
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
There has been tremendous growth in research on measurement invariance over the past two decades. However, given that psychological tests are commonly used for making classification decisions such as personnel selections or diagnoses, surprisingly, there has been little research on how noninvariance impacts classification accuracy. Millsap and Kwok previously proposed a selection accuracy framework for that purpose, which has been recently extended to categorical data. Their framework, however, only deals with classification using a unidimensional test. In contrast, classification in practice usually involves multidimensional tests (e.g., personality) or multiple tests, with different weights assigned to each dimension. In the current paper, we extend Millsap and Kwok’s framework for examining the impact of noninvariance to a multidimensional test on classification. We also provide an R script for the proposed method and illustrate it with a personnel selection example using data from a published report featuring a five-factor personality inventory.
Scores on psychological tests are widely used when making selections, diagnostic, and admission decisions. These tests are used to quantify people’s relative standings on certain psychological constructs, such as conscientiousness, self-esteem, vocational aptitude, or depression. However, the use of a psychological test is only valid when measurement invariance holds, meaning that the test is free of measurement bias such that it measures one or more latent construct in an equivalent and comparable way across demographic subgroups (e.g., race, gender, age, disability status), modes of test administration (e.g., paper-and-pencil vs. computer-based), or any construct-irrelevant differences (Meredith, Citation1993; Millsap, Citation2011; Stark et al., Citation2004; Vandenberg, Citation2002). Given its importance, there has been exponential growth in the number of studies detecting violations of measurement invariance of existing and newly developed psychological tests. For example, Putnick and Bornstein (Citation2016) identified 126 such articles published in peer-reviewed journals in just one year, 2013.
On the other hand, there has been little research investigating how noninvariance affects the quality of classification decisions based on these tests, such as in personnel selection, diagnosis, and admission (Putnick & Bornstein, Citation2016; Schmitt & Kuljanin, Citation2008), which is often of great interest to users of psychological tests. For example, personality assessment is commonly used in personnel selection (e.g., Schmit & Ryan, Citation1993); questionnaire and behavioral checklist are commonly used as screening tools for mental health conditions. Most existing measurement invariance research on psychological tests, however, have focused only on identifying noninvariant items, with little guidance on how to translate those research findings for interpreting test scores. For instance, readers are usually only told, that two items in a test were found noninvariant across ethnic groups, and test users are left wondering whether they should remove those two items when administering the test. Even when effect size indices are reported, those are usually presented in terms of the difference in loadings (e.g., Millsap, Citation2011) or test statistics (e.g., the Mantel-Haenszel statistic; Zwick et al., Citation1999), which do not directly show whether the noninvariance makes selection less effective or creates an unjustified barrier for certain subpopulations.
A useful framework to quantify the impact of measurement bias on selection or classification accuracy was proposed by Millsap and Kwok (Citation2004), which compares classification accuracy indices—such as sensitivity and specificity—of a test with and without measurement invariance (see also Stark et al., Citation2004). It allows researchers and test administrators to directly see the practical impact of measurement bias on the effectiveness of a test for classification purposes. As shown in Millsap and Kwok, violation of measurement invariance at the item level may or may not lead to meaningful impacts on the accuracy of a classification procedure. More recently, Lai et al. (Citation2017) have provided an R program to implement Millsap and Kwok’s classification accuracy framework; Lai et al. (Citation2019) and Gonzalez and Pelham (Citation2021) have extended the framework for binary and ordinal items.
However, so far the classification accuracy framework is limited to a unidimensional test, where participants are measured on only one latent construct. In reality, classification is likely a decision based on multiple tests or subtests. For example, in personnel selection, organizations may use combinations of cognitive ability tests and dimensions of personality to select employees (e.g., Schmidt & Hunter, Citation1998). In college admission, administrators may give different weights to different components of aptitude tests (e.g., verbal, mathematics, reading), together with other criteria, to rank potential students (e.g., Aguinis et al., Citation2016). In these examples, it is common to assign more weights to dimensions deemed more important or found more predictive of some criterion variables, like conscientiousness among personality dimensions (Barrick & Mount, Citation1991; Hurtz & Donovan, Citation2000). Nevertheless, the unidimensional framework by Millsap and Kwok (Citation2004) and the recent extensions only allow examining each dimension separately, and thus do not allow incorporating the relative importance weight of each dimension. Furthermore, some items may tap into more than one dimensions, and how biases in those items affect classification decisions depend on the correlations and the relative importance of the latent dimensions, the intricacies of which can only be evaluated by considering all items and the dimensions simultaneously. Therefore, in the present paper, we extend the classification accuracy framework to a multidimensional setting so that it quantifies the overall impact of measurement noninvariance on the fairness and effectiveness of a classification procedure. In addition, we provide an R script for implementing the proposed analysis.
In the following, we first define the model notations for a multi-group multidimensional factor model and review previous approaches for evaluating measurement invariance. We then present the details of the multidimensional classification accuracy analysis (MCAA) framework as an extension of Millsap and Kwok (Citation2004)’s framework, which includes defining the classification accuracy indices. The framework will then be applied in a hypothetical selection scenario where job applicants are selected based on a weighted composite of their subscale scores on a Big-Five personality test, with a step-by-step tutorial on the relevant analyses using the R script provided.
Factor model
For psychological tests, the factor model (Thurstone, Citation1947) is commonly used to represent the statistical relations between item scores and the underlying constructs measured. Consider a set of items measuring
psychological constructs. Let
be the
item response vector of person
’s score on the items, and
be a
vector containing scores on the underlying latent (i.e., unobserved) constructs. Under a multidimensional common factor model (Thurstone, Citation1947),
and
are linked statistically as a linear system,
where is a
vector of measurement intercepts, which is analogous to regression intercepts, with elements
(
) indicating the expected item scores for a person with zero scores on all latent variables;
is a
matrix of factor loadings, which is analogous to regression slopes, with elements
(
;
) indicating the strength of associations of item
with the
th latent construct; and
is a
column vector of the unique factor random variables, which captures the influence of factors that are irrelevant to
on
. In other words, the factor model expressed in Equationequation (1)
(1)
(1) says that a person’s item scores are linear functions of their standings on the latent constructs (
), plus some construct-irrelevant measurement errors (
).
Let and
be the mean vector and the variance-covariance matrix of the latent variables, respectively. Further, let the variance-covariance matrix among the unique factor variables be
, and assume that each unique factor variable has a zero mean,
. In practice, researchers usually impose the local independence assumption such that
is a diagonal matrix, meaning that the inter-item correlations are attributed solely to the variance of the underlying latent factor; however, the proposed framework can be applied when the local independence assumption is violated. It is assumed that
and
are independent with
, and together the model implies that
and
.
Factorial invariance
Measurement invariance, or lack of item bias, is the condition where individuals from different subpopulations (e.g., age, gender, ethnicity, socioeconomic status), with the same standings on the latent constructs (e.g., cognitive ability or conscientiousness), demonstrate the same propensities in responding to all the items measuring these constructs. As such, measurement invariance is key to the “ideal of fairness” in workplace testing as described in the Standards for Educational and Psychological Testing (American Educational Research Association, American Psychological Association & National Council on Measurement in Education, Citation2014), according to which, fairness “is achieved if a given test score has the same meaning for all individuals and is not substantially influenced by construct-irrelevant barriers to individuals’ performance.” (p. 169). Therefore, the importance of identifying bias in psychological tests and evaluating measurement invariance cannot be understated.
Formally, measurement invariance holds when the conditional distribution of the observed item scores is the same across subpopulations that are not part of the construct domain (Mellenbergh, Citation1989). That is, for the subpopulation membership variable with levels
, like gender and ethnicity,
Under the factor model defined in (1) and assuming multivariate normality of (,
), measurement invariance is also called strict factorial invariance (Meredith, Citation1993), or strict invariance, which holds when the measurement parameters: loadings (
), intercepts (
), and unique factor covariances (
), are equal across all subgroups. In math notations, factorial invariance implies
In practice, however, strict invariance does not commonly hold. Previous researchers have distinguished four stages of factorial invariance (Millsap, Citation2007), each with different implications for the use of test scores. The first stage is configural invariance, which requires that the factor structures be the same across subgroups, including the same number of factors and the same composition of items for each factor. An example violation of configural invariance is that an item is an indicator of math ability in one group, but is an indicator of both math ability and English proficiency in another group. The second stage is metric invariance (Horn & Mcardle, Citation1992), which, in addition to configural invariance, requires equal factor loadings (i.e., for all
). As such, metric invariance ensures that a unit difference in the latent construct is comparable across subgroups. The third stage is scalar invariance, which, in addition to metric invariance, requires equal measurement intercepts across subgroups (i.e.,
for all
). Scalar invariance ensures that a given measure has the same origin or zero point. The final stage is strict invariance as previously discussed, where the unique factor variances and covariances are also identical (i.e.,
for all
).
Partial factorial invariance/item bias
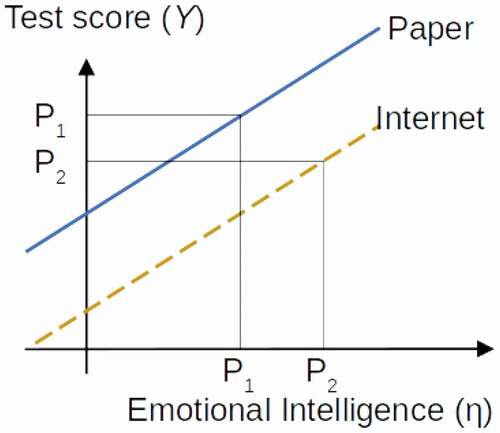
In contrast to full factorial invariance, item bias, also called partial factorial invariance (Millsap & Kwok, Citation2004), is present when two individuals with exactly the same standings on the latent constructs demonstrate different propensities to respond to one or more items. When measurement invariance does not hold for some items, meaning that item bias is present, the comparison of test scores across subpopulations is not valid and can be highly misleading. Consider the hypothetical example in , where scalar invariance is violated for a test of emotional intelligence with respect to paper-and-pencil and Internet-based administrations. The overall bias, due to differences in the intercepts of the items, systematically leads to lower scores for persons using the Internet-based test. Therefore, Person 2, who has a higher true emotional intelligence level than Person 1 and takes the Internet-based test, gets a lower observed test score than Person 1, who takes the paper-and-pencil-based test.
Figure 1. Example of scalar non-invariance where a participant taking a paper test is mistakenly given a lower score.
An abundance of the previous literature has focused on statistical methods for detecting violations of factorial invariance, the most popular ones among which are the likelihood ratio test (LRT or ; Millsap, Citation2011) and the change in goodness-of-fit indices in structural equation modeling (Cheung & Rensvold, Citation2002). Using maximum likelihood estimation, a likelihood ratio
statistic is obtained by comparing the maximized log-likelihoods of a model with invariance constraints (e.g., the metric invariance model with equality constraints on the factor loadings) and a model without such constraints (e.g., the configural invariance model without factor loading constraints). A significant test statistic then indicates that a particular step of measurement invariance is violated. However, the likelihood ratio test is very sensitive to large sample sizes such that items are flagged as noninvariant even when the degree of bias is trivial (Putnick & Bornstein, Citation2016). As an alternative, researchers rely on goodness-of-fit indices that are less sensitive to sample sizes, such as the comparative fit index (CFI; Bentler, Citation1990) and the root mean squared error of approximation (RMSEA; Steiger, Citation1980), and deem a psychological test practically invariant when the change in these indices is within a certain threshold (e.g.,
< .01 by Cheung & Rensvold, Citation2002;
< .005 by Chen, Citation2007). These indices, however, are not meaningful metrics when it comes to communicating the degree of noninvariance of tests, as a
CFI of −.03, for example, does not indicate how using the test will be problematic in any concrete way.
Recently, there have been increased research efforts to define interpretable effect size indices for noninvariance at the item level. For example, Nye and Drasgow (Citation2011) proposed the effect size, which corresponds to the expected standardized difference in observed item scores due to noninvariance; Nye et al. (Citation2019) further provided benchmark values for
based on a systematic review of the organizational literature. Gunn et al. (Citation2020) proposed and evaluated several indices that are conceptually similar to
. However, because these indices focus on the impact of noninvariance on the item mean, they do not directly inform the impact on classification—a common usage of psychological tests—for two reasons. First, previous research usually assumes that biased items are automatically worse than unbiased items and, therefore, should be removed in order to achieve valid cross-group comparisons. However, while reducing bias in cross-group comparisons, removing biased items may make the test less reliable due to reduced test length, resulting in less precise inferences. When using test results for decision-making, both bias (systematic error) and precision (random error) should be taken into account. A slightly biased but highly effective item may contribute more information than an unbiased but ineffective item, but existing approaches for detecting item bias pays less attention to the role of unique variances and covariances (i.e.,
), which is related to score reliability and is relevant to classification.Footnote1
Second, as noted by Millsap and Kwok (Citation2004), the evaluation of item bias should be made “in relation to the purpose of the measure” (pp. 94–95). In the behavioral sciences, a common purpose of a psychological test is to select or identify individuals based on their relative standings or absolute scores on the test (Crocker and Algina, Citation2006). Surprisingly, and unfortunately, very little attention has been paid to how noninvariance impacts selection. In the following section, we briefly review the relevant literature on item bias and classification, after which we define the MCAA framework as an extension to the approach by Millsap and Kwok (Citation2004).
Factorial invariance in the context of selection
Psychological and behavioral measures are commonly used for various classification purposes: identifying people with depressive symptoms, selecting or promoting employees, and providing support for college admissions decisions. Often employers and test administrators compute a scale score or a composite score, denoted as , by applying a scoring rule on the item scores, such as by summing the items. The classification decisions are then based on
.
As a hypothetical personnel selection example, imagine that two subgroups of applicants respond to a battery of assessment items (e.g., personality and cognitive tests). Without loss of generality, denote the two groups as the reference and the focal groups (Millsap & Kwok, Citation2004), where the focal group is considered to have a disadvantage due to potential measurement bias. Assume that the two groups are of equal sizes and have identical distributions on their actual, latent competency level. Based on their responses, each applicant receives a score, and a manager wants to use the battery to select the top
of the combined pool of applicants. If the tests are bias-free, the final pool should consist of roughly
of participants from the reference group and
from the focal group, as shown in (i.e., the combined area of quadrants A and B). However, it is possible that due to noninvariance, or item bias, the reference group on average gets higher scores than the focal group. As a result and as shown in ,
of the reference group but only
of the focal group are selected. In other words, the selection ratio changes from 1:1 to 2:1 between applicants in the reference and the focal groups.
Figure 2. Relationship between true latent construct scores (x-axis) and observed test scores (y-axis) for (a) a test with no item bias and (b) a test with biases against one subgroup. Quadrants A, B, C, and D indicates the proportions of true positives, false positives, true negatives, and false negatives.
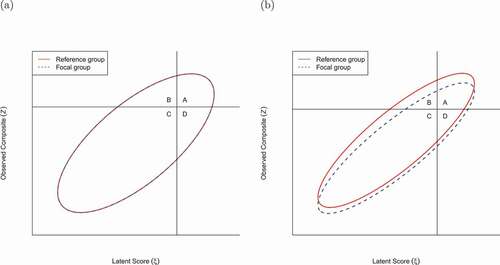
The example is simplified because it assumes an equal number of applicants from the focal and the reference groups with matched qualifications. Also, unless tests are perfectly reliable, some selected individuals in each subgroup will be “false positives;” a selection process that selects equal proportions of applicants in each subgroup is still problematic if it results in more false positives in some subgroups than others. A systematic approach to evaluating selection accuracy, as discussed in the remainder of the current paper, is needed to assess how factors, such as group sizes, differences in the distribution of qualifications, and reliability of the test scores may influence the effect of item bias on classification accuracy.
Classification accuracy analysis
Millsap and Kwok (Citation2004) proposed a framework to quantify how noninvariance affects classification accuracy. Specifically, based on the probabilities of true positives (qualified and selected), false positives (unqualified but selected), true negatives (unqualified and not selected), and false negatives (qualified but not selected) (i.e., quadrants A, B, C, D in ), one can summarize classification accuracy by the following indices:
where denotes the probability of an outcome.
For example, in personnel selection, proportion selected refers to the proportion of candidates selected for the job based on the biodata items. Success ratio is the proportion of candidates who are truly qualified among all the selected candidates; thus, a low success ratio means that the selection procedure selects many unqualified candidates for the job. Sensitivity is the proportion of candidates who are selected among all qualified candidates; thus, a low sensitivity means that only a small proportion of truly qualified candidates are selected. Finally, specificity is the proportion of candidates who are not selected among all the candidates who do not meet the cutoff, so a low specificity means that only a small proportion of truly unqualified candidates are correctly screened out. In this hypothetical example, one can argue that success ratio and sensitivity are more important if the goal is to select the best candidates, so proportion selected, success ratio, and sensitivity are important factors concerning the fairness of the selection procedure across subgroups. In practice, however, different combinations of these indices may matter most, depending on the purpose of the selection procedure.
The analyses originally proposed by Millsap and Kwok (Citation2004) only computed PS, SR, SE, and SP. In the context of personnel selection, one additional index that is of interest is the adverse impact (AI) ratio, defined as (Nye & Drasgow, Citation2011)
where is the proportion selected for the reference group (usually the majority group), and
is the expected proportion selected for the focal group based on the latent score distributions of the reference group. In other words,
is the proportion that would be selected from the focal group when the focal and the reference groups were matched in latent trait levels. When strict invariance holds, the AI ratio is 1, meaning that two candidates with equal latent trait levels—one from the focal group and the other from the reference group—are equally likely to be selected. When AI ratio < 1, it indicates that those in the focal group would be less likely to be selected due to factors not related to the target latent traits.
To evaluate the impact of noninvariance on selection, researchers compute the classification accuracy indices based on the parameter estimates from a partial strict invariance model and a strict invariance model, respectively. They can then compare the two sets of classification accuracy indices, and holistically evaluate the impact of noninvariance on selection for each subpopulation.
Multidimensional classification accuracy analysis (MCAA) framework
Millsap and Kwok (Citation2004)’s framework and follow-up research assumed unidimensionality of the items, meaning that all items used for selection measure one single latent trait. In actual personnel selection as well as in many classification tasks, the items may tap into multiple constructs, or constructs with multiple dimensions. For example, the Mini-International Personality Item Pool (Mini-IPIP; Donnellan et al., Citation2006), a personality inventory commonly used as part of personnel selection, has five dimensions (Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism). Also, classification in practice may assign different weights to different dimensions, which means that individuals are selected based on a weighted composite score on the latent variables. Therefore, in this article, we propose a more general, multidimensional selection accuracy framework, and illustrate it using a secondary data analytic example.
For a selection test with dimensions, let
be the true score for dimension
, and let
be a
row vector of weights. In other words, if we know the true, error-free score
for every person, the selection should be based on
. However, we only have the error-prone scores on
items,
. Usually, the items can be similarly partitioned into
subsets
, where each
component consists of
items with
. Let
be the vector of weights for the items. So with only the item scores, the selection is based on
. Following the derivation in Millsap and Kwok (Citation2004), under the multivariate normal assumption of
, within each subpopulation
,
follows a bivariate normal distribution:
and the marginal distribution of is a finite mixture of bivariate normal distributions, with mixing proportions
based on the relative sizes of the subpopulations.
With a given cutscore on the observed composite, , and the total proportion selected,
, Millsap and Kwok (Citation2004) showed that the cutscore on the latent composite,
, can be determined as the quantile in the mixture bivariate normal distribution corresponding to probability
. Once
and
are set, the classification accuracy indices for group
can be easily obtained as cumulative probabilities in a bivariate normal distribution. We have created an R script with the major function PartInvMulti_we() (see the supplemental material) that automates the computation, so that users simply need to input the parameter values for each subpopulation, together with the mixing proportions and
, to get the selection accuracy indices for each subpopulation. Below, we demonstrate the MCAA using real data of a personality inventory.
Comparing MCAA with the unidimensional counterpart
To demonstrate the need for a multidimensional framework, we conducted a simulation in which classification is based on two mildly correlated latent variables, and compared the classification accuracy indices based on MCAA as opposed to the unidimensional framework by Millsap and Kwok (Citation2004). Specifically, we simulated 1,000 data sets, each with 10 items, where the first five items loaded on the first factor and the next five items loaded (primarily) on the second factor, with all loadings = .70; we also made item 10 to cross-load on the first factor with loading = .30. The items were fully metric invariant but three items were scalar noninvariant, with intercepts = 0 for all items in the first group and were 0.3, −0.1, and 0.5 for items 4, 5, and 10. Both latent factors had unity variance with a .2 correlation in both groups, and the unique variances were .51 for all items. We simulated 1,000 data sets, and for each data set, we obtained classification accuracy indices using MCAA with weights of given to the two factors, respectively. The classification accuracy indices were based on selecting the top 25% on the latent composite. We also applied the unidimensional framework (as implemented in Lai et al., Citation2017) to obtain classification accuracy indices based on the first five items and the last five items separately, and obtained the weighted averages of the two sets of indices with the same weights of .7 and .3.
compares the true population-level classification accuracy indices and the mean values across replications from MCAA and the unidimensional approach, with the first group as the reference group under partial strict invariance models. In summary, whereas MCAA recovered the true values of the indices well for both groups, using the unidimensional approach resulted in biased values of proportions selected and values of other indices being smaller than the true values.
Table 1. Simulation results
Illustrative example
To illustrate the application of the multidimensional classification accuracy analysis (MCAA), we used data from Ock et al. (Citation2020), which examined measurement invariance of the mini-IPIP across gender. The data are a subset of the Eugene-Springfield Community Sample collected from 1994 Spring to 1996 Fall (Goldberg, Citation2018), a well-studied community sample who completed a mail survey, including the mini-IPIP. Ock et al. (Citation2020) performed listwise deletion and provided complete data in their supplemental material. The sample consisted of 564 participants (239 males, 325 females), who were 20–85 years old ( = 51.7,
= 12.5), and nearly all of them being Caucasian (
).
The mini-IPIP is a short form of the International Personality Item Pool, a personality measure based on the Five-Factor model (Donnellan et al., Citation2006; Goldberg, Citation1999). The mini-IPIP had 20 items in total, with four items for each factor. Specifically, items A2, A5, A7, A9 measure the factor Agreeableness; items C3, C4 C6, C8 measure the factor Conscientiousness; items E1, E4, E6, E7 measure the factor Extraversion; items N1, N2, N6, N8 measure the factor Neuroticism; and items O2, O8, O9, O10 measure the factor Openness to Experience. Further details about these items can be found in the Appendix in Donnellan et al. (Citation2006). Questions were descriptive statements answered on a 5-point Likert-type scale from 1 (very inaccurate) to 5 (very accurate). shows the means, standard deviations, and the correlations of the mini-IPIP items by gender.
Table 2. Mean, standard deviations, and item-level correlations of the mini-IPIP scales by gender
To identify noninvariant parameters, we used the lavaan R package (Rosseel, Citation2012) and the forward specification search procedure (Yoon & Kim, Citation2014) using likelihood ratio tests ().Footnote2 Given the categorical nature of the items, we followed Ock et al. (Citation2020) to use the robust maximum likelihood (MLR) estimator, with the scaled
test by Satorra and Bentler (Citation2001). We first fitted a configural invariance model, which showed poor fit,
,
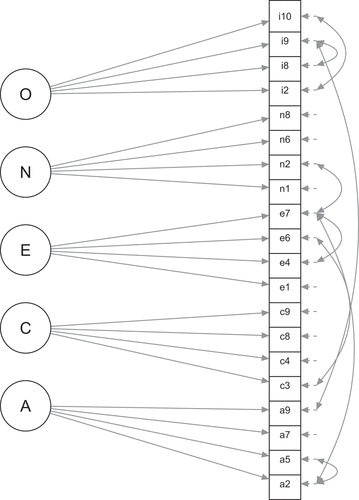
, RMSEA = 0.06, 95%CI [0.06, 0.07], CFI = 0.84, SRMR = 0.06. Based on the modification indices, we decided to free eight pairs of unique factor covariances: A2 and A5, E4 and E7, I2 and I10, I8 and I9, A9 and I9, C3 and E6, A2 and E7, E7 and N2. The modified configural invariance model with five factors (see ) showed acceptable fit,
,
, RMSEA = 0.03, 95%CI [0.03, 0.04], CFI = 0.95, SRMR = 0.05. Equality constraints in the loadings did not result in poorer model fit, scaled
,
. We then added the constraints to the intercepts, which resulted in poorer model fit, scaled
,
. One item in Agreeableness (A2, “Sympathize with others’ feelings”), one item in Extraversion (E6 “Don’t talk a lot”) and two items in Neuroticism (N1, “Am relaxed most of the time”; N2, “Seldom feel blue”) showed noninvariant intercepts across groups (
= 0.16, 0.42, 0.31, 0.24). After freeing these items, the scalar model showed acceptable fit,
,
, RMSEA = 0.03, 95%CI [0.02, 0.04], CFI = 0.95, SRMR = 0.05. A strict invariance model was further fitted to the data, which fitted the data worse than the partial scalar invariance model, scaled
,
. One item in Conscientiousness (C8, “Make a mess of things”) and two items in Neuroticism (N1, “Am relaxed most of the time”; N2, “Seldom feel blue”) showed noninvariant unique factor variance across groups (
= 0.21, 0.28, 0.39). The final model is a partial strict invariance model,
,
, RMSEA = 0.03, 95%CI [0.02, 0.04], CFI = 0.95, SRMR = 0.06. The parameter estimates from the partial strict invariance model can be found in the supplemental material.
Figure 3. Path diagram of the factor model for the mini-IPIP items in the illustrative example.
While the conventional invariance testing identified four items with noninvariant intercepts, the results did not provide information on how these noninvariant parameters may impact personnel selection using the mini-IPIP. For example, do the noninvariant intercepts give a substantial or a negligible advantage to females? Does dropping the noninvariant items improve the selection procedure? To answer these questions, we show how MCAA can be applied in a step-by-step fashion.
Step 1: Selection parameters
As a first step of doing MCAA, we need to consider several parameters related to selection: (a) the mixing proportion (), (b) the relative weights given to each dimension (
), (c) the weights given to each item (
), and (d) the selection cutoff, either in terms of an absolute cutoff score (
) or a relative cutoff proportion (i.e. proportion selected). In this example, because the population sizes for females and for males are roughly equal, we use
. The weights given to the items and to the different dimensions require some more considerations. If the test items are summed together to get one single scale score for selection purposes, and each dimension contains an equal number of items, then we can specify
(i.e., a vector of ones). However, it is well documented in previous research (e.g., Barrick & Mount, Citation1991) that different personality dimensions had different associations with job performance. Instead, we used the regression weights reported by Drasgow et al. (Citation2012), which conducted a meta-analysis to examine the predictive validity of five personality dimensions in eight criteria of job performance (e.g., the predictive validity of conscientiousness ranges from −0.23 to 0.20). After averaging the regression weights for each dimension, we set
for agreeableness, conscientiousness, extraversion, neuroticism (with a negative weight), and openness. Note that the sum of the absolute values of the weights is one. On the item side, because each dimension has the same number of items, we set the item weights to be proportional to the latent weights, while keeping the maximum weighted score for each participant to 100 (same as the unweighted score); specifically,
for 20 items. The codes for obtaining the weights can be found in the supplemental material. For the selection cutoff, we assume that the mini-IPIP is used to select the top 25% of the candidates.
Step 2: Classification accuracy under strict invariance
To establish the baseline information of using the mini-IPIP in selecting males and females, we first obtained the parameter estimates under full strict invariance. The supplemental material contains codes for extracting parameter estimates from a fitted lavaan model object as inputs for the MCAA; however, researchers can also manually input the parameter estimates into the provided R function, PartInvMulti_we(). Following Millsap and Kwok (Citation2004), for the four noninvariant intercepts and the three noninvariant unique factor variances, we obtained the average parameter estimates weighted by the mixing proportions as parameters for the strict invariance model. We used female candidates as the reference group and male candidates as the focal group. Using the selection parameters in Step 1 and the R script in the supplemental material, one can obtain the selection indices when strict invariance holds, as shown in . Specifically, the selection is expected to comprise slightly more female candidates (25.2%) than male candidates. The other classification accuracy indices (success ratio, sensitivity, and specificity) were similar for the two groups.
Table 3. Impact of item bias on selection accuracy indices from the multidimensional classification accuracy analysis
Step 3: Classification accuracy under partial strict invariance
The selection accuracy of mini-IPIP under partial strict invariance can be obtained in the same way as in Step 2, except that the intercept parameters were different for males and females, as well as the unique variances and covariances. The results are again shown in . In the presence of test bias, male candidates are selected in a lower proportion than female candidates (0.260 for female and 0.240 for male). The selection procedure has a higher sensitivity for female than male candidates (0.758 for female and 0.733 for male). However, female candidates have a lower success ratio (0.732 for female and 0.759 for male) and specificity (0.907 for female and 0.923 for male) than male candidates.
Step 4: Compare the change in classification accuracy indices
Comparing the results in Steps 2 and 3, we see male candidates are selected in a lower proportion (24.0%), whereas female candidates are selected in a higher proportion (26.0%). The increased proportion selected for female candidates due to item bias, however, results in a lower success ratio (0.732 as opposed to 0.748 under strict invariance), meaning that there are more false positives among qualified female candidates. Item bias also results in a higher sensitivity (0.758 as opposed to 0.749) and a lower specificity (0.907 as opposed to 0.915) for females. On the contrary, the lower proportion selected for male candidates results in a higher success ratio (0.759 as opposed to 0.743), lower sensitivity (0.733 as opposed to 0.742), and higher specificity (0.923 as opposed to 0.915).
The columns labeled in represent the expected classification performance for male candidates based on the latent score distributions of the female candidates. The differences between columns
and
show the impact of item bias on classification accuracy, as they are identical when strict invariance holds. Our R function also computed the AI ratio for male candidates to be 0.935, which is the ratio of proportions selected for females and the proportions selected for
under strict invariance, that is, .243/.260. The computed AI ratio indicates that, due to item bias, for every 1,000 female candidates selected, only 935 equally qualified male candidates will be selected. Thus, it demonstrates a disadvantage for male candidates when using the mini-IPIP for selection.
Comparison with separate unidimensional analyses
We also applied separate unidimensional analysis to each dimension of the mini-IPIP. Because Agreeableness, Conscientiousness, and Openness were not found to show partial invariance when evaluated separately, only the results of Extraversion and Neuroticism are reported in .Footnote3 Note that the results for Neuroticism were based on reversely coded items, as lower neuroticism is usually preferred in personnel selection. It can be seen that the impact of item bias on selection accuracy is larger when considering each dimension separately than the combined impacts obtained from MCAA. Consider selecting individuals solely based on extraversion. Under strict invariance, female candidates will be selected at a similar proportion (24.7%) as male candidates (25.3%), but more females will be selected (26.7%) under partial strict invariance. The reverse is true for Neuroticism, as more males will be selected under partial strict invariance. The item biases showed a particularly large impact on sensitivity. However, when considering the combined effect of item biases across all dimensions, as shown by MCAA, the impact was much smaller, as the biases in Extraversion and in Neuroticism somewhat canceled out. The sensitivity and specificity also had higher values under MCAA, as the selection was generally more accurate with 20 items from five dimensions as opposed to only 4 items in one dimension. Therefore, when a multidimensional test is used for selection or classification purposes, using the MCAA framework provides results more closely aligned to how item biases affect the actual classification decisions overall.
Table 4. Impact of item bias on selection accuracy indices when the dimensions are considered separately
Discussion
Despite tremendous growth in the measurement invariance literature, there has been a disconnect between how results of invariance testing are presented – usually in the form of statistical significance and change in fit indices – and how psychological measures are used in practice for making classification decisions. The work by Millsap and Kwok (Citation2004) and Stark et al. (Citation2004) provided a foundation for understanding the impact of noninvariance on classification. Nevertheless, the previous work only considered unidimensional items, but in practice, classification is usually done based on multiple dimensions.
The current work proposes a multidimensional classification accuracy framework (MCAA), which examines the change in classification accuracy indices attributable to noninvariance across demographic subgroups. We conceptualize the multidimensional problem by considering the joint distribution of the weighted observed composite score and the weighted latent composite score, and provide software code that computes the change in classification accuracy indices due to noninvariance. We illustrate MCAA with a step-by-step example of a five-dimensional personality inventory commonly used for personnel selection.
Readers should note that the MCAA and the foundational work by Millsap and Kwok (Citation2004) only represent one option for understanding the practical significance of noninvariance. Other effect size indices exist in the literature, some of which were nicely summarized in Meade (Citation2010), and some recent development was made by Nye et al. (Citation2019) and Gunn et al. (Citation2020). In our opinion, information on changes in classification accuracy indices is most relevant for measures that are potentially used for classification purposes, such as tests of cognitive and noncognitive abilities, as well as screening and diagnostic tools. When conducting invariance analysis, we encourage researchers to carefully consider the intended usage of the measure being studied and report the magnitude of noninvariance (if any) in a metric that is easily interpretable and fits the context in which the measure will be used.
While we think the MCAA represents a step closer to linking invariance research and actual practices in the context of classification, we also recognize some limitations of the current work and encourage future research efforts to address them. First, the current framework assumes that item responses are approximately continuous; given that binary and ordinal items are commonly used in psychological measures, future research can combine MCAA and the recent extension by Gonzalez and Pelham (Citation2021) and Lai et al. (Citation2019). Second, as with previous literature, the implied classification accuracy indices under the strict and the partial strict invariance models are only point estimates and are subject to sampling error. Given the recommendations on reporting uncertainty estimates for measures on practical significance (e.g., American Psychological Association, Citation2020), future work is needed to develop methods for obtaining standard errors and confidence intervals for the classification accuracy indices.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 An example of this can be found in the supplemental material, where selection drops after deleting five noninvariant items in a 20-item test.
2 Jung and Yoon (Citation2016) and Jung and Yoon (Citation2017) are accessible introductions to other methods for identifying non-invariant parameters.
3 Evaluating measurement invariance for each dimension, we found one item for Extraversion (E6 “Don’t talk a lot”) had noninvariant intercepts, and two items in Neuroticism (N1, “Am relaxed most of the time”; N2, “Seldom feel blue”) had noninvariant intercepts and unique variances across gender.
References
- Aguinis, H., Culpepper, S. A., & Pierce, C. A. (2016). Differential prediction generalization in college admissions testing. Journal of Educational Psychology, 108, 1045–1059. https://doi.org/https://doi.org/10.1037/edu0000104
- American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. https://www.testingstandards.net/open-access-files.html
- American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.). https://doi.org/https://doi.org/10.1037/000016S-000
- Barrick, M. R., & Mount, M. K. (1991). The Big Five personality dimensions and job performance: A meta-analysis. Personnel Psychology, 44, 1–26. https://doi.org/https://doi.org/10.1111/j.1744-6570.1991.tb00688.x
- Bentler, P. M. (1990). Comparative fit indexes in structural models. Psychological Bulletin, 107, 238–246. https://doi.org/https://doi.org/10.1037/0033-2909.107.2.238
- Chen, F. F. (2007). Sensitivity of goodness of fit indices to lack of measurement invariance. Structural Equation Modeling: A Multidisciplinary Journal, 14, 464–504. https://doi.org/https://doi.org/10.1080/10705510701301834
- Cheung, G. W., & Rensvold, R. B. (2002). Evaluating goodness-of-fit indexes for testing measurement invariance. Structural Equation Modeling: A Multidisciplinary Journal, 9, 233–255. https://doi.org/https://doi.org/10.1207/S15328007SEM0902_5
- Crocker, L.M., and Algina, J. (2006). Introduction to classical and modern test theory. Cengage Learning.
- Donnellan, M., Oswald, F., Baird, B., & Lucas, R. (2006). The Mini-IPIP scales: Tiny-yet-effective measures of the big five factors of personality. Psychological Assessment, 18, 192–203. https://doi.org/https://doi.org/10.1037/1040-3590.18.2.192
- Drasgow, F., Stark, S., Chernyshenko, O. S., Nye, C. D., Hulin, C. L., & White, L. A. (2012). Development of the Tailored Adaptive Personality Assessment System (TAPAS) to support Army personnel selection and classification decisions (Technical Report 1311). U.S. Army Research Institute for the Behavioral and Social Sciences. https://apps.dtic.mil/sti/citations/ADA564422
- Goldberg, L. R. (2018). (2,8,10 & others) International Personality Item Pool (IPIP) (Version V1) [Data set]. Harvard Dataverse. https://doi.org/https://doi.org/10.7910/DVN/UF52WY
- Goldberg, L. R. (1999). A broad-bandwidth, public domain, personality inventory measuring the lower-level facets of several five-factor models. In I. Mervielde, I. J. Deary, F. De Fruyt, & F. Ostendorf (Eds.),Personality Psychology in Europe, 7, 7–28. Tilburg University Press.
- Gonzalez, O., & Pelham, W. E. (2021). When does differential item functioning matter for screening? A method for empirical evaluation. Assessment, 28, 446–456. https://doi.org/https://doi.org/10.1177/1073191120913618
- Gunn, H. J., Grimm, K. J., & Edwards, M. C. (2020). Evaluation of six effect size measures of measurement non-Invariance for continuous outcomes. Structural Equation Modeling: A Multidisciplinary Journal, 27, 503–514. https://doi.org/https://doi.org/10.1080/10705511.2019.1689507
- Horn, J. L., & Mcardle, J. J. (1992). A practical and theoretical guide to measurement invariance in aging research. Experimental Aging Research, 18, 117–144. https://doi.org/https://doi.org/10.1080/03610739208253916
- Hurtz, G. M., & Donovan, J. J. (2000). Personality and job performance: The big five revisited. Journal of Applied Psychology, 85, 869–879. https://doi.org/https://doi.org/10.1037/0021-9010.85.6.869
- Jung, E., & Yoon, M. (2016). Comparisons of three empirical methods for partial factorial invariance: Forward, backward, and factor-ratio tests. Structural Equation Modeling: A Multidisciplinary Journal, 23, 567–584. https://doi.org/https://doi.org/10.1080/10705511.2015.1138092
- Jung, E., & Yoon, M. (2017). Two-step approach to partial factorial invariance: Selecting a reference variable and identifying the source of noninvariance. Structural Equation Modeling: A Multidisciplinary Journal, 24, 65–79. https://doi.org/https://doi.org/10.1080/10705511.2016.1251845
- Lai, M. H. C., Kwok, O.-M., Yoon, M., & Hsiao, -Y.-Y. (2017). Understanding the impact of partial factorial invariance on selection accuracy: An R script. Structural Equation Modeling: A Multidisciplinary Journal, 24, 783–799. https://doi.org/https://doi.org/10.1080/10705511.2017.1318703
- Lai, M. H. C., Richardson, G. B., & Mak, H. W. (2019). Quantifying the impact of partial measurement invariance in diagnostic research: An application to addiction research. Addictive Behaviors, 94, 50–56. https://doi.org/https://doi.org/10.1016/j.addbeh.2018.11.029
- Meade, A. W. (2010). A taxonomy of effect size measures for the differential functioning of items and scales. Journal of Applied Psychology, 95, 728–743. https://doi.org/https://doi.org/10.1037/a0018966
- Mellenbergh, G. J. (1989). Item bias and item response theory. International Journal of Educational Research, 13, 127–143. https://doi.org/https://doi.org/10.1016/0883-0355(89)90002-5
- Meredith, W. (1993). Measurement invariance, factor analysis and factorial invariance. Psychometrika, 58, 525–543. https://doi.org/https://doi.org/10.1007/BF02294825
- Millsap, R. E., & Kwok, O.-M. (2004). Evaluating the impact of partial factorial invariance on selection in two populations. Psychological Methods, 9, 93–115. https://doi.org/https://doi.org/10.1037/1082-989X.9.1.93
- Millsap, R. E. (2007). Invariance in measurement and prediction revisited. Psychometrika, 72, 461–473. https://doi.org/https://doi.org/10.1007/s11336-007-9039-7
- Millsap, R. E. (2011). Statistical approaches to measurement invariance. Routledge.
- Nye, C. D., Bradburn, J., Olenick, J., Bialko, C., & Drasgow, F. (2019). How big are my effects? examining the magnitude of effect sizes in studies of measurement equivalence. Organizational Research Methods, 22, 678–709. https://doi.org/https://doi.org/10.1177/1094428118761122
- Nye, C. D., & Drasgow, F. (2011). Effect size indices for analyses of measurement equivalence: Understanding the practical importance of differences between groups. Journal of Applied Psychology, 96, 966–980. https://doi.org/https://doi.org/10.1037/a0022955
- Ock, J., McAbee, S. T., Mulfinger, E., & Oswald, F. L. (2020). The practical effects of measurement invariance: Gender invariance in two Big Five personality measures. Assessment, 27, 657–674. https://doi.org/https://doi.org/10.1177/1073191119885018
- Putnick, D. L., & Bornstein, M. H. (2016). Measurement invariance conventions and reporting: The state of the art and future directions for psychological research. Developmental Review, 41, 71–90. https://doi.org/https://doi.org/10.1016/j.dr.2016.06.004
- Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48, 1–36. https://doi.org/https://doi.org/10.18637/jss.v048.i02
- Satorra, A., & Bentler, P. M. (2001). A scaled difference chi-square test statistic for moment structure analysis. Psychometrika, 66, 507–514. https://doi.org/https://doi.org/10.1007/BF02296192
- Schmidt, F. L., & Hunter, J. E. (1998). The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychological Bulletin, 124, 262–274. https://doi.org/https://doi.org/10.1037/0033-2909.124.2.262
- Schmit, M. J., & Ryan, A. M. (1993). The Big Five in personnel selection: Factor structure in applicant and nonapplicant populations. Journal of Applied Psychology, 78, 966–974. https://doi.org/https://doi.org/10.1037/0021-9010.78.6.966
- Schmitt, N., & Kuljanin, G. (2008). Measurement invariance: Review of practice and implications. Human Resource Management Review, 18, 210–222. https://doi.org/https://doi.org/10.1016/j.hrmr.2008.03.003
- Stark, S., Chernyshenko, O. S., & Drasgow, F. (2004). Examining the effects of differential item (functioning and differential) test functioning on selection decisions: When are statistically significant effects practically important? Journal of Applied Psychology, 89, 497–508. https://doi.org/https://doi.org/10.1037/0021-9010.89.3.497
- Steiger, J. H. (1980). Statistically-based tests for the number of common factors. Paper presented at the annual meeting of the Psychometric Society. Iowa City, IA. Retrieved March 8, 2021, from https://ci.nii.ac.jp/naid/10012870999/
- Thurstone, L. L. (1947). Multiple factor analysis. University of Chicago Press.
- Vandenberg, R. J. (2002). Toward a further understanding of and improvement in measurement invariance methods and procedures. Organizational Research Methods, 5, 139–158. https://doi.org/https://doi.org/10.1177/1094428102005002001
- Yoon, M., & Kim, E. S. (2014). A comparison of sequential and nonsequential specification searches in testing factorial invariance. Behavior Research Methods, 46, 1199–1206. https://doi.org/https://doi.org/10.3758/s13428-013-0430-2
- Zwick, R., Thayer, D. T., & Lewis, C. (1999). An empirical Bayes approach to Mantel-Haenszel DIF analysis. Journal of Educational Measurement, 36, 1–28. https://doi.org/https://doi.org/10.1111/j.1745-3984.1999.tb00543.x