equation of the CDM model by using limited dependent variable techniques to estimate the probability that a firm engages in innovative activity. When a continuous variable of innovative activity, such as the percentage of sales generated by new products, is available, standard regression models can be used. However, because these are usually measured with error in the CIS, Mairesse and Robin (Citation2008) recommend using limited dependent variable techniques as well to transform innovative activity into a latent probability measure.Footnote5
In most industry-level data on innovation, the underlying firm-level categorical responses are aggregated into a continuous variable such as the percentage of firms in an industry that are in each category. In the MMD, by contrast, industry-level aggregates of firm’s inputs and outputs are available for sub-populations of firm’s inputs, based on categories of age, size, export status, or of innovative activity (e.g. firms that did or did not engage in product innovation). For example, industry aggregates are available for firms in a country-industry-year, split by their binary response to undertaking a particular innovative activity, or for unique combinations of binary responses for two or three innovative activities. This means that the limited dependent variable approach can be implemented with the MMD by using the category of binary responses as dependent variable and sub-industry aggregates as explanatory variables.
In the MMD we have observations at a level of aggregation below an industry but above individual firms. For example, within an industry, there is averaged and aggregated (weighted average) firm-level information for firms that did and firms that did not innovate. In the case of using averaged data, the data point is considered an observation from a ‘representative firm’ in that industry with that value of innovative activity. As such, the data are a less noisy version of firm-level data. By contrast, the aggregate data weigh firm-level outcomes with their size and thus are closer to the industry and macro figures usually published in official statistics.
An insightful empirical contribution that compares the use of firm-level data and aggregate data are presented in Grunfeld and Griliches (Citation1960). They point out the tradeoff between aggregation and specification errors, amongst others by investigating the omitted variable bias due to the neglect of aggregate behavior for explaining results of firm-level regressions. Further, they emphasize that the metric of interest may not be the estimation (error) of size-effects but the power of the statistical exercise to provide an explanation to the question at hand.
If one were to produce firm-level regression results for all countries and industries used in the creation of the MMD, although feasible in principle, it does not give a direct answer to the macro question. While Grunfeld and Griliches (Citation1960) provide conditions where the explanation or fit of aggregate outcomes is better with aggregate estimation than from aggregation of micro estimates, we follow a different route by comparing the results for the fit and size-effects of applying a model to averaged and aggregate data. In this exercise, we are mostly interested in how individual innovative decisions lead to macro outcomes and less in the exact estimate of parameters of firm-level behavior. We generate estimates using averaged data to mimic what could have been done with firm-level data for comparison. Our novel contribution is in comparing these estimates with results from aggregate (weighted average) data, after including macro variables to account for possible specification biases as suggested by Grunfeld and Griliches. Footnote6 In the first application, the same model is estimated using both averaged and aggregate data. The reasoning behind this model and the chosen macro variables of interest are discussed in the next subsections.
Innovation from micro to macro
Typically, the CDM approach looks at firm-level decisions, providing estimates of production functions, factor input decisions, innovative activity, and choice of technology. As mentioned above, these decisions however take place in a market environment: the firm has interactions with other firms in own, downstream, and upstream sectors, and interactions on labor and capital markets, all taking place given a local institutional and policy environment. The aggregate outcomes of innovative activity undertaken at the firm-level thus depend not only on what innovative output the firm produces, but more importantly how the market rewards the innovation compared with other possible suppliers. This market selection mechanism itself is likely to play an important role in firm-level decisions.
Having data on average firm behavior as well as indicators of resource allocation across firms can aid in tracking innovation from micro decisions to macro outcomes. With only aggregate industry data one can look at aggregate output and productivity outcomes of changes in, for example, input markets or policy environment, but the firm-level behavioral mechanisms cannot be traced. The MMD offers some possibility to overcome this difficulty.
Using the MMD, we run a simple augmented production function, with labor productivity as the dependent variable, and capital intensity and broadband intensity as explanatory variables (along with fixed effects for industry, country and time). The results are shown in . The column ‘Averaged data’, denotes that we use the industry average of labor productivity and the explanatory variables, while ‘Aggregated data’ denotes an industry aggregate, that is, weighted average using firm size as a weight. Interestingly, on average broadband intensity does not have a significant effect, which corroborates the findings from firm-level regressions in the separate countries.Footnote7 By contrast, the aggregate, or weighted average, regressions show a significant effect, indicating that the more productive firms that use broadband intensively are larger. A simple statistical possibility for this result would be a situation where the average productivity of firms does not increase with broadband intensity, but the variance of productivity does. Then, if the firms with high productivity are larger, aggregate productivity will be positively correlated with broadband intensity.
Table 1. Augmented productivity regression.
We explore this possibility further, by seeing how broadband intensity, as a proxy for intangibles, and the variance of productivity relate. Using the MMD, we have for each country, industry, and year a measure of the cross-sectional variance of firm-level productivity. We can then regress the standard deviation of productivity on the broadband intensity and on fixed effects, as shown in .
Table 2. Productivity dispersion regressed on broadband intensity.
The above has shown that broadband intensity and variance of firm outcomes are correlated. The next part of the story that explains why average firm-level impact of ICT may be lower than the aggregate impact, is to describe how allocation of resources is related to productivity. The literature of (mis)allocation (e.g. Hsieh and Klenow Citation2009; or Bartelsman, Haltiwanger, and Scarpetta Citation2013) discusses theoretical arguments for linking productivity variance, or the covariance between productivity and firm size to aggregate productivity. The MMD contains a measure of resource allocation, called the Olley–Pakes cross-term (Olley and Pakes Citation1996, first explored this covariance between productivity and size). As shown in Bartelsman, Haltiwanger, and Scarpetta (Citation2013), the cross-term varies across countries and industries, and affects aggregate productivity in an accounting sense. Further, in the model of Bartelsman, Haltiwanger, and Scarpetta (Citation2013), policy distortions that cause resource misallocation also reduce the covariance between productivity and size. If the resource allocation variable is large in an industry, it implies that firms with high productivity outcomes are larger.
We can put the findings together in a set of regressions inspired by the CDM approach and using the MMD data. First we can find factors affecting firm-level innovative activity, in this case conducting product innovation or not. Next, we can find how product innovation and the efficiency of resource allocation affect productivity. While industry- and country-level data typically do not allow the estimation of such limited dependent variable models, the MMD contains information on the number of innovators by type, country, industry, and year, as well as moments of variables for the same breakdown. This allows one to mimic a micro-data regression, use weighted regression and correcting standard errors for clustering. Therefore, using a binary variable for product innovation as an industry characteristic, we can estimate a (weighted) probit equation for the probability of a product innovation, with explanatory variables on ICT usage, ICT human capital (measured as the proportion of workers with college in ICT-related subjects), and average firm size (all by industry and innovation status), as well as the measure of resource allocation. Similar to , the probit regressions use for all independent variables either averages across firms or aggregates (size weighted averages).
Next, in the innovation augmented productivity equation, we contrast the same two types of data for investigating the link between productivity and the explanatory variables, including (predicted) innovation, the capital-labor ratio, employment (to check for increasing returns to scale), and the ICT human capital indicator. As an additional explanatory variable again we use the reallocation indicator, namely the covariance between productivity and size as described above, that is correlated with aggregate productivity through an accounting relationship.
The Probit regression results are presented in . In both cases, there is a strong positive impact on the adoption of product innovation of broadband intensity, the ICT skill level of employment and the involvement in ICT use such as electronic selling, after controlling for size and industry and time effects. Surprisingly, the estimate for electronic buying is negative for aggregate data, while insignificant for the averages, indicating that the negative effect comes primarily from the larger firms. Possibly, e-purchases are more strongly related to other types of innovation, which could substitute for product innovation in the case of larger firms, but further research would be needed to explain the result. Overall, the results roughly corroborate the results of Polder et al. (Citation2010), who find a positive impact of broadband intensity and e-commerce for Dutch firms, although the e-commerce variables are only important in services. Reallocation also seems to play a minor positive role for adopting product innovation, at least for the average firm, although it has no impact on aggregate innovation.
Table 3. Marginal effects (ME) Probit regressions for product innovation.
With the adoption of innovation depending already strongly on the ICT characteristics of firms, we next look into the question of determining the impact of product innovation, the ICT human capital indicator, and reallocation on productivity. shows the results of the productivity regressions. As in the original CDM contribution we account for the endogeneity of product innovation, using Generalized method of moments (GMM) with predictions of the propensities to innovate obtained from the probit regressions as instruments, following Wooldridge (Citation2002). In this simple exercise we assume that the ICT human capital indicator and the reallocation indicator are not themselves caused by the unobserved productivity shock in the productivity equation. The results show that we have a more reasonable estimate for capital intensity when using aggregate data compared to averaged data. Besides that, both ICT human capital and reallocation seem to be more important for productivity in case of using aggregated data. Further explorations, using dynamic panel specifications are needed to improve identification of the above model and for conducting specification and diagnostic tests. The main message is that the effect of innovation on average productivity is insignificant, while the effect on aggregate productivity is significant for aggregate data (albeit on the 10% level of significance). The magnitude of the coefficient of product innovation dummy is similar to that found in studies using micro-data, for example, Griffith et al. (Citation2006) and Mairesse and Robin (Citation2008).
Table 4. GMM Productivity regression with product innovation.
Complementarities in enterprise system adoption
Our second example of using MMD is inspired by Milgrom and Roberts (Citation1990, Citation1995). They looked into the question of whether different types of innovation are complements or substitutes. The Milgrom–Roberts strand of research has been incorporated into the CDM-style analysis, for example to study joint adoption of product and process innovation using a bivariate probit model (see e.g. Mairesse and Robin Citation2008). Other related studies of complementarity in innovation modes include Hall, Lotti, and Mairesse (Citation2013) and Polder et al. (Citation2010). We expand the scope of innovation modes beyond those captured in the CIS and consider innovation related technology as measured in the harmonized survey on ICT technology use of firms. In particular we look at the complementarity or substitutability of the use of three related Enterprise Systems (ES); (1) systems for Enterprise Resource Planning (ERP), (2) systems for Customer Resource Management (CRM) and (3) systems for Supply Change Management (SCM).
Considering three innovation types jointly requires some extension of the standard latent variable approach. In recent research (see e.g. Van Leeuwen and Mohnen Citation2016), the Multivariate Probit method of Cappellari and Jenkins (Citation2006) was extended to assess the issue of complementarity or substitutability between innovation modes as suggested by the modeling approach of Lewbel (Citation2007). We follow the same approach in this example, applied to MMD.Footnote8
In this exercise, the three ES (with embodied software) are considered as important examples of organizational innovations whose adoption may capture ICT-related innovation spill-overs. The analysis looks into the complementarities of joint adoption of the ES types ERP, CRM, and SCM, thereby following the solution of Lewbel (Citation2007) for solving the coherency and incompleteness problem when estimating systems of adoption equations with dummy endogenous variables. Moreover, we analyze the complementarities in performance by taking into account that innovation adoption is endogenous to the productivity or the overall efficiency of firms. A complete account of this MMD application can be found in a discussion paper of van Leeuwen and Polder (Citation2013).
The framework of Lewbel (Citation2007) starts from the following value function:(1) where the dichotomous variables for the three types of innovation are given by
and a ‘.’ represents a cluster of firms.
In Equation (1) the (latent) value depends on three related discrete choices. The choice for a certain type of innovation is explained by a set of regressors
, which may differ between innovations, the adoption of other innovations and an idiosyncratic term
. Each of the
can take on a value of 1 if the innovation has been adopted and a value of 0 otherwise. Thus, there are in total
possible combinations of ES innovations yielding eight different value function outcomes. To give an example: the value from adopting ERP
and SCM
and not adopting CRM
can be expressed as
. Notice, that we use
to express that only the sum of
and
can be identified.
If , then the corresponding pair of innovations are complements (substitutes). Model (1) is complete because a (latent) value is specified for all possible strategies. In order to be a coherent system it is required that every strategy should have a latent value that exceeds the value of all other strategies. So for each strategy adopted there are seven
comparisons at stake. In our example, for the firms that adopted the strategy
, it should follow that
(2)
The inequalities (2) are used to derive the likelihood function (LF) and to enable Geweke-Hajivassiliou-Keane simulation for evaluating the integration bounds in the LF. To save space we refer to Appendix A of van Leeuwen and Polder (Citation2013) for more details on the estimation. presents the marginal effects of the Lewbel model for the adoption of the three ES modes and obtained after using aggregate (employment weighted) data for the period 2007–2009. For each innovation mode we relate the probability of adopting the new technologies to (i) the existing ICT usage of the firms (i.e. the usage of broadband and e-commerce practices), (ii) DTF, or the distance of the firms to the technological frontier, and (iii) the simultaneous adoption of the other modes.
Table 5. Marginal effects (ME) Lewbel adoption model.
We see that the probability of adopting a certain ES type increases with the intensity of fast internet usage. Thus, the availability and penetration within the firm of fast internet can be thought to increase the value of adoption of all types of e-business considered. The results for the two e-commerce predictors are also clear cut. The extent to which a firm has engaged in e-commerce (e-purchasing as well as e-selling) increases the probability of adoption for all types of e-business, although e-sales is only weakly significant for CRM adoption. Looking next at the results for the distance to the frontier, it can be concluded the results are insignificant in general. These negative results may be due to the crude measures used for the construction of our DTF measure.Footnote9 Finally, the bottom part of summarizes the results for the complementarity/substitutability parameters of the model. After controlling for the correlations between the equation errors (low and insignificant and for this reason not included in the table), the estimates clearly point to substitutability for every combination of ES. This result could be explained by the fact that the application of each system can be embedded in software suites and thus may cover and serve comparable functionalities. From the viewpoint of the full chain of business processes, SCM probably is the most encompassing technology applied to manage the flow of all information and all resources to maintain or increase responsiveness to (changes in) customer demand. It includes processes such as marketing, pricing, order management, production planning, replenishment of all stocks and procurement and the resources to streamline all functionalities. It may therefore include the functionalities offered by other software suites such as those for implementing ERP and CRM.
looks at the complementarities of having adopted combinations of ES systems for productivity. We call this ‘ex-post complementarity or substitutability’, as opposed to the ‘ex ante’ situation at the stage of adoption. To assess its importance, we estimated augmented valued added productivity equations with ES-innovation dummies included as a refinement of value added total factor productivity (TFP). The baseline model uses OLS with ES-dummies added to the traditional inputs. In addition, to check for the robustness of the OLS results for endogeneity of the ES innovation dummies, we apply GMM as an instrumental variable method and use the predicted propensities obtained from the Lewbel adoption model to instrument the endogenous innovation dummies. In both methods we use cluster fixed effects in the estimation of standard errors to account for the fact that the data concerns groups of different size.
Table 6. Productivity regressions.
The estimates for the contribution to productivity of capital intensity are quite comparable for the two models. The employment estimate represents returns-to-scale (RTS). With OLS we find a small but significant decreasing RTS. The GMM results show more profound decreasing RTS, but by contrast a more sizable impact on productivity from innovative ICT use. Finally, there is evidence that combining different ES pays out for productivity, as the estimates for certain innovation profiles that include two or three ES systems show a higher contribution to TFP than profiles where they are not adopted simultaneously. However, adding an additional ES is not always beneficial. As in the previous results, this could be explained by overlapping functionalities between different systems. An explanation for the result that ERP and CRM seem to be substitutes in adoption but complements in productivity could be that firms look at other things than increasing productivity when making the innovation decision, but the finding merits further investigation.
Conclusions
Following 15 years of use, it can be concluded that the empirical CDM literature has been quite successful in estimating the impact of innovativeness at the firm level. This track record for empirical innovation research has greatly benefited from the internationally agreed harmonization of survey designs, and methods for collecting and processing firm-level survey data, all aimed at obtaining a more complete picture of the economics of innovation. Together with these efforts one can witness methodological innovations in the use of the improved data availability. Today, the econometric analysis based on these harmonized and linked firm-level data typically is more advanced and more complicated from an econometric point of view than the analysis on aggregated data. In this paper we show that MMD type datasets, built up using distributed micro-data analysis methods, can be tailored such that it enables the estimation of more complicated models that feature new recent directions in micro-econometric analysis on firm-level data. Pursuing MMD has several advantages: (1) this route may also help us in understanding the effects of measurement as measurement error seems to be of less importance at the aggregate level than at the firm level and (2) the methods underlying MMD manages to tailor data collection and data processing beyond the limits of industry and national boundaries in a way that enables research to assess the importance of (differences in) policies and institutional settings that is difficult to fully comprehended or identify when using country-specific firm-level data.
For future work, much remains to be done. It is our desire to see an increase in research using MMD, in conjunction with cross-country indicators of policy, regulation, and institutional setting. A recent publication of the OECD (Citation2015) is showing one direction for this type research. Other possibilities include calibration and indirect inference with equilibrium growth models (see e.g. Acemoglu et al. Citation2013). On the methodological side, much more needs to be done to understand the role of aggregation, not just for measures of fit, but also to understand how the interpretation of estimated coefficients differ between micro and macro levels. To this end, theoretical considerations can be tested using estimation at the firm-level in a set of countries in conjunction with results from the MMD.
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes
† This paper uses results from the ESSLimit and ESSLait projects, commissioned and financed by the European Commission and EUROSTAT. The micro moments data, officially called ‘Linked micro-aggregated data on ICT usage, innovation and economic performance in enterprises’, is available at Eurostat (http://ec.europa.eu/eurostat/web/microdata/micro-moments-dataset). The content of the database does not necessarily reflect officially published statistics. The views expressed in this paper are those of the authors and do not necessarily reflect any policy of Statistics Netherlands or the European Commission. We thank the consortium partners of the ESSNet projects, two anonymous refererees, and participants of the CAED 2014 Conference, the ZEW 2013 Conference on The Economics of ICTs, and from the CDM meetings for valuable comments. Errors are our own.
1. The stock of intangible assets is proxied by a pyramid – not a completely whimsical caricature. Besides their benefit to the Pharaohs, the pyramids have been delivering utility to millions of people that have viewed them, and possibly to billions of people just through the idea of their existence. Their benefit is thus non-rival and their depreciation rate is rather low. Further, while there is much inspiration needed to envision the pyramid, the actual investment mostly entails perspiration.
2. Jones and Williams (Citation1998) consider both positive and negative wedges as empirical possibilities.
3. Of course, the invention may change the marginal product of future intangible investment through knowledge spillovers, and thus generate indirect social benefits.
4. Specifically, the ESSnet projects Linking of Microdata to Analyse ICT Impact (ESSLait), and Linking of Microdata on ICT Usage (ESSLimit).
5. The bulk of firms respond with discrete answers, such as: the share of innovative sales is 5%, 10%, 15%, and 30%. In some countries, the survey question refers to ranges.
6. An additional advantage of this approach is that firm-level regressions are often plagued by measurement error. It is expected that averaging and aggregating data reduces noise and improves the signal-to-noise ratio. Moreover, aggregation smoothes any non-convexities present at the firm-level. Finally, the econometrician is usually forced to assume equal coefficients across firms even with firm-level data; in this respect, Mairesse and Griliches (Citation1990) conclude that if we are interested in the aggregate or average behavior of productivity, aggregation ”[ … ] may not be necessarily bad”.
7. See the ESSLait final report, 2013: http://www.cros-portal.eu/content/final-reporting-esslait-project.
8. This exercise was first presented in van Leeuwen and Polder (Citation2013) who assess complementarities at the adoption stage as well implications for productivity and compare micro-level and MMD results for the Netherlands.
9. The distance to the country frontier is implemented by calculating the quotient of the (employment weighted industry averages) and the maximum of these industry averages over countries in a particular year.
References
- Acemoglu, Daron, Ufuk Akcigit, Nicholas Bloom, and William Kerr. 2013. Innovation, Reallocation and Growth. Center for Economic Studies Working Paper, U.S. Census Bureau.
- Bartelsman, Eric J., Eva Hagsten, and Michael Polder. 2013. “Cross-Country Analysis of ICT Impact Using Firm-Level Data: The Micro Moments Database and Research Infrastructure.” ESSLait Final Report. Luxembourg: Eurostat.
- Bartelsman, Eric J., John C. Haltiwanger, and Stefano Scarpetta. 2009. “Measuring and Analyzing Cross-Country Differences in Firm Dynamics.” In Producer Dynamics: New Evidence from Micro Data, edited by Timothy Dunne, J. Bradford Jensen and Mark J. Roberts, 15–82. Studies in Income and Wealth. Chicago, IL: University of Chicago Press.
- Bartelsman, Eric J., John C. Haltiwanger, and Stefano Scarpetta. 2013. “Cross-Country Differences in Productivity: The Role of Allocation and Selection.” American Economic Review 103 (1): 305–334. doi: 10.1257/aer.103.1.305
- Broström, Anders, and Staffan Karlsson. 2016. “Unravelling the R&D-Innovation-Productivity relationships: A Study of an Academic Endeavour.” Economics of Innovation and New Technology. doi:10.1080/10438599.2016.1202519
- Cappellari, Lorenzo, and Stephen P. Jenkins. 2006. “Calculation of Multivariate Normal Probabilities By Simulation, With Applications to Maximum Simulated Likelihood Estimation.” The STATA Journal 6 (2): 156–189.
- Corrado, Carol A., and Charles R. Hulten. 2010. “How Do You Measure a ‘Technological Revolution’?.” American Economic Review 100 (2): 99–104. doi: 10.1257/aer.100.2.99
- Crépon, Bruno, Emmanuel Duguet, and Jacques Mairesse. 1998. “Research, Innovation and Productivity: An Econometric Analysis at the Firm Level.” Economics of Innovation and New Technology 7 (2): 115–158. doi: 10.1080/10438599800000031
- De Loecker, Jan. 2011. “Recovering Markups from Production Data.” International Journal of Industrial Organization 29 (3): 350–355. doi: 10.1016/j.ijindorg.2011.02.002
- Griffith, Rachel, Elena Huergo, Jacques Mairesse, and Bettina Peters. 2006. “Innovation and Productivity Across Four European Countries.” Oxford Review of Economic Policy 22 (4): 483–498. doi: 10.1093/oxrep/grj028
- Griliches, Zvi. 1979. “Issues in Assessing the Contribution of Research and Development to Productivity Growth.” The Bell Journal of Economics 10 (1): 92–116. doi: 10.2307/3003321
- Griliches, Zvi, Bronwyn H. Hall, and Ariel Pakes. 1991. “R&D, Patents, and Market Value Revisited: Is There A Second (Technological Opportunity) Factor?” Economics of Innovation and New Technology 1 (3): 183–201. doi: 10.1080/10438599100000001
- Grunfeld, Yehuda, and Zvi Griliches. 1960. “Is Aggregation Necessarily Bad?.” The Review of Economics and Statistics 42 (1): 1–13. doi: 10.2307/1926089
- Hall, Bronwyn H., and Josh Lerner. 2009. The Financing of R&D and Innovation. National Bureau of Economic Research. Working Paper w15325.
- Hall, Bronwyn H., Francesca Lotti, and Jacques Mairesse. 2013. “Evidence on the Impact of R&D and ICT Investments on Innovation and Productivity in Italian Firms.” Economics of Innovation and New Technology 22 (3): 300–328. doi: 10.1080/10438599.2012.708134
- Hall, Bronwyn H., and Jacques Mairesse. 2006. “Empirical Studies of Innovation in the Knowledge-Driven Economy.” Economics of Innovation and New Technology 15 (4–5): 289–299. doi: 10.1080/10438590500512760
- Hsieh, Chang-Tai, and Peter J. Klenow. 2009. “Misallocation and Manufacturing TFP in China and India.” The Quarterly Journal of Economics 124 (4): 1403–1448. doi: 10.1162/qjec.2009.124.4.1403
- Jones, Charles I., and John C. Williams. 1998. “Measuring the Social Return to R&D.” The Quarterly Journal of Economics 113 (4): 1119–1135. doi: 10.1162/003355398555856
- Klette, Tor Jakob, and Zvi Griliches. 1996. “The Inconsistency of Common Scale Estimators When Output Prices Are Unobserved and Endogenous.” Jouranl of Applied Econometrics 11 (4): 343–362. doi: 10.1002/(SICI)1099-1255(199607)11:4<343::AID-JAE404>3.0.CO;2-4
- Leeuwen, George van, and Pierre Mohen. 2016. “Revisiting The Porter Hypothesis: An Empirical Analysis of Green Innovation for The Netherlands.” Economics of Innovation and New Technology. doi:10.1080/10438599.2016.1202521
- Leeuwen, G. van, and M. Polder. 2013. Linking ICT related Innovation Adoption and Productivity: Results from Micro-aggregated Data versus Firm-level Data. Statistics Netherlands Discussion Paper. The Hague.
- Lewbel, Arthur. 2007. “Coherency and Completeness of Structural Models Containing a Dummy Endogenous Variable.” International Economic Review 48 (4): 1379–1392. doi: 10.1111/j.1468-2354.2007.00466.x
- Mairesse, Jacques, and Zvi Griliches. 1990. “Heterogeneity in Panel Data: Are There Stable Production Functions?” In Essays in Honor of Edmond Malinvaud, edited by Paul Champsaur, 193–231. Cambridge: MIT Press.
- Mairesse, Jacques, and Stephane Robin. 2008. “Innovation and Productivity: A Firm-Level Analysis for French Manufacturing and Services Using CIS3 and CIS4 Data (1998-2000 and 2002-2004).” Paper presented at the Druid 25th celebration conference, June 16–18.
- Martin, Ralf. 2008. Productivity Dispersion, Competition and Productivity Measurement. London: LSE Dissertaion.
- Milgrom, Paul, and John Roberts. 1990. “The Economics of Modern Manufacturing: Technology, Strategy, and Organization.” The American Economic Review 80 (3): 511–528.
- Milgrom, Paul, and John Roberts. 1995. “Complementarities and Fit Strategy, Structure, and Organizational Change in Manufacturing.” Journal of Accounting and Economics 19 (2–3): 179–208. doi: 10.1016/0165-4101(94)00382-F
- Mohnen, P., F. C. Palm, S. Schim van der Loeff, and A. Tiwari. 2008. “Financial Constraints and Other Obstacles: Are They a Threat to Innovation Activity?.” De Economist 156 (2): 201–214. doi: 10.1007/s10645-008-9089-y
- OECD. 2015. The Future of Productivity. Paris: OECD Publishing.
- Olley, G. Steven, and Ariel Pakes. 1996. “The Dynamics of Productivity in the Telecommunications Equipment Industry.” Econometrica 64 (6): 1263–1297. doi: 10.2307/2171831
- Polder, Michael, George van Leeuwen, Pierre Mohnen, and Wladimir Raymond. 2010. Product, Process and Organizational Innovation: Drivers, Complementarity and Productivity Effects. Rochester, NY: Social Science Research Network.
- Wooldridge, J. M. 2002. Econometric Analysis of Cross Section and Panel Data. Cambridge, MA: The MIT Press.