
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We construct a zig-zag process targeting a posterior distribution defined on a hybrid state space consisting of both discrete and continuous variables. The construction does not require any assumptions on the structure among discrete variables. We demonstrate our method on two examples in genetics based on the Kingman coalescent, showing that the zig-zag process can lead to efficiency gains of up to several orders of magnitude over classical Metropolis–Hastings algorithms, and that it is well suited to parallel computation. Our construction resembles existing techniques for Hamiltonian Monte Carlo on a hybrid state space, which suffers from implementationally and analytically complex boundary crossings when applied to the coalescent. We demonstrate that the continuous-time zig-zag process avoids these complications. Supplementary materials for this article are available online.
1 Introduction
The zig-zag process is a nonreversible, piecewise deterministic Markov process introduced by Bierkens and Roberts (Citation2017); Bierkens, Fearnhead, and Roberts (Citation2019b) for continuous-time MCMC. It has several advantages over reversible methods such as Metropolis–Hastings (Hastings Citation1970) and Gibbs sampling (Gelfand and Smith Citation1990): it avoids diffusive backtracking which slows their mixing, and is rejection-free so that no computation is wasted on rejected moves.
In brief, the generator of the zig-zag process targeting the probability density (with respect to the product of the Lebesgue and counting measures)
on a state space
is
where
is the derivative with respect to xi
, and Fi
flips the sign of vi
. The flip rates
(1)
(1)
with
, ensure that
leaves
invariant (Bierkens, Fearnhead, and Roberts Citation2019b, theorem 2.2). In words, the coordinates of
move at constant velocities
until a flip at coordinate i, when the corresponding velocity changes sign.
To date, the zig-zag processes have been applied to targets such as the Curie–Weiss model (Bierkens and Roberts Citation2017) and logistic regression (Bierkens, Fearnhead, and Roberts Citation2019b), whose state spaces have simple geometric structures with natural notions of direction and velocity. Discrete variables (other than the velocities) have been restricted to cases with simple partial orders, such as model selection (Chevalier, Fearnhead, and Sutton Citation2020; Gagnon and Doucet Citation2021). We construct a zig-zag process on a general hybrid state space with both continuous and discrete coordinates, without imposing any structure on discrete coordinates. This is done by introducing a separate space of continuous variables for each value of the discrete variable, introducing boundaries into the continuous spaces, and updating the discrete variable when boundaries are hit. The strategy takes advantage of the full generality of piecewise-deterministic Markov processes (Davis Citation1993, sec. 24), and is resembles similar work for Hamiltonian Monte Carlo (HMC) (Dinh et al. Citation2017; Nishimura, Dunson, and Lu Citation2020). Our method can also been seen of as a generalization of the zig-zag process on a restricted domain (Bierkens et al. Citation2018) to a union of many restricted sub-domains, with jumps between sub-domains at boundary hitting events. We illustrate our method with an application to the coalescent (Kingman Citation1982): a tree-valued target with continuous branch lengths, discrete tree topologies with no natural partial order, and no canonical geometric structure.
The coalescent examples illustrate the need for methods which are implementable on complex state spaces. They are also of interest because existing MCMC algorithms for coalescents tend to mix slowly. The key difficulty lies in designing Metropolis–Hastings proposal distributions which combine efficient exploration with a high acceptance rate (Mossel and Vigoda Citation2005; Höhna, Defoin-Platel, and Drummond Citation2008; Lakner et al. Citation2008). Workarounds consist of empirical searches for efficient proposals (Höhna and Drummond Citation2012; Aberer, Stamatakis, and Ronquist Citation2016) or Metropolis-coupled MCMC (Geyer Citation1992). The former does not scale to problems for which empirical optimization is infeasible. The latter helps mixing between modes, but does not overcome low acceptance rates or the backtracking behavior of reversible MCMC.
The zig-zag process has some similarities with HMC (Neal Citation2010), which augments the state space with momentum and uses Hamiltonian dynamics to propose large steps which are accepted with high probability, though they are not rejection-free. Like the zig-zag process, HMC requires gradient information and a suitable geometric embedding of the target. Dinh et al. (Citation2017) provided those for the coalescent using an orthant complex construction of phylogenetic tree space (Billera, Holmes, and Vogtmann Citation2001). Our examples differ from the method of Dinh et al. (Citation2017) in three ways. First, we replace the embedding of Billera, Holmes, and Vogtmann (Citation2001) with τ-space (Gavryushkin and Drummond Citation2016), which is better suited to ultrametric trees. Second, the zig-zag process is readily implementable on τ-space via Poisson thinning without a numerical integrator such as leap-prog (Dinh et al. Citation2017, algorithm 1). Finally, the zig-zag process has simple boundary behavior between orthants and does not require boundary smoothing (Dinh et al. Citation2017, sec. 3.3), chiefly because discontinuous gradients are easier to handle on continuous rather than discretized paths.
The rest of the paper is structured as follows. Section 2 defines the zig-zag algorithm with discrete and continuous variables, and proves that it has the desired invariant distribution. Section 3 recalls the coalescent and the τ-space embedding. In Sections 4 and 5 we recall the popular infinite and finite sites models of mutation, derive zig-zag processes for each, and demonstrate their performance via simulation studies. Section 6 concludes with a discussion. The algorithms and datasets used in the simulation studies are available at https://github.com/JereKoskela/tree-zig-zag.
2 Zig-zag on Hybrid Spaces
The definition of our zig-zag process follows (Davis Citation1993, sec. 24). Let be a countable set. For each
, let
be an open subset of
be its closure, and
be its boundary. We assume that
are piecewise Lipschitz and denote by
the restriction of
to noncorner points. Let
and
. For a point
, let
be the outward unit normal, and let
be the sets of velocities with which a zig-zag process can exit (+) or enter (–)
at
. Zig-zag dynamics imply
. We also define
and
. Integrals over
and
, or subsets thereof, are taken to incorporate discrete sums in the
coordinate.
The zig-zag process is defined on
, with target
on
for a given density
. At
, the process moves with velocity
and each coordinate vi
flips at rate
, defined as in (1) since m is fixed between boundary hitting events. When
, the process jumps according to a Markov kernel
, where
denotes the set of probability measures on
. We assume that Q and
satisfy the skew-detailed balance condition
(2)
(2) for any
and
, as well as
(3)
(3)
for any
, and exclude jumps to paths pointing into corners by assuming
(4)
(4)
where
is the time the line
hits
. We will abuse notation and use
as the target density and Lebesgue measure on
, and as their restrictions to the surface
, on which
is not a probability density.
By Davis (Citation1993, theorem 26.14), the zig-zag process with dynamics defined above is a piecewise-deterministic Markov process with extended generator(5)
(5) whose domain D(L) consists of measurable functions
on
satisfying:
For each
, the limit
For each
For
The random variable
For a set A, let B(A) and be the respective spaces of bounded and continuously differentiable functions on A. Let
. For t > 0, we define
Theorem 1.
Suppose is finite,
for each
and
on
, that
has compact support for each
, and for each t > 0 and
,
(7)
(7)
Suppose the initial distribution of has a density on
and that (2)–(4) hold. Then the zig-zag process with generator (5) and domain D(L) as described above has stationary distribution
.
Proof.
Provided in the supplementary materials. □
Remark 1.
In addition to having the right invariant distribution, a practical algorithm needs to be ergodic. To discuss ergodicity of the zig-zag process from Theorem 1, let
be zig-zag processes restricted to respective spaces
by boundary jump kernels
, each with target proportional to
. When
is finite, a sufficient condition for ergodicity of the global process
is that
are all ergodic, and that
(8)
(8) for ordered pairs
which form a cycle spanning the support of
. Bierkens, Roberts, and Zitt (Citation2019) provide conditions for ergodicity of single-domain zig-zag processes.
We conclude this section with a pseudocode specification of our zig-zag algorithm.
Algorithm 1 Simulation the zig-zag process targeting
Require: Initial condition , target
, jump kernel Q, terminal time
Set
while
Set
for
Sample
Set ρ to be the solution of
if
Set
Set
if I > 0 then
Set
else
Set
3 The Coalescent and a Geometric Embedding
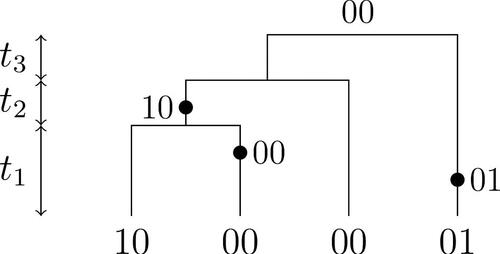
An ultrametric binary tree with n labeled leaves is a rooted binary tree in which each leaf is an equal graph distance away from the root. We follow Gavryushkin and Drummond (Citation2016) and encode such a tree with leaf labels as the pair
, where En
is a ranked topology and
. The continuous variables
encode times between mergers. The time from the leaves to the first merger is t1, and subsequent ti
variables are times between successive mergers. The ranked topology En
is an
-tuple of pairs of labels, where the ith pair specifies the two child nodes of the ith merger. Nonleaf nodes are labeled by the leaves they subtend. For example, the ranked topology
encodes the four leaf caterpillar tree depicted in and with nodes labeled left to right. We order the two entries of
by their least element for definiteness.
The coalescent (Kingman Citation1982) is a seminal model for the genetic ancestry of samples from large populations. Under the coalescent, a tree has probability density
(9)
(9) which arises as the law of a tree constructed by starting a lineage from each leaf, and merging each pair of lineages at rate 1 until the most recent common ancestor (MRCA) is reached. The success of the coalescent is due to robustness: distributions of ancestries of a large class of individual-based models converge to the coalescent in the infinite population limit under suitable rescalings of time. For details, see, for example, Wakeley (Citation2009).
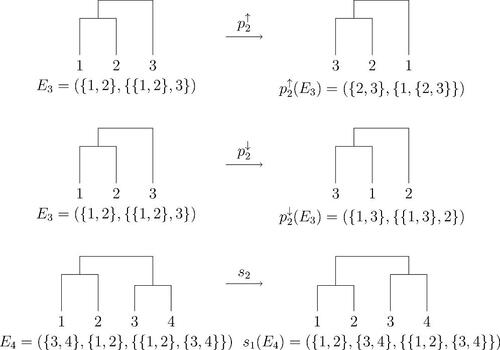
We define swap operators si
for via
In words, si
swaps the order of the th and ith mergers. We also define pivot operators
and
for
as
(10)
(10) where
(resp.
) is the entry of
with the higher (resp. lower) least element, and
is the sibling: the entry of
that is not
. Pivot
is defined by interchanging ↓ and ↑ in (10). The pivots are the two nearest neighbor interchanges between the ith merger and the merger involving its nearest child. illustrates all three operators.
Fig. 1 Operators , and s2. The horizontal arrangement of leaves is arbitrary throughout this article; only vertical distance is meaningful.
Next we describe τ-space, which gives a geometric structure to the set of pairs . For fixed En
, the space of
-vectors is the orthant
. Each boundary point with ti
= 0 corresponds to a degenerate tree in which one of three things happens:
The two leaves of
There are two simultaneous mergers if
There is a simultaneous merger of three lineages if
Type 1 boundaries are boundaries of the whole τ-space. Type 2 boundaries separate orthants corresponding to two ranked topologies separated by an si
-step. Trajectories crossing the boundary move from one ranked topology to the other. Type 3 boundaries separate the three orthants which resolve the triple merger into two binary mergers, which differ by a or
-step. A trajectory that crosses the boundary visits a tree with the triple merger. depicts the τ-space with three leaves, and a type 2 boundary in a general τ-space. An example with five leaves is depicted in (Gavryushkin and Drummond Citation2016, ), and the
variables are illustrated in and in Sections 4 and 5.
Fig. 2 (Left) τ-space with n = 3 embedded into . Each square is a copy of
associated with the given topology. The coordinates
are the respective time of the first merger, and the time between the first and second merger. The dot is the origin, and the line on which all three orthants intersect is a type 3 boundary consisting of trees in which all three leaves merge simultaneously at time t1. The dashed lines are boundaries at
. (Right) A segment of τ-space depicting a type 2 boundary, in which each square represents
. Only the two orthants adjacent to the boundary are shown.
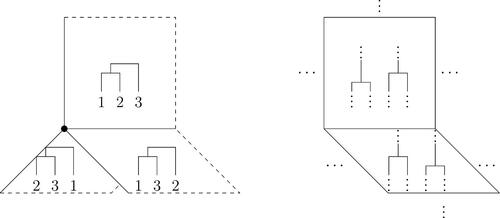
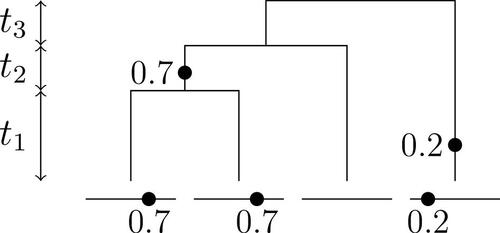
Fig. 3 A realization of the infinite sites model with n = 4, two mutations, three types, and . The holding times
are shown on the left.
We will use τ-space to construct zig-zag processes whose state spaces consist of tree topologies, branch lengths, and a scalar parameter introduced in the next section. The discrete variables will be the ranked topologies, with the boundary crossings described above defining the boundary jump kernel Q. For more on τ-space, for example, existence and uniqueness of geodesics and Fréchet means, we refer to Gavryushkin and Drummond (Citation2016).
4 The Infinite Sites Model
The infinite sites model (Watterson Citation1975) connects the coalescent tree to DNA sequence data by associating the MRCA with the unit interval (0, 1). Mutations with independent, -distributed locations accrue along branches of the tree (with branch lengths as specified by
) at rate
. The type of a leaf consist of the mutations along branches separating it from the MRCA. We denote the resulting list of types of the leaves by Dn
. A realization of a coalescent tree and associated Dn
is shown in . The typical task is to sample from the conditional law
corresponding to observing Dn
, but not the tree which gave rise to it.
To handle mutations, we define Fn
as the rooted graphical tree with nodes, the first n of which are leaves labeled
, while the remaining
are labeled as in En
. Edges connect children to their parents, and edge lengths are determined by
. For an edge
, we denote by
and
the respective labels of the child and parent nodes of γ, by
the number of mutations on γ, and by
the edge length, where we write
if ti
contributes to the length of γ in which case we say γ spans ti
.
Given a prior density for θ, the posterior distribution of
follows from (9), the fact that the number of mutations on branch
is Poisson(
)-distributed given
, and that mutations on distinct branches are independent. In particular,
(11)
(11) provided En
is consistent Dn
, and π = 0 otherwise. This distribution can be sampled using a zig-zag algorithm by taking
to be the set of ranked topologies on n leaves which are consistent with Dn
, as well as
and
for each
. In the boundary classification of Section 3, θ = 0 is another type 1 boundary. For
, we define
as the index of the zero variable, taken to be n in the case of θ.
We augment the state space with n zig-zag velocities , of which
drive
and vn
drives θ. For
, we also define
as the rate of change of
. The boundary kernel Q is defined separately on each boundary type:
(12)
(12)
At a type 1 boundary the process reflects back into via a velocity flip. At a type 2 boundary it undergoes an si
-step and a velocity flip to pass through the boundary. For type 3 boundaries it chooses an adjacent orthant uniformly at random.
In the interiors of orthants, velocity flip rates are(13)
(13)
(14)
(14)
Simulating holding times with these rates is difficult due to the time intervals during which they vanish. One strategy is Poisson thinning via dominating rates consisting of only those terms in the round brackets in (13) and (14) whose sign matches that of the corresponding velocity vi
, but these can result in loose bounds and inefficient algorithms. Instead, we define for brevity, and for
define
as the shorter child branch from parent node
. For
we adopt the short-hands
and finally define the time localization
as
(15)
(15)
where
, and
is a maximum increment for the case when all velocities are positive. The indicator functions in the denominator pick out boundaries where (11) vanishes: type 1 or 3 boundaries corresponding to length 0 branches which carry at least one mutation, and the θ = 0 boundary if there is at least one mutation in total. The parameter c > 0 ensures that, when the current process time is t, such boundaries cannot be hit on
, and at most one other boundary can be reached. We found c = 4 gave good performance across our tests in Sections 4 and 5. A larger value results in tighter bounds on (13) and (14), but wastes more computation as t + T is hit more often before an accepted velocity flip.
On time interval , flip rates (13) and (14) are bounded above by constant rates
where, for each
if
and
if
. Algorithms S1 and S2 in the supplementary materials give pseudocode for simulating holding times, velocity flips, and boundary crossings as outlined above.
Proposition 1.
Suppose that the initial condition has a positive density on
, that
, and that
is bounded on compact subsets of
. Then (11) is stationary under the dynamics simulated by Algorithm S1 and S2, given in the supplementary materials.
Proof.
Provided in the supplementary materials. □
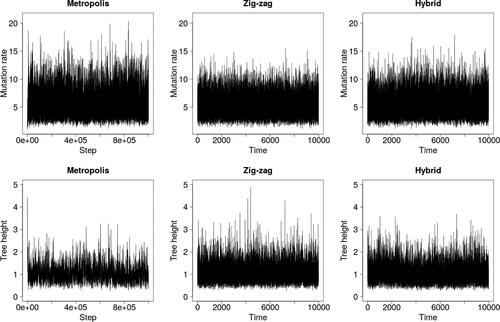
We compared the zig-zag process to a Metropolis–Hastings algorithm by reanalyzing the data of Ward et al. (Citation1991) with n = 55, 14 distinct types, and 18 mutations. We used the improper prior , set
, and set vn
from trial runs to cross the θ-mode in unit time. in the supplementary materials details the Metropolis–Hastings algorithm, and other tuning parameters. We compared both methods to a hybrid combining zig-zag dynamics with continuous time Metropolis–Hastings moves at rate κ = 10. Performance was insensitive to κ provided it was not extreme: small values resemble a zig-zag process, while large values resemble Metropolis–Hastings.
Table 1 Effective sample sizes and run times for all three methods and datasets for the infinite sites model.
shows that the zig-zag and hybrid methods mix visibly better than Metropolis–Hastings over the latent tree, as measured by the tree height . However, they are not as effective at exploring the upper tail of the θ-marginal, likely because they do not stay in regions of short trees for long enough for θ to increase into the tail.
Fig. 4 Trace plots under the infinite sites model and the dataset of Ward et al. (Citation1991).
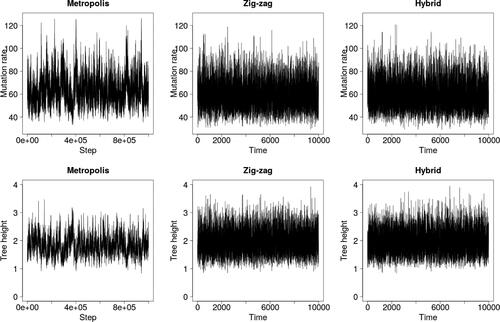
To assess scaling, we simulated two datasets: one of size n = 550 with mutation rate (the approximate posterior mean in ) and one with n = 55 and θ = 55, which models a segment of DNA 10 times longer. and demonstrate that the zig-zag and hybrid processes scale far better than Metropolis–Hastings, particularly when θ = 55. Estimates in quantify the improvement to 1–3 orders of magnitude.
Fig. 5 Trace plots for the infinite sites model and the dataset with n = 550, , 30 distinct types, and 38 mutations.
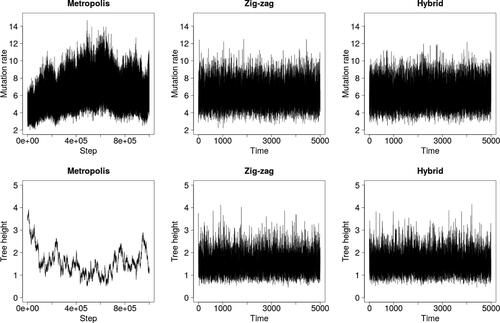
Fig. 6 Trace plots for the infinite sites model and the dataset with n = 55, θ = 55, 40 distinct types, and 252 mutations.
5 The Finite Sites Model
The finite sites model (Jukes and Cantor Citation1969) is more detailed than the infinite sites model, but has greater computational cost. Consider a finite set of sites S with a finite number of possible types H per site; for example or
. Mutations occur along branches of the coalescent tree at each site with rate
, and the type of a mutant child is drawn from stochastic matrix P with unique stationary distribution ν. We denote the transition matrix of the H-valued compound Poisson process with jump rate
and jump transition matrix P by
. depicts a realization of the finite sites coalescent.
Fig. 7 A realization of the finite sites model with n = 4, , three mutations, three types, and
.
As in Section 4, we denote the configuration of types at the leaves by Dn
, and seek to sample from the posterior , which can be written as a sum over the types of internal nodes:
(16)
(16) where
is the type at site
on the node with label
, and
denotes edges which do not end in a leaf. The target (16) can be evaluated efficiently using the pruning algorithm of Felsenstein (Citation1981).
The posterior (16) can be sampled using zig-zag dynamics with the same construction as in Section 4. Velocity flip rates can be written in terms of branch-specific gradients as(17)
(17)
(18)
(18) which can be evaluated using the linear-cost method of Ji et al. (Citation2020).
We show that events with rates (17) and (18) can be simulated using the example of (Griffiths and Tavaré Citation1994, sec. 7.4), in which and P is the 2 × 2 matrix which always changes state, corresponding to
and
(19)
(19)
As (19) is not bounded away from 0 when , (17) and (18) lack simple bounds for Poisson thinning. As in (15), bounds can be obtained by time localization using
where
is a default increment in case all velocities are positive. The variable T localizes the next zig-zag time step beginning at time t so that at most one branch can shrink to length zero on
, θ can fall by at most
of its present value, and t1 can fall by at most
of its present value if the first two leaves to merge are of distinct types. This treatment of θ and t1 is needed as (17) and (18) diverge in these cases, rendering the θ = 0 and
boundaries inaccessible.
Given , we have the following bounds on (19) on the time interval
:
where
. Substituting these bounds into (Ji et al. Citation2020, Equationeq. (9)
(9)
(9) ) provides bounds on flip rates that can be evaluated with
cost.
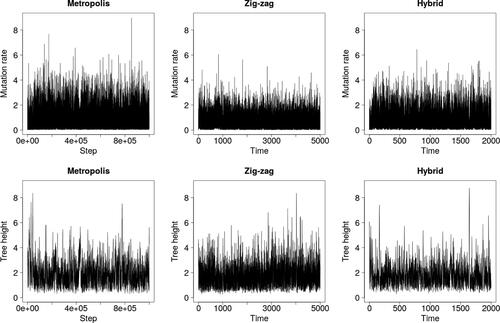
demonstrates that the zig-zag process again mixes over latent trees faster than Metropolis–Hastings, but struggles to explore the upper tail of the θ-marginal. The hybrid method was run with κ = 100 to compensate for shorter run lengths than in Section 4, and thus, resembles Metropolis–Hastings rather than the zig-zag process.
Fig. 8 Trace plots for the finite sites model and data from Griffiths and Tavaré (Citation1994).
and show results for two further simulated datasets: one with n = 500 and S = 20, and one with n = 50 and S = 200. The superior mixing of the zig-zag process over the latent tree is clear, as quantified by effective sample sizes in . The lack of mixing in the upper tail of the θ-marginal is also stark, particularly in where zig-zag significantly underestimates posterior variance. The estimated posterior means of all three methods coincide in all cases (results not shown).
Fig. 9 Trace plots for the finite sites model and dataset with n = 500 and S = 20 consisting of five distinct sequences.
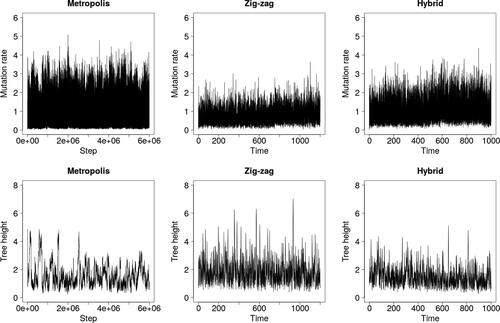
Fig. 10 Trace plots for the finite sites model and dataset with n = 50 and S = 200 consisting of 18 distinct sequences.
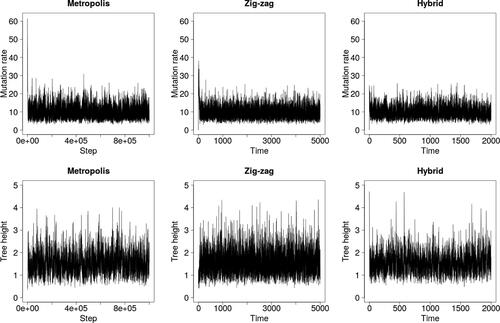
Table 2 Effective sample sizes and run times for all three methods and datasets.
6 Discussion
We have presented a general method for using zig-zag processes to sample targets defined on hybrid spaces consisting of discrete and continuous variables. This was done by introducing boundaries into the state space of continuous variables and updating discrete components via a Markov jump kernel Q whenever a boundary was hit. The resulting algorithm remains a piecewise-deterministic Markov processes in the sense of (Davis Citation1993, sec. 24), and generalizes existing zig-zag processes for restricted domains (Bierkens et al. Citation2018). Crucially, no assumptions of structure among the discrete variables are required. The key conditions on Q are the skew-detailed balance (2), which is local, and (3), which involves an integral with respect to Q but not the target . Both are verifiable in applications, and do not require
to be normalized. Our method is reminiscent of discrete Hamiltonian Monte Carlo (Dinh et al. Citation2017; Nishimura, Dunson, and Lu Citation2020), but the lack of time discretization simplifies boundary crossings (though see Nishimura, Dunson, and Lu Citation2020, sec. S6.4).
We have demonstrated the method on two examples involving the coalescent, which is a gold-standard model in phylogenetics. It is defined on the space of binary trees consisting of discrete tree topologies and continuous branch lengths, which lacks a simple geometric structure, for example, a partial order or a tractable norm. We have also shown that the zig-zag process can improve mixing over trees relative to Metropolis-Hastings, particularly under the infinite sites model. This model is widely used to analyze ever larger datasets, and the zig-zag process shows promise for expanding the scope of feasible MCMC computations.
The zig-zag process was more efficient than Metropolis–Hastings under the infinite sites model in terms of effective sample size, but struggled to explore the tails of the θ-marginal. A likely reason is correlation in the target: high mutation rates are only be attainable when branch lengths are short. A Metropolis–Hastings algorithm can jump to a high mutation rate as soon as the latent tree has short branches, while the zig-zag process must traverse all intervening mutation rates before branch lengths grow. The speed up zig-zag method of Vasdekis and Roberts (Citation2021) has state-dependent velocities, and could provide further improvement. The hybrid method with both zig-zag motion and Metropolis-Hastings updates interpolated between the two algorithms.
All three algorithms exhibited much longer run times under the finite sites model than under infinite sites. For the zig-zag and hybrid methods, that is due to the cost per evaluation of (17) and (18), of which there are O(n). However, flip times for different velocities are conditionally independent given the current state and can be generated in parallel, unlike steps of the Metropolis–Hastings algorithm. Hence, the zig-zag process is well suited to parallel architectures.
Acknowledgments
The author is grateful to Jure Vogrinc and Andi Wang for productive conversations on MCMC for coalescent processes, and nonreversible MCMC in general.
Supplementary Materials
The supplementary materials contains the proofs of Theorem 1 and Proposition 1, as well as details of the zig-zag and Metropolis–Hastings algorithms used in Sections 4 and 5.
Additional information
Funding
References
- Aberer, A. J., Stamatakis, A., and Ronquist, F. (2016), “An Efficient Independence Sampler for Updating Branches in Bayesian Markov Chain Monte Carlo Sampling of Phylogenetic Trees,” Systematic Biology, 65, 161–176. DOI: 10.1093/sysbio/syv051.
- Bierkens, J., Bouchard-Côte, A., Doucet, A., Duncan, A. B., Fearnhead, P., Lienart, T., Roberts, G., and Vollmer, S. J. (2018), “Piecewise Deterministic Markov Processes for Scalable Monte Carlo on Restricted Domains,” Statistics & Probability Letters, 136, 148–154.
- Bierkens, J., Fearnhead, P., and Roberts, G. (2019a), “Supplement to ‘The Zig-zag Process and Super-Efficient Sampling for Bayesian Analysis of Big Data’,” Annals of Statistics, 47.
- Bierkens, J., Fearnhead, P., and Roberts, G. (2019b), “The Zig-zag Process and Super-Efficient Sampling for Bayesian Analysis of Big Data,” Annals of Statistics, 47, 1288–1320.
- Bierkens, J., and Roberts, G. (2017), “A Piecewise Deterministic Scaling Limit of Lifted Metropolis-Hastings for the Curie-Weiss Model,” Annals of Applied Probability, 27, 846–882.
- Bierkens, J., Roberts, G., and Zitt, P.-A. (2019), “Ergodicity of the Zigzag Process,” Annals of Applied Probability, 29, 2266–2301.
- Billera, L. J., Holmes, S. P., and Vogtmann, K. (2001), “Geometry of the Space of Phylogenetic Trees,” Advances in Applied Mathematics, 27, 733–767. DOI: 10.1006/aama.2001.0759.
- Chevalier, A., Fearnhead, P., and Sutton, M. (2020), “Reversible Jump PDMP Samplers for Variable Selection,” preprint, arXiv:2010.11771.
- Davis, M. (1993), Markov Models and Optimization, Boca Raton, FL: Chapman Hall.
- Dinh, V., Bilge, A., Zhang, C., and Matsen, F. A., IV. (2017), “Probabilistic Path Hamiltonian Monte Carlo,” in Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia.
- Felsenstein, J. (1981), “Evolutionary Trees from DNA Sequences: A Maximum Likelihood Approach,” Journal of Molecular Evolution, 17, 368–376. DOI: 10.1007/BF01734359.
- Flegal, J. M., Hughes, J., Vats, D., and Dai, N. (2017), mcmcse: Monte Carlo Standard Errors for MCMC.
- Gagnon, P., and Doucet, A. (2021), “Nonreversible Jump Algorithms for Bayesian Nested Model Selection,” Journal of Computational and Graphical Statistics, 30, 312–323. DOI: 10.1080/10618600.2020.1826955.
- Gavryushkin, A., and Drummond, A. J. (2016), “The Space of Ultrametric Phylogenetic Trees,” Journal of Theoretical Biology, 403, 197–208. DOI: 10.1016/j.jtbi.2016.05.001.
- Gelfand, A. E., and Smith, A. F. M. (1990), “Sampling-Based Approaches to Calculating Marginal Densities,” Journal of the American Statistical Association, 85, 398–409. DOI: 10.1080/01621459.1990.10476213.
- Geyer, C. J. (1992), “Practical Markov Chain Monte Carlo,” Statistical Science, 7, 473–483. DOI: 10.1214/ss/1177011137.
- Griffiths, R. C., and Tavaré, S. (1994), “Simulating Probability Distributions in the Coalescent,” Theoretical Population Biology, 46, 131–159. DOI: 10.1006/tpbi.1994.1023.
- Hastings, W. K. (1970), “Monte Carlo Sampling Methods Using Markov Chains and their Applications,” Biometrika, 57, 97–109. DOI: 10.1093/biomet/57.1.97.
- Höhna, S., Defoin-Platel, M., and Drummond, A. J. (2008), “Clock-Constrained Tree Proposal Operators in Bayesian Phylogenetic Inference,” in 8th IEEE International Conference on BioInformatics and BioEngineering, pp. 1–7.
- Höhna, S., and Drummond, A. J. (2012), “Guided Tree Topology Proposals for Bayesian Phylogenetic Inference, Systematic Biology, 61, 1–11. DOI: 10.1093/sysbio/syr074.
- Ji, X., Zhang, Z., Holbrook, A., Nishimura, A., Baele, G., Rambaut,A., Lemey, P., and Suchard, M. A. (2020), “Gradients Do Grow on Trees: A Linear-time O(N)-Dimensional Gradient for Statistical Phylogenetics,” Molecular Biology and Evolution, 37, 3047–3060. DOI: 10.1093/molbev/msaa130.
- Jukes, T. H., and Cantor, C. R. (1969), “Evolution of Protein Molecules,” in Mammalian protein metabolism, ed. H. N. Munro, pp. 21–132, New York: Academic Press.
- Kingman, J. F. C. (1982), “The Coalescent,” Stochastic Processes and Their Applications, 13, 235–248. DOI: 10.1016/0304-4149(82)90011-4.
- Lakner, C., Van Der Mark, P., Huelsenbeck, J. P., Larget, B., and Ronquist, F. (2008), “Efficiency of Markov Chain Monte Carlo Tree Proposals in Bayesian Phylogenetics,” Systematic Biology, 57, 86–103. DOI: 10.1080/10635150801886156.
- Mossel, E., and Vigoda, E. (2005), “Phylogenetic MCMC Algorithms are Misleading on Mixtures of Trees,” Science, 309, 2207–2209. DOI: 10.1126/science.1115493.
- Neal, R. M. (2010), “MCMC Using Hamiltonian Dynamics,” in Handbook of Markov Chain Monte Carlo, S. Brooks, A. Gelman, G. Jones, and X.-L. Meng, Boca Raton, FL: CRC Press.
- Nishimura, A., Dunson, D. B., and Lu, J. (2020), “Discontinuous Hamiltonian Monte Carlo for Discrete Parameters and Discontinuous Likelihoods,” Biometrika, 107, 365–380. DOI: 10.1093/biomet/asz083.
- Vasdekis, G., and Roberts, G. O. (2021), “Speed Up Zig-zag,” preprint, arXiv:2103.16620.
- Wakeley, J. (2009), Coalescent Theory: An Introduction, Greenwood Village, CO: Roberts & Co.
- Ward, R. H., Frazier, B. L., Dew, K., and Pääbo, S. (1991), “Extensive Mitochondrial Diversity Within a Single Amerindian Tribe,” Proceedings of the National Academy of Sciences of the United States of America, 88, 8720–8724. DOI: 10.1073/pnas.88.19.8720.
- Watterson, G. A. (1975), “On the Number of Segregating Sites in Genetical Models Without Recombination,” Theoretical Population Biology, 7, 256–276. DOI: 10.1016/0040-5809(75)90020-9.