
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Different methods to obtain individual scores from multiple item latent variable models exist, but their performance under realistic conditions is currently underresearched. We investigate the performance of the regression method, the Bartlett method, the Kalman filter, and the mean score under misspecification in autoregressive panel models. Results from three simulations show different patterns of findings for the mean absolute error, for the correlations between individual scores and the true scores (correlation criterion), and for the coverage in our settings: a) all individual score methods are generally quite robust against the chosen misspecification in the loadings, b) all methods are similarly sensitive to positively skewed as well as leptokurtic response distributions with regard to the correlation criterion, c) only the mean score is not robust against an integrated trend component, and d) coverage for the mean score is consistently below the nominal value.
In psychological research, we often aim at understanding individual development with regard to some latent variable such as depression, competencies, or emotional quantities. The question of how we can obtain scores for latent variables that reliably and validly represent the construct we want to measure guides efforts in latent variable modeling. Most of the popular longitudinal models (e. g., multilevel models or autoregressive (AR) models) yield model parameters such as averages, coefficients of variation or regression coefficients, but they do not directly provide information on individual trajectories. Individual score estimates, sometimes also referred to as predictions, allow us to locate persons on an underlying latent variable (often a normally distributed random latent variable), and, thus, to track them for reasons of monitoring, diagnosis, or prognosis. However, as opposed to parameters of longitudinal models themselves, methods to obtain individual scores are comparatively underresearched, especially in regard to model misspecification.
Research on individual score methods and their performance has a long history, beginning in the last century. Most of the research on individual score methods conducted before the turn of the millennium deals with the performance of individual score methods in the context of exploratory factor analysis (e. g., Horn, Citation1965), where one of the leading questions was centered around the indeterminacy of individual scores. For a summary of the history of individual score methods and the problem of factor indeterminacy, see for instance Steiger (Citation1979), Acito and Anderson (Citation1986), and Steiger (Citation1996).
Due to the development and spreading of latent variable modeling during the past decades, the focus of recent research on individual score methods has shifted away from their primary use in exploratory factor analyses towards their use in full latent variable models. In one strand of research, individual score methods are investigated with respect to their performance in multistep procedures (e. g., Croon, Citation2002; Devlieger, Mayer, & Rosseel, Citation2016; Devlieger & Rosseel, Citation2017; Hoshino & Bentler, Citation2013; Skrondal & Laake, Citation2001). Those approaches have in common that individual scores are first obtained based on a measurement model before they are used to study structural relationships between latent variables. A related strand of research focuses on the role of covariates in individual score modeling (Curran, Cole, Bauer, Hussong, & Gottfredson, Citation2016; Curran, Cole, Bauer, Rothenberg, & Hussong, Citation2018). Other applications of individual scores in quantitative psychology include propensity score analysis (Raykov, Citation2012; for problems of this approach see Lockwood & McCaffrey, Citation2016), latent interaction modeling (Schumacker, Citation2002), residual analysis (e. g., Bollen & Arminger, Citation1991; Coffman & Millsap, Citation2006), and integrative data analysis, where individual scores are used for secondary analyses of multiple pooled raw datasets (e. g., Curran & Hussong, Citation2009).
Most of the previous research on individual score method performance is either not tailored to focus on the individuals themselves (e. g., when individual scores are used to study structural relationships between latent variables) or their performance is studied under ideal conditions, that is, when all of the model assumptions are perfectly met. However, in practice, such ideal situations hardly ever exist and findings require further supportive or contradictory evidence (Wackwitz & Horn, Citation1971, p. 406). When analyzing real data, our models are usually somewhat misspecified, that is, the model that is used for data analysis differs from the model that generated the data. To account for this fact, the goal of our article is to investigate the robustness of different individual score methods against model misspecification in a series of simulation studies. We connect to previous research by choosing similar design factors and features. We extend previous studies by focusing on individuals (rather than on average model parameters) and by taking a longitudinal perspective. To account for the longitudinal structure, we use an autoregressive panel model, where one latent variable measured by multiple indicators predicts the value of the same variable at the next time point. Panel models are often characterized by having rather small numbers of measurement occasions but many individuals and are used, for instance, in clinical (e. g., Luoma et al., Citation2001; Nolen-Hoeksema, Girgus, & Seligman, Citation1992) or educational (e. g., Compton, Fuchs, Fuchs, Elleman, & Gilbert, Citation2008; Lowe, Anderson, Williams, & Currie, Citation1987; Osborne & Suddick, Citation1972) contexts.
Our paper is structured as follows. First, we present four common individual score methods: the individual mean score, the regression method, the Bartlett method, and the Kalman filter. As we will show in more detail later on, the individual mean score is usually directly computed by the researchers themselves, whereas the other methods require some latent variable modelFootnote1 and are part of most standard software packages for latent variable modeling. The mean score is the most restrictive method as it does not incorporate any estimated model parameters but implicitly assumes an equal weighting of perfectly measured responses. If these assumptions are met, for instance, because the measurement with the corresponding instrument has been shown to be psychometrically sound, reliable, and valid, it is perfectly fine to use the sum or mean score. If, however, good psychometric properties have not been shown, the implicit assumptions may be violated. The Bartlett method does not incorporate structural model parameters (except for mean structures) but only considers loadings and error variances from the measurement model. The regression method as well as the Kalman filter incorporate structural model parameters in addition to measurement model parameters, but they slightly differ in the extent to which that information is used: the Kalman filter only incorporates information up to the current time point, not from future time points as the regression method, which exploits all available information to estimate the individual scores. Next, we investigate the robustness of the selected methods against model misspecification in three simulation studies. The models are misspecified with regard to the loadings (Study 1), the distributional assumptions of the responses (Study 2), and the structural model (Study 3). In Study 3, we use an autoregressive model with an integrated trend to generate the data but estimate the model based on an autoregressive model without a trend as in Studies 1 and 2. To investigate the performance of different individual score methods under model misspecification in AR panel models, we rely on parameters similar to those by Muthén and Muthén (Citation2002) or we use misspecifications as used in recent studies. We thus connect our research to the most current research of individual score methods, rather than pursuing a “testing the limits”, fully-blown simulation study that focuses on one selected type of misspecification.
We expect that the mean score and the Bartlett method should be more sensitive to misspecifications as specified in Studies 1 and 2. These studies will show whether the incorporation of longitudinal information as done by the regression method and the Kalman filter can compensate for misspecification in the measurement model. The regression method and the Kalman filter might be prone to an omitted linear trend as specified in Study 3. Also the mean score may show worse performance in Study 3 as it does not account for any structural information (i. e., a trend).
By examining the robustness of different, easily accessible individual score methods against common types of model misspecification, we make a step towards determining the appropriateness of individual score methods in a wide range of empirical situations. We investigate what we gain or lose in terms of performance when we apply one or the other method in controlled but realistic scenarios.
Individual scores
For the purpose of the present paper and in line with Hardt, Hecht, Oud, and Voelkle (Citation2019), we consider an individual score as a realization of a normally distributed random latent variable that conceptually represents a psychological construct. Let any construct (e. g., intelligence, depression, positive/negative affect, etc.) be measured by multiple indicators (synonym: items), for which we can observe a response
. Further, let
be the running index of the latent variables representing the constructs of interest with
being the total number of constructs. Let
be the vector of the
latent variable values for
individuals. The common factor model establishes the following linear relationship between the responses and the latent variables:
where is a vector of the manifest responses across items for person
,
is a vector of item intercepts,
is the loading matrix connecting manifest and latent variables, and
is the vector of error terms in the measurement model, with
, where
is the variance-covariance matrix of
. If, in addition, relations among the latent variables are postulated, those can be expressed by
where contains the intercepts of
,
contains all directed effects among the
latent variables and
are the structural disturbances for subject
with
, where
is the variance-covariance matrix of
.
Because denotes values of latent variables that cannot be directly observed, individual score estimates or predictions
need to be obtained. In the following paragraph we present several ways to obtain individual score estimates
from observable responses
.
Individual score methods
One simple way to obtain individual scores is to compute individual sum scores or mean scores for the
latent variables as defined by
where denotes individual scores obtained by computing individual sum scores, and
is a selection matrix that assigns a particular element in
to its corresponding construct. Choosing
yields sum scores for
, whereas we obtain mean scores by choosing
, where
denotes the total number of items
measuring one specific construct
. If there are no missing values, an individual’s sum score and mean score correlate to one and differ only by their scale. These approaches assume that items are equally strongly related to the latent variables (i. e., all
) and that they are measured without any error (i. e., all
). In order to obtain individual confidence intervals, we can use the standard error of measurement according to
, where
is the standard deviation of the sum scores or mean scores, respectively, in the sample. One common choice for the reliability is to use Cronbach’s (Citation1951) Alpha, which, just like the unweighted individual mean or sum score, also makes the assumption of equal loadings and therefore is referred to as tau-equivalent reliability (Cho, Citation2016).
Lessening these assumptions by incorporating the corresponding model parameters in the computation of individual scores yields more sophisticated approaches such as the Bartlett method, the regression method, and the Kalman filter. According to the Bartlett method (Bartlett, Citation1937), an individual score is given by
where are the model implied means for
as computed by
. In order to obtain standard errors, we can take the square root of the diagonal elements of the estimation error variance-covariance matrix
(e. g., Oud, van Den Bercken, & Essers, Citation1990), with
representing the individual score estimates obtained by a particular method and
representing the true scores of the latent variables. For the Bartlett method,
. As we can see, only the measurement model components
and
enter the computation, whereas structural components are ignored.
This is different in the regression method (Thomson, Citation1938; Thurstone, Citation1934), which uses
as an estimate of , where
is the variance-covariance matrix of the latent variables
. For the regression method,
. By capturing temporal dependencies among the latent variables in
, the regression method allows us to incorporate longitudinal structural information.
The same is true for the Kalman filter (Kalman, Citation1960), which is an inherently longitudinal approach and considered to be an optimal method for online individual score estimation (e. g., Hardt et al., Citation2019; Oud et al., Citation1990) in a longitudinal context. The Kalman filter involves two steps: in the first step (prediction step), the individual score at time point
is predicted by the individual score at the previous time point
yielding
where denotes the transition matrix, which connects
over time. It contains autoregressive parameters in the diagonal and, for
, cross-lagged effects between
in the off-diagonals. Thus, the diagonal elements of
reflect the strength of the relationship of a given construct between adjacent measurement occasions: the closer the absolute values are to one, the stronger the relationship and the better the prediction of
at time point
by
at
. With the arrival of data from the new measurement at time point
the prediction from time point
is updated (update step) according to
with being the responses predicted by
. The Kalman gain,
, determines how strongly the new measurement is weighted as compared to the prediction based on the previous time point and is defined by
where is the predicted Kalman estimation error as given by
. The updated Kalman estimation error is defined by
, where
is the identity matrix. Note that the index for the time point in the Kalman filtering approach goes from
to
, where
denotes the total number of measurement occasions. At
, the Kalman filter can be initialized completely “uninformative” for instance by setting
and
to arbitrary values or “informative” by choosing individual score estimates obtained by another individual score method (e. g., the Bartlett method or the regression method, see Oud, Jansen, Van Leeuwe, Aarnoutse, & Voeten, Citation1999; Hardt et al., Citation2019; for more comprehensive research on the initial condition specification, see Losardo, Citation2012).
Simulation studies
Three simulation studies were conducted in order to examine the robustness of the four selected individual score methods against misspecification in the context of an AR(1) panel model. Misspecifications are studied with regard to the loadings (Study 1), the distributional assumptions of the responses (Study 2), and the longitudinal structural model (Study 3). Based on the results we draw conclusions for the use of individual scores in practice.
General setting and procedure
All three simulation studies followed the same steps: data generation, model specification and estimation, computation of individual scores, and analyses of the results. Data generation was different across simulations and will be described for each simulation study separately. The model used for data analysis is always a univariate (i. e., ) autoregressive panel model of order one, AR(1), in which one latent variable with
items is repeatedly measured on
equally-spaced measurement occasions for
individuals.Footnote2
All variables are
-standardized if not indicated otherwise. Adapting Equations (1) and (2) and assuming a stationary process (see e. g., Hamilton, Citation1994, pp. 45–46) with
and measurement invariance across time (i. e.,
,
) yields
with 0
for the measurement model and
with for the structural model. The disturbance term
, also called process noise, reflects the degree to which
cannot be predicted by
. depicts the model used for data analysis as well as the locations of the misspecifications in the simulation studies. After having estimated the models, individual scores are computed according to Equations (3) to (7). Unless stated otherwise, we assumed
and
.
FIGURE 1 Conceptual path diagram of an autoregressive model of order one with five observed indicators; the squared areas indicate locations of misspecification as examined in the three simulation studies.
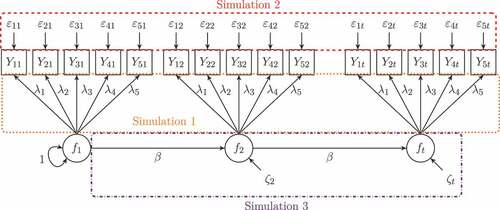
In all three simulation studies, we varied the degree of persistence of the process (referred to as factor beta) to be either 0.25 or 0.75. A parameter of indicates lower persistence, whereas a parameter of
indicates higher persistence. The different individual score methods are represented as a factor Method which comprises the levels Regression, Bartlett, MeanScore, KFiniR, and KFiniB with the latter two being the Kalman filter initialized with the regression method and the Bartlett method, respectively. As the misspecification in simulation Studies 1 and 2 is located in the measurement model, we varied the average of the loadings (referred to as factor LDm). The average of the loadings was either 0.6 or 0.8. Loadings of 0.8 correspond to a latent variable indicator reliability of
when variables are standardized and can be considered prototypical for loadings in psychological studies (Muthén & Muthén, Citation2002). The set of loadings with an average value of 0.6 represents situations with less reliable indicators. In practice, loadings are usually not equal across indicators. Hence, loadings for our five observable indicators were chosen in such a way that they approximately followed a normal distribution around the mean. For
conditions, loadings were 0.65, 0.75, 0.80, 0.85, 0.95 and for
conditions, loadings were 0.45, 0.55, 0.60, 0.65, 0.75. In addition, we incorporated the five time points as control factor Time into the analyses of simulation Studies 1 and 2 in order to capture time-specific effects which may emerge in a longitudinal context. Further study specific design factors that relate to the type of misspecification itself are outlined for each simulation study separately.
All steps were replicated times per condition. If the model converged, we computed individual scores as described before and subsequently evaluated their performance as described next. All analyses were conducted using the package OpenMx (Neale et al., Citation2016; Boker et al., Citation2018, version 2.12.2) in the software environment R (R Core Team, Citation2018, version 3.5.0); individual scores were computed with our own routines. As starting values, we used 0.5 for the loadings, for the process error variance as well as for the autoregression coefficient, and 0.4 for the error variances in the measurement model. For the intercepts in simulation Study 3 we relied on the OpenMx’ default starting value of zero. Further, by specifying lbound = 0.0001 for variances, we ensured that estimates for variances are positive. Regarding model convergence, we relied on OpenMx default values but used the function mxTryHard() with 50 extra attempts to obtain model convergence. In the extra attempts, parameter estimates from the previous attempt are perturbed by random draws from a uniform distribution and then used as starting values for the next attempt.
Outcome criteria
To evaluate the performance of the different individual score methods, we use three criteria: the mean absolute error (MAE), the Fisher--transformed correlation between true scores and individual score estimates, and the coverage rate. We use analysis of variance (ANOVA) or logistic regression models to examine variation in the three criteria. In these models, we consider the unique impact of the simulation design and control factors and all possible interactions between them. The MAE is calculated by
and is a measure of the absolute discrepancy between the true score and the individual score estimate. It is considered to be among the most appropriate measures when all the data are on the same scale (see Hyndman & Koehler, Citation2006). The correlation is expressed as
and it is a relative measure. It describes how well the relative positioning of individuals based on their true scores is maintained by individual score estimates and may thus be considered an index for the individual score reliability. For the MAE and for the correlation criterion, we fit ANOVA models using sums of squares of type III to explain variation in them. The coverage criterion assesses the frequency with which the true score is “captured” by an individual score estimate plus/minus the corresponding 95% confidence interval limits relative to the total number of replications. The confidence intervals are computed by
, where
and the standard errors
at each time point
are obtained based on
as described before. Ideally, the coverage rate matches the nominal confidence of 95%. Because of its range from 0 to 1, the coverage criterion is further analyzed by means of logistic regression models using dummy coding of the design and control factors as well as all possible interactions between them. In dummy coding, one of the factor levels is chosen as reference category (coded as 0), while each other factor level is represented as dichotomous group indicator with code 1 indicating group membership and 0 otherwise. As for the coverage criterion departures from 0.95 are more important to consider than the mere variation in it, we included an additional Method level with the value 0.95 for each person at each time point and for each condition. This “method” reflects the nominal coverage rate for 95% confidence intervals and is the baseline (“reference category”) for the Method factor. Thus, a regression coefficient for a particular individual score method reflects its departure in coverage from the nominal 95% confidence.Footnote3
The three outcome criteria capture very different aspects of individual score method performance. Whereas the MAE and the coverage may be more important in the context of individual diagnostics with predefined diagnostic criteria and thresholds, the correlation criterion may be more important for subsequent (e. g., covariance based) analyses. Note that the MAE and the coverage are calculated for each individual across replications, whereas the correlation criterion is calculated across all individuals per replication, resulting in different numbers of units entering the ANOVA models reported below. Given the extreme power due to the high number of units for the two outcomes (at least 40,000), we only deem factors with both and an
of at least
as meaningful in the ANOVA models. In case of such meaningful factors, we further conducted post hoc pairwise comparisons of the factor levels with Bonferroni adjustment of the
-values to avoid
error inflation. We considered significant effects (i. e.,
) with an effect size of
to be meaningful. For the logistic regression models, we transformed the exponentiated regression coefficients into Cohen’s
according to Borenstein, Hedges, Higgins, and Rothstein (Citation2009, Equation (7.1)) and considered a predictor effect as meaningful if
and
. These thresholds correspond to Cohen’s (Citation1988) conventions for small effects and the
threshold is additionally in line with that used by Curran et al. (Citation2016).
Simulation study 1: loadings
Methods
Data generation
Data were generated according to an autoregressive panel model of order one as described before. First, the trajectories of the true scores were generated according to Equation (8). For we drew
values from a standard normal distribution. Next, based on the trajectories of the true scores, we generated the response data under the common factor model as given in Equation (9) and with the two sets of loadings with an average of 0.6 and 0.8, respectively, as described before. For this, we multiplied an individual’s true score at a given time point by the loadings and added a measurement residual,
, where the variances in
are one minus the squared loading, with zeros in the off-diagonals, in order to obtain standardized items without error covariances.
Design and analyses
In order to study the effect of misspecifications in the loadings on individual score methods, we analyzed the data generated with unequal loadings with a model in which the loadings and measurement error variances are assumed to be equal (LDequal). As reference, we compare our results to those obtained for a model with a correct specification of the loadings, that is, when they are estimated freely (LDfree) and subsumed these specifications under the factor LDspec (with the levels LDequal/misspecified vs. LDfree/correct [reference]). In addition, the following aforementioned design and control factors enter the analyses: beta (reference: ), LDm (reference: average loading of 0.6), Time (reference:
), and Method (reference: nominal 95%).
Results
In simulation Study 1, all models converged. With regard to the MAE, we only find a few statistically significant (i. e., ) effects (see ), of which only the effect of the average loading design factor LDm can be considered practically meaningful
. Unsurprisingly, this means that a mean loading of 0.8 leads on average to a smaller MAE value than a mean loading of 0.6. Considering the coverage criterion (see ), only the mean score leads to a meaningfully smaller odds of capturing the true score by the confidence interval as compared to the nominal 0.95 coverage (
). This effect is more pronounced in
conditions for the mean score than for other individual score methods (
).
TABLE 1 ANOVA Results for the MAE Criterion for Study 1
FIGURE 2 LDspec = loading specification with LDfree = freely estimated loadings and LDeq = loadings constrained to be equal; M06 = average loading of 0.6, M08 = average loading of 0.8; be025 = of 0.25, be075 =
of 0.75. Proportions and confidence intervals for Study 1.
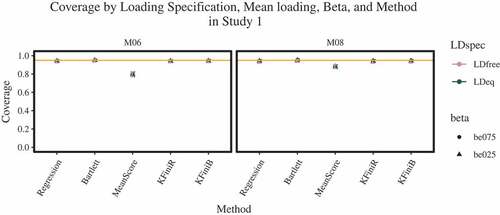
Regarding the correlation criterion (see ), we find the same effect of the average loading on the average -transformed correlation between the true scores and the estimated individual scores (
).
TABLE 2 ANOVA Results for the Correlation Criterion for Study 1
In summary, the effects we found are in line with what we know about the individual score methods’ performance under ideal conditions (i. e., without model misspecification). In turn, this means that loading misspecification, as implemented in this simulation study, neither has a meaningful impact on the MAE nor on the correlation criterion, and that the individual score methods have proven robust against this type of misspecification. However, regardless of the model misspecification, when using the individual mean scores and corresponding confidence intervals, we are testing with a confidence that is actually lower than the nominal confidence. That is, the type I error probability is higher than we assume.
Simulation study 2: response distributions
Methods
Data generation
Data were generated in the same way as described for simulation Study 1 except for the distribution from which the measurement residuals were drawn. In order to generate non-normal response data, measurement residuals were drawn from two different distributions as in Devlieger et al. (Citation2016): for one set of conditions, and multiplied by the square root of the diagonal elements in
, resulting in curved response data that are leptokurtic (
). For another set of conditions,
and were multiplied by the square root of the diagonal elements in
, resulting in positively skewed response data (
) as may be the case when modeling responses times for instance. In the baseline conditions,
as before.
Design and analyses
In order to study the effect of non-normally distributed response data on the performance of different individual score methods, we entered the factor Ydistr (representing different response distributions) with the three levels curved, skewed, and normal (reference) into the analyses of the simulation results. In addition, we included beta, LDm, Time, and Method as control and design factors just as before.
Results
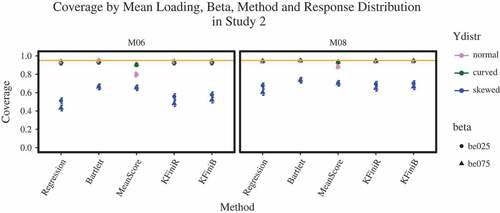
In simulation Study 2, all models converged except for up to three replications in conditions with curved response distributions. With regard to the MAE, none of the factors or interactions became significant and explained at least of the variance in the MAE (see ). That is, the error that we make when estimating individual scores is independent of the design factors, including misspecifications in the response distribution. This is different for the correlation criterion, for which the response distribution (Ydistr) accounts for
of the variance (see ). Post hoc pairwise analyses yielded strong effects of
for curved response distributions as compared to normal response distributions and of
for skewed response distributions as compared to normal response distributions. The difference between skewed and curved distributions is not meaningful. This result means that individual score methods suffer to the same degree from misspecification in the response distributions in terms of their accuracy in maintaining the relative positioning of individuals. Moreover, LDm again turned out to be meaningful (
) indicating, as expected, that individual score methods perform better in high average loading conditions than in low average loading conditions. Considering the coverage (see ), we observe two main findings that are related to the mean score on the one hand, and to the model-based methods on the other. With regard to the mean score, the coverage again results to be meaningfully lower than 0.95 (
), while keeping the other factors at their baseline. This main effect is strengthened if the average loading is 0.6 as compared to the nominal coverage of 0.95 in a more reliable measurement (LDm = 0.8; OR = 0.526,
). This negative effect is lowered if responses are leptokurtic (OR = 1.810,
d = 0.327). It is strengthened if they are skewed (
), particularly, when the average loading is 0.6 as compared to 0.8 (
). With regard to the other, model-based individual score methods, we also find that skewness generally leads to coverage rates meaningfully lower than the nominal 0.95 (
between 0.125 and 0.157, all
between
and
) while keeping
at 0.75,
at 0.8 and
at 1, and that the negative departure from 0.95 is even stronger for
conditions (
between 0.476 and 0.660, all
between
and
). The regression method additionally suffers slightly more at
(OR = 0.635,
) and
(
,
) from skewed responses. However, note that these time point specific effects for the regression method do not occur in the analyses based on
individuals. Further, although we do not find a general Kalman filter initialization effect, we observe a few, time point-specific effects: if the responses are skewed at
(
,
), or, in particular, if
at
(
,
) and
(
,
), the Bartlett initialized Kalman filter leads to a coverage below the nominal 0.95. Note that these Kalman filter initialization effects do not occur in the analyses based on
individuals. Therefore, they are an effect due to bias in the model parameter estimation rather than due to individual score method properties. This will be explained in the discussion. In sum, the results of simulation Study 2 show that all individual score methods are similarly robust against misspecification in the response distribution when their absolute value matters. However, as soon as we consider confidence intervals when the response distributions are skewed, our type I error is inflated. Further, the individual score methods are sensitive to departures from normality when it comes to the relative positioning of individuals.
TABLE 3 ANOVA Results for the MAE Criterion for Study 2
TABLE 4 ANOVA Results for the Correlation Criterion for Study 2
FIGURE 3 Ydistr = response distribution; M06 = average loading of 0.6, M08 = average loading of 0.8; be025 = of 0.25, be075 =
of 0.75. Proportions and confidence intervals for Study 2.
Simulation study 3: structural misspecification
Methods
Data generation
The goal of simulation Study 3 is to simulate the effect of an unmodeled integrated trend component on individual score methods. Trajectories of true scores are generated according to with
, where
with
being the slope and
being the trend variable at time
. Based on these trajectories of the true scores we then generated the responses according to Equation (9) as before.
Design and analyses
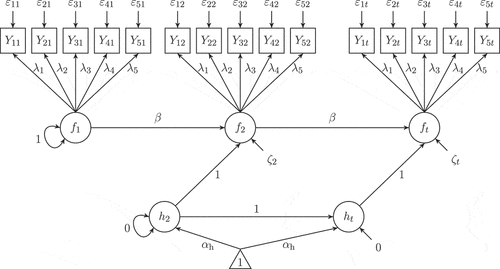
We chose the trend to be either weak with a slope (referred to as factor g) of 0.5 or moderate with a slope of 1. We assess the robustness of individual score methods against ignoring an integrated trend component in an AR(1) model by comparing their performance in an AR(1) model without integrated trend component with their performance in an AR(1) model including an integrated trend component. This trend component can be modeled by an AR(1) process of an additional latent variable (the trend variable) parallel to the AR(1) process of interest while imposing special constraints on this additional process. The two processes are connected by regressing the latent variable of interest on the latent trend variable with the regression coefficient being fixed to one. The variances (initial variance and process noise variance) of the latent trend variable are constrained to zero and the autoregressive coefficient is constrained to 1. The intercept of the latent trend variable is freely estimated from onwards but constrained to be equal across time. All other means and intercepts are constrained to zero. The model-implied mean structure is given in the Appendix. illustrates this model. Example code for specifying this model is provided in the Online Supplemental Material C. The correctly specified model (including the trend; AR1litrend) and the misspecified model (without trend; AR1notrend) were fitted to the same data set, and are subsumed under the factor Model (with the levels AR1notrend/incorrect vs. AR1litrend/correct [reference]) in the following ANOVA and regression models. In addition, we considered beta and Method as design and control factors as before. As simulation Studies 1 and 2 did not yield any meaningful interactions including the LDm conditions, we focused on
in this study. Time was not included as a control factor here because the factor Model already inheres whether the longitudinal structure is appropriately accounted for or not.
FIGURE 4 Conceptual path diagram of an autoregressive model of order one including an integrated trend component, five observed indicators, and measurement invariance assumed as used for simulation Study 3.
Results
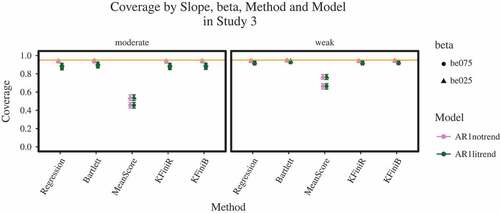
In simulation Study 3, all models converged. For the three outcome criteria, we find different patterns of results, including differences in coverage between the analysis with and
. With regard to the MAE, we find a meaningful main effect for Method (
) as well as meaningful effects for the interactions between Method and slope (
) and between Method and beta (
; see ). Pairwise comparisons for the main effect of Method reveal that the mean score performs meaningfully worse than all other methods (
between 0.592 and 0.600) and that this effect is more pronounced when the trend is moderate (
between 0.617 and 0.645) as compared to weak (
between 0.253 and 0.281) and when the persistence of the process is high (
between 0.515 and 0.527) as compared to low (
between 0.336 and 0.337).
TABLE 5 ANOVA Results for the MAE Criterion for Study 3
With regard to the correlation criterion, we find the same meaningful main effect for Method as for the MAE (; see ). That is, as compared to the other individual score methods, the mean score is meaningfully less capable of accurately positioning individuals than the other methods (
between 1.247 and 1.353). With regard to the coverage (see ), there are five main findings: first, out of all methods, the individual mean score most pronouncedly has a coverage smaller than the nominal 0.95 (
) while keeping the other factors at their baselines. Second, all other methods also yield coverages slightly below the assumed confidence of 0.95 (
between 0.572 and 0.693, all
between
and
). Third, this effect is stronger if a moderate trend is present (
between 0.572 and 0.693, all
between
and
). Fourth, the discrepancy from 0.95 in a model without trend is weaker for methods that incorporate longitudinal information (i. e., the regression method and the Kalman filter versions;
between 1.5 and 1.578, all
between 0.223 and 0.252). Fifth, all effects for the model-based approaches disappear in the analyses based on
individuals. This means that the effects we found for the model-based individual score methods with regard to the coverage criterion are due to bias in the model parameters in the AR(1) model with a trend component (see Online Supplemental Material D), which evokes the reported effects for the coverage. Interestingly, we do not find a meaningful main effect for Model, neither for samples of
, nor for samples of
. This means that an omitted trend component, as implemented in this simulation study, has an effect on model parameters in such a way that it is canceled out when they are combined for computing individual scores. In sum, simulation Study 3 has shown that all the individual score methods, except for the mean score, are similarly robust to the omission of a trend component in the AR(1) panel model as used here. If a trend might be present, methods that incorporate model parameters (all methods except the mean score) are clearly to be preferred, both in situations when the individual score is used to make a decision based on a predefined, diagnostically relevant threshold and in situations when it is used for the relative positioning and covariance based analyses using the individual scores. When there are only relatively few data points (i. e., owing to a small
or small
), individual decisions based on confidence intervals come along with a confidence that is smaller than assumed, and, thus, the type I error probability is increased.
TABLE 6 ANOVA Results for the Correlation Criterion for Study 3
FIGURE 5 Weak = weak trend; moderate = moderate trend; AR1notrend = model estimated without trend, AR1litrend = model estimated with an integrated trend component; be025 = of 0.25, be075 =
of 0.75. Proportions and confidence intervals for Study 3.
Discussion
The main question guiding our research is how robust different, very common, and easily accessible individual score methods are against slight model misspecifications in the context of an AR(1) panel model. Because individual score methods, as considered in this study, are computed after model estimation, model misspecification affects individual scores indirectly via the estimated model parameters. In a series of simulation studies, we used the regression method, the Bartlett method, the mean score, the Kalman filter initialized by the regression method, and the Kalman filter initialized by the Bartlett method to estimate individual scores under various conditions of misspecification. These conditions included unequal loadings constrained to be equal (Study 1), response distributions departing from normality in terms of skewness and kurtosis (Study 2), and an unmodeled trend component (Study 3). We evaluated the relative performance of the individual score methods using the MAE and the Fisher--transformed correlation between the true score and the individual score estimate. We assessed their absolute performance comparing nominal and actual coverage. The MAE and the coverage are important in situations, in which diagnostically relevant, predefined thresholds are used to make individual decisions. In those situations, the individual score itself is of interest, rather than the relative positioning of an individual. In contrast, the correlation criterion becomes particularly relevant when scores are used for subsequent covariance-based analyses or relative comparisons.
Our results have shown that all methods are similarly robust to model misspecification in terms of the two relative performance criteria, the MAE and the correlation criterion. In addition, we found that the mean score yields coverage rates well below the nominal confidence throughout all three simulations. Further, several details and their implications for practice are noteworthy: first, we observed no meaningful difference in performance between methods which incorporate model parameters (all methods except the mean score) with regard to the MAE and the correlation criterion. This is quite interesting given that the Bartlett method does not incorporate any longitudinal structural information, but nevertheless, it does not perform worse than the regression method and the two Kalman filter versions, all of which include longitudinal information. Second, assuming loadings to be equal when they are truly unequal to the extent as realized in our study does not have an impact on the individual score method performance with regard to the two outcome criteria. Third, when response distributions depart from normality either in terms of kurtosis or in terms of skewness, caution is warranted if individual scores are meant for relative comparisons or subsequent covariance-based analyses. Fourth, the coverage criterion yields an initialization impact for the Kalman filter in case of skewed responses in simulation Study 2: when initialized with the Bartlett method, the coverage increasingly becomes lower than the nominal value of 0.95. The Bartlett method induces some — although not meaningful — error to the Kalman filter which is then enhanced and carried forward in time. This occurs because if model parameters are biased, this bias enters the coverage in two ways: via the individual scores themselves and via the standard errors which are based on the estimation error. Bias for the standard errors is given in the Online Supplemental Material E. Fifth, except for the single, aforementioned Kalman filter initialization effect, there was no other initialization effect across simulation studies and performance criteria. This result puts the finding by Oud et al. (Citation1999, pp. 127–130) who argued based on analytical derivations that the Bartlett initialized Kalman filter is preferable over the regression initialized Kalman filter in terms of unbiasedness into perspective from a practical point of view. Finally, in our study, individual score methods that incorporate longitudinal information (i. e., the regression method and the Kalman filters) paradoxically seem to benefit from a misspecified AR(1) model without trend as compared to a model including the trend component when being fitted to samples comprising individuals. This finding has two reasons: first, the autoregressive parameter in an AR(1) model without trend is biased in such a way that it may result in an “unstable” model (
), and, thus, inheres an increase over time. Second, autoregressive models are known to yield biased autoregressive parameters, this effect is even more pronounced if a mean structure additionally is estimated (e. g., Marriott & Pope, Citation1954). Even if the relative bias of parameter estimates is below
and, thus, deemed acceptable (e. g., Muthén & Muthén, Citation2002), it leads to coverages meaningfully below the nominal confidence on the individual level. Many data points due to large sample sizes or a large number of measurement occasions reduce this bias. This latter reason also explains the finding that all model-based approaches deviate from the nominal 0.95 coverage in
but not in
conditions.Footnote4
With this latter finding we encountered one important pitfall in the context of autoregressive modeling: the bias of parameters in case of limited numbers of data points, which is even more pronounced in the presence of a trend component. Thus, declines in individual score method performance become a function of model complexity, bias in the parameter estimates, number of data points, and method specific properties. This interrelationship is a continuum, and we considered only a few selected scenarios but of very different kinds. Rather than pursuing a comprehensive “testing the limits” simulation study that only focuses on one type of misspecification, our aim was to get an intuition of what the “average” researcher might encounter in typical situations. Hence, future research should investigate individual score method performance in the presence of more complex autoregressive models (e. g., including seasonal trends). As we hardly found any differences among the model-based approaches, we further suggest to put the focus more on the usefulness of individual scores than on differential performance of these methods. Exemplary lines of research in this direction have been mentioned in the beginning; in contrast, nearly unexplored is, for instance, the usefulness of individual scores in the context of latent differential equations modeling (e. g., Boker, Neale, & Rausch, Citation2004). In conclusion, for situations comparable to the ones considered here, we recommend using any of the model parameter based approaches (regression method, Bartlett method or the Kalman filter versions) rather than the mean score.
Supplemental Material E
Download PDF (175.4 KB)Supplemental Material D
Download PDF (193.8 KB)Supplemental Material C Code
Download R Objects File (31.1 KB)Supplemental Material C
Download PDF (171.2 KB)Supplemental Material B
Download PDF (201.9 KB)Supplemental Material A
Download PDF (304.7 KB)Acknowledgments
We thank the anonymous reviewers for their helpful and constructive comments that greatly contributed to improving the paper. Katinka Hardt is a pre-doctoral fellow of the International Max Planck Research School on the Life Course (LIFE, www.imprs-life.mpg.de; participating institutions: MPI for Human Development, Freie Universität Berlin, Humboldt-Universität zu Berlin, University of Michigan, University of Virginia, University of Zurich).
Additional information
Funding
Notes
1 For this reason, they are also referred to as model-based approaches.
2 We also ran our analyses based on
individuals and
replications. We mostly found the same pattern of results (see the Online Supplemental Material A); the few differences that occurred are reported in the main text.
3 For reasons of limited space, full regression tables are available in the Online Supplemental Material B. In the text, we only report results and provide figures to illustrate proportions and confidence intervals according to Wilson (Citation1927), which is recommended for binomial proportions (Brown, Cai, & DasGupta, Citation2001; Wallis, Citation2013).
4 In addition, we would like to add a note on the use of individual scores based on the regression method as implemented in OpenMx using RAM notation: when estimating an AR(1) model with a trend component as in our simulation Study 3, we noticed that OpenMx outputs individual scores based on the regression method without taking the mean structure into account (see Online Supplemental Material C for an example figure and for code to reproduce this finding). This will be fixed in future releases of OpenMx (Kirkpatrick, Citation2019).
Related Research Data
References
- Acito, F., & Anderson, R. D. (1986). A simulation study of factor score indeterminacy. Journal of Marketing Research, 23, 111–118. doi:10.2307/3151658
- Bartlett, M. S. (1937). The statistical conception of mental factors. British Journal of Psychology. General Section, 28, 97–104. doi:10.1111/j.2044-8295.1937.tb00863.x
- Boker, S. M., Neale, M. C., Maes, H. H., Wilde, M. J., Spiegel, M., Brick, T. R., & The regents of the university of California. (2018). Openmx 2.9.9-191 user guide [computer software manual].
- Boker, S. M., Neale, M. C., & Rausch, J. R. (2004). Latent differential equation modeling with multivariate multi-occasion indicators. In K. V. Montfort, J. H. L. Oud, & A. Satorra (Eds.), Recent developments on structural equation models: Theory and applications (pp. 151–174). Amsterdam, Netherlands: Kluwer.
- Bollen, K. A., & Arminger, G. (1991). Observational residuals in factor analysis and structural equation models. Sociological Methodology, 21, 235. doi:10.2307/270937
- Borenstein, M., Hedges, L. V., Higgins, J. P. T., & Rothstein, H. R. (2009). Introduction to meta-analysis. Chichester, UK: John Wiley & Sons, Ltd. doi:10.1002/9780470743386
- Brown, L. D., Cai, T. T., & DasGupta, A. (2001). Interval estimation for a binomial proportion. Statistical Science, 16, 101–133. doi:10.1214/ss/1009213286
- Cho, E. (2016). Making reliability reliable: A systematic approach to reliability coefficients. Organizational Research Methods, 19, 651–682. doi:10.1177/1094428116656239
- Coffman, D. L., & Millsap, R. E. (2006). Evaluating latent growth curve models using individual fit statistics. Structural Equation Modeling, 13, 1–27. doi:10.1207/s15328007sem1301_1
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: L. Erlbaum Associates.
- Compton, D. L., Fuchs, D., Fuchs, L. S., Elleman, A. M., & Gilbert, J. K. (2008). Tracking children who fly below the radar: Latent transition modeling of students with late-emerging reading disability. Learning and Individual Differences, 18, 329–337. doi:10.1016/j.lindif.2008.04.003
- Core Team, R. (2018). R: A language and environment for statistical computing, r version 3.5.0 [computer software manual]. Vienna, Austria. Retrieved from https://www.R -project.org/
- Cronbach, L. J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16, 297–334. doi:10.1007/BF02310555
- Croon, M. (2002). Using predicted latent scores in general latent structure models. In G. A. Marcoulides & I. Moustaki (Eds.), Latent variable and latent structure modeling (pp. 195–223). Mahwah, NJ: Erlbaum.
- Curran, P. J., Cole, V., Bauer, D. J., Hussong, A. M., & Gottfredson, N. (2016). Improving factor score estimation through the use of observed background characteristics. Structural Equation Modeling, 23, 827–844. doi:10.1080/10705511.2016.1220839
- Curran, P. J., Cole, V. T., Bauer, D. J., Rothenberg, W. A., & Hussong, A. M. (2018). Recovering predictor–Criterion relations using covariate-informed factor score estimates. Structural Equation Modeling, 1–16. doi:10.1080/10705511.2018.1473773
- Curran, P. J., & Hussong, A. M. (2009). Integrative data analysis: The simultaneous analysis of multiple data sets. Psychological Methods, 14, 81–100. doi:10.1037/a0015914
- Devlieger, I., Mayer, A., & Rosseel, Y. (2016). Hypothesis testing using factor score regression: A comparison of four methods. Educational and Psychological Measurement, 76, 741–770. doi:10.1177/0013164415607618
- Devlieger, I., & Rosseel, Y. (2017). Factor score path analysis: An alternative for SEM? Methodology, 13, 31–38. doi:10.1027/1614-2241/a000130
- Hamilton, J. D. (1994). Time series analysis. Princeton, N. J.: Princeton University Press.
- Hardt, K., Hecht, M., Oud, J. H. L., & Voelkle, M. C. (2019). Where have the persons gone? – An illustration of individual score methods in autoregressive panel models. Structural Equation Modeling, 26, 310–323. doi:10.1080/10705511.2018.1517355
- Horn, J. L. (1965). An empirical comparison of methods for estimating factor scores. Educational and Psychological Measurement, 25, 313–322. doi:10.1177/001316446502500202
- Hoshino, T., & Bentler, P. (2013). Bias in factor score regression and a simple solution. In A. R. De Leon & K. C. Chough (Eds.), Analysis of mixed data: Methods & applications (pp. 43–61). Boca Raton, FL: CRC Press/Taylor & Francis Group.
- Hyndman, R. J., & Koehler, A. B. (2006). Another look at measures of forecast accuracy. International Journal of Forecasting, 22, 679–688. doi:10.1016/j.ijforecast.2006.03.001
- Kalman, R. E. (1960). A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82, 35–45. doi:10.1115/1.3662552
- Kirkpatrick, R. M. (2019, June 11). Thank you for testing! Retrieved from https://openmx.ssri.psu.edu/node/4510#comment-8259
- Lockwood, J. R., & McCaffrey, D. F. (2016). Matching and weighting with functions of error-prone covariates for causal inference. Journal of the American Statistical Association, 111, 1831–1839. doi:10.1080/01621459.2015.1122601
- Losardo, D. (2012). An examination of initial condition specification in the structural equations modeling framework (Unpublished doctoral dissertation). University of North Carolina at Chapel Hill.
- Lowe, J. D., Anderson, H. N., Williams, A., & Currie, B. B. (1987). Long-term predictive validity of the WPPSI and the WISC-R with black school children. Personality and Individual Differences, 8, 551–559. doi:10.1016/0191-8869(87)90218-2
- Luoma, I., Tamminen, T., Kaukonen, P., Laippala, P., Puura, K., Salmelin, R., & Almqvist, F. (2001). Longitudinal study of maternal depressive symptoms and child well-being. Journal of the American Academy of Child & Adolescent Psychiatry, 40, 1367–1374. doi:10.1097/00004583-200112000-00006
- Marriott, F. H. C., & Pope, J. A. (1954). Bias in the estimation of autocorrelations. Biometrika, 41, 390–402. doi:10.2307/2332719
- Muthén, L. K., & Muthén, B. O. (2002). How to use a monte carlo study to decide on sample size and determine power. Structural Equation Modeling, 9, 599–620. doi:10.1207/S15328007SEM0904_8
- Neale, M. C., Hunter, M. D., Pritikin, J. N., Zahery, M., Brick, T. R., Kirkpatrick, R. M., … Boker, S. M. (2016). OpenMx 2.0: Extended structural equation and statistical modeling. Psychometrika, 81, 535–549. doi:10.1007/s11336-014-9435-8
- Nolen-Hoeksema, S., Girgus, J. S., & Seligman, M. E. (1992). Predictors and consequences of childhood depressive symptoms: A 5-year longitudinal study. Journal of Abnormal Psychology, 101, 405–422. doi:10.1037/0021-843X.101.3.405
- Osborne, R. T., & Suddick, D. E. (1972). A longitudinal investigation of the intellectual differentiation hypothesis. The Journal of Genetic Psychology, 121, 83–89. doi:10.1080/00221325.1972.10533131
- Oud, J. H. L., Jansen, R. A. R. G., Van Leeuwe, J. F. J., Aarnoutse, C. A. J., & Voeten, M. J. M. (1999). Monitoring pupil development by means of the kalman filter and smoother based upon SEM state space modeling. Learning and Individual Differences, 11, 121–136. doi:10.1016/S1041-6080(00)80001-1
- Oud, J. H. L., van Den Bercken, J. H., & Essers, R. J. (1990). longitudinal factor score estimation using the kalman filter. Applied Psychological Measurement, 14, 395–418. doi:10.1177/014662169001400406
- Raykov, T. (2012). Propensity score analysis with fallible covariates: A note on a latent variable modeling approach. Educational and Psychological Measurement, 72, 715–733. doi:10.1177/0013164412440999
- Schumacker, R. E. (2002). Latent variable interaction modeling. Structural Equation Modeling, 9, 40–54. doi:10.1207/S15328007SEM0901_3
- Skrondal, A., & Laake, P. (2001). Regression among factor scores. Psychometrika, 66, 563–575. doi:10.1007/BF02296196
- Steiger, J. H. (1979). Factor indeterminacy in the 1930’s and the 1970’s – Some interesting parallels. Psychometrika, 44, 157–167. doi:10.1007/BF02293967
- Steiger, J. H. (1996). Coming full circle in the history of factor indeterminancy. Multi- Variate Behavioral Research, 31, 617–630. doi:10.1207/s15327906mbr3104_14
- Thomson, G. H. (1938). Methods of estimating mental factors. Nature, 141, 246. doi:10.1038/141246a0
- Thurstone, L. L. (1934). The vectors of mind. Psychological Review, 41, 1–32. doi:10.1037/h0075959
- Wackwitz, J., & Horn, J. (1971). On obtaining the best estimates of factor scores within an ideal simple structure. Multivariate Behavioral Research, 6, 389–408. doi:10.1207/s15327906mbr0604_2
- Wallis, S. (2013). Binomial Confidence intervals and contingency tests: Mathematical fundamentals and the evaluation of alternative methods. Journal of Quantitative Linguistics, 20, 178–208. doi:10.1080/09296174.2013.799918
- Wilson, E. B. (1927). Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22, 209–212. doi:10.1080/01621459.1927.10502953
AppendixModel-Implied Means in Study 3
The model-implied means in an AR(1) model with an integrated trend component and measurement occasions can be calculated according to: