Abstract
This article presents a method to solve parameter estimation problems by finding an optimal parameterization of the mathematical model. The pi-theorem of dimensional analysis is used to establish a formulation of the model based on dimensionless products and scaling parameters, together with the rules of a parameterization change. Logarithmic parameters are introduced for the purpose of working in a linear parameter space in which a given base corresponds to a specific parameterization. The optimal parameterization is assumed to yield uncorrelated estimators. A statistical independence criterion based on the Fisher information matrix is derived for maximum-likelihood estimators. The method allows one to solve inverse problems with highly correlated model parameters by identifying well-resolved parameters, leading to a solution expressed in terms of correlation laws between physical quantities.
Introduction
Solving parameter estimation problems in science and engineering requires a mathematical model to describe the physical processes involved in an experiment Citation[1, Citation2]. Generally speaking, the physical quantities of a model can be combined to form other physical quantities. For instance, in heat transfer, thermal conductivity and specific heat can be combined to obtain thermal diffusivity and effusivity. A change in the choice of the physical quantities should give exactly the same solution to the model. However, as Tarantola Citation[2] and Vignaux Citation[3] noted, each parameterization leads to a specific parameter estimation problem. For this reason, it is always useful to identify parameters whose estimation is a well-posed inverse problem satisfying existence, unicity and stability conditions. In many cases, scientists and engineers have a good idea about the significant parameters of their experiments. However, the task is not trivial when multiple physical quantities are involved and couple in complex manners. A number of difficult problems appear for instance in heat conduction and other irreversible phenomena Citation[4] in which parameters are often highly correlated, leading to ill-posed inverse problems.
In this article, we propose a method aimed at identifying the optimal parameterization of a mathematical model for parameter estimation and data fitting. A parameterization is assumed to be optimal under the following conditions:
| 1. | the parameterization should be complete and minimal. | ||||
| 2. | the correlation coefficients between the parameter estimators should be minimal. | ||||
In section 1, the pi-theorem of dimensional analysis is used to derive a method to explicitly formulate any mathematical model using dimensionless products, scaling parameters, explanatory and output variables. The pi-theorem is also applied to derive nonlinear relationships describing a change of parameterization. Logarithmic parameters are introduced to transform these relationships into a linear system. In section 2, the statistical criterion based on the Fisher information matrix is established. This criterion is applied to logarithmic parameters in order to define a new base of uncorrelated parameters. Section 3 presents a regularized maximum-likelihood solution of problems which are linear with respect to logarithmic parameters. In section 4, the regularized linear solution is used to build an iterative algorithm aimed at reaching the solution of general nonlinear problems. A simple example of the technique in the field of heat transfer is presented in section 5.
1. Model parameterization using dimensional analysis
The purpose of dimensional analysis is to determine relationships between parameters using only one assumption: physical laws are independent of arbitrarily chosen units of measure. As a consequence, physical equations must be homogeneous and can be expressed with dimensionless quantities, which are pure numbers. Let x 1, x 2, … , x n be the n physical quantities of the problem. These quantities must involve w independent dimensions s k of the employed system of units. The dimension of quantity x i , noted [x i ], can be expressed as products of powers of dimensions s k :
According to the pi-theorem, the dimensionless form of a mathematical model function is an homogeneous function of parameters π j . In order to use the function for data fitting and parameter estimation, an output variable is needed as well as an explanatory variable. The explanatory and output variables should explicitly appear as dimensional parameters in the model. Let us assume that the output variable is x 1 and the explanatory variable is x 2. In this case, the set of dimensionless products must be built to include two parameters π 1 and π 2, in which x 1 and x 2 appear separately. The model function can be formulated in the following form:
The implicit consequence of the pi-theorem is the existence of an infinite number of dimensionless parameterizations, each corresponding to a particular base of the nullspace of M. Given a dimensionless parameterization π j associated with matrix B, another dimensionless parameterization π′ j associated with a matrix B′ can be obtained through the following relationship:
2. The identification of uncorrelated parameters
The inverse problem is now defined as the problem of estimating a vector u of m log-parameters and finding the linear transformation which gives an optimal parameterization represented by parameter vector p. Let us assume a vector d of N measurement data corresponding to N values of the explanatory variable. The standard model relationship d = g(u) + ε is assumed, in which vector g(u) comprises N values of the nonlinear model function g given by Equationequation (4) and ε is the vector formed by the N values of a zero-mean random noise. The maximum likelihood estimator
From a mathematical point of view, the Fisher information matrix corresponds to a linear mapping from the parameter space to the dual space Citation[2]. If a parameter space is subtended by a base consisting of n dimensional quantities, then the dual base comprises n quantities having reciprocal dimensions. When the parameter space is subtended by a base of logarithmic parameters, the dual base also consists of logarithmic parameters. A remarkable consequence is that the Fisher information matrix of logarithmic estimators maps the parameter space into itself. Under this condition, the eigenvector–eigenvalue decomposition Citation[8, Citation13] of J u can be performed, which leads to the relationship:
When the initial log-parameters u j are highly correlated, the complete set cannot be simultaneously estimated. Since a parameterization change does not modify the amount of information, the set of optimal parameters p j cannot be simultaneously estimated. However, the set of m parameters p j can be divided into two subsets of parameters according to the amount of Fisher information they possess:
| 1. | s parameters | ||||
| 2. | m − s parameters | ||||
The techniques consisting of suppressing small eigenvalues for solving underdetermined problems are well-known Citation[13]. They define a class of regularization methods which eliminates numerical instabilities by improving the conditioning of matrices. The method described here has the same advantage. The suppression of a number s of small eigenvalues Λ j transforms an ill-posed problem of dimension m into a well-posed problem of dimension m − s. Moreover, this procedure is based on consistent mathematical operations and leads to the identification of physically meaningful parameters. The number s can be seen as the degeneracy number of the model, corresponding to the number of parameters that cannot be estimated by data inversion. The number m − s is the true dimension of the inverse problem, corresponding to the effective number of parameters that can be estimated.
It is straightforward to remark that the estimation of m − s well-resolved parameters
Figure 1. Schematic summary of the principles leading to the identification of an optimal parameterization of the mathematical model and the estimation of well-resolved parameters.
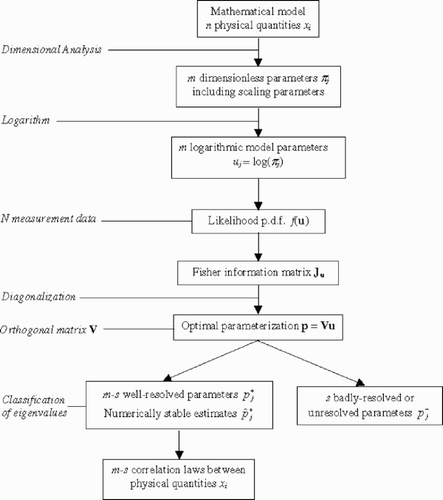
3. The Gaussian linear case
In the presence of Gaussian noise in the data, the maximum-likelihood estimator û is obtained by minimization of the well-known L2-norm S ML Citation[1, Citation2]:
4. The Gaussian nonlinear case
In nonlinear problems, the model function g is not linear with respect to the logarithmic model parameters u j . As a consequence, the mimimum of the L2-norm S ML has to be determined by a numerical procedure. In this case, finding the optimal parameterization is not straightforward because the Fisher information matrix depends on the actual estimates of the model parameters. Nonetheless, a linearized approach can be used to determine the optimal parameterization and to minimize S ML by proceeding step by step from initial guess values of the parameters. The linearization of the model must be performed with respect to log-parameters in order to apply the methodology and formulas of the previous sections. The first order Taylor expansion of g(u) around a reference parameter vector u r gives:
| 1. | Apply dimensional analysis to the model and introduce parameterization u formed by m logarithmic parameters u j . | ||||||||||||||||||||||
| 2. | Define first guess values u 0 | ||||||||||||||||||||||
| 3. | Set initial orthogonal matrix W 0 to I (m × m identity matrix) | ||||||||||||||||||||||
| 4. | Compute model g(u k ) | ||||||||||||||||||||||
| 5. | Compute cost function | ||||||||||||||||||||||
| 6. | Compute sensitivity matrix | ||||||||||||||||||||||
| 7. | Compute Fisher information matrix: | ||||||||||||||||||||||
| 8. | Perform eigenvector–eigenvalue decomposition:
| ||||||||||||||||||||||
| 9. | Define optimal parameters: p k = V k u k | ||||||||||||||||||||||
| 10. | Compute new sensitivity matrix: | ||||||||||||||||||||||
| 11. | Compute total orthogonal matrix: | ||||||||||||||||||||||
| 12. | Partition vector p k with respect to Fisher information:
| ||||||||||||||||||||||
| 13. | Update value of well-resolved parameters by the Gauss-Newton step: | ||||||||||||||||||||||
| 14. | Leave value of badly-resolved parameters | ||||||||||||||||||||||
| 15. | Define new set of parameters: | ||||||||||||||||||||||
| 16. | Check convergence. Three conditions must be simultaneously fulfilled:
| ||||||||||||||||||||||
| 17. | If convergence is not reached, increment k and go to step 4 | ||||||||||||||||||||||
When all the parameters of vector p are well-resolved, their diagonal covariance matrix C p can be directly computed by
The proposed iterative algorithm is able to deal with highly correlated parameters and ensures convergence to the maximum-likelihood point under the following conditions:
| 1. | The mathematical model must be accurate enough to fit the data. | ||||
| 2. | The model function must be differentiable in order to compute the sensitivity and Fisher information matrices. | ||||
| 3. | The model function should not be highly nonlinear to ensure validity of the linearized Equationequation (21) at each step. | ||||
| 4. | Initial guess values should not be too far from maximum-likelihood point (condition resulting from the use of a local minimization technique). Trying multiple starting points is often necessary to find a solution and check its unicity. | ||||
| 5. | Absence of outliers in the data (condition resulting from the Gaussian hypothesis and the use of the corresponding L2-norm). | ||||
5. Example
This section provides an example illustrating the benefits of using an optimal parameterization in a parameter estimation problem of small dimension. The problem consists in measuring thermal properties of titanium nitride (TiN) coatings on steel substrates using photothermal radiometry Citation[14, Citation15]. The coating is heated by a modulated continuous-wave laser beam in order to produce a harmonic temperature field in the sample. An infrared radiometer with a lock-in amplifier provides the amplitude and phase of the surface temperature Citation[14]. The phase ϕ is used for parameter estimation and data fitting. It is measured at different modulation frequencies f in the range of 1 kHz–1 MHz, which gives thermal diffusion lengths varying from about 100 µm to 3 µm, the latter value corresponding to the approximate thickness of the coating. The coating is opaque at the excitation and detection wavelengths. In the experimental configuration of Citation[14], the heat conduction regime is one-dimensional. The surface temperature is modeled using thermal quadrupoles assuming a homogeneous coating, a semi-infinite substrate and a thermal resistance at the interface. The phase ϕ is given by the argument of the complex thermal impedance Citation[14]:
Figure 2. Dimensional analysis of the model function given by Equationequation (24). One row of matrix M has to be rejected because the rank of M is equal to 3 while there are four fundamental units. The row corresponding to the Kelvin unit can be rejected because it is proportional to the row corresponding to the kilogram unit. As described in section 1, matrices M and B are partioned in order to introduce products π 1 and π 2 depending linearly on explanatory variable f and output variable ϕ. This is achieved here by setting submatrix B 1 to the identity matrix. Submatrix B 2 is given by B 2 = − B 1(M 2 −1 M 1)t.
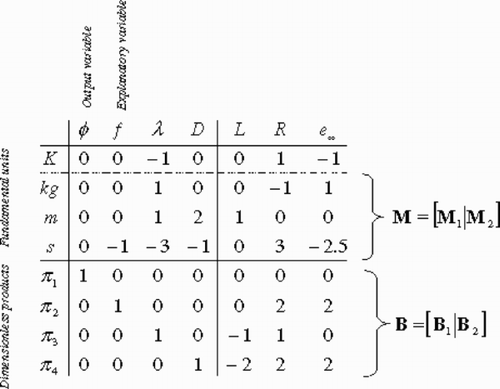
| 1. | Scaling parameter | ||||
| 2. | Dimensionless parameter π3 = λR/L | ||||
| 3. | Dimensionless parameter | ||||
5.1. Sensitivity and expected correlation coefficients
The model parameters are now set to typical values corresponding to the properties of a TiN coating on a steel substrate: λ = 10 K−1 kg m s−3, D = 3.6 × 10−6 m2 s−1, L = 3 × 10−6 m, R = 6 × 10−8 K kg−1 s3, e ∞ = 7000 K−1 kg s−5/2. The value of the scaling parameter X 2 is 0.176 μs. The dimensionless scaling parameter
| 1. | Dimensional parameters λ, D, L, R and e ∞. | ||||
| 2. | Logarithms of dimensional parameters: log(λ), log(D), log(L), log(R) and log(e ∞). | ||||
| 3. | Dimensionless parameters | ||||
| 4. | Logarithmic parameters log( | ||||
Table 1. Condition number and expected correlation coefficients associated with several non-optimal parameterizations of the example in section 5.
In the first case, the very high condition number of the Fisher information matrix shows that the estimation of the five dimensional parameters is an ill-posed inverse problem that cannot be solved directly. The use of logarithms of dimensional quantities in the second case improves the conditioning of the matrix. However, high correlation coefficients are present between the estimators. The dimensionless parameter set of the third case corresponds to a problem of smaller dimension but also exhibits high correlation coefficients. In the fourth case, the use of logarithmic parameters does not reduce the correlation coefficients. These four parameterizations lead to badly conditioned matrices and high correlation coefficients. None is really adapted to solve the parameter estimation problem. shows a plot of the sensitivity coefficients of the phase ϕ to the logarithmic parameters log(
Figure 3. Sensitivity coefficients of the phase ϕ to the logarithmic parameters log(), log(π3) and log(π4).
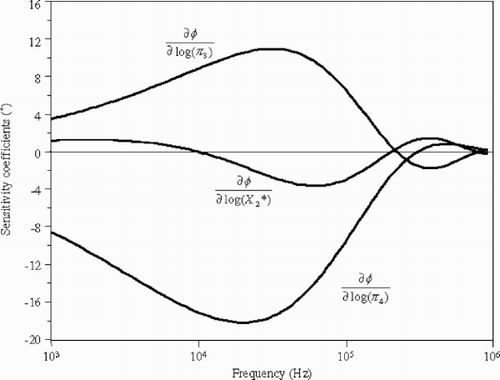
An optimal parameterization is obtained by the diagonalization of the Fisher information matrix corresponding to the logarithmic parameterization of the fourth case. The resulting orthogonal matrix is:
Figure 4. Sensitivity coefficients of the phase ϕ to the optimal parameters p 1, p 2 and p 3.
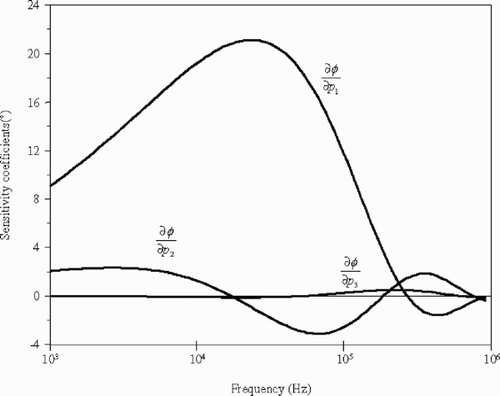
Now, the parameter estimation problem can be solved with respect to well-resolved parameters p 1 and p 2. The condition number of the projected 2 × 2 diagonal Fisher information matrix Λ + is about 60. This value is much smaller than the initial condition numbers obtained with non-optimal parameterizations. It improves the stability of the inverse problem near the reference values.
5.2. Assessment of the iterative algorithm with simulated data
The efficiency of the algorithm given in the previous section can be verified by using simulated data. In this example, a set of theoretical data are obtained using Equationequation (24) with the reference numerical values used above. A random noise with a standard deviation of 1° is added to the data. The chosen initial values of parameters X 2, π3 and π4 differ from the true values by about one order of magnitude or less: (
Table 2. Results given by the iterative algorithm applied to the example in section 5.
At each step, one badly-resolved parameter is rejected and the Gauss-Newton correction acts on two optimal parameters. The orthogonal matrix V 6 obtained after convergence is equal to the identity matrix (in absolute value). The total orthogonal matrix W defines the optimal parameters of the inverse problem. The absolute values of coefficients of matrix W are very close to the coefficients of the matrix V previously computed from the sensitivity coefficients at the reference values. Since the signs of the coefficients of the orthogonal matrices are not constrained, equivalent optimal parameters with opposite values may be obtained. shows the simulated data, the data corresponding to the initial values and the data corresponding to the maximum-likelihood model.
Figure 5. Graph showing the simulated phase data (dots), the data corresponding to the initial parameter values of the iterative algorithm (dashed line) and the best fit data obtained after convergence of the iterative algorithm (plain line).
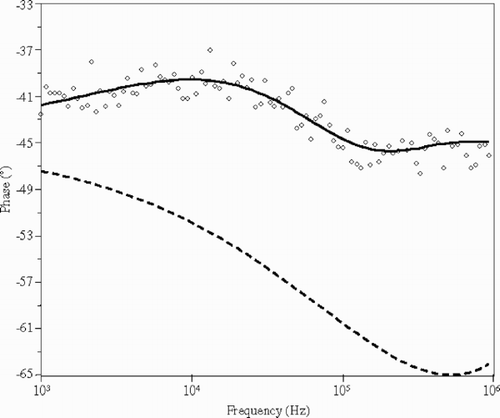
The maximum-likelihood estimates of the optimal parameters are p 1 = −0.220, p 2 = 0.233, p 3 = 4.208. The variances and standard deviations can be computed from the Fisher information values using Equationequation (11): σ(p 1) = 0.0016, σ(p 2) = 0.013 and σ(p 3) = 2.89. According to Equationequation (13), the estimation of well-resolved parameters p 1 and p 2 provides the following correlations laws between the physical parameters:
Using the optimal parameters and their maximum-likelihood estimates, all the other dimensionless parameters of the problem can be estimated. For instance, the logarithmic thermal effusivity ratio between the coating and the substrate, equal to
Conclusion
This article demonstrates that parameter estimation problems can be solved using an optimal parameterization consisting of uncorrelated parameters. These parameters are determined by the diagonalization of the Fisher information matrix relative to logarithmic estimators. This work relies on dimensional analysis to provide minimal and complete sets of dimensionless model parameters, associated with rules for describing parameterization changes. As a result, an initial set of correlated parameters can be transformed into a set of optimal parameters, allowing a reduced number of well-resolved parameters to be identified. The estimates of these well-resolved parameters lead to a solution of the inverse problem expressed as a set of correlation laws between physical quantities.
This method was detailed for maximum-likelihood estimation problems under the Gaussian noise hypothesis. In the linear case, the optimal parameters can be determined directly from the model matrix and the covariance matrix of the data. In the case of nonlinear problems, the optimal parameterization can be determined by an iterative algorithm aimed to minimize the L2-norm of the problem in the subspace of well-resolved parameters. This algorithm has the property of being numerically stable, in the case of high or perfect correlations between the initial parameters.
In this work, the optimal parameters are defined as being uncorrelated. Null correlation coefficients assure the mutual independence of the parameters up to the second order, which is well adapted to Gaussian estimators. However, this criterion is not sufficient to ensure the statistical independence of non-Gaussian estimators. Higher order criteria, commonly used in the independent component analysis Citation[16], could greatly improve the method in the case of non-Gaussian distributions, appearing in many nonlinear inverse problems.
The technique presented in this article was applied in the field of thermal metrology to the characterization of hard coatings by photothermal infrared radiometry Citation[14, Citation15]. The complete experimental results will be the subject of a different paper. The estimation of scaling parameters such as defined in section 1 of this article, is presented in Citation[17] and led to the measurement of the thermal diffusivity of semi-infinite solids.
Acknowledgements
I am grateful to Prof. Albert Tarantola of the Institut de Physique du Globe de Paris, France, for helpful comments made to the early version of this work. I acknowledge stimulating discussions with Dr. Gordon Edwards of the National Physical Laboratory, Teddington, UK. I would also like to thank Prof. Pierre Trebbia of the University of Reims, France, for his graduate course on multivariate statistics and his incentive to use Fisher information in Physics.
Nomenclature
Table
References
References
- Beck JV Arnold KJ 1977 Parameter Estimation in Engineering and Science New York J. Wiley & Sons
- Tarantola A 1987 Inverse Problem Theory, Methods for Data Fitting and Model Parameter Estimation New York Elsevier Science
- Vignaux GA 1992 Dimensional analysis in data modelling C.R. Smith, G.J. Erickson, and P.O. Neudorfer (Eds) Maximum Entropy and Bayesian Methods Dordrecht Kluwer Academic Publishers www https://www.mcs.vuw.ac.nz/~vignaux/diman.html
- Beck JV Blackwell B St Clair Jr CR 1985 Inverse Heat Conduction. Ill-posed Problems New York J. Wiley & Sons
- Kokar , MM . 1979 . The use of dimensional analysis for choosing parameters describing a physical phenomenon . Bulletin de l'Academie Polonaise des Sciences: Série des Sciences Techniques , XXVII ( 5/6 ) : 249
- Palacios J 1960 L’Analyse Dimensionelle Paris Gauthiers-Villars
- Szirtes T 1998 Applied Dimensional Analysis and Modeling New-York McGraw-Hill
- Mostow GD Sampson JH Meyer JP 1963 Fundamental Structures of Algebra New York McGraw-Hill
- Mosegaard K Tarantola A 2002 Probabilistic approach to inverse problems. In: International Handbook of Earthquake and Engineering Seismology Academic Press for the International Association of Seismology and Physics of the Earth Interior., www http://www.ccr.jussieu.fr/tarantola
- International Organization of Standardization (ISO) 1993 Guide to the Expression of Uncertainty in Measurement Switzerland Geneva
- Cox MG Dainton MP Harris PM 2001 Software Support for Metrology Best Practice Guide No. 6: Uncertainty and Statistical Modelling Technical report, National Physical Laboratory Teddington, UK www http://www.npl.co.uk/ssfm
- Van Trees HL 1968 Detection, Estimation and Modulation Theory New York J. Wiley & Sons
- Lanczos C 1961 Linear Differential Operators London D. Van Nostrand Company
- Martinsons , C and Heuret , M . 1999 . Inverse analysis for the measurement of thermal properties of hard coatings . High Temp. High Press. , 31 : 99
- Martinsons , C , Levick , A and Edwards , G . 2003 . Measurement of the thermal diffusivity of solids with an improved accuracy . Int. J. Thermophysics , 24 : 1171
- Hyuvärinen A Karhunen J Oja E 2001 Independent Component Analysis New York J. Wiley & Sons
- Levick , A , Lobato , K and Edwards , G . 2003 . Development of the laser absorption radiation thermometry technique to measure thermal diffusivity in addition to temperature . Rev. Sci. Instrum. , 74 : 612