
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Structural engineers face several code-restricted design decisions. Codes impose many conditions and requirements to the designs of structural frames, such as columns and beams. However, it is difficult to intuitively find optimized solutions, while satisfying all code requirements simultaneously. Engineers commonly make design decisions based on empirical observations. Optimization techniques can be employed to make more rational engineering decisions, which result in designs that can meet various code restrictions simultaneously. Lagrange optimization techniques with constraints, not based on explicit parameterization, are implemented to make rational engineering decisions and find minimized or maximized design values by solving nonlinear optimization problems under strict constraints imposed by design codes. It is difficult to express objective functions analytically directly in terms of design variables to use derivative methods, such as Lagrange multipliers. This study proposes the use of neural network to approximate well-behaved objective functions and other output parameters into one universal function that can also give a generalizable solution for operating Jacobian and Hessian matrices to solve the Lagrangian function. The proposed method was applied successfully in optimizing a cost of a reinforced concrete column under various design requirements. An efficacy of optimal results was also proven by 5 million datasets.
Graphical Abstract
1. Introduction
Several studies, including (Aghaee, Yazdi, and Tsavdaridis Citation2014), (Fanaie, Aghajani, and Dizaj Citation2016), (Madadi et al. Citation2018), (Nasrollahi et al. Citation2018), and (Paknahad, Bazzaz, and Khorami Citation2018), have been conducted to optimize reinforced concrete (RC) structures. These studies mainly focused on minimizing the manufacturing and construction costs; only a few considered structural capabilities against external forces, which are influenced by design codes. Studies of the optimization of RC beams have been reported by (Shariati et al. Citation2010), (Fanaie, Aghajani, and Shamloo Citation2012), (Toghroli et al. Citation2014), (Awal, Shehu, and Ismail Citation2015), (Kaveh and Shokohi Citation2015), (Safa et al. Citation2016), (Shah et al. Citation2016), (Korouzhdeh, Eskandari-Naddaf, and Gharouni-Nik Citation2017), and (Heydari and Shariati Citation2018).
(Barros, Martins, and Barros Citation2005) presented stress–strain diagrams using the conventional Lagrangian multiplier method (LMM) to develop nominal moment strengths based on the optimal area of the upper and lower sections of steel for four classes of concrete. (Shariat et al. Citation2018) obtained analytical objective functions for the cost of frames as a function of the design parameters for structural systems in a limited circumstance; however, it is generally very difficult to derive analytical objective functions that represent the entire behavior of structural components such as columns and beams. (Villarrubia et al. Citation2018) employed artificial neural networks (ANNs) to approximate objective functions to optimized analytical objective functions. They approximated objective functions using nonlinear regression that can optimize problems and employing a multilayer perceptron when the use of linear programming or Lagrange multipliers was not feasible.
2. Significance of the study
There are numerous available computer-aided engineering tools, including CAD packages, FEM software, self-write calculation codes, that are used to study the performance of structures. Objective functions, however, could constitute a mixture of numerical simulations, analytical calculations, and catalog selections, which makes it difficult to apply differentiation to derivative optimization methods, such as the Lagrange multiplier. Some nonderivative optimization methods such as Genetic algorithms were applied in structural design problems (Rajeev and Krishnamoorthy Citation1998)(Camp, Pezeshk, and Hansson Citation2003) as they do not require any derivatives to find an optimal solution. However, computing times of nonderivative methods heavily rely on the computational speed of engineering tools because each trial requires one run of software. In this study, the use of artificial neural networks was adopted to universally approximate objective functions obtained from any computer-aided engineering tools. New objective functions, hence, not only enhance the computational speed compared to conventional software but also can be differentiated and implemented in Lagrange optimization.
Optimization and sensitivity analyses using computational LMM can be based on ANNs. The optimized results were verified using rectangular RC columns. The analysis was conducted to obtain the minimum design cost for reinforced concrete columns, as specified by the American Concrete Institute (ACI) regulations (2014) (ACI-318 Citation2014). Moreover, a sensitivity analysis was performed on the cost with respect to the effective parameters, including the rebar ratios and failure criteria. Accordingly, various failure criteria were developed to be used in designing RC columns. Numerical examples were also presented to better illustrate the design steps. Complex but inaccurate analytical objective functions, such as describing the cost of structural frame and emissions of CO2, were replaced by ANNs-based objective functions. The sensitivity analysis of the LMM revealed that the best optimal values based on constraints can be identified for specific situations. Optimization using artificial intelligence (AI)-based objective functions based on large datasets without the need for primary optimization knowledge can effectively aid the selection of design parameters for best practices.
The goodness of proposed method is that its performance would be less dependent on problem types such as column, beam, frame, seismic design, etc. but relies on characteristics of big datasets of considered problem. Once big data is good enough to generate approximation objective function as well as other parameters using ANN, an optimization solution is then generalizable by using AI-based Lagrange method. Therefore, applications of proposed method would not restrict to optimizing RC columns only but also can expand to other problems, such as optimizing beam-column connection (Ye et al. Citation2021), GFRP RC Columns (Sun et al. Citation2020), RC shear wall (Zhang et al. Citation2019)(Yazdani, Fakhimi, and Alitalesh Citation2018) subjected to lateral impact loading (Zhang, Gholipour, and Mousavi Citation2021), or even severe impulsive loading (Abedini and Zhang Citation2021), etc.
3. Lagrange procedures based on ANNs
Joseph–Louis LMM optimizes objective functions with constraints, identifying the saddle point of the Lagrange function, as mentioned by (Walsh Citation1975) and (Kalman Citation2009), which can be identified among local stationary points based on the Hessian matrix (which are differentiated twice) (Silberberg and Wing. Citation2001). To find the stationary (saddle) points of a Lagrangian function, the function must be formed as a function of the constraining input variables and the Lagrange multiplier ((Protter and Morrey Citation1985)). This can be achieved by solving systems of nonlinear differential equations that lead to the identification of the maximum or minimum of the Lagrange function subjected to inequality and equality constraints (Hoffmann and Bradley Citation2004).
3.1. Optimization using LMM and Newton–Raphson method
LMM finds stationary points (saddle points; maximum or minimum of a Lagrange function) when a Lagrange function, , is considered as a function of the variables
and the Lagrange multiplier for both equality and inequality constraints,
and
, respectively, as shown in EquationEq. (1)
(1)
(1) :
where is a multivariate objective function subjected to equality and inequality constraints,
and
, respectively. The diagonal matrix of the inequality,
(EquationEq. (2
(2)
(2) )), activates the inequality to equality if the condition of inequality is not satisfied or deactivate it if considered parameters are within the range defined by inequality constraints.
where is the status of the inequality constraint
;
when
is active and
when
is inactive. The stationary points of Lagrange functions (EquationEq. (1
(1)
(1) )) can then be identified by solving the partial differential equations with respect to
,
, and
(EquationEq. (3
(3)
(3) )), finding slopes of the parallel tangential lines of the objective functions,
, and constraints,
and
.
where
and
are the Jacobian of the constraint vectors and
, respectively, at
. The main advantage of Lagrange multipliers is that they are added to constrained optimization problems to convert the problems into unconstrained optimization problems. Lagrangian functions are formulated based on the relationships between the gradients of objective functions and those of the constraints of the original problems (Beavis and Dobbs,Citation1990) such that the derivative test for unconstrained problems can still be applied. Lagrange algorithms linearize restrictions and objective functions at a specific space point by employing derivatives and partial derivatives that are solved based on equality constraints, as shown in EquationEq. (3)
(3)
(3) . The Newton–Raphson method is employed in solving a set of partial differential equations representing a tangential line of Lagrange functions (EquationEqs. (3)
(3)
(3) and (Equation5
(5)
(5) )),
, which needs to be differentiated one more time to linearize the partial differential Lagrange functions with respect to
,
, and
(EquationEq. (5
(5)
(5) )), leading to finding the stationary points of the Lagrange function,
. Linear approximation of tangential line of Lagrange functions can be predicted as
, which is very close to
, as shown in EquationEq. (5
(5)
(5) ), where partial differential equations
, is differentiable at
. The Newton–Raphson method is based on first-order approximation, which works for any system of equations whose functions are differentiable in the considered region.
where is the Hessian matrix of Lagrangian
at
. Since seeking
,
can be computed from EquationEq. (6)
(6)
(6) . Generally, the variable
and Lagrange multipliers
can be updated after every iteration as EquationEq. (7)
(7)
(7) .
The first derivative, , can be obtained from EquationEq. (3
(3)
(3) ), while the Hessian matrix,
, of second-order partial derivative of Lagrange function,
(EquationEq. (1
(1)
(1) )), is derived as followed:
where ,
, and
are Hessian matrices of the objective function (
), equality constraint (
), and inequality constraint (
), respectively, with respect to the variable vector (
). The procedure for Newton–Raphson approximation is repeated until convergence is achieved.
3.2. Generalization of objective functions and their derivatives using neural network
3.2.1. Formulation of universal approximation function using neural network
One problem in Lagrange optimization is that the objective function, , and/or the output parameters that appear in constraints,
and
, are sometimes complex or impossible to derive into twice-differentiable functions in order to employ the Lagrange optimization method. Even when it is possible, deriving the Jacobian and Hessian matrices of the objective function, as well as the constraints, is not only difficult and expensive, but also a nongeneralizable solution for any optimization problems (e.g. optimizing columns, beams, and/or any structural systems).
In this study, an artificial neural network was employed to approximate any well-behaved objective functions and other parameters into one universal function, as shown in EquationEq. (10(10)
(10) ), which can also give a generalizable solution for the Jacobian and Hessian matrices.
3.2.2. Neural network-based universal approximation function
where is the input (vector of features);
the number of layers, including hidden and output layers;
the weight matrix between layer
and layer
;
the bias matrix of layer
; and
and
the normalization and denormalization functions, respectively. Min-max normalization function as shown in EquationEquation (10b)
(10b)
(10b) is conducted in this study.
where is a normalization of
between the minimum and maximum value of
and
, respectively. A coefficient
is the ratio of normalization data range (
) to original data range (
) as shown in EquationEq. (10c)
(10c)
(10c) . Similarly, a denormalization function is expressed in EquationEq. (10d)
(10d)
(10d) .
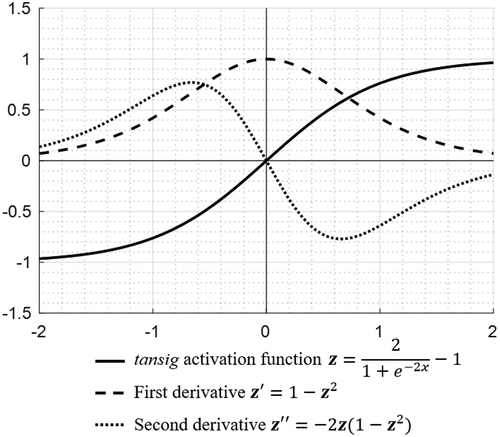
The activation functions (tansig, tanh) shown in , at layer
, were implemented to formulate nonlinear relationships between the networks. As mentioned by Goodfellow (Bengio, Goodfellow, and Courville Citation2017), the hyperbolic tangent activation function (tansig, tanh) generally performs better than a sigmoid activation function. The function takes any real value as input and outputs values in the range −1 to 1. The bigger the input, the closer the output value to 1.0, whereas the smaller the input the closer the output to −1.0. also illustrates first and second derivatives of tansig/tanh activation function, which are needed for Jacobian and Hessian calculations. A linear activation function,
, was selected for the output layer because the output values are unbounded. For example, an output of safety factor (
) varies from 0.5 (normalized as −1) to 2 (normalized as 1) in training datasets, however,
could be either greater than 2 (normalized as 1) or small than 0.5 (normalized as −1) depending on design values. sigmoid or reLu activation functions for an output layer are even worse for this case because their lower bounds are 0 for any normalized safety factor smaller than 0 (denormalized as 1.25), which means they may have vanishing problems in these ranges. Linear activation at the output layer, on the other hand, predicts output values which is not influenced by activation functions.
Figure 1. Tansig activation function and its derivatives.
3.2.3. Formulation of Jacobian matrix for universal approximation function
In neural networks, universal approximation functions can also be expressed as a series of composite mathematical operations, as shown in EquationEq. (11a)(11a)
(11a) :
where is the output vector at layer
, which can be calculated using EquationEq. (11b)
(11b)
(11b) :
where denotes the Hadamard (element-wise) product operation.
,
, and
are normalization parameters of output
; whereas
,
,
are vectors contained normalization parameters of input vectors
.
In calculus, a chain rule is employed to calculate derivatives of such composite functions, as shown in Eq. (11). Formally, the Jacobian matrix of with respect to
can be derived as the Jacobian matrix of
with respect to
multiplied by that of
with respect to
(EquationEq. (12
(12)
(12) ))
The Jacobian matrix for universal approximation, , is then computed by forward propagation as follows:
3.2.4. Formulation of Hessian matrix for universal approximation function
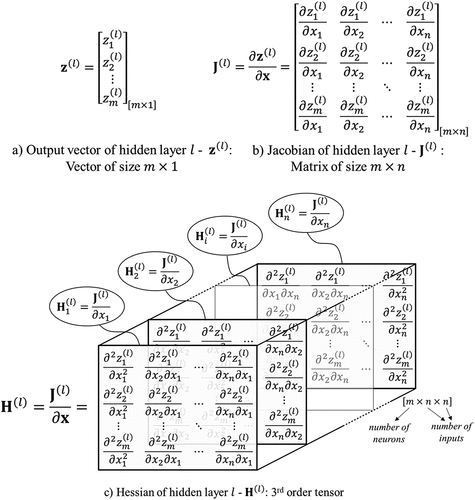
This section summaries derivations of AI based Hessian matrix which was developed by MathWorks Technical Support Department ((MATLAB Citation2020b). The Jacobian matrix of the hidden layer and
neurons with respect to
input variables (
) is a matrix of size
. Then, the corresponding Hessian is a third-order tensor as illustrated in , which could be an expensive operation. A convenient method is to calculate explicitly the slices of the Hessian of the second derivative and then obtain the full Hessian by accurately reshaping the slices ((MATLAB Citation2020b)). A slice of the Hessian,
, is a derivative of Jacobian
with respect to one of the input elements,
(EquationEq. (14)
(14)
(14) ).
Figure 2. Size configuration of output vector, Jacobian, and Hessian of hidden layer l.
where can be obtained by applying the chain rule as:
The expression can be written as
, which is the i-th column of Jacobian
. Substituting EquationEq. (15)
(15)
(15) to EquationEq. (14
(14)
(14) ), we obtain
Applying forward propagation in EquationEq. (16(16)
(16) ), the slice of Hessian at the final layer,
, can be obtained as:
Finally, a Hessian matrix at the output layer, , is obtained by reshaping
Hessian slices of
, which are row vectors of size
, into an
matrix, as expressed in EquationEq. (18)
(18)
(18) :
The Lagrange optimization problem presented in Section 3.1 can then be solved in a generalizable way using a neural network to generate AI-based objective functions, Jacobian, and Hessian matrices, as shown in EquationEqs. (10)(10)
(10) , (Equation13
(13)
(13) ), and (Equation18
(18)
(18) ), respectively.
The concept of AI-based Lagrange Optimization method is explained following three steps as shown in .
Figure 3. AI-based LaGrange optimization flowchart.
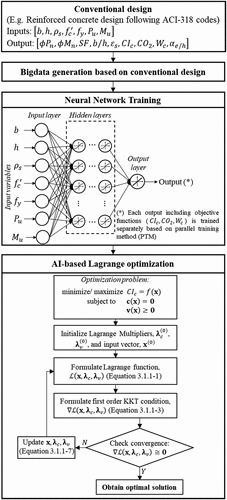
- Step 1: Structural big datasets are generated from conventional design software, such as AutoCol. A proper number of big datasets needed for training should be selected carefully based on level of complexity of considered problem.
- Step 2: AI-based objective functions are achieved based on neural networks trained on big datasets obtained from Step 1. Accuracies of AI-based model are considerably affected by not only number of big datasets but also neural network parameters, such as number of hidden layers, neurons, and required epochs, etc. Therefore, a proper framework of neural network should be employed to get good training results.
- Step 3: Lagrange multiplier method is applied to optimize AI-based objective functions. The aim of AI-based objective functions is to approximate any well-behaved objective functions and generalize calculation procedure of Jacobian and Hessian matrices, which are needed to solve KKT conditions based on Newton–Raphson method.
4. Application of AI-based Lagrange method on optimizing RC columns
In this study, a conventional structural software (AutoCol) is employed to generate big datasets for neural network training. Column configuration (), rebar ratio (
), and material properties are conducted to evaluate structural performance of RC column, such as design axial force (
), design bending moment (
), and rebar strain (
), etc., against factored load pair (
-
). and describe seven inputs
needed to calculate nine corresponding output parameters
.
Table 1. Summary of RC column parameters.
Figure 4. RC column.
4.1. Formulation of objective function and other parameters based on ANNs
The nine output parameters, including the objective function (), are functions of seven variables that are complex and difficult to not only implement analytically but also find their Jacobian and Hessian matrices for solving the Lagrange function (EquationEq. (7)
(7)
(7) ). AI-based neural networks are developed to universally approximate all the output parameters, as expressed in EquationEq. (10
(10)
(10) ), and hence, a unique process of finding their Jacobian and Hessian matrices can be applied. For example, the objective function of column cost index (CIc) is obtained using EquationEq. (19)
(19)
(19) based on the given input parameters
. The equation is forward-network-based weight-bias functions with
layers and 80 neurons, which are linked using weighted interconnections and bias through an activation function, thereby performing nonlinear numerical computations. An activation function (tansig, tanh), as shown in , is used in EquationEq. (19)
(19)
(19) .
The input, , for networks is related to neurons of fully connected successive layers using weights at each neuron and bias in each hidden layer. The layers are then summed up for the outputs, such as CIc, and CO2 emissions, and Wc ((Hong Citation2019)). The neural networks are formulated to be able to generalize trends (recognized as machine learning) between inputs and outputs to obtain objective functions rather than being based on analytical engineering mechanics or knowledge (Berrais Citation1999).
Similarly, the rest of the outputs can also be formulated as functions of seven inputs based on forward ANNs, as shown in . present training results of forward networks, in which three types of hidden layer (1, 2, and 5) with 80 neurons are implemented. Structural datasets of 100,000 are randomly divided into three small subsets: training set, validation set, and test set. According to Brian Ripley (Ripley Citation1996), a training set (70% of big datasets) is a set of examples used for learning, that is to fit parameters, whereas a validation set is used to tune a neural network to avoid overfitting. A test subset, on the other hand, is independent of the training dataset, which does not affect training procedure. It is, therefore, used only to access the performance of a fully specified classifier. Hence, in , a MSE of test set (MSE T. Perf) is suitable for evaluating the goodness of designs, indicating capability of training model against unseen datasets.
Table 2. Training accuracies based on PTM.
4.2. Optimization of RC column using AI-based Lagrange method
The neural network models of RC column presented in are used to minimize cost index (CIc) of a RC column under several design requirements as shown in . All design requirements can be expressed in term of equality constraints as stated in . Besides, the rebar ratio,
, should only be constrained following the ACI-318 code requirements (
), which are expressed in terms of two inequality constraints:
and
().
Table 3. Column design scenarios for optimization.
Table 4. Summary of equality and inequality constraints.
In EquationEq. (19(19)
(19) ), the CIc function for forward optimization is defined as
, as a function of seven input parameters. According to EquationEqs. (1)
(1)
(1) and (Equation3
(3)
(3) ), the Lagrange optimization function of cost index,
, and its KKT conditions are then, expressed as functions of the input variables
and Lagrange multiplier of equality and inequality constraints,
and
, respectively, as shown in EquationEqs. (20
(20)
(20) ) and (Equation21
(21)
(21) ).
CIc Lagrangian function:
KKT condition:
It is well-known that the Newton–Raphson method relies heavily on a good initial vector assumed as to expedite the run progress as well as enhance accuracy. A good initial vector is predetermined based on simple equality and active inequality;
,
and
().
Inequality constraint () is activated
Initial vector when is activated is obtained from
where five input variables (,
,
,
,
) are predetermined based on simple equality constraints
,
,
, and
and active inequality
. The initial vector
is used to find the saddle point of the Lagrange optimization function, as expressed in EquationEq. (20
(20)
(20) ), based on the Newton–Raphson method. Unknown input parameters (b, h) for the initial vector are random in large datasets which are to be determined during optimization.
The Newton–Raphson method is implemented to solve partially differentiated EquationEq. (21)(21)
(21) using one initial Lagrange multiplier vector,
, and 52 initial vectors of
, in which b and h are randomly distributed within a training data range. The initial values of 0 for the Lagrange multipliers are used because they do not have boundaries; they can be any number while the Newton–Raphson model calculates the exact Lagrange multipliers.
is the best value among 25 trials based on the network with five hidden layers and 80 neurons, producing an optimal value of 202,275.4 when inequality (
) is activated, as shown in ). The optimized results based on one and two hidden layers and 80 neurons are also shown in ) and (b) with optimal values of
185,069.2, and 201,942.3, respectively. Similarly, the optimized results of case 2 (Inequality constraint (
) is activated) and case 3 (none is activated) are obtained ().
Table 5. Lowest cost index of columns (CIc) for given constraints based on forward networks
The optimized design results obtained using the Lagrange multipliers based on forward networks trained with one, two, and five layers and 80 neurons are listed in ), (b), and (c), respectively, and are compared with those obtained using a structural software (AutoCol) (), (b), and (c)). In ), the largest error of 11.79% of SF was demonstrated with one layer and 80 neurons. With two and five layers and 80 neurons () and (c)), reduced errors of 1.55% and 2.7% for the design moment () and design axial force (
) were obtained, respectively, by LMM based on forward networks.
Table 6. Accuracies of optimized CIc based on forward Lagrange optimizations (a) Based on forward training with 1 layer – 80 neurons.
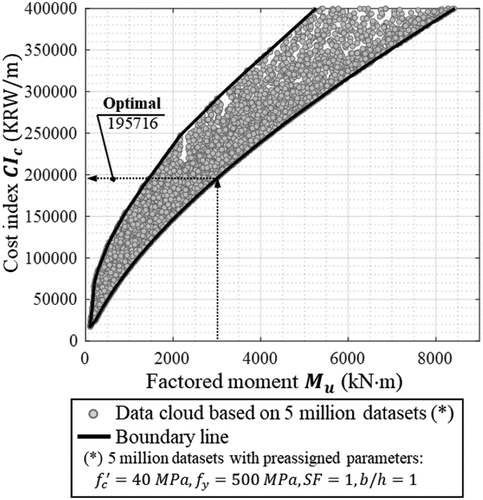
4.3. Verification of CIc by large datasets
The goodness of optimal designs presented in is evaluated by large datasets as shown in . The lowest CIc for large datasets is 195,716, where five million datasets are filtered through MPa,
MPa,
, and
. The accuracy is demonstrated with CIc of 184,684.6 (−5.64%; one layer, )), 195,507.9 (−0.11%; two layers, )), and 195,671.1 (−0.02%; five layers, )) based on AI-based network compared with the optimal CIc (195,716) of large datasets. The CIc obtained by the AI-based Lagrange method with two and five layers and that obtained in large datasets are in good agreement.
Figure 5. Verification of CIc based on large datasets.
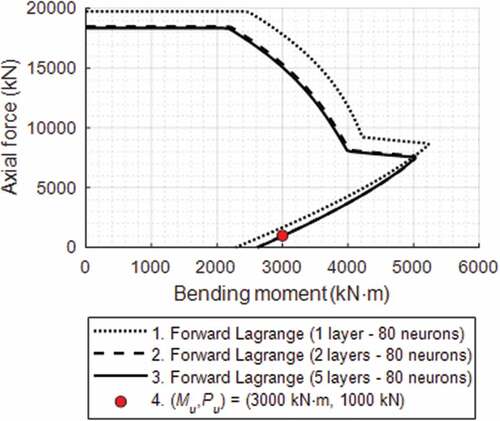
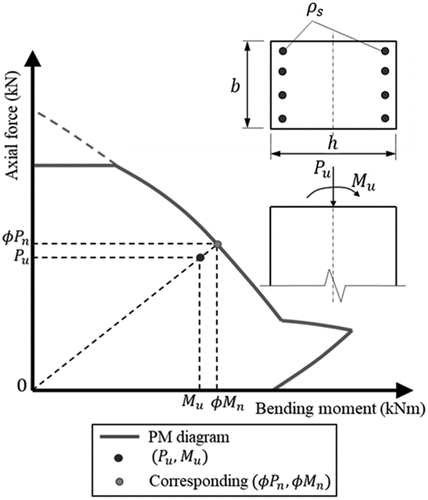
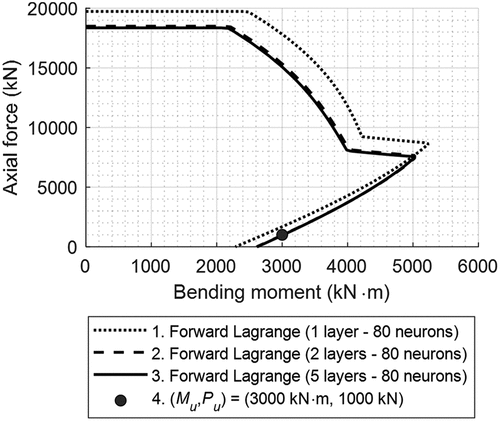
4.4. P–M diagram
The optimal CIc-based P–M interaction diagrams for RC columns that satisfy various design criteria (Table 4.1(b) and Table 4.2) are plotted on the basis of forward networks, as shown in . The P–M diagrams pass through Pu and Mu, as indicated by a solid point. In , the P–M diagrams indicated by Legends 1, 2, and 3 were constructed with the parameters shown in the dashed black box in ), (b), and (c), respectively, which were obtained by AI-based Lagrange optimization. These were used to construct P–M diagrams since the accuracies of the parameters obtained by ANN are acceptable. The P–M diagrams were plotted using AutoCol with appropriate input parameters. The interaction diagrams shown in meet the minimum CIc, as listed in . CIc was optimized by Lagrange multiplier-based forward neural networks with one, two, and five layers and 80 neurons. The dotted curve cannot pass through Pu and Mu (solid point), indicating that the training accuracy of a model with one layer is not sufficient. All three optimized P–M diagrams (Legends 1, 2, and 3) shown in would converge, passing through one P–M diagram when the training accuracies are sufficient.
Figure 6. Axial force–moment (P–M) interaction diagrams for optimal CIc.
5. Conclusions
This study presents hybrid optimization techniques, with which objective functions are proposed based on ANNs. Lagrange optimization techniques with constraints were implemented to achieve rational engineering decisions and find minimized or maximized design values by solving nonlinear optimization problems under strict constraints, conditions, and requirements imposed by design codes for the design of structural frames such as columns and beams. This study helps engineers make the final design decisions, not on the engineers’ empirical observations but on more rational designs, to meet various design requirements, including code restrictions and/or architectural criteria while the objective parameters, such as cost index (CIc), CO2 emissions, and structural weight (Wc), are optimized. The conclusions drawn from the study are as follows:
(1) Constructing objective functions and their derivatives, which is a challenge in the Lagrange multiplier method, can now be generalized to any structural design optimization by using ANN to generate universal AI-based objective functions, Jacobian, and Hessian matrices.
(2) Automatic designs of structural frames are proposed for realistic engineering applications to identify design solutions that optimize all design requirements simultaneously, thereby achieving design decisions not based on engineers’ intuition. The results of the sensitivity analysis of LMM show that the best optimal values based on constraints can be identified for specific situations such as official design codes.
(3) Analytical objective functions were difficult to obtain. This study developed the objective functions for CIc, CO2 emissions, and Wc based on AI-based networks to be implemented for LMM to find the optimized solutions.
(4) The Karush–Kuhn–Tucker conditions were considered to account for inequality constraints, leading to automatic designs of structural frames that meet various code restrictions simultaneously.
(5) Optimization process for CIc was performed, and negligible errors were obtained, which were verified using large structural datasets. Engineering calculations also validated the design accuracies when the optimized CIc was implemented in the designs.
(6) P–M diagrams were are uniquely designed to optimize columns. The proposed optimization will offer generic designs for many types of structures, including machinery and structural frames.
(7) The AI-based objective functions developed in this study can be implemented in broad areas, including engineering, general science, and economics.
A generalizable optimization method proposed herein can be applied to any optimization problem once a sufficient number of data can be collected for establishing approximated objective functions and other parameters to formulate ANN. New objective functions not only enhance the computational speed compared to conventional software but also produce a generalizable calculation method for Jacobian and Hessian matrices for Lagrange optimization. In future work, comprehensive design optimization of a dynamic design of tall buildings would be performed based on AI-based Lagrange optimization. One concerning problem is that computational time of Lagrange optimization is heavily dependent on quantity of inequality constraints because a number of running case (active inequality) corresponds to combinations of inequality constraints. Likewise, a building design is composed of many design requirements considered as inequality constraints, such as lateral displacement, story drift, design strength of each component, and required total base shears, etc.
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT 2019R1A2C2004965).
Disclosure statement
No potential conflict of interest was reported by the author.
Additional information
Funding
Notes on contributors
Won-Kee Hong
Dr. Won-Kee Hong is a Professor of Architectural Engineering at Kyung Hee University. Dr. Hong received his Masters and Ph.D. degrees from UCLA, and he worked for Englelkirk and Hart, Inc. (USA), Nihhon Sekkei (Japan) and Samsung Engineering and Construction Company (Korea) before joining Kyung Hee University (Korea). He also has professional engineering licenses from both Korea and the USA. Dr. Hong has more than 30 years of professional experience in structural engineering. His research interests include new approaches to construction technologies based on value engineering with hybrid composite structures. He has provided many useful solutions to issues in current structural design and construction technologies as a result of his research combining structural engineering with construction technologies. He is the author of numerous papers and patents, both in Korea and the USA. Currently, Dr. Hong is developing new connections that can be used with various types of frames, including hybrid steel–concrete precast composite frames, precast frames and steel frames. These connections would contribute to the modular construction of heavy plant structures and buildings as well. He recently published a book titled as ”Hybrid Composite Precast Systems: Numerical Investigation to Construction„ (Elsevier).
Manh Cuong Nguyen
Manh Cuong Nguyen is currently enrolled as a Combined Master & Ph.D. candidate in the Department of Architectural Engineering at Kyung Hee University, Republic of Korea. His research interest includes precast structures. is currently enrolled as a Combined Master & Ph.D. candidate in the Department of Architectural Engineering at Kyung Hee University, Republic of Korea. His research interest includes precast structures.
References
- Abedini, M., and C. Zhang. 2021. “Dynamic Vulnerability Assessment and Damage Prediction of RC Columns Subjected to Severe Impulsive Loading.” Structural Engineering and Mechanics 77 (4): 441–461. doi:10.12989/sem.2021.77.4.441.
- ACI-318. “Building Code Requirements for Reinforced.” 2014.
- Aghaee, K., M. A. Yazdi, and K. D. Tsavdaridis. 2014. “Mechanical Properties of Structural Lightweight Concrete Reinforced with Waste Steel Wires.” Magazine of Concrete Research 66 (1): 1–9. doi:10.1680/macr.14.00232.
- Awal, A. A., I. A. Shehu, and M. Ismail. 2015. “Effect of Cooling Regime on the Residual Performance of High-volume Palm Oil Fuel Ash Concrete Exposed to High Temperatures.” Construction and Building Materials 98: 875–883. doi:10.1016/j.conbuildmat.2015.09.001.
- Barros, M. H. F. M., R. A. F. Martins, and A. F. M. Barros. 2005. “Cost Optimization of Singly and Doubly Reinforced Concrete Beams with EC2-2001.” Structural and Multidisciplinary Optimization 30 (3): 236–242. doi:10.1007/s00158-005-0516-2.
- Beavis, B., and I. Dobbs. 1990. Optimisation and stability theory for economic analysis .Cambridge University press.
- Bengio, Y., I. Goodfellow, and A. Courville. 2017. Deep Learning. Vol. 1. Massachusetts, USA: MIT press.
- Berrais, A. 1999. “Artificial Neural Networks in Structural Engineering: Concept and Applications.” Engineering Sciences 12: 1.
- Camp, C. V., S. Pezeshk, and H. Hansson. 2003. “Flexural Design of Reinforced Concrete Frames Using a Genetic Algorithm.” Journal of Structural Engineering 129 (1): 105–115. doi:10.1061/(ASCE)0733-9445(2003)129:1(105).
- Fanaie, N., S. Aghajani, and S. Shamloo. 2012. “Theoretical Assessment of Wire Rope Bracing System with Soft Central Cylinder”. Proceedings of the 15th World Conference on Earthquake Engineering. Advances in Structural Engineering
- Fanaie, N., S. Aghajani, and E. A. Dizaj. 2016. “Theoretical Assessment of the Behavior of Cable Bracing System with Central Steel Cylinder.” Advances in Structural Engineering 19 (3): 463–472. doi:10.1177/1369433216630052.
- Heydari, A., and M. Shariati. 2018. “Buckling Analysis of Tapered BDFGM Nano-beam under Variable Axial Compression Resting on Elastic Medium.” Structural Engineering & Mechanics 66 (6): 737–748. doi:10.12989/sem.2018.66.6.737.
- Hoffmann, L. D., and G. L. Bradley. 2004. Calculus for Business, Economics, and the Social and Life Sciences.8th. 575–588. ISBN 0-07-242432–X. New York: McGraw Hill Education
- Hong, W. K. 2019. Hybrid Composite Precast Systems: Numerical Investigation to Construction, 427–478. Kidlington, OX5 1GB, United Kingdom: Woodhead Publishing, Elsevier
- Kalman, D. 2009. “Leveling with Lagrange: An Alternate View of Constrained Optimization.” Mathematics Magazine 82 (3): 186–196. doi:10.1080/0025570X.2009.11953617.
- Kaveh, A., and F. Shokohi. 2015. “Optimum Design of Laterally Supported Castellated Beams Using CBO Algorithm.” Steel & Composite Structures 18 (2): 305–324. doi:10.12989/scs.2015.18.2.305.
- Korouzhdeh, T., H. Eskandari-Naddaf, and M. Gharouni-Nik. 2017. “An Improved Ant Colony Model for Cost Optimization of Composite Beams.” Applied Artificial Intelligence 31 (1): 44–63. doi:10.1080/08839514.2017.1296681.
- Madadi, A., H. Eskandari-Naddaf, R. Shadnia, and L. Zhang. 2018. “Characterization of Ferrocement Slab Panels Containing Lightweight Expanded Clay Aggregate Using Digital Image Correlation Technique.” Construction and Building Materials 180: 464–476. doi:10.1016/j.conbuildmat.2018.06.024.
- MATLAB. 2020b. Version 9.9.0 (R2020b). Natick, Massachusetts: MathWorks .
- Nasrollahi, S., S. Maleki, M. Shariati, A. Marto, and M. Khorami. 2018. “Investigation of Pipe Shear Connectors Using Push Out Test.” Steel & Composite Structures 27 (5): 537–543. doi:10.12989/scs.2018.27.5.537.
- Paknahad, M., M. Bazzaz, and M. Khorami. 2018. “Shear Capacity Equation for Channel Shear Connectors in Steel-concrete Composite Beams.” Steel & Composite Structures 28 (4): 483–494. doi:10.12989/scs.2018.28.4.483.
- Protter, M. H., and C. B. Morrey Jr. 1985. Intermediate Calculus. 2nd. 267. New York: Springer.ISBN 0-387-96058-9.
- Rajeev, S., and C. S. Krishnamoorthy. 1998. “Genetic Algorithm–based Methodology for Design Optimization of Reinforced Concrete Frames.” Computer-Aided Civil and Infrastructure Engineering 13 (1): 63–74. doi:10.1111/0885-9507.00086.
- Ripley, B. D. “Pattern Classification and Neural Networks.” 1996.
- Safa, M., M. Shariati, Z. Ibrahim, A. Toghroli, S. B. Baharom, N. M. Nor, and D. Petkovic. 2016. “Potential of Adaptive Neuro Fuzzy Inference System for Evaluating the Factors Affecting Steel-concrete Composite Beam’s Shear Strength.” Steel & Composite Structures 21 (3): 679–688. doi:10.12989/scs.2016.21.3.679.
- Shah, S. N. R., N. R. Sulong, R. Khan, M. Z. Jumaat, and M. Shariati. 2016. “Behavior of Industrial Steel Rack Connections.” Mechanical Systems and Signal Processing 70-71: 25–740. doi:10.12989/scs.2016.21.3.679.
- Shariat, M., M. Shariati, A. Madadi, and K. Wakil. 2018. “Computational Lagrangian Multiplier Method by Using for Optimization and Sensitivity Analysis of Rectangular Reinforced Concrete Beams.” Steel & Composite Structures 29 (2): 243–256. doi:10.12989/scs.2018.29.2.243.
- Shariati, M., S. N. H. Ramli, S. Maleki, and K. M. M. Arabnejad “Experimental and Analytical Study on Channel Shear Connectors in Light Weight Aggregate Concrete.” Proceedings of the 4th International Conference on Steel & Composite Structures. Sydney, Autralia. 2010; 21–23. 1 0.3 850/978-981-08-6218-3_CC-Fr031.
- Silberberg, E., and S. Wing. 2001. The Structure of Economics: A Mathematical Analysis. Third. 134–141. Boston: Irwin McGraw-Hill.ISBN 0-07-234352-4
- Sun, L., Z. Yang, Q. Jin, and W. Yan. 2020. “Effect of Axial Compression Ratio on Seismic Behavior of GFRP Reinforced Concrete Columns.” International Journal of Structural Stability and Dynamics 20 (6): 2040004. doi:10.1142/S0219455420400040.
- Toghroli, A., M. Mohammadhassani, M. Suhatril, M. Shariati, and Z. Ibrahim. 2014. “Prediction of Shear Capacity of Channel Shear Connectors Using the ANFIS Model.” Steel & Composite Structures 17 (5): 623–639. doi:10.12989/scs.2014.17.5.623.
- Villarrubia, G., J. F. De Paz, P. Chamoso, and F. De la Prieta. 2018. “Artificial Neural Networks Used in Optimization Problems.” Neurocomputing 272: 10–16. doi:10.1016/j.neucom.2017.04.075.
- Walsh, G. R. 1975. Saddle-point Property of Lagrangian Function. Methods of Optimization. 39–44. New York:John Wiley & Sons. ISBN 0-471-91922-5.
- Yazdani, M., A. Fakhimi, and M. Alitalesh (2018). “Numerical Analysis of Effective Parameters in Direct Shear Test by Hybrid Discrete–finite Element Method.”
- Ye, M., J. Jiang, H. M. Chen, H. Y. Zhou, and D. D. Song. 2021. “Seismic Behavior of an Innovative Hybrid Beam-column Connection for Precast Concrete Structures.” Engineering Structures 227: 111436. doi:10.1016/j.engstruct.2020.111436.
- Zhang, C., G. Gholipour, and A. A. Mousavi. 2021. “State-of-the-Art Review on Responses of RC Structures Subjected to Lateral Impact Loads.” Arch Computat Methods Eng 28: 2477–2507. doi:10.1007/s11831-020-09467-5.
- Zhang, C., Z. Alam, L. Sun, Z. Su, and B. Samali. 2019. “Fibre Bragg Grating Sensor‐based Damage Response Monitoring of an Asymmetric Reinforced Concrete Shear Wall Structure Subjected to Progressive Seismic Loads.” Structural Control & Health Monitoring 26 (3): e2307. doi:10.1002/stc.2307.