
Abstract
Recent advances in artificial intelligence (AI) have drawn attention to the need for AI systems to be understandable to human users. The explainable AI (XAI) literature aims to enhance human understanding and human-AI team performance by providing users with necessary information about AI system behavior. Simultaneously, the human factors literature has long addressed important considerations that contribute to human performance, including how to determine human informational needs, human workload, and human trust in autonomous systems. Drawing from the human factors literature, we propose the Situation Awareness Framework for Explainable AI (SAFE-AI), a three-level framework for the development and evaluation of explanations about AI system behavior. Our proposed levels of XAI are based on the informational needs of human users, which can be determined using the levels of situation awareness (SA) framework from the human factors literature. Based on our levels of XAI framework, we also suggest a method for assessing the effectiveness of XAI systems. We further detail human workload considerations for determining the content and frequency of explanations as well as metrics that can be used to assess human workload. Finally, we discuss the importance of appropriately calibrating user trust in AI systems through explanations along with other trust-related considerations for XAI, and we detail metrics that can be used to evaluate user trust in these systems.
1. Introduction
With the recent focus on explainable artificial intelligence (XAI) in the AI literature, defining which information XAI systems should communicate and and how to measure their effectiveness is increasingly important. Gunning and Aha (Citation2019) define XAI as “AI systems that can explain their rationale to a human user, characterize their strengths and weaknesses, and convey an understanding of how they will behave in the future.” We adopt this definition of XAI and define explanations as the information necessary to support human inference of the above details about AI systems, including information about their inputs, models, and outputs. The motivation for development of XAI techniques is often stated as the need for transparency within increasingly complex AI systems (Fox et al., Citation2017; Lipton, Citation2016) and the need to engender user trust in increasingly opaque systems (Borgo et al., Citation2018; Fox et al., Citation2017; Lipton, Citation2016). Both increasing AI system transparency and accounting for human trust in these systems contribute to improved human-AI team performance; thus, supporting human-AI team performance is one of the primary aims of XAI. Indeed, previous studies have demonstrated the positive impact of agent transparency on task performance of human teammates in human-AI teams (Chen et al., Citation2017, Citation2018; Stowers et al., Citation2016). Some literature argues that there is a performance-explainability trade off in that more explainable AI systems sacrifice algorithmic performance in some way (Gunning & Aha, Citation2019; Lipton, Citation2016). However, if a lack of system explainability inhibits overall team performance, benefits provided by improved algorithmic performance might be lost. For example, if a medical machine learning-based imaging system is able to achieve greater accuracy at classifying certain medical issues, but it does so in a way that makes it more difficult for a human doctor to notice errors in its judgement, the performance of the doctor-AI team might suffer overall. Therefore, we view optimization of human-AI team performance, enabled by explanations about the system’s behavior, as the primary goal of XAI.
There exists a rich literature in human factors that explores scenarios in which humans interact with automated systems, as well as the various factors that influence human performance during task execution. The concept of situation awareness (SA), which has been studied within the field of human factors and in the context of human-automation teams (Chen et al., Citation2014; Endsley, Citation1995), defines the informational needs for humans operating in any scenario (Endsley, Citation1995). XAI systems, as systems that provide information about AI behavior, can contribute to the subset of a human user’s SA that is related to AI behavior. Human-AI team performance can be improved through information provided by XAI systems that support SA; however, overall SA, in addition to the subset of SA supported by XAI, are necessary for but not solely sufficient to support team performance (Endsley, Citation1995).
The human factors literature discusses other factors that are similarly imperative for human-AI team performance and also relevant to XAI systems. First, while SA defines the information a human needs, workload considerations impact how and when this information should be provided (Parasuraman et al., Citation2008). Second, the importance of user trust in automated systems has been explicitly explored in prior literature (Lee & See, Citation2004; Schaefer et al., Citation2014). The focus is not on increasing user trust, which is often given as a motivation for XAI (Borgo et al., Citation2018; Fox et al., Citation2017; Krarup et al., Citation2019), but instead on appropriately calibrating trust resulting in appropriate use of AI systems (Chen et al., Citation2014; Ososky et al., Citation2014; Schaefer et al., Citation2014).
Beyond discussing the concepts of SA, workload, and trust and relevant design recommendations for each of these considerations, the literature also operationalizes these concepts, providing methods and metrics for assessment (Parasuraman et al., Citation2008). Just as SA supports but is not equivalent to performance, high-quality explanations provided by XAI systems support but are not equivalent to SA, appropriate human workload, or well-calibrated trust in AI systems. However, assessing XAI systems based on methods and metrics related to these factors can contribute to an understanding of whether the provided explanations achieve the ultimate goal of enhancing human-AI team performance. Measuring SA, workload, and trust as intermediate aims of XAI, in addition to team performance, can provide clarity as to the potential confounds that exist in performance assessment.
While a number of metrics for assessing different aspects of XAI systems have previously been proposed (Doshi-Velez & Kim, Citation2017; Hoffman, Miller, et al., Citation2018; Hoffman, Mueller, et al., Citation2018; Lage et al., Citation2019), the XAI literature currently lacks a comprehensive set of suitable metrics for assessing the quality of explanations. While it may not be possible to explicitly and independently define an explanation’s quality, in many scenarios, an explanation is only “good” insofar as it contributes to the intermediate goals of SA, appropriate trust, and appropriate workload and the ultimate goal of improved performance. In other words, in many cases, SA, trust, and workload along with team performance can act as proxies indicating whether the XAI system is achieving its desired ends, since the goals of XAI systems often relate to these concepts. Therefore, XAI practitioners can leverage existing metrics from human factors in assessing their proposed techniques.
In this paper, we discuss the relevant human factors literature as it relates to XAI (including existing XAI techniques) and propose a set of design considerations and evaluation metrics for XAI systems in light of findings within the human factors community. We first discuss the human factors concept of SA at greater length and propose the Situation Awareness Framework for Explainable AI (SAFE-AI) which includes levels of XAI that define which information about AI algorithms and processes should be supported by XAI systems; these levels map closely to the levels of SA proposed by Endsley (Citation1995). We further highlight how a set of existing XAI techniques fits into our framework and how metrics used to evaluate existing techniques map to assessments of SA. SAFE-AI is intended to provide a structured human-centered approach for defining requirements for XAI systems, providing guidance for the development of XAI techniques, and providing guidance for the evaluation of XAI systems.
SAFE-AI can be used to define informational requirements for XAI systems, but informational requirements on their own do not dictate the entire design of an XAI system. It is also important to consider how much information is presented to users at any given point during an interaction as well as the frequency at which information is presented such that the users can actually process the information. These considerations relate to human workload. Further, it might be necessary for a system to provide additional information to human users in order to appropriately calibrate human trust in the system, which can impact appropriate use and team performance. Therefore, in this paper, we also discuss the human factors concepts of workload and trust, existing works in XAI that have considered these concepts, and how metrics related to each can be applied to assessments of XAI systems. Ideally, SAFE-AI can be applied in order to determine an initial set of informational requirements for an interaction, and trust and workload considerations can be used to refine this initial set and flesh out additional details related to how an XAI system can be integrated into a real-world setting. A preliminary version of this work can be found in Sanneman and Shah (Citation2020). The paper expands upon the preliminary version by extending the literature review of XAI techniques that relate to the SAFE-AI framework and by including additional discussions of workload and trust and how they relate to XAI systems.
The remainder of the paper is organized as follows: in Section 2, we discuss situation awareness, including relevant literature from human factors, our situation awareness-based framework for XAI, relevant examples from the XAI literature, and a motivating example to clarify the discussion of the framework. In Section 3, we expand on the concept of human workload from human factors along with related considerations and metrics for XAI. In Section 4, we discuss trust-related considerations for XAI. In Section 5, we enumerate possible future directions based on results and findings from the human factors literature, and in Section 6, we conclude the paper.
2. Situation awareness considerations and the Situation Awareness Framework for Explainable AI (SAFE-AI)
Here we discuss the concept of situation awareness (SA) from human factors and how it can be used to inform the design and assessment of XAI systems. We first introduce the relevant situation awareness literature from human factors as it relates to XAI. We then propose a framework (SAFE-AI) for design and evaluation of XAI systems in light of findings within the human factors community. This framework constitutes a process for defining requirements of XAI systems in a human-centered manner and for determining how these requirements should be met and how XAI systems should be evaluated. In this framework, we propose levels of XAI that define which information about AI algorithms and processes should be supported by XAI systems; these levels map closely to those of SA as proposed by Endsley (Citation1995) (discussed in Section 2.1). SAFE-AI applies to XAI generally, including explainable machine learning (ML), explainable agents and robots, and multi-agent/multi-human teams.
There exist other frameworks in the XAI literature that are primarily agent-centric in that they categorize systems based on agent attributes, such as stages of explanations (Anjomshoae et al., Citation2019; Neerincx et al., Citation2018), types of errors (Sheh, Citation2017; Sheh & Monteath, Citation2017), or agent internal cognitive states (Harbers et al., Citation2010). One agent-centric framework, the Situation Awareness-Based Transparency (SAT) model, leverages the concept of SA to define which agent-based information to share with human users (Chen et al., Citation2014). Since the SAT model draws on the SA framework from human factors as SAFE-AI does, we discuss how the this model relates to and complements SAFE-AI throughout the remainder of this section. SAFE-AI is generally complementary to these agent-centric frameworks in that ours is human-centric and focuses on specific human informational needs in different contexts rather than pre-specified agent attributes.
Other frameworks propose human-centric approaches (Preece et al., Citation2018; Ribera & Lapedriza, Citation2019), but these are largely human role-based, and our framework applies more generally and is role-agnostic. One other framework focuses on the theory of mind (ToM) of the robot and human (Hellström & Bensch, Citation2018). The authors of that work discuss the need to define which information a robot should communicate, which our framework addresses.
After introducing the SAFE-AI approach, we provide a non-comprehensive set of examples of how a set of existing XAI techniques fit into the framework in order to clarify how it might be applied. We then detail how to determine human informational needs at each of the three levels proposed in the framework. We discuss how methods used to evaluate existing XAI techniques map to assessments of SA from the human factors literature, and we suggest one key SA-related method for the assessment of XAI systems. Finally, we provide a motivating example, which we use to clarify our discussion of the levels of XAI and the suggested SA-related assessment method.
2.1. Situation awareness in the human factors literature
The concept of situation awareness has been widely studied in the human factors literature, especially in the context of human-automation teams operating in complex environments (Endsley, Citation1995). The concept originally received attention in the study of aviation systems, particularly with the rise of cockpit automation and the need to support pilot awareness of aircraft behavior (Stanton et al., Citation2001). However, its applicability extends to any complex scenario in which humans have informational needs for achieving the tasks they are performing. Accordingly, it has additionally been studied in the context of many other domains including air traffic control, emergency management, health care, and space, among others (Endsley, Citation2015).
Different definitions of situation awareness and corresponding frameworks have been proposed in the literature (Bedny & Meister, Citation1999; Endsley, Citation1995; Smith & Hancock, Citation1995). We adopt the three-level definition from Endsley (Citation1995): “the perception of elements in the environment within a volume of time and space (level 1), the comprehension of their meaning (level 2), and the projection of their status in the near future (level 3).” This definition is the most widely cited and applied of the existing definitions (Wickens, Citation2008). It has direct value for designers of complex systems due to its relative simplicity and its division into three levels, which allow for easy definition of SA requirements for different scenarios and for effective measurement of a person’s SA (Salmon et al., Citation2008). The SA construct has been empirically validated in various contexts (Endsley, Citation2017; Wickens, Citation2008), and connections between SA and other task-related measures such as performance and error frequency have been demonstrated in the literature (Endsley, Citation2015).
SA has also been used to define a framework for agent transparency (Chen et al., Citation2014), which has informed which information interfaces should display about agent behavior. We apply a similar approach to that of Chen et al. (Citation2017, Citation2018, Citation2014), but we focus on XAI specifically, including an extended discussion of how existing work in XAI can be applied to support SA and which future directions for XAI research would be of value in order to meet user SA needs. We also extend our discussion beyond the agent framework to consider explainable machine learning systems, which may not involve planning processes.
Endsley (Citation1995) further defines an assessment technique for measuring a person’s SA: the Situation Awareness Global Assessment Technique (SAGAT). Since SA represents the “diagnosis of the continuous state of a dynamic world,” there exists a “ground truth” against which a person’s SA can be measured (Parasuraman et al., Citation2008). The SAGAT test aims to measure the discrepancies between a human user’s SA, or their knowledge of the state of the world, and this “ground truth” state of the world. We detail SAGAT and its applicability to XAI further in Section 2.5.4.
SA is relevant to XAI research since it contributes to defining human informational needs, and XAI aims to meet them. In particular, XAI provides human users with the subset of their SA that relates to AI behavior. It is not equally valuable to provide just any information to human users via XAI, but only information that is relevant to them given their respective tasks and contexts. In fact, providing excessive or irrelevant information can be detrimental to human-AI team performance by causing confusion or unnecessarily increasing workload (Parasuraman et al., Citation2008). Therefore, it is important for XAI practitioners to consider which information is relevant to users and then to measure whether users have received and understood that information. Our proposed framework provides a guideline for determining which information XAI systems should communicate about AI system behavior, and our suggested use of the SAGAT method provides a way to measure how effectively this information is delivered.
2.2. The situation awareness framework for explainable AI (SAFE-AI)
As AI systems become increasingly ubiquitous and humans interact with more complex AI systems, XAI support of adequate SA can benefit human-AI team performance. According to the definition of SA provided by Endsley (Citation1995), an individual working towards a goal requires all three levels of SA to support their decision-making processes, which can in turn improve performance of goal-oriented tasks. It is important to note the distinction between general SA (related to the situation as a whole) and SA related specifically to AI behavior: the latter is a subset of the former and is the focus of this paper. SA, in the most general sense, comprises user awareness of the environment, other situational factors, and other human teammates in addition to information about the AI’s behavior.
The informational needs defined by SA can serve to dictate the information XAI systems should provide about AI behavior. For many scenarios in which XAI systems are useful and relevant, humans in the loop must know what the AI system did or what decision it made (perception), understand why the system took the action or made the decision it did and how this relates to the AI’s own sense of its goals (comprehension), and predict what the system might do next or in a similar scenario (projection). Thus, just as SA is divided into three levels, we introduce three levels of XAI systems to comprise the Situation Awareness Framework for Explainable AI (SAFE-AI). SAFE-AI is shown in . The three levels of XAI in our framework are defined as follows:
Level 1: XAI for Perception—explanations of what an AI system did or is doing and the decisions made by the system
Level 2: XAI for Comprehension—explanations of why an AI system acted in a certain way or made a particular decision and what this means in terms of the system’s goals
Level 3: XAI for Projection—explanations of what an AI system will do next, what it would do in a similar scenario, or what would be required for an alternate outcome
Figure 1. Situation Awareness Framework for Explainable AI (SAFE-AI).

SAFE-AI generalizes to cover both explainable ML and explainable agents and robots. It can also be applied for both “black box” AI systems that are fundamentally uninterpretable to human users and high-complexity systems that may or may not be inherently interpretable/“white box” but that human users cannot grasp due to their complexity. Note that our focus is on the informational content of explanations rather than explanation modality (natural language, communicative actions, interfaces, etc.), which is a separate but important consideration. For extended discussions of how interface design relates to agent transparency, see Chen et al. (Citation2016, Citation2017, Citation2018, Citation2014); Schaefer et al. (Citation2017); Stowers et al. (Citation2016). The following sections further detail each of the levels of XAI in SAFE-AI.
2.2.1. Level 1: XAI for perception
Level 1 XAI includes explanations about what an AI system did or is doing as well as the decisions made by the system. It covers information about both AI system inputs and outputs and aims to answer “what” questions as they are defined by Lim et al. (Citation2009) and discussed by Miller (Citation2019). In the context of explainable ML, level 1 information might include inputted data or outputted classification, regression, or cluster information, for example. For explainable agents and robots, level 1 information could include inputted state information, a particular decision or action taken by the system, an outputted plan/schedule (sequence of decisions/actions) from a planning agent, a particular resource allocation, and others. Note that Chen et al. (Citation2014) include agent actions and plans at level 1 of their framework, which is similar to what we consider to constitute level 1 XAI in the context of explainable agents.
While level 1 XAI might seem straightforward in many applications since it is simply information about a system’s inputs or outputs, providing this information might be challenging when explaining a complex model that makes decisions over many different input factors and produces numerous outputs, only a subset of which are relevant to the user. The primary technical challenge for level 1 XAI is determining which specific information is relevant to users of complex systems.
2.2.2. Level 2: XAI for comprehension
Level 2 XAI includes explanations about why an AI system acted in a particular way or made a certain decision and what this means in terms of the system’s goals. The primary aim of level 2 XAI is to provide information about causality in AI systems (Halpern & Pearl, Citation2005) as it relates to a specific instance or decision made by the system. Level 2 XAI answers “why” questions (as defined and discussed by Lim et al. (Citation2009) and Miller (Citation2019), respectively) and typically provides information about a system’s model. In the context of explainable ML, level 2 information might relate to sensitivities to inputs, semantic feature information, simplified feature or model representations, cluster information, or abstracted representations of model details. For explainable agents and robots, level 2 information could include details about system goals, objectives, constraints, pre-/post-conditions, rules, policies, costs, or rewards. Similar to Chen et al. (Citation2014), constraint-driven reasoning for agents and robots is included in level 2 of SAFE-AI. We also include agent goals at level 2 instead of level 1 (as in Chen et al. (Citation2014)), since goals can be used to explain the agent’s current actions in the context of the overall scenario.
In identifying level 2 XAI informational requirements, it is important to identify which causal information is most relevant to a user attempting to understand the system. Miller (Citation2019) states that explanations are fundamentally contrastive and that when humans seek explanations, they often have a particular “foil” (defined by the author as a counterfactual case) in mind. Reasoning about the most likely foils users have in mind when interacting with a system can help determine which causal information to provide. Note that by our definition, level 2 XAI provides answers to “why” questions for specific instances or in relation to specific foils rather than comprehensively explaining the entirety of the system’s behavior, so it might only involve some limited information about a system’s model. Therefore, level 2 explanations alone do not necessarily enable users to make all necessary predictions; as such, information beyond level 2 XAI may be required for projection (level 3). We detail this distinction further in Section 2.2.3.
2.2.3. Level 3: XAI for projection
Level 3 XAI includes explanations about what an AI system will nominally do next or would do in a different circumstance or context. Level 3 XAI provides answers to “what if”/“how” questions as they are defined and discussed by Lim et al. (Citation2009) and Miller (Citation2019), respectively. It aims to explain what would happen if certain system inputs or parameters changed or what the system would do if human users took particular actions. Level 3 XAI also incorporates counterfactual or other simulated information in order to provide explanations about a system’s future behavior in the presence of changes to either inputs or system parameters, which might occur due to human actions.
While level 2 XAI provides information about why a decision was made based on model-related factors, level 3 XAI provides insight as to what degree of change to inputs, model parameters, or constraints would yield a different outcome. Further, while level 2 explanations provide information about a decision made in a specific instance, level 3 information helps users to reason about what will happen in different contexts and what exactly would need to change about the given circumstance in order to alter the system’s output. In the context of explainable ML, level 3 information could include information about what effect a changed input would have on the output, which changes in the input would be required to achieve a given output, or what would change about the output if the model changed in some way. Similarly, for explainable agents and robots, level 3 information would provide information about changed inputs and outputs, changed models (such as the addition/removal of constraints or differently weighted objectives), or the nominal continued course of action. Chen et al. (Citation2014) include predicted future outcomes, consequences of actions, and information about uncertainty in level 3 of their framework. We expand upon this definition by including counterfactual cases within the scope of level 3 in SAFE-AI.
We define two types of prediction that can be supported with level 3 explanations. First, backward reasoning helps a user start with a desired outcome and work backwards to determine what would be necessary to achieve that outcome. For example, consider a situation in which a user interacting with a neural network hopes to understand what type of input would be required for a particular classification. In such a case, successful level 3 XAI would help the user understand the ranges of inputs to the neural network that would result in the desired classification. Second, forward simulation helps a user understand what will happen given any changes in the inputs or model that occur. An example of forward simulation in a robot planning scenario might involve a user who hopes to add a constraint to the planning problem based on their own preferences about the robot’s actions. Successful level 3 XAI would help such a user to understand the effect the new constraint would have on the outputted plan.
2.3. Example approaches achieving the levels of XAI from the XAI literature
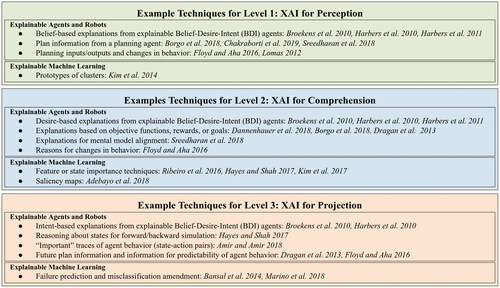
The following sections discuss how a limited, non-comprehensive set of example XAI techniques fit into SAFE-AI. These techniques can be used in order to provide the types of information that correspond to the levels of XAI discussed in the previous section. A table depicting how these techniques fit into our framework is shown in .
Figure 2. Example techniques at each level of XAI in SAFE-AI.
2.3.1. Example approaches achieving level 1 XAI
Level 1 XAI relates to AI system inputs and outputs. Whether a system has provided adequate level 1 explanations depends on whether a human user has sufficient information about these things. Many explainable ML techniques provide level 1 XAI implicitly through their inputs and outputted results. For example, Kim et al. (Citation2017) and Ribeiro et al. (Citation2016) provide users with the system’s outputted classification (level 1) in addition to explanations about the reasons behind the outputs (level 2). In these cases, the entire system output is captured by a single or small number of classifications, and the human user can easily understand the entire set of outputs. In other cases, such as with some clustering techniques, the entire set of outputs (i.e., features that represent a cluster) contains extraneous information in addition to information that is directly relevant to the human user’s understanding of the outputted clusters. Kim et al. (Citation2014) designate a set of clusters in a feature space, find the most quintessential prototype of each, and, for each prototype, down-select to a subset of features to present to the user.
In the explainable agents and robots literature, explainable Belief-Desire-Intention (BDI) agents explain their actions (intentions) based on their goals (desires) and their observations (beliefs) (Broekens et al., Citation2010; Harbers et al., Citation2011, Citation2010). Belief-based explanations are level 1 explanations, since they provide information about inputs that agents use in their decision-making processes. Harbers et al. (Citation2011) implement a BDI agent that produces explanations of both its observations (inputs) and actions (outputs), which both constitute level 1. Beyond BDI agents, Floyd and Aha (Citation2016) implement an agent that explains when it changes its behavior (output) in order to increase transparency. Lomas et al. (Citation2012) propose a framework for explainable robots which includes explanations about which actions a robot took (outputs) and what information it had about the world at the time (inputs). Finally, AI planning systems that provide users with a partial or entire plan (Borgo et al., Citation2018; Chakraborti et al., Citation2019; Sreedharan et al., Citation2018) implicitly provide level 1 XAI through their outputted plans.
2.3.2. Example approaches achieving level 2 XAI
Level 2 XAI is fundamentally related to supporting user comprehension of a system’s behavior through the understanding of its model, including reasoning about objectives, constraints, features, or other model aspects. Successful level 2 XAI adequately explains the relevant aspects of why a system behaved the way it did. Much of the current XAI literature falls into the category of level 2 XAI.
Various XAI techniques for ML models aim to explain which features, parts of the model, or other feature abstractions have the greatest bearing on a system’s decision making. Ribeiro et al. (Citation2016) introduce the LIME technique, which learns an approximation of a complex classifier over a human-understandable set of features in order to explain which of these features were most important in generating a classification for a given input. Kim et al. (Citation2017) propose a technique that allows users to define abstract concepts (which may be distinct from the original set of features used for classification) and learn about the significance of a concept’s contribution to a given classification. Other approaches, such as saliency maps, highlight important aspects of inputs (Adebayo et al., Citation2018).
In the explainable agent and robot literature, explainable BDI agents that explain their actions based on their goals (desires) (Broekens et al., Citation2010; Harbers et al., Citation2011, Citation2010) contribute to level 2 XAI. The agent proposed by Floyd and Aha (Citation2016) provides explanations about why it changes its behavior (level 2) based on user feedback. Hayes and Shah (Citation2017) propose a policy explanation technique that can answer questions about why an agent did not take a given action by reasoning about predicates that constitute its state. The technique proposed by Dannenhauer et al. (Citation2018) explains agent behavior based on the agent’s rationale and goal. Dragan et al. (Citation2013) discuss the distinction between legible and predictable robot motions. By their definition, legible robot motions support human inference of the robot’s goal and would therefore be considered level 2 XAI. Work related to explainable planning has proposed explanations according to human-understandable aspects of AI models, such as predicates or system objectives. Sreedharan et al. (Citation2018) introduce a technique that explains model predicates to a user in order to fill perceived gaps in the user’s understanding of the model based on foils they suggest. Finally, Borgo et al. (Citation2018) propose a set of techniques that explain system decisions by incorporating user-produced foils into planning and demonstrating that the modified plans are sub-optimal or infeasible.
2.3.3. Example approaches achieving level 3 XAI
Fundamentally, level 3 XAI is about supporting user prediction of AI behavior through enabling understanding of what a system would do if its inputs changed or if the model were to change in any way. Successful level 3 XAI helps users to predict what a system will do next or what it would do in a different context and answers “what if” questions about system behavior.
In the explainable ML literature, some approaches provide users with predictions of contexts in which an AI system will fail (Bansal et al., Citation2014) or predictions of which changes in inputs would be required to amend misclassified examples (Marino et al., Citation2018). Others that provide level 2 information could be extended to support level 3. For example, the SP-LIME algorithm (Ribeiro et al., Citation2016) chooses a subset of local model approximations produced by the LIME algorithm (discussed in Section 2.3.2) in order to provide a more “global” explanation of the interpretable features that impact classification in different scenarios. Ideally, if these examples are chosen according to human informational needs for prediction, the human user would be able to predict the outcome of a new example. However, with very complex systems, adequately providing information in this manner might be intractable, and other ways of providing level 3 explanations might be necessary. Other methods, such as the one described by Kim et al. (Citation2017) (discussed in Section 2.3.2), could be augmented to provide combinations of relevant “concepts” or could be complemented with other contextual information in order to support prediction more fully.
In the explainable agent and robot literature, Amir and Amir (Citation2018) provide explanations of global agent behavior by selecting “important” states in the state space and providing traces of subsequent states and actions (determined by the agent’s policy). These state-action pairs support human user prediction of future agent behavior. The policy explanation technique proposed by Hayes and Shah (Citation2017) can support both backward reasoning by answering questions about when (from which states) it will take certain actions and forward reasoning by answering questions about what the agent will do given different states. Some explainable agents provide more direct prediction-related information by explaining their next action(s), such as explainable BDI agents that provide sequence-based explanations (Broekens et al., Citation2010; Harbers et al., Citation2010) and others that provide their plans (Floyd & Aha, Citation2016). Note that providing users with plans that agents are executing online is level 3 XAI, while providing users with plans outputted by a planning agent is level 1 XAI. Finally, in the discussion of legibility versus predictability (Dragan et al., Citation2013), predictability is related to human inference of a robot’s actions based on a known goal, so we categorize predictable robot motions as level 3 XAI. As with explainable ML, information provided by level 2 XAI techniques can be combined and amended in order to produce level 3 XAI to support prediction of future robot or agent actions.
2.4. Determining human informational needs
In designing XAI systems and measuring their effectiveness, defining human informational requirements according to the SAFE-AI approach detailed above is of value. This information depends upon the overall goal of the human-AI team and the individual roles of the autonomous agent(s) and human(s) within that team (Chen et al., Citation2017; Schaefer et al., Citation2017). Endsley (Citation2017) describes a process called goal-directed task analysis (GDTA) for determining SA requirements for a given context, both for individuals and for those operating in larger teams. In this process, the major goals of each human teammate’s task are identified along with their associated sub-goals. Then, required decisions associated with each sub-goal are enumerated. Finally, SA requirements at all three levels are defined for each of these decisions (i.e., the information required to support human decision-making). The GDTA process is detailed at length in Endsley (Citation2017) and can be applied by XAI practitioners to define which information human users need about AI system behavior in order to achieve their respective goals. The definition of informational requirements with GDTA also informs the assessment of XAI systems, which will be discussed further in Section 2.5.
In many scenarios, users do not require information about all of a system’s behavior but only the aspects that are relevant to their specific tasks. Often, a human cannot possess information about the entirety of a complex system’s behavior; therefore, defining the specific information that users require (through GDTA or a similar process) in order to support human-AI team goals is critical. This is especially relevant when considering teams of humans, who each have their own roles and corresponding goals. Informational requirements in these cases are user-specific, and consequently, XAI systems might need to be able to adapt to users playing different roles in the team, providing each with the specific information relevant to his or her own task and potentially at different levels of abstraction. An extended discussion of the definition and support of team SA is provided by Endsley and Jones (Citation2001).
One important aspect of team SA is the interdependence of individual team members. Johnson et al. (Citation2014) detail an “interdependence analysis” process for assessing individual team members’ needs given different possible team configurations. This process results in the definition of observability (level 1) and predictability (level 3) requirements for each teammate in the context of their interdependence on each other. Since it defines information-sharing requirements in the team, it can also be useful for defining information requirements for XAI systems given different possible team configurations. We recommend using a modified version of this process that includes the definition of “comprehensibility” requirements (level 2) in order to define which role an XAI system should play in the context of a team. Once informational needs are identified, appropriate XAI techniques can be chosen to provide necessary information.
2.5. Evaluating explanation quality: A method for situation awareness-based XAI assessment
In the following sections, we discuss a selection of existing human-based metrics for XAI from the literature. We then suggest the use of the SAGAT method from human factors for the assessment of the effectiveness of XAI systems.
2.5.1. Existing level 1 XAI methods and metrics
Since providing a user with a system’s outputs is inherent to many existing XAI techniques, most literature does not aim to assess whether the human properly understood these outputs upon receiving them. Kim et al. (Citation2014) do this in part by assessing whether users are able to appropriately assign outputted prototypes to clusters based on the subset of features presented. Further, users are not often provided with explicit information or explanations about system inputs. As the XAI community moves towards explaining higher-complexity systems with multiple inputs and outputs, it will be increasingly important to measure whether users understand the correct inputs/outputs in the contexts of their intended goals. Section 2.5.4 outlines the SAGAT method, which is one possibility of a technique that could be applied for such assessments.
2.5.2. Existing level 2 XAI methods and metrics
Metrics for level 2 explanations should indicate whether users understand the meaning of a given system’s actions or decisions and what these actions or decisions imply in terms of progress towards team goals. Some of the literature has proposed survey-like questions for assessing explanation quality as it relates to user understanding. For example, Hoffman, Mueller, et al. (Citation2018) propose a “goodness” scale that includes a question about whether the user understands how the given algorithm works. They also detail a set of questions related to the perceived understandability of a system from the Madesen-Gregor scale for trust. Doshi-Velez and Kim (Citation2017) suggest human experiments requiring users to choose which of two possible system outputs is of higher quality, which necessitates understanding of the system. While these questions and metrics represent a step towards measuring whether adequate level 2 explanations have been provided to users, a more comprehensive way of defining comprehension-related informational needs and assessing whether they have been met through XAI is needed. As mentioned previously, we outline the SAGAT method as one possible approach to this in Section 2.5.4. SAGAT-style questions have previously been used to assess the change in users’ level of comprehension with different levels of interface transparency defined by the SAT model, with results suggesting that higher levels of transparency increase comprehension (Chen et al., Citation2016, Citation2017, Citation2018).
2.5.3. Existing level 3 XAI methods and metrics
Metrics for level 3 explanations should indicate whether human users can predict what a system will do next or what it would do given an alternate context or input. To this end, Doshi-Velez and Kim (Citation2017) suggest running human experiments in which human users perform forward simulation, prediction, and counterfactual simulation of system behavior given different inputs for XAI assessment. Hoffman, Mueller, et al. (Citation2018) discuss the use of prediction tasks to measure explanation quality and further detail a Likert-scale survey for trust measurement that includes a question about predictability of system actions. Questions and experiments such as these can be used to assess the quality of level 3 explanations provided by XAI systems. Beyond these assessment techniques, one possible comprehensive way of assessing whether level 3 informational needs are met (the SAGAT technique) is discussed in Section 2.5.4. SAGAT-style questions have previously been used to assess whether users are able to better predict system behavior with increasing interface transparency defined by the SAT model, with results suggesting that higher levels of transparency increased system predictability (Chen et al., Citation2016, Citation2017, Citation2018).
2.5.4. The SAGAT test and its applicability for assessment of XAI
In assessing the quality of XAI techniques, it is important to determine whether human users receive the information they need in order to perform their roles. Miller et al. (Citation2017), in particular, stress the need for human evaluations of XAI systems. As discussed in Sections 2.5.1–2.5.3, existing XAI literature includes some human-based evaluation metrics; however, to our knowledge, none have comprehensively assessed whether human informational needs are met by XAI systems.
Endsley (Citation1988) proposes the situation awareness-based global assessment technique (SAGAT) for SA measurement. SAGAT is a widely-used objective measure of SA that has been empirically shown to have a high degree of sensitivity, reliability, and validity in terms of predicting human performance (Endsley, Citation2017). It has been applied for measurement of SA in a variety of domains (Endsley, Citation2017), has been extensively used to measure team SA (Endsley, Citation2019), and has been shown to outperform other SA measures in terms of sensitivity, intrusivity, and bias, among other factors (Endsley, Citation2019). In addition, as mentioned in previous sections, it has been used to assess SA in the context of agent transparency (Chen et al., Citation2016, Citation2017, Citation2018).
In the SAGAT test, simulations of representative tasks are frozen at randomly selected times, and users are asked questions about their current perceptions of the situation (Endsley, Citation2019). The questions asked are based directly on the human informational needs defined according to a process such as GDTA (discussed in Section 2.4) and therefore directly measure whether humans have the information required. More complete discussions of SAGAT are provided in Endsley (Citation1995, Citation1988, Citation2017), and implementation recommendations for the test are discussed by Endsley (Citation2017).
Since the SAGAT test measures whether human informational needs are met, we propose that a SAGAT-like test can be applied to assess XAI systems. Situational information needs related to AI behavior should be thoroughly defined, and in the assessment of an XAI system, user knowledge of this information can be evaluated through a SAGAT-like test focused on information related specifically to AI behavior. Such a test could more adequately determine whether XAI systems achieve the purpose of communicating relevant information about system behavior to human users than current assessment techniques allow.
2.6. Example application of the SAFE-AI approach
Here we introduce a simple planetary rover example to demonstrate the application of SAFE-AI. We also demonstrate how the SAGAT test could be applied for the assessment of XAI techniques in this example problem. As noted in Section 2.5.4, the SAGAT test is an appropriate process for assessment of XAI systems in contexts such as this one since it measures whether human informational needs are met while XAI systems aim to meet human informational needs.
Our planetary rover example touches on aspects of explainable ML, explainable agents and robots, and XAI for human teams. In our example, a rover on another planet is executing a learned exploration policy. Its objective is to search for water, which is more likely to be found in areas with certain types of rocks. There are costs associated with navigation time and science task duration, and there are differing rewards associated with performing science tasks on the different types of rocks, some of which are more valuable. The rover has a camera onboard and an ML-based image processing system that allows it to classify rocks. There are constraints associated with the rover power requirements, and some terrain is not traversable. Human users include one engineer who monitors rover health and one scientist who monitors science activities. The scientist and engineer can also request new rover actions during the mission.
shows examples of information constituting levels 1–3 XAI for the engineer and scientist in this example, including the types of information they represent in bold. The scientist and engineer have individual informational requirements in addition to some shared requirements, such as which science activities are planned. Each is only provided with necessary information in order to avoid a cognitive overload from excess information, which poses a risk to task performance. In this example, a very skilled engineer or scientist might be able to use information from level 2 to infer the information at level 3 if he or she knows the proper calculations or adjustments required to do so. However, the transition from level 2 to level 3 information often requires complex calculations that users are unable to perform by hand or in a limited timeframe. In these cases, providing level 3 information explicitly is critical to ensuring smooth operations.
Figure 3. Example information at each SAFE-AI level of XAI for the planetary rover scenario.
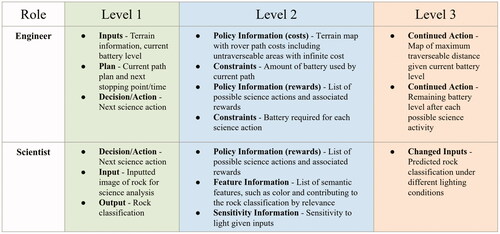
Note that the SAT model (Chen et al., Citation2014) captures much of the planning and decision-making information covered in this example. For example, the “Decision/Action,” “Plan,” “Policy Information (costs/rewards),” “Constraints,” and “Continued Action” categories depicted in would all be included with the application of the SAT model. However, our framework captures additional categories of information, such as “Feature Information,” “Sensitivity Information,” “Changed Inputs,” and “Input” and “Output” information related specifically to the ML-based aspects of the system in this example. Also, since our framework takes a human-centered approach, we are able to identify the break down of specific information needed by each individual for his or her specific tasks which may be a subset of the total information that could be provided. When applying SAT, additional information beyond what is needed for a specific individual in a specific context may be identified. Therefore, a system developed by applying the SAT model would complement our approach in this example in that it could be used as a launching point to meet the human informational needs enumerated through our proposed framework and process. From the information provided in a SAT-based interface, the specific information that applies to a given individual could be identified, and the interface could be augmented with additional necessary information that is not captured by the SAT model.
Measuring SA through SAGAT: In order to apply SAGAT to this example, specific informational requirements can be enumerated from the high-level informational needs listed above. A list of questions regarding this specific information at all three levels can be specified, and a simulated mission can be run with the scientist and engineer. At various randomly-selected points during the simulated mission, the experiment should be frozen, and the scientist and engineer would then be asked a subset of the specified questions for each level. For example, the following questions might be asked of the engineer regarding the battery during rover traversal between two science activity locations: What is the current battery level of the rover? (Level 1); How much power is required to get to the next location? (Level 2); Does the rover have enough battery to get to the next location and perform the science task? (Level 3).
3. Workload considerations for XAI
When communicating information about system behavior through XAI techniques, it is not only important that correct and relevant information is communicated but also that the communication occurs in a way that the human can understand and use to inform their own decision making. One important factor in determining whether a human can receive and use information is mental workload, which Parasuraman et al. (Citation2008) defined as the relationship between the mental resources demanded by a task and those resources available to be supplied by the human. If XAI systems communicate a given amount of information at a time when too much of a user’s mental capacity is required for the performance of other tasks, there is a risk of the user either missing the explanation entirely or receiving only partial information, with his or her performance suffering as a result.
The human factors and cognitive psychology literature have proposed a number of strategies for considering workload in the design of systems that include humans in the decision-making loop. Miller (Citation1956) introduced the “7 ± 2 rule,” which states that humans can maintain 7 ± 2 objects or “chunks” of information in their short-term memory at a time. This rule can serve to guide how much information is communicated by an XAI system in any one explanation (or a number of explanations that must be reasoned over simultaneously). It is also important to consider the mental workload requirements for any other tasks that users will be performing when they receive the explanations in order to ensure that they have enough capacity to both perform their required tasks and process the explanations. In addition, individual differences in mental processing capabilities of users, such as spatial reasoning ability or attentional control, may lead to differing outcomes in terms of workload and performance (Chen, Citation2011). Further studies will need to be performed in order to understand how different individuals are able to process explanations provided by XAI systems in different contexts.
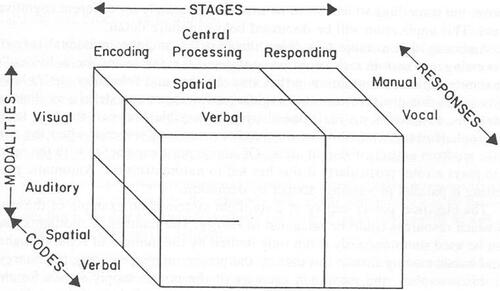
Wickens (Citation2008) introduced the Multiple Resource Model (MRM), depicted in , which considers the different “pools” of cognitive resources that people have available for information processing over different dimensions including the modality of information representation, the form of information encoding in the brain, stages of information processing, and response modality. According to the model, people have capacities in each pool that can be filled independently of the others, with the pools differing based on the combinations of categories comprising each dimension. When designing XAI systems, designers can take into consideration modalities of information representation with regard to input, encoding, and response modalities and stages of information processing in order to ensure that no cognitive resource pool becomes overloaded. Again, in XAI system design, it will be important to account for the cognitive requirements of all the user’s activities when they receive the explanations, so that the human can adequately perform necessary tasks while also processing provided information.
Figure 4. Multiple Resource Model Wickens (Citation2008).
While the levels of explanation introduced as part of the SAFE-AI approach in Section 2.2 dictate which information must be communicated through explanations, workload considerations dictate when and how that information should ideally be communicated so as not to overload the user. Increased AI system transparency can have the effect of increasing workload, since users are provided with additional information about the system that they need to process (Chen et al., Citation2014). However, effective AI system transparency might also reduce workload by reducing the number of calculations a user needs to perform in order to reason about system behavior (Chen et al., Citation2014). Further, a lack of user SA can increase workload and reduce efficiency (Schaefer et al., Citation2017), which reinforces the importance of supporting SA through XAI. Some studies have demonstrated that increasing system transparency improved performance with no significant effect on user workload in a military domain (Chen et al., Citation2016, Citation2017, Citation2018; Wright et al., Citation2016), but further research will be required in order to determine how explanations impact workload in different contexts. Interface design techniques such as Ecological Interface Design (EID), a strategy that aims to ensure that information can be quickly understood by users through a variety of visualization techniques, have been shown to improve user understanding of agent behavior and reduce workload (Chen et al., Citation2014). Once the informational needs of users have been determined using the levels of explanation, EID or similar techniques can be used in interface design in order to mitigate any negative impacts that increased transparency might have on workload or even to reduce workload through increased system transparency.
Drawing from the strategies and considerations discussed above, designers can choose how and when to present information to users via explanations, and they can verify their approaches using the metrics discussed in Section 3.3.
3.1. Local versus global workload considerations in XAI
There are two time-scales at which it is important to consider workload and whether human users of XAI systems have the cognitive resources necessary to execute their tasks. First, designers must address how much information is given in a single communication which we refer to as “local” workload considerations. Designers must also account for overall communication frequency, or the total number of communications that human users can manage given the cognitive load required for their other tasks within a given time-span; we refer to these as “global” workload considerations. Since local and global workload considerations might limit the amount of information an XAI system should provide in order to be maximally effective, algorithmic techniques must be developed to reason over which information is most relevant to users when not all potentially useful can be provided.
3.2. Existing workload considerations in XAI
Prior XAI research has considered workload in explanation generation by metering the amount of information provided based on users’ cognitive requirements; for example, the LIME and SP-LIME algorithms introduced by Ribeiro et al. (Citation2016) account for local and global workload, respectively. The LIME algorithm allows variation and restriction of the total number of features used to provide an explanation, while SP-LIME allows variation and restriction of the total number of representative examples provided to the user overall. Some literature that has addressed workload suggests that minimizing the information provided in an explanation increases interpretability (Chakraborti et al., Citation2019; Sreedharan et al., Citation2017). One example of a technique that minimizes the amount of information provided is detailed in the work by Chakraborti et al. (Citation2019). They minimized the total amount of information in any given explanation by producing a minimally complete explanation to align the optimal plan in the user’s model in order to match that of the planning system. Although some researchers have suggested that less information improves interpretability, others have found that explanation completeness is more important than conciseness or soundness with regard to improving accuracy and engendering user trust in an AI system (Kulesza et al., Citation2013). Additional context-specific studies would serve to further explore these ideas.
3.3. Workload metrics in XAI
While several papers in XAI have mentioned or considered workload as a driving factor for XAI system design, few workload-related metrics have been used to assess explanation quality. Chakraborti et al. (Citation2019) asked human subjects whether the explanations provided in their experiment were easy to understand but did not specifically ask questions about workload; similarly, Sreedharan et al. (Citation2019) explored whether human subjects preferred concise over verbose explanations but did not examine workload beyond that. Doshi-Velez and Kim (Citation2017) proposed a set of explanation-related interpretability factors based on “cognitive chunks” of information provided in explanations. These factors could be used to define different classes of explanation complexity and to assess the impact of explanations of varying complexity on workload accordingly.
Prior human factors literature has proposed and applied a variety of subjective and objective techniques to assess a person’s workload during task performance. One widely used subjective workload measure is the NASA TLX scale, administered after a user performs a task (Hart & Staveland, Citation1988). Objective measures related to task performance have also previously been used to assess workload. For example, primary task measures assess performance on a primary task as the task demands vary, and secondary task measures assess performance on a secondary task as demands for the primary task vary (Wickens et al., Citation2021). These workload assessment techniques and others have also been used to study the impact of agent transparency on user workload in military mission contexts with varying results (Chen et al., Citation2016, Citation2017, Citation2018; Wright et al., Citation2016). In future studies of XAI techniques, we recommend the use of NASA TLX along with performance-based metrics to assess whether users can meet the mental demand required to process the explanations generated by XAI systems in a variety of contexts.
4. Trust considerations for XAI
While meeting the informational needs of human users is one of the key aims of XAI, XAI systems may need to provide additional information in order to account for human trust in the system and the impact of trust on team performance. Lee and See (Citation2004) define “trust in automation” as the attitude that an agent will help achieve an individual’s goals in a situation characterized by uncertainty and vulnerability. Much existing XAI literature has discussed the need to increase trust in AI systems as a motivation for producing explanations (Borgo et al., Citation2018; Fox et al., Citation2017; Krarup et al., Citation2019). However, as Lee and See (Citation2004) stated, it is only appropriate to increase trust when the system is trustworthy. In other words, someone should only maintain the attitude that an agent will help them achieve their goals to the extent that the agent is actually able to do so. More important than increasing trust in AI systems is appropriately calibrating trust to ensure appropriate use (Lee & See, Citation2004; Schaefer et al., Citation2014).
Transparency has been shown to be a key factor in trust development in autonomous systems (Hancock et al., Citation2011; Schaefer et al., Citation2016). Considering how explanations can impact a human teammate’s trust in an AI system is critical, since trust can impact reliance and use of these systems (Dzindolet et al., Citation2003; Parasuraman & Riley, Citation1997; Schaefer et al., Citation2017). Previous work in human factors has explicitly explored the importance of user trust in the use of automated systems (Lee & See, Citation2004; Parasuraman & Riley, Citation1997). Overtrust in a system can lead to overuse, while undertrust can lead to disuse (Parasuraman & Riley, Citation1997). Thus, when considering XAI as it relates to trust in an AI system, the goal should not be to increase trust but to align user trust with the system’s true capabilities or purposes. In other words, a more transparent system should lead to better calibrated trust rather than increased trust (Chen et al., Citation2014).
Appropriate trust calibration, enabled through XAI, can be achieved through XAI systems providing information about system capabilities, limitations, and confidence, as will be discussed in Section 4.1. Other factors related to XAI that have been shown to impact trust in automated systems include accuracy of information provided, reliability of information provided, appropriateness of information, availability of information, and the ability of the system to provide non-conflicting information (Schaefer et al., Citation2014, Citation2016). All of these factors should be considered in the development of XAI systems, and many can be accounted for in the process of determining a user’s informational needs, as discussed in Section 2.4. Additionally, a user’s understanding of how an automated system works and the predictability of the system’s behavior, both of which relate to the levels of explanation in the SAFE-AI framework discussed in Section 2, have been shown to correlate with trust in automated systems (Schaefer et al., Citation2014). Designing interfaces to communicate information using Ecological Interface Design (EID), as mentioned in Section 3, has also been shown to support appropriate trust calibration (Ososky et al., Citation2014).
There are existing XAI techniques that consider trust as a success metric for the explanation system. For example, Wang et al. (Citation2016b) implement a partially-observable Markov decision process (POMDP) explanation-generation technique and measure trust using survey and behavior-based data. They explicitly accounted for trust calibration in their explanation technique by providing a confidence level about the system’s sensor readings along with information related to state, actions, observations, rewards, and transition functions. Chakraborti et al. (Citation2019) produce robot explanations to reconcile a human’s model with a robot’s, and in human subject experiments, they ask participants to indicate whether they trust the robot and whether their trust increased during the study. However, they do not consider trust calibration explicitly. Since human trust in robot systems can directly impact human-robot team performance, we believe that it is not only important to consider trust and trust calibration as success metrics for explanations, but also at the explanation technique design phase.
Drawing from the human factors literature (Lee & See, Citation2004; Parasuraman & Riley, Citation1997), we suggest two additional important trust-related considerations (beyond trust calibration) for the design of XAI systems that can describe their behavior to human teammates: the bases of trust and trust specificity. We then detail existing and potential metrics for assessing whether a person appropriately trusts an AI system based on explanations it provides about its behavior. Here we focus primarily on characteristics of automated systems that influence trust and how XAI can be applied to affect these automation-based characteristics. Other works have considered additional antecedents of trust related to human traits (such as individual ability or propensity to trust) and environment-based factors (such as risk or uncertainty) (Schaefer et al., Citation2016). As future work, it would be interesting to explore how XAI systems can be modified to incorporate or infer these other factors and leverage differences between individual humans or the environment in deciding what to explain and when.
4.1. Bases of trust: Purpose, process, and performance
Lee and See (Citation2004) introduced purpose, process, and performance as three bases for user trust in an automated system. They asserted that providing users with information about these elements can help to ensure appropriately calibrated trust. These three bases of trust are also included as elements of the SAT framework for agent transparency (Chen et al., Citation2014), which has been empirically shown to support user trust through the use of transparent interfaces (Chen et al., Citation2016, Citation2017, Citation2018; Pynadath et al., Citation2018). We believe that it is important for AI systems to communicate information about all three elements through explanations about their behavior.
The authors define “purpose” as the degree to which the system is being used within the realm of the designer’s intent. An AI system providing a purpose-related explanation might tell a human the tasks it can and cannot do according to its design. For example, consider a manufacturing robot that is working alongside a human teammate. This robot could say to its human teammate, “I can lift parts weighing up to 10 kg and move them, but I cannot sense if you are in my workspace.”
“Process” refers to the appropriateness of a system’s algorithm for the situation in which it is working and the extent to which it can contribute to the team’s goals. An AI system providing a process-related explanation might give information about how it performs its tasks. For example, the manufacturing robot could tell its human teammate, “I decide which objects to move and where to move them based on pre-programmed schedules an cannot move un-programmed objects.”
Finally, “performance” is related to an automated system’s demonstrated operations, including characteristics such as reliability, predictability, and ability. An AI system providing performance-related information in an explanation could explain its specifications, limitations, or confidence levels. For example, the manufacturing robot could say to its human teammate, “I place items I move correctly 90% of the time.” One study suggested that communicating information about uncertainty/confidence in addition to other information about system behavior in a military context did not contribute to increased trust (Chen et al., Citation2016; Pynadath et al., Citation2018). Further investigation into how user trust is influenced by communication of uncertainty information in different forms and in different contexts would be of benefit.
Note that there are two important aspects to performance-related communication: communication about the AI system’s task performance and communication about its performance at providing explanations about its own behavior. For example, a complex machine learning system might perform a classification task very well but it might not perform as well at explaining the factors that impacted its classifications. Information about how a system performs at decision-making processes and at production of explanations can help users understand the trustworthiness of both the AI system (with regard to its given tasks) and the XAI system’s explanations.
4.2. Trust specificity: Local versus global trust calibration
Lee and See (Citation2004) discussed the concept of specificity of trust in automation. They defined “functional specificity” as the differentiation of trust between functions, subfunctions, and modes of automation. They argued that with a high degree of functional specificity, a person’s trust can reflect the capabilities of specific subfunctions and modes of an automated system. XAI systems must be able to provide information to support functionally specific trust in AI systems, which we refer to as “local trust” in the system.
Local trust calibration is important for AI systems, because a single system may not be uniformly trustable across all contexts. For example, consider a semi-autonomous vehicle which possesses extensive training data collected from highway driving but relatively little training data from urban environments. This vehicle might perform adequately without human assistance on highways but worse on city streets. In such a scenario, an XAI system must be able to support user understanding of its differing performance across the various contexts. Developing XAI systems able to support local trust calibration can also be beneficial for development of user-specific explanations, tailored to the needs of different individuals who work with the AI system.
While local trust calibration can help different users appropriately trust and engage with an AI system in different contexts, overall understanding of the system’s performance and abilities is important for allowing users to determine how they might trust the system in new scenarios. In our semi-autonomous vehicle example, while local trust can be calibrated for different driving contexts, it is likely not possible for a user to encounter every contextual scenario while learning about how the vehicle operates. Therefore, some global information about the system’s overall performance (such as number of miles between vehicle failures) could help users to maintain a prior on how trustworthy the system will be in new scenarios. In sum, to support global trust calibration, an XAI system should provide information about the AI system’s global performance towards its overall goal in order to improve users’ understanding of the system’s overall trustworthiness.
4.3. Trust metrics for XAI
Some existing literature assesses user trust in an AI system primarily through survey questions. For example, Chakraborti et al. (Citation2019) asked users to rank whether they trusted a robot in their setup to work on its own and whether their trust in the robot increased over the course of the study on a Likert scale. Similarly, Wang et al. (Citation2016a) asked users to rate their trust in a system on a Likert scale. Wang et al. (Citation2016b) also asked human users to rank their trust in the system under different transparency conditions, and they additionally use compliance, defined as the number of participant decisions that match the robot’s, as a behavior-based metric for measuring trust in the system.
In the human factors literature, Billings et al. (Citation2012) enumerated important factors to consider when choosing an appropriate metric to assess trust: the type of trust being studied (initial trust, individual trust propensity, dynamics of trust, etc.), how trust is measured (subjectively, objectively, physiologically, etc.), and when trust is measured (before, during, or after an interaction). These factors should be considered in choosing how to measure trust in human subject experiments with XAI systems. The following are a few possibilities for metrics based on existing research in both human factors and XAI.
Dzindolet et al. (Citation2003) explored the role of trust in automation reliance and concluded that trust impacts reliance upon automated systems regardless of a system’s actual ability, suggesting that reliance could be an appropriate proxy metric for assessing how explanations impact user trust. In the XAI literature, Hoffman, Mueller, et al. (Citation2018) emphasized the importance of appropriate trust calibration and suggested that a trust scale should ask two primary questions: whether a user trusts the system’s outputs and whether they would follow its advice. They further proposed a trust scale that can assess the value of XAI systems based on the user’s trust in the AI before and after it provides explanations. We recommend using a trust scale such as that proposed by Hoffman, Mueller, et al. (Citation2018) in conjunction with a behavior-based (reliance, compliance, etc.) metric in order to determine whether humans appropriately trust and use AI systems in response to explanations they provide. Ideally, a user’s trust and reliance should correspond to a system’s capabilities, amounting to appropriate trust calibration.
5. Future work: Applying SAFE-AI, workload considerations, and trust considerations to XAI systems
The SAFE-AI approach and related human factors considerations discussed in this paper can be used to inform three primary future lines of work in XAI: defining requirements for XAI systems, providing design guidance for developing more comprehensive approaches to XAI, and providing guidance for developing more comprehensive evaluations of XAI systems. So far, much of the existing research in XAI has been focused on developing capabilities for communicating information about various aspects of AI system behavior, but there has not been an extensive focus on matching these capabilities to specific human needs. Using the human-centered SAFE-AI framework proposed in this paper (which is focused on human needs and roles) in order to define requirements for XAI systems being used in different contexts is an area for future work.
In defining the requirements for XAI systems through the application of SAFE-AI, gaps in existing capabilities may be identified, and these gaps can provide guidance for the development of more comprehensive approaches to XAI. For example, to our knowledge, no system exists that can, on its own, address all three levels of XAI. While explainable BDI agents have addressed aspects of each of the three levels (Broekens et al., Citation2010; Harbers et al., Citation2010), additional techniques beyond these solutions will be needed to fully address levels 2 and 3 XAI. In general, development of an XAI system that can independently address all three levels of XAI would be a valuable next direction. Such a system will also require the development of techniques that provide user-tailored explanations in a way that goes beyond what exists in the literature. While there is some existing literature that considers user needs or context in a limited way (Chakraborti et al., Citation2019; Floyd & Aha, Citation2016; Sreedharan et al., Citation2018), producing explanations that fully consider user contexts and tasks remains an understudied area.
SAFE-AI and the associated assessment techniques discussed throughout the paper also provide a way to more comprehensively evaluate XAI systems in the future. Human-subject experiments should be performed to ensure that XAI techniques are appropriately supporting human SA in joint human-AI tasks and that improved SA about AI processes and decisions contributes to improved overall task performance. Additionally, assessing the efficacy of SAFE-AI through human-subject experiments performed in a variety of different contexts will be especially critical, since SA has typically been studied in the context of dynamic environments in the human factors literature. Applying SAFE-AI in environments of differing complexity and in which human-AI joint tasks are performed at varying timescales, and then analyzing how human SA correlates with human-AI team performance in these scenarios will help to map the landscape of the contexts in which SAFE-AI is most effective and most limited.
It will also be important to consider the workload- and trust-related factors discussed in Sections 3 and 4, respectively, and to assess trust and workload according to the metrics proposed in those sections (NASA-TLX along with performance metrics for workload and a trust scale along with behavior-based metrics for trust). Further human subject experiments should be performed for new and existing XAI systems in order to analyze how humans interact with these systems in the contexts in which they will be used. These experiments can be used to determine whether human workload is acceptable in these contexts and whether humans appropriately trust AI systems based on the systems’ capabilities and the explanations XAI systems provide about their behavior. Finally, in this paper we have focused primarily on the concepts of situation awareness, trust, and workload since these concepts all have direct implications for XAI, and there are existing XAI techniques that relate to each. However, future work studying how other human factors concepts such as human error, human decision-making biases, and shared mental models relate to XAI would also be of value.
6. Conclusion
In this paper, we discuss how the concepts of situation awareness, workload, and trust from human factors relate to XAI and how XAI practitioners can leverage these concepts in the design and assessment of XAI systems. We first discuss the situation awareness literature from human factors and propose SAFE-AI, a three-level framework for the design of XAI systems based on human user informational needs. This framework is based on the three-level situation awareness framework (Endsley, Citation1995), which has been studied in relation to performance of human-autonomy teams. We further suggest the use of a method such as the SAGAT test for assessment of explanations with respect to the three levels of information that XAI systems should provide.
While the concept of situation awareness allows us to define which information XAI systems should communicate about AI system behavior, human workload capacities determine when and how the information can be communicated during task execution if the information is to be usable by the human interacting with the system. We discuss the concept of the multiple resource model, which suggests that human mental capacities can be divided into independent “pools” based on modality of of information representation, form of encoding in the brain, stages of information processing, and response modality (Wickens, Citation2008). No cognitive resource pool should be overloaded as humans are performing their tasks, or else task performance might suffer. Designers should take care to consider the entire context in which a human will be using an XAI system to understand what mental capacities they will have available to receive explanations from the XAI system. Workload can be measured through subjective measures, such as NASA-TLX or objective measures, such as performance metrics, and these metrics can be useful to XAI practitioners in determining whether their systems are providing information in an effective way.
Finally, we discuss the concept of trust in AI systems and how XAI systems should contribute to appropriately calibrating trust in AI systems. Calibrated trust is critical to human-AI team performance and can be enabled through explanations of AI system behavior. Human trust in AI systems can be supported through explanations about the system’s purpose, process, and performance. It is further important that trust is appropriately calibrated at both a local level (functional specificity) and a global level and that explanations provide appropriate information at each level. In measuring the success of XAI techniques with regard to trust, researchers should measure the impact of explanations on human trust using a combination of a trust scale and a behavioral metric, such as reliance or compliance.
Moving forward, the XAI community could greatly benefit from leveraging concepts from the human factors literature including situation awareness, workload, and trust in both the design and evaluation of XAI systems. Performing human subject experiments with existing and new XAI systems and assessing these systems based on relevant human-centric metrics will be critical if these systems are going to reach their full potential in providing useful information to their human counterparts.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Lindsay Sanneman
Lindsay Sanneman is a PhD candidate in the Aeronautics and Astronautics department at MIT and a member of the Interactive Robotics Group in the Computer Science and Artificial Intelligence Laboratory. Her research relates to the application of explainable AI to human-machine collaborative contexts such as the AI value alignment setting.
Julie A. Shah
Julie A. Shah is a Professor of Aeronautics and Astronautics at MIT, and director of the Interactive Robotics Group in the Computer Science and Artificial Intelligence Laboratory. Her research focuses on designing collaborative machine teammates that enhance human capability and she has translated her work to manufacturing assembly lines, healthcare applications, transportation and defense.
References
- Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., & Kim, B. (2018). Sanity checks for saliency maps. In Advances in Neural Information Processing Systems, 9505–9515. https://doi.org/10.48550/arXiv.1810.03292
- Amir, D., Amir, O. (2018). Highlights: Summarizing agent behavior to people. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (pp. 1168–1176). International Foundation for Autonomous Agents and Multiagent Systems.
- Anjomshoae, S., Najjar, A., Calvaresi, D., Främling, K. (2019). Explainable agents and robots: Results from a systematic literature review. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, pages 1078–1088. International Foundation for Autonomous Agents and Multiagent Systems.
- Bansal, A., Farhadi, A., & Parikh, D. (2014). Towards transparent systems: Semantic characterization of failure modes. In European Conference on Computer Vision (pp. 366–381). Springer, Cham.
- Bedny, G., & Meister, D. (1999). Theory of activity and situation awareness. International Journal of Cognitive Ergonomics, 3(1), 63–72. https://doi.org/10.1207/s15327566ijce0301_5
- Billings, D. R., Schaefer, K. E., Chen, J. Y., Hancock, P. A. (2012). Human-robot interaction: Developing trust in robots. In Proceedings of the Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction (pp. 109–110).
- Borgo, R., Cashmore, M., & Magazzeni, D. (2018). Towards providing explanations for ai planner decisions. arXiv preprint arXiv:1810.06338
- Broekens, J., Harbers, M., Hindriks, K., Van Den Bosch, K., Jonker, C., Meyer, J.-J. (2010). Do you get it? user-evaluated explainable bdi agents. In German Conference on Multiagent System Technologies (pp. 28–39). Springer.
- Chakraborti, T., Sreedharan, S., Grover, S., Kambhampati, S. (2019). Plan explanations as model reconciliation. In 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (pp. 258–266). Ieee
- Chen, J. Y. (2011). Individual differences in human-robot interaction in a military multitasking environment. Journal of Cognitive Engineering and Decision Making, 5(1), 83–105. https://doi.org/10.1177/1555343411399070
- Chen, J. Y., Barnes, M. J., Selkowitz, A. R., & Stowers, K. (2016). Effects of agent transparency on human-autonomy teaming effectiveness [Paper presentation]. In 2016 IEEE international conference on Systems, man, and cybernetics (SMC) (pp. 001838–001843). IEEE. https://doi.org/10.1109/SMC.2016.7844505
- Chen, J. Y., Barnes, M. J., Wright, J. L., Stowers, K., & Lakhmani, S. G. (2017). Situation awareness-based agent transparency for human-autonomy teaming effectiveness [Paper presentation]. In Micro-and nanotechnology sensors, systems, and applications IX (vol. 10194, pp. 101941V). International Society for Optics and Photonics. https://doi.org/10.1117/12.2263194
- Chen, J. Y., Lakhmani, S. G., Stowers, K., Selkowitz, A. R., Wright, J. L., & Barnes, M. (2018). Situation awareness-based agent transparency and human-autonomy teaming effectiveness. Theoretical Issues in Ergonomics Science, 19(3), 259–282. https://doi.org/10.1080/1463922X.2017.1315750
- Chen, J. Y., Procci, K., Boyce, M., Wright, J., Garcia, A., & Barnes, M. (2014). Situation awareness-based agent transparency. Technical report, Army research lab Aberdeen proving ground MD human research and engineering.
- Dannenhauer, D., Floyd, M. W., Molineaux, M., & Aha, D. W. (2018). Learning from exploration: Towards an explainable goal reasoning agent.
- Doshi-Velez, F., Kim, B. (2017). Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608
- Dragan, A. D., Lee, K. C., & Srinivasa, S. S. (2013). Legibility and predictability of robot motion [Paper presentation]. In 2013 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (pp. 301–308). IEEE. https://doi.org/10.1109/HRI.2013.6483603
- Dzindolet, M. T., Peterson, S. A., Pomranky, R. A., Pierce, L. G., & Beck, H. P. (2003). The role of trust in automation reliance. International Journal of Human-Computer Studies, 58(6), 697–718. https://doi.org/10.1016/S1071-5819(03)00038-7
- Endsley, M. (1995). Measurement of Situation Awareness in Dynamic Systems. Human Factors, 37(1), 65–84. https://doi.org/10.1518/001872095779049499
- Endsley, M., & Jones, W. (2001). A model of inter-and intrateam situation awareness: Implications for design. new trends in cooperative activities: Understanding system dynamics in complex environments. m. mcneese, e. salas and m. endsley. santa monica. CA, Human Factors and Ergonomics Society
- Endsley, M. R. (1988). Situation awareness global assessment technique (sagat) [Paper presentation]. In Proceedings of the IEEE 1988 National Aerospace and Electronics Conference (pp. 789–795). IEEE. https://doi.org/10.1109/NAECON.1988.195097
- Endsley, M. R. (2015). Situation awareness misconceptions and misunderstandings. Journal of Cognitive Engineering and Decision Making, 9(1), 4–32. https://doi.org/10.1177/1555343415572631
- Endsley, M. R. (2017). Direct measurement of situation awareness: Validity and use of sagat. In Situational Awareness (pp. 129–156). Routledge.
- Endsley, M. R. (2019). A systematic review and meta-analysis of direct objective measures of situation awareness: A comparison of sagat and spam. Human Factors, 63(1), 124–150. https://doi.org/10.1177/0018720819875376
- Floyd, M. W., Aha, D. W. (2016). Incorporating transparency during trust-guided behavior adaptation. In International Conference on Case-Based Reasoning (pp. 124–138). Springer.
- Fox, M., Long, D., & Magazzeni, D., (2017). Explainable planning. arXiv preprint arXiv:1709.10256
- Gunning, D., & Aha, D. W. (2019). Darpa’s explainable artificial intelligence program. AI Magazine, 40(2), 44–58. https://doi.org/10.1609/aimag.v40i2.2850
- Halpern, J. Y., & Pearl, J. (2005). Causes and explanations: A structural-model approach. part i: Causes. The British Journal for the Philosophy of Science, 56(4), 843–887. https://doi.org/10.1093/bjps/axi147
- Hancock, P. A., Billings, D. R., Schaefer, K. E., Chen, J. Y., De Visser, E. J., & Parasuraman, R. (2011). A meta-analysis of factors affecting trust in human-robot interaction. Human Factors, 53(5), 517–527. https://doi.org/10.1177/0018720811417254
- Harbers, M., Bradshaw, J. M., Johnson, M., Feltovich, P., Van Den Bosch, K., Meyer, J.-J. (2011). Explanation in human-agent teamwork. In International Workshop on Coordination, Organizations, Institutions, and Norms in Agent Systems (pp. 21–37). Springer.
- Harbers, M., van den Bosch, K., Meyer, J.-J. (2010). Design and evaluation of explainable bdi agents. In 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (vol. 2, pp. 125–132). IEEE.
- Hart, S. G., & Staveland, L. E. (1988). Development of nasa-tlx (task load index): Results of empirical and theoretical research. In Advances in Psychology (vol. 52, pp. 139–183). Elsevier.
- Hayes, B., & Shah, J. A. (2017). Improving robot controller transparency through autonomous policy explanation [Paper presentation]. In 2017 12th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (pp. 303–312). IEEE. https://doi.org/10.1145/2909824.3020233
- Hellström, T., & Bensch, S. (2018). Understandable robots-what, why, and how. Paladyn, Journal of Behavioral Robotics, 9(1), 110–123. https://doi.org/10.1515/pjbr-2018-0009
- Hoffman, R., Miller, T., Mueller, S. T., Klein, G., & Clancey, W. J. (2018). Explaining explanation, part 4: A deep dive on deep nets. IEEE Intelligent Systems, 33(3), 87–95. https://doi.org/10.1109/MIS.2018.033001421
- Hoffman, R. R., Mueller, S. T., Klein, G., & Litman, J. (2018). Metrics for explainable ai: Challenges and prospects. arXiv preprint arXiv:1812.04608
- Johnson, M., Bradshaw, J. M., Feltovich, P. J., Jonker, C. M., Van Riemsdijk, M. B., & Sierhuis, M. (2014). Coactive design: Designing support for interdependence in joint activity. Journal of Human-Robot Interaction, 3(1), 43–69. https://doi.org/10.5898/JHRI.3.1.Johnson
- Kim, B., Rudin, C., & Shah, J. A. (2014). The Bayesian case model: A generative approach for case-based reasoning and prototype classification. In Advances in Neural Information Processing Systems 1952–1960. https://doi.org/10.48550/arXiv.1503.01161
- Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., & Sayres, R. (2017). Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). arXiv preprint arXiv:1711.11279
- Krarup, B., Cashmore, M., Magazzeni, D., & Miller, T. (2019). Model-based contrastive explanations for explainable planning.
- Kulesza, T., Stumpf, S., Burnett, M., Yang, S., Kwan, I., Wong, W.-K. (2013). Too much, too little, or just right? ways explanations impact end users’ mental models. In 2013 IEEE Symposium on Visual Languages and Human Centric Computing, pages 3–10. IEEE
- Lage, I., Chen, E., He, J., Narayanan, M., Kim, B., Gershman, S., & Doshi-Velez, F. (2019). An evaluation of the human-interpretability of explanation. arXiv preprint arXiv:1902.00006
- Lee, J. D., & See, K. A. (2004). Trust in automation: Designing for appropriate reliance. Human Factors, 46(1), 50–80. https://doi.org/10.1518/hfes.46.1.50_30392
- Lim, B. Y., Dey, A. K., Avrahami, D. (2009). Why and why not explanations improve the intelligibility of context-aware intelligent systems. In Proceedings of the SIGCHI conference on human factors in computing systems (pp. 2119–2128).
- Lipton, Z. C. (2016). The mythos of model interpretability. arXiv preprint arXiv:1606.03490
- Lomas, M., Chevalier, R., Cross, E. V., Garrett, R. C., Hoare, J., & Kopack, M. (2012). Explaining robot actions. In Proceedings of the seventh annual ACM/IEEE international conference on Human-Robot Interaction (pp. 187–188). https://doi.org/10.1145/2157689.2157748
- Marino, D. L., Wickramasinghe, C. S., & Manic, M. (2018). An adversarial approach for explainable ai in intrusion detection systems. In IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society (pp. 3237–3243). IEEE.
- Miller, G. A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological Review, 63(2), 81–97. https://doi.org/10.1037/h0043158
- Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence, 267, 1–38. https://doi.org/10.1016/j.artint.2018.07.007
- Miller, T., Howe, P., & Sonenberg, L. (2017). Explainable ai: Beware of inmates running the asylum or: How i learnt to stop worrying and love the social and behavioural sciences. arXiv preprint arXiv:1712.00547
- Neerincx, M. A., van der Waa, J., Kaptein, F., van Diggelen, J. (2018). Using perceptual and cognitive explanations for enhanced human-agent team performance. In International Conference on Engineering Psychology and Cognitive Ergonomics (pp. 204–214). Springer.
- Ososky, S., Sanders, T., Jentsch, F., Hancock, P., & Chen, J. Y. (2014). Determinants of system transparency and its influence on trust in and reliance on unmanned robotic systems. In Unmanned Systems Technology XVI (vol. 9084, pp. 90840E). International Society for Optics and Photonics. https://doi.org/10.1117/12.2050622
- Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253. https://doi.org/10.1518/001872097778543886
- Parasuraman, R., Sheridan, T. B., & Wickens, C. D. (2008). Situation awareness, mental workload, and trust in automation: Viable, empirically supported cognitive engineering constructs. Journal of Cognitive Engineering and Decision Making, 2(2), 140–160. https://doi.org/10.1518/155534308X284417
- Preece, A., Harborne, D., Braines, D., Tomsett, R., & Chakraborty, S. (2018). Stakeholders in explainable ai. arXiv preprint arXiv:1810.00184
- Pynadath, D. V., Barnes, M. J., Wang, N., & Chen, J. Y. (2018). Transparency communication for machine learning in human-automation interaction. In Human and machine learning (pp. 75–90). Springer.
- Ribeiro, M. T., Singh, S., Guestrin, C. (2016). Why should i trust you?: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135–1144). ACM.
- Ribera, M., & Lapedriza, A. (2019). Can we do better explanations? A proposal of user-centered explainable ai. In IUI Workshops.
- Salmon, P. M., Stanton, N. A., Walker, G. H., Baber, C., Jenkins, D. P., McMaster, R., & Young, M. S. (2008). What really is going on? Review of situation awareness models for individuals and teams. Theoretical Issues in Ergonomics Science, 9(4), 297–323. https://doi.org/10.1080/14639220701561775
- Sanneman, L., Shah, J. A. (2020). A situation awareness-based framework for design and evaluation of explainable ai. In International Workshop on Explainable, Transparent Autonomous Agents and Multi-Agent Systems (pp. 94–110). Springer.
- Schaefer, K. E., Billings, D. R., Szalma, J. L., Adams, J. K., Sanders, T. L., Chen, J. Y., & Hancock, P. A. (2014). A meta-analysis of factors influencing the development of trust in automation: Implications for human-robot interaction. Technical report. Army Research Lab Aberdeen Proving Ground Md Human Research And Engineering.
- Schaefer, K. E., Chen, J. Y., Szalma, J. L., & Hancock, P. A. (2016). A meta-analysis of factors influencing the development of trust in automation: Implications for understanding autonomy in future systems. Human Factors, 58(3), 377–400. https://doi.org/10.1177/0018720816634228
- Schaefer, K. E., Straub, E. R., Chen, J. Y., Putney, J., & Evans, A. W. III, (2017). Communicating intent to develop shared situation awareness and engender trust in human-agent teams. Cognitive Systems Research, 46, 26–39. https://doi.org/10.1016/j.cogsys.2017.02.002
- Sheh, R., & Monteath, I. (2017). Introspectively assessing failures through explainable artificial intelligence. In IROS Workshop on Introspective Methods for Reliable Autonomy.
- Sheh, R. K. (2017). Different xai for different hri. In 2017 AAAI Fall Symposium Series.
- Smith, K., & Hancock, P. A. (1995). Situation awareness is adaptive, externally directed consciousness. Human Factors, 37(1), 137–148. https://doi.org/10.1518/001872095779049444
- Sreedharan, S., Kambhampati, S., et al. (2017). Balancing explicability and explanation in human-aware planning. In 2017 AAAI Fall Symposium Series.
- Sreedharan, S., Srivastava, S., & Kambhampati, S. (2018). Hierarchical expertise level modeling for user specific contrastive explanations. In The International Joint Conference on Artificial Intelligence (pp. 4829–4836).
- Sreedharan, S., Srivastava, S., Smith, D., & Kambhampati, S. (2019). Why can’t you do that hal? explaining unsolvability of planning tasks. In Proceedings of The International Joint Conference on Artificial Intelligence.
- Stanton, N. A., Chambers, P. R., & Piggott, J. (2001). Situational awareness and safety. Safety Science, 39(3), 189–204. https://doi.org/10.1016/S0925-7535(01)00010-8
- Stowers, K., Kasdaglis, N., Newton, O., Lakhmani, S., Wohleber, R., Chen, J. (2016). Intelligent agent transparency: The design and evaluation of an interface to facilitate human and intelligent agent collaboration. In Proceedings of the human factors and ergonomics society annual meeting (vol. 60, pp. 1706–1710). SAGE Publications Sage CA. https://doi.org/10.1177/1541931213601392
- Wang, N., Pynadath, D. V., Hill, S. G. (2016a). The impact of pomdp-generated explanations on trust and performance in human-robot teams. In Proceedings of the 2016 international conference on autonomous agents & multiagent systems (pp. 997–1005). International Foundation for Autonomous Agents and Multiagent Systems.
- Wang, N., Pynadath, D. V., & Hill, S. G. (2016b). Trust calibration within a human-robot team: Comparing automatically generated explanations. In 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (pp. 109–116). IEEE. https://doi.org/10.1109/HRI.2016.7451741
- Wickens, C. D. (2008). Multiple resources and mental workload. Human Factors, 50(3), 449–455. https://doi.org/10.1518/001872008X288394
- Wickens, C. D., Helton, W. S., Hollands, J. G., & Banbury, S. (2021). Engineering psychology and human performance. Routledge.
- Wright, J. L., Chen, J. Y., Barnes, M. J., Hancock, P. A. (2016). Agent reasoning transparency’s effect on operator workload. In Proceedings of the human factors and ergonomics society annual meeting (vol. 60, pp. 249–253). SAGE Publications Sage. https://doi.org/10.1177/1541931213601057