
Abstract
T-DNA insertional mutagenesis is a powerful tool in Arabidopsis functional genomics research. Previous studies have developed thermal asymmetric interlaced polymerase chain reaction (TAIL-PCR) as an efficient strategy in isolation of DNA sequences adjacent to known sequences in T-DNA tagged mutants. However, a number of problems are encountered when attempts are made to clone flanking sequences in T-DNA tagged mutants. Therefore, it is necessary to improve the efficiency of cloning mutagenesis. Here, we present the most frequent problems and provide an improved method to increase TAIL-PCR efficiency. Even then, it is not always possible to successfully obtain flanking sequences; in such cases, we recommend using high-throughput sequencing to determine the mutations.
Introduction
Over the past years, different strategies have been developed to obtain mutant pools in plants, such as physical or chemical mutagenesis, homologous recombination and transposable element or T-DNA insertional mutagenesis. However, each method has its own characteristics. By physical or chemical mutagenesis, it is easier to get saturated mutant banks, but the mapping of mutation sites is labour intensive and time consuming. The frequency of homologous recombination in plants may be too low to cover the entire genome span.[Citation1]
Thus, as a classic mutagenesis method, Agrobacterium tumefaciens-mediated transformation is probably the most widely used method to introduce genes into plants.[Citation2,Citation3] Tumour-inducing plasmid encodes most of the major functions required for transferring an oncogenic segment of DNA, the transferred DNA (T-DNA), into the host cell.[Citation4,Citation5] The T-DNA itself does not include genes required for this transfer process. The distribution of T-DNA insertion sites in the genomes of transgenic plants is random, so transfer of T-DNA mediated by Agrobacterium can be highly efficient in plants and can be used to create mutations (for review, see [Citation6]). To date, in the model plant Arabidopsis thaliana, whose whole genome sequence is known,[Citation7] there is a large number of T-DNA tagged mutants created by laboratories all over the world, such as SALK,[Citation8] GABI-Kat [Citation9] and Weigel [Citation10]. All of these pools represent near saturation of the entire Arabidopsis gene space with mutations and have been widely used for forward and reverse genetic research. Researchers can easily obtain flanking sequences and align with genome database to find mutations.
In our research, we built a forward genetic screen system to isolate mutants from some of the T-DNA tagged mutant pools from the Arabidopsis Biological Resource Center (ABRC) or the Institute of Genetics and Developmental Biology (IGDB) of the Chinese Academy of Sciences (CAS). After obtaining mutants, thermal asymmetric interlaced polymerase chain reaction (TAIL-PCR) [Citation11,Citation12] was used to isolate known DNA sequences adjacent to T-DNA insertions. Unfortunately, we cannot always obtain flanking sequences of T-DNA insertions by TAIL-PCR. In the present study, we develop a more efficient strategy by using a nested three-step TAIL-PCR procedure, 22 short arbitrary degenerate (AD) primers, some specific nested primers of different T-DNA borders and some commercial reagents to clone the mutations. We subjected those mutants for which we failed to obtain T-DNA insertion-flanking sequences by TAIL-PCR, to high-throughput sequencing followed by comparative analysis to identify T-DNA insertion(s).
Materials and methods
Mutant pools, vectors, reagents, plant growth and medium
The T-DNA tagged mutant pools CS76502/4/6/8 (PROK2) (ABRC),[Citation8] CS31100 (pSKI015) (ABRC) [Citation10] and DS insertion pools (PWS31) [Citation13] ( IGDB of the CAS) were used to screen mutants. We cloned the flanking sequences in these isolated T-DNA tagged mutants by TAIL-PCR. The DNA polymerase (TaKaRa rTaq™) and dNTP were purchased from TaKaRa (Japan). Other reagents were of analytical grade and commercially available. Arabidopsis seeds were surface-sterilized by washing in a 20% sodium hypochlorite solution for 10 min, rinsed five times with sterile water, spread on Murashige and Skoog medium [Citation14] with 0.8% agar and grown in a growth chamber at 23 °C.
Flanking sequence cloning and primers
Arabidopsis genomic DNA was extracted by the CTAB (cetyltrimethylammonium bromide) method.[Citation15] CTAB was ordered from Sangon Biotech (China). The flanking sequences of T-DNA insertion were obtained by TAIL-PCR.[Citation11] The primers used for TAIL-PCR are listed in and . The settings for TAIL-PCR are shown in (). All primers were synthesized by Sangon Biotech (China). All PCR products were electrophoresed in a 1% agarose gel, the TAIL-2 and TAIL-3 products showing expected sizes were chosen. TAIL-3 products were purified and sequenced with the chain termination method [Citation16] by Sangon Biotech (China).
Table 1. AD primers used in this study.
Table 2. Nested specific primers used in this study.
Table 3. Settings for TAIL-PCR.
Sequence analysis
DNA sequence alignments were conducted with the blastn program [Citation17] and tair10 program.[Citation18] High-throughput sequencing technology analyses were provided by ShangHai Biotechnology Corporation (China).
Results and discussion
Flanking sequences analysis
TAIL-PCR commonly contains three nested amplifications. The primers used in each amplification reaction consist of left or right border primer, corresponding to the border sequence of the T-DNA, and an AD primer (). By sequencing a great number of TAIL-3 products, we found that these sequences can be divided into four categories according to their similarity with the plant genome or the vector: (1) Approximately 39% of the DNA fragments whose sequences were as expected, containing several dozens of base pairs homologous to the T-DNA border, and the remainder having significant similarity (E-value < 10−5) with the Arabidopsis genomic sequence, and thus could be mapped in the Arabidopsis genome. (2) Approximately 20% of the DNA fragments had significant similarity only with the vector sequences (either T-DNA or vector backbone). (3) Approximately 13% of the DNA fragments had significantly similar sequences with the Arabidopsis genomic sequences, but had no significant similarity with the vector sequences. (4) Approximately 28% had similarity only with the T-DNA border. The lengths of these TAIL-PCR DNA fragments were generally less than 200 bp.
In our experiments, it was difficult to obtain a TAIL-3 DNA fragment in about 8% of the mutants, whereas one or more TAIL-3 fragments were generally generated in the remaining 92% of the mutants. With some exceptions, these DNA fragments contain flanking sequence information as expected. Moreover, some mutants harbouring abnormal T-DNA insertions, such as deleted T-DNA border, tandem repeats and multiple copies of insertion, also make the amplification of the T-DNA insertion-flanking sequences difficult.
Selected AD primers
To achieve adequate thermal asymmetric priming for TAIL-PCR, the Tm's (melting temperature) of the AD primers should be at least 10 °C lower than the average Tm's of the specific primers.[Citation11] Apart from Tm, the factors determining the suitability of an AD primer may include its degeneracy level, length and nucleotide sequence. In previous studies, 15–17 bp length and 64-, 128- or 256-fold AD primers were used for TAIL-PCR. The degeneracy of the arbitrary primers can be created either through inclusion of multiple bases at one position or through inosine incorporation.[Citation11]
Overly high degeneracy levels in AD primers may lead to problems in control of priming efficiency, production of undesirably short DNA fragments and generation of primer--dimer artefacts.[Citation11] However, the low levels of degeneracy in primers is always associated with a decrease in the efficiency of TAIL-PCR to obtain expected DNA fragments. Only when there exist one or more AD primer-binding sites at the Arabidopsis genomic sequence which is near the T-DNA border, may the expected specific TAIL-PCR DNA fragments be obtained.
We used 22 AD primers () in our work. As shown in , we obtained TAIL-3 products in the v1 mutant (screened from CS76502/4/6/8 (PROK2)), followed by sequencing and comparison. Here, we only show all product sequences that were as expected, containing several dozens of base pairs homologous to the T-DNA left border with the remaining sequence having significant similarity (E-value < 10−5) with the Arabidopsis genomic sequence (). The sequence alignment of these products suggests four individual T-DNA insertion sites in the v1 mutant.
Figure 1. Four T-DNA insertion sites were cloned by TAIL-PCR in the v1 mutant. AD1-1 and AD1-2 denote two individual DNA fragments amplified by using AD1. Brackets indicate the length of the flanking sequence.

Although we cloned identical T-DNA insertion sites by using different AD primers, such as the T-DNA insertion site 1 between AT1g53930-AT1g53935 cloned by using AD1, 4, 8, 10, 12, 13 and 14 in the v1 mutant (), some sites were cloned merely by using a single AD primer, such as the T-DNA insertion site 2 at AT2g11740, which was only detected when the AD12 primer was used (). Therefore, using more AD primers can indeed improve the efficiency of TAIL-PCR.
The T-DNA border deletion phenomena
According to our sequencing results, approximately 13% of the TAIL-3 DNA fragments only shared significant similarity with the Arabidopsis genomic sequence, whereas no obvious similarity with the vector sequence. For instance, the TAIL-PCR product, which was amplified in the ×10 mutant (screened from CS31100 (pSKI015)), only shared similarity (E-value < 10−5) with the Arabidopsis genomic sequence (, product ×10-Lb3). As shown in , only 12 bp of the sequence was found to be the same as the T-DNA border sequence. This is too short for the NCBI blast tool to find similar sequences. Therefore, we subsequently designed a new primer Lb0, which is an inner sequence of Lb1, and used the nested primers Lb0, Lb1 and Lb2 instead of Lb1, Lb2 and Lb3 to clone flanking sequences in the ×10 mutant. Interestingly, we obtained the expected DNA fragment (, product ×10-Lb2) which contained the T-DNA border sequence and Arabidopsis genomic sequence.
Figure 2. Flanking sequences cloned by TAIL-PCR. Arrows represent the position of the nested specific primers in the T-DNA border. Brackets show the length of flanking sequence. ×10-Lb2 represents the flanking sequences cloned by using three nested primers Lb0, Lb1 and Lb2 in the ×10 mutant. ×10-Lb3 represents the sequences cloned by using Lb1, Lb2 and Lb3 in the ×10 mutant. di2-Lb2 represents the sequences cloned by using Lb0, Lb1 and Lb2 in the di2 mutant.

In our study, we found that T-DNA insertion can cause a deletion of a different length of its border; importantly, when the border deletion was beyond the primer-binding site, we could not obtain the PCR products. For the di2 mutant (screened from CS31100 (pSKI015)), in which we obtained nothing when using Lb1, Lb2 and Lb3, the expected product was obtained by using Lb0, Lb1 and Lb2 (, product di2--Lb2).
Reasons for no flanking sequences being amplified and its solution
There exist some complex situations for T-DNA insertion in transgenic plants (for review, see [Citation6]), such as: multiple copies of T-DNA insertions, transfer of vector backbone, complex arrangement of T-DNA, chromosomal duplication and rearrangements or a combination of these.[Citation19–21] Thus, it may be difficult to obtain an expected DNA sequence by TAIL-PCR due to the above-mentioned variable types of insertion behaviour. Here, we summarize some examples derived from our studies.
First, it is often that complex T-DNA insertions composed of two or more T-DNA repeats may be found in transgenic lines.[Citation22] As shown in , two T-DNA insertion sites were cloned in the same gene (AT2G11740) in the v1 mutant. The sequence analysis shows that these two T-DNAs insert the AT2G11740 gene in a head-to-head orientation. Therefore, we obtained two flanking sequences by using nested left-border specific primers (A)). On the contrary, no flanking sequences were amplified by using right-border primers.
Figure 3. Head-to-head insertion mode in the v1 mutant (A). Abnormal gene structure in the dt1 mutant (B).
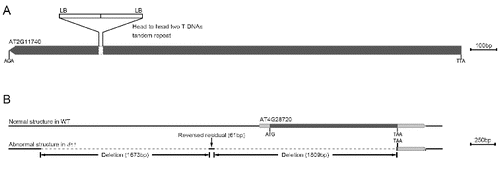
Briefly, we may obtain no flanking sequences when using nested primers from either of the T-DNA borders which is not directly linked with the plant genome, e.g. in a head-to-head orientation. To solve the problem, we designed two sets of nested primers on both the left and the right borders to clone the flanking sequences. However, for some T-DNA borders which contain multiple repeats, it is difficult to design primers (for example, the T-DNA right border of the pSKI015 vector contains 4 × 35S promoters); we can only use nested primers in one border to clone flanking sequences.
Second, in transgenic plants, there are some multiple tandem T-DNA arrays. Some of them show truncated T-DNA regions, some T-DNA regions beyond the border, even sequences of the vector which are far beyond the defined T-DNA region, when the T-DNAs are transferred into the plant genome.[Citation6] In our work, we have observed this to result in a lot of TAIL-PCR product sequences only containing the vector sequence, rather than the plant genomic sequence.
Third, we were not able to amplify the flanking sequence in a few mutants, such as the dt1 mutant (screened from CS31100 (pSKI015)). In order to clone the mutation, we used high-throughput sequencing to analyse the dt1 genomic sequence. Consequently, we found a change in the gene structure in the vicinity of the AT4G28720 locus (B)). The alignment showed deletions of two DNA segments (1673 and 1809 bp) and a reversed residual of a short segment (61 bp) upstream from the AT4G28720 gene (B)).
By using high-throughput sequencing technology, we have been able to easily obtain a vast amount of genomic sequence information to identify mutations. Nevertheless, there are still small areas of genome sequence which cannot be covered. In our research, in some gametophytic mutants, the mutant gene was heterozygous in the sporophyte. The sequence data from the sporophytic DNA can interfere with the analysis and mutations cannot be effectively identified unless the coverage of high-throughput sequencing data increases. In addition, parts of T-DNA tagged mutations were not linked with the mutant phenotypes that we focused on. To find extra mutations, high-throughput sequencing was also used.
By contrast, for T-DNA tagged mutant pools, the TAIL-PCR method is easier, cheaper and extensively used for identifying mutations in large numbers of mutant samples, while high-throughput sequencing is a more suitable method for identification of those mutations which cannot be identified by using TAIL-PCR.
Deletion of two or more genes when T-DNAs are inserted into the genome
Using TAIL-PCR, a large number of mutation sites were identified in our work. Among these, there are a few sites whose flanking sequences are very close to each other, such as the distance of 3357 bp in the w52 mutant (screened from CS31100 (pSKI015)) (A)) and 137 000 bp in the kd361 mutant (screened from DS mutant pools (PWS31)) (B)). The probability of two T-DNA insertions to occur at such a short distance from each other is very low. In the analysis of the Arabidopsis genome sequence between these, we found that there was a deletion of the plant genome sequence between the two cloned flanking sequences from one T-DNA insertion ( (A and B)).
Figure 4. Partial deletion of two genes in the w52 mutant (A). Deletion of 39 genes in the kd361 mutant (B).
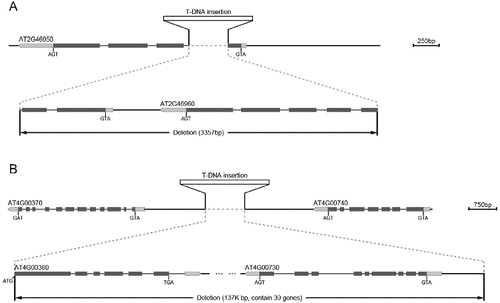
T-DNA insertion can cause the deletion of two or more genes. For example, there was partial deletion of two genes in the w52 mutant (A)) and there were 39 genes deleted in the kd361 mutant (B)). Among the studied mutant clones, those with two or more deleted genes were shown to be different from clones bearing single gene mutations. In order to identify the mutants with two or more genes deleted, after completing the analysis of the TAIL-PCR sequences, we always determined the sequence near the two sides of the T-DNA insertion.
Conclusions
In our studies, for identification of the mutation in each mutant, we first used TAIL-PCR to clone T-DNA flanking sequences and checked whether these T-DNA insertional mutations were linked with phenotypes or not. By using our improved TAIL-PCR method, flanking sequences were cloned in approximately 69% of the mutants. Nevertheless, it was not possible to clone the flanking sequences in the remaining 31% of the mutants (not amplifying TAIL-3 products (8%) and TAIL-3 products containing no flanking sequence information (23%)). Second, the known genes which can cause the same phenotypes need to be checked by allele hybridization and semi-quantitative PCR or real-time quantitative PCR (T-DNA insertional mutagenesis usually causes gene knockout). Finally, after exclusion of the mutations in known possible alleles, high-throughput sequencing was used to find extra mutations. After this, there still needs to be identified which mutation was linked with the phenotypes.
Acknowledgements
We thank Dr Wei-Cai Yang (Institute of Genetics and Developmental Biology (IGDB) of the Chinese Academy of Sciences (CAS)) for DS insertion mutant pools, the Arabidopsis Biological Resource Center (ABRC) for CS76502/4/6/8 and CS31100, Center Laboratory of School of life science, Lanzhou University for instruments and Dr Cai-Guo Zhang, Dr Xiao-Jun Xie (Texas A&M University Health Science Center) and Dr He-Xin Lv (Tianjin University of Science and technology) for providing some suggestions for this article.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Kempin SA, Liljegren SJ, Block LM, Rounsley SD, Lam E, Yanofsky MF. Inactivation of the Arabidopsis AGL5 MADS-box gene by homologous recombination. Nature. 1997;389:802–803.
- Gelvin SB. The introduction and expression of transgenes in plants. Curr Opin Biotechnol. 1998;9(2):227–232. doi:10.1016/S0958-1669(98)80120-1
- Stachel SE, Zambryski PC. Bacteria-yeast conjugation. Generic trans-kingdom sex? Nature. 1989;340(6230): 190–191. doi:10.1038/340190a0
- Gelvin SB. Agrobacterium and plant genes involved in T-DNA transfer and integration. Annu Rev Plant Physiol Plant Mol Biol. 2000;51:223–256. doi:10.1146/annurev.arplant.51.1.223
- Gelvin SB. Agrobacterium-mediated plant transformation: the biology behind the “gene-jockeying” tool. Microbiol Mol Biol Rev. 2003;67(1):16–37. doi:10.1128/MMBR.67.1.16-37.2003
- Nath Radhamony R, Mohan Prasad A, Srinivasan R. T-DNA insertional mutagenesis in Arabidopsis: a tool for functional genomics. Electron J Biotechnol [online]. 2005;8(1). doi:10.2225/vol8-issue1-fulltext-4
- Kaul S, Koo HL, Jenkins J, Rizzo M, Rooney T, Tallon LJ, Feldblyum T, Nierman W, Benito MI, Lin XY, Town CD, Venter JC, Fraser CM, Tabata S, Nakamura Y, Kaneko T, Sato S, Asamizu E, Kato T, Kotani H, Sasamoto S, Ecker JR, Theologis A, Federspiel NA, Palm CJ, Osborne BI, Shinn P, Conway AB, Vysotskaia VS, Dewar K, Conn L, Lenz CA, Kim CJ, Hansen NF, Liu SX, Buehler E, Altafi H, Sakano H, Dunn P, Lam B, Pham PK, Chao Q, Nguyen M, Yu GX, Chen HM, Southwick A, Lee JM, Miranda M, Toriumi MJ, Davis RW, Wambutt R, Murphy G, Dusterhoft A, Stiekema W, Pohl T, Entian KD, Terryn N, Volckaert G, Salanoubat M, Choisne N, Rieger M, Ansorge W, Unseld M, Fartmann B, Valle G, Artiguenave F, Weissenbach J, Quetier F, Wilson RK, de Bastide M, Sekhon M, Huang E, Spiegel L, Gnoj L, Pepin K, Murray J, Johnson D, Habermann K, Dedhia N, Parnell L, Preston R, Hillier L, Chen E, Marra M, Martienssen R, McCombie WR, Mayer K, White O, Bevan M, Lemcke K, Creasy TH, Bielke C, Haas B, Haase D, Maiti R, Rudd S, Peterson J, Schoof H, Frishman D, Morgenstern B, Zaccaria P, Ermolaeva M, Pertea M, Quackenbush J, Volfovsky N, Wu DY, Lowe TM, Salzberg SL, Mewes HW, Rounsley S, Bush D, Subramaniam S, Levin I, Norris S, Schmidt R, Acarkan A, Bancroft I, Quetier F, Brennicke A, Eisen JA, Bureau T, Legault BA, Le QH, Agrawal N, Yu Z, Martienssen R, Copenhaver GP, Luo S, Pikaard CS, Preuss D, Paulsen IT, Sussman M, Britt AB, Selinger DA, Pandey R, Mount DW, Chandler VL, Jorgensen RA, Pikaard C, Juergens G, Meyerowitz EM, Theologis A, Dangl J, Jones JDG, Chen M, Chory J, Somerville MC, In AG. Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature. 2000;408(6814):796–815. doi:10.1038/35048692
- Alonso JM, Stepanova AN, Leisse TJ, Kim CJ, Chen H, Shinn P, Stevenson DK, Zimmerman J, Barajas P, Cheuk R, Gadrinab C, Heller C, Jeske A, Koesema E, Meyers CC, Parker H, Prednis L, Ansari Y, Choy N, Deen H, Geralt M, Hazari N, Hom E, Karnes M, Mulholland C, Ndubaku R, Schmidt I, Guzman P, Aguilar-Henonin L, Schmid M, Weigel D, Carter DE, Marchand T, Risseeuw E, Brogden D, Zeko A, Crosby WL, Berry CC, Ecker JR. Genome-wide insertional mutagenesis of Arabidopsis thaliana. Science. 2003;301(5633):653–657. doi:10.1126/science.1086391
- Rosso MG, Li Y, Strizhov N, Reiss B, Dekker K, Weisshaar B. An Arabidopsis thaliana T-DNA mutagenized population (GABI-Kat) for flanking sequence tag-based reverse genetics. Plant Mol Biol. 2003;53(1–2):247–259. doi:10.1023/B:PLAN.0000009297.37235.4a
- Weigel D, Ahn JH, Blazquez MA, Borevitz JO, Christensen SK, Fankhauser C, Ferrandiz C, Kardailsky I, Malancharuvil EJ, Neff MM, Nguyen JT, Sato S, Wang ZY, Xia Y, Dixon RA, Harrison MJ, Lamb CJ, Yanofsky MF, Chory J. Activation tagging in Arabidopsis. Plant Physiol. 2000;122(4):1003–1013. doi:10.1104/pp.122.4.1003
- Liu YG, Whittier RF. Thermal asymmetric interlaced PCR: automatable amplification and sequencing of insert end fragments from P1 and YAC clones for chromosome walking. Genomics. 1995;25(3):674–681. doi:10.1016/0888-7543(95)80010-J
- Liu YG, Chen Y. High-efficiency thermal asymmetric interlaced PCR for amplification of unknown flanking sequences. Biotechniques. 2007;43(5):649–650. doi: 000112601
- Parinov S, Sevugan M, Ye D, Yang WC, Kumaran M, Sundaresan V. Analysis of flanking sequences from dissociation insertion lines: a database for reverse genetics in Arabidopsis. Plant Cell. 1999;11(12):2263–2270. doi: http://dx.doi.org/10.1105/tpc.11.12.2263
- Murashige T, Skoog F. A revised medium for rapid growth and bio assays with tobacco tissue cultures. Physiol Plant. 1962;15(3):473–497. doi:10.1111/j.1399-3054.1962.tb08052.x
- Dubois P, Cutler S, Belzile FJ. Regional insertional mutagenesis on chromosome III of Arabidopsis thaliana using the maize Ac element. Plant J. 1998;13(1):141–151. doi:10.1046/j.1365-313X.1998.00006.x
- Sanger F, Nicklen S, Coulson AR. DNA sequencing with chain-terminating inhibitors. Proc Natl Acad Sci USA. 1977;74(12):5463–5467.
- Online Blast tool of National Center for Biotechnology Information [ Internet]. U.S. National Library of Medicine. [cited 2014 Aug 3]. Available from: http://www.ncbi.nlm.nih.gov/BLAST/
- Online Blast tool of The Arabidopsis Information Resource [ Internet]. Phoenix Bioinformatics Corporation. [cited 2014 Aug 5]. Available from: http://www.arabidopsis.org/Blast/
- Jorgensen R, Snyder C, Jones JG. T-DNA is organized predominantly in inverted repeat structures in plants transformed with Agrobacterium tumefaciens C58 derivatives. Mol Gen Genet. 1987;207(3):471–477. doi:10.1007/BF00331617
- Tax FE, Vernon DM. T-DNA-associated duplication/translocations in Arabidopsis. Implications for mutant analysis and functional genomics. Plant Physiol. 2001;126(4):1527–1538. doi:10.1104/pp.126.4.1527
- Veluthambi K, Ream W, Gelvin SB. Virulence genes, borders, and overdrive generate single-stranded T-DNA molecules from the A6 Ti plasmid of Agrobacterium tumefaciens. J Bacteriol. 1988;170(4):1523–1532.
- De Buck S, Jacobs A, Van Montagu M, Depicker A. The DNA sequences of T-DNA junctions suggest that complex T-DNA loci are formed by a recombination process resembling T-DNA integration. Plant J. 1999;20(3):295–304. doi:10.1046/j.1365-313X.1999.00602.x