
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We present PLSIM, a new method for generating nonnormal data with a pre-specified covariance matrix that is based on coordinate-wise piecewise linear transformations of standard normal variables. In our presentation, the piecewise linear transforms are chosen to match pre-specified skewness and kurtosis values for each marginal distribution. We demonstrate the flexibility of the new method, and an implementation using R software is provided.
It is well known that multivariate normally distributed data are rare in the social sciences (Cain et al., Citation2017; Micceri, Citation1989). Nevertheless, statistical estimation procedures and inferences that are based on multivariate normality are routinely used in data analysis in the educational and behavioral sciences. The study of whether this practice leads to approximately valid inference, i.e. whether methods based on the normality assumption are robust to non-normality, is most often based on a simulation design. Such simulation studies are thus important in evaluating various statistical procedures in structural equation modeling (SEM) and in multivariate statistics in general. A main concern in the context of SEM is to be able to generate random samples from a distribution whose covariance matrix is controlled. In addition, most simulation techniques control some other aspects of the simulated data, such as skewness and kurtosis.
In the present study, we introduce a new and flexible simulation technique for non-normal data that matches a pre-specified population covariance matrix, and which also allows researchers to specify values for some univariate moments. Our approach is based on transforming univariate normal variables using piecewise linear (PL) functions.
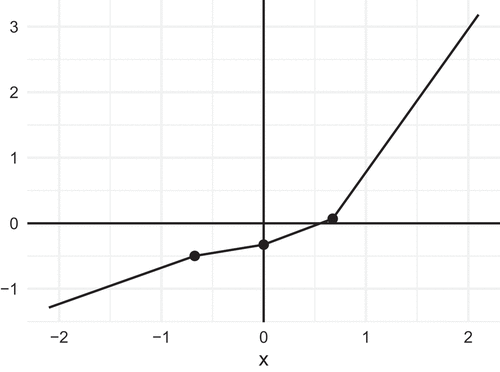
Let us limit our attention to PL functions that are continuous, so that their graphs consist of a finite number of line segments that are glued together at the end points. depicts one such PL function, where four line segments with different slopes are joined together. Now, assume
is a standard normal variable,
. Consider the random variable
, which is generally non-normal. Since
is based on two analytically simple and well-known concepts, that of a standard normal variable and that of piecewise linearity, many aspects of the distribution of
are amenable to analytical and computational treatment. For instance, there are exact and computationally tractable formulas for the mean, variance, skewness, and kurtosis of
. The same tractability holds for the bivariate case. That is, define
and
, where
is a bivariate normal vector. Then, as outlined below, we may use straightforward formulas to calculate the covariance between
and
. In the following, we refer to the piecewise linear simulation approach as PLSIM.
Figure 1. Graph of the continuous piecewise linear function
This article is organized as follows. We next review simulation techniques for non-normal data with pre-specified population covariance matrix. We then present our method formally, and include some illustrations in this discussion. A data illustration is thereafter given. We finally discuss strengths and limitations of PLSIM. Some R (R Core Team, Citation2020) code is provided in the text, and complete R code is provided in the supplemental material.
Simulating multivariate data with pre-specified covariance matrix
Given the importance of variances and covariances in factor analysis and SEM, it is not surprising that several methods have been proposed for drawing random samples from multivariate distributions whose covariance matrix is fixed. The most popular approach is the transform of Vale and Maurelli (Citation1983), which starts with a multivariate normal vector and then applies polynomial transforms in each coordinate. The polynomials are so chosen as to produce given univariate skewness and kurtosis in the resulting vector. If feasible, the method identifies the correlation matrix in the multivariate normal vector that ensures that the polynomially transformed variables have the required covariance matrix. A thorough theoretical study of the Vale-Maurelli (VM) transform is given by Foldnes and Grønneberg (Citation2015). The VM transform is the default method for generating non-normal data in commercial software such as EQS (Bentler, Citation2006) and LISREL (Jöreskog & Sörbom, Citation2006), and in the R package lavaan (Rosseel, Citation2012).
Recently, several alternative methods that also control the moments have been developed. The independent generator approach proposed by Foldnes and Olsson (Citation2016) is available in the R package covsim (Grønneberg et al., Citation2021), and can match pre-specified univariate skewness and kurtosis. It offers more flexibility than VM, since many possible marginal distributions are attainable. Based on the independent generator idea, Qu et al. (Citation2019) recently proposed a method which controls multivariate skewness and kurtosis, available in the R package mnonr (Qu & Zhang, Citation2020).
Both VM and the independent generator approach allows the asymptotic covariance matrix of the empirical covariances to be exactly calculated (Foldnes & Grønneberg, Citation2017). This means that the population-level properties of standard errors and fit statistics in SEM models may be exactly calculated using well-known formulas (Browne, Citation1984).
The above methods have in common with PLSIM that only some lower-order moments of the univariate distributions are controlled. Mair et al. (Citation2012) offered a different approach, based on the concept of a copula. A copula is a multivariate distribution with uniform marginals on [0,1]. In general, multivariate distributions may be split up into a copula component and the univariate distributions. In the Mair et al. (Citation2012) approach the marginals are specified together with the copula class, but in a final step the simulated vector is obtained by pre-multiplication with a matrix in order to reach the target covariance, leading to perturbations in the marginal distributions. We are aware of two approaches that allow complete control over the univariate distributions. First, the NORTA method of Cario and Nelson (Citation1997), which is implemented in package SimCorMultRes (Touloumis, Citation2016). In common with VM and PLSIM, it is based on generating multivariate normal data and then transforming each variable according to univariate specifications. A limitation of this method is that it can only produce data with a normal copula. Second, the VITA method of Grønneberg and Foldnes (Citation2017), implemented in package covsim (Grønneberg et al., Citation2021), fully specifies the marginal distributions. In addition, since VITA is based on regular vine distributions, the user may specify for each variable pair the (conditional) copula. The VITA approach is particularly suited for ordinal data simulation, as recently demonstrated by Foldnes and Grønneberg (Citation2021).
Piecewise linear simulation: The univariate case
In this section, we consider a random variable that is stochastically represented as a PL function of a standard normal variable . A general expression for a PL function consisting of
line segments is
where . The indicator function
evaluates to
if
is true, and to
otherwise. The
are breakpoints where function evaluation shifts from one affine function to another. The
line segments have slopes denoted by
and
-intercepts denoted by
. The requirement that
be continuous means that
for
. Therefore,
is parameterized by the
and
vectors, in addition to
(a total of
parameters).
As an example, consider the graph in , which depicts the following function, where :
In this example the breakpoints are , and
. The breakpoints are regular in the sense that they correspond to quantiles of regularly spaced probabilities (
, and
) for the normal distribution. Note that all the slopes in this example are positive, so that
is a monotone function.
We now assume that is a standard normal variable, and define the random variable
The cumulative distribution and density functions of may be deduced following straightforward arguments (See also Foldnes & Grønneberg, Citation2015, Prop.1). For instance, the density may, without further assumptions, be calculated as
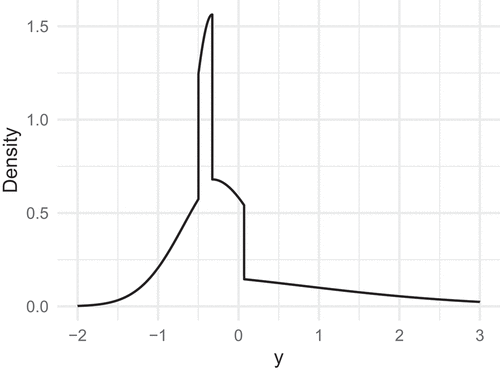
where is the density function of a standard normal variable. depicts the density of
. It is evident that the four line segments in
contribute separately to the density, producing rather pronounced shifts in the density curve.
Figure 2. The density of
In order to calculate the moments of , it is useful to first obtain the conditional moments
, that is, the moments of a truncated normal variable. These may be obtained with the following recursive formula (Burkardt, Citation2014; Orjebin, Citation2014), where we initialize by
and
:
where is the cumulative distribution function of a standard normal variable. Now, to calculate the
-th moment of
, we apply the following formula, which is derived in Appendix A:
Using this formula, the first four centralized moments of from EquationEquation (2)
(2)
(2) are
In other words, is a zero mean unit variance random variable whose skewness is
and whose excess kurtosis is
.
We have shown how to calculate the moments of a given PL random variable. However, in simulation applications we need to move in the opposite direction: We first specify the moments, and then we search for a PL function that generates the pre-specified moments. That is, we use a fast numerical routine to calibrate , based on the formula in EquationEquation (5)
(5)
(5) . For given breakpoints, slope values
and
-intercepts
, this equation allows us to calculate the first four moments of
. If we are given pre-specified values
,
,
, and
for mean, variance, skewness, and excess kurtosis, respectively, we can therefore use numerical optimization to minimize
as a function of . The above expression is not dependent upon the specific
-values, but we assume that these are such that
is continuous in each optimization step. The final step involves shifting the
so that
, and scaling the
so that
. The optimization routine has been implemented in the function rPLSIM in package covsim Foldnes and Grønneberg (Citation2020b). The default setting of rPLSIM is to use three regularly spaced break-points. We here demonstrate how one may request a sample of size
from a population with skewness
and excess kurtosis
, where the PL function is forced to be monotonous:
library(covsim)
library(psych)#for sample skew/kurtosis
set.seed(1)
res <- rPLSIM(N = 10^3, sigma.target = 1, skewness = 2, + excesskurtosis =5, monot = TRUE)
sim.sample <- res[[1]][[1]]# a simulated sample
skew(sim.sample)
kurtosi(sim.sample)
res[[2]]$b#print slopes and intercepts
In the output below we see that the sample skewness and excess kurtosis values are close to the population values. Also, in the second element of the output we can inspect the fitted slope and intercept values, which agree with the values in EquationEquation (2)(2)
(2) :
[1] 1.973825
[1] 4.987873
[1] 0.5519887 0.2583700 0.5849776 2.1849716
[1] −0.1271060 −0.3251488 −0.3251488 −1.4043284
Matching pre-specified mean, variance, skewness, and kurtosis
In the example above the slopes and the
-intercepts
were carefully chosen so that
has mean zero, unit variance, skewness
and excess kurtosis
. One reason for choosing the first four moments in this way was to produce a condition of non-normality where the VM transform is not helpful, since the third-order Fleishman polynomial cannot produce skewness
in combination with excess kurtosis of
. Using the lavaan package for calibration of Fleishman polynomials yields:
library(lavaan)
res <- simulateData(“x1~~x2,” skewness = 2, + kurtosis = 5)
lavaan WARNING: ValeMaurelli1983 method
+ did not convergence,
+ or it did not find the roots
So the skewness , kurtosis
case illustrates that there are conditions in which VM is infeasible but that are still within reach of PLSIM.
Given the flexibility of piecewise linear functions, it is not surprising that even with the same breakpoints, there are other PL functions that produce the same first four moments as . For instance, we may relax the monotonicity constraint:
res <- rPLSIM(N = 10^3, sigma.target = 1,
+ skewness = 2, excesskurtosis =5, monot = FALSE)
res[[2]]$a[[1]]
[1] 0.8500105 −0.9079488 1.2142742 2.1681442
The result is a non-monotonous function depicted in , which ensures that
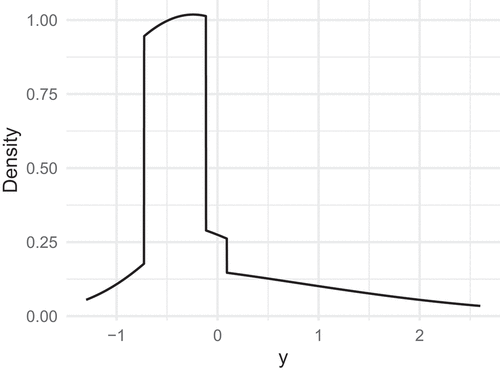
also has zero mean, unit variance, skewness 2 and excess kurtosis 5. The density of
is depicted in . We observe that although
and
share the first four moments, their densities are quite dissimilar.
Figure 3. Graph of the piecewise linear function .
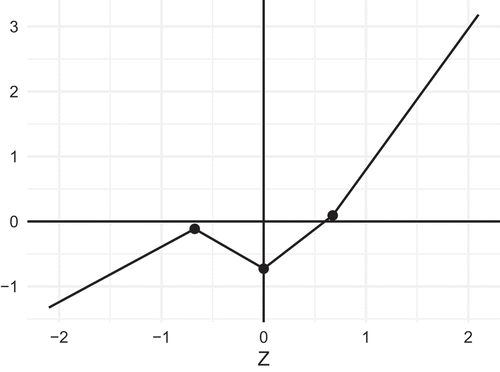
Figure 4. The density of .
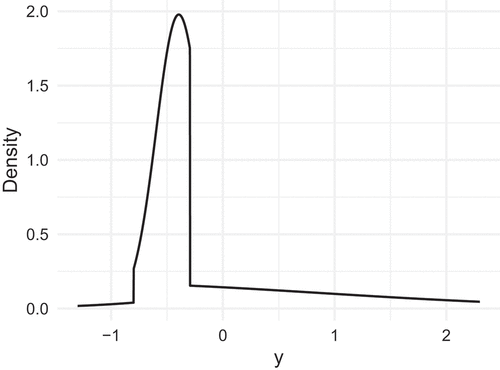
To further illustrate the flexibility of piecewise linear transforms, we next specify skewness 2 and excess kurtosis 4. With the default breakpoint settings, as also used in , our routine did not identify a PL that attained these skewness and excess kurtosis values. To find a valid PL function the breakpoints therefore need to be altered, either by introducing more line segments, or by keeping d = 4 and changing the location of the breakpoints. In our case, the latter was a viable option:
g <- list(c(−2,0.5, 2))
res <- rPLSIM(N = 10^3, sigma.target = 1,
+ skewness = 2, excesskurtosis =4,
+ monot = FALSE, gammalist = g) res[[2]]$a[[1]]
[1] 1.350564 0.201702 2.284732 1.398601
For the set of feasible breakpoints , and
, the function
depicted in produces the density for
depicted in . This density has skewness
and excess kurtosis
. Note that, although we did not constrain the routine to monotonous solutions, the result is still monotonous in this special case.
Figure 5. Graph of the piecewise linear function .
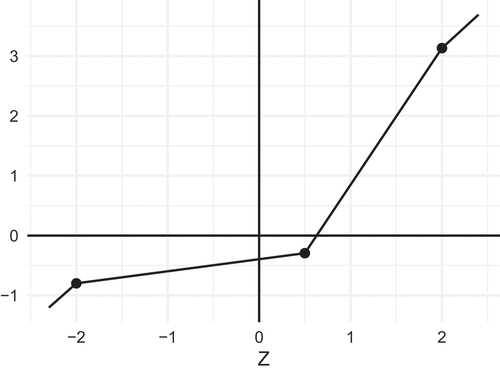
Figure 6. The density of .
The generality of univariate PLSIM
As exemplified above, PLSIM accommodates a much larger class of univariate marginal distributions than those provided under the VM transform. In fact, PLSIM may approximate to arbitrary precision the distribution of any continuous random variable
. For, given the quantile function
,
, then
, provided
is a uniform variable on
. Therefore,
, where
(Shorack & Wellner, Citation2009, Theorem 1, p. 3). With increasing number of breakpoints we can approximate the function
using a PL function
arbitrarily well. It then follows that
will converge in distribution to
as the number of breakpoints increases, provided the breakpoints and line segments are suitably chosen.
The bivariate case
In the previous section, we demonstrated how a PL function could be fitted to accommodate univariate moments for the random variable
. In this section we move to the bivariate case where we consider
-dimensional random vectors
where each coordinate is a PL transform of a standard normal variable. Moreover, and
are assumed to be bivariate normally distributed and have correlation
. We assume, without loss of generality, that
and
are such that
and
each has zero mean and unit variance.
Next consider the covariance/correlation between and
. For less notational burden, we let
denote the rectangle
. Then,
This gives
Procedures for calculating the moments
of a truncated bivariate normal variable is a well-studied problem (e.g., Leppard & Tallis, Citation1989). In our implementation we use the R package tmvtnorm (Wilhelm & Manjunath, Citation2015) to calculate these moments.
It is important to notice that the expression in EquationEquation (6)(6)
(6) , in addition to being dependent upon the slopes,
-intercepts and breakpoints in
and
, also depends on an additional parameter, namely
, the intermediate correlation between
and
. We emphasize this in notation by writing
.
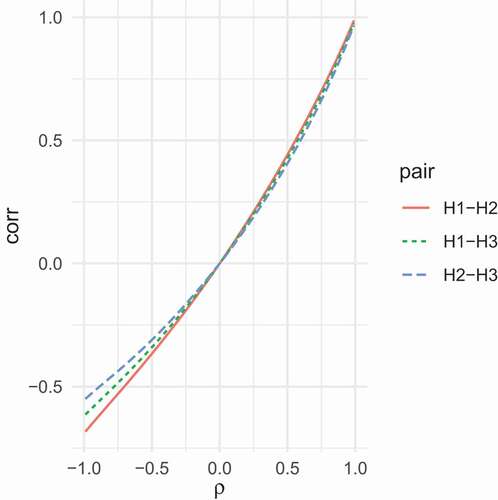
We next illustrate the dependency of on
. We consider the three PL functions
, and
introduced in the previous section. For values of
between
and
, we calculated the correlation
,
, and
. In we graphically depict the dependence of the correlations upon the correlation
between
and
. Clearly, combining
and
yields the largest possible range of correlations, although there is no way to produce a correlation below
for this pair of PL transforms. Combining
and
yields the smallest range, with the lowest attainable correlation being
. The figure demonstrates that not all correlations are attainable once the univariate specification of skewness and excess kurtosis have been given.
Figure 7. The correlation among piecewise linear transforms of bivariate normal variables with correlation .
The PLSIM simulation procedure
In the previous sections, we demonstrated how a PL function could be fitted to accommodate univariate moments of the simulated variable , and how to calculate the covariance among two such variables. We now move to the full multivariate case and consider
-dimensional random vectors
where each coordinate is a PL transform of a standard normal variable,Footnote1
. We assume, without loss of generality, that the
functions (
) have been calibrated so that
has zero mean and unit variance. We also assume that
is multivariate normally distributed with standardized marginals and a covariance matrix equal to
. Note that
is in fact a correlation matrix containing
non-redundant off-diagonal elements.
The steps in PLSIM are as follows:
The user specifies
(a) Univariate properties (e.g., skewness and excess kurtosis) of each marginal variable
.
(b) A target correlation matrix
(2) The PL functions
(3) For each correlation
(4) The matrix
There are two ways the above procedure may fail to complete. First, in Step 2, we may fail to identify a for some
, that reaches the given skewness and kurtosis values. Although we may then change the breakpoint locations or increase the number of breakpoints, it is computationally burdensome to run PLSIM with, say, 20 breakpoints in each of 40 variables. In the R implementation provided in the supplemental material, the default number of breakpoints is
, which are regularly placed (
) so that each line segment is associated with the same probability
. In our experiments, this seems to offer a reasonable compromise between computational tractability and flexibility across various skewness, kurtosis and correlations combinations.
The second way the above PLSIM procedure may fail, is in Step 4, should be negative definite. That is, it may happen that
is not a proper correlation matrix. The reason for this is that we, for computational simplicity, calibrate the entries in
independently. The alternative is full simultaneous calibration of all the entries, under the additional restraint of positive definiteness. However, we did not find this option viable in our numerical experiments. The issue of the intermediate matrix not being a proper correlation matrix arises also in the VM procedure. We here propose a simple solution to this problem, which is applicable to both PLSIM and VM. If
is negative definite, we calculate its nearest correlation matrix
. There are various approaches to defining
, and in our current implementation we use the method proposed by Higham (Citation2002), as implemented in package Matrix (Bates & Maechler, Citation2019). Then, in Step 4, we replace
by
. This means that the target covariance
is no longer reached. However, we may correct this by pre-multiplying the PLSIM vector
by
where is the implied covariance matrix of
, when the
,
have covariance
. The square root matrices are symmetric and such that
and
. Note that, due to EquationEquation (6)
(6)
(6) , exact calculation of
is straightforward. In most cases
will be fairly close to the identity matrix, so that the marginal distributions will be only slightly modified by pre-multiplication. So the pre-specified marginal properties, e.g., skewness and kurtosis, will still be closely matched, while the covariance matrix will be exactly matched. To summarize, to avoid the problem of negative definiteness, we rewrite Step 4 above as follows:
4. The matrix is formed, with elements
. If
is negative definite, let
denotes its closest positive definite matrix. Draw a random sample from the multivariate normal distribution with zero mean and covariance matrix
(or
when needed). Apply the functions
,
, coordinate-wise to the random sample. If
was used, the final random sample is obtained by post-multiplying the random data matrix by
.
On the asymptotic covariance matrix for PLSIM
As argued by Foldnes and Grønneberg (Citation2017), it is desirable in a simulation study to specify non-normality more precisely than just reporting univariate skewness and kurtosis. Ideally, the full asymptotic covariance matrix of the empirical second-order moments should be computed in each simulation condition. For SEM, access to
means that the population-level properties of standard errors and fit statistics may be exactly calculated using well-known formulas (Browne, Citation1984). For PLSIM, we here show that there are closed form formulas available from
. Unfortunately, no presently available implementation of these formulas are able to calculate these quantities within either an acceptable running time, or at an acceptable numerical precision. New implementations will be needed for calculating
for PLSIM. In light of this future availability, we here sketch how
can be obtained.
Consider a random -dimensional vector
whose expectation is zero and whose fourth-order moments exist. Let
be the covariance matrix of
. Then
is defined as the
matrix with elements
where all or some indices are allowed to be equal. To obtain under PLSIM, we need to perform calculations for the expectation similar to the deductions in EquationEquation (6)
(6)
(6) . The full expression for
is a linear combination of elements of the type
where is a four-dimensional rectangle defined by four pairs of breakpoints in
and
, and again indices are allowed to be equal. We therefore need to calculate higher-order moments of a truncated multivariate normal vector, and there exist both exact recursive and non-recursive formulas for this task. A numerical routine implementing the recursive formulas is found in package MomTrunc (Galarza et al., Citation2021), and succeeds in calculating a subset of the required moments at an acceptable speed and precision. However, in our experiments, tri- and four-variate moments as calculated by MomTrunc are sometimes not satisfactory, a finding echoed by Ogasawara (Citation2021), who developed non-recursive formulas which can be used to calculate higher-order moments of a truncated normal vector to arbitrary precision. Unfortunately, the only available implementation for the formulas in Ogasawara (Citation2021), which is given in the supplementary material of Ogasawara (Citation2021), takes an excessive long time to terminate in one of the cases we need, namely when all indices in EquationEquation (8)
(8)
(8) are distinct, and genuine four-dimensional integration is required. There is therefore no available implementation of an algorithm capable of computing
in reasonable time, and we therefore do not provide a function to calculate
in our implementation. This will be added when future efficiency improvements in the procedure proposed by Ogasawara (Citation2021) is made available. A rough approximation to
can be obtained, as always, by direct simulation from PLSIM.
Limitations
As argued above, the univariate generality of PLSIM is only limited by computational considerations. However, this is not the case in terms of multivariate dependency properties, as PLSIM takes a multivariate normal random vector and apply only coordinate-wise transformations. Since the transformation from to
has no interaction between the coordinates, this restricts the multivariate dependency properties of
, as shown in Foldnes and Grønneberg (Citation2015).
Recall that the copula of a continuous random vector is the distribution of
where
are the marginal cumulative distribution functions of
. In the case where each of the coordinate-wise transformations
are monotonous, the copula of the PLSIM random vector
of EquationEquation (7)
(7)
(7) is exactly normal, meaning that it has the same copula as the multivariate normal vector
.
A recent discovery (Grønneberg & Foldnes, Citation2019) warns against the widespread practice of using VM in robustness studies for ordinal SEM. In many relevant cases encountered in the simulation literature, VM has the normal copula, which in ordinal SEM has the unfortunate consequence of making the ordinal vector generated by discretizing a VM random vector numerically equal to a discretization of an exactly normal random vector. The distribution of the manifest variables in ordinal SEM is a function only of the copula of the latent continuous vector at certain points (Foldnes & Grønneberg, Citation2019, Citation2020a, Citation2021; Grønneberg & Foldnes, Citation2021; Grønneberg & Moss, Citation2021). Since PLSIM will have a normal copula when each are monotonous, the discovery of Grønneberg and Foldnes (Citation2019) also applies to PLSIM. Therefore, PLSIM for simulation studies with ordinal SEM is not recommended, and if used, must be used for non-monotonous
. One important exception is if a normal copula is desired. For instance, Grønneberg and Foldnes (Citation2021) employed a simple bivariate PLSIM distribution to illustrate that ordinal SEM estimation is biased unless knowledge of all latent marginal distributions is provided. In that case, profiting from PLSIM’s marginal flexibility, a bivariate vector
was constructed who followed a two-factor model, while the bivariate generator vector
followed a one-factor model. Since
had a normal copula, all normal theory methods based on discretizing
estimate features of
and not
, illustrating the impossibility of identifying even the number of factors in ordinal SEM without latent marginal knowledge.
In general, PLSIM distributions are contained in the class investigated by Foldnes and Grønneberg (Citation2015), as is the coordinate-wise transformation of a continuous random vector
, where each transformation is piecewise strictly monotonous over a finite set of intervals. In PLSIM, we have that
is multivariate normal with standardized marginals, and the transformations are straight lines in each interval segment. When some of the coordinate-wise transformations are non-monotonous, the copula of
is not exactly normal, but the multivariate distribution is still strongly connected to the normal generator variable
, and for example,
cannot have what is known as tail dependence, see Section 3.3 of Foldnes and Grønneberg (Citation2015).
The main limitation of PLSIM is therefore its close connection to the normal distribution in terms of copula properties. This limitation may be remedied by replacing the normal random vector with another class of distributions capable of detailed control of lower moments, and with computationally feasible formulas for conditional distributions over rectangles. As mentioned above, calculating the fourth-order moments contained in leads to serious computational challenges even when
is multivariate normal. It therefore seems that such extensions would either be restricted to very simple distributional classes which would limit its usefulness, or would depend on as of yet unavailable numerical methods.
A comparison of Fleishman polynomials and PLSIM
As discussed above, PLSIM and VM are similar in terms of multivariate dependency, as both are generated by coordinate-wise transformations of a normal random vector. We here further inquire into the univariate distributional differences between PLSIM and VM. In the latter procedure, the marginal distributions are generated by third-order polynomial transformations as proposed by Fleishman (Citation1978). Third-order polynomials grow more quickly to
as
than PL functions, who involve only a simple scale-and-shift of the identity function. In this sense PL functions are more stable transformations compared to Fleishman polynomials, yet they preserve the capability of approximating general functions to arbitrary precision. The stability concerns the tails of the resulting univariate distributions. As implied from EquationEquation (4)
(4)
(4) , PL functions have the same tail behavior as a normal distribution. That is, when
, PL density approaches zero as
, and when
, the density goes to zero as
. That is, in PL functions, the tail behavior is still driven solely by the quick decrease to zero of
. This is not the case for VM, which has heavier tails due to the third-order transformation. Whether heavier tails are desirable, and whether considerations as
are relevant or not, depends on the application.
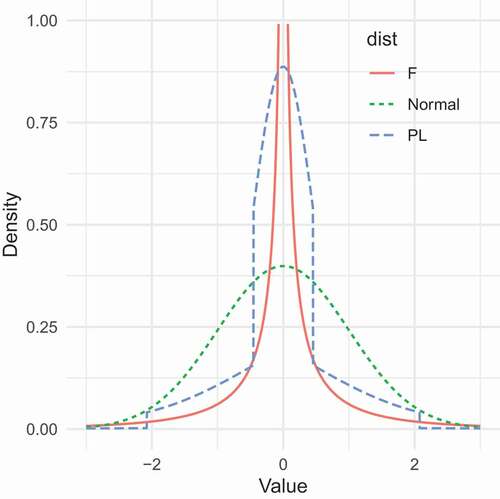
Let us consider in a concrete example the relation between a normal (), a PL (
) and a Fleishman (
) variable. The simplest case of a Fleishman polynomial is the standardized third-order transformation
. We have
and
. Therefore,
. The excess kurtosis of
is extreme, namely
43.2. The density of
is
. While the term
quickens the convergence to zero, the
term inside
slows down convergence, and this is the dominant term. We also fitted, using breakpoints
and
, a PL function
so that
had zero mean, unit variance, skew zero, and excess kurtosis 43.2. depicts the density curves of the three densities. Clearly, although the Fleishman and the PL distribution have common moments up to the fourth order, their distributions differ markedly. Both distributions are more peaked and more heavy-tailed than the standard normal distribution. But the peakedness of the Fleishman polynomial is much more pronounced than that of the PL distribution. Moreover, although not depicted in the figure, for extreme values, the tails of the Fleishman polynomial are fatter than those of the PL distribution. To illustrate this point, we simulated
sample from both distributions, and found that the 99th-percentiles for the PL and Fleishman data were
and
, respectively (see the supplemental material).
Figure 8. Graph of the density of and the standardized version of
when
.
Illustration
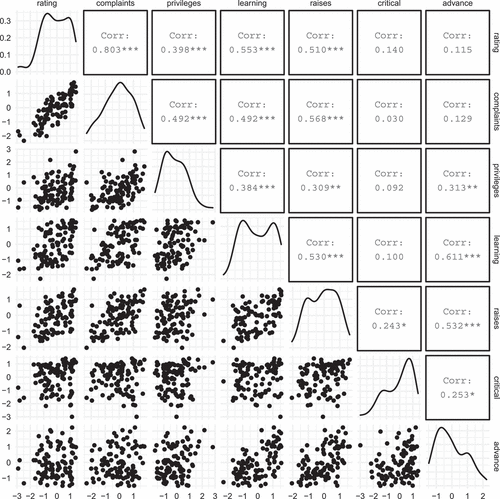
Let us illustrate PLSIM with a real-world example. The datasets package contains the dataset attitude, based on a survey given to employees in a large financial organization related to satisfaction with their supervisors. For 30 randomly chosen departments the proportion of favorable responses for each item was collected in the attitude dataset. The correlation matrix and the marginal sample skewnesses and excess kurtosi are given . Our aim here is to construct a 7-variate distribution whose correlation matrix and marginal skewness and excess kurtosis values match exactly the values in .
library(datasets)
attach(attitude)
s <- skew(attitude)
k <- kurtosi(attitude)
sigma <- cor(attitude)
set.seed(1)
res <- rPLSIM(100, sigma.target = sigma, + skewness = s, excesskurtosis = k)
sim.sample <- res[[1]][[1]]
Table 1. Correlation matrix and marginal skewnesses and excess kurtosi for the attitude dataset
Note that the VM approach as implemented in lavaan is not up to this task, since it can not match the skewness and excess kurtosis of variable learning. However, with three regularly spaced thresholds, monotonous PL functions may be identified (Step 2) for each of the seven variables that match skewness and excess kurtosis exactly. In Step 3 we fit each pair of variables separately, and in Step 4 the correlations are aggregated into:
This matrix is positive definite, so we need not pre-multiply by . A sample of size
was simulated using PLSIM, with resulting scatter plots and univariate densities depicted in .
Figure 9. Plots for dataset simulated from PLSIM.
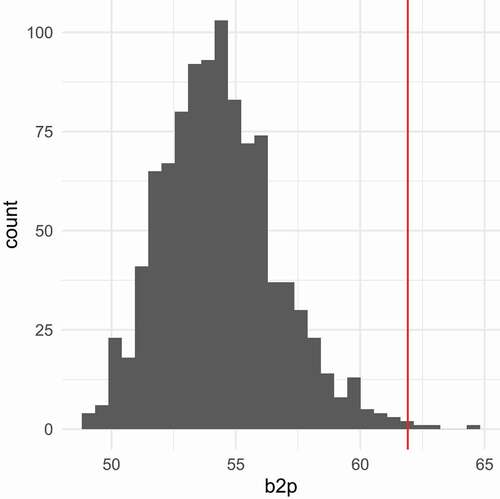
Finally, let us inspect sample estimates of kurtosis with respect to the pre-specified kurtosis values. In a generated sample, sample kurtosis will differ substantially from the specified kurtosis value. The latter holds at the population level but not in samples. To illustrate, we generated 1000 samples, each of size 30, from PLSIM. In each sample univariate kurtosis was estimated for each of the seven variables. The results are depicted in , where each panel is associated with one variable. It is seen that sample excess kurtosis varies substantially across samples. In each panel, the vertical red line indicates population excess kurtosis. Small-sample bias of the kurtosis estimator is manifested for most variables, with general downward bias in our case. Let us also consider the statistic (Mardia, Citation1970) for multivariate kurtosis. Qu et al. (Citation2019) proposed a simulation method where samples are generated from a distribution with pre-specified multivariate kurtosis. In our development of PLSIM, we control the univariate kurtosi, but we have no control over multivariate kurtosis. Over the same 1000 samples described above, we calculated
, with results given in . The red line represents this statistic calculated in the attitude dataset. It is seen that the PLSIM datasets have lower
values than the original attitude data. This illustrates that we do not control multivariate kurtosis with our method.
Figure 10. Histograms of sample estimates of univariate kurtosis based on 1000 simulated datasets of size . The red line represents the population kurtosis derived from the attitude dataset.
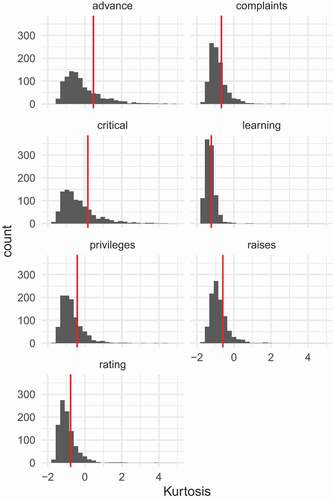
Figure 11. Histogram of multivariate kurtosis based on 1000 simulated datasets of size
. The red line represents
calculated for the attitude dataset.
Conclusion
We have presented a new method to simulate univariate and multivariate non-normal data. We employ piecewise linear transforms of standard normal variables. This method is flexible since we may manipulate the slopes of the line segments in order to reach pre-specified skewness and kurtosis values. This is possible since the fourth-order moments of the transformed variable is exactly computable. The same holds for pairs of piecewise linearly transformed variables, i.e., the covariance may be calculated using exact formulas. This means that we may pairwise calibrate the correlation among the two standard normal variables in order to reach a given covariance among the transformed variables.
PLSIM has been implemented in R and is available in package covsim. We have demonstrated that PLSIM may be used in cases (e.g., skewness and excess kurtosis
) where the Vale-Maurelli procedure fails. PLSIM supports a flexible class of univariate distributions, since its framework is based on choosing arbitrary number and placement of breakpoints, and arbitrary line segments between the breakpoints. In our implementation the default number of line segments is four, separated by regularly spaced breakpoints. We have deduced the formulas necessary to exactly compute the asymptotic covariance matrix of the generated second-order moments under PLSIM. However, at the present time the needed routines to calculate moments of the truncated multivariate normal distributions are too slow for practical use. However, we project that this situation will be soon remedied, given the present active development around truncated multivariate moments in the field of multivariate statistics. We also proposed a simple correction to the case of negative definiteness of the intermediate correlation matrix, based on finding the nearest positive definite matrix. This correctional step may likewise be useful for extending the generality of the Vale-Maurelli procedure.
Notes
1 denote general functions of the form of EquationEquation (1)
(1)
(1) , and not the specific illustrative functions defined in the previous sections.
References
- Bates, D., & Maechler, M. (2019). Matrix: Sparse and dense matrix classes and methods [Computer software manual]. https://CRAN.R-project.org/package=Matrix(Rpackageversion1.2–18)
- Bentler, P. (2006). Eqs 6 structural equations program manual. Multivariate Software, Inc.
- Browne, M. W. (1984). Asymptotically distribution-free methods for the analysis of covariance structures. British Journal of Mathematical and Statistical Psychology, 37, 62–83. https://doi.org/https://doi.org/10.1111/j.2044-8317.1984.tb00789.x
- Burkardt, J. (2014). The truncated normal distribution (Tech. Rep.). Department of Scientific Computing Website, Florida State University.
- Cain, M. K., Zhang, Z., & Yuan, K.-H. (2017). Univariate and multivariate skewness and kurtosis for measuring nonnormality: Prevalence, influence and estimation. Behavior Research Methods, 49, 1716–1735. https://doi.org/https://doi.org/10.3758/s13428-016-0814-1
- Cario, M. C., & Nelson, B. L. (1997). Modeling and generating random vectors with arbitrary marginal distributions and correlation matrix (Tech. Rep.). Department of Industrial Engineering and Management Sciences, Northwestern University.
- Fleishman, A. (1978). A method for simulating non-normal distributions. Psychometrika, 43(4), 521–532. https://doi.org/https://doi.org/10.1007/BF02293811
- Foldnes, N., & Grønneberg, S. (2015). How general is the Vale–Maurelli simulation approach? Psychometrika, 80, 1066–1083. https://doi.org/https://doi.org/10.1007/s11336-014-9414-0
- Foldnes, N., & Grønneberg, S. (2017). The asymptotic covariance matrix and its use in simulation studies. Structural Equation Modeling: A Multidisciplinary Journal, 24, 881–896. doi:https://doi.org/10.1080/10705511.2017.1341320.
- Foldnes, N., & Grønneberg, S. (2019). On identification and non-normal simulation in ordinal covariance and item response models. Psychometrika, 84, 1000–1017. https://doi.org/https://doi.org/10.1007/s11336-019-09688-z
- Foldnes, N., & Grønneberg, S. (2020a). Pernicious polychorics: The impact and detection of underlying non- normality. Structural Equation Modeling: A Multidisciplinary Journal, 27, 525–543. doi:https://doi.org/10.1080/10705511.2019.1673168.
- Foldnes, N., & Grønneberg, S. (2020b). covsim: Simulate from distributions with given covariance matrix and marginal information [Computer software manual]. https://CRAN.R-project.org/package=covsim(Rpackageversion0.2.0)
- Foldnes, N., & Grønneberg, S. (2021). The sensitivity of structural equation modeling with ordinal data to underlying non-normality and observed distributional forms. Psychological Methods. (Online first). https://doi.org/https://doi.org/10.1037/met0000385
- Foldnes, N., & Olsson, U. H. (2016). A simple simulation technique for nonnormal data with prespecified skewness, kurtosis, and covariance matrix. Multivariate Behavioral Research, 51, 207–219. https://doi.org/https://doi.org/10.1080/00273171.2015.1133274
- Galarza, C. E., Kan, R., & Lachos, V. H. (2021). Momtrunc: Moments of folded and doubly truncated multivariate distributions [Computer software manual]. https://CRAN.R-project.org/package= MomTrunc (R package version 5.97)
- Grønneberg, S., & Foldnes, N. (2017). Covariance model simulation using regular vines. Psychometrika, 82, 1035–1051. https://doi.org/https://doi.org/10.1007/s11336-017-9569-6
- Grønneberg, S., & Foldnes, N. (2019). A problem with discretizing Vale-Maurelli in simulation studies. Psychometrika, 84, 554–561. https://doi.org/https://doi.org/10.1007/s11336-019-09663-8
- Grønneberg, S., & Foldnes, N. (2021). Factor analyzing ordinal items requires substantive knowledge of response marginals. Psychological Methods. (Submitted). https://doi.org/https://doi.org/10.1037/met0000385
- Grønneberg, S., Foldnes, N., & Marcoulides, K. M. (2021). covsim: An r package for simulating non-normal data for structural equation models using copulas. Journal of Statistical Software. forthcoming.
- Grønneberg, S., & Moss, J. (2021). Partial identification of latent correlations with polytomous data. Psychometrika. (Submitted).
- Higham, N. J. (2002). Computing the nearest correlation matrix—a problem from finance. IMA Journal of Numerical Analysis, 22, 329–343. https://doi.org/https://doi.org/10.1093/imanum/22.3.329
- Johnson, N. L., Kotz, S., & Balakrishnan, N. (1994). Continuous univariate distributions (Vol. 1). John Wiley & Sons.
- Jöreskog, K., & Sörbom, D. (2006). Lisrel version 8.8. lincolnwood, il: Scientific software international. Inc.
- Leppard, P., & Tallis, G. (1989). Algorithm as 249: Evaluation of the mean and covariance of the truncated multinormal distribution. Journal of the Royal Statistical Society. Series C, Applied Statistics, 38, 543–553.
- Mair, P., Satorra, A., & Bentler, P. M. (2012). Generating Nonnormal Multivariate Data Using Copulas: Applications to SEM. Multivariate Behavioral Research, 47, 547–565. https://doi.org/https://doi.org/10.1080/00273171.2012.692629
- Mardia, K. (1970). Measures of multivariate skewness and kurtosis with applications. Biometrika, 57, 519–530. https://doi.org/https://doi.org/10.1093/biomet/57.3.519
- Micceri, T. (1989). The unicorn, the normal curve, and other improbable creatures. Psychological Bulletin, 105, 156.
- Ogasawara, H. (2021). A non-recursive formula for various moments of the multivariate normal distribution with sectional truncation. Journal of Multivariate Analysis, 183, 104729. https://doi.org/https://doi.org/10.1016/j.jmva.2021.104729
- Orjebin, E. (2014). A recursive formula for the moments of a truncated univariate normal distribution [Master’s thesis]. The University of Queensland. https://people.smp.uq.edu.au/YoniNazarathy/teaching_projects/studentWork/EricOrjebin_TruncatedNormalMoments.pdf
- Qu, W., Liu, H., & Zhang, Z. (2019). A method of generating multivariate non-normal random numbers with desired multivariate skewness and kurtosis. Behavior Research Methods, 51, 1–8. https://doi.org/https://doi.org/10.3758/s13428-018-1072-1
- Qu, W., & Zhang, Z. (2020). mnonr: A generator of multivariate non-normal random numbers [Computer software manual]. https://CRAN.R -project.org/package=mnonr (R package version 1.0.0)
- R Core Team. (2020). R: A language and environment for statistical computing [Computer software manual]. https://www.R-project.org/
- Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48, 1–36. https://doi.org/https://doi.org/10.18637/jss.v048.i02
- Shorack, G. R., & Wellner, J. A. (2009). Empirical processes with applications to statistics (Vol. 59). Society for Industrial and Applied Mathematics (SIAM.
- Touloumis, A. (2016). Simulating correlated binary and multinomial responses under marginal model specification: The simcormultres package. The R Journal, 8, 79–91. https://doi.org/https://doi.org/10.32614/RJ-2016-034
- Vale, C. D., & Maurelli, V. A. (1983). Simulating multivariate nonnormal distributions. Psychometrika, 48, 465–471. https://doi.org/https://doi.org/10.1007/BF02293687
- Wilhelm, S., & Manjunath, B. G. (2015). tmvtnorm: Truncated multivariate normal and student t distribution [Computer software manual]. http://CRAN.R-project.org/package=tmvtnorm(Rpackageversion1.4–10)
Appendix
Calculating the moments of Consider the random variable
. Then
Now, since
the -th moment is
To evaluate this expression we need to calculate the conditional moments , that is, the
-th moment of a truncated normal variable. Mean and variance formulas are provided in Johnson et al. (Citation1994). Higher-order moments may be obtained with the following recursive formula (Burkardt, Citation2014; Orjebin, Citation2014), where we initialize by
and
:
To sum up, we may calculate by first using the above recursive formula to calculate the conditional moments
. Then we apply the formula