?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Regression trees and their ensemble methods are popular methods for nonparametric regression: they combine strong predictive performance with interpretable estimators. To improve their utility for locally smooth response surfaces, we study regression trees and random forests with linear aggregation functions. We introduce a new algorithm that finds the best axis-aligned split to fit linear aggregation functions on the corresponding nodes, and we offer a quasilinear time implementation. We demonstrate the algorithm’s favorable performance on real-world benchmarks and in an extensive simulation study, and we demonstrate its improved interpretability using a large get-out-the-vote experiment. We provide an open-source software package that implements several tree-based estimators with linear aggregation functions. Supplementary materials for this article are available online.
1 Introduction
Classification and regression trees (CART) (Morgan and Sonquist Citation1963; Breiman et al. Citation1984) have long been used in many domains. Their simple structure makes them interpretable and useful for statistical inference, data mining, and visualizations. Random forests (RF) (Breiman Citation2001) and gradient boosting machines (GBM) (Friedman Citation2001) build on tree algorithms. They are less interpretable and more laborious to visualize than single trees, but they often perform better in predictive tasks and lead to smoother estimates (Bühlmann and Yu Citation2002; Svetnik et al. Citation2003; Touw et al. Citation2012).
As these tree-based algorithms predict piece-wise constant responses, this leads to (a) weaker performance when the underlying data generating process exhibits smoothness and (b) relatively deep trees that are harder to interpret.
To address these weaknesses, we study regression trees with linear aggregation functions implemented in the leaves. Specifically, we introduce three core changes to the classical CART algorithm:
Instead of returning for each leaf the mean of the corresponding training observations as in the classical CART algorithm, we fit a ridge regression in each leaf. That is, for a unit with features,
, that falls in a leaf S, the tree prediction is
Crucial to the success of such an aggregation function, we take into account the fact that we fit a regularized linear model on the leaves when constructing the tree by following a greedy strategy that finds the optimal (we define what we mean by optimal in Section 2) splitting point at each node. That is, for each candidate split that leads to two child nodes SL and SR , we take the split such that the total MSE after fitting an
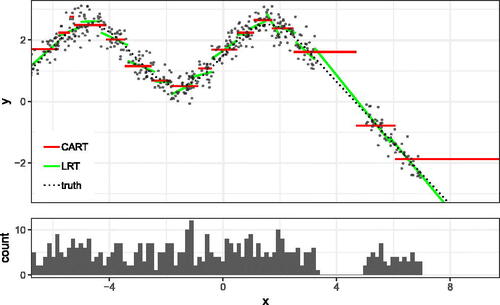
Furthermore, we use a cross-validation stopping criteria that determines when to continue splitting as opposed to when to construct a leaf node. After selecting the optimal split, the improvement in R2 that is introduced by the potential split is calculated. If the potential split increases the R2 by less than a predetermined percentage, then the splitting procedure is halted and a leaf node is created. This leads to trees that can create large nodes with smooth aggregation functions on smooth parts of data, while taking much smaller nodes which mimic the performance of standard CART aggregation on separate subsets of the response surface. This adaptivity over varying degrees of smoothness is displayed in and explored in greater detail in Section 3.
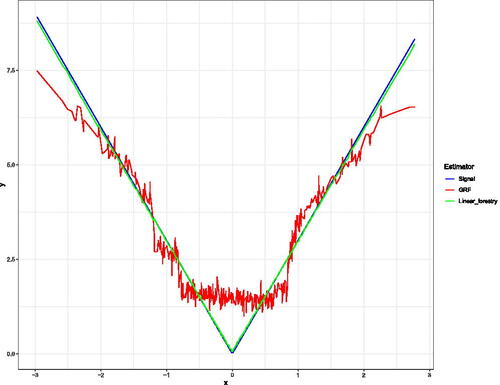
Fig. 1 Comparison of the classical CART and LRT. The top of the figure shows the fit of LRT and the fit of classical CART, and the lower part shows the density of the training set.
These changes improve the predictive performance of such linear regression trees (LRT) substantially, and—as we see in Section 3—our algorithm compares favorably on real-world examples when used in a linear random forests (LRF) ensemble. In Section 3, we see that across a range of setups, LRF has consistently the highest average performance ranking. We also connect our algorithm with an effective hyperparameter tuning algorithm, and we find that it can behave like both a regularized linear model and a CART/RF estimator depending on the chosen hyperparameters. This is explored in a set of experiments in Section 3.
The linear aggregation functions lead to much shallower trees without losing predictive performance. This improves the interpretability of the trees substantially—a direction which has always been a major motivation for studying regression trees with linear aggregation functions (Karalič Citation1992).
When the actual underlying problem is smooth, as is the case in many natural phenomena, the method’s ability to express that smoothness in an interpretable way is especially important. As Efron notes, it is not a coincidence that Newton’s calculus accompanied Newton’s laws of motion: the underlying physical phenomena itself is an “infinitely smooth one in which small changes in cause yield small changes in effect; a world where derivatives of many orders make physical sense” (Efron Citation2020, pp. 646–647). The use of linear response functions helps researchers discover smooth structures in the data generating process, unlike RF and GBM.2
Finally, in Section 4, we apply our algorithm to a causal inference problem. Specifically, we illustrate the advantages for interpretability our algorithm has using a large dataset measuring the treatment effect of several treatments on voter turnout (Gerber, Green, and Larimer Citation2008). We adapt the S-Learner with random forests as implemented in causalToolbox (Künzel et al. Citation2019) to use the linear aggregation function and visualize several trees. This allows us to identify groups of potential voters with similar voting behavior, make predictions of their future voting propensity, and see the effects the different mailers have on future voter turnout.
1.1 Literature
Studying regression trees with linear aggregation functions has a long history. The earliest reference we are aware of is by Breiman and Meisel (Citation1976) which precedes the original CART publication (Breiman et al. Citation1984). The algorithm can be interpreted as a tree algorithm: at each node, the algorithm attempts to introduce a new split along a randomly oriented plane. It then fits a linear model in both children, and it accepts the split if it sufficiently reduces the residual sum of squares as captured by an F-ratio test. If the split is not accepted, the algorithm attempts more splits a limited number of times before declaring the node a leaf node.
There has been much research on tree-based estimators with linear aggregation functions that builds on this first algorithm, and many different variants of it have been proposed. Apart from a few exceptions (Zhu, Zeng, and Kosorok Citation2015), the trees are constructed in a recursive strategy and the main differences between the algorithms are, how the splits are generated—the splitting criteria—and when splitting is halted for a node to be defined as a leaf—the stopping criteria.
For the splitting criteria, there have been many different suggestions. Torgo (Citation1997) spans the trees similar to the standard CART algorithm without adaptations to the new aggregation function. Chaudhuri et al. (Citation1994) and Li, Lue, and Chen (Citation2000), on the other hand, fit a linear model, or more generally, a polynomial model, on all units in the current node and then suggest a split by looking at the residuals of the fitted model. Zeileis, Hothorn, and Hornik (Citation2008) and Rusch and Zeileis (Citation2013), in turn, use a two-step procedure to find a good split. In the first step, the algorithms fit a linear model on all units in the current node, and they then screen for good splitting covariates using a test statistic that can be computed relatively fast. In a second step, the algorithm then exhaustively searches through all possible splits along the selected features.
Early stopping and pruning of the trees after they have been trained have both been used for regression trees with linear aggregation functions. For example, Quinlan (Citation1992) and Gama (Citation2004) build linear models in the pruning phase of each leaf, while Chaudhuri et al. (Citation1994) use a stopping criterion that is based on cross-validation and attempts to estimate whether a further split sufficiently improves the mean squared error.
In contrast to these existing methods, our stopping criterion accounts for the linear regressions which are fit in the child leaves, and if their combined R2 does not improve on that of the parent node by some amount, the split is rejected. This both incorporates the linear regressions used in the final aggregation, and allows the depth of the trees to be adaptive to the structure of the data.
While it is always possible to bootstrap these algorithms and combine them with ideas introduced in Random Forests (Breiman Citation2001), these ideas were mainly studied as regression trees, even though one would expect better predictive power and smoother prediction surfaces in the bagged versions (Bühlmann and Yu Citation2002). Additionally, some of these algorithms would be computationally too expensive to be used in a bagged version.
However, there has been some work done combining RF and bagged trees with linear models. Bloniarz et al. (Citation2016) interpret random forests as an adaptive potential nearest neighbor method, following ideas by Hothorn et al. (Citation2004), Lin and Jeon (Citation2006), and Meinshausen (2006). Their method, supervised local modeling (SILO), uses the random forests algorithm to provide a distance measure, w, based on the proximity distance of random forests. It then defines the random forests prediction, , as a local linear model (Stone Citation1977) via the following equations,
(2)
(2)
Here, is some set of functions. In their paper, they focused in particular on linear models and demonstrated its superior performance over other local models such as LOESS (Cleveland and Devlin Citation1988) and untuned RF.
In a recent paper, Friedberg et al. (Citation2020) also combined random forests with linear models. Their work is similar to that of Bloniarz et al. (Citation2016) in the sense that they also use the proximity weights of random forests to fit a local linear model. Specifically, they focus on linear models, and they fit a ridge regularized linear model,(3)
(3) and use
as the estimate for
. Similar to Chaudhuri et al. (Citation1994), they adapt the splitting function to account for the fitting of such local models. When evaluating a split on a parent node P, the potential split is evaluated by fitting a ridge regression in each parent node P to predict
from XP
and then using the standard CART split point selection procedure on the residuals
. This results in a fast splitting algorithm which uses the residuals to model for local effects in forest creation. In order to emphasize the difference between this recursive splitting scheme and the scheme presented in this paper, we explore a simple example in Appendix A. By contrast, our splitting algorithm finds the optimal binary split which will result in the minimum training MSE when linear aggregation is used. We believe this makes it well suited to settings in which there are both discontinuities and smooth effects in the underlying data.
1.2 Our Contribution
Our main contribution is to develop a fast algorithm to find the best partition for a tree with a ridge regularized linear model as aggregation function.
In Section 2, we explain the algorithm and we show that its run time is where n is the number of observations in the current node, p is the number of dimensions that is fit with a linear model, and m is the number of potential splitting covariates. In Section 3, we use the splitting algorithm with random forests, and we show that it compares favorably on many datasets. Depending on the chosen hyperparameters, the LRF algorithm can mimic either the default RF algorithm or a ridge regularized linear model. Because the algorithms can be trained relatively fast, we were able to connect them with a tuning algorithm, and show how it can quickly adapt to the underlying smoothness levels in different datasets. In Section 4, we then apply a single LRT to a real dataset to show how its simple structure leads to a deeper understanding of the underlying processes.
2 The Splitting Algorithm
Random forests are based on regression tree algorithms, which are themselves based on splitting algorithms. These splitting algorithms are typically used to recursively split the space into subspaces which are then encoded in binary regression trees. In this section, we will introduce a new splitting algorithm and discuss its asymptotic runtime.
To describe our novel splitting algorithm, we assume that there are n observations, , where
is the d-dimensional feature vector, and
is the dependent variable of unit i. For a feature
, the goal is to find a splitting point s to separate the space into two parts,
(4)
(4)
We call L and R the left and right sides of the partition, respectively.
In many tree-based algorithms, including CART, RF, and GBM, the splitting point is a point that minimizes the combined RSS when fitting a constant in both sides of the potential split,
(5)
(5)
Here is the mean of all units in the left partition and
is the mean of all units in the right partition. Note that L and R depend on s.
We generalize this idea to Ridge regression (Hoerl and Kennard Citation1970). We want to find that minimizes the overall RSS when—in both partitions—a Ridge-regularized linear model is fitted instead of a constant value,
(6)
(6)
is the fitted value of unit i when a Ridge regression is fit on the left side of the split, and similarly,
is the fitted value of unit i when a Ridge regression is fit on the right side of the split.
2.1 Ridge-Splitting Algorithm
To find an that satisfies (6), it would be enough to exhaustively search through the set
. However, there are n potential splitting points. Naively fitting a ridge regression to both sides for each potential splitting point requires at least
many steps. This is too slow for most datasets, since the splitting algorithm is applied up to
times for a single regression tree. In order to remedy this, we have developed an algorithm for evaluating all of the potential splitting points in a quasilinear runtime in n.
Below we outline the algorithm for finding the optimal splitting point for a continuous feature; the procedure for a categorical feature is outlined in Appendix B.
Specifically, the algorithm first sorts the values of feature in ascending order. To simplify the notation, let us redefine the ordering of the units in such a way that
Such a sorting can be done in .3
The algorithm then evaluates the n – 1 potential splitting points that lie exactly between two observations,in such a way that each evaluation only requires
many computations.4
To motivate the algorithm, define(7)
(7) and the RSS when splitting at sk
as
,
(8)
(8)
We are then interested in finding:(9)
(9)
The RSS can now be decomposed into the following terms:
Here we use the definition that for a set ,
Our algorithm then exploits the fact that for H = Lk
or H = Rk
, each of these terms can be computed in time based on the terms for
and
. For example,
can be computed in 2d many computations based on
using the following trivial identity,
The updates for the other terms are presented in Appendix C. The algorithm thus, computes in sequence from k = 1 to n, and it is thus, possible to jointly compute all
in
many steps.5 This is a significant improvement over a computationally infeasible naive implementation that would have a runtime of
.6
Theorem 1.
The runtime for computing and finding the best splitting point along one variable has a runtime
.
We prove this Theorem in Appendix C. In the appendix, we also elaborate a stopping criteria that we have found to be useful to create smaller trees while improving prediction accuracy and computation speed.
2.2 Early Stopping Algorithm
Although regression trees are prized for their predictive performance, practitioners have long grappled with improving their runtime and interpretability. It is common for regression trees—especially when part of an ensemble—to be grown to purity (where each leaf node contains only one observation), however, this can lead to trees which overfit the training data. A variety of methods have been developed in order to preserve the predictive strength of regression trees while modifying their structure to be simpler, faster to train, and give more stable predictions.
The postpruning approach grows a full depth tree, and then iteratively merges child nodes in a way to minimize the empirical error and complexity (number of nodes) of the resulting tree. When an independent dataset is used to prune an existing tree, Nobel (Citation2002) provides bounds for the performance of pruned classification trees, and Klusowski (Citation2020) provides bounds for the performance of pruned regression trees. Klusowski (Citation2020) also show that for sparse additive outcomes, a CART tree pruned in this way will asymptotically recover the true sparse structure.
An alternative approach limits the depth of trees during construction rather than after a full tree has been constructed. The Bayesian additive regression trees (Chipman, George, and McCulloch Citation2006, Citation2010) algorithm limits the depth of individual regression trees by placing an exponential prior on the depth of each tree, limiting the depth drastically, but allowing deeper trees when such a tree fits the data well. The RuleFit algorithm (Friedman and Popescu Citation2008) creates an ensemble of trees where each tree is given a different random maximum depth, and all splits that would make the tree deeper than this depth are automatically rejected.
We introduce the early stopping algorithm in order to provide simpler trees, a runtime improvement on large datasets, and larger leaf nodes—without reducing the adaptivity or predictive power of the trees. Unlike pruning procedures, our algorithm rejects potential splits during runtime, which leads to a large speedup over creating full trees. Our algorithm also varies from those which limit depth, node sizes, or node counts across the tree as it allows for some branches of the tree to grow quite deep, and other branches to grow much shorter, based on the improvement in predictive accuracy brought by further splits.
The early stopping algorithm follows the following steps (for details, see Algorithm 4):
Once the optimal split for a parent node is calculated, the current observations for the node are split into k folds.
For each fold, the predictions—using a regularized linear model—are made for both the parent, and the two child nodes which result from the split.
The R2 of the parent node regression is compared to the R2 of the two child nodes, if the two resulting linear models increase the R2 for the current node’s observations by a prespecified percentage, the potential split is accepted, otherwise, the split is rejected, and the parent node becomes a leaf node.
As the overall runtime of creating a decision tree of depth D, which samples mtry potential splitting features at each node is , decreasing the depth of potential trees (or even several branches of the tree) has a large effect on the overall runtime of the tree. This provides a runtime advantage for early stopping which can be very impactful on large datasets. As the early stopping algorithm prohibits further splits which do not increase the R2 of the fit, this can also help the tree avoid continued splitting when there are no informative splits available. This is important as it allows the leaf node sizes to remain large while removing uninformative splits which might have caused the tree to overfit the data.
3 Predictive Performance
In this section, we will evaluate different tree-based estimators with linear aggregation functions and some natural baseline estimators. It is well known that RF outperforms regression trees, and we have therefore, implemented a version of RF that utilizes our new splitting algorithm. We call this LRF and we demonstrate its predictive performance in the following. A version of LRF is implemented in our Rforestry package (Künzel et al. Citation2019). For further details of the software package, see Appendix G.
3.1 Methods and Tuning
We compare the predictive performance of LRF with seven competitors:
The random forest algorithm as implemented in the ranger package (Wright and Ziegler Citation2015) and in the Rforestry package.
The Bayesian Additive Regression Trees (BART) (Chipman, George, and McCulloch Citation2006, Citation2010) algorithm as implemented in the dbarts package (Dorie Citation2020).
Local linear forests (Friedberg et al. Citation2020) as implemented in the grf package (Athey, Tibshirani, and Wager Citation2019).
The Rule and Instance based Regression Model presented in Quinlan (Citation1992) as implemented in the Cubist package.
Generalized Linear Models as implemented in the glmnet package (Friedman, Hastie, and Tibshirani Citation2010).
The RuleFit algorithm (Friedman and Popescu Citation2008) as implemented in the pre package (Fokkema Citation2020).
Gradient Boosting (Friedman Citation2001) as implemented in the gbm package (Ridgeway Citation2004).
In most real world prediction tasks, appliers carefully tune their methods to get the best possible performance. We believe that this is also important when comparing different methods. That is why we use the caret package (Kuhn Citation2008) to tune the hyperparameters of all of the above methods. 7 Specifically, we use the caret package’s adaptive random tuning over 100 hyperparameter settings, using 8-fold cross-validation tuning repeated and averaged over four iterations. The hyperparameters tuned for each algorithm are presented in in Appendix D. As with the other hyperparameters, we use caret to tune the value of λ used in LRF. For more details, see Appendix F.
Table D1 Above displays the software packages and tuned hyperparameters used by the caret package for each estimator in Section 3.
3.2 Experiments
LRF is particularly well suited for picking up smooth signals, however, depending on the hyperparameter choice, it can behave similar to a regularized linear model, a classical RF, or a mixture of the two. To demonstrate this adaptivity, we first analyze artificially generated examples. We will see that LRF automatically adapts to the smoothness of the underlying data generating distribution. In the second part of this study, we show the predictive performance of our estimator on real world data.
3.2.1 Adaptivity for the Appropriate Level of Smoothness
We analyze three different setups. In the first setup, we use linear models to generate the data. Here we expect glmnet to perform well and the default versions of RF as implemented in ranger and Rforestry to not perform well. In the second setup we use step functions. Naturally, we expect RF and other tree-based algorithms to perform well and glmnet to perform relatively worse. In the third setup, there are areas that are highly nonlinear and other areas that are linear. It will thus, be difficult for both the default RF algorithms and glmnet to perform well on this dataset, but we expect the adaptivity of LRF to excel here.
1. Linear Response Surface
In Experiment 1, we start with a purely linear response surface. We simulate the features from a normal distribution and we generate Y according to the following linear model:
2. Step Functions
Next, we are interested in the other extreme. In Experiment 2, we simulate the features from a 10-dimensional normal distribution, , and we create a regression function from a regression tree with random splits, 50 leaf nodes, and randomly sampled response values between –10 and 10 and we call this function fS
. Y is then generated according to the following model:
A specific description of how fS was generated can be found in detail in Appendix E.
3. Linear Function with Steps
Finally, we look at a dataset that exhibits both a linear part and a step-wise constant part. Specifically, we split the space into two parts and we combine the regression functions from Experiment 1 and Experiment 2 to create a new regression function as follows:
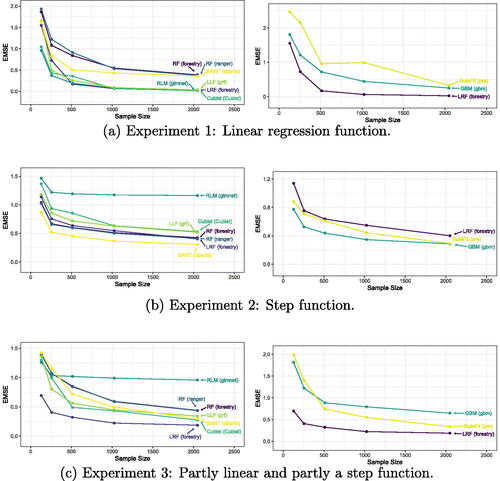
The results of these simulations for a range of sample sizes can be found in . For each training sample size, the EMSE was calculated over a 10,000 point test set drawn from the same data generating process.
Fig. 2 Different levels of smoothness. In Experiment 1, the response surface is a linear function, in Experiment 2, it is a step function, and in Experiment 3, it is partly a step function and partly a linear function.
3.2.2 Smoothness Simulation Results
In Experiment 1, RF and BART perform relatively poorly estimating a purely linear response. In contrast, the algorithms designed to handle smoothness do quite well here, with Cubist, Local Linear Forests, Linear RF, and regularized linear models all performing quite well.
In the second experiment, where we have a highly nonlinear response, BART performs very well, followed by RF and Linear RF. Although the performance of Linear RF closely trails that of RF, performance of the other algorithms exploiting smoothness fall behind here.
Experiment 3 contains a response function which is in some local neighborhoods linear and in others a step function. We see that Linear RF does quite well compared to both the tree based methods such as RF and BART, and the models which utilize smoothness.
Through examining three simple experiments with varying degrees of smoothness, we see that Linear RF can be quite adaptive to the underlying smoothness in the response function. This allows Linear RF to act as a Random Forest, a regularized linear model, or anything in between.
3.2.3 Real World Datasets
To analyze the behavior of these estimators on real data, we used a variety of datasets. describes the metrics of the datasets that we have used and shows the performance of the different estimators.
Table 1 Summary of real world datasets.
Table 2 Estimator RMSE compared across real world datasets.
Of these datasets, Autos describes pricing data and many related features scraped from German Ebay listings, Bike describes Capital Bikeshare user counts and corresponding weather features. These datasets are available on Kaggle (Leka Citation2016) and the UCI repository, respectively, (Fanaee-T Citation2013). The remaining datasets were taken from Breiman’s original regression performance section (Breiman Citation2001), with the test setups altered only slightly.
In order to evaluate the performance of the different models, we used a hold out dataset as test set for the Abalone, Autos, and Bike dataset. The Boston, Ozone, and Servo datasets are relatively small and we thus, used 5-fold cross-validation to estimate the Root Mean Squared Error (RMSE). For the three Friedman simulations, we kept Breiman’s original scheme by using 2000 simulated test points.
We include a variety of datasets which have a range of dimensions and noise levels to compare estimators across a range of scenarios practitioners might encounter in real data problems. It is well known that bagging estimators perform variance reduction on the base learners they utilize. With this in mind, we recommend bagging LRT in data examples where the noise is high.
3.3 Results
shows the results for the different estimators on the simulated response surfaces detailed in Section 3. As expected, we find that regularized linear models (RLM) as implemented in the glmnet package perform very well on Experiment 1 where the response is linear, while it performs poorly on Experiments 2 and 3. The default random forest estimators implemented for example in ranger performs very well on Experiment 2, but it performs rather poorly on Experiment 1 and 3, as estimators which can exploit the linearity benefit greatly here. The estimators which can pick up linear signals (RLM, LLF, and LRF), perform nearly identically on Experiment 1, showing a tuned LRF can mimic the linear performance of a linear model such as RLM. Experiment 2 showcases a step function, in which smooth estimators such as RLM and LLF suffer, while RF and boosting algorithms such as BART excel. In this scenario, the performance of LRF now converges to match that of the purely random forest algorithms. Finally, in Experiment 3, the response surface is evenly distributed between smooth response values, and a step function. In this case, there are areas of weakness for both the smooth estimators and the RF estimators, but the adaptivity of LRF allows it to adapt to the differences across the response surface, and fit the appropriately different estimators on each portion.
The results shown in are mixed, but display the adaptivity of LRF on datasets that are linear as well as datasets that are highly nonlinear. This adaptivity results in an estimator that can exploit the presence of smooth signals very well and remain competitive over a wide range of response surfaces.
3.4 High Dimensional Simulation
One benefit of using regularized linear models as the aggregation functions is the ability of regularized linear models to shrink the effects of spurious predictors toward zero. In this section, we explore a simple simulation where the outcome is a nonlinear function of four covariates and there are many noisy covariates included in the model.
3.4.1 Data Generating Process
We follow an example from Athey, Tibshirani, and Wager (Citation2019) with the outcome modeled as follows. First, , then Y is generated as follows:
(10)
(10)
Where:(11)
(11)
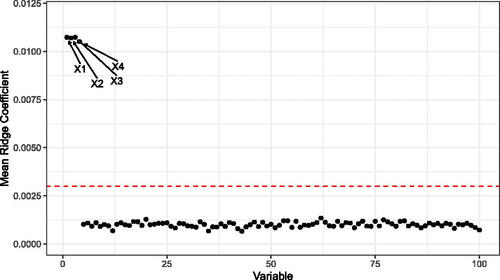
And ϵ is selected to give a signal-to-noise ratio of 2. As the true outcome depends on only the first four covariates, the majority of the covariates are noisy ().
Fig. 3 The mean Ridge Coefficients from simulated data generated according to EquationEquation (10)(10)
(10) , repeated over 100 Monte Carlo replications. The true outcome relies on only the first four covariates, and these coefficients have nonzero slope which is picked up by the LRF. The horizontal line corresponds to 1.96 times the sample standard deviation of the coefficients over the Monte Carlo replications.
4 Interpretability
In this section, we wish to show how linear aggregation can be used to create more interpretable estimators, and we illustrate this by analyzing a large voter turnout experiment. We will show the usefulness of linear aggregation to better understand the heterogeneity in the data. We first introduce the dataset used, outline the problem of estimating the conditional average treatment effect (CATE), and then apply LRF to the dataset to estimate the CATE.
4.1 Social Pressure and Voter Turnout Dataset
We use a dataset from a large field experiment that has been conducted by Gerber, Green, and Larimer (Citation2008) to measure the effectiveness of four different mailers on voter turnout. The dataset contains 344,084 potential voters in the August 2006 Michigan statewide election with a wide range of offices and proposals on the ballot.
There are four mailers used, each of which is designed to apply a different amount of social pressure to the potential voter in order to incentivize voting in the upcoming election. In increasing order of social pressure, the mailers are summarized as follows:
Civic Duty (CD): The civic duty mailer reminds the recipient that it is their civic duty to vote.
Hawthorne (HT): The Hawthorne mailer informs the potential voter that they are being studied in a survey of voter turnout, but reassures them that their decision to vote will remain anonymous.
Self (SE): The self mailer informs the potential voter that the other members of their household will be informed on whether or not they vote in the coming election.
Neighbors (NE): The neighbors mailer informs the potential voters that their neighbors will be informed on whether or not they vote in the coming election.
For the full text of each mailer, see Gerber, Green, and Larimer (Citation2008). The dataset also contains seven key individual-level covariates: gender, age, and indicators of whether or not the individual voted in the primary elections in 2000, 2002, 2004, or the general election in 2000 and 2002. We also derived three further covariates from the ones above:
Cumulative Voting History (CVH): The number of times the voter has voted within the last five elections before the 2004 general election.
Cumulative Primary Voting History (CPVH): The number of primary elections a voter has participated in between 2000 and 2004.
Cumulative General election Voting History (CGVH): The number of general elections a voter has participated in between 2000 and 2002.
Künzel et al. (Citation2019) analyze the effect of the Neighbors mailer while paying specific attention to uncovering the heterogeneity in the data. Specifically, they estimate the CATE,
Where, is the indicator of voting when a unit is treated (is assigned to receive a Neighbors mailer), and Y(0) is the indicator of voting when the unit is in the control group, and x is the vector of covariates.
Estimating the CATE is useful for targeting treatment to individuals with a particularly strong effect. Künzel, Walter, and Sekhon (Citation2018); Künzel et al. (Citation2019), for example, uncover the heterogeneity by using partial dependence plots (Friedman Citation2001) in combination with looking at specific subgroups that have been defined through subject knowledge and exhaustive exploratory data analysis. This process involved a lot of hand selection of subgroups and covariates of interest and prior knowledge of the causal process. This is a common approach used by substantive researchers to find heterogeneous treatment effects (e.g., Arceneaux and Nickerson Citation2009; Enos, Fowler, and Vavreck Citation2014). In contrast to this approach, using a linear aggregation function in RF directly enables us discover subgroups of interest in a data-driven and algorithmic way that is still interpretable.
4.2 Interpretable Estimators with LRF
Introduced in Künzel et al. (Citation2019), the S-Learner estimates the outcome by using all of the features and the treatment indicator, without giving the treatment indicator a special role,
The predicted CATE for a unit is then the difference between the predicted values when the treatment-assignment indicator is changed from control to treatment, with all other features held fixed,(12)
(12)
Any machine learning algorithm can be used for the regression step, and here we use LRF. We additionally make several changes to the standard formulation of the S-Learner outlined in Künzel et al. (Citation2019):
1. As we have four different treatments, we encode a treatment indicator for each of the four treatments and we estimate the response function using all covariates and the treatment indicators as independent variables,
The CATE for the CD mailer is then defined as:and the treatment effects for the other mailers are defined equivalently.
2. We choose to linearly adapt the four treatment indicators and we allow splits on all covariates except the variables that encode the treatment assignment. This allows splits to uncover heterogeneity in the CATE function, and the linear model in each leaf to contain coefficients corresponding to the treatment effect of each mailer in the current leaf. Thus, , the intercept of the linear model (untr BL in the figure), is an estimate for the baseline turnout of voters falling into this leaf and the
(TE(i) for
in the figure) is an estimate for the treatment effect of the different mailers.8
3. We implement the trees with honesty. Specifically, we split the training set into two disjoint sets: A splitting set that is used to select splits for the tree structure and an averaging set that is used to compute the linear models in each terminal node.9 This means the splits and thus, the structure of the trees are based on a set that is independent from the set that is used to estimate the linear model coefficients.
4. In order to avoid overfitting and create interpretable estimators with performance that is comparable to that of much deeper CART trees, we use the one step look-ahead stopping criteria introduced in Section 2.2. This also allows us to fit a linear model on a large number of observations in each leaf, resulting in increased stability of the resulting coefficients.
In practice, the overfit penalty can be chosen by cross-validation or taken heuristically to penalize linearity based on subjective knowledge. Here we take essentially linear splits () as it allows the coefficients of the linear models in each leaf to be interpreted as the average treatment effect of each mailer in the particular leaf (Lin Citation2013).
By using LRF, this formulation of the S-Learner can take advantage of the linear splitting algorithm in order to evaluate splits on all covariates that result in treatment effect heterogeneity, and LRF can grow much shallower trees which are still optimized for predictive accuracy. We find in this dataset that the LRT displayed below have comparable performance to a standard CART tree that is up to 100 levels deep.10 Further, we find that the LRF ensemble has base learner predictions which are more highly correlated than those of a standard random forest, implying that the comparative performance of the ensemble relative to the base learner will lower for LRF.
4.3 Results
As the LRF trees use linear aggregation functions, the predictions of the ensemble tend to be more correlated than those of a standard random forest. For this reason, a single linear tree has quite strong performance compared to that of the full ensemble, and can provide a much more interpretable estimator. In order to understand the form of the CATE function, we study a single tree. The conclusions still hold based on examining additional trees in the ensemble (shown in Appendix H).
Examining the results, we find several subgroups for which the various treatments display stark heterogeneity. There seems to be a subgroup of voters, the voters falling into Node 3, that have a very low previous election participation. This group has very low baseline turnout, and low treatment effects for all of the mailers. This could correspond to a disaffected group of voters which have very little interest in participating in the elections under any circumstances. The low baseline turnout and low treatment effects invite further experimentation on methods of increasing the turnout of this subgroup.
We also find that there is a subgroup of citizens that have voted in at least two out of the three recorded primary elections (Those falling into Nodes 6 and 7). These units have a high voting propensity even if they do not receive any of the mailers. The treatment effects are large for this group of high propensity voters. In short, these treatments widen disparities in participation by mobilizing high-propensity citizens more than low-propensity citizens. This may be surprising because one may not expect a letter in the mail to significantly impact the turnout decisions of voters with a high propensity to vote.
It turns out that substantive researchers have reached the same conclusion previously using heuristic methods that rely on substantive knowledge for selecting subgroups (e.g., Enos, Fowler, and Vavreck Citation2014). We were able to find the results using an algorithmic approach ().
Fig. 4 The first tree of the S-Learner as described in Section 4.2. The first row in each leaf contains the number of observations in the averaging set that fall into the leaf. The second part of each leaf displays the regression coefficients. Baseline stands for untreated base turnout of that leaf and it can be interpreted as the proportion of units that fall into that leaf who voted in the 2004 general election. Each coefficient corresponds to the ATE of the specific mailer in the leaf. The color strength is chosen proportional to the treatment effect for the neighbors treatment.
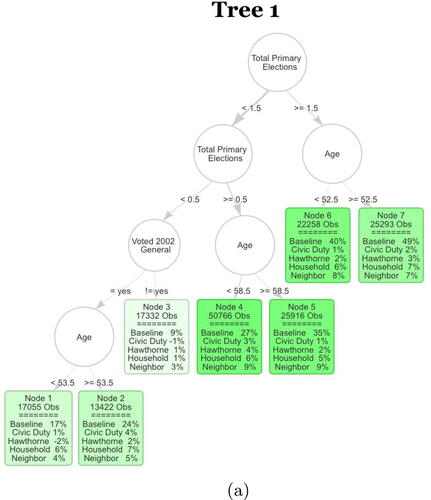
Another consistent trend is a number of splits on age around 50–55 years old. Older voters tend to have a much higher baseline turnout of approximately an additional 10%. This is also in line with known results on voter turnout increasing among older voters.
The simple and expressive form of the tree enables us to find subgroups based on our covariates which display heterogeneity in the treatment effects of the various mailers. Further, the data driven construction of the tree provides both a strong predictive model, and does not require expert input to specify subgroups of interest, and it uncovers them in an unsupervised way. This is a strong tool for scientists to use in order to understand large and complex datasets through interpretable and expressive nonparametric models.
5 Conclusion
In this article, we have proposed three main changes to tree-based estimators and explored their consequences in several experiments, real world data examples, and a runtime analysis. Specifically, our changes were focused on introducing linear aggregation functions for prediction in the leaf nodes of regression trees, modifying the splitting algorithm to efficiently find optimal splits for these aggregation functions, and adding a stopping criteria which limits further node creation when splitting would not increase the R2 by a predetermined percentage.
In 12 different prediction tasks, we found that these new estimators increased the predictive power and that they can adapt to the underlying local smoothness conditions of the datasets (Section 3). We then illustrated in a real world experiment how these new algorithms lead to more interpretable estimators, and we demonstrated how a visualization of regression trees can be used to perform inference through both the selected splits and resulting regression coefficients in the leaves (Section 4).
We have also implemented several tree-based estimators including, CART (as LCART), random forests (as LRF), and gradient boosting in the Rforestry package. In future work, we are interested in extending these ideas to other estimators such as BART. We believe that LRF can be less biased than the usual versions of RF, and we wonder whether it would improve nonparametric confidence interval estimation. Finally, we believe that the regression coefficients could be substantively informative, and we would like to study statistical tests that can be used to determine whether the estimated coefficients for the leaves vary significantly across leaves.
Supplemental Material
Download Zip (4.9 KB)Supplemental Material
Download Zip (94 KB)Supplemental Material
Download Zip (617 B)Supplemental Material
Download Zip (2.2 MB)Supplemental Material
Download Zip (20.6 MB)Supplemental Material
Download Zip (487.5 KB)Acknowledgments
The authors would like to thank two anonymous reviewers, the associate editor, and the editor Tyler McCormick for useful comments and suggestions.
Supplementary Materials
The supplementary materials include code, data, and instructions to replicate all experiments contained in the main body of the paper and the appendices.
Data Availability Statement
Code for replication of results can be found at https://github.com/forestry-labs/RidgePaperReplication.
The Rforestry package can be found at https://github.com/forestry-labs/Rforestry
Additional information
Funding
Related Research Data
References
- Arceneaux, K., and Nickerson, D. W. (2009), “Who is Mobilized to Vote? A Re-analysis of 11 Field Experiments,” American Journal of Political Science, 53, 1–16. DOI: 10.1111/j.1540-5907.2008.00354.x.
- Athey, S., Tibshirani, J., and Wager, S. (2019), “Generalized Random Forests,” The Annals of Statistics, 47, 1148–1178. DOI: 10.1214/18-AOS1709.
- Biau, G. (2010), “Analysis of a Random Forests Model,” The Journal of Machine Learning Research, 13, 1063–1095.
- Bloniarz, A., Talwalkar, A., Yu, B., and Wu, C. (2016), “Supervised Neighborhoods for Distributed Nonparametric Regression,” in Artificial Intelligence and Statistics, pp. 1450–1459.
- Breiman, L. (2001), “Random Forests,” Machine Learning, 45, 5–32. DOI: 10.1023/A:1010933404324.
- Breiman, L., Friedman, J., Olshen, R., and Stone, C. (1984), Classification and Regression Trees, Boca Raton, FL: Routledge.
- Breiman, L., and Meisel, W. (1976), “General Estimates of the Intrinsic Variability of Data in Nonlinear Regression Models,” Journal of the American Statistical Association, 71, 301–307. DOI: 10.1080/01621459.1976.10480336.
- Bühlmann, P., and Yu, B. (2002), “Analyzing Bagging,” The Annals of Statistics, 30, 927–961. DOI: 10.1214/aos/1031689014.
- Chaudhuri, P., Huang, M.-C., Loh, W.-Y., and Yao, R. (1994), “Piecewise-Polynomial Regression Trees,” Statistica Sinica, 4, 143–167.
- Chipman, H. A., George, E. I., and McCulloch, R. E. (2006), “Bayesian Ensemble Learning,” in Proceedings of the 19th International Conference on Neural Information Processing Systems, NIPS’06, pp. 265–272, Cambridge, MA: MIT Press.
- Chipman, H. A., George, E. I., and McCulloch, R. E. (2010). “Bart: Bayesian Additive Regression Trees,” The Annals of Applied Statistics, 4, 266–298.
- Cleveland, W. S., and Devlin, S. J. (1988), “Locally Weighted Regression: An Approach to Regression Analysis by Local Fitting,” Journal of the American Statistical Association, 83, 596–610. DOI: 10.1080/01621459.1988.10478639.
- Donoho, D. (1995), “De-noising by Soft-Thresholding,” IEEE Transactions on Information Theory, 41, 613–627. DOI: 10.1109/18.382009.
- Dorie, V. (2020), “dbarts: Discrete Bayesian Additive Regression Trees Sampler,” R package version 0.9-19.
- Dorie, V., Hill, J., Shalit, U., Scott, M., and Cervone, D. (2018), “Automated Versus Do-it-Yourself Methods for Causal Inference: Lessons Learned from a Data Analysis Competition,” Statistical Science, 34, 43–68 DOI: 10.1214/18-STS667.
- Efron, B. (2020), “Prediction, Estimation, and Attribution,” Journal of the American Statistical Association, 115, 636–655. DOI: 10.1080/01621459.2020.1762613.
- Enos, R. D., Fowler, A., and Vavreck, L. (2014), “Increasing Inequality: The Effect of GOTV Mobilization on the Composition of the Electorate,” The Journal of Politics, 76, 273–288. DOI: 10.1017/S0022381613001308.
- Fanaee-T, H. (2013), “Capital bikeshare database. Hourly and daily count of rental bikes between years 2011 and 2012 in Capital bikeshare system with the corresponding weather and seasonal information.”
- Fokkema, M. (2020), “Fitting Prediction Rule Ensembles with R Package Pre,” Journal of Statistical Software, 92, 1–30. DOI: 10.18637/jss.v092.i12.
- Friedberg, R., Tibshirani, J., Athey, S., and Wager, S. (2020), “Local Linear Forests,” Journal of Computational and Graphical Statistics, 30, 503–517. DOI: 10.1080/10618600.2020.1831930.
- Friedman, J., Hastie, T., and Tibshirani, R. (2010), “Regularization Paths for Generalized Linear Models via Coordinate Descent,” Journal of Statistical Software, 33, 1–22. DOI: 10.18637/jss.v033.i01.
- Friedman, J. H. (2001), “Greedy Function Approximation: A Gradient Boosting Machine,” The Annals of Statistics, 29, 1189–1232. DOI: 10.1214/aos/1013203451.
- Friedman, J. H., and Popescu, B. E. (2008), “Predictive Learning via Rule Ensembles,” The Annals of Applied Statistics, 2, 916–954. DOI: 10.1214/07-AOAS148.
- Gama, J. (2004), “Functional Trees,” Machine Learning, 55, 219–250. DOI: 10.1023/B:MACH.0000027782.67192.13.
- Garrigues, P., and Ghaoui, L. (2009), “An Homotopy Algorithm for the Lasso with Online Observations,” Advances in Neural Information Processing Systems (Vol. 21), eds. D. Koller, D. Schuurmans, Y. Bengio, and L. Bottou. Red Hook; NY: Curran Associates, Inc.
- Gerber, A. S., Green, D. P., and Larimer, C. W. (2008), “Social Pressure and Voter Turnout: Evidence from a Large-Scale Field Experiment,” American Political Science Review, 102, 33–48. DOI: 10.1017/S000305540808009X.
- Hill, J., Linero, A., and Murray, J. (2020), “Bayesian Additive Regression Trees: A Review and Look Forward,” Annual Review of Statistics and Its Application, 7, 251–278. DOI: 10.1146/annurev-statistics-031219-041110.
- Hill, J. L. (2011), “Bayesian Nonparametric Modeling for Causal Inference,” Journal of Computational and Graphical Statistics, 20, 217–240. DOI: 10.1198/jcgs.2010.08162.
- Hoerl, A. E., and Kennard, R. W. (1970), “Ridge Regression: Biased Estimation for Nonorthogonal Problems,” Technometrics, 12, 55–67. DOI: 10.1080/00401706.1970.10488634.
- Hothorn, T., Lausen, B., Benner, A., and Radespiel-Tröger, M. (2004), “Bagging Survival Trees,” Statistics in Medicine, 23, 77–91. DOI: 10.1002/sim.1593.
- Karalič, A. (1992), “Employing Linear Regression in Regression Tree Leaves,” in Proceedings of the 10th European Conference on Artificial Intelligence, pp. 440–441. Wiley.
- Klusowski, J. (2020), “Sparse Learning with Cart,” in Advances in Neural Information Processing Systems (Vol. 33), eds. H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, pp. 11612–11622. Red Hook; NY: Curran Associates, Inc.
- Kuhn, M. (2008), “Building Predictive Models in R Using the Caret Package,” Journal of Statistical Software, 28, 1–26. DOI: 10.18637/jss.v028.i05.
- Künzel, S. R., Sekhon, J. S., Bickel, P. J., and Yu, B. (2019), “Metalearners for Estimating Heterogeneous Treatment Effects Using Machine Learning,” Proceedings of the National Academy of Sciences, 116, 4156–4165. DOI: 10.1073/pnas.1804597116.
- Künzel, S. R., Tang, A., Saarinen, T. F., Liu, E. W., and Sekhon, J. S. (2019), “Rforestry: Random Forests, Linear Trees, and Gradient Boosting for Inference and Interpretability,” available at https://cran.r-project.org/web//packages/Rforestry/index.html.
- Künzel, S. R., Walter, S. J., and Sekhon, J. S. (2018), “Causaltoolbox—Estimator Stability for Heterogeneous Treatment Effects,” arXiv preprint arXiv:1811.02833.
- Leka, O. (2016), “Used cars database. Over 370,000 used cars scraped from Ebay Kleinanzeigen.”
- Li, K.-C., Lue, H.-H., and Chen, C.-H. (2000), “Interactive Tree-Structured Regression via Principal Hessian Directions,” Journal of the American Statistical Association, 95, 547–560. DOI: 10.1080/01621459.2000.10474231.
- Lin, W. (2013), “Agnostic Notes on Regression Adjustments to Experimental Data: Reexamining Freedman’s Critique,” The Annals of Applied Statistics, 7, 295–318. DOI: 10.1214/12-AOAS583.
- Lin, Y., and Jeon, Y. (2006), “Random Forests and Adaptive Nearest Neighbors,” Journal of the American Statistical Association, 101, 578–590. DOI: 10.1198/016214505000001230.
- Meinshausen, N. (2006), “Quantile Regression Forests,” Journal of Machine Learning Research, 7, 983–999.
- Morgan, J. N., and Sonquist, J. A. (1963), “Problems in the Analysis of Survey Data, and a Proposal,” Journal of the American Statistical Association, 58, 415–434. DOI: 10.1080/01621459.1963.10500855.
- Nobel, A. (2002), “Analysis of a Complexity-Based Pruning Scheme for Classification Trees,” IEEE Transactions on Information Theory, 48, 2362–2368. DOI: 10.1109/TIT.2002.800482.
- Quinlan, J. R. (1992). “Learning with Continuous Classes,” in 5th Australian Joint Conference on Artificial Intelligence (Vol. 92), pp. 343–348. World Scientific.
- Ridgeway, G. (2004), gbm: Generalized Boosted Regression Models. R package, 1.5. R package version, 1.
- Rothenhäusler, D., and Yu, B. (2020), “Incremental Causal Effects,” arXiv https://arxiv.org/abs/1907.13258.
- Rusch, T., and Zeileis, A. (2013), “Gaining Insight with Recursive Partitioning of Generalized Linear Models,” Journal of Statistical Computation and Simulation, 83, 1301–1315. DOI: 10.1080/00949655.2012.658804.
- Scornet, E., Biau, G., and Vert, J.-P. (2015), “Consistency of Random Forests,” The Annals of Statistics, 43, 1716–1741. DOI: 10.1214/15-AOS1321.
- Stone, C. J. (1977), “Consistent Nonparametric Regression,” The Annals of Statistics, 5, 595–620. DOI: 10.1214/aos/1176343886.
- Svetnik, V., Liaw, A., Tong, C., Culberson, J. C., Sheridan, R. P., and Feuston, B. P. (2003), “Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling,” Journal of Chemical Information and Computer Sciences, 43, 1947–1958. DOI: 10.1021/ci034160g.
- Torgo, L. (1997), “Functional Models for Regression Tree Leaves,” in Proceedings of the Fourteenth International Conference on Machine Learning, ICML ’97, pp. 385–393. Morgan Kaufmann Publishers Inc.
- Touw, W. G., Bayjanov, J. R., Overmars, L., Backus, L., Boekhorst, J., Wels, M., and van Hijum, S. A. (2012), “Data Mining in the Life Sciences with Random Forest: A Walk in the Park or Lost in the Jungle?” Briefings in Bioinformatics, 14, 315–326. DOI: 10.1093/bib/bbs034.
- Wager, S., and Athey, S. (2017), “Estimation and Inference of Heterogeneous Treatment Effects Using Random Forests,” Journal of the American Statistical Association, 113, 1228–1242. DOI: 10.1080/01621459.2017.1319839.
- Wright, M. N., and Ziegler, A. (2015), “ranger: A Fast Implementation of Random Forests for High Dimensional Data in c++ and r,” arXiv preprint arXiv:1508.04409.
- Zeileis, A., Hothorn, T., and Hornik, K. (2008), “Model-Based Recursive Partitioning,” Journal of Computational and Graphical Statistics, 17, 492–514. DOI: 10.1198/106186008X319331.
- Zhu, R., Zeng, D., and Kosorok, M. R. (2015), “Reinforcement Learning Trees,” Journal of the American Statistical Association, 110, 1770–1784. DOI: 10.1080/01621459.2015.1036994.
Appendix A
Linear Splits Comparison
In order to illustrate the difference between the recursive splitting function of Local Linear Forests (Friedberg et al. Citation2020) as implemented in the grf package (Athey, Tibshirani, and Wager Citation2019), and that of LRF, as implemented in the Rforestry package, we create a simple simulated example to visualize the different splits.
A.1 Comparing the Selected Split
The simulated dataset for the comparison consists of a piecewise linear model with changing slope in the first covariate of a 10 dimensional dataset.(13)
(13)
(14)
(14)
In this simulated example, we generate n = 500 points from the above scheme, and fit a LRF, with one tree, and a Local Linear Forest, with 11 trees on the resulting data.11 displays the difference in fits between LRF and Local Linear Forest in this example.
Fig. A1 This example has a piecewise linear response, with alternating slopes in the first covariate. Here we plot X1 against the outcome y, and overlay the fitted values which are returned by both the Local Linear Forest and Linear Regression Tree.
Appendix B
Splitting on a Categorical Feature
To split on a categorical feature, we use one-hot encoding to split based on equal or not equal to the given feature category. In order to evaluate the split RSS, we examine linear models fit on the set of observations containing the feature and the set not containing the feature. In order to evaluate this split quickly, we make use of the fact that we can quickly compute RSS components by keeping track of the total aggregated sum of outer products. Let
This means that given , we can immediately begin evaluating splits along any split feature by using the sequence of indices corresponding to the ascending sequence of values in the current split feature.
This fact helps us quickly evaluate the sum of RSS of separate regressions on the two sides of inclusion/exclusion splits on categorical variables.
On a split on categorical variable X(l), when evaluating the split RSS on the value of category k, the RSS components can be calculated as follows:
Let
The same method can be used to update SLeft and SRight at each step, so we can use this update rule generally to quickly compute the RSS for categorical splits in the algorithm that follows.
Algorithm 1 Find Best Split for Categorical Features
Input: Features: , Dependent Outcome:
, overfitPenalty (regularization for split):
,
Output: Best Split point k
1:procedure FindBestSplitRidgeCategorical
Initialization:
2:
3:
4:
for do
5:
6:
7:
8:
9:
10:
11:
12:
Compute the RSS sum for the current split:
13:return
B.1 Runtime Analysis of Finding Categorical Split Point
Using a set to keep track of category membership, we can create the set in O(NlogN) time and access a member of any specific category in amortized constant time. Once we begin iterating through the categories, we can access the elements and create the left model RSS components in where
is the size of category k, and using the Gtotal
and Stotal
matrices, we can find the right model RSS components in
time once we calculate GL
and SL
. As the sum of sizes of the various categories sums to the number of observations, we end up doing the same number of RSS component update steps as the continuous case as well as one additional step to get the right RSS components for each category. The overall asymptotic runtime remains
.
Appendix C
Splitting Algorithm and Runtime
For a given and leaf, L, the ridge-regression (Hoerl and Kennard 1970) is defined as
that minimize the ridge penalized least squares equation,
(15)
(15) and a closed form solution of this problem is given by:
(16)
(16)
Recall that for a set , we define
With this notation, we can decompose :
Here, we use the definition which gives for some
by:
(17)
(17)
As is constant in k, it can be discarded when considering the optimization problem and thus:
(18)
(18)
C.1 Pseudo Code of the Splitting Algorithm
In order to have a manageable overall runtime, the algorithm needs to quickly find the minimizer of (9). The fundamental idea behind the fast splitting algorithm is that we reuse many terms that were computed when finding in order to calculate
. This enables us to loop very quickly from k = 1 to k = n and calculate the RSS for each iteration. Specifically, the algorithm can be expressed in the following pseudo code.
1. Compute , and
.
2. Compute the for
in an iterative way:
(a), and
can be directly computed from
, and
by a simple addition or subtraction.
(b)For and
, we use the Sherman–Morrison Formula:
An explicit implementation of the split algorithm can be found in Algorithm 2.
Algorithm 2 Find Split to Minimize Sum of RSS
Input: Features: , Dependent outcome:
, overfitPenalty (regularization for split):
,
Output: Best Split point k
1:procedure FindBestSplitRidge
Initialization:
2:
3:
4:
5:
6:
7:
8:
Compute the RSS sum:
9:
for do
10:
11:
12:
13:
14:
15:
16:
Compute the RSS sum for the current split:
17:return
Update_A_inv is defined in Algorithm 3
C.2 Runtime Analysis of Finding Split Points
The ability to use an online update for calculating the iterated RSS at each step is crucial for maintaining a quasilinear runtime. Here we will provide a detailed breakdown of the runtime for calculating the best split point on a given feature. As we have several steps for updating the RSS components, the runtime depends on both the number of observations, as well as the number of features and therefore, may be affected by either. We begin each split by sorting the current split feature taking time. Within the split iterations, we iterate over the entire range of split values once, however, at each step we must update the RSS components.
While updating the component, as we use the Sherman–Morrison Formula to update the inverse of the sum with an outer product, we must compute one matrix vector product (
), one vector outer product (
), one vector inner product (
), division of a matrix by scalars and addition of matrices (both
). While updating the G component, we need to both add and subtract an outer product (both
), and while updating the S component, we need to add and subtract a vector (
). At each step of the iteration, we must evaluate the RSS of the right and left models. To do this, we need 8 matrix vector products, each of which is
, and 4 vector inner products, each of which is
. Putting these parts together gives us a total runtime of
to find the best split point for a given node with n observations and a d-dimensional feature space.
C.3 Early Stopping
As we will see in Section 3, early stopping can prevent overfitting in the regression tree algorithm and the RF algorithm. Furthermore, as we discuss in Section 4, it leads to well performing yet shallow trees that are much easier to understand and interpret.
We use a one step look-ahead stopping criteria to stop the trees from growing too deep. Specifically, we first compute a potential split as outlined in the algorithm above. We then use cross-validation to compute the R2 increase of this split and only accept it, if the increase of the split is larger than the specified minSplitGain parameter. A larger minSplitGain thus, leads to smaller trees. The precise description of this parameter can be found in Algorithm 4.
D Tuned Simulation Hyperparameters
Algorithm 3 Update the Component of the RSS
Input: ,
, leftNode (indicator whether this updates
or
)
Output: Updated matrix
1:procedure Update_A_inv
2:
3:
if leftNode then
4:
5:else
6:
7:return
Algorithm 4 Early Stopping: The One Step Look-Ahead Algorithm
Input: Features: , Dependent outcome:
, Indices of potential left child:
, minSplitGain:
, numTimesCV:
, overfitPenalty:
Output: Boolean: TRUE if split is accepted, FALSE otherwise
1:procedure Check_split
2:
Partition into k disjoint subsets:
.
3:
for i in do
Predict the outcome without the split:
4:
For set
Predict the outcome with the split:
5:
For set
6:
For set
7:
Compute the estimated RSS with and without split:
8:
Compute the total variation:
9:
if thenreturn TRUE
10:else return FALSE
For a set S we define its compliment as .
Appendix E
Generating Random Step Function
The Simulated-Step-Function in Section 3 was generated according to the following scheme:
Algorithm 5 Generate Simulated Step
Input: numLevels (number of random levels for step function), n (dimension of data)
Output: Independent Input: , Step Function Outcome:
,
1:procedure Generate_Simulated_Step
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:return
Appendix F
Optimal Regularization Parameters
As noted in Section 3, the value of λ used for the ridge regression can allow LRF to behave like either a regularized linear model or a standard random forest.
In order to take advantage of this adaptivity, we allow the user to specify the desired regularization parameter in our software using the overfitPenalty parameter. In Section 3, as we have a variety of datasets which exhibit varying smoothness, we select the optimal overfitPenalty using the caret package (Kuhn Citation2008).
As the value of λ is considered in the optimization problem which finds the optimal splitting point at each iteration, we study only the case where we have a globally fixed overfitPenalty. It is also possible to replace the final value of λ in each leaf node with a value different from that used to select the splits for the tree. As there may be many leaf nodes which may make complicated estimation schemes for individual λ’s computationally intensive, we suggest selecting λ for each node following a simple rule of thumb. One such rule, inspired by (Donoho Citation1995), would select λ for each node based on:(21)
(21)
Where σ is the square root of the variance of outcomes in the leaf node, p is the number of linear features the ridge regression is fit on, and n is the number of observations in the node.
Appendix G
Software Solutions
To aid researchers in analyzing regression trees, we implemented a plotting function in the Rforestry package that is fast, easy to use, and flexible.12 It enables researchers to quickly look at many trees in a RF algorithm. The analysis done in Section 4.2 was created using this package and using the tree.id parameter to specify different trees to plot.rft <- forestry(x = x,y = y,minSplitGain =.005,linear = TRUE,overfitPenalty = 1e-8,linFeats = 1:4,splitratio =.5)plot(forest, tree.id = 1)
In the above code segment, the linear parameter specifies to use the ridge splitting criterion, the linFeats parameter specifies the columns of the design matrix on which to evaluate the ridge split, and the overfitPenalty parameter gives the ridge penalty for the splitting algorithm- as detailed in Algorithm 2. The minSplitGain parameter specifies the percentage increase in R2 required for any split to be accepted. We recommend using a smaller minSplitGain to draw even more personalized conclusions. For details on the role of minSplitGain in the acceptance of a split, refer to Algorithm 4.
Appendix H
Interpretability
H.1 Voter Turnout Dataset
We use a dataset from a large field experiment that has been conducted by Gerber, Green, and Larimer (Citation2008) to measure the effectiveness of four different mailers on voter turnout. The dataset contains 344,084 potential voters in the August 2006 Michigan statewide election with a wide range of offices and proposals on the ballot. The sample was restricted to voters that voted in the 2004 general election, because the turnout in the 2006 election was expected to be extremely low among potential voters who did not vote in the 2004 general election.
The specific mailers can be found in Gerber, Green, and Larimer (Citation2008) and we briefly describe the mailers as follows. Each mailer carries the message “DO YOUR CIVIC DUTY — VOTE!” and applies a different level of social pressure. We present the different mailers ordered by the amount of social pressure they put on the recipients.
Civic Duty (CD): The Civic Duty mailer contains the least amount of social pressure and only reminds the recipient that the whole point of democracy is that citizens are active participants in government.
Hawthorne (HT): Households receiving the Hawthorne mailer were told “YOU ARE BEING STUDIED!” and it explains that voter turnout will be studied in the upcoming August primary election, but whether or not an individual votes “will remain confidential and will not be disclosed to anyone else.”
Self (SE): The Self mailer exerts even more pressure. It informs the recipient that “WHO VOTES IS PUBLIC INFORMATION!” and presents a table showing who voted in the past two elections within the household to which the letter was addressed. It also contains a field for the upcoming August 2006 election, and it promises that an updated table will be sent to households after the election.
Neighbors (NE): The Neighbors mailer increases the social pressure even more and starts with the rhetorical question: “WHAT IF YOUR NEIGHBORS KNEW WHETHER YOU VOTED?” It lists the voting records not only of the people living in the household, but also of those people living close by and it promises to send an updated chart after the election. This treatment mailer implies that the voting turnout of the recipients are publicized to their neighbors and thereby creates the strongest social pressure.
The randomization was done on a household level. The set of all households was split into four treatment groups and a control group. Each of the four treatment groups contained about 11% of all voters, while the control group contained about 56% of all households.
H.2 S-Learner Using LRF
While there are several ways in which the S-Learner could be implemented using LRF, we believe that the way we have done so offers several advantages.
Our implementation utilizes the linear model in each node in order to handle several treatments simultaneously. Thus, for a leaf, L, the regression coefficients for each treatment indicator becomes estimates for the average treatment effect for that treatment for observations in that leaf,(22)
(22)
Where is the four dimensional vector containing the indicator for the treatment group of unit i and Xi
and Yi
are the features and the dependent outcome of unit i. As the tree splits are done on the other covariates, this allows the tree structure to uncover heterogeneity in the CATE function while providing estimates for the CATE of all four treatments. The use of many trees, with bootstrap samples to build the trees on, allows us to reduce the variance of our CATE estimates.
Due to the use of honesty when constructing each tree, the linear model in each node is fit on a dataset which is independent of the dataset used to construct the tree.
Finally, as we make use of the stopping criterion (Algorithm 4), we prevent splits which do not sufficiently uncover heterogeneity of the treatment effects, which prevents the trees from overfitting, and provides much more interpretable estimators.
H.3 Additional Trees
Below we plot several additional trees from the ensemble studied in Section 4. In Section 4 we focus on conclusions drawn from a single tree of the ensemble, however, we can see that these conclusions are supported as we examine additional trees in the forest.
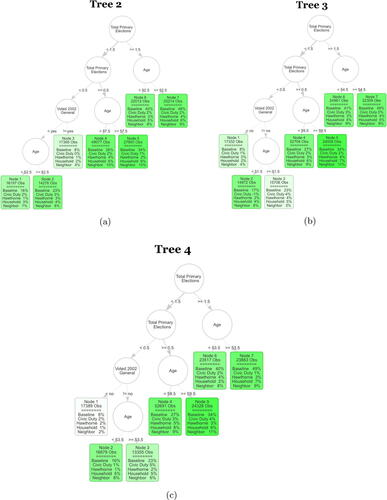
We still see a subgroup of voters where there seems to be very little interest in participating in past or future elections, regardless of treatment received. We also see a subgroup which seems to be highly engaged in voting, however, still sees some of the highest treatment effects for the various mailers. Finally, there are consistently splits on age in the early 50’s, suggesting that this is a stable cutpoint which determines a large difference in potential voter turnout ().
Fig. H1 The next three trees of the S-Learner as described in Section 4.2. The first row in each leaf contains the number of observations in the averaging set that fall into the leaf. The second part of each leaf displays the regression coefficients. Baseline stands for untreated base turnout of that leaf and it can be interpreted as the proportion of units that fall into that leaf who voted in the 2004 general election. Each coefficient corresponds to the ATE of the specific mailer in the leaf. The color strength is chosen proportional to the treatment effect for the neighbors treatment.
Appendix I
Interpreting LRF Outputs
I.1 Local Linear Aggregation
As the base learners in LRF vary substantially from those in the standard random forest algorithm, it is of interest to see how the different functional form of the base learners effects the predictions of the ensemble.
As the predictions of an LRF ensemble come from a locally linear model, this gives information not only about the point predictions, but also how these predictions might change when the covariates are perturbed slightly.
To aid researchers in utilizing the smooth regression surface of linearly aggregated trees, we implemented a prediction function in the Rforestry package that allows users to examine the forest wide average coefficient for each covariate used to predict a given observation.13rft <- forestry(x = x,y = y,linear = TRUE,overfitPenalty =.1)predict(rft, newdata = x, aggregation
= "coefs")
One example of where this might be useful is in the estimation of incremental causal effects (Rothenhäusler and Yu Citation2020). A setting where practitioners might be interested in the change in treatment effect due to a slight perturbation of either a single or multiple covariates.
I.2 Variable Importance Metrics
The use of linear aggregation functions also modifies how the standard random forest variable importance (Breiman Citation2001) behaves. In order to understand the differences produced in the variable importances of different features, we show a simple simulation.
I.2.1 Data-Generating Process
Again we follow the example from Athey, Tibshirani, and Wager (Citation2019) used in Section 3.4 to study the performance of LRF in the prescence of many noisy covariates. We make one modification to this simulation in changing the dimension of the covariates from 100 to 10 and selecting a higher amount of noise. The setup now becomes , then Y is generated as follows:
(23)
(23)
Where:(24)
(24)
And . As the true outcome depends on only the first four covariates, we wish to pick up these as the most important covariates.
I.2.2 Results
We train both a LRF and the standard RF algorithm on the DGP above and present the normalized variable importances. For this simulation we take the standard RF variable importance introduced in Breiman (Citation2001), and average our results over 100 Monte Carlo replications.
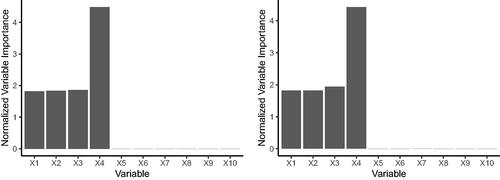
We can see that both LRF and RF are able to pick up the important features quite well in this example. The normalized feature importances are nearly identical for both algorithms, however, the unnormalized importances are consistently higher for the standard RF algorithm. This suggests that the linear aggregation algorithm is less sensitive to perturbations in the covariates than the standard CART predictions ().
Fig. I1 The left shows the mean normalized variable importances from LRF on simulated data, repeated over 100 Monte Carlo replications. The right shows the mean normalized variable importances from RF on simulated data, repeated over 100 Monte Carlo replications. The true outcome relies on only the first four covariates.
Appendix J
Runtime Comparison
In order to show the practical implications of Theorem 1, we show several simulations to show the magnitude of the speedup when running the LRF algorithm on real datasets. We generate data according to , with Y generated according to:
(25)
(25)
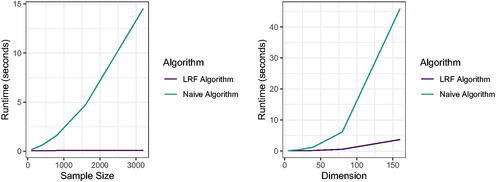
Where . We then generate data from this model for a range of dimensions p and samples sizes n ().
Fig. J1 We run both the naive linear regression tree algorithm and the fast LRF algorithm from Section 2 for 100 Monte Carlo replications on the same data generated according to EquationEquation 25(25)
(25) . The left figure shows the mean timing of both algorithms as we keep the dimension fixed and vary the sample size, and the right figure shows the mean timing of both algorithms as we fix the sample size and vary the dimension.